今天是农历初八了,年前一个月的时候就准备做下今年的年终总结,可是写了一点觉得太情绪化了,希望后面写个平淡点的,正好最近技术方面还没有看到一个完整成文的内容,就来写一下这一年的总结,尽量少写一点太情绪化的东西。
跳槽
年初换了个公司,也算换了个环境,跟前公司不太一样,做的事情方向也不同,可能是侧重点不同,一开始有些不适应,主要是压力上,会觉得压力比较大,但是总体来说与人相处的部分还是不错的,做的技术方向还是Java,这里也感谢前东家让我有机会转了Java,个人感觉杭州整个市场还是Java比较有优势,不过在开始的时候总觉得对Java有点不适应,应该值得深究的东西还是很多的,而且对于面试来说,也是有很多可以问的,后面慢慢发现除开某里等一线超一线互联网公司之外,大部分的面试还是有大概的套路跟大纲的,不过更细致的则因人而异了,面试有时候也还看缘分,面试官关注的点跟应试者比较契合的话就很容易通过面试,不然的话总会有能刁难或者理性化地说比较难回答的问题。这个后面可以单独说一下,先按下不表。
刚进公司没多久就负责比较重要的项目,工期也比较紧张,整体来说那段时间的压力的确是比较大的,不过总算最后结果不坏,这里应该说对一些原来在前东家都是掌握的不太好的部分,比如maven,其实maven对于java程序员来说还是很重要的,但是我碰到过的面试基本没问过这个,我自己也在后面的面试中没问过相关的,不知道咋问,比如dependence分析、冲突解决,比如对bean的理解,这个算是我一直以来的疑问点,因为以前刚开始学Java学spring,上来就是bean,但是bean到底是啥,IOC是啥,可能网上的文章跟大多数书籍跟我的理解思路不太match,导致一直不能很好的理解这玩意,到后面才理解,要理解这个bean,需要有两个基本概念,一个是面向对象,一个是对象容器跟依赖反转,还是只说到这,后面可以有专题说一下,总之自认为技术上有了不小的长进了,方向上应该是偏实用的。这个重要的项目完成后慢慢能喘口气了,后面也有一些比较紧急且工作量大的,不过在我TL的帮助下还是能尽量协调好资源。
面试
后面因为项目比较多,缺少开发,所以也参与帮忙做一些面试,这里总体感觉是面的候选人还是比较多样的,有些工作了蛮多年但是一些基础问题回答的不好,有些还是在校学生,但是面试技巧不错,针对常见的面试题都有不错的准备,不过还是觉得光靠这些面试题不能完全说明问题,真正工作了需要的是解决问题的人,而不是会背题的,退一步来说能好好准备面试还是比较重要的,也是双向选择中的基本尊重,印象比较深刻的是参加了去杭州某高校的校招面试,感觉参加校招的同学还是很多的,大部分是20年将毕业的研究生,挺多都是基础很扎实,对比起我刚要毕业时还是很汗颜,挺多来面试的同学都非常不错,那天强度也很大,从下午到那开始一直面到六七点,在这祝福那些来面试的同学,也都不容易的,能找到心仪的工作。
