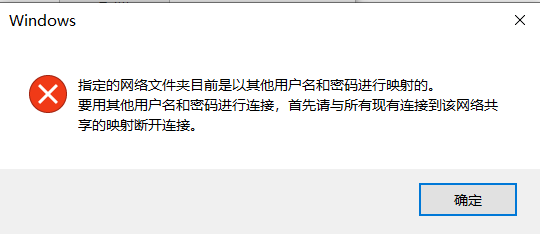
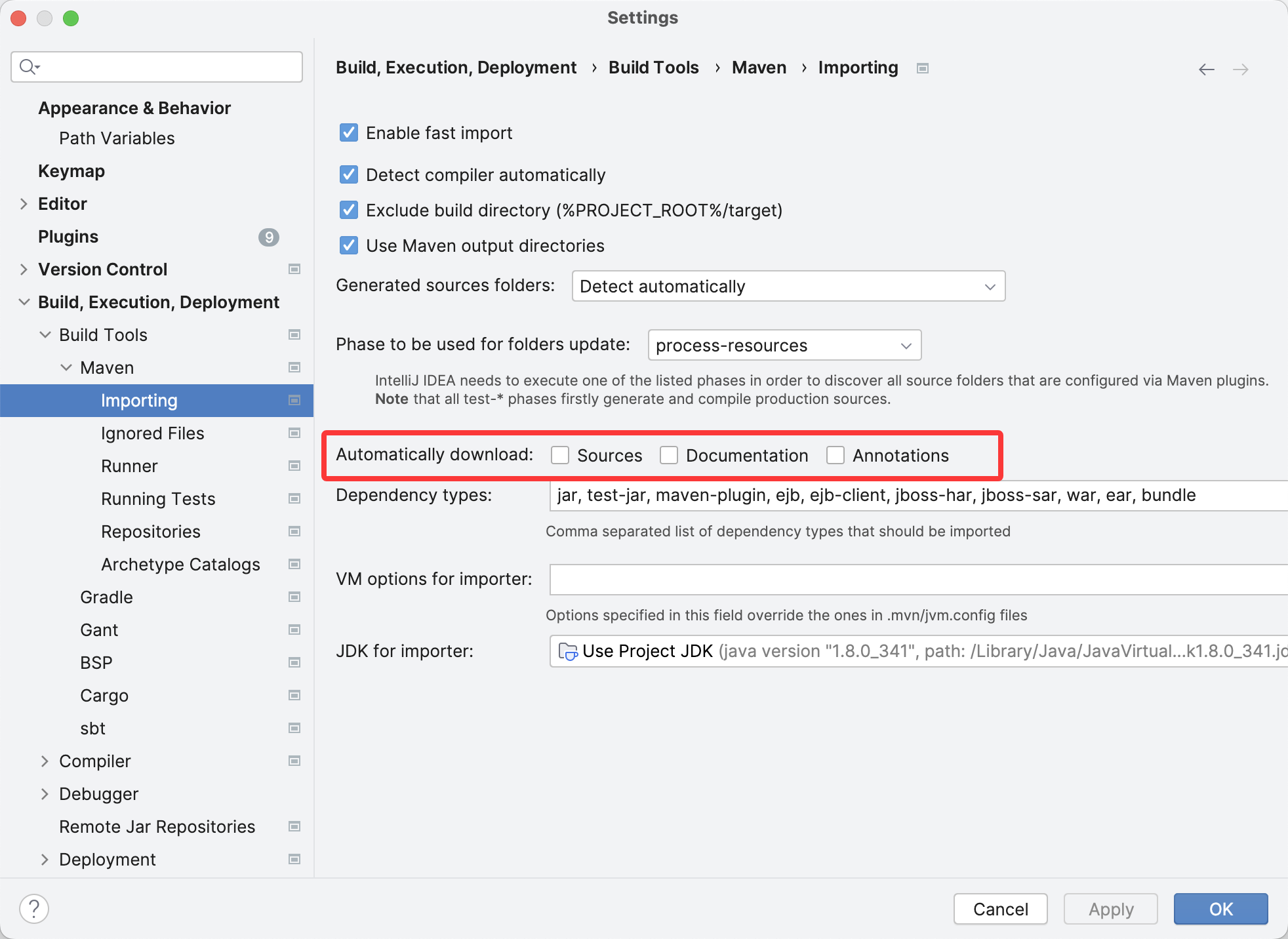
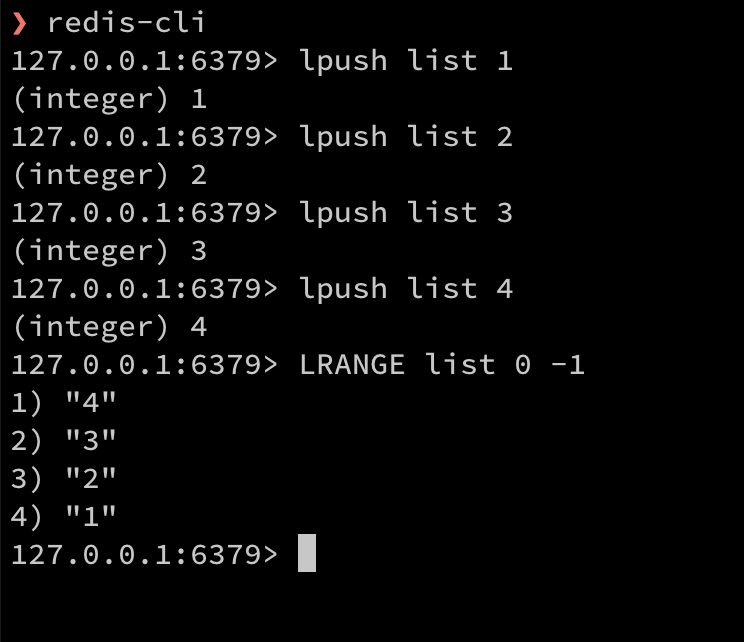
Mysql 字符编码和排序规则这个一直是属于一知半解的状态,知道 utf8 跟 utf8mb4 的区别主要是能不能支持 emoji,但是具体后面配置的排序规则是用来干嘛,或者有什么区别,应该使用哪个,所以在 stackoverflow 上找了下,有两个比较不错的解答,就搬过来并且配合机翻做了点修改
For those people still arriving at this question in 2020 or later, there are newer options that may be better than both of these. For example, utf8mb4_0900_ai_ci.
