G1收集器概述
G1: The Garbage-First Collector, 垃圾回收优先的垃圾回收器,目标是用户多核 cpu 和大内存的机器,最大的特点就是可预测的停顿时间,官方给出的介绍是提供一个用户在大的堆内存情况下一个低延迟表现的解决方案,通常是 6GB 及以上的堆大小,有低于 0.5 秒稳定的可预测的停顿时间。
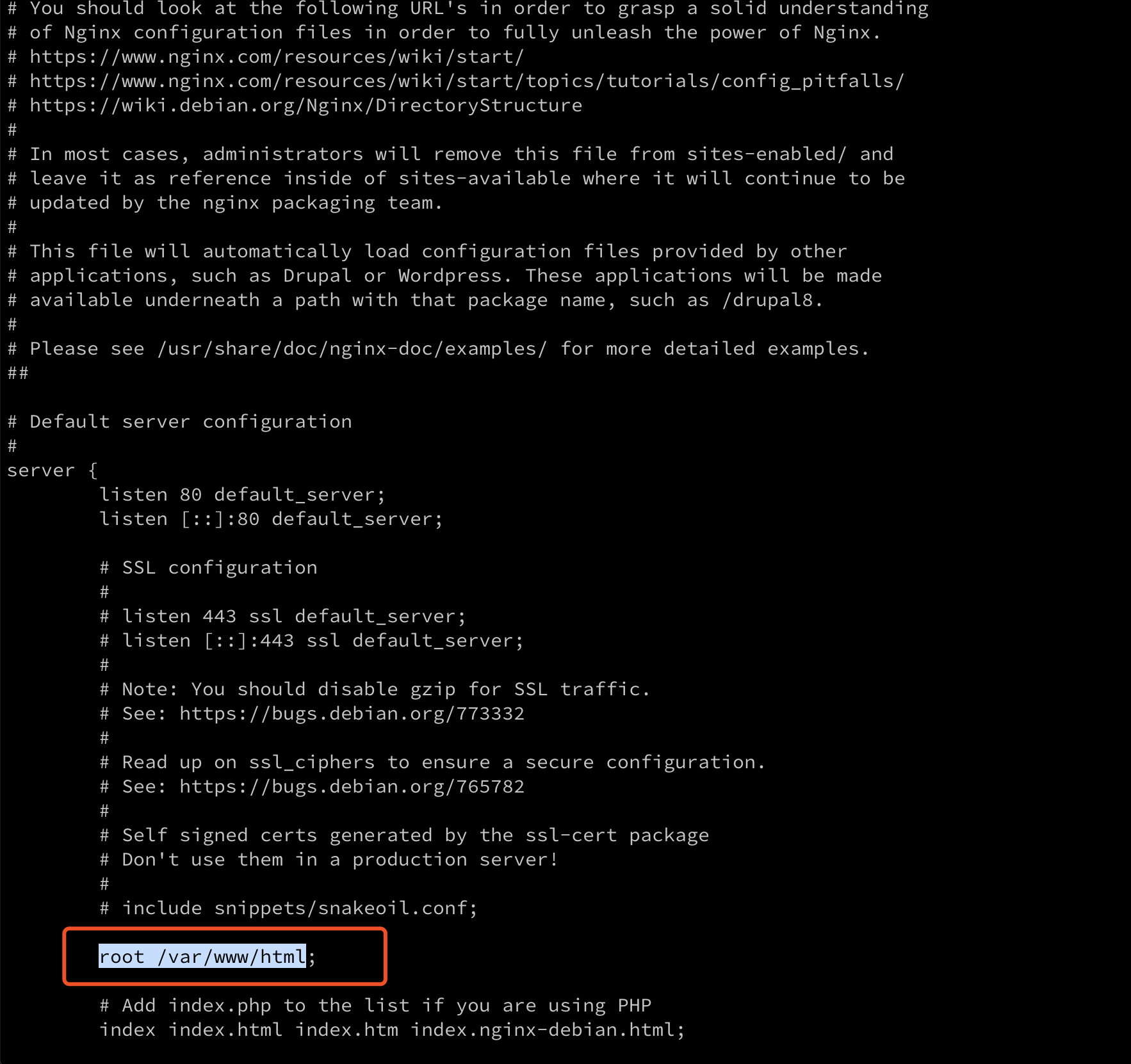
这里主要介绍这个比较新的垃圾回收器,在 G1 之前的垃圾回收器都是基于如下图的内存结构分布,有新生代,老年代和永久代(jdk8 之前),然后G1 往前的那些垃圾回收器都有个分代,比如 serial,parallel 等,一般有个应用的组合,最初的 serial 和 serial old,因为新生代和老年代的收集方式不太一样,新生代主要是标记复制,所以有 eden 跟两个 survival区,老年代一般用标记整理方式,而 G1 对这个不太一样。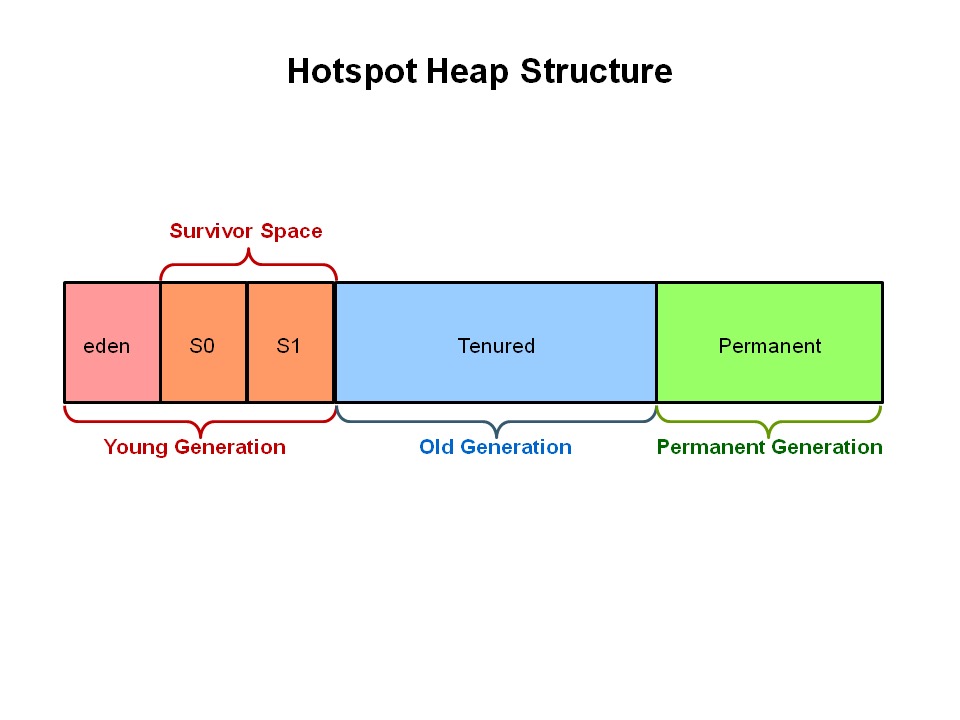
看一下 G1 的内存分布
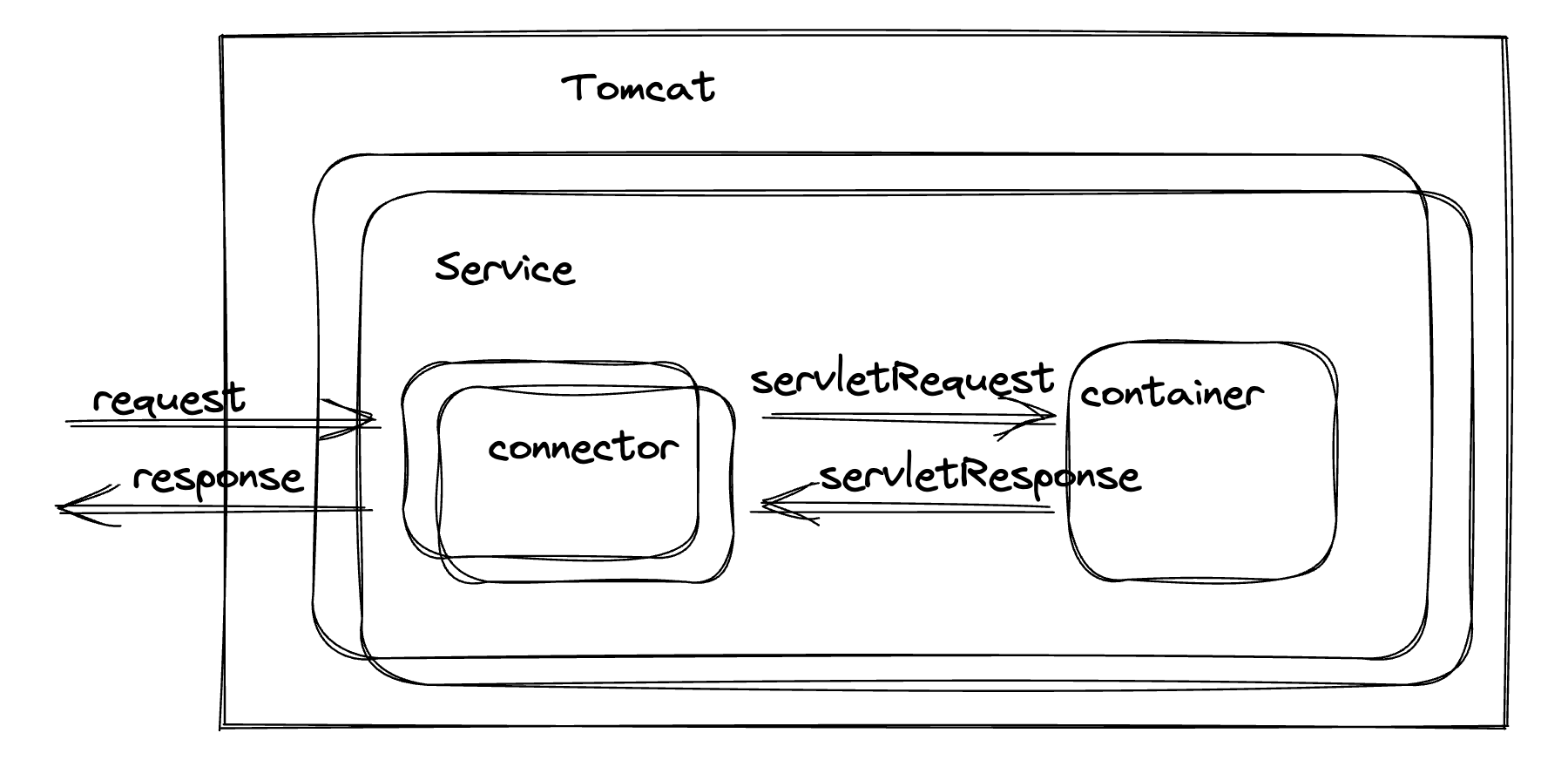
可以看到这有很大的不同,G1 通过将内存分成大小相等的 region,每个region是存在于一个连续的虚拟内存范围,对于某个 region 来说其角色是类似于原来的收集器的Eden、Survivor、Old Generation,这个具体在代码层面
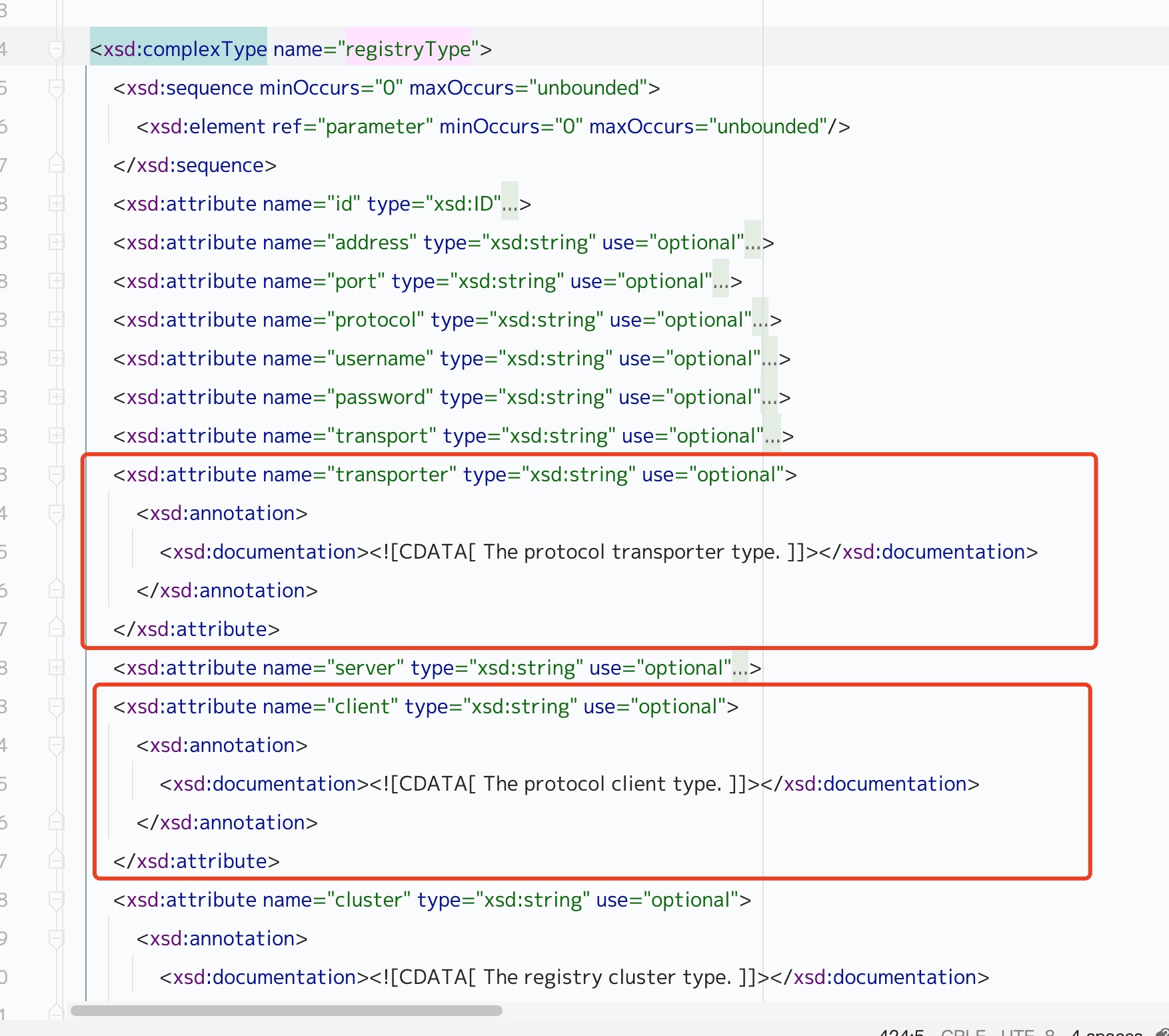
