redis数据结构介绍-第一部分 SDS,链表,字典
redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍
struct sdshdr {
+redis数据结构介绍-第一部分 SDS,链表,字典 | Nicksxs's Blog redis数据结构介绍-第一部分 SDS,链表,字典
redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍
struct sdshdr {
// 字符串长度
int len;
// 字符串空余字符数
diff --git a/2020/01/04/redis数据结构介绍二/index.html b/2020/01/04/redis数据结构介绍二/index.html
index b9fe0cfc59..5087ff17fc 100644
--- a/2020/01/04/redis数据结构介绍二/index.html
+++ b/2020/01/04/redis数据结构介绍二/index.html
@@ -1,4 +1,4 @@
-redis数据结构介绍二-第二部分 跳表 | Nicksxs's Blog redis数据结构介绍二-第二部分 跳表
跳表 skiplist
跳表是个在我们日常的代码中不太常用到的数据结构,相对来讲就没有像数组,链表,字典,散列,树等结构那么熟悉,所以就从头开始分析下,首先是链表,跳表跟链表都有个表字(太硬扯了我🤦♀️),注意这是个有序链表
![]()
如上图,在这个链表里如果我要找到 23,是不是我需要从3,5,9开始一直往后找直到找到 23,也就是说时间复杂度是 O(N),N 的一次幂复杂度,那么我们来看看第二个
![]()
这个结构跟原先有点不一样,它给链表中偶数位的节点又加了一个指针把它们链接起来,这样子当我们要寻找 23 的时候就可以从原来的一个个往下找变成跳着找,先找到 5,然后是 10,接着是 19,然后是 28,这时候发现 28 比 23 大了,那我在退回到 19,然后从下一层原来的链表往前找,
![]()
这里毛估估是不是前面的节点我就少找了一半,有那么点二分法的意思。
前面的其实是跳表的引子,真正的跳表其实不是这样,因为上面的其实有个比较大的问题,就是插入一个元素后需要调整每个元素的指针,在 redis 中的跳表其实是做了个随机层数的优化,因为沿着前面的例子,其实当数据量很大的时候,是不是层数越多,其查询效率越高,但是随着层数变多,要保持这种严格的层数规则其实也会增大处理复杂度,所以 redis 插入每个元素的时候都是使用随机的方式,看一眼代码
/* ZSETs use a specialized version of Skiplists */
+redis数据结构介绍二-第二部分 跳表 | Nicksxs's Blog redis数据结构介绍二-第二部分 跳表
跳表 skiplist
跳表是个在我们日常的代码中不太常用到的数据结构,相对来讲就没有像数组,链表,字典,散列,树等结构那么熟悉,所以就从头开始分析下,首先是链表,跳表跟链表都有个表字(太硬扯了我🤦♀️),注意这是个有序链表
![]()
如上图,在这个链表里如果我要找到 23,是不是我需要从3,5,9开始一直往后找直到找到 23,也就是说时间复杂度是 O(N),N 的一次幂复杂度,那么我们来看看第二个
![]()
这个结构跟原先有点不一样,它给链表中偶数位的节点又加了一个指针把它们链接起来,这样子当我们要寻找 23 的时候就可以从原来的一个个往下找变成跳着找,先找到 5,然后是 10,接着是 19,然后是 28,这时候发现 28 比 23 大了,那我在退回到 19,然后从下一层原来的链表往前找,
![]()
这里毛估估是不是前面的节点我就少找了一半,有那么点二分法的意思。
前面的其实是跳表的引子,真正的跳表其实不是这样,因为上面的其实有个比较大的问题,就是插入一个元素后需要调整每个元素的指针,在 redis 中的跳表其实是做了个随机层数的优化,因为沿着前面的例子,其实当数据量很大的时候,是不是层数越多,其查询效率越高,但是随着层数变多,要保持这种严格的层数规则其实也会增大处理复杂度,所以 redis 插入每个元素的时候都是使用随机的方式,看一眼代码
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
diff --git a/2020/01/10/redis数据结构介绍三/index.html b/2020/01/10/redis数据结构介绍三/index.html
index 7f1a56f835..b8c9c4ad22 100644
--- a/2020/01/10/redis数据结构介绍三/index.html
+++ b/2020/01/10/redis数据结构介绍三/index.html
@@ -1,4 +1,4 @@
-redis数据结构介绍三-第三部分 整数集合 | Nicksxs's Blog redis数据结构介绍三-第三部分 整数集合
redis中对于 set 其实有两种处理,对于元素均为整型,并且元素数目较少时,使用 intset 作为底层数据结构,否则使用 dict 作为底层数据结构,先看一下代码先
typedef struct intset {
+redis数据结构介绍三-第三部分 整数集合 | Nicksxs's Blog redis数据结构介绍三-第三部分 整数集合
redis中对于 set 其实有两种处理,对于元素均为整型,并且元素数目较少时,使用 intset 作为底层数据结构,否则使用 dict 作为底层数据结构,先看一下代码先
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
diff --git a/2020/01/19/redis数据结构介绍四/index.html b/2020/01/19/redis数据结构介绍四/index.html
index 3509c64e3a..e79fc4f6c0 100644
--- a/2020/01/19/redis数据结构介绍四/index.html
+++ b/2020/01/19/redis数据结构介绍四/index.html
@@ -1,4 +1,4 @@
-redis数据结构介绍四-第四部分 压缩表 | Nicksxs's Blog redis数据结构介绍四-第四部分 压缩表
在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient.
这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
其中
<zlbytes>表示 ziplist 占用的字节总数,类型是uint32_t,32 位的无符号整型,当然表示的字节数也包含自己本身占用的 4 个
<zltail> 类型也是是uint32_t,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
<uint16_t zllen> 表示ziplist 中的数据项个数,因为是 16 位,所以当数量超过所能表示的最大的数量,它的 16 位全会置为 1,但是真实的数量需要遍历整个 ziplist 才能知道
<entry>是具体的数据项,后面解释
<zlend> ziplist 的最后一个字节,固定是255。
再看一下<entry>中的具体结构,
<prevlen> <encoding> <entry-data>
首先这个<prevlen>有两种情况,一种是前面的元素的长度,如果是小于等于 253的时候就用一个uint8_t 来表示前一元素的长度,如果大于的话他将占用五个字节,第一个字节是 254,即表示这个字节已经表示不下了,需要后面的四个字节帮忙表示
<encoding>这个就比较复杂,把源码的注释放下面先看下
* |00pppppp| - 1 byte
+redis数据结构介绍四-第四部分 压缩表 | Nicksxs's Blog redis数据结构介绍四-第四部分 压缩表
在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient.
这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
其中
<zlbytes>表示 ziplist 占用的字节总数,类型是uint32_t,32 位的无符号整型,当然表示的字节数也包含自己本身占用的 4 个
<zltail> 类型也是是uint32_t,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
<uint16_t zllen> 表示ziplist 中的数据项个数,因为是 16 位,所以当数量超过所能表示的最大的数量,它的 16 位全会置为 1,但是真实的数量需要遍历整个 ziplist 才能知道
<entry>是具体的数据项,后面解释
<zlend> ziplist 的最后一个字节,固定是255。
再看一下<entry>中的具体结构,
<prevlen> <encoding> <entry-data>
首先这个<prevlen>有两种情况,一种是前面的元素的长度,如果是小于等于 253的时候就用一个uint8_t 来表示前一元素的长度,如果大于的话他将占用五个字节,第一个字节是 254,即表示这个字节已经表示不下了,需要后面的四个字节帮忙表示
<encoding>这个就比较复杂,把源码的注释放下面先看下
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* "pppppp" represents the unsigned 6 bit length.
* |01pppppp|qqqqqqqq| - 2 bytes
diff --git a/2020/01/20/redis数据结构介绍五/index.html b/2020/01/20/redis数据结构介绍五/index.html
index b6afd2ba0c..f05d53ee24 100644
--- a/2020/01/20/redis数据结构介绍五/index.html
+++ b/2020/01/20/redis数据结构介绍五/index.html
@@ -1,4 +1,4 @@
-redis数据结构介绍五-第五部分 对象 | Nicksxs's Blog redis数据结构介绍五-第五部分 对象
前面说了这么些数据结构,其实大家对于 redis 最初的印象应该就是个 key-value 的缓存,类似于 memcache,redis 其实也是个 key-value,key 还是一样的字符串,或者说就是用 redis 自己的动态字符串实现,但是 value 其实就是前面说的那些数据结构,差不多快说完了,还有个 quicklist 后面还有一篇,这里先介绍下 redis 对于这些不同类型的 value 是怎么实现的,首先看下 redisObject 的源码头文件
/* The actual Redis Object */
+redis数据结构介绍五-第五部分 对象 | Nicksxs's Blog redis数据结构介绍五-第五部分 对象
前面说了这么些数据结构,其实大家对于 redis 最初的印象应该就是个 key-value 的缓存,类似于 memcache,redis 其实也是个 key-value,key 还是一样的字符串,或者说就是用 redis 自己的动态字符串实现,但是 value 其实就是前面说的那些数据结构,差不多快说完了,还有个 quicklist 后面还有一篇,这里先介绍下 redis 对于这些不同类型的 value 是怎么实现的,首先看下 redisObject 的源码头文件
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
diff --git a/2020/01/22/redis数据结构介绍六/index.html b/2020/01/22/redis数据结构介绍六/index.html
index dbc92a6212..9d29d3bf67 100644
--- a/2020/01/22/redis数据结构介绍六/index.html
+++ b/2020/01/22/redis数据结构介绍六/index.html
@@ -1,4 +1,4 @@
-redis数据结构介绍六 快表 | Nicksxs's Blog redis数据结构介绍六 快表
这应该是 redis 系列的最后一篇了,讲下快表,其实最前面讲的链表在早先的 redis 版本中也作为 list 的数据结构使用过,但是单纯的链表的缺陷之前也说了,插入便利,但是空间利用率低,并且不能进行二分查找等,检索效率低,ziplist 压缩表的产生也是同理,希望获得更好的性能,包括存储空间和访问性能等,原来我也不懂这个快表要怎么快,然后明白了一个道理,其实并没有什么银弹,只是大牛们会在适合的时候使用最适合的数据结构来实现性能的最大化,这里面有一招就是不同数据结构的组合调整,比如 Java 中的 HashMap,在链表节点数大于 8 时会转变成红黑树,以此提高访问效率,不费话了,回到快表,quicklist,这个数据结构主要使用在 list 类型中,如果我说其实这个 quicklist 就是个链表,可能大家不太会相信,但是事实上的确可以认为 quicklist 是个双向链表,看下代码
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
+redis数据结构介绍六 快表 | Nicksxs's Blog redis数据结构介绍六 快表
这应该是 redis 系列的最后一篇了,讲下快表,其实最前面讲的链表在早先的 redis 版本中也作为 list 的数据结构使用过,但是单纯的链表的缺陷之前也说了,插入便利,但是空间利用率低,并且不能进行二分查找等,检索效率低,ziplist 压缩表的产生也是同理,希望获得更好的性能,包括存储空间和访问性能等,原来我也不懂这个快表要怎么快,然后明白了一个道理,其实并没有什么银弹,只是大牛们会在适合的时候使用最适合的数据结构来实现性能的最大化,这里面有一招就是不同数据结构的组合调整,比如 Java 中的 HashMap,在链表节点数大于 8 时会转变成红黑树,以此提高访问效率,不费话了,回到快表,quicklist,这个数据结构主要使用在 list 类型中,如果我说其实这个 quicklist 就是个链表,可能大家不太会相信,但是事实上的确可以认为 quicklist 是个双向链表,看下代码
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
diff --git a/2020/04/12/redis系列介绍七/index.html b/2020/04/12/redis系列介绍七/index.html
index 502fac0261..a56f889d51 100644
--- a/2020/04/12/redis系列介绍七/index.html
+++ b/2020/04/12/redis系列介绍七/index.html
@@ -1,4 +1,4 @@
-redis系列介绍七-过期策略 | Nicksxs's Blog redis系列介绍七-过期策略
这一篇不再是数据结构介绍了,大致的数据结构基本都介绍了,这一篇主要是查漏补缺,或者说讲一些重要且基本的概念,也可能是经常被忽略的,很多讲 redis 的系列文章可能都会忽略,学习 redis 的时候也会,因为觉得源码学习就是讲主要的数据结构和“算法”学习了就好了。
redis 的主要应用就是拿来作为高性能的缓存,那么缓存一般有些啥需要注意的,首先是访问速度,如果取得跟数据库一样快,那就没什么存在的意义,第二个是缓存的字面意思,我只是为了让数据读取快一些,通常大部分的场景这个是需要更新过期的,这里就把我要讲的第一点引出来了(真累,
redis过期策略
redis 是如何过期缓存的,可以猜测下,最无脑的就是每个设置了过期时间的 key 都设个定时器,过期了就删除,这种显然消耗太大,清理地最及时,还有的就是 redis 正在采用的懒汉清理策略和定期清理
懒汉策略就是在使用的时候去检查缓存是否过期,比如 get 操作时,先判断下这个 key 是否已经过期了,如果过期了就删掉,并且返回空,如果没过期则正常返回
主要代码是
/* This function is called when we are going to perform some operation
+redis系列介绍七-过期策略 | Nicksxs's Blog redis系列介绍七-过期策略
这一篇不再是数据结构介绍了,大致的数据结构基本都介绍了,这一篇主要是查漏补缺,或者说讲一些重要且基本的概念,也可能是经常被忽略的,很多讲 redis 的系列文章可能都会忽略,学习 redis 的时候也会,因为觉得源码学习就是讲主要的数据结构和“算法”学习了就好了。
redis 的主要应用就是拿来作为高性能的缓存,那么缓存一般有些啥需要注意的,首先是访问速度,如果取得跟数据库一样快,那就没什么存在的意义,第二个是缓存的字面意思,我只是为了让数据读取快一些,通常大部分的场景这个是需要更新过期的,这里就把我要讲的第一点引出来了(真累,
redis过期策略
redis 是如何过期缓存的,可以猜测下,最无脑的就是每个设置了过期时间的 key 都设个定时器,过期了就删除,这种显然消耗太大,清理地最及时,还有的就是 redis 正在采用的懒汉清理策略和定期清理
懒汉策略就是在使用的时候去检查缓存是否过期,比如 get 操作时,先判断下这个 key 是否已经过期了,如果过期了就删掉,并且返回空,如果没过期则正常返回
主要代码是
/* This function is called when we are going to perform some operation
* in a given key, but such key may be already logically expired even if
* it still exists in the database. The main way this function is called
* is via lookupKey*() family of functions.
diff --git a/2020/04/18/redis系列介绍八/index.html b/2020/04/18/redis系列介绍八/index.html
index d2dbecce8b..335e588398 100644
--- a/2020/04/18/redis系列介绍八/index.html
+++ b/2020/04/18/redis系列介绍八/index.html
@@ -1,4 +1,4 @@
-redis系列介绍八-淘汰策略 | Nicksxs's Blog redis系列介绍八-淘汰策略
LRU
说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍
![]() ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
redis 针对这个策略的改进做了一个实验,这里借用下图
![]()
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
typedef struct redisObject {
+redis系列介绍八-淘汰策略 | Nicksxs's Blog redis系列介绍八-淘汰策略
LRU
说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍
![]() ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
redis 针对这个策略的改进做了一个实验,这里借用下图
![]()
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
diff --git a/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html b/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html
index 1bff45b140..672c6c52db 100644
--- a/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html
+++ b/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html
@@ -1,4 +1,4 @@
-Linux 下 grep 命令的一点小技巧 | Nicksxs's Blog Linux 下 grep 命令的一点小技巧
用了比较久的 grep 命令,其实都只是用了最最基本的功能来查日志,
譬如
+Linux 下 grep 命令的一点小技巧 | Nicksxs's Blog Linux 下 grep 命令的一点小技巧
用了比较久的 grep 命令,其实都只是用了最最基本的功能来查日志,
譬如
grep 'xxx' xxxx.log
然后有挺多情况比如想要找日志里带一些符号什么的,就需要用到一些特殊的
比如这样\"userId\":\"123456\",因为比如用户 ID 有时候会跟其他的 id 一样,只用具体的值 123456 来查的话干扰信息太多了,如果直接这样
grep '\"userId\":\"123456\"' xxxx.log
diff --git a/2020/09/06/mybatis-的-和-是有啥区别/index.html b/2020/09/06/mybatis-的-和-是有啥区别/index.html
index 59660c751a..5075c70316 100644
--- a/2020/09/06/mybatis-的-和-是有啥区别/index.html
+++ b/2020/09/06/mybatis-的-和-是有啥区别/index.html
@@ -1,4 +1,4 @@
-mybatis 的 $ 和 # 是有啥区别 | Nicksxs's Blog mybatis 的 $ 和 # 是有啥区别
这个问题也是面试中常被问到的,就抽空来了解下这个,跳过一大段前面初始化的逻辑,
对于一条select * from t1 where id = #{id}这样的 sql,在初始化扫描 mapper 的xml文件的时候会根据是否是 dynamic 来判断生成 DynamicSqlSource 还是 RawSqlSource,这里它是一条 RawSqlSource,
在这里做了替换,将#{}替换成了?
![]()
前面说的是否 dynamic 就是在这里进行判断
![]()
// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
+mybatis 的 $ 和 # 是有啥区别 | Nicksxs's Blog mybatis 的 $ 和 # 是有啥区别
这个问题也是面试中常被问到的,就抽空来了解下这个,跳过一大段前面初始化的逻辑,
对于一条select * from t1 where id = #{id}这样的 sql,在初始化扫描 mapper 的xml文件的时候会根据是否是 dynamic 来判断生成 DynamicSqlSource 还是 RawSqlSource,这里它是一条 RawSqlSource,
在这里做了替换,将#{}替换成了?
![]()
前面说的是否 dynamic 就是在这里进行判断
![]()
// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
public SqlSource parseScriptNode() {
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
diff --git a/2020/10/03/mybatis-的缓存是怎么回事/index.html b/2020/10/03/mybatis-的缓存是怎么回事/index.html
index 3c0747c038..fba186994f 100644
--- a/2020/10/03/mybatis-的缓存是怎么回事/index.html
+++ b/2020/10/03/mybatis-的缓存是怎么回事/index.html
@@ -1,4 +1,4 @@
-mybatis 的缓存是怎么回事 | Nicksxs's Blog mybatis 的缓存是怎么回事
Java 真的是任何一个中间件,比较常用的那种,都有很多内容值得深挖,比如这个缓存,慢慢有过一些感悟,比如如何提升性能,缓存无疑是一大重要手段,最底层开始 CPU 就有缓存,而且又小又贵,再往上一点内存一般作为硬盘存储在运行时的存储,一般在代码里也会用内存作为一些本地缓存,譬如数据库,像 mysql 这种也是有innodb_buffer_pool来提升查询效率,本质上理解就是用更快的存储作为相对慢存储的缓存,减少查询直接访问较慢的存储,并且这个都是相对的,比起 cpu 的缓存,那内存也是渣,但是与普通机械硬盘相比,那也是两个次元的水平。
闲扯这么多来说说 mybatis 的缓存,mybatis 一般作为一个轻量级的 orm 使用,相对应的就是比较重量级的 hibernate,不过不在这次讨论范围,上一次是主要讲了 mybatis 在解析 sql 过程中,对于两种占位符的不同替换实现策略,这次主要聊下 mybatis 的缓存,前面其实得了解下前置的东西,比如 sqlsession,先当做我们知道 sqlsession 是个什么玩意,可能或多或少的知道 mybatis 是有两级缓存,
一级缓存
第一级的缓存是在 BaseExecutor 中的 PerpetualCache,它是个最基本的缓存实现类,使用了 HashMap 实现缓存功能,代码其实没几十行
public class PerpetualCache implements Cache {
+mybatis 的缓存是怎么回事 | Nicksxs's Blog mybatis 的缓存是怎么回事
Java 真的是任何一个中间件,比较常用的那种,都有很多内容值得深挖,比如这个缓存,慢慢有过一些感悟,比如如何提升性能,缓存无疑是一大重要手段,最底层开始 CPU 就有缓存,而且又小又贵,再往上一点内存一般作为硬盘存储在运行时的存储,一般在代码里也会用内存作为一些本地缓存,譬如数据库,像 mysql 这种也是有innodb_buffer_pool来提升查询效率,本质上理解就是用更快的存储作为相对慢存储的缓存,减少查询直接访问较慢的存储,并且这个都是相对的,比起 cpu 的缓存,那内存也是渣,但是与普通机械硬盘相比,那也是两个次元的水平。
闲扯这么多来说说 mybatis 的缓存,mybatis 一般作为一个轻量级的 orm 使用,相对应的就是比较重量级的 hibernate,不过不在这次讨论范围,上一次是主要讲了 mybatis 在解析 sql 过程中,对于两种占位符的不同替换实现策略,这次主要聊下 mybatis 的缓存,前面其实得了解下前置的东西,比如 sqlsession,先当做我们知道 sqlsession 是个什么玩意,可能或多或少的知道 mybatis 是有两级缓存,
一级缓存
第一级的缓存是在 BaseExecutor 中的 PerpetualCache,它是个最基本的缓存实现类,使用了 HashMap 实现缓存功能,代码其实没几十行
public class PerpetualCache implements Cache {
private final String id;
diff --git a/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html b/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html
index 67fdd7e6bc..806109ec76 100644
--- a/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html
+++ b/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html
@@ -1,4 +1,4 @@
-Apollo 的 value 注解是怎么自动更新的 | Nicksxs's Blog AQS篇一 | Nicksxs's Blog AQS篇二 之 Condition 浅析笔记 | Nicksxs's Blog 2022-06-19
- https://nicksxs.me/2021/02/21/AQS-%E4%B9%8B-Condition-%E6%B5%85%E6%9E%90%E7%AC%94%E8%AE%B0/
+ https://nicksxs.me/2021/03/31/2020-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
2022-06-11
- https://nicksxs.me/2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
+ https://nicksxs.me/2021/02/21/AQS-%E4%B9%8B-Condition-%E6%B5%85%E6%9E%90%E7%AC%94%E8%AE%B0/
2022-06-11
@@ -289,19 +289,19 @@
2022-06-11
- https://nicksxs.me/2020/08/22/Filter-Intercepter-Aop-%E5%95%A5-%E5%95%A5-%E5%95%A5-%E8%BF%99%E4%BA%9B%E9%83%BD%E6%98%AF%E5%95%A5/
+ https://nicksxs.me/2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
2022-06-11
- https://nicksxs.me/2021/01/24/Leetcode-124-%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E7%9A%84%E6%9C%80%E5%A4%A7%E8%B7%AF%E5%BE%84%E5%92%8C-Binary-Tree-Maximum-Path-Sum-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2020/08/22/Filter-Intercepter-Aop-%E5%95%A5-%E5%95%A5-%E5%95%A5-%E8%BF%99%E4%BA%9B%E9%83%BD%E6%98%AF%E5%95%A5/
2022-06-11
- https://nicksxs.me/2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2021/01/24/Leetcode-124-%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E7%9A%84%E6%9C%80%E5%A4%A7%E8%B7%AF%E5%BE%84%E5%92%8C-Binary-Tree-Maximum-Path-Sum-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
- https://nicksxs.me/2021/07/04/Leetcode-42-%E6%8E%A5%E9%9B%A8%E6%B0%B4-Trapping-Rain-Water-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
@@ -309,15 +309,15 @@
2022-06-11
- https://nicksxs.me/2022/03/13/Leetcode-83-%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0-Remove-Duplicates-from-Sorted-List-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2020/08/06/Linux-%E4%B8%8B-grep-%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E7%82%B9%E5%B0%8F%E6%8A%80%E5%B7%A7/
2022-06-11
- https://nicksxs.me/2020/08/06/Linux-%E4%B8%8B-grep-%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E7%82%B9%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ https://nicksxs.me/2022/03/13/Leetcode-83-%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0-Remove-Duplicates-from-Sorted-List-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
- https://nicksxs.me/2021/03/31/2020-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ https://nicksxs.me/2021/07/04/Leetcode-42-%E6%8E%A5%E9%9B%A8%E6%B0%B4-Trapping-Rain-Water-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
@@ -337,11 +337,11 @@
2022-06-11
- https://nicksxs.me/2021/12/05/wordpress-%E5%BF%98%E8%AE%B0%E5%AF%86%E7%A0%81%E7%9A%84%E4%B8%80%E7%A7%8D%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
+ https://nicksxs.me/2021/03/07/%E3%80%8A%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E7%AE%97%E6%B3%95%E6%89%8B%E5%86%8C%E8%AF%BB%E4%B9%A6%E3%80%8B%E7%AC%94%E8%AE%B0%E4%B9%8B%E6%95%B4%E7%90%86%E7%AE%97%E6%B3%95/
2022-06-11
- https://nicksxs.me/2021/03/07/%E3%80%8A%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E7%AE%97%E6%B3%95%E6%89%8B%E5%86%8C%E8%AF%BB%E4%B9%A6%E3%80%8B%E7%AC%94%E8%AE%B0%E4%B9%8B%E6%95%B4%E7%90%86%E7%AE%97%E6%B3%95/
+ https://nicksxs.me/2021/12/05/wordpress-%E5%BF%98%E8%AE%B0%E5%AF%86%E7%A0%81%E7%9A%84%E4%B8%80%E7%A7%8D%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
2022-06-11
@@ -365,11 +365,11 @@
2022-06-11
- https://nicksxs.me/2021/09/12/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E4%BA%8C/
+ https://nicksxs.me/2021/09/19/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E4%B8%AD%E4%BD%BF%E7%94%A8%E7%9A%84-cglib-%E4%BD%9C%E4%B8%BA%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86%E4%B8%AD%E7%9A%84%E4%B8%80%E4%B8%AA%E6%B3%A8%E6%84%8F%E7%82%B9/
2022-06-11
- https://nicksxs.me/2021/10/17/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E5%9B%9B/
+ https://nicksxs.me/2021/09/12/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E4%BA%8C/
2022-06-11
@@ -377,31 +377,31 @@
2022-06-11
- https://nicksxs.me/2021/09/19/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E4%B8%AD%E4%BD%BF%E7%94%A8%E7%9A%84-cglib-%E4%BD%9C%E4%B8%BA%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86%E4%B8%AD%E7%9A%84%E4%B8%80%E4%B8%AA%E6%B3%A8%E6%84%8F%E7%82%B9/
+ https://nicksxs.me/2021/10/17/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E5%9B%9B/
2022-06-11
- https://nicksxs.me/2021/06/27/%E8%81%8A%E8%81%8A-Java-%E4%B8%AD%E7%BB%95%E4%B8%8D%E5%BC%80%E7%9A%84-Synchronized-%E5%85%B3%E9%94%AE%E5%AD%97-%E4%BA%8C/
+ https://nicksxs.me/2020/11/22/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
2022-06-11
- https://nicksxs.me/2020/11/22/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
+ https://nicksxs.me/2021/06/27/%E8%81%8A%E8%81%8A-Java-%E4%B8%AD%E7%BB%95%E4%B8%8D%E5%BC%80%E7%9A%84-Synchronized-%E5%85%B3%E9%94%AE%E5%AD%97-%E4%BA%8C/
2022-06-11
- https://nicksxs.me/2020/08/02/%E8%81%8A%E8%81%8A-Java-%E8%87%AA%E5%B8%A6%E7%9A%84%E9%82%A3%E4%BA%9B%E9%80%86%E5%A4%A9%E5%B7%A5%E5%85%B7/
+ https://nicksxs.me/2021/06/13/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6%E4%BA%8C/
2022-06-11
- https://nicksxs.me/2021/06/13/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6%E4%BA%8C/
+ https://nicksxs.me/2020/08/02/%E8%81%8A%E8%81%8A-Java-%E8%87%AA%E5%B8%A6%E7%9A%84%E9%82%A3%E4%BA%9B%E9%80%86%E5%A4%A9%E5%B7%A5%E5%85%B7/
2022-06-11
- https://nicksxs.me/2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
+ https://nicksxs.me/2022/01/09/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E4%B8%8B%E7%9A%84%E5%88%86%E9%A1%B5%E6%96%B9%E6%A1%88/
2022-06-11
- https://nicksxs.me/2021/12/26/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E5%8E%9F%E7%90%86%E5%88%9D%E7%AF%87/
+ https://nicksxs.me/2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
2022-06-11
@@ -409,19 +409,19 @@
2022-06-11
- https://nicksxs.me/2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
+ https://nicksxs.me/2021/12/26/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E5%8E%9F%E7%90%86%E5%88%9D%E7%AF%87/
2022-06-11
- https://nicksxs.me/2021/05/30/%E8%81%8A%E8%81%8A%E4%BC%A0%E8%AF%B4%E4%B8%AD%E7%9A%84-ThreadLocal/
+ https://nicksxs.me/2021/04/04/%E8%81%8A%E8%81%8A-dubbo-%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/
2022-06-11
- https://nicksxs.me/2022/01/09/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E4%B8%8B%E7%9A%84%E5%88%86%E9%A1%B5%E6%96%B9%E6%A1%88/
+ https://nicksxs.me/2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
2022-06-11
- https://nicksxs.me/2021/04/04/%E8%81%8A%E8%81%8A-dubbo-%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/
+ https://nicksxs.me/2021/05/30/%E8%81%8A%E8%81%8A%E4%BC%A0%E8%AF%B4%E4%B8%AD%E7%9A%84-ThreadLocal/
2022-06-11
@@ -801,11 +801,11 @@
2020-01-12
- https://nicksxs.me/2019/12/10/Redis-Part-1/
+ https://nicksxs.me/2015/03/11/Reverse-Bits/
2020-01-12
- https://nicksxs.me/2015/03/11/Reverse-Bits/
+ https://nicksxs.me/2019/12/10/Redis-Part-1/
2020-01-12
@@ -813,7 +813,7 @@
2020-01-12
- https://nicksxs.me/2015/01/14/Two-Sum/
+ https://nicksxs.me/2016/09/29/binary-watch/
2020-01-12
@@ -821,7 +821,7 @@
2020-01-12
- https://nicksxs.me/2016/09/29/binary-watch/
+ https://nicksxs.me/2015/01/14/Two-Sum/
2020-01-12
@@ -861,15 +861,15 @@
2020-01-12
- https://nicksxs.me/2015/04/15/Leetcode-No-3/
+ https://nicksxs.me/2015/03/11/Number-Of-1-Bits/
2020-01-12
- https://nicksxs.me/2015/03/11/Number-Of-1-Bits/
+ https://nicksxs.me/2015/01/04/Path-Sum/
2020-01-12
- https://nicksxs.me/2015/01/04/Path-Sum/
+ https://nicksxs.me/2015/04/15/Leetcode-No-3/
2020-01-12
@@ -881,15 +881,15 @@
2020-01-12
- https://nicksxs.me/2017/04/25/rabbitmq-tips/
+ https://nicksxs.me/2015/01/16/pcre-intro-and-a-simple-package/
2020-01-12
- https://nicksxs.me/2017/03/28/spark-little-tips/
+ https://nicksxs.me/2017/04/25/rabbitmq-tips/
2020-01-12
- https://nicksxs.me/2015/01/16/pcre-intro-and-a-simple-package/
+ https://nicksxs.me/2017/03/28/spark-little-tips/
2020-01-12
diff --git a/categories/docker/index.html b/categories/docker/index.html
index a5da822c38..13365c063e 100644
--- a/categories/docker/index.html
+++ b/categories/docker/index.html
@@ -1 +1 @@
-分类: Docker | Nicksxs's Blog 分类: docker | Nicksxs's Blog
这里唯二需要注意的就是两个点,一个是循环条件需要包含进位值还存在的情况,还有一个是最后一个节点,如果是空的了,就不要在 new 一个出来了,写的比较挫
mybatis 的缓存是怎么回事
Java 真的是任何一个中间件,比较常用的那种,都有很多内容值得深挖,比如这个缓存,慢慢有过一些感悟,比如如何提升性能,缓存无疑是一大重要手段,最底层开始 CPU 就有缓存,而且又小又贵,再往上一点内存一般作为硬盘存储在运行时的存储,一般在代码里也会用内存作为一些本地缓存,譬如数据库,像 mysql 这种也是有innodb_buffer_pool来提升查询效率,本质上理解就是用更快的存储作为相对慢存储的缓存,减少查询直接访问较慢的存储,并且这个都是相对的,比起 cpu 的缓存,那内存也是渣,但是与普通机械硬盘相比,那也是两个次元的水平。
闲扯这么多来说说 mybatis 的缓存,mybatis 一般作为一个轻量级的 orm 使用,相对应的就是比较重量级的 hibernate,不过不在这次讨论范围,上一次是主要讲了 mybatis 在解析 sql 过程中,对于两种占位符的不同替换实现策略,这次主要聊下 mybatis 的缓存,前面其实得了解下前置的东西,比如 sqlsession,先当做我们知道 sqlsession 是个什么玩意,可能或多或少的知道 mybatis 是有两级缓存,
一级缓存
第一级的缓存是在 BaseExecutor 中的 PerpetualCache,它是个最基本的缓存实现类,使用了 HashMap 实现缓存功能,代码其实没几十行
public class PerpetualCache implements Cache {
+ }
这里唯二需要注意的就是两个点,一个是循环条件需要包含进位值还存在的情况,还有一个是最后一个节点,如果是空的了,就不要在 new 一个出来了,写的比较挫
mybatis 的缓存是怎么回事
Java 真的是任何一个中间件,比较常用的那种,都有很多内容值得深挖,比如这个缓存,慢慢有过一些感悟,比如如何提升性能,缓存无疑是一大重要手段,最底层开始 CPU 就有缓存,而且又小又贵,再往上一点内存一般作为硬盘存储在运行时的存储,一般在代码里也会用内存作为一些本地缓存,譬如数据库,像 mysql 这种也是有innodb_buffer_pool来提升查询效率,本质上理解就是用更快的存储作为相对慢存储的缓存,减少查询直接访问较慢的存储,并且这个都是相对的,比起 cpu 的缓存,那内存也是渣,但是与普通机械硬盘相比,那也是两个次元的水平。
闲扯这么多来说说 mybatis 的缓存,mybatis 一般作为一个轻量级的 orm 使用,相对应的就是比较重量级的 hibernate,不过不在这次讨论范围,上一次是主要讲了 mybatis 在解析 sql 过程中,对于两种占位符的不同替换实现策略,这次主要聊下 mybatis 的缓存,前面其实得了解下前置的东西,比如 sqlsession,先当做我们知道 sqlsession 是个什么玩意,可能或多或少的知道 mybatis 是有两级缓存,
一级缓存
第一级的缓存是在 BaseExecutor 中的 PerpetualCache,它是个最基本的缓存实现类,使用了 HashMap 实现缓存功能,代码其实没几十行
public class PerpetualCache implements Cache {
private final String id;
diff --git a/page/33/index.html b/page/33/index.html
index 228ade0268..1d0781bf9a 100644
--- a/page/33/index.html
+++ b/page/33/index.html
@@ -38,7 +38,7 @@ Output: 0
注释应该写的比较清楚了。
在老丈人家的小工记三
小工记三
前面这两周周末也都去老丈人家帮忙了,上上周周六先是去了那个在装修的旧房子那,把三楼收拾了下,因为要搬进来住,来不及等二楼装修好,就要把三楼里的东西都整理干净,这个活感觉是比较 easy,原来是就准备把三楼当放东西仓储的地方了,我们乡下大部分三层楼都是这么用的,这次也是没办法,之前搬进来的木头什么的都搬出去,主要是这上面灰尘太多,后面清理鼻孔的时候都是黑色的了,把东西都搬出去以后主要是地还是很脏,就扫了地拖了地,因为是水泥地,灰尘又太多了,拖起来都是会灰尘扬起来,整个脱完了的确干净很多,然而这会就出了个大乌龙,我们清理的是三楼的西边一间,结果老丈人上来说要住东边那间的🤦♂️,不过其实西边的也得清理,因为还是要放被子什么的,不算是白费功夫,接着清理东边那间,之前这个房子做过群租房,里面有个高低铺的床,当时觉得可以用在放被子什么的就没扔,只是拆掉了放旁边,我们就把它擦干净了又装好,发现螺丝🔩少了几个,亘古不变的真理,拆了以后装要不就多几个要不就少几个,不是很牢靠,不过用来放放被子省得放地上总还是可以的,对了前面还做了个事情就是铺地毯,其实也不是地毯,就是类似于墙布雨篷布那种,别人不用了送给我们的,三楼水泥地也不会铺瓷砖地板了就放一下,干净好看点,不过大小不合适要裁一下,那把剪刀是真的太难用了,我手都要抽筋了,它就是刀口只有一小个点是能剪下来的,其他都是钝的,后来还是用刀片直接裁,铺好以后,真的感觉也不太一样了,焕然一新的感觉
差不多中午了就去吃饭了,之前两次是去了一家小饭店,还是还比较干净,但是店里菜不好吃,还死贵,这次去了一家小快餐店,口味好,便宜,味道是真的不错,带鱼跟黄鱼都好吃,一点都不腥,我对这类比较腥的鱼真的是很挑剔的,基本上除了家里做的很少吃外面的,那天抱着试试的态度吃了下,真的还不错,后来丈母娘说好像这家老板是给别人结婚喜事酒席当厨师的,怪不得做的好吃,其实本来是有一点小抗拒,怕不干净什么的,后来发现菜很好吃,而且可能是老丈人跟干活的师傅去吃的比较多,老板很客气,我们吃完饭,还给我们买了葡萄吃,不过这家店有一个槽点,就是饭比较不好吃,有时候会夹生,不过后面聊起来其实是这种小菜馆饭点的通病,烧的太早太多容易多出来浪费,烧的迟了不够吃,而且大的电饭锅比较不容易烧好。
下午前面还是在处理三楼的,窗户上各种钉子,实在是太多了,我后面在走廊上排了一排🤦♂️,有些是直接断了,有些是就撬了出来,感觉我在杭州租房也没有这样子各种钉钉子,挂下衣服什么的也不用这么多吧,比较不能理解,搞得到处都是钉子。那天我爸也去帮忙了,主要是在卫生间里做白缝,其实也是个技术活,印象中好像我小时候自己家里也做过这个事情,但是比较模糊了,后面我们三楼搞完了就去帮我爸了,前面是我老婆二爹在那先刷上白缝,这里叫白缝,有些考究的也叫美缝,就是瓷砖铺完之后的缝,如果不去弄的话,里面水泥的颜色就露出来了,而且容易渗水,所以就要用白水泥加胶水搅拌之后糊在缝上,但是也不是直接糊,先要把缝抠一抠,因为铺瓷砖的还不会仔细到每个缝里的水泥都是一样满,而且也需要一些空间糊上去,不然就太表面的一层很容易被水直接冲掉了,然后这次其实也不是用的白水泥,而是直接现成买来就已经配好的用来填缝的,兑水搅拌均匀就好了,后面就主要是我跟我爸在搞,那个时候真的觉得我实在是太胖了,蹲下去真的没一会就受不了了,膝盖什么的太难受了,后面我跪着刷,然后膝盖又疼,也是比较不容易,不过我爸动作很快,我中间跪累了休息一会,我爸就能搞一大片,后面其实我也没做多少(谦虚一下),总体来讲这次不是很累,就是蹲着跪着腿有点受不了,是应该好好减肥了。
mybatis 的 $ 和 # 是有啥区别
这个问题也是面试中常被问到的,就抽空来了解下这个,跳过一大段前面初始化的逻辑,
对于一条select * from t1 where id = #{id}这样的 sql,在初始化扫描 mapper 的xml文件的时候会根据是否是 dynamic 来判断生成 DynamicSqlSource 还是 RawSqlSource,这里它是一条 RawSqlSource,
在这里做了替换,将#{}替换成了?
![]()
前面说的是否 dynamic 就是在这里进行判断
![]()
// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
+}
注释应该写的比较清楚了。
在老丈人家的小工记三
小工记三
前面这两周周末也都去老丈人家帮忙了,上上周周六先是去了那个在装修的旧房子那,把三楼收拾了下,因为要搬进来住,来不及等二楼装修好,就要把三楼里的东西都整理干净,这个活感觉是比较 easy,原来是就准备把三楼当放东西仓储的地方了,我们乡下大部分三层楼都是这么用的,这次也是没办法,之前搬进来的木头什么的都搬出去,主要是这上面灰尘太多,后面清理鼻孔的时候都是黑色的了,把东西都搬出去以后主要是地还是很脏,就扫了地拖了地,因为是水泥地,灰尘又太多了,拖起来都是会灰尘扬起来,整个脱完了的确干净很多,然而这会就出了个大乌龙,我们清理的是三楼的西边一间,结果老丈人上来说要住东边那间的🤦♂️,不过其实西边的也得清理,因为还是要放被子什么的,不算是白费功夫,接着清理东边那间,之前这个房子做过群租房,里面有个高低铺的床,当时觉得可以用在放被子什么的就没扔,只是拆掉了放旁边,我们就把它擦干净了又装好,发现螺丝🔩少了几个,亘古不变的真理,拆了以后装要不就多几个要不就少几个,不是很牢靠,不过用来放放被子省得放地上总还是可以的,对了前面还做了个事情就是铺地毯,其实也不是地毯,就是类似于墙布雨篷布那种,别人不用了送给我们的,三楼水泥地也不会铺瓷砖地板了就放一下,干净好看点,不过大小不合适要裁一下,那把剪刀是真的太难用了,我手都要抽筋了,它就是刀口只有一小个点是能剪下来的,其他都是钝的,后来还是用刀片直接裁,铺好以后,真的感觉也不太一样了,焕然一新的感觉
差不多中午了就去吃饭了,之前两次是去了一家小饭店,还是还比较干净,但是店里菜不好吃,还死贵,这次去了一家小快餐店,口味好,便宜,味道是真的不错,带鱼跟黄鱼都好吃,一点都不腥,我对这类比较腥的鱼真的是很挑剔的,基本上除了家里做的很少吃外面的,那天抱着试试的态度吃了下,真的还不错,后来丈母娘说好像这家老板是给别人结婚喜事酒席当厨师的,怪不得做的好吃,其实本来是有一点小抗拒,怕不干净什么的,后来发现菜很好吃,而且可能是老丈人跟干活的师傅去吃的比较多,老板很客气,我们吃完饭,还给我们买了葡萄吃,不过这家店有一个槽点,就是饭比较不好吃,有时候会夹生,不过后面聊起来其实是这种小菜馆饭点的通病,烧的太早太多容易多出来浪费,烧的迟了不够吃,而且大的电饭锅比较不容易烧好。
下午前面还是在处理三楼的,窗户上各种钉子,实在是太多了,我后面在走廊上排了一排🤦♂️,有些是直接断了,有些是就撬了出来,感觉我在杭州租房也没有这样子各种钉钉子,挂下衣服什么的也不用这么多吧,比较不能理解,搞得到处都是钉子。那天我爸也去帮忙了,主要是在卫生间里做白缝,其实也是个技术活,印象中好像我小时候自己家里也做过这个事情,但是比较模糊了,后面我们三楼搞完了就去帮我爸了,前面是我老婆二爹在那先刷上白缝,这里叫白缝,有些考究的也叫美缝,就是瓷砖铺完之后的缝,如果不去弄的话,里面水泥的颜色就露出来了,而且容易渗水,所以就要用白水泥加胶水搅拌之后糊在缝上,但是也不是直接糊,先要把缝抠一抠,因为铺瓷砖的还不会仔细到每个缝里的水泥都是一样满,而且也需要一些空间糊上去,不然就太表面的一层很容易被水直接冲掉了,然后这次其实也不是用的白水泥,而是直接现成买来就已经配好的用来填缝的,兑水搅拌均匀就好了,后面就主要是我跟我爸在搞,那个时候真的觉得我实在是太胖了,蹲下去真的没一会就受不了了,膝盖什么的太难受了,后面我跪着刷,然后膝盖又疼,也是比较不容易,不过我爸动作很快,我中间跪累了休息一会,我爸就能搞一大片,后面其实我也没做多少(谦虚一下),总体来讲这次不是很累,就是蹲着跪着腿有点受不了,是应该好好减肥了。
mybatis 的 $ 和 # 是有啥区别
这个问题也是面试中常被问到的,就抽空来了解下这个,跳过一大段前面初始化的逻辑,
对于一条select * from t1 where id = #{id}这样的 sql,在初始化扫描 mapper 的xml文件的时候会根据是否是 dynamic 来判断生成 DynamicSqlSource 还是 RawSqlSource,这里它是一条 RawSqlSource,
在这里做了替换,将#{}替换成了?
![]()
前面说的是否 dynamic 就是在这里进行判断
![]()
// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
public SqlSource parseScriptNode() {
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
diff --git a/page/34/index.html b/page/34/index.html
index 6bf4717466..7f7efc934b 100644
--- a/page/34/index.html
+++ b/page/34/index.html
@@ -1,4 +1,4 @@
-Nicksxs's Blog - What hurts more, the pain of hard work or the pain of regret? 周末我在老丈人家打了天小工
这周回家提前约好了要去老丈人家帮下忙,因为在翻修下老房子,活不是特别整的那种,所以大部分都是自己干,或者找个大工临时干几天(我们这那种比较专业的泥工匠叫做大工),像我这样去帮忙的,就是干点小工(把给大工帮忙的,干些偏体力活的叫做小工)的活。从大学毕业以后真的蛮少帮家里干活了,以前上学的时候放假还是帮家里淘个米,简单的扫地拖地啥的,当然刚高考完的时候,还去我爸厂里帮忙干了几天的活,实在是比较累,不过现在想着是觉得自己那时候比较牛,而不是特别排斥这个活,相对于现在的工作来说,导致了一系列的职业病,颈椎腰背都很僵硬,眼镜也不好,还有反流,像我爸那种活反而是脑力加体力的比较好的结合。
这一天的活前半部分主要是在清理厨房,瓷砖上的油污和墙上天花板上即将脱落的石灰或者白色涂料层,这种活特别是瓷砖上的油污,之前在自己家里也干活,还是比较熟悉的,不过前面主要是LD 在干,我主要是先搞墙上和天花板上的,干活还是很需要技巧的,如果直接去铲,那基本我会变成一个灰人,而且吸一鼻子灰,老丈人比较专业,先接上软管用水冲,一冲效果特别好,有些石灰涂料层直接就冲掉了,冲完之后先用带加长杆的刀片铲铲了一圈墙面,说实话因为老房子之前租出去了,所以墙面什么的被糟蹋的比较难看,一层一层的,不过这还算还好,后面主要是天花板上的,这可难倒我了,从小我爸妈是比较把我当小孩管着,爬上爬下的基本都是我爸搞定,但是到了老丈人家也只得硬着头皮上了,爬到跳(一种建筑工地用的架子)上,还有点晃,小心脏扑通扑通跳,而且带加长杆的铲子还是比较重的,铲一会手也有点累,不过坚持着铲完了,上面还是比较平整的,不过下来的时候又把我难住了🤦♂️,往下爬的时候有根杆子要跨过去,由于裤子比较紧,强行一把跨过去怕抽筋,所以以一个非常尴尬的姿势停留休息了一会,再跨了过去,幸好事后问 LD,他们都没看到,哈哈哈,然后就是帮忙一起搞瓷砖上的油污,这个太有经验了,不过老丈人更有意思,一会试试啤酒,一会用用沙子,后面在午饭前基本就弄的比较干净了,就坐着等吃饭了,下午午休了会,就继续干活了。
下午是我这次体验的重点了,因为要清理以前贴的墙纸,真的是个很麻烦的活,只能说贴墙纸的师傅活干得太好了,基本不可能整个撕下来,想用铲子一点点铲下来也不行,太轻了就只铲掉表面一层,太重了就把墙纸跟墙面的石灰啥的整个铲下来了,而且手又累又酸,后来想着是不是继续用水冲一下,对着一小面墙试验了下,效果还不错,但是又发现了个问题,那一面墙又有一块是后面糊上去的,铲掉外层的石灰后不平,然后就是最最重头的,也是让我后遗症持续到第二天的,要把那一块糊上去的水泥敲下来,毛估下大概是敲了80%左右,剩下的我的手已经不会用力了,因为那一块应该是要糊上去的始作俑者,就一块里面凹进去的,我拿着榔头敲到我手已经没法使劲了,而且大下午,感觉没五分钟,我的汗已经糊满脸,眼睛也睁不开,不然就流到眼睛里了,此处获得成就一:用榔头敲墙壁,也是个技术加体力的活,而且需要非常好的技巧,否则手马上就废了,敲下去的反作用力,没一会就不行了,然后是看着老丈人兄弟帮忙拆一个柜子,在我看来是个几天都搞不定的活,他轻轻松松在我敲墙的那会就搞定了,以前总觉得我干的活非常有技术含量,可是这个事情真的也是很有技巧啊,它是个把一间房间分隔开的柜子,从底到顶上,还带着门,我还在旁边帮忙撬一下脚踢,一根木条撬半天,唉,成就二:专业的人就是不一样。
最后就是成就三了:我之前沾沾自喜的跑了多少步,做了什么锻炼,其实都是渣渣,像这样干一天活,没经历过的,基本大半天就废了,反过来说,如果能经常去这么干一天活,跑步啥的都是渣渣,消耗的能量远远超过跑个十公里啥的。
Linux 下 grep 命令的一点小技巧
用了比较久的 grep 命令,其实都只是用了最最基本的功能来查日志,
譬如
+Nicksxs's Blog - What hurts more, the pain of hard work or the pain of regret? 周末我在老丈人家打了天小工
这周回家提前约好了要去老丈人家帮下忙,因为在翻修下老房子,活不是特别整的那种,所以大部分都是自己干,或者找个大工临时干几天(我们这那种比较专业的泥工匠叫做大工),像我这样去帮忙的,就是干点小工(把给大工帮忙的,干些偏体力活的叫做小工)的活。从大学毕业以后真的蛮少帮家里干活了,以前上学的时候放假还是帮家里淘个米,简单的扫地拖地啥的,当然刚高考完的时候,还去我爸厂里帮忙干了几天的活,实在是比较累,不过现在想着是觉得自己那时候比较牛,而不是特别排斥这个活,相对于现在的工作来说,导致了一系列的职业病,颈椎腰背都很僵硬,眼镜也不好,还有反流,像我爸那种活反而是脑力加体力的比较好的结合。
这一天的活前半部分主要是在清理厨房,瓷砖上的油污和墙上天花板上即将脱落的石灰或者白色涂料层,这种活特别是瓷砖上的油污,之前在自己家里也干活,还是比较熟悉的,不过前面主要是LD 在干,我主要是先搞墙上和天花板上的,干活还是很需要技巧的,如果直接去铲,那基本我会变成一个灰人,而且吸一鼻子灰,老丈人比较专业,先接上软管用水冲,一冲效果特别好,有些石灰涂料层直接就冲掉了,冲完之后先用带加长杆的刀片铲铲了一圈墙面,说实话因为老房子之前租出去了,所以墙面什么的被糟蹋的比较难看,一层一层的,不过这还算还好,后面主要是天花板上的,这可难倒我了,从小我爸妈是比较把我当小孩管着,爬上爬下的基本都是我爸搞定,但是到了老丈人家也只得硬着头皮上了,爬到跳(一种建筑工地用的架子)上,还有点晃,小心脏扑通扑通跳,而且带加长杆的铲子还是比较重的,铲一会手也有点累,不过坚持着铲完了,上面还是比较平整的,不过下来的时候又把我难住了🤦♂️,往下爬的时候有根杆子要跨过去,由于裤子比较紧,强行一把跨过去怕抽筋,所以以一个非常尴尬的姿势停留休息了一会,再跨了过去,幸好事后问 LD,他们都没看到,哈哈哈,然后就是帮忙一起搞瓷砖上的油污,这个太有经验了,不过老丈人更有意思,一会试试啤酒,一会用用沙子,后面在午饭前基本就弄的比较干净了,就坐着等吃饭了,下午午休了会,就继续干活了。
下午是我这次体验的重点了,因为要清理以前贴的墙纸,真的是个很麻烦的活,只能说贴墙纸的师傅活干得太好了,基本不可能整个撕下来,想用铲子一点点铲下来也不行,太轻了就只铲掉表面一层,太重了就把墙纸跟墙面的石灰啥的整个铲下来了,而且手又累又酸,后来想着是不是继续用水冲一下,对着一小面墙试验了下,效果还不错,但是又发现了个问题,那一面墙又有一块是后面糊上去的,铲掉外层的石灰后不平,然后就是最最重头的,也是让我后遗症持续到第二天的,要把那一块糊上去的水泥敲下来,毛估下大概是敲了80%左右,剩下的我的手已经不会用力了,因为那一块应该是要糊上去的始作俑者,就一块里面凹进去的,我拿着榔头敲到我手已经没法使劲了,而且大下午,感觉没五分钟,我的汗已经糊满脸,眼睛也睁不开,不然就流到眼睛里了,此处获得成就一:用榔头敲墙壁,也是个技术加体力的活,而且需要非常好的技巧,否则手马上就废了,敲下去的反作用力,没一会就不行了,然后是看着老丈人兄弟帮忙拆一个柜子,在我看来是个几天都搞不定的活,他轻轻松松在我敲墙的那会就搞定了,以前总觉得我干的活非常有技术含量,可是这个事情真的也是很有技巧啊,它是个把一间房间分隔开的柜子,从底到顶上,还带着门,我还在旁边帮忙撬一下脚踢,一根木条撬半天,唉,成就二:专业的人就是不一样。
最后就是成就三了:我之前沾沾自喜的跑了多少步,做了什么锻炼,其实都是渣渣,像这样干一天活,没经历过的,基本大半天就废了,反过来说,如果能经常去这么干一天活,跑步啥的都是渣渣,消耗的能量远远超过跑个十公里啥的。
Linux 下 grep 命令的一点小技巧
用了比较久的 grep 命令,其实都只是用了最最基本的功能来查日志,
譬如
grep 'xxx' xxxx.log
然后有挺多情况比如想要找日志里带一些符号什么的,就需要用到一些特殊的
比如这样\"userId\":\"123456\",因为比如用户 ID 有时候会跟其他的 id 一样,只用具体的值 123456 来查的话干扰信息太多了,如果直接这样
grep '\"userId\":\"123456\"' xxxx.log
diff --git a/page/37/index.html b/page/37/index.html
index 8fc9cfabd0..24da6bc3dd 100644
--- a/page/37/index.html
+++ b/page/37/index.html
@@ -48,7 +48,7 @@ constexpr size_t DATA_ROLL_PTR_LEN
剩下来一点是啥呢,就是 Read Committed 和 Repeated Read 也不一样,那前面说的 read view 都能支持吗,又是怎么支持呢,假如这个 read view 是在事务一开始就创建,那好像能支持的只是 RR 事务隔离级别,其实呢,这是通过创建 read view的时机,对于 RR 级别,就是在事务的第一个 select 语句是创建,对于 RC 级别,是在每个 select 语句执行前都是创建一次,那样就可以保证能读到所有已提交的数据redis系列介绍八-淘汰策略
LRU
说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍
![]() ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
redis 针对这个策略的改进做了一个实验,这里借用下图
![]()
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
typedef struct redisObject {
+ }
剩下来一点是啥呢,就是 Read Committed 和 Repeated Read 也不一样,那前面说的 read view 都能支持吗,又是怎么支持呢,假如这个 read view 是在事务一开始就创建,那好像能支持的只是 RR 事务隔离级别,其实呢,这是通过创建 read view的时机,对于 RR 级别,就是在事务的第一个 select 语句是创建,对于 RC 级别,是在每个 select 语句执行前都是创建一次,那样就可以保证能读到所有已提交的数据redis系列介绍八-淘汰策略
LRU
说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍
![]() ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
redis 针对这个策略的改进做了一个实验,这里借用下图
![]()
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
@@ -529,7 +529,7 @@ uint8_t LFULogIncr(uint8_t counter) {
| 10 | 10 | 18 | 142 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 100 | 8 | 11 | 49 | 143 | 255 |
-+--------+------------+------------+------------+------------+------------+
简而言之就是 lfu_log_factor 越大变化的越慢
总结
总结一下,redis 实现了近似的 lru 淘汰策略,通过增加了淘汰 key 的池子(pool),并且增大每次抽样的 key 的数量来将淘汰效果更进一步地接近于 lru,这是 lru 策略,但是对于前面举的一个例子,其实 lru 并不能保证 key 的淘汰就如我们预期,所以在后期又引入了 lfu 的策略,lfu的策略比较巧妙,复用了 redis 对象的 lru 字段,并且使用了factor 参数来控制计数器递增的速度,防止 8 位的计数器太早溢出。
redis系列介绍七-过期策略
这一篇不再是数据结构介绍了,大致的数据结构基本都介绍了,这一篇主要是查漏补缺,或者说讲一些重要且基本的概念,也可能是经常被忽略的,很多讲 redis 的系列文章可能都会忽略,学习 redis 的时候也会,因为觉得源码学习就是讲主要的数据结构和“算法”学习了就好了。
redis 的主要应用就是拿来作为高性能的缓存,那么缓存一般有些啥需要注意的,首先是访问速度,如果取得跟数据库一样快,那就没什么存在的意义,第二个是缓存的字面意思,我只是为了让数据读取快一些,通常大部分的场景这个是需要更新过期的,这里就把我要讲的第一点引出来了(真累,
redis过期策略
redis 是如何过期缓存的,可以猜测下,最无脑的就是每个设置了过期时间的 key 都设个定时器,过期了就删除,这种显然消耗太大,清理地最及时,还有的就是 redis 正在采用的懒汉清理策略和定期清理
懒汉策略就是在使用的时候去检查缓存是否过期,比如 get 操作时,先判断下这个 key 是否已经过期了,如果过期了就删掉,并且返回空,如果没过期则正常返回
主要代码是
/* This function is called when we are going to perform some operation
++--------+------------+------------+------------+------------+------------+
简而言之就是 lfu_log_factor 越大变化的越慢
总结
总结一下,redis 实现了近似的 lru 淘汰策略,通过增加了淘汰 key 的池子(pool),并且增大每次抽样的 key 的数量来将淘汰效果更进一步地接近于 lru,这是 lru 策略,但是对于前面举的一个例子,其实 lru 并不能保证 key 的淘汰就如我们预期,所以在后期又引入了 lfu 的策略,lfu的策略比较巧妙,复用了 redis 对象的 lru 字段,并且使用了factor 参数来控制计数器递增的速度,防止 8 位的计数器太早溢出。
redis系列介绍七-过期策略
这一篇不再是数据结构介绍了,大致的数据结构基本都介绍了,这一篇主要是查漏补缺,或者说讲一些重要且基本的概念,也可能是经常被忽略的,很多讲 redis 的系列文章可能都会忽略,学习 redis 的时候也会,因为觉得源码学习就是讲主要的数据结构和“算法”学习了就好了。
redis 的主要应用就是拿来作为高性能的缓存,那么缓存一般有些啥需要注意的,首先是访问速度,如果取得跟数据库一样快,那就没什么存在的意义,第二个是缓存的字面意思,我只是为了让数据读取快一些,通常大部分的场景这个是需要更新过期的,这里就把我要讲的第一点引出来了(真累,
redis过期策略
redis 是如何过期缓存的,可以猜测下,最无脑的就是每个设置了过期时间的 key 都设个定时器,过期了就删除,这种显然消耗太大,清理地最及时,还有的就是 redis 正在采用的懒汉清理策略和定期清理
懒汉策略就是在使用的时候去检查缓存是否过期,比如 get 操作时,先判断下这个 key 是否已经过期了,如果过期了就删掉,并且返回空,如果没过期则正常返回
主要代码是
/* This function is called when we are going to perform some operation
* in a given key, but such key may be already logically expired even if
* it still exists in the database. The main way this function is called
* is via lookupKey*() family of functions.
diff --git a/page/39/index.html b/page/39/index.html
index 1b2b737452..839faac2be 100644
--- a/page/39/index.html
+++ b/page/39/index.html
@@ -158,7 +158,7 @@ OS name: "mac os x", version: "10.14.6", arch: "x86_64", family: "mac"
hotspot/share/gc/g1/heapRegionType.hpp
当执行垃圾收集时,G1以类似于CMS收集器的方式运行。 G1执行并发全局标记阶段,以确定整个堆中对象的存活性。标记阶段完成后,G1知道哪些region是基本空的。它首先收集这些region,通常会产生大量的可用空间。这就是为什么这种垃圾收集方法称为“垃圾优先”的原因。顾名思义,G1将其收集和压缩活动集中在可能充满可回收对象(即垃圾)的堆区域。 G1使用暂停预测模型来满足用户定义的暂停时间目标,并根据指定的暂停时间目标选择要收集的区域数。
由G1标识为可回收的区域是使用撤离的方式(Evacuation)。 G1将对象从堆的一个或多个区域复制到堆上的单个区域,并在此过程中压缩并释放内存。撤离是在多处理器上并行执行的,以减少暂停时间并增加吞吐量。因此,对于每次垃圾收集,G1都在用户定义的暂停时间内连续工作以减少碎片。这是优于前面两种方法的。 CMS(并发标记扫描)垃圾收集器不进行压缩。 ParallelOld垃圾回收仅执行整个堆压缩,这导致相当长的暂停时间。
需要重点注意的是,G1不是实时收集器。它很有可能达到设定的暂停时间目标,但并非绝对确定。 G1根据先前收集的数据,估算在用户指定的目标时间内可以收集多少个区域。因此,收集器具有收集区域成本的合理准确的模型,并且收集器使用此模型来确定要收集哪些和多少个区域,同时保持在暂停时间目标之内。
注意:G1同时具有并发(与应用程序线程一起运行,例如优化,标记,清理)和并行(多线程,例如stw)阶段。Full GC仍然是单线程的,但是如果正确调优,您的应用程序应该可以避免Full GC。
在前面那篇中在代码层面简单的了解了这个可预测时间的过程,这也是 G1 的一大特点。
2019年终总结
今天是农历初八了,年前一个月的时候就准备做下今年的年终总结,可是写了一点觉得太情绪化了,希望后面写个平淡点的,正好最近技术方面还没有看到一个完整成文的内容,就来写一下这一年的总结,尽量少写一点太情绪化的东西。
跳槽
年初换了个公司,也算换了个环境,跟前公司不太一样,做的事情方向也不同,可能是侧重点不同,一开始有些不适应,主要是压力上,会觉得压力比较大,但是总体来说与人相处的部分还是不错的,做的技术方向还是Java,这里也感谢前东家让我有机会转了Java,个人感觉杭州整个市场还是Java比较有优势,不过在开始的时候总觉得对Java有点不适应,应该值得深究的东西还是很多的,而且对于面试来说,也是有很多可以问的,后面慢慢发现除开某里等一线超一线互联网公司之外,大部分的面试还是有大概的套路跟大纲的,不过更细致的则因人而异了,面试有时候也还看缘分,面试官关注的点跟应试者比较契合的话就很容易通过面试,不然的话总会有能刁难或者理性化地说比较难回答的问题。这个后面可以单独说一下,先按下不表。
刚进公司没多久就负责比较重要的项目,工期也比较紧张,整体来说那段时间的压力的确是比较大的,不过总算最后结果不坏,这里应该说对一些原来在前东家都是掌握的不太好的部分,比如maven,其实maven对于java程序员来说还是很重要的,但是我碰到过的面试基本没问过这个,我自己也在后面的面试中没问过相关的,不知道咋问,比如dependence分析、冲突解决,比如对bean的理解,这个算是我一直以来的疑问点,因为以前刚开始学Java学spring,上来就是bean,但是bean到底是啥,IOC是啥,可能网上的文章跟大多数书籍跟我的理解思路不太match,导致一直不能很好的理解这玩意,到后面才理解,要理解这个bean,需要有两个基本概念,一个是面向对象,一个是对象容器跟依赖反转,还是只说到这,后面可以有专题说一下,总之自认为技术上有了不小的长进了,方向上应该是偏实用的。这个重要的项目完成后慢慢能喘口气了,后面也有一些比较紧急且工作量大的,不过在我TL的帮助下还是能尽量协调好资源。
面试
后面因为项目比较多,缺少开发,所以也参与帮忙做一些面试,这里总体感觉是面的候选人还是比较多样的,有些工作了蛮多年但是一些基础问题回答的不好,有些还是在校学生,但是面试技巧不错,针对常见的面试题都有不错的准备,不过还是觉得光靠这些面试题不能完全说明问题,真正工作了需要的是解决问题的人,而不是会背题的,退一步来说能好好准备面试还是比较重要的,也是双向选择中的基本尊重,印象比较深刻的是参加了去杭州某高校的校招面试,感觉参加校招的同学还是很多的,大部分是20年将毕业的研究生,挺多都是基础很扎实,对比起我刚要毕业时还是很汗颜,挺多来面试的同学都非常不错,那天强度也很大,从下午到那开始一直面到六七点,在这祝福那些来面试的同学,也都不容易的,能找到心仪的工作。
技术方向
这一年前大半部分还是比较焦虑不能恢复那种主动找时间学习的状态,可能换了公司是主要的原因,初期有个适应的过程也比较正常,总体来说可能是到九十月份开始慢慢有所改善,对这些方面有学习了下,
- spring方向,spring真的是个庞然大物,但是还是要先抓住根本,慢慢发散去了解其他的细节,抓住bean的生命周期,当然也不是死记硬背,让我一个个背下来我也不行,但是知道它究竟是干嘛的,有啥用,并且在工作中能用起来是最重要的
- mysql数据库,这部分主要是关注了mvcc,知道了个大概,源码实现细节还没具体研究,有时间可以来个专题(一大堆待写的内容)
- java的一些源码,比如aqs这种,结合文章看了下源码,一开始总感觉静不下心来看,然后有一次被LD刺激了下就看完了,包括conditionObject等
- redis的源码,这里包括了Redis分布式锁和redis的数据结构源码,已经写成文章,不过比较着急成文,所以质量不是特别好,希望后面再来补补
- jvm源码,这部分正好是想了解下g1收集器,大概把周志明的书看完了,但是还没完整的理解掌握,还有就是g1收集器的部分,一是概念部分大概理解了,后面是就是想从源码层面去学习理解,这也是新一年的主要计划
- mq的部分是了解了zero copy,sendfile等,跟消息队列主题关系不大🤦♂️
这么看还是学了点东西的,希望新一年再接再厉。
生活
住的地方没变化,主要是周边设施比较方便,暂时没找到更好的就没打算换,主要的问题是没电梯,一开始没觉得有啥,真正住起来还是觉得比较累的,希望后面租的可以有电梯,或者楼层低一点,还有就是要通下水道,第一次让师傅上门,花了两百大洋,后来自学成才了,让师傅通了一次才撑了一个月就不行了,后面自己通的差不多可以撑半年,还是比较有成就感的😀,然后就是跑步了,年初的时候去了紫金港跑步,后面因为工作的原因没去了,但是公司的跑步机倒是让我重拾起这个唯一的运动健身项目,后面因为肠胃问题,体重也需要控制,所以就周末回来也在家这边坚持跑步,下半年的话基本保持每周一次以上,比较那些跑马拉松的大牛还是差距很大,不过也是突破自我了,有一次跑了12公里,最远的距离,而且后面感觉跑十公里也不是特别吃不消了,这一年达成了300公里的目标,体重也稍有下降,比较满意的结果。
期待
希望工作方面技术方面能有所长进,生活上能多点时间陪家人,继续跑步减肥,家人健健康康的,嗯
redis数据结构介绍六 快表
这应该是 redis 系列的最后一篇了,讲下快表,其实最前面讲的链表在早先的 redis 版本中也作为 list 的数据结构使用过,但是单纯的链表的缺陷之前也说了,插入便利,但是空间利用率低,并且不能进行二分查找等,检索效率低,ziplist 压缩表的产生也是同理,希望获得更好的性能,包括存储空间和访问性能等,原来我也不懂这个快表要怎么快,然后明白了一个道理,其实并没有什么银弹,只是大牛们会在适合的时候使用最适合的数据结构来实现性能的最大化,这里面有一招就是不同数据结构的组合调整,比如 Java 中的 HashMap,在链表节点数大于 8 时会转变成红黑树,以此提高访问效率,不费话了,回到快表,quicklist,这个数据结构主要使用在 list 类型中,如果我说其实这个 quicklist 就是个链表,可能大家不太会相信,但是事实上的确可以认为 quicklist 是个双向链表,看下代码
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
+ } Tag;
hotspot/share/gc/g1/heapRegionType.hpp
当执行垃圾收集时,G1以类似于CMS收集器的方式运行。 G1执行并发全局标记阶段,以确定整个堆中对象的存活性。标记阶段完成后,G1知道哪些region是基本空的。它首先收集这些region,通常会产生大量的可用空间。这就是为什么这种垃圾收集方法称为“垃圾优先”的原因。顾名思义,G1将其收集和压缩活动集中在可能充满可回收对象(即垃圾)的堆区域。 G1使用暂停预测模型来满足用户定义的暂停时间目标,并根据指定的暂停时间目标选择要收集的区域数。
由G1标识为可回收的区域是使用撤离的方式(Evacuation)。 G1将对象从堆的一个或多个区域复制到堆上的单个区域,并在此过程中压缩并释放内存。撤离是在多处理器上并行执行的,以减少暂停时间并增加吞吐量。因此,对于每次垃圾收集,G1都在用户定义的暂停时间内连续工作以减少碎片。这是优于前面两种方法的。 CMS(并发标记扫描)垃圾收集器不进行压缩。 ParallelOld垃圾回收仅执行整个堆压缩,这导致相当长的暂停时间。
需要重点注意的是,G1不是实时收集器。它很有可能达到设定的暂停时间目标,但并非绝对确定。 G1根据先前收集的数据,估算在用户指定的目标时间内可以收集多少个区域。因此,收集器具有收集区域成本的合理准确的模型,并且收集器使用此模型来确定要收集哪些和多少个区域,同时保持在暂停时间目标之内。
注意:G1同时具有并发(与应用程序线程一起运行,例如优化,标记,清理)和并行(多线程,例如stw)阶段。Full GC仍然是单线程的,但是如果正确调优,您的应用程序应该可以避免Full GC。
在前面那篇中在代码层面简单的了解了这个可预测时间的过程,这也是 G1 的一大特点。
2019年终总结
今天是农历初八了,年前一个月的时候就准备做下今年的年终总结,可是写了一点觉得太情绪化了,希望后面写个平淡点的,正好最近技术方面还没有看到一个完整成文的内容,就来写一下这一年的总结,尽量少写一点太情绪化的东西。
跳槽
年初换了个公司,也算换了个环境,跟前公司不太一样,做的事情方向也不同,可能是侧重点不同,一开始有些不适应,主要是压力上,会觉得压力比较大,但是总体来说与人相处的部分还是不错的,做的技术方向还是Java,这里也感谢前东家让我有机会转了Java,个人感觉杭州整个市场还是Java比较有优势,不过在开始的时候总觉得对Java有点不适应,应该值得深究的东西还是很多的,而且对于面试来说,也是有很多可以问的,后面慢慢发现除开某里等一线超一线互联网公司之外,大部分的面试还是有大概的套路跟大纲的,不过更细致的则因人而异了,面试有时候也还看缘分,面试官关注的点跟应试者比较契合的话就很容易通过面试,不然的话总会有能刁难或者理性化地说比较难回答的问题。这个后面可以单独说一下,先按下不表。
刚进公司没多久就负责比较重要的项目,工期也比较紧张,整体来说那段时间的压力的确是比较大的,不过总算最后结果不坏,这里应该说对一些原来在前东家都是掌握的不太好的部分,比如maven,其实maven对于java程序员来说还是很重要的,但是我碰到过的面试基本没问过这个,我自己也在后面的面试中没问过相关的,不知道咋问,比如dependence分析、冲突解决,比如对bean的理解,这个算是我一直以来的疑问点,因为以前刚开始学Java学spring,上来就是bean,但是bean到底是啥,IOC是啥,可能网上的文章跟大多数书籍跟我的理解思路不太match,导致一直不能很好的理解这玩意,到后面才理解,要理解这个bean,需要有两个基本概念,一个是面向对象,一个是对象容器跟依赖反转,还是只说到这,后面可以有专题说一下,总之自认为技术上有了不小的长进了,方向上应该是偏实用的。这个重要的项目完成后慢慢能喘口气了,后面也有一些比较紧急且工作量大的,不过在我TL的帮助下还是能尽量协调好资源。
面试
后面因为项目比较多,缺少开发,所以也参与帮忙做一些面试,这里总体感觉是面的候选人还是比较多样的,有些工作了蛮多年但是一些基础问题回答的不好,有些还是在校学生,但是面试技巧不错,针对常见的面试题都有不错的准备,不过还是觉得光靠这些面试题不能完全说明问题,真正工作了需要的是解决问题的人,而不是会背题的,退一步来说能好好准备面试还是比较重要的,也是双向选择中的基本尊重,印象比较深刻的是参加了去杭州某高校的校招面试,感觉参加校招的同学还是很多的,大部分是20年将毕业的研究生,挺多都是基础很扎实,对比起我刚要毕业时还是很汗颜,挺多来面试的同学都非常不错,那天强度也很大,从下午到那开始一直面到六七点,在这祝福那些来面试的同学,也都不容易的,能找到心仪的工作。
技术方向
这一年前大半部分还是比较焦虑不能恢复那种主动找时间学习的状态,可能换了公司是主要的原因,初期有个适应的过程也比较正常,总体来说可能是到九十月份开始慢慢有所改善,对这些方面有学习了下,
- spring方向,spring真的是个庞然大物,但是还是要先抓住根本,慢慢发散去了解其他的细节,抓住bean的生命周期,当然也不是死记硬背,让我一个个背下来我也不行,但是知道它究竟是干嘛的,有啥用,并且在工作中能用起来是最重要的
- mysql数据库,这部分主要是关注了mvcc,知道了个大概,源码实现细节还没具体研究,有时间可以来个专题(一大堆待写的内容)
- java的一些源码,比如aqs这种,结合文章看了下源码,一开始总感觉静不下心来看,然后有一次被LD刺激了下就看完了,包括conditionObject等
- redis的源码,这里包括了Redis分布式锁和redis的数据结构源码,已经写成文章,不过比较着急成文,所以质量不是特别好,希望后面再来补补
- jvm源码,这部分正好是想了解下g1收集器,大概把周志明的书看完了,但是还没完整的理解掌握,还有就是g1收集器的部分,一是概念部分大概理解了,后面是就是想从源码层面去学习理解,这也是新一年的主要计划
- mq的部分是了解了zero copy,sendfile等,跟消息队列主题关系不大🤦♂️
这么看还是学了点东西的,希望新一年再接再厉。
生活
住的地方没变化,主要是周边设施比较方便,暂时没找到更好的就没打算换,主要的问题是没电梯,一开始没觉得有啥,真正住起来还是觉得比较累的,希望后面租的可以有电梯,或者楼层低一点,还有就是要通下水道,第一次让师傅上门,花了两百大洋,后来自学成才了,让师傅通了一次才撑了一个月就不行了,后面自己通的差不多可以撑半年,还是比较有成就感的😀,然后就是跑步了,年初的时候去了紫金港跑步,后面因为工作的原因没去了,但是公司的跑步机倒是让我重拾起这个唯一的运动健身项目,后面因为肠胃问题,体重也需要控制,所以就周末回来也在家这边坚持跑步,下半年的话基本保持每周一次以上,比较那些跑马拉松的大牛还是差距很大,不过也是突破自我了,有一次跑了12公里,最远的距离,而且后面感觉跑十公里也不是特别吃不消了,这一年达成了300公里的目标,体重也稍有下降,比较满意的结果。
期待
希望工作方面技术方面能有所长进,生活上能多点时间陪家人,继续跑步减肥,家人健健康康的,嗯
redis数据结构介绍六 快表
这应该是 redis 系列的最后一篇了,讲下快表,其实最前面讲的链表在早先的 redis 版本中也作为 list 的数据结构使用过,但是单纯的链表的缺陷之前也说了,插入便利,但是空间利用率低,并且不能进行二分查找等,检索效率低,ziplist 压缩表的产生也是同理,希望获得更好的性能,包括存储空间和访问性能等,原来我也不懂这个快表要怎么快,然后明白了一个道理,其实并没有什么银弹,只是大牛们会在适合的时候使用最适合的数据结构来实现性能的最大化,这里面有一招就是不同数据结构的组合调整,比如 Java 中的 HashMap,在链表节点数大于 8 时会转变成红黑树,以此提高访问效率,不费话了,回到快表,quicklist,这个数据结构主要使用在 list 类型中,如果我说其实这个 quicklist 就是个链表,可能大家不太会相信,但是事实上的确可以认为 quicklist 是个双向链表,看下代码
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
diff --git a/page/40/index.html b/page/40/index.html
index 5ac965417a..e683dcec8f 100644
--- a/page/40/index.html
+++ b/page/40/index.html
@@ -1,4 +1,4 @@
-Nicksxs's Blog - What hurts more, the pain of hard work or the pain of regret? redis数据结构介绍五-第五部分 对象
前面说了这么些数据结构,其实大家对于 redis 最初的印象应该就是个 key-value 的缓存,类似于 memcache,redis 其实也是个 key-value,key 还是一样的字符串,或者说就是用 redis 自己的动态字符串实现,但是 value 其实就是前面说的那些数据结构,差不多快说完了,还有个 quicklist 后面还有一篇,这里先介绍下 redis 对于这些不同类型的 value 是怎么实现的,首先看下 redisObject 的源码头文件
/* The actual Redis Object */
+Nicksxs's Blog - What hurts more, the pain of hard work or the pain of regret? redis数据结构介绍五-第五部分 对象
前面说了这么些数据结构,其实大家对于 redis 最初的印象应该就是个 key-value 的缓存,类似于 memcache,redis 其实也是个 key-value,key 还是一样的字符串,或者说就是用 redis 自己的动态字符串实现,但是 value 其实就是前面说的那些数据结构,差不多快说完了,还有个 quicklist 后面还有一篇,这里先介绍下 redis 对于这些不同类型的 value 是怎么实现的,首先看下 redisObject 的源码头文件
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
@@ -33,7 +33,7 @@ typedef struct redisObject {
* and most significant 16 bits access time). */
int refcount;
void *ptr;
-} robj;
主体结构就是这个 redisObject,
- type: 字段表示对象的类型,它对应的就是 redis 的对外暴露的,或者说用户可以使用的五种类型,OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH
- encoding: 字段表示这个对象在 redis 内部的编码方式,由OBJ_ENCODING_开头的 11 种
- lru: 做LRU替换算法用,占24个bit
- refcount: 引用计数。它允许robj对象在某些情况下被共享。
- ptr: 指向底层实现数据结构的指针
当 type 是 OBJ_STRING 时,表示类型是个 string,它的编码方式 encoding 可能有 OBJ_ENCODING_RAW,OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR 三种
当 type 是 OBJ_LIST 时,表示类型是 list,它的编码方式 encoding 是 OBJ_ENCODING_QUICKLIST,对于早一些的版本,2.2这种可能还会使用 OBJ_ENCODING_ZIPLIST,OBJ_ENCODING_LINKEDLIST
当 type 是 OBJ_SET 时,是个集合,但是得看具体元素的类型,有可能使用整数集合,OBJ_ENCODING_INTSET, 如果元素不全是整型或者数量超过一定限制,那么编码就是 OBJ_ENCODING_HT hash table 了
当 type 是 OBJ_ZSET 时,是个有序集合,它底层有可能使用的是 OBJ_ENCODING_ZIPLIST 或者 OBJ_ENCODING_SKIPLIST
当 type 是 OBJ_HASH 时,一开始也是 OBJ_ENCODING_ZIPLIST,然后当数据量大于 hash_max_ziplist_entries 时会转成 OBJ_ENCODING_HT
redis数据结构介绍四-第四部分 压缩表
在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient.
这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
其中
<zlbytes>表示 ziplist 占用的字节总数,类型是uint32_t,32 位的无符号整型,当然表示的字节数也包含自己本身占用的 4 个
<zltail> 类型也是是uint32_t,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
<uint16_t zllen> 表示ziplist 中的数据项个数,因为是 16 位,所以当数量超过所能表示的最大的数量,它的 16 位全会置为 1,但是真实的数量需要遍历整个 ziplist 才能知道
<entry>是具体的数据项,后面解释
<zlend> ziplist 的最后一个字节,固定是255。
再看一下<entry>中的具体结构,
<prevlen> <encoding> <entry-data>
首先这个<prevlen>有两种情况,一种是前面的元素的长度,如果是小于等于 253的时候就用一个uint8_t 来表示前一元素的长度,如果大于的话他将占用五个字节,第一个字节是 254,即表示这个字节已经表示不下了,需要后面的四个字节帮忙表示
<encoding>这个就比较复杂,把源码的注释放下面先看下
* |00pppppp| - 1 byte
+} robj;
主体结构就是这个 redisObject,
- type: 字段表示对象的类型,它对应的就是 redis 的对外暴露的,或者说用户可以使用的五种类型,OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH
- encoding: 字段表示这个对象在 redis 内部的编码方式,由OBJ_ENCODING_开头的 11 种
- lru: 做LRU替换算法用,占24个bit
- refcount: 引用计数。它允许robj对象在某些情况下被共享。
- ptr: 指向底层实现数据结构的指针
当 type 是 OBJ_STRING 时,表示类型是个 string,它的编码方式 encoding 可能有 OBJ_ENCODING_RAW,OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR 三种
当 type 是 OBJ_LIST 时,表示类型是 list,它的编码方式 encoding 是 OBJ_ENCODING_QUICKLIST,对于早一些的版本,2.2这种可能还会使用 OBJ_ENCODING_ZIPLIST,OBJ_ENCODING_LINKEDLIST
当 type 是 OBJ_SET 时,是个集合,但是得看具体元素的类型,有可能使用整数集合,OBJ_ENCODING_INTSET, 如果元素不全是整型或者数量超过一定限制,那么编码就是 OBJ_ENCODING_HT hash table 了
当 type 是 OBJ_ZSET 时,是个有序集合,它底层有可能使用的是 OBJ_ENCODING_ZIPLIST 或者 OBJ_ENCODING_SKIPLIST
当 type 是 OBJ_HASH 时,一开始也是 OBJ_ENCODING_ZIPLIST,然后当数据量大于 hash_max_ziplist_entries 时会转成 OBJ_ENCODING_HT
redis数据结构介绍四-第四部分 压缩表
在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient.
这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
其中
<zlbytes>表示 ziplist 占用的字节总数,类型是uint32_t,32 位的无符号整型,当然表示的字节数也包含自己本身占用的 4 个
<zltail> 类型也是是uint32_t,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
<uint16_t zllen> 表示ziplist 中的数据项个数,因为是 16 位,所以当数量超过所能表示的最大的数量,它的 16 位全会置为 1,但是真实的数量需要遍历整个 ziplist 才能知道
<entry>是具体的数据项,后面解释
<zlend> ziplist 的最后一个字节,固定是255。
再看一下<entry>中的具体结构,
<prevlen> <encoding> <entry-data>
首先这个<prevlen>有两种情况,一种是前面的元素的长度,如果是小于等于 253的时候就用一个uint8_t 来表示前一元素的长度,如果大于的话他将占用五个字节,第一个字节是 254,即表示这个字节已经表示不下了,需要后面的四个字节帮忙表示
<encoding>这个就比较复杂,把源码的注释放下面先看下
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* "pppppp" represents the unsigned 6 bit length.
* |01pppppp|qqqqqqqq| - 2 bytes
@@ -60,7 +60,7 @@ typedef struct redisObject {
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| - End of ziplist special entry.
首先如果 encoding 的前两位是 00 的话代表这个元素是个 6 位的字符串,即直接将数据保存在 encoding 中,不消耗额外的<entry-data>,如果前两位是 01 的话表示是个 14 位的字符串,如果是 10 的话表示encoding 块之后的四个字节是存放字符串类型的数据,encoding 的剩余 6 位置 0。
如果 encoding 的前两位是 11 的话表示这是个整型,具体的如果后两位是00的话,表示后面是个2字节的 int16_t 类型,如果是01的话,后面是个4字节的int32_t,如果是10的话后面是8字节的int64_t,如果是 11 的话后面是 3 字节的有符号整型,这些都要最后 4 位都是 0 的情况噢
剩下当是11111110时,则表示是一个1 字节的有符号数,如果是 1111xxxx,其中xxxx在0000 到 1101 表示实际的 1 到 13,为啥呢,因为 0000 前面已经用过了,而 1110 跟 1111 也都有用了。
看个具体的例子(上下有点对不齐,将就看)
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
-|**zlbytes***| |***zltail***| |*zllen*| |entry1 entry2| |zlend|
第一部分代表整个 ziplist 有 15 个字节,zlbytes 自己占了 4 个 zltail 表示最后一个元素的偏移量,第 13 个字节起,zllen 表示有 2 个元素,第一个元素是00f3,00表示前一个元素长度是 0,本来前面就没元素(不过不知道这个能不能优化这一字节),然后是 f3,换成二进制就是11110011,对照上面的注释,是落在|1111xxxx|这个类型里,注意这个其实是用 0001 到 1101 也就是 1到 13 来表示 0到 12,所以 f3 应该就是 2,第一个元素是 2,第二个元素呢,02 代表前一个元素也就是刚才说的这个,占用 2 字节,f6 展开也是刚才的类型,实际是 5,ff 表示 ziplist 的结尾,所以这个 ziplist 里面是两个元素,2 跟 5
redis数据结构介绍三-第三部分 整数集合
redis中对于 set 其实有两种处理,对于元素均为整型,并且元素数目较少时,使用 intset 作为底层数据结构,否则使用 dict 作为底层数据结构,先看一下代码先
typedef struct intset {
+|**zlbytes***| |***zltail***| |*zllen*| |entry1 entry2| |zlend|
第一部分代表整个 ziplist 有 15 个字节,zlbytes 自己占了 4 个 zltail 表示最后一个元素的偏移量,第 13 个字节起,zllen 表示有 2 个元素,第一个元素是00f3,00表示前一个元素长度是 0,本来前面就没元素(不过不知道这个能不能优化这一字节),然后是 f3,换成二进制就是11110011,对照上面的注释,是落在|1111xxxx|这个类型里,注意这个其实是用 0001 到 1101 也就是 1到 13 来表示 0到 12,所以 f3 应该就是 2,第一个元素是 2,第二个元素呢,02 代表前一个元素也就是刚才说的这个,占用 2 字节,f6 展开也是刚才的类型,实际是 5,ff 表示 ziplist 的结尾,所以这个 ziplist 里面是两个元素,2 跟 5
redis数据结构介绍三-第三部分 整数集合
redis中对于 set 其实有两种处理,对于元素均为整型,并且元素数目较少时,使用 intset 作为底层数据结构,否则使用 dict 作为底层数据结构,先看一下代码先
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
@@ -76,7 +76,7 @@ typedef struct redisObject {
#define INTSET_ENC_INT64 (sizeof(int64_t))
一眼看,为啥整型还需要编码,然后 int8_t 怎么能存下大整形呢,带着这些疑问,我们一步步分析下去,这里的编码其实指的是这个整型集合里存的究竟是多大的整型,16 位,还是 32 位,还是 64 位,结构体下面的宏定义就是表示了 encoding 的可能取值,INTSET_ENC_INT16 表示每个元素用2个字节存储,INTSET_ENC_INT32 表示每个元素用4个字节存储,INTSET_ENC_INT64 表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。length 就是正常的表示集合中元素的数量。最奇怪的应该就是这个 contents 了,是个 int8_t 的数组,那放毛线数据啊,最小的都有 16 位,这里我在看代码和《redis 设计与实现》的时候也有点懵逼,后来查了下发现这是个比较取巧的用法,这里我用自己的理解表述一下,先看看 8,16,32,64 的关系,一眼看就知道都是 2 的 N 次,并且呈两倍关系,而且 8 位刚好一个字节,所以呢其实这里的contents 不是个常规意义上的 int8_t 类型的数组,而是个柔性数组。看下 wiki 的定义
Flexible array members1 were introduced in the C99 standard of the C programming language (in particular, in section §6.7.2.1, item 16, page 103).2 It is a member of a struct, which is an array without a given dimension. It must be the last member of such a struct and it must be accompanied by at least one other member, as in the following example:
struct vectord {
size_t len;
double arr[]; // the flexible array member must be last
-};
在初始化这个 intset 的时候,这个contents数组是不占用空间的,后面的反正用到了申请,那么这里就有一个问题,给出了三种可能的 encoding 值,他们能随便换吗,显然不行,首先在 intset 中数据的存放是有序的,这个有部分原因是方便二分查找,然后存放数据其实随着数据的大小不同会有一个升级的过程,看下图
![]()
新创建的intset只有一个header,总共8个字节。其中encoding = 2, length = 0, 类型都是uint32_t,各占 4 字节,添加15, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以encoding不变,值还是2,也就是默认的 INTSET_ENC_INT16,当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。在添加每个元素的过程中,intset始终保持从小到大有序。与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示encoding字段的4个字节应该解释成0x00000004,而第4个数据应该解释成0x00008000 = 32768
redis数据结构介绍二-第二部分 跳表
跳表 skiplist
跳表是个在我们日常的代码中不太常用到的数据结构,相对来讲就没有像数组,链表,字典,散列,树等结构那么熟悉,所以就从头开始分析下,首先是链表,跳表跟链表都有个表字(太硬扯了我🤦♀️),注意这是个有序链表
![]()
如上图,在这个链表里如果我要找到 23,是不是我需要从3,5,9开始一直往后找直到找到 23,也就是说时间复杂度是 O(N),N 的一次幂复杂度,那么我们来看看第二个
![]()
这个结构跟原先有点不一样,它给链表中偶数位的节点又加了一个指针把它们链接起来,这样子当我们要寻找 23 的时候就可以从原来的一个个往下找变成跳着找,先找到 5,然后是 10,接着是 19,然后是 28,这时候发现 28 比 23 大了,那我在退回到 19,然后从下一层原来的链表往前找,
![]()
这里毛估估是不是前面的节点我就少找了一半,有那么点二分法的意思。
前面的其实是跳表的引子,真正的跳表其实不是这样,因为上面的其实有个比较大的问题,就是插入一个元素后需要调整每个元素的指针,在 redis 中的跳表其实是做了个随机层数的优化,因为沿着前面的例子,其实当数据量很大的时候,是不是层数越多,其查询效率越高,但是随着层数变多,要保持这种严格的层数规则其实也会增大处理复杂度,所以 redis 插入每个元素的时候都是使用随机的方式,看一眼代码
/* ZSETs use a specialized version of Skiplists */
+};
在初始化这个 intset 的时候,这个contents数组是不占用空间的,后面的反正用到了申请,那么这里就有一个问题,给出了三种可能的 encoding 值,他们能随便换吗,显然不行,首先在 intset 中数据的存放是有序的,这个有部分原因是方便二分查找,然后存放数据其实随着数据的大小不同会有一个升级的过程,看下图
![]()
新创建的intset只有一个header,总共8个字节。其中encoding = 2, length = 0, 类型都是uint32_t,各占 4 字节,添加15, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以encoding不变,值还是2,也就是默认的 INTSET_ENC_INT16,当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。在添加每个元素的过程中,intset始终保持从小到大有序。与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示encoding字段的4个字节应该解释成0x00000004,而第4个数据应该解释成0x00008000 = 32768
redis数据结构介绍二-第二部分 跳表
跳表 skiplist
跳表是个在我们日常的代码中不太常用到的数据结构,相对来讲就没有像数组,链表,字典,散列,树等结构那么熟悉,所以就从头开始分析下,首先是链表,跳表跟链表都有个表字(太硬扯了我🤦♀️),注意这是个有序链表
![]()
如上图,在这个链表里如果我要找到 23,是不是我需要从3,5,9开始一直往后找直到找到 23,也就是说时间复杂度是 O(N),N 的一次幂复杂度,那么我们来看看第二个
![]()
这个结构跟原先有点不一样,它给链表中偶数位的节点又加了一个指针把它们链接起来,这样子当我们要寻找 23 的时候就可以从原来的一个个往下找变成跳着找,先找到 5,然后是 10,接着是 19,然后是 28,这时候发现 28 比 23 大了,那我在退回到 19,然后从下一层原来的链表往前找,
![]()
这里毛估估是不是前面的节点我就少找了一半,有那么点二分法的意思。
前面的其实是跳表的引子,真正的跳表其实不是这样,因为上面的其实有个比较大的问题,就是插入一个元素后需要调整每个元素的指针,在 redis 中的跳表其实是做了个随机层数的优化,因为沿着前面的例子,其实当数据量很大的时候,是不是层数越多,其查询效率越高,但是随着层数变多,要保持这种严格的层数规则其实也会增大处理复杂度,所以 redis 插入每个元素的时候都是使用随机的方式,看一眼代码
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
@@ -102,7 +102,7 @@ int zslRandomLevel(void) {
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
-}
当随机值跟0xFFFF进行与操作小于ZSKIPLIST_P * 0xFFFF时才会增大 level 的值,因此保持了一个相对递减的概率
可以简单分析下,当 random() 的值小于 0xFFFF 的 1/4,才会 level + 1,就意味着当有 1 - 1/4也就是3/4的概率是直接跳出,所以一层的概率是3/4,也就是 1-P,二层的概率是 P*(1-P),三层的概率是 P² * (1-P) 依次递推。
redis数据结构介绍-第一部分 SDS,链表,字典
redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍
struct sdshdr {
+}
当随机值跟0xFFFF进行与操作小于ZSKIPLIST_P * 0xFFFF时才会增大 level 的值,因此保持了一个相对递减的概率
可以简单分析下,当 random() 的值小于 0xFFFF 的 1/4,才会 level + 1,就意味着当有 1 - 1/4也就是3/4的概率是直接跳出,所以一层的概率是3/4,也就是 1-P,二层的概率是 P*(1-P),三层的概率是 P² * (1-P) 依次递推。
redis数据结构介绍-第一部分 SDS,链表,字典
redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍
struct sdshdr {
// 字符串长度
int len;
// 字符串空余字符数
diff --git a/search.xml b/search.xml
index c146db02c1..85077b712c 100644
--- a/search.xml
+++ b/search.xml
@@ -20,6 +20,31 @@
读后感
+
+ 2020 年终总结
+ /2021/03/31/2020-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ 拖更原因这篇年终总结本来应该在农历过完年就出来的,结果是对没有受疫情影响的春节放假时间空闲情况预估太良好,虽然公司调了几天假,但是因为春节期间疫情状况比较好,本来酒店都不让接待聚餐什么的,后来统统放开,结果就是从初一到初六每天要不就是去亲戚家,要不就是去酒店饭店吃饭,计划很丰满,现实很骨感,时间感觉一下就没了,然后年后感觉有点犯懒了,所以才拖到现在。
+生活-健身跑步
去年(19 年)的时候跑步突破了 300 公里,然后20 年给自己定了个 400 公里的目标,结果意料之中的没成功,原因可能疫情算一点吧,后面买了跑步机之后,基本周末回家都能跑一下,但是最后还是只跑了300 多公里,总的keep 记录跑量也没超过 1000 公里,所以跑步这个目标还是没成功的,不过还算是比去年多跑一点,这样也算后面好突破点,后面的目标就不定的太高了,每年能比前一年多一点就好,其实跑步已经从一种减肥方式变成一种习惯了,一周一次的跑步已经比较难有效减重了,但是对于保持精力和身体状态还是很有效和重要的,只是对于目前的体重还是要多减下去一些跑步才好,太重了对膝盖负担太大了,可惜还是时间呐,游泳骑车什么的都需要更苛刻的条件和时间,饮食呢控制起来比较难(贪吃
终于在 3 月底之前跑到了 1000 公里,迟了三个月,不过也总算达到了,只是体重控制还是不行,有试着走走楼梯,但是感觉对膝盖负担比较大,得再想想用什么方式
+![]()
+技术成长
一直提不起笔来写这篇年终总结还有个比较大的原因是觉得20 年的成长不如预期,大小目标都没怎么完成,比如深入了解 jvm,是想能有些深入的见解,而不再是某些点的比较片面的理解,系统性的归纳总结也比较少,每个方向或多或少有些看法和理解,但是不全面,一些东西看过了也会忘记,需要温故而知新,比如 AQS 的内容,第一次读其实理解比较浅,后面就强迫自己去读,去写,才有了一些比之前更深入的理解,因为很多文章都是带有作者思路的引导,适不适合自己都要看是否能从他的思路把它看懂,有些就差别很大,这个跟看书也一样,有些书大众一致推荐,一般情况下大多是经典的好的,但是也有可能是不太适合自己的,可能有时候机缘巧合看到的反而让人茅塞顿开,在 todo 里已经积攒了好多的点和面需要去学习实践,一方面是自己懒,一方面是时间也相对偏少,看看 21 年能不能有所提升,加强“时间管理”,哈哈
+技术上主要是看了 mysql 的 mvcc 相关内容,rocketmq 的,redis 的代码,还有 mybatis 等,其实每一个都能写很多,也有很多值得学习的,需要全面系统学习,之前想好好画一个思维导图,将整个技术体系都梳理下,还只做了一点点,方式也有点问题,应该从大到小,而不是深度优先,细节有很多,每一个方面都有自己比较熟悉擅长的,也有不太了解的,可以做一个评分,这个也是亟待改善的,希望今年能完成。
+博客
博客方面 20 年一年整是写了 53 篇,差不多是一周一篇的节奏,这个还是不错的,虽然博客质量参差不齐,但是这个更新频率还是比较好的,并且也定了个潜规则,可以一周技术一周生活,这样能缓解水文的频率,提高些技术文章的质量,虽然结果并没有好多少,不过感觉还是可以这么坚持的,能提高一些技术文章的质量那就更好了
+]]>
+
+ 生活
+ 年终总结
+ 2020
+ 年终总结
+ 2020
+
+
+ 生活
+ 年终总结
+ 2020
+ 2021
+ 拖更
+
+
2019年终总结
/2020/02/01/2019%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
@@ -154,6 +179,72 @@ public:
c++
+
+ AbstractQueuedSynchronizer
+ /2019/09/23/AbstractQueuedSynchronizer/
+ 最近看了大神的 AQS 的文章,之前总是断断续续地看一点,每次都知难而退,下次看又从头开始,昨天总算硬着头皮看完了第一部分
首先 AQS 只要有这些属性
+// 头结点,你直接把它当做 当前持有锁的线程 可能是最好理解的
+private transient volatile Node head;
+
+// 阻塞的尾节点,每个新的节点进来,都插入到最后,也就形成了一个链表
+private transient volatile Node tail;
+
+// 这个是最重要的,代表当前锁的状态,0代表没有被占用,大于 0 代表有线程持有当前锁
+// 这个值可以大于 1,是因为锁可以重入,每次重入都加上 1
+private volatile int state;
+
+// 代表当前持有独占锁的线程,举个最重要的使用例子,因为锁可以重入
+// reentrantLock.lock()可以嵌套调用多次,所以每次用这个来判断当前线程是否已经拥有了锁
+// if (currentThread == getExclusiveOwnerThread()) {state++}
+private transient Thread exclusiveOwnerThread; //继承自AbstractOwnableSynchronizer
+大概了解了 aqs 底层的双向等待队列,
结构是这样的
![]()
每个 node 里面主要是的代码结构也比较简单
+static final class Node {
+ // 标识节点当前在共享模式下
+ static final Node SHARED = new Node();
+ // 标识节点当前在独占模式下
+ static final Node EXCLUSIVE = null;
+
+ // ======== 下面的几个int常量是给waitStatus用的 ===========
+ /** waitStatus value to indicate thread has cancelled */
+ // 代码此线程取消了争抢这个锁
+ static final int CANCELLED = 1;
+ /** waitStatus value to indicate successor's thread needs unparking */
+ // 官方的描述是,其表示当前node的后继节点对应的线程需要被唤醒
+ static final int SIGNAL = -1;
+ /** waitStatus value to indicate thread is waiting on condition */
+ // 本文不分析condition,所以略过吧,下一篇文章会介绍这个
+ static final int CONDITION = -2;
+ /**
+ * waitStatus value to indicate the next acquireShared should
+ * unconditionally propagate
+ */
+ // 同样的不分析,略过吧
+ static final int PROPAGATE = -3;
+ // =====================================================
+
+
+ // 取值为上面的1、-1、-2、-3,或者0(以后会讲到)
+ // 这么理解,暂时只需要知道如果这个值 大于0 代表此线程取消了等待,
+ // ps: 半天抢不到锁,不抢了,ReentrantLock是可以指定timeouot的。。。
+ volatile int waitStatus;
+ // 前驱节点的引用
+ volatile Node prev;
+ // 后继节点的引用
+ volatile Node next;
+ // 这个就是线程本尊
+ volatile Thread thread;
+
+}
+其实可以主要关注这个 waitStatus 因为这个是后面的节点给前面的节点设置的,等于-1 的时候代表后面有节点等待,需要去唤醒,
这里使用了一个变种的 CLH 队列实现,CLH 队列相关内容可以查看这篇 自旋锁、排队自旋锁、MCS锁、CLH锁
+]]>
+
+ java
+
+
+ java
+ aqs
+
+
AQS篇二 之 Condition 浅析笔记
/2021/02/21/AQS-%E4%B9%8B-Condition-%E6%B5%85%E6%9E%90%E7%AC%94%E8%AE%B0/
@@ -641,9 +732,9 @@ public:
java
+ aqs
并发
j.u.c
- aqs
condition
await
signal
@@ -652,300 +743,194 @@ public:
- AQS篇一
- /2021/02/14/AQS%E7%AF%87%E4%B8%80/
- 很多东西都是时看时新,而且时间长了也会忘,所以再来复习下,也会有一些新的角度看法这次来聊下AQS的内容,主要是这几个点,
-第一个线程
第一个线程抢到锁了,此时state跟阻塞队列是怎么样的,其实这里是之前没理解对的地方
-/**
- * Fair version of tryAcquire. Don't grant access unless
- * recursive call or no waiters or is first.
- */
- protected final boolean tryAcquire(int acquires) {
- final Thread current = Thread.currentThread();
- int c = getState();
- // 这里如果state还是0说明锁还空着
- if (c == 0) {
- // 因为是公平锁版本的,先去看下是否阻塞队列里有排着队的
- if (!hasQueuedPredecessors() &&
- compareAndSetState(0, acquires)) {
- // 没有排队的,并且state使用cas设置成功的就标记当前占有锁的线程是我
- setExclusiveOwnerThread(current);
- // 然后其实就返回了,包括阻塞队列的head和tail节点和waitStatus都没有设置
- return true;
- }
- }
- else if (current == getExclusiveOwnerThread()) {
- int nextc = c + acquires;
- if (nextc < 0)
- throw new Error("Maximum lock count exceeded");
- setState(nextc);
- return true;
- }
- // 这里就是第二个线程会返回false
- return false;
- }
- }
+ Apollo 的 value 注解是怎么自动更新的
+ /2020/11/01/Apollo-%E7%9A%84-value-%E6%B3%A8%E8%A7%A3%E6%98%AF%E6%80%8E%E4%B9%88%E8%87%AA%E5%8A%A8%E6%9B%B4%E6%96%B0%E7%9A%84/
+ 在前司和目前公司,用的配置中心都是使用的 Apollo,经过了业界验证,比较强大的配置管理系统,特别是在0.10 后开始支持对使用 value 注解的配置值进行自动更新,今天刚好有个同学问到我,就顺便写篇文章记录下,其实也是借助于 spring 强大的 bean 生命周期管理,可以实现BeanPostProcessor接口,使用postProcessBeforeInitialization方法,来对bean 内部的属性和方法进行判断,是否有 value 注解,如果有就是将它注册到一个 map 中,可以看到这个方法com.ctrip.framework.apollo.spring.annotation.SpringValueProcessor#processField
+@Override
+ protected void processField(Object bean, String beanName, Field field) {
+ // register @Value on field
+ Value value = field.getAnnotation(Value.class);
+ if (value == null) {
+ return;
+ }
+ Set<String> keys = placeholderHelper.extractPlaceholderKeys(value.value());
-第二个线程
当第二个线程进来的时候应该是怎么样,结合代码来看
-/**
- * Acquires in exclusive mode, ignoring interrupts. Implemented
- * by invoking at least once {@link #tryAcquire},
- * returning on success. Otherwise the thread is queued, possibly
- * repeatedly blocking and unblocking, invoking {@link
- * #tryAcquire} until success. This method can be used
- * to implement method {@link Lock#lock}.
- *
- * @param arg the acquire argument. This value is conveyed to
- * {@link #tryAcquire} but is otherwise uninterpreted and
- * can represent anything you like.
- */
- public final void acquire(int arg) {
- // 前面第一种情况是tryAcquire直接成功了,这个if判断第一个条件就是false,就不往下执行了
- // 如果是第二个线程,第一个条件获取锁不成功,条件判断!tryAcquire(arg) == true,就会走
- // acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
- if (!tryAcquire(arg) &&
- acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
- selfInterrupt();
- }
+ if (keys.isEmpty()) {
+ return;
+ }
-然后来看下addWaiter的逻辑
-/**
- * Creates and enqueues node for current thread and given mode.
- *
- * @param mode Node.EXCLUSIVE for exclusive, Node.SHARED for shared
- * @return the new node
- */
- private Node addWaiter(Node mode) {
- // 这里是包装成一个node
- Node node = new Node(Thread.currentThread(), mode);
- // Try the fast path of enq; backup to full enq on failure
- // 最快的方式就是把当前线程的节点放在阻塞队列的最后
- Node pred = tail;
- // 只有当tail,也就是pred不为空的时候可以直接接上
- if (pred != null) {
- node.prev = pred;
- // 如果这里cas成功了,就直接接上返回了
- if (compareAndSetTail(pred, node)) {
- pred.next = node;
- return node;
- }
- }
- // 不然就会继续走到这里
- enq(node);
- return node;
- }
+ for (String key : keys) {
+ SpringValue springValue = new SpringValue(key, value.value(), bean, beanName, field, false);
+ springValueRegistry.register(beanFactory, key, springValue);
+ logger.debug("Monitoring {}", springValue);
+ }
+ }
+然后我们看下这个springValueRegistry是啥玩意
+public class SpringValueRegistry {
+ private static final long CLEAN_INTERVAL_IN_SECONDS = 5;
+ private final Map<BeanFactory, Multimap<String, SpringValue>> registry = Maps.newConcurrentMap();
+ private final AtomicBoolean initialized = new AtomicBoolean(false);
+ private final Object LOCK = new Object();
-然后就是enq的逻辑了
-/**
- * Inserts node into queue, initializing if necessary. See picture above.
- * @param node the node to insert
- * @return node's predecessor
- */
- private Node enq(final Node node) {
- for (;;) {
- // 如果状态没变化的话,tail这时还是null的
- Node t = tail;
- if (t == null) { // Must initialize
- // 这里就会初始化头结点,就是个空节点
- if (compareAndSetHead(new Node()))
- // tail也赋值成head
- tail = head;
- } else {
- // 这里就设置tail了
- node.prev = t;
- if (compareAndSetTail(t, node)) {
- t.next = node;
- return t;
- }
- }
+ public void register(BeanFactory beanFactory, String key, SpringValue springValue) {
+ if (!registry.containsKey(beanFactory)) {
+ synchronized (LOCK) {
+ if (!registry.containsKey(beanFactory)) {
+ registry.put(beanFactory, LinkedListMultimap.<String, SpringValue>create());
}
- }
+ }
+ }
-所以从这里可以看出来,其实head头结点不是个真实的带有线程的节点,并且不是在第一个线程进来的时候设置的
-解锁
通过代码来看下
-/**
- * Attempts to release this lock.
- *
- * <p>If the current thread is the holder of this lock then the hold
- * count is decremented. If the hold count is now zero then the lock
- * is released. If the current thread is not the holder of this
- * lock then {@link IllegalMonitorStateException} is thrown.
- *
- * @throws IllegalMonitorStateException if the current thread does not
- * hold this lock
- */
- public void unlock() {
- // 释放锁
- sync.release(1);
+ registry.get(beanFactory).put(key, springValue);
+
+ // lazy initialize
+ if (initialized.compareAndSet(false, true)) {
+ initialize();
}
-/**
- * Releases in exclusive mode. Implemented by unblocking one or
- * more threads if {@link #tryRelease} returns true.
- * This method can be used to implement method {@link Lock#unlock}.
- *
- * @param arg the release argument. This value is conveyed to
- * {@link #tryRelease} but is otherwise uninterpreted and
- * can represent anything you like.
- * @return the value returned from {@link #tryRelease}
- */
- public final boolean release(int arg) {
- // 尝试去释放
- if (tryRelease(arg)) {
- Node h = head;
- if (h != null && h.waitStatus != 0)
- unparkSuccessor(h);
- return true;
- }
- return false;
- }
-protected final boolean tryRelease(int releases) {
- int c = getState() - releases;
- if (Thread.currentThread() != getExclusiveOwnerThread())
- throw new IllegalMonitorStateException();
- boolean free = false;
- // 判断是否完全释放锁,因为可重入
- if (c == 0) {
- free = true;
- setExclusiveOwnerThread(null);
- }
- setState(c);
- return free;
- }
-// 这段代码和上面的一致,只是为了顺序性,又拷下来看下
-
-public final boolean release(int arg) {
- // 尝试去释放,如果是完全释放,返回的就是true,否则是false
- if (tryRelease(arg)) {
- Node h = head;
- // 这里判断头结点是否为空以及waitStatus的状态,前面说了head节点其实是
- // 在第二个线程进来的时候初始化的,如果是空的话说明没后续节点,并且waitStatus
- // 也表示了后续的等待状态
- if (h != null && h.waitStatus != 0)
- unparkSuccessor(h);
- return true;
- }
- return false;
- }
-
-/**
- * Wakes up node's successor, if one exists.
- *
- * @param node the node
- */
-// 唤醒后继节点
- private void unparkSuccessor(Node node) {
- /*
- * If status is negative (i.e., possibly needing signal) try
- * to clear in anticipation of signalling. It is OK if this
- * fails or if status is changed by waiting thread.
- */
- int ws = node.waitStatus;
- if (ws < 0)
- compareAndSetWaitStatus(node, ws, 0);
-
- /*
- * Thread to unpark is held in successor, which is normally
- * just the next node. But if cancelled or apparently null,
- * traverse backwards from tail to find the actual
- * non-cancelled successor.
