LRU
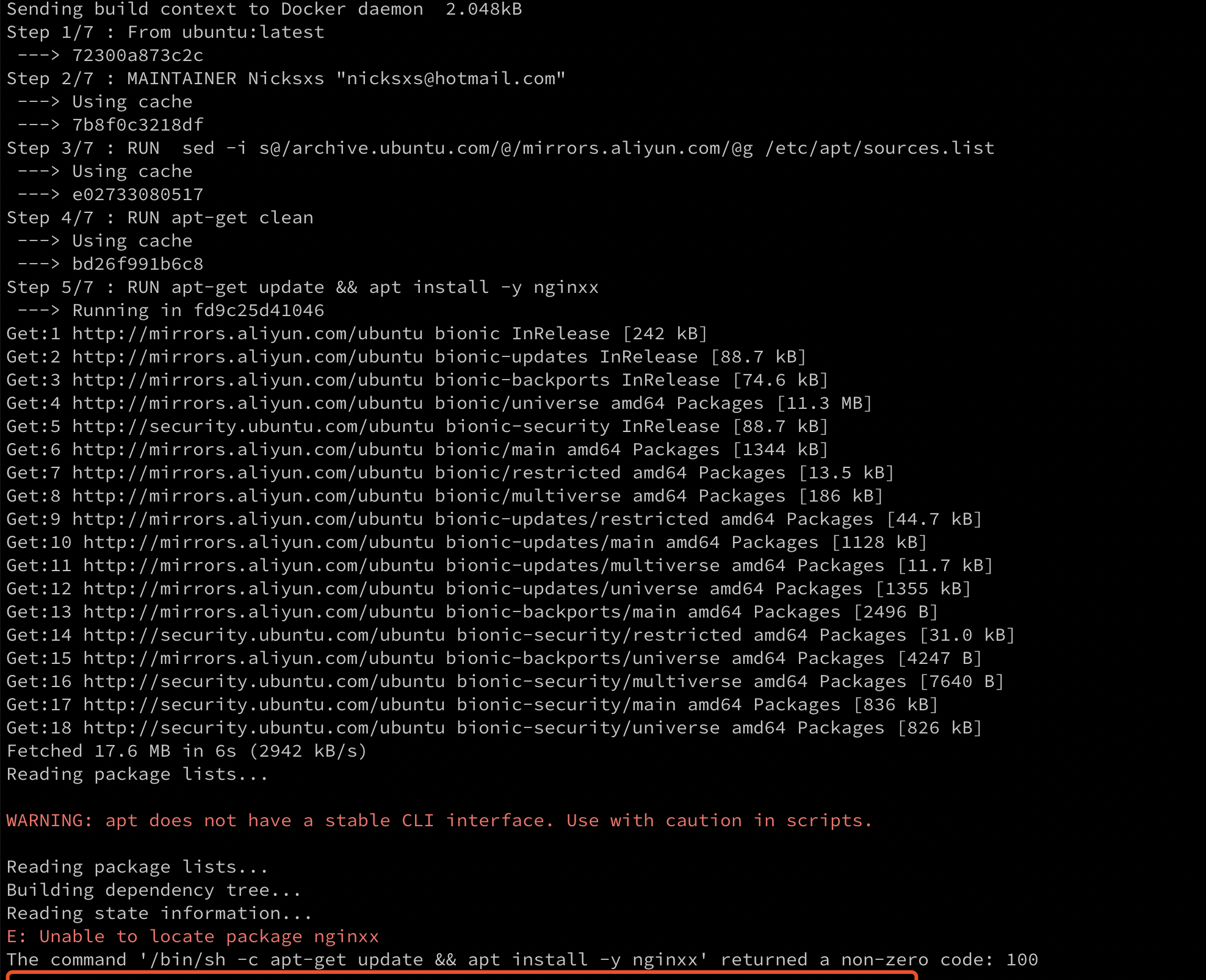
说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍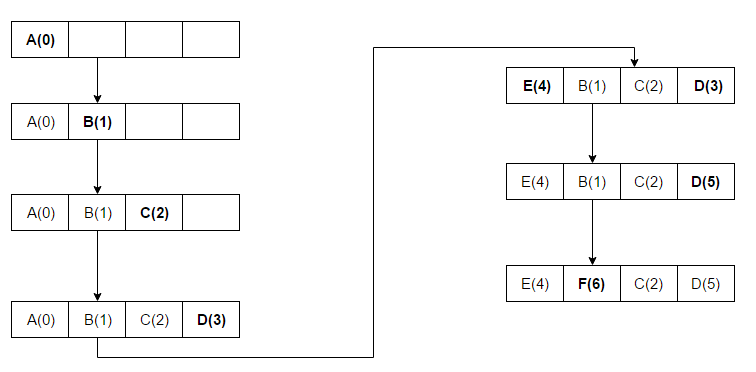 ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
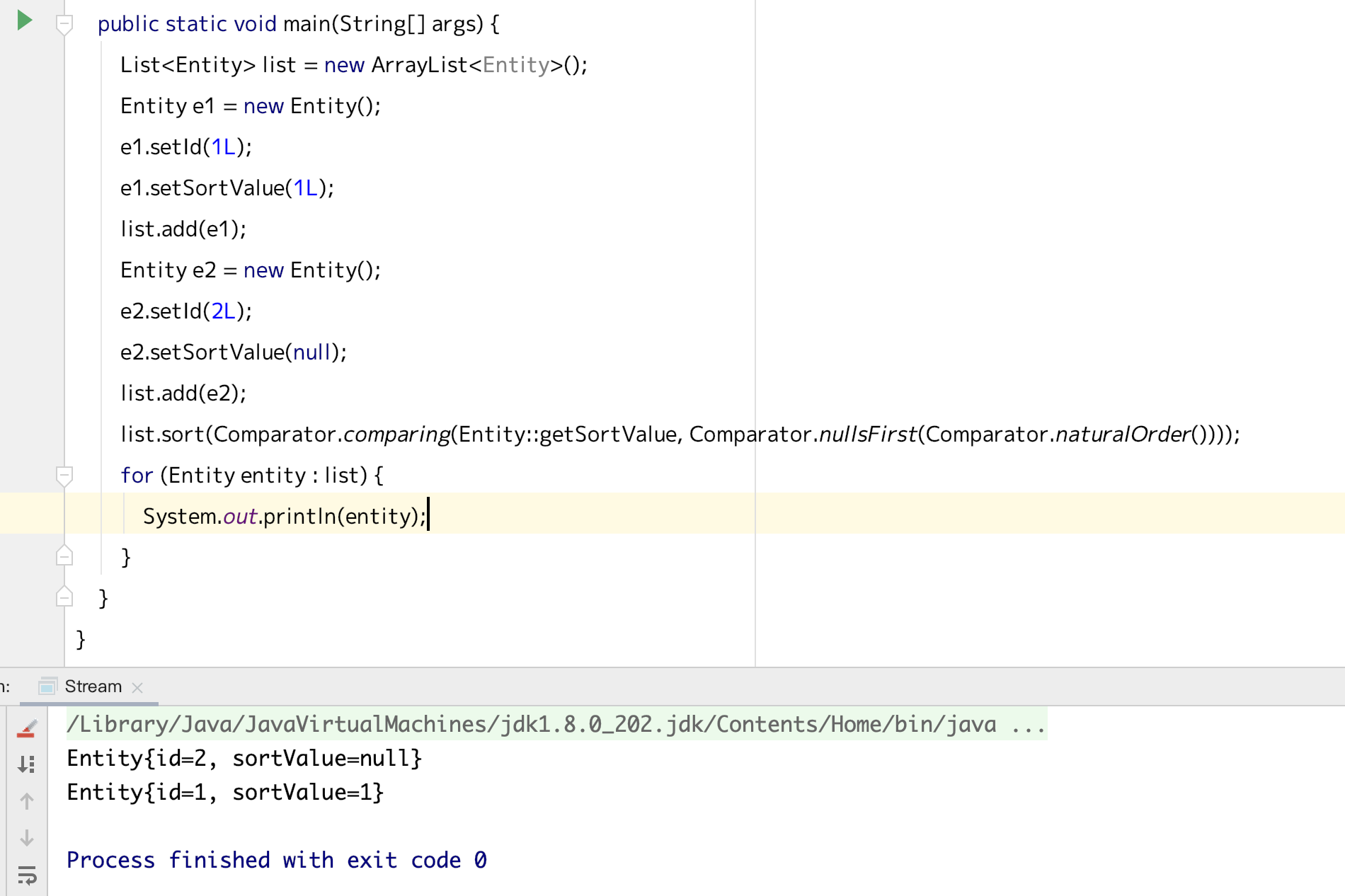
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
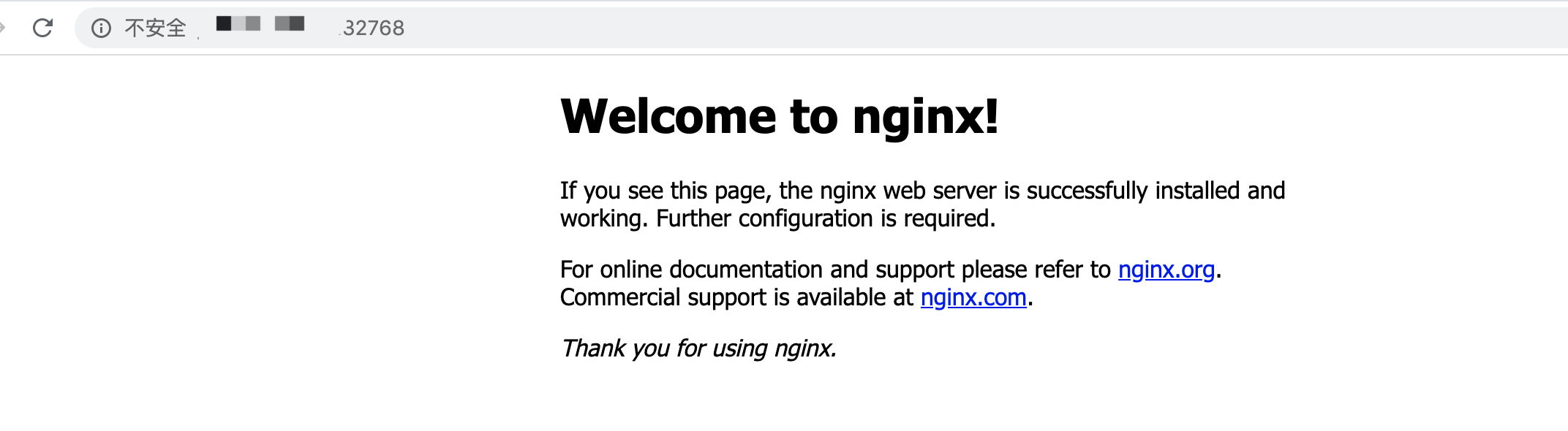
redis 针对这个策略的改进做了一个实验,这里借用下图
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
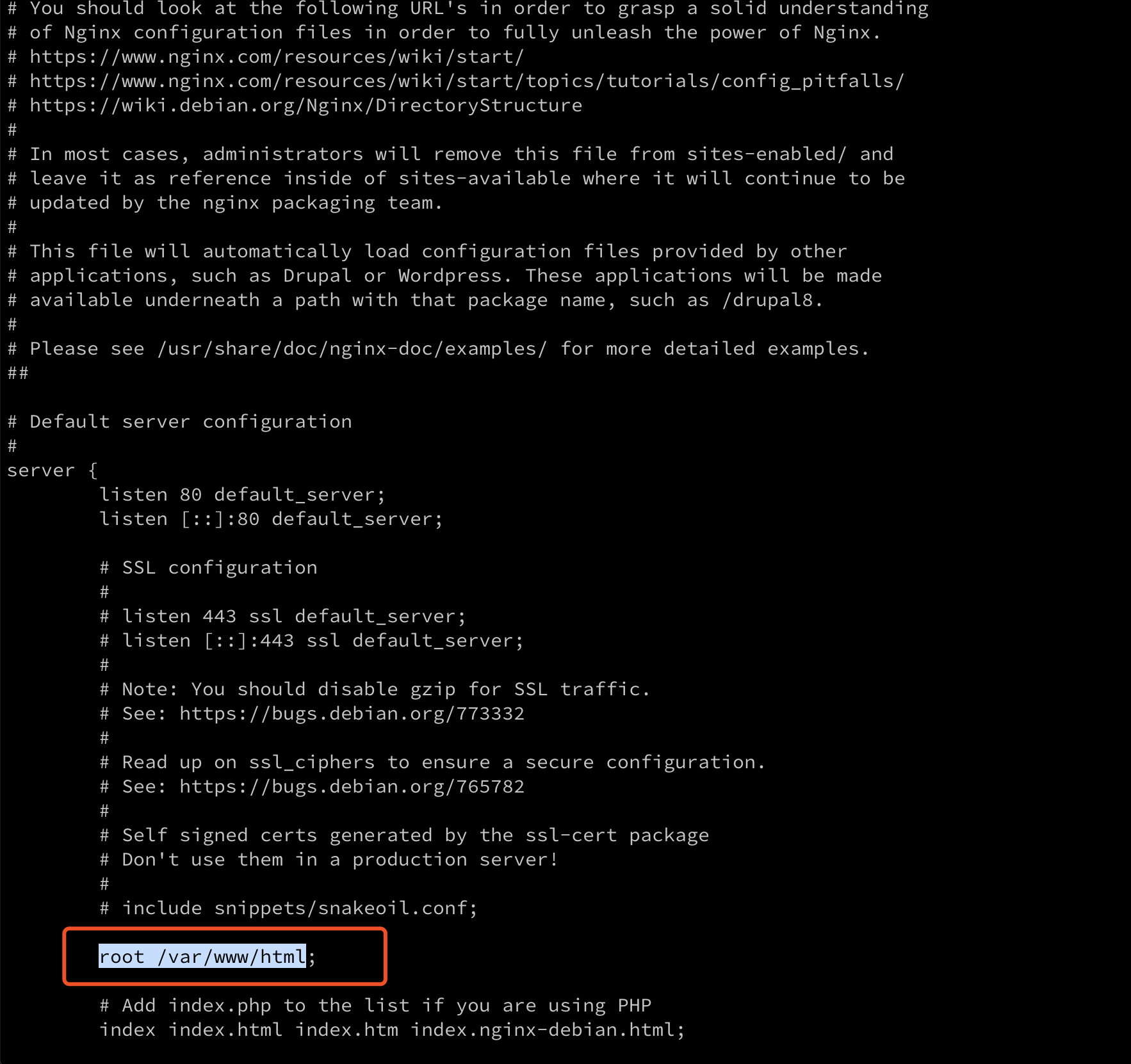
1 | typedef struct redisObject { |
