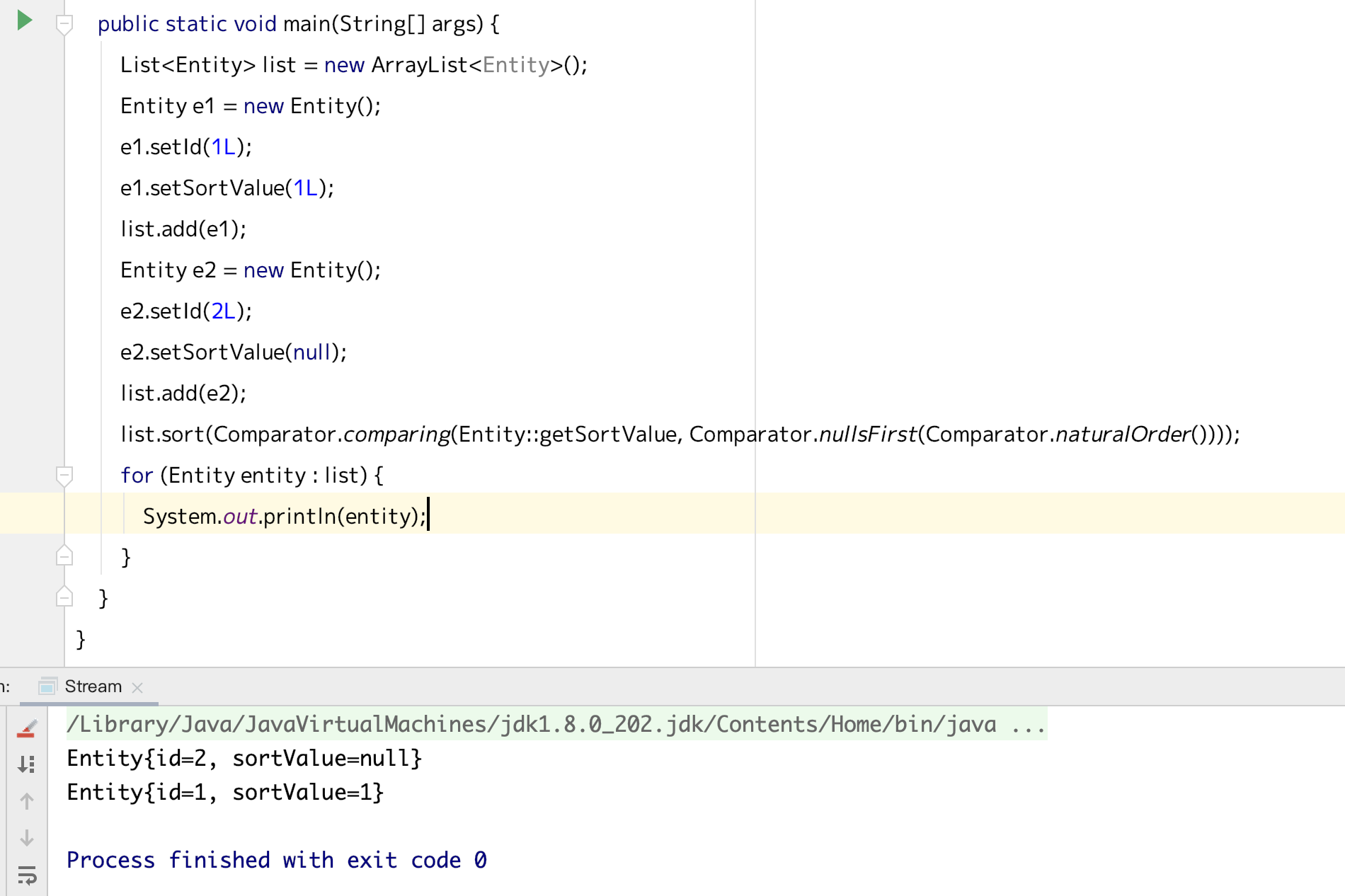
因为传说中的出身问题,我以前写的是PHP,在使用 swoole 之前,基本的应用调试手段就是简单粗暴的 var_dump,exit,对于单进程模型的 PHP 也是简单有效,技术栈换成 Java 之后,就变得没那么容易,一方面是需要编译,另一方面是一般都是基于 spring 的项目,如果问题定位比较模糊,那框架层的是很难靠简单的 System.out.println 或者打 log 解决,(PS:我觉得可能我写的东西比较适合从 PHP 这种弱类型语言转到 Java 的小白同学)这个时候一方面因为是 Java,有了非常好用的 idea IDE 的支持,可以各种花式调试,条件断点尤其牛叉,但是又因为有 Spring+Java 的双重原因,有些情况下单步调试可以把手按废掉,这也是我之前一直比较困惑苦逼的点,后来随着慢慢精(jiang)进(you)之后,比如对于一个 oom 的情况,我们可以通过启动参数加上-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=xx/xx 来配置溢出时的堆dump 日志,获取到这个文件后,我们可以通过像 Memory Analyzer (MAT)[https://www.eclipse.org/mat/] (The Eclipse Memory Analyzer is a fast and feature-rich Java heap analyzer that helps you find memory leaks and reduce memory consumption.)来查看诊断问题所在,之前用到的时候是因为有个死循环一直往链表里塞数据,属于比较简单的,后来一次是由于运维进行应用迁移时按默认的统一配置了堆内存大小,导致内存的确不够用,所以溢出了, 今天想说的其实主要是我们的 thread dump,这也是我最近才真正用的一个方法,可能真的很小白了,用过 ide 的单步调试其实都知道会有一个一层层的玩意,比如函数从 A,调用了 B,再从 B 调用了 C,一直往下(因为是 Java,所以还有很多🤦♂️),这个其实也是大部分语言的调用模型,利用了栈这个数据结构,通过这个结构我们可以知道代码的调用链路,由于对于一个 spring 应用,在本身框架代码量非常庞大的情况下,外加如果应用代码也是非常多的时候,有时候通过单步调试真的很难短时间定位到问题,需要非常大的耐心和仔细观察,当然不是说完全不行,举个例子当我的应用经常启动需要非常长的时间,因为本身应用有非常多个 bean,比较难说究竟是 bean 的加载的确很慢还是有什么异常原因,这种时候就可以使用 thread dump 了,具体怎么操作呢 如果在idea 中运行或者调试时,可以直接点击这个照相机一样的按钮,右边就会出现了左边会显示所有的线程,右边会显示线程栈,
1 2 3 4 5 6 7
"main@1" prio=5 tid=0x1 nid=NA runnable java.lang.Thread.State: RUNNABLE at TreeDistance.treeDist(TreeDistance.java:64) at TreeDistance.treeDist(TreeDistance.java:65) at TreeDistance.treeDist(TreeDistance.java:65) at TreeDistance.treeDist(TreeDistance.java:65) at TreeDistance.main(TreeDistance.java:45)
下单的是后要冻结核销优惠券,如果账户里有钱要冻结扣除账户里的钱,如果使用了J 豆也一样,可能还有 E 卡,忽略我借用的平台,因为目前一般后台服务化之后,可能每一项都是对应的一个后台服务,我们期望的执行过程是要不全成功,要不就全保持执行前状态,不能是部分扣减核销成功了,部分还不行,所以我们处理这种情况会引入一些通用的方案,第一种叫二阶段提交,
对于上面的例子,我们将整个过程分成两个阶段,首先是提交请求阶段,这个阶段大概需要做的是确定资源存在,锁定资源,可能还要做好失败后回滚的准备,如果这些都 ok 了那么就响应成功,这里其实用到了一个叫事务的协调者的角色,类似于裁判员,每个节点都反馈第一阶段成功后,开始执行第二阶段,也就是实际执行操作,这里也是需要所有节点都反馈成功后才是执行成功,要不就是失败回滚。其实常用的分布式事务的解决方案主要也是基于此方案的改进,比如后面介绍的三阶段提交,有三阶段提交就是因为二阶段提交比较尴尬的几个点,
看完前面两篇水文之后,感觉不得不来分析下 mysql 的锁了,其实前面说到幻读的时候是有个前提没提到的,比如一个select * from table1 where id = 1这种查询语句其实是不会加传说中的锁的,当然这里是指在 RR 或者 RC 隔离级别下, 看一段 mysql官方文档
SELECT ... FROM is a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set to SERIALIZABLE. For SERIALIZABLE level, the search sets shared next-key locks on the index records it encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
除了第一条是 S 锁之外,其他都是 X 排他锁,这边在顺带下,S 锁表示共享锁, X 表示独占锁,同为 S 锁之间不冲突,S 与 X,X 与 S,X 与 X 之间都冲突,也就是加了前者,后者就加不上了 我们知道对于 RC 级别会出现幻读现象,对于 RR 级别不会出现,主要的区别是 RR 级别下对于以上的加锁读取都根据情况加上了 gap 锁,那么是不是 RR 级别下以上所有的都是要加 gap 锁呢,当然不是 举个例子,RR 事务隔离级别下,table1 有个主键id 字段 select * from table1 where id = 10 for update 这条语句要加 gap 锁吗? 答案是不需要,这里其实算是我看了这么久的一点自己的理解,啥时候要加 gap 锁,判断的条件是根据我查询的数据是否会因为不加 gap 锁而出现数量的不一致,我上面这条查询语句,在什么情况下会出现查询结果数量不一致呢,只要在这条记录被更新或者删除的时候,有没有可能我第一次查出来一条,第二次变成两条了呢,不可能,因为是主键索引。 再变更下这个题的条件,当 id 不是主键,但是是唯一索引,这样需要怎么加锁,注意问题是怎么加锁,不是需不需要加 gap 锁,这里呢就是稍微延伸一下,把聚簇索引(主键索引)和二级索引带一下,当 id 不是主键,说明是个二级索引,但是它是唯一索引,体会下,首先对于 id = 10这个二级索引肯定要加锁,要不要锁 gap 呢,不用,因为是唯一索引,id = 10 只可能有这一条记录,然后呢,这样是不是就好了,还不行,因为啥,因为它是二级索引,对应的主键索引的记录才是真正的数据,万一被更新掉了咋办,所以在 id = 10 对应的主键索引上也需要加上锁(默认都是 record lock行锁),那主键索引上要不要加 gap 呢,也不用,也是精确定位到这一条记录 最后呢,当 id 不是主键,也不是唯一索引,只是个普通的索引,这里就需要大名鼎鼎的 gap 锁了, 是时候画个图了 其实核心的目的还是不让这个 id=10 的记录不会出现幻读,那么就需要在 id 这个索引上加上三个 gap 锁,主键索引上就不用了,在 id 索引上已经控制住了id = 10 不会出现幻读,主键索引上这两条对应的记录已经锁了,所以就这样 OK 了
还有一个问题是幻读的问题,这貌似也是个高频面试题,啥意思呢,或者说跟它最常拿来比较的脏读,脏读是指读到了别的事务未提交的数据,因为未提交,严格意义上来讲,不一定是会被最后落到库里,可能会回滚,也就是在 read uncommitted 级别下会出现的问题,但是幻读不太一样,幻读是指两次查询的结果数量不一样,比如我查了第一次是 select * from table1 where id < 10 for update,查出来了一条结果 id 是 5,然后再查一下发现出来了一条 id 是 5,一条 id 是 7,那是不是有点尴尬了,其实呢这个点我觉得脏读跟幻读也比较是从原理层面来命名,如果第一次接触的同学发觉有点不理解也比较正常,因为从逻辑上讲总之都是数据不符合预期,但是基于源码层面其实是不同的情况,幻读是在原先的 read view 无法完全解决的,怎么解决呢,简单的来说就是锁咯,我们知道innodb 是基于 record lock 行锁的,但是貌似没有办法解决这种问题,那么 innodb 就引入了 gap lock 间隙锁,比如上面说的情况下,id 小于 10 的情况下,是都应该锁住的,gap lock 其实是基于索引结构来锁的,因为索引树除了树形结构之外,还有一个next record 的指针,gap lock 也是基于这个来锁的 看一下 mysql 的文档
SELECT … FOR UPDATE sets an exclusive next-key lock on every record the search encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
对于一个 for update 查询,在 RR 级别下,会设置一个 next-key lock在每一条被查询到的记录上,next-lock 又是啥呢,其实就是 gap 锁和 record 锁的结合体,比如我在数据库里有 id 是 1,3,5,7,10,对于上面那条查询,查出来的结果就是 1,3,5,7,那么按照文档里描述的,对于这几条记录都会加上next-key lock,也就是(-∞, 1], (1, 3], (3, 5], (5, 7], (7, 10) 这些区间和记录会被锁起来,不让插入,再唠叨一下呢,就是其实如果是只读的事务,光 read view 一致性读就够了,如果是有写操作的呢,就需要锁了。