// We encode the value of the heap region type so the generation can be
+G1收集器概述 | Nicksxs's Blog G1收集器概述
G1: The Garbage-First Collector, 垃圾回收优先的垃圾回收器,目标是用户多核 cpu 和大内存的机器,最大的特点就是可预测的停顿时间,官方给出的介绍是提供一个用户在大的堆内存情况下一个低延迟表现的解决方案,通常是 6GB 及以上的堆大小,有低于 0.5 秒稳定的可预测的停顿时间。
这里主要介绍这个比较新的垃圾回收器,在 G1 之前的垃圾回收器都是基于如下图的内存结构分布,有新生代,老年代和永久代(jdk8 之前),然后G1 往前的那些垃圾回收器都有个分代,比如 serial,parallel 等,一般有个应用的组合,最初的 serial 和 serial old,因为新生代和老年代的收集方式不太一样,新生代主要是标记复制,所以有 eden 跟两个 survival区,老年代一般用标记整理方式,而 G1 对这个不太一样。
![]()
看一下 G1 的内存分布
![]()
可以看到这有很大的不同,G1 通过将内存分成大小相等的 region,每个region是存在于一个连续的虚拟内存范围,对于某个 region 来说其角色是类似于原来的收集器的Eden、Survivor、Old Generation,这个具体在代码层面
// We encode the value of the heap region type so the generation can be