All these collations are for the UTF-8 character encoding. The differences are in how text is sorted and compared.
_unicode_ci and _general_ci are two different sets of rules for sorting and comparing text according to the way we expect. Newer versions of MySQL introduce new sets of rules, too, such as _0900_ai_ci for equivalent rules based on Unicode 9.0 - and with no equivalent _general_ci variant. People reading this now should probably use one of these newer collations instead of either _unicode_ci or _general_ci. The description of those older collations below is provided for interest only.
MySQL is currently transitioning away from an older, flawed UTF-8 implementation. For now, you need to use utf8mb4 instead of utf8 for the character encoding part, to ensure you are getting the fixed version. The flawed version remains for backward compatibility, though it is being deprecated.
Key differences
utf8mb4_unicode_ci is based on the official Unicode rules for universal sorting and comparison, which sorts accurately in a wide range of languages.
utf8mb4_general_ci is a simplified set of sorting rules which aims to do as well as it can while taking many short-cuts designed to improve speed. It does not follow the Unicode rules and will result in undesirable sorting or comparison in some situations, such as when using particular languages or characters.
On modern servers, this performance boost will be all but negligible. It was devised in a time when servers had a tiny fraction of the CPU performance of today’s computers.
Benefits of utf8mb4_unicode_ci over utf8mb4_general_ci
utf8mb4_unicode_ci, which uses the Unicode rules for sorting and comparison, employs a fairly complex algorithm for correct sorting in a wide range of languages and when using a wide range of special characters. These rules need to take into account language-specific conventions; not everybody sorts their characters in what we would call ‘alphabetical order’.
As far as Latin (ie “European”) languages go, there is not much difference between the Unicode sorting and the simplified utf8mb4_general_cisorting in MySQL, but there are still a few differences:
For examples, the Unicode collation sorts “ß” like “ss”, and “Œ” like “OE” as people using those characters would normally want, whereas utf8mb4_general_cisorts them as single characters (presumably like “s” and “e” respectively).
Some Unicode characters are defined as ignorable, which means they shouldn’t count toward the sort order and the comparison should move on to the next character instead. utf8mb4_unicode_cihandles these properly.
In non-latin languages, such as Asian languages or languages with different alphabets, there may be a lot more differences between Unicode sorting and the simplified utf8mb4_general_cisorting. The suitability of utf8mb4_general_ciwill depend heavily on the language used. For some languages, it’ll be quite inadequate.
What should you use?
There is almost certainly no reason to use utf8mb4_general_cianymore, as we have left behind the point where CPU speed is low enough that the performance difference would be important. Your database will almost certainly be limited by other bottlenecks than this.
In the past, some people recommended to use utf8mb4_general_ciexcept when accurate sorting was going to be important enough to justify the performance cost. Today, that performance cost has all but disappeared, and developers are treating internationalization more seriously.
There’s an argument to be made that if speed is more important to you than accuracy, you may as well not do any sorting at all. It’s trivial to make an algorithm faster if you do not need it to be accurate. So, utf8mb4_general_ciis a compromise that’s probably not needed for speed reasons and probably also not suitable for accuracy reasons.
One other thing I’ll add is that even if you know your application only supports the English language, it may still need to deal with people’s names, which can often contain characters used in other languages in which it is just as important to sort correctly. Using the Unicode rules for everything helps add peace of mind that the very smart Unicode people have worked very hard to make sorting work properly.
What the parts mean
Firstly, ci is for case-insensitive sorting and comparison. This means it’s suitable for textual data, and case is not important. The other types of collation are cs (case-sensitive) for textual data where case is important, and bin, for where the encoding needs to match, bit for bit, which is suitable for fields which are really encoded binary data (including, for example, Base64). Case-sensitive sorting leads to some weird results and case-sensitive comparison can result in duplicate values differing only in letter case, so case-sensitive collations are falling out of favor for textual data - if case is significant to you, then otherwise ignorable punctuation and so on is probably also significant, and a binary collation might be more appropriate.