腆着脸说虽然这个不可行,但是思路是对的,具体实行起来需要做一系列(肥肠多)的改动,首先根据我的理解,其实这个拷贝一个表是变成拷贝一条记录,但是如果有多个事务,那就得拷贝多次,这个问题其实可以借助版本管理系统来解释,在用版本管理系统,git 之类的之前,很原始的可能是开发完一个功能后,就打个压缩包用时间等信息命名,然后如果后面要找回这个就直接用这个压缩包的就行了,后来有了 svn,git 中心式和分布式的版本管理系统,它的一个特点是粒度可以控制到文件和代码行级别,对应的我们的 mysql 事务是不是也可以从一开始预想的表级别细化到行的级别,可能之前很多人都了解过,数据库的一行记录除了我们用户自定义的字段,还有一些额外的字段,去源码data0type.h里捞一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* Precise data types for system columns and the length of those columns; NOTE: the values must run from 0 up in the order given! All codes must be less than 256 */ #define DATA_ROW_ID 0 /* row id: a 48-bit integer */ #define DATA_ROW_ID_LEN 6 /* stored length for row id */
/** Check whether the changes by id are visible. @param[in] id transaction id to check against the view @param[in] name table name @return whether the view sees the modifications of id. */ boolchanges_visible(trx_id_t id, consttable_name_t &name)const MY_ATTRIBUTE((warn_unused_result)){ ut_ad(id > 0);
if (id < m_up_limit_id || id == m_creator_trx_id) { return (true); }
check_trx_id_sanity(id, name);
if (id >= m_low_limit_id) { return (false);
} elseif (m_ids.empty()) { return (true); }
constids_t::value_type *p = m_ids.data();
return (!std::binary_search(p, p + m_ids.size(), id)); }
说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍 ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F, 当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。 redis 针对这个策略的改进做了一个实验,这里借用下图 首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
1 2 3 4 5 6 7 8 9
typedefstructredisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr; } robj;
/* Low level key lookup API, not actually called directly from commands * implementations that should instead rely on lookupKeyRead(), * lookupKeyWrite() and lookupKeyReadWithFlags(). */ robj *lookupKey(redisDb *db, robj *key, int flags){ dictEntry *de = dictFind(db->dict,key->ptr); if (de) { robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm. * Don't do it if we have a saving child, as this will trigger * a copy on write madness. */ if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { // 这个是后面一节的内容 updateLFU(val); } else { // 对于这个分支,访问时就会去更新 lru 值 val->lru = LRU_CLOCK(); } } return val; } else { returnNULL; } } /* This function is used to obtain the current LRU clock. * If the current resolution is lower than the frequency we refresh the * LRU clock (as it should be in production servers) we return the * precomputed value, otherwise we need to resort to a system call. */ unsignedintLRU_CLOCK(void){ unsignedint lruclock; if (1000/server.hz <= LRU_CLOCK_RESOLUTION) { // 如果服务器的频率server.hz大于 1 时就是用系统预设的 lruclock lruclock = server.lruclock; } else { lruclock = getLRUClock(); } return lruclock; } /* Return the LRU clock, based on the clock resolution. This is a time * in a reduced-bits format that can be used to set and check the * object->lru field of redisObject structures. */ unsignedintgetLRUClock(void){ return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX; }
/* If this function gets called we already read a whole * command, arguments are in the client argv/argc fields. * processCommand() execute the command or prepare the * server for a bulk read from the client. * * If C_OK is returned the client is still alive and valid and * other operations can be performed by the caller. Otherwise * if C_ERR is returned the client was destroyed (i.e. after QUIT). */ intprocessCommand(client *c){ moduleCallCommandFilters(c);
/* Handle the maxmemory directive. * * Note that we do not want to reclaim memory if we are here re-entering * the event loop since there is a busy Lua script running in timeout * condition, to avoid mixing the propagation of scripts with the * propagation of DELs due to eviction. */ if (server.maxmemory && !server.lua_timedout) { int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR; /* freeMemoryIfNeeded may flush slave output buffers. This may result * into a slave, that may be the active client, to be freed. */ if (server.current_client == NULL) return C_ERR;
