Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit1]}]...done.
这里碰到过一个坑,对于使用exchange来做消息路由的,会有一个情况,就是在routing_key没被订阅的时候,会将该条找不到路由对应的queue的消息丢掉What happens if we break our contract and send a message with one or four words, like "orange" or "quick.orange.male.rabbit"? Well, these messages won't match any bindings and will be lost.对应链接,而当使用空的exchange时,会保留消息,当出现消费者的时候就可以将收到之前生产者所推送的消息对应链接,这里就是用了空的exchange。
这里碰到过一个坑,对于使用exchange来做消息路由的,会有一个情况,就是在routing_key没被订阅的时候,会将该条找不到路由对应的queue的消息丢掉What happens if we break our contract and send a message with one or four words, like "orange" or "quick.orange.male.rabbit"? Well, these messages won't match any bindings and will be lost.对应链接,而当使用空的exchange时,会保留消息,当出现消费者的时候就可以将收到之前生产者所推送的消息对应链接,这里就是用了空的exchange。
\ No newline at end of file
diff --git a/2020/05/31/聊聊-Dubbo-的-SPI/index.html b/2020/05/31/聊聊-Dubbo-的-SPI/index.html
index 9f60a9fff8..1478a4e725 100644
--- a/2020/05/31/聊聊-Dubbo-的-SPI/index.html
+++ b/2020/05/31/聊聊-Dubbo-的-SPI/index.html
@@ -1,4 +1,4 @@
-聊聊 Dubbo 的 SPI | Nicksxs's Blog
Given a singly linked list, determine if it is a palindrome. 给定一个单向链表,判断是否是回文链表
例一 Example 1:
Input: 1->2 Output: false
例二 Example 2:
Input: 1->2->2->1 Output: true
挑战下自己
Follow up: Could you do it in O(n) time and O(1) space?
简要分析
首先这是个单向链表,如果是双向的就可以一个从头到尾,一个从尾到头,显然那样就没啥意思了,然后想过要不找到中点,然后用一个栈,把前一半塞进栈里,但是这种其实也比较麻烦,比如长度是奇偶数,然后如何找到中点,这倒是可以借助于双指针,还是比较麻烦,再想一想,回文链表,就跟最开始的一样,链表只有单向的,我用个栈不就可以逆向了么,先把链表整个塞进栈里,然后在一个个 pop 出来跟链表从头开始比较,全对上了就是回文了
/**
+Leetcode 234 回文链表(Palindrome Linked List) 题解分析 | Nicksxs's Blog
Given a singly linked list, determine if it is a palindrome. 给定一个单向链表,判断是否是回文链表
例一 Example 1:
Input: 1->2 Output: false
例二 Example 2:
Input: 1->2->2->1 Output: true
挑战下自己
Follow up: Could you do it in O(n) time and O(1) space?
简要分析