// determined quickly. The tag is split into two parts:
//
// major type (young, old, humongous, archive) : top N-1 bits
@@ -52,4 +52,4 @@
ArchiveMask = 32,
OpenArchiveTag = ArchiveMask | PinnedMask | OldMask,
ClosedArchiveTag = ArchiveMask | PinnedMask | OldMask + 1
- } Tag;
hotspot/share/gc/g1/heapRegionType.hpp
当执行垃圾收集时,G1以类似于CMS收集器的方式运行。 G1执行并发全局标记阶段,以确定整个堆中对象的存活性。标记阶段完成后,G1知道哪些region是基本空的。它首先收集这些region,通常会产生大量的可用空间。这就是为什么这种垃圾收集方法称为“垃圾优先”的原因。顾名思义,G1将其收集和压缩活动集中在可能充满可回收对象(即垃圾)的堆区域。 G1使用暂停预测模型来满足用户定义的暂停时间目标,并根据指定的暂停时间目标选择要收集的区域数。
由G1标识为可回收的区域是使用撤离的方式(Evacuation)。 G1将对象从堆的一个或多个区域复制到堆上的单个区域,并在此过程中压缩并释放内存。撤离是在多处理器上并行执行的,以减少暂停时间并增加吞吐量。因此,对于每次垃圾收集,G1都在用户定义的暂停时间内连续工作以减少碎片。这是优于前面两种方法的。 CMS(并发标记扫描)垃圾收集器不进行压缩。 ParallelOld垃圾回收仅执行整个堆压缩,这导致相当长的暂停时间。