/* It was impossible to free enough memory, and the command the client * is trying to execute is denied during OOM conditions or the client * is in MULTI/EXEC context? Error. */ if (out_of_memory && (c->cmd->flags & CMD_DENYOOM || (c->flags & CLIENT_MULTI && c->cmd->proc != execCommand && c->cmd->proc != discardCommand))) { flagTransaction(c); addReply(c, shared.oomerr); return C_OK; } } }
/* This is a wrapper for freeMemoryIfNeeded() that only really calls the * function if right now there are the conditions to do so safely: * * - There must be no script in timeout condition. * - Nor we are loading data right now. * */ intfreeMemoryIfNeededAndSafe(void){ if (server.lua_timedout || server.loading) return C_OK; return freeMemoryIfNeeded(); } /* This function is periodically called to see if there is memory to free * according to the current "maxmemory" settings. In case we are over the * memory limit, the function will try to free some memory to return back * under the limit. * * The function returns C_OK if we are under the memory limit or if we * were over the limit, but the attempt to free memory was successful. * Otehrwise if we are over the memory limit, but not enough memory * was freed to return back under the limit, the function returns C_ERR. */ intfreeMemoryIfNeeded(void){ int keys_freed = 0; /* By default replicas should ignore maxmemory * and just be masters exact copies. */ if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
/* When clients are paused the dataset should be static not just from the * POV of clients not being able to write, but also from the POV of * expires and evictions of keys not being performed. */ if (clientsArePaused()) return C_OK; if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK) return C_OK;
mem_freed = 0;
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION) goto cant_free; /* We need to free memory, but policy forbids. */
latencyStartMonitor(latency); while (mem_freed < mem_tofree) { int j, k, i; staticunsignedint next_db = 0; sds bestkey = NULL; int bestdbid; redisDb *db; dict *dict; dictEntry *de;
/* We don't want to make local-db choices when expiring keys, * so to start populate the eviction pool sampling keys from * every DB. */ for (i = 0; i < server.dbnum; i++) { db = server.db+i; dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires; if ((keys = dictSize(dict)) != 0) { evictionPoolPopulate(i, dict, db->dict, pool); total_keys += keys; } } if (!total_keys) break; /* No keys to evict. */
/* Go backward from best to worst element to evict. */ for (k = EVPOOL_SIZE-1; k >= 0; k--) { if (pool[k].key == NULL) continue; bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) { de = dictFind(server.db[pool[k].dbid].dict, pool[k].key); } else { de = dictFind(server.db[pool[k].dbid].expires, pool[k].key); }
/* Remove the entry from the pool. */ if (pool[k].key != pool[k].cached) sdsfree(pool[k].key); pool[k].key = NULL; pool[k].idle = 0;
/* If the key exists, is our pick. Otherwise it is * a ghost and we need to try the next element. */ if (de) { bestkey = dictGetKey(de); break; } else { /* Ghost... Iterate again. */ } } } }
/* volatile-random and allkeys-random policy */ elseif (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM || server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM) { /* When evicting a random key, we try to evict a key for * each DB, so we use the static 'next_db' variable to * incrementally visit all DBs. */ for (i = 0; i < server.dbnum; i++) { j = (++next_db) % server.dbnum; db = server.db+j; dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ? db->dict : db->expires; if (dictSize(dict) != 0) { de = dictGetRandomKey(dict); bestkey = dictGetKey(de); bestdbid = j; break; } } }
/* Finally remove the selected key. */ if (bestkey) { db = server.db+bestdbid; robj *keyobj = createStringObject(bestkey,sdslen(bestkey)); propagateExpire(db,keyobj,server.lazyfree_lazy_eviction); /* We compute the amount of memory freed by db*Delete() alone. * It is possible that actually the memory needed to propagate * the DEL in AOF and replication link is greater than the one * we are freeing removing the key, but we can't account for * that otherwise we would never exit the loop. * * AOF and Output buffer memory will be freed eventually so * we only care about memory used by the key space. */ delta = (longlong) zmalloc_used_memory(); latencyStartMonitor(eviction_latency); if (server.lazyfree_lazy_eviction) dbAsyncDelete(db,keyobj); else dbSyncDelete(db,keyobj); latencyEndMonitor(eviction_latency); latencyAddSampleIfNeeded("eviction-del",eviction_latency); latencyRemoveNestedEvent(latency,eviction_latency); delta -= (longlong) zmalloc_used_memory(); mem_freed += delta; server.stat_evictedkeys++; notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted", keyobj, db->id); decrRefCount(keyobj); keys_freed++;