首先这是个单向链表,如果是双向的就可以一个从头到尾,一个从尾到头,显然那样就没啥意思了,然后想过要不找到中点,然后用一个栈,把前一半塞进栈里,但是这种其实也比较麻烦,比如长度是奇偶数,然后如何找到中点,这倒是可以借助于双指针,还是比较麻烦,再想一想,回文链表,就跟最开始的一样,链表只有单向的,我用个栈不就可以逆向了么,先把链表整个塞进栈里,然后在一个个 pop 出来跟链表从头开始比较,全对上了就是回文了
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
@@ -31,4 +31,4 @@
}returntrue;}
-}
\ No newline at end of file
+}
\ No newline at end of file
diff --git a/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html b/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html
index 9d9adb1dae..59b09e84d2 100644
--- a/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html
+++ b/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 105 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal) 题解分析 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html b/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html
index 646c3925a9..4e637a77ce 100644
--- a/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html
+++ b/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析 | Nicksxs's Blog
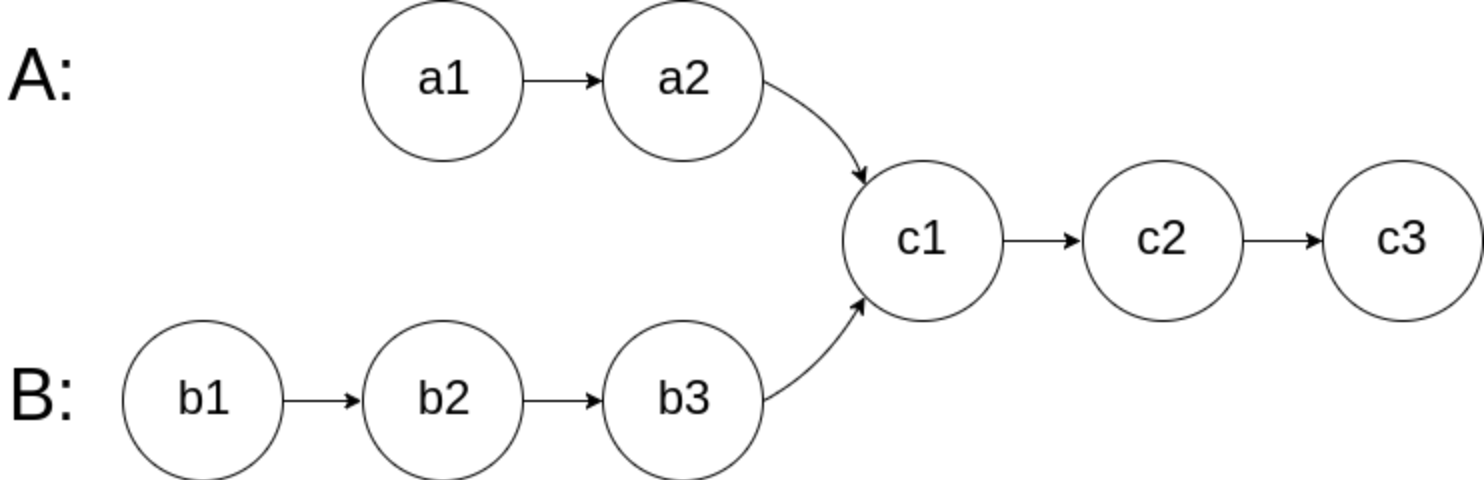
写一个程序找出两个单向链表的交叉起始点,可能是我英语不好,图里画的其实还有一点是交叉以后所有节点都是相同的 Write a program to find the node at which the intersection of two singly linked lists begins.
For example, the following two linked lists: begin to intersect at node c1.
Example 1:
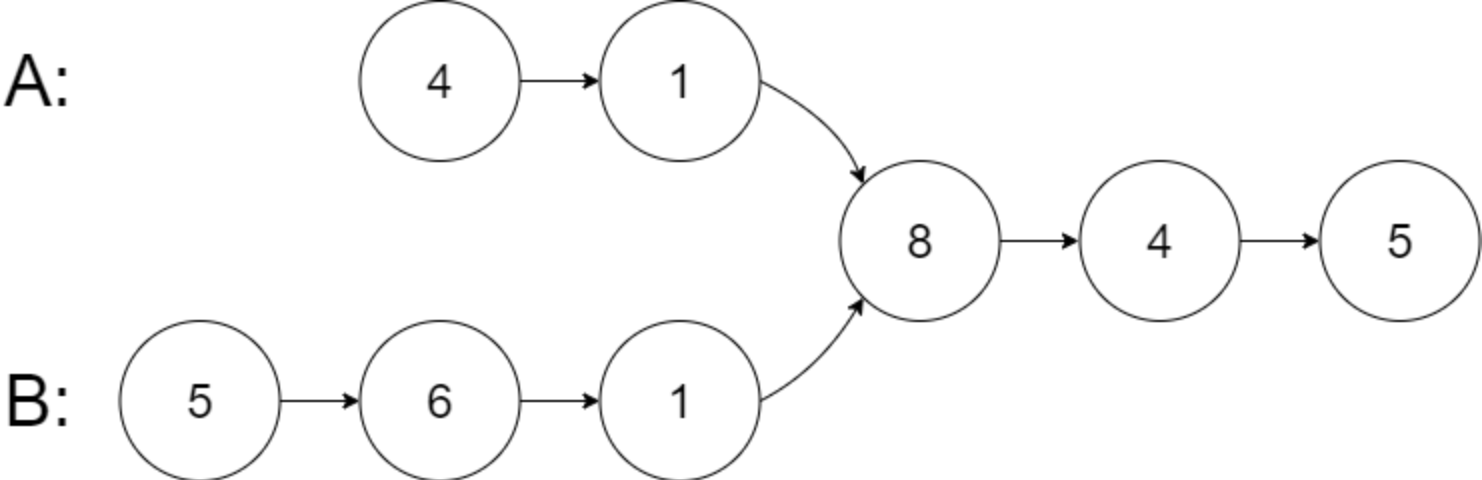
Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
Output: Reference of the node with value = 8
Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
publicListNodegetIntersectionNode(ListNode headA,ListNode headB){if(headA ==null|| headB ==null){
@@ -42,4 +42,4 @@ Input Explanation: The intersected node's value is 8 (note that this must no
}}returnnull;
- }
\ No newline at end of file
diff --git a/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html b/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html