- */
- Node s = node.next;
- // 如果后继节点是空或者当前节点取消等待了
- if (s == null || s.waitStatus > 0) {
- s = null;
- // 从后往前找,找到非取消的节点,注意这里不是找到就退出,而是一直找到头
- // 所以不必担心中间有取消的
- for (Node t = tail; t != null && t != node; t = t.prev)
- if (t.waitStatus <= 0)
- s = t;
- }
- if (s != null)
- // 将其唤醒
- LockSupport.unpark(s.thread);
- }
-
-
+ }
+这类其实就是个 map 来存放 springvalue,然后有com.ctrip.framework.apollo.spring.property.AutoUpdateConfigChangeListener来监听更新操作,当有变更时
+@Override
+ public void onChange(ConfigChangeEvent changeEvent) {
+ Set<String> keys = changeEvent.changedKeys();
+ if (CollectionUtils.isEmpty(keys)) {
+ return;
+ }
+ for (String key : keys) {
+ // 1. check whether the changed key is relevant
+ Collection<SpringValue> targetValues = springValueRegistry.get(beanFactory, key);
+ if (targetValues == null || targetValues.isEmpty()) {
+ continue;
+ }
+ // 2. check whether the value is really changed or not (since spring property sources have hierarchies)
+ // 这里其实有一点比较绕,是因为 Apollo 里的 namespace 划分,会出现 key 相同,但是 namespace 不同的情况,所以会有个优先级存在,所以需要去校验 environment 里面的是否已经更新,如果未更新则表示不需要更新
+ if (!shouldTriggerAutoUpdate(changeEvent, key)) {
+ continue;
+ }
+ // 3. update the value
+ for (SpringValue val : targetValues) {
+ updateSpringValue(val);
+ }
+ }
+ }
+其实原理很简单,就是得了解知道下
]]>
Java
- 并发
+ Apollo
+ value
- java
- 并发
- j.u.c
- aqs
+ Java
+ Apollo
+ value
+ 注解
+ environment
- AbstractQueuedSynchronizer
- /2019/09/23/AbstractQueuedSynchronizer/
- 最近看了大神的 AQS 的文章,之前总是断断续续地看一点,每次都知难而退,下次看又从头开始,昨天总算硬着头皮看完了第一部分
首先 AQS 只要有这些属性
-// 头结点,你直接把它当做 当前持有锁的线程 可能是最好理解的
-private transient volatile Node head;
+ Comparator使用小记
+ /2020/04/05/Comparator%E4%BD%BF%E7%94%A8%E5%B0%8F%E8%AE%B0/
+ 在Java8的stream之前,将对象进行排序的时候,可能需要对象实现Comparable接口,或者自己实现一个Comparator,
+比如这样子
+我的对象是Entity
+public class Entity {
-// 阻塞的尾节点,每个新的节点进来,都插入到最后,也就形成了一个链表
-private transient volatile Node tail;
+ private Long id;
-// 这个是最重要的,代表当前锁的状态,0代表没有被占用,大于 0 代表有线程持有当前锁
-// 这个值可以大于 1,是因为锁可以重入,每次重入都加上 1
-private volatile int state;
+ private Long sortValue;
-// 代表当前持有独占锁的线程,举个最重要的使用例子,因为锁可以重入
-// reentrantLock.lock()可以嵌套调用多次,所以每次用这个来判断当前线程是否已经拥有了锁
-// if (currentThread == getExclusiveOwnerThread()) {state++}
-private transient Thread exclusiveOwnerThread; //继承自AbstractOwnableSynchronizer
-大概了解了 aqs 底层的双向等待队列,
结构是这样的
![]()
每个 node 里面主要是的代码结构也比较简单
-static final class Node {
- // 标识节点当前在共享模式下
- static final Node SHARED = new Node();
- // 标识节点当前在独占模式下
- static final Node EXCLUSIVE = null;
+ public Long getId() {
+ return id;
+ }
- // ======== 下面的几个int常量是给waitStatus用的 ===========
- /** waitStatus value to indicate thread has cancelled */
- // 代码此线程取消了争抢这个锁
- static final int CANCELLED = 1;
- /** waitStatus value to indicate successor's thread needs unparking */
- // 官方的描述是,其表示当前node的后继节点对应的线程需要被唤醒
- static final int SIGNAL = -1;
- /** waitStatus value to indicate thread is waiting on condition */
- // 本文不分析condition,所以略过吧,下一篇文章会介绍这个
- static final int CONDITION = -2;
- /**
- * waitStatus value to indicate the next acquireShared should
- * unconditionally propagate
- */
- // 同样的不分析,略过吧
- static final int PROPAGATE = -3;
- // =====================================================
+ public void setId(Long id) {
+ this.id = id;
+ }
+ public Long getSortValue() {
+ return sortValue;
+ }
- // 取值为上面的1、-1、-2、-3,或者0(以后会讲到)
- // 这么理解,暂时只需要知道如果这个值 大于0 代表此线程取消了等待,
- // ps: 半天抢不到锁,不抢了,ReentrantLock是可以指定timeouot的。。。
- volatile int waitStatus;
- // 前驱节点的引用
- volatile Node prev;
- // 后继节点的引用
- volatile Node next;
- // 这个就是线程本尊
- volatile Thread thread;
+ public void setSortValue(Long sortValue) {
+ this.sortValue = sortValue;
+ }
+}
-}
-其实可以主要关注这个 waitStatus 因为这个是后面的节点给前面的节点设置的,等于-1 的时候代表后面有节点等待,需要去唤醒,
这里使用了一个变种的 CLH 队列实现,CLH 队列相关内容可以查看这篇 自旋锁、排队自旋锁、MCS锁、CLH锁
+Comparator
+public class MyComparator implements Comparator {
+ @Override
+ public int compare(Object o1, Object o2) {
+ Entity e1 = (Entity) o1;
+ Entity e2 = (Entity) o2;
+ if (e1.getSortValue() < e2.getSortValue()) {
+ return -1;
+ } else if (e1.getSortValue().equals(e2.getSortValue())) {
+ return 0;
+ } else {
+ return 1;
+ }
+ }
+}
+
+比较代码
+private static MyComparator myComparator = new MyComparator();
+
+ public static void main(String[] args) {
+ List<Entity> list = new ArrayList<Entity>();
+ Entity e1 = new Entity();
+ e1.setId(1L);
+ e1.setSortValue(1L);
+ list.add(e1);
+ Entity e2 = new Entity();
+ e2.setId(2L);
+ e2.setSortValue(null);
+ list.add(e2);
+ Collections.sort(list, myComparator);
+
+看到这里的e2的排序值是null,在Comparator中如果要正常运行的话,就得判空之类的,这里有两点需要,一个是不想写这个MyComparator,然后也没那么好排除掉list里排序值,那么有什么办法能解决这种问题呢,应该说java的这方面真的是很强大
+![]()
+看一下nullsFirst的实现
+final static class NullComparator<T> implements Comparator<T>, Serializable {
+ private static final long serialVersionUID = -7569533591570686392L;
+ private final boolean nullFirst;
+ // if null, non-null Ts are considered equal
+ private final Comparator<T> real;
+
+ @SuppressWarnings("unchecked")
+ NullComparator(boolean nullFirst, Comparator<? super T> real) {
+ this.nullFirst = nullFirst;
+ this.real = (Comparator<T>) real;
+ }
+
+ @Override
+ public int compare(T a, T b) {
+ if (a == null) {
+ return (b == null) ? 0 : (nullFirst ? -1 : 1);
+ } else if (b == null) {
+ return nullFirst ? 1: -1;
+ } else {
+ return (real == null) ? 0 : real.compare(a, b);
+ }
+ }
+
+核心代码就是下面这段,其实就是帮我们把前面要做的事情做掉了,是不是挺方便的,小记一下哈
]]>
- java
+ Java
+ 集合
- java
- aqs
-
-
-
+ Java
+ Stream
+ Comparator
+ 排序
+ sort
+ nullsfirst
+
+
+
add-two-number
/2015/04/14/Add-Two-Number/
problemYou are given two linked lists representing two non-negative numbers. The digits are stored in reverse order and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.
@@ -1048,47 +1033,6 @@ public:
c++
-
- Apollo 如何获取当前环境
- /2022/09/04/Apollo-%E5%A6%82%E4%BD%95%E8%8E%B7%E5%8F%96%E5%BD%93%E5%89%8D%E7%8E%AF%E5%A2%83/
- 在用 Apollo 作为配置中心的过程中才到过几个坑,这边记录下,因为运行 java 服务的启动参数一般比较固定,所以我们在一个新环境里运行的时候没有特意去检查,然后突然发现业务上有一些数据异常,排查之后才发现java 服务连接了测试环境的 apollo,而原因是因为环境变量传了-Denv=fat,而在我们的环境配置中 fat 就是代表测试环境, 其实应该是-Denv=pro,而 apollo 总共有这些环境
-public enum Env{
- LOCAL, DEV, FWS, FAT, UAT, LPT, PRO, TOOLS, UNKNOWN;
-
- public static Env fromString(String env) {
- Env environment = EnvUtils.transformEnv(env);
- Preconditions.checkArgument(environment != UNKNOWN, String.format("Env %s is invalid", env));
- return environment;
- }
-}
-而这些解释
-/**
- * Here is the brief description for all the predefined environments:
- * <ul>
- * <li>LOCAL: Local Development environment, assume you are working at the beach with no network access</li>
- * <li>DEV: Development environment</li>
- * <li>FWS: Feature Web Service Test environment</li>
- * <li>FAT: Feature Acceptance Test environment</li>
- * <li>UAT: User Acceptance Test environment</li>
- * <li>LPT: Load and Performance Test environment</li>
- * <li>PRO: Production environment</li>
- * <li>TOOLS: Tooling environment, a special area in production environment which allows
- * access to test environment, e.g. Apollo Portal should be deployed in tools environment</li>
- * </ul>
- */
-那如果要在运行时知道 apollo 当前使用的环境可以用这个
-Env apolloEnv = ApolloInjector.getInstance(ConfigUtil.class).getApolloEnv();
-简单记录下。
-]]>
-
- Java
-
-
- Java
- Apollo
- environment
-
-
Apollo 客户端启动过程分析
/2022/09/18/Apollo-%E5%AE%A2%E6%88%B7%E7%AB%AF%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B%E5%88%86%E6%9E%90/
@@ -1488,191 +1432,272 @@ Node *clone(Node *graph) {
- Apollo 的 value 注解是怎么自动更新的
- /2020/11/01/Apollo-%E7%9A%84-value-%E6%B3%A8%E8%A7%A3%E6%98%AF%E6%80%8E%E4%B9%88%E8%87%AA%E5%8A%A8%E6%9B%B4%E6%96%B0%E7%9A%84/
- 在前司和目前公司,用的配置中心都是使用的 Apollo,经过了业界验证,比较强大的配置管理系统,特别是在0.10 后开始支持对使用 value 注解的配置值进行自动更新,今天刚好有个同学问到我,就顺便写篇文章记录下,其实也是借助于 spring 强大的 bean 生命周期管理,可以实现BeanPostProcessor接口,使用postProcessBeforeInitialization方法,来对bean 内部的属性和方法进行判断,是否有 value 注解,如果有就是将它注册到一个 map 中,可以看到这个方法com.ctrip.framework.apollo.spring.annotation.SpringValueProcessor#processField
-@Override
- protected void processField(Object bean, String beanName, Field field) {
- // register @Value on field
- Value value = field.getAnnotation(Value.class);
- if (value == null) {
- return;
- }
- Set<String> keys = placeholderHelper.extractPlaceholderKeys(value.value());
-
- if (keys.isEmpty()) {
- return;
- }
+ AQS篇一
+ /2021/02/14/AQS%E7%AF%87%E4%B8%80/
+ 很多东西都是时看时新,而且时间长了也会忘,所以再来复习下,也会有一些新的角度看法这次来聊下AQS的内容,主要是这几个点,
+第一个线程
第一个线程抢到锁了,此时state跟阻塞队列是怎么样的,其实这里是之前没理解对的地方
+/**
+ * Fair version of tryAcquire. Don't grant access unless
+ * recursive call or no waiters or is first.
+ */
+ protected final boolean tryAcquire(int acquires) {
+ final Thread current = Thread.currentThread();
+ int c = getState();
+ // 这里如果state还是0说明锁还空着
+ if (c == 0) {
+ // 因为是公平锁版本的,先去看下是否阻塞队列里有排着队的
+ if (!hasQueuedPredecessors() &&
+ compareAndSetState(0, acquires)) {
+ // 没有排队的,并且state使用cas设置成功的就标记当前占有锁的线程是我
+ setExclusiveOwnerThread(current);
+ // 然后其实就返回了,包括阻塞队列的head和tail节点和waitStatus都没有设置
+ return true;
+ }
+ }
+ else if (current == getExclusiveOwnerThread()) {
+ int nextc = c + acquires;
+ if (nextc < 0)
+ throw new Error("Maximum lock count exceeded");
+ setState(nextc);
+ return true;
+ }
+ // 这里就是第二个线程会返回false
+ return false;
+ }
+ }
- for (String key : keys) {
- SpringValue springValue = new SpringValue(key, value.value(), bean, beanName, field, false);
- springValueRegistry.register(beanFactory, key, springValue);
- logger.debug("Monitoring {}", springValue);
- }
- }
-然后我们看下这个springValueRegistry是啥玩意
-public class SpringValueRegistry {
- private static final long CLEAN_INTERVAL_IN_SECONDS = 5;
- private final Map<BeanFactory, Multimap<String, SpringValue>> registry = Maps.newConcurrentMap();
- private final AtomicBoolean initialized = new AtomicBoolean(false);
- private final Object LOCK = new Object();
+第二个线程
当第二个线程进来的时候应该是怎么样,结合代码来看
+/**
+ * Acquires in exclusive mode, ignoring interrupts. Implemented
+ * by invoking at least once {@link #tryAcquire},
+ * returning on success. Otherwise the thread is queued, possibly
+ * repeatedly blocking and unblocking, invoking {@link
+ * #tryAcquire} until success. This method can be used
+ * to implement method {@link Lock#lock}.
+ *
+ * @param arg the acquire argument. This value is conveyed to
+ * {@link #tryAcquire} but is otherwise uninterpreted and
+ * can represent anything you like.
+ */
+ public final void acquire(int arg) {
+ // 前面第一种情况是tryAcquire直接成功了,这个if判断第一个条件就是false,就不往下执行了
+ // 如果是第二个线程,第一个条件获取锁不成功,条件判断!tryAcquire(arg) == true,就会走
+ // acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
+ if (!tryAcquire(arg) &&
+ acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
+ selfInterrupt();
+ }
- public void register(BeanFactory beanFactory, String key, SpringValue springValue) {
- if (!registry.containsKey(beanFactory)) {
- synchronized (LOCK) {
- if (!registry.containsKey(beanFactory)) {
- registry.put(beanFactory, LinkedListMultimap.<String, SpringValue>create());
+然后来看下addWaiter的逻辑
+/**
+ * Creates and enqueues node for current thread and given mode.
+ *
+ * @param mode Node.EXCLUSIVE for exclusive, Node.SHARED for shared
+ * @return the new node
+ */
+ private Node addWaiter(Node mode) {
+ // 这里是包装成一个node
+ Node node = new Node(Thread.currentThread(), mode);
+ // Try the fast path of enq; backup to full enq on failure
+ // 最快的方式就是把当前线程的节点放在阻塞队列的最后
+ Node pred = tail;
+ // 只有当tail,也就是pred不为空的时候可以直接接上
+ if (pred != null) {
+ node.prev = pred;
+ // 如果这里cas成功了,就直接接上返回了
+ if (compareAndSetTail(pred, node)) {
+ pred.next = node;
+ return node;
+ }
}
- }
- }
+ // 不然就会继续走到这里
+ enq(node);
+ return node;
+ }
- registry.get(beanFactory).put(key, springValue);
+然后就是enq的逻辑了
+/**
+ * Inserts node into queue, initializing if necessary. See picture above.
+ * @param node the node to insert
+ * @return node's predecessor
+ */
+ private Node enq(final Node node) {
+ for (;;) {
+ // 如果状态没变化的话,tail这时还是null的
+ Node t = tail;
+ if (t == null) { // Must initialize
+ // 这里就会初始化头结点,就是个空节点
+ if (compareAndSetHead(new Node()))
+ // tail也赋值成head
+ tail = head;
+ } else {
+ // 这里就设置tail了
+ node.prev = t;
+ if (compareAndSetTail(t, node)) {
+ t.next = node;
+ return t;
+ }
+ }
+ }
+ }
- // lazy initialize
- if (initialized.compareAndSet(false, true)) {
- initialize();
+所以从这里可以看出来,其实head头结点不是个真实的带有线程的节点,并且不是在第一个线程进来的时候设置的
+解锁
通过代码来看下
+/**
+ * Attempts to release this lock.
+ *
+ * <p>If the current thread is the holder of this lock then the hold
+ * count is decremented. If the hold count is now zero then the lock
+ * is released. If the current thread is not the holder of this
+ * lock then {@link IllegalMonitorStateException} is thrown.
+ *
+ * @throws IllegalMonitorStateException if the current thread does not
+ * hold this lock
+ */
+ public void unlock() {
+ // 释放锁
+ sync.release(1);
}
- }
-这类其实就是个 map 来存放 springvalue,然后有com.ctrip.framework.apollo.spring.property.AutoUpdateConfigChangeListener来监听更新操作,当有变更时
-@Override
- public void onChange(ConfigChangeEvent changeEvent) {
- Set<String> keys = changeEvent.changedKeys();
- if (CollectionUtils.isEmpty(keys)) {
- return;
- }
- for (String key : keys) {
- // 1. check whether the changed key is relevant
- Collection<SpringValue> targetValues = springValueRegistry.get(beanFactory, key);
- if (targetValues == null || targetValues.isEmpty()) {
- continue;
- }
+/**
+ * Releases in exclusive mode. Implemented by unblocking one or
+ * more threads if {@link #tryRelease} returns true.
+ * This method can be used to implement method {@link Lock#unlock}.
+ *
+ * @param arg the release argument. This value is conveyed to
+ * {@link #tryRelease} but is otherwise uninterpreted and
+ * can represent anything you like.
+ * @return the value returned from {@link #tryRelease}
+ */
+ public final boolean release(int arg) {
+ // 尝试去释放
+ if (tryRelease(arg)) {
+ Node h = head;
+ if (h != null && h.waitStatus != 0)
+ unparkSuccessor(h);
+ return true;
+ }
+ return false;
+ }
+protected final boolean tryRelease(int releases) {
+ int c = getState() - releases;
+ if (Thread.currentThread() != getExclusiveOwnerThread())
+ throw new IllegalMonitorStateException();
+ boolean free = false;
+ // 判断是否完全释放锁,因为可重入
+ if (c == 0) {
+ free = true;
+ setExclusiveOwnerThread(null);
+ }
+ setState(c);
+ return free;
+ }
+// 这段代码和上面的一致,只是为了顺序性,又拷下来看下
+
+public final boolean release(int arg) {
+ // 尝试去释放,如果是完全释放,返回的就是true,否则是false
+ if (tryRelease(arg)) {
+ Node h = head;
+ // 这里判断头结点是否为空以及waitStatus的状态,前面说了head节点其实是
+ // 在第二个线程进来的时候初始化的,如果是空的话说明没后续节点,并且waitStatus
+ // 也表示了后续的等待状态
+ if (h != null && h.waitStatus != 0)
+ unparkSuccessor(h);
+ return true;
+ }
+ return false;
+ }
+
+/**
+ * Wakes up node's successor, if one exists.
+ *
+ * @param node the node
+ */
+// 唤醒后继节点
+ private void unparkSuccessor(Node node) {
+ /*
+ * If status is negative (i.e., possibly needing signal) try
+ * to clear in anticipation of signalling. It is OK if this
+ * fails or if status is changed by waiting thread.
+ */
+ int ws = node.waitStatus;
+ if (ws < 0)
+ compareAndSetWaitStatus(node, ws, 0);
+
+ /*
+ * Thread to unpark is held in successor, which is normally
+ * just the next node. But if cancelled or apparently null,
+ * traverse backwards from tail to find the actual
+ * non-cancelled successor.
+ */
+ Node s = node.next;
+ // 如果后继节点是空或者当前节点取消等待了
+ if (s == null || s.waitStatus > 0) {
+ s = null;
+ // 从后往前找,找到非取消的节点,注意这里不是找到就退出,而是一直找到头
+ // 所以不必担心中间有取消的
+ for (Node t = tail; t != null && t != node; t = t.prev)
+ if (t.waitStatus <= 0)
+ s = t;
+ }
+ if (s != null)
+ // 将其唤醒
+ LockSupport.unpark(s.thread);
+ }
+
+
- // 2. check whether the value is really changed or not (since spring property sources have hierarchies)
- // 这里其实有一点比较绕,是因为 Apollo 里的 namespace 划分,会出现 key 相同,但是 namespace 不同的情况,所以会有个优先级存在,所以需要去校验 environment 里面的是否已经更新,如果未更新则表示不需要更新
- if (!shouldTriggerAutoUpdate(changeEvent, key)) {
- continue;
- }
- // 3. update the value
- for (SpringValue val : targetValues) {
- updateSpringValue(val);
- }
- }
- }
-其实原理很简单,就是得了解知道下
]]>
Java
- Apollo
- value
+ 并发
- Java
- Apollo
- environment
- value
- 注解
+ java
+ aqs
+ 并发
+ j.u.c
- Comparator使用小记
- /2020/04/05/Comparator%E4%BD%BF%E7%94%A8%E5%B0%8F%E8%AE%B0/
- 在Java8的stream之前,将对象进行排序的时候,可能需要对象实现Comparable接口,或者自己实现一个Comparator,
-比如这样子
-我的对象是Entity
-public class Entity {
-
- private Long id;
-
- private Long sortValue;
-
- public Long getId() {
- return id;
- }
-
- public void setId(Long id) {
- this.id = id;
- }
-
- public Long getSortValue() {
- return sortValue;
- }
-
- public void setSortValue(Long sortValue) {
- this.sortValue = sortValue;
- }
-}
-
-Comparator
-public class MyComparator implements Comparator {
- @Override
- public int compare(Object o1, Object o2) {
- Entity e1 = (Entity) o1;
- Entity e2 = (Entity) o2;
- if (e1.getSortValue() < e2.getSortValue()) {
- return -1;
- } else if (e1.getSortValue().equals(e2.getSortValue())) {
- return 0;
- } else {
- return 1;
- }
- }
-}
-
-比较代码
-private static MyComparator myComparator = new MyComparator();
-
- public static void main(String[] args) {
- List<Entity> list = new ArrayList<Entity>();
- Entity e1 = new Entity();
- e1.setId(1L);
- e1.setSortValue(1L);
- list.add(e1);
- Entity e2 = new Entity();
- e2.setId(2L);
- e2.setSortValue(null);
- list.add(e2);
- Collections.sort(list, myComparator);
-
-看到这里的e2的排序值是null,在Comparator中如果要正常运行的话,就得判空之类的,这里有两点需要,一个是不想写这个MyComparator,然后也没那么好排除掉list里排序值,那么有什么办法能解决这种问题呢,应该说java的这方面真的是很强大
-![]()
-看一下nullsFirst的实现
-final static class NullComparator<T> implements Comparator<T>, Serializable {
- private static final long serialVersionUID = -7569533591570686392L;
- private final boolean nullFirst;
- // if null, non-null Ts are considered equal
- private final Comparator<T> real;
-
- @SuppressWarnings("unchecked")
- NullComparator(boolean nullFirst, Comparator<? super T> real) {
- this.nullFirst = nullFirst;
- this.real = (Comparator<T>) real;
- }
-
- @Override
- public int compare(T a, T b) {
- if (a == null) {
- return (b == null) ? 0 : (nullFirst ? -1 : 1);
- } else if (b == null) {
- return nullFirst ? 1: -1;
- } else {
- return (real == null) ? 0 : real.compare(a, b);
- }
- }
+ Apollo 如何获取当前环境
+ /2022/09/04/Apollo-%E5%A6%82%E4%BD%95%E8%8E%B7%E5%8F%96%E5%BD%93%E5%89%8D%E7%8E%AF%E5%A2%83/
+ 在用 Apollo 作为配置中心的过程中才到过几个坑,这边记录下,因为运行 java 服务的启动参数一般比较固定,所以我们在一个新环境里运行的时候没有特意去检查,然后突然发现业务上有一些数据异常,排查之后才发现java 服务连接了测试环境的 apollo,而原因是因为环境变量传了-Denv=fat,而在我们的环境配置中 fat 就是代表测试环境, 其实应该是-Denv=pro,而 apollo 总共有这些环境
+public enum Env{
+ LOCAL, DEV, FWS, FAT, UAT, LPT, PRO, TOOLS, UNKNOWN;
-核心代码就是下面这段,其实就是帮我们把前面要做的事情做掉了,是不是挺方便的,小记一下哈
+ public static Env fromString(String env) {
+ Env environment = EnvUtils.transformEnv(env);
+ Preconditions.checkArgument(environment != UNKNOWN, String.format("Env %s is invalid", env));
+ return environment;
+ }
+}
+而这些解释
+/**
+ * Here is the brief description for all the predefined environments:
+ * <ul>
+ * <li>LOCAL: Local Development environment, assume you are working at the beach with no network access</li>
+ * <li>DEV: Development environment</li>
+ * <li>FWS: Feature Web Service Test environment</li>
+ * <li>FAT: Feature Acceptance Test environment</li>
+ * <li>UAT: User Acceptance Test environment</li>
+ * <li>LPT: Load and Performance Test environment</li>
+ * <li>PRO: Production environment</li>
+ * <li>TOOLS: Tooling environment, a special area in production environment which allows
+ * access to test environment, e.g. Apollo Portal should be deployed in tools environment</li>
+ * </ul>
+ */
+那如果要在运行时知道 apollo 当前使用的环境可以用这个
+Env apolloEnv = ApolloInjector.getInstance(ConfigUtil.class).getApolloEnv();
+简单记录下。
]]>
Java
- 集合
Java
- Stream
- Comparator
- 排序
- sort
- nullsfirst
+ Apollo
+ environment
@@ -1820,42 +1845,19 @@ Node *clone(Node *graph) {
- Disruptor 系列二
- /2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
- 这里开始慢慢深入的讲一下 disruptor,首先是 lock free , 相比于前面介绍的两个阻塞队列,
disruptor 本身是不直接使用锁的,因为本身的设计是单个线程去生产,通过 cas 来维护头指针,
不直接维护尾指针,这样就减少了锁的使用,提升了性能;第二个是这次介绍的重点,
减少 false sharing 的情况,也就是常说的 伪共享 问题,那么什么叫 伪共享 呢,
这里要扯到一些 cpu 缓存的知识,
![]()
譬如我在用的这个笔记本
![]()
这里就可能看到 L2 Cache 就是针对每个核的
![]()
这里可以看到现代 CPU 的结构里,分为三级缓存,越靠近 cpu 的速度越快,存储容量越小,
而 L1 跟 L2 是 CPU 核专属的每个核都有自己的 L1 和 L2 的,其中 L1 还分为数据和指令,
像我上面的图中显示的 L1 Cache 只有 64KB 大小,其中数据 32KB,指令 32KB,
而 L2 则有 256KB,L3 有 4MB,其中的 Line Size 是我们这里比较重要的一个值,
CPU 其实会就近地从 Cache 中读取数据,碰到 Cache Miss 就再往下一级 Cache 读取,
每次读取是按照缓存行 Cache Line 读取,并且也遵循了“就近原则”,
也就是相近的数据有可能也会马上被读取,所以以行的形式读取,然而这也造成了 false sharing,
因为类似于 ArrayBlockingQueue,需要有 takeIndex , putIndex , count , 因为在同一个类中,
很有可能存在于同一个 Cache Line 中,但是这几个值会被不同的线程修改,
导致从 Cache 取出来以后立马就会被失效,所谓的就近原则也就没用了,
因为需要反复地标记 dirty 脏位,然后把 Cache 刷掉,就造成了false sharing这种情况
而在 disruptor 中则使用了填充的方式,让我的头指针能够不产生false sharing
-class LhsPadding
-{
- protected long p1, p2, p3, p4, p5, p6, p7;
-}
-
-class Value extends LhsPadding
-{
- protected volatile long value;
-}
-
-class RhsPadding extends Value
-{
- protected long p9, p10, p11, p12, p13, p14, p15;
-}
-
-/**
- * <p>Concurrent sequence class used for tracking the progress of
- * the ring buffer and event processors. Support a number
- * of concurrent operations including CAS and order writes.
- *
- * <p>Also attempts to be more efficient with regards to false
- * sharing by adding padding around the volatile field.
- */
-public class Sequence extends RhsPadding
-{
-通过代码可以看到,sequence 中其实真正有意义的是 value 字段,因为需要在多线程环境下可见也
使用了volatile 关键字,而 LhsPadding 和 RhsPadding 分别在value 前后填充了各
7 个 long 型的变量,long 型的变量在 Java 中是占用 8 bytes,这样就相当于不管怎么样,
value 都会单独使用一个缓存行,使得其不会产生 false sharing 的问题。
+ 2022 年终总结
+ /2023/01/15/2022-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ 一年又一年,时间匆匆,这一年过得不太容易,很多事情都是来得猝不及防,很多规划也照例是没有完成,今年更多了一些,又是比较丧的一篇总结
工作上的变化让我多理解了一些社会跟职场的现实吧,可能的确是我不够优秀,也可能是其他,说回我自身,在工作中今年应该是收获比较一般的一年,不能说没有,对原先不熟悉的业务的掌握程度有了比较大的提升,只是问题依旧存在,也挺难推动完全改变,只能尽自己所能,而这一点也主要是在团队中的定位因为前面说的一些原因,在前期不明确,限制比较大,虽然现在并没有完全解决,但也有了一些明显的改善,如果明年继续为这家公司服务,希望能有所突破,在人心沟通上的技巧总是比较反感,可也是不得不使用或者说被迫学习使用的,LD说我的对错观太强了,拗不过来,希望能有所改变。
长远的规划上没有什么明确的想法,很容易否定原来的各种想法,见识过各种现实的残酷,明白以前的一些想法不够全面或者比较幼稚,想有更上一层楼的机会,只是不希望是通过自己不认可的方式。比较能接受的是通过提升自己的技术和执行力,能够有更进一步的可能。
技术上是挺失败的去年跟前年还是能看一些书,学一些东西,今年少了很多,可能对原来比较熟悉的都有些遗忘,最近有在改善博客的内容,能更多的是系列化的,由浅入深,只是还很不完善,没什么规划,体系上也还不完整,不过还是以mybatis作为一个开头,后续新开始的内容或者原先写过的相关的都能做个整理,不再是想到啥就写点啥。最近的一个重点是在k8s上,学习方式跟一些特别优秀的人比起来还是会慢一些,不过也是自己的方法,能够更深入的理解整个体系,并讲解出来,可能会尝试采用视频的方式,对一些比较好的内容做尝试,看看会不会有比较好的数据和反馈,在22年还苟着周更的独立技术博客也算是比较稀有了的,其他站的发布也要勤一些,形成所谓的“矩阵”。
跑步减肥这个么还是比较惨,22年只跑了368公里,比21年少了85公里,有一些客观但很多是主观的原因,还是需要跑起来,只是减肥也很迫切,体重比较大跑步还是有些压力的,买了动感单车,就是时间稍长屁股痛这个目前比较难解决,骑还是每天在骑就是强度跟时间不太够,要保证每天30分钟的量可能会比较好。
加油吧,愿23年家人和自己都健康,顺遂。大家也一样。
]]>
- Java
+ 生活
+ 年终总结
- Java
- Disruptor
+ 生活
+ 年终总结
+ 2022
+ 2023
@@ -1948,25 +1950,42 @@ Node *clone(Node *graph) {
- Dubbo 使用的几个记忆点
- /2022/04/02/Dubbo-%E4%BD%BF%E7%94%A8%E7%9A%84%E5%87%A0%E4%B8%AA%E8%AE%B0%E5%BF%86%E7%82%B9/
- 因为后台使用的 dubbo 作为 rpc 框架,并且会有一些日常使用情景有一些小的技巧,在这里做下记录作笔记用
-dubbo 只拉取不注册
<dubbo:registry address="zookeeper://127.0.0.1:2181" register="false" />
-就是只要 register="false" 就可以了,这样比如我们在开发环境想运行服务,但又不想让开发环境正常的请求调用到本地来,当然这不是唯一的方式,通过 dubbo 2.7 以上的 tag 路由也可以实现或者自行改造拉取和注册服务的逻辑,因为注册到注册中心的其实是一串带参数的 url,还是比较方便改造的。相反的就是只注册,不拉取
-dubbo 只注册不拉取
<dubbo:registry address="zookeeper://127.0.0.1:2181" subscribe="false" />
-这个使用场景就是如果我这个服务只作为 provider,没有任何调用其他的服务,其实就可以这么设置
-权重配置
<dubbo:provider loadbalance="random" weight="50"/>
-首先这是在使用了随机的负载均衡策略的时候可以进行配置,并且是对于多个 provider 的情况下,这样其实也可以部分解决上面的只拉取不注册的问题,我把自己的权重调成 0 或者很低
-]]>
-
- Java
- Dubbo
-
-
- Java
- Dubbo
- RPC
- 负载均衡
+ Disruptor 系列二
+ /2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
+ 这里开始慢慢深入的讲一下 disruptor,首先是 lock free , 相比于前面介绍的两个阻塞队列,
disruptor 本身是不直接使用锁的,因为本身的设计是单个线程去生产,通过 cas 来维护头指针,
不直接维护尾指针,这样就减少了锁的使用,提升了性能;第二个是这次介绍的重点,
减少 false sharing 的情况,也就是常说的 伪共享 问题,那么什么叫 伪共享 呢,
这里要扯到一些 cpu 缓存的知识,
![]()
譬如我在用的这个笔记本
![]()
这里就可能看到 L2 Cache 就是针对每个核的
![]()
这里可以看到现代 CPU 的结构里,分为三级缓存,越靠近 cpu 的速度越快,存储容量越小,
而 L1 跟 L2 是 CPU 核专属的每个核都有自己的 L1 和 L2 的,其中 L1 还分为数据和指令,
像我上面的图中显示的 L1 Cache 只有 64KB 大小,其中数据 32KB,指令 32KB,
而 L2 则有 256KB,L3 有 4MB,其中的 Line Size 是我们这里比较重要的一个值,
CPU 其实会就近地从 Cache 中读取数据,碰到 Cache Miss 就再往下一级 Cache 读取,
每次读取是按照缓存行 Cache Line 读取,并且也遵循了“就近原则”,
也就是相近的数据有可能也会马上被读取,所以以行的形式读取,然而这也造成了 false sharing,
因为类似于 ArrayBlockingQueue,需要有 takeIndex , putIndex , count , 因为在同一个类中,
很有可能存在于同一个 Cache Line 中,但是这几个值会被不同的线程修改,
导致从 Cache 取出来以后立马就会被失效,所谓的就近原则也就没用了,
因为需要反复地标记 dirty 脏位,然后把 Cache 刷掉,就造成了false sharing这种情况
而在 disruptor 中则使用了填充的方式,让我的头指针能够不产生false sharing
+class LhsPadding
+{
+ protected long p1, p2, p3, p4, p5, p6, p7;
+}
+
+class Value extends LhsPadding
+{
+ protected volatile long value;
+}
+
+class RhsPadding extends Value
+{
+ protected long p9, p10, p11, p12, p13, p14, p15;
+}
+
+/**
+ * <p>Concurrent sequence class used for tracking the progress of
+ * the ring buffer and event processors. Support a number
+ * of concurrent operations including CAS and order writes.
+ *
+ * <p>Also attempts to be more efficient with regards to false
+ * sharing by adding padding around the volatile field.
+ */
+public class Sequence extends RhsPadding
+{
+通过代码可以看到,sequence 中其实真正有意义的是 value 字段,因为需要在多线程环境下可见也
使用了volatile 关键字,而 LhsPadding 和 RhsPadding 分别在value 前后填充了各
7 个 long 型的变量,long 型的变量在 Java 中是占用 8 bytes,这样就相当于不管怎么样,
value 都会单独使用一个缓存行,使得其不会产生 false sharing 的问题。
+]]>
+
+ Java
+
+
+ Java
+ Disruptor
@@ -2437,4992 +2456,3868 @@ Node *clone(Node *graph) {
- G1收集器概述
- /2020/02/09/G1%E6%94%B6%E9%9B%86%E5%99%A8%E6%A6%82%E8%BF%B0/
- G1: The Garbage-First Collector, 垃圾回收优先的垃圾回收器,目标是用户多核 cpu 和大内存的机器,最大的特点就是可预测的停顿时间,官方给出的介绍是提供一个用户在大的堆内存情况下一个低延迟表现的解决方案,通常是 6GB 及以上的堆大小,有低于 0.5 秒稳定的可预测的停顿时间。
-这里主要介绍这个比较新的垃圾回收器,在 G1 之前的垃圾回收器都是基于如下图的内存结构分布,有新生代,老年代和永久代(jdk8 之前),然后G1 往前的那些垃圾回收器都有个分代,比如 serial,parallel 等,一般有个应用的组合,最初的 serial 和 serial old,因为新生代和老年代的收集方式不太一样,新生代主要是标记复制,所以有 eden 跟两个 survival区,老年代一般用标记整理方式,而 G1 对这个不太一样。
![]()
看一下 G1 的内存分布
![]()
可以看到这有很大的不同,G1 通过将内存分成大小相等的 region,每个region是存在于一个连续的虚拟内存范围,对于某个 region 来说其角色是类似于原来的收集器的Eden、Survivor、Old Generation,这个具体在代码层面
-// We encode the value of the heap region type so the generation can be
- // determined quickly. The tag is split into two parts:
- //
- // major type (young, old, humongous, archive) : top N-1 bits
- // minor type (eden / survivor, starts / cont hum, etc.) : bottom 1 bit
- //
- // If there's need to increase the number of minor types in the
- // future, we'll have to increase the size of the latter and hence
- // decrease the size of the former.
- //
- // 00000 0 [ 0] Free
- //
- // 00001 0 [ 2] Young Mask
- // 00001 0 [ 2] Eden
- // 00001 1 [ 3] Survivor
- //
- // 00010 0 [ 4] Humongous Mask
- // 00100 0 [ 8] Pinned Mask
- // 00110 0 [12] Starts Humongous
- // 00110 1 [13] Continues Humongous
- //
- // 01000 0 [16] Old Mask
- //
- // 10000 0 [32] Archive Mask
- // 11100 0 [56] Open Archive
- // 11100 1 [57] Closed Archive
- //
- typedef enum {
- FreeTag = 0,
-
- YoungMask = 2,
- EdenTag = YoungMask,
- SurvTag = YoungMask + 1,
-
- HumongousMask = 4,
- PinnedMask = 8,
- StartsHumongousTag = HumongousMask | PinnedMask,
- ContinuesHumongousTag = HumongousMask | PinnedMask + 1,
-
- OldMask = 16,
- OldTag = OldMask,
-
- // Archive regions are regions with immutable content (i.e. not reclaimed, and
- // not allocated into during regular operation). They differ in the kind of references
- // allowed for the contained objects:
- // - Closed archive regions form a separate self-contained (closed) object graph
- // within the set of all of these regions. No references outside of closed
- // archive regions are allowed.
- // - Open archive regions have no restrictions on the references of their objects.
- // Objects within these regions are allowed to have references to objects
- // contained in any other kind of regions.
- ArchiveMask = 32,
- OpenArchiveTag = ArchiveMask | PinnedMask | OldMask,
- ClosedArchiveTag = ArchiveMask | PinnedMask | OldMask + 1
- } Tag;
-
-hotspot/share/gc/g1/heapRegionType.hpp
-当执行垃圾收集时,G1以类似于CMS收集器的方式运行。 G1执行并发全局标记阶段,以确定整个堆中对象的存活性。标记阶段完成后,G1知道哪些region是基本空的。它首先收集这些region,通常会产生大量的可用空间。这就是为什么这种垃圾收集方法称为“垃圾优先”的原因。顾名思义,G1将其收集和压缩活动集中在可能充满可回收对象(即垃圾)的堆区域。 G1使用暂停预测模型来满足用户定义的暂停时间目标,并根据指定的暂停时间目标选择要收集的区域数。
-由G1标识为可回收的区域是使用撤离的方式(Evacuation)。 G1将对象从堆的一个或多个区域复制到堆上的单个区域,并在此过程中压缩并释放内存。撤离是在多处理器上并行执行的,以减少暂停时间并增加吞吐量。因此,对于每次垃圾收集,G1都在用户定义的暂停时间内连续工作以减少碎片。这是优于前面两种方法的。 CMS(并发标记扫描)垃圾收集器不进行压缩。 ParallelOld垃圾回收仅执行整个堆压缩,这导致相当长的暂停时间。
-需要重点注意的是,G1不是实时收集器。它很有可能达到设定的暂停时间目标,但并非绝对确定。 G1根据先前收集的数据,估算在用户指定的目标时间内可以收集多少个区域。因此,收集器具有收集区域成本的合理准确的模型,并且收集器使用此模型来确定要收集哪些和多少个区域,同时保持在暂停时间目标之内。
-注意:G1同时具有并发(与应用程序线程一起运行,例如优化,标记,清理)和并行(多线程,例如stw)阶段。Full GC仍然是单线程的,但是如果正确调优,您的应用程序应该可以避免Full GC。
-在前面那篇中在代码层面简单的了解了这个可预测时间的过程,这也是 G1 的一大特点。
+ Dubbo 使用的几个记忆点
+ /2022/04/02/Dubbo-%E4%BD%BF%E7%94%A8%E7%9A%84%E5%87%A0%E4%B8%AA%E8%AE%B0%E5%BF%86%E7%82%B9/
+ 因为后台使用的 dubbo 作为 rpc 框架,并且会有一些日常使用情景有一些小的技巧,在这里做下记录作笔记用
+dubbo 只拉取不注册
<dubbo:registry address="zookeeper://127.0.0.1:2181" register="false" />
+就是只要 register="false" 就可以了,这样比如我们在开发环境想运行服务,但又不想让开发环境正常的请求调用到本地来,当然这不是唯一的方式,通过 dubbo 2.7 以上的 tag 路由也可以实现或者自行改造拉取和注册服务的逻辑,因为注册到注册中心的其实是一串带参数的 url,还是比较方便改造的。相反的就是只注册,不拉取
+dubbo 只注册不拉取
<dubbo:registry address="zookeeper://127.0.0.1:2181" subscribe="false" />
+这个使用场景就是如果我这个服务只作为 provider,没有任何调用其他的服务,其实就可以这么设置
+权重配置
<dubbo:provider loadbalance="random" weight="50"/>
+首先这是在使用了随机的负载均衡策略的时候可以进行配置,并且是对于多个 provider 的情况下,这样其实也可以部分解决上面的只拉取不注册的问题,我把自己的权重调成 0 或者很低
]]>
Java
- JVM
- GC
- C++
+ Dubbo
Java
- JVM
- C++
- G1
- GC
- Garbage-First Collector
-
-
-
- 2022 年终总结
- /2023/01/15/2022-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
- 一年又一年,时间匆匆,这一年过得不太容易,很多事情都是来得猝不及防,很多规划也照例是没有完成,今年更多了一些,又是比较丧的一篇总结
工作上的变化让我多理解了一些社会跟职场的现实吧,可能的确是我不够优秀,也可能是其他,说回我自身,在工作中今年应该是收获比较一般的一年,不能说没有,对原先不熟悉的业务的掌握程度有了比较大的提升,只是问题依旧存在,也挺难推动完全改变,只能尽自己所能,而这一点也主要是在团队中的定位因为前面说的一些原因,在前期不明确,限制比较大,虽然现在并没有完全解决,但也有了一些明显的改善,如果明年继续为这家公司服务,希望能有所突破,在人心沟通上的技巧总是比较反感,可也是不得不使用或者说被迫学习使用的,LD说我的对错观太强了,拗不过来,希望能有所改变。
长远的规划上没有什么明确的想法,很容易否定原来的各种想法,见识过各种现实的残酷,明白以前的一些想法不够全面或者比较幼稚,想有更上一层楼的机会,只是不希望是通过自己不认可的方式。比较能接受的是通过提升自己的技术和执行力,能够有更进一步的可能。
技术上是挺失败的去年跟前年还是能看一些书,学一些东西,今年少了很多,可能对原来比较熟悉的都有些遗忘,最近有在改善博客的内容,能更多的是系列化的,由浅入深,只是还很不完善,没什么规划,体系上也还不完整,不过还是以mybatis作为一个开头,后续新开始的内容或者原先写过的相关的都能做个整理,不再是想到啥就写点啥。最近的一个重点是在k8s上,学习方式跟一些特别优秀的人比起来还是会慢一些,不过也是自己的方法,能够更深入的理解整个体系,并讲解出来,可能会尝试采用视频的方式,对一些比较好的内容做尝试,看看会不会有比较好的数据和反馈,在22年还苟着周更的独立技术博客也算是比较稀有了的,其他站的发布也要勤一些,形成所谓的“矩阵”。
跑步减肥这个么还是比较惨,22年只跑了368公里,比21年少了85公里,有一些客观但很多是主观的原因,还是需要跑起来,只是减肥也很迫切,体重比较大跑步还是有些压力的,买了动感单车,就是时间稍长屁股痛这个目前比较难解决,骑还是每天在骑就是强度跟时间不太够,要保证每天30分钟的量可能会比较好。
加油吧,愿23年家人和自己都健康,顺遂。大家也一样。
-]]>
-
- 生活
- 年终总结
-
-
- 生活
- 年终总结
- 2022
- 2023
+ Dubbo
+ RPC
+ 负载均衡
- Leetcode 021 合并两个有序链表 ( Merge Two Sorted Lists ) 题解分析
- /2021/10/07/Leetcode-021-%E5%90%88%E5%B9%B6%E4%B8%A4%E4%B8%AA%E6%9C%89%E5%BA%8F%E9%93%BE%E8%A1%A8-Merge-Two-Sorted-Lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Merge two sorted linked lists and return it as a sorted list. The list should be made by splicing together the nodes of the first two lists.
-将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
-示例 1
![]()
-
-输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
-
-示例 2
-输入: l1 = [], l2 = []
输出: []
-
-示例 3
-输入: l1 = [], l2 = [0]
输出: [0]
-
-简要分析
这题是 Easy 的,看着也挺简单,两个链表进行合并,就是比较下大小,可能将就点的话最好就在两个链表中原地合并
-题解代码
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
- // 下面两个if判断了入参的边界,如果其一为null,直接返回另一个就可以了
- if (l1 == null) {
- return l2;
- }
- if (l2 == null) {
- return l1;
- }
- // new 一个合并后的头结点
- ListNode merged = new ListNode();
- // 这个是当前节点
- ListNode current = merged;
- // 一开始给这个while加了l1和l2不全为null的条件,后面想了下不需要
- // 因为内部前两个if就是跳出条件
- while (true) {
- if (l1 == null) {
- // 这里其实跟开头类似,只不过这里需要将l2剩余部分接到merged链表后面
- // 所以不能是直接current = l2,这样就是把后面的直接丢了
- current.val = l2.val;
- current.next = l2.next;
- break;
- }
- if (l2 == null) {
- current.val = l1.val;
- current.next = l1.next;
- break;
- }
- // 这里是两个链表都不为空的时候,就比较下大小
- if (l1.val < l2.val) {
- current.val = l1.val;
- l1 = l1.next;
- } else {
- current.val = l2.val;
- l2 = l2.next;
- }
- // 这里是new个新的,其实也可以放在循环头上
- current.next = new ListNode();
- current = current.next;
- }
- current = null;
- // 返回这个头结点
- return merged;
- }
+ Headscale初体验以及踩坑记
+ /2023/01/22/Headscale%E5%88%9D%E4%BD%93%E9%AA%8C%E4%BB%A5%E5%8F%8A%E8%B8%A9%E5%9D%91%E8%AE%B0/
+ 最近或者说很久以前就想着能够把几个散装服务器以及家里的网络连起来,譬如一些remote desktop的访问,之前搞了下frp,因为家里电脑没怎么注意安全性就被搞了一下,所以还是想用相对更安全的方式,比如限定ip和端口进行访问,但是感觉ip也不固定就比较难搞,后来看到了 Tailscale 和 Headscale 的方式,就想着试试看,没想到一开始就踩了几个比较莫名其妙的坑。
可以按官方文档去搭建,也可以在网上找一些其他人搭建的教程。我碰到的主要是关于配置文件的问题
+第一个问题
Error initializing error="failed to read or create private key: failed to save private key to disk: open /etc/headscale/private.key: read-only file system"
+其实一开始看到这个我都有点懵了,咋回事呢,read-only file system一般有可能是文件系统出问题了,不可写入,需要重启或者修改挂载方式,被这个错误的错误日志给误导了,后面才知道是配置文件,在另一个教程中也有个类似的回复,一开始没注意,其实就是同一个问题。
默认的配置文件是这样的
+---
+# headscale will look for a configuration file named `config.yaml` (or `config.json`) in the following order:
+#
+# - `/etc/headscale`
+# - `~/.headscale`
+# - current working directory
-结果
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
-
-
-
- Leetcode 028 实现 strStr() ( Implement strStr() ) 题解分析
- /2021/10/31/Leetcode-028-%E5%AE%9E%E7%8E%B0-strStr-Implement-strStr-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Implement strStr().
-Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
-Clarification:
What should we return when needle is an empty string? This is a great question to ask during an interview.
-For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C’s strstr() and Java’s indexOf().
-示例
Example 1:
-Input: haystack = "hello", needle = "ll"
-Output: 2
-Example 2:
-Input: haystack = "aaaaa", needle = "bba"
-Output: -1
-Example 3:
-Input: haystack = "", needle = ""
-Output: 0
-
-题解
字符串比较其实是写代码里永恒的主题,底层的编译器等处理肯定需要字符串对比,像 kmp 算法也是很厉害
-code
public int strStr(String haystack, String needle) {
- // 如果两个字符串都为空,返回 -1
- if (haystack == null || needle == null) {
- return -1;
- }
- // 如果 haystack 长度小于 needle 长度,返回 -1
- if (haystack.length() < needle.length()) {
- return -1;
- }
- // 如果 needle 为空字符串,返回 0
- if (needle.equals("")) {
- return 0;
- }
- // 如果两者相等,返回 0
- if (haystack.equals(needle)) {
- return 0;
- }
- int needleLength = needle.length();
- int haystackLength = haystack.length();
- for (int i = needleLength - 1; i <= haystackLength - 1; i++) {
- // 比较 needle 最后一个字符,倒着比较稍微节省点时间
- if (needle.charAt(needleLength - 1) == haystack.charAt(i)) {
- // 如果needle 是 1 的话直接可以返回 i 作为位置了
- if (needle.length() == 1) {
- return i;
- }
- boolean flag = true;
- // 原来比的是 needle 的最后一个位置,然后这边从倒数第二个位置开始
- int j = needle.length() - 2;
- for (; j >= 0; j--) {
- // 这里的 i- (needleLength - j) + 1 ) 比较绕,其实是外循环的 i 表示当前 i 位置的字符跟 needle 最后一个字符
- // 相同,j 在上面的循环中--,对应的 haystack 也要在 i 这个位置 -- ,对应的位置就是 i - (needleLength - j) + 1
- if (needle.charAt(j) != haystack.charAt(i - (needleLength - j) + 1)) {
- flag = false;
- break;
- }
- }
- // 循环完了之后,如果 flag 为 true 说明 从 i 开始倒着对比都相同,但是这里需要起始位置,就需要
- // i - needleLength + 1
- if (flag) {
- return i - needleLength + 1;
- }
- }
- }
- // 这里表示未找到
- return -1;
- }
]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
-
-
-
- Leetcode 053 最大子序和 ( Maximum Subarray ) 题解分析
- /2021/11/28/Leetcode-053-%E6%9C%80%E5%A4%A7%E5%AD%90%E5%BA%8F%E5%92%8C-Maximum-Subarray-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given an integer array nums, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.
-A subarray is a contiguous part of an array.
-示例
Example 1:
-
-Input: nums = [-2,1,-3,4,-1,2,1,-5,4]
Output: 6
Explanation: [4,-1,2,1] has the largest sum = 6.
-
-Example 2:
-
-Input: nums = [1]
Output: 1
-
-Example 3:
-
-Input: nums = [5,4,-1,7,8]
Output: 23
-
-说起来这个题其实非常有渊源,大学数据结构的第一个题就是这个,而最佳的算法就是传说中的 online 算法,就是遍历一次就完了,最基本的做法就是记下来所有的连续子数组,然后求出最大的那个。
-代码
public int maxSubArray(int[] nums) {
- int max = nums[0];
- int sum = nums[0];
- for (int i = 1; i < nums.length; i++) {
- // 这里最重要的就是这一行了,其实就是如果前面的 sum 是小于 0 的,那么就不需要前面的 sum,反正加上了还不如不加大
- sum = Math.max(nums[i], sum + nums[i]);
- // max 是用来承载最大值的
- max = Math.max(max, sum);
- }
- return max;
- }
]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
-
-
-
- Leetcode 104 二叉树的最大深度(Maximum Depth of Binary Tree) 题解分析
- /2020/10/25/Leetcode-104-%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E6%9C%80%E5%A4%A7%E6%B7%B1%E5%BA%A6-Maximum-Depth-of-Binary-Tree-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍给定一个二叉树,找出其最大深度。
-二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
-说明: 叶子节点是指没有子节点的节点。
-示例:
给定二叉树 [3,9,20,null,null,15,7],
- 3
- / \
-9 20
- / \
- 15 7
-返回它的最大深度 3 。
-代码
// 主体是个递归的应用
-public int maxDepth(TreeNode root) {
- // 节点的退出条件之一
- if (root == null) {
- return 0;
- }
- int left = 0;
- int right = 0;
- // 存在左子树,就递归左子树
- if (root.left != null) {
- left = maxDepth(root.left);
- }
- // 存在右子树,就递归右子树
- if (root.right != null) {
- right = maxDepth(root.right);
- }
- // 前面返回后,左右取大者
- return Math.max(left + 1, right + 1);
-}
-分析
其实对于树这类题,一般是以递归形式比较方便,只是要注意退出条件
-]]>
-
- Java
- leetcode
- Binary Tree
- java
- Binary Tree
- DFS
-
-
- leetcode
- java
- Binary Tree
- DFS
- 二叉树
- 题解
-
-
-
- Leetcode 105 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal) 题解分析
- /2020/12/13/Leetcode-105-%E4%BB%8E%E5%89%8D%E5%BA%8F%E4%B8%8E%E4%B8%AD%E5%BA%8F%E9%81%8D%E5%8E%86%E5%BA%8F%E5%88%97%E6%9E%84%E9%80%A0%E4%BA%8C%E5%8F%89%E6%A0%91-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given preorder and inorder traversal of a tree, construct the binary tree.
给定一棵树的前序和中序遍历,构造出一棵二叉树
-注意
You may assume that duplicates do not exist in the tree.
你可以假设树中没有重复的元素。(PS: 不然就没法做了呀)
-例子:
preorder = [3,9,20,15,7]
-inorder = [9,3,15,20,7]
-返回的二叉树
- 3
- / \
-9 20
- / \
- 15 7
+# The url clients will connect to.
+# Typically this will be a domain like:
+#
+# https://myheadscale.example.com:443
+#
+server_url: http://127.0.0.1:8080
+# Address to listen to / bind to on the server
+#
+# For production:
+# listen_addr: 0.0.0.0:8080
+listen_addr: 127.0.0.1:8080
-简要分析
看到这个题可以想到一个比较常规的解法就是递归拆树,前序就是根左右,中序就是左根右,然后就是通过前序已经确定的根在中序中找到,然后去划分左右子树,这个例子里是 3,找到中序中的位置,那么就可以确定,9 是左子树,15,20,7是右子树,然后对应的可以根据左右子树的元素数量在前序中划分左右子树,再继续递归就行
-class Solution {
- public TreeNode buildTree(int[] preorder, int[] inorder) {
- // 获取下数组长度
- int n = preorder.length;
- // 排除一下异常和边界
- if (n != inorder.length) {
- return null;
- }
- if (n == 0) {
- return null;
- }
- if (n == 1) {
- return new TreeNode(preorder[0]);
- }
- // 获得根节点
- TreeNode node = new TreeNode(preorder[0]);
- int pos = 0;
- // 找到中序中的位置
- for (int i = 0; i < inorder.length; i++) {
- if (node.val == inorder[i]) {
- pos = i;
- break;
- }
- }
- // 划分左右再进行递归,注意下`Arrays.copyOfRange`的用法
- node.left = buildTree(Arrays.copyOfRange(preorder, 1, pos + 1), Arrays.copyOfRange(inorder, 0, pos));
- node.right = buildTree(Arrays.copyOfRange(preorder, pos + 1, n), Arrays.copyOfRange(inorder, pos + 1, n));
- return node;
- }
-}
]]>
-
- Java
- leetcode
- Binary Tree
- java
- Binary Tree
- DFS
-
-
- leetcode
- java
- Binary Tree
- 二叉树
- 题解
- 递归
- Preorder Traversal
- Inorder Traversal
- 前序
- 中序
-
-
-
- Leetcode 1115 交替打印 FooBar ( Print FooBar Alternately *Medium* ) 题解分析
- /2022/05/01/Leetcode-1115-%E4%BA%A4%E6%9B%BF%E6%89%93%E5%8D%B0-FooBar-Print-FooBar-Alternately-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 无聊想去 roll 一题就看到了有并发题,就找到了这题,其实一眼看我的想法也是用信号量,但是用 condition 应该也是可以处理的,不过这类问题好像本地有点难调,因为它好像是抽取代码执行的,跟直观的逻辑比较不一样
Suppose you are given the following code:
-class FooBar {
- public void foo() {
- for (int i = 0; i < n; i++) {
- print("foo");
- }
- }
+# Address to listen to /metrics, you may want
+# to keep this endpoint private to your internal
+# network
+#
+metrics_listen_addr: 127.0.0.1:9090
- public void bar() {
- for (int i = 0; i < n; i++) {
- print("bar");
- }
- }
-}
-The same instance of FooBar will be passed to two different threads:
-
-- thread
A will call foo(), while
-- thread
B will call bar().
Modify the given program to output "foobar" n times.
-
-示例
Example 1:
-Input: n = 1
Output: “foobar”
Explanation: There are two threads being fired asynchronously. One of them calls foo(), while the other calls bar().
“foobar” is being output 1 time.
-
-Example 2:
-Input: n = 2
Output: “foobarfoobar”
Explanation: “foobar” is being output 2 times.
-
-题解
简析
其实用信号量是很直观的,就是让打印 foo 的线程先拥有信号量,打印后就等待,给 bar 信号量 + 1,然后 bar 线程运行打印消耗 bar 信号量,再给 foo 信号量 + 1
-code
class FooBar {
-
- private final Semaphore foo = new Semaphore(1);
- private final Semaphore bar = new Semaphore(0);
- private int n;
+# Address to listen for gRPC.
+# gRPC is used for controlling a headscale server
+# remotely with the CLI
+# Note: Remote access _only_ works if you have
+# valid certificates.
+#
+# For production:
+# grpc_listen_addr: 0.0.0.0:50443
+grpc_listen_addr: 127.0.0.1:50443
- public FooBar(int n) {
- this.n = n;
- }
+# Allow the gRPC admin interface to run in INSECURE
+# mode. This is not recommended as the traffic will
+# be unencrypted. Only enable if you know what you
+# are doing.
+grpc_allow_insecure: false
- public void foo(Runnable printFoo) throws InterruptedException {
-
- for (int i = 0; i < n; i++) {
- foo.acquire();
- // printFoo.run() outputs "foo". Do not change or remove this line.
- printFoo.run();
- bar.release();
- }
- }
+# Private key used to encrypt the traffic between headscale
+# and Tailscale clients.
+# The private key file will be autogenerated if it's missing.
+#
+# For production:
+# /var/lib/headscale/private.key
+private_key_path: ./private.key
- public void bar(Runnable printBar) throws InterruptedException {
-
- for (int i = 0; i < n; i++) {
- bar.acquire();
- // printBar.run() outputs "bar". Do not change or remove this line.
- printBar.run();
- foo.release();
- }
- }
-}
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- Print FooBar Alternately
-
-
-
- Leetcode 121 买卖股票的最佳时机(Best Time to Buy and Sell Stock) 题解分析
- /2021/03/14/Leetcode-121-%E4%B9%B0%E5%8D%96%E8%82%A1%E7%A5%A8%E7%9A%84%E6%9C%80%E4%BD%B3%E6%97%B6%E6%9C%BA-Best-Time-to-Buy-and-Sell-Stock-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍You are given an array prices where prices[i] is the price of a given stock on the ith day.
-You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
-Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
-给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
-你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
-返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
-简单分析
其实这个跟二叉树的最长路径和有点类似,需要找到整体的最大收益,但是在迭代过程中需要一个当前的值
-int maxSofar = 0;
-public int maxProfit(int[] prices) {
- if (prices.length <= 1) {
- return 0;
- }
- int maxIn = prices[0];
- int maxOut = prices[0];
- for (int i = 1; i < prices.length; i++) {
- if (maxIn > prices[i]) {
- // 当循环当前值小于之前的买入值时就当成买入值,同时卖出也要更新
- maxIn = prices[i];
- maxOut = prices[i];
- }
- if (prices[i] > maxOut) {
- // 表示一个可卖出点,即比买入值高时
- maxOut = prices[i];
- // 需要设置一个历史值
- maxSofar = Math.max(maxSofar, maxOut - maxIn);
- }
- }
- return maxSofar;
-}
+# The Noise section includes specific configuration for the
+# TS2021 Noise protocol
+noise:
+ # The Noise private key is used to encrypt the
+ # traffic between headscale and Tailscale clients when
+ # using the new Noise-based protocol. It must be different
+ # from the legacy private key.
+ #
+ # For production:
+ # private_key_path: /var/lib/headscale/noise_private.key
+ private_key_path: ./noise_private.key
-总结下
一开始看到 easy 就觉得是很简单,就没有 maxSofar ,但是一提交就出现问题了
对于[2, 4, 1]这种就会变成 0,所以还是需要一个历史值来存放历史最大值,这题有点动态规划的意思
-]]>
-
- Java
- leetcode
- java
- DP
- DP
-
-
- leetcode
- java
- 题解
- DP
-
-
-
- Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析
- /2021/01/24/Leetcode-124-%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E7%9A%84%E6%9C%80%E5%A4%A7%E8%B7%AF%E5%BE%84%E5%92%8C-Binary-Tree-Maximum-Path-Sum-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
-The path sum of a path is the sum of the node’s values in the path.
-Given the root of a binary tree, return the maximum path sum of any path.
-路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。该路径 至少包含一个 节点,且不一定经过根节点。
-路径和 是路径中各节点值的总和。
-给你一个二叉树的根节点 root ,返回其 最大路径和
-简要分析
其实这个题目会被误解成比较简单,左子树最大的,或者右子树最大的,或者两边加一下,仔细想想都不对,其实有可能是产生于左子树中,或者右子树中,这两个都是指跟左子树根还有右子树根没关系的,这么说感觉不太容易理解,画个图
![]()
可以看到图里,其实最长路径和是左边这个子树组成的,跟根节点还有右子树完全没关系,然后再想一种情况,如果是整棵树就是图中的左子树,那么这个最长路径和就是左子树加右子树加根节点了,所以不是我一开始想得那么简单,在代码实现中也需要一些技巧
-代码
int ansNew = Integer.MIN_VALUE;
-public int maxPathSum(TreeNode root) {
- maxSumNew(root);
- return ansNew;
- }
-
-public int maxSumNew(TreeNode root) {
- if (root == null) {
- return 0;
- }
- // 这里是个简单的递归,就是去递归左右子树,但是这里其实有个概念,当这样处理时,其实相当于把子树的内部的最大路径和已经算出来了
- int left = maxSumNew(root.left);
- int right = maxSumNew(root.right);
- // 这里前面我有点没想明白,但是看到 ansNew 的比较,其实相当于,返回的是三种情况里的最大值,一个是左子树+根,一个是右子树+根,一个是单独根节点,
- // 这样这个递归的返回才会有意义,不然像原来的方法,它可能是跳着的,但是这种情况其实是借助于 ansNew 这个全局的最大值,因为原来我觉得要比较的是
- // left, right, left + root , right + root, root, left + right + root 这些的最大值,这里是分成了两个阶段,left 跟 right 的最大值已经在上面的
- // 调用过程中赋值给 ansNew 了
- int currentSum = Math.max(Math.max(root.val + left , root.val + right), root.val);
- // 这边返回的是 currentSum,然后再用它跟 left + right + root 进行对比,然后再去更新 ans
- // PS: 有个小点也是这边的破局点,就是这个 ansNew
- int res = Math.max(left + right + root.val, currentSum);
- ans = Math.max(res, ans);
- return currentSum;
-}
+# List of IP prefixes to allocate tailaddresses from.
+# Each prefix consists of either an IPv4 or IPv6 address,
+# and the associated prefix length, delimited by a slash.
+# While this looks like it can take arbitrary values, it
+# needs to be within IP ranges supported by the Tailscale
+# client.
+# IPv6: https://github.com/tailscale/tailscale/blob/22ebb25e833264f58d7c3f534a8b166894a89536/net/tsaddr/tsaddr.go#LL81C52-L81C71
+# IPv4: https://github.com/tailscale/tailscale/blob/22ebb25e833264f58d7c3f534a8b166894a89536/net/tsaddr/tsaddr.go#L33
+ip_prefixes:
+ - fd7a:115c:a1e0::/48
+ - 100.64.0.0/10
-这里非常重要的就是 ansNew 是最后的一个结果,而对于 maxSumNew 这个函数的返回值其实是需要包含了一个连续结果,因为要返回继续去算路径和,所以返回的是 currentSum,最终结果是 ansNew
-结果图
难得有个 100%,贴个图哈哈
![]()
-]]>
-
- Java
- leetcode
- Binary Tree
- java
- Binary Tree
-
-
- leetcode
- java
- Binary Tree
- 二叉树
- 题解
-
-
-
- Leetcode 1260 二维网格迁移 ( Shift 2D Grid *Easy* ) 题解分析
- /2022/07/22/Leetcode-1260-%E4%BA%8C%E7%BB%B4%E7%BD%91%E6%A0%BC%E8%BF%81%E7%A7%BB-Shift-2D-Grid-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given a 2D grid of size m x n and an integer k. You need to shift the grid k times.
-In one shift operation:
-Element at grid[i][j] moves to grid[i][j + 1].
Element at grid[i][n - 1] moves to grid[i + 1][0].
Element at grid[m - 1][n - 1] moves to grid[0][0].
Return the 2D grid after applying shift operation k times.
-示例
Example 1:
![]()
-
-Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 1
Output: [[9,1,2],[3,4,5],[6,7,8]]
-
-Example 2:
![]()
-
-Input: grid = [[3,8,1,9],[19,7,2,5],[4,6,11,10],[12,0,21,13]], k = 4
Output: [[12,0,21,13],[3,8,1,9],[19,7,2,5],[4,6,11,10]]
-
-Example 3:
-Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 9
Output: [[1,2,3],[4,5,6],[7,8,9]]
-
-提示
-m == grid.lengthn == grid[i].length1 <= m <= 501 <= n <= 50-1000 <= grid[i][j] <= 10000 <= k <= 100
-解析
这个题主要是矩阵或者说数组的操作,并且题目要返回的是个 List,所以也不用原地操作,只需要找对位置就可以了,k 是多少就相当于让这个二维数组头尾衔接移动 k 个元素
-代码
public List<List<Integer>> shiftGrid(int[][] grid, int k) {
- // 行数
- int m = grid.length;
- // 列数
- int n = grid[0].length;
- // 偏移值,取下模
- k = k % (m * n);
- // 反向取下数量,因为我打算直接从头填充新的矩阵
- /*
- * 比如
- * 1 2 3
- * 4 5 6
- * 7 8 9
- * 需要变成
- * 9 1 2
- * 3 4 5
- * 6 7 8
- * 就要从 9 开始填充
- */
- int reverseK = m * n - k;
- List<List<Integer>> matrix = new ArrayList<>();
- // 这类就是两层循环
- for (int i = 0; i < m; i++) {
- List<Integer> line = new ArrayList<>();
- for (int j = 0; j < n; j++) {
- // 数量会随着循环迭代增长, 确认是第几个
- int currentNum = reverseK + i * n + (j + 1);
- // 这里处理下到达矩阵末尾后减掉 m * n
- if (currentNum > m * n) {
- currentNum -= m * n;
- }
- // 根据矩阵列数 n 算出在原来矩阵的位置
- int last = (currentNum - 1) % n;
- int passLine = (currentNum - 1) / n;
+# DERP is a relay system that Tailscale uses when a direct
+# connection cannot be established.
+# https://tailscale.com/blog/how-tailscale-works/#encrypted-tcp-relays-derp
+#
+# headscale needs a list of DERP servers that can be presented
+# to the clients.
+derp:
+ server:
+ # If enabled, runs the embedded DERP server and merges it into the rest of the DERP config
+ # The Headscale server_url defined above MUST be using https, DERP requires TLS to be in place
+ enabled: false
- line.add(grid[passLine][last]);
- }
- matrix.add(line);
- }
- return matrix;
- }
+ # Region ID to use for the embedded DERP server.
+ # The local DERP prevails if the region ID collides with other region ID coming from
+ # the regular DERP config.
+ region_id: 999
-结果数据
![]()
比较慢
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- Shift 2D Grid
-
-
-
- Leetcode 155 最小栈(Min Stack) 题解分析
- /2020/12/06/Leetcode-155-%E6%9C%80%E5%B0%8F%E6%A0%88-Min-Stack-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
设计一个栈,支持压栈,出站,获取栈顶元素,通过常数级复杂度获取栈中的最小元素
-
-- push(x) – Push element x onto stack.
-- pop() – Removes the element on top of the stack.
-- top() – Get the top element.
-- getMin() – Retrieve the minimum element in the stack.
-
-示例
Example 1:
-Input
-["MinStack","push","push","push","getMin","pop","top","getMin"]
-[[],[-2],[0],[-3],[],[],[],[]]
+ # Region code and name are displayed in the Tailscale UI to identify a DERP region
+ region_code: "headscale"
+ region_name: "Headscale Embedded DERP"
-Output
-[null,null,null,null,-3,null,0,-2]
+ # Listens over UDP at the configured address for STUN connections - to help with NAT traversal.
+ # When the embedded DERP server is enabled stun_listen_addr MUST be defined.
+ #
+ # For more details on how this works, check this great article: https://tailscale.com/blog/how-tailscale-works/
+ stun_listen_addr: "0.0.0.0:3478"
-Explanation
-MinStack minStack = new MinStack();
-minStack.push(-2);
-minStack.push(0);
-minStack.push(-3);
-minStack.getMin(); // return -3
-minStack.pop();
-minStack.top(); // return 0
-minStack.getMin(); // return -2
+ # List of externally available DERP maps encoded in JSON
+ urls:
+ - https://controlplane.tailscale.com/derpmap/default
-简要分析
其实现在大部分语言都自带类栈的数据结构,Java 也自带 stack 这个数据结构,所以这个题的主要难点的就是常数级的获取最小元素,最开始的想法是就一个栈外加一个记录最小值的变量就行了,但是仔细一想是不行的,因为随着元素被 pop 出去,这个最小值也可能需要梗着变化,就不太好判断了,所以后面是用了一个辅助栈。
-代码
class MinStack {
- // 这个作为主栈
- Stack<Integer> s1 = new Stack<>();
- // 这个作为辅助栈,放最小值的栈
- Stack<Integer> s2 = new Stack<>();
- /** initialize your data structure here. */
- public MinStack() {
+ # Locally available DERP map files encoded in YAML
+ #
+ # This option is mostly interesting for people hosting
+ # their own DERP servers:
+ # https://tailscale.com/kb/1118/custom-derp-servers/
+ #
+ # paths:
+ # - /etc/headscale/derp-example.yaml
+ paths: []
- }
+ # If enabled, a worker will be set up to periodically
+ # refresh the given sources and update the derpmap
+ # will be set up.
+ auto_update_enabled: true
- public void push(int x) {
- // 放入主栈
- s1.push(x);
- // 当 s2 是空或者当前值是小于"等于" s2 栈顶时,压入辅助最小值的栈
- // 注意这里的"等于"非常必要,因为当最小值有多个的情况下,也需要压入栈,否则在 pop 的时候就会不对等
- if (s2.isEmpty() || x <= s2.peek()) {
- s2.push(x);
- }
- }
+ # How often should we check for DERP updates?
+ update_frequency: 24h
- public void pop() {
- // 首先就是主栈要 pop,然后就是第二个了,跟上面的"等于"很有关系,
- // 因为如果有两个最小值,如果前面等于的情况没有压栈,那这边相等的时候 pop 就会少一个了,可能就导致最小值不对了
- int x = s1.pop();
- if (x == s2.peek()) {
- s2.pop();
- }
- }
+# Disables the automatic check for headscale updates on startup
+disable_check_updates: false
- public int top() {
- // 栈顶的元素
- return s1.peek();
- }
+# Time before an inactive ephemeral node is deleted?
+ephemeral_node_inactivity_timeout: 30m
- public int getMin() {
- // 辅助最小栈的栈顶
- return s2.peek();
- }
- }
+# Period to check for node updates within the tailnet. A value too low will severely affect
+# CPU consumption of Headscale. A value too high (over 60s) will cause problems
+# for the nodes, as they won't get updates or keep alive messages frequently enough.
+# In case of doubts, do not touch the default 10s.
+node_update_check_interval: 10s
-]]>
-
- Java
- leetcode
- java
- stack
- stack
-
-
- leetcode
- java
- 题解
- stack
- min stack
- 最小栈
- leetcode 155
-
-
-
- Leetcode 16 最接近的三数之和 ( 3Sum Closest *Medium* ) 题解分析
- /2022/08/06/Leetcode-16-%E6%9C%80%E6%8E%A5%E8%BF%91%E7%9A%84%E4%B8%89%E6%95%B0%E4%B9%8B%E5%92%8C-3Sum-Closest-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given an integer array nums of length n and an integer target, find three integers in nums such that the sum is closest to target.
-Return the sum of the three integers.
-You may assume that each input would have exactly one solution.
-简单解释下就是之前是要三数之和等于目标值,现在是找到最接近的三数之和。
-示例
Example 1:
-Input: nums = [-1,2,1,-4], target = 1
Output: 2
Explanation: The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).
-
-Example 2:
-Input: nums = [0,0,0], target = 1
Output: 0
-
-Constraints:
-3 <= nums.length <= 1000-1000 <= nums[i] <= 1000-10^4 <= target <= 10^4
-简单解析
这个题思路上来讲不难,也是用原来三数之和的方式去做,利用”双指针法”或者其它描述法,但是需要简化逻辑
-code
public int threeSumClosest(int[] nums, int target) {
- Arrays.sort(nums);
- // 当前最近的和
- int closestSum = nums[0] + nums[1] + nums[nums.length - 1];
- for (int i = 0; i < nums.length - 2; i++) {
- if (i == 0 || nums[i] != nums[i - 1]) {
- // 左指针
- int left = i + 1;
- // 右指针
- int right = nums.length - 1;
- // 判断是否遍历完了
- while (left < right) {
- // 当前的和
- int sum = nums[i] + nums[left] + nums[right];
- // 小优化,相等就略过了
- while (left < right && nums[left] == nums[left + 1]) {
- left++;
- }
- while (left < right && nums[right] == nums[right - 1]) {
- right--;
- }
- // 这里判断,其实也还是希望趋近目标值
- if (sum < target) {
- left++;
- } else {
- right--;
- }
- // 判断是否需要替换
- if (Math.abs(sum - target) < Math.abs(closestSum - target)) {
- closestSum = sum;
- }
- }
- }
- }
- return closestSum;
- }
+# SQLite config
+db_type: sqlite3
-结果
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- 3Sum Closest
-
-
-
- Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析
- /2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍写一个程序找出两个单向链表的交叉起始点,可能是我英语不好,图里画的其实还有一点是交叉以后所有节点都是相同的
Write a program to find the node at which the intersection of two singly linked lists begins.
-For example, the following two linked lists:
![]()
begin to intersect at node c1.
-Example 1:
![]()
-Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
-Output: Reference of the node with value = 8
-Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
-分析题解
一开始没什么头绪,感觉只能最原始的遍历,后来看了一些文章,发现比较简单的方式就是先找两个链表的长度差,因为从相交点开始肯定是长度一致的,这是个很好的解题突破口,找到长度差以后就是先跳过长链表的较长部分,然后开始同步遍历比较 A,B 链表;
-代码
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
- if (headA == null || headB == null) {
- return null;
- }
- // 算 A 的长度
- int countA = 0;
- ListNode tailA = headA;
- while (tailA != null) {
- tailA = tailA.next;
- countA++;
- }
- // 算 B 的长度
- int countB = 0;
- ListNode tailB = headB;
- while (tailB != null) {
- tailB = tailB.next;
- countB++;
- }
- tailA = headA;
- tailB = headB;
- // 依据长度差,先让长的链表 tail 指针往后移
- if (countA > countB) {
- while (countA > countB) {
- tailA = tailA.next;
- countA--;
- }
- } else if (countA < countB) {
- while (countA < countB) {
- tailB = tailB.next;
- countB--;
- }
- }
- // 然后以相同速度遍历两个链表比较
- while (tailA != null) {
- if (tailA == tailB) {
- return tailA;
- } else {
- tailA = tailA.next;
- tailB = tailB.next;
- }
- }
- return null;
- }
-总结
可能缺少这种思维,做的还是比较少,所以没法一下子反应过来,需要锻炼,我的第一反应是两重遍历,不过那样复杂度就高了,这里应该是只有 O(N) 的复杂度。
-]]>
-
- Java
- leetcode
- Linked List
- java
- Linked List
-
-
- leetcode
- java
- 题解
- Linked List
-
-
-
- Leetcode 1862 向下取整数对和 ( Sum of Floored Pairs *Hard* ) 题解分析
- /2022/09/11/Leetcode-1862-%E5%90%91%E4%B8%8B%E5%8F%96%E6%95%B4%E6%95%B0%E5%AF%B9%E5%92%8C-Sum-of-Floored-Pairs-Hard-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given an integer array nums, return the sum of floor(nums[i] / nums[j]) for all pairs of indices 0 <= i, j < nums.length in the array. Since the answer may be too large, return it modulo 10^9 + 7.
-The floor() function returns the integer part of the division.
-对应中文
给你一个整数数组 nums ,请你返回所有下标对 0 <= i, j < nums.length 的 floor(nums[i] / nums[j]) 结果之和。由于答案可能会很大,请你返回答案对10^9 + 7 取余 的结果。
-函数 floor() 返回输入数字的整数部分。
-示例
Example 1:
-Input: nums = [2,5,9]
Output: 10
Explanation:
floor(2 / 5) = floor(2 / 9) = floor(5 / 9) = 0
floor(2 / 2) = floor(5 / 5) = floor(9 / 9) = 1
floor(5 / 2) = 2
floor(9 / 2) = 4
floor(9 / 5) = 1
We calculate the floor of the division for every pair of indices in the array then sum them up.
-
-Example 2:
-Input: nums = [7,7,7,7,7,7,7]
Output: 49
-
-Constraints:
-1 <= nums.length <= 10^51 <= nums[i] <= 10^5
-简析
这题不愧是 hard,要不是看了讨论区的一个大神的解答感觉从头做得想好久,
主要是两点,对于任何一个在里面的数,随便举个例子是 k,最简单的就是循环所有数对 k 除一下,
这样效率会很低,那么对于 k 有什么规律呢,就是对于所有小于 k 的数,往下取整都是 0,所以不用考虑,
对于所有大于 k 的数我们可以分成一个个的区间,[k,2k-1),[2k,3k-1),[3k,4k-1)……对于这些区间的
除了 k 往下取整,每个区间内的都是一样的,所以可以简化为对于任意一个 k,我只要知道与k 相同的有多少个,然后比 k 大的各个区间各有多少个数就可以了
-代码
static final int MAXE5 = 100_000;
+# For production:
+# db_path: /var/lib/headscale/db.sqlite
+db_path: ./db.sqlite
-static final int MODULUSE9 = 1_000_000_000 + 7;
+# # Postgres config
+# If using a Unix socket to connect to Postgres, set the socket path in the 'host' field and leave 'port' blank.
+# db_type: postgres
+# db_host: localhost
+# db_port: 5432
+# db_name: headscale
+# db_user: foo
+# db_pass: bar
-public int sumOfFlooredPairs(int[] nums) {
- int[] counts = new int[MAXE5+1];
- for (int num : nums) {
- counts[num]++;
- }
- // 这里就是很巧妙的给后一个加上前一个的值,这样其实前后任意两者之差就是这中间的元素数量
- for (int i = 1; i <= MAXE5; i++) {
- counts[i] += counts[i - 1];
- }
- long total = 0;
- for (int i = 1; i <= MAXE5; i++) {
- long sum = 0;
- if (counts[i] == counts[i-1]) {
- continue;
- }
- for (int j = 1; i*j <= MAXE5; j++) {
- int min = i * j - 1;
- int upper = i * (j + 1) - 1;
- // 在每一个区间内的数量,
- sum += (counts[Math.min(upper, MAXE5)] - counts[min]) * (long)j;
- }
- // 左边乘数的数量,即 i 位置的元素数量
- total = (total + (sum % MODULUSE9 ) * (counts[i] - counts[i-1])) % MODULUSE9;
- }
- return (int)total;
-}
+# If other 'sslmode' is required instead of 'require(true)' and 'disabled(false)', set the 'sslmode' you need
+# in the 'db_ssl' field. Refers to https://www.postgresql.org/docs/current/libpq-ssl.html Table 34.1.
+# db_ssl: false
-贴出来大神的解析,解析
-结果
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
-
-
-
- Leetcode 2 Add Two Numbers 题解分析
- /2020/10/11/Leetcode-2-Add-Two-Numbers-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 又 roll 到了一个以前做过的题,不过现在用 Java 也来写一下,是 easy 级别的,所以就简单说下
-简要介绍
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
-You may assume the two numbers do not contain any leading zero, except the number 0 itself.
就是给了两个链表,用来表示两个非负的整数,在链表中倒序放着,每个节点包含一位的数字,把他们加起来以后也按照原来的链表结构输出
-样例
example 1
Input: l1 = [2,4,3], l2 = [5,6,4]
-Output: [7,0,8]
-Explanation: 342 + 465 = 807.
+### TLS configuration
+#
+## Let's encrypt / ACME
+#
+# headscale supports automatically requesting and setting up
+# TLS for a domain with Let's Encrypt.
+#
+# URL to ACME directory
+acme_url: https://acme-v02.api.letsencrypt.org/directory
-example 2
Input: l1 = [0], l2 = [0]
-Output: [0]
+# Email to register with ACME provider
+acme_email: ""
-example 3
Input: l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
-Output: [8,9,9,9,0,0,0,1]
+# Domain name to request a TLS certificate for:
+tls_letsencrypt_hostname: ""
-题解
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
- ListNode root = new ListNode();
- if (l1 == null && l2 == null) {
- return root;
- }
- ListNode tail = root;
- int entered = 0;
- // 这个条件加了 entered,就是还有进位的数
- while (l1 != null || l2 != null || entered != 0) {
- int temp = entered;
- if (l1 != null) {
- temp += l1.val;
- l1 = l1.next;
- }
- if (l2 != null) {
- temp += l2.val;
- l2 = l2.next;
- }
- entered = (temp - temp % 10) / 10;
- tail.val = temp % 10;
- // 循环内部的控制是为了排除最后的空节点
- if (l1 != null || l2 != null || entered != 0) {
- tail.next = new ListNode();
- tail = tail.next;
- }
- }
-// tail = null;
- return root;
- }
-这里唯二需要注意的就是两个点,一个是循环条件需要包含进位值还存在的情况,还有一个是最后一个节点,如果是空的了,就不要在 new 一个出来了,写的比较挫
-]]>
-
- Java
- leetcode
- java
- linked list
- linked list
-
-
- leetcode
- java
- 题解
- linked list
-
-
-
- Leetcode 20 有效的括号 ( Valid Parentheses *Easy* ) 题解分析
- /2022/07/02/Leetcode-20-%E6%9C%89%E6%95%88%E7%9A%84%E6%8B%AC%E5%8F%B7-Valid-Parentheses-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given a string s containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
-An input string is valid if:
-
-- Open brackets must be closed by the same type of brackets.
-- Open brackets must be closed in the correct order.
-
-示例
Example 1:
-Input: s = “()”
Output: true
-
-Example 2:
-Input: s = “()[]{}”
Output: true
-
-Example 3:
-Input: s = “(]”
Output: false
-
-Constraints:
-1 <= s.length <= 10^4s consists of parentheses only '()[]{}'.
-解析
easy题,并且看起来也是比较简单的,三种括号按对匹配,直接用栈来做,栈里面存的是括号的类型,如果是左括号,就放入栈中,如果是右括号,就把栈顶的元素弹出,如果弹出的元素不是左括号,就返回false,如果弹出的元素是左括号,就继续往下走,如果遍历完了,如果栈里面还有元素,就返回false,如果遍历完了,如果栈里面没有元素,就返回true
-代码
class Solution {
- public boolean isValid(String s) {
+# Path to store certificates and metadata needed by
+# letsencrypt
+# For production:
+# tls_letsencrypt_cache_dir: /var/lib/headscale/cache
+tls_letsencrypt_cache_dir: ./cache
- if (s.length() % 2 != 0) {
- return false;
- }
- Stack<String> stk = new Stack<>();
- for (int i = 0; i < s.length(); i++) {
- if (s.charAt(i) == '{' || s.charAt(i) == '(' || s.charAt(i) == '[') {
- stk.push(String.valueOf(s.charAt(i)));
- continue;
- }
- if (s.charAt(i) == '}') {
- if (stk.isEmpty()) {
- return false;
- }
- String cur = stk.peek();
- if (cur.charAt(0) != '{') {
- return false;
- } else {
- stk.pop();
- }
- continue;
- }
- if (s.charAt(i) == ']') {
- if (stk.isEmpty()) {
- return false;
- }
- String cur = stk.peek();
- if (cur.charAt(0) != '[') {
- return false;
- } else {
- stk.pop();
- }
- continue;
- }
- if (s.charAt(i) == ')') {
- if (stk.isEmpty()) {
- return false;
- }
- String cur = stk.peek();
- if (cur.charAt(0) != '(') {
- return false;
- } else {
- stk.pop();
- }
- continue;
- }
+# Type of ACME challenge to use, currently supported types:
+# HTTP-01 or TLS-ALPN-01
+# See [docs/tls.md](docs/tls.md) for more information
+tls_letsencrypt_challenge_type: HTTP-01
+# When HTTP-01 challenge is chosen, letsencrypt must set up a
+# verification endpoint, and it will be listening on:
+# :http = port 80
+tls_letsencrypt_listen: ":http"
- }
- return stk.size() == 0;
- }
-}
+## Use already defined certificates:
+tls_cert_path: ""
+tls_key_path: ""
+log:
+ # Output formatting for logs: text or json
+ format: text
+ level: info
+
+# Path to a file containg ACL policies.
+# ACLs can be defined as YAML or HUJSON.
+# https://tailscale.com/kb/1018/acls/
+acl_policy_path: ""
+
+## DNS
+#
+# headscale supports Tailscale's DNS configuration and MagicDNS.
+# Please have a look to their KB to better understand the concepts:
+#
+# - https://tailscale.com/kb/1054/dns/
+# - https://tailscale.com/kb/1081/magicdns/
+# - https://tailscale.com/blog/2021-09-private-dns-with-magicdns/
+#
+dns_config:
+ # Whether to prefer using Headscale provided DNS or use local.
+ override_local_dns: true
+
+ # List of DNS servers to expose to clients.
+ nameservers:
+ - 1.1.1.1
+
+ # NextDNS (see https://tailscale.com/kb/1218/nextdns/).
+ # "abc123" is example NextDNS ID, replace with yours.
+ #
+ # With metadata sharing:
+ # nameservers:
+ # - https://dns.nextdns.io/abc123
+ #
+ # Without metadata sharing:
+ # nameservers:
+ # - 2a07:a8c0::ab:c123
+ # - 2a07:a8c1::ab:c123
+
+ # Split DNS (see https://tailscale.com/kb/1054/dns/),
+ # list of search domains and the DNS to query for each one.
+ #
+ # restricted_nameservers:
+ # foo.bar.com:
+ # - 1.1.1.1
+ # darp.headscale.net:
+ # - 1.1.1.1
+ # - 8.8.8.8
+
+ # Search domains to inject.
+ domains: []
+
+ # Extra DNS records
+ # so far only A-records are supported (on the tailscale side)
+ # See https://github.com/juanfont/headscale/blob/main/docs/dns-records.md#Limitations
+ # extra_records:
+ # - name: "grafana.myvpn.example.com"
+ # type: "A"
+ # value: "100.64.0.3"
+ #
+ # # you can also put it in one line
+ # - { name: "prometheus.myvpn.example.com", type: "A", value: "100.64.0.3" }
+
+ # Whether to use [MagicDNS](https://tailscale.com/kb/1081/magicdns/).
+ # Only works if there is at least a nameserver defined.
+ magic_dns: true
+
+ # Defines the base domain to create the hostnames for MagicDNS.
+ # `base_domain` must be a FQDNs, without the trailing dot.
+ # The FQDN of the hosts will be
+ # `hostname.user.base_domain` (e.g., _myhost.myuser.example.com_).
+ base_domain: example.com
+
+# Unix socket used for the CLI to connect without authentication
+# Note: for production you will want to set this to something like:
+# unix_socket: /var/run/headscale.sock
+unix_socket: ./headscale.sock
+unix_socket_permission: "0770"
+#
+# headscale supports experimental OpenID connect support,
+# it is still being tested and might have some bugs, please
+# help us test it.
+# OpenID Connect
+# oidc:
+# only_start_if_oidc_is_available: true
+# issuer: "https://your-oidc.issuer.com/path"
+# client_id: "your-oidc-client-id"
+# client_secret: "your-oidc-client-secret"
+# # Alternatively, set `client_secret_path` to read the secret from the file.
+# # It resolves environment variables, making integration to systemd's
+# # `LoadCredential` straightforward:
+# client_secret_path: "${CREDENTIALS_DIRECTORY}/oidc_client_secret"
+# # client_secret and client_secret_path are mutually exclusive.
+#
+# Customize the scopes used in the OIDC flow, defaults to "openid", "profile" and "email" and add custom query
+# parameters to the Authorize Endpoint request. Scopes default to "openid", "profile" and "email".
+#
+# scope: ["openid", "profile", "email", "custom"]
+# extra_params:
+# domain_hint: example.com
+#
+# List allowed principal domains and/or users. If an authenticated user's domain is not in this list, the
+# authentication request will be rejected.
+#
+# allowed_domains:
+# - example.com
+# Groups from keycloak have a leading '/'
+# allowed_groups:
+# - /headscale
+# allowed_users:
+# - alice@example.com
+#
+# If `strip_email_domain` is set to `true`, the domain part of the username email address will be removed.
+# This will transform `first-name.last-name@example.com` to the user `first-name.last-name`
+# If `strip_email_domain` is set to `false` the domain part will NOT be removed resulting to the following
+# user: `first-name.last-name.example.com`
+#
+# strip_email_domain: true
+
+# Logtail configuration
+# Logtail is Tailscales logging and auditing infrastructure, it allows the control panel
+# to instruct tailscale nodes to log their activity to a remote server.
+logtail:
+ # Enable logtail for this headscales clients.
+ # As there is currently no support for overriding the log server in headscale, this is
+ # disabled by default. Enabling this will make your clients send logs to Tailscale Inc.
+ enabled: false
+
+# Enabling this option makes devices prefer a random port for WireGuard traffic over the
+# default static port 41641. This option is intended as a workaround for some buggy
+# firewall devices. See https://tailscale.com/kb/1181/firewalls/ for more information.
+randomize_client_port: false
+
+问题就是出在几个文件路径的配置,默认都是当前目录,也就是headscale的可执行文件所在目录,需要按它配置说明中的生产配置进行修改
+# For production:
+# /var/lib/headscale/private.key
+private_key_path: /var/lib/headscale/private.key
+直接改成绝对路径就好了,还有两个文件路径
另一个也是个秘钥的路径问题
+noise:
+ # The Noise private key is used to encrypt the
+ # traffic between headscale and Tailscale clients when
+ # using the new Noise-based protocol. It must be different
+ # from the legacy private key.
+ #
+ # For production:
+ # private_key_path: /var/lib/headscale/noise_private.key
+ private_key_path: /var/lib/headscale/noise_private.key
+第二个问题
这个问题也是一种误导,
错误信息是
+Error initializing error="unable to open database file: out of memory (14)"
+这就是个文件,内存也完全没有被占满的迹象,原来也是文件路径的问题
+# For production:
+# db_path: /var/lib/headscale/db.sqlite
+db_path: /var/lib/headscale/db.sqlite
+都改成绝对路径就可以了,然后这里还有个就是要对/var/lib/headscale/和/etc/headscale/等路径赋予headscale用户权限,有时候对这类问题的排查真的蛮头疼,日志报错都不是真实的错误信息,开源项目对这些错误的提示真的也需要优化,后续的譬如mac也加入节点等后面再开篇讲
]]>
- Java
- leetcode
-
-
- leetcode
- java
-
-
-
- Leetcode 234 回文链表(Palindrome Linked List) 题解分析
- /2020/11/15/Leetcode-234-%E5%9B%9E%E6%96%87%E8%81%94%E8%A1%A8-Palindrome-Linked-List-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given a singly linked list, determine if it is a palindrome.
给定一个单向链表,判断是否是回文链表
-例一 Example 1:
Input: 1->2
Output: false
-例二 Example 2:
Input: 1->2->2->1
Output: true
-挑战下自己
Follow up:
Could you do it in O(n) time and O(1) space?
-简要分析
首先这是个单向链表,如果是双向的就可以一个从头到尾,一个从尾到头,显然那样就没啥意思了,然后想过要不找到中点,然后用一个栈,把前一半塞进栈里,但是这种其实也比较麻烦,比如长度是奇偶数,然后如何找到中点,这倒是可以借助于双指针,还是比较麻烦,再想一想,回文链表,就跟最开始的一样,链表只有单向的,我用个栈不就可以逆向了么,先把链表整个塞进栈里,然后在一个个 pop 出来跟链表从头开始比较,全对上了就是回文了
-/**
- * Definition for singly-linked list.
- * public class ListNode {
- * int val;
- * ListNode next;
- * ListNode() {}
- * ListNode(int val) { this.val = val; }
- * ListNode(int val, ListNode next) { this.val = val; this.next = next; }
- * }
- */
-class Solution {
- public boolean isPalindrome(ListNode head) {
- if (head == null) {
- return true;
- }
- ListNode tail = head;
- LinkedList<Integer> stack = new LinkedList<>();
- // 这里就是一个循环,将所有元素依次压入栈
- while (tail != null) {
- stack.push(tail.val);
- tail = tail.next;
- }
- // 在逐个 pop 出来,其实这个出来的顺序就等于链表从尾到头遍历,同时跟链表从头到尾遍历进行逐对对比
- while (!stack.isEmpty()) {
- if (stack.peekFirst() == head.val) {
- stack.pollFirst();
- head = head.next;
- } else {
- return false;
- }
- }
- return true;
- }
-}
]]>
-
- Java
- leetcode
- Linked List
- java
- Linked List
-
-
- leetcode
- java
- 题解
- Linked List
-
-
-
- Leetcode 236 二叉树的最近公共祖先(Lowest Common Ancestor of a Binary Tree) 题解分析
- /2021/05/23/Leetcode-236-%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88-Lowest-Common-Ancestor-of-a-Binary-Tree-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
-According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
-给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
-百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
-代码
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
- // 如果当前节点就是 p 或者是 q 的时候,就直接返回了
- // 当没找到,即 root == null 的时候也会返回 null,这是个重要的点
- if (root == null || root == p || root == q) return root;
- // 在左子树中找 p 和 q
- TreeNode left = lowestCommonAncestor(root.left, p, q);
- // 在右子树中找 p 和 q
- TreeNode right = lowestCommonAncestor(root.right, p, q);
- // 当左边是 null 就直接返回右子树,但是这里不表示右边不是 null,所以这个顺序是不影响的
- // 考虑一种情况,如果一个节点的左右子树都是 null,那么其实对于这个节点来说首先两个子树分别调用
- // lowestCommonAncestor会在开头就返回 null,那么就是上面 left 跟 right 都是 null,然后走下面的判断的时候
- // 其实第一个 if 就返回了 null,如此递归返回就能达到当子树中没有找到 p 或者 q 的时候只返回 null
- if (left == null) {
- return right;
- } else if (right == null) {
- return left;
- } else {
- return root;
- }
-// if (right == null) {
-// return left;
-// } else if (left == null) {
-// return right;
-// } else {
-// return root;
-// }
-// return left == null ? right : right == null ? left : root;
- }
-]]>
-
- Java
- leetcode
- Lowest Common Ancestor of a Binary Tree
+ headscale
- leetcode
- java
- 题解
- Lowest Common Ancestor of a Binary Tree
+ headscale
- Leetcode 278 第一个错误的版本 ( First Bad Version *Easy* ) 题解分析
- /2022/08/14/Leetcode-278-%E7%AC%AC%E4%B8%80%E4%B8%AA%E9%94%99%E8%AF%AF%E7%9A%84%E7%89%88%E6%9C%AC-First-Bad-Version-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
-Suppose you have n versions [1, 2, ..., n] and you want to find out the first bad one, which causes all the following ones to be bad.
-You are given an API bool isBadVersion(version) which returns whether version is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
-示例
Example 1:
-Input: n = 5, bad = 4
Output: 4
Explanation:
call isBadVersion(3) -> false
call isBadVersion(5) -> true
call isBadVersion(4) -> true
Then 4 is the first bad version.
-
-Example 2:
-Input: n = 1, bad = 1
Output: 1
-
-简析
简单来说就是一个二分查找,但是这个问题其实处理起来还是需要搞清楚一些边界问题
-代码
public int firstBadVersion(int n) {
- // 类似于双指针法
- int left = 1, right = n, mid;
- while (left < right) {
- // 取中点
- mid = left + (right - left) / 2;
- // 如果不是错误版本,就往右找
- if (!isBadVersion(mid)) {
- left = mid + 1;
- } else {
- // 如果是的话就往左查找
- right = mid;
- }
- }
- // 这里考虑交界情况是,在上面循环中如果 left 是好的,right 是坏的,那进入循环的时候 mid == left
- // 然后 left = mid + 1 就会等于 right,循环条件就跳出了,此时 left 就是那个起始的错误点了
- // 其实这两个是同一个值
- return left;
-}
+ JVM源码分析之G1垃圾收集器分析一
+ /2019/12/07/JVM-G1-Part-1/
+ 对 Java 的 gc 实现比较感兴趣,原先一般都是看周志明的书,但其实并没有讲具体的 gc 源码,而是把整个思路和流程讲解了一下
特别是 G1 的具体实现
一般对 G1 的理解其实就是把原先整块的新生代老年代分成了以 region 为单位的小块内存,简而言之,就是原先对新生代老年代的收集会涉及到整个代的堆内存空间,而G1 把它变成了更细致的小块内存
这带来了一个很明显的好处和一个很明显的坏处,好处是内存收集可以更灵活,耗时会变短,但整个收集的处理复杂度就变高了
目前看了一点点关于 G1 收集的预期时间相关的代码
+HeapWord* G1CollectedHeap::do_collection_pause(size_t word_size,
+ uint gc_count_before,
+ bool* succeeded,
+ GCCause::Cause gc_cause) {
+ assert_heap_not_locked_and_not_at_safepoint();
+ VM_G1CollectForAllocation op(word_size,
+ gc_count_before,
+ gc_cause,
+ false, /* should_initiate_conc_mark */
+ g1_policy()->max_pause_time_ms());
+ VMThread::execute(&op);
-往右移动示例
![]()
往左移动示例
![]()
-结果
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- First Bad Version
-
-
-
- Leetcode 3 Longest Substring Without Repeating Characters 题解分析
- /2020/09/20/Leetcode-3-Longest-Substring-Without-Repeating-Characters-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 又做了个题,看记录是以前用 C++写过的,现在捋一捋思路,用 Java 再写了一下,思路还是比较清晰的,但是边界细节处理得比较差
-简要介绍
Given a string s, find the length of the longest substring without repeating characters.
-样例
Example 1:
Input: s = "abcabcbb"
-Output: 3
-Explanation: The answer is "abc", with the length of 3.
+ HeapWord* result = op.result();
+ bool ret_succeeded = op.prologue_succeeded() && op.pause_succeeded();
+ assert(result == NULL || ret_succeeded,
+ "the result should be NULL if the VM did not succeed");
+ *succeeded = ret_succeeded;
-Example 2:
Input: s = "bbbbb"
-Output: 1
-Explanation: The answer is "b", with the length of 1.
-Example 3:
Input: s = "pwwkew"
-Output: 3
-Explanation: The answer is "wke", with the length of 3.
-Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
-Example 4:
Input: s = ""
-Output: 0
+ assert_heap_not_locked();
+ return result;
+}
+这里就是收集时需要停顿的,其中VMThread::execute(&op);是具体执行的,真正执行的是VM_G1CollectForAllocation::doit方法
+void VM_G1CollectForAllocation::doit() {
+ G1CollectedHeap* g1h = G1CollectedHeap::heap();
+ assert(!_should_initiate_conc_mark || g1h->should_do_concurrent_full_gc(_gc_cause),
+ "only a GC locker, a System.gc(), stats update, whitebox, or a hum allocation induced GC should start a cycle");
-就是一个最长不重复的字符串长度,因为也是中等难度的题,不太需要特别复杂的思考,最基本的就是O(N*N)两重循环,不过显然不太好,万一超时间,还有一种就是线性复杂度的了,这个就是需要搞定一个思路,比如字符串时 abcdefgaqwrty,比如遍历到第二个a的时候其实不用再从头去遍历了,只要把前面那个a给排除掉,继续往下算就好了
-class Solution {
- Map<String, Integer> counter = new HashMap<>();
- public int lengthOfLongestSubstring(String s) {
- int length = s.length();
- // 当前的长度
- int subStringLength = 0;
- // 最长的长度
- int maxSubStringLength = 0;
- // 考虑到重复的位置已经被跳过的情况,即已经在当前长度的字符串范围之前的重复字符不需要回溯
- int lastDuplicatePos = -1;
- for (int i = 0; i < length; i++) {
- // 使用 map 存储字符和上一次出现的位置,如果存在并且大于上一次重复位置
- if (counter.get(String.valueOf(s.charAt(i))) != null && counter.get(String.valueOf(s.charAt(i))) > lastDuplicatePos) {
- // 记录重复位置
- lastDuplicatePos = counter.get(String.valueOf(s.charAt(i)));
- // 重置不重复子串的长度,减去重复起点
- subStringLength = i - counter.get(String.valueOf(s.charAt(i))) - 1;
- // 替换当前位置
- counter.replace(String.valueOf(s.charAt(i)), i);
- } else {
- // 如果不存在就直接 put
- counter.put(String.valueOf(s.charAt(i)), i);
- }
- // 长度累加
- subStringLength++;
- if (subStringLength > maxSubStringLength) {
- // 简单替换
- maxSubStringLength = subStringLength;
- }
- }
- return maxSubStringLength;
+ if (_word_size > 0) {
+ // An allocation has been requested. So, try to do that first.
+ _result = g1h->attempt_allocation_at_safepoint(_word_size,
+ false /* expect_null_cur_alloc_region */);
+ if (_result != NULL) {
+ // If we can successfully allocate before we actually do the
+ // pause then we will consider this pause successful.
+ _pause_succeeded = true;
+ return;
}
-}
-注释应该写的比较清楚了。
-]]>
-
- Java
- leetcode
- java
- 字符串 - online
- string
-
-
- leetcode
- java
- 题解
- string
-
-
-
- Leetcode 349 两个数组的交集 ( Intersection of Two Arrays *Easy* ) 题解分析
- /2022/03/07/Leetcode-349-%E4%B8%A4%E4%B8%AA%E6%95%B0%E7%BB%84%E7%9A%84%E4%BA%A4%E9%9B%86-Intersection-of-Two-Arrays-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
-
-示例
-示例 1:
-输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
-
-
-示例 2:
-输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
-
-
-提示:
-1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
-分析与题解
两个数组的交集,最简单就是两层循环了把两个都存在的找出来,不过还有个要去重的问题,稍微思考下可以使用集合 set 来处理,先把一个数组全丢进去,再对比另外一个,如果出现在第一个集合里就丢进一个新的集合,最后转换成数组,这次我稍微取了个巧,因为看到了提示里的条件,两个数组中的元素都是不大于 1000 的,所以就搞了个 1000 长度的数组,如果在第一个数组出现,就在对应的下标设置成 1,如果在第二个数组也出现了就加 1,
-code
public int[] intersection(int[] nums1, int[] nums2) {
- // 大小是 1000 的数组,如果没有提示的条件就没法这么做
- // define a array which size is 1000, and can not be done like this without the condition in notice
- int[] inter = new int[1000];
- int[] outer;
- int m = 0;
- for (int j : nums1) {
- // 这里得是设置成 1,因为有可能 nums1 就出现了重复元素,如果直接++会造成结果重复
- // need to be set 1, cause element in nums1 can be duplicated
- inter[j] = 1;
- }
- for (int j : nums2) {
- if (inter[j] > 0) {
- // 这里可以直接+1,因为后面判断只需要判断大于 1
- // just plus 1, cause we can judge with condition that larger than 1
- inter[j] += 1;
- }
- }
- for (int i = 0; i < inter.length; i++) {
- // 统计下元素数量
- // count distinct elements
- if (inter[i] > 1) {
- m++;
- }
- }
- // initial a array of size m
- outer = new int[m];
- m = 0;
- for (int i = 0; i < inter.length; i++) {
- if (inter[i] > 1) {
- // add to outer
- outer[m++] = i;
- }
- }
- return outer;
- }
]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- Intersection of Two Arrays
-
-
-
- Headscale初体验以及踩坑记
- /2023/01/22/Headscale%E5%88%9D%E4%BD%93%E9%AA%8C%E4%BB%A5%E5%8F%8A%E8%B8%A9%E5%9D%91%E8%AE%B0/
- 最近或者说很久以前就想着能够把几个散装服务器以及家里的网络连起来,譬如一些remote desktop的访问,之前搞了下frp,因为家里电脑没怎么注意安全性就被搞了一下,所以还是想用相对更安全的方式,比如限定ip和端口进行访问,但是感觉ip也不固定就比较难搞,后来看到了 Tailscale 和 Headscale 的方式,就想着试试看,没想到一开始就踩了几个比较莫名其妙的坑。
可以按官方文档去搭建,也可以在网上找一些其他人搭建的教程。我碰到的主要是关于配置文件的问题
-第一个问题
Error initializing error="failed to read or create private key: failed to save private key to disk: open /etc/headscale/private.key: read-only file system"
-其实一开始看到这个我都有点懵了,咋回事呢,read-only file system一般有可能是文件系统出问题了,不可写入,需要重启或者修改挂载方式,被这个错误的错误日志给误导了,后面才知道是配置文件,在另一个教程中也有个类似的回复,一开始没注意,其实就是同一个问题。
默认的配置文件是这样的
----
-# headscale will look for a configuration file named `config.yaml` (or `config.json`) in the following order:
-#
-# - `/etc/headscale`
-# - `~/.headscale`
-# - current working directory
-
-# The url clients will connect to.
-# Typically this will be a domain like:
-#
-# https://myheadscale.example.com:443
-#
-server_url: http://127.0.0.1:8080
-
-# Address to listen to / bind to on the server
-#
-# For production:
-# listen_addr: 0.0.0.0:8080
-listen_addr: 127.0.0.1:8080
-
-# Address to listen to /metrics, you may want
-# to keep this endpoint private to your internal
-# network
-#
-metrics_listen_addr: 127.0.0.1:9090
+ }
-# Address to listen for gRPC.
-# gRPC is used for controlling a headscale server
-# remotely with the CLI
-# Note: Remote access _only_ works if you have
-# valid certificates.
-#
-# For production:
-# grpc_listen_addr: 0.0.0.0:50443
-grpc_listen_addr: 127.0.0.1:50443
+ GCCauseSetter x(g1h, _gc_cause);
+ if (_should_initiate_conc_mark) {
+ // It's safer to read old_marking_cycles_completed() here, given
+ // that noone else will be updating it concurrently. Since we'll
+ // only need it if we're initiating a marking cycle, no point in
+ // setting it earlier.
+ _old_marking_cycles_completed_before = g1h->old_marking_cycles_completed();
-# Allow the gRPC admin interface to run in INSECURE
-# mode. This is not recommended as the traffic will
-# be unencrypted. Only enable if you know what you
-# are doing.
-grpc_allow_insecure: false
+ // At this point we are supposed to start a concurrent cycle. We
+ // will do so if one is not already in progress.
+ bool res = g1h->g1_policy()->force_initial_mark_if_outside_cycle(_gc_cause);
-# Private key used to encrypt the traffic between headscale
-# and Tailscale clients.
-# The private key file will be autogenerated if it's missing.
-#
-# For production:
-# /var/lib/headscale/private.key
-private_key_path: ./private.key
+ // The above routine returns true if we were able to force the
+ // next GC pause to be an initial mark; it returns false if a
+ // marking cycle is already in progress.
+ //
+ // If a marking cycle is already in progress just return and skip the
+ // pause below - if the reason for requesting this initial mark pause
+ // was due to a System.gc() then the requesting thread should block in
+ // doit_epilogue() until the marking cycle is complete.
+ //
+ // If this initial mark pause was requested as part of a humongous
+ // allocation then we know that the marking cycle must just have
+ // been started by another thread (possibly also allocating a humongous
+ // object) as there was no active marking cycle when the requesting
+ // thread checked before calling collect() in
+ // attempt_allocation_humongous(). Retrying the GC, in this case,
+ // will cause the requesting thread to spin inside collect() until the
+ // just started marking cycle is complete - which may be a while. So
+ // we do NOT retry the GC.
+ if (!res) {
+ assert(_word_size == 0, "Concurrent Full GC/Humongous Object IM shouldn't be allocating");
+ if (_gc_cause != GCCause::_g1_humongous_allocation) {
+ _should_retry_gc = true;
+ }
+ return;
+ }
+ }
-# The Noise section includes specific configuration for the
-# TS2021 Noise protocol
-noise:
- # The Noise private key is used to encrypt the
- # traffic between headscale and Tailscale clients when
- # using the new Noise-based protocol. It must be different
- # from the legacy private key.
- #
- # For production:
- # private_key_path: /var/lib/headscale/noise_private.key
- private_key_path: ./noise_private.key
+ // Try a partial collection of some kind.
+ _pause_succeeded = g1h->do_collection_pause_at_safepoint(_target_pause_time_ms);
-# List of IP prefixes to allocate tailaddresses from.
-# Each prefix consists of either an IPv4 or IPv6 address,
-# and the associated prefix length, delimited by a slash.
-# While this looks like it can take arbitrary values, it
-# needs to be within IP ranges supported by the Tailscale
-# client.
-# IPv6: https://github.com/tailscale/tailscale/blob/22ebb25e833264f58d7c3f534a8b166894a89536/net/tsaddr/tsaddr.go#LL81C52-L81C71
-# IPv4: https://github.com/tailscale/tailscale/blob/22ebb25e833264f58d7c3f534a8b166894a89536/net/tsaddr/tsaddr.go#L33
-ip_prefixes:
- - fd7a:115c:a1e0::/48
- - 100.64.0.0/10
+ if (_pause_succeeded) {
+ if (_word_size > 0) {
+ // An allocation had been requested. Do it, eventually trying a stronger
+ // kind of GC.
+ _result = g1h->satisfy_failed_allocation(_word_size, &_pause_succeeded);
+ } else {
+ bool should_upgrade_to_full = !g1h->should_do_concurrent_full_gc(_gc_cause) &&
+ !g1h->has_regions_left_for_allocation();
+ if (should_upgrade_to_full) {
+ // There has been a request to perform a GC to free some space. We have no
+ // information on how much memory has been asked for. In case there are
+ // absolutely no regions left to allocate into, do a maximally compacting full GC.
+ log_info(gc, ergo)("Attempting maximally compacting collection");
+ _pause_succeeded = g1h->do_full_collection(false, /* explicit gc */
+ true /* clear_all_soft_refs */);
+ }
+ }
+ guarantee(_pause_succeeded, "Elevated collections during the safepoint must always succeed.");
+ } else {
+ assert(_result == NULL, "invariant");
+ // The only reason for the pause to not be successful is that, the GC locker is
+ // active (or has become active since the prologue was executed). In this case
+ // we should retry the pause after waiting for the GC locker to become inactive.
+ _should_retry_gc = true;
+ }
+}
+这里可以看到核心的是G1CollectedHeap::do_collection_pause_at_safepoint这个方法,它带上了目标暂停时间的值
+G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
+ assert_at_safepoint_on_vm_thread();
+ guarantee(!is_gc_active(), "collection is not reentrant");
-# DERP is a relay system that Tailscale uses when a direct
-# connection cannot be established.
-# https://tailscale.com/blog/how-tailscale-works/#encrypted-tcp-relays-derp
-#
-# headscale needs a list of DERP servers that can be presented
-# to the clients.
-derp:
- server:
- # If enabled, runs the embedded DERP server and merges it into the rest of the DERP config
- # The Headscale server_url defined above MUST be using https, DERP requires TLS to be in place
- enabled: false
+ if (GCLocker::check_active_before_gc()) {
+ return false;
+ }
- # Region ID to use for the embedded DERP server.
- # The local DERP prevails if the region ID collides with other region ID coming from
- # the regular DERP config.
- region_id: 999
+ _gc_timer_stw->register_gc_start();
- # Region code and name are displayed in the Tailscale UI to identify a DERP region
- region_code: "headscale"
- region_name: "Headscale Embedded DERP"
+ GCIdMark gc_id_mark;
+ _gc_tracer_stw->report_gc_start(gc_cause(), _gc_timer_stw->gc_start());
- # Listens over UDP at the configured address for STUN connections - to help with NAT traversal.
- # When the embedded DERP server is enabled stun_listen_addr MUST be defined.
- #
- # For more details on how this works, check this great article: https://tailscale.com/blog/how-tailscale-works/
- stun_listen_addr: "0.0.0.0:3478"
+ SvcGCMarker sgcm(SvcGCMarker::MINOR);
+ ResourceMark rm;
- # List of externally available DERP maps encoded in JSON
- urls:
- - https://controlplane.tailscale.com/derpmap/default
+ g1_policy()->note_gc_start();
- # Locally available DERP map files encoded in YAML
- #
- # This option is mostly interesting for people hosting
- # their own DERP servers:
- # https://tailscale.com/kb/1118/custom-derp-servers/
- #
- # paths:
- # - /etc/headscale/derp-example.yaml
- paths: []
+ wait_for_root_region_scanning();
- # If enabled, a worker will be set up to periodically
- # refresh the given sources and update the derpmap
- # will be set up.
- auto_update_enabled: true
+ print_heap_before_gc();
+ print_heap_regions();
+ trace_heap_before_gc(_gc_tracer_stw);
- # How often should we check for DERP updates?
- update_frequency: 24h
+ _verifier->verify_region_sets_optional();
+ _verifier->verify_dirty_young_regions();
-# Disables the automatic check for headscale updates on startup
-disable_check_updates: false
+ // We should not be doing initial mark unless the conc mark thread is running
+ if (!_cm_thread->should_terminate()) {
+ // This call will decide whether this pause is an initial-mark
+ // pause. If it is, in_initial_mark_gc() will return true
+ // for the duration of this pause.
+ g1_policy()->decide_on_conc_mark_initiation();
+ }
-# Time before an inactive ephemeral node is deleted?
-ephemeral_node_inactivity_timeout: 30m
+ // We do not allow initial-mark to be piggy-backed on a mixed GC.
+ assert(!collector_state()->in_initial_mark_gc() ||
+ collector_state()->in_young_only_phase(), "sanity");
-# Period to check for node updates within the tailnet. A value too low will severely affect
-# CPU consumption of Headscale. A value too high (over 60s) will cause problems
-# for the nodes, as they won't get updates or keep alive messages frequently enough.
-# In case of doubts, do not touch the default 10s.
-node_update_check_interval: 10s
+ // We also do not allow mixed GCs during marking.
+ assert(!collector_state()->mark_or_rebuild_in_progress() || collector_state()->in_young_only_phase(), "sanity");
-# SQLite config
-db_type: sqlite3
+ // Record whether this pause is an initial mark. When the current
+ // thread has completed its logging output and it's safe to signal
+ // the CM thread, the flag's value in the policy has been reset.