/* When the memory to free starts to be big enough, we may * start spending so much time here that is impossible to * deliver data to the slaves fast enough, so we force the * transmission here inside the loop. */ if (slaves) flushSlavesOutputBuffers();
/* Normally our stop condition is the ability to release * a fixed, pre-computed amount of memory. However when we * are deleting objects in another thread, it's better to * check, from time to time, if we already reached our target * memory, since the "mem_freed" amount is computed only * across the dbAsyncDelete() call, while the thread can * release the memory all the time. */ if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) { if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) { /* Let's satisfy our stop condition. */ mem_freed = mem_tofree; } } } else { latencyEndMonitor(latency); latencyAddSampleIfNeeded("eviction-cycle",latency); goto cant_free; /* nothing to free... */ } } latencyEndMonitor(latency); latencyAddSampleIfNeeded("eviction-cycle",latency); return C_OK;
cant_free: /* We are here if we are not able to reclaim memory. There is only one * last thing we can try: check if the lazyfree thread has jobs in queue * and wait... */ while(bioPendingJobsOfType(BIO_LAZY_FREE)) { if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree) break; usleep(1000); } return C_ERR; }
/* If the dictionary we are sampling from is not the main * dictionary (but the expires one) we need to lookup the key * again in the key dictionary to obtain the value object. */ if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) { if (sampledict != keydict) de = dictFind(keydict, key); o = dictGetVal(de); }
/* Calculate the idle time according to the policy. This is called * idle just because the code initially handled LRU, but is in fact * just a score where an higher score means better candidate. */ if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) { idle = estimateObjectIdleTime(o); } elseif (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { /* When we use an LRU policy, we sort the keys by idle time * so that we expire keys starting from greater idle time. * However when the policy is an LFU one, we have a frequency * estimation, and we want to evict keys with lower frequency * first. So inside the pool we put objects using the inverted * frequency subtracting the actual frequency to the maximum * frequency of 255. */ idle = 255-LFUDecrAndReturn(o); } elseif (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { /* In this case the sooner the expire the better. */ idle = ULLONG_MAX - (long)dictGetVal(de); } else { serverPanic("Unknown eviction policy in evictionPoolPopulate()"); }
/* Insert the element inside the pool. * First, find the first empty bucket or the first populated * bucket that has an idle time smaller than our idle time. */ k = 0; while (k < EVPOOL_SIZE && pool[k].key && pool[k].idle < idle) k++; if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) { /* Can't insert if the element is < the worst element we have * and there are no empty buckets. */ continue; } elseif (k < EVPOOL_SIZE && pool[k].key == NULL) { /* Inserting into empty position. No setup needed before insert. */ } else { /* Inserting in the middle. Now k points to the first element * greater than the element to insert. */ if (pool[EVPOOL_SIZE-1].key == NULL) { /* Free space on the right? Insert at k shifting * all the elements from k to end to the right. */
/* Save SDS before overwriting. */ sds cached = pool[EVPOOL_SIZE-1].cached; memmove(pool+k+1,pool+k, sizeof(pool[0])*(EVPOOL_SIZE-k-1)); pool[k].cached = cached; } else { /* No free space on right? Insert at k-1 */ k--; /* Shift all elements on the left of k (included) to the * left, so we discard the element with smaller idle time. */ sds cached = pool[0].cached; /* Save SDS before overwriting. */ if (pool[0].key != pool[0].cached) sdsfree(pool[0].key); memmove(pool,pool+1,sizeof(pool[0])*k); pool[k].cached = cached; } }