Next, unicode or general refers to the specific sorting and comparison rules - in particular, the way text is normalized or compared. There are many different sets of rules for the utf8mb4 character encoding, with unicode and general being two that attempt to work well in all possible languages rather than one specific one. The differences between these two sets of rules are the subject of this answer. Note that unicode uses rules from Unicode 4.0. Recent versions of MySQL add the rulesets unicode_520 using rules from Unicode 5.2, and 0900 (dropping the “unicode_” part) using rules from Unicode 9.0.
And lastly, utf8mb4 is of course the character encoding used internally. In this answer I’m talking only about Unicode based encodings.
翻译
对于那些在 2020 年或之后仍会遇到这个问题的人,有可能比这两个更好的新选项。例如,utf8mb4_0900_ai_ci。
所有这些排序规则都用于 UTF-8 字符编码。不同之处在于文本的排序和比较方式。
_unicode_ci和 _general_ci是两组不同的规则,用于按照我们期望的方式对文本进行排序和比较。较新版本的 MySQL 也引入了新的规则集,例如 _0900_ai_ci用于基于 Unicode 9.0 的等效规则 - 并且没有等效的 _general_ci变体。现在阅读本文的人可能应该使用这些较新的排序规则之一,而不是 _unicode_ci或 _general_ci。下面对那些较旧的排序规则的描述仅供参考。
MySQL 目前正在从旧的、有缺陷的 UTF-8 实现过渡。现在,您需要使用 utf8mb4 而不是 utf8作为字符编码部分,以确保您获得的是固定版本。有缺陷的版本仍然是为了向后兼容,尽管它已被弃用。
主要区别
utf8mb4_unicode_ci基于官方 Unicode 规则进行通用排序和比较,可在多种语言中准确排序。
utf8mb4_general_ci是一组简化的排序规则,旨在尽其所能,同时采用许多旨在提高速度的捷径。它不遵循 Unicode 规则,并且在某些情况下会导致不希望的排序或比较,例如在使用特定语言或字符时。
在现代服务器上,这种性能提升几乎可以忽略不计。它是在服务器的 CPU 性能只有当今计算机的一小部分时设计的。
utf8mb4_unicode_ci 相对于 utf8mb4_general_ci的优势
utf8mb4_unicode_ci使用 Unicode 规则进行排序和比较,采用相当复杂的算法在多种语言中以及在使用多种特殊字符时进行正确排序。这些规则需要考虑特定语言的约定;不是每个人都按照我们所说的“字母顺序”对他们的字符进行排序。
就拉丁语(即“欧洲”)语言而言,Unicode 排序和 MySQL 中简化的 utf8mb4_general_ci排序没有太大区别,但仍有一些区别:
例如,Unicode 排序规则将“ß”排序为“ss”,将“Œ”排序为“OE”,因为使用这些字符的人通常需要这些字符,而 utf8mb4_general_ci将它们排序为单个字符(大概分别像“s”和“e” )。
一些 Unicode 字符被定义为可忽略,这意味着它们不应该计入排序顺序,并且比较应该转到下一个字符。 utf8mb4_unicode_ci正确处理这些。
在非拉丁语言中,例如亚洲语言或具有不同字母的语言,Unicode 排序和简化的 utf8mb4_general_ci排序之间可能存在更多差异。 utf8mb4_general_ci的适用性在很大程度上取决于所使用的语言。对于某些语言,这将是非常不充分的。
你应该用什么?
几乎可以肯定没有理由再使用 utf8mb4_general_ci,因为我们已经将 CPU 速度低到会严重影响性能表现的时代远抛在脑后了。您的数据库几乎肯定会受到除此之外的其他瓶颈的限制。
过去,有些人建议使用 utf8mb4_general_ci,除非准确排序足够重要以证明性能成本是合理的。如今,这种性能成本几乎消失了,开发人员正在更加认真地对待国际化。
有一个论点是,如果速度对您来说比准确性更重要,那么您可能根本不进行任何排序。如果您不需要准确的算法,那么使算法更快是微不足道的。因此,utf8mb4_general_ci是一种折衷方案,出于速度原因可能不需要,也可能出于准确性原因也不适合。
我要补充的另一件事是,即使您知道您的应用程序仅支持英语,它可能仍需要处理人名,这些人名通常包含其他语言中使用的字符,在这些语言中正确排序同样重要.对所有事情都使用 Unicode 规则有助于让您更加安心,因为非常聪明的 Unicode 人员已经非常努力地工作以使排序正常工作。
其余各个部分是什么意思
首先, ci 用于不区分大小写的排序和比较。这意味着它适用于文本数据,大小写并不重要。其他类型的排序规则是 cs(区分大小写),用于区分大小写的文本数据,以及 bin,用于编码需要匹配的地方,逐位匹配,适用于真正编码二进制数据的字段(包括,用于例如,Base64)。区分大小写的排序会导致一些奇怪的结果,区分大小写的比较可能会导致重复值仅在字母大小写上有所不同,因此区分大小写的排序规则对文本数据不受欢迎 - 如果大小写对您很重要,那么标点符号就可以忽略等等可能也很重要,二进制排序规则可能更合适。
接下来,unicode 或general 指的是具体的排序和比较规则——特别是文本被规范化或比较的方式。 utf8mb4 字符编码有许多不同的规则集,其中 unicode 和 general 是两种,它们试图在所有可能的语言中都很好地工作,而不是在一种特定的语言中。这两组规则之间的差异是此答案的主题。请注意,unicode 使用 Unicode 4.0 中的规则。 MySQL 的最新版本使用 Unicode 5.2 的规则添加规则集 unicode_520,使用 Unicode 9.0 的规则添加 0900(删除“unicode_”部分)。
最后,utf8mb4 当然是内部使用的字符编码。在这个答案中,我只谈论基于 Unicode 的编码。
utf8 和 utf8mb4 编码有什么区别
UTF-8is a variable-length encoding. In the case of UTF-8, this means that storing one code point requires one to four bytes. However, MySQL’s encoding called “utf8” (alias of “utf8mb3”) only stores a maximum of three bytes per code point.