对于 lru 策略来说,lru 字段记录的就是redisObj 的LRU time,
redis 在访问数据时,都会调用lookupKey方法
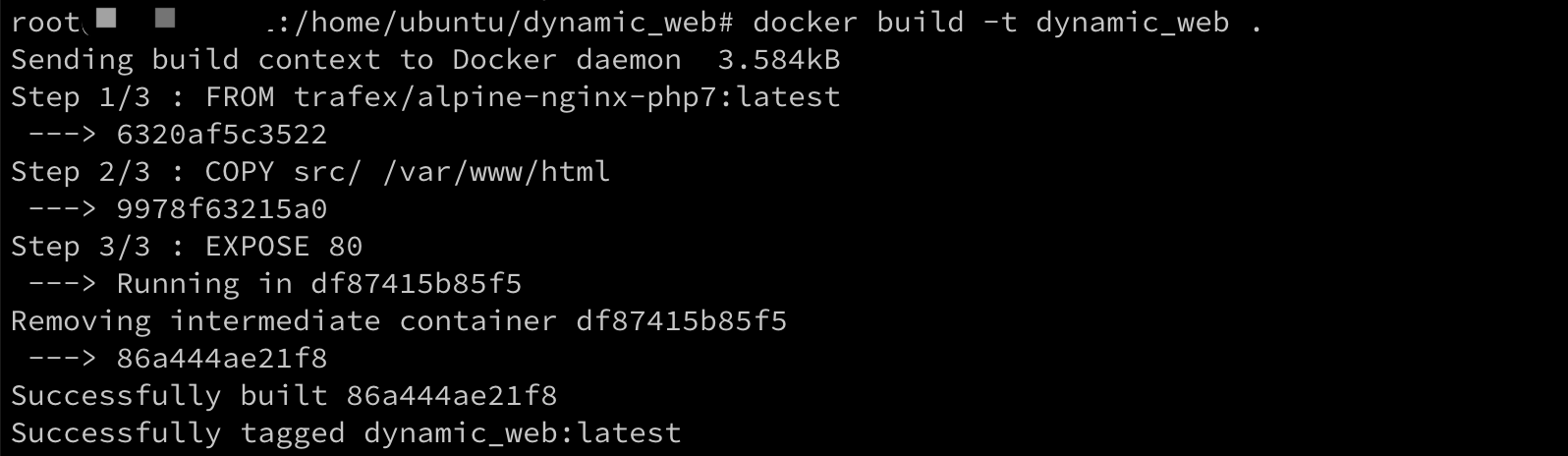
1 | /* Low level key lookup API, not actually called directly from commands |
redis 处理命令是在这里processCommand
1 | /* If this function gets called we already read a whole |
这里只摘了部分,当需要清理内存时就会调用, 然后调用了freeMemoryIfNeededAndSafe
1 | /* This is a wrapper for freeMemoryIfNeeded() that only really calls the |
这里就是根据具体策略去淘汰 key,首先是要往 pool 更新 key,更新key 的方法是evictionPoolPopulate
1 | void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) { |