/* Try to reuse the cached SDS string allocated in the pool entry, * because allocating and deallocating this object is costly * (according to the profiler, not my fantasy. Remember: * premature optimizbla bla bla bla. */ int klen = sdslen(key); if (klen > EVPOOL_CACHED_SDS_SIZE) { pool[k].key = sdsdup(key); } else { memcpy(pool[k].cached,key,klen+1); sdssetlen(pool[k].cached,klen); pool[k].key = pool[k].cached; } pool[k].idle = idle; pool[k].dbid = dbid; } }
/* Given an object returns the min number of milliseconds the object was never * requested, using an approximated LRU algorithm. */ unsignedlonglongestimateObjectIdleTime(robj *o){ unsignedlonglong lruclock = LRU_CLOCK(); if (lruclock >= o->lru) { return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION; } else { return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION; } }
`lfu-decay-time`是一个以分钟为单位的数值,可以调整counter的减少速度 这里有个问题是 8 位大小够计么,访问一次加 1 的话的确不够,不过大神就是大神,才不会这么简单的加一。往下看代码 ```C /* Low level key lookup API, not actually called directly from commands * implementations that should instead rely on lookupKeyRead(), * lookupKeyWrite() and lookupKeyReadWithFlags(). */ robj *lookupKey(redisDb *db, robj *key, int flags) { dictEntry *de = dictFind(db->dict,key->ptr); if (de) { robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm. * Don't do it if we have a saving child, as this will trigger * a copy on write madness. */ if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { // 当淘汰策略是 LFU 时,就会调用这个updateLFU updateLFU(val); } else { val->lru = LRU_CLOCK(); } } return val; } else { return NULL; } }
/* Update LFU when an object is accessed. * Firstly, decrement the counter if the decrement time is reached. * Then logarithmically increment the counter, and update the access time. */ voidupdateLFU(robj *val){ unsignedlong counter = LFUDecrAndReturn(val); counter = LFULogIncr(counter); val->lru = (LFUGetTimeInMinutes()<<8) | counter; }
/* If the object decrement time is reached decrement the LFU counter but * do not update LFU fields of the object, we update the access time * and counter in an explicit way when the object is really accessed. * And we will times halve the counter according to the times of * elapsed time than server.lfu_decay_time. * Return the object frequency counter. * * This function is used in order to scan the dataset for the best object * to fit: as we check for the candidate, we incrementally decrement the * counter of the scanned objects if needed. */ unsignedlongLFUDecrAndReturn(robj *o){ // 右移 8 位,拿到上次衰减时间 unsignedlong ldt = o->lru >> 8; // 对 255 做与操作,拿到 counter 值 unsignedlong counter = o->lru & 255; // 根据lfu_decay_time来算出过了多少个衰减周期 unsignedlong num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0; if (num_periods) counter = (num_periods > counter) ? 0 : counter - num_periods; return counter; }
/* Logarithmically increment a counter. The greater is the current counter value * the less likely is that it gets really implemented. Saturate it at 255. */ uint8_tLFULogIncr(uint8_t counter){ // 最大值就是 255,到顶了就不加了 if (counter == 255) return255; // 生成个随机小数 double r = (double)rand()/RAND_MAX; // 减去个基础值,LFU_INIT_VAL = 5,防止刚进来就被逐出 double baseval = counter - LFU_INIT_VAL; // 如果是小于 0, if (baseval < 0) baseval = 0; // 如果 baseval 是 0,那么 p 就是 1了,后面 counter 直接加一,如果不是的话,得看系统参数lfu_log_factor,这个越大,除出来的 p 越小,那么 counter++的可能性也越小,这样子就把前面的疑问给解决了,不是直接+1 的 double p = 1.0/(baseval*server.lfu_log_factor+1); if (r < p) counter++; return counter; }
/* This function is called when we are going to perform some operation * in a given key, but such key may be already logically expired even if * it still exists in the database. The main way this function is called * is via lookupKey*() family of functions. * * The behavior of the function depends on the replication role of the * instance, because slave instances do not expire keys, they wait * for DELs from the master for consistency matters. However even * slaves will try to have a coherent return value for the function, * so that read commands executed in the slave side will be able to * behave like if the key is expired even if still present (because the * master has yet to propagate the DEL). * * In masters as a side effect of finding a key which is expired, such * key will be evicted from the database. Also this may trigger the * propagation of a DEL/UNLINK command in AOF / replication stream. * * The return value of the function is 0 if the key is still valid, * otherwise the function returns 1 if the key is expired. */ intexpireIfNeeded(redisDb *db, robj *key){ if (!keyIsExpired(db,key)) return0;