+ bool should_start_conc_mark = collector_state()->in_initial_mark_gc();
-# For production:
-# db_path: /var/lib/headscale/db.sqlite
-db_path: ./db.sqlite
+ // Inner scope for scope based logging, timers, and stats collection
+ {
+ EvacuationInfo evacuation_info;
-# # Postgres config
-# If using a Unix socket to connect to Postgres, set the socket path in the 'host' field and leave 'port' blank.
-# db_type: postgres
-# db_host: localhost
-# db_port: 5432
-# db_name: headscale
-# db_user: foo
-# db_pass: bar
+ if (collector_state()->in_initial_mark_gc()) {
+ // We are about to start a marking cycle, so we increment the
+ // full collection counter.
+ increment_old_marking_cycles_started();
+ _cm->gc_tracer_cm()->set_gc_cause(gc_cause());
+ }
-# If other 'sslmode' is required instead of 'require(true)' and 'disabled(false)', set the 'sslmode' you need
-# in the 'db_ssl' field. Refers to https://www.postgresql.org/docs/current/libpq-ssl.html Table 34.1.
-# db_ssl: false
+ _gc_tracer_stw->report_yc_type(collector_state()->yc_type());
-### TLS configuration
-#
-## Let's encrypt / ACME
-#
-# headscale supports automatically requesting and setting up
-# TLS for a domain with Let's Encrypt.
-#
-# URL to ACME directory
-acme_url: https://acme-v02.api.letsencrypt.org/directory
+ GCTraceCPUTime tcpu;
-# Email to register with ACME provider
-acme_email: ""
+ G1HeapVerifier::G1VerifyType verify_type;
+ FormatBuffer<> gc_string("Pause Young ");
+ if (collector_state()->in_initial_mark_gc()) {
+ gc_string.append("(Concurrent Start)");
+ verify_type = G1HeapVerifier::G1VerifyConcurrentStart;
+ } else if (collector_state()->in_young_only_phase()) {
+ if (collector_state()->in_young_gc_before_mixed()) {
+ gc_string.append("(Prepare Mixed)");
+ } else {
+ gc_string.append("(Normal)");
+ }
+ verify_type = G1HeapVerifier::G1VerifyYoungNormal;
+ } else {
+ gc_string.append("(Mixed)");
+ verify_type = G1HeapVerifier::G1VerifyMixed;
+ }
+ GCTraceTime(Info, gc) tm(gc_string, NULL, gc_cause(), true);
-# Domain name to request a TLS certificate for:
-tls_letsencrypt_hostname: ""
+ uint active_workers = AdaptiveSizePolicy::calc_active_workers(workers()->total_workers(),
+ workers()->active_workers(),
+ Threads::number_of_non_daemon_threads());
+ active_workers = workers()->update_active_workers(active_workers);
+ log_info(gc,task)("Using %u workers of %u for evacuation", active_workers, workers()->total_workers());
-# Path to store certificates and metadata needed by
-# letsencrypt
-# For production:
-# tls_letsencrypt_cache_dir: /var/lib/headscale/cache
-tls_letsencrypt_cache_dir: ./cache
+ TraceCollectorStats tcs(g1mm()->incremental_collection_counters());
+ TraceMemoryManagerStats tms(&_memory_manager, gc_cause(),
+ collector_state()->yc_type() == Mixed /* allMemoryPoolsAffected */);
-# Type of ACME challenge to use, currently supported types:
-# HTTP-01 or TLS-ALPN-01
-# See [docs/tls.md](docs/tls.md) for more information
-tls_letsencrypt_challenge_type: HTTP-01
-# When HTTP-01 challenge is chosen, letsencrypt must set up a
-# verification endpoint, and it will be listening on:
-# :http = port 80
-tls_letsencrypt_listen: ":http"
+ G1HeapTransition heap_transition(this);
+ size_t heap_used_bytes_before_gc = used();
-## Use already defined certificates:
-tls_cert_path: ""
-tls_key_path: ""
+ // Don't dynamically change the number of GC threads this early. A value of
+ // 0 is used to indicate serial work. When parallel work is done,
+ // it will be set.
-log:
- # Output formatting for logs: text or json
- format: text
- level: info
+ { // Call to jvmpi::post_class_unload_events must occur outside of active GC
+ IsGCActiveMark x;
-# Path to a file containg ACL policies.
-# ACLs can be defined as YAML or HUJSON.
-# https://tailscale.com/kb/1018/acls/
-acl_policy_path: ""
+ gc_prologue(false);
-## DNS
-#
-# headscale supports Tailscale's DNS configuration and MagicDNS.
-# Please have a look to their KB to better understand the concepts:
-#
-# - https://tailscale.com/kb/1054/dns/
-# - https://tailscale.com/kb/1081/magicdns/
-# - https://tailscale.com/blog/2021-09-private-dns-with-magicdns/
-#
-dns_config:
- # Whether to prefer using Headscale provided DNS or use local.
- override_local_dns: true
+ if (VerifyRememberedSets) {
+ log_info(gc, verify)("[Verifying RemSets before GC]");
+ VerifyRegionRemSetClosure v_cl;
+ heap_region_iterate(&v_cl);
+ }
- # List of DNS servers to expose to clients.
- nameservers:
- - 1.1.1.1
+ _verifier->verify_before_gc(verify_type);
- # NextDNS (see https://tailscale.com/kb/1218/nextdns/).
- # "abc123" is example NextDNS ID, replace with yours.
- #
- # With metadata sharing:
- # nameservers:
- # - https://dns.nextdns.io/abc123
- #
- # Without metadata sharing:
- # nameservers:
- # - 2a07:a8c0::ab:c123
- # - 2a07:a8c1::ab:c123
+ _verifier->check_bitmaps("GC Start");
- # Split DNS (see https://tailscale.com/kb/1054/dns/),
- # list of search domains and the DNS to query for each one.
- #
- # restricted_nameservers:
- # foo.bar.com:
- # - 1.1.1.1
- # darp.headscale.net:
- # - 1.1.1.1
- # - 8.8.8.8
+#if COMPILER2_OR_JVMCI
+ DerivedPointerTable::clear();
+#endif
- # Search domains to inject.
- domains: []
+ // Please see comment in g1CollectedHeap.hpp and
+ // G1CollectedHeap::ref_processing_init() to see how
+ // reference processing currently works in G1.
- # Extra DNS records
- # so far only A-records are supported (on the tailscale side)
- # See https://github.com/juanfont/headscale/blob/main/docs/dns-records.md#Limitations
- # extra_records:
- # - name: "grafana.myvpn.example.com"
- # type: "A"
- # value: "100.64.0.3"
- #
- # # you can also put it in one line
- # - { name: "prometheus.myvpn.example.com", type: "A", value: "100.64.0.3" }
+ // Enable discovery in the STW reference processor
+ _ref_processor_stw->enable_discovery();
- # Whether to use [MagicDNS](https://tailscale.com/kb/1081/magicdns/).
- # Only works if there is at least a nameserver defined.
- magic_dns: true
+ {
+ // We want to temporarily turn off discovery by the
+ // CM ref processor, if necessary, and turn it back on
+ // on again later if we do. Using a scoped
+ // NoRefDiscovery object will do this.
+ NoRefDiscovery no_cm_discovery(_ref_processor_cm);
- # Defines the base domain to create the hostnames for MagicDNS.
- # `base_domain` must be a FQDNs, without the trailing dot.
- # The FQDN of the hosts will be
- # `hostname.user.base_domain` (e.g., _myhost.myuser.example.com_).
- base_domain: example.com
+ // Forget the current alloc region (we might even choose it to be part
+ // of the collection set!).
+ _allocator->release_mutator_alloc_region();
-# Unix socket used for the CLI to connect without authentication
-# Note: for production you will want to set this to something like:
-# unix_socket: /var/run/headscale.sock
-unix_socket: ./headscale.sock
-unix_socket_permission: "0770"
-#
-# headscale supports experimental OpenID connect support,
-# it is still being tested and might have some bugs, please
-# help us test it.
-# OpenID Connect
-# oidc:
-# only_start_if_oidc_is_available: true
-# issuer: "https://your-oidc.issuer.com/path"
-# client_id: "your-oidc-client-id"
-# client_secret: "your-oidc-client-secret"
-# # Alternatively, set `client_secret_path` to read the secret from the file.
-# # It resolves environment variables, making integration to systemd's
-# # `LoadCredential` straightforward:
-# client_secret_path: "${CREDENTIALS_DIRECTORY}/oidc_client_secret"
-# # client_secret and client_secret_path are mutually exclusive.
-#
-# Customize the scopes used in the OIDC flow, defaults to "openid", "profile" and "email" and add custom query
-# parameters to the Authorize Endpoint request. Scopes default to "openid", "profile" and "email".
-#
-# scope: ["openid", "profile", "email", "custom"]
-# extra_params:
-# domain_hint: example.com
-#
-# List allowed principal domains and/or users. If an authenticated user's domain is not in this list, the
-# authentication request will be rejected.
-#
-# allowed_domains:
-# - example.com
-# Groups from keycloak have a leading '/'
-# allowed_groups:
-# - /headscale
-# allowed_users:
-# - alice@example.com
-#
-# If `strip_email_domain` is set to `true`, the domain part of the username email address will be removed.
-# This will transform `first-name.last-name@example.com` to the user `first-name.last-name`
-# If `strip_email_domain` is set to `false` the domain part will NOT be removed resulting to the following
-# user: `first-name.last-name.example.com`
-#
-# strip_email_domain: true
+ // This timing is only used by the ergonomics to handle our pause target.
+ // It is unclear why this should not include the full pause. We will
+ // investigate this in CR 7178365.
+ //
+ // Preserving the old comment here if that helps the investigation:
+ //
+ // The elapsed time induced by the start time below deliberately elides
+ // the possible verification above.
+ double sample_start_time_sec = os::elapsedTime();
-# Logtail configuration
-# Logtail is Tailscales logging and auditing infrastructure, it allows the control panel
-# to instruct tailscale nodes to log their activity to a remote server.
-logtail:
- # Enable logtail for this headscales clients.
- # As there is currently no support for overriding the log server in headscale, this is
- # disabled by default. Enabling this will make your clients send logs to Tailscale Inc.
- enabled: false
+ g1_policy()->record_collection_pause_start(sample_start_time_sec);
-# Enabling this option makes devices prefer a random port for WireGuard traffic over the
-# default static port 41641. This option is intended as a workaround for some buggy
-# firewall devices. See https://tailscale.com/kb/1181/firewalls/ for more information.
-randomize_client_port: false
+ if (collector_state()->in_initial_mark_gc()) {
+ concurrent_mark()->pre_initial_mark();
+ }
-问题就是出在几个文件路径的配置,默认都是当前目录,也就是headscale的可执行文件所在目录,需要按它配置说明中的生产配置进行修改
-# For production:
-# /var/lib/headscale/private.key
-private_key_path: /var/lib/headscale/private.key
-直接改成绝对路径就好了,还有两个文件路径
另一个也是个秘钥的路径问题
-noise:
- # The Noise private key is used to encrypt the
- # traffic between headscale and Tailscale clients when
- # using the new Noise-based protocol. It must be different
- # from the legacy private key.
- #
- # For production:
- # private_key_path: /var/lib/headscale/noise_private.key
- private_key_path: /var/lib/headscale/noise_private.key
-第二个问题
这个问题也是一种误导,
错误信息是
-Error initializing error="unable to open database file: out of memory (14)"
-这就是个文件,内存也完全没有被占满的迹象,原来也是文件路径的问题
-# For production:
-# db_path: /var/lib/headscale/db.sqlite
-db_path: /var/lib/headscale/db.sqlite
-都改成绝对路径就可以了,然后这里还有个就是要对/var/lib/headscale/和/etc/headscale/等路径赋予headscale用户权限,有时候对这类问题的排查真的蛮头疼,日志报错都不是真实的错误信息,开源项目对这些错误的提示真的也需要优化,后续的譬如mac也加入节点等后面再开篇讲
-]]>
-
- headscale
-
-
- headscale
-
-
-
- Leetcode 4 寻找两个正序数组的中位数 ( Median of Two Sorted Arrays *Hard* ) 题解分析
- /2022/03/27/Leetcode-4-%E5%AF%BB%E6%89%BE%E4%B8%A4%E4%B8%AA%E6%AD%A3%E5%BA%8F%E6%95%B0%E7%BB%84%E7%9A%84%E4%B8%AD%E4%BD%8D%E6%95%B0-Median-of-Two-Sorted-Arrays-Hard-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
-算法的时间复杂度应该为 O(log (m+n)) 。
-示例 1:
-输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
-
-示例 2:
-输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
-
-分析与题解
这个题也是我随机出来的,之前都是随机到 easy 的,而且是序号这么靠前的,然后翻一下,之前应该是用 C++做过的,具体的方法其实可以从他的算法时间复杂度要求看出来,大概率是要二分法这种,后面就结合代码来讲了
-public double findMedianSortedArrays(int[] nums1, int[] nums2) {
- int n1 = nums1.length;
- int n2 = nums2.length;
- if (n1 > n2) {
- return findMedianSortedArrays(nums2, nums1);
- }
+ g1_policy()->finalize_collection_set(target_pause_time_ms, &_survivor);
- // 找到两个数组的中点下标
- int k = (n1 + n2 + 1 ) / 2;
- // 使用一个类似于二分法的查找方法
- // 起始值就是 num1 的头跟尾
- int left = 0;
- int right = n1;
- while (left < right) {
- // m1 表示我取的是 nums1 的中点,即二分法的方式
- int m1 = left + (right - left) / 2;
- // *** 这里是重点,因为这个问题也可以转换成找成 n1 + n2 那么多个数中的前 (n1 + n2 + 1) / 2 个
- // *** 因为两个数组都是排好序的,那么我从 num1 中取了 m1 个,从 num2 中就是去 k - m1 个
- // *** 但是不知道取出来大小是否正好是整体排序的第 (n1 + n2 + 1) / 2 个,所以需要二分法上下对比
- int m2 = k - m1;
- // 如果 nums1[m1] 小,那我在第一个数组 nums1 的二分查找就要把左端点改成前一次的中点 + 1 (不然就进死循环了
- if (nums1[m1] < nums2[m2 - 1]) {
- left = m1 + 1;
- } else {
- right = m1;
- }
- }
+ evacuation_info.set_collectionset_regions(collection_set()->region_length());
- // 因为对比后其实我们只是拿到了一个位置,具体哪个是第 k 个就需要继续判断
- int m1 = left;
- int m2 = k - left;
- // 如果 m1 或者 m2 有小于等于 0 的,那这个值可以先抛弃
- // m1 如果等于 0,就是 num1[0] 都比 nums2 中所有值都要大
- // m2 等于 0 的话 刚好相反
- // 可以这么推断,当其中一个是 0 的时候那么另一个 mx 值肯定是> 0 的,那么就是取的对应的这个下标的值
- int c1 = Math.max( m1 <= 0 ? Integer.MIN_VALUE : nums1[m1 - 1] , m2 <= 0 ? Integer.MIN_VALUE : nums2[m2 - 1]);
- // 如果两个数组的元素数量和是奇数,那就直接可以返回了,因为 m1 + m2 就是 k, 如果是一个数组,那这个元素其实就是 nums[k - 1]
- // 如果 m1 或者 m2 是 0,那另一个就是 k,取 mx - 1的下标就等于是 k - 1
- // 如果都不是 0,那就是取的了 nums1[m1 - 1] 与 nums2[m2 - 1]中的较大者,如果取得是后者,那么也就是 m1 + m2 - 1 的下标就是 k - 1
- if ((n1 + n2) % 2 == 1) {
- return c1;
- }
- // 如果是偶数个,那还要取两个数组后面的较小者,然后求平均值
- int c2 = Math.min(m1 >= n1 ? Integer.MAX_VALUE : nums1[m1], m2 >= n2 ? Integer.MAX_VALUE : nums2[m2]);
- return (c1 + c2) / 2.0;
- }
-前面考虑的方法还是比较繁琐,考虑了两个数组的各种交叉情况,后面这个参考了一些网上的解法,代码比较简洁,但是可能不容易一下子就搞明白,所以配合了比较多的注释。
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- Median of Two Sorted Arrays
-
-
-
- Leetcode 42 接雨水 (Trapping Rain Water) 题解分析
- /2021/07/04/Leetcode-42-%E6%8E%A5%E9%9B%A8%E6%B0%B4-Trapping-Rain-Water-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
-示例
![]()
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
-简单分析
其实最开始的想法是从左到右扫区间,就是示例中的第一个水槽跟第二个水槽都可以用这个办法解决
![]()
前面这种是属于右侧比左侧高的情况,对于左侧高右侧低的就不行了,(写这篇的时候想起来可以再反着扫一遍可能可以)
![]()
所以这个方案不好,贴一下这个方案的代码
-public int trap(int[] height) {
- int lastLeft = -1;
- int sum = 0;
- int tempSum = 0;
- boolean startFlag = true;
- for (int j : height) {
- if (startFlag && j <= 0) {
- startFlag = false;
- continue;
- }
- if (j >= lastLeft) {
- sum += tempSum;
- tempSum = 0;
- lastLeft = j;
- } else {
- tempSum += lastLeft - j;
- }
- }
- return sum;
-}
-后面结合网上的解法,其实可以反过来,对于每个格子找左右侧的最大值,取小的那个和当前格子的差值就是这一个的储水量了
![]()
理解了这种想法,代码其实就不难了
-代码
int n = height.length;
-if (n <= 2) {
- return 0;
-}
-// 思路转变下,其实可以对于每一格算储水量,算法就是找到这一格左边的最高点跟这一格右边的最高点,
-// 比较两侧的最高点,取小的那个,然后再跟当前格子的高度对比,差值就是当前格的储水量
-int maxL[] = new int[n];
-int maxR[] = new int[n];
-int max = height[0];
-maxL[0] = 0;
-// 计算左侧的最高点
-for (int i = 1; i < n - 1; i++) {
- maxL[i] = max;
- if (max < height[i]) {
- max = height[i];
- }
-}
-max = height[n - 1];
-maxR[n - 1] = 0;
-int tempSum, sum = 0;
-// 计算右侧的最高点,并且同步算出来储水量,节省一个循环
-for (int i = n - 2; i > 0; i--) {
- maxR[i] = max;
- if (height[i] > max) {
- max = height[i];
- }
- tempSum = Math.min(maxL[i], maxR[i]) - height[i];
- if (tempSum > 0) {
- sum += tempSum;
- }
-}
-return sum;
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- dp
- 代码题解
- Trapping Rain Water
- 接雨水
- Leetcode 42
-
-
-
- Leetcode 48 旋转图像(Rotate Image) 题解分析
- /2021/05/01/Leetcode-48-%E6%97%8B%E8%BD%AC%E5%9B%BE%E5%83%8F-Rotate-Image-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
-You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
![]()
如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
-代码
直接上码
-public void rotate(int[][] matrix) {
- // 这里真的傻了,长宽应该是一致的,所以取一次就够了
- int lengthX = matrix[0].length;
- int lengthY = matrix.length;
- int temp;
- System.out.println(lengthY - (lengthY % 2) / 2);
- // 这里除错了,应该是减掉余数再除 2
-// for (int i = 0; i < lengthY - (lengthY % 2) / 2; i++) {
- /**
- * 1 2 3 7 8 9
- * 4 5 6 => 4 5 6 先沿着 4 5 6 上下交换
- * 7 8 9 1 2 3
- */
- for (int i = 0; i < (lengthY - (lengthY % 2)) / 2; i++) {
- for (int j = 0; j < lengthX; j++) {
- temp = matrix[i][j];
- matrix[i][j] = matrix[lengthY-i-1][j];
- matrix[lengthY-i-1][j] = temp;
- }
- }
+ // Make sure the remembered sets are up to date. This needs to be
+ // done before register_humongous_regions_with_cset(), because the
+ // remembered sets are used there to choose eager reclaim candidates.
+ // If the remembered sets are not up to date we might miss some
+ // entries that need to be handled.
+ g1_rem_set()->cleanupHRRS();
- /**
- * 7 8 9 7 4 1
- * 4 5 6 => 8 5 2 这里再沿着 7 5 3 这条对角线交换
- * 1 2 3 9 6 3
- */
- for (int i = 0; i < lengthX; i++) {
- for (int j = 0; j <= i; j++) {
- if (i == j) {
- continue;
- }
- temp = matrix[i][j];
- matrix[i][j] = matrix[j][i];
- matrix[j][i] = temp;
- }
- }
- }
-还没到可以直接归纳题目类型的水平,主要是几年前做过,可能有那么点模糊的记忆,当然应该也有直接转的方法
-]]>
-
- Java
- leetcode
- Rotate Image
-
-
- leetcode
- java
- 题解
- Rotate Image
- 矩阵
-
-
-
- Leetcode 698 划分为k个相等的子集 ( Partition to K Equal Sum Subsets *Medium* ) 题解分析
- /2022/06/19/Leetcode-698-%E5%88%92%E5%88%86%E4%B8%BAk%E4%B8%AA%E7%9B%B8%E7%AD%89%E7%9A%84%E5%AD%90%E9%9B%86-Partition-to-K-Equal-Sum-Subsets-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍Given an integer array nums and an integer k, return true if it is possible to divide this array into k non-empty subsets whose sums are all equal.
-示例
Example 1:
-
-Input: nums = [4,3,2,3,5,2,1], k = 4
Output: true
Explanation: It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) with equal sums.
-
-Example 2:
-
-Input: nums = [1,2,3,4], k = 3
Output: false
-
-Constraints:
-
-- 1 <= k <= nums.length <= 16
-- 1 <= nums[i] <= 10^4
-- The frequency of each element is in the range [1, 4].
-
-解析
看到这个题一开始以为挺简单,但是仔细想想问题还是挺多的,首先是分成 k 组,但是数量不限,应该需要用到回溯的方式,同时对于时间和空间复杂度也有要求,一开始这个代码是超时的,我也试了下 leetcode 上 discussion 里 vote 最高的提交也是超时的,不过看 discussion 里的帖子,貌似是后面加了一些条件,可以帮忙提高执行效率,第三条提示不太清楚意图,具体可以看下代码
-代码
public boolean canPartitionKSubsets(int[] nums, int k) {
- if (k == 1) {
- return true;
- }
- int sum = 0, n;
- n = nums.length;
- for (int num : nums) {
- sum += num;
- }
- if (sum % k != 0) {
- return false;
- }
+ register_humongous_regions_with_cset();
- int avg = sum / k;
- // 排序
- Arrays.sort(nums);
- // 做个前置判断,如果最大值超过分组平均值了就可以返回 false 了
- if (nums[n - 1] > avg) {
- return false;
- }
- // 这里取了个巧,先将数组中元素就等于分组平均值的直接排除了
- int calculated = 0;
- for (int i = n - 1; i > 0; i--) {
- if (nums[i] == avg) {
- k--;
- calculated++;
- }
- }
+ assert(_verifier->check_cset_fast_test(), "Inconsistency in the InCSetState table.");
- int[] bucket = new int[k];
- // 初始化 bucket
- for (int i = 0; i < k; i++) {
- bucket[i] = avg;
- }
+ // We call this after finalize_cset() to
+ // ensure that the CSet has been finalized.
+ _cm->verify_no_cset_oops();
- // 提前做下边界判断
- if (nums[n - 1] > avg) {
- return false;
- }
+ if (_hr_printer.is_active()) {
+ G1PrintCollectionSetClosure cl(&_hr_printer);
+ _collection_set.iterate(&cl);
+ }
- return backTraversal(nums, bucket, k, n - 1 - calculated);
-}
+ // Initialize the GC alloc regions.
+ _allocator->init_gc_alloc_regions(evacuation_info);
-private boolean backTraversal(int[] nums, int[] bucket, int k, int cur) {
- if (cur < 0) {
- return true;
- }
- for (int i = 0; i < k; i++) {
- if (bucket[i] == nums[cur] || bucket[i] >= nums[cur] + nums[0]) {
- // 判断如果当前 bucket[i] 剩余的数字等于nums[cur], 即当前bucket已经满了
- // 或者如果当前 bucket[i] 剩余的数字大于等于 nums[cur] + nums[0] ,
- // 因为nums 在经过排序后 nums[0]是最小值,如果加上 nums[0] 都已经超过bucket[i] 了,
- // 那当前bucket[i] 肯定是没法由包含 nums[cur] 的组合组成一个满足和为前面 s/k 的组合了
- // 这里判断的是 nums[cur] ,如果第一次 k 次循环都不符合其实就返回 false 了
+ G1ParScanThreadStateSet per_thread_states(this, workers()->active_workers(), collection_set()->young_region_length());
+ pre_evacuate_collection_set();
- // 而如果符合,就将 bucket[i] 减去 nums[cur] 再次进入递归,
- // 这里进入递归有个收敛参数就是 cur - 1,因为其实判断 cur 递减作为一个结束条件
- bucket[i] -= nums[cur];
- // 符合条件,这里对应着入口,当 cur 被减到 0 了,就表示都符合了因为是根据所有值的和 s 和 k 组除出来的平均值,当所有数都通过前面的 if 判断符合了,并且每个数字都使用了,
- // 即说明已经符合要求了
- if (backTraversal(nums, bucket, k, cur - 1)) return true;
- // 这边是个回退机制,如果前面 nums[cur]没办法组合成和为平均值的话就减掉进入下一个循环
- bucket[i] += nums[cur];
- }
- }
- return false;
-}
+ // Actually do the work...
+ evacuate_collection_set(&per_thread_states);
-最后贴个图
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
-
-
-
- Leetcode 83 删除排序链表中的重复元素 ( Remove Duplicates from Sorted List *Easy* ) 题解分析
- /2022/03/13/Leetcode-83-%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0-Remove-Duplicates-from-Sorted-List-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
PS:注意已排序,还有返回也要已排序
-示例 1:
![]()
-
-输入:head = [1,1,2]
输出:[1,2]
-
-示例 2:
![]()
-
-输入:head = [1,1,2,3,3]
输出:[1,2,3]
-
-提示:
-- 链表中节点数目在范围
[0, 300] 内
--100 <= Node.val <= 100- 题目数据保证链表已经按 升序 排列
-
-分析与题解
这题其实是比较正常的 easy 级别的题目,链表已经排好序了,如果还带一个排序就更复杂一点,
只需要前后项做个对比,如果一致则移除后项,因为可能存在多个重复项,所以只有在前后项不同
时才会更新被比较项
-code
public ListNode deleteDuplicates(ListNode head) {
- // 链表头是空的或者只有一个头结点,就不用处理了
- if (head == null || head.next == null) {
- return head;
- }
- ListNode tail = head;
- // 以处理节点还有后续节点作为循环边界条件
- while (tail.next != null) {
- ListNode temp = tail.next;
- // 如果前后相同,那么可以跳过这个节点,将 Tail ----> temp ---> temp.next
- // 更新成 Tail ----> temp.next
- if (temp.val == tail.val) {
- tail.next = temp.next;
- } else {
- // 不相同,则更新 tail
- tail = tail.next;
- }
- }
- // 最后返回头结点
- return head;
-}
-链表应该是个需要反复的训练的数据结构,因为涉及到前后指针,然后更新操作,判空等,
我在这块也是掌握的不太好,需要多练习。
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
- Remove Duplicates from Sorted List
-
-
-
- Leetcode 885 螺旋矩阵 III ( Spiral Matrix III *Medium* ) 题解分析
- /2022/08/23/Leetcode-885-%E8%9E%BA%E6%97%8B%E7%9F%A9%E9%98%B5-III-Spiral-Matrix-III-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍You start at the cell (rStart, cStart) of an rows x cols grid facing east. The northwest corner is at the first row and column in the grid, and the southeast corner is at the last row and column.
-You will walk in a clockwise spiral shape to visit every position in this grid. Whenever you move outside the grid’s boundary, we continue our walk outside the grid (but may return to the grid boundary later.). Eventually, we reach all rows * cols spaces of the grid.
-Return an array of coordinates representing the positions of the grid in the order you visited them.
-Example 1:
-Input: rows = 1, cols = 4, rStart = 0, cStart = 0
Output: [[0,0],[0,1],[0,2],[0,3]]
-
-Example 2:
-Input: rows = 5, cols = 6, rStart = 1, cStart = 4
Output: [[1,4],[1,5],[2,5],[2,4],[2,3],[1,3],[0,3],[0,4],[0,5],[3,5],[3,4],[3,3],[3,2],[2,2],[1,2],[0,2],[4,5],[4,4],[4,3],[4,2],[4,1],[3,1],[2,1],[1,1],[0,1],[4,0],[3,0],[2,0],[1,0],[0,0]]
-
-Constraints:
-
-1 <= rows, cols <= 100 0 <= rStart < rows 0 <= cStart < cols
-简析
这个题主要是要相同螺旋矩阵的转变方向的边界判断,已经相同步长会行进两次这个规律,写代码倒不复杂
-代码
public int[][] spiralMatrixIII(int rows, int cols, int rStart, int cStart) {
- int size = rows * cols;
- int x = rStart, y = cStart;
- // 返回的二维矩阵
- int[][] matrix = new int[size][2];
- // 传入的参数就是入口第一个
- matrix[0][0] = rStart;
- matrix[0][1] = cStart;
- // 作为数量
- int z = 1;
- // 步进,1,1,2,2,3,3,4 ... 螺旋矩阵的增长
- int a = 1;
- // 方向 1 表示右,2 表示下,3 表示左,4 表示上
- int dir = 1;
- while (z < size) {
- for (int i = 0; i < 2; i++) {
- for (int j= 0; j < a; j++) {
- // 处理方向
- if (dir % 4 == 1) {
- y++;
- } else if (dir % 4 == 2) {
- x++;
- } else if (dir % 4 == 3) {
- y--;
- } else {
- x--;
- }
- // 如果在实际矩阵内
- if (x < rows && y < cols && x >= 0 && y >= 0) {
- matrix[z][0] = x;
- matrix[z][1] = y;
- z++;
- }
- }
- // 转变方向
- dir++;
- }
- // 步进++
- a++;
- }
- return matrix;
- }
+ post_evacuate_collection_set(evacuation_info, &per_thread_states);
-结果
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
-
-
-
- leetcode no.3
- /2015/04/15/Leetcode-No-3/
- **Longest Substring Without Repeating Characters **
-
-description
Given a string, find the length of the longest substring without repeating characters.
For example, the longest substring without repeating letters for “abcabcbb” is “abc”,
which the length is 3. For “bbbbb” the longest substring is “b”, with the length of 1.
-分析
源码这次是参考了这个代码,
tail 表示的当前子串的起始点位置,tail从-1开始就包括的串的长度是1的边界。其实我
也是猜的(逃
-int ct[256];
- memset(ct, -1, sizeof(ct));
- int tail = -1;
- int max = 0;
- for (int i = 0; i < s.size(); i++){
- if (ct[s[i]] > tail)
- tail = ct[s[i]];
- if (i - tail > max)
- max = i - tail;
- ct[s[i]] = i;
- }
- return max;
-]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- Linux 下 grep 命令的一点小技巧
- /2020/08/06/Linux-%E4%B8%8B-grep-%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E7%82%B9%E5%B0%8F%E6%8A%80%E5%B7%A7/
- 用了比较久的 grep 命令,其实都只是用了最最基本的功能来查日志,
-譬如
-
-grep 'xxx' xxxx.log
-
+ const size_t* surviving_young_words = per_thread_states.surviving_young_words();
+ free_collection_set(&_collection_set, evacuation_info, surviving_young_words);
-然后有挺多情况比如想要找日志里带一些符号什么的,就需要用到一些特殊的
-比如这样\"userId\":\"123456\",因为比如用户 ID 有时候会跟其他的 id 一样,只用具体的值 123456 来查的话干扰信息太多了,如果直接这样
-
-grep '\"userId\":\"123456\"' xxxx.log
-
+ eagerly_reclaim_humongous_regions();
-好像不行,盲猜就是符号的问题,特别是\和"这两个,
-之前一直是想试一下,但是没成功,昨天在排查一个问题的时候发现了,只要把这些都转义了就行了
-grep '\\\"userId\\\":\\\"123456\\\"' xxxx.log
-![]()
-]]>
-
- Linux
- 命令
- grep
- 小技巧
- grep
- 查日志
-
-
- linux
- grep
- 转义
-
-
-
- MFC 模态对话框
- /2014/12/24/MFC%20%E6%A8%A1%E6%80%81%E5%AF%B9%E8%AF%9D%E6%A1%86/
- void CTestDialog::OnBnClickedOk()
-{
- CString m_SrcTest;
- int nIndex = m_CbTest.GetCurSel();
- m_CbTest.GetLBText(nIndex, m_SrcTest);
- OnOK();
-}
+ record_obj_copy_mem_stats();
+ _survivor_evac_stats.adjust_desired_plab_sz();
+ _old_evac_stats.adjust_desired_plab_sz();
-模态对话框弹出确定后,在弹出对话框时新建的类及其变量会存在,但是对于其中的控件
对象无法调用函数,即如果要在主对话框中获得弹出对话框的Combo box选中值的话,需
要在弹出 对话框的确定函数内将其值取出,赋值给弹出对话框的公有变量,这样就可以
在主对话框类得到值。
-]]>
- C++
-
-
- c++
- mfc
-
-
-
- Maven实用小技巧
- /2020/02/16/Maven%E5%AE%9E%E7%94%A8%E5%B0%8F%E6%8A%80%E5%B7%A7/
- Maven 翻译为”专家”、”内行”,是 Apache 下的一个纯 Java 开发的开源项目。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。
-Maven 是一个项目管理工具,可以对 Java 项目进行构建、依赖管理。
-Maven 也可被用于构建和管理各种项目,例如 C#,Ruby,Scala 和其他语言编写的项目。Maven 曾是 Jakarta 项目的子项目,现为由 Apache 软件基金会主持的独立 Apache 项目。
-maven也是我们日常项目中实用的包管理工具,相比以前需要用把包下载下来,放进 lib 中,在平时工作中使用的话,其实像 idea 这样的 ide 工具都会自带 maven 工具和插件
-maven的基本操作
-mvn -v
查看 maven 信息mvn compile
将 Java 编译成 class 文件mvn test
执行 test 包下的测试用例mvn package
将项目打成 jar 包mvn clean
删除package 在 target 目录下面打出来的 jar 包和 target 目录mvn install
将打出来的 jar 包复制到 maven 的本地仓库里mvn deploy
将打出来的 jar 包上传到远程仓库里
-与 composer 对比
因为我也是个 PHP 程序员,所以对比一下两种语言,很容易想到在 PHP 的 composer 跟 Java 的 maven 是比较类似的作用,有一点两者是非常相似的,就是原仓库都是因为某些原因连接拉取都会很慢,所以像 composer 会有一些国内源,前阵子阿里也出了一个,类似的 maven 一般也会使用阿里的镜像仓库,通过在 setting.xml 文件中的设置
-<mirrors>
- <mirror>
- <id>aliyun</id>
- <name>aliyun maven</name>
- <url>http://maven.aliyun.com/nexus/content/groups/public/</url>
- <mirrorOf>central</mirrorOf>
- </mirror>
-</mirrors>
-这算是个尴尬的共同点,然后因为 PHP 是解释型脚本语言,所以 php 打出来的 composer 包其实就是个 php 代码包,使用SPL Autoload等方式加载代码包,maven 包则是经过编译的 class 包,还有一点是 composer 也可以直接使用 github 地址作为包代码的拉取源,这点也是比较大的区别,maven使用 pom 文件管理依赖
-maven 的个人小技巧
-- maven 拉取依赖时,同时将 snapshot 也更新了,就是
mvn compile加个-U参数,如果还不行就需要将本地仓库的 snapshot 删掉,
这个命令的 help 命令解释是 -U,–update-snapshots Forces a check for missing releases and updated snapshots on
remote repositories,这个在日常使用中还是很经常使用的
-- maven 出现依赖冲突的时候的解决方法
首先是依赖分析,使用mvn dependency:tree分析下依赖关系,如果要找具体某个包的依赖引用关系可以使用mvn dependency:tree -Dverbose -Dincludes=org.springframework:spring-webmvc命令进行分析,如果发现有冲突的依赖关系,本身 maven 中依赖引用有相对的顺序,大致来说是引用路径短的优先,pom 文件中定义的顺序优先,如果要把冲突的包排除掉可以在 pom 中用<exclusions>
- <exclusion>
- <groupId>ch.qos.logback</groupId>
- <artifactId>logback-classic</artifactId>
- </exclusion>
-</exclusions>
-将冲突的包排除掉
-- maven 依赖的 jdk 版本管理
前面介绍的mvn -v可以查看 maven 的安装信息
比如Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
-Maven home: /usr/local/Cellar/maven/3.6.3_1/libexec
-Java version: 1.8.0_201, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre
-Default locale: zh_CN, platform encoding: UTF-8
-OS name: "mac os x", version: "10.14.6", arch: "x86_64", family: "mac"
-这里可以看到用了 mac 自带的 jdk1.8,结合我之前碰到的一个问题,因为使用 homebrew 升级了 gradle,而 gradle 又依赖了 jdk13,因为这个 mvn 的 Java version 也变成 jdk13 了,然后 mvn 编译的时候出现了 java.lang.ExceptionInInitializerError: com.sun.tools.javac.code.TypeTags这个问题,所以需要把这个版本给改回来,但是咋改呢,网上搜来的一大堆都是在 pom 文件里的
source和 target 版本<build>
- <plugins>
-<plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <configuration>
- <source>1.8</source>
- <target>1.8</target>
- <encoding>UTF-8</encoding>
- </configuration>
-</plugin>
- </plugins>
-<build>
-或者修改 maven 的 setting.xml中的<profiles>
- <profile>
- <id>ngmm-nexus</id>
- <activation>
- <jdk>1.8</jdk>
- </activation>
- <properties>
- <maven.compiler.source>1.8</maven.compiler.source>
- <maven.compiler.target>1.8</maven.compiler.target>
- <maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
- </properties>
- </profile>
-</profiles>
-但是这些都没啥用啊,真正有办法的是建个 .mavenrc,这个顾名思义就是 maven 的资源文件,类似于 .bashrc和.zshrc,在里面添加 MAVEN_HOME 和 JAVA_HOME,然后执行 source .mavenrc就 OK 啦
-
-]]>
-
- Java
- Maven
-
-
- Java
- Maven
-
-
-
- Number of 1 Bits
- /2015/03/11/Number-Of-1-Bits/
- Number of 1 Bits Write a function that takes an unsigned integer and returns the number of ’1’ bits it has (also known as the Hamming weight). For example, the 32-bit integer ‘11’ has binary representation 00000000000000000000000000001011, so the function should return 3.
+ double start = os::elapsedTime();
+ start_new_collection_set();
+ g1_policy()->phase_times()->record_start_new_cset_time_ms((os::elapsedTime() - start) * 1000.0);
-分析
从1位到2位到4位逐步的交换
-
-code
int hammingWeight(uint32_t n) {
- const uint32_t m1 = 0x55555555; //binary: 0101...
- const uint32_t m2 = 0x33333333; //binary: 00110011..
- const uint32_t m4 = 0x0f0f0f0f; //binary: 4 zeros, 4 ones ...
- const uint32_t m8 = 0x00ff00ff; //binary: 8 zeros, 8 ones ...
- const uint32_t m16 = 0x0000ffff; //binary: 16 zeros, 16 ones ...
-
- n = (n & m1 ) + ((n >> 1) & m1 ); //put count of each 2 bits into those 2 bits
- n = (n & m2 ) + ((n >> 2) & m2 ); //put count of each 4 bits into those 4 bits
- n = (n & m4 ) + ((n >> 4) & m4 ); //put count of each 8 bits into those 8 bits
- n = (n & m8 ) + ((n >> 8) & m8 ); //put count of each 16 bits into those 16 bits
- n = (n & m16) + ((n >> 16) & m16); //put count of each 32 bits into those 32 bits
- return n;
+ if (evacuation_failed()) {
+ set_used(recalculate_used());
+ if (_archive_allocator != NULL) {
+ _archive_allocator->clear_used();
+ }
+ for (uint i = 0; i < ParallelGCThreads; i++) {
+ if (_evacuation_failed_info_array[i].has_failed()) {
+ _gc_tracer_stw->report_evacuation_failed(_evacuation_failed_info_array[i]);
+ }
+ }
+ } else {
+ // The "used" of the the collection set have already been subtracted
+ // when they were freed. Add in the bytes evacuated.
+ increase_used(g1_policy()->bytes_copied_during_gc());
+ }
-}
]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- Path Sum
- /2015/01/04/Path-Sum/
- problemGiven a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all the values along the path equals the given sum.
-
-For example:
Given the below binary tree and sum = 22,
- 5
- / \
- 4 8
- / / \
- 11 13 4
- / \ \
-7 2 1
-return true, as there exist a root-to-leaf path 5->4->11->2 which sum is 22.
-Analysis
using simple deep first search
-code
/*
- Definition for binary tree
- struct TreeNode {
- int val;
- TreeNode *left;
- TreeNode *right;
- TreeNode(int x) : val(x), left(NULL), right(NULL)}
- };
- */
-class Solution {
-public:
- bool deep_first_search(TreeNode *node, int sum, int curSum)
- {
- if (node == NULL)
- return false;
-
- if (node->left == NULL && node->right == NULL)
- return curSum + node->val == sum;
-
- return deep_first_search(node->left, sum, curSum + node->val) || deep_first_search(node->right, sum, curSum + node->val);
- }
-
- bool hasPathSum(TreeNode *root, int sum) {
- // Start typing your C/C++ solution below
- // DO NOT write int main() function
- return deep_first_search(root, sum, 0);
- }
-};
-]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- Redis_分布式锁
- /2019/12/10/Redis-Part-1/
- 今天看了一下 redis 分布式锁 redlock 的实现,简单记录下,
-加锁
原先我对 redis 锁的概念就是加锁使用 setnx,解锁使用 lua 脚本,但是 setnx 具体是啥,lua 脚本是啥不是很清楚
首先简单思考下这个问题,首先为啥不是先 get 一下 key 存不存在,然后再 set 一个 key value,因为加锁这个操作我们是要保证两点,一个是不能中途被打断,也就是说要原子性,如果是先 get 一下 key,如果不存在再 set 值的话,那就不是原子操作了;第二个是可不可以直接 set 值呢,显然不行,锁要保证唯一性,有且只能有一个线程或者其他应用单位获得该锁,正好 setnx 给了我们这种原子命令
-然后是 setnx 的键和值分别是啥,键比较容易想到是要锁住的资源,比如 user_id, 这里有个我自己之前比较容易陷进去的误区,但是这个误区后
面再说,这里其实是把user_id 作为要锁住的资源,在我获得锁的时候别的线程不允许操作,以此保证业务的正确性,不会被多个线程同时修改,确定了键,再来看看值是啥,其实原先我认为值是啥都没关系,我只要锁住了,光键就够我用了,但是考虑下多个线程的问题,如果我这个线程加了锁,然后我因为 gc 停顿等原因卡死了,这个时候redis 的锁或者说就是 redis 的缓存已经过期了,这时候另一个线程获得锁成功,然后我这个线程又活过来了,然后我就仍然认为我拿着锁,我去对数据进行修改或者释放锁,是不是就出现问题了,所以是不是我们还需要一个东西来区分这个锁是哪个线程加的,所以我们可以将值设置成为一个线程独有识别的值,至少在相对长的一段时间内不会重复。
-上面其实还有两个问题,一个是当 gc 超时时,我这个线程如何知道我手里的锁已经过期了,一种方法是我在加好锁之后就维护一个超时时间,这里其实还有个问题,不过跟第二个问题相关,就一起说了,就是设置超时时间,有些对于不是锁的 redis 缓存操作可以是先设置好值,然后在设置过期时间,那么这就又有上面说到的不是原子性的问题,那么就需要在同一条指令里把超时时间也设置了,幸好 redis 提供了这种支持
-SET resource_name my_random_value NX PX 30000
-这里借鉴一下解释下,resource_name就是 key,代表要锁住的东西,my_random_value就是识别我这个线程的,NX代表只有在不存在的时候才设置,然后PX 30000表示超时时间是 30秒自动过期
-PS:记录下我原先有的一个误区,是不是要用 key 来区分加锁的线程,这样只有一个用处,就是自身线程可以识别是否是自己加的锁,但是最大的问题是别的线程不知道,其实这个用户的出发点是我在担心前面提过的一个问题,就是当 gc 停顿后,我要去判断当前的这个锁是否是我加的,还有就是当释放锁的时候,如果保证不会错误释放了其他线程加的锁,但是这样附带很多其他问题,最大的就是其他线程怎么知道能不能加这个锁。
-解锁
当线程在锁过期之前就处理完了业务逻辑,那就可以提前释放这个锁,那么提前释放要怎么操作,直接del key显然是不行的,因为这样就是我前面想用线程随机值加资源名作为锁的初衷,我不能去释放别的线程加的锁,那么我要怎么办呢,先 get 一下看是不是我的?那又变成非原子的操作了,幸好redis 也考虑到了这个问题,给了lua 脚本来操作这种
-if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
-else
- return 0
-end
-这里的KEYS[1]就是前面加锁的resource_name,ARGV[1]就是线程的随机值my_random_value
-多节点
前面说的其实是单节点 redis 作为分布式锁的情况,那么当我们的 redis 有多节点的情况呢,如果多节点下处于加锁或者解锁或者锁有效情况下
redis 的某个节点宕掉了怎么办,这里就有一些需要思考的地方,是否单独搞一个单节点的 redis作为分布式锁专用的,但是如果这个单节点的挂了呢,还有就是成本问题,所以我们需要一个多节点的分布式锁方案
这里就引出了开头说到的redlock,这个可是 redis的作者写的, 他的加锁过程是分以下几步去做这个事情
-
-- 获取当前时间(毫秒数)。
-- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
-- 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
-- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
-- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。这里为什么要向所有的节点发送释放锁的操作呢,这里是因为有部分的节点的失败原因可能是加锁时阻塞,加锁成功的结果没有及时返回,所以为了防止这种情况还是需要向所有发起这个释放锁的操作。
初步记录就先到这。
-
-]]>
-
- Redis
- Distributed Lock
- C
- Redis
-
-
- C
- Redis
- Distributed Lock
- 分布式锁
-
-
-
- Reverse Bits
- /2015/03/11/Reverse-Bits/
- Reverse Bits Reverse bits of a given 32 bits unsigned integer.
For example, given input 43261596 (represented in binary as 00000010100101000001111010011100), return 964176192 (represented in binary as 00111001011110000010100101000000).
-
-Follow up:
If this function is called many times, how would you optimize it?
-
-code
class Solution {
-public:
- uint32_t reverseBits(uint32_t n) {
- n = ((n >> 1) & 0x55555555) | ((n & 0x55555555) << 1);
- n = ((n >> 2) & 0x33333333) | ((n & 0x33333333) << 2);
- n = ((n >> 4) & 0x0f0f0f0f) | ((n & 0x0f0f0f0f) << 4);
- n = ((n >> 8) & 0x00ff00ff) | ((n & 0x00ff00ff) << 8);
- n = ((n >> 16) & 0x0000ffff) | ((n & 0x0000ffff) << 16);
- return n;
- }
-};
-]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- Reverse Integer
- /2015/03/13/Reverse-Integer/
- Reverse IntegerReverse digits of an integer.
Example1: x = 123, return 321
Example2: x = -123, return -321
-
-spoilers
Have you thought about this?
Here are some good questions to ask before coding. Bonus points for you if you have already thought through this!
-If the integer’s last digit is 0, what should the output be? ie, cases such as 10, 100.
-Did you notice that the reversed integer might overflow? Assume the input is a 32-bit integer, then the reverse of 1000000003 overflows. How should you handle such cases?
-For the purpose of this problem, assume that your function returns 0 when the reversed integer overflows.
-
-code
class Solution {
-public:
- int reverse(int x) {
+ if (collector_state()->in_initial_mark_gc()) {
+ // We have to do this before we notify the CM threads that
+ // they can start working to make sure that all the
+ // appropriate initialization is done on the CM object.
+ concurrent_mark()->post_initial_mark();
+ // Note that we don't actually trigger the CM thread at
+ // this point. We do that later when we're sure that
+ // the current thread has completed its logging output.
+ }
- int max = 1 << 31 - 1;
- int ret = 0;
- max = (max - 1) * 2 + 1;
- int min = 1 << 31;
- if(x < 0)
- while(x != 0){
- if(ret < (min - x % 10) / 10)
- return 0;
- ret = ret * 10 + x % 10;
- x = x / 10;
- }
- else
- while(x != 0){
- if(ret > (max -x % 10) / 10)
- return 0;
- ret = ret * 10 + x % 10;
- x = x / 10;
+ allocate_dummy_regions();
+
+ _allocator->init_mutator_alloc_region();
+
+ {
+ size_t expand_bytes = _heap_sizing_policy->expansion_amount();
+ if (expand_bytes > 0) {
+ size_t bytes_before = capacity();
+ // No need for an ergo logging here,
+ // expansion_amount() does this when it returns a value > 0.
+ double expand_ms;
+ if (!expand(expand_bytes, _workers, &expand_ms)) {
+ // We failed to expand the heap. Cannot do anything about it.
}
- return ret;
- }
-};
-]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- two sum
- /2015/01/14/Two-Sum/
- problemGiven an array of integers, find two numbers such that they add up to a specific target number.
-The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
-
-You may assume that each input would have exactly one solution.
-Input: numbers={2, 7, 11, 15}, target=9
Output: index1=1, index2=2
-code
struct Node
-{
- int num, pos;
-};
-bool cmp(Node a, Node b)
-{
- return a.num < b.num;
-}
-class Solution {
-public:
- vector<int> twoSum(vector<int> &numbers, int target) {
- // Start typing your C/C++ solution below
- // DO NOT write int main() function
- vector<int> result;
- vector<Node> array;
- for (int i = 0; i < numbers.size(); i++)
- {
- Node temp;
- temp.num = numbers[i];
- temp.pos = i;
- array.push_back(temp);
+ g1_policy()->phase_times()->record_expand_heap_time(expand_ms);
+ }
}
- sort(array.begin(), array.end(), cmp);
- for (int i = 0, j = array.size() - 1; i != j;)
- {
- int sum = array[i].num + array[j].num;
- if (sum == target)
- {
- if (array[i].pos < array[j].pos)
- {
- result.push_back(array[i].pos + 1);
- result.push_back(array[j].pos + 1);
- } else
- {
- result.push_back(array[j].pos + 1);
- result.push_back(array[i].pos + 1);
- }
- break;
- } else if (sum < target)
- {
- i++;
- } else if (sum > target)
- {
- j--;
- }
- }
- return result;
- }
-};
+ // We redo the verification but now wrt to the new CSet which
+ // has just got initialized after the previous CSet was freed.
+ _cm->verify_no_cset_oops();
-Analysis
sort the array, then test from head and end, until catch the right answer
-]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- ambari-summary
- /2017/05/09/ambari-summary/
- 初识ambariambari是一个大数据平台的管理工具,包含了hadoop, yarn, hive, hbase, spark等大数据的基础架构和工具,简化了数据平台的搭建,之前只是在同事搭建好平台后的一些使用,这次有机会从头开始用ambari来搭建一个测试的数据平台,过程中也踩到不少坑,简单记录下。
-简单过程
-- 第一个坑
在刚开始是按照官网的指南,用maven构建,因为GFW的原因,导致反复失败等待,也就是这个guide,因为对maven不熟悉导致有些按图索骥,浪费了很多时间,之后才知道可以直接加repo用yum安装,然而用yum安装马上就出现了第二个坑。
-- 第二个坑
因为在线的repo还是因为网络原因很慢很慢,用proxychains勉强把ambari-server本身安装好了,ambari.repo将这个放进/etc/yum.repos.d/路径下,然后yum update && yum install ambari-server安装即可,如果有条件就用proxychains走下代理。
-- 第三步
安装好ambari-server后先执行ambari-server setup做一些初始化设置,其中包含了JDK路径的设置,数据库设置,设置好就OK了,然后执行ambari-server start启动服务,这里有个小插曲,因为ambari-server涉及到这么多服务,所以管理控制监控之类的模块是必不可少的,这部分可以在ambari-server的web ui界面安装,也可以命令行提前安装,这部分被称为HDF Management Pack,运行ambari-server install-mpack \ --mpack=http://public-repo-1.hortonworks.com/HDF/centos7/2.x/updates/2.1.4.0/tars/hdf_ambari_mp/hdf-ambari-mpack-2.1.4.0-5.tar.gz \ --purge \ --verbose
安装,当然这个压缩包可以下载之后指到本地路径安装,然后就可以重启ambari-server
-
-]]>
-
- data analysis
-
-
- hadoop
- cluster
-
-
-
- binary-watch
- /2016/09/29/binary-watch/
- problemA binary watch has 4 LEDs on the top which represent the hours (0-11), and the 6 LEDs on the bottom represent the minutes (0-59).
-Each LED represents a zero or one, with the least significant bit on the right.
-![]()
-For example, the above binary watch reads “3:25”.
-Given a non-negative integer n which represents the number of LEDs that are currently on, return all possible times the watch could represent.
-Example:
Input: n = 1
-Return: ["1:00", "2:00", "4:00", "8:00", "0:01", "0:02", "0:04", "0:08", "0:16", "0:32"]
-Note:
-- The order of output does not matter.
-- The hour must not contain a leading zero, for example “01:00” is not valid, it should be “1:00”.
-- The minute must be consist of two digits and may contain a leading zero, for example “10:2” is not valid, it should be “10:02”.
-
-题解
又是参(chao)考(xi)别人的代码,嗯,就是这么不要脸,链接
-Code
class Solution {
-public:
- vector<string> readBinaryWatch(int num) {
- vector<string> res;
- for (int h = 0; h < 12; ++h) {
- for (int m = 0; m < 60; ++m) {
- if (bitset<10>((h << 6) + m).count() == num) {
- res.push_back(to_string(h) + (m < 10 ? ":0" : ":") + to_string(m));
- }
- }
- }
- return res;
- }
-};
]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- Leetcode 747 至少是其他数字两倍的最大数 ( Largest Number At Least Twice of Others *Easy* ) 题解分析
- /2022/10/02/Leetcode-747-%E8%87%B3%E5%B0%91%E6%98%AF%E5%85%B6%E4%BB%96%E6%95%B0%E5%AD%97%E4%B8%A4%E5%80%8D%E7%9A%84%E6%9C%80%E5%A4%A7%E6%95%B0-Largest-Number-At-Least-Twice-of-Others-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍You are given an integer array nums where the largest integer is unique.
-Determine whether the largest element in the array is at least twice as much as every other number in the array. If it is, return the index of the largest element, or return -1 otherwise.
确认在数组中的最大数是否是其余任意数的两倍大及以上,如果是返回索引,如果不是返回-1
-示例
Example 1:
-Input: nums = [3,6,1,0]
Output: 1
Explanation: 6 is the largest integer.
For every other number in the array x, 6 is at least twice as big as x.
The index of value 6 is 1, so we return 1.
-
-Example 2:
-Input: nums = [1,2,3,4]
Output: -1
Explanation: 4 is less than twice the value of 3, so we return -1.
-
-提示:
-2 <= nums.length <= 500 <= nums[i] <= 100- The largest element in
nums is unique.
-
-简要解析
这个题easy是题意也比较简单,找最大值,并且最大值是其他任意值的两倍及以上,其实就是找最大值跟次大值,比较下就好了
-代码
public int dominantIndex(int[] nums) {
- int largest = Integer.MIN_VALUE;
- int second = Integer.MIN_VALUE;
- int largestIndex = -1;
- for (int i = 0; i < nums.length; i++) {
- // 如果有最大的就更新,同时更新最大值和第二大的
- if (nums[i] > largest) {
- second = largest;
- largest = nums[i];
- largestIndex = i;
- } else if (nums[i] > second) {
- // 没有超过最大的,但是比第二大的更大就更新第二大的
- second = nums[i];
- }
- }
+ // This timing is only used by the ergonomics to handle our pause target.
+ // It is unclear why this should not include the full pause. We will
+ // investigate this in CR 7178365.
+ double sample_end_time_sec = os::elapsedTime();
+ double pause_time_ms = (sample_end_time_sec - sample_start_time_sec) * MILLIUNITS;
+ size_t total_cards_scanned = g1_policy()->phase_times()->sum_thread_work_items(G1GCPhaseTimes::ScanRS, G1GCPhaseTimes::ScanRSScannedCards);
+ g1_policy()->record_collection_pause_end(pause_time_ms, total_cards_scanned, heap_used_bytes_before_gc);
- // 判断下是否符合题目要求,要是所有值的两倍及以上
- if (largest >= 2 * second) {
- return largestIndex;
- } else {
- return -1;
- }
-}
-通过图
第一次错了是把第二大的情况只考虑第一种,也有可能最大值完全没经过替换就变成最大值了
![]()
-]]>
-
- Java
- leetcode
-
-
- leetcode
- java
- 题解
-
-
-
- docker-mysql-cluster
- /2016/08/14/docker-mysql-cluster/
- docker-mysql-cluster基于docker搭了个mysql集群,稍微记一下,
首先是新建mysql主库容
docker run -d -e MYSQL_ROOT_PASSWORD=admin --name mysql-master -p 3307:3306 mysql:latest
-d表示容器运行在后台,-e表示设置环境变量,即MYSQL_ROOT_PASSWORD=admin,设置了mysql的root密码,
--name表示容器名,-p表示端口映射,将内部mysql:3306映射为外部的3307,最后的mysql:latest表示镜像名
此外还可以用-v /local_path/my-master.cnf:/etc/mysql/my.cnf来映射配置文件
然后同理启动从库
docker run -d -e MYSQL_ROOT_PASSWORD=admin --name mysql-slave -p 3308:3306 mysql:latest
然后进入主库改下配置文件
docker-enter mysql-master如果无法进入就用docker ps -a看下容器是否在正常运行,如果status显示
未正常运行,则用docker logs mysql-master看下日志哪里出错了。
进入容器后,我这边使用的镜像的mysqld配置文件是在/etc/mysql下面,这个最新版本的mysql的配置文件包含
三部分,/etc/mysql/my.cnf和/etc/mysql/conf.d/mysql.cnf,还有/etc/mysql/mysql.conf.d/mysqld.cnf
这里需要改的是最后一个,加上
-log-bin = mysql-bin
-server_id = 1
-保存后退出容器重启主库容器,然后进入从库更改相同文件,
-log-bin = mysql-bin
-server_id = 2
-主从配置
同样退出重启容器,然后是配置主从,首先进入主库,用命令mysql -u root -pxxxx进入mysql,然后赋予一个同步
权限GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';还是同样说明下,ON *.*表示了数
据库全部的权限,如果要指定数据库/表的话可以使用类似testDb/testTable,然后是'backup'@'%'表示给予同步
权限的用户名及其主机ip,%表示不限制ip,当然如果有防火墙的话还是会有限制的,最后的identified by '123456'
表示同步用户的密码,然后就查看下主库的状态信息show master status,如下图:
![9G5FE[9%@7%G(B`Q7]E)5@R.png]()
把file跟position记下来,然后再开一个terminal,进入从库容器,登陆mysql,然后设置主库
-change master to
-master_host='xxx.xxx.xxx.xxx', //如果主从库的容器都在同一个宿主机上,这里的ip是docker容器的ip
-master_user='backup', //就是上面的赋予权限的用户
-master_password='123456',
-master_log_file='mysql-bin.000004', //主库中查看到的file
-master_log_pos=312, //主库中查看到的position
-master_port=3306; //如果是同一宿主机,这里使用真实的3306端口,3308及主库的3307是给外部连接使用的
-通过docker-ip mysql-master可以查看容器的ip
![S(GP)P(M$N3~N1764@OW3E0.png]()
这里有一点是要注意的,也是我踩的坑,就是如果是同一宿主机下两个mysql容器互联,我这里只能通过docker-ip和真实
的3306端口能够连接成功。
本文参考了这位同学的文章
-]]>
-
- docker
-
-
- docker
- mysql
-
-
-
- dnsmasq的一个使用注意点
- /2023/04/16/dnsmasq%E7%9A%84%E4%B8%80%E4%B8%AA%E4%BD%BF%E7%94%A8%E6%B3%A8%E6%84%8F%E7%82%B9/
- 在本地使用了 valet 做 php 的开发环境,因为可以指定自定义域名和证书,碰巧最近公司的网络环境比较糟糕,就想要在自定义 dns 上下点功夫,本来我们经常要在 dns 那配置个内部的 dns 地址,就想是不是可以通过 dnsmasq 来解决,
却在第一步碰到个低级的问题,在 dnsmasq 的主配置文件里
我配置了解析文件路径配置
像这样
-resolv-file=/opt/homebrew/etc/dnsmasq.d/resolv.dnsmasq.conf
-结果发现 dnsmasq 就起不来了,因为是 brew 服务的形式起来,发现日志也没有, dnsmasq 配置文件本身也没什么日志,这个是最讨厌的,网上搜了一圈也都没有, brew services 的服务如果启动状态是 error,并且服务本身没有日志的话就是一头雾水,并且对于 plist 来说,即使我手动加了标准输出和错误输出,brew services restart 的时候也是会被重新覆盖,
后来仔细看了下这个问题,发现它下面有这么一行配置
-conf-dir=/opt/homebrew/etc/dnsmasq.d/,*.conf
-想了一下发现这个问题其实很简单,dnsmasq 应该是不支持同一配置文件加载两次,
我把 resolv 文件放在了同一个配置文件目录下,所以就被加载了两次,所以改掉目录就行了,但是目前看 dnsmasq 还不符合我的要求,也有可能我还没完全了解 dnsmasq 的使用方法,我想要的是比如按特定的域名后缀来配置对应的 dns 服务器,这样就不太会被影响,可以试试 AdGuard 看
-]]>
-
- dns
-
-
- dnsmasq
-
-
-
- docker比一般多一点的初学者介绍
- /2020/03/08/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D/
- 因为最近想搭一个phabricator用来做看板和任务管理,一开始了解这个是Easy大大有在微博推荐过,后来苏洋也在群里和博客里说到了,看上去还不错的样子,因为主角是docker所以就不介绍太多,后面有机会写一下。
-docker最开始是之前在某位大佬的博客看到的,看上去有点神奇,感觉是一种轻量级的虚拟机,但是能做的事情好像差不多,那时候是在Ubuntu系统的vps里起一个Ubuntu的docker,然后在里面装个nginx,配置端口映射就可以访问了,后来也草草写过一篇使用docker搭建mysql集群,但是最近看了下好像是因为装docker的大佬做了一些别名还是什么操作,导致里面用的操作都不具有普遍性,而且主要是把搭的过程写了下,属于囫囵吞枣,没理解docker是干啥的,为啥用docker,就是操作了下,这几天借着搭phabricator的过程,把一些原来不理解,或者原来理解错误的地方重新理一下。
-之前写的 mysql 集群,一主二备,这种架构在很多小型应用里都是这么配置的,而且一般是直接在三台 vps 里启动三个 mysql 实例,但是如果换成 docker 会有什么好处呢,其实就是方便部署,比如其中一台备库挂了,我要加一台,或者说备库的 qps 太高了,需要再加一个,如果要在 vps 上搭建的话,首先要买一台机器,等初始化,然后在上面修改源,更新,装 mysql ,然后配置主从,可能还要处理防火墙等等,如果把这些打包成一个 docker 镜像,并且放在自己的 docker registry,那就直接run 一下就可以了;还有比如在公司要给一个新同学整一套开发测试环境,以 Java 开发为例,要装 git,maven,jdk,配置 maven settings 和各种 rc,整合在一个镜像里的话,就会很方便了;再比如微服务的水平扩展。
-但是为啥 docker 会有这种优势,听起来好像虚拟机也可以干这个事,但是虚拟机动辄上 G,而且需要 VMware,virtual box 等支持,不适合在Linux服务器环境使用,而且占用资源也会非常大。说得这么好,那么 docker 是啥呢
-docker 主要使用 Linux 中已经存在的两种技术的一个整合升级,一个是 namespace,一个是cgroups,相比于虚拟机需要完整虚拟出一个操作系统运行基础,docker 基于宿主机内核,通过 namespace 和 cgroups 分隔进程,理念就是提供一个隔离的最小化运行依赖,这样子相对于虚拟机就有了巨大的便利性,具体的 namespace 和 cgroups 就先不展开讲,可以参考耗子叔的文章
-安装
那么我们先安装下 docker,参考官方的教程,安装,我的系统是 ubuntu 的,就贴了 ubuntu 的链接,用其他系统的可以找到对应的系统文档安装,安装完了的话看看 docker 的信息
-sudo docker info
+ evacuation_info.set_collectionset_used_before(collection_set()->bytes_used_before());
+ evacuation_info.set_bytes_copied(g1_policy()->bytes_copied_during_gc());
-输出以下信息
![]()
-简单运行
然后再来运行个 hello world 呗,
-sudo docker run hello-world
+ if (VerifyRememberedSets) {
+ log_info(gc, verify)("[Verifying RemSets after GC]");
+ VerifyRegionRemSetClosure v_cl;
+ heap_region_iterate(&v_cl);
+ }
-输出了这些
![]()
-看看这个运行命令是怎么用的,一般都会看到这样子的,sudo docker run -it ubuntu bash, 前面的 docker run 反正就是运行一个容器的意思,-it是啥呢,还有这个什么 ubuntu bash,来看看docker run`的命令帮助信息
--i, --interactive Keep STDIN open even if not attached
+ _verifier->verify_after_gc(verify_type);
+ _verifier->check_bitmaps("GC End");
-就是要有输入,我们运行的时候能输入
--t, --tty Allocate a pseudo-TTY
+ assert(!_ref_processor_stw->discovery_enabled(), "Postcondition");
+ _ref_processor_stw->verify_no_references_recorded();
-要有个虚拟终端,
-Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
+ // CM reference discovery will be re-enabled if necessary.
+ }
-Run a command in a new container
+#ifdef TRACESPINNING
+ ParallelTaskTerminator::print_termination_counts();
+#endif
-镜像
上面说的-it 就是这里的 options,后面那个 ubuntu 就是 image 辣,image 是啥呢
-Docker 把应用程序及其依赖,打包在 image 文件里面,可以把它理解成为类似于虚拟机的镜像或者运行一个进程的代码,跑起来了的叫docker 容器或者进程,比如我们将要运行的docker run -it ubuntu bash的ubuntu 就是个 ubuntu 容器的镜像,将这个镜像运行起来后,我们可以进入容器像使用 ubuntu 一样使用它,来看下我们的镜像,使用sudo docker image ls就能列出我们宿主机上的 docker 镜像了
-![]()
-一个 ubuntu 镜像才 64MB,非常小巧,然后是后面的bash,我通过交互式启动了一个 ubuntu 容器,然后在这个启动的容器里运行了 bash 命令,这样就可以在容器里玩一下了
-在容器里看下进程,
![]()
-只有刚才运行容器的 bash 进程和我刚执行的 ps,这里有个可以注意下的,bash 这个进程的 pid 是 1,其实这里就用到了 linux 中的PID Namespace,容器会隔离出一个 pid 的名字空间,这里面的进程跟外部的 pid 命名独立
-查看宿主机上的容器
sudo docker ps -a
+ gc_epilogue(false);
+ }
-![]()
-如何进入一个正在运行中的 docker 容器
这个应该是比较常用的,因为比如是一个微服务容器,有时候就像看下运行状态,日志啥的
-sudo docker exec -it [containerID] bash
+ // Print the remainder of the GC log output.
+ if (evacuation_failed()) {
+ log_info(gc)("To-space exhausted");
+ }
-![]()
-查看日志
sudo docker logs [containerID]
+ g1_policy()->print_phases();
+ heap_transition.print();
-我在运行容器的终端里胡乱输入点啥,然后通过上面的命令就可以看到啦
-![]()
-![]()
+ // It is not yet to safe to tell the concurrent mark to
+ // start as we have some optional output below. We don't want the
+ // output from the concurrent mark thread interfering with this
+ // logging output either.
+
+ _hrm.verify_optional();
+ _verifier->verify_region_sets_optional();
+
+ TASKQUEUE_STATS_ONLY(print_taskqueue_stats());
+ TASKQUEUE_STATS_ONLY(reset_taskqueue_stats());
+
+ print_heap_after_gc();
+ print_heap_regions();
+ trace_heap_after_gc(_gc_tracer_stw);
+
+ // We must call G1MonitoringSupport::update_sizes() in the same scoping level
+ // as an active TraceMemoryManagerStats object (i.e. before the destructor for the
+ // TraceMemoryManagerStats is called) so that the G1 memory pools are updated
+ // before any GC notifications are raised.
+ g1mm()->update_sizes();
+
+ _gc_tracer_stw->report_evacuation_info(&evacuation_info);
+ _gc_tracer_stw->report_tenuring_threshold(_g1_policy->tenuring_threshold());
+ _gc_timer_stw->register_gc_end();
+ _gc_tracer_stw->report_gc_end(_gc_timer_stw->gc_end(), _gc_timer_stw->time_partitions());
+ }
+ // It should now be safe to tell the concurrent mark thread to start
+ // without its logging output interfering with the logging output
+ // that came from the pause.
+
+ if (should_start_conc_mark) {
+ // CAUTION: after the doConcurrentMark() call below,
+ // the concurrent marking thread(s) could be running
+ // concurrently with us. Make sure that anything after
+ // this point does not assume that we are the only GC thread
+ // running. Note: of course, the actual marking work will
+ // not start until the safepoint itself is released in
+ // SuspendibleThreadSet::desynchronize().
+ do_concurrent_mark();
+ }
+
+ return true;
+}
+往下走就是这一步G1Policy::finalize_collection_set,去处理新生代和老年代
+void G1Policy::finalize_collection_set(double target_pause_time_ms, G1SurvivorRegions* survivor) {
+ double time_remaining_ms = _collection_set->finalize_young_part(target_pause_time_ms, survivor);
+ _collection_set->finalize_old_part(time_remaining_ms);
+}
+这里分别调用了两个方法,可以看到剩余时间是往下传的,来看一下具体的方法
+double G1CollectionSet::finalize_young_part(double target_pause_time_ms, G1SurvivorRegions* survivors) {
+ double young_start_time_sec = os::elapsedTime();
+
+ finalize_incremental_building();
+
+ guarantee(target_pause_time_ms > 0.0,
+ "target_pause_time_ms = %1.6lf should be positive", target_pause_time_ms);
+
+ size_t pending_cards = _policy->pending_cards();
+ double base_time_ms = _policy->predict_base_elapsed_time_ms(pending_cards);
+ double time_remaining_ms = MAX2(target_pause_time_ms - base_time_ms, 0.0);
+
+ log_trace(gc, ergo, cset)("Start choosing CSet. pending cards: " SIZE_FORMAT " predicted base time: %1.2fms remaining time: %1.2fms target pause time: %1.2fms",
+ pending_cards, base_time_ms, time_remaining_ms, target_pause_time_ms);
+
+ // The young list is laid with the survivor regions from the previous
+ // pause are appended to the RHS of the young list, i.e.
+ // [Newly Young Regions ++ Survivors from last pause].
+
+ uint survivor_region_length = survivors->length();
+ uint eden_region_length = _g1h->eden_regions_count();
+ init_region_lengths(eden_region_length, survivor_region_length);
+
+ verify_young_cset_indices();
+
+ // Clear the fields that point to the survivor list - they are all young now.
+ survivors->convert_to_eden();
+
+ _bytes_used_before = _inc_bytes_used_before;
+ time_remaining_ms = MAX2(time_remaining_ms - _inc_predicted_elapsed_time_ms, 0.0);
+
+ log_trace(gc, ergo, cset)("Add young regions to CSet. eden: %u regions, survivors: %u regions, predicted young region time: %1.2fms, target pause time: %1.2fms",
+ eden_region_length, survivor_region_length, _inc_predicted_elapsed_time_ms, target_pause_time_ms);
+
+ // The number of recorded young regions is the incremental
+ // collection set's current size
+ set_recorded_rs_lengths(_inc_recorded_rs_lengths);
+
+ double young_end_time_sec = os::elapsedTime();
+ phase_times()->record_young_cset_choice_time_ms((young_end_time_sec - young_start_time_sec) * 1000.0);
+
+ return time_remaining_ms;
+}
+下面是老年代的部分
+void G1CollectionSet::finalize_old_part(double time_remaining_ms) {
+ double non_young_start_time_sec = os::elapsedTime();
+ double predicted_old_time_ms = 0.0;
+
+ if (collector_state()->in_mixed_phase()) {
+ cset_chooser()->verify();
+ const uint min_old_cset_length = _policy->calc_min_old_cset_length();
+ const uint max_old_cset_length = _policy->calc_max_old_cset_length();
+
+ uint expensive_region_num = 0;
+ bool check_time_remaining = _policy->adaptive_young_list_length();
+
+ HeapRegion* hr = cset_chooser()->peek();
+ while (hr != NULL) {
+ if (old_region_length() >= max_old_cset_length) {
+ // Added maximum number of old regions to the CSet.
+ log_debug(gc, ergo, cset)("Finish adding old regions to CSet (old CSet region num reached max). old %u regions, max %u regions",
+ old_region_length(), max_old_cset_length);
+ break;
+ }
+
+ // Stop adding regions if the remaining reclaimable space is
+ // not above G1HeapWastePercent.
+ size_t reclaimable_bytes = cset_chooser()->remaining_reclaimable_bytes();
+ double reclaimable_percent = _policy->reclaimable_bytes_percent(reclaimable_bytes);
+ double threshold = (double) G1HeapWastePercent;
+ if (reclaimable_percent <= threshold) {
+ // We've added enough old regions that the amount of uncollected
+ // reclaimable space is at or below the waste threshold. Stop
+ // adding old regions to the CSet.
+ log_debug(gc, ergo, cset)("Finish adding old regions to CSet (reclaimable percentage not over threshold). "
+ "old %u regions, max %u regions, reclaimable: " SIZE_FORMAT "B (%1.2f%%) threshold: " UINTX_FORMAT "%%",
+ old_region_length(), max_old_cset_length, reclaimable_bytes, reclaimable_percent, G1HeapWastePercent);
+ break;
+ }
+
+ double predicted_time_ms = predict_region_elapsed_time_ms(hr);
+ if (check_time_remaining) {
+ if (predicted_time_ms > time_remaining_ms) {
+ // Too expensive for the current CSet.
+
+ if (old_region_length() >= min_old_cset_length) {
+ // We have added the minimum number of old regions to the CSet,
+ // we are done with this CSet.
+ log_debug(gc, ergo, cset)("Finish adding old regions to CSet (predicted time is too high). "
+ "predicted time: %1.2fms, remaining time: %1.2fms old %u regions, min %u regions",
+ predicted_time_ms, time_remaining_ms, old_region_length(), min_old_cset_length);
+ break;
+ }
+
+ // We'll add it anyway given that we haven't reached the
+ // minimum number of old regions.
+ expensive_region_num += 1;
+ }
+ } else {
+ if (old_region_length() >= min_old_cset_length) {
+ // In the non-auto-tuning case, we'll finish adding regions
+ // to the CSet if we reach the minimum.
+
+ log_debug(gc, ergo, cset)("Finish adding old regions to CSet (old CSet region num reached min). old %u regions, min %u regions",
+ old_region_length(), min_old_cset_length);
+ break;
+ }
+ }
+
+ // We will add this region to the CSet.
+ time_remaining_ms = MAX2(time_remaining_ms - predicted_time_ms, 0.0);
+ predicted_old_time_ms += predicted_time_ms;
+ cset_chooser()->pop(); // already have region via peek()
+ _g1h->old_set_remove(hr);
+ add_old_region(hr);
+
+ hr = cset_chooser()->peek();
+ }
+ if (hr == NULL) {
+ log_debug(gc, ergo, cset)("Finish adding old regions to CSet (candidate old regions not available)");
+ }
+
+ if (expensive_region_num > 0) {
+ // We print the information once here at the end, predicated on
+ // whether we added any apparently expensive regions or not, to
+ // avoid generating output per region.
+ log_debug(gc, ergo, cset)("Added expensive regions to CSet (old CSet region num not reached min)."
+ "old: %u regions, expensive: %u regions, min: %u regions, remaining time: %1.2fms",
+ old_region_length(), expensive_region_num, min_old_cset_length, time_remaining_ms);
+ }
+
+ cset_chooser()->verify();
+ }
+
+ stop_incremental_building();
+
+ log_debug(gc, ergo, cset)("Finish choosing CSet. old: %u regions, predicted old region time: %1.2fms, time remaining: %1.2f",
+ old_region_length(), predicted_old_time_ms, time_remaining_ms);
+
+ double non_young_end_time_sec = os::elapsedTime();
+ phase_times()->record_non_young_cset_choice_time_ms((non_young_end_time_sec - non_young_start_time_sec) * 1000.0);
+
+ QuickSort::sort(_collection_set_regions, _collection_set_cur_length, compare_region_idx, true);
+}
+上面第三行是个判断,当前是否是 mixed 回收阶段,如果不是的话其实是没有老年代什么事的,所以可以看到代码基本是从这个 if 判断
if (collector_state()->in_mixed_phase()) {开始往下走的
先写到这,偏向于做笔记用,有错轻拍
]]>
- Docker
- 介绍
+ Java
+ JVM
+ GC
+ C++
- Docker
- namespace
- cgroup
+ Java
+ JVM
+ C++
- docker比一般多一点的初学者介绍三
- /2020/03/21/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D%E4%B8%89/
- 运行第一个 Dockerfile上一篇的 Dockerfile 我们停留在构建阶段,现在来把它跑起来
-docker run -d -p 80 --name static_web nicksxs/static_web \
-nginx -g "daemon off;"
-这里的-d表示以分离模型运行docker (detached),然后-p 是表示将容器的 80 端口开放给宿主机,然后容器名就叫 static_web,使用了我们上次构建的 static_web 镜像,后面的是让 nginx 在前台运行
![]()
可以看到返回了个容器 id,但是具体情况没出现,也没连上去,那我们想看看怎么访问在 Dockerfile 里写的静态页面,我们来看下docker 进程
![]()
发现为我们随机分配了一个宿主机的端口,32768,去服务器的防火墙把这个外网端口开一下,看看是不是符合我们的预期呢
![]()
好像不太对额,应该是 ubuntu 安装的 nginx 的默认工作目录不对,我们来进容器看看,再熟悉下命令docker exec -it 4792455ca2ed /bin/bash
记得容器 id 换成自己的,进入容器后得找找 nginx 的配置文件,通常在/etc/nginx,/usr/local/etc等目录下,然后找到我们的目录是在这
![]()
所以把刚才的内容复制过去再试试
![]()
目标达成,give me five✌️
-第二个 Dockerfile
然后就想来动态一点的,毕竟写过 PHP,就来试试 PHP
再建一个目录叫 dynamic_web,里面创建 src 目录,放一个 index.php
内容是
-<?php
-echo "Hello World!";
-然后在 dynamic_web 目录下创建 Dockerfile,
-FROM trafex/alpine-nginx-php7:latest
-COPY src/ /var/www/html
-EXPOSE 80
-Dockerfile 虽然只有三行,不过要着重说明下,这个底包其实不是docker 官方的,有两点考虑,一点是官方的基本都是 php apache 的镜像,还有就是 alpine这个,截取一段中文介绍
+ Leetcode 021 合并两个有序链表 ( Merge Two Sorted Lists ) 题解分析
+ /2021/10/07/Leetcode-021-%E5%90%88%E5%B9%B6%E4%B8%A4%E4%B8%AA%E6%9C%89%E5%BA%8F%E9%93%BE%E8%A1%A8-Merge-Two-Sorted-Lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Merge two sorted linked lists and return it as a sorted list. The list should be made by splicing together the nodes of the first two lists.
+将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
+示例 1
![]()
-Alpine 操作系统是一个面向安全的轻型 Linux 发行版。它不同于通常 Linux 发行版,Alpine 采用了 musl libc 和 busybox 以减小系统的体积和运行时资源消耗,但功能上比 busybox 又完善的多,因此得到开源社区越来越多的青睐。在保持瘦身的同时,Alpine 还提供了自己的包管理工具 apk,可以通过 https://pkgs.alpinelinux.org/packages 网站上查询包信息,也可以直接通过 apk 命令直接查询和安装各种软件。
Alpine 由非商业组织维护的,支持广泛场景的 Linux发行版,它特别为资深/重度Linux用户而优化,关注安全,性能和资源效能。Alpine 镜像可以适用于更多常用场景,并且是一个优秀的可以适用于生产的基础系统/环境。
+输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
-
-Alpine Docker 镜像也继承了 Alpine Linux 发行版的这些优势。相比于其他 Docker 镜像,它的容量非常小,仅仅只有 5 MB 左右(对比 Ubuntu 系列镜像接近 200 MB),且拥有非常友好的包管理机制。官方镜像来自 docker-alpine 项目。
+示例 2
+输入: l1 = [], l2 = []
输出: []
-
-目前 Docker 官方已开始推荐使用 Alpine 替代之前的 Ubuntu 做为基础镜像环境。这样会带来多个好处。包括镜像下载速度加快,镜像安全性提高,主机之间的切换更方便,占用更少磁盘空间等。
+示例 3
+输入: l1 = [], l2 = [0]
输出: [0]
-一方面在没有镜像的情况下,拉取 docker 镜像还是比较费力的,第二个就是也能节省硬盘空间,所以目前有大部分的 docker 镜像都将 alpine 作为基础镜像了
然后再来构建下
![]()
这里还有个点,就是上面的那个镜像我们也是 EXPOSE 80端口,然后外部宿主机会随机映射一个端口,为了偷个懒,我们就直接指定外部端口了
docker run -d -p 80:80 dynamic_web打开浏览器发现访问不了,咋回事呢
因为我们没看trafex/alpine-nginx-php7:latest这个镜像说明,它内部的服务是 8080 端口的,所以我们映射的暴露端口应该是 8080,再用 docker run -d -p 80:8080 dynamic_web这个启动,
![]()
+简要分析
这题是 Easy 的,看着也挺简单,两个链表进行合并,就是比较下大小,可能将就点的话最好就在两个链表中原地合并
+题解代码
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
+ // 下面两个if判断了入参的边界,如果其一为null,直接返回另一个就可以了
+ if (l1 == null) {
+ return l2;
+ }
+ if (l2 == null) {
+ return l1;
+ }
+ // new 一个合并后的头结点
+ ListNode merged = new ListNode();
+ // 这个是当前节点
+ ListNode current = merged;
+ // 一开始给这个while加了l1和l2不全为null的条件,后面想了下不需要
+ // 因为内部前两个if就是跳出条件
+ while (true) {
+ if (l1 == null) {
+ // 这里其实跟开头类似,只不过这里需要将l2剩余部分接到merged链表后面
+ // 所以不能是直接current = l2,这样就是把后面的直接丢了
+ current.val = l2.val;
+ current.next = l2.next;
+ break;
+ }
+ if (l2 == null) {
+ current.val = l1.val;
+ current.next = l1.next;
+ break;
+ }
+ // 这里是两个链表都不为空的时候,就比较下大小
+ if (l1.val < l2.val) {
+ current.val = l1.val;
+ l1 = l1.next;
+ } else {
+ current.val = l2.val;
+ l2 = l2.next;
+ }
+ // 这里是new个新的,其实也可以放在循环头上
+ current.next = new ListNode();
+ current = current.next;
+ }
+ current = null;
+ // 返回这个头结点
+ return merged;
+ }
+
+结果
![]()
]]>
- Docker
- 介绍
+ Java
+ leetcode
- Docker
- namespace
- Dockerfile
+ leetcode
+ java
+ 题解
- docker比一般多一点的初学者介绍二
- /2020/03/15/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D%E4%BA%8C/
- 限制下 docker 的 cpu 使用率这里我们开始玩一点有意思的,我们在容器里装下 vim 和 gcc,然后写这样一段 c 代码
-#include <stdio.h>
-int main(void)
-{
- int i = 0;
- for(;;) i++;
- return 0;
-}
-就是一个最简单的死循环,然后在容器里跑起来
-$ gcc 1.c
-$ ./a.out
-然后我们来看下系统资源占用(CPU)
![Xs562iawhHyMxeO]()
上图是在容器里的,可以看到 cpu 已经 100%了
然后看看容器外面的
![ecqH8XJ4k7rKhzu]()
可以看到一个核的 cpu 也被占满了,因为是个双核的机器,并且代码是单线程的
然后呢我们要做点啥
因为已经在这个 ubuntu 容器中装了 vim 和 gcc,考虑到国内的网络,所以我们先把这个容器 commit 一下,
-docker commit -a "nick" -m "my ubuntu" f63c5607df06 my_ubuntu:v1
-然后再运行起来
-docker run -it --cpus=0.1 my_ubuntu:v1 bash
-![]()
我们的代码跟可执行文件都还在,要的就是这个效果,然后再运行一下
![]()
结果是这个样子的,有点神奇是不,关键就在于 run 的时候的--cpus=0.1这个参数,它其实就是基于我前一篇说的 cgroup 技术,能将进程之间的cpu,内存等资源进行隔离
-开始第一个 Dockerfile
上一面为了复用那个我装了 vim 跟 gcc 的容器,我把它提交到了本地,使用了docker commit命令,有点类似于 git 的 commit,但是这个不是个很好的操作方式,需要手动介入,这里更推荐使用 Dockerfile 来构建镜像
-From ubuntu:latest
-MAINTAINER Nicksxs "nicksxs@hotmail.com"
-RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
-RUN apt-get clean
-RUN apt-get update && apt install -y nginx
-RUN echo 'Hi, i am in container' \
- > /usr/share/nginx/html/index.html
-EXPOSE 80
-先解释下这是在干嘛,首先是这个From ubuntu:latest基于的 ubuntu 的最新版本的镜像,然后第二行是维护人的信息,第三四行么作为墙内人你懂的,把 ubuntu 的源换成阿里云的,不然就有的等了,然后就是装下 nginx,往默认的 nginx 的入口 html 文件里输入一行欢迎语,然后暴露 80 端口
然后我们使用sudo docker build -t="nicksxs/static_web" .命令来基于这个 Dockerfile 构建我们自己的镜像,过程中是这样的
![]()
![]()
可以看到图中,我的 Dockerfile 是 7 行,里面就执行了 7 步,并且每一步都有一个类似于容器 id 的层 id 出来,这里就是一个比较重要的东西,docker 在构建的时候其实是有这个层的概念,Dockerfile 里的每一行都会往上加一层,这里有还注意下命令后面的.,代表当前目录下会自行去寻找 Dockerfile 进行构建,构建完了之后我们再看下我们的本地镜像
![]()
我们自己的镜像出现啦
然后有个问题,如果这个构建中途报了错咋办呢,来试试看,我们把 nginx 改成随便的一个错误名,nginxx(不知道会不会运气好真的有这玩意),再来 build 一把
![]()
找不到 nginxx 包,是不是这个镜像就完全不能用呢,当然也不是,因为前面说到了,docker 是基于层去构建的,可以看到前面的 4 个 step 都没报错,那我们基于最后的成功步骤创建下容器看看
也就是sudo docker run -t -i bd26f991b6c8 /bin/bash
答案是可以的,只是没装成功 nginx
![]()
还有一点注意到没,前面的几个 step 都有一句 Using cache,说明 docker 在构建镜像的时候是有缓存的,这也更能说明 docker 是基于层去构建镜像,同样的底包,同样的步骤,这些层是可以被复用的,这就是 docker 的构建缓存,当然我们也可以在 build 的时候加上--no-cache去把构建缓存禁用掉。
-]]>
+ Leetcode 028 实现 strStr() ( Implement strStr() ) 题解分析
+ /2021/10/31/Leetcode-028-%E5%AE%9E%E7%8E%B0-strStr-Implement-strStr-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Implement strStr().
+Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
+Clarification:
What should we return when needle is an empty string? This is a great question to ask during an interview.
+For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C’s strstr() and Java’s indexOf().
+示例
Example 1:
+Input: haystack = "hello", needle = "ll"
+Output: 2
+Example 2:
+Input: haystack = "aaaaa", needle = "bba"
+Output: -1
+Example 3:
+Input: haystack = "", needle = ""
+Output: 0
+
+题解
字符串比较其实是写代码里永恒的主题,底层的编译器等处理肯定需要字符串对比,像 kmp 算法也是很厉害
+code
public int strStr(String haystack, String needle) {
+ // 如果两个字符串都为空,返回 -1
+ if (haystack == null || needle == null) {
+ return -1;
+ }
+ // 如果 haystack 长度小于 needle 长度,返回 -1
+ if (haystack.length() < needle.length()) {
+ return -1;
+ }
+ // 如果 needle 为空字符串,返回 0
+ if (needle.equals("")) {
+ return 0;
+ }
+ // 如果两者相等,返回 0
+ if (haystack.equals(needle)) {
+ return 0;
+ }
+ int needleLength = needle.length();
+ int haystackLength = haystack.length();
+ for (int i = needleLength - 1; i <= haystackLength - 1; i++) {
+ // 比较 needle 最后一个字符,倒着比较稍微节省点时间
+ if (needle.charAt(needleLength - 1) == haystack.charAt(i)) {
+ // 如果needle 是 1 的话直接可以返回 i 作为位置了
+ if (needle.length() == 1) {
+ return i;
+ }
+ boolean flag = true;
+ // 原来比的是 needle 的最后一个位置,然后这边从倒数第二个位置开始
+ int j = needle.length() - 2;
+ for (; j >= 0; j--) {
+ // 这里的 i- (needleLength - j) + 1 ) 比较绕,其实是外循环的 i 表示当前 i 位置的字符跟 needle 最后一个字符
+ // 相同,j 在上面的循环中--,对应的 haystack 也要在 i 这个位置 -- ,对应的位置就是 i - (needleLength - j) + 1
+ if (needle.charAt(j) != haystack.charAt(i - (needleLength - j) + 1)) {
+ flag = false;
+ break;
+ }
+ }
+ // 循环完了之后,如果 flag 为 true 说明 从 i 开始倒着对比都相同,但是这里需要起始位置,就需要
+ // i - needleLength + 1
+ if (flag) {
+ return i - needleLength + 1;
+ }
+ }
+ }
+ // 这里表示未找到
+ return -1;
+ }
]]>
- Docker
- 介绍
+ Java
+ leetcode
- Docker
- namespace
- cgroup
+ leetcode
+ java
+ 题解
- docker比一般多一点的初学者介绍四
- /2022/12/25/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D%E5%9B%9B/
- 这次单独介绍下docker体系里非常重要的cgroup,docker对资源的限制也是基于cgroup构建的,
简单尝试
新建一个shell脚本
-#!/bin/bash
-while true;do
- echo "1"
-done
-
-直接执行的话就是单核100%的cpu
![]()
-首先在cgroup下面建个目录
-mkdir -p /sys/fs/cgroup/cpu/sxs_test/
-查看目录下的文件
![]()
其中cpuacct开头的表示cpu相关的统计信息,
我们要配置cpu的额度,是在cpu.cfs_quota_us中
-echo 2000 > /sys/fs/cgroup/cpu/sxs_test/cpu.cfs_quota_us
-这样表示可以使用2%的cpu,总的配额是在cpu.cfs_period_us中
![]()
-然后将当前进程输入到cgroup.procs,
-echo $$ > /sys/fs/cgroup/cpu/sxs_test/cgroup.procs
-这样就会自动继承当前进程产生的新进程
再次执行就可以看到cpu被限制了
![]()
-]]>
+ Leetcode 053 最大子序和 ( Maximum Subarray ) 题解分析
+ /2021/11/28/Leetcode-053-%E6%9C%80%E5%A4%A7%E5%AD%90%E5%BA%8F%E5%92%8C-Maximum-Subarray-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given an integer array nums, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.
+A subarray is a contiguous part of an array.
+示例
Example 1:
+
+Input: nums = [-2,1,-3,4,-1,2,1,-5,4]
Output: 6
Explanation: [4,-1,2,1] has the largest sum = 6.
+
+Example 2:
+
+Input: nums = [1]
Output: 1
+
+Example 3:
+
+Input: nums = [5,4,-1,7,8]
Output: 23
+
+说起来这个题其实非常有渊源,大学数据结构的第一个题就是这个,而最佳的算法就是传说中的 online 算法,就是遍历一次就完了,最基本的做法就是记下来所有的连续子数组,然后求出最大的那个。
+代码
public int maxSubArray(int[] nums) {
+ int max = nums[0];
+ int sum = nums[0];
+ for (int i = 1; i < nums.length; i++) {
+ // 这里最重要的就是这一行了,其实就是如果前面的 sum 是小于 0 的,那么就不需要前面的 sum,反正加上了还不如不加大
+ sum = Math.max(nums[i], sum + nums[i]);
+ // max 是用来承载最大值的
+ max = Math.max(max, sum);
+ }
+ return max;
+ }
]]>
- Docker
+ Java
+ leetcode
- Docker
+ leetcode
+ java
+ 题解
- dubbo 客户端配置的一个重要知识点
- /2022/06/11/dubbo-%E5%AE%A2%E6%88%B7%E7%AB%AF%E9%85%8D%E7%BD%AE%E7%9A%84%E4%B8%80%E4%B8%AA%E9%87%8D%E8%A6%81%E7%9F%A5%E8%AF%86%E7%82%B9/
- 在配置项目中其实会留着比较多的问题,由于不同的项目没有比较统一的规划和框架模板,一般都是只有创建者会比较了解(可能也不了解),譬如前阵子在配置一个 springboot + dubbo 的项目,发现了dubbo 连接注册中间客户端的问题,这里可以结合下代码来看
比如有的应用是用的这个
-<dependency>
- <groupId>org.apache.curator</groupId>
- <artifactId>curator-client</artifactId>
- <version>${curator.version}</version>
-</dependency>
-<dependency>
- <groupId>org.apache.curator</groupId>
- <artifactId>curator-recipes</artifactId>
- <version>${curator.version}</version>
-</dependency>
-有个别应用用的是这个
-<dependency>
- <groupId>com.101tec</groupId>
- <artifactId>zkclient</artifactId>
- <version>0.11</version>
-</dependency>
-还有的应用是找不到相关的依赖,并且这些的使用没有个比较好的说明,为啥用前者,为啥用后者,有啥注意点,
首先在使用 2.6.5 的 alibaba 的 dubbo 的时候,只使用后者是会报错的,至于为啥会报错,其实就是这篇文章想说明的点
报错的内容其实很简单, 就是缺少这个 org.apache.curator.framework.CuratorFrameworkFactory 类
这个类看着像是依赖上面的配置,但是应该不需要两个配置一块用的,所以还是需要去看代码
通过找上面类被依赖的和 dubbo 连接注册中心相关的代码,看到了这段指点迷津的代码
-@SPI("curator")
-public interface ZookeeperTransporter {
-
- @Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
- ZookeeperClient connect(URL url);
-
-}
-众所周知,dubbo 创造了叫自适应扩展点加载的神奇技术,这里的 adaptive 注解中的Constants.CLIENT_KEY 和 Constants.TRANSPORTER_KEY 可以在配置 dubbo 的注册信息的时候进行配置,如果是通过 xml 配置的话,可以在 <dubbo:registry/> 这个 tag 中的以上两个 key 进行配置,
具体在 dubbo.xsd 中有描述
-<xsd:element name="registry" type="registryType">
- <xsd:annotation>
- <xsd:documentation><![CDATA[ The registry config ]]></xsd:documentation>
- </xsd:annotation>
- </xsd:element>
-
-![]()
并且在 spi 的配置com.alibaba.dubbo.remoting.zookeeper.ZookeeperTransporter 中可以看到
-zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
-curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
+ G1收集器概述
+ /2020/02/09/G1%E6%94%B6%E9%9B%86%E5%99%A8%E6%A6%82%E8%BF%B0/
+ G1: The Garbage-First Collector, 垃圾回收优先的垃圾回收器,目标是用户多核 cpu 和大内存的机器,最大的特点就是可预测的停顿时间,官方给出的介绍是提供一个用户在大的堆内存情况下一个低延迟表现的解决方案,通常是 6GB 及以上的堆大小,有低于 0.5 秒稳定的可预测的停顿时间。
+这里主要介绍这个比较新的垃圾回收器,在 G1 之前的垃圾回收器都是基于如下图的内存结构分布,有新生代,老年代和永久代(jdk8 之前),然后G1 往前的那些垃圾回收器都有个分代,比如 serial,parallel 等,一般有个应用的组合,最初的 serial 和 serial old,因为新生代和老年代的收集方式不太一样,新生代主要是标记复制,所以有 eden 跟两个 survival区,老年代一般用标记整理方式,而 G1 对这个不太一样。
![]()
看一下 G1 的内存分布
![]()
可以看到这有很大的不同,G1 通过将内存分成大小相等的 region,每个region是存在于一个连续的虚拟内存范围,对于某个 region 来说其角色是类似于原来的收集器的Eden、Survivor、Old Generation,这个具体在代码层面
+// We encode the value of the heap region type so the generation can be
+ // determined quickly. The tag is split into two parts:
+ //
+ // major type (young, old, humongous, archive) : top N-1 bits
+ // minor type (eden / survivor, starts / cont hum, etc.) : bottom 1 bit
+ //
+ // If there's need to increase the number of minor types in the
+ // future, we'll have to increase the size of the latter and hence
+ // decrease the size of the former.
+ //
+ // 00000 0 [ 0] Free
+ //
+ // 00001 0 [ 2] Young Mask
+ // 00001 0 [ 2] Eden
+ // 00001 1 [ 3] Survivor
+ //
+ // 00010 0 [ 4] Humongous Mask
+ // 00100 0 [ 8] Pinned Mask
+ // 00110 0 [12] Starts Humongous
+ // 00110 1 [13] Continues Humongous
+ //
+ // 01000 0 [16] Old Mask
+ //
+ // 10000 0 [32] Archive Mask
+ // 11100 0 [56] Open Archive
+ // 11100 1 [57] Closed Archive
+ //
+ typedef enum {
+ FreeTag = 0,
-zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
-curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
+ YoungMask = 2,
+ EdenTag = YoungMask,
+ SurvTag = YoungMask + 1,
-zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
-curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
-而在上面的代码里默认的SPI 值是 curator,所以如果不配置,那就会报上面找不到类的问题,所以如果需要使用 zkclient 的,就需要在<dubbo:registry/> 配置中添加 client="zkclient"这个配置,所以有些地方还是需要懂一些更深层次的原理,但也不至于每个东西都要抠到每一行代码原理,除非就是专门做这一块的。
还有一点是发现有些应用是碰运气,刚好有个三方包把这个类带进来了,但是这个应用就没有单独配置这块,如果不了解或者后续忘了再来查问题就会很奇怪
+ HumongousMask = 4,
+ PinnedMask = 8,
+ StartsHumongousTag = HumongousMask | PinnedMask,
+ ContinuesHumongousTag = HumongousMask | PinnedMask + 1,
+
+ OldMask = 16,
+ OldTag = OldMask,
+
+ // Archive regions are regions with immutable content (i.e. not reclaimed, and
+ // not allocated into during regular operation). They differ in the kind of references
+ // allowed for the contained objects:
+ // - Closed archive regions form a separate self-contained (closed) object graph
+ // within the set of all of these regions. No references outside of closed
+ // archive regions are allowed.
+ // - Open archive regions have no restrictions on the references of their objects.
+ // Objects within these regions are allowed to have references to objects
+ // contained in any other kind of regions.
+ ArchiveMask = 32,
+ OpenArchiveTag = ArchiveMask | PinnedMask | OldMask,
+ ClosedArchiveTag = ArchiveMask | PinnedMask | OldMask + 1
+ } Tag;
+
+hotspot/share/gc/g1/heapRegionType.hpp
+当执行垃圾收集时,G1以类似于CMS收集器的方式运行。 G1执行并发全局标记阶段,以确定整个堆中对象的存活性。标记阶段完成后,G1知道哪些region是基本空的。它首先收集这些region,通常会产生大量的可用空间。这就是为什么这种垃圾收集方法称为“垃圾优先”的原因。顾名思义,G1将其收集和压缩活动集中在可能充满可回收对象(即垃圾)的堆区域。 G1使用暂停预测模型来满足用户定义的暂停时间目标,并根据指定的暂停时间目标选择要收集的区域数。
+由G1标识为可回收的区域是使用撤离的方式(Evacuation)。 G1将对象从堆的一个或多个区域复制到堆上的单个区域,并在此过程中压缩并释放内存。撤离是在多处理器上并行执行的,以减少暂停时间并增加吞吐量。因此,对于每次垃圾收集,G1都在用户定义的暂停时间内连续工作以减少碎片。这是优于前面两种方法的。 CMS(并发标记扫描)垃圾收集器不进行压缩。 ParallelOld垃圾回收仅执行整个堆压缩,这导致相当长的暂停时间。
+需要重点注意的是,G1不是实时收集器。它很有可能达到设定的暂停时间目标,但并非绝对确定。 G1根据先前收集的数据,估算在用户指定的目标时间内可以收集多少个区域。因此,收集器具有收集区域成本的合理准确的模型,并且收集器使用此模型来确定要收集哪些和多少个区域,同时保持在暂停时间目标之内。
+注意:G1同时具有并发(与应用程序线程一起运行,例如优化,标记,清理)和并行(多线程,例如stw)阶段。Full GC仍然是单线程的,但是如果正确调优,您的应用程序应该可以避免Full GC。
+在前面那篇中在代码层面简单的了解了这个可预测时间的过程,这也是 G1 的一大特点。
]]>
Java
- Dubbo
+ JVM
+ GC
+ C++
Java
- Dubbo
+ JVM
+ C++
+ G1
+ GC
+ Garbage-First Collector
- docker使用中发现的echo命令的一个小技巧及其他
- /2020/03/29/echo%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E4%B8%AA%E5%B0%8F%E6%8A%80%E5%B7%A7/
- echo 实操技巧最近做 docker 系列,会经常需要进到 docker 内部,如上一篇介绍的,这些镜像一般都有用 ubuntu 或者alpine 这样的 Linux 系统作为底包,如果构建镜像的时候没有替换源的话,因为特殊的网络原因,在内部想编辑下东西要安装个类似于 vim 这样的编辑器就会很慢很慢,像视频里 two thousand years later~ 而且如果在容器内部想改源配置的话也要编辑器,就陷入了一个鸡生蛋,跟蛋生鸡的死锁问题中,对于 linux 大神来说应该有一万种方法解决这个问题,对于我这个渣渣来说可能只想到了这个土方法,先 cp backup 一下 sources.list, 再 echo “xxx” > sources.list, 这里就碰到了一个问题,这个 sources.list 一般不止一行,直接 echo 的话就解析不了了,不过 echo 可以支持”\n”转义,就是加-e看一下解释和示例,我这里使用了 tldr ,可以用 npm install -g tldr 安装,也可以直接用man, 或者–help 来查看使用方式
![]()
-查看镜像底包
还有一点也是在这个时候要安装 vim 之类的,得知道是什么镜像底包,如果是用 uname 指令,其实看到的是宿主机的系统,得用cat /etc/issue
-![]()
这里稍稍记一下
-寻找系统镜像源
目前国内系统源用得比较多的是阿里云源,不过这里也推荐清华源, 中科大源, 浙大源 这里不要脸的推荐下母校的源,不过还不是很完善,尽情期待下。
+ Leetcode 104 二叉树的最大深度(Maximum Depth of Binary Tree) 题解分析
+ /2020/10/25/Leetcode-104-%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E6%9C%80%E5%A4%A7%E6%B7%B1%E5%BA%A6-Maximum-Depth-of-Binary-Tree-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍给定一个二叉树,找出其最大深度。
+二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
+说明: 叶子节点是指没有子节点的节点。
+示例:
给定二叉树 [3,9,20,null,null,15,7],
+ 3
+ / \
+9 20
+ / \
+ 15 7
+返回它的最大深度 3 。
+代码
// 主体是个递归的应用
+public int maxDepth(TreeNode root) {
+ // 节点的退出条件之一
+ if (root == null) {
+ return 0;
+ }
+ int left = 0;
+ int right = 0;
+ // 存在左子树,就递归左子树
+ if (root.left != null) {
+ left = maxDepth(root.left);
+ }
+ // 存在右子树,就递归右子树
+ if (root.right != null) {
+ right = maxDepth(root.right);
+ }
+ // 前面返回后,左右取大者
+ return Math.max(left + 1, right + 1);
+}
+分析
其实对于树这类题,一般是以递归形式比较方便,只是要注意退出条件
]]>
- Linux
- Docker
- 命令
- echo
- 发行版本
+ Java
+ leetcode
+ Binary Tree
+ java
+ Binary Tree
+ DFS
- linux
- Docker
- echo
- uname
- 发行版
+ leetcode
+ java
+ Binary Tree
+ DFS
+ 二叉树
+ 题解
- gogs使用webhook部署react单页应用
- /2020/02/22/gogs%E4%BD%BF%E7%94%A8webhook%E9%83%A8%E7%BD%B2react%E5%8D%95%E9%A1%B5%E5%BA%94%E7%94%A8/
- 众所周知,我是个前端彩笔,但是也想做点自己可以用的工具页面,所以就让朋友推荐了蚂蚁出品的 ant design,说基本可以直接 ctrl-c ctrl-v,实测对我这种来说还是有点难的,不过也能写点,但是现在碰到的问题是怎么部署到自己的服务器上去
用 ant design 写的是个单页应用,实际来说就是一个 html 加 css 跟 js,最初的时候是直接 build 完就 scp 上去,也考虑过 rsync 之类的,但是都感觉不够自动化,正好自己还没这方面的经验就想折腾下,因为我自己搭的仓库应用是 gogs,搜了一下主要是跟 drones 配合做 ci/cd,研究了一下发现其实这个事情没必要这么搞(PS:drone 也不好用),整个 hook 就可以了, 但是实际上呢,这东西也不是那么简单
首先是需要在服务器上装 webhook,这个我一开始用 snap 安装,但是出现问题,run 的时候会出现后面参数带的 hooks.json 文件找不到,然后索性就直接 github 上下最新版,放 /usr/local/bin 了,webhook 的原理呢其实也比较简单,就是起一个 http 服务,通过 post 请求调用,解析下参数,如果跟配置的参数一致,就调用对应的命令或者脚本。
-配置 hooks.json
webhook 的配置,需要的两个文件,一个是 hooks.json,这个是 webhook 服务的配置文件,像这样
-[
- {
- "id": "redeploy-app",
- "execute-command": "/opt/scripts/redeploy.sh",
- "command-working-directory": "/opt/scripts",
- "pass-arguments-to-command":
- [
- {
- "source": "payload",
- "name": "head_commit.message"
- },
- {
- "source": "payload",
- "name": "pusher.name"
- },
- {
- "source": "payload",
- "name": "head_commit.id"
- }
- ],
- "trigger-rule":
- {
- "and":
- [
- {
- "match":
- {
- "type": "payload-hash-sha1",
- "secret": "your-github-secret",
- "parameter":
- {
- "source": "header",
- "name": "X-Hub-Signature"
- }
- }
- },
- {
- "match":
- {
- "type": "value",
- "value": "refs/heads/master",
- "parameter":
- {
- "source": "payload",
- "name": "ref"
- }
- }
- }
- ]
+ Leetcode 1115 交替打印 FooBar ( Print FooBar Alternately *Medium* ) 题解分析
+ /2022/05/01/Leetcode-1115-%E4%BA%A4%E6%9B%BF%E6%89%93%E5%8D%B0-FooBar-Print-FooBar-Alternately-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 无聊想去 roll 一题就看到了有并发题,就找到了这题,其实一眼看我的想法也是用信号量,但是用 condition 应该也是可以处理的,不过这类问题好像本地有点难调,因为它好像是抽取代码执行的,跟直观的逻辑比较不一样
Suppose you are given the following code:
+class FooBar {
+ public void foo() {
+ for (int i = 0; i < n; i++) {
+ print("foo");
}
}
-]
-这是个跟 github搭配的示例,首先 id 表示的是这个对应 hook 的识别 id,也可以看到这个 hooks.json 的结构是这样的一个数组,然后就是要执行的命令和命令执行的参数,值得注意的是这个trigger-rule,就是请求进来了回去匹配里面的,比如前一个是一个加密的,放在请求头里,第二个 match 表示请求里的 ref 是个 master 分支,就可以区分分支进行不同操作,但是前面的加密配合 gogs 使用的时候有个问题(PS: webhook 的文档是真的烂),gogs 设置 webhook 的加密是用的
-
-密钥文本将被用于计算推送内容的 SHA256 HMAC 哈希值,并设置为 X-Gogs-Signature 请求头的值。
+ public void bar() {
+ for (int i = 0; i < n; i++) {
+ print("bar");
+ }
+ }
+}
+The same instance of FooBar will be passed to two different threads:
+
+- thread
A will call foo(), while
+- thread
B will call bar().
Modify the given program to output "foobar" n times.
+
+示例
Example 1:
+Input: n = 1
Output: “foobar”
Explanation: There are two threads being fired asynchronously. One of them calls foo(), while the other calls bar().
“foobar” is being output 1 time.
-这种加密方式,所以 webhook 的这个示例的加密方式不行,但这货的文档里居然没有说明支持哪些加密,神TM,后来还是翻 issue 翻到了, 需要使用这个payload-hash-sha256
-执行脚本 redeploy.sh
脚本类似于这样
-#!/bin/bash -e
-
-function cleanup {
- echo "Error occoured"
-}
-trap cleanup ERR
-
-commit_message=$1 # head_commit.message
-pusher_name=$2 # pusher.name
-commit_id=$3 # head_commit.id
+Example 2:
+Input: n = 2
Output: “foobarfoobar”
Explanation: “foobar” is being output 2 times.
+
+题解
简析
其实用信号量是很直观的,就是让打印 foo 的线程先拥有信号量,打印后就等待,给 bar 信号量 + 1,然后 bar 线程运行打印消耗 bar 信号量,再给 foo 信号量 + 1
+code
class FooBar {
+
+ private final Semaphore foo = new Semaphore(1);
+ private final Semaphore bar = new Semaphore(0);
+ private int n;
+ public FooBar(int n) {
+ this.n = n;
+ }
-cd ~/do-react-example-app/
-git pull origin master
-yarn && yarn build
+ public void foo(Runnable printFoo) throws InterruptedException {
+
+ for (int i = 0; i < n; i++) {
+ foo.acquire();
+ // printFoo.run() outputs "foo". Do not change or remove this line.
+ printFoo.run();
+ bar.release();
+ }
+ }
-就是简单的拉代码,然后构建下,真实使用时可能不是这样,因为页面会部署在 nginx 的作用目录,还需要 rsync 过去,这部分可能还涉及到两个问题第一个是使用 rsync 还是其他的 cp,不过这个无所谓;第二个是目录权限的问题,以我的系统ubuntu 为例,默认用户是 ubuntu,nginx 部署的目录是 www,所以需要切换用户等操作,一开始是想用在shell 文件中直接写了密码,但是不知道咋传,查了下是类似于这样 echo "passwd" | sudo -S cmd,通过管道命令往后传,然后就是这个-S, 参数的解释是-S, --stdin read password from standard input,但是这样么也不是太安全的赶脚,又看了下还有两种方法,
-
-就是给root 设置一个不需要密码的命令类似于这样,
-myusername ALL = (ALL) ALL
-myusername ALL = (root) NOPASSWD: /path/to/my/program
-另一种就是把默认用户跟 root 设置成同一个 group 的
-
-使用
真正实操的时候其实还有不少问题,首先运行 webhook 就碰到了我前面说的,使用 snap 运行的时候会找不到前面的 hooks.json配置文件,执行snap run webhook -hooks /opt/hooks/hooks.json -verbose就碰到下面的couldn't load hooks from file! open /opt/hooks/hooks.json: no such file or directory,后来直接下了个官方最新的 release,就直接执行 webhook -hooks /opt/hooks/hooks.json -verbose 就可以了,然后是前面的示例配置文件里的几个参数,比如head_commit.message 其实 gogs 推过来的根本没这玩意,而且都是数组,不知道咋取,烂文档,不过总比搭个 drone 好一点就忍了。补充一点就是在 debug 的时候需要看下问题出在哪,看看脚本有没有执行,所以需要在前面的 json 里加这个参数"include-command-output-in-response": true, 就能输出来脚本执行结果
-]]>
-
- 持续集成
-
-
- Gogs
- Webhook
-
-
-
- headscale 添加节点
- /2023/07/09/headscale-%E6%B7%BB%E5%8A%A0%E8%8A%82%E7%82%B9/
- 添加节点添加节点非常简单,比如 app store 或者官网可以下载 mac 的安装包,
-安装包直接下载可以在这里,下载安装完后还需要做一些处理,才能让 Tailscale 使用 Headscale 作为控制服务器。当然,Headscale 已经给我们提供了详细的操作步骤,你只需要在浏览器中打开 URL:http://<HEADSCALE_PUB_IP>:<HEADSCALE_PUB_PORT>/apple,记得端口替换成自己的,就会看到这样的说明页
-![image]()
-然后对于像我这样自己下载的客户端安装包,也就是standalone client,就可以用下面的命令
-defaults write io.tailscale.ipn.macsys ControlURL http://<HEADSCALE_PUB_IP>:<HEADSCALE_PUB_PORT> 类似于 Windows 客户端需要写入注册表,就是把控制端的地址改成了我们自己搭建的 headscale 的,设置完以后就打开 tailscale 客户端右键点击 login,就会弹出一个浏览器地址
-![image]()
-按照这个里面的命令去 headscale 的机器上执行,注意要替换 namespace,对于最新的 headscale 已经把 namespace 废弃改成 user 了,这点要注意了,其他客户端也同理,现在还有个好消息,安卓和 iOS 客户端也已经都可以用了,后面可以在介绍下局域网怎么部分打通和自建 derper。
+ public void bar(Runnable printBar) throws InterruptedException {
+
+ for (int i = 0; i < n; i++) {
+ bar.acquire();
+ // printBar.run() outputs "bar". Do not change or remove this line.