So the character set “utf8”/“utf8mb3” cannot store all Unicode code points: it only supports the range 0x000 to 0xFFFF, which is called the “Basic Multilingual Plane“. See also Comparison of Unicode encodings.
This is what (a previous version of the same page at)the MySQL documentationhas to say about it:
The character set named utf8[/utf8mb3] uses a maximum of three bytes per character and contains only BMP characters. As of MySQL 5.5.3, the utf8mb4 character set uses a maximum of four bytes per character supports supplemental characters:
- For a BMP character, utf8[/utf8mb3] and utf8mb4 have identical storage characteristics: same code values, same encoding, same length.
- For a supplementary character, utf8[/utf8mb3] cannot store the character at all, while utf8mb4 requires four bytes to store it. Since utf8[/utf8mb3] cannot store the character at all, you do not have any supplementary characters in utf8[/utf8mb3] columns and you need not worry about converting characters or losing data when upgrading utf8[/utf8mb3] data from older versions of MySQL.
So if you want your column to support storing characters lying outside the BMP (and you usually want to), such as emoji, use “utf8mb4”. See also What are the most common non-BMP Unicode characters in actual use?.
译文
UTF-8 是一种可变长度编码。对于 UTF-8,这意味着存储一个代码点需要一到四个字节。但是,MySQL 的编码称为“utf8”(“utf8mb3”的别名)每个代码点最多只能存储三个字节。
所以字符集“utf8”/“utf8mb3”不能存储所有的Unicode码位:它只支持0x000到0xFFFF的范围,被称为“基本多语言平面”。另请参阅 Unicode 编码比较。
这就是(同一页面的先前版本)MySQL 文档 不得不说的:
名为 utf8[/utf8mb3] 的字符集每个字符最多使用三个字节,并且仅包含 BMP 字符。从 MySQL 5.5.3 开始,utf8mb4 字符集每个字符最多使用四个字节,支持补充字符:
- 对于 BMP 字符,utf8[/utf8mb3] 和 utf8mb4 具有相同的存储特性:相同的代码值、相同的编码、相同的长度。
- 对于补充字符,utf8[/utf8mb3] 根本无法存储该字符,而 utf8mb4 需要四个字节来存储它。由于 utf8[/utf8mb3] 根本无法存储字符,因此您在 utf8[/utf8mb3] 列中没有任何补充字符,您不必担心从旧版本升级 utf8[/utf8mb3] 数据时转换字符或丢失数据mysql。