/* If we are running in the context of a slave, instead of * evicting the expired key from the database, we return ASAP: * the slave key expiration is controlled by the master that will * send us synthesized DEL operations for expired keys. * * Still we try to return the right information to the caller, * that is, 0 if we think the key should be still valid, 1 if * we think the key is expired at this time. */ if (server.masterhost != NULL) return1;
/* Check if the key is expired. */ intkeyIsExpired(redisDb *db, robj *key){ mstime_t when = getExpire(db,key); mstime_t now;
if (when < 0) return0; /* No expire for this key */
/* Don't expire anything while loading. It will be done later. */ if (server.loading) return0;
/* If we are in the context of a Lua script, we pretend that time is * blocked to when the Lua script started. This way a key can expire * only the first time it is accessed and not in the middle of the * script execution, making propagation to slaves / AOF consistent. * See issue #1525 on Github for more information. */ if (server.lua_caller) { now = server.lua_time_start; } /* If we are in the middle of a command execution, we still want to use * a reference time that does not change: in that case we just use the * cached time, that we update before each call in the call() function. * This way we avoid that commands such as RPOPLPUSH or similar, that * may re-open the same key multiple times, can invalidate an already * open object in a next call, if the next call will see the key expired, * while the first did not. */ elseif (server.fixed_time_expire > 0) { now = server.mstime; } /* For the other cases, we want to use the most fresh time we have. */ else { now = mstime(); }
/* The key expired if the current (virtual or real) time is greater * than the expire time of the key. */ return now > when; } /* Return the expire time of the specified key, or -1 if no expire * is associated with this key (i.e. the key is non volatile) */ longlonggetExpire(redisDb *db, robj *key){ dictEntry *de;
/* No expire? return ASAP */ if (dictSize(db->expires) == 0 || (de = dictFind(db->expires,key->ptr)) == NULL) return-1;
/* The entry was found in the expire dict, this means it should also * be present in the main dict (safety check). */ serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL); return dictGetSignedIntegerVal(de); }
/* This function handles 'background' operations we are required to do * incrementally in Redis databases, such as active key expiring, resizing, * rehashing. */ voiddatabasesCron(void){ /* Expire keys by random sampling. Not required for slaves * as master will synthesize DELs for us. */ if (server.active_expire_enabled) { if (server.masterhost == NULL) { activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW); } else { expireSlaveKeys(); } }
/* Defrag keys gradually. */ activeDefragCycle();
/* Perform hash tables rehashing if needed, but only if there are no * other processes saving the DB on disk. Otherwise rehashing is bad * as will cause a lot of copy-on-write of memory pages. */ if (!hasActiveChildProcess()) { /* We use global counters so if we stop the computation at a given * DB we'll be able to start from the successive in the next * cron loop iteration. */ staticunsignedint resize_db = 0; staticunsignedint rehash_db = 0; int dbs_per_call = CRON_DBS_PER_CALL; int j;
/* Don't test more DBs than we have. */ if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