+ printBar.run();
+ foo.release();
+ }
+ }
+}
]]>
- headscale
+ Java
+ leetcode
- headscale
+ leetcode
+ java
+ 题解
+ Print FooBar Alternately
- 2020 年终总结
- /2021/03/31/2020-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
- 拖更原因这篇年终总结本来应该在农历过完年就出来的,结果是对没有受疫情影响的春节放假时间空闲情况预估太良好,虽然公司调了几天假,但是因为春节期间疫情状况比较好,本来酒店都不让接待聚餐什么的,后来统统放开,结果就是从初一到初六每天要不就是去亲戚家,要不就是去酒店饭店吃饭,计划很丰满,现实很骨感,时间感觉一下就没了,然后年后感觉有点犯懒了,所以才拖到现在。
-生活-健身跑步
去年(19 年)的时候跑步突破了 300 公里,然后20 年给自己定了个 400 公里的目标,结果意料之中的没成功,原因可能疫情算一点吧,后面买了跑步机之后,基本周末回家都能跑一下,但是最后还是只跑了300 多公里,总的keep 记录跑量也没超过 1000 公里,所以跑步这个目标还是没成功的,不过还算是比去年多跑一点,这样也算后面好突破点,后面的目标就不定的太高了,每年能比前一年多一点就好,其实跑步已经从一种减肥方式变成一种习惯了,一周一次的跑步已经比较难有效减重了,但是对于保持精力和身体状态还是很有效和重要的,只是对于目前的体重还是要多减下去一些跑步才好,太重了对膝盖负担太大了,可惜还是时间呐,游泳骑车什么的都需要更苛刻的条件和时间,饮食呢控制起来比较难(贪吃
终于在 3 月底之前跑到了 1000 公里,迟了三个月,不过也总算达到了,只是体重控制还是不行,有试着走走楼梯,但是感觉对膝盖负担比较大,得再想想用什么方式
-![]()
-技术成长
一直提不起笔来写这篇年终总结还有个比较大的原因是觉得20 年的成长不如预期,大小目标都没怎么完成,比如深入了解 jvm,是想能有些深入的见解,而不再是某些点的比较片面的理解,系统性的归纳总结也比较少,每个方向或多或少有些看法和理解,但是不全面,一些东西看过了也会忘记,需要温故而知新,比如 AQS 的内容,第一次读其实理解比较浅,后面就强迫自己去读,去写,才有了一些比之前更深入的理解,因为很多文章都是带有作者思路的引导,适不适合自己都要看是否能从他的思路把它看懂,有些就差别很大,这个跟看书也一样,有些书大众一致推荐,一般情况下大多是经典的好的,但是也有可能是不太适合自己的,可能有时候机缘巧合看到的反而让人茅塞顿开,在 todo 里已经积攒了好多的点和面需要去学习实践,一方面是自己懒,一方面是时间也相对偏少,看看 21 年能不能有所提升,加强“时间管理”,哈哈
-技术上主要是看了 mysql 的 mvcc 相关内容,rocketmq 的,redis 的代码,还有 mybatis 等,其实每一个都能写很多,也有很多值得学习的,需要全面系统学习,之前想好好画一个思维导图,将整个技术体系都梳理下,还只做了一点点,方式也有点问题,应该从大到小,而不是深度优先,细节有很多,每一个方面都有自己比较熟悉擅长的,也有不太了解的,可以做一个评分,这个也是亟待改善的,希望今年能完成。
-博客
博客方面 20 年一年整是写了 53 篇,差不多是一周一篇的节奏,这个还是不错的,虽然博客质量参差不齐,但是这个更新频率还是比较好的,并且也定了个潜规则,可以一周技术一周生活,这样能缓解水文的频率,提高些技术文章的质量,虽然结果并没有好多少,不过感觉还是可以这么坚持的,能提高一些技术文章的质量那就更好了
-]]>
+ Leetcode 105 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal) 题解分析
+ /2020/12/13/Leetcode-105-%E4%BB%8E%E5%89%8D%E5%BA%8F%E4%B8%8E%E4%B8%AD%E5%BA%8F%E9%81%8D%E5%8E%86%E5%BA%8F%E5%88%97%E6%9E%84%E9%80%A0%E4%BA%8C%E5%8F%89%E6%A0%91-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given preorder and inorder traversal of a tree, construct the binary tree.
给定一棵树的前序和中序遍历,构造出一棵二叉树
+注意
You may assume that duplicates do not exist in the tree.
你可以假设树中没有重复的元素。(PS: 不然就没法做了呀)
+例子:
preorder = [3,9,20,15,7]
+inorder = [9,3,15,20,7]
+返回的二叉树
+ 3
+ / \
+9 20
+ / \
+ 15 7
+
+
+简要分析
看到这个题可以想到一个比较常规的解法就是递归拆树,前序就是根左右,中序就是左根右,然后就是通过前序已经确定的根在中序中找到,然后去划分左右子树,这个例子里是 3,找到中序中的位置,那么就可以确定,9 是左子树,15,20,7是右子树,然后对应的可以根据左右子树的元素数量在前序中划分左右子树,再继续递归就行
+class Solution {
+ public TreeNode buildTree(int[] preorder, int[] inorder) {
+ // 获取下数组长度
+ int n = preorder.length;
+ // 排除一下异常和边界
+ if (n != inorder.length) {
+ return null;
+ }
+ if (n == 0) {
+ return null;
+ }
+ if (n == 1) {
+ return new TreeNode(preorder[0]);
+ }
+ // 获得根节点
+ TreeNode node = new TreeNode(preorder[0]);
+ int pos = 0;
+ // 找到中序中的位置
+ for (int i = 0; i < inorder.length; i++) {
+ if (node.val == inorder[i]) {
+ pos = i;
+ break;
+ }
+ }
+ // 划分左右再进行递归,注意下`Arrays.copyOfRange`的用法
+ node.left = buildTree(Arrays.copyOfRange(preorder, 1, pos + 1), Arrays.copyOfRange(inorder, 0, pos));
+ node.right = buildTree(Arrays.copyOfRange(preorder, pos + 1, n), Arrays.copyOfRange(inorder, pos + 1, n));
+ return node;
+ }
+}
]]>
- 生活
- 年终总结
- 2020
- 年终总结
- 2020
+ Java
+ leetcode
+ Binary Tree
+ java
+ Binary Tree
+ DFS
- 生活
- 年终总结
- 2020
- 2021
- 拖更
+ leetcode
+ java
+ Binary Tree
+ 二叉树
+ 题解
+ 递归
+ Preorder Traversal
+ Inorder Traversal
+ 前序
+ 中序
- invert-binary-tree
- /2015/06/22/invert-binary-tree/
- Invert a binary tree
- 4
- / \
- 2 7
- / \ / \
-1 3 6 9
-
-to
- 4
- / \
- 7 2
- / \ / \
-9 6 3 1
-
-Trivia:
This problem was inspired by this original tweet by Max Howell:
-
-Google: 90% of our engineers use the software you wrote (Homebrew),
but you can’t invert a binary tree on a whiteboard so fuck off.
+ Leetcode 16 最接近的三数之和 ( 3Sum Closest *Medium* ) 题解分析
+ /2022/08/06/Leetcode-16-%E6%9C%80%E6%8E%A5%E8%BF%91%E7%9A%84%E4%B8%89%E6%95%B0%E4%B9%8B%E5%92%8C-3Sum-Closest-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given an integer array nums of length n and an integer target, find three integers in nums such that the sum is closest to target.
+Return the sum of the three integers.
+You may assume that each input would have exactly one solution.
+简单解释下就是之前是要三数之和等于目标值,现在是找到最接近的三数之和。
+示例
Example 1:
+Input: nums = [-1,2,1,-4], target = 1
Output: 2
Explanation: The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).
-/**
- * Definition for a binary tree node.
- * struct TreeNode {
- * int val;
- * TreeNode *left;
- * TreeNode *right;
- * TreeNode(int x) : val(x), left(NULL), right(NULL) {}
- * };
- */
-class Solution {
-public:
- TreeNode* invertTree(TreeNode* root) {
- if(root == NULL) return root;
- TreeNode* temp;
- temp = invertTree(root->left);
- root->left = invertTree(root->right);
- root->right = temp;
- return root;
- }
-};
]]>
+Example 2:
+Input: nums = [0,0,0], target = 1
Output: 0
+
+Constraints:
+3 <= nums.length <= 1000-1000 <= nums[i] <= 1000-10^4 <= target <= 10^4
+简单解析
这个题思路上来讲不难,也是用原来三数之和的方式去做,利用”双指针法”或者其它描述法,但是需要简化逻辑
+code
public int threeSumClosest(int[] nums, int target) {
+ Arrays.sort(nums);
+ // 当前最近的和
+ int closestSum = nums[0] + nums[1] + nums[nums.length - 1];
+ for (int i = 0; i < nums.length - 2; i++) {
+ if (i == 0 || nums[i] != nums[i - 1]) {
+ // 左指针
+ int left = i + 1;
+ // 右指针
+ int right = nums.length - 1;
+ // 判断是否遍历完了
+ while (left < right) {
+ // 当前的和
+ int sum = nums[i] + nums[left] + nums[right];
+ // 小优化,相等就略过了
+ while (left < right && nums[left] == nums[left + 1]) {
+ left++;
+ }
+ while (left < right && nums[right] == nums[right - 1]) {
+ right--;
+ }
+ // 这里判断,其实也还是希望趋近目标值
+ if (sum < target) {
+ left++;
+ } else {
+ right--;
+ }
+ // 判断是否需要替换
+ if (Math.abs(sum - target) < Math.abs(closestSum - target)) {
+ closestSum = sum;
+ }
+ }
+ }
+ }
+ return closestSum;
+ }
+
+结果
![]()
+]]>
+ Java
leetcode
leetcode
- c++
+ java
+ 题解
+ 3Sum Closest
- github 小技巧-更新 github host key
- /2023/03/28/github-%E5%B0%8F%E6%8A%80%E5%B7%A7-%E6%9B%B4%E6%96%B0-github-host-key/
- 最近一次推送博客,发现报了个错推不上去,
-WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
-
-IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
-Someone could be eavesdropping on you right now (man-in-the-middle attack)!
-It is also possible that a host key has just been changed.
-错误信息是这样,有点奇怪也没干啥,网上一搜发现是We updated our RSA SSH host key
简单翻一下就是
+ Leetcode 1260 二维网格迁移 ( Shift 2D Grid *Easy* ) 题解分析
+ /2022/07/22/Leetcode-1260-%E4%BA%8C%E7%BB%B4%E7%BD%91%E6%A0%BC%E8%BF%81%E7%A7%BB-Shift-2D-Grid-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given a 2D grid of size m x n and an integer k. You need to shift the grid k times.
+In one shift operation:
+Element at grid[i][j] moves to grid[i][j + 1].
Element at grid[i][n - 1] moves to grid[i + 1][0].
Element at grid[m - 1][n - 1] moves to grid[0][0].
Return the 2D grid after applying shift operation k times.
+示例
Example 1:
![]()
-在3月24日协调世界时大约05:00时,出于谨慎,我们更换了用于保护 GitHub.com 的 Git 操作的 RSA SSH 主机密钥。我们这样做是为了保护我们的用户免受任何对手模仿 GitHub 或通过 SSH 窃听他们的 Git 操作的机会。此密钥不授予对 GitHub 基础设施或客户数据的访问权限。此更改仅影响通过使用 RSA 的 SSH 进行的 Git 操作。GitHub.com 和 HTTPS Git 操作的网络流量不受影响。
+Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 1
Output: [[9,1,2],[3,4,5],[6,7,8]]
-要解决也比较简单就是重置下 host key,
+Example 2:
![]()
-Host Key是服务器用来证明自己身份的一个永久性的非对称密钥
+Input: grid = [[3,8,1,9],[19,7,2,5],[4,6,11,10],[12,0,21,13]], k = 4
Output: [[12,0,21,13],[3,8,1,9],[19,7,2,5],[4,6,11,10]]
-使用
-ssh-keygen -R github.com
-然后在首次建立连接的时候同意下就可以了
-]]>
-
- ssh
- 技巧
-
-
- ssh
- 端口转发
-
+Example 3:
+Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 9
Output: [[1,2,3],[4,5,6],[7,8,9]]
+
+提示
+m == grid.lengthn == grid[i].length1 <= m <= 501 <= n <= 50-1000 <= grid[i][j] <= 10000 <= k <= 100
+解析
这个题主要是矩阵或者说数组的操作,并且题目要返回的是个 List,所以也不用原地操作,只需要找对位置就可以了,k 是多少就相当于让这个二维数组头尾衔接移动 k 个元素
+代码
public List<List<Integer>> shiftGrid(int[][] grid, int k) {
+ // 行数
+ int m = grid.length;
+ // 列数
+ int n = grid[0].length;
+ // 偏移值,取下模
+ k = k % (m * n);
+ // 反向取下数量,因为我打算直接从头填充新的矩阵
+ /*
+ * 比如
+ * 1 2 3
+ * 4 5 6
+ * 7 8 9
+ * 需要变成
+ * 9 1 2
+ * 3 4 5
+ * 6 7 8
+ * 就要从 9 开始填充
+ */
+ int reverseK = m * n - k;
+ List<List<Integer>> matrix = new ArrayList<>();
+ // 这类就是两层循环
+ for (int i = 0; i < m; i++) {
+ List<Integer> line = new ArrayList<>();
+ for (int j = 0; j < n; j++) {
+ // 数量会随着循环迭代增长, 确认是第几个
+ int currentNum = reverseK + i * n + (j + 1);
+ // 这里处理下到达矩阵末尾后减掉 m * n
+ if (currentNum > m * n) {
+ currentNum -= m * n;
+ }
+ // 根据矩阵列数 n 算出在原来矩阵的位置
+ int last = (currentNum - 1) % n;
+ int passLine = (currentNum - 1) / n;
+
+ line.add(grid[passLine][last]);
+ }
+ matrix.add(line);
+ }
+ return matrix;
+ }
+
+结果数据
![]()
比较慢
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+ Shift 2D Grid
+
- minimum-size-subarray-sum-209
- /2016/10/11/minimum-size-subarray-sum-209/
- problemGiven an array of n positive integers and a positive integer s, find the minimal length of a subarray of which the sum ≥ s. If there isn’t one, return 0 instead.
-For example, given the array [2,3,1,2,4,3] and s = 7,
the subarray [4,3] has the minimal length under the problem constraint.
-题解
参考,滑动窗口,跟之前Data Structure课上的online算法有点像,链接
-Code
class Solution {
-public:
- int minSubArrayLen(int s, vector<int>& nums) {
- int len = nums.size();
- if(len == 0) return 0;
- int minlen = INT_MAX;
- int sum = 0;
-
- int left = 0;
- int right = -1;
- while(right < len)
- {
- while(sum < s && right < len)
- sum += nums[++right];
- if(sum >= s)
- {
- minlen = minlen < right - left + 1 ? minlen : right - left + 1;
- sum -= nums[left++];
- }
- }
- return minlen > len ? 0 : minlen;
- }
-};
+ Leetcode 155 最小栈(Min Stack) 题解分析
+ /2020/12/06/Leetcode-155-%E6%9C%80%E5%B0%8F%E6%A0%88-Min-Stack-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
设计一个栈,支持压栈,出站,获取栈顶元素,通过常数级复杂度获取栈中的最小元素
+
+- push(x) – Push element x onto stack.
+- pop() – Removes the element on top of the stack.
+- top() – Get the top element.
+- getMin() – Retrieve the minimum element in the stack.
+
+示例
Example 1:
+Input
+["MinStack","push","push","push","getMin","pop","top","getMin"]
+[[],[-2],[0],[-3],[],[],[],[]]
+
+Output
+[null,null,null,null,-3,null,0,-2]
+
+Explanation
+MinStack minStack = new MinStack();
+minStack.push(-2);
+minStack.push(0);
+minStack.push(-3);
+minStack.getMin(); // return -3
+minStack.pop();
+minStack.top(); // return 0
+minStack.getMin(); // return -2
+
+简要分析
其实现在大部分语言都自带类栈的数据结构,Java 也自带 stack 这个数据结构,所以这个题的主要难点的就是常数级的获取最小元素,最开始的想法是就一个栈外加一个记录最小值的变量就行了,但是仔细一想是不行的,因为随着元素被 pop 出去,这个最小值也可能需要梗着变化,就不太好判断了,所以后面是用了一个辅助栈。
+代码
class MinStack {
+ // 这个作为主栈
+ Stack<Integer> s1 = new Stack<>();
+ // 这个作为辅助栈,放最小值的栈
+ Stack<Integer> s2 = new Stack<>();
+ /** initialize your data structure here. */
+ public MinStack() {
+
+ }
+
+ public void push(int x) {
+ // 放入主栈
+ s1.push(x);
+ // 当 s2 是空或者当前值是小于"等于" s2 栈顶时,压入辅助最小值的栈
+ // 注意这里的"等于"非常必要,因为当最小值有多个的情况下,也需要压入栈,否则在 pop 的时候就会不对等
+ if (s2.isEmpty() || x <= s2.peek()) {
+ s2.push(x);
+ }
+ }
+
+ public void pop() {
+ // 首先就是主栈要 pop,然后就是第二个了,跟上面的"等于"很有关系,
+ // 因为如果有两个最小值,如果前面等于的情况没有压栈,那这边相等的时候 pop 就会少一个了,可能就导致最小值不对了
+ int x = s1.pop();
+ if (x == s2.peek()) {
+ s2.pop();
+ }
+ }
+
+ public int top() {
+ // 栈顶的元素
+ return s1.peek();
+ }
+
+ public int getMin() {
+ // 辅助最小栈的栈顶
+ return s2.peek();
+ }
+ }
+
]]>
+ Java
leetcode
+ java
+ stack
+ stack
leetcode
- c++
+ java
+ 题解
+ stack
+ min stack
+ 最小栈
+ leetcode 155
- C++ 指针使用中的一个小问题
- /2014/12/23/my-new-post/
- 在工作中碰到的一点C++指针上的一点小问题
-在C++中,应该是从C语言就开始了,除了void型指针之外都是需要有分配对应的内存才可以使用,同时malloc与free成对使用,new与delete成对使用,否则造成内存泄漏。
+ Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析
+ /2021/01/24/Leetcode-124-%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E7%9A%84%E6%9C%80%E5%A4%A7%E8%B7%AF%E5%BE%84%E5%92%8C-Binary-Tree-Maximum-Path-Sum-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
+The path sum of a path is the sum of the node’s values in the path.
+Given the root of a binary tree, return the maximum path sum of any path.
+路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。该路径 至少包含一个 节点,且不一定经过根节点。
+路径和 是路径中各节点值的总和。
+给你一个二叉树的根节点 root ,返回其 最大路径和
+简要分析
其实这个题目会被误解成比较简单,左子树最大的,或者右子树最大的,或者两边加一下,仔细想想都不对,其实有可能是产生于左子树中,或者右子树中,这两个都是指跟左子树根还有右子树根没关系的,这么说感觉不太容易理解,画个图
![]()
可以看到图里,其实最长路径和是左边这个子树组成的,跟根节点还有右子树完全没关系,然后再想一种情况,如果是整棵树就是图中的左子树,那么这个最长路径和就是左子树加右子树加根节点了,所以不是我一开始想得那么简单,在代码实现中也需要一些技巧
+代码
int ansNew = Integer.MIN_VALUE;
+public int maxPathSum(TreeNode root) {
+ maxSumNew(root);
+ return ansNew;
+ }
+
+public int maxSumNew(TreeNode root) {
+ if (root == null) {
+ return 0;
+ }
+ // 这里是个简单的递归,就是去递归左右子树,但是这里其实有个概念,当这样处理时,其实相当于把子树的内部的最大路径和已经算出来了
+ int left = maxSumNew(root.left);
+ int right = maxSumNew(root.right);
+ // 这里前面我有点没想明白,但是看到 ansNew 的比较,其实相当于,返回的是三种情况里的最大值,一个是左子树+根,一个是右子树+根,一个是单独根节点,
+ // 这样这个递归的返回才会有意义,不然像原来的方法,它可能是跳着的,但是这种情况其实是借助于 ansNew 这个全局的最大值,因为原来我觉得要比较的是
+ // left, right, left + root , right + root, root, left + right + root 这些的最大值,这里是分成了两个阶段,left 跟 right 的最大值已经在上面的
+ // 调用过程中赋值给 ansNew 了
+ int currentSum = Math.max(Math.max(root.val + left , root.val + right), root.val);
+ // 这边返回的是 currentSum,然后再用它跟 left + right + root 进行对比,然后再去更新 ans
+ // PS: 有个小点也是这边的破局点,就是这个 ansNew
+ int res = Math.max(left + right + root.val, currentSum);
+ ans = Math.max(res, ans);
+ return currentSum;
+}
+
+这里非常重要的就是 ansNew 是最后的一个结果,而对于 maxSumNew 这个函数的返回值其实是需要包含了一个连续结果,因为要返回继续去算路径和,所以返回的是 currentSum,最终结果是 ansNew
+结果图
难得有个 100%,贴个图哈哈
![]()
]]>
- C++
+ Java
+ leetcode
+ Binary Tree
+ java
+ Binary Tree
- 博客,文章
+ leetcode
+ java
+ Binary Tree
+ 二叉树
+ 题解
- mybatis 的 foreach 使用的注意点
- /2022/07/09/mybatis-%E7%9A%84-foreach-%E4%BD%BF%E7%94%A8%E7%9A%84%E6%B3%A8%E6%84%8F%E7%82%B9/
- mybatis 在作为轻量级 orm 框架,如果要使用类似于 in 查询的语句,除了直接替换字符串,还可以使用 foreach 标签
在mybatis的 dtd 文件中可以看到可以配置这些字段,
-<!ELEMENT foreach (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*>
-<!ATTLIST foreach
-collection CDATA #REQUIRED
-item CDATA #IMPLIED
-index CDATA #IMPLIED
-open CDATA #IMPLIED
-close CDATA #IMPLIED
-separator CDATA #IMPLIED
->
-collection 表示需要使用 foreach 的集合,item 表示进行迭代的变量名,index 就是索引值,而 open 跟 close
代表拼接的起始和结束符号,一般就是左右括号,separator 则是每个 item 直接的分隔符
-例如写了一个简单的 sql 查询
-<select id="search" parameterType="list" resultMap="StudentMap">
- select * from student
- <where>
- id in
- <foreach collection="list" item="item" open="(" close=")" separator=",">
- #{item}
- </foreach>
- </where>
-</select>
-这里就发现了一个问题,collection 对应的这个值,如果传入的参数是个 HashMap,collection 的这个值就是以此作为
key 从这个 HashMap 获取对应的集合,但是这里有几个特殊的小技巧,
在上面的这个方法对应的接口方法定义中
-public List<Student> search(List<Long> userIds);
-我是这么定义的,而 collection 的值是list,这里就有一点不能理解了,但其实是 mybatis 考虑到使用的方便性,
帮我们做了一点点小转换,我们翻一下 mybatis 的DefaultSqlSession 中的代码可以看到
-@Override
-public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
- try {
- MappedStatement ms = configuration.getMappedStatement(statement);
- return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
- } catch (Exception e) {
- throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
- } finally {
- ErrorContext.instance().reset();
- }
-}
-// 就是在这帮我们做了转换
- private Object wrapCollection(final Object object) {
- if (object instanceof Collection) {
- StrictMap<Object> map = new StrictMap<Object>();
- map.put("collection", object);
- if (object instanceof List) {
- // 如果类型是list 就会转成以 list 为 key 的 map
- map.put("list", object);
+ Leetcode 121 买卖股票的最佳时机(Best Time to Buy and Sell Stock) 题解分析
+ /2021/03/14/Leetcode-121-%E4%B9%B0%E5%8D%96%E8%82%A1%E7%A5%A8%E7%9A%84%E6%9C%80%E4%BD%B3%E6%97%B6%E6%9C%BA-Best-Time-to-Buy-and-Sell-Stock-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍You are given an array prices where prices[i] is the price of a given stock on the ith day.
+You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
+Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
+给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
+你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
+返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
+简单分析
其实这个跟二叉树的最长路径和有点类似,需要找到整体的最大收益,但是在迭代过程中需要一个当前的值
+int maxSofar = 0;
+public int maxProfit(int[] prices) {
+ if (prices.length <= 1) {
+ return 0;
}
- return map;
- } else if (object != null && object.getClass().isArray()) {
- StrictMap<Object> map = new StrictMap<Object>();
- map.put("array", object);
- return map;
- }
- return object;
- }
]]>
+ int maxIn = prices[0];
+ int maxOut = prices[0];
+ for (int i = 1; i < prices.length; i++) {
+ if (maxIn > prices[i]) {
+ // 当循环当前值小于之前的买入值时就当成买入值,同时卖出也要更新
+ maxIn = prices[i];
+ maxOut = prices[i];
+ }
+ if (prices[i] > maxOut) {
+ // 表示一个可卖出点,即比买入值高时
+ maxOut = prices[i];
+ // 需要设置一个历史值
+ maxSofar = Math.max(maxSofar, maxOut - maxIn);
+ }
+ }
+ return maxSofar;
+}
+
+总结下
一开始看到 easy 就觉得是很简单,就没有 maxSofar ,但是一提交就出现问题了
对于[2, 4, 1]这种就会变成 0,所以还是需要一个历史值来存放历史最大值,这题有点动态规划的意思
+]]>
Java
- Mybatis
- Mysql
+ leetcode
+ java
+ DP
+ DP
- Java
- Mysql
- Mybatis
+ leetcode
+ java
+ 题解
+ DP
- mybatis 的 $ 和 # 是有啥区别
- /2020/09/06/mybatis-%E7%9A%84-%E5%92%8C-%E6%98%AF%E6%9C%89%E5%95%A5%E5%8C%BA%E5%88%AB/
- 这个问题也是面试中常被问到的,就抽空来了解下这个,跳过一大段前面初始化的逻辑,
对于一条select * from t1 where id = #{id}这样的 sql,在初始化扫描 mapper 的xml文件的时候会根据是否是 dynamic 来判断生成 DynamicSqlSource 还是 RawSqlSource,这里它是一条 RawSqlSource,
在这里做了替换,将#{}替换成了?
![]()
前面说的是否 dynamic 就是在这里进行判断
![]() -
-// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
-public SqlSource parseScriptNode() {
- MixedSqlNode rootSqlNode = parseDynamicTags(context);
- SqlSource sqlSource;
- if (isDynamic) {
- sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
- } else {
- sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
- }
- return sqlSource;
- }
-// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseDynamicTags
-protected MixedSqlNode parseDynamicTags(XNode node) {
- List<SqlNode> contents = new ArrayList<>();
- NodeList children = node.getNode().getChildNodes();
- for (int i = 0; i < children.getLength(); i++) {
- XNode child = node.newXNode(children.item(i));
- if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
- String data = child.getStringBody("");
- TextSqlNode textSqlNode = new TextSqlNode(data);
- if (textSqlNode.isDynamic()) {
- contents.add(textSqlNode);
- isDynamic = true;
- } else {
- contents.add(new StaticTextSqlNode(data));
- }
- } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
- String nodeName = child.getNode().getNodeName();
- NodeHandler handler = nodeHandlerMap.get(nodeName);
- if (handler == null) {
- throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
- }
- handler.handleNode(child, contents);
- isDynamic = true;
- }
- }
- return new MixedSqlNode(contents);
- }
-// org.apache.ibatis.scripting.xmltags.TextSqlNode#isDynamic
- public boolean isDynamic() {
- DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
- GenericTokenParser parser = createParser(checker);
- parser.parse(text);
- return checker.isDynamic();
- }
- private GenericTokenParser createParser(TokenHandler handler) {
- return new GenericTokenParser("${", "}", handler);
- }
-可以看到其中一个条件就是是否有${}这种占位符,假如说上面的 sql 换成 ${},那么可以看到它会在这里创建一个 dynamicSqlSource,
-// org.apache.ibatis.scripting.xmltags.DynamicSqlSource
-public class DynamicSqlSource implements SqlSource {
-
- private final Configuration configuration;
- private final SqlNode rootSqlNode;
-
- public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) {
- this.configuration = configuration;
- this.rootSqlNode = rootSqlNode;
- }
-
- @Override
- public BoundSql getBoundSql(Object parameterObject) {
- DynamicContext context = new DynamicContext(configuration, parameterObject);
- rootSqlNode.apply(context);
- SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
- Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
- SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
- BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
- context.getBindings().forEach(boundSql::setAdditionalParameter);
- return boundSql;
- }
-
-}
-
-这里眼尖的同学可能就可以看出来了,RawSqlSource 在初始化的时候已经经过了 parse,把#{}替换成了?占位符,但是 DynamicSqlSource 并没有
![]() 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换
然后往里跟
![]() 好像是这里了
好像是这里了
![]()
这里 rootSqlNode.apply 其实是一个对原来 sql 的解析结果的一个循环调用,不同类型的标签会构成不同的 node,像这里就是一个 textSqlNode
![]()
可以发现到这我们的 sql 已经被替换了,而且是直接作为 string 类型替换的,所以可以明白了这个问题所在,就是注入,不过细心的同学发现其实这里是有个
![]()
理论上还是可以做过滤的,不过好像现在没用起来。
我们前面可以发现对于#{}是在启动扫描 mapper的 xml 文件就替换成了 ?,然后是在什么时候变成实际的值的呢
![]()
发现到这的时候还是没有替换,其实说白了也就是 prepareStatement 那一套,
![]()
在这里进行替换,会拿到 org.apache.ibatis.mapping.ParameterMapping,然后进行替换,因为会带着类型信息,所以不用担心注入咯
+ Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析
+ /2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍写一个程序找出两个单向链表的交叉起始点,可能是我英语不好,图里画的其实还有一点是交叉以后所有节点都是相同的
Write a program to find the node at which the intersection of two singly linked lists begins.
+For example, the following two linked lists:
![]()
begin to intersect at node c1.
+Example 1:
![]()
+Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
+Output: Reference of the node with value = 8
+Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
+分析题解
一开始没什么头绪,感觉只能最原始的遍历,后来看了一些文章,发现比较简单的方式就是先找两个链表的长度差,因为从相交点开始肯定是长度一致的,这是个很好的解题突破口,找到长度差以后就是先跳过长链表的较长部分,然后开始同步遍历比较 A,B 链表;
+代码
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
+ if (headA == null || headB == null) {
+ return null;
+ }
+ // 算 A 的长度
+ int countA = 0;
+ ListNode tailA = headA;
+ while (tailA != null) {
+ tailA = tailA.next;
+ countA++;
+ }
+ // 算 B 的长度
+ int countB = 0;
+ ListNode tailB = headB;
+ while (tailB != null) {
+ tailB = tailB.next;
+ countB++;
+ }
+ tailA = headA;
+ tailB = headB;
+ // 依据长度差,先让长的链表 tail 指针往后移
+ if (countA > countB) {
+ while (countA > countB) {
+ tailA = tailA.next;
+ countA--;
+ }
+ } else if (countA < countB) {
+ while (countA < countB) {
+ tailB = tailB.next;
+ countB--;
+ }
+ }
+ // 然后以相同速度遍历两个链表比较
+ while (tailA != null) {
+ if (tailA == tailB) {
+ return tailA;
+ } else {
+ tailA = tailA.next;
+ tailB = tailB.next;
+ }
+ }
+ return null;
+ }
+总结
可能缺少这种思维,做的还是比较少,所以没法一下子反应过来,需要锻炼,我的第一反应是两重遍历,不过那样复杂度就高了,这里应该是只有 O(N) 的复杂度。
]]>
Java
- Spring
- Mybatis
- Mysql
- Sql注入
- Mybatis
+ leetcode
+ Linked List
+ java
+ Linked List
- Java
- Mysql
- Mybatis
- Sql注入
+ leetcode
+ java
+ 题解
+ Linked List
- JVM源码分析之G1垃圾收集器分析一
- /2019/12/07/JVM-G1-Part-1/
- 对 Java 的 gc 实现比较感兴趣,原先一般都是看周志明的书,但其实并没有讲具体的 gc 源码,而是把整个思路和流程讲解了一下
特别是 G1 的具体实现
一般对 G1 的理解其实就是把原先整块的新生代老年代分成了以 region 为单位的小块内存,简而言之,就是原先对新生代老年代的收集会涉及到整个代的堆内存空间,而G1 把它变成了更细致的小块内存
这带来了一个很明显的好处和一个很明显的坏处,好处是内存收集可以更灵活,耗时会变短,但整个收集的处理复杂度就变高了
目前看了一点点关于 G1 收集的预期时间相关的代码
-HeapWord* G1CollectedHeap::do_collection_pause(size_t word_size,
- uint gc_count_before,
- bool* succeeded,
- GCCause::Cause gc_cause) {
- assert_heap_not_locked_and_not_at_safepoint();
- VM_G1CollectForAllocation op(word_size,
- gc_count_before,
- gc_cause,
- false, /* should_initiate_conc_mark */
- g1_policy()->max_pause_time_ms());
- VMThread::execute(&op);
+ Leetcode 1862 向下取整数对和 ( Sum of Floored Pairs *Hard* ) 题解分析
+ /2022/09/11/Leetcode-1862-%E5%90%91%E4%B8%8B%E5%8F%96%E6%95%B4%E6%95%B0%E5%AF%B9%E5%92%8C-Sum-of-Floored-Pairs-Hard-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given an integer array nums, return the sum of floor(nums[i] / nums[j]) for all pairs of indices 0 <= i, j < nums.length in the array. Since the answer may be too large, return it modulo 10^9 + 7.
+The floor() function returns the integer part of the division.
+对应中文
给你一个整数数组 nums ,请你返回所有下标对 0 <= i, j < nums.length 的 floor(nums[i] / nums[j]) 结果之和。由于答案可能会很大,请你返回答案对10^9 + 7 取余 的结果。
+函数 floor() 返回输入数字的整数部分。
+示例
Example 1:
+Input: nums = [2,5,9]
Output: 10
Explanation:
floor(2 / 5) = floor(2 / 9) = floor(5 / 9) = 0
floor(2 / 2) = floor(5 / 5) = floor(9 / 9) = 1
floor(5 / 2) = 2
floor(9 / 2) = 4
floor(9 / 5) = 1
We calculate the floor of the division for every pair of indices in the array then sum them up.
+
+Example 2:
+Input: nums = [7,7,7,7,7,7,7]
Output: 49
+
+Constraints:
+1 <= nums.length <= 10^51 <= nums[i] <= 10^5
+简析
这题不愧是 hard,要不是看了讨论区的一个大神的解答感觉从头做得想好久,
主要是两点,对于任何一个在里面的数,随便举个例子是 k,最简单的就是循环所有数对 k 除一下,
这样效率会很低,那么对于 k 有什么规律呢,就是对于所有小于 k 的数,往下取整都是 0,所以不用考虑,
对于所有大于 k 的数我们可以分成一个个的区间,[k,2k-1),[2k,3k-1),[3k,4k-1)……对于这些区间的
除了 k 往下取整,每个区间内的都是一样的,所以可以简化为对于任意一个 k,我只要知道与k 相同的有多少个,然后比 k 大的各个区间各有多少个数就可以了
+代码
static final int MAXE5 = 100_000;
- HeapWord* result = op.result();
- bool ret_succeeded = op.prologue_succeeded() && op.pause_succeeded();
- assert(result == NULL || ret_succeeded,
- "the result should be NULL if the VM did not succeed");
- *succeeded = ret_succeeded;
+static final int MODULUSE9 = 1_000_000_000 + 7;
- assert_heap_not_locked();
- return result;
-}
-这里就是收集时需要停顿的,其中VMThread::execute(&op);是具体执行的,真正执行的是VM_G1CollectForAllocation::doit方法
-void VM_G1CollectForAllocation::doit() {
- G1CollectedHeap* g1h = G1CollectedHeap::heap();
- assert(!_should_initiate_conc_mark || g1h->should_do_concurrent_full_gc(_gc_cause),
- "only a GC locker, a System.gc(), stats update, whitebox, or a hum allocation induced GC should start a cycle");
-
- if (_word_size > 0) {
- // An allocation has been requested. So, try to do that first.
- _result = g1h->attempt_allocation_at_safepoint(_word_size,
- false /* expect_null_cur_alloc_region */);
- if (_result != NULL) {
- // If we can successfully allocate before we actually do the
- // pause then we will consider this pause successful.
- _pause_succeeded = true;
- return;
- }
- }
-
- GCCauseSetter x(g1h, _gc_cause);
- if (_should_initiate_conc_mark) {
- // It's safer to read old_marking_cycles_completed() here, given
- // that noone else will be updating it concurrently. Since we'll
- // only need it if we're initiating a marking cycle, no point in
- // setting it earlier.
- _old_marking_cycles_completed_before = g1h->old_marking_cycles_completed();
-
- // At this point we are supposed to start a concurrent cycle. We
- // will do so if one is not already in progress.
- bool res = g1h->g1_policy()->force_initial_mark_if_outside_cycle(_gc_cause);
-
- // The above routine returns true if we were able to force the
- // next GC pause to be an initial mark; it returns false if a
- // marking cycle is already in progress.
- //
- // If a marking cycle is already in progress just return and skip the
- // pause below - if the reason for requesting this initial mark pause
- // was due to a System.gc() then the requesting thread should block in
- // doit_epilogue() until the marking cycle is complete.
- //
- // If this initial mark pause was requested as part of a humongous
- // allocation then we know that the marking cycle must just have
- // been started by another thread (possibly also allocating a humongous
- // object) as there was no active marking cycle when the requesting
- // thread checked before calling collect() in
- // attempt_allocation_humongous(). Retrying the GC, in this case,
- // will cause the requesting thread to spin inside collect() until the
- // just started marking cycle is complete - which may be a while. So
- // we do NOT retry the GC.
- if (!res) {
- assert(_word_size == 0, "Concurrent Full GC/Humongous Object IM shouldn't be allocating");
- if (_gc_cause != GCCause::_g1_humongous_allocation) {
- _should_retry_gc = true;
- }
- return;
- }
- }
-
- // Try a partial collection of some kind.
- _pause_succeeded = g1h->do_collection_pause_at_safepoint(_target_pause_time_ms);
-
- if (_pause_succeeded) {
- if (_word_size > 0) {
- // An allocation had been requested. Do it, eventually trying a stronger
- // kind of GC.
- _result = g1h->satisfy_failed_allocation(_word_size, &_pause_succeeded);
- } else {
- bool should_upgrade_to_full = !g1h->should_do_concurrent_full_gc(_gc_cause) &&
- !g1h->has_regions_left_for_allocation();
- if (should_upgrade_to_full) {
- // There has been a request to perform a GC to free some space. We have no
- // information on how much memory has been asked for. In case there are
- // absolutely no regions left to allocate into, do a maximally compacting full GC.
- log_info(gc, ergo)("Attempting maximally compacting collection");
- _pause_succeeded = g1h->do_full_collection(false, /* explicit gc */
- true /* clear_all_soft_refs */);
- }
- }
- guarantee(_pause_succeeded, "Elevated collections during the safepoint must always succeed.");
- } else {
- assert(_result == NULL, "invariant");
- // The only reason for the pause to not be successful is that, the GC locker is
- // active (or has become active since the prologue was executed). In this case
- // we should retry the pause after waiting for the GC locker to become inactive.
- _should_retry_gc = true;
- }
-}
-这里可以看到核心的是G1CollectedHeap::do_collection_pause_at_safepoint这个方法,它带上了目标暂停时间的值
-G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
- assert_at_safepoint_on_vm_thread();
- guarantee(!is_gc_active(), "collection is not reentrant");
-
- if (GCLocker::check_active_before_gc()) {
- return false;
- }
-
- _gc_timer_stw->register_gc_start();
-
- GCIdMark gc_id_mark;
- _gc_tracer_stw->report_gc_start(gc_cause(), _gc_timer_stw->gc_start());
-
- SvcGCMarker sgcm(SvcGCMarker::MINOR);
- ResourceMark rm;
-
- g1_policy()->note_gc_start();
-
- wait_for_root_region_scanning();
-
- print_heap_before_gc();
- print_heap_regions();
- trace_heap_before_gc(_gc_tracer_stw);
-
- _verifier->verify_region_sets_optional();
- _verifier->verify_dirty_young_regions();
-
- // We should not be doing initial mark unless the conc mark thread is running
- if (!_cm_thread->should_terminate()) {
- // This call will decide whether this pause is an initial-mark
- // pause. If it is, in_initial_mark_gc() will return true
- // for the duration of this pause.
- g1_policy()->decide_on_conc_mark_initiation();
- }
-
- // We do not allow initial-mark to be piggy-backed on a mixed GC.
- assert(!collector_state()->in_initial_mark_gc() ||
- collector_state()->in_young_only_phase(), "sanity");
-
- // We also do not allow mixed GCs during marking.
- assert(!collector_state()->mark_or_rebuild_in_progress() || collector_state()->in_young_only_phase(), "sanity");
-
- // Record whether this pause is an initial mark. When the current
- // thread has completed its logging output and it's safe to signal
- // the CM thread, the flag's value in the policy has been reset.
- bool should_start_conc_mark = collector_state()->in_initial_mark_gc();
-
- // Inner scope for scope based logging, timers, and stats collection
- {
- EvacuationInfo evacuation_info;
-
- if (collector_state()->in_initial_mark_gc()) {
- // We are about to start a marking cycle, so we increment the
- // full collection counter.
- increment_old_marking_cycles_started();
- _cm->gc_tracer_cm()->set_gc_cause(gc_cause());
- }
-
- _gc_tracer_stw->report_yc_type(collector_state()->yc_type());
-
- GCTraceCPUTime tcpu;
-
- G1HeapVerifier::G1VerifyType verify_type;
- FormatBuffer<> gc_string("Pause Young ");
- if (collector_state()->in_initial_mark_gc()) {
- gc_string.append("(Concurrent Start)");
- verify_type = G1HeapVerifier::G1VerifyConcurrentStart;
- } else if (collector_state()->in_young_only_phase()) {
- if (collector_state()->in_young_gc_before_mixed()) {
- gc_string.append("(Prepare Mixed)");
- } else {
- gc_string.append("(Normal)");
- }
- verify_type = G1HeapVerifier::G1VerifyYoungNormal;
- } else {
- gc_string.append("(Mixed)");
- verify_type = G1HeapVerifier::G1VerifyMixed;
- }
- GCTraceTime(Info, gc) tm(gc_string, NULL, gc_cause(), true);
-
- uint active_workers = AdaptiveSizePolicy::calc_active_workers(workers()->total_workers(),
- workers()->active_workers(),
- Threads::number_of_non_daemon_threads());
- active_workers = workers()->update_active_workers(active_workers);
- log_info(gc,task)("Using %u workers of %u for evacuation", active_workers, workers()->total_workers());
-
- TraceCollectorStats tcs(g1mm()->incremental_collection_counters());
- TraceMemoryManagerStats tms(&_memory_manager, gc_cause(),
- collector_state()->yc_type() == Mixed /* allMemoryPoolsAffected */);
-
- G1HeapTransition heap_transition(this);
- size_t heap_used_bytes_before_gc = used();
-
- // Don't dynamically change the number of GC threads this early. A value of
- // 0 is used to indicate serial work. When parallel work is done,
- // it will be set.
-
- { // Call to jvmpi::post_class_unload_events must occur outside of active GC
- IsGCActiveMark x;
-
- gc_prologue(false);
-
- if (VerifyRememberedSets) {
- log_info(gc, verify)("[Verifying RemSets before GC]");
- VerifyRegionRemSetClosure v_cl;
- heap_region_iterate(&v_cl);
- }
-
- _verifier->verify_before_gc(verify_type);
+public int sumOfFlooredPairs(int[] nums) {
+ int[] counts = new int[MAXE5+1];
+ for (int num : nums) {
+ counts[num]++;
+ }
+ // 这里就是很巧妙的给后一个加上前一个的值,这样其实前后任意两者之差就是这中间的元素数量
+ for (int i = 1; i <= MAXE5; i++) {
+ counts[i] += counts[i - 1];
+ }
+ long total = 0;
+ for (int i = 1; i <= MAXE5; i++) {
+ long sum = 0;
+ if (counts[i] == counts[i-1]) {
+ continue;
+ }
+ for (int j = 1; i*j <= MAXE5; j++) {
+ int min = i * j - 1;
+ int upper = i * (j + 1) - 1;
+ // 在每一个区间内的数量,
+ sum += (counts[Math.min(upper, MAXE5)] - counts[min]) * (long)j;
+ }
+ // 左边乘数的数量,即 i 位置的元素数量
+ total = (total + (sum % MODULUSE9 ) * (counts[i] - counts[i-1])) % MODULUSE9;
+ }
+ return (int)total;
+}
- _verifier->check_bitmaps("GC Start");
+贴出来大神的解析,解析
+结果
![]()
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+
+
+
+ Leetcode 2 Add Two Numbers 题解分析
+ /2020/10/11/Leetcode-2-Add-Two-Numbers-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 又 roll 到了一个以前做过的题,不过现在用 Java 也来写一下,是 easy 级别的,所以就简单说下
+简要介绍
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
+You may assume the two numbers do not contain any leading zero, except the number 0 itself.
就是给了两个链表,用来表示两个非负的整数,在链表中倒序放着,每个节点包含一位的数字,把他们加起来以后也按照原来的链表结构输出
+样例
example 1
Input: l1 = [2,4,3], l2 = [5,6,4]
+Output: [7,0,8]
+Explanation: 342 + 465 = 807.
-#if COMPILER2_OR_JVMCI
- DerivedPointerTable::clear();
-#endif
+example 2
Input: l1 = [0], l2 = [0]
+Output: [0]
- // Please see comment in g1CollectedHeap.hpp and
- // G1CollectedHeap::ref_processing_init() to see how
- // reference processing currently works in G1.
+example 3
Input: l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
+Output: [8,9,9,9,0,0,0,1]
- // Enable discovery in the STW reference processor
- _ref_processor_stw->enable_discovery();
-
- {
- // We want to temporarily turn off discovery by the
- // CM ref processor, if necessary, and turn it back on
- // on again later if we do. Using a scoped
- // NoRefDiscovery object will do this.
- NoRefDiscovery no_cm_discovery(_ref_processor_cm);
-
- // Forget the current alloc region (we might even choose it to be part
- // of the collection set!).
- _allocator->release_mutator_alloc_region();
-
- // This timing is only used by the ergonomics to handle our pause target.
- // It is unclear why this should not include the full pause. We will
- // investigate this in CR 7178365.
- //
- // Preserving the old comment here if that helps the investigation:
- //
- // The elapsed time induced by the start time below deliberately elides
- // the possible verification above.
- double sample_start_time_sec = os::elapsedTime();
-
- g1_policy()->record_collection_pause_start(sample_start_time_sec);
-
- if (collector_state()->in_initial_mark_gc()) {
- concurrent_mark()->pre_initial_mark();
- }
-
- g1_policy()->finalize_collection_set(target_pause_time_ms, &_survivor);
-
- evacuation_info.set_collectionset_regions(collection_set()->region_length());
-
- // Make sure the remembered sets are up to date. This needs to be
- // done before register_humongous_regions_with_cset(), because the
- // remembered sets are used there to choose eager reclaim candidates.
- // If the remembered sets are not up to date we might miss some
- // entries that need to be handled.
- g1_rem_set()->cleanupHRRS();
+题解
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
+ ListNode root = new ListNode();
+ if (l1 == null && l2 == null) {
+ return root;
+ }
+ ListNode tail = root;
+ int entered = 0;
+ // 这个条件加了 entered,就是还有进位的数
+ while (l1 != null || l2 != null || entered != 0) {
+ int temp = entered;
+ if (l1 != null) {
+ temp += l1.val;
+ l1 = l1.next;
+ }
+ if (l2 != null) {
+ temp += l2.val;
+ l2 = l2.next;
+ }
+ entered = (temp - temp % 10) / 10;
+ tail.val = temp % 10;
+ // 循环内部的控制是为了排除最后的空节点
+ if (l1 != null || l2 != null || entered != 0) {
+ tail.next = new ListNode();
+ tail = tail.next;
+ }
+ }
+// tail = null;
+ return root;
+ }
+这里唯二需要注意的就是两个点,一个是循环条件需要包含进位值还存在的情况,还有一个是最后一个节点,如果是空的了,就不要在 new 一个出来了,写的比较挫
+]]>
+
+ Java
+ leetcode
+ java
+ linked list
+ linked list
+
+
+ leetcode
+ java
+ 题解
+ linked list
+
+
+
+ Leetcode 234 回文链表(Palindrome Linked List) 题解分析
+ /2020/11/15/Leetcode-234-%E5%9B%9E%E6%96%87%E8%81%94%E8%A1%A8-Palindrome-Linked-List-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given a singly linked list, determine if it is a palindrome.
给定一个单向链表,判断是否是回文链表
+例一 Example 1:
Input: 1->2
Output: false
+例二 Example 2:
Input: 1->2->2->1
Output: true
+挑战下自己
Follow up:
Could you do it in O(n) time and O(1) space?
+简要分析
首先这是个单向链表,如果是双向的就可以一个从头到尾,一个从尾到头,显然那样就没啥意思了,然后想过要不找到中点,然后用一个栈,把前一半塞进栈里,但是这种其实也比较麻烦,比如长度是奇偶数,然后如何找到中点,这倒是可以借助于双指针,还是比较麻烦,再想一想,回文链表,就跟最开始的一样,链表只有单向的,我用个栈不就可以逆向了么,先把链表整个塞进栈里,然后在一个个 pop 出来跟链表从头开始比较,全对上了就是回文了
+/**
+ * Definition for singly-linked list.
+ * public class ListNode {
+ * int val;
+ * ListNode next;
+ * ListNode() {}
+ * ListNode(int val) { this.val = val; }
+ * ListNode(int val, ListNode next) { this.val = val; this.next = next; }
+ * }
+ */
+class Solution {
+ public boolean isPalindrome(ListNode head) {
+ if (head == null) {
+ return true;
+ }
+ ListNode tail = head;
+ LinkedList<Integer> stack = new LinkedList<>();
+ // 这里就是一个循环,将所有元素依次压入栈
+ while (tail != null) {
+ stack.push(tail.val);
+ tail = tail.next;
+ }
+ // 在逐个 pop 出来,其实这个出来的顺序就等于链表从尾到头遍历,同时跟链表从头到尾遍历进行逐对对比
+ while (!stack.isEmpty()) {
+ if (stack.peekFirst() == head.val) {
+ stack.pollFirst();
+ head = head.next;
+ } else {
+ return false;
+ }
+ }
+ return true;
+ }
+}
]]>
+
+ Java
+ leetcode
+ Linked List
+ java
+ Linked List
+
+
+ leetcode
+ java
+ 题解
+ Linked List
+
+
+
+ Leetcode 236 二叉树的最近公共祖先(Lowest Common Ancestor of a Binary Tree) 题解分析
+ /2021/05/23/Leetcode-236-%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88-Lowest-Common-Ancestor-of-a-Binary-Tree-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
+According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
+给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
+百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
+代码
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
+ // 如果当前节点就是 p 或者是 q 的时候,就直接返回了
+ // 当没找到,即 root == null 的时候也会返回 null,这是个重要的点
+ if (root == null || root == p || root == q) return root;
+ // 在左子树中找 p 和 q
+ TreeNode left = lowestCommonAncestor(root.left, p, q);
+ // 在右子树中找 p 和 q
+ TreeNode right = lowestCommonAncestor(root.right, p, q);
+ // 当左边是 null 就直接返回右子树,但是这里不表示右边不是 null,所以这个顺序是不影响的
+ // 考虑一种情况,如果一个节点的左右子树都是 null,那么其实对于这个节点来说首先两个子树分别调用
+ // lowestCommonAncestor会在开头就返回 null,那么就是上面 left 跟 right 都是 null,然后走下面的判断的时候
+ // 其实第一个 if 就返回了 null,如此递归返回就能达到当子树中没有找到 p 或者 q 的时候只返回 null
+ if (left == null) {
+ return right;
+ } else if (right == null) {
+ return left;
+ } else {
+ return root;
+ }
+// if (right == null) {
+// return left;
+// } else if (left == null) {
+// return right;
+// } else {
+// return root;
+// }
+// return left == null ? right : right == null ? left : root;
+ }
+]]>
+
+ Java
+ leetcode
+ Lowest Common Ancestor of a Binary Tree
+
+
+ leetcode
+ java
+ 题解
+ Lowest Common Ancestor of a Binary Tree
+
+
+
+ Leetcode 278 第一个错误的版本 ( First Bad Version *Easy* ) 题解分析
+ /2022/08/14/Leetcode-278-%E7%AC%AC%E4%B8%80%E4%B8%AA%E9%94%99%E8%AF%AF%E7%9A%84%E7%89%88%E6%9C%AC-First-Bad-Version-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
+Suppose you have n versions [1, 2, ..., n] and you want to find out the first bad one, which causes all the following ones to be bad.
+You are given an API bool isBadVersion(version) which returns whether version is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
+示例
Example 1:
+Input: n = 5, bad = 4
Output: 4
Explanation:
call isBadVersion(3) -> false
call isBadVersion(5) -> true
call isBadVersion(4) -> true
Then 4 is the first bad version.
+
+Example 2:
+Input: n = 1, bad = 1
Output: 1
+
+简析
简单来说就是一个二分查找,但是这个问题其实处理起来还是需要搞清楚一些边界问题
+代码
public int firstBadVersion(int n) {
+ // 类似于双指针法
+ int left = 1, right = n, mid;
+ while (left < right) {
+ // 取中点
+ mid = left + (right - left) / 2;
+ // 如果不是错误版本,就往右找
+ if (!isBadVersion(mid)) {
+ left = mid + 1;
+ } else {
+ // 如果是的话就往左查找
+ right = mid;
+ }
+ }
+ // 这里考虑交界情况是,在上面循环中如果 left 是好的,right 是坏的,那进入循环的时候 mid == left
+ // 然后 left = mid + 1 就会等于 right,循环条件就跳出了,此时 left 就是那个起始的错误点了
+ // 其实这两个是同一个值
+ return left;
+}
- register_humongous_regions_with_cset();
+往右移动示例
![]()
往左移动示例
![]()
+结果
![]()
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+ First Bad Version
+
+
+
+ Leetcode 3 Longest Substring Without Repeating Characters 题解分析
+ /2020/09/20/Leetcode-3-Longest-Substring-Without-Repeating-Characters-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 又做了个题,看记录是以前用 C++写过的,现在捋一捋思路,用 Java 再写了一下,思路还是比较清晰的,但是边界细节处理得比较差
+简要介绍
Given a string s, find the length of the longest substring without repeating characters.
+样例
Example 1:
Input: s = "abcabcbb"
+Output: 3
+Explanation: The answer is "abc", with the length of 3.
- assert(_verifier->check_cset_fast_test(), "Inconsistency in the InCSetState table.");
+Example 2:
Input: s = "bbbbb"
+Output: 1
+Explanation: The answer is "b", with the length of 1.
+Example 3:
Input: s = "pwwkew"
+Output: 3
+Explanation: The answer is "wke", with the length of 3.
+Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
+Example 4:
Input: s = ""
+Output: 0
- // We call this after finalize_cset() to
- // ensure that the CSet has been finalized.
- _cm->verify_no_cset_oops();
-
- if (_hr_printer.is_active()) {
- G1PrintCollectionSetClosure cl(&_hr_printer);
- _collection_set.iterate(&cl);
+就是一个最长不重复的字符串长度,因为也是中等难度的题,不太需要特别复杂的思考,最基本的就是O(N*N)两重循环,不过显然不太好,万一超时间,还有一种就是线性复杂度的了,这个就是需要搞定一个思路,比如字符串时 abcdefgaqwrty,比如遍历到第二个a的时候其实不用再从头去遍历了,只要把前面那个a给排除掉,继续往下算就好了
+class Solution {
+ Map<String, Integer> counter = new HashMap<>();
+ public int lengthOfLongestSubstring(String s) {
+ int length = s.length();
+ // 当前的长度
+ int subStringLength = 0;
+ // 最长的长度
+ int maxSubStringLength = 0;
+ // 考虑到重复的位置已经被跳过的情况,即已经在当前长度的字符串范围之前的重复字符不需要回溯
+ int lastDuplicatePos = -1;
+ for (int i = 0; i < length; i++) {
+ // 使用 map 存储字符和上一次出现的位置,如果存在并且大于上一次重复位置
+ if (counter.get(String.valueOf(s.charAt(i))) != null && counter.get(String.valueOf(s.charAt(i))) > lastDuplicatePos) {
+ // 记录重复位置
+ lastDuplicatePos = counter.get(String.valueOf(s.charAt(i)));
+ // 重置不重复子串的长度,减去重复起点
+ subStringLength = i - counter.get(String.valueOf(s.charAt(i))) - 1;
+ // 替换当前位置
+ counter.replace(String.valueOf(s.charAt(i)), i);
+ } else {
+ // 如果不存在就直接 put
+ counter.put(String.valueOf(s.charAt(i)), i);
+ }
+ // 长度累加
+ subStringLength++;
+ if (subStringLength > maxSubStringLength) {
+ // 简单替换
+ maxSubStringLength = subStringLength;
+ }
}
+ return maxSubStringLength;
+ }
+}
+注释应该写的比较清楚了。
+]]>
+
+ Java
+ leetcode
+ java
+ 字符串 - online
+ string
+
+
+ leetcode
+ java
+ 题解
+ string
+
+
+
+ Leetcode 349 两个数组的交集 ( Intersection of Two Arrays *Easy* ) 题解分析
+ /2022/03/07/Leetcode-349-%E4%B8%A4%E4%B8%AA%E6%95%B0%E7%BB%84%E7%9A%84%E4%BA%A4%E9%9B%86-Intersection-of-Two-Arrays-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
+
+示例
+示例 1:
+输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
+
+
+示例 2:
+输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
+
+
+提示:
+1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
+分析与题解
两个数组的交集,最简单就是两层循环了把两个都存在的找出来,不过还有个要去重的问题,稍微思考下可以使用集合 set 来处理,先把一个数组全丢进去,再对比另外一个,如果出现在第一个集合里就丢进一个新的集合,最后转换成数组,这次我稍微取了个巧,因为看到了提示里的条件,两个数组中的元素都是不大于 1000 的,所以就搞了个 1000 长度的数组,如果在第一个数组出现,就在对应的下标设置成 1,如果在第二个数组也出现了就加 1,
+code
public int[] intersection(int[] nums1, int[] nums2) {
+ // 大小是 1000 的数组,如果没有提示的条件就没法这么做
+ // define a array which size is 1000, and can not be done like this without the condition in notice
+ int[] inter = new int[1000];
+ int[] outer;
+ int m = 0;
+ for (int j : nums1) {
+ // 这里得是设置成 1,因为有可能 nums1 就出现了重复元素,如果直接++会造成结果重复
+ // need to be set 1, cause element in nums1 can be duplicated
+ inter[j] = 1;
+ }
+ for (int j : nums2) {
+ if (inter[j] > 0) {
+ // 这里可以直接+1,因为后面判断只需要判断大于 1
+ // just plus 1, cause we can judge with condition that larger than 1
+ inter[j] += 1;
+ }
+ }
+ for (int i = 0; i < inter.length; i++) {
+ // 统计下元素数量
+ // count distinct elements
+ if (inter[i] > 1) {
+ m++;
+ }
+ }
+ // initial a array of size m
+ outer = new int[m];
+ m = 0;
+ for (int i = 0; i < inter.length; i++) {
+ if (inter[i] > 1) {
+ // add to outer
+ outer[m++] = i;
+ }
+ }
+ return outer;
+ }
]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+ Intersection of Two Arrays
+
+
+
+ Leetcode 20 有效的括号 ( Valid Parentheses *Easy* ) 题解分析
+ /2022/07/02/Leetcode-20-%E6%9C%89%E6%95%88%E7%9A%84%E6%8B%AC%E5%8F%B7-Valid-Parentheses-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given a string s containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
+An input string is valid if:
+
+- Open brackets must be closed by the same type of brackets.
+- Open brackets must be closed in the correct order.
+
+示例
Example 1:
+Input: s = “()”
Output: true
+
+Example 2:
+Input: s = “()[]{}”
Output: true
+
+Example 3:
+Input: s = “(]”
Output: false
+
+Constraints:
+1 <= s.length <= 10^4s consists of parentheses only '()[]{}'.
+解析
easy题,并且看起来也是比较简单的,三种括号按对匹配,直接用栈来做,栈里面存的是括号的类型,如果是左括号,就放入栈中,如果是右括号,就把栈顶的元素弹出,如果弹出的元素不是左括号,就返回false,如果弹出的元素是左括号,就继续往下走,如果遍历完了,如果栈里面还有元素,就返回false,如果遍历完了,如果栈里面没有元素,就返回true
+代码
class Solution {
+ public boolean isValid(String s) {
- // Initialize the GC alloc regions.
- _allocator->init_gc_alloc_regions(evacuation_info);
-
- G1ParScanThreadStateSet per_thread_states(this, workers()->active_workers(), collection_set()->young_region_length());
- pre_evacuate_collection_set();
-
- // Actually do the work...
- evacuate_collection_set(&per_thread_states);
+ if (s.length() % 2 != 0) {
+ return false;
+ }
+ Stack<String> stk = new Stack<>();
+ for (int i = 0; i < s.length(); i++) {
+ if (s.charAt(i) == '{' || s.charAt(i) == '(' || s.charAt(i) == '[') {
+ stk.push(String.valueOf(s.charAt(i)));
+ continue;
+ }
+ if (s.charAt(i) == '}') {
+ if (stk.isEmpty()) {
+ return false;
+ }
+ String cur = stk.peek();
+ if (cur.charAt(0) != '{') {
+ return false;
+ } else {
+ stk.pop();
+ }
+ continue;
+ }
+ if (s.charAt(i) == ']') {
+ if (stk.isEmpty()) {
+ return false;
+ }
+ String cur = stk.peek();
+ if (cur.charAt(0) != '[') {
+ return false;
+ } else {
+ stk.pop();
+ }
+ continue;
+ }
+ if (s.charAt(i) == ')') {
+ if (stk.isEmpty()) {
+ return false;
+ }
+ String cur = stk.peek();
+ if (cur.charAt(0) != '(') {
+ return false;
+ } else {
+ stk.pop();
+ }
+ continue;
+ }
- post_evacuate_collection_set(evacuation_info, &per_thread_states);
+ }
+ return stk.size() == 0;
+ }
+}
- const size_t* surviving_young_words = per_thread_states.surviving_young_words();
- free_collection_set(&_collection_set, evacuation_info, surviving_young_words);
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+
+
+
+ Leetcode 4 寻找两个正序数组的中位数 ( Median of Two Sorted Arrays *Hard* ) 题解分析
+ /2022/03/27/Leetcode-4-%E5%AF%BB%E6%89%BE%E4%B8%A4%E4%B8%AA%E6%AD%A3%E5%BA%8F%E6%95%B0%E7%BB%84%E7%9A%84%E4%B8%AD%E4%BD%8D%E6%95%B0-Median-of-Two-Sorted-Arrays-Hard-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
+算法的时间复杂度应该为 O(log (m+n)) 。
+示例 1:
+输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
+
+示例 2:
+输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
+
+分析与题解
这个题也是我随机出来的,之前都是随机到 easy 的,而且是序号这么靠前的,然后翻一下,之前应该是用 C++做过的,具体的方法其实可以从他的算法时间复杂度要求看出来,大概率是要二分法这种,后面就结合代码来讲了
+public double findMedianSortedArrays(int[] nums1, int[] nums2) {
+ int n1 = nums1.length;
+ int n2 = nums2.length;
+ if (n1 > n2) {
+ return findMedianSortedArrays(nums2, nums1);
+ }
- eagerly_reclaim_humongous_regions();
+ // 找到两个数组的中点下标
+ int k = (n1 + n2 + 1 ) / 2;
+ // 使用一个类似于二分法的查找方法
+ // 起始值就是 num1 的头跟尾
+ int left = 0;
+ int right = n1;
+ while (left < right) {
+ // m1 表示我取的是 nums1 的中点,即二分法的方式
+ int m1 = left + (right - left) / 2;
+ // *** 这里是重点,因为这个问题也可以转换成找成 n1 + n2 那么多个数中的前 (n1 + n2 + 1) / 2 个
+ // *** 因为两个数组都是排好序的,那么我从 num1 中取了 m1 个,从 num2 中就是去 k - m1 个
+ // *** 但是不知道取出来大小是否正好是整体排序的第 (n1 + n2 + 1) / 2 个,所以需要二分法上下对比
+ int m2 = k - m1;
+ // 如果 nums1[m1] 小,那我在第一个数组 nums1 的二分查找就要把左端点改成前一次的中点 + 1 (不然就进死循环了
+ if (nums1[m1] < nums2[m2 - 1]) {
+ left = m1 + 1;
+ } else {
+ right = m1;
+ }
+ }
- record_obj_copy_mem_stats();
- _survivor_evac_stats.adjust_desired_plab_sz();
- _old_evac_stats.adjust_desired_plab_sz();
-
- double start = os::elapsedTime();
- start_new_collection_set();
- g1_policy()->phase_times()->record_start_new_cset_time_ms((os::elapsedTime() - start) * 1000.0);
-
- if (evacuation_failed()) {
- set_used(recalculate_used());
- if (_archive_allocator != NULL) {
- _archive_allocator->clear_used();
- }
- for (uint i = 0; i < ParallelGCThreads; i++) {
- if (_evacuation_failed_info_array[i].has_failed()) {
- _gc_tracer_stw->report_evacuation_failed(_evacuation_failed_info_array[i]);
- }
- }
- } else {
- // The "used" of the the collection set have already been subtracted
- // when they were freed. Add in the bytes evacuated.
- increase_used(g1_policy()->bytes_copied_during_gc());
- }
-
- if (collector_state()->in_initial_mark_gc()) {
- // We have to do this before we notify the CM threads that
- // they can start working to make sure that all the
- // appropriate initialization is done on the CM object.
- concurrent_mark()->post_initial_mark();
- // Note that we don't actually trigger the CM thread at
- // this point. We do that later when we're sure that
- // the current thread has completed its logging output.
- }
-
- allocate_dummy_regions();
-
- _allocator->init_mutator_alloc_region();
-
- {
- size_t expand_bytes = _heap_sizing_policy->expansion_amount();
- if (expand_bytes > 0) {
- size_t bytes_before = capacity();
- // No need for an ergo logging here,
- // expansion_amount() does this when it returns a value > 0.
- double expand_ms;
- if (!expand(expand_bytes, _workers, &expand_ms)) {
- // We failed to expand the heap. Cannot do anything about it.
- }
- g1_policy()->phase_times()->record_expand_heap_time(expand_ms);
- }
- }
-
- // We redo the verification but now wrt to the new CSet which
- // has just got initialized after the previous CSet was freed.
- _cm->verify_no_cset_oops();
-
- // This timing is only used by the ergonomics to handle our pause target.
- // It is unclear why this should not include the full pause. We will
- // investigate this in CR 7178365.
- double sample_end_time_sec = os::elapsedTime();
- double pause_time_ms = (sample_end_time_sec - sample_start_time_sec) * MILLIUNITS;
- size_t total_cards_scanned = g1_policy()->phase_times()->sum_thread_work_items(G1GCPhaseTimes::ScanRS, G1GCPhaseTimes::ScanRSScannedCards);
- g1_policy()->record_collection_pause_end(pause_time_ms, total_cards_scanned, heap_used_bytes_before_gc);
-
- evacuation_info.set_collectionset_used_before(collection_set()->bytes_used_before());
- evacuation_info.set_bytes_copied(g1_policy()->bytes_copied_during_gc());
-
- if (VerifyRememberedSets) {
- log_info(gc, verify)("[Verifying RemSets after GC]");
- VerifyRegionRemSetClosure v_cl;
- heap_region_iterate(&v_cl);
- }
+ // 因为对比后其实我们只是拿到了一个位置,具体哪个是第 k 个就需要继续判断
+ int m1 = left;
+ int m2 = k - left;
+ // 如果 m1 或者 m2 有小于等于 0 的,那这个值可以先抛弃
+ // m1 如果等于 0,就是 num1[0] 都比 nums2 中所有值都要大
+ // m2 等于 0 的话 刚好相反
+ // 可以这么推断,当其中一个是 0 的时候那么另一个 mx 值肯定是> 0 的,那么就是取的对应的这个下标的值
+ int c1 = Math.max( m1 <= 0 ? Integer.MIN_VALUE : nums1[m1 - 1] , m2 <= 0 ? Integer.MIN_VALUE : nums2[m2 - 1]);
+ // 如果两个数组的元素数量和是奇数,那就直接可以返回了,因为 m1 + m2 就是 k, 如果是一个数组,那这个元素其实就是 nums[k - 1]
+ // 如果 m1 或者 m2 是 0,那另一个就是 k,取 mx - 1的下标就等于是 k - 1
+ // 如果都不是 0,那就是取的了 nums1[m1 - 1] 与 nums2[m2 - 1]中的较大者,如果取得是后者,那么也就是 m1 + m2 - 1 的下标就是 k - 1
+ if ((n1 + n2) % 2 == 1) {
+ return c1;
+ }
+ // 如果是偶数个,那还要取两个数组后面的较小者,然后求平均值
+ int c2 = Math.min(m1 >= n1 ? Integer.MAX_VALUE : nums1[m1], m2 >= n2 ? Integer.MAX_VALUE : nums2[m2]);
+ return (c1 + c2) / 2.0;
+ }
+前面考虑的方法还是比较繁琐,考虑了两个数组的各种交叉情况,后面这个参考了一些网上的解法,代码比较简洁,但是可能不容易一下子就搞明白,所以配合了比较多的注释。
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+ Median of Two Sorted Arrays
+
+
+
+ Leetcode 48 旋转图像(Rotate Image) 题解分析
+ /2021/05/01/Leetcode-48-%E6%97%8B%E8%BD%AC%E5%9B%BE%E5%83%8F-Rotate-Image-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
+You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
![]()
如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
+代码
直接上码
+public void rotate(int[][] matrix) {
+ // 这里真的傻了,长宽应该是一致的,所以取一次就够了
+ int lengthX = matrix[0].length;
+ int lengthY = matrix.length;
+ int temp;
+ System.out.println(lengthY - (lengthY % 2) / 2);
+ // 这里除错了,应该是减掉余数再除 2
+// for (int i = 0; i < lengthY - (lengthY % 2) / 2; i++) {
+ /**
+ * 1 2 3 7 8 9
+ * 4 5 6 => 4 5 6 先沿着 4 5 6 上下交换
+ * 7 8 9 1 2 3
+ */
+ for (int i = 0; i < (lengthY - (lengthY % 2)) / 2; i++) {
+ for (int j = 0; j < lengthX; j++) {
+ temp = matrix[i][j];
+ matrix[i][j] = matrix[lengthY-i-1][j];
+ matrix[lengthY-i-1][j] = temp;
+ }
+ }
- _verifier->verify_after_gc(verify_type);
- _verifier->check_bitmaps("GC End");
+ /**
+ * 7 8 9 7 4 1
+ * 4 5 6 => 8 5 2 这里再沿着 7 5 3 这条对角线交换
+ * 1 2 3 9 6 3
+ */
+ for (int i = 0; i < lengthX; i++) {
+ for (int j = 0; j <= i; j++) {
+ if (i == j) {
+ continue;
+ }
+ temp = matrix[i][j];
+ matrix[i][j] = matrix[j][i];
+ matrix[j][i] = temp;
+ }
+ }
+ }
+还没到可以直接归纳题目类型的水平,主要是几年前做过,可能有那么点模糊的记忆,当然应该也有直接转的方法
+]]>
+
+ Java
+ leetcode
+ Rotate Image
+
+
+ leetcode
+ java
+ 题解
+ Rotate Image
+ 矩阵
+
+
+
+ Leetcode 698 划分为k个相等的子集 ( Partition to K Equal Sum Subsets *Medium* ) 题解分析
+ /2022/06/19/Leetcode-698-%E5%88%92%E5%88%86%E4%B8%BAk%E4%B8%AA%E7%9B%B8%E7%AD%89%E7%9A%84%E5%AD%90%E9%9B%86-Partition-to-K-Equal-Sum-Subsets-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍Given an integer array nums and an integer k, return true if it is possible to divide this array into k non-empty subsets whose sums are all equal.
+示例
Example 1:
+
+Input: nums = [4,3,2,3,5,2,1], k = 4
Output: true
Explanation: It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) with equal sums.
+
+Example 2:
+
+Input: nums = [1,2,3,4], k = 3
Output: false
+
+Constraints:
+
+- 1 <= k <= nums.length <= 16
+- 1 <= nums[i] <= 10^4
+- The frequency of each element is in the range [1, 4].
+
+解析
看到这个题一开始以为挺简单,但是仔细想想问题还是挺多的,首先是分成 k 组,但是数量不限,应该需要用到回溯的方式,同时对于时间和空间复杂度也有要求,一开始这个代码是超时的,我也试了下 leetcode 上 discussion 里 vote 最高的提交也是超时的,不过看 discussion 里的帖子,貌似是后面加了一些条件,可以帮忙提高执行效率,第三条提示不太清楚意图,具体可以看下代码
+代码
public boolean canPartitionKSubsets(int[] nums, int k) {
+ if (k == 1) {
+ return true;
+ }
+ int sum = 0, n;
+ n = nums.length;
+ for (int num : nums) {
+ sum += num;
+ }
+ if (sum % k != 0) {
+ return false;
+ }
- assert(!_ref_processor_stw->discovery_enabled(), "Postcondition");
- _ref_processor_stw->verify_no_references_recorded();
+ int avg = sum / k;
+ // 排序
+ Arrays.sort(nums);
+ // 做个前置判断,如果最大值超过分组平均值了就可以返回 false 了
+ if (nums[n - 1] > avg) {
+ return false;
+ }
+ // 这里取了个巧,先将数组中元素就等于分组平均值的直接排除了
+ int calculated = 0;
+ for (int i = n - 1; i > 0; i--) {
+ if (nums[i] == avg) {
+ k--;
+ calculated++;
+ }
+ }
- // CM reference discovery will be re-enabled if necessary.
- }
+ int[] bucket = new int[k];
+ // 初始化 bucket
+ for (int i = 0; i < k; i++) {
+ bucket[i] = avg;
+ }
-#ifdef TRACESPINNING
- ParallelTaskTerminator::print_termination_counts();
-#endif
+ // 提前做下边界判断
+ if (nums[n - 1] > avg) {
+ return false;
+ }
- gc_epilogue(false);
- }
+ return backTraversal(nums, bucket, k, n - 1 - calculated);
+}
- // Print the remainder of the GC log output.
- if (evacuation_failed()) {
- log_info(gc)("To-space exhausted");
- }
+private boolean backTraversal(int[] nums, int[] bucket, int k, int cur) {
+ if (cur < 0) {
+ return true;
+ }
+ for (int i = 0; i < k; i++) {
+ if (bucket[i] == nums[cur] || bucket[i] >= nums[cur] + nums[0]) {
+ // 判断如果当前 bucket[i] 剩余的数字等于nums[cur], 即当前bucket已经满了
+ // 或者如果当前 bucket[i] 剩余的数字大于等于 nums[cur] + nums[0] ,
+ // 因为nums 在经过排序后 nums[0]是最小值,如果加上 nums[0] 都已经超过bucket[i] 了,
+ // 那当前bucket[i] 肯定是没法由包含 nums[cur] 的组合组成一个满足和为前面 s/k 的组合了
+ // 这里判断的是 nums[cur] ,如果第一次 k 次循环都不符合其实就返回 false 了
- g1_policy()->print_phases();
- heap_transition.print();
+ // 而如果符合,就将 bucket[i] 减去 nums[cur] 再次进入递归,
+ // 这里进入递归有个收敛参数就是 cur - 1,因为其实判断 cur 递减作为一个结束条件
+ bucket[i] -= nums[cur];
+ // 符合条件,这里对应着入口,当 cur 被减到 0 了,就表示都符合了因为是根据所有值的和 s 和 k 组除出来的平均值,当所有数都通过前面的 if 判断符合了,并且每个数字都使用了,
+ // 即说明已经符合要求了
+ if (backTraversal(nums, bucket, k, cur - 1)) return true;
+ // 这边是个回退机制,如果前面 nums[cur]没办法组合成和为平均值的话就减掉进入下一个循环
+ bucket[i] += nums[cur];
+ }
+ }
+ return false;
+}
- // It is not yet to safe to tell the concurrent mark to
- // start as we have some optional output below. We don't want the
- // output from the concurrent mark thread interfering with this
- // logging output either.
-
- _hrm.verify_optional();
- _verifier->verify_region_sets_optional();
-
- TASKQUEUE_STATS_ONLY(print_taskqueue_stats());
- TASKQUEUE_STATS_ONLY(reset_taskqueue_stats());
-
- print_heap_after_gc();
- print_heap_regions();
- trace_heap_after_gc(_gc_tracer_stw);
-
- // We must call G1MonitoringSupport::update_sizes() in the same scoping level
- // as an active TraceMemoryManagerStats object (i.e. before the destructor for the
- // TraceMemoryManagerStats is called) so that the G1 memory pools are updated
- // before any GC notifications are raised.
- g1mm()->update_sizes();
-
- _gc_tracer_stw->report_evacuation_info(&evacuation_info);
- _gc_tracer_stw->report_tenuring_threshold(_g1_policy->tenuring_threshold());
- _gc_timer_stw->register_gc_end();
- _gc_tracer_stw->report_gc_end(_gc_timer_stw->gc_end(), _gc_timer_stw->time_partitions());
- }
- // It should now be safe to tell the concurrent mark thread to start
- // without its logging output interfering with the logging output
- // that came from the pause.
-
- if (should_start_conc_mark) {
- // CAUTION: after the doConcurrentMark() call below,
- // the concurrent marking thread(s) could be running
- // concurrently with us. Make sure that anything after
- // this point does not assume that we are the only GC thread
- // running. Note: of course, the actual marking work will
- // not start until the safepoint itself is released in
- // SuspendibleThreadSet::desynchronize().
- do_concurrent_mark();
- }
-
- return true;
-}
-往下走就是这一步G1Policy::finalize_collection_set,去处理新生代和老年代
-void G1Policy::finalize_collection_set(double target_pause_time_ms, G1SurvivorRegions* survivor) {
- double time_remaining_ms = _collection_set->finalize_young_part(target_pause_time_ms, survivor);
- _collection_set->finalize_old_part(time_remaining_ms);
-}
-这里分别调用了两个方法,可以看到剩余时间是往下传的,来看一下具体的方法
-double G1CollectionSet::finalize_young_part(double target_pause_time_ms, G1SurvivorRegions* survivors) {
- double young_start_time_sec = os::elapsedTime();
-
- finalize_incremental_building();
-
- guarantee(target_pause_time_ms > 0.0,
- "target_pause_time_ms = %1.6lf should be positive", target_pause_time_ms);
-
- size_t pending_cards = _policy->pending_cards();
- double base_time_ms = _policy->predict_base_elapsed_time_ms(pending_cards);
- double time_remaining_ms = MAX2(target_pause_time_ms - base_time_ms, 0.0);
-
- log_trace(gc, ergo, cset)("Start choosing CSet. pending cards: " SIZE_FORMAT " predicted base time: %1.2fms remaining time: %1.2fms target pause time: %1.2fms",
- pending_cards, base_time_ms, time_remaining_ms, target_pause_time_ms);
-
- // The young list is laid with the survivor regions from the previous
- // pause are appended to the RHS of the young list, i.e.
- // [Newly Young Regions ++ Survivors from last pause].
-
- uint survivor_region_length = survivors->length();
- uint eden_region_length = _g1h->eden_regions_count();
- init_region_lengths(eden_region_length, survivor_region_length);
-
- verify_young_cset_indices();
-
- // Clear the fields that point to the survivor list - they are all young now.
- survivors->convert_to_eden();
-
- _bytes_used_before = _inc_bytes_used_before;
- time_remaining_ms = MAX2(time_remaining_ms - _inc_predicted_elapsed_time_ms, 0.0);
-
- log_trace(gc, ergo, cset)("Add young regions to CSet. eden: %u regions, survivors: %u regions, predicted young region time: %1.2fms, target pause time: %1.2fms",
- eden_region_length, survivor_region_length, _inc_predicted_elapsed_time_ms, target_pause_time_ms);
-
- // The number of recorded young regions is the incremental
- // collection set's current size
- set_recorded_rs_lengths(_inc_recorded_rs_lengths);
-
- double young_end_time_sec = os::elapsedTime();
- phase_times()->record_young_cset_choice_time_ms((young_end_time_sec - young_start_time_sec) * 1000.0);
-
- return time_remaining_ms;
-}
-下面是老年代的部分
-void G1CollectionSet::finalize_old_part(double time_remaining_ms) {
- double non_young_start_time_sec = os::elapsedTime();
- double predicted_old_time_ms = 0.0;
-
- if (collector_state()->in_mixed_phase()) {
- cset_chooser()->verify();
- const uint min_old_cset_length = _policy->calc_min_old_cset_length();
- const uint max_old_cset_length = _policy->calc_max_old_cset_length();
-
- uint expensive_region_num = 0;
- bool check_time_remaining = _policy->adaptive_young_list_length();
-
- HeapRegion* hr = cset_chooser()->peek();
- while (hr != NULL) {
- if (old_region_length() >= max_old_cset_length) {
- // Added maximum number of old regions to the CSet.
- log_debug(gc, ergo, cset)("Finish adding old regions to CSet (old CSet region num reached max). old %u regions, max %u regions",
- old_region_length(), max_old_cset_length);
- break;
- }
-
- // Stop adding regions if the remaining reclaimable space is
- // not above G1HeapWastePercent.
- size_t reclaimable_bytes = cset_chooser()->remaining_reclaimable_bytes();
- double reclaimable_percent = _policy->reclaimable_bytes_percent(reclaimable_bytes);
- double threshold = (double) G1HeapWastePercent;
- if (reclaimable_percent <= threshold) {
- // We've added enough old regions that the amount of uncollected
- // reclaimable space is at or below the waste threshold. Stop
- // adding old regions to the CSet.
- log_debug(gc, ergo, cset)("Finish adding old regions to CSet (reclaimable percentage not over threshold). "
- "old %u regions, max %u regions, reclaimable: " SIZE_FORMAT "B (%1.2f%%) threshold: " UINTX_FORMAT "%%",
- old_region_length(), max_old_cset_length, reclaimable_bytes, reclaimable_percent, G1HeapWastePercent);
- break;
- }
+最后贴个图
![]()
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+
+
+
+ Leetcode 885 螺旋矩阵 III ( Spiral Matrix III *Medium* ) 题解分析
+ /2022/08/23/Leetcode-885-%E8%9E%BA%E6%97%8B%E7%9F%A9%E9%98%B5-III-Spiral-Matrix-III-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍You start at the cell (rStart, cStart) of an rows x cols grid facing east. The northwest corner is at the first row and column in the grid, and the southeast corner is at the last row and column.
+You will walk in a clockwise spiral shape to visit every position in this grid. Whenever you move outside the grid’s boundary, we continue our walk outside the grid (but may return to the grid boundary later.). Eventually, we reach all rows * cols spaces of the grid.
+Return an array of coordinates representing the positions of the grid in the order you visited them.
+Example 1:
+Input: rows = 1, cols = 4, rStart = 0, cStart = 0
Output: [[0,0],[0,1],[0,2],[0,3]]
+
+Example 2:
+Input: rows = 5, cols = 6, rStart = 1, cStart = 4
Output: [[1,4],[1,5],[2,5],[2,4],[2,3],[1,3],[0,3],[0,4],[0,5],[3,5],[3,4],[3,3],[3,2],[2,2],[1,2],[0,2],[4,5],[4,4],[4,3],[4,2],[4,1],[3,1],[2,1],[1,1],[0,1],[4,0],[3,0],[2,0],[1,0],[0,0]]
+
+Constraints:
+
+1 <= rows, cols <= 100 0 <= rStart < rows 0 <= cStart < cols
+简析
这个题主要是要相同螺旋矩阵的转变方向的边界判断,已经相同步长会行进两次这个规律,写代码倒不复杂
+代码
public int[][] spiralMatrixIII(int rows, int cols, int rStart, int cStart) {
+ int size = rows * cols;
+ int x = rStart, y = cStart;
+ // 返回的二维矩阵
+ int[][] matrix = new int[size][2];
+ // 传入的参数就是入口第一个
+ matrix[0][0] = rStart;
+ matrix[0][1] = cStart;
+ // 作为数量
+ int z = 1;
+ // 步进,1,1,2,2,3,3,4 ... 螺旋矩阵的增长
+ int a = 1;
+ // 方向 1 表示右,2 表示下,3 表示左,4 表示上
+ int dir = 1;
+ while (z < size) {
+ for (int i = 0; i < 2; i++) {
+ for (int j= 0; j < a; j++) {
+ // 处理方向
+ if (dir % 4 == 1) {
+ y++;
+ } else if (dir % 4 == 2) {
+ x++;
+ } else if (dir % 4 == 3) {
+ y--;
+ } else {
+ x--;
+ }
+ // 如果在实际矩阵内
+ if (x < rows && y < cols && x >= 0 && y >= 0) {
+ matrix[z][0] = x;
+ matrix[z][1] = y;
+ z++;
+ }
+ }
+ // 转变方向
+ dir++;
+ }
+ // 步进++
+ a++;
+ }
+ return matrix;
+ }
- double predicted_time_ms = predict_region_elapsed_time_ms(hr);
- if (check_time_remaining) {
- if (predicted_time_ms > time_remaining_ms) {
- // Too expensive for the current CSet.
+结果
![]()
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+
+
+
+ Linux 下 grep 命令的一点小技巧
+ /2020/08/06/Linux-%E4%B8%8B-grep-%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E7%82%B9%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 用了比较久的 grep 命令,其实都只是用了最最基本的功能来查日志,
+譬如
+
+grep 'xxx' xxxx.log
+
- if (old_region_length() >= min_old_cset_length) {
- // We have added the minimum number of old regions to the CSet,
- // we are done with this CSet.
- log_debug(gc, ergo, cset)("Finish adding old regions to CSet (predicted time is too high). "
- "predicted time: %1.2fms, remaining time: %1.2fms old %u regions, min %u regions",
- predicted_time_ms, time_remaining_ms, old_region_length(), min_old_cset_length);
- break;
- }
+然后有挺多情况比如想要找日志里带一些符号什么的,就需要用到一些特殊的
+比如这样\"userId\":\"123456\",因为比如用户 ID 有时候会跟其他的 id 一样,只用具体的值 123456 来查的话干扰信息太多了,如果直接这样
+
+grep '\"userId\":\"123456\"' xxxx.log
+
- // We'll add it anyway given that we haven't reached the
- // minimum number of old regions.
- expensive_region_num += 1;
- }
- } else {
- if (old_region_length() >= min_old_cset_length) {
- // In the non-auto-tuning case, we'll finish adding regions
- // to the CSet if we reach the minimum.
+好像不行,盲猜就是符号的问题,特别是\和"这两个,
+之前一直是想试一下,但是没成功,昨天在排查一个问题的时候发现了,只要把这些都转义了就行了
+grep '\\\"userId\\\":\\\"123456\\\"' xxxx.log
+![]()
+]]>
+
+ Linux
+ 命令
+ 小技巧
+ grep
+ grep
+ 查日志
+
+
+ linux
+ grep
+ 转义
+
+
+
+ Leetcode 83 删除排序链表中的重复元素 ( Remove Duplicates from Sorted List *Easy* ) 题解分析
+ /2022/03/13/Leetcode-83-%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0-Remove-Duplicates-from-Sorted-List-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
PS:注意已排序,还有返回也要已排序
+示例 1:
![]()
+
+输入:head = [1,1,2]
输出:[1,2]
+
+示例 2:
![]()
+
+输入:head = [1,1,2,3,3]
输出:[1,2,3]
+
+提示:
+- 链表中节点数目在范围
[0, 300] 内
+-100 <= Node.val <= 100- 题目数据保证链表已经按 升序 排列
+
+分析与题解
这题其实是比较正常的 easy 级别的题目,链表已经排好序了,如果还带一个排序就更复杂一点,
只需要前后项做个对比,如果一致则移除后项,因为可能存在多个重复项,所以只有在前后项不同
时才会更新被比较项
+code
public ListNode deleteDuplicates(ListNode head) {
+ // 链表头是空的或者只有一个头结点,就不用处理了
+ if (head == null || head.next == null) {
+ return head;
+ }
+ ListNode tail = head;
+ // 以处理节点还有后续节点作为循环边界条件
+ while (tail.next != null) {
+ ListNode temp = tail.next;
+ // 如果前后相同,那么可以跳过这个节点,将 Tail ----> temp ---> temp.next
+ // 更新成 Tail ----> temp.next
+ if (temp.val == tail.val) {
+ tail.next = temp.next;
+ } else {
+ // 不相同,则更新 tail
+ tail = tail.next;
+ }
+ }
+ // 最后返回头结点
+ return head;
+}
+链表应该是个需要反复的训练的数据结构,因为涉及到前后指针,然后更新操作,判空等,
我在这块也是掌握的不太好,需要多练习。
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+ Remove Duplicates from Sorted List
+
+
+
+ Leetcode 42 接雨水 (Trapping Rain Water) 题解分析
+ /2021/07/04/Leetcode-42-%E6%8E%A5%E9%9B%A8%E6%B0%B4-Trapping-Rain-Water-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
+示例
![]()
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
+简单分析
其实最开始的想法是从左到右扫区间,就是示例中的第一个水槽跟第二个水槽都可以用这个办法解决
![]()
前面这种是属于右侧比左侧高的情况,对于左侧高右侧低的就不行了,(写这篇的时候想起来可以再反着扫一遍可能可以)
![]()
所以这个方案不好,贴一下这个方案的代码
+public int trap(int[] height) {
+ int lastLeft = -1;
+ int sum = 0;
+ int tempSum = 0;
+ boolean startFlag = true;
+ for (int j : height) {
+ if (startFlag && j <= 0) {
+ startFlag = false;
+ continue;
+ }
+ if (j >= lastLeft) {
+ sum += tempSum;
+ tempSum = 0;
+ lastLeft = j;
+ } else {
+ tempSum += lastLeft - j;
+ }
+ }
+ return sum;
+}
+后面结合网上的解法,其实可以反过来,对于每个格子找左右侧的最大值,取小的那个和当前格子的差值就是这一个的储水量了
![]()
理解了这种想法,代码其实就不难了
+代码
int n = height.length;
+if (n <= 2) {
+ return 0;
+}
+// 思路转变下,其实可以对于每一格算储水量,算法就是找到这一格左边的最高点跟这一格右边的最高点,
+// 比较两侧的最高点,取小的那个,然后再跟当前格子的高度对比,差值就是当前格的储水量
+int maxL[] = new int[n];
+int maxR[] = new int[n];
+int max = height[0];
+maxL[0] = 0;
+// 计算左侧的最高点
+for (int i = 1; i < n - 1; i++) {
+ maxL[i] = max;
+ if (max < height[i]) {
+ max = height[i];
+ }
+}
+max = height[n - 1];
+maxR[n - 1] = 0;
+int tempSum, sum = 0;
+// 计算右侧的最高点,并且同步算出来储水量,节省一个循环
+for (int i = n - 2; i > 0; i--) {
+ maxR[i] = max;
+ if (height[i] > max) {
+ max = height[i];
+ }
+ tempSum = Math.min(maxL[i], maxR[i]) - height[i];
+ if (tempSum > 0) {
+ sum += tempSum;
+ }
+}
+return sum;
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ dp
+ 代码题解
+ Trapping Rain Water
+ 接雨水
+ Leetcode 42
+
+
+
+ MFC 模态对话框
+ /2014/12/24/MFC%20%E6%A8%A1%E6%80%81%E5%AF%B9%E8%AF%9D%E6%A1%86/
+ void CTestDialog::OnBnClickedOk()
+{
+ CString m_SrcTest;
+ int nIndex = m_CbTest.GetCurSel();
+ m_CbTest.GetLBText(nIndex, m_SrcTest);
+ OnOK();
+}
- log_debug(gc, ergo, cset)("Finish adding old regions to CSet (old CSet region num reached min). old %u regions, min %u regions",
- old_region_length(), min_old_cset_length);
- break;
- }
- }
+模态对话框弹出确定后,在弹出对话框时新建的类及其变量会存在,但是对于其中的控件
对象无法调用函数,即如果要在主对话框中获得弹出对话框的Combo box选中值的话,需
要在弹出 对话框的确定函数内将其值取出,赋值给弹出对话框的公有变量,这样就可以
在主对话框类得到值。
+]]>
+ C++
+
+
+ c++
+ mfc
+
+
+
+ Maven实用小技巧
+ /2020/02/16/Maven%E5%AE%9E%E7%94%A8%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ Maven 翻译为”专家”、”内行”,是 Apache 下的一个纯 Java 开发的开源项目。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。
+Maven 是一个项目管理工具,可以对 Java 项目进行构建、依赖管理。
+Maven 也可被用于构建和管理各种项目,例如 C#,Ruby,Scala 和其他语言编写的项目。Maven 曾是 Jakarta 项目的子项目,现为由 Apache 软件基金会主持的独立 Apache 项目。
+maven也是我们日常项目中实用的包管理工具,相比以前需要用把包下载下来,放进 lib 中,在平时工作中使用的话,其实像 idea 这样的 ide 工具都会自带 maven 工具和插件
+maven的基本操作
+mvn -v
查看 maven 信息mvn compile
将 Java 编译成 class 文件mvn test
执行 test 包下的测试用例mvn package
将项目打成 jar 包mvn clean
删除package 在 target 目录下面打出来的 jar 包和 target 目录mvn install
将打出来的 jar 包复制到 maven 的本地仓库里mvn deploy
将打出来的 jar 包上传到远程仓库里
+与 composer 对比
因为我也是个 PHP 程序员,所以对比一下两种语言,很容易想到在 PHP 的 composer 跟 Java 的 maven 是比较类似的作用,有一点两者是非常相似的,就是原仓库都是因为某些原因连接拉取都会很慢,所以像 composer 会有一些国内源,前阵子阿里也出了一个,类似的 maven 一般也会使用阿里的镜像仓库,通过在 setting.xml 文件中的设置
+<mirrors>
+ <mirror>
+ <id>aliyun</id>
+ <name>aliyun maven</name>
+ <url>http://maven.aliyun.com/nexus/content/groups/public/</url>
+ <mirrorOf>central</mirrorOf>
+ </mirror>
+</mirrors>
+这算是个尴尬的共同点,然后因为 PHP 是解释型脚本语言,所以 php 打出来的 composer 包其实就是个 php 代码包,使用SPL Autoload等方式加载代码包,maven 包则是经过编译的 class 包,还有一点是 composer 也可以直接使用 github 地址作为包代码的拉取源,这点也是比较大的区别,maven使用 pom 文件管理依赖
+maven 的个人小技巧
+- maven 拉取依赖时,同时将 snapshot 也更新了,就是
mvn compile加个-U参数,如果还不行就需要将本地仓库的 snapshot 删掉,
这个命令的 help 命令解释是 -U,–update-snapshots Forces a check for missing releases and updated snapshots on
remote repositories,这个在日常使用中还是很经常使用的
+- maven 出现依赖冲突的时候的解决方法
首先是依赖分析,使用mvn dependency:tree分析下依赖关系,如果要找具体某个包的依赖引用关系可以使用mvn dependency:tree -Dverbose -Dincludes=org.springframework:spring-webmvc命令进行分析,如果发现有冲突的依赖关系,本身 maven 中依赖引用有相对的顺序,大致来说是引用路径短的优先,pom 文件中定义的顺序优先,如果要把冲突的包排除掉可以在 pom 中用<exclusions>
+ <exclusion>
+ <groupId>ch.qos.logback</groupId>
+ <artifactId>logback-classic</artifactId>
+ </exclusion>
+</exclusions>
+将冲突的包排除掉
+- maven 依赖的 jdk 版本管理
前面介绍的mvn -v可以查看 maven 的安装信息
比如Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
+Maven home: /usr/local/Cellar/maven/3.6.3_1/libexec
+Java version: 1.8.0_201, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_201.jdk/Contents/Home/jre
+Default locale: zh_CN, platform encoding: UTF-8
+OS name: "mac os x", version: "10.14.6", arch: "x86_64", family: "mac"
+这里可以看到用了 mac 自带的 jdk1.8,结合我之前碰到的一个问题,因为使用 homebrew 升级了 gradle,而 gradle 又依赖了 jdk13,因为这个 mvn 的 Java version 也变成 jdk13 了,然后 mvn 编译的时候出现了 java.lang.ExceptionInInitializerError: com.sun.tools.javac.code.TypeTags这个问题,所以需要把这个版本给改回来,但是咋改呢,网上搜来的一大堆都是在 pom 文件里的
source和 target 版本<build>
+ <plugins>
+<plugin>
+ <groupId>org.apache.maven.plugins</groupId>
+ <artifactId>maven-compiler-plugin</artifactId>
+ <configuration>
+ <source>1.8</source>
+ <target>1.8</target>
+ <encoding>UTF-8</encoding>
+ </configuration>
+</plugin>
+ </plugins>
+<build>
+或者修改 maven 的 setting.xml中的<profiles>
+ <profile>
+ <id>ngmm-nexus</id>
+ <activation>
+ <jdk>1.8</jdk>
+ </activation>
+ <properties>
+ <maven.compiler.source>1.8</maven.compiler.source>
+ <maven.compiler.target>1.8</maven.compiler.target>
+ <maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
+ </properties>
+ </profile>
+</profiles>
+但是这些都没啥用啊,真正有办法的是建个 .mavenrc,这个顾名思义就是 maven 的资源文件,类似于 .bashrc和.zshrc,在里面添加 MAVEN_HOME 和 JAVA_HOME,然后执行 source .mavenrc就 OK 啦
+
+]]>
+
+ Java
+ Maven
+
+
+ Java
+ Maven
+
+
+
+ Number of 1 Bits
+ /2015/03/11/Number-Of-1-Bits/
+ Number of 1 Bits Write a function that takes an unsigned integer and returns the number of ’1’ bits it has (also known as the Hamming weight). For example, the 32-bit integer ‘11’ has binary representation 00000000000000000000000000001011, so the function should return 3.
- // We will add this region to the CSet.
- time_remaining_ms = MAX2(time_remaining_ms - predicted_time_ms, 0.0);
- predicted_old_time_ms += predicted_time_ms;
- cset_chooser()->pop(); // already have region via peek()
- _g1h->old_set_remove(hr);
- add_old_region(hr);
+分析
从1位到2位到4位逐步的交换
+
+code
int hammingWeight(uint32_t n) {
+ const uint32_t m1 = 0x55555555; //binary: 0101...
+ const uint32_t m2 = 0x33333333; //binary: 00110011..
+ const uint32_t m4 = 0x0f0f0f0f; //binary: 4 zeros, 4 ones ...
+ const uint32_t m8 = 0x00ff00ff; //binary: 8 zeros, 8 ones ...
+ const uint32_t m16 = 0x0000ffff; //binary: 16 zeros, 16 ones ...
+
+ n = (n & m1 ) + ((n >> 1) & m1 ); //put count of each 2 bits into those 2 bits
+ n = (n & m2 ) + ((n >> 2) & m2 ); //put count of each 4 bits into those 4 bits
+ n = (n & m4 ) + ((n >> 4) & m4 ); //put count of each 8 bits into those 8 bits
+ n = (n & m8 ) + ((n >> 8) & m8 ); //put count of each 16 bits into those 16 bits
+ n = (n & m16) + ((n >> 16) & m16); //put count of each 32 bits into those 32 bits
+ return n;
- hr = cset_chooser()->peek();
+}
]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ Path Sum
+ /2015/01/04/Path-Sum/
+ problemGiven a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all the values along the path equals the given sum.
+
+For example:
Given the below binary tree and sum = 22,
+ 5
+ / \
+ 4 8
+ / / \
+ 11 13 4
+ / \ \
+7 2 1
+return true, as there exist a root-to-leaf path 5->4->11->2 which sum is 22.
+Analysis
using simple deep first search
+code
/*
+ Definition for binary tree
+ struct TreeNode {
+ int val;
+ TreeNode *left;
+ TreeNode *right;
+ TreeNode(int x) : val(x), left(NULL), right(NULL)}
+ };
+ */
+class Solution {
+public:
+ bool deep_first_search(TreeNode *node, int sum, int curSum)
+ {
+ if (node == NULL)
+ return false;
+
+ if (node->left == NULL && node->right == NULL)
+ return curSum + node->val == sum;
+
+ return deep_first_search(node->left, sum, curSum + node->val) || deep_first_search(node->right, sum, curSum + node->val);
}
- if (hr == NULL) {
- log_debug(gc, ergo, cset)("Finish adding old regions to CSet (candidate old regions not available)");
+
+ bool hasPathSum(TreeNode *root, int sum) {
+ // Start typing your C/C++ solution below
+ // DO NOT write int main() function
+ return deep_first_search(root, sum, 0);
+ }
+};
+]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ Reverse Bits
+ /2015/03/11/Reverse-Bits/
+ Reverse Bits Reverse bits of a given 32 bits unsigned integer.
For example, given input 43261596 (represented in binary as 00000010100101000001111010011100), return 964176192 (represented in binary as 00111001011110000010100101000000).
+
+Follow up:
If this function is called many times, how would you optimize it?
+
+code
class Solution {
+public:
+ uint32_t reverseBits(uint32_t n) {
+ n = ((n >> 1) & 0x55555555) | ((n & 0x55555555) << 1);
+ n = ((n >> 2) & 0x33333333) | ((n & 0x33333333) << 2);
+ n = ((n >> 4) & 0x0f0f0f0f) | ((n & 0x0f0f0f0f) << 4);
+ n = ((n >> 8) & 0x00ff00ff) | ((n & 0x00ff00ff) << 8);
+ n = ((n >> 16) & 0x0000ffff) | ((n & 0x0000ffff) << 16);
+ return n;
}
+};
+]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ leetcode no.3
+ /2015/04/15/Leetcode-No-3/
+ **Longest Substring Without Repeating Characters **
+
+description
Given a string, find the length of the longest substring without repeating characters.
For example, the longest substring without repeating letters for “abcabcbb” is “abc”,
which the length is 3. For “bbbbb” the longest substring is “b”, with the length of 1.
+分析
源码这次是参考了这个代码,
tail 表示的当前子串的起始点位置,tail从-1开始就包括的串的长度是1的边界。其实我
也是猜的(逃
+int ct[256];
+ memset(ct, -1, sizeof(ct));
+ int tail = -1;
+ int max = 0;
+ for (int i = 0; i < s.size(); i++){
+ if (ct[s[i]] > tail)
+ tail = ct[s[i]];
+ if (i - tail > max)
+ max = i - tail;
+ ct[s[i]] = i;
+ }
+ return max;
+]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ Redis_分布式锁
+ /2019/12/10/Redis-Part-1/
+ 今天看了一下 redis 分布式锁 redlock 的实现,简单记录下,
+加锁
原先我对 redis 锁的概念就是加锁使用 setnx,解锁使用 lua 脚本,但是 setnx 具体是啥,lua 脚本是啥不是很清楚
首先简单思考下这个问题,首先为啥不是先 get 一下 key 存不存在,然后再 set 一个 key value,因为加锁这个操作我们是要保证两点,一个是不能中途被打断,也就是说要原子性,如果是先 get 一下 key,如果不存在再 set 值的话,那就不是原子操作了;第二个是可不可以直接 set 值呢,显然不行,锁要保证唯一性,有且只能有一个线程或者其他应用单位获得该锁,正好 setnx 给了我们这种原子命令
+然后是 setnx 的键和值分别是啥,键比较容易想到是要锁住的资源,比如 user_id, 这里有个我自己之前比较容易陷进去的误区,但是这个误区后
面再说,这里其实是把user_id 作为要锁住的资源,在我获得锁的时候别的线程不允许操作,以此保证业务的正确性,不会被多个线程同时修改,确定了键,再来看看值是啥,其实原先我认为值是啥都没关系,我只要锁住了,光键就够我用了,但是考虑下多个线程的问题,如果我这个线程加了锁,然后我因为 gc 停顿等原因卡死了,这个时候redis 的锁或者说就是 redis 的缓存已经过期了,这时候另一个线程获得锁成功,然后我这个线程又活过来了,然后我就仍然认为我拿着锁,我去对数据进行修改或者释放锁,是不是就出现问题了,所以是不是我们还需要一个东西来区分这个锁是哪个线程加的,所以我们可以将值设置成为一个线程独有识别的值,至少在相对长的一段时间内不会重复。
+上面其实还有两个问题,一个是当 gc 超时时,我这个线程如何知道我手里的锁已经过期了,一种方法是我在加好锁之后就维护一个超时时间,这里其实还有个问题,不过跟第二个问题相关,就一起说了,就是设置超时时间,有些对于不是锁的 redis 缓存操作可以是先设置好值,然后在设置过期时间,那么这就又有上面说到的不是原子性的问题,那么就需要在同一条指令里把超时时间也设置了,幸好 redis 提供了这种支持
+SET resource_name my_random_value NX PX 30000
+这里借鉴一下解释下,resource_name就是 key,代表要锁住的东西,my_random_value就是识别我这个线程的,NX代表只有在不存在的时候才设置,然后PX 30000表示超时时间是 30秒自动过期
+PS:记录下我原先有的一个误区,是不是要用 key 来区分加锁的线程,这样只有一个用处,就是自身线程可以识别是否是自己加的锁,但是最大的问题是别的线程不知道,其实这个用户的出发点是我在担心前面提过的一个问题,就是当 gc 停顿后,我要去判断当前的这个锁是否是我加的,还有就是当释放锁的时候,如果保证不会错误释放了其他线程加的锁,但是这样附带很多其他问题,最大的就是其他线程怎么知道能不能加这个锁。
+解锁
当线程在锁过期之前就处理完了业务逻辑,那就可以提前释放这个锁,那么提前释放要怎么操作,直接del key显然是不行的,因为这样就是我前面想用线程随机值加资源名作为锁的初衷,我不能去释放别的线程加的锁,那么我要怎么办呢,先 get 一下看是不是我的?那又变成非原子的操作了,幸好redis 也考虑到了这个问题,给了lua 脚本来操作这种
+if redis.call("get",KEYS[1]) == ARGV[1] then
+ return redis.call("del",KEYS[1])
+else
+ return 0
+end
+这里的KEYS[1]就是前面加锁的resource_name,ARGV[1]就是线程的随机值my_random_value
+多节点
前面说的其实是单节点 redis 作为分布式锁的情况,那么当我们的 redis 有多节点的情况呢,如果多节点下处于加锁或者解锁或者锁有效情况下
redis 的某个节点宕掉了怎么办,这里就有一些需要思考的地方,是否单独搞一个单节点的 redis作为分布式锁专用的,但是如果这个单节点的挂了呢,还有就是成本问题,所以我们需要一个多节点的分布式锁方案
这里就引出了开头说到的redlock,这个可是 redis的作者写的, 他的加锁过程是分以下几步去做这个事情
+
+- 获取当前时间(毫秒数)。
+- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
+- 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
+- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
+- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。这里为什么要向所有的节点发送释放锁的操作呢,这里是因为有部分的节点的失败原因可能是加锁时阻塞,加锁成功的结果没有及时返回,所以为了防止这种情况还是需要向所有发起这个释放锁的操作。
初步记录就先到这。
+
+]]>
+
+ Redis
+ Distributed Lock
+ C
+ Redis
+
+
+ C
+ Redis
+ Distributed Lock
+ 分布式锁
+
+
+
+ Leetcode 747 至少是其他数字两倍的最大数 ( Largest Number At Least Twice of Others *Easy* ) 题解分析
+ /2022/10/02/Leetcode-747-%E8%87%B3%E5%B0%91%E6%98%AF%E5%85%B6%E4%BB%96%E6%95%B0%E5%AD%97%E4%B8%A4%E5%80%8D%E7%9A%84%E6%9C%80%E5%A4%A7%E6%95%B0-Largest-Number-At-Least-Twice-of-Others-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍You are given an integer array nums where the largest integer is unique.
+Determine whether the largest element in the array is at least twice as much as every other number in the array. If it is, return the index of the largest element, or return -1 otherwise.
确认在数组中的最大数是否是其余任意数的两倍大及以上,如果是返回索引,如果不是返回-1
+示例
Example 1:
+Input: nums = [3,6,1,0]
Output: 1
Explanation: 6 is the largest integer.
For every other number in the array x, 6 is at least twice as big as x.
The index of value 6 is 1, so we return 1.
+
+Example 2:
+Input: nums = [1,2,3,4]
Output: -1
Explanation: 4 is less than twice the value of 3, so we return -1.
+
+提示:
+2 <= nums.length <= 500 <= nums[i] <= 100- The largest element in
nums is unique.
+
+简要解析
这个题easy是题意也比较简单,找最大值,并且最大值是其他任意值的两倍及以上,其实就是找最大值跟次大值,比较下就好了
+代码
public int dominantIndex(int[] nums) {
+ int largest = Integer.MIN_VALUE;
+ int second = Integer.MIN_VALUE;
+ int largestIndex = -1;
+ for (int i = 0; i < nums.length; i++) {
+ // 如果有最大的就更新,同时更新最大值和第二大的
+ if (nums[i] > largest) {
+ second = largest;
+ largest = nums[i];
+ largestIndex = i;
+ } else if (nums[i] > second) {
+ // 没有超过最大的,但是比第二大的更大就更新第二大的
+ second = nums[i];
+ }
+ }
- if (expensive_region_num > 0) {
- // We print the information once here at the end, predicated on
- // whether we added any apparently expensive regions or not, to
- // avoid generating output per region.
- log_debug(gc, ergo, cset)("Added expensive regions to CSet (old CSet region num not reached min)."
- "old: %u regions, expensive: %u regions, min: %u regions, remaining time: %1.2fms",
- old_region_length(), expensive_region_num, min_old_cset_length, time_remaining_ms);
+ // 判断下是否符合题目要求,要是所有值的两倍及以上
+ if (largest >= 2 * second) {
+ return largestIndex;
+ } else {
+ return -1;
+ }
+}
+通过图
第一次错了是把第二大的情况只考虑第一种,也有可能最大值完全没经过替换就变成最大值了
![]()
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+
+
+
+ Reverse Integer
+ /2015/03/13/Reverse-Integer/
+ Reverse IntegerReverse digits of an integer.
Example1: x = 123, return 321
Example2: x = -123, return -321
+
+spoilers
Have you thought about this?
Here are some good questions to ask before coding. Bonus points for you if you have already thought through this!
+If the integer’s last digit is 0, what should the output be? ie, cases such as 10, 100.
+Did you notice that the reversed integer might overflow? Assume the input is a 32-bit integer, then the reverse of 1000000003 overflows. How should you handle such cases?
+For the purpose of this problem, assume that your function returns 0 when the reversed integer overflows.
+
+code
class Solution {
+public:
+ int reverse(int x) {
+
+ int max = 1 << 31 - 1;
+ int ret = 0;
+ max = (max - 1) * 2 + 1;
+ int min = 1 << 31;
+ if(x < 0)
+ while(x != 0){
+ if(ret < (min - x % 10) / 10)
+ return 0;
+ ret = ret * 10 + x % 10;
+ x = x / 10;
+ }
+ else
+ while(x != 0){
+ if(ret > (max -x % 10) / 10)
+ return 0;
+ ret = ret * 10 + x % 10;
+ x = x / 10;
+ }
+ return ret;
}
-
- cset_chooser()->verify();
- }
-
- stop_incremental_building();
-
- log_debug(gc, ergo, cset)("Finish choosing CSet. old: %u regions, predicted old region time: %1.2fms, time remaining: %1.2f",
- old_region_length(), predicted_old_time_ms, time_remaining_ms);
-
- double non_young_end_time_sec = os::elapsedTime();
- phase_times()->record_non_young_cset_choice_time_ms((non_young_end_time_sec - non_young_start_time_sec) * 1000.0);
-
- QuickSort::sort(_collection_set_regions, _collection_set_cur_length, compare_region_idx, true);
-}
-上面第三行是个判断,当前是否是 mixed 回收阶段,如果不是的话其实是没有老年代什么事的,所以可以看到代码基本是从这个 if 判断
if (collector_state()->in_mixed_phase()) {开始往下走的
先写到这,偏向于做笔记用,有错轻拍
+};
]]>
- Java
- JVM
- GC
- C++
+ leetcode
- Java
- JVM
- C++
+ leetcode
+ c++
- hexo 配置系列-接入Algolia搜索
- /2023/04/02/hexo-%E9%85%8D%E7%BD%AE%E7%B3%BB%E5%88%97-%E6%8E%A5%E5%85%A5Algolia%E6%90%9C%E7%B4%A2/
- 博客之前使用的是 local search,最开始感觉使用体验还不错,速度也不慢,最近自己搜了下觉得效果差了很多,不知道是啥原因,所以接入有 next 主题支持的 Algolia 搜索,next 主题的文档已经介绍的很清楚了,这边就记录下,
首先要去 Algolia 开通下账户,创建一个索引
![]()
创建好后要去找一下 api key 的配置,这个跟 next 主题的说明已经有些不一样了
在设置里可以找到
![]()
这里默认会有两个 key
![]()
一个是 search only,一个是 admin key,需要再创建一个自定义 key
这个 key 需要有这些权限,称为 High-privilege API key, 后面有用
![]()
然后就是到博客目录下安装
-cd hexo-site
-npm install hexo-algolia
-然后在 hexo 站点配置中添加
-algolia:
- applicationID: "Application ID"
- apiKey: "Search-only API key"
- indexName: "indexName"
-包括应用 Id,只搜索的 api key(默认给创建好的那个),indexName 就是最开始创建的 index 名,
-export HEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Git Bash
-# set HEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Windows command line
-hexo clean
-hexo algolia
-然后再到 next 配置中开启 algolia_search
-# Algolia Search
-algolia_search:
- enable: true
- hits:
- per_page: 10
-搜索的界面其实跟 local 的差不多,就是搜索效果会好一些
![]()
也推荐可以搜搜过往的内容,已经左边有个热度的,做了个按阅读量排序的榜单。
+ binary-watch
+ /2016/09/29/binary-watch/
+ problemA binary watch has 4 LEDs on the top which represent the hours (0-11), and the 6 LEDs on the bottom represent the minutes (0-59).