因此,如果您希望您的列支持存储位于 BMP 之外的字符(并且您通常希望这样做),例如 emoji,请使用“utf8mb4”。另请参阅
实际使用中最常见的非 BMP Unicode 字符是什么? 。
]]>












































![9G5FE[9%@7%G(B`Q7]E)5@R.png](https://ooo.0o0.ooo/2016/08/10/57aac43029559.png)








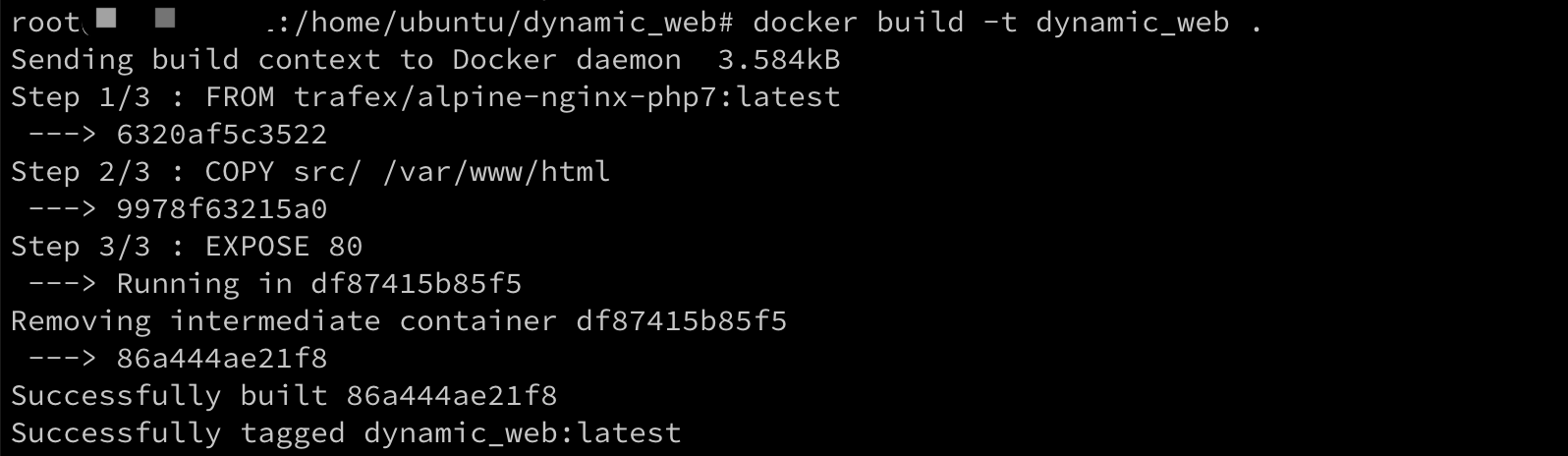
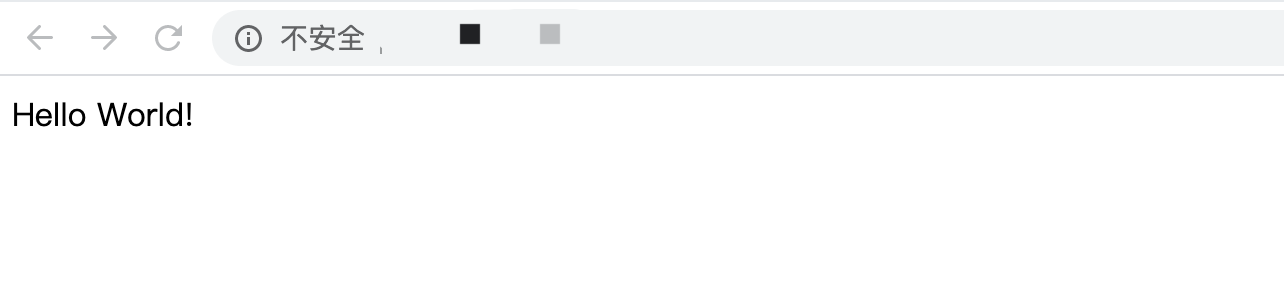


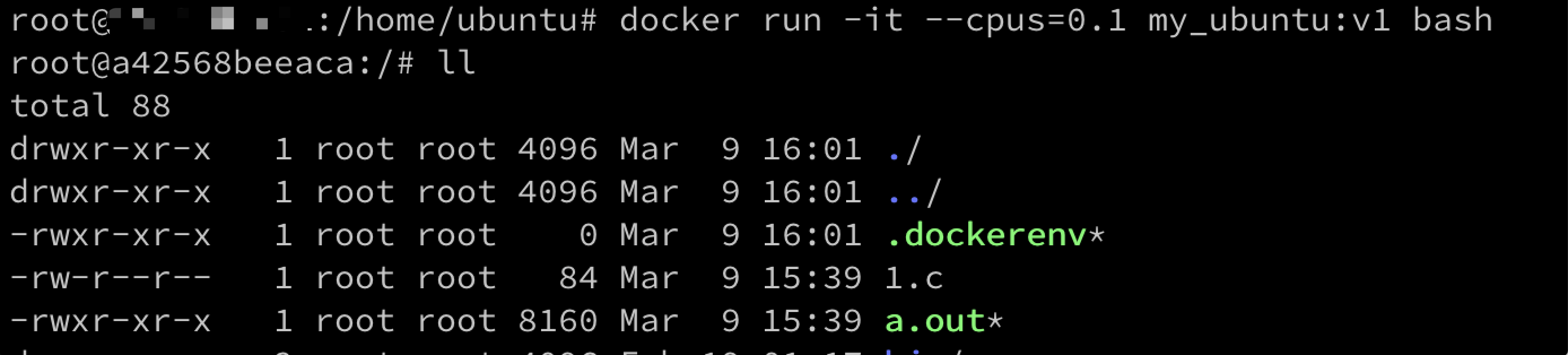

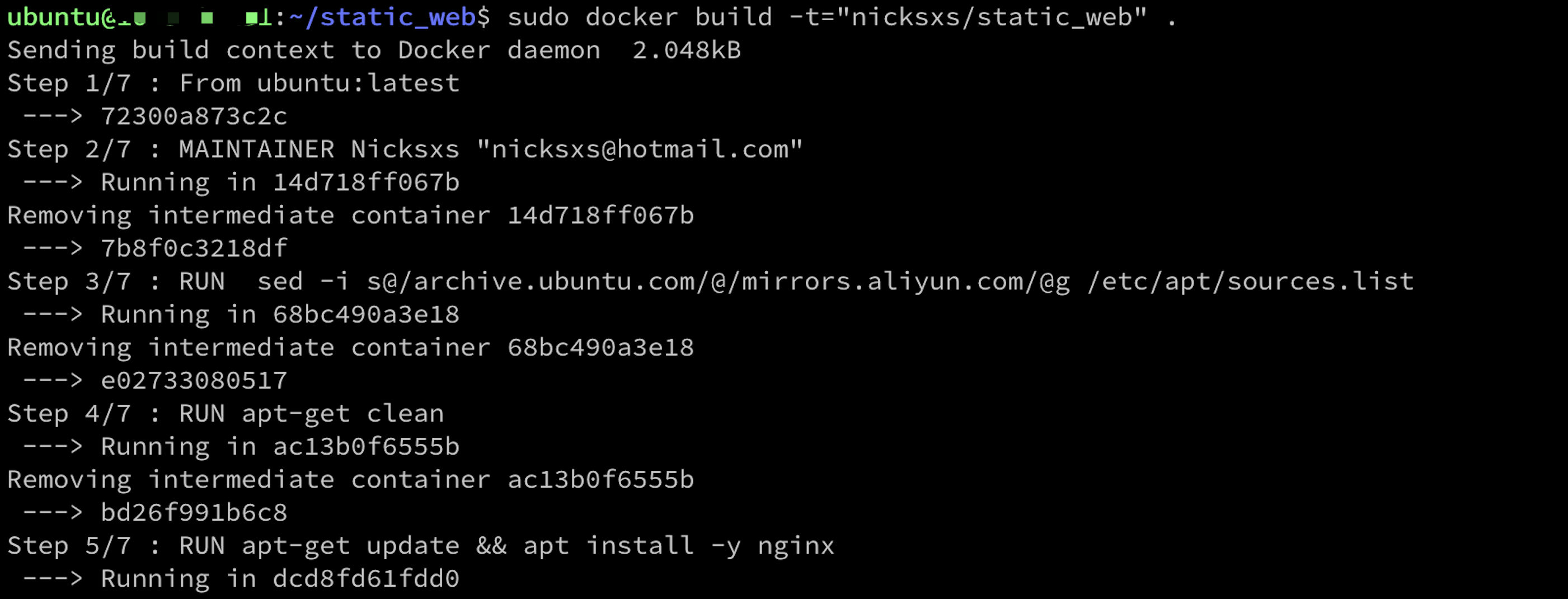



































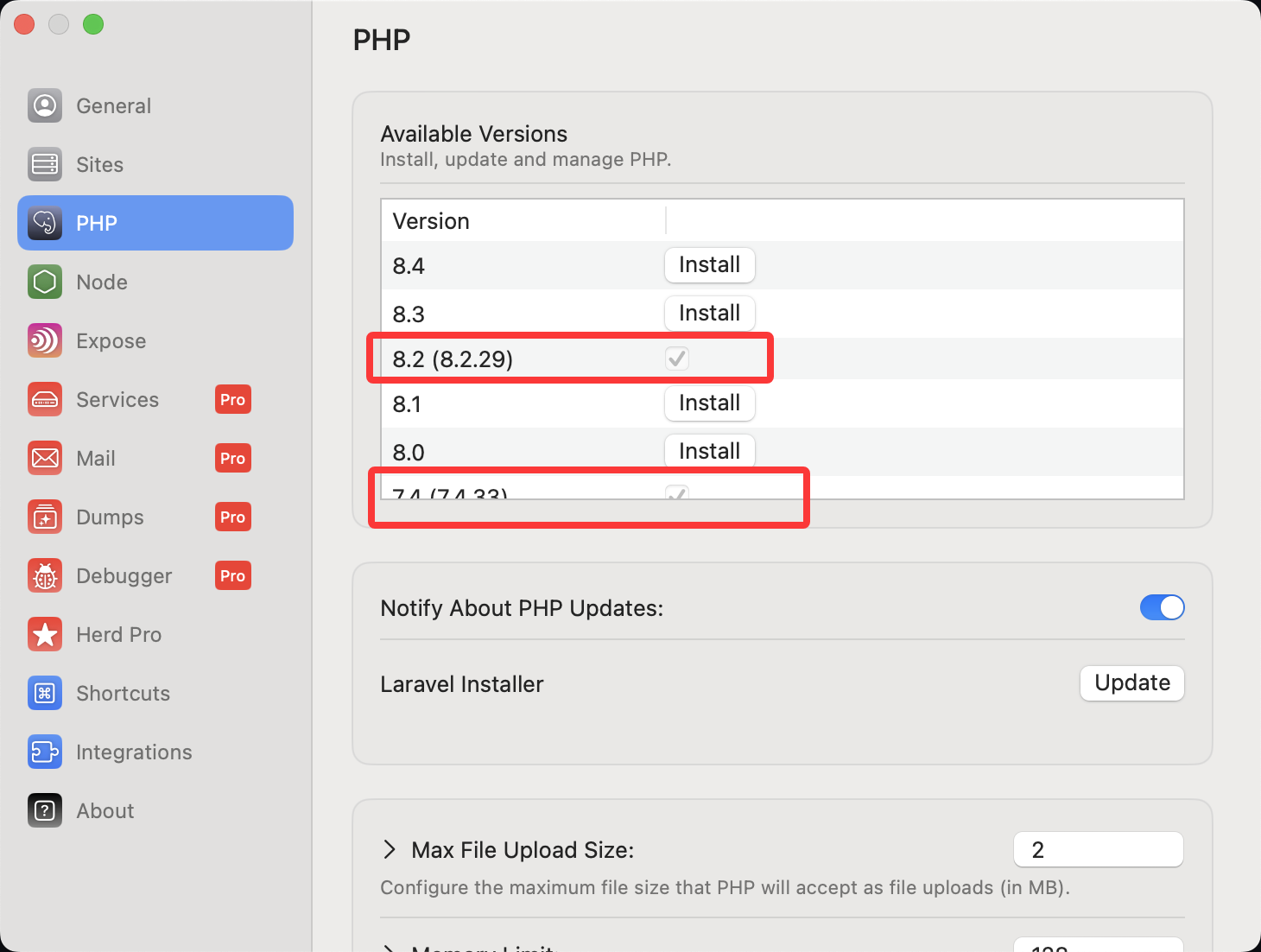
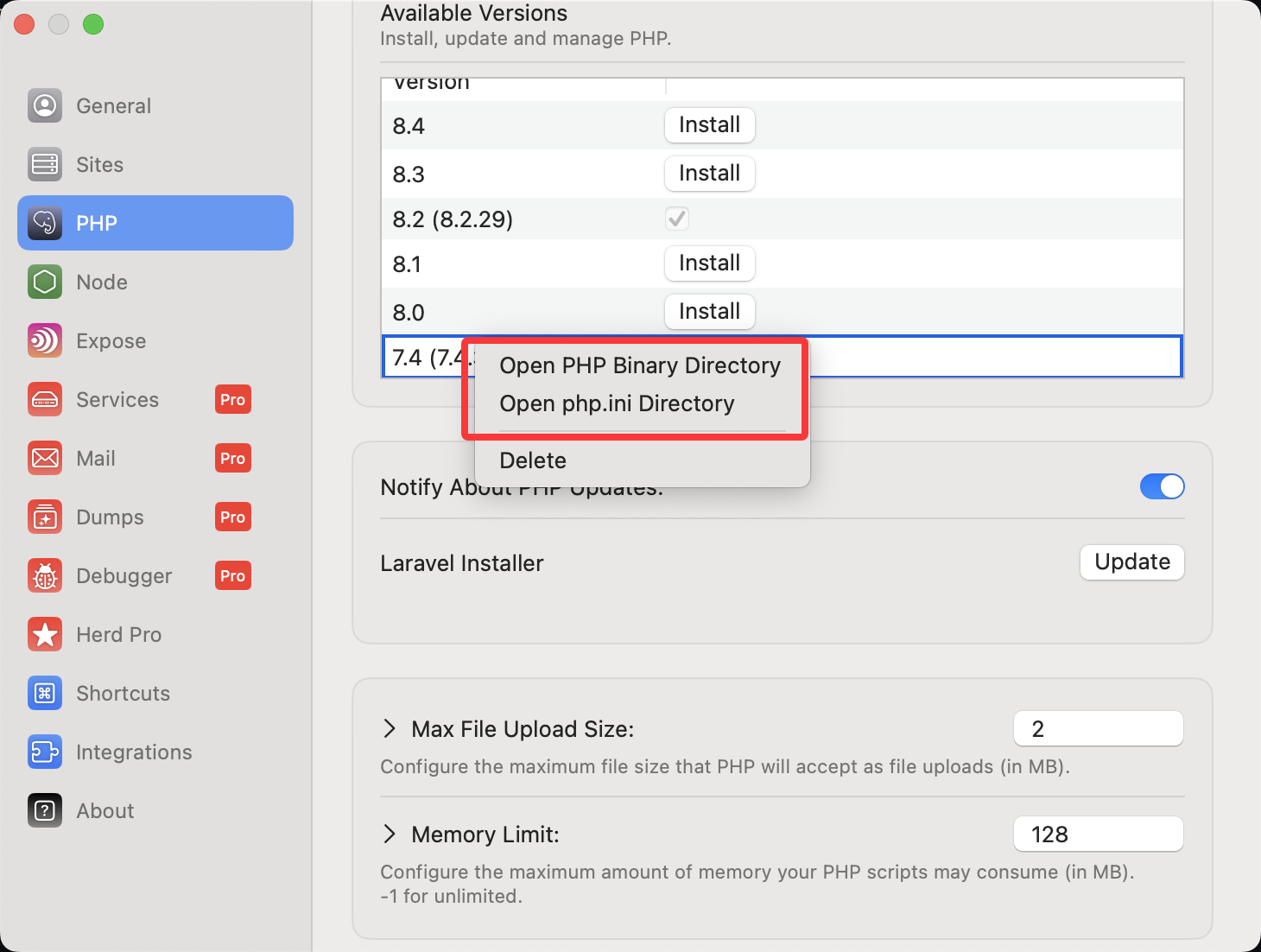
 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换 好像是这里了
好像是这里了




