/* Rehash */ if (server.activerehashing) { for (j = 0; j < dbs_per_call; j++) { int work_done = incrementallyRehash(rehash_db); if (work_done) { /* If the function did some work, stop here, we'll do * more at the next cron loop. */ break; } else { /* If this db didn't need rehash, we'll try the next one. */ rehash_db++; rehash_db %= server.dbnum; } } } } } /* Try to expire a few timed out keys. The algorithm used is adaptive and * will use few CPU cycles if there are few expiring keys, otherwise * it will get more aggressive to avoid that too much memory is used by * keys that can be removed from the keyspace. * * Every expire cycle tests multiple databases: the next call will start * again from the next db, with the exception of exists for time limit: in that * case we restart again from the last database we were processing. Anyway * no more than CRON_DBS_PER_CALL databases are tested at every iteration. * * The function can perform more or less work, depending on the "type" * argument. It can execute a "fast cycle" or a "slow cycle". The slow * cycle is the main way we collect expired cycles: this happens with * the "server.hz" frequency (usually 10 hertz). * * However the slow cycle can exit for timeout, since it used too much time. * For this reason the function is also invoked to perform a fast cycle * at every event loop cycle, in the beforeSleep() function. The fast cycle * will try to perform less work, but will do it much more often. * * The following are the details of the two expire cycles and their stop * conditions: * * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION * microseconds, and is not repeated again before the same amount of time. * The cycle will also refuse to run at all if the latest slow cycle did not * terminate because of a time limit condition. * * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is * executed, where the time limit is a percentage of the REDIS_HZ period * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. In the * fast cycle, the check of every database is interrupted once the number * of already expired keys in the database is estimated to be lower than * a given percentage, in order to avoid doing too much work to gain too * little memory. * * The configured expire "effort" will modify the baseline parameters in * order to do more work in both the fast and slow expire cycles. */
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */ #define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */ #define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */ #define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which we do extra efforts. */ voidactiveExpireCycle(int type){ /* Adjust the running parameters according to the configured expire * effort. The default effort is 1, and the maximum configurable effort * is 10. */ unsignedlong effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */ config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP + ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort, config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION + ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort, config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC + 2*effort, config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE- effort;
/* This function has some global state in order to continue the work * incrementally across calls. */ staticunsignedint current_db = 0; /* Last DB tested. */ staticint timelimit_exit = 0; /* Time limit hit in previous call? */ staticlonglong last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0; int dbs_per_call = CRON_DBS_PER_CALL; longlong start = ustime(), timelimit, elapsed;
/* When clients are paused the dataset should be static not just from the * POV of clients not being able to write, but also from the POV of * expires and evictions of keys not being performed. */ if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) { /* Don't start a fast cycle if the previous cycle did not exit * for time limit, unless the percentage of estimated stale keys is * too high. Also never repeat a fast cycle for the same period * as the fast cycle total duration itself. */ if (!timelimit_exit && server.stat_expired_stale_perc < config_cycle_acceptable_stale) return;
if (start < last_fast_cycle + (longlong)config_cycle_fast_duration*2) return;
last_fast_cycle = start; }
/* We usually should test CRON_DBS_PER_CALL per iteration, with * two exceptions: * * 1) Don't test more DBs than we have. * 2) If last time we hit the time limit, we want to scan all DBs * in this iteration, as there is work to do in some DB and we don't want * expired keys to use memory for too much time. */ if (dbs_per_call > server.dbnum || timelimit_exit) dbs_per_call = server.dbnum;