+Each LED represents a zero or one, with the least significant bit on the right.
+![]()
+For example, the above binary watch reads “3:25”.
+Given a non-negative integer n which represents the number of LEDs that are currently on, return all possible times the watch could represent.
+Example:
Input: n = 1
+Return: ["1:00", "2:00", "4:00", "8:00", "0:01", "0:02", "0:04", "0:08", "0:16", "0:32"]
+Note:
+- The order of output does not matter.
+- The hour must not contain a leading zero, for example “01:00” is not valid, it should be “1:00”.
+- The minute must be consist of two digits and may contain a leading zero, for example “10:2” is not valid, it should be “10:02”.
+
+题解
又是参(chao)考(xi)别人的代码,嗯,就是这么不要脸,链接
+Code
class Solution {
+public:
+ vector<string> readBinaryWatch(int num) {
+ vector<string> res;
+ for (int h = 0; h < 12; ++h) {
+ for (int m = 0; m < 60; ++m) {
+ if (bitset<10>((h << 6) + m).count() == num) {
+ res.push_back(to_string(h) + (m < 10 ? ":0" : ":") + to_string(m));
+ }
+ }
+ }
+ return res;
+ }
+};
]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ ambari-summary
+ /2017/05/09/ambari-summary/
+ 初识ambariambari是一个大数据平台的管理工具,包含了hadoop, yarn, hive, hbase, spark等大数据的基础架构和工具,简化了数据平台的搭建,之前只是在同事搭建好平台后的一些使用,这次有机会从头开始用ambari来搭建一个测试的数据平台,过程中也踩到不少坑,简单记录下。
+简单过程
+- 第一个坑
在刚开始是按照官网的指南,用maven构建,因为GFW的原因,导致反复失败等待,也就是这个guide,因为对maven不熟悉导致有些按图索骥,浪费了很多时间,之后才知道可以直接加repo用yum安装,然而用yum安装马上就出现了第二个坑。
+- 第二个坑
因为在线的repo还是因为网络原因很慢很慢,用proxychains勉强把ambari-server本身安装好了,ambari.repo将这个放进/etc/yum.repos.d/路径下,然后yum update && yum install ambari-server安装即可,如果有条件就用proxychains走下代理。
+- 第三步
安装好ambari-server后先执行ambari-server setup做一些初始化设置,其中包含了JDK路径的设置,数据库设置,设置好就OK了,然后执行ambari-server start启动服务,这里有个小插曲,因为ambari-server涉及到这么多服务,所以管理控制监控之类的模块是必不可少的,这部分可以在ambari-server的web ui界面安装,也可以命令行提前安装,这部分被称为HDF Management Pack,运行ambari-server install-mpack \ --mpack=http://public-repo-1.hortonworks.com/HDF/centos7/2.x/updates/2.1.4.0/tars/hdf_ambari_mp/hdf-ambari-mpack-2.1.4.0-5.tar.gz \ --purge \ --verbose
安装,当然这个压缩包可以下载之后指到本地路径安装,然后就可以重启ambari-server
+
]]>
- hexo
- 技巧
+ data analysis
- hexo
+ hadoop
+ cluster
- mybatis 的缓存是怎么回事
- /2020/10/03/mybatis-%E7%9A%84%E7%BC%93%E5%AD%98%E6%98%AF%E6%80%8E%E4%B9%88%E5%9B%9E%E4%BA%8B/
- Java 真的是任何一个中间件,比较常用的那种,都有很多内容值得深挖,比如这个缓存,慢慢有过一些感悟,比如如何提升性能,缓存无疑是一大重要手段,最底层开始 CPU 就有缓存,而且又小又贵,再往上一点内存一般作为硬盘存储在运行时的存储,一般在代码里也会用内存作为一些本地缓存,譬如数据库,像 mysql 这种也是有innodb_buffer_pool来提升查询效率,本质上理解就是用更快的存储作为相对慢存储的缓存,减少查询直接访问较慢的存储,并且这个都是相对的,比起 cpu 的缓存,那内存也是渣,但是与普通机械硬盘相比,那也是两个次元的水平。
-闲扯这么多来说说 mybatis 的缓存,mybatis 一般作为一个轻量级的 orm 使用,相对应的就是比较重量级的 hibernate,不过不在这次讨论范围,上一次是主要讲了 mybatis 在解析 sql 过程中,对于两种占位符的不同替换实现策略,这次主要聊下 mybatis 的缓存,前面其实得了解下前置的东西,比如 sqlsession,先当做我们知道 sqlsession 是个什么玩意,可能或多或少的知道 mybatis 是有两级缓存,
-一级缓存
第一级的缓存是在 BaseExecutor 中的 PerpetualCache,它是个最基本的缓存实现类,使用了 HashMap 实现缓存功能,代码其实没几十行
-public class PerpetualCache implements Cache {
-
- private final String id;
-
- private final Map<Object, Object> cache = new HashMap<>();
-
- public PerpetualCache(String id) {
- this.id = id;
- }
-
- @Override
- public String getId() {
- return id;
- }
-
- @Override
- public int getSize() {
- return cache.size();
- }
-
- @Override
- public void putObject(Object key, Object value) {
- cache.put(key, value);
- }
-
- @Override
- public Object getObject(Object key) {
- return cache.get(key);
- }
-
- @Override
- public Object removeObject(Object key) {
- return cache.remove(key);
- }
-
- @Override
- public void clear() {
- cache.clear();
- }
-
- @Override
- public boolean equals(Object o) {
- if (getId() == null) {
- throw new CacheException("Cache instances require an ID.");
- }
- if (this == o) {
- return true;
- }
- if (!(o instanceof Cache)) {
- return false;
- }
-
- Cache otherCache = (Cache) o;
- return getId().equals(otherCache.getId());
- }
-
- @Override
- public int hashCode() {
- if (getId() == null) {
- throw new CacheException("Cache instances require an ID.");
- }
- return getId().hashCode();
- }
-
-}
-可以看一下BaseExecutor 的构造函数
-protected BaseExecutor(Configuration configuration, Transaction transaction) {
- this.transaction = transaction;
- this.deferredLoads = new ConcurrentLinkedQueue<>();
- this.localCache = new PerpetualCache("LocalCache");
- this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
- this.closed = false;
- this.configuration = configuration;
- this.wrapper = this;
- }
-就是把 PerpetualCache 作为 localCache,然后怎么使用我看简单看一下,BaseExecutor 的查询首先是调用这个函数
-@Override
- public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
- BoundSql boundSql = ms.getBoundSql(parameter);
- CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
- return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
- }
-可以看到首先是调用了 createCacheKey 方法,这个方法呢,先不看怎么写的,如果我们自己要实现这么个缓存,首先这个缓存 key 的设计也是个问题,如果是以表名加主键作为 key,那么分页查询,或者没有主键的时候就不行,来看看 mybatis 是怎么设计的
-@Override
- public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
- if (closed) {
- throw new ExecutorException("Executor was closed.");
- }
- CacheKey cacheKey = new CacheKey();
- cacheKey.update(ms.getId());
- cacheKey.update(rowBounds.getOffset());
- cacheKey.update(rowBounds.getLimit());
- cacheKey.update(boundSql.getSql());
- List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
- TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
- // mimic DefaultParameterHandler logic
- for (ParameterMapping parameterMapping : parameterMappings) {
- if (parameterMapping.getMode() != ParameterMode.OUT) {
- Object value;
- String propertyName = parameterMapping.getProperty();
- if (boundSql.hasAdditionalParameter(propertyName)) {
- value = boundSql.getAdditionalParameter(propertyName);
- } else if (parameterObject == null) {
- value = null;
- } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
- value = parameterObject;
- } else {
- MetaObject metaObject = configuration.newMetaObject(parameterObject);
- value = metaObject.getValue(propertyName);
- }
- cacheKey.update(value);
- }
- }
- if (configuration.getEnvironment() != null) {
- // issue #176
- cacheKey.update(configuration.getEnvironment().getId());
- }
- return cacheKey;
- }
-
-首先需要 id,这个 id 是 mapper 里方法的 id, 然后是偏移量跟返回行数,再就是 sql,然后是参数,基本上是会有影响的都加进去了,在这个 update 里面
-public void update(Object object) {
- int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
+ two sum
+ /2015/01/14/Two-Sum/
+ problemGiven an array of integers, find two numbers such that they add up to a specific target number.
+The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
+
+You may assume that each input would have exactly one solution.
+Input: numbers={2, 7, 11, 15}, target=9
Output: index1=1, index2=2
+code
struct Node
+{
+ int num, pos;
+};
+bool cmp(Node a, Node b)
+{
+ return a.num < b.num;
+}
+class Solution {
+public:
+ vector<int> twoSum(vector<int> &numbers, int target) {
+ // Start typing your C/C++ solution below
+ // DO NOT write int main() function
+ vector<int> result;
+ vector<Node> array;
+ for (int i = 0; i < numbers.size(); i++)
+ {
+ Node temp;
+ temp.num = numbers[i];
+ temp.pos = i;
+ array.push_back(temp);
+ }
- count++;
- checksum += baseHashCode;
- baseHashCode *= count;
+ sort(array.begin(), array.end(), cmp);
+ for (int i = 0, j = array.size() - 1; i != j;)
+ {
+ int sum = array[i].num + array[j].num;
+ if (sum == target)
+ {
+ if (array[i].pos < array[j].pos)
+ {
+ result.push_back(array[i].pos + 1);
+ result.push_back(array[j].pos + 1);
+ } else
+ {
+ result.push_back(array[j].pos + 1);
+ result.push_back(array[i].pos + 1);
+ }
+ break;
+ } else if (sum < target)
+ {
+ i++;
+ } else if (sum > target)
+ {
+ j--;
+ }
+ }
+ return result;
+ }
+};
- hashcode = multiplier * hashcode + baseHashCode;
+Analysis
sort the array, then test from head and end, until catch the right answer
+]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ docker比一般多一点的初学者介绍
+ /2020/03/08/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D/
+ 因为最近想搭一个phabricator用来做看板和任务管理,一开始了解这个是Easy大大有在微博推荐过,后来苏洋也在群里和博客里说到了,看上去还不错的样子,因为主角是docker所以就不介绍太多,后面有机会写一下。
+docker最开始是之前在某位大佬的博客看到的,看上去有点神奇,感觉是一种轻量级的虚拟机,但是能做的事情好像差不多,那时候是在Ubuntu系统的vps里起一个Ubuntu的docker,然后在里面装个nginx,配置端口映射就可以访问了,后来也草草写过一篇使用docker搭建mysql集群,但是最近看了下好像是因为装docker的大佬做了一些别名还是什么操作,导致里面用的操作都不具有普遍性,而且主要是把搭的过程写了下,属于囫囵吞枣,没理解docker是干啥的,为啥用docker,就是操作了下,这几天借着搭phabricator的过程,把一些原来不理解,或者原来理解错误的地方重新理一下。
+之前写的 mysql 集群,一主二备,这种架构在很多小型应用里都是这么配置的,而且一般是直接在三台 vps 里启动三个 mysql 实例,但是如果换成 docker 会有什么好处呢,其实就是方便部署,比如其中一台备库挂了,我要加一台,或者说备库的 qps 太高了,需要再加一个,如果要在 vps 上搭建的话,首先要买一台机器,等初始化,然后在上面修改源,更新,装 mysql ,然后配置主从,可能还要处理防火墙等等,如果把这些打包成一个 docker 镜像,并且放在自己的 docker registry,那就直接run 一下就可以了;还有比如在公司要给一个新同学整一套开发测试环境,以 Java 开发为例,要装 git,maven,jdk,配置 maven settings 和各种 rc,整合在一个镜像里的话,就会很方便了;再比如微服务的水平扩展。
+但是为啥 docker 会有这种优势,听起来好像虚拟机也可以干这个事,但是虚拟机动辄上 G,而且需要 VMware,virtual box 等支持,不适合在Linux服务器环境使用,而且占用资源也会非常大。说得这么好,那么 docker 是啥呢
+docker 主要使用 Linux 中已经存在的两种技术的一个整合升级,一个是 namespace,一个是cgroups,相比于虚拟机需要完整虚拟出一个操作系统运行基础,docker 基于宿主机内核,通过 namespace 和 cgroups 分隔进程,理念就是提供一个隔离的最小化运行依赖,这样子相对于虚拟机就有了巨大的便利性,具体的 namespace 和 cgroups 就先不展开讲,可以参考耗子叔的文章
+安装
那么我们先安装下 docker,参考官方的教程,安装,我的系统是 ubuntu 的,就贴了 ubuntu 的链接,用其他系统的可以找到对应的系统文档安装,安装完了的话看看 docker 的信息
+sudo docker info
- updateList.add(object);
- }
-其实是一个 hash 转换,具体不纠结,就是提高特异性,然后回来就是继续调用 query
-@Override
- public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
- ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
- if (closed) {
- throw new ExecutorException("Executor was closed.");
- }
- if (queryStack == 0 && ms.isFlushCacheRequired()) {
- clearLocalCache();
- }
- List<E> list;
- try {
- queryStack++;
- list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
- if (list != null) {
- handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
- } else {
- list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
- }
- } finally {
- queryStack--;
- }
- if (queryStack == 0) {
- for (DeferredLoad deferredLoad : deferredLoads) {
- deferredLoad.load();
- }
- // issue #601
- deferredLoads.clear();
- if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
- // issue #482
- clearLocalCache();
- }
- }
- return list;
- }
-可以看到是先从 localCache 里取,取不到再 queryFromDatabase,其实比较简单,这是一级缓存,考虑到 sqlsession 跟 BaseExecutor 的关系,其实是随着 sqlsession 来保证这个缓存不会出现脏数据幻读的情况,当然事务相关的后面可能再单独聊。
-二级缓存
其实这个一级二级顺序有点反过来,其实查询的是先走的二级缓存,当然二级的需要配置开启,默认不开,
需要通过
-<setting name="cacheEnabled" value="true"/>
-来开启,然后我们的查询就会走到
-public class CachingExecutor implements Executor {
+输出以下信息
![]()
+简单运行
然后再来运行个 hello world 呗,
+sudo docker run hello-world
- private final Executor delegate;
- private final TransactionalCacheManager tcm = new TransactionalCacheManager();
-这个 Executor 中,这里我放了类里面的元素,发现没有一个 Cache 类,这就是一个特点了,往下看查询过程
-@Override
- public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
- BoundSql boundSql = ms.getBoundSql(parameterObject);
- CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
- return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- }
+输出了这些
![]()
+看看这个运行命令是怎么用的,一般都会看到这样子的,sudo docker run -it ubuntu bash, 前面的 docker run 反正就是运行一个容器的意思,-it是啥呢,还有这个什么 ubuntu bash,来看看docker run`的命令帮助信息
+-i, --interactive Keep STDIN open even if not attached
- @Override
- public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
- throws SQLException {
- Cache cache = ms.getCache();
- if (cache != null) {
- flushCacheIfRequired(ms);
- if (ms.isUseCache() && resultHandler == null) {
- ensureNoOutParams(ms, boundSql);
- @SuppressWarnings("unchecked")
- List<E> list = (List<E>) tcm.getObject(cache, key);
- if (list == null) {
- list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- tcm.putObject(cache, key, list); // issue #578 and #116
- }
- return list;
- }
- }
- return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- }
-看到没,其实缓存是从 tcm 这个成员变量里取,而这个是什么呢,事务性缓存(直译下),因为这个其实是用 MappedStatement 里的 Cache 作为key 从 tcm 的 map 取出来的
-public class TransactionalCacheManager {
+就是要有输入,我们运行的时候能输入
+-t, --tty Allocate a pseudo-TTY
- private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
-MappedStatement是被全局使用的,所以其实二级缓存是跟着 mapper 的 namespace 走的,可以被多个 CachingExecutor 获取到,就会出现线程安全问题,线程安全问题可以用SynchronizedCache来解决,就是加锁,但是对于事务中的脏读,使用了TransactionalCache来解决这个问题,
-public class TransactionalCache implements Cache {
+要有个虚拟终端,
+Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
- private static final Log log = LogFactory.getLog(TransactionalCache.class);
+Run a command in a new container
- private final Cache delegate;
- private boolean clearOnCommit;
- private final Map<Object, Object> entriesToAddOnCommit;
- private final Set<Object> entriesMissedInCache;
-在事务还没提交的时候,会把中间状态的数据放在 entriesToAddOnCommit 中,只有在提交后会放进共享缓存中,
-public void commit() {
- if (clearOnCommit) {
- delegate.clear();
- }
- flushPendingEntries();
- reset();
- }
]]>
+镜像
上面说的-it 就是这里的 options,后面那个 ubuntu 就是 image 辣,image 是啥呢
+Docker 把应用程序及其依赖,打包在 image 文件里面,可以把它理解成为类似于虚拟机的镜像或者运行一个进程的代码,跑起来了的叫docker 容器或者进程,比如我们将要运行的docker run -it ubuntu bash的ubuntu 就是个 ubuntu 容器的镜像,将这个镜像运行起来后,我们可以进入容器像使用 ubuntu 一样使用它,来看下我们的镜像,使用sudo docker image ls就能列出我们宿主机上的 docker 镜像了
+![]()
+一个 ubuntu 镜像才 64MB,非常小巧,然后是后面的bash,我通过交互式启动了一个 ubuntu 容器,然后在这个启动的容器里运行了 bash 命令,这样就可以在容器里玩一下了
+在容器里看下进程,
![]()
+只有刚才运行容器的 bash 进程和我刚执行的 ps,这里有个可以注意下的,bash 这个进程的 pid 是 1,其实这里就用到了 linux 中的PID Namespace,容器会隔离出一个 pid 的名字空间,这里面的进程跟外部的 pid 命名独立
+查看宿主机上的容器
sudo docker ps -a
+
+![]()
+如何进入一个正在运行中的 docker 容器
这个应该是比较常用的,因为比如是一个微服务容器,有时候就像看下运行状态,日志啥的
+sudo docker exec -it [containerID] bash
+
+![]()
+查看日志
sudo docker logs [containerID]
+
+我在运行容器的终端里胡乱输入点啥,然后通过上面的命令就可以看到啦
+![]()
+![]()
+]]>
- Java
- Spring
- Mybatis
- Mybatis
- Mybatis
- 缓存
+ Docker
+ 介绍
+
+
+ Docker
+ namespace
+ cgroup
+
+
+
+ docker-mysql-cluster
+ /2016/08/14/docker-mysql-cluster/
+ docker-mysql-cluster基于docker搭了个mysql集群,稍微记一下,
首先是新建mysql主库容
docker run -d -e MYSQL_ROOT_PASSWORD=admin --name mysql-master -p 3307:3306 mysql:latest
-d表示容器运行在后台,-e表示设置环境变量,即MYSQL_ROOT_PASSWORD=admin,设置了mysql的root密码,
--name表示容器名,-p表示端口映射,将内部mysql:3306映射为外部的3307,最后的mysql:latest表示镜像名
此外还可以用-v /local_path/my-master.cnf:/etc/mysql/my.cnf来映射配置文件
然后同理启动从库
docker run -d -e MYSQL_ROOT_PASSWORD=admin --name mysql-slave -p 3308:3306 mysql:latest
然后进入主库改下配置文件
docker-enter mysql-master如果无法进入就用docker ps -a看下容器是否在正常运行,如果status显示
未正常运行,则用docker logs mysql-master看下日志哪里出错了。
进入容器后,我这边使用的镜像的mysqld配置文件是在/etc/mysql下面,这个最新版本的mysql的配置文件包含
三部分,/etc/mysql/my.cnf和/etc/mysql/conf.d/mysql.cnf,还有/etc/mysql/mysql.conf.d/mysqld.cnf
这里需要改的是最后一个,加上
+log-bin = mysql-bin
+server_id = 1
+保存后退出容器重启主库容器,然后进入从库更改相同文件,
+log-bin = mysql-bin
+server_id = 2
+主从配置
同样退出重启容器,然后是配置主从,首先进入主库,用命令mysql -u root -pxxxx进入mysql,然后赋予一个同步
权限GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';还是同样说明下,ON *.*表示了数
据库全部的权限,如果要指定数据库/表的话可以使用类似testDb/testTable,然后是'backup'@'%'表示给予同步
权限的用户名及其主机ip,%表示不限制ip,当然如果有防火墙的话还是会有限制的,最后的identified by '123456'
表示同步用户的密码,然后就查看下主库的状态信息show master status,如下图:
![9G5FE[9%@7%G(B`Q7]E)5@R.png]()
把file跟position记下来,然后再开一个terminal,进入从库容器,登陆mysql,然后设置主库
+change master to
+master_host='xxx.xxx.xxx.xxx', //如果主从库的容器都在同一个宿主机上,这里的ip是docker容器的ip
+master_user='backup', //就是上面的赋予权限的用户
+master_password='123456',
+master_log_file='mysql-bin.000004', //主库中查看到的file
+master_log_pos=312, //主库中查看到的position
+master_port=3306; //如果是同一宿主机,这里使用真实的3306端口,3308及主库的3307是给外部连接使用的
+通过docker-ip mysql-master可以查看容器的ip
![S(GP)P(M$N3~N1764@OW3E0.png]()
这里有一点是要注意的,也是我踩的坑,就是如果是同一宿主机下两个mysql容器互联,我这里只能通过docker-ip和真实
的3306端口能够连接成功。
本文参考了这位同学的文章
+]]>
+
+ docker
+
+
+ docker
+ mysql
+
+
+
+ dnsmasq的一个使用注意点
+ /2023/04/16/dnsmasq%E7%9A%84%E4%B8%80%E4%B8%AA%E4%BD%BF%E7%94%A8%E6%B3%A8%E6%84%8F%E7%82%B9/
+ 在本地使用了 valet 做 php 的开发环境,因为可以指定自定义域名和证书,碰巧最近公司的网络环境比较糟糕,就想要在自定义 dns 上下点功夫,本来我们经常要在 dns 那配置个内部的 dns 地址,就想是不是可以通过 dnsmasq 来解决,
却在第一步碰到个低级的问题,在 dnsmasq 的主配置文件里
我配置了解析文件路径配置
像这样
+resolv-file=/opt/homebrew/etc/dnsmasq.d/resolv.dnsmasq.conf
+结果发现 dnsmasq 就起不来了,因为是 brew 服务的形式起来,发现日志也没有, dnsmasq 配置文件本身也没什么日志,这个是最讨厌的,网上搜了一圈也都没有, brew services 的服务如果启动状态是 error,并且服务本身没有日志的话就是一头雾水,并且对于 plist 来说,即使我手动加了标准输出和错误输出,brew services restart 的时候也是会被重新覆盖,
后来仔细看了下这个问题,发现它下面有这么一行配置
+conf-dir=/opt/homebrew/etc/dnsmasq.d/,*.conf
+想了一下发现这个问题其实很简单,dnsmasq 应该是不支持同一配置文件加载两次,
我把 resolv 文件放在了同一个配置文件目录下,所以就被加载了两次,所以改掉目录就行了,但是目前看 dnsmasq 还不符合我的要求,也有可能我还没完全了解 dnsmasq 的使用方法,我想要的是比如按特定的域名后缀来配置对应的 dns 服务器,这样就不太会被影响,可以试试 AdGuard 看
+]]>
+
+ dns
+
+
+ dnsmasq
+
+
+
+ docker比一般多一点的初学者介绍三
+ /2020/03/21/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D%E4%B8%89/
+ 运行第一个 Dockerfile上一篇的 Dockerfile 我们停留在构建阶段,现在来把它跑起来
+docker run -d -p 80 --name static_web nicksxs/static_web \
+nginx -g "daemon off;"
+这里的-d表示以分离模型运行docker (detached),然后-p 是表示将容器的 80 端口开放给宿主机,然后容器名就叫 static_web,使用了我们上次构建的 static_web 镜像,后面的是让 nginx 在前台运行
![]()
可以看到返回了个容器 id,但是具体情况没出现,也没连上去,那我们想看看怎么访问在 Dockerfile 里写的静态页面,我们来看下docker 进程
![]()
发现为我们随机分配了一个宿主机的端口,32768,去服务器的防火墙把这个外网端口开一下,看看是不是符合我们的预期呢
![]()
好像不太对额,应该是 ubuntu 安装的 nginx 的默认工作目录不对,我们来进容器看看,再熟悉下命令docker exec -it 4792455ca2ed /bin/bash
记得容器 id 换成自己的,进入容器后得找找 nginx 的配置文件,通常在/etc/nginx,/usr/local/etc等目录下,然后找到我们的目录是在这
![]()
所以把刚才的内容复制过去再试试
![]()
目标达成,give me five✌️
+第二个 Dockerfile
然后就想来动态一点的,毕竟写过 PHP,就来试试 PHP
再建一个目录叫 dynamic_web,里面创建 src 目录,放一个 index.php
内容是
+<?php
+echo "Hello World!";
+然后在 dynamic_web 目录下创建 Dockerfile,
+FROM trafex/alpine-nginx-php7:latest
+COPY src/ /var/www/html
+EXPOSE 80
+Dockerfile 虽然只有三行,不过要着重说明下,这个底包其实不是docker 官方的,有两点考虑,一点是官方的基本都是 php apache 的镜像,还有就是 alpine这个,截取一段中文介绍
+
+Alpine 操作系统是一个面向安全的轻型 Linux 发行版。它不同于通常 Linux 发行版,Alpine 采用了 musl libc 和 busybox 以减小系统的体积和运行时资源消耗,但功能上比 busybox 又完善的多,因此得到开源社区越来越多的青睐。在保持瘦身的同时,Alpine 还提供了自己的包管理工具 apk,可以通过 https://pkgs.alpinelinux.org/packages 网站上查询包信息,也可以直接通过 apk 命令直接查询和安装各种软件。
Alpine 由非商业组织维护的,支持广泛场景的 Linux发行版,它特别为资深/重度Linux用户而优化,关注安全,性能和资源效能。Alpine 镜像可以适用于更多常用场景,并且是一个优秀的可以适用于生产的基础系统/环境。
+
+
+Alpine Docker 镜像也继承了 Alpine Linux 发行版的这些优势。相比于其他 Docker 镜像,它的容量非常小,仅仅只有 5 MB 左右(对比 Ubuntu 系列镜像接近 200 MB),且拥有非常友好的包管理机制。官方镜像来自 docker-alpine 项目。
+
+
+目前 Docker 官方已开始推荐使用 Alpine 替代之前的 Ubuntu 做为基础镜像环境。这样会带来多个好处。包括镜像下载速度加快,镜像安全性提高,主机之间的切换更方便,占用更少磁盘空间等。
+
+一方面在没有镜像的情况下,拉取 docker 镜像还是比较费力的,第二个就是也能节省硬盘空间,所以目前有大部分的 docker 镜像都将 alpine 作为基础镜像了
然后再来构建下
![]()
这里还有个点,就是上面的那个镜像我们也是 EXPOSE 80端口,然后外部宿主机会随机映射一个端口,为了偷个懒,我们就直接指定外部端口了
docker run -d -p 80:80 dynamic_web打开浏览器发现访问不了,咋回事呢
因为我们没看trafex/alpine-nginx-php7:latest这个镜像说明,它内部的服务是 8080 端口的,所以我们映射的暴露端口应该是 8080,再用 docker run -d -p 80:8080 dynamic_web这个启动,
![]()
+]]>
+
+ Docker
+ 介绍
- Java
- Mysql
- Mybatis
- 缓存
+ Docker
+ namespace
+ Dockerfile
- java 中发起 http 请求时证书问题解决记录
- /2023/07/29/java-%E4%B8%AD%E5%8F%91%E8%B5%B7-http-%E8%AF%B7%E6%B1%82%E6%97%B6%E8%AF%81%E4%B9%A6%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3%E8%AE%B0%E5%BD%95/
- 再一次环境部署是发现了个问题,就是在请求微信 https 请求的时候,出现了个错误
No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
一开始以为是环境问题,从 oracle 的 jdk 换成了基于 openjdk 的底包,没有 javax 的关系,
完整的提示包含了 javax 的异常
java.lang.RuntimeException: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
后面再看了下,是不是也可能是证书的问题,然后就去找了下是不是证书相关的,
可以看到在 /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/security 路径下的 java.security 中
jdk.tls.disabledAlgorithms=SSLv3, TLSv1, TLSv1.1, RC4, DES, MD5withRSA,
而正好在我们代码里 createSocketFactory 的时候使用了 TLSv1 这个证书协议
-SSLContext sslContext = SSLContext.getInstance("TLS");
-sslContext.init(kmf.getKeyManagers(), null, new SecureRandom());
-return new SSLConnectionSocketFactory(sslContext, new String[]{"TLSv1"}, null, new DefaultHostnameVerifier());
-所以就有两种方案,一个是使用更新版本的 TLS 或者另一个就是使用比较久的 jdk,这也说明其实即使都是 jdk8 的,不同的小版本差异还是会有些影响,有的时候对于这些错误还是需要更深入地学习,不能一概而之认为就是 jdk 用的是 oracle 还是 openjdk 的,不同的错误可能就需要仔细确认原因所在。
+ docker比一般多一点的初学者介绍二
+ /2020/03/15/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D%E4%BA%8C/
+ 限制下 docker 的 cpu 使用率这里我们开始玩一点有意思的,我们在容器里装下 vim 和 gcc,然后写这样一段 c 代码
+#include <stdio.h>
+int main(void)
+{
+ int i = 0;
+ for(;;) i++;
+ return 0;
+}
+就是一个最简单的死循环,然后在容器里跑起来
+$ gcc 1.c
+$ ./a.out
+然后我们来看下系统资源占用(CPU)
![Xs562iawhHyMxeO]()
上图是在容器里的,可以看到 cpu 已经 100%了
然后看看容器外面的
![ecqH8XJ4k7rKhzu]()
可以看到一个核的 cpu 也被占满了,因为是个双核的机器,并且代码是单线程的
然后呢我们要做点啥
因为已经在这个 ubuntu 容器中装了 vim 和 gcc,考虑到国内的网络,所以我们先把这个容器 commit 一下,
+docker commit -a "nick" -m "my ubuntu" f63c5607df06 my_ubuntu:v1
+然后再运行起来
+docker run -it --cpus=0.1 my_ubuntu:v1 bash
+![]()
我们的代码跟可执行文件都还在,要的就是这个效果,然后再运行一下
![]()
结果是这个样子的,有点神奇是不,关键就在于 run 的时候的--cpus=0.1这个参数,它其实就是基于我前一篇说的 cgroup 技术,能将进程之间的cpu,内存等资源进行隔离
+开始第一个 Dockerfile
上一面为了复用那个我装了 vim 跟 gcc 的容器,我把它提交到了本地,使用了docker commit命令,有点类似于 git 的 commit,但是这个不是个很好的操作方式,需要手动介入,这里更推荐使用 Dockerfile 来构建镜像
+From ubuntu:latest
+MAINTAINER Nicksxs "nicksxs@hotmail.com"
+RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
+RUN apt-get clean
+RUN apt-get update && apt install -y nginx
+RUN echo 'Hi, i am in container' \
+ > /usr/share/nginx/html/index.html
+EXPOSE 80
+先解释下这是在干嘛,首先是这个From ubuntu:latest基于的 ubuntu 的最新版本的镜像,然后第二行是维护人的信息,第三四行么作为墙内人你懂的,把 ubuntu 的源换成阿里云的,不然就有的等了,然后就是装下 nginx,往默认的 nginx 的入口 html 文件里输入一行欢迎语,然后暴露 80 端口
然后我们使用sudo docker build -t="nicksxs/static_web" .命令来基于这个 Dockerfile 构建我们自己的镜像,过程中是这样的
![]()
![]()
可以看到图中,我的 Dockerfile 是 7 行,里面就执行了 7 步,并且每一步都有一个类似于容器 id 的层 id 出来,这里就是一个比较重要的东西,docker 在构建的时候其实是有这个层的概念,Dockerfile 里的每一行都会往上加一层,这里有还注意下命令后面的.,代表当前目录下会自行去寻找 Dockerfile 进行构建,构建完了之后我们再看下我们的本地镜像
![]()
我们自己的镜像出现啦
然后有个问题,如果这个构建中途报了错咋办呢,来试试看,我们把 nginx 改成随便的一个错误名,nginxx(不知道会不会运气好真的有这玩意),再来 build 一把
![]()
找不到 nginxx 包,是不是这个镜像就完全不能用呢,当然也不是,因为前面说到了,docker 是基于层去构建的,可以看到前面的 4 个 step 都没报错,那我们基于最后的成功步骤创建下容器看看
也就是sudo docker run -t -i bd26f991b6c8 /bin/bash
答案是可以的,只是没装成功 nginx
![]()
还有一点注意到没,前面的几个 step 都有一句 Using cache,说明 docker 在构建镜像的时候是有缓存的,这也更能说明 docker 是基于层去构建镜像,同样的底包,同样的步骤,这些层是可以被复用的,这就是 docker 的构建缓存,当然我们也可以在 build 的时候加上--no-cache去把构建缓存禁用掉。
]]>
- java
+ Docker
+ 介绍
- java
+ Docker
+ namespace
+ cgroup
- mybatis系列-connection连接池解析
- /2023/02/19/mybatis%E7%B3%BB%E5%88%97-connection%E8%BF%9E%E6%8E%A5%E6%B1%A0%E8%A7%A3%E6%9E%90/
- 连接池主要是两个逻辑,首先是获取连接的逻辑,结合代码来讲一讲
-private PooledConnection popConnection(String username, String password) throws SQLException {
- boolean countedWait = false;
- PooledConnection conn = null;
- long t = System.currentTimeMillis();
- int localBadConnectionCount = 0;
-
- // 循环获取连接
- while (conn == null) {
- // 加锁
- lock.lock();
- try {
- // 如果闲置的连接列表不为空
- if (!state.idleConnections.isEmpty()) {
- // Pool has available connection
- // 连接池有可用的连接
- conn = state.idleConnections.remove(0);
- if (log.isDebugEnabled()) {
- log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
- }
- } else {
- // Pool does not have available connection
- // 进入这个分支表示没有空闲连接,但是活跃连接数还没达到最大活跃连接数上限,那么这时候就可以创建一个新连接
- if (state.activeConnections.size() < poolMaximumActiveConnections) {
- // Can create new connection
- // 这里创建连接我们之前讲过,
- conn = new PooledConnection(dataSource.getConnection(), this);
- if (log.isDebugEnabled()) {
- log.debug("Created connection " + conn.getRealHashCode() + ".");
- }
- } else {
- // Cannot create new connection
- // 进到这个分支了就表示没法创建新连接了,那么怎么办呢,这里引入了一个 poolMaximumCheckoutTime,这代表了我去控制连接一次被使用的最长时间,如果超过这个时间了,我就要去关闭失效它
- PooledConnection oldestActiveConnection = state.activeConnections.get(0);
- long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
- if (longestCheckoutTime > poolMaximumCheckoutTime) {
- // Can claim overdue connection
- // 所有超时连接从池中被借出的次数+1
- state.claimedOverdueConnectionCount++;
- // 所有超时连接从池中被借出并归还的时间总和 + 当前连接借出时间
- state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
- // 所有连接从池中被借出并归还的时间总和 + 当前连接借出时间
- state.accumulatedCheckoutTime += longestCheckoutTime;
- // 从活跃连接数中移除此连接
- state.activeConnections.remove(oldestActiveConnection);
- // 如果该连接不是自动提交的,则尝试回滚
- if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
- try {
- oldestActiveConnection.getRealConnection().rollback();
- } catch (SQLException e) {
- /*
- Just log a message for debug and continue to execute the following
- statement like nothing happened.
- Wrap the bad connection with a new PooledConnection, this will help
- to not interrupt current executing thread and give current thread a
- chance to join the next competition for another valid/good database
- connection. At the end of this loop, bad {@link @conn} will be set as null.
- */
- log.debug("Bad connection. Could not roll back");
- }
- }
- // 用此连接的真实连接再创建一个连接,并设置时间
- conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
- conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
- conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
- oldestActiveConnection.invalidate();
- if (log.isDebugEnabled()) {
- log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
- }
- } else {
- // Must wait
- // 这样还是获取不到连接就只能等待了
- try {
- // 标记状态,然后把等待计数+1
- if (!countedWait) {
- state.hadToWaitCount++;
- countedWait = true;
- }
- if (log.isDebugEnabled()) {
- log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
- }
- long wt = System.currentTimeMillis();
- // 等待 poolTimeToWait 时间
- condition.await(poolTimeToWait, TimeUnit.MILLISECONDS);
- // 记录等待时间
- state.accumulatedWaitTime += System.currentTimeMillis() - wt;
- } catch (InterruptedException e) {
- // set interrupt flag
- Thread.currentThread().interrupt();
- break;
- }
- }
- }
- }
- // 如果连接不为空
- if (conn != null) {
- // ping to server and check the connection is valid or not
- // 判断是否有效
- if (conn.isValid()) {
- if (!conn.getRealConnection().getAutoCommit()) {
- // 回滚未提交的
- conn.getRealConnection().rollback();
- }
- conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
- // 设置时间
- conn.setCheckoutTimestamp(System.currentTimeMillis());
- conn.setLastUsedTimestamp(System.currentTimeMillis());
- // 添加进活跃连接
- state.activeConnections.add(conn);
- state.requestCount++;
- state.accumulatedRequestTime += System.currentTimeMillis() - t;
- } else {
- if (log.isDebugEnabled()) {
- log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
- }
- // 连接无效,坏连接+1
- state.badConnectionCount++;
- localBadConnectionCount++;
- conn = null;
- // 如果坏连接已经超过了容忍上限,就抛异常
- if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
- if (log.isDebugEnabled()) {
- log.debug("PooledDataSource: Could not get a good connection to the database.");
- }
- throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
- }
- }
- }
- } finally {
- // 释放锁
- lock.unlock();
- }
-
- }
-
- if (conn == null) {
- // 连接仍为空
- if (log.isDebugEnabled()) {
- log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
- // 抛出异常
- throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
- // fanhui
- return conn;
- }
-
-然后是还回连接
-protected void pushConnection(PooledConnection conn) throws SQLException {
- // 加锁
- lock.lock();
- try {
- // 从活跃连接中移除当前连接
- state.activeConnections.remove(conn);
- if (conn.isValid()) {
- // 当前的空闲连接数小于连接池中允许的最大空闲连接数
- if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
- // 记录借出时间
- state.accumulatedCheckoutTime += conn.getCheckoutTime();
- if (!conn.getRealConnection().getAutoCommit()) {
- // 同样是做回滚
- conn.getRealConnection().rollback();
- }
- // 新建一个连接
- PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
- // 加入到空闲连接列表中
- state.idleConnections.add(newConn);
- newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
- newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
- // 原连接失效
- conn.invalidate();
- if (log.isDebugEnabled()) {
- log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
- }
- // 提醒前面等待的
- condition.signal();
- } else {
- // 上面是相同的,就是这里是空闲连接数已经超过上限
- state.accumulatedCheckoutTime += conn.getCheckoutTime();
- if (!conn.getRealConnection().getAutoCommit()) {
- conn.getRealConnection().rollback();
- }
- conn.getRealConnection().close();
- if (log.isDebugEnabled()) {
- log.debug("Closed connection " + conn.getRealHashCode() + ".");
- }
- conn.invalidate();
- }
- } else {
- if (log.isDebugEnabled()) {
- log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
- }
- state.badConnectionCount++;
- }
- } finally {
- lock.unlock();
- }
- }
+ docker比一般多一点的初学者介绍四
+ /2022/12/25/docker%E6%AF%94%E4%B8%80%E8%88%AC%E5%A4%9A%E4%B8%80%E7%82%B9%E7%9A%84%E5%88%9D%E5%AD%A6%E8%80%85%E4%BB%8B%E7%BB%8D%E5%9B%9B/
+ 这次单独介绍下docker体系里非常重要的cgroup,docker对资源的限制也是基于cgroup构建的,
简单尝试
新建一个shell脚本
+#!/bin/bash
+while true;do
+ echo "1"
+done
+
+直接执行的话就是单核100%的cpu
![]()
+首先在cgroup下面建个目录
+mkdir -p /sys/fs/cgroup/cpu/sxs_test/
+查看目录下的文件
![]()
其中cpuacct开头的表示cpu相关的统计信息,
我们要配置cpu的额度,是在cpu.cfs_quota_us中
+echo 2000 > /sys/fs/cgroup/cpu/sxs_test/cpu.cfs_quota_us
+这样表示可以使用2%的cpu,总的配额是在cpu.cfs_period_us中
![]()
+然后将当前进程输入到cgroup.procs,
+echo $$ > /sys/fs/cgroup/cpu/sxs_test/cgroup.procs
+这样就会自动继承当前进程产生的新进程
再次执行就可以看到cpu被限制了
![]()
]]>
- Java
- Mybatis
+ Docker
- Java
- Mysql
- Mybatis
+ Docker
- mybatis系列-dataSource解析
- /2023/01/08/mybatis%E7%B3%BB%E5%88%97-dataSource%E8%A7%A3%E6%9E%90/
- DataSource 作为数据库查询的最重要的数据源,在 mybatis 中也展开来说下
首先是解析的过程
-SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
-
-在构建 SqlSessionFactory 也就是 DefaultSqlSessionFactory 的时候,
-public SqlSessionFactory build(InputStream inputStream) {
- return build(inputStream, null, null);
- }
-public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
- try {
- XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
- return build(parser.parse());
- } catch (Exception e) {
- throw ExceptionFactory.wrapException("Error building SqlSession.", e);
- } finally {
- ErrorContext.instance().reset();
- try {
- if (inputStream != null) {
- inputStream.close();
- }
- } catch (IOException e) {
- // Intentionally ignore. Prefer previous error.
- }
- }
- }
-前面也说过,就是解析 mybatis-config.xml 成 Configuration
-public Configuration parse() {
- if (parsed) {
- throw new BuilderException("Each XMLConfigBuilder can only be used once.");
- }
- parsed = true;
- parseConfiguration(parser.evalNode("/configuration"));
- return configuration;
-}
-private void parseConfiguration(XNode root) {
- try {
- // issue #117 read properties first
- propertiesElement(root.evalNode("properties"));
- Properties settings = settingsAsProperties(root.evalNode("settings"));
- loadCustomVfs(settings);
- loadCustomLogImpl(settings);
- typeAliasesElement(root.evalNode("typeAliases"));
- pluginElement(root.evalNode("plugins"));
- objectFactoryElement(root.evalNode("objectFactory"));
- objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
- reflectorFactoryElement(root.evalNode("reflectorFactory"));
- settingsElement(settings);
- // read it after objectFactory and objectWrapperFactory issue #631
- // -------------> 是在这里解析了DataSource
- environmentsElement(root.evalNode("environments"));
- databaseIdProviderElement(root.evalNode("databaseIdProvider"));
- typeHandlerElement(root.evalNode("typeHandlers"));
- mapperElement(root.evalNode("mappers"));
- } catch (Exception e) {
- throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
- }
-}
-环境解析了这一块的内容
-<environments default="development">
- <environment id="development">
- <transactionManager type="JDBC"/>
- <dataSource type="POOLED">
- <property name="driver" value="${driver}"/>
- <property name="url" value="${url}"/>
- <property name="username" value="${username}"/>
- <property name="password" value="${password}"/>
- </dataSource>
- </environment>
- </environments>
-解析也是自上而下的,
-private void environmentsElement(XNode context) throws Exception {
- if (context != null) {
- if (environment == null) {
- environment = context.getStringAttribute("default");
- }
- for (XNode child : context.getChildren()) {
- String id = child.getStringAttribute("id");
- if (isSpecifiedEnvironment(id)) {
- TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
- DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
- DataSource dataSource = dsFactory.getDataSource();
- Environment.Builder environmentBuilder = new Environment.Builder(id)
- .transactionFactory(txFactory)
- .dataSource(dataSource);
- configuration.setEnvironment(environmentBuilder.build());
- break;
- }
- }
- }
-}
-前面第一步是解析事务管理器元素
-private TransactionFactory transactionManagerElement(XNode context) throws Exception {
- if (context != null) {
- String type = context.getStringAttribute("type");
- Properties props = context.getChildrenAsProperties();
- TransactionFactory factory = (TransactionFactory) resolveClass(type).getDeclaredConstructor().newInstance();
- factory.setProperties(props);
- return factory;
- }
- throw new BuilderException("Environment declaration requires a TransactionFactory.");
-}
-而这里的 resolveClass 其实就使用了上一篇的 typeAliases 系统,这里是使用了 JdbcTransactionFactory 作为事务管理器,
后面的就是 DataSourceFactory 的创建也是 DataSource 的创建
-private DataSourceFactory dataSourceElement(XNode context) throws Exception {
- if (context != null) {
- String type = context.getStringAttribute("type");
- Properties props = context.getChildrenAsProperties();
- DataSourceFactory factory = (DataSourceFactory) resolveClass(type).getDeclaredConstructor().newInstance();
- factory.setProperties(props);
- return factory;
- }
- throw new BuilderException("Environment declaration requires a DataSourceFactory.");
-}
-因为在config文件中设置了Pooled,所以对应创建的就是 PooledDataSourceFactory
但是这里其实有个比较需要注意的,mybatis 这里的其实是继承了 UnpooledDataSourceFactory
将基础方法都放在了 UnpooledDataSourceFactory 中
-public class PooledDataSourceFactory extends UnpooledDataSourceFactory {
-
- public PooledDataSourceFactory() {
- this.dataSource = new PooledDataSource();
- }
-
-}
-这里只保留了在构造方法里创建 DataSource
而这个 PooledDataSource 虽然没有直接继承 UnpooledDataSource,但其实
在构造方法里也是
-public PooledDataSource() {
- dataSource = new UnpooledDataSource();
-}
-至于为什么这么做呢应该也是考虑到能比较多的复用代码,因为 Pooled 其实跟 Unpooled 最重要的差别就在于是不是每次都重开连接
使用连接池能够让应用在有大量查询的时候不用反复创建连接,省去了建联的网络等开销,Unpooled就是完成与数据库的连接,并可以获取该连接
主要的代码
-@Override
-public Connection getConnection() throws SQLException {
- return doGetConnection(username, password);
-}
-
-@Override
-public Connection getConnection(String username, String password) throws SQLException {
- return doGetConnection(username, password);
-}
-private Connection doGetConnection(String username, String password) throws SQLException {
- Properties props = new Properties();
- if (driverProperties != null) {
- props.putAll(driverProperties);
- }
- if (username != null) {
- props.setProperty("user", username);
- }
- if (password != null) {
- props.setProperty("password", password);
- }
- return doGetConnection(props);
-}
-private Connection doGetConnection(Properties properties) throws SQLException {
- initializeDriver();
- Connection connection = DriverManager.getConnection(url, properties);
- configureConnection(connection);
- return connection;
-}
-而对于Pooled就会处理池化的逻辑
-private PooledConnection popConnection(String username, String password) throws SQLException {
- boolean countedWait = false;
- PooledConnection conn = null;
- long t = System.currentTimeMillis();
- int localBadConnectionCount = 0;
-
- while (conn == null) {
- lock.lock();
- try {
- if (!state.idleConnections.isEmpty()) {
- // Pool has available connection
- conn = state.idleConnections.remove(0);
- if (log.isDebugEnabled()) {
- log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
- }
- } else {
- // Pool does not have available connection
- if (state.activeConnections.size() < poolMaximumActiveConnections) {
- // Can create new connection
- conn = new PooledConnection(dataSource.getConnection(), this);
- if (log.isDebugEnabled()) {
- log.debug("Created connection " + conn.getRealHashCode() + ".");
- }
- } else {
- // Cannot create new connection
- PooledConnection oldestActiveConnection = state.activeConnections.get(0);
- long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
- if (longestCheckoutTime > poolMaximumCheckoutTime) {
- // Can claim overdue connection
- state.claimedOverdueConnectionCount++;
- state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
- state.accumulatedCheckoutTime += longestCheckoutTime;
- state.activeConnections.remove(oldestActiveConnection);
- if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
- try {
- oldestActiveConnection.getRealConnection().rollback();
- } catch (SQLException e) {
- /*
- Just log a message for debug and continue to execute the following
- statement like nothing happened.
- Wrap the bad connection with a new PooledConnection, this will help
- to not interrupt current executing thread and give current thread a
- chance to join the next competition for another valid/good database
- connection. At the end of this loop, bad {@link @conn} will be set as null.
- */
- log.debug("Bad connection. Could not roll back");
- }
- }
- conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
- conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
- conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
- oldestActiveConnection.invalidate();
- if (log.isDebugEnabled()) {
- log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
- }
- } else {
- // Must wait
- try {
- if (!countedWait) {
- state.hadToWaitCount++;
- countedWait = true;
- }
- if (log.isDebugEnabled()) {
- log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
- }
- long wt = System.currentTimeMillis();
- condition.await(poolTimeToWait, TimeUnit.MILLISECONDS);
- state.accumulatedWaitTime += System.currentTimeMillis() - wt;
- } catch (InterruptedException e) {
- // set interrupt flag
- Thread.currentThread().interrupt();
- break;
- }
+ dubbo 客户端配置的一个重要知识点
+ /2022/06/11/dubbo-%E5%AE%A2%E6%88%B7%E7%AB%AF%E9%85%8D%E7%BD%AE%E7%9A%84%E4%B8%80%E4%B8%AA%E9%87%8D%E8%A6%81%E7%9F%A5%E8%AF%86%E7%82%B9/
+ 在配置项目中其实会留着比较多的问题,由于不同的项目没有比较统一的规划和框架模板,一般都是只有创建者会比较了解(可能也不了解),譬如前阵子在配置一个 springboot + dubbo 的项目,发现了dubbo 连接注册中间客户端的问题,这里可以结合下代码来看
比如有的应用是用的这个
+<dependency>
+ <groupId>org.apache.curator</groupId>
+ <artifactId>curator-client</artifactId>
+ <version>${curator.version}</version>
+</dependency>
+<dependency>
+ <groupId>org.apache.curator</groupId>
+ <artifactId>curator-recipes</artifactId>
+ <version>${curator.version}</version>
+</dependency>
+有个别应用用的是这个
+<dependency>
+ <groupId>com.101tec</groupId>
+ <artifactId>zkclient</artifactId>
+ <version>0.11</version>
+</dependency>
+还有的应用是找不到相关的依赖,并且这些的使用没有个比较好的说明,为啥用前者,为啥用后者,有啥注意点,
首先在使用 2.6.5 的 alibaba 的 dubbo 的时候,只使用后者是会报错的,至于为啥会报错,其实就是这篇文章想说明的点
报错的内容其实很简单, 就是缺少这个 org.apache.curator.framework.CuratorFrameworkFactory 类
这个类看着像是依赖上面的配置,但是应该不需要两个配置一块用的,所以还是需要去看代码
通过找上面类被依赖的和 dubbo 连接注册中心相关的代码,看到了这段指点迷津的代码
+@SPI("curator")
+public interface ZookeeperTransporter {
+
+ @Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
+ ZookeeperClient connect(URL url);
+
+}
+众所周知,dubbo 创造了叫自适应扩展点加载的神奇技术,这里的 adaptive 注解中的Constants.CLIENT_KEY 和 Constants.TRANSPORTER_KEY 可以在配置 dubbo 的注册信息的时候进行配置,如果是通过 xml 配置的话,可以在 <dubbo:registry/> 这个 tag 中的以上两个 key 进行配置,
具体在 dubbo.xsd 中有描述
+<xsd:element name="registry" type="registryType">
+ <xsd:annotation>
+ <xsd:documentation><![CDATA[ The registry config ]]></xsd:documentation>
+ </xsd:annotation>
+ </xsd:element>
+
+![]()
并且在 spi 的配置com.alibaba.dubbo.remoting.zookeeper.ZookeeperTransporter 中可以看到
+zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
+curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
+
+zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
+curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
+
+zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
+curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
+而在上面的代码里默认的SPI 值是 curator,所以如果不配置,那就会报上面找不到类的问题,所以如果需要使用 zkclient 的,就需要在<dubbo:registry/> 配置中添加 client="zkclient"这个配置,所以有些地方还是需要懂一些更深层次的原理,但也不至于每个东西都要抠到每一行代码原理,除非就是专门做这一块的。
还有一点是发现有些应用是碰运气,刚好有个三方包把这个类带进来了,但是这个应用就没有单独配置这块,如果不了解或者后续忘了再来查问题就会很奇怪
+]]>
+
+ Java
+ Dubbo
+
+
+ Java
+ Dubbo
+
+
+
+ docker使用中发现的echo命令的一个小技巧及其他
+ /2020/03/29/echo%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E4%B8%AA%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ echo 实操技巧最近做 docker 系列,会经常需要进到 docker 内部,如上一篇介绍的,这些镜像一般都有用 ubuntu 或者alpine 这样的 Linux 系统作为底包,如果构建镜像的时候没有替换源的话,因为特殊的网络原因,在内部想编辑下东西要安装个类似于 vim 这样的编辑器就会很慢很慢,像视频里 two thousand years later~ 而且如果在容器内部想改源配置的话也要编辑器,就陷入了一个鸡生蛋,跟蛋生鸡的死锁问题中,对于 linux 大神来说应该有一万种方法解决这个问题,对于我这个渣渣来说可能只想到了这个土方法,先 cp backup 一下 sources.list, 再 echo “xxx” > sources.list, 这里就碰到了一个问题,这个 sources.list 一般不止一行,直接 echo 的话就解析不了了,不过 echo 可以支持”\n”转义,就是加-e看一下解释和示例,我这里使用了 tldr ,可以用 npm install -g tldr 安装,也可以直接用man, 或者–help 来查看使用方式
![]()
+查看镜像底包
还有一点也是在这个时候要安装 vim 之类的,得知道是什么镜像底包,如果是用 uname 指令,其实看到的是宿主机的系统,得用cat /etc/issue
+![]()
这里稍稍记一下
+寻找系统镜像源
目前国内系统源用得比较多的是阿里云源,不过这里也推荐清华源, 中科大源, 浙大源 这里不要脸的推荐下母校的源,不过还不是很完善,尽情期待下。
+]]>
+
+ Linux
+ Docker
+ 命令
+ echo
+ 发行版本
+
+
+ linux
+ Docker
+ echo
+ uname
+ 发行版
+
+
+
+ gogs使用webhook部署react单页应用
+ /2020/02/22/gogs%E4%BD%BF%E7%94%A8webhook%E9%83%A8%E7%BD%B2react%E5%8D%95%E9%A1%B5%E5%BA%94%E7%94%A8/
+ 众所周知,我是个前端彩笔,但是也想做点自己可以用的工具页面,所以就让朋友推荐了蚂蚁出品的 ant design,说基本可以直接 ctrl-c ctrl-v,实测对我这种来说还是有点难的,不过也能写点,但是现在碰到的问题是怎么部署到自己的服务器上去
用 ant design 写的是个单页应用,实际来说就是一个 html 加 css 跟 js,最初的时候是直接 build 完就 scp 上去,也考虑过 rsync 之类的,但是都感觉不够自动化,正好自己还没这方面的经验就想折腾下,因为我自己搭的仓库应用是 gogs,搜了一下主要是跟 drones 配合做 ci/cd,研究了一下发现其实这个事情没必要这么搞(PS:drone 也不好用),整个 hook 就可以了, 但是实际上呢,这东西也不是那么简单
首先是需要在服务器上装 webhook,这个我一开始用 snap 安装,但是出现问题,run 的时候会出现后面参数带的 hooks.json 文件找不到,然后索性就直接 github 上下最新版,放 /usr/local/bin 了,webhook 的原理呢其实也比较简单,就是起一个 http 服务,通过 post 请求调用,解析下参数,如果跟配置的参数一致,就调用对应的命令或者脚本。
+配置 hooks.json
webhook 的配置,需要的两个文件,一个是 hooks.json,这个是 webhook 服务的配置文件,像这样
+[
+ {
+ "id": "redeploy-app",
+ "execute-command": "/opt/scripts/redeploy.sh",
+ "command-working-directory": "/opt/scripts",
+ "pass-arguments-to-command":
+ [
+ {
+ "source": "payload",
+ "name": "head_commit.message"
+ },
+ {
+ "source": "payload",
+ "name": "pusher.name"
+ },
+ {
+ "source": "payload",
+ "name": "head_commit.id"
+ }
+ ],
+ "trigger-rule":
+ {
+ "and":
+ [
+ {
+ "match":
+ {
+ "type": "payload-hash-sha1",
+ "secret": "your-github-secret",
+ "parameter":
+ {
+ "source": "header",
+ "name": "X-Hub-Signature"
}
}
- }
- if (conn != null) {
- // ping to server and check the connection is valid or not
- if (conn.isValid()) {
- if (!conn.getRealConnection().getAutoCommit()) {
- conn.getRealConnection().rollback();
- }
- conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
- conn.setCheckoutTimestamp(System.currentTimeMillis());
- conn.setLastUsedTimestamp(System.currentTimeMillis());
- state.activeConnections.add(conn);
- state.requestCount++;
- state.accumulatedRequestTime += System.currentTimeMillis() - t;
- } else {
- if (log.isDebugEnabled()) {
- log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
- }
- state.badConnectionCount++;
- localBadConnectionCount++;
- conn = null;
- if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
- if (log.isDebugEnabled()) {
- log.debug("PooledDataSource: Could not get a good connection to the database.");
- }
- throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
+ },
+ {
+ "match":
+ {
+ "type": "value",
+ "value": "refs/heads/master",
+ "parameter":
+ {
+ "source": "payload",
+ "name": "ref"
}
}
}
- } finally {
- lock.unlock();
- }
-
+ ]
}
+ }
+]
- if (conn == null) {
- if (log.isDebugEnabled()) {
- log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
- throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
+这是个跟 github搭配的示例,首先 id 表示的是这个对应 hook 的识别 id,也可以看到这个 hooks.json 的结构是这样的一个数组,然后就是要执行的命令和命令执行的参数,值得注意的是这个trigger-rule,就是请求进来了回去匹配里面的,比如前一个是一个加密的,放在请求头里,第二个 match 表示请求里的 ref 是个 master 分支,就可以区分分支进行不同操作,但是前面的加密配合 gogs 使用的时候有个问题(PS: webhook 的文档是真的烂),gogs 设置 webhook 的加密是用的
+
+密钥文本将被用于计算推送内容的 SHA256 HMAC 哈希值,并设置为 X-Gogs-Signature 请求头的值。
+
+这种加密方式,所以 webhook 的这个示例的加密方式不行,但这货的文档里居然没有说明支持哪些加密,神TM,后来还是翻 issue 翻到了, 需要使用这个payload-hash-sha256
+执行脚本 redeploy.sh
脚本类似于这样
+#!/bin/bash -e
- return conn;
- }
-它的入口不是个get方法,而是pop,从含义来来讲就不一样
org.apache.ibatis.datasource.pooled.PooledDataSource#getConnection()
-@Override
-public Connection getConnection() throws SQLException {
- return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
-}
-对于具体怎么获取连接我们可以下一篇具体讲下
+function cleanup {
+ echo "Error occoured"
+}
+trap cleanup ERR
+
+commit_message=$1 # head_commit.message
+pusher_name=$2 # pusher.name
+commit_id=$3 # head_commit.id
+
+
+cd ~/do-react-example-app/
+git pull origin master
+yarn && yarn build
+
+就是简单的拉代码,然后构建下,真实使用时可能不是这样,因为页面会部署在 nginx 的作用目录,还需要 rsync 过去,这部分可能还涉及到两个问题第一个是使用 rsync 还是其他的 cp,不过这个无所谓;第二个是目录权限的问题,以我的系统ubuntu 为例,默认用户是 ubuntu,nginx 部署的目录是 www,所以需要切换用户等操作,一开始是想用在shell 文件中直接写了密码,但是不知道咋传,查了下是类似于这样 echo "passwd" | sudo -S cmd,通过管道命令往后传,然后就是这个-S, 参数的解释是-S, --stdin read password from standard input,但是这样么也不是太安全的赶脚,又看了下还有两种方法,
+
+就是给root 设置一个不需要密码的命令类似于这样,
+myusername ALL = (ALL) ALL
+myusername ALL = (root) NOPASSWD: /path/to/my/program
+另一种就是把默认用户跟 root 设置成同一个 group 的
+
+使用
真正实操的时候其实还有不少问题,首先运行 webhook 就碰到了我前面说的,使用 snap 运行的时候会找不到前面的 hooks.json配置文件,执行snap run webhook -hooks /opt/hooks/hooks.json -verbose就碰到下面的couldn't load hooks from file! open /opt/hooks/hooks.json: no such file or directory,后来直接下了个官方最新的 release,就直接执行 webhook -hooks /opt/hooks/hooks.json -verbose 就可以了,然后是前面的示例配置文件里的几个参数,比如head_commit.message 其实 gogs 推过来的根本没这玩意,而且都是数组,不知道咋取,烂文档,不过总比搭个 drone 好一点就忍了。补充一点就是在 debug 的时候需要看下问题出在哪,看看脚本有没有执行,所以需要在前面的 json 里加这个参数"include-command-output-in-response": true, 就能输出来脚本执行结果
+]]>
+
+ 持续集成
+
+
+ Gogs
+ Webhook
+
+
+
+ headscale 添加节点
+ /2023/07/09/headscale-%E6%B7%BB%E5%8A%A0%E8%8A%82%E7%82%B9/
+ 添加节点添加节点非常简单,比如 app store 或者官网可以下载 mac 的安装包,
+安装包直接下载可以在这里,下载安装完后还需要做一些处理,才能让 Tailscale 使用 Headscale 作为控制服务器。当然,Headscale 已经给我们提供了详细的操作步骤,你只需要在浏览器中打开 URL:http://<HEADSCALE_PUB_IP>:<HEADSCALE_PUB_PORT>/apple,记得端口替换成自己的,就会看到这样的说明页
+![image]()
+然后对于像我这样自己下载的客户端安装包,也就是standalone client,就可以用下面的命令
+defaults write io.tailscale.ipn.macsys ControlURL http://<HEADSCALE_PUB_IP>:<HEADSCALE_PUB_PORT> 类似于 Windows 客户端需要写入注册表,就是把控制端的地址改成了我们自己搭建的 headscale 的,设置完以后就打开 tailscale 客户端右键点击 login,就会弹出一个浏览器地址
+![image]()
+按照这个里面的命令去 headscale 的机器上执行,注意要替换 namespace,对于最新的 headscale 已经把 namespace 废弃改成 user 了,这点要注意了,其他客户端也同理,现在还有个好消息,安卓和 iOS 客户端也已经都可以用了,后面可以在介绍下局域网怎么部分打通和自建 derper。
+]]>
+
+ headscale
+
+
+ headscale
+
+
+
+ invert-binary-tree
+ /2015/06/22/invert-binary-tree/
+ Invert a binary tree
+ 4
+ / \
+ 2 7
+ / \ / \
+1 3 6 9
+
+to
+ 4
+ / \
+ 7 2
+ / \ / \
+9 6 3 1
+
+Trivia:
This problem was inspired by this original tweet by Max Howell:
+
+Google: 90% of our engineers use the software you wrote (Homebrew),
but you can’t invert a binary tree on a whiteboard so fuck off.
+
+/**
+ * Definition for a binary tree node.
+ * struct TreeNode {
+ * int val;
+ * TreeNode *left;
+ * TreeNode *right;
+ * TreeNode(int x) : val(x), left(NULL), right(NULL) {}
+ * };
+ */
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ if(root == NULL) return root;
+ TreeNode* temp;
+ temp = invertTree(root->left);
+ root->left = invertTree(root->right);
+ root->right = temp;
+ return root;
+ }
+};
]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ java 中发起 http 请求时证书问题解决记录
+ /2023/07/29/java-%E4%B8%AD%E5%8F%91%E8%B5%B7-http-%E8%AF%B7%E6%B1%82%E6%97%B6%E8%AF%81%E4%B9%A6%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3%E8%AE%B0%E5%BD%95/
+ 再一次环境部署是发现了个问题,就是在请求微信 https 请求的时候,出现了个错误
No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
一开始以为是环境问题,从 oracle 的 jdk 换成了基于 openjdk 的底包,没有 javax 的关系,
完整的提示包含了 javax 的异常
java.lang.RuntimeException: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
后面再看了下,是不是也可能是证书的问题,然后就去找了下是不是证书相关的,
可以看到在 /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/security 路径下的 java.security 中
jdk.tls.disabledAlgorithms=SSLv3, TLSv1, TLSv1.1, RC4, DES, MD5withRSA,
而正好在我们代码里 createSocketFactory 的时候使用了 TLSv1 这个证书协议
+SSLContext sslContext = SSLContext.getInstance("TLS");
+sslContext.init(kmf.getKeyManagers(), null, new SecureRandom());
+return new SSLConnectionSocketFactory(sslContext, new String[]{"TLSv1"}, null, new DefaultHostnameVerifier());
+所以就有两种方案,一个是使用更新版本的 TLS 或者另一个就是使用比较久的 jdk,这也说明其实即使都是 jdk8 的,不同的小版本差异还是会有些影响,有的时候对于这些错误还是需要更深入地学习,不能一概而之认为就是 jdk 用的是 oracle 还是 openjdk 的,不同的错误可能就需要仔细确认原因所在。
]]>
- Java
- Mybatis
+ java
- Java
- Mysql
- Mybatis
+ java
- mybatis系列-sql 类的简单使用
- /2023/03/12/mybatis%E7%B3%BB%E5%88%97-sql-%E7%B1%BB%E7%9A%84%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8/
- mybatis 还有个比较有趣的功能,就是使用 SQL 类生成 sql,有点类似于 hibernate 或者像 php 的 laravel 框架等的,就是把sql 这种放在 xml 里或者代码里直接写 sql 用对象的形式
-select语句
比如这样
-public static void main(String[] args) {
- String selectSql = new SQL() {{
- SELECT("id", "name");
- FROM("student");
- WHERE("id = #{id}");
- }}.toString();
- System.out.println(selectSql);
-}
-打印出来就是
-SELECT id, name
-FROM student
-WHERE (id = #{id})
-应付简单的 sql 查询基本都可以这么解决,如果习惯这种模式,还是不错的,
其实以面向对象的编程模式来说,这样是比较符合面向对象的,先不深入的解析这块的源码,先从使用角度讲一下
-比如 update 语句
String updateSql = new SQL() {{
- UPDATE("student");
- SET("name = #{name}");
- WHERE("id = #{id}");
- }}.toString();
-打印输出就是
-UPDATE student
-SET name = #{name}
-WHERE (id = #{id})
-
-insert 语句
String insertSql = new SQL() {{
- INSERT_INTO("student");
- VALUES("name", "#{name}");
- VALUES("age", "#{age}");
- }}.toString();
- System.out.println(insertSql);
-打印输出
-INSERT INTO student
- (name, age)
-VALUES (#{name}, #{age})
-delete语句
String deleteSql = new SQL() {{
- DELETE_FROM("student");
- WHERE("id = #{id}");
- }}.toString();
- System.out.println(deleteSql);
-打印输出
-DELETE FROM student
-WHERE (id = #{id})
+ minimum-size-subarray-sum-209
+ /2016/10/11/minimum-size-subarray-sum-209/
+ problemGiven an array of n positive integers and a positive integer s, find the minimal length of a subarray of which the sum ≥ s. If there isn’t one, return 0 instead.
+For example, given the array [2,3,1,2,4,3] and s = 7,
the subarray [4,3] has the minimal length under the problem constraint.
+题解
参考,滑动窗口,跟之前Data Structure课上的online算法有点像,链接
+Code
class Solution {
+public:
+ int minSubArrayLen(int s, vector<int>& nums) {
+ int len = nums.size();
+ if(len == 0) return 0;
+ int minlen = INT_MAX;
+ int sum = 0;
+
+ int left = 0;
+ int right = -1;
+ while(right < len)
+ {
+ while(sum < s && right < len)
+ sum += nums[++right];
+ if(sum >= s)
+ {
+ minlen = minlen < right - left + 1 ? minlen : right - left + 1;
+ sum -= nums[left++];
+ }
+ }
+ return minlen > len ? 0 : minlen;
+ }
+};
]]>
- Java
- Mybatis
+ leetcode
- Java
- Mysql
- Mybatis
+ leetcode
+ c++
- mybatis系列-sql 类的简要分析
- /2023/03/19/mybatis%E7%B3%BB%E5%88%97-sql-%E7%B1%BB%E7%9A%84%E7%AE%80%E8%A6%81%E5%88%86%E6%9E%90/
- 上次就比较简单的讲了使用,这块也比较简单,因为封装得不是很复杂,首先我们从 select 作为入口来看看,这个具体的实现,
-String selectSql = new SQL() {{
- SELECT("id", "name");
- FROM("student");
- WHERE("id = #{id}");
- }}.toString();
-SELECT 方法的实现,
-public T SELECT(String... columns) {
- sql().statementType = SQLStatement.StatementType.SELECT;
- sql().select.addAll(Arrays.asList(columns));
- return getSelf();
-}
-statementType是个枚举
-public enum StatementType {
- DELETE, INSERT, SELECT, UPDATE
-}
-那这个就是个 select 语句,然后会把参数转成 list 添加到 select 变量里,
然后是 from 语句,这个大概也能猜到就是设置下表名,
-public T FROM(String table) {
- sql().tables.add(table);
- return getSelf();
-}
-往 tables 里添加了 table,这个 tables 是什么呢
这里也可以看下所有的变量,
-StatementType statementType;
-List<String> sets = new ArrayList<>();
-List<String> select = new ArrayList<>();
-List<String> tables = new ArrayList<>();
-List<String> join = new ArrayList<>();
-List<String> innerJoin = new ArrayList<>();
-List<String> outerJoin = new ArrayList<>();
-List<String> leftOuterJoin = new ArrayList<>();
-List<String> rightOuterJoin = new ArrayList<>();
-List<String> where = new ArrayList<>();
-List<String> having = new ArrayList<>();
-List<String> groupBy = new ArrayList<>();
-List<String> orderBy = new ArrayList<>();
-List<String> lastList = new ArrayList<>();
-List<String> columns = new ArrayList<>();
-List<List<String>> valuesList = new ArrayList<>();
-可以看到是一堆 List 先暂存这些sql 片段,然后再拼装成 sql 语句,
因为它重写了 toString 方法
+ mybatis 的 foreach 使用的注意点
+ /2022/07/09/mybatis-%E7%9A%84-foreach-%E4%BD%BF%E7%94%A8%E7%9A%84%E6%B3%A8%E6%84%8F%E7%82%B9/
+ mybatis 在作为轻量级 orm 框架,如果要使用类似于 in 查询的语句,除了直接替换字符串,还可以使用 foreach 标签
在mybatis的 dtd 文件中可以看到可以配置这些字段,
+<!ELEMENT foreach (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*>
+<!ATTLIST foreach
+collection CDATA #REQUIRED
+item CDATA #IMPLIED
+index CDATA #IMPLIED
+open CDATA #IMPLIED
+close CDATA #IMPLIED
+separator CDATA #IMPLIED
+>
+collection 表示需要使用 foreach 的集合,item 表示进行迭代的变量名,index 就是索引值,而 open 跟 close
代表拼接的起始和结束符号,一般就是左右括号,separator 则是每个 item 直接的分隔符
+例如写了一个简单的 sql 查询
+<select id="search" parameterType="list" resultMap="StudentMap">
+ select * from student
+ <where>
+ id in
+ <foreach collection="list" item="item" open="(" close=")" separator=",">
+ #{item}
+ </foreach>
+ </where>
+</select>
+这里就发现了一个问题,collection 对应的这个值,如果传入的参数是个 HashMap,collection 的这个值就是以此作为
key 从这个 HashMap 获取对应的集合,但是这里有几个特殊的小技巧,
在上面的这个方法对应的接口方法定义中
+public List<Student> search(List<Long> userIds);
+我是这么定义的,而 collection 的值是list,这里就有一点不能理解了,但其实是 mybatis 考虑到使用的方便性,
帮我们做了一点点小转换,我们翻一下 mybatis 的DefaultSqlSession 中的代码可以看到
@Override
-public String toString() {
- StringBuilder sb = new StringBuilder();
- sql().sql(sb);
- return sb.toString();
-}
-调用的 sql 方法是
-public String sql(Appendable a) {
- SafeAppendable builder = new SafeAppendable(a);
- if (statementType == null) {
- return null;
- }
-
- String answer;
-
- switch (statementType) {
- case DELETE:
- answer = deleteSQL(builder);
- break;
-
- case INSERT:
- answer = insertSQL(builder);
- break;
-
- case SELECT:
- answer = selectSQL(builder);
- break;
-
- case UPDATE:
- answer = updateSQL(builder);
- break;
-
- default:
- answer = null;
- }
-
- return answer;
- }
-根据上面的 statementType判断是个什么 sql,我们这个是 selectSQL 就走的 SELECT 这个分支
-private String selectSQL(SafeAppendable builder) {
- if (distinct) {
- sqlClause(builder, "SELECT DISTINCT", select, "", "", ", ");
- } else {
- sqlClause(builder, "SELECT", select, "", "", ", ");
- }
-
- sqlClause(builder, "FROM", tables, "", "", ", ");
- joins(builder);
- sqlClause(builder, "WHERE", where, "(", ")", " AND ");
- sqlClause(builder, "GROUP BY", groupBy, "", "", ", ");
- sqlClause(builder, "HAVING", having, "(", ")", " AND ");
- sqlClause(builder, "ORDER BY", orderBy, "", "", ", ");
- limitingRowsStrategy.appendClause(builder, offset, limit);
- return builder.toString();
-}
-上面的可以看出来就是按我们常规的 sql 理解顺序来处理
就是select ... from ... where ... 这样子
再看下 sqlClause 的代码
-private void sqlClause(SafeAppendable builder, String keyword, List<String> parts, String open, String close,
- String conjunction) {
- if (!parts.isEmpty()) {
- if (!builder.isEmpty()) {
- builder.append("\n");
- }
- builder.append(keyword);
- builder.append(" ");
- builder.append(open);
- String last = "________";
- for (int i = 0, n = parts.size(); i < n; i++) {
- String part = parts.get(i);
- if (i > 0 && !part.equals(AND) && !part.equals(OR) && !last.equals(AND) && !last.equals(OR)) {
- builder.append(conjunction);
- }
- builder.append(part);
- last = part;
- }
- builder.append(close);
- }
- }
-这里的拼接方式还需要判断 AND 和 OR 的判断逻辑,其他就没什么特别的了,只是where 语句中的 lastList 不知道是干嘛的,好像只有添加跟赋值的操作,有知道的大神也可以评论指导下
-]]>
+public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
+ try {
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+}
+// 就是在这帮我们做了转换
+ private Object wrapCollection(final Object object) {
+ if (object instanceof Collection) {
+ StrictMap<Object> map = new StrictMap<Object>();
+ map.put("collection", object);
+ if (object instanceof List) {
+ // 如果类型是list 就会转成以 list 为 key 的 map
+ map.put("list", object);
+ }
+ return map;
+ } else if (object != null && object.getClass().isArray()) {
+ StrictMap<Object> map = new StrictMap<Object>();
+ map.put("array", object);
+ return map;
+ }
+ return object;
+ }]]>
Java
Mybatis
+ Mysql
Java
@@ -7431,840 +6326,870 @@ WHERE (id = #{id})
- mybatis系列-入门篇
- /2022/11/27/mybatis%E7%B3%BB%E5%88%97-%E5%85%A5%E9%97%A8%E7%AF%87/
- mybatis是我们比较常用的orm框架,下面是官网的介绍
-
- MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
-
-mybatis一大特点,或者说比较为人熟知的应该就是比 hibernate 是更轻量化,为国人所爱好的orm框架,对于hibernate目前还没有深入的拆解过,后续可以也写一下,在使用体验上觉得是个比较精巧的框架,看代码也比较容易,所以就想写个系列,第一篇先是介绍下使用
根据官网的文档上我们先来尝试一下简单使用
首先我们有个简单的配置,这个文件是mybatis-config.xml
-<?xml version="1.0" encoding="UTF-8" ?>
-<!DOCTYPE configuration
- PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
- "https://mybatis.org/dtd/mybatis-3-config.dtd">
-<configuration>
- <!-- 需要加入的properties-->
- <properties resource="application-development.properties"/>
- <!-- 指出使用哪个环境,默认是development-->
- <environments default="development">
- <environment id="development">
- <!-- 指定事务管理器类型-->
- <transactionManager type="JDBC"/>
- <!-- 指定数据源类型-->
- <dataSource type="POOLED">
- <!-- 下面就是具体的参数占位了-->
- <property name="driver" value="${driver}"/>
- <property name="url" value="${url}"/>
- <property name="username" value="${username}"/>
- <property name="password" value="${password}"/>
- </dataSource>
- </environment>
- </environments>
- <mappers>
- <!-- 指定mapper xml的位置或文件-->
- <mapper resource="mapper/StudentMapper.xml"/>
- </mappers>
-</configuration>
-在代码里创建mybatis里重要入口
-String resource = "mybatis-config.xml";
-InputStream inputStream = Resources.getResourceAsStream(resource);
-SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
-然后我们上面的StudentMapper.xml
-<?xml version="1.0" encoding="UTF-8" ?>
-<!DOCTYPE mapper
- PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
- "https://mybatis.org/dtd/mybatis-3-mapper.dtd">
-<mapper namespace="com.nicksxs.mybatisdemo.StudentMapper">
- <select id="selectStudent" resultType="com.nicksxs.mybatisdemo.StudentDO">
- select * from student where id = #{id}
- </select>
-</mapper>
-那么我们就要使用这个mapper,
-String resource = "mybatis-config.xml";
-InputStream inputStream = Resources.getResourceAsStream(resource);
-SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
-try (SqlSession session = sqlSessionFactory.openSession()) {
- StudentDO studentDO = session.selectOne("com.nicksxs.mybatisdemo.StudentMapper.selectStudent", 1);
- System.out.println("id is " + studentDO.getId() + " name is " +studentDO.getName());
-} catch (Exception e) {
- e.printStackTrace();
-}
-sqlSessionFactory是sqlSession的工厂,我们可以通过sqlSessionFactory来创建sqlSession,而SqlSession 提供了在数据库执行 SQL 命令所需的所有方法。你可以通过 SqlSession 实例来直接执行已映射的 SQL 语句。可以看到mapper.xml中有定义mapper的namespace,就可以通过session.selectOne()传入namespace+id来调用这个方法
但是这样调用比较不合理的点,或者说按后面mybatis优化之后我们可以指定mapper接口
-public interface StudentMapper {
+ mybatis 的 $ 和 # 是有啥区别
+ /2020/09/06/mybatis-%E7%9A%84-%E5%92%8C-%E6%98%AF%E6%9C%89%E5%95%A5%E5%8C%BA%E5%88%AB/
+ 这个问题也是面试中常被问到的,就抽空来了解下这个,跳过一大段前面初始化的逻辑,
对于一条select * from t1 where id = #{id}这样的 sql,在初始化扫描 mapper 的xml文件的时候会根据是否是 dynamic 来判断生成 DynamicSqlSource 还是 RawSqlSource,这里它是一条 RawSqlSource,
在这里做了替换,将#{}替换成了?
![]()
前面说的是否 dynamic 就是在这里进行判断
![]() +
+// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
+public SqlSource parseScriptNode() {
+ MixedSqlNode rootSqlNode = parseDynamicTags(context);
+ SqlSource sqlSource;
+ if (isDynamic) {
+ sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
+ } else {
+ sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
+ }
+ return sqlSource;
+ }
+// org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseDynamicTags
+protected MixedSqlNode parseDynamicTags(XNode node) {
+ List<SqlNode> contents = new ArrayList<>();
+ NodeList children = node.getNode().getChildNodes();
+ for (int i = 0; i < children.getLength(); i++) {
+ XNode child = node.newXNode(children.item(i));
+ if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
+ String data = child.getStringBody("");
+ TextSqlNode textSqlNode = new TextSqlNode(data);
+ if (textSqlNode.isDynamic()) {
+ contents.add(textSqlNode);
+ isDynamic = true;
+ } else {
+ contents.add(new StaticTextSqlNode(data));
+ }
+ } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
+ String nodeName = child.getNode().getNodeName();
+ NodeHandler handler = nodeHandlerMap.get(nodeName);
+ if (handler == null) {
+ throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
+ }
+ handler.handleNode(child, contents);
+ isDynamic = true;
+ }
+ }
+ return new MixedSqlNode(contents);
+ }
+// org.apache.ibatis.scripting.xmltags.TextSqlNode#isDynamic
+ public boolean isDynamic() {
+ DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
+ GenericTokenParser parser = createParser(checker);
+ parser.parse(text);
+ return checker.isDynamic();
+ }
+ private GenericTokenParser createParser(TokenHandler handler) {
+ return new GenericTokenParser("${", "}", handler);
+ }
+可以看到其中一个条件就是是否有${}这种占位符,假如说上面的 sql 换成 ${},那么可以看到它会在这里创建一个 dynamicSqlSource,
+// org.apache.ibatis.scripting.xmltags.DynamicSqlSource
+public class DynamicSqlSource implements SqlSource {
+
+ private final Configuration configuration;
+ private final SqlNode rootSqlNode;
+
+ public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) {
+ this.configuration = configuration;
+ this.rootSqlNode = rootSqlNode;
+ }
+
+ @Override
+ public BoundSql getBoundSql(Object parameterObject) {
+ DynamicContext context = new DynamicContext(configuration, parameterObject);
+ rootSqlNode.apply(context);
+ SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
+ Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
+ SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
+ BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
+ context.getBindings().forEach(boundSql::setAdditionalParameter);
+ return boundSql;
+ }
- public StudentDO selectStudent(Long id);
-}
-就可以可以通过mapper接口获取方法,这样就不用涉及到未知的变量转换等异常
-try (SqlSession session = sqlSessionFactory.openSession()) {
- StudentMapper mapper = session.getMapper(StudentMapper.class);
- StudentDO studentDO = mapper.selectStudent(1L);
- System.out.println("id is " + studentDO.getId() + " name is " +studentDO.getName());
-} catch (Exception e) {
- e.printStackTrace();
-}
-这一篇咱们先介绍下简单的使用,后面可以先介绍下这些的原理。
+}
+
+这里眼尖的同学可能就可以看出来了,RawSqlSource 在初始化的时候已经经过了 parse,把#{}替换成了?占位符,但是 DynamicSqlSource 并没有
![]() 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换
然后往里跟
![]() 好像是这里了
好像是这里了
![]()
这里 rootSqlNode.apply 其实是一个对原来 sql 的解析结果的一个循环调用,不同类型的标签会构成不同的 node,像这里就是一个 textSqlNode
![]()
可以发现到这我们的 sql 已经被替换了,而且是直接作为 string 类型替换的,所以可以明白了这个问题所在,就是注入,不过细心的同学发现其实这里是有个
![]()
理论上还是可以做过滤的,不过好像现在没用起来。
我们前面可以发现对于#{}是在启动扫描 mapper的 xml 文件就替换成了 ?,然后是在什么时候变成实际的值的呢
![]()
发现到这的时候还是没有替换,其实说白了也就是 prepareStatement 那一套,
![]()
在这里进行替换,会拿到 org.apache.ibatis.mapping.ParameterMapping,然后进行替换,因为会带着类型信息,所以不用担心注入咯
]]>
Java
Mybatis
+ Spring
+ Mysql
+ Sql注入
+ Mybatis
Java
Mysql
Mybatis
+ Sql注入
- mybatis系列-第一条sql的更多细节
- /2022/12/18/mybatis%E7%B3%BB%E5%88%97-%E7%AC%AC%E4%B8%80%E6%9D%A1sql%E7%9A%84%E6%9B%B4%E5%A4%9A%E7%BB%86%E8%8A%82/
- 执行细节
首先设置了默认的languageDriver
org/mybatis/mybatis/3.5.11/mybatis-3.5.11-sources.jar!/org/apache/ibatis/session/Configuration.java:215
在configuration的构造方法里
-languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
-
-而在
org.apache.ibatis.builder.xml.XMLStatementBuilder#parseStatementNode
中,创建了sqlSource,这里就会根据前面的 LanguageDriver 的实现选择对应的 sqlSource ,
-SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
+ github 小技巧-更新 github host key
+ /2023/03/28/github-%E5%B0%8F%E6%8A%80%E5%B7%A7-%E6%9B%B4%E6%96%B0-github-host-key/
+ 最近一次推送博客,发现报了个错推不上去,
+WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
-createSqlSource 就会调用
-@Override
-public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
- XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
- return builder.parseScriptNode();
-}
+IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
+Someone could be eavesdropping on you right now (man-in-the-middle attack)!
+It is also possible that a host key has just been changed.
+错误信息是这样,有点奇怪也没干啥,网上一搜发现是We updated our RSA SSH host key
简单翻一下就是
+
+在3月24日协调世界时大约05:00时,出于谨慎,我们更换了用于保护 GitHub.com 的 Git 操作的 RSA SSH 主机密钥。我们这样做是为了保护我们的用户免受任何对手模仿 GitHub 或通过 SSH 窃听他们的 Git 操作的机会。此密钥不授予对 GitHub 基础设施或客户数据的访问权限。此更改仅影响通过使用 RSA 的 SSH 进行的 Git 操作。GitHub.com 和 HTTPS Git 操作的网络流量不受影响。
+
+要解决也比较简单就是重置下 host key,
+
+Host Key是服务器用来证明自己身份的一个永久性的非对称密钥
+
+使用
+ssh-keygen -R github.com
+然后在首次建立连接的时候同意下就可以了
+]]>
+
+ ssh
+ 技巧
+
+
+ ssh
+ 端口转发
+
+
+
+ hexo 配置系列-接入Algolia搜索
+ /2023/04/02/hexo-%E9%85%8D%E7%BD%AE%E7%B3%BB%E5%88%97-%E6%8E%A5%E5%85%A5Algolia%E6%90%9C%E7%B4%A2/
+ 博客之前使用的是 local search,最开始感觉使用体验还不错,速度也不慢,最近自己搜了下觉得效果差了很多,不知道是啥原因,所以接入有 next 主题支持的 Algolia 搜索,next 主题的文档已经介绍的很清楚了,这边就记录下,
首先要去 Algolia 开通下账户,创建一个索引
![]()
创建好后要去找一下 api key 的配置,这个跟 next 主题的说明已经有些不一样了
在设置里可以找到
![]()
这里默认会有两个 key
![]()
一个是 search only,一个是 admin key,需要再创建一个自定义 key
这个 key 需要有这些权限,称为 High-privilege API key, 后面有用
![]()
然后就是到博客目录下安装
+cd hexo-site
+npm install hexo-algolia
+然后在 hexo 站点配置中添加
+algolia:
+ applicationID: "Application ID"
+ apiKey: "Search-only API key"
+ indexName: "indexName"
+包括应用 Id,只搜索的 api key(默认给创建好的那个),indexName 就是最开始创建的 index 名,
+export HEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Git Bash
+# set HEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Windows command line
+hexo clean
+hexo algolia
+然后再到 next 配置中开启 algolia_search
+# Algolia Search
+algolia_search:
+ enable: true
+ hits:
+ per_page: 10
+搜索的界面其实跟 local 的差不多,就是搜索效果会好一些
![]()
也推荐可以搜搜过往的内容,已经左边有个热度的,做了个按阅读量排序的榜单。
+]]>
+
+ hexo
+ 技巧
+
+
+ hexo
+
+
+
+ mybatis系列-dataSource解析
+ /2023/01/08/mybatis%E7%B3%BB%E5%88%97-dataSource%E8%A7%A3%E6%9E%90/
+ DataSource 作为数据库查询的最重要的数据源,在 mybatis 中也展开来说下
首先是解析的过程
+SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
-再往下的逻辑在 parseScriptNode 中,org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
-public SqlSource parseScriptNode() {
- MixedSqlNode rootSqlNode = parseDynamicTags(context);
- SqlSource sqlSource;
- if (isDynamic) {
- sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
- } else {
- sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
+在构建 SqlSessionFactory 也就是 DefaultSqlSessionFactory 的时候,
+public SqlSessionFactory build(InputStream inputStream) {
+ return build(inputStream, null, null);
}
- return sqlSource;
-}
-
-首先要解析dynamicTag,调用了org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseDynamicTags
-protected MixedSqlNode parseDynamicTags(XNode node) {
- List<SqlNode> contents = new ArrayList<>();
- NodeList children = node.getNode().getChildNodes();
- for (int i = 0; i < children.getLength(); i++) {
- XNode child = node.newXNode(children.item(i));
- if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
- String data = child.getStringBody("");
- TextSqlNode textSqlNode = new TextSqlNode(data);
- // ---------> 主要是这边的逻辑
- if (textSqlNode.isDynamic()) {
- contents.add(textSqlNode);
- isDynamic = true;
- } else {
- contents.add(new StaticTextSqlNode(data));
- }
- } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
- String nodeName = child.getNode().getNodeName();
- NodeHandler handler = nodeHandlerMap.get(nodeName);
- if (handler == null) {
- throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
- }
- handler.handleNode(child, contents);
- isDynamic = true;
+public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
+ try {
+ XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
+ return build(parser.parse());
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error building SqlSession.", e);
+ } finally {
+ ErrorContext.instance().reset();
+ try {
+ if (inputStream != null) {
+ inputStream.close();
+ }
+ } catch (IOException e) {
+ // Intentionally ignore. Prefer previous error.
}
}
- return new MixedSqlNode(contents);
- }
-
-判断是否是动态sql,调用了org.apache.ibatis.scripting.xmltags.TextSqlNode#isDynamic
-public boolean isDynamic() {
- DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
- // ----------> 主要是这里的方法
- GenericTokenParser parser = createParser(checker);
- parser.parse(text);
- return checker.isDynamic();
-}
-
-创建parser的时候可以看到这个parser是干了啥,其实就是找有没有${ , }
-private GenericTokenParser createParser(TokenHandler handler) {
- return new GenericTokenParser("${", "}", handler);
-}
-
-如果是的话,就在上面把 isDynamic 设置为true 如果是true 的话就创建 DynamicSqlSource
-sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
-
-如果不是的话就创建RawSqlSource
-sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
-```java
-
-但是这不是一个真实可用的 `sqlSource` ,
-实际创建的时候会走到这
-```java
-public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) {
- this(configuration, getSql(configuration, rootSqlNode), parameterType);
+ }
+前面也说过,就是解析 mybatis-config.xml 成 Configuration
+public Configuration parse() {
+ if (parsed) {
+ throw new BuilderException("Each XMLConfigBuilder can only be used once.");
+ }
+ parsed = true;
+ parseConfiguration(parser.evalNode("/configuration"));
+ return configuration;
+}
+private void parseConfiguration(XNode root) {
+ try {
+ // issue #117 read properties first
+ propertiesElement(root.evalNode("properties"));
+ Properties settings = settingsAsProperties(root.evalNode("settings"));
+ loadCustomVfs(settings);
+ loadCustomLogImpl(settings);
+ typeAliasesElement(root.evalNode("typeAliases"));
+ pluginElement(root.evalNode("plugins"));
+ objectFactoryElement(root.evalNode("objectFactory"));
+ objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
+ reflectorFactoryElement(root.evalNode("reflectorFactory"));
+ settingsElement(settings);
+ // read it after objectFactory and objectWrapperFactory issue #631
+ // -------------> 是在这里解析了DataSource
+ environmentsElement(root.evalNode("environments"));
+ databaseIdProviderElement(root.evalNode("databaseIdProvider"));
+ typeHandlerElement(root.evalNode("typeHandlers"));
+ mapperElement(root.evalNode("mappers"));
+ } catch (Exception e) {
+ throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
+ }
+}
+环境解析了这一块的内容
+<environments default="development">
+ <environment id="development">
+ <transactionManager type="JDBC"/>
+ <dataSource type="POOLED">
+ <property name="driver" value="${driver}"/>
+ <property name="url" value="${url}"/>
+ <property name="username" value="${username}"/>
+ <property name="password" value="${password}"/>
+ </dataSource>
+ </environment>
+ </environments>
+解析也是自上而下的,
+private void environmentsElement(XNode context) throws Exception {
+ if (context != null) {
+ if (environment == null) {
+ environment = context.getStringAttribute("default");
+ }
+ for (XNode child : context.getChildren()) {
+ String id = child.getStringAttribute("id");
+ if (isSpecifiedEnvironment(id)) {
+ TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
+ DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
+ DataSource dataSource = dsFactory.getDataSource();
+ Environment.Builder environmentBuilder = new Environment.Builder(id)
+ .transactionFactory(txFactory)
+ .dataSource(dataSource);
+ configuration.setEnvironment(environmentBuilder.build());
+ break;
+ }
+ }
+ }
+}
+前面第一步是解析事务管理器元素
+private TransactionFactory transactionManagerElement(XNode context) throws Exception {
+ if (context != null) {
+ String type = context.getStringAttribute("type");
+ Properties props = context.getChildrenAsProperties();
+ TransactionFactory factory = (TransactionFactory) resolveClass(type).getDeclaredConstructor().newInstance();
+ factory.setProperties(props);
+ return factory;
}
-
- public RawSqlSource(Configuration configuration, String sql, Class<?> parameterType) {
- SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
- Class<?> clazz = parameterType == null ? Object.class : parameterType;
- sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap<>());
- }
-
-具体的sqlSource是通过org.apache.ibatis.builder.SqlSourceBuilder#parse 创建的
具体的代码逻辑是
-public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
- ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
- GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
- String sql;
- if (configuration.isShrinkWhitespacesInSql()) {
- sql = parser.parse(removeExtraWhitespaces(originalSql));
- } else {
- sql = parser.parse(originalSql);
+ throw new BuilderException("Environment declaration requires a TransactionFactory.");
+}
+而这里的 resolveClass 其实就使用了上一篇的 typeAliases 系统,这里是使用了 JdbcTransactionFactory 作为事务管理器,
后面的就是 DataSourceFactory 的创建也是 DataSource 的创建
+private DataSourceFactory dataSourceElement(XNode context) throws Exception {
+ if (context != null) {
+ String type = context.getStringAttribute("type");
+ Properties props = context.getChildrenAsProperties();
+ DataSourceFactory factory = (DataSourceFactory) resolveClass(type).getDeclaredConstructor().newInstance();
+ factory.setProperties(props);
+ return factory;
}
- return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
-}
+ throw new BuilderException("Environment declaration requires a DataSourceFactory.");
+}
+因为在config文件中设置了Pooled,所以对应创建的就是 PooledDataSourceFactory
但是这里其实有个比较需要注意的,mybatis 这里的其实是继承了 UnpooledDataSourceFactory
将基础方法都放在了 UnpooledDataSourceFactory 中
+public class PooledDataSourceFactory extends UnpooledDataSourceFactory {
-这里创建的其实是StaticSqlSource ,多带一句前面的parser是将原来这样select * from student where id = #{id} 的 sql 解析成了select * from student where id = ? 然后创建了StaticSqlSource
-public StaticSqlSource(Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {
- this.sql = sql;
- this.parameterMappings = parameterMappings;
- this.configuration = configuration;
-}
+ public PooledDataSourceFactory() {
+ this.dataSource = new PooledDataSource();
+ }
-为什么前面要讲这么多好像没什么关系的代码呢,其实在最开始我们执行sql的代码中
+}
+这里只保留了在构造方法里创建 DataSource
而这个 PooledDataSource 虽然没有直接继承 UnpooledDataSource,但其实
在构造方法里也是
+public PooledDataSource() {
+ dataSource = new UnpooledDataSource();
+}
+至于为什么这么做呢应该也是考虑到能比较多的复用代码,因为 Pooled 其实跟 Unpooled 最重要的差别就在于是不是每次都重开连接
使用连接池能够让应用在有大量查询的时候不用反复创建连接,省去了建联的网络等开销,Unpooled就是完成与数据库的连接,并可以获取该连接
主要的代码
@Override
- public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
- BoundSql boundSql = ms.getBoundSql(parameterObject);
- CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
- return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- }
+public Connection getConnection() throws SQLException {
+ return doGetConnection(username, password);
+}
-这里获取了BoundSql,而BoundSql是怎么来的呢,首先调用了org.apache.ibatis.mapping.MappedStatement#getBoundSql
-public BoundSql getBoundSql(Object parameterObject) {
- BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
- List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
- if (parameterMappings == null || parameterMappings.isEmpty()) {
- boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
- }
+@Override
+public Connection getConnection(String username, String password) throws SQLException {
+ return doGetConnection(username, password);
+}
+private Connection doGetConnection(String username, String password) throws SQLException {
+ Properties props = new Properties();
+ if (driverProperties != null) {
+ props.putAll(driverProperties);
+ }
+ if (username != null) {
+ props.setProperty("user", username);
+ }
+ if (password != null) {
+ props.setProperty("password", password);
+ }
+ return doGetConnection(props);
+}
+private Connection doGetConnection(Properties properties) throws SQLException {
+ initializeDriver();
+ Connection connection = DriverManager.getConnection(url, properties);
+ configureConnection(connection);
+ return connection;
+}
+而对于Pooled就会处理池化的逻辑
+private PooledConnection popConnection(String username, String password) throws SQLException {
+ boolean countedWait = false;
+ PooledConnection conn = null;
+ long t = System.currentTimeMillis();
+ int localBadConnectionCount = 0;
- // check for nested result maps in parameter mappings (issue #30)
- for (ParameterMapping pm : boundSql.getParameterMappings()) {
- String rmId = pm.getResultMapId();
- if (rmId != null) {
- ResultMap rm = configuration.getResultMap(rmId);
- if (rm != null) {
- hasNestedResultMaps |= rm.hasNestedResultMaps();
+ while (conn == null) {
+ lock.lock();
+ try {
+ if (!state.idleConnections.isEmpty()) {
+ // Pool has available connection
+ conn = state.idleConnections.remove(0);
+ if (log.isDebugEnabled()) {
+ log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
+ }
+ } else {
+ // Pool does not have available connection
+ if (state.activeConnections.size() < poolMaximumActiveConnections) {
+ // Can create new connection
+ conn = new PooledConnection(dataSource.getConnection(), this);
+ if (log.isDebugEnabled()) {
+ log.debug("Created connection " + conn.getRealHashCode() + ".");
+ }
+ } else {
+ // Cannot create new connection
+ PooledConnection oldestActiveConnection = state.activeConnections.get(0);
+ long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
+ if (longestCheckoutTime > poolMaximumCheckoutTime) {
+ // Can claim overdue connection
+ state.claimedOverdueConnectionCount++;
+ state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
+ state.accumulatedCheckoutTime += longestCheckoutTime;
+ state.activeConnections.remove(oldestActiveConnection);
+ if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
+ try {
+ oldestActiveConnection.getRealConnection().rollback();
+ } catch (SQLException e) {
+ /*
+ Just log a message for debug and continue to execute the following
+ statement like nothing happened.
+ Wrap the bad connection with a new PooledConnection, this will help
+ to not interrupt current executing thread and give current thread a
+ chance to join the next competition for another valid/good database
+ connection. At the end of this loop, bad {@link @conn} will be set as null.
+ */
+ log.debug("Bad connection. Could not roll back");
+ }
+ }
+ conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
+ conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
+ conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
+ oldestActiveConnection.invalidate();
+ if (log.isDebugEnabled()) {
+ log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
+ }
+ } else {
+ // Must wait
+ try {
+ if (!countedWait) {
+ state.hadToWaitCount++;
+ countedWait = true;
+ }
+ if (log.isDebugEnabled()) {
+ log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
+ }
+ long wt = System.currentTimeMillis();
+ condition.await(poolTimeToWait, TimeUnit.MILLISECONDS);
+ state.accumulatedWaitTime += System.currentTimeMillis() - wt;
+ } catch (InterruptedException e) {
+ // set interrupt flag
+ Thread.currentThread().interrupt();
+ break;
+ }
+ }
+ }
+ }
+ if (conn != null) {
+ // ping to server and check the connection is valid or not
+ if (conn.isValid()) {
+ if (!conn.getRealConnection().getAutoCommit()) {
+ conn.getRealConnection().rollback();
+ }
+ conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
+ conn.setCheckoutTimestamp(System.currentTimeMillis());
+ conn.setLastUsedTimestamp(System.currentTimeMillis());
+ state.activeConnections.add(conn);
+ state.requestCount++;
+ state.accumulatedRequestTime += System.currentTimeMillis() - t;
+ } else {
+ if (log.isDebugEnabled()) {
+ log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
+ }
+ state.badConnectionCount++;
+ localBadConnectionCount++;
+ conn = null;
+ if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
+ if (log.isDebugEnabled()) {
+ log.debug("PooledDataSource: Could not get a good connection to the database.");
+ }
+ throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
+ }
+ }
}
+ } finally {
+ lock.unlock();
}
+
}
- return boundSql;
- }
+ if (conn == null) {
+ if (log.isDebugEnabled()) {
+ log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
+ throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
-而我们从上面的解析中可以看到这里的sqlSource是一层RawSqlSource , 它的getBoundSql又是调用内部的sqlSource的方法
+ return conn;
+ }
+它的入口不是个get方法,而是pop,从含义来来讲就不一样
org.apache.ibatis.datasource.pooled.PooledDataSource#getConnection()
@Override
-public BoundSql getBoundSql(Object parameterObject) {
- return sqlSource.getBoundSql(parameterObject);
+public Connection getConnection() throws SQLException {
+ return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
+对于具体怎么获取连接我们可以下一篇具体讲下
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ mybatis系列-sql 类的简单使用
+ /2023/03/12/mybatis%E7%B3%BB%E5%88%97-sql-%E7%B1%BB%E7%9A%84%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8/
+ mybatis 还有个比较有趣的功能,就是使用 SQL 类生成 sql,有点类似于 hibernate 或者像 php 的 laravel 框架等的,就是把sql 这种放在 xml 里或者代码里直接写 sql 用对象的形式
+select语句
比如这样
+public static void main(String[] args) {
+ String selectSql = new SQL() {{
+ SELECT("id", "name");
+ FROM("student");
+ WHERE("id = #{id}");
+ }}.toString();
+ System.out.println(selectSql);
+}
+打印出来就是
+SELECT id, name
+FROM student
+WHERE (id = #{id})
+应付简单的 sql 查询基本都可以这么解决,如果习惯这种模式,还是不错的,
其实以面向对象的编程模式来说,这样是比较符合面向对象的,先不深入的解析这块的源码,先从使用角度讲一下
+比如 update 语句
String updateSql = new SQL() {{
+ UPDATE("student");
+ SET("name = #{name}");
+ WHERE("id = #{id}");
+ }}.toString();
+打印输出就是
+UPDATE student
+SET name = #{name}
+WHERE (id = #{id})
-内部的sqlSource 就是StaticSqlSource ,
-@Override
-public BoundSql getBoundSql(Object parameterObject) {
- return new BoundSql(configuration, sql, parameterMappings, parameterObject);
+insert 语句
String insertSql = new SQL() {{
+ INSERT_INTO("student");
+ VALUES("name", "#{name}");
+ VALUES("age", "#{age}");
+ }}.toString();
+ System.out.println(insertSql);
+打印输出
+INSERT INTO student
+ (name, age)
+VALUES (#{name}, #{age})
+delete语句
String deleteSql = new SQL() {{
+ DELETE_FROM("student");
+ WHERE("id = #{id}");
+ }}.toString();
+ System.out.println(deleteSql);
+打印输出
+DELETE FROM student
+WHERE (id = #{id})
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ mybatis系列-mybatis是如何初始化mapper的
+ /2022/12/04/mybatis%E6%98%AF%E5%A6%82%E4%BD%95%E5%88%9D%E5%A7%8B%E5%8C%96mapper%E7%9A%84/
+ 前一篇讲了mybatis的初始化使用,如果我第一次看到这个使用入门文档,比较会产生疑惑的是配置了mapper,怎么就能通过selectOne跟语句id就能执行sql了,那么第一个问题,就是mapper是怎么被解析的,存在哪里,怎么被拿出来的
+添加解析mapper
org.apache.ibatis.session.SqlSessionFactoryBuilder#build(java.io.InputStream)
+public SqlSessionFactory build(InputStream inputStream) {
+ return build(inputStream, null, null);
}
-这个BoundSql的内容也比较简单
-public BoundSql(Configuration configuration, String sql, List<ParameterMapping> parameterMappings, Object parameterObject) {
- this.sql = sql;
- this.parameterMappings = parameterMappings;
- this.parameterObject = parameterObject;
- this.additionalParameters = new HashMap<>();
- this.metaParameters = configuration.newMetaObject(additionalParameters);
-}
-
-而上次在这边org.apache.ibatis.executor.SimpleExecutor#doQuery 的时候落了个东西,就是StatementHandler的逻辑
-@Override
-public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
- Statement stmt = null;
+通过读取mybatis-config.xml来构建SqlSessionFactory,
+public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
- Configuration configuration = ms.getConfiguration();
- StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
- stmt = prepareStatement(handler, ms.getStatementLog());
- return handler.query(stmt, resultHandler);
+ // 创建下xml的解析器
+ XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
+ // 进行解析,后再构建
+ return build(parser.parse());
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
- closeStatement(stmt);
- }
-}
+ ErrorContext.instance().reset();
+ try {
+ if (inputStream != null) {
+ inputStream.close();
+ }
+ } catch (IOException e) {
+ // Intentionally ignore. Prefer previous error.
+ }
+ }
-它是通过statementType来区分应该使用哪个statementHandler,我们这使用的就是PreparedStatementHandler
-public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
+创建XMLConfigBuilder
+public XMLConfigBuilder(InputStream inputStream, String environment, Properties props) {
+ // --------> 创建 XPathParser
+ this(new XPathParser(inputStream, true, props, new XMLMapperEntityResolver()), environment, props);
+}
- switch (ms.getStatementType()) {
- case STATEMENT:
- delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
- break;
- case PREPARED:
- delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
- break;
- case CALLABLE:
- delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
- break;
- default:
- throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
+public XPathParser(InputStream inputStream, boolean validation, Properties variables, EntityResolver entityResolver) {
+ commonConstructor(validation, variables, entityResolver);
+ this.document = createDocument(new InputSource(inputStream));
}
-}
+private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
+ super(new Configuration());
+ ErrorContext.instance().resource("SQL Mapper Configuration");
+ this.configuration.setVariables(props);
+ this.parsed = false;
+ this.environment = environment;
+ this.parser = parser;
+}
-所以上次有个细节可以补充,这边的doQuery里面的handler.query 应该是调用了PreparedStatementHandler 的query方法
-@Override
-public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
- Statement stmt = null;
- try {
- Configuration configuration = ms.getConfiguration();
- StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
- stmt = prepareStatement(handler, ms.getStatementLog());
- return handler.query(stmt, resultHandler);
- } finally {
- closeStatement(stmt);
+这里主要是创建了Builder包含了Parser
然后调用parse方法
+public Configuration parse() {
+ if (parsed) {
+ throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
-}
-
-
-因为上面prepareStatement中getConnection拿到connection是com.mysql.cj.jdbc.ConnectionImpl#ConnectionImpl(com.mysql.cj.conf.HostInfo)
-@Override
-public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
- PreparedStatement ps = (PreparedStatement) statement;
- ps.execute();
- return resultSetHandler.handleResultSets(ps);
-}
-
-那又为什么是这个呢,可以在网上找,我们在mybatis-config.xml里配置的
-<transactionManager type="JDBC"/>
+ // 标记下是否已解析,但是这里是否有线程安全问题
+ parsed = true;
+ // --------> 解析配置
+ parseConfiguration(parser.evalNode("/configuration"));
+ return configuration;
+}
-因此在parseConfiguration中配置environment时
+实际的解析区分了各类标签
private void parseConfiguration(XNode root) {
- try {
- // issue #117 read properties first
- propertiesElement(root.evalNode("properties"));
- Properties settings = settingsAsProperties(root.evalNode("settings"));
- loadCustomVfs(settings);
- loadCustomLogImpl(settings);
- typeAliasesElement(root.evalNode("typeAliases"));
- pluginElement(root.evalNode("plugins"));
- objectFactoryElement(root.evalNode("objectFactory"));
- objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
- reflectorFactoryElement(root.evalNode("reflectorFactory"));
- settingsElement(settings);
- // read it after objectFactory and objectWrapperFactory issue #631
- // ----------> 就是这里
- environmentsElement(root.evalNode("environments"));
- databaseIdProviderElement(root.evalNode("databaseIdProvider"));
- typeHandlerElement(root.evalNode("typeHandlers"));
- mapperElement(root.evalNode("mappers"));
- } catch (Exception e) {
- throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
- }
- }
-
-调用的这个方法通过获取xml中的transactionManager 配置的类型,也就是JDBC
-private void environmentsElement(XNode context) throws Exception {
- if (context != null) {
- if (environment == null) {
- environment = context.getStringAttribute("default");
- }
- for (XNode child : context.getChildren()) {
- String id = child.getStringAttribute("id");
- if (isSpecifiedEnvironment(id)) {
- // -------> 找到这里
- TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
- DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
- DataSource dataSource = dsFactory.getDataSource();
- Environment.Builder environmentBuilder = new Environment.Builder(id)
- .transactionFactory(txFactory)
- .dataSource(dataSource);
- configuration.setEnvironment(environmentBuilder.build());
- break;
- }
- }
- }
-}
-
-是通过以下方法获取的,
-// 方法全限定名 org.apache.ibatis.builder.xml.XMLConfigBuilder#transactionManagerElement
-private TransactionFactory transactionManagerElement(XNode context) throws Exception {
- if (context != null) {
- String type = context.getStringAttribute("type");
- Properties props = context.getChildrenAsProperties();
- TransactionFactory factory = (TransactionFactory) resolveClass(type).getDeclaredConstructor().newInstance();
- factory.setProperties(props);
- return factory;
- }
- throw new BuilderException("Environment declaration requires a TransactionFactory.");
- }
-
-// 方法全限定名 org.apache.ibatis.builder.BaseBuilder#resolveClass
-protected <T> Class<? extends T> resolveClass(String alias) {
- if (alias == null) {
- return null;
- }
- try {
- return resolveAlias(alias);
- } catch (Exception e) {
- throw new BuilderException("Error resolving class. Cause: " + e, e);
- }
+ try {
+ // issue #117 read properties first
+ // 解析properties,这个不是spring自带的,需要额外配置,并且在config文件里应该放在最前
+ propertiesElement(root.evalNode("properties"));
+ Properties settings = settingsAsProperties(root.evalNode("settings"));
+ loadCustomVfs(settings);
+ loadCustomLogImpl(settings);
+ typeAliasesElement(root.evalNode("typeAliases"));
+ pluginElement(root.evalNode("plugins"));
+ objectFactoryElement(root.evalNode("objectFactory"));
+ objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
+ reflectorFactoryElement(root.evalNode("reflectorFactory"));
+ settingsElement(settings);
+ // read it after objectFactory and objectWrapperFactory issue #631
+ environmentsElement(root.evalNode("environments"));
+ databaseIdProviderElement(root.evalNode("databaseIdProvider"));
+ typeHandlerElement(root.evalNode("typeHandlers"));
+ // ----------> 我们需要关注的是mapper的处理
+ mapperElement(root.evalNode("mappers"));
+ } catch (Exception e) {
+ throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
+}
-// 方法全限定名 org.apache.ibatis.builder.BaseBuilder#resolveAlias
- protected <T> Class<? extends T> resolveAlias(String alias) {
- return typeAliasRegistry.resolveAlias(alias);
- }
-// 方法全限定名 org.apache.ibatis.type.TypeAliasRegistry#resolveAlias
- public <T> Class<T> resolveAlias(String string) {
- try {
- if (string == null) {
- return null;
- }
- // issue #748
- String key = string.toLowerCase(Locale.ENGLISH);
- Class<T> value;
- if (typeAliases.containsKey(key)) {
- value = (Class<T>) typeAliases.get(key);
+然后就是调用到mapperElement方法了
+private void mapperElement(XNode parent) throws Exception {
+ if (parent != null) {
+ for (XNode child : parent.getChildren()) {
+ if ("package".equals(child.getName())) {
+ String mapperPackage = child.getStringAttribute("name");
+ configuration.addMappers(mapperPackage);
} else {
- value = (Class<T>) Resources.classForName(string);
+ String resource = child.getStringAttribute("resource");
+ String url = child.getStringAttribute("url");
+ String mapperClass = child.getStringAttribute("class");
+ if (resource != null && url == null && mapperClass == null) {
+ ErrorContext.instance().resource(resource);
+ try(InputStream inputStream = Resources.getResourceAsStream(resource)) {
+ XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
+ // --------> 我们这没有指定package,所以是走到这
+ mapperParser.parse();
+ }
+ } else if (resource == null && url != null && mapperClass == null) {
+ ErrorContext.instance().resource(url);
+ try(InputStream inputStream = Resources.getUrlAsStream(url)){
+ XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
+ mapperParser.parse();
+ }
+ } else if (resource == null && url == null && mapperClass != null) {
+ Class<?> mapperInterface = Resources.classForName(mapperClass);
+ configuration.addMapper(mapperInterface);
+ } else {
+ throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
+ }
}
- return value;
- } catch (ClassNotFoundException e) {
- throw new TypeException("Could not resolve type alias '" + string + "'. Cause: " + e, e);
}
- }
-而通过JDBC获取得是啥的,就是在Configuration的构造方法里写了的JdbcTransactionFactory
-public Configuration() {
- typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
-
-所以我们在这
-private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
- Transaction tx = null;
- try {
- final Environment environment = configuration.getEnvironment();
- final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
+ }
+}
-获得到的TransactionFactory 就是 JdbcTransactionFactory ,而后
-tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
-```java
+核心就在这个parse()方法
+public void parse() {
+ if (!configuration.isResourceLoaded(resource)) {
+ // -------> 然后就是走到这里,配置xml的mapper节点的内容
+ configurationElement(parser.evalNode("/mapper"));
+ configuration.addLoadedResource(resource);
+ bindMapperForNamespace();
+ }
-创建的transaction就是JdbcTransaction
-```java
- @Override
- public Transaction newTransaction(DataSource ds, TransactionIsolationLevel level, boolean autoCommit) {
- return new JdbcTransaction(ds, level, autoCommit, skipSetAutoCommitOnClose);
- }
+ parsePendingResultMaps();
+ parsePendingCacheRefs();
+ parsePendingStatements();
+}
-然后我们再会上去看代码getConnection ,
-protected Connection getConnection(Log statementLog) throws SQLException {
- // -------> 这里的transaction就是JdbcTransaction
- Connection connection = transaction.getConnection();
- if (statementLog.isDebugEnabled()) {
- return ConnectionLogger.newInstance(connection, statementLog, queryStack);
- } else {
- return connection;
+具体的处理逻辑
+private void configurationElement(XNode context) {
+ try {
+ String namespace = context.getStringAttribute("namespace");
+ if (namespace == null || namespace.isEmpty()) {
+ throw new BuilderException("Mapper's namespace cannot be empty");
+ }
+ builderAssistant.setCurrentNamespace(namespace);
+ cacheRefElement(context.evalNode("cache-ref"));
+ cacheElement(context.evalNode("cache"));
+ parameterMapElement(context.evalNodes("/mapper/parameterMap"));
+ resultMapElements(context.evalNodes("/mapper/resultMap"));
+ sqlElement(context.evalNodes("/mapper/sql"));
+ // -------> 走到这,从上下文构建statement
+ buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
+ } catch (Exception e) {
+ throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
-}
+}
-即调用了
- @Override
- public Connection getConnection() throws SQLException {
- if (connection == null) {
- openConnection();
- }
- return connection;
+具体代码在这,从上下文构建statement,只不过区分了下databaseId
+private void buildStatementFromContext(List<XNode> list) {
+ if (configuration.getDatabaseId() != null) {
+ buildStatementFromContext(list, configuration.getDatabaseId());
}
+ // -----> 判断databaseId
+ buildStatementFromContext(list, null);
+}
- protected void openConnection() throws SQLException {
- if (log.isDebugEnabled()) {
- log.debug("Opening JDBC Connection");
- }
- connection = dataSource.getConnection();
- if (level != null) {
- connection.setTransactionIsolation(level.getLevel());
+判断下databaseId
+private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
+ for (XNode context : list) {
+ final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
+ try {
+ // -------> 解析statement节点
+ statementParser.parseStatementNode();
+ } catch (IncompleteElementException e) {
+ configuration.addIncompleteStatement(statementParser);
}
- setDesiredAutoCommit(autoCommit);
- }
- @Override
- public Connection getConnection() throws SQLException {
- return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
+}
-private PooledConnection popConnection(String username, String password) throws SQLException {
- boolean countedWait = false;
- PooledConnection conn = null;
- long t = System.currentTimeMillis();
- int localBadConnectionCount = 0;
+接下来就是真正处理的xml语句内容的,各个节点的信息内容
+public void parseStatementNode() {
+ String id = context.getStringAttribute("id");
+ String databaseId = context.getStringAttribute("databaseId");
- while (conn == null) {
- lock.lock();
- try {
- if (!state.idleConnections.isEmpty()) {
- // Pool has available connection
- conn = state.idleConnections.remove(0);
- if (log.isDebugEnabled()) {
- log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
- }
- } else {
- // Pool does not have available connection
- if (state.activeConnections.size() < poolMaximumActiveConnections) {
- // Can create new connection
- // ------------> 走到这里会创建PooledConnection,但是里面会先调用dataSource.getConnection()
- conn = new PooledConnection(dataSource.getConnection(), this);
- if (log.isDebugEnabled()) {
- log.debug("Created connection " + conn.getRealHashCode() + ".");
- }
- } else {
- // Cannot create new connection
- PooledConnection oldestActiveConnection = state.activeConnections.get(0);
- long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
- if (longestCheckoutTime > poolMaximumCheckoutTime) {
- // Can claim overdue connection
- state.claimedOverdueConnectionCount++;
- state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
- state.accumulatedCheckoutTime += longestCheckoutTime;
- state.activeConnections.remove(oldestActiveConnection);
- if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
- try {
- oldestActiveConnection.getRealConnection().rollback();
- } catch (SQLException e) {
- /*
- Just log a message for debug and continue to execute the following
- statement like nothing happened.