Redis随机选择maxmemory_samples数量的key,然后计算这些key的空闲时间idle time,当满足条件时(比pool中的某些键的空闲时间还大)就可以进pool。pool更新之后,就淘汰pool中空闲时间最大的键。
estimateObjectIdleTime用来计算Redis对象的空闲时间:
1 | /* Given an object returns the min number of milliseconds the object was never |
空闲时间第一种是 lurclock 大于对象的 lru,那么就是减一下乘以精度,因为 lruclock 有可能是已经预生成的,所以会可能走下面这个
LFU
上面介绍了LRU 的算法,但是考虑一种场景
1 | ~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~| |
可以发现,当采用 lru 的淘汰策略的时候,D 是最新的,会被认为是最值得保留的,但是事实上还不如 A 跟 B,然后 antirez 大神就想到了LFU (Least Frequently Used) 这个算法, 显然对于上面的四个 key 的访问频率,保留优先级应该是 B > A > C = D
那要怎么来实现这个 LFU 算法呢,其实像LRU,理想的情况就是维护个链表,把最新访问的放到头上去,但是这个会影响访问速度,注意到前面代码的应该可以看到,redisObject 的 lru 字段其实是两用的,当策略是 LFU 时,这个字段就另作他用了,它的 24 位长度被分成两部分
1 | 16 bits 8 bits |
前16位字段是最后一次递减时间,因此Redis知道 上一次计数器递减,后8位是 计数器 counter。
LFU 的主体策略就是当这个 key 被访问的次数越多频率越高他就越容易被保留下来,并且是最近被访问的频率越高。这其实有两个事情要做,一个是在访问的时候增加计数值,在一定长时间不访问时进行衰减,所以这里用了两个值,前 16 位记录上一次衰减的时间,后 8 位记录具体的计数值。
Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式:
volatile-lfu:对有过期时间的key采用LFU淘汰策略allkeys-lfu:对全部key采用LFU淘汰策略
还有2个配置可以调整LFU算法:
1 | lfu-log-factor 10 |
updateLFU 这个其实个入口,调用了两个重要的方法
1 | /* Update LFU when an object is accessed. |
首先来看看LFUDecrAndReturn,这个方法的作用是根据上一次衰减时间和系统配置的 lfu-decay-time 参数来确定需要将 counter 减去多少
1 | /* If the object decrement time is reached decrement the LFU counter but |
然后是加
1 | /* Logarithmically increment a counter. The greater is the current counter value |
大概的变化速度可以参考
1 | +--------+------------+------------+------------+------------+------------+ |
factor 越大变化的越慢