/* We can use at max 'config_cycle_slow_time_perc' percentage of CPU * time per iteration. Since this function gets called with a frequency of * server.hz times per second, the following is the max amount of * microseconds we can spend in this function. */ timelimit = config_cycle_slow_time_perc*1000000/server.hz/100; timelimit_exit = 0; if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) timelimit = config_cycle_fast_duration; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea * about the number of keys that are already logically expired, but still * existing inside the database. */ long total_sampled = 0; long total_expired = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) { /* Expired and checked in a single loop. */ unsignedlong expired, sampled;
/* Increment the DB now so we are sure if we run out of time * in the current DB we'll restart from the next. This allows to * distribute the time evenly across DBs. */ current_db++;
/* Continue to expire if at the end of the cycle more than 25% * of the keys were expired. */ do { unsignedlong num, slots; longlong now, ttl_sum; int ttl_samples; iteration++;
/* If there is nothing to expire try next DB ASAP. */ if ((num = dictSize(db->expires)) == 0) { db->avg_ttl = 0; break; } slots = dictSlots(db->expires); now = mstime();
/* When there are less than 1% filled slots, sampling the key * space is expensive, so stop here waiting for better times... * The dictionary will be resized asap. */ if (num && slots > DICT_HT_INITIAL_SIZE && (num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys * with an expire set, checking for expired ones. */ expired = 0; sampled = 0; ttl_sum = 0; ttl_samples = 0;
if (num > config_keys_per_loop) num = config_keys_per_loop;
/* Here we access the low level representation of the hash table * for speed concerns: this makes this code coupled with dict.c, * but it hardly changed in ten years. * * Note that certain places of the hash table may be empty, * so we want also a stop condition about the number of * buckets that we scanned. However scanning for free buckets * is very fast: we are in the cache line scanning a sequential * array of NULL pointers, so we can scan a lot more buckets * than keys in the same time. */ long max_buckets = num*20; long checked_buckets = 0;
while (sampled < num && checked_buckets < max_buckets) { for (int table = 0; table < 2; table++) { if (table == 1 && !dictIsRehashing(db->expires)) break;
/* Scan the current bucket of the current table. */ checked_buckets++; while(de) { /* Get the next entry now since this entry may get * deleted. */ dictEntry *e = de; de = de->next;
ttl = dictGetSignedIntegerVal(e)-now; if (activeExpireCycleTryExpire(db,e,now)) expired++; if (ttl > 0) { /* We want the average TTL of keys yet * not expired. */ ttl_sum += ttl; ttl_samples++; } sampled++; } } db->expires_cursor++; } total_expired += expired; total_sampled += sampled;
/* Update the average TTL stats for this database. */ if (ttl_samples) { longlong avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples. * We just use the current estimate with a weight of 2% * and the previous estimate with a weight of 98%. */ if (db->avg_ttl == 0) db->avg_ttl = avg_ttl; db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50); }
/* We can't block forever here even if there are many keys to * expire. So after a given amount of milliseconds return to the * caller waiting for the other active expire cycle. */ if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */ elapsed = ustime()-start; if (elapsed > timelimit) { timelimit_exit = 1; server.stat_expired_time_cap_reached_count++; break; } } /* We don't repeat the cycle for the current database if there are * an acceptable amount of stale keys (logically expired but yet * not reclained). */ } while ((expired*100/sampled) > config_cycle_acceptable_stale); }
/* Update our estimate of keys existing but yet to be expired. * Running average with this sample accounting for 5%. */ double current_perc; if (total_sampled) { current_perc = (double)total_expired/total_sampled; } else current_perc = 0; server.stat_expired_stale_perc = (current_perc*0.05)+ (server.stat_expired_stale_perc*0.95); }



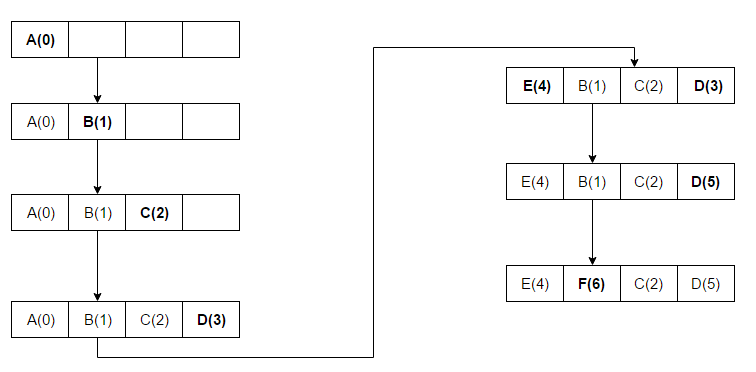 ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,