- Wrap the bad connection with a new PooledConnection, this will help
- to not interrupt current executing thread and give current thread a
- chance to join the next competition for another valid/good database
- connection. At the end of this loop, bad {@link @conn} will be set as null.
- */
- log.debug("Bad connection. Could not roll back");
- }
- }
- conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
- conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
- conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
- oldestActiveConnection.invalidate();
- if (log.isDebugEnabled()) {
- log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
- }
- } else {
- // Must wait
- try {
- if (!countedWait) {
- state.hadToWaitCount++;
- countedWait = true;
- }
- if (log.isDebugEnabled()) {
- log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
- }
- long wt = System.currentTimeMillis();
- condition.await(poolTimeToWait, TimeUnit.MILLISECONDS);
- state.accumulatedWaitTime += System.currentTimeMillis() - wt;
- } catch (InterruptedException e) {
- // set interrupt flag
- Thread.currentThread().interrupt();
- break;
- }
- }
- }
- }
- if (conn != null) {
- // ping to server and check the connection is valid or not
- if (conn.isValid()) {
- if (!conn.getRealConnection().getAutoCommit()) {
- conn.getRealConnection().rollback();
- }
- conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
- conn.setCheckoutTimestamp(System.currentTimeMillis());
- conn.setLastUsedTimestamp(System.currentTimeMillis());
- state.activeConnections.add(conn);
- state.requestCount++;
- state.accumulatedRequestTime += System.currentTimeMillis() - t;
- } else {
- if (log.isDebugEnabled()) {
- log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
- }
- state.badConnectionCount++;
- localBadConnectionCount++;
- conn = null;
- if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
- if (log.isDebugEnabled()) {
- log.debug("PooledDataSource: Could not get a good connection to the database.");
- }
- throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
- }
- }
- }
- } finally {
- lock.unlock();
- }
+ if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
+ return;
+ }
- }
+ String nodeName = context.getNode().getNodeName();
+ SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
+ boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
+ boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
+ boolean useCache = context.getBooleanAttribute("useCache", isSelect);
+ boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
- if (conn == null) {
- if (log.isDebugEnabled()) {
- log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
- throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
+ // Include Fragments before parsing
+ XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
+ includeParser.applyIncludes(context.getNode());
+
+ String parameterType = context.getStringAttribute("parameterType");
+ Class<?> parameterTypeClass = resolveClass(parameterType);
- return conn;
- }
+ String lang = context.getStringAttribute("lang");
+ LanguageDriver langDriver = getLanguageDriver(lang);
-其实就是调用的
-// org.apache.ibatis.datasource.unpooled.UnpooledDataSource#getConnection()
- @Override
- public Connection getConnection() throws SQLException {
- return doGetConnection(username, password);
- }
-```java
+ // Parse selectKey after includes and remove them.
+ processSelectKeyNodes(id, parameterTypeClass, langDriver);
-然后就是
-```java
-private Connection doGetConnection(String username, String password) throws SQLException {
- Properties props = new Properties();
- if (driverProperties != null) {
- props.putAll(driverProperties);
- }
- if (username != null) {
- props.setProperty("user", username);
- }
- if (password != null) {
- props.setProperty("password", password);
- }
- return doGetConnection(props);
- }
+ // Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
+ KeyGenerator keyGenerator;
+ String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
+ keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
+ if (configuration.hasKeyGenerator(keyStatementId)) {
+ keyGenerator = configuration.getKeyGenerator(keyStatementId);
+ } else {
+ keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
+ configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
+ ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
+ }
-继续这个逻辑
- private Connection doGetConnection(Properties properties) throws SQLException {
- initializeDriver();
- Connection connection = DriverManager.getConnection(url, properties);
- configureConnection(connection);
- return connection;
+ // 语句的主要参数解析
+ SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
+ StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
+ Integer fetchSize = context.getIntAttribute("fetchSize");
+ Integer timeout = context.getIntAttribute("timeout");
+ String parameterMap = context.getStringAttribute("parameterMap");
+ String resultType = context.getStringAttribute("resultType");
+ Class<?> resultTypeClass = resolveClass(resultType);
+ String resultMap = context.getStringAttribute("resultMap");
+ String resultSetType = context.getStringAttribute("resultSetType");
+ ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
+ if (resultSetTypeEnum == null) {
+ resultSetTypeEnum = configuration.getDefaultResultSetType();
}
- @CallerSensitive
- public static Connection getConnection(String url,
- java.util.Properties info) throws SQLException {
+ String keyProperty = context.getStringAttribute("keyProperty");
+ String keyColumn = context.getStringAttribute("keyColumn");
+ String resultSets = context.getStringAttribute("resultSets");
- return (getConnection(url, info, Reflection.getCallerClass()));
- }
-private static Connection getConnection(
- String url, java.util.Properties info, Class<?> caller) throws SQLException {
- /*
- * When callerCl is null, we should check the application's
- * (which is invoking this class indirectly)
- * classloader, so that the JDBC driver class outside rt.jar
- * can be loaded from here.
- */
- ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;
- synchronized(DriverManager.class) {
- // synchronize loading of the correct classloader.
- if (callerCL == null) {
- callerCL = Thread.currentThread().getContextClassLoader();
- }
- }
+ // --------> 添加映射的statement
+ builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
+ fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
+ resultSetTypeEnum, flushCache, useCache, resultOrdered,
+ keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
+}
- if(url == null) {
- throw new SQLException("The url cannot be null", "08001");
- }
- println("DriverManager.getConnection(\"" + url + "\")");
+添加的逻辑具体可以看下
+public MappedStatement addMappedStatement(
+ String id,
+ SqlSource sqlSource,
+ StatementType statementType,
+ SqlCommandType sqlCommandType,
+ Integer fetchSize,
+ Integer timeout,
+ String parameterMap,
+ Class<?> parameterType,
+ String resultMap,
+ Class<?> resultType,
+ ResultSetType resultSetType,
+ boolean flushCache,
+ boolean useCache,
+ boolean resultOrdered,
+ KeyGenerator keyGenerator,
+ String keyProperty,
+ String keyColumn,
+ String databaseId,
+ LanguageDriver lang,
+ String resultSets) {
- // Walk through the loaded registeredDrivers attempting to make a connection.
- // Remember the first exception that gets raised so we can reraise it.
- SQLException reason = null;
+ if (unresolvedCacheRef) {
+ throw new IncompleteElementException("Cache-ref not yet resolved");
+ }
- for(DriverInfo aDriver : registeredDrivers) {
- // If the caller does not have permission to load the driver then
- // skip it.
- if(isDriverAllowed(aDriver.driver, callerCL)) {
- try {
- // ----------> driver[className=com.mysql.cj.jdbc.Driver@64030b91]
- println(" trying " + aDriver.driver.getClass().getName());
- Connection con = aDriver.driver.connect(url, info);
- if (con != null) {
- // Success!
- println("getConnection returning " + aDriver.driver.getClass().getName());
- return (con);
- }
- } catch (SQLException ex) {
- if (reason == null) {
- reason = ex;
- }
- }
+ id = applyCurrentNamespace(id, false);
+ boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
- } else {
- println(" skipping: " + aDriver.getClass().getName());
- }
+ MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
+ .resource(resource)
+ .fetchSize(fetchSize)
+ .timeout(timeout)
+ .statementType(statementType)
+ .keyGenerator(keyGenerator)
+ .keyProperty(keyProperty)
+ .keyColumn(keyColumn)
+ .databaseId(databaseId)
+ .lang(lang)
+ .resultOrdered(resultOrdered)
+ .resultSets(resultSets)
+ .resultMaps(getStatementResultMaps(resultMap, resultType, id))
+ .resultSetType(resultSetType)
+ .flushCacheRequired(valueOrDefault(flushCache, !isSelect))
+ .useCache(valueOrDefault(useCache, isSelect))
+ .cache(currentCache);
- }
+ ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
+ if (statementParameterMap != null) {
+ statementBuilder.parameterMap(statementParameterMap);
+ }
- // if we got here nobody could connect.
- if (reason != null) {
- println("getConnection failed: " + reason);
- throw reason;
- }
+ MappedStatement statement = statementBuilder.build();
+ // ------> 正好是这里在configuration中添加了映射好的statement
+ configuration.addMappedStatement(statement);
+ return statement;
+}
- println("getConnection: no suitable driver found for "+ url);
- throw new SQLException("No suitable driver found for "+ url, "08001");
- }
+而里面就是往map里添加
+public void addMappedStatement(MappedStatement ms) {
+ mappedStatements.put(ms.getId(), ms);
+}
+获取mapper
StudentDO studentDO = session.selectOne("com.nicksxs.mybatisdemo.StudentMapper.selectStudent", 1);
-上面的driver就是driver[className=com.mysql.cj.jdbc.Driver@64030b91]
-// com.mysql.cj.jdbc.NonRegisteringDriver#connect
-public Connection connect(String url, Properties info) throws SQLException {
- try {
- try {
- if (!ConnectionUrl.acceptsUrl(url)) {
- return null;
- } else {
- ConnectionUrl conStr = ConnectionUrl.getConnectionUrlInstance(url, info);
- switch (conStr.getType()) {
- case SINGLE_CONNECTION:
- return ConnectionImpl.getInstance(conStr.getMainHost());
- case FAILOVER_CONNECTION:
- case FAILOVER_DNS_SRV_CONNECTION:
- return FailoverConnectionProxy.createProxyInstance(conStr);
- case LOADBALANCE_CONNECTION:
- case LOADBALANCE_DNS_SRV_CONNECTION:
- return LoadBalancedConnectionProxy.createProxyInstance(conStr);
- case REPLICATION_CONNECTION:
- case REPLICATION_DNS_SRV_CONNECTION:
- return ReplicationConnectionProxy.createProxyInstance(conStr);
- default:
- return null;
- }
- }
- } catch (UnsupportedConnectionStringException var5) {
- return null;
- } catch (CJException var6) {
- throw (UnableToConnectException)ExceptionFactory.createException(UnableToConnectException.class, Messages.getString("NonRegisteringDriver.17", new Object[]{var6.toString()}), var6);
- }
- } catch (CJException var7) {
- throw SQLExceptionsMapping.translateException(var7);
- }
- }
+就是调用了 org.apache.ibatis.session.defaults.DefaultSqlSession#selectOne(java.lang.String, java.lang.Object)
+public <T> T selectOne(String statement, Object parameter) {
+ // Popular vote was to return null on 0 results and throw exception on too many.
+ List<T> list = this.selectList(statement, parameter);
+ if (list.size() == 1) {
+ return list.get(0);
+ } else if (list.size() > 1) {
+ throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
+ } else {
+ return null;
+ }
+}
-这是个 SINGLE_CONNECTION ,所以调用的就是 return ConnectionImpl.getInstance(conStr.getMainHost());
然后在这里设置了代理类
-public PooledConnection(Connection connection, PooledDataSource dataSource) {
- this.hashCode = connection.hashCode();
- this.realConnection = connection;
- this.dataSource = dataSource;
- this.createdTimestamp = System.currentTimeMillis();
- this.lastUsedTimestamp = System.currentTimeMillis();
- this.valid = true;
- this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
- }
+调用实际的实现方法
+public <E> List<E> selectList(String statement, Object parameter) {
+ return this.selectList(statement, parameter, RowBounds.DEFAULT);
+}
-结合这个
-@Override
-public Connection getConnection() throws SQLException {
- return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
-}
+这里还有一层
+public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
+ return selectList(statement, parameter, rowBounds, Executor.NO_RESULT_HANDLER);
+}
-所以最终的connection就是com.mysql.cj.jdbc.ConnectionImpl@358ab600
+
+根本的就是从configuration里获取了mappedStatement
+private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
+ try {
+ // 这里进行了获取
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+}
]]>
Java
@@ -8277,439 +7202,1258 @@ WHERE (id = #{id})
- openresty
- /2019/06/18/openresty/
- 目前公司要对一些新的产品功能做灰度测试,因为在后端业务代码层面添加判断比较麻烦,所以想在nginx上做点手脚,就想到了openresty
前后也踩了不少坑,这边先写一点
-首先是日志
error_log logs/error.log debug;
需要nginx开启日志的debug才能看到日志
-使用 lua_code_cache off即可, 另外注意只有使用 content_by_lua_file 才会生效
-http {
- lua_code_cache off;
-}
+ mybatis系列-typeAliases系统
+ /2023/01/01/mybatis%E7%B3%BB%E5%88%97-typeAliases%E7%B3%BB%E7%BB%9F/
+ 其实前面已经聊到过这个概念,在mybatis的配置中,以及一些初始化逻辑都是用了typeAliases,
+<typeAliases>
+ <typeAlias alias="Author" type="domain.blog.Author"/>
+ <typeAlias alias="Blog" type="domain.blog.Blog"/>
+ <typeAlias alias="Comment" type="domain.blog.Comment"/>
+ <typeAlias alias="Post" type="domain.blog.Post"/>
+ <typeAlias alias="Section" type="domain.blog.Section"/>
+ <typeAlias alias="Tag" type="domain.blog.Tag"/>
+</typeAliases>
+可以在这里注册类型别名,然后在mybatis中配置使用时,可以简化这些类型的使用,其底层逻辑主要是一个map,
+public class TypeAliasRegistry {
-location ~* /(\d+-.*)/api/orgunits/load_all(.*) {
- default_type 'application/json;charset=utf-8';
- content_by_lua_file /data/projects/xxx/current/lua/controller/load_data.lua;
-}
+ private final Map<String, Class<?>> typeAliases = new HashMap<>();
+以string作为key,class对象作为value,比如我们在一开始使用的配置文件
+<dataSource type="POOLED">
+ <property name="driver" value="${driver}"/>
+ <property name="url" value="${url}"/>
+ <property name="username" value="${username}"/>
+ <property name="password" value="${password}"/>
+</dataSource>
+这里使用的dataSource是POOLED,那它肯定是个别名或者需要对应处理
而这个别名就是在Configuration的构造方法里初始化
+public Configuration() {
+ typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
+ typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
-使用lua给nginx请求response头添加内容可以用这个
-ngx.header['response'] = 'header'
+ typeAliasRegistry.registerAlias("JNDI", JndiDataSourceFactory.class);
+ typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class);
+ typeAliasRegistry.registerAlias("UNPOOLED", UnpooledDataSourceFactory.class);
+
+ typeAliasRegistry.registerAlias("PERPETUAL", PerpetualCache.class);
+ typeAliasRegistry.registerAlias("FIFO", FifoCache.class);
+ typeAliasRegistry.registerAlias("LRU", LruCache.class);
+ typeAliasRegistry.registerAlias("SOFT", SoftCache.class);
+ typeAliasRegistry.registerAlias("WEAK", WeakCache.class);
+ typeAliasRegistry.registerAlias("DB_VENDOR", VendorDatabaseIdProvider.class);
-
-后续:
-
-一开始在本地环境的时候使用content_by_lua_file只关注了头,后来发到测试环境发现请求内容都没代理转发到后端服务上
网上查了下发现content_by_lua_file是将请求的所有内容包括response都用这里面的lua脚本生成了,content这个词就表示是请求内容
后来改成了access_by_lua_file就正常了,只是要去获取请求内容和修改响应头,并不是要完整的接管请求
-后来又碰到了一个坑是nginx有个client_body_buffer_size的配置参数,nginx在32位和64位系统里有8K和16K两个默认值,当请求内容大于这两个值的时候,会把请求内容放到临时文件里,这个时候openresty里的ngx.req.get_post_args()就会报“failed to get post args: requesty body in temp file not supported”这个错误,将client_body_buffer_size这个参数配置调大一点就好了
-还有就是lua的异常捕获,网上看一般是用pcall和xpcall来进行保护调用,因为问题主要出在cjson的decode,这里有两个解决方案,一个就是将cjson.decode使用pcall封装,
- local decode = require("cjson").decode
+ typeAliasRegistry.registerAlias("XML", XMLLanguageDriver.class);
+ typeAliasRegistry.registerAlias("RAW", RawLanguageDriver.class);
-function json_decode( str )
- local ok, t = pcall(decode, str)
- if not ok then
- return nil
- end
+ typeAliasRegistry.registerAlias("SLF4J", Slf4jImpl.class);
+ typeAliasRegistry.registerAlias("COMMONS_LOGGING", JakartaCommonsLoggingImpl.class);
+ typeAliasRegistry.registerAlias("LOG4J", Log4jImpl.class);
+ typeAliasRegistry.registerAlias("LOG4J2", Log4j2Impl.class);
+ typeAliasRegistry.registerAlias("JDK_LOGGING", Jdk14LoggingImpl.class);
+ typeAliasRegistry.registerAlias("STDOUT_LOGGING", StdOutImpl.class);
+ typeAliasRegistry.registerAlias("NO_LOGGING", NoLoggingImpl.class);
- return t
-end
- 这个是使用了pcall,称为保护调用,会在内部错误后返回两个参数,第一个是false,第二个是错误信息
还有一种是使用cjson.safe包
- local json = require("cjson.safe")
-local str = [[ {"key:"value"} ]]
+ typeAliasRegistry.registerAlias("CGLIB", CglibProxyFactory.class);
+ typeAliasRegistry.registerAlias("JAVASSIST", JavassistProxyFactory.class);
-local t = json.decode(str)
-if t then
- ngx.say(" --> ", type(t))
-end
- cjson.safe包会在解析失败的时候返回nil
-还有一个是redis链接时如果host使用的是域名的话会提示“failed to connect: no resolver defined to resolve “redis.xxxxxx.com””,这里需要使用nginx的resolver指令,
resolver 8.8.8.8 valid=3600s;
-还有一点补充下
就是业务在使用redis的时候使用了db的特性,所以在lua访问redis的时候也需要执行db,这里lua的redis库也支持了这个特性,可以使用instance:select(config:get(‘db’))来切换db
--
-
-发现一个不错的openresty站点
地址
-
+ languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
+ languageRegistry.register(RawLanguageDriver.class);
+ }
+正是通过typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class);这一行,注册了
POOLED对应的别名类型是PooledDataSourceFactory.class
具体的注册方法是在
+public void registerAlias(String alias, Class<?> value) {
+ if (alias == null) {
+ throw new TypeException("The parameter alias cannot be null");
+ }
+ // issue #748
+ // 转换成小写,
+ String key = alias.toLowerCase(Locale.ENGLISH);
+ // 判断是否已经注册过了
+ if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
+ throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
+ }
+ // 放进map里
+ typeAliases.put(key, value);
+}
+而获取的逻辑在这
+public <T> Class<T> resolveAlias(String string) {
+ try {
+ if (string == null) {
+ return null;
+ }
+ // issue #748
+ // 同样的转成小写
+ String key = string.toLowerCase(Locale.ENGLISH);
+ Class<T> value;
+ if (typeAliases.containsKey(key)) {
+ value = (Class<T>) typeAliases.get(key);
+ } else {
+ // 这里还有从路径下处理的逻辑
+ value = (Class<T>) Resources.classForName(string);
+ }
+ return value;
+ } catch (ClassNotFoundException e) {
+ throw new TypeException("Could not resolve type alias '" + string + "'. Cause: " + e, e);
+ }
+ }
+逻辑比较简单,但是在mybatis中也是不可或缺的一块概念
]]>
- nginx
+ Java
+ Mybatis
- nginx
- openresty
+ Java
+ Mysql
+ Mybatis
- mybatis系列-第一条sql的细节
- /2022/12/11/mybatis%E7%B3%BB%E5%88%97-%E7%AC%AC%E4%B8%80%E6%9D%A1sql%E7%9A%84%E7%BB%86%E8%8A%82/
- 先补充两个点,
第一是前面我们说了
使用org.apache.ibatis.builder.xml.XMLConfigBuilder 创建了parser解析器,那么解析的结果是什么
看这个方法的返回值
-public Configuration parse() {
- if (parsed) {
- throw new BuilderException("Each XMLConfigBuilder can only be used once.");
- }
- parsed = true;
- parseConfiguration(parser.evalNode("/configuration"));
- return configuration;
-}
-
-返回的是 org.apache.ibatis.session.Configuration , 而这个 Configuration 也是 mybatis 中特别重要的配置核心类,贴一下里面的成员变量,
-public class Configuration {
-
- protected Environment environment;
-
- protected boolean safeRowBoundsEnabled;
- protected boolean safeResultHandlerEnabled = true;
- protected boolean mapUnderscoreToCamelCase;
- protected boolean aggressiveLazyLoading;
- protected boolean multipleResultSetsEnabled = true;
- protected boolean useGeneratedKeys;
- protected boolean useColumnLabel = true;
- protected boolean cacheEnabled = true;
- protected boolean callSettersOnNulls;
- protected boolean useActualParamName = true;
- protected boolean returnInstanceForEmptyRow;
- protected boolean shrinkWhitespacesInSql;
- protected boolean nullableOnForEach;
- protected boolean argNameBasedConstructorAutoMapping;
-
- protected String logPrefix;
- protected Class<? extends Log> logImpl;
- protected Class<? extends VFS> vfsImpl;
- protected Class<?> defaultSqlProviderType;
- protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION;
- protected JdbcType jdbcTypeForNull = JdbcType.OTHER;
- protected Set<String> lazyLoadTriggerMethods = new HashSet<>(Arrays.asList("equals", "clone", "hashCode", "toString"));
- protected Integer defaultStatementTimeout;
- protected Integer defaultFetchSize;
- protected ResultSetType defaultResultSetType;
- protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
- protected AutoMappingBehavior autoMappingBehavior = AutoMappingBehavior.PARTIAL;
- protected AutoMappingUnknownColumnBehavior autoMappingUnknownColumnBehavior = AutoMappingUnknownColumnBehavior.NONE;
+ mybatis系列-入门篇
+ /2022/11/27/mybatis%E7%B3%BB%E5%88%97-%E5%85%A5%E9%97%A8%E7%AF%87/
+ mybatis是我们比较常用的orm框架,下面是官网的介绍
+
+ MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
+
+mybatis一大特点,或者说比较为人熟知的应该就是比 hibernate 是更轻量化,为国人所爱好的orm框架,对于hibernate目前还没有深入的拆解过,后续可以也写一下,在使用体验上觉得是个比较精巧的框架,看代码也比较容易,所以就想写个系列,第一篇先是介绍下使用
根据官网的文档上我们先来尝试一下简单使用
首先我们有个简单的配置,这个文件是mybatis-config.xml
+<?xml version="1.0" encoding="UTF-8" ?>
+<!DOCTYPE configuration
+ PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
+ "https://mybatis.org/dtd/mybatis-3-config.dtd">
+<configuration>
+ <!-- 需要加入的properties-->
+ <properties resource="application-development.properties"/>
+ <!-- 指出使用哪个环境,默认是development-->
+ <environments default="development">
+ <environment id="development">
+ <!-- 指定事务管理器类型-->
+ <transactionManager type="JDBC"/>
+ <!-- 指定数据源类型-->
+ <dataSource type="POOLED">
+ <!-- 下面就是具体的参数占位了-->
+ <property name="driver" value="${driver}"/>
+ <property name="url" value="${url}"/>
+ <property name="username" value="${username}"/>
+ <property name="password" value="${password}"/>
+ </dataSource>
+ </environment>
+ </environments>
+ <mappers>
+ <!-- 指定mapper xml的位置或文件-->
+ <mapper resource="mapper/StudentMapper.xml"/>
+ </mappers>
+</configuration>
+在代码里创建mybatis里重要入口
+String resource = "mybatis-config.xml";
+InputStream inputStream = Resources.getResourceAsStream(resource);
+SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
+然后我们上面的StudentMapper.xml
+<?xml version="1.0" encoding="UTF-8" ?>
+<!DOCTYPE mapper
+ PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
+ "https://mybatis.org/dtd/mybatis-3-mapper.dtd">
+<mapper namespace="com.nicksxs.mybatisdemo.StudentMapper">
+ <select id="selectStudent" resultType="com.nicksxs.mybatisdemo.StudentDO">
+ select * from student where id = #{id}
+ </select>
+</mapper>
+那么我们就要使用这个mapper,
+String resource = "mybatis-config.xml";
+InputStream inputStream = Resources.getResourceAsStream(resource);
+SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
+try (SqlSession session = sqlSessionFactory.openSession()) {
+ StudentDO studentDO = session.selectOne("com.nicksxs.mybatisdemo.StudentMapper.selectStudent", 1);
+ System.out.println("id is " + studentDO.getId() + " name is " +studentDO.getName());
+} catch (Exception e) {
+ e.printStackTrace();
+}
+sqlSessionFactory是sqlSession的工厂,我们可以通过sqlSessionFactory来创建sqlSession,而SqlSession 提供了在数据库执行 SQL 命令所需的所有方法。你可以通过 SqlSession 实例来直接执行已映射的 SQL 语句。可以看到mapper.xml中有定义mapper的namespace,就可以通过session.selectOne()传入namespace+id来调用这个方法
但是这样调用比较不合理的点,或者说按后面mybatis优化之后我们可以指定mapper接口
+public interface StudentMapper {
- protected Properties variables = new Properties();
- protected ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
- protected ObjectFactory objectFactory = new DefaultObjectFactory();
- protected ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
+ public StudentDO selectStudent(Long id);
+}
+就可以可以通过mapper接口获取方法,这样就不用涉及到未知的变量转换等异常
+try (SqlSession session = sqlSessionFactory.openSession()) {
+ StudentMapper mapper = session.getMapper(StudentMapper.class);
+ StudentDO studentDO = mapper.selectStudent(1L);
+ System.out.println("id is " + studentDO.getId() + " name is " +studentDO.getName());
+} catch (Exception e) {
+ e.printStackTrace();
+}
+这一篇咱们先介绍下简单的使用,后面可以先介绍下这些的原理。
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ mybatis系列-foreach 解析
+ /2023/06/11/mybatis%E7%B3%BB%E5%88%97-foreach-%E8%A7%A3%E6%9E%90/
+ 在 org.apache.ibatis.builder.xml.XMLConfigBuilder#parseConfiguration 中进行配置解析,其中这一行就是解析 mappers
+mapperElement(root.evalNode("mappers"));
+具体的代码会执行到这
+private void mapperElement(XNode parent) throws Exception {
+ if (parent != null) {
+ for (XNode child : parent.getChildren()) {
+ if ("package".equals(child.getName())) {
+ // 这里解析的不是 package
+ String mapperPackage = child.getStringAttribute("name");
+ configuration.addMappers(mapperPackage);
+ } else {
+ // 根据 resource 和 url 还有 mapperClass 判断
+ String resource = child.getStringAttribute("resource");
+ String url = child.getStringAttribute("url");
+ String mapperClass = child.getStringAttribute("class");
+ // resource 不为空其他为空的情况,就开始将 resource 读成输入流
+ if (resource != null && url == null && mapperClass == null) {
+ ErrorContext.instance().resource(resource);
+ try(InputStream inputStream = Resources.getResourceAsStream(resource)) {
+ // 初始化 XMLMapperBuilder 来解析 mapper
+ XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
+ mapperParser.parse();
+ }
+然后再是 parse 过程
+public void parse() {
+ if (!configuration.isResourceLoaded(resource)) {
+ // 解析 mapper 节点,也就是下图中的mapper
+ configurationElement(parser.evalNode("/mapper"));
+ configuration.addLoadedResource(resource);
+ bindMapperForNamespace();
+ }
- protected boolean lazyLoadingEnabled = false;
- protected ProxyFactory proxyFactory = new JavassistProxyFactory(); // #224 Using internal Javassist instead of OGNL
+ parsePendingResultMaps();
+ parsePendingCacheRefs();
+ parsePendingStatements();
+}
+![image]()
+继续往下走
+private void configurationElement(XNode context) {
+ try {
+ String namespace = context.getStringAttribute("namespace");
+ if (namespace == null || namespace.isEmpty()) {
+ throw new BuilderException("Mapper's namespace cannot be empty");
+ }
+ builderAssistant.setCurrentNamespace(namespace);
+ // 处理cache 和 cache 应用
+ cacheRefElement(context.evalNode("cache-ref"));
+ cacheElement(context.evalNode("cache"));
+ parameterMapElement(context.evalNodes("/mapper/parameterMap"));
+ resultMapElements(context.evalNodes("/mapper/resultMap"));
+ sqlElement(context.evalNodes("/mapper/sql"));
+ // 因为我们是个 sql 查询,所以具体逻辑是在这里面
+ buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
+ } catch (Exception e) {
+ throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
+ }
+ }
+然后是
+private void buildStatementFromContext(List<XNode> list) {
+ if (configuration.getDatabaseId() != null) {
+ buildStatementFromContext(list, configuration.getDatabaseId());
+ }
+ // 然后没有 databaseId 就走到这
+ buildStatementFromContext(list, null);
+}
+继续
+private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
+ for (XNode context : list) {
+ // 创建语句解析器
+ final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
+ try {
+ // 解析节点
+ statementParser.parseStatementNode();
+ } catch (IncompleteElementException e) {
+ configuration.addIncompleteStatement(statementParser);
+ }
+ }
+}
+这个代码比较长,做下简略,只保留相关代码
+public void parseStatementNode() {
+ String id = context.getStringAttribute("id");
+ String databaseId = context.getStringAttribute("databaseId");
- protected String databaseId;
- /**
- * Configuration factory class.
- * Used to create Configuration for loading deserialized unread properties.
- *
- * @see <a href='https://github.com/mybatis/old-google-code-issues/issues/300'>Issue 300 (google code)</a>
- */
- protected Class<?> configurationFactory;
+ if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
+ return;
+ }
- protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
- protected final InterceptorChain interceptorChain = new InterceptorChain();
- protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry(this);
- protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
- protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
+ String nodeName = context.getNode().getNodeName();
+ SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
+ boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
+ boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
+ boolean useCache = context.getBooleanAttribute("useCache", isSelect);
+ boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
- protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection")
- .conflictMessageProducer((savedValue, targetValue) ->
- ". please check " + savedValue.getResource() + " and " + targetValue.getResource());
- protected final Map<String, Cache> caches = new StrictMap<>("Caches collection");
- protected final Map<String, ResultMap> resultMaps = new StrictMap<>("Result Maps collection");
- protected final Map<String, ParameterMap> parameterMaps = new StrictMap<>("Parameter Maps collection");
- protected final Map<String, KeyGenerator> keyGenerators = new StrictMap<>("Key Generators collection");
- protected final Set<String> loadedResources = new HashSet<>();
- protected final Map<String, XNode> sqlFragments = new StrictMap<>("XML fragments parsed from previous mappers");
+ // 简略前后代码,主要看这里,创建 sqlSource
- protected final Collection<XMLStatementBuilder> incompleteStatements = new LinkedList<>();
- protected final Collection<CacheRefResolver> incompleteCacheRefs = new LinkedList<>();
- protected final Collection<ResultMapResolver> incompleteResultMaps = new LinkedList<>();
- protected final Collection<MethodResolver> incompleteMethods = new LinkedList<>();
+ SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
+
+
+然后根据 LanguageDriver,我们这用的 XMLLanguageDriver,先是初始化
+ @Override
+ public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
+ XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
+ return builder.parseScriptNode();
+ }
+// 初始化有一些逻辑
+ public XMLScriptBuilder(Configuration configuration, XNode context, Class<?> parameterType) {
+ super(configuration);
+ this.context = context;
+ this.parameterType = parameterType;
+ // 特别是这,我这次特意在 mapper 中加了 foreach,就是为了说下这一块的解析
+ initNodeHandlerMap();
+ }
+// 设置各种类型的处理器
+ private void initNodeHandlerMap() {
+ nodeHandlerMap.put("trim", new TrimHandler());
+ nodeHandlerMap.put("where", new WhereHandler());
+ nodeHandlerMap.put("set", new SetHandler());
+ nodeHandlerMap.put("foreach", new ForEachHandler());
+ nodeHandlerMap.put("if", new IfHandler());
+ nodeHandlerMap.put("choose", new ChooseHandler());
+ nodeHandlerMap.put("when", new IfHandler());
+ nodeHandlerMap.put("otherwise", new OtherwiseHandler());
+ nodeHandlerMap.put("bind", new BindHandler());
+ }
+初始化解析器以后就开始解析了
+public SqlSource parseScriptNode() {
+ // 先是解析 parseDynamicTags
+ MixedSqlNode rootSqlNode = parseDynamicTags(context);
+ SqlSource sqlSource;
+ if (isDynamic) {
+ sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
+ } else {
+ sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
+ }
+ return sqlSource;
+}
+但是这里可能做的事情比较多
+protected MixedSqlNode parseDynamicTags(XNode node) {
+ List<SqlNode> contents = new ArrayList<>();
+ // 获取子节点,这里可以把我 xml 中的 SELECT 语句分成三部分,第一部分是 select 到 in,然后是 foreach 部分,最后是\n结束符
+ NodeList children = node.getNode().getChildNodes();
+ for (int i = 0; i < children.getLength(); i++) {
+ XNode child = node.newXNode(children.item(i));
+ // 第一个节点是个纯 text 节点就会走到这
+ if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
+ String data = child.getStringBody("");
+ TextSqlNode textSqlNode = new TextSqlNode(data);
+ if (textSqlNode.isDynamic()) {
+ contents.add(textSqlNode);
+ isDynamic = true;
+ } else {
+ // 在 content 中添加这个 node
+ contents.add(new StaticTextSqlNode(data));
+ }
+ } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
+ // 第二个节点是个带 foreach 的,是个内部元素节点
+ String nodeName = child.getNode().getNodeName();
+ // 通过 nodeName 获取处理器
+ NodeHandler handler = nodeHandlerMap.get(nodeName);
+ if (handler == null) {
+ throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
+ }
+ // 调用处理器来处理
+ handler.handleNode(child, contents);
+ isDynamic = true;
+ }
+ }
+ // 然后返回这个混合 sql 节点
+ return new MixedSqlNode(contents);
+ }
+再看下 handleNode 的逻辑
+ @Override
+ public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
+ // 又会套娃执行这里的 parseDynamicTags
+ MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
+ String collection = nodeToHandle.getStringAttribute("collection");
+ Boolean nullable = nodeToHandle.getBooleanAttribute("nullable");
+ String item = nodeToHandle.getStringAttribute("item");
+ String index = nodeToHandle.getStringAttribute("index");
+ String open = nodeToHandle.getStringAttribute("open");
+ String close = nodeToHandle.getStringAttribute("close");
+ String separator = nodeToHandle.getStringAttribute("separator");
+ ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, nullable, index, item, open, close, separator);
+ targetContents.add(forEachSqlNode);
+ }
+// 这里走的逻辑不一样了
+protected MixedSqlNode parseDynamicTags(XNode node) {
+ List<SqlNode> contents = new ArrayList<>();
+ // 这里是 foreach 内部的,所以是个 text_node
+ NodeList children = node.getNode().getChildNodes();
+ for (int i = 0; i < children.getLength(); i++) {
+ XNode child = node.newXNode(children.item(i));
+ // 第一个节点是个纯 text 节点就会走到这
+ if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
+ String data = child.getStringBody("");
+ TextSqlNode textSqlNode = new TextSqlNode(data);
+ // 判断是否动态是根据代码里是否有 ${}
+ if (textSqlNode.isDynamic()) {
+ contents.add(textSqlNode);
+ isDynamic = true;
+ } else {
+ // 所以还是会走到这
+ // 在 content 中添加这个 node
+ contents.add(new StaticTextSqlNode(data));
+ }
+// 最后继续包装成 MixedSqlNode
+// 再回到这里
+ @Override
+ public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
+ MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
+ // 处理 foreach 内部的各个变量
+ String collection = nodeToHandle.getStringAttribute("collection");
+ Boolean nullable = nodeToHandle.getBooleanAttribute("nullable");
+ String item = nodeToHandle.getStringAttribute("item");
+ String index = nodeToHandle.getStringAttribute("index");
+ String open = nodeToHandle.getStringAttribute("open");
+ String close = nodeToHandle.getStringAttribute("close");
+ String separator = nodeToHandle.getStringAttribute("separator");
+ ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, nullable, index, item, open, close, separator);
+ targetContents.add(forEachSqlNode);
+ }
+再回过来
+public SqlSource parseScriptNode() {
+ MixedSqlNode rootSqlNode = parseDynamicTags(context);
+ SqlSource sqlSource;
+ // 因为在 foreach 节点处理时直接是把 isDynamic 置成了 true
+ if (isDynamic) {
+ // 所以是个 DynamicSqlSource
+ sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
+ } else {
+ sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
+ }
+ return sqlSource;
+}
+这里就做完了预处理工作,真正在执行的执行的时候还需要进一步解析
+因为前面讲过很多了,所以直接跳到这里
+ @Override
+ public <T> T selectOne(String statement, Object parameter) {
+ // Popular vote was to return null on 0 results and throw exception on too many.
+ // 都知道是在这进去
+ List<T> list = this.selectList(statement, parameter);
+ if (list.size() == 1) {
+ return list.get(0);
+ } else if (list.size() > 1) {
+ throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
+ } else {
+ return null;
+ }
+ }
-这么多成员变量,先不一一解释作用,但是其中的几个参数我们应该是已经知道了的,第一个就是 mappedStatements ,上一篇我们知道被解析的mapper就是放在这里,后面的 resultMaps ,parameterMaps 也比较常用的就是我们参数和结果的映射map,这里跟我之前有一篇解释为啥我们一些变量的使用会比较特殊,比如list,可以参考这篇,keyGenerators是在我们需要定义主键生成器的时候使用。
然后第二点是我们创建的 org.apache.ibatis.session.SqlSessionFactory 是哪个,
-public SqlSessionFactory build(Configuration config) {
- return new DefaultSqlSessionFactory(config);
-}
+ @Override
+ public <E> List<E> selectList(String statement, Object parameter) {
+ return this.selectList(statement, parameter, RowBounds.DEFAULT);
+ }
+ @Override
+ public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
+ return selectList(statement, parameter, rowBounds, Executor.NO_RESULT_HANDLER);
+ }
+ private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
+ try {
+ // 前面也讲过这个,
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+ // 包括这里,是调用的org.apache.ibatis.executor.CachingExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler)
+ @Override
+ public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
+ BoundSql boundSql = ms.getBoundSql(parameterObject);
+ CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
+ return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
+ }
+// 然后是获取 BoundSql
+ public BoundSql getBoundSql(Object parameterObject) {
+ BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
+ List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
+ if (parameterMappings == null || parameterMappings.isEmpty()) {
+ boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
+ }
-是这个 DefaultSqlSessionFactory ,这是其中一个 SqlSessionFactory 的实现
接下来我们看看 openSession 里干了啥
-public SqlSession openSession() {
- return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
-}
+ // check for nested result maps in parameter mappings (issue #30)
+ for (ParameterMapping pm : boundSql.getParameterMappings()) {
+ String rmId = pm.getResultMapId();
+ if (rmId != null) {
+ ResultMap rm = configuration.getResultMap(rmId);
+ if (rm != null) {
+ hasNestedResultMaps |= rm.hasNestedResultMaps();
+ }
+ }
+ }
-这边有几个参数,第一个是默认的执行器类型,往上找找上面贴着的 Configuration 的成员变量里可以看到默认是
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
-因为没有指明特殊的执行逻辑,所以默认我们也就用简单类型的,第二个参数是是事务级别,第三个是是否自动提交
-private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
- Transaction tx = null;
- try {
- final Environment environment = configuration.getEnvironment();
- final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
- tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
- // --------> 先关注这里
- final Executor executor = configuration.newExecutor(tx, execType);
- return new DefaultSqlSession(configuration, executor, autoCommit);
- } catch (Exception e) {
- closeTransaction(tx); // may have fetched a connection so lets call close()
- throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
- } finally {
- ErrorContext.instance().reset();
+ return boundSql;
}
-}
-
-具体是调用了 Configuration 的这个方法
-public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
- executorType = executorType == null ? defaultExecutorType : executorType;
- Executor executor;
- if (ExecutorType.BATCH == executorType) {
- executor = new BatchExecutor(this, transaction);
- } else if (ExecutorType.REUSE == executorType) {
- executor = new ReuseExecutor(this, transaction);
- } else {
- // ---------> 会走到这个分支
- executor = new SimpleExecutor(this, transaction);
+// 因为前面讲了是生成的 DynamicSqlSource,所以也是调用这个的 getBoundSql
+ @Override
+ public BoundSql getBoundSql(Object parameterObject) {
+ DynamicContext context = new DynamicContext(configuration, parameterObject);
+ // 重点关注着
+ rootSqlNode.apply(context);
+ SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
+ Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
+ SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
+ BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
+ context.getBindings().forEach(boundSql::setAdditionalParameter);
+ return boundSql;
}
- if (cacheEnabled) {
- executor = new CachingExecutor(executor);
+// 继续是这个 DynamicSqlNode 的 apply
+ public boolean apply(DynamicContext context) {
+ contents.forEach(node -> node.apply(context));
+ return true;
}
- executor = (Executor) interceptorChain.pluginAll(executor);
- return executor;
-}
-
-上面传入的 executorType 是 Configuration 的默认类型,也就是 simple 类型,并且 cacheEnabled 在 Configuration 默认为 true,所以会包装成CachingExecutor ,然后后面就是插件了,这块我们先不展开
然后我们的openSession返回的就是创建了DefaultSqlSession
-public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) {
- this.configuration = configuration;
- this.executor = executor;
- this.dirty = false;
- this.autoCommit = autoCommit;
- }
+// 看下面的图
+![image]()
+我们重点看 foreach 的逻辑
+@Override
+ public boolean apply(DynamicContext context) {
+ Map<String, Object> bindings = context.getBindings();
+ final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings,
+ Optional.ofNullable(nullable).orElseGet(configuration::isNullableOnForEach));
+ if (iterable == null || !iterable.iterator().hasNext()) {
+ return true;
+ }
+ boolean first = true;
+ // 开始符号
+ applyOpen(context);
+ int i = 0;
+ for (Object o : iterable) {
+ DynamicContext oldContext = context;
+ if (first || separator == null) {
+ context = new PrefixedContext(context, "");
+ } else {
+ context = new PrefixedContext(context, separator);
+ }
+ int uniqueNumber = context.getUniqueNumber();
+ // Issue #709
+ if (o instanceof Map.Entry) {
+ @SuppressWarnings("unchecked")
+ Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
+ applyIndex(context, mapEntry.getKey(), uniqueNumber);
+ applyItem(context, mapEntry.getValue(), uniqueNumber);
+ } else {
+ applyIndex(context, i, uniqueNumber);
+ applyItem(context, o, uniqueNumber);
+ }
+ // 转换变量名,变成这种形式 select * from student where id in
+ // (
+ // #{__frch_id_0}
+ // )
+ contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
+ if (first) {
+ first = !((PrefixedContext) context).isPrefixApplied();
+ }
+ context = oldContext;
+ i++;
+ }
+ applyClose(context);
+ context.getBindings().remove(item);
+ context.getBindings().remove(index);
+ return true;
+ }
+// 回到外层就会调用 parse 方法, 把#{} 这段替换成 ?
+public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
+ ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
+ GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
+ String sql;
+ if (configuration.isShrinkWhitespacesInSql()) {
+ sql = parser.parse(removeExtraWhitespaces(originalSql));
+ } else {
+ sql = parser.parse(originalSql);
+ }
+ return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
+ }
+![image]()
+可以看到这里,然后再进行替换
+![image]()
+真实的从 ? 替换成具体的变量值,是在这里
org.apache.ibatis.executor.SimpleExecutor#doQuery
调用了
+private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
+ Statement stmt;
+ Connection connection = getConnection(statementLog);
+ stmt = handler.prepare(connection, transaction.getTimeout());
+ handler.parameterize(stmt);
+ return stmt;
+ }
+ @Override
+ public void parameterize(Statement statement) throws SQLException {
+ parameterHandler.setParameters((PreparedStatement) statement);
+ }
+ @Override
+ public void setParameters(PreparedStatement ps) {
+ ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
+ List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
+ if (parameterMappings != null) {
+ for (int i = 0; i < parameterMappings.size(); i++) {
+ ParameterMapping parameterMapping = parameterMappings.get(i);
+ if (parameterMapping.getMode() != ParameterMode.OUT) {
+ Object value;
+ String propertyName = parameterMapping.getProperty();
+ if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
+ value = boundSql.getAdditionalParameter(propertyName);
+ } else if (parameterObject == null) {
+ value = null;
+ } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
+ value = parameterObject;
+ } else {
+ MetaObject metaObject = configuration.newMetaObject(parameterObject);
+ value = metaObject.getValue(propertyName);
+ }
+ TypeHandler typeHandler = parameterMapping.getTypeHandler();
+ JdbcType jdbcType = parameterMapping.getJdbcType();
+ if (value == null && jdbcType == null) {
+ jdbcType = configuration.getJdbcTypeForNull();
+ }
+ try {
+ // -------------------------->
+ // 替换变量
+ typeHandler.setParameter(ps, i + 1, value, jdbcType);
+ } catch (TypeException | SQLException e) {
+ throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
+ }
+ }
+ }
+ }
+ }
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ mybatis系列-connection连接池解析
+ /2023/02/19/mybatis%E7%B3%BB%E5%88%97-connection%E8%BF%9E%E6%8E%A5%E6%B1%A0%E8%A7%A3%E6%9E%90/
+ 连接池主要是两个逻辑,首先是获取连接的逻辑,结合代码来讲一讲
+private PooledConnection popConnection(String username, String password) throws SQLException {
+ boolean countedWait = false;
+ PooledConnection conn = null;
+ long t = System.currentTimeMillis();
+ int localBadConnectionCount = 0;
-然后就是调用 selectOne, 因为前面已经把这部分代码说过了,就直接跳转过来
org.apache.ibatis.session.defaults.DefaultSqlSession#selectList(java.lang.String, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler)
-private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
- try {
- MappedStatement ms = configuration.getMappedStatement(statement);
- return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
- } catch (Exception e) {
- throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
- } finally {
- ErrorContext.instance().reset();
- }
-}
+ // 循环获取连接
+ while (conn == null) {
+ // 加锁
+ lock.lock();
+ try {
+ // 如果闲置的连接列表不为空
+ if (!state.idleConnections.isEmpty()) {
+ // Pool has available connection
+ // 连接池有可用的连接
+ conn = state.idleConnections.remove(0);
+ if (log.isDebugEnabled()) {
+ log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
+ }
+ } else {
+ // Pool does not have available connection
+ // 进入这个分支表示没有空闲连接,但是活跃连接数还没达到最大活跃连接数上限,那么这时候就可以创建一个新连接
+ if (state.activeConnections.size() < poolMaximumActiveConnections) {
+ // Can create new connection
+ // 这里创建连接我们之前讲过,
+ conn = new PooledConnection(dataSource.getConnection(), this);
+ if (log.isDebugEnabled()) {
+ log.debug("Created connection " + conn.getRealHashCode() + ".");
+ }
+ } else {
+ // Cannot create new connection
+ // 进到这个分支了就表示没法创建新连接了,那么怎么办呢,这里引入了一个 poolMaximumCheckoutTime,这代表了我去控制连接一次被使用的最长时间,如果超过这个时间了,我就要去关闭失效它
+ PooledConnection oldestActiveConnection = state.activeConnections.get(0);
+ long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
+ if (longestCheckoutTime > poolMaximumCheckoutTime) {
+ // Can claim overdue connection
+ // 所有超时连接从池中被借出的次数+1
+ state.claimedOverdueConnectionCount++;
+ // 所有超时连接从池中被借出并归还的时间总和 + 当前连接借出时间
+ state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
+ // 所有连接从池中被借出并归还的时间总和 + 当前连接借出时间
+ state.accumulatedCheckoutTime += longestCheckoutTime;
+ // 从活跃连接数中移除此连接
+ state.activeConnections.remove(oldestActiveConnection);
+ // 如果该连接不是自动提交的,则尝试回滚
+ if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
+ try {
+ oldestActiveConnection.getRealConnection().rollback();
+ } catch (SQLException e) {
+ /*
+ Just log a message for debug and continue to execute the following
+ statement like nothing happened.
+ Wrap the bad connection with a new PooledConnection, this will help
+ to not interrupt current executing thread and give current thread a
+ chance to join the next competition for another valid/good database
+ connection. At the end of this loop, bad {@link @conn} will be set as null.
+ */
+ log.debug("Bad connection. Could not roll back");
+ }
+ }
+ // 用此连接的真实连接再创建一个连接,并设置时间
+ conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
+ conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
+ conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
+ oldestActiveConnection.invalidate();
+ if (log.isDebugEnabled()) {
+ log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
+ }
+ } else {
+ // Must wait
+ // 这样还是获取不到连接就只能等待了
+ try {
+ // 标记状态,然后把等待计数+1
+ if (!countedWait) {
+ state.hadToWaitCount++;
+ countedWait = true;
+ }
+ if (log.isDebugEnabled()) {
+ log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
+ }
+ long wt = System.currentTimeMillis();
+ // 等待 poolTimeToWait 时间
+ condition.await(poolTimeToWait, TimeUnit.MILLISECONDS);
+ // 记录等待时间
+ state.accumulatedWaitTime += System.currentTimeMillis() - wt;
+ } catch (InterruptedException e) {
+ // set interrupt flag
+ Thread.currentThread().interrupt();
+ break;
+ }
+ }
+ }
+ }
+ // 如果连接不为空
+ if (conn != null) {
+ // ping to server and check the connection is valid or not
+ // 判断是否有效
+ if (conn.isValid()) {
+ if (!conn.getRealConnection().getAutoCommit()) {
+ // 回滚未提交的
+ conn.getRealConnection().rollback();
+ }
+ conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
+ // 设置时间
+ conn.setCheckoutTimestamp(System.currentTimeMillis());
+ conn.setLastUsedTimestamp(System.currentTimeMillis());
+ // 添加进活跃连接
+ state.activeConnections.add(conn);
+ state.requestCount++;
+ state.accumulatedRequestTime += System.currentTimeMillis() - t;
+ } else {
+ if (log.isDebugEnabled()) {
+ log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
+ }
+ // 连接无效,坏连接+1
+ state.badConnectionCount++;
+ localBadConnectionCount++;
+ conn = null;
+ // 如果坏连接已经超过了容忍上限,就抛异常
+ if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
+ if (log.isDebugEnabled()) {
+ log.debug("PooledDataSource: Could not get a good connection to the database.");
+ }
+ throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
+ }
+ }
+ }
+ } finally {
+ // 释放锁
+ lock.unlock();
+ }
-因为前面说了 executor 包装了 CachingExecutor ,所以会先调用
-@Override
-public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
- BoundSql boundSql = ms.getBoundSql(parameterObject);
- CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
- return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
-}
+ }
-然后是调用的真实的query方法
-@Override
-public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
- throws SQLException {
- Cache cache = ms.getCache();
- if (cache != null) {
- flushCacheIfRequired(ms);
- if (ms.isUseCache() && resultHandler == null) {
- ensureNoOutParams(ms, boundSql);
- @SuppressWarnings("unchecked")
- List<E> list = (List<E>) tcm.getObject(cache, key);
- if (list == null) {
- list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- tcm.putObject(cache, key, list); // issue #578 and #116
+ if (conn == null) {
+ // 连接仍为空
+ if (log.isDebugEnabled()) {
+ log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
- return list;
+ // 抛出异常
+ throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
- }
- return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
-}
+ // fanhui
+ return conn;
+ }
-这里是第一次查询,没有缓存就先到最后一行,继续是调用到 org.apache.ibatis.executor.BaseExecutor#queryFromDatabase
-@Override
- public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
- ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
- if (closed) {
- throw new ExecutorException("Executor was closed.");
- }
- if (queryStack == 0 && ms.isFlushCacheRequired()) {
- clearLocalCache();
- }
- List<E> list;
+然后是还回连接
+protected void pushConnection(PooledConnection conn) throws SQLException {
+ // 加锁
+ lock.lock();
try {
- queryStack++;
- list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
- if (list != null) {
- handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
+ // 从活跃连接中移除当前连接
+ state.activeConnections.remove(conn);
+ if (conn.isValid()) {
+ // 当前的空闲连接数小于连接池中允许的最大空闲连接数
+ if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
+ // 记录借出时间
+ state.accumulatedCheckoutTime += conn.getCheckoutTime();
+ if (!conn.getRealConnection().getAutoCommit()) {
+ // 同样是做回滚
+ conn.getRealConnection().rollback();
+ }
+ // 新建一个连接
+ PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
+ // 加入到空闲连接列表中
+ state.idleConnections.add(newConn);
+ newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
+ newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
+ // 原连接失效
+ conn.invalidate();
+ if (log.isDebugEnabled()) {
+ log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
+ }
+ // 提醒前面等待的
+ condition.signal();
+ } else {
+ // 上面是相同的,就是这里是空闲连接数已经超过上限
+ state.accumulatedCheckoutTime += conn.getCheckoutTime();
+ if (!conn.getRealConnection().getAutoCommit()) {
+ conn.getRealConnection().rollback();
+ }
+ conn.getRealConnection().close();
+ if (log.isDebugEnabled()) {
+ log.debug("Closed connection " + conn.getRealHashCode() + ".");
+ }
+ conn.invalidate();
+ }
} else {
- // ----------->会走到这里
- list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
+ if (log.isDebugEnabled()) {
+ log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
+ }
+ state.badConnectionCount++;
}
} finally {
- queryStack--;
- }
- if (queryStack == 0) {
- for (DeferredLoad deferredLoad : deferredLoads) {
- deferredLoad.load();
- }
- // issue #601
- deferredLoads.clear();
- if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
- // issue #482
- clearLocalCache();
- }
+ lock.unlock();
}
- return list;
- }
+ }
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ nginx 日志小记
+ /2022/04/17/nginx-%E6%97%A5%E5%BF%97%E5%B0%8F%E8%AE%B0/
+ nginx 默认的日志有特定的格式,我们也可以自定义,
+默认的格式是预定义的 combined
+log_format combined '$remote_addr - $remote_user [$time_local] '
+ '"$request" $status $body_bytes_sent '
+ '"$http_referer" "$http_user_agent"';
-然后是
-private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
- List<E> list;
- localCache.putObject(key, EXECUTION_PLACEHOLDER);
- try {
- list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
- } finally {
- localCache.removeObject(key);
- }
- localCache.putObject(key, list);
- if (ms.getStatementType() == StatementType.CALLABLE) {
- localOutputParameterCache.putObject(key, parameter);
- }
- return list;
-}
+配置的日志可以使用这个默认的,如果满足需求的话
+Syntax: access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]];
+ access_log off;
+Default: access_log logs/access.log combined;
+Context: http, server, location, if in location, limit_except
-然后就是 simpleExecutor 的执行过程
-@Override
-public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
- Statement stmt = null;
- try {
- Configuration configuration = ms.getConfiguration();
- StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
- stmt = prepareStatement(handler, ms.getStatementLog());
- return handler.query(stmt, resultHandler);
- } finally {
- closeStatement(stmt);
- }
-}
+而如果需要额外的一些配置的话可以自己定义 log_format ,比如我想要给日志里加上请求时间,那就可以自己定义一个 log_format 比如添加下
+$request_time
+request processing time in seconds with a milliseconds resolution;
+time elapsed between the first bytes were read from the client and the log write after the last bytes were sent to the client
-接下去其实就是跟jdbc交互了
+log_format combined_extend '$remote_addr - $remote_user [$time_local] '
+ '"$request" $status $body_bytes_sent '
+ '"$http_referer" "$http_user_agent" "$request_time"';
+
+然后其他的比如还有 gzip 压缩,可以设置压缩级别,flush 刷盘时间还有根据条件控制
+这里的条件控制简单看了下还比较厉害
+比如我想对2xx 跟 3xx 的访问不记录日志
+map $status $loggable {
+ ~^[23] 0;
+ default 1;
+}
+
+access_log /path/to/access.log combined if=$loggable;
+
+当 $loggable 是 0 或者空时表示 if 条件为否,上面的默认就是 1,只有当请求状态 status 是 2xx 或 3xx 时才是 0,代表不用记录,有了这个特性就可以更灵活地配置日志
+文章主要参考了 nginx 的 log 模块的文档
+]]>
+
+ nginx
+
+
+ nginx
+ 日志
+
+
+
+ mybatis系列-sql 类的简要分析
+ /2023/03/19/mybatis%E7%B3%BB%E5%88%97-sql-%E7%B1%BB%E7%9A%84%E7%AE%80%E8%A6%81%E5%88%86%E6%9E%90/
+ 上次就比较简单的讲了使用,这块也比较简单,因为封装得不是很复杂,首先我们从 select 作为入口来看看,这个具体的实现,
+String selectSql = new SQL() {{
+ SELECT("id", "name");
+ FROM("student");
+ WHERE("id = #{id}");
+ }}.toString();
+SELECT 方法的实现,
+public T SELECT(String... columns) {
+ sql().statementType = SQLStatement.StatementType.SELECT;
+ sql().select.addAll(Arrays.asList(columns));
+ return getSelf();
+}
+statementType是个枚举
+public enum StatementType {
+ DELETE, INSERT, SELECT, UPDATE
+}
+那这个就是个 select 语句,然后会把参数转成 list 添加到 select 变量里,
然后是 from 语句,这个大概也能猜到就是设置下表名,
+public T FROM(String table) {
+ sql().tables.add(table);
+ return getSelf();
+}
+往 tables 里添加了 table,这个 tables 是什么呢
这里也可以看下所有的变量,
+StatementType statementType;
+List<String> sets = new ArrayList<>();
+List<String> select = new ArrayList<>();
+List<String> tables = new ArrayList<>();
+List<String> join = new ArrayList<>();
+List<String> innerJoin = new ArrayList<>();
+List<String> outerJoin = new ArrayList<>();
+List<String> leftOuterJoin = new ArrayList<>();
+List<String> rightOuterJoin = new ArrayList<>();
+List<String> where = new ArrayList<>();
+List<String> having = new ArrayList<>();
+List<String> groupBy = new ArrayList<>();
+List<String> orderBy = new ArrayList<>();
+List<String> lastList = new ArrayList<>();
+List<String> columns = new ArrayList<>();
+List<List<String>> valuesList = new ArrayList<>();
+可以看到是一堆 List 先暂存这些sql 片段,然后再拼装成 sql 语句,
因为它重写了 toString 方法
@Override
-public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
- PreparedStatement ps = (PreparedStatement) statement;
- ps.execute();
- return resultSetHandler.handleResultSets(ps);
+public String toString() {
+ StringBuilder sb = new StringBuilder();
+ sql().sql(sb);
+ return sb.toString();
}
+调用的 sql 方法是
+public String sql(Appendable a) {
+ SafeAppendable builder = new SafeAppendable(a);
+ if (statementType == null) {
+ return null;
+ }
-com.mysql.cj.jdbc.ClientPreparedStatement#execute
-public boolean execute() throws SQLException {
- try {
- synchronized(this.checkClosed().getConnectionMutex()) {
- JdbcConnection locallyScopedConn = this.connection;
- if (!this.doPingInstead && !this.checkReadOnlySafeStatement()) {
- throw SQLError.createSQLException(Messages.getString("PreparedStatement.20") + Messages.getString("PreparedStatement.21"), "S1009", this.exceptionInterceptor);
- } else {
- ResultSetInternalMethods rs = null;
- this.lastQueryIsOnDupKeyUpdate = false;
- if (this.retrieveGeneratedKeys) {
- this.lastQueryIsOnDupKeyUpdate = this.containsOnDuplicateKeyUpdate();
- }
+ String answer;
- this.batchedGeneratedKeys = null;
- this.resetCancelledState();
- this.implicitlyCloseAllOpenResults();
- this.clearWarnings();
- if (this.doPingInstead) {
- this.doPingInstead();
- return true;
- } else {
- this.setupStreamingTimeout(locallyScopedConn);
- Message sendPacket = ((PreparedQuery)this.query).fillSendPacket(((PreparedQuery)this.query).getQueryBindings());
- String oldDb = null;
- if (!locallyScopedConn.getDatabase().equals(this.getCurrentDatabase())) {
- oldDb = locallyScopedConn.getDatabase();
- locallyScopedConn.setDatabase(this.getCurrentDatabase());
- }
+ switch (statementType) {
+ case DELETE:
+ answer = deleteSQL(builder);
+ break;
- CachedResultSetMetaData cachedMetadata = null;
- boolean cacheResultSetMetadata = (Boolean)locallyScopedConn.getPropertySet().getBooleanProperty(PropertyKey.cacheResultSetMetadata).getValue();
- if (cacheResultSetMetadata) {
- cachedMetadata = locallyScopedConn.getCachedMetaData(((PreparedQuery)this.query).getOriginalSql());
- }
+ case INSERT:
+ answer = insertSQL(builder);
+ break;
- locallyScopedConn.setSessionMaxRows(this.getQueryInfo().getFirstStmtChar() == 'S' ? this.maxRows : -1);
- rs = this.executeInternal(this.maxRows, sendPacket, this.createStreamingResultSet(), this.getQueryInfo().getFirstStmtChar() == 'S', cachedMetadata, false);
- if (cachedMetadata != null) {
- locallyScopedConn.initializeResultsMetadataFromCache(((PreparedQuery)this.query).getOriginalSql(), cachedMetadata, rs);
- } else if (rs.hasRows() && cacheResultSetMetadata) {
- locallyScopedConn.initializeResultsMetadataFromCache(((PreparedQuery)this.query).getOriginalSql(), (CachedResultSetMetaData)null, rs);
- }
+ case SELECT:
+ answer = selectSQL(builder);
+ break;
- if (this.retrieveGeneratedKeys) {
- rs.setFirstCharOfQuery(this.getQueryInfo().getFirstStmtChar());
- }
+ case UPDATE:
+ answer = updateSQL(builder);
+ break;
- if (oldDb != null) {
- locallyScopedConn.setDatabase(oldDb);
- }
+ default:
+ answer = null;
+ }
- if (rs != null) {
- this.lastInsertId = rs.getUpdateID();
- this.results = rs;
- }
+ return answer;
+ }
+根据上面的 statementType判断是个什么 sql,我们这个是 selectSQL 就走的 SELECT 这个分支
+private String selectSQL(SafeAppendable builder) {
+ if (distinct) {
+ sqlClause(builder, "SELECT DISTINCT", select, "", "", ", ");
+ } else {
+ sqlClause(builder, "SELECT", select, "", "", ", ");
+ }
- return rs != null && rs.hasRows();
- }
- }
- }
- } catch (CJException var11) {
- throw SQLExceptionsMapping.translateException(var11, this.getExceptionInterceptor());
+ sqlClause(builder, "FROM", tables, "", "", ", ");
+ joins(builder);
+ sqlClause(builder, "WHERE", where, "(", ")", " AND ");
+ sqlClause(builder, "GROUP BY", groupBy, "", "", ", ");
+ sqlClause(builder, "HAVING", having, "(", ")", " AND ");
+ sqlClause(builder, "ORDER BY", orderBy, "", "", ", ");
+ limitingRowsStrategy.appendClause(builder, offset, limit);
+ return builder.toString();
+}
+上面的可以看出来就是按我们常规的 sql 理解顺序来处理
就是select ... from ... where ... 这样子
再看下 sqlClause 的代码
+private void sqlClause(SafeAppendable builder, String keyword, List<String> parts, String open, String close,
+ String conjunction) {
+ if (!parts.isEmpty()) {
+ if (!builder.isEmpty()) {
+ builder.append("\n");
}
- }
-
+ builder.append(keyword);
+ builder.append(" ");
+ builder.append(open);
+ String last = "________";
+ for (int i = 0, n = parts.size(); i < n; i++) {
+ String part = parts.get(i);
+ if (i > 0 && !part.equals(AND) && !part.equals(OR) && !last.equals(AND) && !last.equals(OR)) {
+ builder.append(conjunction);
+ }
+ builder.append(part);
+ last = part;
+ }
+ builder.append(close);
+ }
+ }
+这里的拼接方式还需要判断 AND 和 OR 的判断逻辑,其他就没什么特别的了,只是where 语句中的 lastList 不知道是干嘛的,好像只有添加跟赋值的操作,有知道的大神也可以评论指导下
]]>
Java
@@ -8722,1044 +8466,1472 @@ location ~*
- php-abstract-class-and-interface
- /2016/11/10/php-abstract-class-and-interface/
- PHP抽象类和接口
-- 抽象类与接口
-- 抽象类内可以包含非抽象函数,即可实现函数
-- 抽象类内必须包含至少一个抽象方法,抽象类和接口均不能实例化
-- 抽象类可以设置访问级别,接口默认都是public
-- 类可以实现多个接口但不能继承多个抽象类
-- 类必须实现抽象类和接口里的抽象方法,不一定要实现抽象类的非抽象方法
-- 接口内不能定义变量,但是可以定义常量
-
-示例代码
<?php
-interface int1{
- const INTER1 = 111;
- function inter1();
-}
-interface int2{
- const INTER1 = 222;
- function inter2();
-}
-abstract class abst1{
- public function abstr1(){
- echo 1111;
- }
- abstract function abstra1(){
- echo 'ahahahha';
- }
-}
-abstract class abst2{
- public function abstr2(){
- echo 1111;
- }
- abstract function abstra2();
-}
-class normal1 extends abst1{
- protected function abstr2(){
- echo 222;
- }
-}
+ openresty
+ /2019/06/18/openresty/
+ 目前公司要对一些新的产品功能做灰度测试,因为在后端业务代码层面添加判断比较麻烦,所以想在nginx上做点手脚,就想到了openresty
前后也踩了不少坑,这边先写一点
+首先是日志
error_log logs/error.log debug;
需要nginx开启日志的debug才能看到日志
+使用 lua_code_cache off即可, 另外注意只有使用 content_by_lua_file 才会生效
+http {
+ lua_code_cache off;
+}
-result
PHP Fatal error: Abstract function abst1::abstra1() cannot contain body in new.php on line 17
+location ~* /(\d+-.*)/api/orgunits/load_all(.*) {
+ default_type 'application/json;charset=utf-8';
+ content_by_lua_file /data/projects/xxx/current/lua/controller/load_data.lua;
+}
-Fatal error: Abstract function abst1::abstra1() cannot contain body in php on line 17
-]]>
-
- php
-
-
- php
-
-
-
- powershell 初体验
- /2022/11/13/powershell-%E5%88%9D%E4%BD%93%E9%AA%8C/
- powershell变量变量命名类似于php
-PS C:\Users\Nicks> $a=1
-PS C:\Users\Nicks> $b=2
-PS C:\Users\Nicks> $a*$b
-2
-有一个比较好用的是变量交换
一般的语言做两个变量交换一般需要一个临时变量
-$tmp=$a
-$a=$b
-$b=$tmp
-而在powershell中可以这样
-$a,$b=$b,$a
-PS C:\Users\Nicks> $a,$b=$b,$a
-PS C:\Users\Nicks> $a
-2
-PS C:\Users\Nicks> $b
-1
-还可以通过这个
-PS C:\Users\Nicks> ls variable:
+使用lua给nginx请求response头添加内容可以用这个
+ngx.header['response'] = 'header'
-Name Value
----- -----
-$ $b
-? True
-^ $b
-a 2
-args {}
-b 1
-查看现存的变量
当然一般脚本都是动态类型的,
可以通过
gettype方法
![]()
+
+
+后续:
+
+一开始在本地环境的时候使用content_by_lua_file只关注了头,后来发到测试环境发现请求内容都没代理转发到后端服务上
网上查了下发现content_by_lua_file是将请求的所有内容包括response都用这里面的lua脚本生成了,content这个词就表示是请求内容
后来改成了access_by_lua_file就正常了,只是要去获取请求内容和修改响应头,并不是要完整的接管请求
+后来又碰到了一个坑是nginx有个client_body_buffer_size的配置参数,nginx在32位和64位系统里有8K和16K两个默认值,当请求内容大于这两个值的时候,会把请求内容放到临时文件里,这个时候openresty里的ngx.req.get_post_args()就会报“failed to get post args: requesty body in temp file not supported”这个错误,将client_body_buffer_size这个参数配置调大一点就好了
+还有就是lua的异常捕获,网上看一般是用pcall和xpcall来进行保护调用,因为问题主要出在cjson的decode,这里有两个解决方案,一个就是将cjson.decode使用pcall封装,
+ local decode = require("cjson").decode
+
+function json_decode( str )
+ local ok, t = pcall(decode, str)
+ if not ok then
+ return nil
+ end
+
+ return t
+end
+ 这个是使用了pcall,称为保护调用,会在内部错误后返回两个参数,第一个是false,第二个是错误信息
还有一种是使用cjson.safe包
+ local json = require("cjson.safe")
+local str = [[ {"key:"value"} ]]
+
+local t = json.decode(str)
+if t then
+ ngx.say(" --> ", type(t))
+end
+ cjson.safe包会在解析失败的时候返回nil
+还有一个是redis链接时如果host使用的是域名的话会提示“failed to connect: no resolver defined to resolve “redis.xxxxxx.com””,这里需要使用nginx的resolver指令,
resolver 8.8.8.8 valid=3600s;
+还有一点补充下
就是业务在使用redis的时候使用了db的特性,所以在lua访问redis的时候也需要执行db,这里lua的redis库也支持了这个特性,可以使用instance:select(config:get(‘db’))来切换db
+-
+
+发现一个不错的openresty站点
地址
+
]]>
- 语言
+ nginx
- powershell
+ nginx
+ openresty
- powershell 初体验二
- /2022/11/20/powershell-%E5%88%9D%E4%BD%93%E9%AA%8C%E4%BA%8C/
- powershell创建数组也很方便
可以这样
-$nums=2,0,1,2
-顺便可以用下我们上次学到的gettype()
![]()
-如果是想创建连续数字的数组还可以用这个方便的方法
-$nums=1..5
-![]()
而且数组还可以存放各种类型的数据
-$array=1,"哈哈",([System.Guid]::NewGuid()),(get-date)
-![]()
还有判断类型可以用-is
![]()
创建一个空数组
-$array=@()
-![]()
数组添加元素
-$array+="a"
-![]()
数组删除元素
-$a=1..4
-$a=$a[0..1]+$a[3]
-![]()
+ pcre-intro-and-a-simple-package
+ /2015/01/16/pcre-intro-and-a-simple-package/
+ Pcre
+Perl Compatible Regular Expressions (PCRE) is a regular
expression C library inspired by the regular expression
capabilities in the Perl programming language, written
by Philip Hazel, starting in summer 1997.
+
+因为最近工作内容的一部分需要做字符串的识别处理,所以就顺便用上了之前在PHP中用过的正则,在C/C++中本身不包含正则库,这里使用的pcre,对MFC开发,在这里提供了静态链接库,在引入lib跟.h文件后即可使用。
+
+
+Regular Expression Syntax
然后是一些正则语法,官方的语法文档比较科学严谨,特别是对类似于贪婪匹配等细节的说明,当然一般的使用可以在网上找到很多匹配语法,例如这个。
+PCRE函数介绍
+pcre_compile
原型:
+
+#include <pcre.h>
+pcre *pcre_compile(const char *pattern, int options, const char **errptr, int *erroffset, const unsigned char *tableptr);
+功能:将一个正则表达式编译成一个内部表示,在匹配多个字符串时,可以加速匹配。其同pcre_compile2功能一样只是缺少一个参数errorcodeptr。
参数:
pattern 正则表达式
options 为0,或者其他参数选项
errptr 出错消息
erroffset 出错位置
tableptr 指向一个字符数组的指针,可以设置为空NULL
+
+pcre_exec
原型:
+
+#include <pcre.h>
+int pcre_exec(const pcre *code, const pcre_extra *extra, const char *subject, int length, int startoffset, int options, int *ovector, int ovecsize)
+功能:使用编译好的模式进行匹配,采用与Perl相似的算法,返回匹配串的偏移位置。
参数:
code 编译好的模式
extra 指向一个pcre_extra结构体,可以为NULL
subject 需要匹配的字符串
length 匹配的字符串长度(Byte)
startoffset 匹配的开始位置
options 选项位
ovector 指向一个结果的整型数组
ovecsize 数组大小。
+这里是两个最常用的函数的简单说明,pcre的静态库提供了一系列的函数以供使用,可以参考这个博客说明,另外对于以上函数的具体参数详细说明可以参考官网此处
+一个丑陋的封装
void COcxDemoDlg::pcre_exec_all(const pcre * re, PCRE_SPTR src, vector<pair<int, int>> &vc)
+{
+ int rc;
+ int ovector[30];
+ int i = 0;
+ pair<int, int> pr;
+ rc = pcre_exec(re, NULL, src, strlen(src), i, 0, ovector, 30);
+ for (; rc > 0;)
+ {
+ i = ovector[1];
+ pr.first = ovector[2];
+ pr.second = ovector[3];
+ vc.push_back(pr);
+ rc = pcre_exec(re, NULL, src, strlen(src), i, 0, ovector, 30);
+ }
+}
+vector中是全文匹配后的索引对,只是简单地用下。
]]>
- 语言
+ C++
- powershell
+ c++
+ mfc
- rabbitmq-tips
- /2017/04/25/rabbitmq-tips/
- rabbitmq 介绍接触了一下rabbitmq,原来在选型的时候是在rabbitmq跟kafka之间做选择,网上搜了一下之后发现kafka的优势在于吞吐量,而rabbitmq相对注重可靠性,因为应用在im上,需要保证消息不能丢失所以就暂时选定rabbitmq,
Message Queue的需求由来已久,80年代最早在金融交易中,高盛等公司采用Teknekron公司的产品,当时的Message queuing软件叫做:the information bus(TIB)。 TIB被电信和通讯公司采用,路透社收购了Teknekron公司。之后,IBM开发了MQSeries,微软开发了Microsoft Message Queue(MSMQ)。这些商业MQ供应商的问题是厂商锁定,价格高昂。2001年,Java Message queuing试图解决锁定和交互性的问题,但对应用来说反而更加麻烦了。
RabbitMQ采用Erlang语言开发。Erlang语言由Ericson设计,专门为开发concurrent和distribution系统的一种语言,在电信领域使用广泛。OTP(Open Telecom Platform)作为Erlang语言的一部分,包含了很多基于Erlang开发的中间件/库/工具,如mnesia/SASL,极大方便了Erlang应用的开发。OTP就类似于Python语言中众多的module,用户借助这些module可以很方便的开发应用。
于是2004年,摩根大通和iMatrix开始着手Advanced Message Queuing Protocol (AMQP)开放标准的开发。2006年,AMQP规范发布。2007年,Rabbit技术公司基于AMQP标准开发的RabbitMQ 1.0 发布。所有主要的编程语言均有与代理接口通讯的客户端库。
-简单的使用经验
通俗的理解
这里介绍下其中的一些概念,connection表示和队列服务器的连接,一般情况下是tcp连接, channel表示通道,可以在一个连接上建立多个通道,这里主要是节省了tcp连接握手的成本,exchange可以理解成一个路由器,将消息推送给对应的队列queue,其实是像一个订阅的模式。
-集群经验
rabbitmqctl stop这个是关闭rabbitmq,在搭建集群时候先关闭服务,然后使用rabbitmq-server -detached静默启动,这时候使用rabbitmqctl cluster_status查看集群状态,因为还没将节点加入集群,所以只能看到类似
-Cluster status of node rabbit@rabbit1 ...
-[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
- {running_nodes,[rabbit@rabbit2,rabbit@rabbit1]}]
-...done.
-然后就可以把当前节点加入集群,
-rabbit2$ rabbitmqctl stop_app #这个stop_app与stop的区别是前者停的是rabbitmq应用,保留erlang节点,
- #后者是停止了rabbitmq和erlang节点
-Stopping node rabbit@rabbit2 ...done.
-rabbit2$ rabbitmqctl join_cluster rabbit@rabbit1 #这里可以用--ram指定将当前节点作为内存节点加入集群
-Clustering node rabbit@rabbit2 with [rabbit@rabbit1] ...done.
-rabbit2$ rabbitmqctl start_app
-Starting node rabbit@rabbit2 ...done.
-其他可以参考官方文档
-一些坑
消息丢失
这里碰到过一个坑,对于使用exchange来做消息路由的,会有一个情况,就是在routing_key没被订阅的时候,会将该条找不到路由对应的queue的消息丢掉What happens if we break our contract and send a message with one or four words, like "orange" or "quick.orange.male.rabbit"? Well, these messages won't match any bindings and will be lost.对应链接,而当使用空的exchange时,会保留消息,当出现消费者的时候就可以将收到之前生产者所推送的消息对应链接,这里就是用了空的exchange。
-集群搭建
集群搭建的时候有个erlang vm生成的random cookie,这个是用来做集群之间认证的,相同的cookie才能连接,但是如果通过vim打开复制后在其他几点新建文件写入会多一个换行,导致集群建立是报错,所以这里最好使用scp等传输命令直接传输cookie文件,同时要注意下cookie的文件权限。
另外在集群搭建的时候如果更改过hostname,那么要把rabbitmq的数据库删除,否则启动后会马上挂掉
+ php-abstract-class-and-interface
+ /2016/11/10/php-abstract-class-and-interface/
+ PHP抽象类和接口
+- 抽象类与接口
+- 抽象类内可以包含非抽象函数,即可实现函数
+- 抽象类内必须包含至少一个抽象方法,抽象类和接口均不能实例化
+- 抽象类可以设置访问级别,接口默认都是public
+- 类可以实现多个接口但不能继承多个抽象类
+- 类必须实现抽象类和接口里的抽象方法,不一定要实现抽象类的非抽象方法
+- 接口内不能定义变量,但是可以定义常量
+
+示例代码
<?php
+interface int1{
+ const INTER1 = 111;
+ function inter1();
+}
+interface int2{
+ const INTER1 = 222;
+ function inter2();
+}
+abstract class abst1{
+ public function abstr1(){
+ echo 1111;
+ }
+ abstract function abstra1(){
+ echo 'ahahahha';
+ }
+}
+abstract class abst2{
+ public function abstr2(){
+ echo 1111;
+ }
+ abstract function abstra2();
+}
+class normal1 extends abst1{
+ protected function abstr2(){
+ echo 222;
+ }
+}
+
+result
PHP Fatal error: Abstract function abst1::abstra1() cannot contain body in new.php on line 17
+
+Fatal error: Abstract function abst1::abstra1() cannot contain body in php on line 17
]]>
php
php
- mq
- im
-
-
-
- redis 的 rdb 和 COW 介绍
- /2021/08/15/redis-%E7%9A%84-rdb-%E5%92%8C-COW-%E4%BB%8B%E7%BB%8D/
- redis 在使用 rdb 策略进行备份时,rdb 的意思是会在开启备份的时候将开启时间点的内存数据进行备份,并且可以设置时间,这样子就是这个策略其实还是不完全可靠的,如果是在这个间隔中宕机了,或者间隔过长,不过这个不在这次的要说的内容中,如果自己去写这个 rdb 的策略可能就有点类似于 mvcc 的 redolog,需要知道这个时间点之前的数据是怎么样的,防止后面更改的干扰,但是这样一方面需要有比较复杂的 mvcc 实现,另一方面是很占用存储空间,所以 redis 在这里面使用了 COW (Copy On Write) 技术,这个技术呢以前听过,也大致了解是怎么个意思,这次稍微具体地来看下,其实 redis 的 copy-on-write 就是来自于 linux 的 cow
-Linux中的CopyOnWrite
fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。这个操作其实可以类比为写屏障,正常的读取是没问题的,当有写入时就会分裂。
-CopyOnWrite的好处:
1、减少分配和复制资源时带来的瞬时延迟;
2、减少不必要的资源分配;
CopyOnWrite的缺点:
1、如果父子进程都需要进行大量的写操作,会产生大量的分页错误(页异常中断page-fault);
-Redis中的CopyOnWrite
Redis在持久化时,如果是采用BGSAVE命令或者BGREWRITEAOF的方式,那Redis会fork出一个子进程来读取数据,从而写到磁盘中。
总体来看,Redis还是读操作比较多。如果子进程存在期间,发生了大量的写操作,那可能就会出现很多的分页错误(页异常中断page-fault),这样就得耗费不少性能在复制上。
而在rehash阶段上,写操作是无法避免的。所以Redis在fork出子进程之后,将负载因子阈值提高,尽量减少写操作,避免不必要的内存写入操作,最大限度地节约内存。这里其实更巧妙了,在细节上去优化会产生大量页异常中断的情况。
-]]>
-
- redis
-
-
- redis
- redis数据结构介绍-第一部分 SDS,链表,字典
- /2019/12/26/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D/
- redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
-SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍
-struct sdshdr {
- // 字符串长度
- int len;
- // 字符串空余字符数
- int free;
- // 字符串内容
- char buf[];
-};
-这里引用了 redis 在 github 上最早的 2.2 版本的代码,代码路径是https://github.com/antirez/redis/blob/2.2/src/sds.h,可以看到这个结构体里只有仨元素,两个 int 型和一个 char 型数组,两个 int 型其实就是我说的优化,因为 C 语言本身的字符串数组,有两个问题,一个是要知道它实际已被占用的长度,需要去遍历这个数组,第二个就是比较容易踩坑的是遍历的时候要注意它有个以\0作为结尾的特点;通过上面的两个 int 型参数,一个是知道字符串目前的长度,一个是知道字符串还剩余多少位空间,这样子坐着两个操作从 O(N)简化到了O(1)了,还有第二个 free 还有个比较重要的作用就是能防止 C 字符串的溢出问题,在存储之前可以先判断 free 长度,如果长度不够就先扩容了,先介绍到这,这个系列可以写蛮多的,慢慢介绍吧
-链表
链表是比较常见的数据结构了,但是因为 redis 是用 C 写的,所以在不依赖第三方库的情况下只能自己写一个了,redis 的链表是个有头的链表,而且是无环的,具体的结构我也找了 github 上最早版本的代码
-typedef struct listNode {
- // 前置节点
- struct listNode *prev;
- // 后置节点
- struct listNode *next;
- // 值
- void *value;
-} listNode;
+ mybatis系列-第一条sql的细节
+ /2022/12/11/mybatis%E7%B3%BB%E5%88%97-%E7%AC%AC%E4%B8%80%E6%9D%A1sql%E7%9A%84%E7%BB%86%E8%8A%82/
+ 先补充两个点,
第一是前面我们说了
使用org.apache.ibatis.builder.xml.XMLConfigBuilder 创建了parser解析器,那么解析的结果是什么
看这个方法的返回值
+public Configuration parse() {
+ if (parsed) {
+ throw new BuilderException("Each XMLConfigBuilder can only be used once.");
+ }
+ parsed = true;
+ parseConfiguration(parser.evalNode("/configuration"));
+ return configuration;
+}
+
+返回的是 org.apache.ibatis.session.Configuration , 而这个 Configuration 也是 mybatis 中特别重要的配置核心类,贴一下里面的成员变量,
+public class Configuration {
+
+ protected Environment environment;
+
+ protected boolean safeRowBoundsEnabled;
+ protected boolean safeResultHandlerEnabled = true;
+ protected boolean mapUnderscoreToCamelCase;
+ protected boolean aggressiveLazyLoading;
+ protected boolean multipleResultSetsEnabled = true;
+ protected boolean useGeneratedKeys;
+ protected boolean useColumnLabel = true;
+ protected boolean cacheEnabled = true;
+ protected boolean callSettersOnNulls;
+ protected boolean useActualParamName = true;
+ protected boolean returnInstanceForEmptyRow;
+ protected boolean shrinkWhitespacesInSql;
+ protected boolean nullableOnForEach;
+ protected boolean argNameBasedConstructorAutoMapping;
+
+ protected String logPrefix;
+ protected Class<? extends Log> logImpl;
+ protected Class<? extends VFS> vfsImpl;
+ protected Class<?> defaultSqlProviderType;
+ protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION;
+ protected JdbcType jdbcTypeForNull = JdbcType.OTHER;
+ protected Set<String> lazyLoadTriggerMethods = new HashSet<>(Arrays.asList("equals", "clone", "hashCode", "toString"));
+ protected Integer defaultStatementTimeout;
+ protected Integer defaultFetchSize;
+ protected ResultSetType defaultResultSetType;
+ protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
+ protected AutoMappingBehavior autoMappingBehavior = AutoMappingBehavior.PARTIAL;
+ protected AutoMappingUnknownColumnBehavior autoMappingUnknownColumnBehavior = AutoMappingUnknownColumnBehavior.NONE;
+
+ protected Properties variables = new Properties();
+ protected ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
+ protected ObjectFactory objectFactory = new DefaultObjectFactory();
+ protected ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
+
+ protected boolean lazyLoadingEnabled = false;
+ protected ProxyFactory proxyFactory = new JavassistProxyFactory(); // #224 Using internal Javassist instead of OGNL
+
+ protected String databaseId;
+ /**
+ * Configuration factory class.
+ * Used to create Configuration for loading deserialized unread properties.
+ *
+ * @see <a href='https://github.com/mybatis/old-google-code-issues/issues/300'>Issue 300 (google code)</a>
+ */
+ protected Class<?> configurationFactory;
+
+ protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
+ protected final InterceptorChain interceptorChain = new InterceptorChain();
+ protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry(this);
+ protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
+ protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
+
+ protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection")
+ .conflictMessageProducer((savedValue, targetValue) ->
+ ". please check " + savedValue.getResource() + " and " + targetValue.getResource());
+ protected final Map<String, Cache> caches = new StrictMap<>("Caches collection");
+ protected final Map<String, ResultMap> resultMaps = new StrictMap<>("Result Maps collection");
+ protected final Map<String, ParameterMap> parameterMaps = new StrictMap<>("Parameter Maps collection");
+ protected final Map<String, KeyGenerator> keyGenerators = new StrictMap<>("Key Generators collection");
+
+ protected final Set<String> loadedResources = new HashSet<>();
+ protected final Map<String, XNode> sqlFragments = new StrictMap<>("XML fragments parsed from previous mappers");
+
+ protected final Collection<XMLStatementBuilder> incompleteStatements = new LinkedList<>();
+ protected final Collection<CacheRefResolver> incompleteCacheRefs = new LinkedList<>();
+ protected final Collection<ResultMapResolver> incompleteResultMaps = new LinkedList<>();
+ protected final Collection<MethodResolver> incompleteMethods = new LinkedList<>();
+
+这么多成员变量,先不一一解释作用,但是其中的几个参数我们应该是已经知道了的,第一个就是 mappedStatements ,上一篇我们知道被解析的mapper就是放在这里,后面的 resultMaps ,parameterMaps 也比较常用的就是我们参数和结果的映射map,这里跟我之前有一篇解释为啥我们一些变量的使用会比较特殊,比如list,可以参考这篇,keyGenerators是在我们需要定义主键生成器的时候使用。
然后第二点是我们创建的 org.apache.ibatis.session.SqlSessionFactory 是哪个,
+public SqlSessionFactory build(Configuration config) {
+ return new DefaultSqlSessionFactory(config);
+}
+
+是这个 DefaultSqlSessionFactory ,这是其中一个 SqlSessionFactory 的实现
接下来我们看看 openSession 里干了啥
+public SqlSession openSession() {
+ return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
+}
+
+这边有几个参数,第一个是默认的执行器类型,往上找找上面贴着的 Configuration 的成员变量里可以看到默认是
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
+因为没有指明特殊的执行逻辑,所以默认我们也就用简单类型的,第二个参数是是事务级别,第三个是是否自动提交
+private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
+ Transaction tx = null;
+ try {
+ final Environment environment = configuration.getEnvironment();
+ final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
+ tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
+ // --------> 先关注这里
+ final Executor executor = configuration.newExecutor(tx, execType);
+ return new DefaultSqlSession(configuration, executor, autoCommit);
+ } catch (Exception e) {
+ closeTransaction(tx); // may have fetched a connection so lets call close()
+ throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+}
+
+具体是调用了 Configuration 的这个方法
+public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
+ executorType = executorType == null ? defaultExecutorType : executorType;
+ Executor executor;
+ if (ExecutorType.BATCH == executorType) {
+ executor = new BatchExecutor(this, transaction);
+ } else if (ExecutorType.REUSE == executorType) {
+ executor = new ReuseExecutor(this, transaction);
+ } else {
+ // ---------> 会走到这个分支
+ executor = new SimpleExecutor(this, transaction);
+ }
+ if (cacheEnabled) {
+ executor = new CachingExecutor(executor);
+ }
+ executor = (Executor) interceptorChain.pluginAll(executor);
+ return executor;
+}
+
+上面传入的 executorType 是 Configuration 的默认类型,也就是 simple 类型,并且 cacheEnabled 在 Configuration 默认为 true,所以会包装成CachingExecutor ,然后后面就是插件了,这块我们先不展开
然后我们的openSession返回的就是创建了DefaultSqlSession
+public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) {
+ this.configuration = configuration;
+ this.executor = executor;
+ this.dirty = false;
+ this.autoCommit = autoCommit;
+ }
+
+然后就是调用 selectOne, 因为前面已经把这部分代码说过了,就直接跳转过来
org.apache.ibatis.session.defaults.DefaultSqlSession#selectList(java.lang.String, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler)
+private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
+ try {
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+}
+
+因为前面说了 executor 包装了 CachingExecutor ,所以会先调用
+@Override
+public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
+ BoundSql boundSql = ms.getBoundSql(parameterObject);
+ CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
+ return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
+}
+
+然后是调用的真实的query方法
+@Override
+public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
+ throws SQLException {
+ Cache cache = ms.getCache();
+ if (cache != null) {
+ flushCacheIfRequired(ms);
+ if (ms.isUseCache() && resultHandler == null) {
+ ensureNoOutParams(ms, boundSql);
+ @SuppressWarnings("unchecked")
+ List<E> list = (List<E>) tcm.getObject(cache, key);
+ if (list == null) {
+ list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
+ tcm.putObject(cache, key, list); // issue #578 and #116
+ }
+ return list;
+ }
+ }
+ return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
+}
+
+这里是第一次查询,没有缓存就先到最后一行,继续是调用到 org.apache.ibatis.executor.BaseExecutor#queryFromDatabase
+@Override
+ public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
+ ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
+ if (closed) {
+ throw new ExecutorException("Executor was closed.");
+ }
+ if (queryStack == 0 && ms.isFlushCacheRequired()) {
+ clearLocalCache();
+ }
+ List<E> list;
+ try {
+ queryStack++;
+ list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
+ if (list != null) {
+ handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
+ } else {
+ // ----------->会走到这里
+ list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
+ }
+ } finally {
+ queryStack--;
+ }
+ if (queryStack == 0) {
+ for (DeferredLoad deferredLoad : deferredLoads) {
+ deferredLoad.load();
+ }
+ // issue #601
+ deferredLoads.clear();
+ if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
+ // issue #482
+ clearLocalCache();
+ }
+ }
+ return list;
+ }
-typedef struct list {
- // 链表表头
- listNode *head;
- // 当前节点,也可以说是最后节点
- listNode *tail;
- // 节点复制函数
- void *(*dup)(void *ptr);
- // 节点值释放函数
- void (*free)(void *ptr);
- // 节点值比较函数
- int (*match)(void *ptr, void *key);
- // 链表包含的节点数量
- unsigned int len;
-} list;
-代码地址是这个https://github.com/antirez/redis/blob/2.2/src/adlist.h
可以看下节点是由listNode承载的,包括值和一个指向前节点跟一个指向后一节点的两个指针,然后值是 void 指针类型,所以可以承载不同类型的值
然后是 list结构用来承载一个链表,包含了表头,和表尾,复制函数,释放函数和比较函数,还有链表长度,因为包含了前两个节点,找到表尾节点跟表头都是 O(1)的时间复杂度,还有节点数量,其实这个跟 SDS 是同一个做法,就是空间换时间,这也是写代码里比较常见的做法,以此让一些高频的操作提速。
-字典
字典也是个常用的数据结构,其实只是叫法不同,数据结构中叫 hash 散列,Java 中叫 Map,PHP 中是数组 array,Python 中也叫字典 dict,因为纯 C 语言本身不带这些数据结构,所以这也是个痛并快乐着的过程,享受 C 语言的高性能的同时也要接受它只提供了语言的基本功能的现实,各种轮子都需要自己造,redis 同样实现了自己的字典
下面来看看代码
-typedef struct dictEntry {
- void *key;
- void *val;
- struct dictEntry *next;
-} dictEntry;
+然后是
+private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
+ List<E> list;
+ localCache.putObject(key, EXECUTION_PLACEHOLDER);
+ try {
+ list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
+ } finally {
+ localCache.removeObject(key);
+ }
+ localCache.putObject(key, list);
+ if (ms.getStatementType() == StatementType.CALLABLE) {
+ localOutputParameterCache.putObject(key, parameter);
+ }
+ return list;
+}
-typedef struct dictType {
- unsigned int (*hashFunction)(const void *key);
- void *(*keyDup)(void *privdata, const void *key);
- void *(*valDup)(void *privdata, const void *obj);
- int (*keyCompare)(void *privdata, const void *key1, const void *key2);
- void (*keyDestructor)(void *privdata, void *key);
- void (*valDestructor)(void *privdata, void *obj);
-} dictType;
+然后就是 simpleExecutor 的执行过程
+@Override
+public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
+ Statement stmt = null;
+ try {
+ Configuration configuration = ms.getConfiguration();
+ StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
+ stmt = prepareStatement(handler, ms.getStatementLog());
+ return handler.query(stmt, resultHandler);
+ } finally {
+ closeStatement(stmt);
+ }
+}
-/* This is our hash table structure. Every dictionary has two of this as we
- * implement incremental rehashing, for the old to the new table. */
-typedef struct dictht {
- dictEntry **table;
- unsigned long size;
- unsigned long sizemask;
- unsigned long used;
-} dictht;
+接下去其实就是跟jdbc交互了
+@Override
+public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
+ PreparedStatement ps = (PreparedStatement) statement;
+ ps.execute();
+ return resultSetHandler.handleResultSets(ps);
+}
-typedef struct dict {
- dictType *type;
- void *privdata;
- dictht ht[2];
- int rehashidx; /* rehashing not in progress if rehashidx == -1 */
- int iterators; /* number of iterators currently running */
-} dict;
-看了下这个 2.2 版本的代码跟最新版的其实也差的不是很多,所以还是照旧用老代码,可以看到上面四个结构体中,其实只有三个是存储数据用的,dictType 是用来放操作函数的,那么三个存放数据的结构体分别是干嘛的,这时候感觉需要一个图来说明比较好,稍等,我去画个图~
![]()
这个图看着应该比较清楚这些都是用来干嘛的了,dict 是我们的主体结构,它有一个指向 dictType 的指针,这里面包含了字典的操作函数,然后是一个私有数据指针,接下来是一个 dictht 的数组,包含两个dictht,这个就是用来存数据的了,然后是 rehashidx 表示重哈希的状态,当是-1 的时候表示当前没有重哈希,iterators 表示正在遍历的迭代器的数量。
首先说说为啥需要有两个 dictht,这是因为字典 dict 这个数据结构随着数据量的增减,会需要在中途做扩容或者缩容操作,如果只有一个的话,对它进行扩容缩容时会影响正常的访问和修改操作,或者说保证正常查询,修改的正确性会比较复杂,并且因为需要高效利用空间,不能一下子申请一个非常大的空间来存很少的数据。当 dict 中 dictht 中的数据量超过 size 的时候负载就超过了 1,就需要进行扩容,这里的其实跟 Java 中的 HashMap 比较类似,超过一定的负载之后进行扩容。这里为啥 size 会超过 1 呢,可能有部分不了解这类结构的同学会比较奇怪,其实就是上图中画的,在数据结构中对于散列的冲突有几类解决方法,比如转换成链表,二次散列,找下个空槽等,这里就使用了链表法,或者说拉链法。当一个新元素通过 hashFunction 得出的 key 跟 sizemask 取模之后的值相同了,那就将其放在原来的节点之前,变成链表挂在数组 dictht.table下面,放在原有节点前是考虑到可能会优先访问。
忘了说明下 dictht 跟 dictEntry 的关系了,dictht 就是个哈希表,它里面是个dictEntry 的二维数组,而 dictEntry 是个包含了 key-value 结构之外还有一个 next 指针,因此可以将哈希冲突的以链表的形式保存下来。
在重点说下重哈希,可能同样写 Java 的同学对这个比较有感觉,跟 HashMap 一样,会以 2 的 N 次方进行扩容,那么扩容的方法就会比较简单,每个键重哈希要不就在原来这个槽,要不就在原来的槽加原 dictht.size 的位置;然后是重头戏,具体是怎么做扩容呢,其实这里就把第二个 ht 用上了,其实这两个hashtable 的具体作用有点类似于 jvm 中的两个 survival 区,但是又不全一样,因为 redis 在扩容的时候是采用的渐进式地重哈希,什么叫渐进式的呢,就是它不是像 jvm 那种标记复制的模式直接将一个 eden 区和原来的 survival 区存活的对象复制到另一个 survival 区,而是在每一次添加,删除,查找或者更新操作时,都会额外的帮忙搬运一部分的原 dictht 中的数据,这里会根据 rehashidx 的值来判断,如果是-1 表示并没有在重哈希中,如果是 0 表示开始重哈希了,然后rehashidx 还会随着每次的帮忙搬运往上加,但全部被搬运完成后 rehashidx 又变回了-1,又可以扯到Java 中的 Concurrent HashMap, 他在扩容的时候也使用了类似的操作。
-]]>
-
- Redis
- C
- Redis
- 数据结构
- 源码
-
-
- redis
- 数据结构
- 源码
-
-
-
- redis数据结构介绍三-第三部分 整数集合
- /2020/01/10/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E4%B8%89/
- redis中对于 set 其实有两种处理,对于元素均为整型,并且元素数目较少时,使用 intset 作为底层数据结构,否则使用 dict 作为底层数据结构,先看一下代码先
-typedef struct intset {
- // 编码方式
- uint32_t encoding;
- // 集合包含的元素数量
- uint32_t length;
- // 保存元素的数组
- int8_t contents[];
-} intset;
+com.mysql.cj.jdbc.ClientPreparedStatement#execute
+public boolean execute() throws SQLException {
+ try {
+ synchronized(this.checkClosed().getConnectionMutex()) {
+ JdbcConnection locallyScopedConn = this.connection;
+ if (!this.doPingInstead && !this.checkReadOnlySafeStatement()) {
+ throw SQLError.createSQLException(Messages.getString("PreparedStatement.20") + Messages.getString("PreparedStatement.21"), "S1009", this.exceptionInterceptor);
+ } else {
+ ResultSetInternalMethods rs = null;
+ this.lastQueryIsOnDupKeyUpdate = false;
+ if (this.retrieveGeneratedKeys) {
+ this.lastQueryIsOnDupKeyUpdate = this.containsOnDuplicateKeyUpdate();
+ }
-/* Note that these encodings are ordered, so:
- * INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
-#define INTSET_ENC_INT16 (sizeof(int16_t))
-#define INTSET_ENC_INT32 (sizeof(int32_t))
-#define INTSET_ENC_INT64 (sizeof(int64_t))
-一眼看,为啥整型还需要编码,然后 int8_t 怎么能存下大整形呢,带着这些疑问,我们一步步分析下去,这里的编码其实指的是这个整型集合里存的究竟是多大的整型,16 位,还是 32 位,还是 64 位,结构体下面的宏定义就是表示了 encoding 的可能取值,INTSET_ENC_INT16 表示每个元素用2个字节存储,INTSET_ENC_INT32 表示每个元素用4个字节存储,INTSET_ENC_INT64 表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。length 就是正常的表示集合中元素的数量。最奇怪的应该就是这个 contents 了,是个 int8_t 的数组,那放毛线数据啊,最小的都有 16 位,这里我在看代码和《redis 设计与实现》的时候也有点懵逼,后来查了下发现这是个比较取巧的用法,这里我用自己的理解表述一下,先看看 8,16,32,64 的关系,一眼看就知道都是 2 的 N 次,并且呈两倍关系,而且 8 位刚好一个字节,所以呢其实这里的contents 不是个常规意义上的 int8_t 类型的数组,而是个柔性数组。看下 wiki 的定义
-
-Flexible array members1 were introduced in the C99 standard of the C programming language (in particular, in section §6.7.2.1, item 16, page 103).2 It is a member of a struct, which is an array without a given dimension. It must be the last member of such a struct and it must be accompanied by at least one other member, as in the following example:
-
-struct vectord {
- size_t len;
- double arr[]; // the flexible array member must be last
-};
-在初始化这个 intset 的时候,这个contents数组是不占用空间的,后面的反正用到了申请,那么这里就有一个问题,给出了三种可能的 encoding 值,他们能随便换吗,显然不行,首先在 intset 中数据的存放是有序的,这个有部分原因是方便二分查找,然后存放数据其实随着数据的大小不同会有一个升级的过程,看下图
![]()
新创建的intset只有一个header,总共8个字节。其中encoding = 2, length = 0, 类型都是uint32_t,各占 4 字节,添加15, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以encoding不变,值还是2,也就是默认的 INTSET_ENC_INT16,当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。在添加每个元素的过程中,intset始终保持从小到大有序。与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示encoding字段的4个字节应该解释成0x00000004,而第4个数据应该解释成0x00008000 = 32768
-]]>
-
- Redis
- C
- Redis
- 数据结构
- 源码
-
-
- redis
- 数据结构
- 源码
-
-
-
- redis数据结构介绍二-第二部分 跳表
- /2020/01/04/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E4%BA%8C/
- 跳表 skiplist跳表是个在我们日常的代码中不太常用到的数据结构,相对来讲就没有像数组,链表,字典,散列,树等结构那么熟悉,所以就从头开始分析下,首先是链表,跳表跟链表都有个表字(太硬扯了我🤦♀️),注意这是个有序链表
![]()
如上图,在这个链表里如果我要找到 23,是不是我需要从3,5,9开始一直往后找直到找到 23,也就是说时间复杂度是 O(N),N 的一次幂复杂度,那么我们来看看第二个
![]()
这个结构跟原先有点不一样,它给链表中偶数位的节点又加了一个指针把它们链接起来,这样子当我们要寻找 23 的时候就可以从原来的一个个往下找变成跳着找,先找到 5,然后是 10,接着是 19,然后是 28,这时候发现 28 比 23 大了,那我在退回到 19,然后从下一层原来的链表往前找,
![]()
这里毛估估是不是前面的节点我就少找了一半,有那么点二分法的意思。
前面的其实是跳表的引子,真正的跳表其实不是这样,因为上面的其实有个比较大的问题,就是插入一个元素后需要调整每个元素的指针,在 redis 中的跳表其实是做了个随机层数的优化,因为沿着前面的例子,其实当数据量很大的时候,是不是层数越多,其查询效率越高,但是随着层数变多,要保持这种严格的层数规则其实也会增大处理复杂度,所以 redis 插入每个元素的时候都是使用随机的方式,看一眼代码
-/* ZSETs use a specialized version of Skiplists */
-typedef struct zskiplistNode {
- sds ele;
- double score;
- struct zskiplistNode *backward;
- struct zskiplistLevel {
- struct zskiplistNode *forward;
- unsigned long span;
- } level[];
-} zskiplistNode;
+ this.batchedGeneratedKeys = null;
+ this.resetCancelledState();
+ this.implicitlyCloseAllOpenResults();
+ this.clearWarnings();
+ if (this.doPingInstead) {
+ this.doPingInstead();
+ return true;
+ } else {
+ this.setupStreamingTimeout(locallyScopedConn);
+ Message sendPacket = ((PreparedQuery)this.query).fillSendPacket(((PreparedQuery)this.query).getQueryBindings());
+ String oldDb = null;
+ if (!locallyScopedConn.getDatabase().equals(this.getCurrentDatabase())) {
+ oldDb = locallyScopedConn.getDatabase();
+ locallyScopedConn.setDatabase(this.getCurrentDatabase());
+ }
-typedef struct zskiplist {
- struct zskiplistNode *header, *tail;
- unsigned long length;
- int level;
-} zskiplist;
+ CachedResultSetMetaData cachedMetadata = null;
+ boolean cacheResultSetMetadata = (Boolean)locallyScopedConn.getPropertySet().getBooleanProperty(PropertyKey.cacheResultSetMetadata).getValue();
+ if (cacheResultSetMetadata) {
+ cachedMetadata = locallyScopedConn.getCachedMetaData(((PreparedQuery)this.query).getOriginalSql());
+ }
+
+ locallyScopedConn.setSessionMaxRows(this.getQueryInfo().getFirstStmtChar() == 'S' ? this.maxRows : -1);
+ rs = this.executeInternal(this.maxRows, sendPacket, this.createStreamingResultSet(), this.getQueryInfo().getFirstStmtChar() == 'S', cachedMetadata, false);
+ if (cachedMetadata != null) {
+ locallyScopedConn.initializeResultsMetadataFromCache(((PreparedQuery)this.query).getOriginalSql(), cachedMetadata, rs);
+ } else if (rs.hasRows() && cacheResultSetMetadata) {
+ locallyScopedConn.initializeResultsMetadataFromCache(((PreparedQuery)this.query).getOriginalSql(), (CachedResultSetMetaData)null, rs);
+ }
+
+ if (this.retrieveGeneratedKeys) {
+ rs.setFirstCharOfQuery(this.getQueryInfo().getFirstStmtChar());
+ }
+
+ if (oldDb != null) {
+ locallyScopedConn.setDatabase(oldDb);
+ }
+
+ if (rs != null) {
+ this.lastInsertId = rs.getUpdateID();
+ this.results = rs;
+ }
+
+ return rs != null && rs.hasRows();
+ }
+ }
+ }
+ } catch (CJException var11) {
+ throw SQLExceptionsMapping.translateException(var11, this.getExceptionInterceptor());
+ }
+ }
-typedef struct zset {
- dict *dict;
- zskiplist *zsl;
-} zset;
-忘了说了,redis 是把 skiplist 跳表用在 zset 里,zset 是个有序的集合,可以看到 zskiplist 就是个跳表的结构,里面用 header 保存跳表的表头,tail 保存表尾,还有长度和最大层级,具体的跳表节点元素使用 zskiplistNode 表示,里面包含了 sds 类型的元素值,double 类型的分值,用来排序,一个 backward 后向指针和一个 zskiplistLevel 数组,每个 level 包含了一个前向指针,和一个 span,span 表示的是跳表前向指针的跨度,这里再补充一点,前面说了为了灵活这个跳表的新增修改,redis 使用了随机层高的方式插入新节点,但是如果所有节点都随机到很高的层级或者所有都很低的话,跳表的效率优势就会减小,所以 redis 使用了个小技巧,贴下代码
-#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
-int zslRandomLevel(void) {
- int level = 1;
- while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
- level += 1;
- return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
-}
-当随机值跟0xFFFF进行与操作小于ZSKIPLIST_P * 0xFFFF时才会增大 level 的值,因此保持了一个相对递减的概率
可以简单分析下,当 random() 的值小于 0xFFFF 的 1/4,才会 level + 1,就意味着当有 1 - 1/4也就是3/4的概率是直接跳出,所以一层的概率是3/4,也就是 1-P,二层的概率是 P*(1-P),三层的概率是 P² * (1-P) 依次递推。
]]>
- Redis
- C
- Redis
- 数据结构
- 源码
+ Java
+ Mybatis
- redis
- 数据结构
- 源码
+ Java
+ Mysql
+ Mybatis
- redis数据结构介绍五-第五部分 对象
- /2020/01/20/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E4%BA%94/
- 前面说了这么些数据结构,其实大家对于 redis 最初的印象应该就是个 key-value 的缓存,类似于 memcache,redis 其实也是个 key-value,key 还是一样的字符串,或者说就是用 redis 自己的动态字符串实现,但是 value 其实就是前面说的那些数据结构,差不多快说完了,还有个 quicklist 后面还有一篇,这里先介绍下 redis 对于这些不同类型的 value 是怎么实现的,首先看下 redisObject 的源码头文件
-/* The actual Redis Object */
-#define OBJ_STRING 0 /* String object. */
-#define OBJ_LIST 1 /* List object. */
-#define OBJ_SET 2 /* Set object. */
-#define OBJ_ZSET 3 /* Sorted set object. */
-#define OBJ_HASH 4 /* Hash object. */
-/*
- * Objects encoding. Some kind of objects like Strings and Hashes can be
- * internally represented in multiple ways. The 'encoding' field of the object
- * is set to one of this fields for this object. */
-#define OBJ_ENCODING_RAW 0 /* Raw representation */
-#define OBJ_ENCODING_INT 1 /* Encoded as integer */
-#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
-#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
-#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
-#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
-#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
-#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
-#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
-#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
-#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
-
-#define LRU_BITS 24
-#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
-#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
-
-#define OBJ_SHARED_REFCOUNT INT_MAX
-typedef struct redisObject {
- unsigned type:4;
- unsigned encoding:4;
- unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
- * LFU data (least significant 8 bits frequency
- * and most significant 16 bits access time). */
- int refcount;
- void *ptr;
-} robj;
-主体结构就是这个 redisObject,
-
-- type: 字段表示对象的类型,它对应的就是 redis 的对外暴露的,或者说用户可以使用的五种类型,OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH
-- encoding: 字段表示这个对象在 redis 内部的编码方式,由OBJ_ENCODING_开头的 11 种
-- lru: 做LRU替换算法用,占24个bit
-- refcount: 引用计数。它允许robj对象在某些情况下被共享。
-- ptr: 指向底层实现数据结构的指针
当 type 是 OBJ_STRING 时,表示类型是个 string,它的编码方式 encoding 可能有 OBJ_ENCODING_RAW,OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR 三种
当 type 是 OBJ_LIST 时,表示类型是 list,它的编码方式 encoding 是 OBJ_ENCODING_QUICKLIST,对于早一些的版本,2.2这种可能还会使用 OBJ_ENCODING_ZIPLIST,OBJ_ENCODING_LINKEDLIST
当 type 是 OBJ_SET 时,是个集合,但是得看具体元素的类型,有可能使用整数集合,OBJ_ENCODING_INTSET, 如果元素不全是整型或者数量超过一定限制,那么编码就是 OBJ_ENCODING_HT hash table 了
当 type 是 OBJ_ZSET 时,是个有序集合,它底层有可能使用的是 OBJ_ENCODING_ZIPLIST 或者 OBJ_ENCODING_SKIPLIST
当 type 是 OBJ_HASH 时,一开始也是 OBJ_ENCODING_ZIPLIST,然后当数据量大于 hash_max_ziplist_entries 时会转成 OBJ_ENCODING_HT
-
+ redis 的 rdb 和 COW 介绍
+ /2021/08/15/redis-%E7%9A%84-rdb-%E5%92%8C-COW-%E4%BB%8B%E7%BB%8D/
+ redis 在使用 rdb 策略进行备份时,rdb 的意思是会在开启备份的时候将开启时间点的内存数据进行备份,并且可以设置时间,这样子就是这个策略其实还是不完全可靠的,如果是在这个间隔中宕机了,或者间隔过长,不过这个不在这次的要说的内容中,如果自己去写这个 rdb 的策略可能就有点类似于 mvcc 的 redolog,需要知道这个时间点之前的数据是怎么样的,防止后面更改的干扰,但是这样一方面需要有比较复杂的 mvcc 实现,另一方面是很占用存储空间,所以 redis 在这里面使用了 COW (Copy On Write) 技术,这个技术呢以前听过,也大致了解是怎么个意思,这次稍微具体地来看下,其实 redis 的 copy-on-write 就是来自于 linux 的 cow
+Linux中的CopyOnWrite
fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。这个操作其实可以类比为写屏障,正常的读取是没问题的,当有写入时就会分裂。
+CopyOnWrite的好处:
1、减少分配和复制资源时带来的瞬时延迟;
2、减少不必要的资源分配;
CopyOnWrite的缺点:
1、如果父子进程都需要进行大量的写操作,会产生大量的分页错误(页异常中断page-fault);
+Redis中的CopyOnWrite
Redis在持久化时,如果是采用BGSAVE命令或者BGREWRITEAOF的方式,那Redis会fork出一个子进程来读取数据,从而写到磁盘中。
总体来看,Redis还是读操作比较多。如果子进程存在期间,发生了大量的写操作,那可能就会出现很多的分页错误(页异常中断page-fault),这样就得耗费不少性能在复制上。
而在rehash阶段上,写操作是无法避免的。所以Redis在fork出子进程之后,将负载因子阈值提高,尽量减少写操作,避免不必要的内存写入操作,最大限度地节约内存。这里其实更巧妙了,在细节上去优化会产生大量页异常中断的情况。
]]>
- Redis
- C
- Redis
- 数据结构
- 源码
+ redis
redis
- 数据结构
- 源码
- redis数据结构介绍六 快表
- /2020/01/22/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E5%85%AD/
- 这应该是 redis 系列的最后一篇了,讲下快表,其实最前面讲的链表在早先的 redis 版本中也作为 list 的数据结构使用过,但是单纯的链表的缺陷之前也说了,插入便利,但是空间利用率低,并且不能进行二分查找等,检索效率低,ziplist 压缩表的产生也是同理,希望获得更好的性能,包括存储空间和访问性能等,原来我也不懂这个快表要怎么快,然后明白了一个道理,其实并没有什么银弹,只是大牛们会在适合的时候使用最适合的数据结构来实现性能的最大化,这里面有一招就是不同数据结构的组合调整,比如 Java 中的 HashMap,在链表节点数大于 8 时会转变成红黑树,以此提高访问效率,不费话了,回到快表,quicklist,这个数据结构主要使用在 list 类型中,如果我说其实这个 quicklist 就是个链表,可能大家不太会相信,但是事实上的确可以认为 quicklist 是个双向链表,看下代码
-/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
- * We use bit fields keep the quicklistNode at 32 bytes.