index f081e62bde..79733b27c6 100644
--- a/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html
+++ b/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析 | Nicksxs's Blog
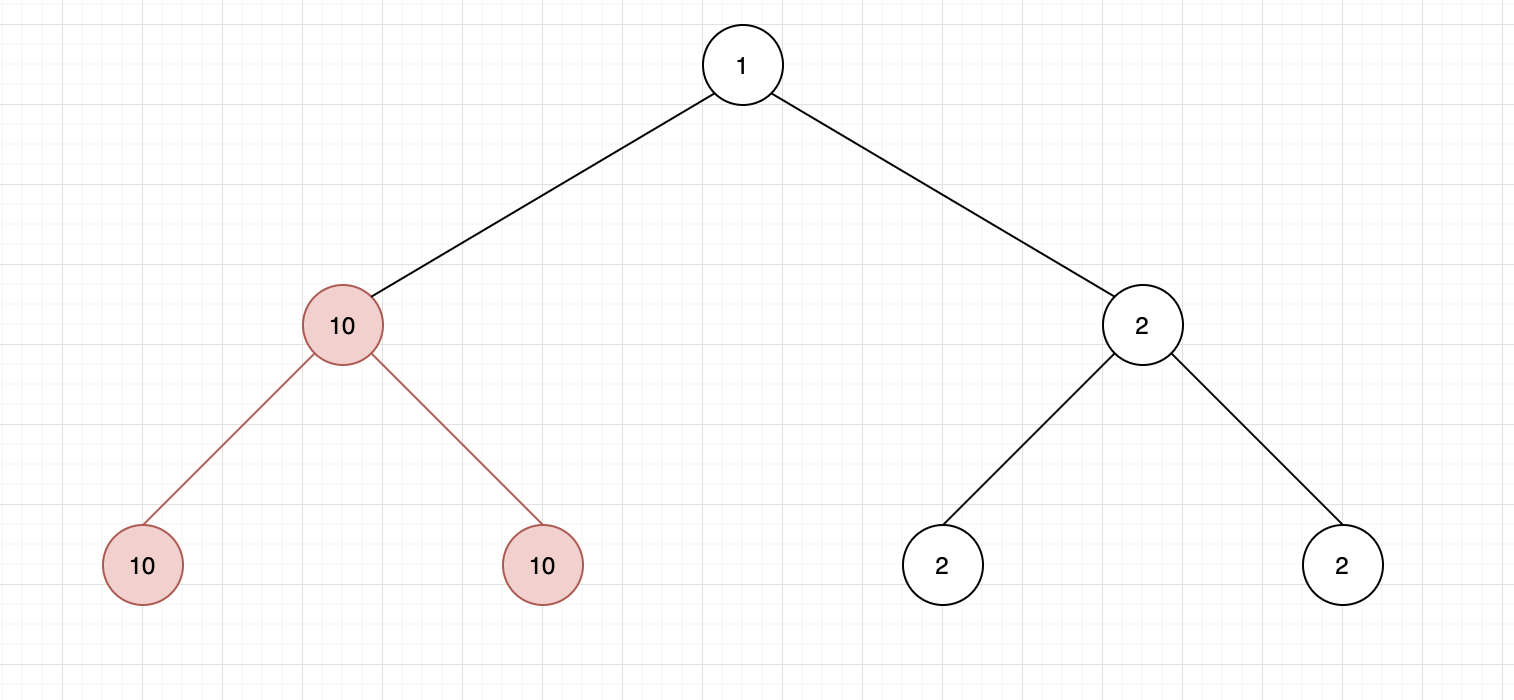
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
int ansNew =Integer.MIN_VALUE;publicintmaxPathSum(TreeNode root){maxSumNew(root);return ansNew;
@@ -21,4 +21,4 @@
int res =Math.max(left + right + root.val, currentSum);
ans =Math.max(res, ans);return currentSum;
-}
\ No newline at end of file
diff --git a/categories/Java/index.html b/categories/Java/index.html
index 0c25ec0cfa..f6804b2988 100644
--- a/categories/Java/index.html
+++ b/categories/Java/index.html
@@ -1 +1 @@
-分类: java | Nicksxs's Blog
\ No newline at end of file
diff --git a/categories/Redis/index.html b/categories/Redis/index.html
index 738f8e7944..cfc0e1a5ea 100644
--- a/categories/Redis/index.html
+++ b/categories/Redis/index.html
@@ -1 +1 @@
-分类: redis | Nicksxs's Blog
xo-generator-searchdb/1.4.0/search.js" integrity="sha256-vXZMYLEqsROAXkEw93GGIvaB2ab+QW6w3+1ahD9nXXA=" crossorigin="anonymous">
\ No newline at end of file
+分类: redis | Nicksxs's Blog
\ No newline at end of file
diff --git a/categories/leetcode/java/linked-list/index.html b/categories/leetcode/java/linked-list/index.html
index c2025bbf3d..1c9cf0f6ab 100644
--- a/categories/leetcode/java/linked-list/index.html
+++ b/categories/leetcode/java/linked-list/index.html
@@ -1 +1 @@
-分类: linked list | Nicksxs's Blog
\ No newline at end of file
diff --git a/categories/linked-list/index.html b/categories/linked-list/index.html
index 41593dac42..e2aaa09d62 100644
--- a/categories/linked-list/index.html
+++ b/categories/linked-list/index.html
@@ -1 +1 @@
-分类: linked list | Nicksxs's Blog