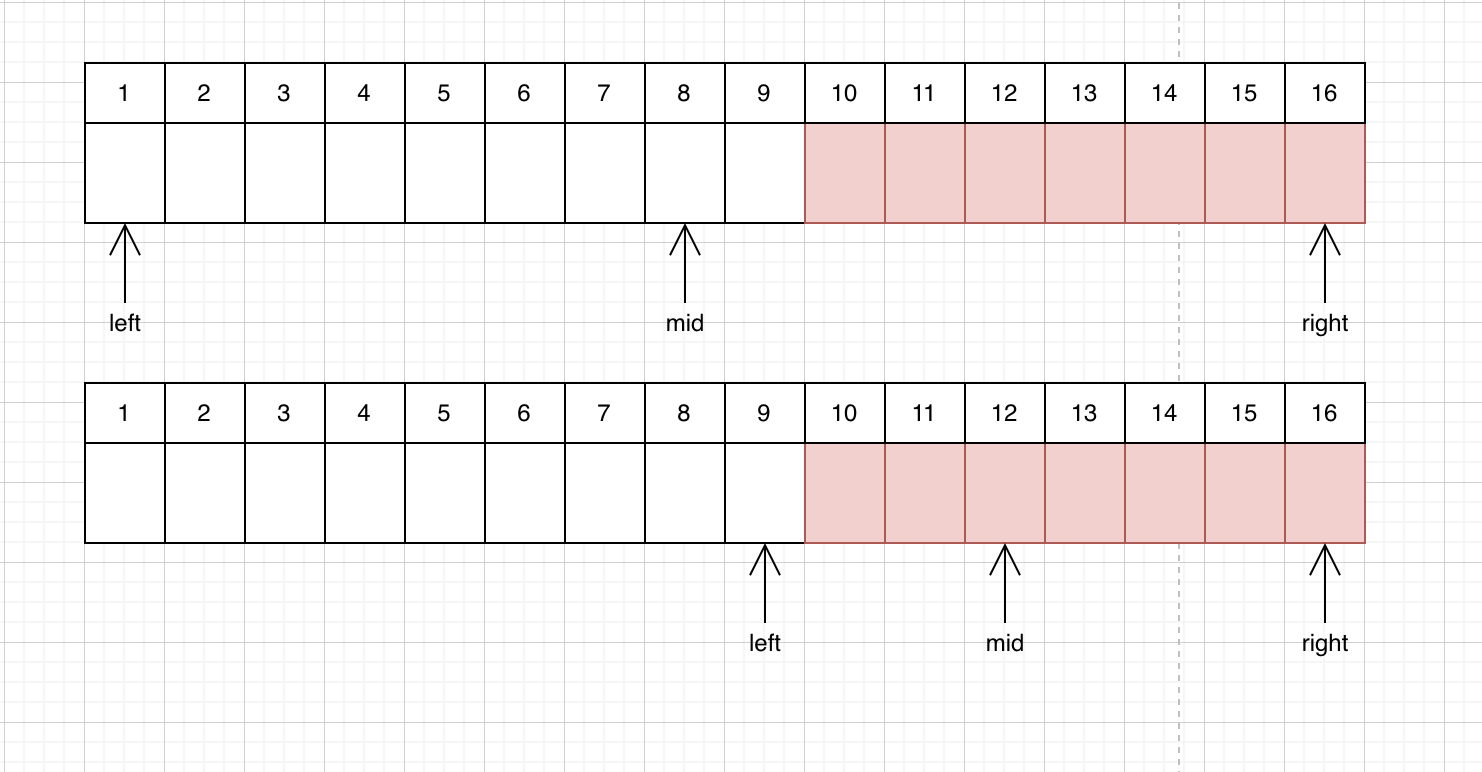
 ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,














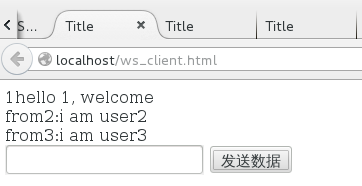
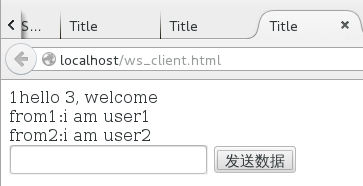
user2:
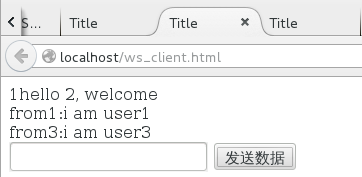
user3:




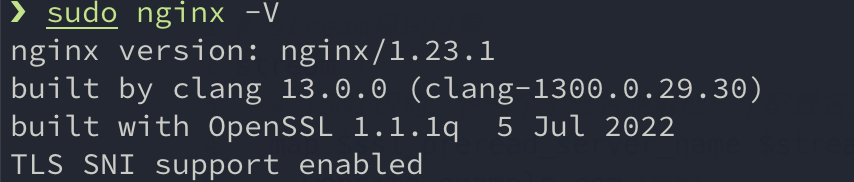



















 的url进行配置,以及确定模型名是 deepseek-r1-250120
的url进行配置,以及确定模型名是 deepseek-r1-250120


 ]]>
]]>



 ,这样就不会被覆盖
]]>
,这样就不会被覆盖
]]>




 ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息












































































































 , 正好又解决了下
, 正好又解决了下