- * count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
- * encoding: 2 bits, RAW=1, LZF=2.
- * container: 2 bits, NONE=1, ZIPLIST=2.
- * recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
- * attempted_compress: 1 bit, boolean, used for verifying during testing.
- * extra: 10 bits, free for future use; pads out the remainder of 32 bits */
-typedef struct quicklistNode {
- struct quicklistNode *prev;
- struct quicklistNode *next;
- unsigned char *zl;
- unsigned int sz; /* ziplist size in bytes */
- unsigned int count : 16; /* count of items in ziplist */
- unsigned int encoding : 2; /* RAW==1 or LZF==2 */
- unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
- unsigned int recompress : 1; /* was this node previous compressed? */
- unsigned int attempted_compress : 1; /* node can't compress; too small */
- unsigned int extra : 10; /* more bits to steal for future usage */
-} quicklistNode;
+ mybatis系列-第一条sql的更多细节
+ /2022/12/18/mybatis%E7%B3%BB%E5%88%97-%E7%AC%AC%E4%B8%80%E6%9D%A1sql%E7%9A%84%E6%9B%B4%E5%A4%9A%E7%BB%86%E8%8A%82/
+ 执行细节
首先设置了默认的languageDriver
org/mybatis/mybatis/3.5.11/mybatis-3.5.11-sources.jar!/org/apache/ibatis/session/Configuration.java:215
在configuration的构造方法里
+languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
-/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
- * 'sz' is byte length of 'compressed' field.
- * 'compressed' is LZF data with total (compressed) length 'sz'
- * NOTE: uncompressed length is stored in quicklistNode->sz.
- * When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
-typedef struct quicklistLZF {
- unsigned int sz; /* LZF size in bytes*/
- char compressed[];
-} quicklistLZF;
+而在
org.apache.ibatis.builder.xml.XMLStatementBuilder#parseStatementNode
中,创建了sqlSource,这里就会根据前面的 LanguageDriver 的实现选择对应的 sqlSource ,
+SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
-/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
- * 'count' is the number of total entries.
- * 'len' is the number of quicklist nodes.
- * 'compress' is: -1 if compression disabled, otherwise it's the number
- * of quicklistNodes to leave uncompressed at ends of quicklist.
- * 'fill' is the user-requested (or default) fill factor. */
-typedef struct quicklist {
- quicklistNode *head;
- quicklistNode *tail;
- unsigned long count; /* total count of all entries in all ziplists */
- unsigned long len; /* number of quicklistNodes */
- int fill : 16; /* fill factor for individual nodes */
- unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
-} quicklist;
-粗略看下,quicklist 里有 head,tail, quicklistNode里有 prev,next 指针,是不是有链表的基本轮廓了,那么为啥这玩意要称为快表呢,快在哪,关键就在这个unsigned char *zl;zl 是不是前面又看到过,就是 ziplist ,这是什么鬼,链表里用压缩表,这不套娃么,先别急,回顾下前面说的 ziplist,ziplist 有哪些特点,内存利用率高,可以从表头快速定位到尾节点,节点可以从后往前找,但是有个缺点,就是从中间插入的效率比较低,需要整体往后移,这个其实是普通数组的优化版,但还是有数组的一些劣势,所以要真的快,是不是可以将链表跟数组真的结合起来。
-ziplist
这里有两个 redis 的配置参数,list-max-ziplist-size 和 list-compress-depth,先来说第一个,既然快表是将链表跟压缩表数组结合起来使用,那么具体怎么用呢,比如我有一个 10 个元素的 list,那具体怎么放,每个 quicklistNode 里放多大的 ziplist,假如每个快表节点的 ziplist 只放一个元素,那么其实这就退化成了一个链表,如果 10 个元素放在一个 quicklistNode 的 ziplist 里,那就退化成了一个 ziplist,所以有了这个 list-max-ziplist-size,而且它还比较牛,能取正负值,当是正值时,对应的就是每个 quicklistNode 的 ziplist 中的元素个数,比如配置了 list-max-ziplist-size = 5,那么我刚才的 10 个元素的 list 就是一个两个 quicklistNode 组成的快表,每个 quicklistNode 中的 ziplist 包含了五个元素,当 list-max-ziplist-size取负值的时候,它限制了 ziplist 的字节数
-size_t offset = (-fill) - 1;
-if (offset < (sizeof(optimization_level) / sizeof(*optimization_level))) {
- if (sz <= optimization_level[offset]) {
- return 1;
- } else {
- return 0;
- }
-} else {
- return 0;
-}
+createSqlSource 就会调用
+@Override
+public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
+ XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
+ return builder.parseScriptNode();
+}
-/* Optimization levels for size-based filling */
-static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};
+再往下的逻辑在 parseScriptNode 中,org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseScriptNode
+public SqlSource parseScriptNode() {
+ MixedSqlNode rootSqlNode = parseDynamicTags(context);
+ SqlSource sqlSource;
+ if (isDynamic) {
+ sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
+ } else {
+ sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
+ }
+ return sqlSource;
+}
-/* Create a new quicklist.
- * Free with quicklistRelease(). */
-quicklist *quicklistCreate(void) {
- struct quicklist *quicklist;
+首先要解析dynamicTag,调用了org.apache.ibatis.scripting.xmltags.XMLScriptBuilder#parseDynamicTags
+protected MixedSqlNode parseDynamicTags(XNode node) {
+ List<SqlNode> contents = new ArrayList<>();
+ NodeList children = node.getNode().getChildNodes();
+ for (int i = 0; i < children.getLength(); i++) {
+ XNode child = node.newXNode(children.item(i));
+ if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
+ String data = child.getStringBody("");
+ TextSqlNode textSqlNode = new TextSqlNode(data);
+ // ---------> 主要是这边的逻辑
+ if (textSqlNode.isDynamic()) {
+ contents.add(textSqlNode);
+ isDynamic = true;
+ } else {
+ contents.add(new StaticTextSqlNode(data));
+ }
+ } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
+ String nodeName = child.getNode().getNodeName();
+ NodeHandler handler = nodeHandlerMap.get(nodeName);
+ if (handler == null) {
+ throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
+ }
+ handler.handleNode(child, contents);
+ isDynamic = true;
+ }
+ }
+ return new MixedSqlNode(contents);
+ }
- quicklist = zmalloc(sizeof(*quicklist));
- quicklist->head = quicklist->tail = NULL;
- quicklist->len = 0;
- quicklist->count = 0;
- quicklist->compress = 0;
- quicklist->fill = -2;
- return quicklist;
-}
-这个 fill 就是传进来的 list-max-ziplist-size, 具体对应的就是
-
-- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
-- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)也就是上面的
quicklist->fill = -2;
-- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
-
-压缩
list-compress-depth这个参数呢是用来配置压缩的,等等压缩是为啥,不是里面已经是压缩表了么,大牛们就是为了性能殚精竭虑,这里考虑到的是一个场景,一般状况下,list 都是两端的访问频率比较高,那么是不是可以对中间的数据进行压缩,那么这个参数就是用来表示
-/* depth of end nodes not to compress;0=off */
-
-- 0,代表不压缩,默认值
-- 1,两端各一个节点不压缩
-- 2,两端各两个节点不压缩
-- … 依次类推
压缩后的 ziplist 就会变成 quicklistLZF,然后替换 zl 指针,这里使用的是 LZF 压缩算法,压缩后的 quicklistLZF 中的 compressed 也是个柔性数组,压缩后的 ziplist 整个就放进这个柔性数组
-
-插入过程
简单说下插入元素的过程
-/* Wrapper to allow argument-based switching between HEAD/TAIL pop */
-void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
- int where) {
- if (where == QUICKLIST_HEAD) {
- quicklistPushHead(quicklist, value, sz);
- } else if (where == QUICKLIST_TAIL) {
- quicklistPushTail(quicklist, value, sz);
- }
-}
+判断是否是动态sql,调用了org.apache.ibatis.scripting.xmltags.TextSqlNode#isDynamic
+public boolean isDynamic() {
+ DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
+ // ----------> 主要是这里的方法
+ GenericTokenParser parser = createParser(checker);
+ parser.parse(text);
+ return checker.isDynamic();
+}
+
+创建parser的时候可以看到这个parser是干了啥,其实就是找有没有${ , }
+private GenericTokenParser createParser(TokenHandler handler) {
+ return new GenericTokenParser("${", "}", handler);
+}
+
+如果是的话,就在上面把 isDynamic 设置为true 如果是true 的话就创建 DynamicSqlSource
+sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
+
+如果不是的话就创建RawSqlSource
+sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
+```java
+
+但是这不是一个真实可用的 `sqlSource` ,
+实际创建的时候会走到这
+```java
+public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) {
+ this(configuration, getSql(configuration, rootSqlNode), parameterType);
+ }
-/* Add new entry to head node of quicklist.
- *
- * Returns 0 if used existing head.
- * Returns 1 if new head created. */
-int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
- quicklistNode *orig_head = quicklist->head;
- if (likely(
- _quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
- quicklist->head->zl =
- ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
- quicklistNodeUpdateSz(quicklist->head);
- } else {
- quicklistNode *node = quicklistCreateNode();
- node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
+ public RawSqlSource(Configuration configuration, String sql, Class<?> parameterType) {
+ SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
+ Class<?> clazz = parameterType == null ? Object.class : parameterType;
+ sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap<>());
+ }
- quicklistNodeUpdateSz(node);
- _quicklistInsertNodeBefore(quicklist, quicklist->head, node);
- }
- quicklist->count++;
- quicklist->head->count++;
- return (orig_head != quicklist->head);
-}
+具体的sqlSource是通过org.apache.ibatis.builder.SqlSourceBuilder#parse 创建的
具体的代码逻辑是
+public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
+ ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
+ GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
+ String sql;
+ if (configuration.isShrinkWhitespacesInSql()) {
+ sql = parser.parse(removeExtraWhitespaces(originalSql));
+ } else {
+ sql = parser.parse(originalSql);
+ }
+ return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
+}
-/* Add new entry to tail node of quicklist.
- *
- * Returns 0 if used existing tail.
- * Returns 1 if new tail created. */
-int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
- quicklistNode *orig_tail = quicklist->tail;
- if (likely(
- _quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
- quicklist->tail->zl =
- ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
- quicklistNodeUpdateSz(quicklist->tail);
- } else {
- quicklistNode *node = quicklistCreateNode();
- node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
+这里创建的其实是StaticSqlSource ,多带一句前面的parser是将原来这样select * from student where id = #{id} 的 sql 解析成了select * from student where id = ? 然后创建了StaticSqlSource
+public StaticSqlSource(Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {
+ this.sql = sql;
+ this.parameterMappings = parameterMappings;
+ this.configuration = configuration;
+}
- quicklistNodeUpdateSz(node);
- _quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
- }
- quicklist->count++;
- quicklist->tail->count++;
- return (orig_tail != quicklist->tail);
-}
+为什么前面要讲这么多好像没什么关系的代码呢,其实在最开始我们执行sql的代码中
+@Override
+ public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
+ BoundSql boundSql = ms.getBoundSql(parameterObject);
+ CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
+ return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
+ }
-/* Wrappers for node inserting around existing node. */
-REDIS_STATIC void _quicklistInsertNodeBefore(quicklist *quicklist,
- quicklistNode *old_node,
- quicklistNode *new_node) {
- __quicklistInsertNode(quicklist, old_node, new_node, 0);
-}
+这里获取了BoundSql,而BoundSql是怎么来的呢,首先调用了org.apache.ibatis.mapping.MappedStatement#getBoundSql
+public BoundSql getBoundSql(Object parameterObject) {
+ BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
+ List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
+ if (parameterMappings == null || parameterMappings.isEmpty()) {
+ boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
+ }
-REDIS_STATIC void _quicklistInsertNodeAfter(quicklist *quicklist,
- quicklistNode *old_node,
- quicklistNode *new_node) {
- __quicklistInsertNode(quicklist, old_node, new_node, 1);
-}
+ // check for nested result maps in parameter mappings (issue #30)
+ for (ParameterMapping pm : boundSql.getParameterMappings()) {
+ String rmId = pm.getResultMapId();
+ if (rmId != null) {
+ ResultMap rm = configuration.getResultMap(rmId);
+ if (rm != null) {
+ hasNestedResultMaps |= rm.hasNestedResultMaps();
+ }
+ }
+ }
-/* Insert 'new_node' after 'old_node' if 'after' is 1.
- * Insert 'new_node' before 'old_node' if 'after' is 0.
- * Note: 'new_node' is *always* uncompressed, so if we assign it to
- * head or tail, we do not need to uncompress it. */
-REDIS_STATIC void __quicklistInsertNode(quicklist *quicklist,
- quicklistNode *old_node,
- quicklistNode *new_node, int after) {
- if (after) {
- new_node->prev = old_node;
- if (old_node) {
- new_node->next = old_node->next;
- if (old_node->next)
- old_node->next->prev = new_node;
- old_node->next = new_node;
- }
- if (quicklist->tail == old_node)
- quicklist->tail = new_node;
- } else {
- new_node->next = old_node;
- if (old_node) {
- new_node->prev = old_node->prev;
- if (old_node->prev)
- old_node->prev->next = new_node;
- old_node->prev = new_node;
- }
- if (quicklist->head == old_node)
- quicklist->head = new_node;
- }
- /* If this insert creates the only element so far, initialize head/tail. */
- if (quicklist->len == 0) {
- quicklist->head = quicklist->tail = new_node;
- }
+ return boundSql;
+ }
- if (old_node)
- quicklistCompress(quicklist, old_node);
+而我们从上面的解析中可以看到这里的sqlSource是一层RawSqlSource , 它的getBoundSql又是调用内部的sqlSource的方法
+@Override
+public BoundSql getBoundSql(Object parameterObject) {
+ return sqlSource.getBoundSql(parameterObject);
+}
- quicklist->len++;
-}
-前面第一步先根据插入的是头还是尾选择不同的 push 函数,quicklistPushHead 或者 quicklistPushTail,举例分析下从头插入的 quicklistPushHead,先判断当前的 quicklistNode 节点还能不能允许再往 ziplist 里添加元素,如果可以就添加,如果不允许就新建一个 quicklistNode,然后调用 _quicklistInsertNodeBefore 将节点插进去,具体插入quicklist节点的操作类似链表的插入。
-]]>
-
- Redis
- C
- Redis
- 数据结构
- 源码
-
-
- redis
- 数据结构
- 源码
-
-
-
- redis系列介绍七-过期策略
- /2020/04/12/redis%E7%B3%BB%E5%88%97%E4%BB%8B%E7%BB%8D%E4%B8%83/
- 这一篇不再是数据结构介绍了,大致的数据结构基本都介绍了,这一篇主要是查漏补缺,或者说讲一些重要且基本的概念,也可能是经常被忽略的,很多讲 redis 的系列文章可能都会忽略,学习 redis 的时候也会,因为觉得源码学习就是讲主要的数据结构和“算法”学习了就好了。
redis 的主要应用就是拿来作为高性能的缓存,那么缓存一般有些啥需要注意的,首先是访问速度,如果取得跟数据库一样快,那就没什么存在的意义,第二个是缓存的字面意思,我只是为了让数据读取快一些,通常大部分的场景这个是需要更新过期的,这里就把我要讲的第一点引出来了(真累,
-redis过期策略
redis 是如何过期缓存的,可以猜测下,最无脑的就是每个设置了过期时间的 key 都设个定时器,过期了就删除,这种显然消耗太大,清理地最及时,还有的就是 redis 正在采用的懒汉清理策略和定期清理
懒汉策略就是在使用的时候去检查缓存是否过期,比如 get 操作时,先判断下这个 key 是否已经过期了,如果过期了就删掉,并且返回空,如果没过期则正常返回
主要代码是
-/* This function is called when we are going to perform some operation
- * in a given key, but such key may be already logically expired even if
- * it still exists in the database. The main way this function is called
- * is via lookupKey*() family of functions.
- *
- * The behavior of the function depends on the replication role of the
- * instance, because slave instances do not expire keys, they wait
- * for DELs from the master for consistency matters. However even
- * slaves will try to have a coherent return value for the function,
- * so that read commands executed in the slave side will be able to
- * behave like if the key is expired even if still present (because the
- * master has yet to propagate the DEL).
- *
- * In masters as a side effect of finding a key which is expired, such
- * key will be evicted from the database. Also this may trigger the
- * propagation of a DEL/UNLINK command in AOF / replication stream.
- *
- * The return value of the function is 0 if the key is still valid,
- * otherwise the function returns 1 if the key is expired. */
-int expireIfNeeded(redisDb *db, robj *key) {
- if (!keyIsExpired(db,key)) return 0;
+内部的sqlSource 就是StaticSqlSource ,
+@Override
+public BoundSql getBoundSql(Object parameterObject) {
+ return new BoundSql(configuration, sql, parameterMappings, parameterObject);
+}
- /* If we are running in the context of a slave, instead of
- * evicting the expired key from the database, we return ASAP:
- * the slave key expiration is controlled by the master that will
- * send us synthesized DEL operations for expired keys.
- *
- * Still we try to return the right information to the caller,
- * that is, 0 if we think the key should be still valid, 1 if
- * we think the key is expired at this time. */
- if (server.masterhost != NULL) return 1;
+这个BoundSql的内容也比较简单
+public BoundSql(Configuration configuration, String sql, List<ParameterMapping> parameterMappings, Object parameterObject) {
+ this.sql = sql;
+ this.parameterMappings = parameterMappings;
+ this.parameterObject = parameterObject;
+ this.additionalParameters = new HashMap<>();
+ this.metaParameters = configuration.newMetaObject(additionalParameters);
+}
- /* Delete the key */
- server.stat_expiredkeys++;
- propagateExpire(db,key,server.lazyfree_lazy_expire);
- notifyKeyspaceEvent(NOTIFY_EXPIRED,
- "expired",key,db->id);
- return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
- dbSyncDelete(db,key);
-}
+而上次在这边org.apache.ibatis.executor.SimpleExecutor#doQuery 的时候落了个东西,就是StatementHandler的逻辑
+@Override
+public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
+ Statement stmt = null;
+ try {
+ Configuration configuration = ms.getConfiguration();
+ StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
+ stmt = prepareStatement(handler, ms.getStatementLog());
+ return handler.query(stmt, resultHandler);
+ } finally {
+ closeStatement(stmt);
+ }
+}
-/* Check if the key is expired. */
-int keyIsExpired(redisDb *db, robj *key) {
- mstime_t when = getExpire(db,key);
- mstime_t now;
+它是通过statementType来区分应该使用哪个statementHandler,我们这使用的就是PreparedStatementHandler
+public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
+
+ switch (ms.getStatementType()) {
+ case STATEMENT:
+ delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
+ break;
+ case PREPARED:
+ delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
+ break;
+ case CALLABLE:
+ delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
+ break;
+ default:
+ throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
+ }
+
+}
+
+所以上次有个细节可以补充,这边的doQuery里面的handler.query 应该是调用了PreparedStatementHandler 的query方法
+@Override
+public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
+ Statement stmt = null;
+ try {
+ Configuration configuration = ms.getConfiguration();
+ StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
+ stmt = prepareStatement(handler, ms.getStatementLog());
+ return handler.query(stmt, resultHandler);
+ } finally {
+ closeStatement(stmt);
+ }
+}
- if (when < 0) return 0; /* No expire for this key */
- /* Don't expire anything while loading. It will be done later. */
- if (server.loading) return 0;
+因为上面prepareStatement中getConnection拿到connection是com.mysql.cj.jdbc.ConnectionImpl#ConnectionImpl(com.mysql.cj.conf.HostInfo)
+@Override
+public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
+ PreparedStatement ps = (PreparedStatement) statement;
+ ps.execute();
+ return resultSetHandler.handleResultSets(ps);
+}
- /* If we are in the context of a Lua script, we pretend that time is
- * blocked to when the Lua script started. This way a key can expire
- * only the first time it is accessed and not in the middle of the
- * script execution, making propagation to slaves / AOF consistent.
- * See issue #1525 on Github for more information. */
- if (server.lua_caller) {
- now = server.lua_time_start;
- }
- /* If we are in the middle of a command execution, we still want to use
- * a reference time that does not change: in that case we just use the
- * cached time, that we update before each call in the call() function.
- * This way we avoid that commands such as RPOPLPUSH or similar, that
- * may re-open the same key multiple times, can invalidate an already
- * open object in a next call, if the next call will see the key expired,
- * while the first did not. */
- else if (server.fixed_time_expire > 0) {
- now = server.mstime;
- }
- /* For the other cases, we want to use the most fresh time we have. */
- else {
- now = mstime();
- }
+那又为什么是这个呢,可以在网上找,我们在mybatis-config.xml里配置的
+<transactionManager type="JDBC"/>
- /* The key expired if the current (virtual or real) time is greater
- * than the expire time of the key. */
- return now > when;
-}
-/* Return the expire time of the specified key, or -1 if no expire
- * is associated with this key (i.e. the key is non volatile) */
-long long getExpire(redisDb *db, robj *key) {
- dictEntry *de;
+因此在parseConfiguration中配置environment时
+private void parseConfiguration(XNode root) {
+ try {
+ // issue #117 read properties first
+ propertiesElement(root.evalNode("properties"));
+ Properties settings = settingsAsProperties(root.evalNode("settings"));
+ loadCustomVfs(settings);
+ loadCustomLogImpl(settings);
+ typeAliasesElement(root.evalNode("typeAliases"));
+ pluginElement(root.evalNode("plugins"));
+ objectFactoryElement(root.evalNode("objectFactory"));
+ objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
+ reflectorFactoryElement(root.evalNode("reflectorFactory"));
+ settingsElement(settings);
+ // read it after objectFactory and objectWrapperFactory issue #631
+ // ----------> 就是这里
+ environmentsElement(root.evalNode("environments"));
+ databaseIdProviderElement(root.evalNode("databaseIdProvider"));
+ typeHandlerElement(root.evalNode("typeHandlers"));
+ mapperElement(root.evalNode("mappers"));
+ } catch (Exception e) {
+ throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
+ }
+ }
- /* No expire? return ASAP */
- if (dictSize(db->expires) == 0 ||
- (de = dictFind(db->expires,key->ptr)) == NULL) return -1;
+调用的这个方法通过获取xml中的transactionManager 配置的类型,也就是JDBC
+private void environmentsElement(XNode context) throws Exception {
+ if (context != null) {
+ if (environment == null) {
+ environment = context.getStringAttribute("default");
+ }
+ for (XNode child : context.getChildren()) {
+ String id = child.getStringAttribute("id");
+ if (isSpecifiedEnvironment(id)) {
+ // -------> 找到这里
+ TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
+ DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
+ DataSource dataSource = dsFactory.getDataSource();
+ Environment.Builder environmentBuilder = new Environment.Builder(id)
+ .transactionFactory(txFactory)
+ .dataSource(dataSource);
+ configuration.setEnvironment(environmentBuilder.build());
+ break;
+ }
+ }
+ }
+}
- /* The entry was found in the expire dict, this means it should also
- * be present in the main dict (safety check). */
- serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
- return dictGetSignedIntegerVal(de);
-}
-这里有几点要注意的,第一是当惰性删除时会根据lazyfree_lazy_expire这个参数去判断是执行同步删除还是异步删除,另外一点是对于 slave,是不需要执行的,因为会在 master 过期时向 slave 发送 del 指令。
光采用这个策略会有什么问题呢,假如一些key 一直未被访问,那这些 key 就不会过期了,导致一直被占用着内存,所以 redis 采取了懒汉式过期加定期过期策略,定期策略是怎么执行的呢
-/* This function handles 'background' operations we are required to do
- * incrementally in Redis databases, such as active key expiring, resizing,
- * rehashing. */
-void databasesCron(void) {
- /* Expire keys by random sampling. Not required for slaves
- * as master will synthesize DELs for us. */
- if (server.active_expire_enabled) {
- if (server.masterhost == NULL) {
- activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
- } else {
- expireSlaveKeys();
- }
- }
+是通过以下方法获取的,
+// 方法全限定名 org.apache.ibatis.builder.xml.XMLConfigBuilder#transactionManagerElement
+private TransactionFactory transactionManagerElement(XNode context) throws Exception {
+ if (context != null) {
+ String type = context.getStringAttribute("type");
+ Properties props = context.getChildrenAsProperties();
+ TransactionFactory factory = (TransactionFactory) resolveClass(type).getDeclaredConstructor().newInstance();
+ factory.setProperties(props);
+ return factory;
+ }
+ throw new BuilderException("Environment declaration requires a TransactionFactory.");
+ }
- /* Defrag keys gradually. */
- activeDefragCycle();
+// 方法全限定名 org.apache.ibatis.builder.BaseBuilder#resolveClass
+protected <T> Class<? extends T> resolveClass(String alias) {
+ if (alias == null) {
+ return null;
+ }
+ try {
+ return resolveAlias(alias);
+ } catch (Exception e) {
+ throw new BuilderException("Error resolving class. Cause: " + e, e);
+ }
+ }
- /* Perform hash tables rehashing if needed, but only if there are no
- * other processes saving the DB on disk. Otherwise rehashing is bad
- * as will cause a lot of copy-on-write of memory pages. */
- if (!hasActiveChildProcess()) {
- /* We use global counters so if we stop the computation at a given
- * DB we'll be able to start from the successive in the next
- * cron loop iteration. */
- static unsigned int resize_db = 0;
- static unsigned int rehash_db = 0;
- int dbs_per_call = CRON_DBS_PER_CALL;
- int j;
+// 方法全限定名 org.apache.ibatis.builder.BaseBuilder#resolveAlias
+ protected <T> Class<? extends T> resolveAlias(String alias) {
+ return typeAliasRegistry.resolveAlias(alias);
+ }
+// 方法全限定名 org.apache.ibatis.type.TypeAliasRegistry#resolveAlias
+ public <T> Class<T> resolveAlias(String string) {
+ try {
+ if (string == null) {
+ return null;
+ }
+ // issue #748
+ String key = string.toLowerCase(Locale.ENGLISH);
+ Class<T> value;
+ if (typeAliases.containsKey(key)) {
+ value = (Class<T>) typeAliases.get(key);
+ } else {
+ value = (Class<T>) Resources.classForName(string);
+ }
+ return value;
+ } catch (ClassNotFoundException e) {
+ throw new TypeException("Could not resolve type alias '" + string + "'. Cause: " + e, e);
+ }
+ }
+而通过JDBC获取得是啥的,就是在Configuration的构造方法里写了的JdbcTransactionFactory
+public Configuration() {
+ typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
- /* Don't test more DBs than we have. */
- if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
+所以我们在这
+private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
+ Transaction tx = null;
+ try {
+ final Environment environment = configuration.getEnvironment();
+ final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
- /* Resize */
- for (j = 0; j < dbs_per_call; j++) {
- tryResizeHashTables(resize_db % server.dbnum);
- resize_db++;
- }
+获得到的TransactionFactory 就是 JdbcTransactionFactory ,而后
+tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
+```java
- /* Rehash */
- if (server.activerehashing) {
- for (j = 0; j < dbs_per_call; j++) {
- int work_done = incrementallyRehash(rehash_db);
- if (work_done) {
- /* If the function did some work, stop here, we'll do
- * more at the next cron loop. */
- break;
- } else {
- /* If this db didn't need rehash, we'll try the next one. */
- rehash_db++;
- rehash_db %= server.dbnum;
- }
- }
- }
- }
-}
-/* Try to expire a few timed out keys. The algorithm used is adaptive and
- * will use few CPU cycles if there are few expiring keys, otherwise
- * it will get more aggressive to avoid that too much memory is used by
- * keys that can be removed from the keyspace.
- *
- * Every expire cycle tests multiple databases: the next call will start
- * again from the next db, with the exception of exists for time limit: in that
- * case we restart again from the last database we were processing. Anyway
- * no more than CRON_DBS_PER_CALL databases are tested at every iteration.
- *
- * The function can perform more or less work, depending on the "type"
- * argument. It can execute a "fast cycle" or a "slow cycle". The slow
- * cycle is the main way we collect expired cycles: this happens with
- * the "server.hz" frequency (usually 10 hertz).
- *
- * However the slow cycle can exit for timeout, since it used too much time.
- * For this reason the function is also invoked to perform a fast cycle
- * at every event loop cycle, in the beforeSleep() function. The fast cycle
- * will try to perform less work, but will do it much more often.
- *
- * The following are the details of the two expire cycles and their stop
- * conditions:
- *
- * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a
- * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION
- * microseconds, and is not repeated again before the same amount of time.
- * The cycle will also refuse to run at all if the latest slow cycle did not
- * terminate because of a time limit condition.
- *
- * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is
- * executed, where the time limit is a percentage of the REDIS_HZ period
- * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. In the
- * fast cycle, the check of every database is interrupted once the number
- * of already expired keys in the database is estimated to be lower than
- * a given percentage, in order to avoid doing too much work to gain too
- * little memory.
- *
- * The configured expire "effort" will modify the baseline parameters in
- * order to do more work in both the fast and slow expire cycles.
- */
+创建的transaction就是JdbcTransaction
+```java
+ @Override
+ public Transaction newTransaction(DataSource ds, TransactionIsolationLevel level, boolean autoCommit) {
+ return new JdbcTransaction(ds, level, autoCommit, skipSetAutoCommitOnClose);
+ }
-#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
-#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
-#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
-#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
- we do extra efforts. */
-void activeExpireCycle(int type) {
- /* Adjust the running parameters according to the configured expire
- * effort. The default effort is 1, and the maximum configurable effort
- * is 10. */
- unsigned long
- effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
- config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
- ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
- config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
- ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
- config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
- 2*effort,
- config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
- effort;
+然后我们再会上去看代码getConnection ,
+protected Connection getConnection(Log statementLog) throws SQLException {
+ // -------> 这里的transaction就是JdbcTransaction
+ Connection connection = transaction.getConnection();
+ if (statementLog.isDebugEnabled()) {
+ return ConnectionLogger.newInstance(connection, statementLog, queryStack);
+ } else {
+ return connection;
+ }
+}
- /* This function has some global state in order to continue the work
- * incrementally across calls. */
- static unsigned int current_db = 0; /* Last DB tested. */
- static int timelimit_exit = 0; /* Time limit hit in previous call? */
- static long long last_fast_cycle = 0; /* When last fast cycle ran. */
+即调用了
+ @Override
+ public Connection getConnection() throws SQLException {
+ if (connection == null) {
+ openConnection();
+ }
+ return connection;
+ }
- int j, iteration = 0;
- int dbs_per_call = CRON_DBS_PER_CALL;
- long long start = ustime(), timelimit, elapsed;
+ protected void openConnection() throws SQLException {
+ if (log.isDebugEnabled()) {
+ log.debug("Opening JDBC Connection");
+ }
+ connection = dataSource.getConnection();
+ if (level != null) {
+ connection.setTransactionIsolation(level.getLevel());
+ }
+ setDesiredAutoCommit(autoCommit);
+ }
+ @Override
+ public Connection getConnection() throws SQLException {
+ return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
+ }
- /* When clients are paused the dataset should be static not just from the
- * POV of clients not being able to write, but also from the POV of
- * expires and evictions of keys not being performed. */
- if (clientsArePaused()) return;
+private PooledConnection popConnection(String username, String password) throws SQLException {
+ boolean countedWait = false;
+ PooledConnection conn = null;
+ long t = System.currentTimeMillis();
+ int localBadConnectionCount = 0;
- if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
- /* Don't start a fast cycle if the previous cycle did not exit
- * for time limit, unless the percentage of estimated stale keys is
- * too high. Also never repeat a fast cycle for the same period
- * as the fast cycle total duration itself. */
- if (!timelimit_exit &&
- server.stat_expired_stale_perc < config_cycle_acceptable_stale)
- return;
+ while (conn == null) {
+ lock.lock();
+ try {
+ if (!state.idleConnections.isEmpty()) {
+ // Pool has available connection
+ conn = state.idleConnections.remove(0);
+ if (log.isDebugEnabled()) {
+ log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
+ }
+ } else {
+ // Pool does not have available connection
+ if (state.activeConnections.size() < poolMaximumActiveConnections) {
+ // Can create new connection
+ // ------------> 走到这里会创建PooledConnection,但是里面会先调用dataSource.getConnection()
+ conn = new PooledConnection(dataSource.getConnection(), this);
+ if (log.isDebugEnabled()) {
+ log.debug("Created connection " + conn.getRealHashCode() + ".");
+ }
+ } else {
+ // Cannot create new connection
+ PooledConnection oldestActiveConnection = state.activeConnections.get(0);
+ long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
+ if (longestCheckoutTime > poolMaximumCheckoutTime) {
+ // Can claim overdue connection
+ state.claimedOverdueConnectionCount++;
+ state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
+ state.accumulatedCheckoutTime += longestCheckoutTime;
+ state.activeConnections.remove(oldestActiveConnection);
+ if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
+ try {
+ oldestActiveConnection.getRealConnection().rollback();
+ } catch (SQLException e) {
+ /*
+ Just log a message for debug and continue to execute the following
+ statement like nothing happened.
+ Wrap the bad connection with a new PooledConnection, this will help
+ to not interrupt current executing thread and give current thread a
+ chance to join the next competition for another valid/good database
+ connection. At the end of this loop, bad {@link @conn} will be set as null.
+ */
+ log.debug("Bad connection. Could not roll back");
+ }
+ }
+ conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
+ conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
+ conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
+ oldestActiveConnection.invalidate();
+ if (log.isDebugEnabled()) {
+ log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
+ }
+ } else {
+ // Must wait
+ try {
+ if (!countedWait) {
+ state.hadToWaitCount++;
+ countedWait = true;
+ }
+ if (log.isDebugEnabled()) {
+ log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
+ }
+ long wt = System.currentTimeMillis();
+ condition.await(poolTimeToWait, TimeUnit.MILLISECONDS);
+ state.accumulatedWaitTime += System.currentTimeMillis() - wt;
+ } catch (InterruptedException e) {
+ // set interrupt flag
+ Thread.currentThread().interrupt();
+ break;
+ }
+ }
+ }
+ }
+ if (conn != null) {
+ // ping to server and check the connection is valid or not
+ if (conn.isValid()) {
+ if (!conn.getRealConnection().getAutoCommit()) {
+ conn.getRealConnection().rollback();
+ }
+ conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
+ conn.setCheckoutTimestamp(System.currentTimeMillis());
+ conn.setLastUsedTimestamp(System.currentTimeMillis());
+ state.activeConnections.add(conn);
+ state.requestCount++;
+ state.accumulatedRequestTime += System.currentTimeMillis() - t;
+ } else {
+ if (log.isDebugEnabled()) {
+ log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
+ }
+ state.badConnectionCount++;
+ localBadConnectionCount++;
+ conn = null;
+ if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
+ if (log.isDebugEnabled()) {
+ log.debug("PooledDataSource: Could not get a good connection to the database.");
+ }
+ throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
+ }
+ }
+ }
+ } finally {
+ lock.unlock();
+ }
- if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
- return;
+ }
- last_fast_cycle = start;
- }
+ if (conn == null) {
+ if (log.isDebugEnabled()) {
+ log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
+ throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
- /* We usually should test CRON_DBS_PER_CALL per iteration, with
- * two exceptions:
- *
- * 1) Don't test more DBs than we have.
- * 2) If last time we hit the time limit, we want to scan all DBs
- * in this iteration, as there is work to do in some DB and we don't want
- * expired keys to use memory for too much time. */
- if (dbs_per_call > server.dbnum || timelimit_exit)
- dbs_per_call = server.dbnum;
+ return conn;
+ }
+
+其实就是调用的
+// org.apache.ibatis.datasource.unpooled.UnpooledDataSource#getConnection()
+ @Override
+ public Connection getConnection() throws SQLException {
+ return doGetConnection(username, password);
+ }
+```java
+
+然后就是
+```java
+private Connection doGetConnection(String username, String password) throws SQLException {
+ Properties props = new Properties();
+ if (driverProperties != null) {
+ props.putAll(driverProperties);
+ }
+ if (username != null) {
+ props.setProperty("user", username);
+ }
+ if (password != null) {
+ props.setProperty("password", password);
+ }
+ return doGetConnection(props);
+ }
+
+继续这个逻辑
+ private Connection doGetConnection(Properties properties) throws SQLException {
+ initializeDriver();
+ Connection connection = DriverManager.getConnection(url, properties);
+ configureConnection(connection);
+ return connection;
+ }
+ @CallerSensitive
+ public static Connection getConnection(String url,
+ java.util.Properties info) throws SQLException {
+
+ return (getConnection(url, info, Reflection.getCallerClass()));
+ }
+private static Connection getConnection(
+ String url, java.util.Properties info, Class<?> caller) throws SQLException {
+ /*
+ * When callerCl is null, we should check the application's
+ * (which is invoking this class indirectly)
+ * classloader, so that the JDBC driver class outside rt.jar
+ * can be loaded from here.
+ */
+ ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;
+ synchronized(DriverManager.class) {
+ // synchronize loading of the correct classloader.
+ if (callerCL == null) {
+ callerCL = Thread.currentThread().getContextClassLoader();
+ }
+ }
- /* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
- * time per iteration. Since this function gets called with a frequency of
- * server.hz times per second, the following is the max amount of
- * microseconds we can spend in this function. */
- timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
- timelimit_exit = 0;
- if (timelimit <= 0) timelimit = 1;
+ if(url == null) {
+ throw new SQLException("The url cannot be null", "08001");
+ }
- if (type == ACTIVE_EXPIRE_CYCLE_FAST)
- timelimit = config_cycle_fast_duration; /* in microseconds. */
+ println("DriverManager.getConnection(\"" + url + "\")");
- /* Accumulate some global stats as we expire keys, to have some idea
- * about the number of keys that are already logically expired, but still
- * existing inside the database. */
- long total_sampled = 0;
- long total_expired = 0;
+ // Walk through the loaded registeredDrivers attempting to make a connection.
+ // Remember the first exception that gets raised so we can reraise it.
+ SQLException reason = null;
- for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
- /* Expired and checked in a single loop. */
- unsigned long expired, sampled;
+ for(DriverInfo aDriver : registeredDrivers) {
+ // If the caller does not have permission to load the driver then
+ // skip it.
+ if(isDriverAllowed(aDriver.driver, callerCL)) {
+ try {
+ // ----------> driver[className=com.mysql.cj.jdbc.Driver@64030b91]
+ println(" trying " + aDriver.driver.getClass().getName());
+ Connection con = aDriver.driver.connect(url, info);
+ if (con != null) {
+ // Success!
+ println("getConnection returning " + aDriver.driver.getClass().getName());
+ return (con);
+ }
+ } catch (SQLException ex) {
+ if (reason == null) {
+ reason = ex;
+ }
+ }
- redisDb *db = server.db+(current_db % server.dbnum);
+ } else {
+ println(" skipping: " + aDriver.getClass().getName());
+ }
- /* Increment the DB now so we are sure if we run out of time
- * in the current DB we'll restart from the next. This allows to
- * distribute the time evenly across DBs. */
- current_db++;
+ }
- /* Continue to expire if at the end of the cycle more than 25%
- * of the keys were expired. */
- do {
- unsigned long num, slots;
- long long now, ttl_sum;
- int ttl_samples;
- iteration++;
+ // if we got here nobody could connect.
+ if (reason != null) {
+ println("getConnection failed: " + reason);
+ throw reason;
+ }
- /* If there is nothing to expire try next DB ASAP. */
- if ((num = dictSize(db->expires)) == 0) {
- db->avg_ttl = 0;
- break;
- }
- slots = dictSlots(db->expires);
- now = mstime();
+ println("getConnection: no suitable driver found for "+ url);
+ throw new SQLException("No suitable driver found for "+ url, "08001");
+ }
- /* When there are less than 1% filled slots, sampling the key
- * space is expensive, so stop here waiting for better times...
- * The dictionary will be resized asap. */
- if (num && slots > DICT_HT_INITIAL_SIZE &&
- (num*100/slots < 1)) break;
- /* The main collection cycle. Sample random keys among keys
- * with an expire set, checking for expired ones. */
- expired = 0;
- sampled = 0;
- ttl_sum = 0;
- ttl_samples = 0;
+上面的driver就是driver[className=com.mysql.cj.jdbc.Driver@64030b91]
+// com.mysql.cj.jdbc.NonRegisteringDriver#connect
+public Connection connect(String url, Properties info) throws SQLException {
+ try {
+ try {
+ if (!ConnectionUrl.acceptsUrl(url)) {
+ return null;
+ } else {
+ ConnectionUrl conStr = ConnectionUrl.getConnectionUrlInstance(url, info);
+ switch (conStr.getType()) {
+ case SINGLE_CONNECTION:
+ return ConnectionImpl.getInstance(conStr.getMainHost());
+ case FAILOVER_CONNECTION:
+ case FAILOVER_DNS_SRV_CONNECTION:
+ return FailoverConnectionProxy.createProxyInstance(conStr);
+ case LOADBALANCE_CONNECTION:
+ case LOADBALANCE_DNS_SRV_CONNECTION:
+ return LoadBalancedConnectionProxy.createProxyInstance(conStr);
+ case REPLICATION_CONNECTION:
+ case REPLICATION_DNS_SRV_CONNECTION:
+ return ReplicationConnectionProxy.createProxyInstance(conStr);
+ default:
+ return null;
+ }
+ }
+ } catch (UnsupportedConnectionStringException var5) {
+ return null;
+ } catch (CJException var6) {
+ throw (UnableToConnectException)ExceptionFactory.createException(UnableToConnectException.class, Messages.getString("NonRegisteringDriver.17", new Object[]{var6.toString()}), var6);
+ }
+ } catch (CJException var7) {
+ throw SQLExceptionsMapping.translateException(var7);
+ }
+ }
- if (num > config_keys_per_loop)
- num = config_keys_per_loop;
+这是个 SINGLE_CONNECTION ,所以调用的就是 return ConnectionImpl.getInstance(conStr.getMainHost());
然后在这里设置了代理类
+public PooledConnection(Connection connection, PooledDataSource dataSource) {
+ this.hashCode = connection.hashCode();
+ this.realConnection = connection;
+ this.dataSource = dataSource;
+ this.createdTimestamp = System.currentTimeMillis();
+ this.lastUsedTimestamp = System.currentTimeMillis();
+ this.valid = true;
+ this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
+ }
- /* Here we access the low level representation of the hash table
- * for speed concerns: this makes this code coupled with dict.c,
- * but it hardly changed in ten years.
- *
- * Note that certain places of the hash table may be empty,
- * so we want also a stop condition about the number of
- * buckets that we scanned. However scanning for free buckets
- * is very fast: we are in the cache line scanning a sequential
- * array of NULL pointers, so we can scan a lot more buckets
- * than keys in the same time. */
- long max_buckets = num*20;
- long checked_buckets = 0;
+结合这个
+@Override
+public Connection getConnection() throws SQLException {
+ return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
+}
- while (sampled < num && checked_buckets < max_buckets) {
- for (int table = 0; table < 2; table++) {
- if (table == 1 && !dictIsRehashing(db->expires)) break;
+所以最终的connection就是com.mysql.cj.jdbc.ConnectionImpl@358ab600
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ redis数据结构介绍-第一部分 SDS,链表,字典
+ /2019/12/26/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D/
+ redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
+SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍
+struct sdshdr {
+ // 字符串长度
+ int len;
+ // 字符串空余字符数
+ int free;
+ // 字符串内容
+ char buf[];
+};
+这里引用了 redis 在 github 上最早的 2.2 版本的代码,代码路径是https://github.com/antirez/redis/blob/2.2/src/sds.h,可以看到这个结构体里只有仨元素,两个 int 型和一个 char 型数组,两个 int 型其实就是我说的优化,因为 C 语言本身的字符串数组,有两个问题,一个是要知道它实际已被占用的长度,需要去遍历这个数组,第二个就是比较容易踩坑的是遍历的时候要注意它有个以\0作为结尾的特点;通过上面的两个 int 型参数,一个是知道字符串目前的长度,一个是知道字符串还剩余多少位空间,这样子坐着两个操作从 O(N)简化到了O(1)了,还有第二个 free 还有个比较重要的作用就是能防止 C 字符串的溢出问题,在存储之前可以先判断 free 长度,如果长度不够就先扩容了,先介绍到这,这个系列可以写蛮多的,慢慢介绍吧
+链表
链表是比较常见的数据结构了,但是因为 redis 是用 C 写的,所以在不依赖第三方库的情况下只能自己写一个了,redis 的链表是个有头的链表,而且是无环的,具体的结构我也找了 github 上最早版本的代码
+typedef struct listNode {
+ // 前置节点
+ struct listNode *prev;
+ // 后置节点
+ struct listNode *next;
+ // 值
+ void *value;
+} listNode;
- unsigned long idx = db->expires_cursor;
- idx &= db->expires->ht[table].sizemask;
- dictEntry *de = db->expires->ht[table].table[idx];
- long long ttl;
+typedef struct list {
+ // 链表表头
+ listNode *head;
+ // 当前节点,也可以说是最后节点
+ listNode *tail;
+ // 节点复制函数
+ void *(*dup)(void *ptr);
+ // 节点值释放函数
+ void (*free)(void *ptr);
+ // 节点值比较函数
+ int (*match)(void *ptr, void *key);
+ // 链表包含的节点数量
+ unsigned int len;
+} list;
+代码地址是这个https://github.com/antirez/redis/blob/2.2/src/adlist.h
可以看下节点是由listNode承载的,包括值和一个指向前节点跟一个指向后一节点的两个指针,然后值是 void 指针类型,所以可以承载不同类型的值
然后是 list结构用来承载一个链表,包含了表头,和表尾,复制函数,释放函数和比较函数,还有链表长度,因为包含了前两个节点,找到表尾节点跟表头都是 O(1)的时间复杂度,还有节点数量,其实这个跟 SDS 是同一个做法,就是空间换时间,这也是写代码里比较常见的做法,以此让一些高频的操作提速。
+字典
字典也是个常用的数据结构,其实只是叫法不同,数据结构中叫 hash 散列,Java 中叫 Map,PHP 中是数组 array,Python 中也叫字典 dict,因为纯 C 语言本身不带这些数据结构,所以这也是个痛并快乐着的过程,享受 C 语言的高性能的同时也要接受它只提供了语言的基本功能的现实,各种轮子都需要自己造,redis 同样实现了自己的字典
下面来看看代码
+typedef struct dictEntry {
+ void *key;
+ void *val;
+ struct dictEntry *next;
+} dictEntry;
- /* Scan the current bucket of the current table. */
- checked_buckets++;
- while(de) {
- /* Get the next entry now since this entry may get
- * deleted. */
- dictEntry *e = de;
- de = de->next;
+typedef struct dictType {
+ unsigned int (*hashFunction)(const void *key);
+ void *(*keyDup)(void *privdata, const void *key);
+ void *(*valDup)(void *privdata, const void *obj);
+ int (*keyCompare)(void *privdata, const void *key1, const void *key2);
+ void (*keyDestructor)(void *privdata, void *key);
+ void (*valDestructor)(void *privdata, void *obj);
+} dictType;
- ttl = dictGetSignedIntegerVal(e)-now;
- if (activeExpireCycleTryExpire(db,e,now)) expired++;
- if (ttl > 0) {
- /* We want the average TTL of keys yet
- * not expired. */
- ttl_sum += ttl;
- ttl_samples++;
- }
- sampled++;
- }
- }
- db->expires_cursor++;
- }
- total_expired += expired;
- total_sampled += sampled;
+/* This is our hash table structure. Every dictionary has two of this as we
+ * implement incremental rehashing, for the old to the new table. */
+typedef struct dictht {
+ dictEntry **table;
+ unsigned long size;
+ unsigned long sizemask;
+ unsigned long used;
+} dictht;
- /* Update the average TTL stats for this database. */
- if (ttl_samples) {
- long long avg_ttl = ttl_sum/ttl_samples;
+typedef struct dict {
+ dictType *type;
+ void *privdata;
+ dictht ht[2];
+ int rehashidx; /* rehashing not in progress if rehashidx == -1 */
+ int iterators; /* number of iterators currently running */
+} dict;
+看了下这个 2.2 版本的代码跟最新版的其实也差的不是很多,所以还是照旧用老代码,可以看到上面四个结构体中,其实只有三个是存储数据用的,dictType 是用来放操作函数的,那么三个存放数据的结构体分别是干嘛的,这时候感觉需要一个图来说明比较好,稍等,我去画个图~
![]()
这个图看着应该比较清楚这些都是用来干嘛的了,dict 是我们的主体结构,它有一个指向 dictType 的指针,这里面包含了字典的操作函数,然后是一个私有数据指针,接下来是一个 dictht 的数组,包含两个dictht,这个就是用来存数据的了,然后是 rehashidx 表示重哈希的状态,当是-1 的时候表示当前没有重哈希,iterators 表示正在遍历的迭代器的数量。
首先说说为啥需要有两个 dictht,这是因为字典 dict 这个数据结构随着数据量的增减,会需要在中途做扩容或者缩容操作,如果只有一个的话,对它进行扩容缩容时会影响正常的访问和修改操作,或者说保证正常查询,修改的正确性会比较复杂,并且因为需要高效利用空间,不能一下子申请一个非常大的空间来存很少的数据。当 dict 中 dictht 中的数据量超过 size 的时候负载就超过了 1,就需要进行扩容,这里的其实跟 Java 中的 HashMap 比较类似,超过一定的负载之后进行扩容。这里为啥 size 会超过 1 呢,可能有部分不了解这类结构的同学会比较奇怪,其实就是上图中画的,在数据结构中对于散列的冲突有几类解决方法,比如转换成链表,二次散列,找下个空槽等,这里就使用了链表法,或者说拉链法。当一个新元素通过 hashFunction 得出的 key 跟 sizemask 取模之后的值相同了,那就将其放在原来的节点之前,变成链表挂在数组 dictht.table下面,放在原有节点前是考虑到可能会优先访问。
忘了说明下 dictht 跟 dictEntry 的关系了,dictht 就是个哈希表,它里面是个dictEntry 的二维数组,而 dictEntry 是个包含了 key-value 结构之外还有一个 next 指针,因此可以将哈希冲突的以链表的形式保存下来。
在重点说下重哈希,可能同样写 Java 的同学对这个比较有感觉,跟 HashMap 一样,会以 2 的 N 次方进行扩容,那么扩容的方法就会比较简单,每个键重哈希要不就在原来这个槽,要不就在原来的槽加原 dictht.size 的位置;然后是重头戏,具体是怎么做扩容呢,其实这里就把第二个 ht 用上了,其实这两个hashtable 的具体作用有点类似于 jvm 中的两个 survival 区,但是又不全一样,因为 redis 在扩容的时候是采用的渐进式地重哈希,什么叫渐进式的呢,就是它不是像 jvm 那种标记复制的模式直接将一个 eden 区和原来的 survival 区存活的对象复制到另一个 survival 区,而是在每一次添加,删除,查找或者更新操作时,都会额外的帮忙搬运一部分的原 dictht 中的数据,这里会根据 rehashidx 的值来判断,如果是-1 表示并没有在重哈希中,如果是 0 表示开始重哈希了,然后rehashidx 还会随着每次的帮忙搬运往上加,但全部被搬运完成后 rehashidx 又变回了-1,又可以扯到Java 中的 Concurrent HashMap, 他在扩容的时候也使用了类似的操作。
+]]>
+
+ Redis
+ 数据结构
+ C
+ 源码
+ Redis
+
+
+ redis
+ 数据结构
+ 源码
+
+
+
+ powershell 初体验
+ /2022/11/13/powershell-%E5%88%9D%E4%BD%93%E9%AA%8C/
+ powershell变量变量命名类似于php
+PS C:\Users\Nicks> $a=1
+PS C:\Users\Nicks> $b=2
+PS C:\Users\Nicks> $a*$b
+2
+有一个比较好用的是变量交换
一般的语言做两个变量交换一般需要一个临时变量
+$tmp=$a
+$a=$b
+$b=$tmp
+而在powershell中可以这样
+$a,$b=$b,$a
+PS C:\Users\Nicks> $a,$b=$b,$a
+PS C:\Users\Nicks> $a
+2
+PS C:\Users\Nicks> $b
+1
+还可以通过这个
+PS C:\Users\Nicks> ls variable:
- /* Do a simple running average with a few samples.
- * We just use the current estimate with a weight of 2%
- * and the previous estimate with a weight of 98%. */
- if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
- db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
- }
+Name Value
+---- -----
+$ $b
+? True
+^ $b
+a 2
+args {}
+b 1
+查看现存的变量
当然一般脚本都是动态类型的,
可以通过
gettype方法
![]()
+]]>
+
+ 语言
+
+
+ powershell
+
+
+
+ rabbitmq-tips
+ /2017/04/25/rabbitmq-tips/
+ rabbitmq 介绍接触了一下rabbitmq,原来在选型的时候是在rabbitmq跟kafka之间做选择,网上搜了一下之后发现kafka的优势在于吞吐量,而rabbitmq相对注重可靠性,因为应用在im上,需要保证消息不能丢失所以就暂时选定rabbitmq,
Message Queue的需求由来已久,80年代最早在金融交易中,高盛等公司采用Teknekron公司的产品,当时的Message queuing软件叫做:the information bus(TIB)。 TIB被电信和通讯公司采用,路透社收购了Teknekron公司。之后,IBM开发了MQSeries,微软开发了Microsoft Message Queue(MSMQ)。这些商业MQ供应商的问题是厂商锁定,价格高昂。2001年,Java Message queuing试图解决锁定和交互性的问题,但对应用来说反而更加麻烦了。
RabbitMQ采用Erlang语言开发。Erlang语言由Ericson设计,专门为开发concurrent和distribution系统的一种语言,在电信领域使用广泛。OTP(Open Telecom Platform)作为Erlang语言的一部分,包含了很多基于Erlang开发的中间件/库/工具,如mnesia/SASL,极大方便了Erlang应用的开发。OTP就类似于Python语言中众多的module,用户借助这些module可以很方便的开发应用。
于是2004年,摩根大通和iMatrix开始着手Advanced Message Queuing Protocol (AMQP)开放标准的开发。2006年,AMQP规范发布。2007年,Rabbit技术公司基于AMQP标准开发的RabbitMQ 1.0 发布。所有主要的编程语言均有与代理接口通讯的客户端库。
+简单的使用经验
通俗的理解
这里介绍下其中的一些概念,connection表示和队列服务器的连接,一般情况下是tcp连接, channel表示通道,可以在一个连接上建立多个通道,这里主要是节省了tcp连接握手的成本,exchange可以理解成一个路由器,将消息推送给对应的队列queue,其实是像一个订阅的模式。
+集群经验
rabbitmqctl stop这个是关闭rabbitmq,在搭建集群时候先关闭服务,然后使用rabbitmq-server -detached静默启动,这时候使用rabbitmqctl cluster_status查看集群状态,因为还没将节点加入集群,所以只能看到类似
+Cluster status of node rabbit@rabbit1 ...
+[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
+ {running_nodes,[rabbit@rabbit2,rabbit@rabbit1]}]
+...done.
+然后就可以把当前节点加入集群,
+rabbit2$ rabbitmqctl stop_app #这个stop_app与stop的区别是前者停的是rabbitmq应用,保留erlang节点,
+ #后者是停止了rabbitmq和erlang节点
+Stopping node rabbit@rabbit2 ...done.
+rabbit2$ rabbitmqctl join_cluster rabbit@rabbit1 #这里可以用--ram指定将当前节点作为内存节点加入集群
+Clustering node rabbit@rabbit2 with [rabbit@rabbit1] ...done.
+rabbit2$ rabbitmqctl start_app
+Starting node rabbit@rabbit2 ...done.
+其他可以参考官方文档
+一些坑
消息丢失
这里碰到过一个坑,对于使用exchange来做消息路由的,会有一个情况,就是在routing_key没被订阅的时候,会将该条找不到路由对应的queue的消息丢掉What happens if we break our contract and send a message with one or four words, like "orange" or "quick.orange.male.rabbit"? Well, these messages won't match any bindings and will be lost.对应链接,而当使用空的exchange时,会保留消息,当出现消费者的时候就可以将收到之前生产者所推送的消息对应链接,这里就是用了空的exchange。
+集群搭建
集群搭建的时候有个erlang vm生成的random cookie,这个是用来做集群之间认证的,相同的cookie才能连接,但是如果通过vim打开复制后在其他几点新建文件写入会多一个换行,导致集群建立是报错,所以这里最好使用scp等传输命令直接传输cookie文件,同时要注意下cookie的文件权限。
另外在集群搭建的时候如果更改过hostname,那么要把rabbitmq的数据库删除,否则启动后会马上挂掉
+]]>
+
+ php
+
+
+ php
+ mq
+ im
+
+
+
+ redis数据结构介绍三-第三部分 整数集合
+ /2020/01/10/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E4%B8%89/
+ redis中对于 set 其实有两种处理,对于元素均为整型,并且元素数目较少时,使用 intset 作为底层数据结构,否则使用 dict 作为底层数据结构,先看一下代码先
+typedef struct intset {
+ // 编码方式
+ uint32_t encoding;
+ // 集合包含的元素数量
+ uint32_t length;
+ // 保存元素的数组
+ int8_t contents[];
+} intset;
- /* We can't block forever here even if there are many keys to
- * expire. So after a given amount of milliseconds return to the
- * caller waiting for the other active expire cycle. */
- if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
- elapsed = ustime()-start;
- if (elapsed > timelimit) {
- timelimit_exit = 1;
- server.stat_expired_time_cap_reached_count++;
- break;
- }
- }
- /* We don't repeat the cycle for the current database if there are
- * an acceptable amount of stale keys (logically expired but yet
- * not reclained). */
- } while ((expired*100/sampled) > config_cycle_acceptable_stale);
- }
+/* Note that these encodings are ordered, so:
+ * INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
+#define INTSET_ENC_INT16 (sizeof(int16_t))
+#define INTSET_ENC_INT32 (sizeof(int32_t))
+#define INTSET_ENC_INT64 (sizeof(int64_t))
+一眼看,为啥整型还需要编码,然后 int8_t 怎么能存下大整形呢,带着这些疑问,我们一步步分析下去,这里的编码其实指的是这个整型集合里存的究竟是多大的整型,16 位,还是 32 位,还是 64 位,结构体下面的宏定义就是表示了 encoding 的可能取值,INTSET_ENC_INT16 表示每个元素用2个字节存储,INTSET_ENC_INT32 表示每个元素用4个字节存储,INTSET_ENC_INT64 表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。length 就是正常的表示集合中元素的数量。最奇怪的应该就是这个 contents 了,是个 int8_t 的数组,那放毛线数据啊,最小的都有 16 位,这里我在看代码和《redis 设计与实现》的时候也有点懵逼,后来查了下发现这是个比较取巧的用法,这里我用自己的理解表述一下,先看看 8,16,32,64 的关系,一眼看就知道都是 2 的 N 次,并且呈两倍关系,而且 8 位刚好一个字节,所以呢其实这里的contents 不是个常规意义上的 int8_t 类型的数组,而是个柔性数组。看下 wiki 的定义
+
+Flexible array members1 were introduced in the C99 standard of the C programming language (in particular, in section §6.7.2.1, item 16, page 103).2 It is a member of a struct, which is an array without a given dimension. It must be the last member of such a struct and it must be accompanied by at least one other member, as in the following example:
+
+struct vectord {
+ size_t len;
+ double arr[]; // the flexible array member must be last
+};
+在初始化这个 intset 的时候,这个contents数组是不占用空间的,后面的反正用到了申请,那么这里就有一个问题,给出了三种可能的 encoding 值,他们能随便换吗,显然不行,首先在 intset 中数据的存放是有序的,这个有部分原因是方便二分查找,然后存放数据其实随着数据的大小不同会有一个升级的过程,看下图
![]()
新创建的intset只有一个header,总共8个字节。其中encoding = 2, length = 0, 类型都是uint32_t,各占 4 字节,添加15, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以encoding不变,值还是2,也就是默认的 INTSET_ENC_INT16,当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。在添加每个元素的过程中,intset始终保持从小到大有序。与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示encoding字段的4个字节应该解释成0x00000004,而第4个数据应该解释成0x00008000 = 32768
+]]>
+
+ Redis
+ 数据结构
+ C
+ 源码
+ Redis
+
+
+ redis
+ 数据结构
+ 源码
+
+
+
+ redis数据结构介绍二-第二部分 跳表
+ /2020/01/04/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E4%BA%8C/
+ 跳表 skiplist跳表是个在我们日常的代码中不太常用到的数据结构,相对来讲就没有像数组,链表,字典,散列,树等结构那么熟悉,所以就从头开始分析下,首先是链表,跳表跟链表都有个表字(太硬扯了我🤦♀️),注意这是个有序链表
![]()
如上图,在这个链表里如果我要找到 23,是不是我需要从3,5,9开始一直往后找直到找到 23,也就是说时间复杂度是 O(N),N 的一次幂复杂度,那么我们来看看第二个
![]()
这个结构跟原先有点不一样,它给链表中偶数位的节点又加了一个指针把它们链接起来,这样子当我们要寻找 23 的时候就可以从原来的一个个往下找变成跳着找,先找到 5,然后是 10,接着是 19,然后是 28,这时候发现 28 比 23 大了,那我在退回到 19,然后从下一层原来的链表往前找,
![]()
这里毛估估是不是前面的节点我就少找了一半,有那么点二分法的意思。
前面的其实是跳表的引子,真正的跳表其实不是这样,因为上面的其实有个比较大的问题,就是插入一个元素后需要调整每个元素的指针,在 redis 中的跳表其实是做了个随机层数的优化,因为沿着前面的例子,其实当数据量很大的时候,是不是层数越多,其查询效率越高,但是随着层数变多,要保持这种严格的层数规则其实也会增大处理复杂度,所以 redis 插入每个元素的时候都是使用随机的方式,看一眼代码
+/* ZSETs use a specialized version of Skiplists */
+typedef struct zskiplistNode {
+ sds ele;
+ double score;
+ struct zskiplistNode *backward;
+ struct zskiplistLevel {
+ struct zskiplistNode *forward;
+ unsigned long span;
+ } level[];
+} zskiplistNode;
- elapsed = ustime()-start;
- server.stat_expire_cycle_time_used += elapsed;
- latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
+typedef struct zskiplist {
+ struct zskiplistNode *header, *tail;
+ unsigned long length;
+ int level;
+} zskiplist;
- /* Update our estimate of keys existing but yet to be expired.
- * Running average with this sample accounting for 5%. */
- double current_perc;
- if (total_sampled) {
- current_perc = (double)total_expired/total_sampled;
- } else
- current_perc = 0;
- server.stat_expired_stale_perc = (current_perc*0.05)+
- (server.stat_expired_stale_perc*0.95);
-}
-执行定期清除分成两种类型,快和慢,分别由beforeSleep和databasesCron调用,快版有两个限制,一个是执行时长由ACTIVE_EXPIRE_CYCLE_FAST_DURATION限制,另一个是执行间隔是 2 倍的ACTIVE_EXPIRE_CYCLE_FAST_DURATION,另外这还可以由配置的server.active_expire_effort参数来控制,默认是 1,最大是 10
-onfig_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
- ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort
-然后会从一定数量的 db 中找出一定数量的带过期时间的 key(保存在 expires中),这里的数量是由
-config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
- ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort
-```
-控制,慢速的执行时长是
-```C
-config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
- 2*effort
-timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
-这里还有一个额外的退出条件,如果当前数据库的抽样结果已经达到我们所允许的过期 key 百分比,则下次不再处理当前 db,继续处理下个 db
+typedef struct zset {
+ dict *dict;
+ zskiplist *zsl;
+} zset;
+忘了说了,redis 是把 skiplist 跳表用在 zset 里,zset 是个有序的集合,可以看到 zskiplist 就是个跳表的结构,里面用 header 保存跳表的表头,tail 保存表尾,还有长度和最大层级,具体的跳表节点元素使用 zskiplistNode 表示,里面包含了 sds 类型的元素值,double 类型的分值,用来排序,一个 backward 后向指针和一个 zskiplistLevel 数组,每个 level 包含了一个前向指针,和一个 span,span 表示的是跳表前向指针的跨度,这里再补充一点,前面说了为了灵活这个跳表的新增修改,redis 使用了随机层高的方式插入新节点,但是如果所有节点都随机到很高的层级或者所有都很低的话,跳表的效率优势就会减小,所以 redis 使用了个小技巧,贴下代码
+#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
+int zslRandomLevel(void) {
+ int level = 1;
+ while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
+ level += 1;
+ return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
+}
+当随机值跟0xFFFF进行与操作小于ZSKIPLIST_P * 0xFFFF时才会增大 level 的值,因此保持了一个相对递减的概率
可以简单分析下,当 random() 的值小于 0xFFFF 的 1/4,才会 level + 1,就意味着当有 1 - 1/4也就是3/4的概率是直接跳出,所以一层的概率是3/4,也就是 1-P,二层的概率是 P*(1-P),三层的概率是 P² * (1-P) 依次递推。
+]]>
+
+ Redis
+ 数据结构
+ C
+ 源码
+ Redis
+
+
+ redis
+ 数据结构
+ 源码
+
+
+
+ redis数据结构介绍四-第四部分 压缩表
+ /2020/01/19/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E5%9B%9B/
+ 在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
+
+The ziplist is a specially encoded dually linked list that is designed to be very memory efficient.
这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
+
+<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
+其中
<zlbytes>表示 ziplist 占用的字节总数,类型是uint32_t,32 位的无符号整型,当然表示的字节数也包含自己本身占用的 4 个
<zltail> 类型也是是uint32_t,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
<uint16_t zllen> 表示ziplist 中的数据项个数,因为是 16 位,所以当数量超过所能表示的最大的数量,它的 16 位全会置为 1,但是真实的数量需要遍历整个 ziplist 才能知道
<entry>是具体的数据项,后面解释
<zlend> ziplist 的最后一个字节,固定是255。
再看一下<entry>中的具体结构,
+<prevlen> <encoding> <entry-data>
+首先这个<prevlen>有两种情况,一种是前面的元素的长度,如果是小于等于 253的时候就用一个uint8_t 来表示前一元素的长度,如果大于的话他将占用五个字节,第一个字节是 254,即表示这个字节已经表示不下了,需要后面的四个字节帮忙表示
<encoding>这个就比较复杂,把源码的注释放下面先看下
+* |00pppppp| - 1 byte
+* String value with length less than or equal to 63 bytes (6 bits).
+* "pppppp" represents the unsigned 6 bit length.
+* |01pppppp|qqqqqqqq| - 2 bytes
+* String value with length less than or equal to 16383 bytes (14 bits).
+* IMPORTANT: The 14 bit number is stored in big endian.
+* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
+* String value with length greater than or equal to 16384 bytes.
+* Only the 4 bytes following the first byte represents the length
+* up to 32^2-1. The 6 lower bits of the first byte are not used and
+* are set to zero.
+* IMPORTANT: The 32 bit number is stored in big endian.
+* |11000000| - 3 bytes
+* Integer encoded as int16_t (2 bytes).
+* |11010000| - 5 bytes
+* Integer encoded as int32_t (4 bytes).
+* |11100000| - 9 bytes
+* Integer encoded as int64_t (8 bytes).
+* |11110000| - 4 bytes
+* Integer encoded as 24 bit signed (3 bytes).
+* |11111110| - 2 bytes
+* Integer encoded as 8 bit signed (1 byte).
+* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
+* Unsigned integer from 0 to 12. The encoded value is actually from
+* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
+* subtracted from the encoded 4 bit value to obtain the right value.
+* |11111111| - End of ziplist special entry.
+首先如果 encoding 的前两位是 00 的话代表这个元素是个 6 位的字符串,即直接将数据保存在 encoding 中,不消耗额外的<entry-data>,如果前两位是 01 的话表示是个 14 位的字符串,如果是 10 的话表示encoding 块之后的四个字节是存放字符串类型的数据,encoding 的剩余 6 位置 0。
如果 encoding 的前两位是 11 的话表示这是个整型,具体的如果后两位是00的话,表示后面是个2字节的 int16_t 类型,如果是01的话,后面是个4字节的int32_t,如果是10的话后面是8字节的int64_t,如果是 11 的话后面是 3 字节的有符号整型,这些都要最后 4 位都是 0 的情况噢
剩下当是11111110时,则表示是一个1 字节的有符号数,如果是 1111xxxx,其中xxxx在0000 到 1101 表示实际的 1 到 13,为啥呢,因为 0000 前面已经用过了,而 1110 跟 1111 也都有用了。
看个具体的例子(上下有点对不齐,将就看)
+[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
+|**zlbytes***| |***zltail***| |*zllen*| |entry1 entry2| |zlend|
+第一部分代表整个 ziplist 有 15 个字节,zlbytes 自己占了 4 个 zltail 表示最后一个元素的偏移量,第 13 个字节起,zllen 表示有 2 个元素,第一个元素是00f3,00表示前一个元素长度是 0,本来前面就没元素(不过不知道这个能不能优化这一字节),然后是 f3,换成二进制就是11110011,对照上面的注释,是落在|1111xxxx|这个类型里,注意这个其实是用 0001 到 1101 也就是 1到 13 来表示 0到 12,所以 f3 应该就是 2,第一个元素是 2,第二个元素呢,02 代表前一个元素也就是刚才说的这个,占用 2 字节,f6 展开也是刚才的类型,实际是 5,ff 表示 ziplist 的结尾,所以这个 ziplist 里面是两个元素,2 跟 5
]]>
- Redis
- C
Redis
数据结构
+ C
源码
+ Redis
redis
@@ -9767,6 +9939,32 @@ timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;源码
+
+ powershell 初体验二
+ /2022/11/20/powershell-%E5%88%9D%E4%BD%93%E9%AA%8C%E4%BA%8C/
+ powershell创建数组也很方便
可以这样
+$nums=2,0,1,2
+顺便可以用下我们上次学到的gettype()
![]()
+如果是想创建连续数字的数组还可以用这个方便的方法
+$nums=1..5
+![]()
而且数组还可以存放各种类型的数据
+$array=1,"哈哈",([System.Guid]::NewGuid()),(get-date)
+![]()
还有判断类型可以用-is
![]()
创建一个空数组
+$array=@()
+![]()
数组添加元素
+$array+="a"
+![]()
数组删除元素
+$a=1..4
+$a=$a[0..1]+$a[3]
+![]()
+]]>
+
+ 语言
+
+
+ powershell
+
+
redis淘汰策略复习
/2021/08/01/redis%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5%E5%A4%8D%E4%B9%A0/
@@ -9824,54 +10022,215 @@ timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
- redis数据结构介绍四-第四部分 压缩表
- /2020/01/19/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E5%9B%9B/
- 在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
-
-The ziplist is a specially encoded dually linked list that is designed to be very memory efficient.
这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
-
-<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
-其中
<zlbytes>表示 ziplist 占用的字节总数,类型是uint32_t,32 位的无符号整型,当然表示的字节数也包含自己本身占用的 4 个
<zltail> 类型也是是uint32_t,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。
<uint16_t zllen> 表示ziplist 中的数据项个数,因为是 16 位,所以当数量超过所能表示的最大的数量,它的 16 位全会置为 1,但是真实的数量需要遍历整个 ziplist 才能知道
<entry>是具体的数据项,后面解释
<zlend> ziplist 的最后一个字节,固定是255。
再看一下<entry>中的具体结构,
-<prevlen> <encoding> <entry-data>
-首先这个<prevlen>有两种情况,一种是前面的元素的长度,如果是小于等于 253的时候就用一个uint8_t 来表示前一元素的长度,如果大于的话他将占用五个字节,第一个字节是 254,即表示这个字节已经表示不下了,需要后面的四个字节帮忙表示
<encoding>这个就比较复杂,把源码的注释放下面先看下
-* |00pppppp| - 1 byte
-* String value with length less than or equal to 63 bytes (6 bits).
-* "pppppp" represents the unsigned 6 bit length.
-* |01pppppp|qqqqqqqq| - 2 bytes
-* String value with length less than or equal to 16383 bytes (14 bits).
-* IMPORTANT: The 14 bit number is stored in big endian.
-* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
-* String value with length greater than or equal to 16384 bytes.
-* Only the 4 bytes following the first byte represents the length
-* up to 32^2-1. The 6 lower bits of the first byte are not used and
-* are set to zero.
-* IMPORTANT: The 32 bit number is stored in big endian.
-* |11000000| - 3 bytes
-* Integer encoded as int16_t (2 bytes).
-* |11010000| - 5 bytes
-* Integer encoded as int32_t (4 bytes).
-* |11100000| - 9 bytes
-* Integer encoded as int64_t (8 bytes).
-* |11110000| - 4 bytes
-* Integer encoded as 24 bit signed (3 bytes).
-* |11111110| - 2 bytes
-* Integer encoded as 8 bit signed (1 byte).
-* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
-* Unsigned integer from 0 to 12. The encoded value is actually from
-* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
-* subtracted from the encoded 4 bit value to obtain the right value.
-* |11111111| - End of ziplist special entry.
-首先如果 encoding 的前两位是 00 的话代表这个元素是个 6 位的字符串,即直接将数据保存在 encoding 中,不消耗额外的<entry-data>,如果前两位是 01 的话表示是个 14 位的字符串,如果是 10 的话表示encoding 块之后的四个字节是存放字符串类型的数据,encoding 的剩余 6 位置 0。
如果 encoding 的前两位是 11 的话表示这是个整型,具体的如果后两位是00的话,表示后面是个2字节的 int16_t 类型,如果是01的话,后面是个4字节的int32_t,如果是10的话后面是8字节的int64_t,如果是 11 的话后面是 3 字节的有符号整型,这些都要最后 4 位都是 0 的情况噢
剩下当是11111110时,则表示是一个1 字节的有符号数,如果是 1111xxxx,其中xxxx在0000 到 1101 表示实际的 1 到 13,为啥呢,因为 0000 前面已经用过了,而 1110 跟 1111 也都有用了。
看个具体的例子(上下有点对不齐,将就看)
-[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
-|**zlbytes***| |***zltail***| |*zllen*| |entry1 entry2| |zlend|
-第一部分代表整个 ziplist 有 15 个字节,zlbytes 自己占了 4 个 zltail 表示最后一个元素的偏移量,第 13 个字节起,zllen 表示有 2 个元素,第一个元素是00f3,00表示前一个元素长度是 0,本来前面就没元素(不过不知道这个能不能优化这一字节),然后是 f3,换成二进制就是11110011,对照上面的注释,是落在|1111xxxx|这个类型里,注意这个其实是用 0001 到 1101 也就是 1到 13 来表示 0到 12,所以 f3 应该就是 2,第一个元素是 2,第二个元素呢,02 代表前一个元素也就是刚才说的这个,占用 2 字节,f6 展开也是刚才的类型,实际是 5,ff 表示 ziplist 的结尾,所以这个 ziplist 里面是两个元素,2 跟 5
+ redis数据结构介绍六 快表
+ /2020/01/22/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E5%85%AD/
+ 这应该是 redis 系列的最后一篇了,讲下快表,其实最前面讲的链表在早先的 redis 版本中也作为 list 的数据结构使用过,但是单纯的链表的缺陷之前也说了,插入便利,但是空间利用率低,并且不能进行二分查找等,检索效率低,ziplist 压缩表的产生也是同理,希望获得更好的性能,包括存储空间和访问性能等,原来我也不懂这个快表要怎么快,然后明白了一个道理,其实并没有什么银弹,只是大牛们会在适合的时候使用最适合的数据结构来实现性能的最大化,这里面有一招就是不同数据结构的组合调整,比如 Java 中的 HashMap,在链表节点数大于 8 时会转变成红黑树,以此提高访问效率,不费话了,回到快表,quicklist,这个数据结构主要使用在 list 类型中,如果我说其实这个 quicklist 就是个链表,可能大家不太会相信,但是事实上的确可以认为 quicklist 是个双向链表,看下代码
+/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
+ * We use bit fields keep the quicklistNode at 32 bytes.
+ * count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
+ * encoding: 2 bits, RAW=1, LZF=2.
+ * container: 2 bits, NONE=1, ZIPLIST=2.
+ * recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
+ * attempted_compress: 1 bit, boolean, used for verifying during testing.
+ * extra: 10 bits, free for future use; pads out the remainder of 32 bits */
+typedef struct quicklistNode {
+ struct quicklistNode *prev;
+ struct quicklistNode *next;
+ unsigned char *zl;
+ unsigned int sz; /* ziplist size in bytes */
+ unsigned int count : 16; /* count of items in ziplist */
+ unsigned int encoding : 2; /* RAW==1 or LZF==2 */
+ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
+ unsigned int recompress : 1; /* was this node previous compressed? */
+ unsigned int attempted_compress : 1; /* node can't compress; too small */
+ unsigned int extra : 10; /* more bits to steal for future usage */
+} quicklistNode;
+
+/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
+ * 'sz' is byte length of 'compressed' field.
+ * 'compressed' is LZF data with total (compressed) length 'sz'
+ * NOTE: uncompressed length is stored in quicklistNode->sz.
+ * When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
+typedef struct quicklistLZF {
+ unsigned int sz; /* LZF size in bytes*/
+ char compressed[];
+} quicklistLZF;
+
+/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
+ * 'count' is the number of total entries.
+ * 'len' is the number of quicklist nodes.
+ * 'compress' is: -1 if compression disabled, otherwise it's the number
+ * of quicklistNodes to leave uncompressed at ends of quicklist.
+ * 'fill' is the user-requested (or default) fill factor. */
+typedef struct quicklist {
+ quicklistNode *head;
+ quicklistNode *tail;
+ unsigned long count; /* total count of all entries in all ziplists */
+ unsigned long len; /* number of quicklistNodes */
+ int fill : 16; /* fill factor for individual nodes */
+ unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
+} quicklist;
+粗略看下,quicklist 里有 head,tail, quicklistNode里有 prev,next 指针,是不是有链表的基本轮廓了,那么为啥这玩意要称为快表呢,快在哪,关键就在这个unsigned char *zl;zl 是不是前面又看到过,就是 ziplist ,这是什么鬼,链表里用压缩表,这不套娃么,先别急,回顾下前面说的 ziplist,ziplist 有哪些特点,内存利用率高,可以从表头快速定位到尾节点,节点可以从后往前找,但是有个缺点,就是从中间插入的效率比较低,需要整体往后移,这个其实是普通数组的优化版,但还是有数组的一些劣势,所以要真的快,是不是可以将链表跟数组真的结合起来。
+ziplist
这里有两个 redis 的配置参数,list-max-ziplist-size 和 list-compress-depth,先来说第一个,既然快表是将链表跟压缩表数组结合起来使用,那么具体怎么用呢,比如我有一个 10 个元素的 list,那具体怎么放,每个 quicklistNode 里放多大的 ziplist,假如每个快表节点的 ziplist 只放一个元素,那么其实这就退化成了一个链表,如果 10 个元素放在一个 quicklistNode 的 ziplist 里,那就退化成了一个 ziplist,所以有了这个 list-max-ziplist-size,而且它还比较牛,能取正负值,当是正值时,对应的就是每个 quicklistNode 的 ziplist 中的元素个数,比如配置了 list-max-ziplist-size = 5,那么我刚才的 10 个元素的 list 就是一个两个 quicklistNode 组成的快表,每个 quicklistNode 中的 ziplist 包含了五个元素,当 list-max-ziplist-size取负值的时候,它限制了 ziplist 的字节数
+size_t offset = (-fill) - 1;
+if (offset < (sizeof(optimization_level) / sizeof(*optimization_level))) {
+ if (sz <= optimization_level[offset]) {
+ return 1;
+ } else {
+ return 0;
+ }
+} else {
+ return 0;
+}
+
+/* Optimization levels for size-based filling */
+static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};
+
+/* Create a new quicklist.
+ * Free with quicklistRelease(). */
+quicklist *quicklistCreate(void) {
+ struct quicklist *quicklist;
+
+ quicklist = zmalloc(sizeof(*quicklist));
+ quicklist->head = quicklist->tail = NULL;
+ quicklist->len = 0;
+ quicklist->count = 0;
+ quicklist->compress = 0;
+ quicklist->fill = -2;
+ return quicklist;
+}
+这个 fill 就是传进来的 list-max-ziplist-size, 具体对应的就是
+
+- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
+- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
+- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
+- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)也就是上面的
quicklist->fill = -2;
+- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
+
+压缩
list-compress-depth这个参数呢是用来配置压缩的,等等压缩是为啥,不是里面已经是压缩表了么,大牛们就是为了性能殚精竭虑,这里考虑到的是一个场景,一般状况下,list 都是两端的访问频率比较高,那么是不是可以对中间的数据进行压缩,那么这个参数就是用来表示
+/* depth of end nodes not to compress;0=off */
+
+- 0,代表不压缩,默认值
+- 1,两端各一个节点不压缩
+- 2,两端各两个节点不压缩
+- … 依次类推
压缩后的 ziplist 就会变成 quicklistLZF,然后替换 zl 指针,这里使用的是 LZF 压缩算法,压缩后的 quicklistLZF 中的 compressed 也是个柔性数组,压缩后的 ziplist 整个就放进这个柔性数组
+
+插入过程
简单说下插入元素的过程
+/* Wrapper to allow argument-based switching between HEAD/TAIL pop */
+void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
+ int where) {
+ if (where == QUICKLIST_HEAD) {
+ quicklistPushHead(quicklist, value, sz);
+ } else if (where == QUICKLIST_TAIL) {
+ quicklistPushTail(quicklist, value, sz);
+ }
+}
+
+/* Add new entry to head node of quicklist.
+ *
+ * Returns 0 if used existing head.
+ * Returns 1 if new head created. */
+int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
+ quicklistNode *orig_head = quicklist->head;
+ if (likely(
+ _quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
+ quicklist->head->zl =
+ ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
+ quicklistNodeUpdateSz(quicklist->head);
+ } else {
+ quicklistNode *node = quicklistCreateNode();
+ node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
+
+ quicklistNodeUpdateSz(node);
+ _quicklistInsertNodeBefore(quicklist, quicklist->head, node);
+ }
+ quicklist->count++;
+ quicklist->head->count++;
+ return (orig_head != quicklist->head);
+}
+
+/* Add new entry to tail node of quicklist.
+ *
+ * Returns 0 if used existing tail.
+ * Returns 1 if new tail created. */
+int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
+ quicklistNode *orig_tail = quicklist->tail;
+ if (likely(
+ _quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
+ quicklist->tail->zl =
+ ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
+ quicklistNodeUpdateSz(quicklist->tail);
+ } else {
+ quicklistNode *node = quicklistCreateNode();
+ node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
+
+ quicklistNodeUpdateSz(node);
+ _quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
+ }
+ quicklist->count++;
+ quicklist->tail->count++;
+ return (orig_tail != quicklist->tail);
+}
+
+/* Wrappers for node inserting around existing node. */
+REDIS_STATIC void _quicklistInsertNodeBefore(quicklist *quicklist,
+ quicklistNode *old_node,
+ quicklistNode *new_node) {
+ __quicklistInsertNode(quicklist, old_node, new_node, 0);
+}
+
+REDIS_STATIC void _quicklistInsertNodeAfter(quicklist *quicklist,
+ quicklistNode *old_node,
+ quicklistNode *new_node) {
+ __quicklistInsertNode(quicklist, old_node, new_node, 1);
+}
+
+/* Insert 'new_node' after 'old_node' if 'after' is 1.
+ * Insert 'new_node' before 'old_node' if 'after' is 0.
+ * Note: 'new_node' is *always* uncompressed, so if we assign it to
+ * head or tail, we do not need to uncompress it. */
+REDIS_STATIC void __quicklistInsertNode(quicklist *quicklist,
+ quicklistNode *old_node,
+ quicklistNode *new_node, int after) {
+ if (after) {
+ new_node->prev = old_node;
+ if (old_node) {
+ new_node->next = old_node->next;
+ if (old_node->next)
+ old_node->next->prev = new_node;
+ old_node->next = new_node;
+ }
+ if (quicklist->tail == old_node)
+ quicklist->tail = new_node;
+ } else {
+ new_node->next = old_node;
+ if (old_node) {
+ new_node->prev = old_node->prev;
+ if (old_node->prev)
+ old_node->prev->next = new_node;
+ old_node->prev = new_node;
+ }
+ if (quicklist->head == old_node)
+ quicklist->head = new_node;
+ }
+ /* If this insert creates the only element so far, initialize head/tail. */
+ if (quicklist->len == 0) {
+ quicklist->head = quicklist->tail = new_node;
+ }
+
+ if (old_node)
+ quicklistCompress(quicklist, old_node);
+
+ quicklist->len++;
+}
+前面第一步先根据插入的是头还是尾选择不同的 push 函数,quicklistPushHead 或者 quicklistPushTail,举例分析下从头插入的 quicklistPushHead,先判断当前的 quicklistNode 节点还能不能允许再往 ziplist 里添加元素,如果可以就添加,如果不允许就新建一个 quicklistNode,然后调用 _quicklistInsertNodeBefore 将节点插进去,具体插入quicklist节点的操作类似链表的插入。
]]>
- Redis
- C
Redis
数据结构
+ C
源码
+ Redis
redis
@@ -9880,1583 +10239,1273 @@ timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
- redis系列介绍八-淘汰策略
- /2020/04/18/redis%E7%B3%BB%E5%88%97%E4%BB%8B%E7%BB%8D%E5%85%AB/
- LRU说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍
![]() ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
redis 针对这个策略的改进做了一个实验,这里借用下图
![]()
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
-typedef struct redisObject {
- unsigned type:4;
- unsigned encoding:4;
- unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
- * LFU data (least significant 8 bits frequency
- * and most significant 16 bits access time). */
- int refcount;
- void *ptr;
-} robj;
-对于 lru 策略来说,lru 字段记录的就是redisObj 的LRU time,
redis 在访问数据时,都会调用lookupKey方法
-/* Low level key lookup API, not actually called directly from commands
- * implementations that should instead rely on lookupKeyRead(),
- * lookupKeyWrite() and lookupKeyReadWithFlags(). */
-robj *lookupKey(redisDb *db, robj *key, int flags) {
- dictEntry *de = dictFind(db->dict,key->ptr);
- if (de) {
- robj *val = dictGetVal(de);
-
- /* Update the access time for the ageing algorithm.
- * Don't do it if we have a saving child, as this will trigger
- * a copy on write madness. */
- if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
- if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
- // 这个是后面一节的内容
- updateLFU(val);
- } else {
- // 对于这个分支,访问时就会去更新 lru 值
- val->lru = LRU_CLOCK();
- }
- }
- return val;
- } else {
- return NULL;
- }
-}
-/* This function is used to obtain the current LRU clock.
- * If the current resolution is lower than the frequency we refresh the
- * LRU clock (as it should be in production servers) we return the
- * precomputed value, otherwise we need to resort to a system call. */
-unsigned int LRU_CLOCK(void) {
- unsigned int lruclock;
- if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
- // 如果服务器的频率server.hz大于 1 时就是用系统预设的 lruclock
- lruclock = server.lruclock;
- } else {
- lruclock = getLRUClock();
- }
- return lruclock;
-}
-/* Return the LRU clock, based on the clock resolution. This is a time
- * in a reduced-bits format that can be used to set and check the
- * object->lru field of redisObject structures. */
-unsigned int getLRUClock(void) {
- return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
-}
-redis 处理命令是在这里processCommand
-/* If this function gets called we already read a whole
- * command, arguments are in the client argv/argc fields.
- * processCommand() execute the command or prepare the
- * server for a bulk read from the client.
- *
- * If C_OK is returned the client is still alive and valid and
- * other operations can be performed by the caller. Otherwise
- * if C_ERR is returned the client was destroyed (i.e. after QUIT). */
-int processCommand(client *c) {
- moduleCallCommandFilters(c);
-
-
-
- /* Handle the maxmemory directive.
- *
- * Note that we do not want to reclaim memory if we are here re-entering
- * the event loop since there is a busy Lua script running in timeout
- * condition, to avoid mixing the propagation of scripts with the
- * propagation of DELs due to eviction. */
- if (server.maxmemory && !server.lua_timedout) {
- int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
- /* freeMemoryIfNeeded may flush slave output buffers. This may result
- * into a slave, that may be the active client, to be freed. */
- if (server.current_client == NULL) return C_ERR;
-
- /* It was impossible to free enough memory, and the command the client
- * is trying to execute is denied during OOM conditions or the client
- * is in MULTI/EXEC context? Error. */
- if (out_of_memory &&
- (c->cmd->flags & CMD_DENYOOM ||
- (c->flags & CLIENT_MULTI &&
- c->cmd->proc != execCommand &&
- c->cmd->proc != discardCommand)))
- {
- flagTransaction(c);
- addReply(c, shared.oomerr);
- return C_OK;
- }
- }
-}
-这里只摘了部分,当需要清理内存时就会调用, 然后调用了freeMemoryIfNeededAndSafe
-/* This is a wrapper for freeMemoryIfNeeded() that only really calls the
- * function if right now there are the conditions to do so safely:
+ redis系列介绍七-过期策略
+ /2020/04/12/redis%E7%B3%BB%E5%88%97%E4%BB%8B%E7%BB%8D%E4%B8%83/
+ 这一篇不再是数据结构介绍了,大致的数据结构基本都介绍了,这一篇主要是查漏补缺,或者说讲一些重要且基本的概念,也可能是经常被忽略的,很多讲 redis 的系列文章可能都会忽略,学习 redis 的时候也会,因为觉得源码学习就是讲主要的数据结构和“算法”学习了就好了。
redis 的主要应用就是拿来作为高性能的缓存,那么缓存一般有些啥需要注意的,首先是访问速度,如果取得跟数据库一样快,那就没什么存在的意义,第二个是缓存的字面意思,我只是为了让数据读取快一些,通常大部分的场景这个是需要更新过期的,这里就把我要讲的第一点引出来了(真累,
+redis过期策略
redis 是如何过期缓存的,可以猜测下,最无脑的就是每个设置了过期时间的 key 都设个定时器,过期了就删除,这种显然消耗太大,清理地最及时,还有的就是 redis 正在采用的懒汉清理策略和定期清理
懒汉策略就是在使用的时候去检查缓存是否过期,比如 get 操作时,先判断下这个 key 是否已经过期了,如果过期了就删掉,并且返回空,如果没过期则正常返回
主要代码是
+/* This function is called when we are going to perform some operation
+ * in a given key, but such key may be already logically expired even if
+ * it still exists in the database. The main way this function is called
+ * is via lookupKey*() family of functions.
*
- * - There must be no script in timeout condition.
- * - Nor we are loading data right now.
+ * The behavior of the function depends on the replication role of the
+ * instance, because slave instances do not expire keys, they wait
+ * for DELs from the master for consistency matters. However even
+ * slaves will try to have a coherent return value for the function,
+ * so that read commands executed in the slave side will be able to
+ * behave like if the key is expired even if still present (because the
+ * master has yet to propagate the DEL).
*
- */
-int freeMemoryIfNeededAndSafe(void) {
- if (server.lua_timedout || server.loading) return C_OK;
- return freeMemoryIfNeeded();
-}
-/* This function is periodically called to see if there is memory to free
- * according to the current "maxmemory" settings. In case we are over the
- * memory limit, the function will try to free some memory to return back
- * under the limit.
+ * In masters as a side effect of finding a key which is expired, such
+ * key will be evicted from the database. Also this may trigger the
+ * propagation of a DEL/UNLINK command in AOF / replication stream.
*
- * The function returns C_OK if we are under the memory limit or if we
- * were over the limit, but the attempt to free memory was successful.
- * Otehrwise if we are over the memory limit, but not enough memory
- * was freed to return back under the limit, the function returns C_ERR. */
-int freeMemoryIfNeeded(void) {
- int keys_freed = 0;
- /* By default replicas should ignore maxmemory
- * and just be masters exact copies. */
- if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
-
- size_t mem_reported, mem_tofree, mem_freed;
- mstime_t latency, eviction_latency;
- long long delta;
- int slaves = listLength(server.slaves);
-
- /* When clients are paused the dataset should be static not just from the
- * POV of clients not being able to write, but also from the POV of
- * expires and evictions of keys not being performed. */
- if (clientsArePaused()) return C_OK;
- if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
- return C_OK;
-
- mem_freed = 0;
+ * The return value of the function is 0 if the key is still valid,
+ * otherwise the function returns 1 if the key is expired. */
+int expireIfNeeded(redisDb *db, robj *key) {
+ if (!keyIsExpired(db,key)) return 0;
- if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
- goto cant_free; /* We need to free memory, but policy forbids. */
+ /* If we are running in the context of a slave, instead of
+ * evicting the expired key from the database, we return ASAP:
+ * the slave key expiration is controlled by the master that will
+ * send us synthesized DEL operations for expired keys.
+ *
+ * Still we try to return the right information to the caller,
+ * that is, 0 if we think the key should be still valid, 1 if
+ * we think the key is expired at this time. */
+ if (server.masterhost != NULL) return 1;
- latencyStartMonitor(latency);
- while (mem_freed < mem_tofree) {
- int j, k, i;
- static unsigned int next_db = 0;
- sds bestkey = NULL;
- int bestdbid;
- redisDb *db;
- dict *dict;
- dictEntry *de;
+ /* Delete the key */
+ server.stat_expiredkeys++;
+ propagateExpire(db,key,server.lazyfree_lazy_expire);
+ notifyKeyspaceEvent(NOTIFY_EXPIRED,
+ "expired",key,db->id);
+ return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
+ dbSyncDelete(db,key);
+}
- if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
- server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
- {
- struct evictionPoolEntry *pool = EvictionPoolLRU;
+/* Check if the key is expired. */
+int keyIsExpired(redisDb *db, robj *key) {
+ mstime_t when = getExpire(db,key);
+ mstime_t now;
- while(bestkey == NULL) {
- unsigned long total_keys = 0, keys;
+ if (when < 0) return 0; /* No expire for this key */
- /* We don't want to make local-db choices when expiring keys,
- * so to start populate the eviction pool sampling keys from
- * every DB. */
- for (i = 0; i < server.dbnum; i++) {
- db = server.db+i;
- dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
- db->dict : db->expires;
- if ((keys = dictSize(dict)) != 0) {
- evictionPoolPopulate(i, dict, db->dict, pool);
- total_keys += keys;
- }
- }
- if (!total_keys) break; /* No keys to evict. */
+ /* Don't expire anything while loading. It will be done later. */
+ if (server.loading) return 0;
- /* Go backward from best to worst element to evict. */
- for (k = EVPOOL_SIZE-1; k >= 0; k--) {
- if (pool[k].key == NULL) continue;
- bestdbid = pool[k].dbid;
+ /* If we are in the context of a Lua script, we pretend that time is
+ * blocked to when the Lua script started. This way a key can expire
+ * only the first time it is accessed and not in the middle of the
+ * script execution, making propagation to slaves / AOF consistent.
+ * See issue #1525 on Github for more information. */
+ if (server.lua_caller) {
+ now = server.lua_time_start;
+ }
+ /* If we are in the middle of a command execution, we still want to use
+ * a reference time that does not change: in that case we just use the
+ * cached time, that we update before each call in the call() function.
+ * This way we avoid that commands such as RPOPLPUSH or similar, that
+ * may re-open the same key multiple times, can invalidate an already
+ * open object in a next call, if the next call will see the key expired,
+ * while the first did not. */
+ else if (server.fixed_time_expire > 0) {
+ now = server.mstime;
+ }
+ /* For the other cases, we want to use the most fresh time we have. */
+ else {
+ now = mstime();
+ }
- if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
- de = dictFind(server.db[pool[k].dbid].dict,
- pool[k].key);
- } else {
- de = dictFind(server.db[pool[k].dbid].expires,
- pool[k].key);
- }
+ /* The key expired if the current (virtual or real) time is greater
+ * than the expire time of the key. */
+ return now > when;
+}
+/* Return the expire time of the specified key, or -1 if no expire
+ * is associated with this key (i.e. the key is non volatile) */
+long long getExpire(redisDb *db, robj *key) {
+ dictEntry *de;
- /* Remove the entry from the pool. */
- if (pool[k].key != pool[k].cached)
- sdsfree(pool[k].key);
- pool[k].key = NULL;
- pool[k].idle = 0;
+ /* No expire? return ASAP */
+ if (dictSize(db->expires) == 0 ||
+ (de = dictFind(db->expires,key->ptr)) == NULL) return -1;
- /* If the key exists, is our pick. Otherwise it is
- * a ghost and we need to try the next element. */
- if (de) {
- bestkey = dictGetKey(de);
- break;
- } else {
- /* Ghost... Iterate again. */
- }
- }
- }
+ /* The entry was found in the expire dict, this means it should also
+ * be present in the main dict (safety check). */
+ serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
+ return dictGetSignedIntegerVal(de);
+}
+这里有几点要注意的,第一是当惰性删除时会根据lazyfree_lazy_expire这个参数去判断是执行同步删除还是异步删除,另外一点是对于 slave,是不需要执行的,因为会在 master 过期时向 slave 发送 del 指令。
光采用这个策略会有什么问题呢,假如一些key 一直未被访问,那这些 key 就不会过期了,导致一直被占用着内存,所以 redis 采取了懒汉式过期加定期过期策略,定期策略是怎么执行的呢
+/* This function handles 'background' operations we are required to do
+ * incrementally in Redis databases, such as active key expiring, resizing,
+ * rehashing. */
+void databasesCron(void) {
+ /* Expire keys by random sampling. Not required for slaves
+ * as master will synthesize DELs for us. */
+ if (server.active_expire_enabled) {
+ if (server.masterhost == NULL) {
+ activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
+ } else {
+ expireSlaveKeys();
}
+ }
- /* volatile-random and allkeys-random policy */
- else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
- server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
- {
- /* When evicting a random key, we try to evict a key for
- * each DB, so we use the static 'next_db' variable to
- * incrementally visit all DBs. */
- for (i = 0; i < server.dbnum; i++) {
- j = (++next_db) % server.dbnum;
- db = server.db+j;
- dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?
- db->dict : db->expires;
- if (dictSize(dict) != 0) {
- de = dictGetRandomKey(dict);
- bestkey = dictGetKey(de);
- bestdbid = j;
- break;
- }
- }
- }
+ /* Defrag keys gradually. */
+ activeDefragCycle();
- /* Finally remove the selected key. */
- if (bestkey) {
- db = server.db+bestdbid;
- robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
- propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
- /* We compute the amount of memory freed by db*Delete() alone.
- * It is possible that actually the memory needed to propagate
- * the DEL in AOF and replication link is greater than the one
- * we are freeing removing the key, but we can't account for
- * that otherwise we would never exit the loop.
- *
- * AOF and Output buffer memory will be freed eventually so
- * we only care about memory used by the key space. */
- delta = (long long) zmalloc_used_memory();
- latencyStartMonitor(eviction_latency);
- if (server.lazyfree_lazy_eviction)
- dbAsyncDelete(db,keyobj);
- else
- dbSyncDelete(db,keyobj);
- latencyEndMonitor(eviction_latency);
- latencyAddSampleIfNeeded("eviction-del",eviction_latency);
- latencyRemoveNestedEvent(latency,eviction_latency);
- delta -= (long long) zmalloc_used_memory();
- mem_freed += delta;
- server.stat_evictedkeys++;
- notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted",
- keyobj, db->id);
- decrRefCount(keyobj);
- keys_freed++;
+ /* Perform hash tables rehashing if needed, but only if there are no
+ * other processes saving the DB on disk. Otherwise rehashing is bad
+ * as will cause a lot of copy-on-write of memory pages. */
+ if (!hasActiveChildProcess()) {
+ /* We use global counters so if we stop the computation at a given
+ * DB we'll be able to start from the successive in the next
+ * cron loop iteration. */
+ static unsigned int resize_db = 0;
+ static unsigned int rehash_db = 0;
+ int dbs_per_call = CRON_DBS_PER_CALL;
+ int j;
- /* When the memory to free starts to be big enough, we may
- * start spending so much time here that is impossible to
- * deliver data to the slaves fast enough, so we force the
- * transmission here inside the loop. */
- if (slaves) flushSlavesOutputBuffers();
+ /* Don't test more DBs than we have. */
+ if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
- /* Normally our stop condition is the ability to release
- * a fixed, pre-computed amount of memory. However when we
- * are deleting objects in another thread, it's better to
- * check, from time to time, if we already reached our target
- * memory, since the "mem_freed" amount is computed only
- * across the dbAsyncDelete() call, while the thread can
- * release the memory all the time. */
- if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) {
- if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
- /* Let's satisfy our stop condition. */
- mem_freed = mem_tofree;
+ /* Resize */
+ for (j = 0; j < dbs_per_call; j++) {
+ tryResizeHashTables(resize_db % server.dbnum);
+ resize_db++;
+ }
+
+ /* Rehash */
+ if (server.activerehashing) {
+ for (j = 0; j < dbs_per_call; j++) {
+ int work_done = incrementallyRehash(rehash_db);
+ if (work_done) {
+ /* If the function did some work, stop here, we'll do
+ * more at the next cron loop. */
+ break;
+ } else {
+ /* If this db didn't need rehash, we'll try the next one. */
+ rehash_db++;
+ rehash_db %= server.dbnum;
}
}
- } else {
- latencyEndMonitor(latency);
- latencyAddSampleIfNeeded("eviction-cycle",latency);
- goto cant_free; /* nothing to free... */
}
}
- latencyEndMonitor(latency);
- latencyAddSampleIfNeeded("eviction-cycle",latency);
- return C_OK;
-
-cant_free:
- /* We are here if we are not able to reclaim memory. There is only one
- * last thing we can try: check if the lazyfree thread has jobs in queue
- * and wait... */
- while(bioPendingJobsOfType(BIO_LAZY_FREE)) {
- if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree)
- break;
- usleep(1000);
- }
- return C_ERR;
-}
-这里就是根据具体策略去淘汰 key,首先是要往 pool 更新 key,更新key 的方法是evictionPoolPopulate
-void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
- int j, k, count;
- dictEntry *samples[server.maxmemory_samples];
-
- count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
- for (j = 0; j < count; j++) {
- unsigned long long idle;
- sds key;
- robj *o;
- dictEntry *de;
-
- de = samples[j];
- key = dictGetKey(de);
+}
+/* Try to expire a few timed out keys. The algorithm used is adaptive and
+ * will use few CPU cycles if there are few expiring keys, otherwise
+ * it will get more aggressive to avoid that too much memory is used by
+ * keys that can be removed from the keyspace.
+ *
+ * Every expire cycle tests multiple databases: the next call will start
+ * again from the next db, with the exception of exists for time limit: in that
+ * case we restart again from the last database we were processing. Anyway
+ * no more than CRON_DBS_PER_CALL databases are tested at every iteration.
+ *
+ * The function can perform more or less work, depending on the "type"
+ * argument. It can execute a "fast cycle" or a "slow cycle". The slow
+ * cycle is the main way we collect expired cycles: this happens with
+ * the "server.hz" frequency (usually 10 hertz).
+ *
+ * However the slow cycle can exit for timeout, since it used too much time.
+ * For this reason the function is also invoked to perform a fast cycle
+ * at every event loop cycle, in the beforeSleep() function. The fast cycle
+ * will try to perform less work, but will do it much more often.
+ *
+ * The following are the details of the two expire cycles and their stop
+ * conditions:
+ *
+ * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a
+ * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION
+ * microseconds, and is not repeated again before the same amount of time.
+ * The cycle will also refuse to run at all if the latest slow cycle did not
+ * terminate because of a time limit condition.
+ *
+ * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is
+ * executed, where the time limit is a percentage of the REDIS_HZ period
+ * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. In the
+ * fast cycle, the check of every database is interrupted once the number
+ * of already expired keys in the database is estimated to be lower than
+ * a given percentage, in order to avoid doing too much work to gain too
+ * little memory.
+ *
+ * The configured expire "effort" will modify the baseline parameters in
+ * order to do more work in both the fast and slow expire cycles.
+ */
- /* If the dictionary we are sampling from is not the main
- * dictionary (but the expires one) we need to lookup the key
- * again in the key dictionary to obtain the value object. */
- if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
- if (sampledict != keydict) de = dictFind(keydict, key);
- o = dictGetVal(de);
- }
+#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
+#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
+#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
+#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
+ we do extra efforts. */
+void activeExpireCycle(int type) {
+ /* Adjust the running parameters according to the configured expire
+ * effort. The default effort is 1, and the maximum configurable effort
+ * is 10. */
+ unsigned long
+ effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
+ config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
+ ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
+ config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
+ ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
+ config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
+ 2*effort,
+ config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
+ effort;
- /* Calculate the idle time according to the policy. This is called
- * idle just because the code initially handled LRU, but is in fact
- * just a score where an higher score means better candidate. */
- if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
- idle = estimateObjectIdleTime(o);
- } else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
- /* When we use an LRU policy, we sort the keys by idle time
- * so that we expire keys starting from greater idle time.
- * However when the policy is an LFU one, we have a frequency
- * estimation, and we want to evict keys with lower frequency
- * first. So inside the pool we put objects using the inverted
- * frequency subtracting the actual frequency to the maximum
- * frequency of 255. */
- idle = 255-LFUDecrAndReturn(o);
- } else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
- /* In this case the sooner the expire the better. */
- idle = ULLONG_MAX - (long)dictGetVal(de);
- } else {
- serverPanic("Unknown eviction policy in evictionPoolPopulate()");
- }
+ /* This function has some global state in order to continue the work
+ * incrementally across calls. */
+ static unsigned int current_db = 0; /* Last DB tested. */
+ static int timelimit_exit = 0; /* Time limit hit in previous call? */
+ static long long last_fast_cycle = 0; /* When last fast cycle ran. */
- /* Insert the element inside the pool.