需要重点注意的是,G1不是实时收集器。它很有可能达到设定的暂停时间目标,但并非绝对确定。 G1根据先前收集的数据,估算在用户指定的目标时间内可以收集多少个区域。因此,收集器具有收集区域成本的合理准确的模型,并且收集器使用此模型来确定要收集哪些和多少个区域,同时保持在暂停时间目标之内。
注意:G1同时具有并发(与应用程序线程一起运行,例如优化,标记,清理)和并行(多线程,例如stw)阶段。Full GC仍然是单线程的,但是如果正确调优,您的应用程序应该可以避免Full GC。
在前面那篇中在代码层面简单的了解了这个可预测时间的过程,这也是 G1 的一大特点。
hotspot/share/gc/g1/heapRegionType.hpp
当执行垃圾收集时,G1以类似于CMS收集器的方式运行。 G1执行并发全局标记阶段,以确定整个堆中对象的存活性。标记阶段完成后,G1知道哪些region是基本空的。它首先收集这些region,通常会产生大量的可用空间。这就是为什么这种垃圾收集方法称为“垃圾优先”的原因。顾名思义,G1将其收集和压缩活动集中在可能充满可回收对象(即垃圾)的堆区域。 G1使用暂停预测模型来满足用户定义的暂停时间目标,并根据指定的暂停时间目标选择要收集的区域数。
由G1标识为可回收的区域是使用撤离的方式(Evacuation)。 G1将对象从堆的一个或多个区域复制到堆上的单个区域,并在此过程中压缩并释放内存。撤离是在多处理器上并行执行的,以减少暂停时间并增加吞吐量。因此,对于每次垃圾收集,G1都在用户定义的暂停时间内连续工作以减少碎片。这是优于前面两种方法的。 CMS(并发标记扫描)垃圾收集器不进行压缩。 ParallelOld垃圾回收仅执行整个堆压缩,这导致相当长的暂停时间。
需要重点注意的是,G1不是实时收集器。它很有可能达到设定的暂停时间目标,但并非绝对确定。 G1根据先前收集的数据,估算在用户指定的目标时间内可以收集多少个区域。因此,收集器具有收集区域成本的合理准确的模型,并且收集器使用此模型来确定要收集哪些和多少个区域,同时保持在暂停时间目标之内。
注意:G1同时具有并发(与应用程序线程一起运行,例如优化,标记,清理)和并行(多线程,例如stw)阶段。Full GC仍然是单线程的,但是如果正确调优,您的应用程序应该可以避免Full GC。
在前面那篇中在代码层面简单的了解了这个可预测时间的过程,这也是 G1 的一大特点。

































![9G5FE[9%@7%G(B`Q7]E)5@R.png](https://ooo.0o0.ooo/2016/08/10/57aac43029559.png)













 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换 好像是这里了
好像是这里了




















 ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,







 -
-










 ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息