技术方向
这一年前大半部分还是比较焦虑不能恢复那种主动找时间学习的状态,可能换了公司是主要的原因,初期有个适应的过程也比较正常,总体来说可能是到九十月份开始慢慢有所改善,对这些方面有学习了下,
- spring方向,spring真的是个庞然大物,但是还是要先抓住根本,慢慢发散去了解其他的细节,抓住bean的生命周期,当然也不是死记硬背,让我一个个背下来我也不行,但是知道它究竟是干嘛的,有啥用,并且在工作中能用起来是最重要的
- mysql数据库,这部分主要是关注了mvcc,知道了个大概,源码实现细节还没具体研究,有时间可以来个专题(一大堆待写的内容)
- java的一些源码,比如aqs这种,结合文章看了下源码,一开始总感觉静不下心来看,然后有一次被LD刺激了下就看完了,包括conditionObject等
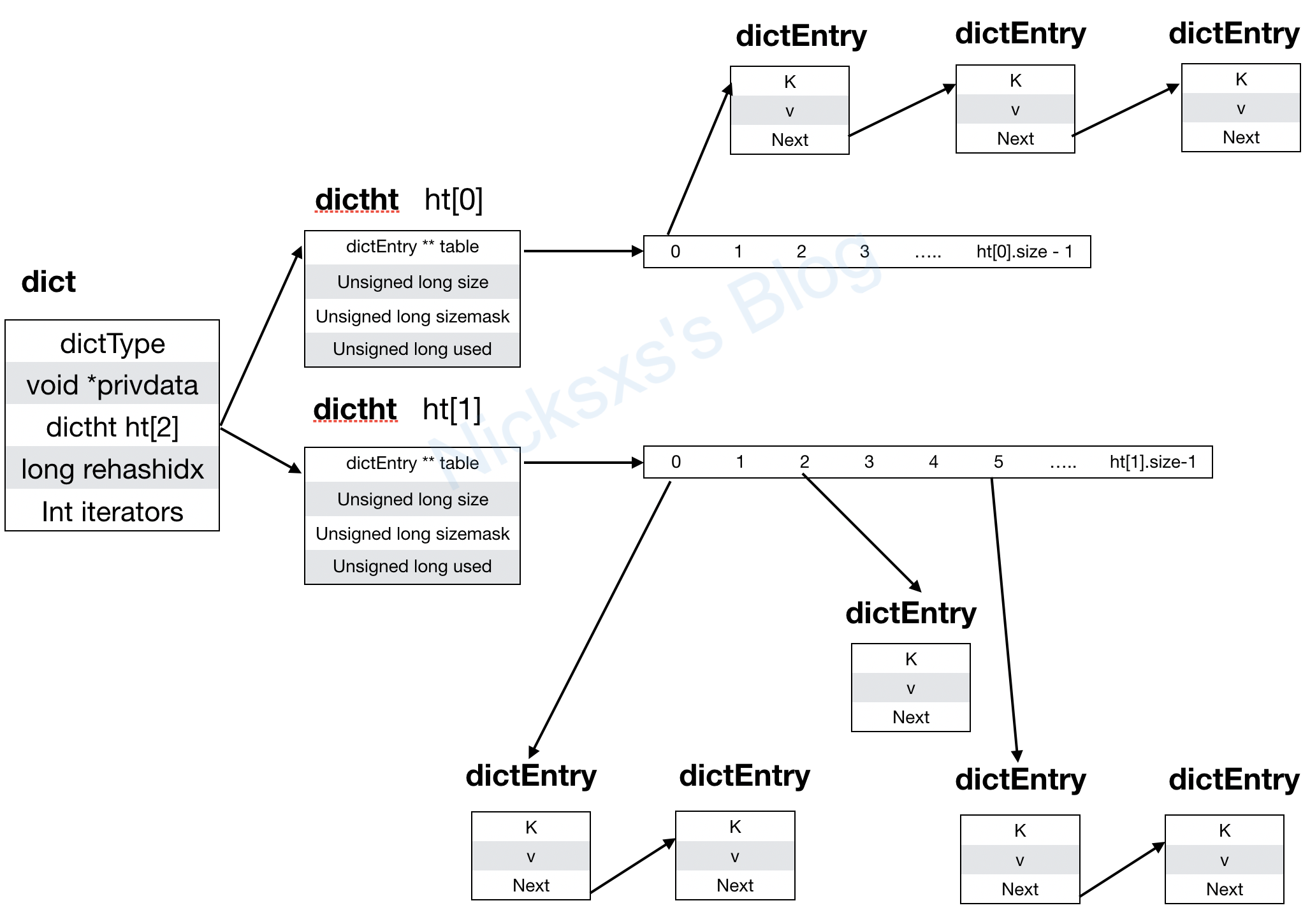
- redis的源码,这里包括了Redis分布式锁和redis的数据结构源码,已经写成文章,不过比较着急成文,所以质量不是特别好,希望后面再来补补
- jvm源码,这部分正好是想了解下g1收集器,大概把周志明的书看完了,但是还没完整的理解掌握,还有就是g1收集器的部分,一是概念部分大概理解了,后面是就是想从源码层面去学习理解,这也是新一年的主要计划
- mq的部分是了解了zero copy,sendfile等,跟消息队列主题关系不大🤦♂️
这么看还是学了点东西的,希望新一年再接再厉。
生活
住的地方没变化,主要是周边设施比较方便,暂时没找到更好的就没打算换,主要的问题是没电梯,一开始没觉得有啥,真正住起来还是觉得比较累的,希望后面租的可以有电梯,或者楼层低一点,还有就是要通下水道,第一次让师傅上门,花了两百大洋,后来自学成才了,让师傅通了一次才撑了一个月就不行了,后面自己通的差不多可以撑半年,还是比较有成就感的😀,然后就是跑步了,年初的时候去了紫金港跑步,后面因为工作的原因没去了,但是公司的跑步机倒是让我重拾起这个唯一的运动健身项目,后面因为肠胃问题,体重也需要控制,所以就周末回来也在家这边坚持跑步,下半年的话基本保持每周一次以上,比较那些跑马拉松的大牛还是差距很大,不过也是突破自我了,有一次跑了12公里,最远的距离,而且后面感觉跑十公里也不是特别吃不消了,这一年达成了300公里的目标,体重也稍有下降,比较满意的结果。
期待
希望工作方面技术方面能有所长进,生活上能多点时间陪家人,继续跑步减肥,家人健健康康的,嗯