- * First, find the first empty bucket or the first populated
- * bucket that has an idle time smaller than our idle time. */
- k = 0;
- while (k < EVPOOL_SIZE &&
- pool[k].key &&
- pool[k].idle < idle) k++;
- if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
- /* Can't insert if the element is < the worst element we have
- * and there are no empty buckets. */
- continue;
- } else if (k < EVPOOL_SIZE && pool[k].key == NULL) {
- /* Inserting into empty position. No setup needed before insert. */
- } else {
- /* Inserting in the middle. Now k points to the first element
- * greater than the element to insert. */
- if (pool[EVPOOL_SIZE-1].key == NULL) {
- /* Free space on the right? Insert at k shifting
- * all the elements from k to end to the right. */
+ int j, iteration = 0;
+ int dbs_per_call = CRON_DBS_PER_CALL;
+ long long start = ustime(), timelimit, elapsed;
- /* Save SDS before overwriting. */
- sds cached = pool[EVPOOL_SIZE-1].cached;
- memmove(pool+k+1,pool+k,
- sizeof(pool[0])*(EVPOOL_SIZE-k-1));
- pool[k].cached = cached;
- } else {
- /* No free space on right? Insert at k-1 */
- k--;
- /* Shift all elements on the left of k (included) to the
- * left, so we discard the element with smaller idle time. */
- sds cached = pool[0].cached; /* Save SDS before overwriting. */
- if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
- memmove(pool,pool+1,sizeof(pool[0])*k);
- pool[k].cached = cached;
- }
- }
+ /* When clients are paused the dataset should be static not just from the
+ * POV of clients not being able to write, but also from the POV of
+ * expires and evictions of keys not being performed. */
+ if (clientsArePaused()) return;
- /* Try to reuse the cached SDS string allocated in the pool entry,
- * because allocating and deallocating this object is costly
- * (according to the profiler, not my fantasy. Remember:
- * premature optimizbla bla bla bla. */
- int klen = sdslen(key);
- if (klen > EVPOOL_CACHED_SDS_SIZE) {
- pool[k].key = sdsdup(key);
- } else {
- memcpy(pool[k].cached,key,klen+1);
- sdssetlen(pool[k].cached,klen);
- pool[k].key = pool[k].cached;
- }
- pool[k].idle = idle;
- pool[k].dbid = dbid;
- }
-}
-Redis随机选择maxmemory_samples数量的key,然后计算这些key的空闲时间idle time,当满足条件时(比pool中的某些键的空闲时间还大)就可以进pool。pool更新之后,就淘汰pool中空闲时间最大的键。
-estimateObjectIdleTime用来计算Redis对象的空闲时间:
-/* Given an object returns the min number of milliseconds the object was never
- * requested, using an approximated LRU algorithm. */
-unsigned long long estimateObjectIdleTime(robj *o) {
- unsigned long long lruclock = LRU_CLOCK();
- if (lruclock >= o->lru) {
- return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
- } else {
- return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
- LRU_CLOCK_RESOLUTION;
- }
-}
-空闲时间第一种是 lurclock 大于对象的 lru,那么就是减一下乘以精度,因为 lruclock 有可能是已经预生成的,所以会可能走下面这个
-LFU
上面介绍了LRU 的算法,但是考虑一种场景
-~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~|
-~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~|
-~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~~|
-~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D|
-可以发现,当采用 lru 的淘汰策略的时候,D 是最新的,会被认为是最值得保留的,但是事实上还不如 A 跟 B,然后 antirez 大神就想到了LFU (Least Frequently Used) 这个算法, 显然对于上面的四个 key 的访问频率,保留优先级应该是 B > A > C = D
那要怎么来实现这个 LFU 算法呢,其实像LRU,理想的情况就是维护个链表,把最新访问的放到头上去,但是这个会影响访问速度,注意到前面代码的应该可以看到,redisObject 的 lru 字段其实是两用的,当策略是 LFU 时,这个字段就另作他用了,它的 24 位长度被分成两部分
- 16 bits 8 bits
-+----------------+--------+
-+ Last decr time | LOG_C |
-+----------------+--------+
-前16位字段是最后一次递减时间,因此Redis知道 上一次计数器递减,后8位是 计数器 counter。
LFU 的主体策略就是当这个 key 被访问的次数越多频率越高他就越容易被保留下来,并且是最近被访问的频率越高。这其实有两个事情要做,一个是在访问的时候增加计数值,在一定长时间不访问时进行衰减,所以这里用了两个值,前 16 位记录上一次衰减的时间,后 8 位记录具体的计数值。
Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式:
-volatile-lfu:对有过期时间的key采用LFU淘汰策略
allkeys-lfu:对全部key采用LFU淘汰策略
还有2个配置可以调整LFU算法:
-lfu-log-factor 10
-lfu-decay-time 1
-```
-`lfu-log-factor` 可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
+ if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
+ /* Don't start a fast cycle if the previous cycle did not exit
+ * for time limit, unless the percentage of estimated stale keys is
+ * too high. Also never repeat a fast cycle for the same period
+ * as the fast cycle total duration itself. */
+ if (!timelimit_exit &&
+ server.stat_expired_stale_perc < config_cycle_acceptable_stale)
+ return;
-`lfu-decay-time`是一个以分钟为单位的数值,可以调整counter的减少速度
-这里有个问题是 8 位大小够计么,访问一次加 1 的话的确不够,不过大神就是大神,才不会这么简单的加一。往下看代码
-```C
-/* Low level key lookup API, not actually called directly from commands
- * implementations that should instead rely on lookupKeyRead(),
- * lookupKeyWrite() and lookupKeyReadWithFlags(). */
-robj *lookupKey(redisDb *db, robj *key, int flags) {
- dictEntry *de = dictFind(db->dict,key->ptr);
- if (de) {
- robj *val = dictGetVal(de);
+ if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
+ return;
- /* Update the access time for the ageing algorithm.
- * Don't do it if we have a saving child, as this will trigger
- * a copy on write madness. */
- if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
- if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
- // 当淘汰策略是 LFU 时,就会调用这个updateLFU
- updateLFU(val);
- } else {
- val->lru = LRU_CLOCK();
- }
- }
- return val;
- } else {
- return NULL;
+ last_fast_cycle = start;
}
-}
-updateLFU 这个其实个入口,调用了两个重要的方法
-/* Update LFU when an object is accessed.
- * Firstly, decrement the counter if the decrement time is reached.
- * Then logarithmically increment the counter, and update the access time. */
-void updateLFU(robj *val) {
- unsigned long counter = LFUDecrAndReturn(val);
- counter = LFULogIncr(counter);
- val->lru = (LFUGetTimeInMinutes()<<8) | counter;
-}
-首先来看看LFUDecrAndReturn,这个方法的作用是根据上一次衰减时间和系统配置的 lfu-decay-time 参数来确定需要将 counter 减去多少
-/* If the object decrement time is reached decrement the LFU counter but
- * do not update LFU fields of the object, we update the access time
- * and counter in an explicit way when the object is really accessed.
- * And we will times halve the counter according to the times of
- * elapsed time than server.lfu_decay_time.
- * Return the object frequency counter.
- *
- * This function is used in order to scan the dataset for the best object
- * to fit: as we check for the candidate, we incrementally decrement the
- * counter of the scanned objects if needed. */
-unsigned long LFUDecrAndReturn(robj *o) {
- // 右移 8 位,拿到上次衰减时间
- unsigned long ldt = o->lru >> 8;
- // 对 255 做与操作,拿到 counter 值
- unsigned long counter = o->lru & 255;
- // 根据lfu_decay_time来算出过了多少个衰减周期
- unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
- if (num_periods)
- counter = (num_periods > counter) ? 0 : counter - num_periods;
- return counter;
-}
-然后是加,调用了LFULogIncr
-/* Logarithmically increment a counter. The greater is the current counter value
- * the less likely is that it gets really implemented. Saturate it at 255. */
-uint8_t LFULogIncr(uint8_t counter) {
- // 最大值就是 255,到顶了就不加了
- if (counter == 255) return 255;
- // 生成个随机小数
- double r = (double)rand()/RAND_MAX;
- // 减去个基础值,LFU_INIT_VAL = 5,防止刚进来就被逐出
- double baseval = counter - LFU_INIT_VAL;
- // 如果是小于 0,
- if (baseval < 0) baseval = 0;
- // 如果 baseval 是 0,那么 p 就是 1了,后面 counter 直接加一,如果不是的话,得看系统参数lfu_log_factor,这个越大,除出来的 p 越小,那么 counter++的可能性也越小,这样子就把前面的疑问给解决了,不是直接+1 的
- double p = 1.0/(baseval*server.lfu_log_factor+1);
- if (r < p) counter++;
- return counter;
-}
-大概的变化速度可以参考
-+--------+------------+------------+------------+------------+------------+
-| factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
-+--------+------------+------------+------------+------------+------------+
-| 0 | 104 | 255 | 255 | 255 | 255 |
-+--------+------------+------------+------------+------------+------------+
-| 1 | 18 | 49 | 255 | 255 | 255 |
-+--------+------------+------------+------------+------------+------------+
-| 10 | 10 | 18 | 142 | 255 | 255 |
-+--------+------------+------------+------------+------------+------------+
-| 100 | 8 | 11 | 49 | 143 | 255 |
-+--------+------------+------------+------------+------------+------------+
-简而言之就是 lfu_log_factor 越大变化的越慢
-总结
总结一下,redis 实现了近似的 lru 淘汰策略,通过增加了淘汰 key 的池子(pool),并且增大每次抽样的 key 的数量来将淘汰效果更进一步地接近于 lru,这是 lru 策略,但是对于前面举的一个例子,其实 lru 并不能保证 key 的淘汰就如我们预期,所以在后期又引入了 lfu 的策略,lfu的策略比较巧妙,复用了 redis 对象的 lru 字段,并且使用了factor 参数来控制计数器递增的速度,防止 8 位的计数器太早溢出。
-]]>
-
- Redis
- C
- Redis
- 数据结构
- 源码
-
-
- redis
- 数据结构
- 源码
-
-
-
- redis过期策略复习
- /2021/07/25/redis%E8%BF%87%E6%9C%9F%E7%AD%96%E7%95%A5%E5%A4%8D%E4%B9%A0/
- redis过期策略复习之前其实写过redis的过期的一些原理,这次主要是记录下,一些使用上的概念,主要是redis使用的过期策略是懒过期和定时清除,懒过期的其实比较简单,即是在key被访问的时候会顺带着判断下这个key是否已过期了,如果已经过期了,就不返回了,但是这种策略有个漏洞是如果有些key之后一直不会被访问了,就等于沉在池底了,所以需要有一个定时的清理机制,去从设置了过期的key池子(expires)里随机地捞key,具体的策略我们看下官网的解释
-
-- Test 20 random keys from the set of keys with an associated expire.
-- Delete all the keys found expired.
-- If more than 25% of keys were expired, start again from step 1.
-
-从池子里随机获取20个key,将其中过期的key删掉,如果这其中有超过25%的key已经过期了,那就再来一次,以此保持过期的key不超过25%(左右),并且这个定时策略可以在redis的配置文件
-# Redis calls an internal function to perform many background tasks, like
-# closing connections of clients in timeout, purging expired keys that are
-# never requested, and so forth.
-#
-# Not all tasks are performed with the same frequency, but Redis checks for
-# tasks to perform according to the specified "hz" value.
-#
-# By default "hz" is set to 10. Raising the value will use more CPU when
-# Redis is idle, but at the same time will make Redis more responsive when
-# there are many keys expiring at the same time, and timeouts may be
-# handled with more precision.
-#
-# The range is between 1 and 500, however a value over 100 is usually not
-# a good idea. Most users should use the default of 10 and raise this up to
-# 100 only in environments where very low latency is required.
-hz 10
-可以配置这个hz的值,代表的含义是每秒的执行次数,默认是10,其实也用了hz的普遍含义。有兴趣可以看看之前写的一篇文章redis系列介绍七-过期策略
-]]>
-
- redis
-
-
- redis
- 应用
- 过期策略
-
-
-
- rust学习笔记-所有权三之切片
- /2021/05/16/rust%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0-%E6%89%80%E6%9C%89%E6%9D%83%E4%B8%89%E4%B9%8B%E5%88%87%E7%89%87/
- 除了引用,Rust 还有另外一种不持有所有权的数据类型:切片(slice)。切片允许我们引用集合中某一段连续的元素序列,而不是整个集合。
例如代码
-fn main() {
- let mut s = String::from("hello world");
+ /* We usually should test CRON_DBS_PER_CALL per iteration, with
+ * two exceptions:
+ *
+ * 1) Don't test more DBs than we have.
+ * 2) If last time we hit the time limit, we want to scan all DBs
+ * in this iteration, as there is work to do in some DB and we don't want
+ * expired keys to use memory for too much time. */
+ if (dbs_per_call > server.dbnum || timelimit_exit)
+ dbs_per_call = server.dbnum;
+
+ /* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
+ * time per iteration. Since this function gets called with a frequency of
+ * server.hz times per second, the following is the max amount of
+ * microseconds we can spend in this function. */
+ timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
+ timelimit_exit = 0;
+ if (timelimit <= 0) timelimit = 1;
- let word = first_word(&s);
+ if (type == ACTIVE_EXPIRE_CYCLE_FAST)
+ timelimit = config_cycle_fast_duration; /* in microseconds. */
- s.clear();
+ /* Accumulate some global stats as we expire keys, to have some idea
+ * about the number of keys that are already logically expired, but still
+ * existing inside the database. */
+ long total_sampled = 0;
+ long total_expired = 0;
- // 这时候虽然 word 还是 5,但是 s 已经被清除了,所以就没存在的意义
-}
-这里其实我们就需要关注 s 的存在性,代码的逻辑合理性就需要额外去维护,此时我们就可以用切片
-let s = String::from("hello world")
+ for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
+ /* Expired and checked in a single loop. */
+ unsigned long expired, sampled;
-let hello = &s[0..5];
-let world = &s[6..11];
-其实跟 Python 的list 之类的语法有点类似,当然里面还有些语法糖,比如可以直接用省略后面的数字表示直接引用到结尾
-let hello = &s[0..];
-甚至再进一步
-let hello = &s[..];
-使用了切片之后
-fn first_word(s: &String) -> &str {
- let bytes = s.as_bytes();
+ redisDb *db = server.db+(current_db % server.dbnum);
- for (i, &item) in bytes.iter().enumerate() {
- if item == b' ' {
- return &s[0..i];
- }
- }
+ /* Increment the DB now so we are sure if we run out of time
+ * in the current DB we'll restart from the next. This allows to
+ * distribute the time evenly across DBs. */
+ current_db++;
- &s[..]
-}
-fn main() {
- let mut s = String::from("hello world");
+ /* Continue to expire if at the end of the cycle more than 25%
+ * of the keys were expired. */
+ do {
+ unsigned long num, slots;
+ long long now, ttl_sum;
+ int ttl_samples;
+ iteration++;
- let word = first_word(&s);
+ /* If there is nothing to expire try next DB ASAP. */
+ if ((num = dictSize(db->expires)) == 0) {
+ db->avg_ttl = 0;
+ break;
+ }
+ slots = dictSlots(db->expires);
+ now = mstime();
- s.clear(); // error!
+ /* When there are less than 1% filled slots, sampling the key
+ * space is expensive, so stop here waiting for better times...
+ * The dictionary will be resized asap. */
+ if (num && slots > DICT_HT_INITIAL_SIZE &&
+ (num*100/slots < 1)) break;
- println!("the first word is: {}", word);
-}
-那再执行 main 函数的时候就会抛错,因为 word 还是个切片,需要保证 s 的有效性,并且其实我们可以将函数申明成
-fn first_word(s: &str) -> &str {
-这样就既能处理&String 的情况,就是当成完整字符串的切片,也能处理普通的切片。
其他类型的切片
-let a = [1, 2, 3, 4, 5];
-let slice = &a[1..3];
-简单记录下,具体可以去看看这本书
-]]>
-
- 语言
- Rust
-
-
- Rust
- 所有权
- 内存分布
- 新语言
- 可变引用
- 不可变引用
- 切片
-
-
-
- rust学习笔记-所有权二
- /2021/04/18/rust%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0-%E6%89%80%E6%9C%89%E6%9D%83%E4%BA%8C/
- 这里需要说道函数和返回值了
可以看书上的这个例子
![]()
对于这种情况,当进入函数内部时,会把传入的变量的所有权转移进函数内部,如果最后还是要返回该变量,但是如果此时还要返回别的计算结果,就可能需要笨拙地使用元组
![]() -
-引用
此时我们就可以用引用来解决这个问题
-fn main() {
- let s1 = String::from("hello");
- let len = calculate_length(&s1);
+ /* The main collection cycle. Sample random keys among keys
+ * with an expire set, checking for expired ones. */
+ expired = 0;
+ sampled = 0;
+ ttl_sum = 0;
+ ttl_samples = 0;
- println!("The length of '{}' is {}", s1, len);
-}
-fn calculate_length(s: &String) -> usize {
- s.len()
-}
-这里的&符号就是引用的语义,它们允许你在不获得所有权的前提下使用值
![]()
由于引用不持有值的所有权,所以当引用离开当前作用域时,它指向的值也不会被丢弃
-可变引用
而当我们尝试对引用的字符串进行修改时
-fn main() {
- let s1 = String::from("hello");
- change(&s1);
-}
-fn change(s: &String) {
- s.push_str(", world");
-}
-就会有以下报错,
![]()
其实也很容易发现,毕竟没有 mut 指出这是可变引用,同时需要将 s1 改成 mut 可变的
-fn main() {
- let mut s1 = String::from("hello");
- change(&mut s1);
-}
+ if (num > config_keys_per_loop)
+ num = config_keys_per_loop;
+ /* Here we access the low level representation of the hash table
+ * for speed concerns: this makes this code coupled with dict.c,
+ * but it hardly changed in ten years.
+ *
+ * Note that certain places of the hash table may be empty,
+ * so we want also a stop condition about the number of
+ * buckets that we scanned. However scanning for free buckets
+ * is very fast: we are in the cache line scanning a sequential
+ * array of NULL pointers, so we can scan a lot more buckets
+ * than keys in the same time. */
+ long max_buckets = num*20;
+ long checked_buckets = 0;
-fn change(s: &mut String) {
- s.push_str(", world");
-}
-再看一个例子
-fn main() {
- let mut s1 = String::from("hello");
- let r1 = &mut s1;
- let r2 = &mut s1;
-}
-这个例子在书里是会报错的,因为同时存在一个以上的可变引用,但是在我运行的版本里前面这段没有报错,只有当我真的要去更改的时候
-fn main() {
- let mut s1 = String::from("hello");
- let mut r1 = &mut s1;
- let mut r2 = &mut s1;
- change(&mut r1);
- change(&mut r2);
-}
+ while (sampled < num && checked_buckets < max_buckets) {
+ for (int table = 0; table < 2; table++) {
+ if (table == 1 && !dictIsRehashing(db->expires)) break;
+ unsigned long idx = db->expires_cursor;
+ idx &= db->expires->ht[table].sizemask;
+ dictEntry *de = db->expires->ht[table].table[idx];
+ long long ttl;
-fn change(s: &mut String) {
- s.push_str(", world");
-}
-![]()
这里可能就是具体版本在实现上的一个差异,我用的 rustc 是 1.44.0 版本
其实上面的主要是由 rust 想要避免这类多重可变更导致的异常问题,总结下就是三个点
-
-- 两个或两个以上的指针同时同时访问同一空间
-- 其中至少有一个指针会想空间中写入数据
-- 没有同步数据访问的机制
并且我们不能在拥有不可变引用的情况下创建可变引用
-
-悬垂引用
还有一点需要注意的就是悬垂引用
-fn main() {
- let reference_to_nothing = dangle();
-}
+ /* Scan the current bucket of the current table. */
+ checked_buckets++;
+ while(de) {
+ /* Get the next entry now since this entry may get
+ * deleted. */
+ dictEntry *e = de;
+ de = de->next;
-fn dangle() -> &String {
- let s = String::from("hello");
- &s
-}
-这里可以看到其实在 dangle函数返回后,这里的 s 理论上就离开了作用域,但是由于返回了 s 的引用,在 main 函数中就会拿着这个引用,就会出现如下错误
![]()
-总结
最后总结下
-
-- 在任何一个段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用。
-- 引用总是有效的。
-
-]]>
-
- 语言
- Rust
-
-
- Rust
- 所有权
- 内存分布
- 新语言
- 可变引用
- 不可变引用
-
-
-
- rust学习笔记-所有权一
- /2021/04/18/rust%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
- 最近在看 《rust 权威指南》,还是难度比较大的,它里面的一些概念跟之前的用过的都有比较大的差别
比起有 gc 的虚拟机语言,跟像 C 和 C++这种主动释放内存的,rust 有他的独特点,主要是有三条
-
-- Rust中的每一个值都有一个对应的变量作为它的所有者。
-- 在同一时间内,值有且只有一个所有者。
-- 当所有者离开自己的作用域时,它持有的值就会被释放掉。
![]()
这里有两个重点:
-- s 在进入作用域后才变得有效
-- 它会保持自己的有效性直到自己离开作用域为止
-
-然后看个案例
-let x = 5;
-let y = x;
-这个其实有两种,一般可以认为比较多实现的会使用 copy on write 之类的,先让两个都指向同一个快 5 的存储,在发生变更后开始正式拷贝,但是涉及到内存处理的便利性,对于这类简单类型,可以直接拷贝
但是对于非基础类型
-let s1 = String::from("hello");
-let s2 = s1;
+ ttl = dictGetSignedIntegerVal(e)-now;
+ if (activeExpireCycleTryExpire(db,e,now)) expired++;
+ if (ttl > 0) {
+ /* We want the average TTL of keys yet
+ * not expired. */
+ ttl_sum += ttl;
+ ttl_samples++;
+ }
+ sampled++;
+ }
+ }
+ db->expires_cursor++;
+ }
+ total_expired += expired;
+ total_sampled += sampled;
-println!("{}, world!", s1);
-有可能认为有两种内存分布可能
先看下 string 的内存结构
![]()
第一种可能是
![]()
第二种是
![]()
我们来尝试编译下
![]()
发现有这个错误,其实在 rust 中let y = x这个行为的实质是移动,在赋值给 y 之后 x 就无效了
![]()
这样子就不会造成脱离作用域时,对同一块内存区域的二次释放,如果需要复制,可以使用 clone 方法
-let s1 = String::from("hello");
-let s2 = s1.clone();
+ /* Update the average TTL stats for this database. */
+ if (ttl_samples) {
+ long long avg_ttl = ttl_sum/ttl_samples;
-println!("s1 = {}, s2 = {}", s1, s2);
-这里其实会有点疑惑,为什么前面的x, y 的行为跟 s1, s2 的不一样,其实主要是基本类型和 string 这类的不定大小的类型的内存分配方式不同,x, y这类整型可以直接确定大小,可以直接在栈上分配,而像 string 和其他的变体结构体,其大小都是不能在编译时确定,所以需要在堆上进行分配
-]]>
-
- 语言
- Rust
-
-
- Rust
- 所有权
- 内存分布
- 新语言
-
-
-
- spark-little-tips
- /2017/03/28/spark-little-tips/
- spark 的一些粗浅使用经验工作中学习使用了一下Spark做数据分析,主要是用spark的python接口,首先是pyspark.SparkContext(appName=xxx),这是初始化一个Spark应用实例或者说会话,不能重复,
返回的实例句柄就可以调用textFile(path)读取文本文件,这里的文本文件可以是HDFS上的文本文件,也可以普通文本文件,但是需要在Spark的所有集群上都存在,否则会
读取失败,parallelize则可以将python生成的集合数据读取后转换成rdd(A Resilient Distributed Dataset (RDD),一种spark下的基本抽象数据集),基于这个RDD就可以做
数据的流式计算,例如map reduce,在Spark中可以非常方便地实现
-简单的mapreduce word count示例
textFile = sc.parallelize([(1,1), (2,1), (3,1), (4,1), (5,1),(1,1), (2,1), (3,1), (4,1), (5,1)])
-data = textFile.reduceByKey(lambda x, y: x + y).collect()
-for _ in data:
- print(_)
+ /* Do a simple running average with a few samples.
+ * We just use the current estimate with a weight of 2%
+ * and the previous estimate with a weight of 98%. */
+ if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
+ db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
+ }
+ /* We can't block forever here even if there are many keys to
+ * expire. So after a given amount of milliseconds return to the
+ * caller waiting for the other active expire cycle. */
+ if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
+ elapsed = ustime()-start;
+ if (elapsed > timelimit) {
+ timelimit_exit = 1;
+ server.stat_expired_time_cap_reached_count++;
+ break;
+ }
+ }
+ /* We don't repeat the cycle for the current database if there are
+ * an acceptable amount of stale keys (logically expired but yet
+ * not reclained). */
+ } while ((expired*100/sampled) > config_cycle_acceptable_stale);
+ }
-结果
(3, 2)
-(1, 2)
-(4, 2)
-(2, 2)
-(5, 2)
+ elapsed = ustime()-start;
+ server.stat_expire_cycle_time_used += elapsed;
+ latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
+
+ /* Update our estimate of keys existing but yet to be expired.
+ * Running average with this sample accounting for 5%. */
+ double current_perc;
+ if (total_sampled) {
+ current_perc = (double)total_expired/total_sampled;
+ } else
+ current_perc = 0;
+ server.stat_expired_stale_perc = (current_perc*0.05)+
+ (server.stat_expired_stale_perc*0.95);
+}
+执行定期清除分成两种类型,快和慢,分别由beforeSleep和databasesCron调用,快版有两个限制,一个是执行时长由ACTIVE_EXPIRE_CYCLE_FAST_DURATION限制,另一个是执行间隔是 2 倍的ACTIVE_EXPIRE_CYCLE_FAST_DURATION,另外这还可以由配置的server.active_expire_effort参数来控制,默认是 1,最大是 10
+onfig_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
+ ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort
+然后会从一定数量的 db 中找出一定数量的带过期时间的 key(保存在 expires中),这里的数量是由
+config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
+ ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort
+```
+控制,慢速的执行时长是
+```C
+config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
+ 2*effort
+timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
+这里还有一个额外的退出条件,如果当前数据库的抽样结果已经达到我们所允许的过期 key 百分比,则下次不再处理当前 db,继续处理下个 db
]]>
- data analysis
+ Redis
+ 数据结构
+ C
+ 源码
+ Redis
- spark
- python
+ redis
+ 数据结构
+ 源码
- mybatis系列-mybatis是如何初始化mapper的
- /2022/12/04/mybatis%E6%98%AF%E5%A6%82%E4%BD%95%E5%88%9D%E5%A7%8B%E5%8C%96mapper%E7%9A%84/
- 前一篇讲了mybatis的初始化使用,如果我第一次看到这个使用入门文档,比较会产生疑惑的是配置了mapper,怎么就能通过selectOne跟语句id就能执行sql了,那么第一个问题,就是mapper是怎么被解析的,存在哪里,怎么被拿出来的
-添加解析mapper
org.apache.ibatis.session.SqlSessionFactoryBuilder#build(java.io.InputStream)
-public SqlSessionFactory build(InputStream inputStream) {
- return build(inputStream, null, null);
-}
-
-通过读取mybatis-config.xml来构建SqlSessionFactory,
-public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
- try {
- // 创建下xml的解析器
- XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
- // 进行解析,后再构建
- return build(parser.parse());
- } catch (Exception e) {
- throw ExceptionFactory.wrapException("Error building SqlSession.", e);
- } finally {
- ErrorContext.instance().reset();
- try {
- if (inputStream != null) {
- inputStream.close();
- }
- } catch (IOException e) {
- // Intentionally ignore. Prefer previous error.
- }
- }
-
-创建XMLConfigBuilder
-public XMLConfigBuilder(InputStream inputStream, String environment, Properties props) {
- // --------> 创建 XPathParser
- this(new XPathParser(inputStream, true, props, new XMLMapperEntityResolver()), environment, props);
-}
-
-public XPathParser(InputStream inputStream, boolean validation, Properties variables, EntityResolver entityResolver) {
- commonConstructor(validation, variables, entityResolver);
- this.document = createDocument(new InputSource(inputStream));
- }
-
-private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
- super(new Configuration());
- ErrorContext.instance().resource("SQL Mapper Configuration");
- this.configuration.setVariables(props);
- this.parsed = false;
- this.environment = environment;
- this.parser = parser;
-}
-
-这里主要是创建了Builder包含了Parser
然后调用parse方法
-public Configuration parse() {
- if (parsed) {
- throw new BuilderException("Each XMLConfigBuilder can only be used once.");
- }
- // 标记下是否已解析,但是这里是否有线程安全问题
- parsed = true;
- // --------> 解析配置
- parseConfiguration(parser.evalNode("/configuration"));
- return configuration;
-}
-
-实际的解析区分了各类标签
-private void parseConfiguration(XNode root) {
- try {
- // issue #117 read properties first
- // 解析properties,这个不是spring自带的,需要额外配置,并且在config文件里应该放在最前
- propertiesElement(root.evalNode("properties"));
- Properties settings = settingsAsProperties(root.evalNode("settings"));
- loadCustomVfs(settings);
- loadCustomLogImpl(settings);
- typeAliasesElement(root.evalNode("typeAliases"));
- pluginElement(root.evalNode("plugins"));
- objectFactoryElement(root.evalNode("objectFactory"));
- objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
- reflectorFactoryElement(root.evalNode("reflectorFactory"));
- settingsElement(settings);
- // read it after objectFactory and objectWrapperFactory issue #631
- environmentsElement(root.evalNode("environments"));
- databaseIdProviderElement(root.evalNode("databaseIdProvider"));
- typeHandlerElement(root.evalNode("typeHandlers"));
- // ----------> 我们需要关注的是mapper的处理
- mapperElement(root.evalNode("mappers"));
- } catch (Exception e) {
- throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
- }
-}
+ redis系列介绍八-淘汰策略
+ /2020/04/18/redis%E7%B3%BB%E5%88%97%E4%BB%8B%E7%BB%8D%E5%85%AB/
+ LRU说完了过期策略再说下淘汰策略,redis 使用的策略是近似的 lru 策略,为什么是近似的呢,先来看下什么是 lru,看下 wiki 的介绍
![]() ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
当第一次访问 D 时刚好占满了坑,并且值是 4,这个值越小代表越先被淘汰,当 E 进来时,看了下已经存在的四个里 A 是最小的,代表是最早存在并且最早被访问的,那就先淘汰它了,E 占领了 A 的位置,并设置值为 4,然后又访问 D 了,D 已经存在了,不过又被访问到了,得更新值为 5,然后是 F 进来了,这时 B 是最老的且最近未被访问,所以就淘汰它了。以上是一个 lru 的简要说明,但是 redis 没有严格按照这个去执行,理由跟前面过期策略一致,最严格的过期策略应该是每个 key 都有对应的定时器,当超时时马上就能清除,但是问题是这样的cpu 消耗太大,所换来的内存效率不太值得,淘汰策略也是这样,类似于上图,要维护所有 key 的一个有序 lru 值,并且遍历将最小的淘汰,redis 采用的是抽样的形式,最初的实现方式是随机从 dict 抽取 5 个 key,淘汰一个 lru 最小的,这样子勉强能达到淘汰的目的,但是效果不是特别好,后面在 redis 3.0开始,将随机抽取改成了维护一个 pool,pool 的大小默认是 16,每次放入的都是按lru 值有序排列好,每一次放入的必须是 lru小于 pool 中最小的 lru 才允许放入,直到放满,后面再有新的就会将大的踢出。
redis 针对这个策略的改进做了一个实验,这里借用下图
![]()
首先背景是这图中的所有点都对应一个 redis 的 key,灰色部分加入后被顺序访问过一遍,然后又加入了绿色部分,那么按照理论的 lru 算法,应该是图左上中,浅灰色部分全都被淘汰,那么对比来看看图右上,左下和右下,左下表示 2.8 版本就是随机抽样 5 个 key,淘汰其中 lru 最小的一个,发现是灰色和浅灰色的都有被淘汰的,右下的 3.0 版本抽样数量不变的情况下,稍好一些,当 3.0 版本的抽样数量调整成 10 后,已经较为接近理论上的 lru 策略了,通过代码来简要分析下
+typedef struct redisObject {
+ unsigned type:4;
+ unsigned encoding:4;
+ unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
+ * LFU data (least significant 8 bits frequency
+ * and most significant 16 bits access time). */
+ int refcount;
+ void *ptr;
+} robj;
+对于 lru 策略来说,lru 字段记录的就是redisObj 的LRU time,
redis 在访问数据时,都会调用lookupKey方法
+/* Low level key lookup API, not actually called directly from commands
+ * implementations that should instead rely on lookupKeyRead(),
+ * lookupKeyWrite() and lookupKeyReadWithFlags(). */
+robj *lookupKey(redisDb *db, robj *key, int flags) {
+ dictEntry *de = dictFind(db->dict,key->ptr);
+ if (de) {
+ robj *val = dictGetVal(de);
-然后就是调用到mapperElement方法了
-private void mapperElement(XNode parent) throws Exception {
- if (parent != null) {
- for (XNode child : parent.getChildren()) {
- if ("package".equals(child.getName())) {
- String mapperPackage = child.getStringAttribute("name");
- configuration.addMappers(mapperPackage);
- } else {
- String resource = child.getStringAttribute("resource");
- String url = child.getStringAttribute("url");
- String mapperClass = child.getStringAttribute("class");
- if (resource != null && url == null && mapperClass == null) {
- ErrorContext.instance().resource(resource);
- try(InputStream inputStream = Resources.getResourceAsStream(resource)) {
- XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
- // --------> 我们这没有指定package,所以是走到这
- mapperParser.parse();
- }
- } else if (resource == null && url != null && mapperClass == null) {
- ErrorContext.instance().resource(url);
- try(InputStream inputStream = Resources.getUrlAsStream(url)){
- XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
- mapperParser.parse();
- }
- } else if (resource == null && url == null && mapperClass != null) {
- Class<?> mapperInterface = Resources.classForName(mapperClass);
- configuration.addMapper(mapperInterface);
- } else {
- throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
- }
- }
- }
- }
-}
+ /* Update the access time for the ageing algorithm.
+ * Don't do it if we have a saving child, as this will trigger
+ * a copy on write madness. */
+ if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
+ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
+ // 这个是后面一节的内容
+ updateLFU(val);
+ } else {
+ // 对于这个分支,访问时就会去更新 lru 值
+ val->lru = LRU_CLOCK();
+ }
+ }
+ return val;
+ } else {
+ return NULL;
+ }
+}
+/* This function is used to obtain the current LRU clock.
+ * If the current resolution is lower than the frequency we refresh the
+ * LRU clock (as it should be in production servers) we return the
+ * precomputed value, otherwise we need to resort to a system call. */
+unsigned int LRU_CLOCK(void) {
+ unsigned int lruclock;
+ if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
+ // 如果服务器的频率server.hz大于 1 时就是用系统预设的 lruclock
+ lruclock = server.lruclock;
+ } else {
+ lruclock = getLRUClock();
+ }
+ return lruclock;
+}
+/* Return the LRU clock, based on the clock resolution. This is a time
+ * in a reduced-bits format that can be used to set and check the
+ * object->lru field of redisObject structures. */
+unsigned int getLRUClock(void) {
+ return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
+}
+redis 处理命令是在这里processCommand
+/* If this function gets called we already read a whole
+ * command, arguments are in the client argv/argc fields.
+ * processCommand() execute the command or prepare the
+ * server for a bulk read from the client.
+ *
+ * If C_OK is returned the client is still alive and valid and
+ * other operations can be performed by the caller. Otherwise
+ * if C_ERR is returned the client was destroyed (i.e. after QUIT). */
+int processCommand(client *c) {
+ moduleCallCommandFilters(c);
-核心就在这个parse()方法
-public void parse() {
- if (!configuration.isResourceLoaded(resource)) {
- // -------> 然后就是走到这里,配置xml的mapper节点的内容
- configurationElement(parser.evalNode("/mapper"));
- configuration.addLoadedResource(resource);
- bindMapperForNamespace();
- }
+
- parsePendingResultMaps();
- parsePendingCacheRefs();
- parsePendingStatements();
-}
+ /* Handle the maxmemory directive.
+ *
+ * Note that we do not want to reclaim memory if we are here re-entering
+ * the event loop since there is a busy Lua script running in timeout
+ * condition, to avoid mixing the propagation of scripts with the
+ * propagation of DELs due to eviction. */
+ if (server.maxmemory && !server.lua_timedout) {
+ int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
+ /* freeMemoryIfNeeded may flush slave output buffers. This may result
+ * into a slave, that may be the active client, to be freed. */
+ if (server.current_client == NULL) return C_ERR;
-具体的处理逻辑
-private void configurationElement(XNode context) {
- try {
- String namespace = context.getStringAttribute("namespace");
- if (namespace == null || namespace.isEmpty()) {
- throw new BuilderException("Mapper's namespace cannot be empty");
- }
- builderAssistant.setCurrentNamespace(namespace);
- cacheRefElement(context.evalNode("cache-ref"));
- cacheElement(context.evalNode("cache"));
- parameterMapElement(context.evalNodes("/mapper/parameterMap"));
- resultMapElements(context.evalNodes("/mapper/resultMap"));
- sqlElement(context.evalNodes("/mapper/sql"));
- // -------> 走到这,从上下文构建statement
- buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
- } catch (Exception e) {
- throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
- }
-}
+ /* It was impossible to free enough memory, and the command the client
+ * is trying to execute is denied during OOM conditions or the client
+ * is in MULTI/EXEC context? Error. */
+ if (out_of_memory &&
+ (c->cmd->flags & CMD_DENYOOM ||
+ (c->flags & CLIENT_MULTI &&
+ c->cmd->proc != execCommand &&
+ c->cmd->proc != discardCommand)))
+ {
+ flagTransaction(c);
+ addReply(c, shared.oomerr);
+ return C_OK;
+ }
+ }
+}
+这里只摘了部分,当需要清理内存时就会调用, 然后调用了freeMemoryIfNeededAndSafe
+/* This is a wrapper for freeMemoryIfNeeded() that only really calls the
+ * function if right now there are the conditions to do so safely:
+ *
+ * - There must be no script in timeout condition.
+ * - Nor we are loading data right now.
+ *
+ */
+int freeMemoryIfNeededAndSafe(void) {
+ if (server.lua_timedout || server.loading) return C_OK;
+ return freeMemoryIfNeeded();
+}
+/* This function is periodically called to see if there is memory to free
+ * according to the current "maxmemory" settings. In case we are over the
+ * memory limit, the function will try to free some memory to return back
+ * under the limit.
+ *
+ * The function returns C_OK if we are under the memory limit or if we
+ * were over the limit, but the attempt to free memory was successful.
+ * Otehrwise if we are over the memory limit, but not enough memory
+ * was freed to return back under the limit, the function returns C_ERR. */
+int freeMemoryIfNeeded(void) {
+ int keys_freed = 0;
+ /* By default replicas should ignore maxmemory
+ * and just be masters exact copies. */
+ if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
-具体代码在这,从上下文构建statement,只不过区分了下databaseId
-private void buildStatementFromContext(List<XNode> list) {
- if (configuration.getDatabaseId() != null) {
- buildStatementFromContext(list, configuration.getDatabaseId());
- }
- // -----> 判断databaseId
- buildStatementFromContext(list, null);
-}
+ size_t mem_reported, mem_tofree, mem_freed;
+ mstime_t latency, eviction_latency;
+ long long delta;
+ int slaves = listLength(server.slaves);
-判断下databaseId
-private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
- for (XNode context : list) {
- final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
- try {
- // -------> 解析statement节点
- statementParser.parseStatementNode();
- } catch (IncompleteElementException e) {
- configuration.addIncompleteStatement(statementParser);
- }
- }
-}
+ /* When clients are paused the dataset should be static not just from the
+ * POV of clients not being able to write, but also from the POV of
+ * expires and evictions of keys not being performed. */
+ if (clientsArePaused()) return C_OK;
+ if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
+ return C_OK;
-接下来就是真正处理的xml语句内容的,各个节点的信息内容
-public void parseStatementNode() {
- String id = context.getStringAttribute("id");
- String databaseId = context.getStringAttribute("databaseId");
+ mem_freed = 0;
- if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
- return;
- }
+ if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
+ goto cant_free; /* We need to free memory, but policy forbids. */
- String nodeName = context.getNode().getNodeName();
- SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
- boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
- boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
- boolean useCache = context.getBooleanAttribute("useCache", isSelect);
- boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
+ latencyStartMonitor(latency);
+ while (mem_freed < mem_tofree) {
+ int j, k, i;
+ static unsigned int next_db = 0;
+ sds bestkey = NULL;
+ int bestdbid;
+ redisDb *db;
+ dict *dict;
+ dictEntry *de;
- // Include Fragments before parsing
- XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
- includeParser.applyIncludes(context.getNode());
+ if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
+ server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
+ {
+ struct evictionPoolEntry *pool = EvictionPoolLRU;
- String parameterType = context.getStringAttribute("parameterType");
- Class<?> parameterTypeClass = resolveClass(parameterType);
+ while(bestkey == NULL) {
+ unsigned long total_keys = 0, keys;
- String lang = context.getStringAttribute("lang");
- LanguageDriver langDriver = getLanguageDriver(lang);
+ /* We don't want to make local-db choices when expiring keys,
+ * so to start populate the eviction pool sampling keys from
+ * every DB. */
+ for (i = 0; i < server.dbnum; i++) {
+ db = server.db+i;
+ dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
+ db->dict : db->expires;
+ if ((keys = dictSize(dict)) != 0) {
+ evictionPoolPopulate(i, dict, db->dict, pool);
+ total_keys += keys;
+ }
+ }
+ if (!total_keys) break; /* No keys to evict. */
- // Parse selectKey after includes and remove them.
- processSelectKeyNodes(id, parameterTypeClass, langDriver);
+ /* Go backward from best to worst element to evict. */
+ for (k = EVPOOL_SIZE-1; k >= 0; k--) {
+ if (pool[k].key == NULL) continue;
+ bestdbid = pool[k].dbid;
- // Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
- KeyGenerator keyGenerator;
- String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
- keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
- if (configuration.hasKeyGenerator(keyStatementId)) {
- keyGenerator = configuration.getKeyGenerator(keyStatementId);
- } else {
- keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
- configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
- ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
- }
+ if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
+ de = dictFind(server.db[pool[k].dbid].dict,
+ pool[k].key);
+ } else {
+ de = dictFind(server.db[pool[k].dbid].expires,
+ pool[k].key);
+ }
- // 语句的主要参数解析
- SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
- StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
- Integer fetchSize = context.getIntAttribute("fetchSize");
- Integer timeout = context.getIntAttribute("timeout");
- String parameterMap = context.getStringAttribute("parameterMap");
- String resultType = context.getStringAttribute("resultType");
- Class<?> resultTypeClass = resolveClass(resultType);
- String resultMap = context.getStringAttribute("resultMap");
- String resultSetType = context.getStringAttribute("resultSetType");
- ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
- if (resultSetTypeEnum == null) {
- resultSetTypeEnum = configuration.getDefaultResultSetType();
- }
- String keyProperty = context.getStringAttribute("keyProperty");
- String keyColumn = context.getStringAttribute("keyColumn");
- String resultSets = context.getStringAttribute("resultSets");
+ /* Remove the entry from the pool. */
+ if (pool[k].key != pool[k].cached)
+ sdsfree(pool[k].key);
+ pool[k].key = NULL;
+ pool[k].idle = 0;
- // --------> 添加映射的statement
- builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
- fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
- resultSetTypeEnum, flushCache, useCache, resultOrdered,
- keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
-}
+ /* If the key exists, is our pick. Otherwise it is
+ * a ghost and we need to try the next element. */
+ if (de) {
+ bestkey = dictGetKey(de);
+ break;
+ } else {
+ /* Ghost... Iterate again. */
+ }
+ }
+ }
+ }
+ /* volatile-random and allkeys-random policy */
+ else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
+ server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
+ {
+ /* When evicting a random key, we try to evict a key for
+ * each DB, so we use the static 'next_db' variable to
+ * incrementally visit all DBs. */
+ for (i = 0; i < server.dbnum; i++) {
+ j = (++next_db) % server.dbnum;
+ db = server.db+j;
+ dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?
+ db->dict : db->expires;
+ if (dictSize(dict) != 0) {
+ de = dictGetRandomKey(dict);
+ bestkey = dictGetKey(de);
+ bestdbid = j;
+ break;
+ }
+ }
+ }
-添加的逻辑具体可以看下
-public MappedStatement addMappedStatement(
- String id,
- SqlSource sqlSource,
- StatementType statementType,
- SqlCommandType sqlCommandType,
- Integer fetchSize,
- Integer timeout,
- String parameterMap,
- Class<?> parameterType,
- String resultMap,
- Class<?> resultType,
- ResultSetType resultSetType,
- boolean flushCache,
- boolean useCache,
- boolean resultOrdered,
- KeyGenerator keyGenerator,
- String keyProperty,
- String keyColumn,
- String databaseId,
- LanguageDriver lang,
- String resultSets) {
+ /* Finally remove the selected key. */
+ if (bestkey) {
+ db = server.db+bestdbid;
+ robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
+ propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
+ /* We compute the amount of memory freed by db*Delete() alone.
+ * It is possible that actually the memory needed to propagate
+ * the DEL in AOF and replication link is greater than the one
+ * we are freeing removing the key, but we can't account for
+ * that otherwise we would never exit the loop.
+ *
+ * AOF and Output buffer memory will be freed eventually so
+ * we only care about memory used by the key space. */
+ delta = (long long) zmalloc_used_memory();
+ latencyStartMonitor(eviction_latency);
+ if (server.lazyfree_lazy_eviction)
+ dbAsyncDelete(db,keyobj);
+ else
+ dbSyncDelete(db,keyobj);
+ latencyEndMonitor(eviction_latency);
+ latencyAddSampleIfNeeded("eviction-del",eviction_latency);
+ latencyRemoveNestedEvent(latency,eviction_latency);
+ delta -= (long long) zmalloc_used_memory();
+ mem_freed += delta;
+ server.stat_evictedkeys++;
+ notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted",
+ keyobj, db->id);
+ decrRefCount(keyobj);
+ keys_freed++;
- if (unresolvedCacheRef) {
- throw new IncompleteElementException("Cache-ref not yet resolved");
- }
+ /* When the memory to free starts to be big enough, we may
+ * start spending so much time here that is impossible to
+ * deliver data to the slaves fast enough, so we force the
+ * transmission here inside the loop. */
+ if (slaves) flushSlavesOutputBuffers();
- id = applyCurrentNamespace(id, false);
- boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
+ /* Normally our stop condition is the ability to release
+ * a fixed, pre-computed amount of memory. However when we
+ * are deleting objects in another thread, it's better to
+ * check, from time to time, if we already reached our target
+ * memory, since the "mem_freed" amount is computed only
+ * across the dbAsyncDelete() call, while the thread can
+ * release the memory all the time. */
+ if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) {
+ if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
+ /* Let's satisfy our stop condition. */
+ mem_freed = mem_tofree;
+ }
+ }
+ } else {
+ latencyEndMonitor(latency);
+ latencyAddSampleIfNeeded("eviction-cycle",latency);
+ goto cant_free; /* nothing to free... */
+ }
+ }
+ latencyEndMonitor(latency);
+ latencyAddSampleIfNeeded("eviction-cycle",latency);
+ return C_OK;
- MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
- .resource(resource)
- .fetchSize(fetchSize)
- .timeout(timeout)
- .statementType(statementType)
- .keyGenerator(keyGenerator)
- .keyProperty(keyProperty)
- .keyColumn(keyColumn)
- .databaseId(databaseId)
- .lang(lang)
- .resultOrdered(resultOrdered)
- .resultSets(resultSets)
- .resultMaps(getStatementResultMaps(resultMap, resultType, id))
- .resultSetType(resultSetType)
- .flushCacheRequired(valueOrDefault(flushCache, !isSelect))
- .useCache(valueOrDefault(useCache, isSelect))
- .cache(currentCache);
+cant_free:
+ /* We are here if we are not able to reclaim memory. There is only one
+ * last thing we can try: check if the lazyfree thread has jobs in queue
+ * and wait... */
+ while(bioPendingJobsOfType(BIO_LAZY_FREE)) {
+ if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree)
+ break;
+ usleep(1000);
+ }
+ return C_ERR;
+}
+这里就是根据具体策略去淘汰 key,首先是要往 pool 更新 key,更新key 的方法是evictionPoolPopulate
+void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
+ int j, k, count;
+ dictEntry *samples[server.maxmemory_samples];
- ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
- if (statementParameterMap != null) {
- statementBuilder.parameterMap(statementParameterMap);
- }
+ count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
+ for (j = 0; j < count; j++) {
+ unsigned long long idle;
+ sds key;
+ robj *o;
+ dictEntry *de;
- MappedStatement statement = statementBuilder.build();
- // ------> 正好是这里在configuration中添加了映射好的statement
- configuration.addMappedStatement(statement);
- return statement;
-}
+ de = samples[j];
+ key = dictGetKey(de);
-而里面就是往map里添加
-public void addMappedStatement(MappedStatement ms) {
- mappedStatements.put(ms.getId(), ms);
-}
+ /* If the dictionary we are sampling from is not the main
+ * dictionary (but the expires one) we need to lookup the key
+ * again in the key dictionary to obtain the value object. */
+ if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
+ if (sampledict != keydict) de = dictFind(keydict, key);
+ o = dictGetVal(de);
+ }
-获取mapper
StudentDO studentDO = session.selectOne("com.nicksxs.mybatisdemo.StudentMapper.selectStudent", 1);
+ /* Calculate the idle time according to the policy. This is called
+ * idle just because the code initially handled LRU, but is in fact
+ * just a score where an higher score means better candidate. */
+ if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
+ idle = estimateObjectIdleTime(o);
+ } else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
+ /* When we use an LRU policy, we sort the keys by idle time
+ * so that we expire keys starting from greater idle time.
+ * However when the policy is an LFU one, we have a frequency
+ * estimation, and we want to evict keys with lower frequency
+ * first. So inside the pool we put objects using the inverted
+ * frequency subtracting the actual frequency to the maximum
+ * frequency of 255. */
+ idle = 255-LFUDecrAndReturn(o);
+ } else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
+ /* In this case the sooner the expire the better. */
+ idle = ULLONG_MAX - (long)dictGetVal(de);
+ } else {
+ serverPanic("Unknown eviction policy in evictionPoolPopulate()");
+ }
-就是调用了 org.apache.ibatis.session.defaults.DefaultSqlSession#selectOne(java.lang.String, java.lang.Object)
-public <T> T selectOne(String statement, Object parameter) {
- // Popular vote was to return null on 0 results and throw exception on too many.
- List<T> list = this.selectList(statement, parameter);
- if (list.size() == 1) {
- return list.get(0);
- } else if (list.size() > 1) {
- throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
- } else {
- return null;
- }
-}
+ /* Insert the element inside the pool.
+ * First, find the first empty bucket or the first populated
+ * bucket that has an idle time smaller than our idle time. */
+ k = 0;
+ while (k < EVPOOL_SIZE &&
+ pool[k].key &&
+ pool[k].idle < idle) k++;
+ if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
+ /* Can't insert if the element is < the worst element we have
+ * and there are no empty buckets. */
+ continue;
+ } else if (k < EVPOOL_SIZE && pool[k].key == NULL) {
+ /* Inserting into empty position. No setup needed before insert. */
+ } else {
+ /* Inserting in the middle. Now k points to the first element
+ * greater than the element to insert. */
+ if (pool[EVPOOL_SIZE-1].key == NULL) {
+ /* Free space on the right? Insert at k shifting
+ * all the elements from k to end to the right. */
-调用实际的实现方法
-public <E> List<E> selectList(String statement, Object parameter) {
- return this.selectList(statement, parameter, RowBounds.DEFAULT);
-}
+ /* Save SDS before overwriting. */
+ sds cached = pool[EVPOOL_SIZE-1].cached;
+ memmove(pool+k+1,pool+k,
+ sizeof(pool[0])*(EVPOOL_SIZE-k-1));
+ pool[k].cached = cached;
+ } else {
+ /* No free space on right? Insert at k-1 */
+ k--;
+ /* Shift all elements on the left of k (included) to the
+ * left, so we discard the element with smaller idle time. */
+ sds cached = pool[0].cached; /* Save SDS before overwriting. */
+ if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
+ memmove(pool,pool+1,sizeof(pool[0])*k);
+ pool[k].cached = cached;
+ }
+ }
-这里还有一层
-public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
- return selectList(statement, parameter, rowBounds, Executor.NO_RESULT_HANDLER);
-}
+ /* Try to reuse the cached SDS string allocated in the pool entry,
+ * because allocating and deallocating this object is costly
+ * (according to the profiler, not my fantasy. Remember:
+ * premature optimizbla bla bla bla. */
+ int klen = sdslen(key);
+ if (klen > EVPOOL_CACHED_SDS_SIZE) {
+ pool[k].key = sdsdup(key);
+ } else {
+ memcpy(pool[k].cached,key,klen+1);
+ sdssetlen(pool[k].cached,klen);
+ pool[k].key = pool[k].cached;
+ }
+ pool[k].idle = idle;
+ pool[k].dbid = dbid;
+ }
+}
+Redis随机选择maxmemory_samples数量的key,然后计算这些key的空闲时间idle time,当满足条件时(比pool中的某些键的空闲时间还大)就可以进pool。pool更新之后,就淘汰pool中空闲时间最大的键。
+estimateObjectIdleTime用来计算Redis对象的空闲时间:
+/* Given an object returns the min number of milliseconds the object was never
+ * requested, using an approximated LRU algorithm. */
+unsigned long long estimateObjectIdleTime(robj *o) {
+ unsigned long long lruclock = LRU_CLOCK();
+ if (lruclock >= o->lru) {
+ return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
+ } else {
+ return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
+ LRU_CLOCK_RESOLUTION;
+ }
+}
+空闲时间第一种是 lurclock 大于对象的 lru,那么就是减一下乘以精度,因为 lruclock 有可能是已经预生成的,所以会可能走下面这个
+LFU
上面介绍了LRU 的算法,但是考虑一种场景
+~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~|
+~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~|
+~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~~|
+~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D|
+可以发现,当采用 lru 的淘汰策略的时候,D 是最新的,会被认为是最值得保留的,但是事实上还不如 A 跟 B,然后 antirez 大神就想到了LFU (Least Frequently Used) 这个算法, 显然对于上面的四个 key 的访问频率,保留优先级应该是 B > A > C = D
那要怎么来实现这个 LFU 算法呢,其实像LRU,理想的情况就是维护个链表,把最新访问的放到头上去,但是这个会影响访问速度,注意到前面代码的应该可以看到,redisObject 的 lru 字段其实是两用的,当策略是 LFU 时,这个字段就另作他用了,它的 24 位长度被分成两部分
+ 16 bits 8 bits
++----------------+--------+
++ Last decr time | LOG_C |
++----------------+--------+
+前16位字段是最后一次递减时间,因此Redis知道 上一次计数器递减,后8位是 计数器 counter。
LFU 的主体策略就是当这个 key 被访问的次数越多频率越高他就越容易被保留下来,并且是最近被访问的频率越高。这其实有两个事情要做,一个是在访问的时候增加计数值,在一定长时间不访问时进行衰减,所以这里用了两个值,前 16 位记录上一次衰减的时间,后 8 位记录具体的计数值。
Redis4.0之后为maxmemory_policy淘汰策略添加了两个LFU模式:
+volatile-lfu:对有过期时间的key采用LFU淘汰策略
allkeys-lfu:对全部key采用LFU淘汰策略
还有2个配置可以调整LFU算法:
+lfu-log-factor 10
+lfu-decay-time 1
+```
+`lfu-log-factor` 可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
+`lfu-decay-time`是一个以分钟为单位的数值,可以调整counter的减少速度
+这里有个问题是 8 位大小够计么,访问一次加 1 的话的确不够,不过大神就是大神,才不会这么简单的加一。往下看代码
+```C
+/* Low level key lookup API, not actually called directly from commands
+ * implementations that should instead rely on lookupKeyRead(),
+ * lookupKeyWrite() and lookupKeyReadWithFlags(). */
+robj *lookupKey(redisDb *db, robj *key, int flags) {
+ dictEntry *de = dictFind(db->dict,key->ptr);
+ if (de) {
+ robj *val = dictGetVal(de);
-根本的就是从configuration里获取了mappedStatement
-private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
- try {
- // 这里进行了获取
- MappedStatement ms = configuration.getMappedStatement(statement);
- return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
- } catch (Exception e) {
- throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
- } finally {
- ErrorContext.instance().reset();
- }
-}
+ /* Update the access time for the ageing algorithm.
+ * Don't do it if we have a saving child, as this will trigger
+ * a copy on write madness. */
+ if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
+ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
+ // 当淘汰策略是 LFU 时,就会调用这个updateLFU
+ updateLFU(val);
+ } else {
+ val->lru = LRU_CLOCK();
+ }
+ }
+ return val;
+ } else {
+ return NULL;
+ }
+}
+updateLFU 这个其实个入口,调用了两个重要的方法
+/* Update LFU when an object is accessed.
+ * Firstly, decrement the counter if the decrement time is reached.
+ * Then logarithmically increment the counter, and update the access time. */
+void updateLFU(robj *val) {
+ unsigned long counter = LFUDecrAndReturn(val);
+ counter = LFULogIncr(counter);
+ val->lru = (LFUGetTimeInMinutes()<<8) | counter;
+}
+首先来看看LFUDecrAndReturn,这个方法的作用是根据上一次衰减时间和系统配置的 lfu-decay-time 参数来确定需要将 counter 减去多少
+/* If the object decrement time is reached decrement the LFU counter but
+ * do not update LFU fields of the object, we update the access time
+ * and counter in an explicit way when the object is really accessed.
+ * And we will times halve the counter according to the times of
+ * elapsed time than server.lfu_decay_time.
+ * Return the object frequency counter.
+ *
+ * This function is used in order to scan the dataset for the best object
+ * to fit: as we check for the candidate, we incrementally decrement the
+ * counter of the scanned objects if needed. */
+unsigned long LFUDecrAndReturn(robj *o) {
+ // 右移 8 位,拿到上次衰减时间
+ unsigned long ldt = o->lru >> 8;
+ // 对 255 做与操作,拿到 counter 值
+ unsigned long counter = o->lru & 255;
+ // 根据lfu_decay_time来算出过了多少个衰减周期
+ unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
+ if (num_periods)
+ counter = (num_periods > counter) ? 0 : counter - num_periods;
+ return counter;
+}
+然后是加,调用了LFULogIncr
+/* Logarithmically increment a counter. The greater is the current counter value
+ * the less likely is that it gets really implemented. Saturate it at 255. */
+uint8_t LFULogIncr(uint8_t counter) {
+ // 最大值就是 255,到顶了就不加了
+ if (counter == 255) return 255;
+ // 生成个随机小数
+ double r = (double)rand()/RAND_MAX;
+ // 减去个基础值,LFU_INIT_VAL = 5,防止刚进来就被逐出
+ double baseval = counter - LFU_INIT_VAL;
+ // 如果是小于 0,
+ if (baseval < 0) baseval = 0;
+ // 如果 baseval 是 0,那么 p 就是 1了,后面 counter 直接加一,如果不是的话,得看系统参数lfu_log_factor,这个越大,除出来的 p 越小,那么 counter++的可能性也越小,这样子就把前面的疑问给解决了,不是直接+1 的
+ double p = 1.0/(baseval*server.lfu_log_factor+1);
+ if (r < p) counter++;
+ return counter;
+}
+大概的变化速度可以参考
++--------+------------+------------+------------+------------+------------+
+| factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
++--------+------------+------------+------------+------------+------------+
+| 0 | 104 | 255 | 255 | 255 | 255 |
++--------+------------+------------+------------+------------+------------+
+| 1 | 18 | 49 | 255 | 255 | 255 |
++--------+------------+------------+------------+------------+------------+
+| 10 | 10 | 18 | 142 | 255 | 255 |
++--------+------------+------------+------------+------------+------------+
+| 100 | 8 | 11 | 49 | 143 | 255 |
++--------+------------+------------+------------+------------+------------+
+简而言之就是 lfu_log_factor 越大变化的越慢
+总结
总结一下,redis 实现了近似的 lru 淘汰策略,通过增加了淘汰 key 的池子(pool),并且增大每次抽样的 key 的数量来将淘汰效果更进一步地接近于 lru,这是 lru 策略,但是对于前面举的一个例子,其实 lru 并不能保证 key 的淘汰就如我们预期,所以在后期又引入了 lfu 的策略,lfu的策略比较巧妙,复用了 redis 对象的 lru 字段,并且使用了factor 参数来控制计数器递增的速度,防止 8 位的计数器太早溢出。
]]>
- Java
- Mybatis
+ Redis
+ 数据结构
+ C
+ 源码
+ Redis
- Java
- Mysql
- Mybatis
+ redis
+ 数据结构
+ 源码
- mybatis系列-foreach 解析
- /2023/06/11/mybatis%E7%B3%BB%E5%88%97-foreach-%E8%A7%A3%E6%9E%90/
- 在 org.apache.ibatis.builder.xml.XMLConfigBuilder#parseConfiguration 中进行配置解析,其中这一行就是解析 mappers
-mapperElement(root.evalNode("mappers"));
-具体的代码会执行到这
-private void mapperElement(XNode parent) throws Exception {
- if (parent != null) {
- for (XNode child : parent.getChildren()) {
- if ("package".equals(child.getName())) {
- // 这里解析的不是 package
- String mapperPackage = child.getStringAttribute("name");
- configuration.addMappers(mapperPackage);
- } else {
- // 根据 resource 和 url 还有 mapperClass 判断
- String resource = child.getStringAttribute("resource");
- String url = child.getStringAttribute("url");
- String mapperClass = child.getStringAttribute("class");
- // resource 不为空其他为空的情况,就开始将 resource 读成输入流
- if (resource != null && url == null && mapperClass == null) {
- ErrorContext.instance().resource(resource);
- try(InputStream inputStream = Resources.getResourceAsStream(resource)) {
- // 初始化 XMLMapperBuilder 来解析 mapper
- XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
- mapperParser.parse();
- }
-然后再是 parse 过程
-public void parse() {
- if (!configuration.isResourceLoaded(resource)) {
- // 解析 mapper 节点,也就是下图中的mapper
- configurationElement(parser.evalNode("/mapper"));
- configuration.addLoadedResource(resource);
- bindMapperForNamespace();
- }
+ redis过期策略复习
+ /2021/07/25/redis%E8%BF%87%E6%9C%9F%E7%AD%96%E7%95%A5%E5%A4%8D%E4%B9%A0/
+ redis过期策略复习之前其实写过redis的过期的一些原理,这次主要是记录下,一些使用上的概念,主要是redis使用的过期策略是懒过期和定时清除,懒过期的其实比较简单,即是在key被访问的时候会顺带着判断下这个key是否已过期了,如果已经过期了,就不返回了,但是这种策略有个漏洞是如果有些key之后一直不会被访问了,就等于沉在池底了,所以需要有一个定时的清理机制,去从设置了过期的key池子(expires)里随机地捞key,具体的策略我们看下官网的解释
+
+- Test 20 random keys from the set of keys with an associated expire.
+- Delete all the keys found expired.
+- If more than 25% of keys were expired, start again from step 1.
+
+从池子里随机获取20个key,将其中过期的key删掉,如果这其中有超过25%的key已经过期了,那就再来一次,以此保持过期的key不超过25%(左右),并且这个定时策略可以在redis的配置文件
+# Redis calls an internal function to perform many background tasks, like
+# closing connections of clients in timeout, purging expired keys that are
+# never requested, and so forth.
+#
+# Not all tasks are performed with the same frequency, but Redis checks for
+# tasks to perform according to the specified "hz" value.
+#
+# By default "hz" is set to 10. Raising the value will use more CPU when
+# Redis is idle, but at the same time will make Redis more responsive when
+# there are many keys expiring at the same time, and timeouts may be
+# handled with more precision.
+#
+# The range is between 1 and 500, however a value over 100 is usually not
+# a good idea. Most users should use the default of 10 and raise this up to
+# 100 only in environments where very low latency is required.
+hz 10
- parsePendingResultMaps();
- parsePendingCacheRefs();
- parsePendingStatements();
-}
-![image]()
-继续往下走
-private void configurationElement(XNode context) {
- try {
- String namespace = context.getStringAttribute("namespace");
- if (namespace == null || namespace.isEmpty()) {
- throw new BuilderException("Mapper's namespace cannot be empty");
- }
- builderAssistant.setCurrentNamespace(namespace);
- // 处理cache 和 cache 应用
- cacheRefElement(context.evalNode("cache-ref"));
- cacheElement(context.evalNode("cache"));
- parameterMapElement(context.evalNodes("/mapper/parameterMap"));
- resultMapElements(context.evalNodes("/mapper/resultMap"));
- sqlElement(context.evalNodes("/mapper/sql"));
- // 因为我们是个 sql 查询,所以具体逻辑是在这里面
- buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
- } catch (Exception e) {
- throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
- }
- }
-然后是
-private void buildStatementFromContext(List<XNode> list) {
- if (configuration.getDatabaseId() != null) {
- buildStatementFromContext(list, configuration.getDatabaseId());
- }
- // 然后没有 databaseId 就走到这
- buildStatementFromContext(list, null);
-}
-继续
-private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
- for (XNode context : list) {
- // 创建语句解析器
- final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
- try {
- // 解析节点
- statementParser.parseStatementNode();
- } catch (IncompleteElementException e) {
- configuration.addIncompleteStatement(statementParser);
- }
- }
-}
-这个代码比较长,做下简略,只保留相关代码
-public void parseStatementNode() {
- String id = context.getStringAttribute("id");
- String databaseId = context.getStringAttribute("databaseId");
+可以配置这个hz的值,代表的含义是每秒的执行次数,默认是10,其实也用了hz的普遍含义。有兴趣可以看看之前写的一篇文章redis系列介绍七-过期策略
+]]>
+
+ redis
+
+
+ redis
+ 应用
+ 过期策略
+
+
+
+ redis数据结构介绍五-第五部分 对象
+ /2020/01/20/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E4%BA%94/
+ 前面说了这么些数据结构,其实大家对于 redis 最初的印象应该就是个 key-value 的缓存,类似于 memcache,redis 其实也是个 key-value,key 还是一样的字符串,或者说就是用 redis 自己的动态字符串实现,但是 value 其实就是前面说的那些数据结构,差不多快说完了,还有个 quicklist 后面还有一篇,这里先介绍下 redis 对于这些不同类型的 value 是怎么实现的,首先看下 redisObject 的源码头文件
+/* The actual Redis Object */
+#define OBJ_STRING 0 /* String object. */
+#define OBJ_LIST 1 /* List object. */
+#define OBJ_SET 2 /* Set object. */
+#define OBJ_ZSET 3 /* Sorted set object. */
+#define OBJ_HASH 4 /* Hash object. */
+/*
+ * Objects encoding. Some kind of objects like Strings and Hashes can be
+ * internally represented in multiple ways. The 'encoding' field of the object
+ * is set to one of this fields for this object. */
+#define OBJ_ENCODING_RAW 0 /* Raw representation */
+#define OBJ_ENCODING_INT 1 /* Encoded as integer */
+#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
+#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
+#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
+#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
+#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
+#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
+#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
+#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
+#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
- if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
- return;
- }
+#define LRU_BITS 24
+#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
+#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
- String nodeName = context.getNode().getNodeName();
- SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
- boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
- boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
- boolean useCache = context.getBooleanAttribute("useCache", isSelect);
- boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
+#define OBJ_SHARED_REFCOUNT INT_MAX
+typedef struct redisObject {
+ unsigned type:4;
+ unsigned encoding:4;
+ unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
+ * LFU data (least significant 8 bits frequency
+ * and most significant 16 bits access time). */
+ int refcount;
+ void *ptr;
+} robj;
+主体结构就是这个 redisObject,
+
+- type: 字段表示对象的类型,它对应的就是 redis 的对外暴露的,或者说用户可以使用的五种类型,OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH
+- encoding: 字段表示这个对象在 redis 内部的编码方式,由OBJ_ENCODING_开头的 11 种
+- lru: 做LRU替换算法用,占24个bit
+- refcount: 引用计数。它允许robj对象在某些情况下被共享。
+- ptr: 指向底层实现数据结构的指针
当 type 是 OBJ_STRING 时,表示类型是个 string,它的编码方式 encoding 可能有 OBJ_ENCODING_RAW,OBJ_ENCODING_INT,OBJ_ENCODING_EMBSTR 三种
当 type 是 OBJ_LIST 时,表示类型是 list,它的编码方式 encoding 是 OBJ_ENCODING_QUICKLIST,对于早一些的版本,2.2这种可能还会使用 OBJ_ENCODING_ZIPLIST,OBJ_ENCODING_LINKEDLIST
当 type 是 OBJ_SET 时,是个集合,但是得看具体元素的类型,有可能使用整数集合,OBJ_ENCODING_INTSET, 如果元素不全是整型或者数量超过一定限制,那么编码就是 OBJ_ENCODING_HT hash table 了
当 type 是 OBJ_ZSET 时,是个有序集合,它底层有可能使用的是 OBJ_ENCODING_ZIPLIST 或者 OBJ_ENCODING_SKIPLIST
当 type 是 OBJ_HASH 时,一开始也是 OBJ_ENCODING_ZIPLIST,然后当数据量大于 hash_max_ziplist_entries 时会转成 OBJ_ENCODING_HT
+
+]]>
+
+ Redis
+ 数据结构
+ C
+ 源码
+ Redis
+
+
+ redis
+ 数据结构
+ 源码
+
+
+
+ rust学习笔记-所有权二
+ /2021/04/18/rust%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0-%E6%89%80%E6%9C%89%E6%9D%83%E4%BA%8C/
+ 这里需要说道函数和返回值了
可以看书上的这个例子
![]()
对于这种情况,当进入函数内部时,会把传入的变量的所有权转移进函数内部,如果最后还是要返回该变量,但是如果此时还要返回别的计算结果,就可能需要笨拙地使用元组
![]() +
+引用
此时我们就可以用引用来解决这个问题
+fn main() {
+ let s1 = String::from("hello");
+ let len = calculate_length(&s1);
+ println!("The length of '{}' is {}", s1, len);
+}
+fn calculate_length(s: &String) -> usize {
+ s.len()
+}
+这里的&符号就是引用的语义,它们允许你在不获得所有权的前提下使用值
![]()
由于引用不持有值的所有权,所以当引用离开当前作用域时,它指向的值也不会被丢弃
+可变引用
而当我们尝试对引用的字符串进行修改时
+fn main() {
+ let s1 = String::from("hello");
+ change(&s1);
+}
+fn change(s: &String) {
+ s.push_str(", world");
+}
+就会有以下报错,
![]()
其实也很容易发现,毕竟没有 mut 指出这是可变引用,同时需要将 s1 改成 mut 可变的
+fn main() {
+ let mut s1 = String::from("hello");
+ change(&mut s1);
+}
- // 简略前后代码,主要看这里,创建 sqlSource
- SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
-
-
-然后根据 LanguageDriver,我们这用的 XMLLanguageDriver,先是初始化
- @Override
- public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
- XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
- return builder.parseScriptNode();
- }
-// 初始化有一些逻辑
- public XMLScriptBuilder(Configuration configuration, XNode context, Class<?> parameterType) {
- super(configuration);
- this.context = context;
- this.parameterType = parameterType;
- // 特别是这,我这次特意在 mapper 中加了 foreach,就是为了说下这一块的解析
- initNodeHandlerMap();
- }
-// 设置各种类型的处理器
- private void initNodeHandlerMap() {
- nodeHandlerMap.put("trim", new TrimHandler());
- nodeHandlerMap.put("where", new WhereHandler());
- nodeHandlerMap.put("set", new SetHandler());
- nodeHandlerMap.put("foreach", new ForEachHandler());
- nodeHandlerMap.put("if", new IfHandler());
- nodeHandlerMap.put("choose", new ChooseHandler());
- nodeHandlerMap.put("when", new IfHandler());
- nodeHandlerMap.put("otherwise", new OtherwiseHandler());
- nodeHandlerMap.put("bind", new BindHandler());
- }
-初始化解析器以后就开始解析了
-public SqlSource parseScriptNode() {
- // 先是解析 parseDynamicTags
- MixedSqlNode rootSqlNode = parseDynamicTags(context);
- SqlSource sqlSource;
- if (isDynamic) {
- sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
- } else {
- sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
- }
- return sqlSource;
-}
-但是这里可能做的事情比较多
-protected MixedSqlNode parseDynamicTags(XNode node) {
- List<SqlNode> contents = new ArrayList<>();
- // 获取子节点,这里可以把我 xml 中的 SELECT 语句分成三部分,第一部分是 select 到 in,然后是 foreach 部分,最后是\n结束符
- NodeList children = node.getNode().getChildNodes();
- for (int i = 0; i < children.getLength(); i++) {
- XNode child = node.newXNode(children.item(i));
- // 第一个节点是个纯 text 节点就会走到这
- if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
- String data = child.getStringBody("");
- TextSqlNode textSqlNode = new TextSqlNode(data);
- if (textSqlNode.isDynamic()) {
- contents.add(textSqlNode);
- isDynamic = true;
- } else {
- // 在 content 中添加这个 node
- contents.add(new StaticTextSqlNode(data));
- }
- } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
- // 第二个节点是个带 foreach 的,是个内部元素节点
- String nodeName = child.getNode().getNodeName();
- // 通过 nodeName 获取处理器
- NodeHandler handler = nodeHandlerMap.get(nodeName);
- if (handler == null) {
- throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
- }
- // 调用处理器来处理
- handler.handleNode(child, contents);
- isDynamic = true;
- }
- }
- // 然后返回这个混合 sql 节点
- return new MixedSqlNode(contents);
- }
-再看下 handleNode 的逻辑
- @Override
- public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
- // 又会套娃执行这里的 parseDynamicTags
- MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
- String collection = nodeToHandle.getStringAttribute("collection");
- Boolean nullable = nodeToHandle.getBooleanAttribute("nullable");
- String item = nodeToHandle.getStringAttribute("item");
- String index = nodeToHandle.getStringAttribute("index");
- String open = nodeToHandle.getStringAttribute("open");
- String close = nodeToHandle.getStringAttribute("close");
- String separator = nodeToHandle.getStringAttribute("separator");
- ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, nullable, index, item, open, close, separator);
- targetContents.add(forEachSqlNode);
- }
-// 这里走的逻辑不一样了
-protected MixedSqlNode parseDynamicTags(XNode node) {
- List<SqlNode> contents = new ArrayList<>();
- // 这里是 foreach 内部的,所以是个 text_node
- NodeList children = node.getNode().getChildNodes();
- for (int i = 0; i < children.getLength(); i++) {
- XNode child = node.newXNode(children.item(i));
- // 第一个节点是个纯 text 节点就会走到这
- if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
- String data = child.getStringBody("");
- TextSqlNode textSqlNode = new TextSqlNode(data);
- // 判断是否动态是根据代码里是否有 ${}
- if (textSqlNode.isDynamic()) {
- contents.add(textSqlNode);
- isDynamic = true;
- } else {
- // 所以还是会走到这
- // 在 content 中添加这个 node
- contents.add(new StaticTextSqlNode(data));
- }
-// 最后继续包装成 MixedSqlNode
-// 再回到这里
- @Override
- public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
- MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
- // 处理 foreach 内部的各个变量
- String collection = nodeToHandle.getStringAttribute("collection");
- Boolean nullable = nodeToHandle.getBooleanAttribute("nullable");
- String item = nodeToHandle.getStringAttribute("item");
- String index = nodeToHandle.getStringAttribute("index");
- String open = nodeToHandle.getStringAttribute("open");
- String close = nodeToHandle.getStringAttribute("close");
- String separator = nodeToHandle.getStringAttribute("separator");
- ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, nullable, index, item, open, close, separator);
- targetContents.add(forEachSqlNode);
- }
-再回过来
-public SqlSource parseScriptNode() {
- MixedSqlNode rootSqlNode = parseDynamicTags(context);
- SqlSource sqlSource;
- // 因为在 foreach 节点处理时直接是把 isDynamic 置成了 true
- if (isDynamic) {
- // 所以是个 DynamicSqlSource
- sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
- } else {
- sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
- }
- return sqlSource;
+fn change(s: &mut String) {
+ s.push_str(", world");
+}
+再看一个例子
+fn main() {
+ let mut s1 = String::from("hello");
+ let r1 = &mut s1;
+ let r2 = &mut s1;
+}
+这个例子在书里是会报错的,因为同时存在一个以上的可变引用,但是在我运行的版本里前面这段没有报错,只有当我真的要去更改的时候
+fn main() {
+ let mut s1 = String::from("hello");
+ let mut r1 = &mut s1;
+ let mut r2 = &mut s1;
+ change(&mut r1);
+ change(&mut r2);
+}
+
+
+fn change(s: &mut String) {
+ s.push_str(", world");
}
-这里就做完了预处理工作,真正在执行的执行的时候还需要进一步解析
-因为前面讲过很多了,所以直接跳到这里
- @Override
- public <T> T selectOne(String statement, Object parameter) {
- // Popular vote was to return null on 0 results and throw exception on too many.
- // 都知道是在这进去
- List<T> list = this.selectList(statement, parameter);
- if (list.size() == 1) {
- return list.get(0);
- } else if (list.size() > 1) {
- throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
- } else {
- return null;
- }
- }
+![]()
这里可能就是具体版本在实现上的一个差异,我用的 rustc 是 1.44.0 版本
其实上面的主要是由 rust 想要避免这类多重可变更导致的异常问题,总结下就是三个点
+
+- 两个或两个以上的指针同时同时访问同一空间
+- 其中至少有一个指针会想空间中写入数据
+- 没有同步数据访问的机制
并且我们不能在拥有不可变引用的情况下创建可变引用
+
+悬垂引用
还有一点需要注意的就是悬垂引用
+fn main() {
+ let reference_to_nothing = dangle();
+}
- @Override
- public <E> List<E> selectList(String statement, Object parameter) {
- return this.selectList(statement, parameter, RowBounds.DEFAULT);
- }
- @Override
- public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
- return selectList(statement, parameter, rowBounds, Executor.NO_RESULT_HANDLER);
- }
- private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
- try {
- // 前面也讲过这个,
- MappedStatement ms = configuration.getMappedStatement(statement);
- return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
- } catch (Exception e) {
- throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
- } finally {
- ErrorContext.instance().reset();
- }
- }
- // 包括这里,是调用的org.apache.ibatis.executor.CachingExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler)
- @Override
- public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
- BoundSql boundSql = ms.getBoundSql(parameterObject);
- CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
- return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
- }
-// 然后是获取 BoundSql
- public BoundSql getBoundSql(Object parameterObject) {
- BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
- List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
- if (parameterMappings == null || parameterMappings.isEmpty()) {
- boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
- }
+fn dangle() -> &String {
+ let s = String::from("hello");
+ &s
+}
+这里可以看到其实在 dangle函数返回后,这里的 s 理论上就离开了作用域,但是由于返回了 s 的引用,在 main 函数中就会拿着这个引用,就会出现如下错误
![]()
+总结
最后总结下
+
+- 在任何一个段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用。
+- 引用总是有效的。
+
+]]>
+
+ 语言
+ Rust
+
+
+ Rust
+ 所有权
+ 内存分布
+ 新语言
+ 可变引用
+ 不可变引用
+
+
+
+ spark-little-tips
+ /2017/03/28/spark-little-tips/
+ spark 的一些粗浅使用经验工作中学习使用了一下Spark做数据分析,主要是用spark的python接口,首先是pyspark.SparkContext(appName=xxx),这是初始化一个Spark应用实例或者说会话,不能重复,
返回的实例句柄就可以调用textFile(path)读取文本文件,这里的文本文件可以是HDFS上的文本文件,也可以普通文本文件,但是需要在Spark的所有集群上都存在,否则会
读取失败,parallelize则可以将python生成的集合数据读取后转换成rdd(A Resilient Distributed Dataset (RDD),一种spark下的基本抽象数据集),基于这个RDD就可以做
数据的流式计算,例如map reduce,在Spark中可以非常方便地实现
+简单的mapreduce word count示例
textFile = sc.parallelize([(1,1), (2,1), (3,1), (4,1), (5,1),(1,1), (2,1), (3,1), (4,1), (5,1)])
+data = textFile.reduceByKey(lambda x, y: x + y).collect()
+for _ in data:
+ print(_)
- // check for nested result maps in parameter mappings (issue #30)
- for (ParameterMapping pm : boundSql.getParameterMappings()) {
- String rmId = pm.getResultMapId();
- if (rmId != null) {
- ResultMap rm = configuration.getResultMap(rmId);
- if (rm != null) {
- hasNestedResultMaps |= rm.hasNestedResultMaps();
- }
- }
- }
- return boundSql;
- }
-// 因为前面讲了是生成的 DynamicSqlSource,所以也是调用这个的 getBoundSql
- @Override
- public BoundSql getBoundSql(Object parameterObject) {
- DynamicContext context = new DynamicContext(configuration, parameterObject);
- // 重点关注着
- rootSqlNode.apply(context);
- SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
- Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
- SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
- BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
- context.getBindings().forEach(boundSql::setAdditionalParameter);
- return boundSql;
- }
-// 继续是这个 DynamicSqlNode 的 apply
- public boolean apply(DynamicContext context) {
- contents.forEach(node -> node.apply(context));
- return true;
- }
-// 看下面的图
-![image]()
-我们重点看 foreach 的逻辑
-@Override
- public boolean apply(DynamicContext context) {
- Map<String, Object> bindings = context.getBindings();
- final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings,
- Optional.ofNullable(nullable).orElseGet(configuration::isNullableOnForEach));
- if (iterable == null || !iterable.iterator().hasNext()) {
- return true;
- }
- boolean first = true;
- // 开始符号
- applyOpen(context);
- int i = 0;
- for (Object o : iterable) {
- DynamicContext oldContext = context;
- if (first || separator == null) {
- context = new PrefixedContext(context, "");
- } else {
- context = new PrefixedContext(context, separator);
- }
- int uniqueNumber = context.getUniqueNumber();
- // Issue #709
- if (o instanceof Map.Entry) {
- @SuppressWarnings("unchecked")
- Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
- applyIndex(context, mapEntry.getKey(), uniqueNumber);
- applyItem(context, mapEntry.getValue(), uniqueNumber);
- } else {
- applyIndex(context, i, uniqueNumber);
- applyItem(context, o, uniqueNumber);
- }
- // 转换变量名,变成这种形式 select * from student where id in
- // (
- // #{__frch_id_0}
- // )
- contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
- if (first) {
- first = !((PrefixedContext) context).isPrefixApplied();
- }
- context = oldContext;
- i++;
- }
- applyClose(context);
- context.getBindings().remove(item);
- context.getBindings().remove(index);
- return true;
- }
-// 回到外层就会调用 parse 方法, 把#{} 这段替换成 ?
-public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
- ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
- GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
- String sql;
- if (configuration.isShrinkWhitespacesInSql()) {
- sql = parser.parse(removeExtraWhitespaces(originalSql));
- } else {
- sql = parser.parse(originalSql);
- }
- return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
- }
-![image]()
-可以看到这里,然后再进行替换
-![image]()
-真实的从 ? 替换成具体的变量值,是在这里
org.apache.ibatis.executor.SimpleExecutor#doQuery
调用了
-private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
- Statement stmt;
- Connection connection = getConnection(statementLog);
- stmt = handler.prepare(connection, transaction.getTimeout());
- handler.parameterize(stmt);
- return stmt;
- }
- @Override
- public void parameterize(Statement statement) throws SQLException {
- parameterHandler.setParameters((PreparedStatement) statement);
- }
- @Override
- public void setParameters(PreparedStatement ps) {
- ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
- List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
- if (parameterMappings != null) {
- for (int i = 0; i < parameterMappings.size(); i++) {
- ParameterMapping parameterMapping = parameterMappings.get(i);
- if (parameterMapping.getMode() != ParameterMode.OUT) {
- Object value;
- String propertyName = parameterMapping.getProperty();
- if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
- value = boundSql.getAdditionalParameter(propertyName);
- } else if (parameterObject == null) {
- value = null;
- } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
- value = parameterObject;
- } else {
- MetaObject metaObject = configuration.newMetaObject(parameterObject);
- value = metaObject.getValue(propertyName);
- }
- TypeHandler typeHandler = parameterMapping.getTypeHandler();
- JdbcType jdbcType = parameterMapping.getJdbcType();
- if (value == null && jdbcType == null) {
- jdbcType = configuration.getJdbcTypeForNull();
- }
- try {
- // -------------------------->
- // 替换变量
- typeHandler.setParameter(ps, i + 1, value, jdbcType);
- } catch (TypeException | SQLException e) {
- throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
- }
+结果
(3, 2)
+(1, 2)
+(4, 2)
+(2, 2)
+(5, 2)
+]]>
+
+ data analysis
+
+
+ spark
+ python
+
+
+
+ rust学习笔记-所有权一
+ /2021/04/18/rust%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
+ 最近在看 《rust 权威指南》,还是难度比较大的,它里面的一些概念跟之前的用过的都有比较大的差别
比起有 gc 的虚拟机语言,跟像 C 和 C++这种主动释放内存的,rust 有他的独特点,主要是有三条
+
+- Rust中的每一个值都有一个对应的变量作为它的所有者。
+- 在同一时间内,值有且只有一个所有者。
+- 当所有者离开自己的作用域时,它持有的值就会被释放掉。
![]()
这里有两个重点:
+- s 在进入作用域后才变得有效
+- 它会保持自己的有效性直到自己离开作用域为止
+
+然后看个案例
+let x = 5;
+let y = x;
+这个其实有两种,一般可以认为比较多实现的会使用 copy on write 之类的,先让两个都指向同一个快 5 的存储,在发生变更后开始正式拷贝,但是涉及到内存处理的便利性,对于这类简单类型,可以直接拷贝
但是对于非基础类型
+let s1 = String::from("hello");
+let s2 = s1;
+
+println!("{}, world!", s1);
+有可能认为有两种内存分布可能
先看下 string 的内存结构
![]()
第一种可能是
![]()
第二种是
![]()
我们来尝试编译下
![]()
发现有这个错误,其实在 rust 中let y = x这个行为的实质是移动,在赋值给 y 之后 x 就无效了
![]()
这样子就不会造成脱离作用域时,对同一块内存区域的二次释放,如果需要复制,可以使用 clone 方法
+let s1 = String::from("hello");
+let s2 = s1.clone();
+
+println!("s1 = {}, s2 = {}", s1, s2);
+这里其实会有点疑惑,为什么前面的x, y 的行为跟 s1, s2 的不一样,其实主要是基本类型和 string 这类的不定大小的类型的内存分配方式不同,x, y这类整型可以直接确定大小,可以直接在栈上分配,而像 string 和其他的变体结构体,其大小都是不能在编译时确定,所以需要在堆上进行分配
+]]>
+
+ 语言
+ Rust
+
+
+ Rust
+ 所有权
+ 内存分布
+ 新语言
+
+
+
+ rust学习笔记-所有权三之切片
+ /2021/05/16/rust%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0-%E6%89%80%E6%9C%89%E6%9D%83%E4%B8%89%E4%B9%8B%E5%88%87%E7%89%87/
+ 除了引用,Rust 还有另外一种不持有所有权的数据类型:切片(slice)。切片允许我们引用集合中某一段连续的元素序列,而不是整个集合。
例如代码
+fn main() {
+ let mut s = String::from("hello world");
+
+ let word = first_word(&s);
+
+ s.clear();
+
+ // 这时候虽然 word 还是 5,但是 s 已经被清除了,所以就没存在的意义
+}
+这里其实我们就需要关注 s 的存在性,代码的逻辑合理性就需要额外去维护,此时我们就可以用切片
+let s = String::from("hello world")
+
+let hello = &s[0..5];
+let world = &s[6..11];
+其实跟 Python 的list 之类的语法有点类似,当然里面还有些语法糖,比如可以直接用省略后面的数字表示直接引用到结尾
+let hello = &s[0..];
+甚至再进一步
+let hello = &s[..];
+使用了切片之后
+fn first_word(s: &String) -> &str {
+ let bytes = s.as_bytes();
+
+ for (i, &item) in bytes.iter().enumerate() {
+ if item == b' ' {
+ return &s[0..i];
}
- }
}
- }
+
+ &s[..]
+}
+fn main() {
+ let mut s = String::from("hello world");
+
+ let word = first_word(&s);
+
+ s.clear(); // error!
+
+ println!("the first word is: {}", word);
+}
+那再执行 main 函数的时候就会抛错,因为 word 还是个切片,需要保证 s 的有效性,并且其实我们可以将函数申明成
+fn first_word(s: &str) -> &str {
+这样就既能处理&String 的情况,就是当成完整字符串的切片,也能处理普通的切片。
其他类型的切片
+let a = [1, 2, 3, 4, 5];
+let slice = &a[1..3];
+简单记录下,具体可以去看看这本书
]]>
- Java
- Mybatis
+ 语言
+ Rust
- Java
- Mysql
- Mybatis
+ Rust
+ 所有权
+ 内存分布
+ 新语言
+ 可变引用
+ 不可变引用
+ 切片
@@ -11760,55 +11809,6 @@ for _ in data:
SpringBoot
-
- pcre-intro-and-a-simple-package
- /2015/01/16/pcre-intro-and-a-simple-package/
- Pcre
-Perl Compatible Regular Expressions (PCRE) is a regular
expression C library inspired by the regular expression
capabilities in the Perl programming language, written
by Philip Hazel, starting in summer 1997.
-
-因为最近工作内容的一部分需要做字符串的识别处理,所以就顺便用上了之前在PHP中用过的正则,在C/C++中本身不包含正则库,这里使用的pcre,对MFC开发,在这里提供了静态链接库,在引入lib跟.h文件后即可使用。
-
-
-Regular Expression Syntax
然后是一些正则语法,官方的语法文档比较科学严谨,特别是对类似于贪婪匹配等细节的说明,当然一般的使用可以在网上找到很多匹配语法,例如这个。
-PCRE函数介绍
-pcre_compile
原型:
-
-#include <pcre.h>
-pcre *pcre_compile(const char *pattern, int options, const char **errptr, int *erroffset, const unsigned char *tableptr);
-功能:将一个正则表达式编译成一个内部表示,在匹配多个字符串时,可以加速匹配。其同pcre_compile2功能一样只是缺少一个参数errorcodeptr。
参数:
pattern 正则表达式
options 为0,或者其他参数选项
errptr 出错消息
erroffset 出错位置
tableptr 指向一个字符数组的指针,可以设置为空NULL
-
-pcre_exec
原型:
-
-#include <pcre.h>
-int pcre_exec(const pcre *code, const pcre_extra *extra, const char *subject, int length, int startoffset, int options, int *ovector, int ovecsize)
-功能:使用编译好的模式进行匹配,采用与Perl相似的算法,返回匹配串的偏移位置。
参数:
code 编译好的模式
extra 指向一个pcre_extra结构体,可以为NULL
subject 需要匹配的字符串
length 匹配的字符串长度(Byte)
startoffset 匹配的开始位置
options 选项位
ovector 指向一个结果的整型数组
ovecsize 数组大小。
-这里是两个最常用的函数的简单说明,pcre的静态库提供了一系列的函数以供使用,可以参考这个博客说明,另外对于以上函数的具体参数详细说明可以参考官网此处
-一个丑陋的封装
void COcxDemoDlg::pcre_exec_all(const pcre * re, PCRE_SPTR src, vector<pair<int, int>> &vc)
-{
- int rc;
- int ovector[30];
- int i = 0;
- pair<int, int> pr;
- rc = pcre_exec(re, NULL, src, strlen(src), i, 0, ovector, 30);
- for (; rc > 0;)
- {
- i = ovector[1];
- pr.first = ovector[2];
- pr.second = ovector[3];
- vc.push_back(pr);
- rc = pcre_exec(re, NULL, src, strlen(src), i, 0, ovector, 30);
- }
-}
-vector中是全文匹配后的索引对,只是简单地用下。
-]]>
-
- C++
-
-
- c++
- mfc
-
-
springboot 处理请求的小分支-跳转 & cookie
/2023/09/03/springboot-%E5%A4%84%E7%90%86%E8%AF%B7%E6%B1%82%E7%9A%84%E5%B0%8F%E5%88%86%E6%94%AF-%E8%B7%B3%E8%BD%AC-cookie/
@@ -11852,31 +11852,6 @@ int pcre_exec(const pcre *code, const pcre_extra *extra, const char *subject, in
SpringBoot
-
- spring boot中的 http 接口返回 json 形式的小注意点
- /2023/06/25/spring-boot%E4%B8%AD%E7%9A%84-http-%E6%8E%A5%E5%8F%A3%E8%BF%94%E5%9B%9E-json-%E5%BD%A2%E5%BC%8F%E7%9A%84%E5%B0%8F%E6%B3%A8%E6%84%8F%E7%82%B9/
- 这个可能是个很简单的点,不过之前碰到了就记录下,我们常规的应用都是使用统一的请求响应转换器去处理请求和响应返回,但是对于有文件上传或者返回的是文件的情况,一般都是不使用统一的处理,但是在响应返回的时候可能会存在这样的情况,如果文件正常被处理那就返回文件,如果处理异常需要给前端返回 json类型的响应,里面能够取到响应码错误描述等
-比如在请求中参数就使用 httpRequest(HttpServletRequest request, HttpServletResponse response)
然后在返回的时候就使用 response.getOutputStream().write(result),而如果是要返回 json 形式的话就可以像这个文章说明的
链接
-Employee employee = new Employee(1, "Karan", "IT", 5000);
-String employeeJsonString = this.gson.toJson(employee);
-
-PrintWriter out = response.getWriter();
-response.setContentType("application/json");
-response.setCharacterEncoding("UTF-8");
-out.print(employeeJsonString);
-out.flush();
-一开始我也是这么一搜就用了,后来发现返回的一直是乱码,仔细看了下发现了个问题,就是这个 response 设置 contentType 是在getWriter之后的,这样自然就不会起作用了,所以要在设置 setContentType 和 setCharacterEncoding 之后再 getWriter,之后就可以正常返回了。
-]]>
-
- Java
- SpringBoot
-
-
- Java
- Spring
- SpringBoot
-
-
springboot mappings 注册逻辑
/2023/08/13/springboot-mappings-%E6%B3%A8%E5%86%8C%E9%80%BB%E8%BE%91/
@@ -12060,6 +12035,31 @@ public:
c++
+
+ spring boot中的 http 接口返回 json 形式的小注意点
+ /2023/06/25/spring-boot%E4%B8%AD%E7%9A%84-http-%E6%8E%A5%E5%8F%A3%E8%BF%94%E5%9B%9E-json-%E5%BD%A2%E5%BC%8F%E7%9A%84%E5%B0%8F%E6%B3%A8%E6%84%8F%E7%82%B9/
+ 这个可能是个很简单的点,不过之前碰到了就记录下,我们常规的应用都是使用统一的请求响应转换器去处理请求和响应返回,但是对于有文件上传或者返回的是文件的情况,一般都是不使用统一的处理,但是在响应返回的时候可能会存在这样的情况,如果文件正常被处理那就返回文件,如果处理异常需要给前端返回 json类型的响应,里面能够取到响应码错误描述等
+比如在请求中参数就使用 httpRequest(HttpServletRequest request, HttpServletResponse response)
然后在返回的时候就使用 response.getOutputStream().write(result),而如果是要返回 json 形式的话就可以像这个文章说明的
链接
+Employee employee = new Employee(1, "Karan", "IT", 5000);
+String employeeJsonString = this.gson.toJson(employee);
+
+PrintWriter out = response.getWriter();
+response.setContentType("application/json");
+response.setCharacterEncoding("UTF-8");
+out.print(employeeJsonString);
+out.flush();
+一开始我也是这么一搜就用了,后来发现返回的一直是乱码,仔细看了下发现了个问题,就是这个 response 设置 contentType 是在getWriter之后的,这样自然就不会起作用了,所以要在设置 setContentType 和 setCharacterEncoding 之后再 getWriter,之后就可以正常返回了。
+]]>
+
+ Java
+ SpringBoot
+
+
+ Java
+ Spring
+ SpringBoot
+
+
swoole-websocket-test
/2016/07/13/swoole-websocket-test/
@@ -12403,22 +12403,6 @@ user3:
SpringBoot
-
- wordpress 忘记密码的一种解决方法
- /2021/12/05/wordpress-%E5%BF%98%E8%AE%B0%E5%AF%86%E7%A0%81%E7%9A%84%E4%B8%80%E7%A7%8D%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
- 前阵子搭了个 WordPress,但是没怎么用,前两天发现忘了登录密码了,最近不知道是什么情况,chrome 的记住密码跟历史记录感觉有点问题,历史记录丢了不少东西,可能是时间太久了,但是理论上应该有 LRU 这种策略的,有些还比较常用,还有记住密码,因为个人域名都是用子域名分配给各个服务,有些记住了,有些又没记住密码,略蛋疼,所以就找了下这个方案。
当然这个方案不是最优的,有很多限制,首先就是要能够登陆 WordPress 的数据库,不然这个方法是没用的。
首先不管用什么方式(别违法)先登陆数据库,选择 WordPress 的数据库,可以看到里面有几个表,我们的目标就是 wp_users 表,用 select 查询看下可以看到有用户的数据,如果是像我这样搭着玩的没有创建其他用户的话应该就只有一个用户,那我们的表里的用户数据就只会有一条,当然多条的话可以通过用户名来找
![]()
然后可能我这个版本是这样,没有装额外的插件,密码只是经过了 MD5 的单向哈希,所以我们可以设定一个新密码,然后用 MD5 编码后直接更新进去
-UPDATE wp_users SET user_pass = MD5('123456') WHERE ID = 1;
-
-然后就能用自己的账户跟刚才更新的密码登录了。
-]]>
-
- 小技巧
-
-
- WordPress
- 小技巧
-
-
《垃圾回收算法手册读书》笔记之整理算法
/2021/03/07/%E3%80%8A%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E7%AE%97%E6%B3%95%E6%89%8B%E5%86%8C%E8%AF%BB%E4%B9%A6%E3%80%8B%E7%AC%94%E8%AE%B0%E4%B9%8B%E6%95%B4%E7%90%86%E7%AE%97%E6%B3%95/
@@ -12442,28 +12426,16 @@ user3:
- ssh 小技巧-端口转发
- /2023/03/26/ssh-%E5%B0%8F%E6%8A%80%E5%B7%A7-%E7%AB%AF%E5%8F%A3%E8%BD%AC%E5%8F%91/
- 我们在使用 ssh 连接的使用有一个很好用功能,就是端口转发,而且使用的方式也很多样,比如我们经常用 vscode 来做远程开发的话,一般远程连接就可以基于 ssh,前面也介绍过 vscode 的端口转发,并且可以配置到 .ssh/config 配置文件里,只不过最近在一次使用的过程中发现了一个问题,就是在一台 Ubuntu 的某云服务器上想 ssh 到另一台服务器上,并且做下端口映射,但是发现报了个错,
-bind: Cannot assign requested address
-查了下这个问题,猜测是不是端口已经被占用了,查了下并不是,然后想到是不是端口是系统保留的,
-sysctl -a |grep port_range
-结果中
-net.ipv4.ip_local_port_range = 50000 65000 -----意味着50000~65000端口可用
-发现也不是,没有限制,最后才查到这个原因是默认如果有 ipv6 的话会使用 ipv6 的地址做映射
所以如果是命令连接做端口转发的话,
-ssh -4 -L 11234:localhost:1234 x.x.x.x
-使用-4来制定通过 ipv4 地址来做映射
如果是在 .ssh/config 中配置的话可以直接指定所有的连接都走 ipv4
-Host *
- AddressFamily inet
-inet代表 ipv4,inet6代表 ipv6
AddressFamily 的所有取值范围是:”any”(默认)、”inet”(仅IPv4)、”inet6”(仅IPv6)。
另外此类问题还可以通过 ssh -v 来打印更具体的信息
+ 《寻羊历险记》读后感
+ /2023/07/23/%E3%80%8A%E5%AF%BB%E7%BE%8A%E5%8E%86%E9%99%A9%E8%AE%B0%E3%80%8B%E8%AF%BB%E5%90%8E%E6%84%9F/
+ 最近本来是在读《舞舞舞》,然后看到有介绍说,这个跟《寻羊历险记》是有情节上的关联,所以就先去看了《寻羊历险记》,《寻羊历险记》也是村上春树的第一本成规模的长篇小说,也可以认为是《舞舞舞》的前篇。
最开始这个情节跟之前的刺杀骑士团长还是哪本有点类似,都有跟老婆离婚了,主角应该是个跟朋友一起开翻译社的,后面也开始做广告相关的,做到了经济收益还不错的阶段,也有一些挺哲学的对话,朋友觉得这么赚钱不地道(可能也是觉得这样忘了初心),在离婚以后又结交了一个耳朵很好看的女友,这个女友也是个比较抽象的存在,描述中给人感觉是一个外貌很普通的女孩,但是耳朵漂亮的惊为天人,不知道是不是有什么隐喻,感觉现实中没见过这样的人,女友平时把耳朵遮起来不轻易露出来,只有在跟主角做爱的时候才露出来
主体剧情是因为男主在广告中用了一张一位叫“鼠”的朋友寄给他的一张包含一只特殊的羊的照片,就有个政界大佬的秘书找过来,逼迫主角要找到照片上的羊,这只羊背上有星纹,基本不可能属于在日本当时可能存在的羊的品种,因为这位政界大佬快病危了,所以要求主角必须在一个月内找到这只羊,因为这里把这只神秘的羊塑造成神一样的存在,这位政界大佬在年轻时被这只羊上身,后面就开始在政治事业上大展宏图,就基本成了能左右整个日本走向的巨佬,但近期随着巨佬,身体状态慢慢变差,这只羊就从他身上消失了,所以秘书要主角必须找到这只羊,不然基本会让主角的翻译社完蛋,这样主角就会面临破产赔偿等严重后果,只是说主角本来也一直是这种丧气存在,再说这么茫茫人海找个人都难,还要找这么一只玄乎的不太可能真实存在的羊,所以基本是想要放弃的,结果刚才说的耳朵很漂亮的女友却有着神乎其神的直觉,就觉得能找到,然后他们就踏上了巡羊的旅程,一开始到了札幌,寻找一无所获,然后神奇的是女友推荐一定要住的海豚宾馆,恰恰是一切线索的源头,宾馆老板的父亲正好是羊博士,在年轻的时候被羊上身过,后面离开后就去了那位巨佬身上,让巨佬成了真正控制日本的地下帝国的王,跟羊博士咨询后知道羊可能在十二瀑镇的牧场出现过,所以一路找寻,发现其实这个牧场中有个别墅正好是主角朋友“鼠”的,到了别墅后出现了个神秘的羊男,这个羊男真的不太明白是怎么个存在,就是让主角的女友回去了,然后最后一个肉体承载着“鼠”的灵魂跟主角有了一次接触,主角呆在这个别墅过着百无聊赖的生活,在才到有一次羊男来跟他交流的时候其实是承载着鼠的灵魂,就觉得是不是一切都是在忽悠他,离一个月期限也越来越近了,而在发怒之后,“鼠”真的出现后,但是不是真的“鼠”,而是只有他的灵魂,因为“鼠”已经死了,因为不想被“羊”附身,成为羊壳,并且让主角设定好时钟后的装置后尽快下山,第二天主角离开上了火车后山上牧场就传来爆炸声,“鼠”已经跟羊同归于尽了,免得再有其他人被羊附身,主角也很难过,回到故乡在四周大海已经被填掉了的旧防波堤上大哭悼念逝去的“鼠”。
其实对于没什么时代概念或者对村上一直以来的观念不是特别敏感的,对这本书讲了啥有点云里雾里,后面看了一些简单的解释就是羊其实代表日本帝国主义和资本主义,可能是村上本人反帝国主义,军国主义和资本主义的一个表征,想来也有些道理,不然“鼠”的牺牲就感觉比较没意义,但是另一方面我的理解也可能是对自由的向往的表达,被羊控制,虽然可以成就“伟大”的事业,但是也丧失了自我。
]]>
- ssh
- 技巧
+ 读后感
+ 生活
- ssh
- 端口转发
+ 读后感
@@ -12481,16 +12453,32 @@ user3:
- 《寻羊历险记》读后感
- /2023/07/23/%E3%80%8A%E5%AF%BB%E7%BE%8A%E5%8E%86%E9%99%A9%E8%AE%B0%E3%80%8B%E8%AF%BB%E5%90%8E%E6%84%9F/
- 最近本来是在读《舞舞舞》,然后看到有介绍说,这个跟《寻羊历险记》是有情节上的关联,所以就先去看了《寻羊历险记》,《寻羊历险记》也是村上春树的第一本成规模的长篇小说,也可以认为是《舞舞舞》的前篇。
最开始这个情节跟之前的刺杀骑士团长还是哪本有点类似,都有跟老婆离婚了,主角应该是个跟朋友一起开翻译社的,后面也开始做广告相关的,做到了经济收益还不错的阶段,也有一些挺哲学的对话,朋友觉得这么赚钱不地道(可能也是觉得这样忘了初心),在离婚以后又结交了一个耳朵很好看的女友,这个女友也是个比较抽象的存在,描述中给人感觉是一个外貌很普通的女孩,但是耳朵漂亮的惊为天人,不知道是不是有什么隐喻,感觉现实中没见过这样的人,女友平时把耳朵遮起来不轻易露出来,只有在跟主角做爱的时候才露出来
主体剧情是因为男主在广告中用了一张一位叫“鼠”的朋友寄给他的一张包含一只特殊的羊的照片,就有个政界大佬的秘书找过来,逼迫主角要找到照片上的羊,这只羊背上有星纹,基本不可能属于在日本当时可能存在的羊的品种,因为这位政界大佬快病危了,所以要求主角必须在一个月内找到这只羊,因为这里把这只神秘的羊塑造成神一样的存在,这位政界大佬在年轻时被这只羊上身,后面就开始在政治事业上大展宏图,就基本成了能左右整个日本走向的巨佬,但近期随着巨佬,身体状态慢慢变差,这只羊就从他身上消失了,所以秘书要主角必须找到这只羊,不然基本会让主角的翻译社完蛋,这样主角就会面临破产赔偿等严重后果,只是说主角本来也一直是这种丧气存在,再说这么茫茫人海找个人都难,还要找这么一只玄乎的不太可能真实存在的羊,所以基本是想要放弃的,结果刚才说的耳朵很漂亮的女友却有着神乎其神的直觉,就觉得能找到,然后他们就踏上了巡羊的旅程,一开始到了札幌,寻找一无所获,然后神奇的是女友推荐一定要住的海豚宾馆,恰恰是一切线索的源头,宾馆老板的父亲正好是羊博士,在年轻的时候被羊上身过,后面离开后就去了那位巨佬身上,让巨佬成了真正控制日本的地下帝国的王,跟羊博士咨询后知道羊可能在十二瀑镇的牧场出现过,所以一路找寻,发现其实这个牧场中有个别墅正好是主角朋友“鼠”的,到了别墅后出现了个神秘的羊男,这个羊男真的不太明白是怎么个存在,就是让主角的女友回去了,然后最后一个肉体承载着“鼠”的灵魂跟主角有了一次接触,主角呆在这个别墅过着百无聊赖的生活,在才到有一次羊男来跟他交流的时候其实是承载着鼠的灵魂,就觉得是不是一切都是在忽悠他,离一个月期限也越来越近了,而在发怒之后,“鼠”真的出现后,但是不是真的“鼠”,而是只有他的灵魂,因为“鼠”已经死了,因为不想被“羊”附身,成为羊壳,并且让主角设定好时钟后的装置后尽快下山,第二天主角离开上了火车后山上牧场就传来爆炸声,“鼠”已经跟羊同归于尽了,免得再有其他人被羊附身,主角也很难过,回到故乡在四周大海已经被填掉了的旧防波堤上大哭悼念逝去的“鼠”。
其实对于没什么时代概念或者对村上一直以来的观念不是特别敏感的,对这本书讲了啥有点云里雾里,后面看了一些简单的解释就是羊其实代表日本帝国主义和资本主义,可能是村上本人反帝国主义,军国主义和资本主义的一个表征,想来也有些道理,不然“鼠”的牺牲就感觉比较没意义,但是另一方面我的理解也可能是对自由的向往的表达,被羊控制,虽然可以成就“伟大”的事业,但是也丧失了自我。
+ wordpress 忘记密码的一种解决方法
+ /2021/12/05/wordpress-%E5%BF%98%E8%AE%B0%E5%AF%86%E7%A0%81%E7%9A%84%E4%B8%80%E7%A7%8D%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
+ 前阵子搭了个 WordPress,但是没怎么用,前两天发现忘了登录密码了,最近不知道是什么情况,chrome 的记住密码跟历史记录感觉有点问题,历史记录丢了不少东西,可能是时间太久了,但是理论上应该有 LRU 这种策略的,有些还比较常用,还有记住密码,因为个人域名都是用子域名分配给各个服务,有些记住了,有些又没记住密码,略蛋疼,所以就找了下这个方案。
当然这个方案不是最优的,有很多限制,首先就是要能够登陆 WordPress 的数据库,不然这个方法是没用的。
首先不管用什么方式(别违法)先登陆数据库,选择 WordPress 的数据库,可以看到里面有几个表,我们的目标就是 wp_users 表,用 select 查询看下可以看到有用户的数据,如果是像我这样搭着玩的没有创建其他用户的话应该就只有一个用户,那我们的表里的用户数据就只会有一条,当然多条的话可以通过用户名来找
![]()
然后可能我这个版本是这样,没有装额外的插件,密码只是经过了 MD5 的单向哈希,所以我们可以设定一个新密码,然后用 MD5 编码后直接更新进去
+UPDATE wp_users SET user_pass = MD5('123456') WHERE ID = 1;
+
+然后就能用自己的账户跟刚才更新的密码登录了。
+]]>
+
+ 小技巧
+
+
+ WordPress
+ 小技巧
+
+
+
+ 上次的其他 外行聊国足
+ /2022/03/06/%E4%B8%8A%E6%AC%A1%E7%9A%84%E5%85%B6%E4%BB%96-%E5%A4%96%E8%A1%8C%E8%81%8A%E5%9B%BD%E8%B6%B3/
+ 上次本来想在换车牌后面聊下这个话题,为啥要聊这个话题呢,也很简单,在地铁上看到一对猜测是情侣或者比较关系好的男女同学在聊,因为是这位男同学是大学学的工科,然后自己爱好设计绘画相关的,可能还以此赚了点钱,在地铁上讨论男的要不要好好努力把大学课程完成好,大致的观点是没必要,本来就不适合,这一段我就不说了,恋爱人的嘴,信你个鬼。
后面男的说在家里又跟他爹吵了关于男足的,估计是那次输了越南,实话说我不是个足球迷,对各方面技术相关也不熟,只是对包括这个人的解释和网上一些观点的看法,纯主观,这次地铁上这位说的大概意思是足球这个训练什么的很难的,要想赢越南也很难的,不是我们能嘴炮的;在网上看到一个赞同数很多的一个回答,说什么中国是个体育弱国,但是由于有一些乒乓球,跳水等小众项目比较厉害,让民众给误解了,首先我先来反驳下这个偷换概念的观点,第一所谓的体育弱国,跟我们觉得足球不应该这么差没半毛钱关系,因为体育弱国,我们的足球本来就不是顶尖的,也并不是去跟顶尖的球队去争,以足球为例,跟巴西,阿根廷,英国,德国,西班牙,意大利,法国这些足球强国,去比较,我相信没有一个足球迷会这么去做对比,因为我们足球历史最高排名是 1998 年的 37 名,最差是 100 名,把能数出来的强队都数完,估计都还不会到 37,所以根本没有跟强队去做对比,第二体育弱国,我们的体育投入是在逐年降低吗,我们是因战乱没法好好训练踢球?还是这帮傻逼就不争气,前面也说了我们足球世界排名最高 37,最低 100,那么前阵子我们输的越南是第几,目前我们的排名 77 名,越南 92 名,看明白了么,轮排名我们都不至于输越南,然后就是这个排名,这也是我想回应那位地铁上的兄弟,我觉得除了造核弹这种高精尖技术,绝大部分包含足球这类运动,遵循类二八原则,比如满分是 100 分,从 80 提到 90 分或者 90 分提到 100 分非常难,30 分提到 40 分,50 分提到 60 分我觉得都是可以凭后天努力达成的,基本不受天赋限制,这里可以以篮球来类比下,相对足球的确篮球没有那么火,或者行业市值没法比,但是也算是相对大众了,中国在篮球方面相对比较好一点,在 08 年奥运会冲进过八强,那也不是唯一的巅峰,但是我说这个其实是想说明两方面的事情,第一,像篮球一样,状态是有起起伏伏,排名也会变动,但是我觉得至少能维持一个相对稳定的总体排名和持平或者上升的趋势,这恰恰是我们这种所谓的“体育弱国”应该走的路线,第二就是去支持我的类二八原则的,可以看到我们的篮球这两年也很垃圾,排名跌到 29 了,那问题我觉得跟足球是一样的,就是不能脚踏实地,如斯科拉说的,中国篮球太缺少竞争,打得好不好都是这些人打,打输了还是照样拿钱,相对足球,篮球的技术我还是懂一些的,对比 08 年的中国男篮,的确像姚明跟王治郅这样的天赋型+努力型球员少了以后竞争力下降在所难免,但是去对比下基本功,传球,投篮,罚球稳定性,也完全不是一个水平的,这些就是我说的,可以通过努力训练拿 80 分的,只要拿到 80 分,甚至只要拿到 60 分,我觉得应该就还算对得起球迷了,就像 NBA 里球队也会有核心球员的更替,战绩起起伏伏,但是基本功这东西,防守积极性,我觉得不随核心球员的变化而变化,就像姚明这样的天赋,其实他应该还有一些先天缺陷,大脚趾较长等,但是他从 CBA 到 NBA,在 NBA 适应并且打成顶尖中锋,离不开刻苦训练,任何的成功都不是纯天赋的,必须要付出足够的努力。
说回足球,如果像前面那么洗地(体育弱国),那能给我维持住一个稳定的排名我也能接受,问题是我们的经济物质资源比 2000 年前应该有了质的变化,身体素质也越来越好,即使是体育弱国,这么继续走下坡路,半死不活的,不觉得是打了自己的脸么。足球也需要基本功,基本的体能,力量这些,看看现在这些国足运动员的体型,对比下女足,说实话,如果男足这些运动员都练得不错的体脂率,耐力等,成绩即使不好,也不会比现在更差。
纯主观吐槽,勿喷。
]]>
- 读后感
生活
+ 运动
- 读后感
+ 生活
@@ -12540,19 +12528,6 @@ user3:
nas
-
- 上次的其他 外行聊国足
- /2022/03/06/%E4%B8%8A%E6%AC%A1%E7%9A%84%E5%85%B6%E4%BB%96-%E5%A4%96%E8%A1%8C%E8%81%8A%E5%9B%BD%E8%B6%B3/
- 上次本来想在换车牌后面聊下这个话题,为啥要聊这个话题呢,也很简单,在地铁上看到一对猜测是情侣或者比较关系好的男女同学在聊,因为是这位男同学是大学学的工科,然后自己爱好设计绘画相关的,可能还以此赚了点钱,在地铁上讨论男的要不要好好努力把大学课程完成好,大致的观点是没必要,本来就不适合,这一段我就不说了,恋爱人的嘴,信你个鬼。
后面男的说在家里又跟他爹吵了关于男足的,估计是那次输了越南,实话说我不是个足球迷,对各方面技术相关也不熟,只是对包括这个人的解释和网上一些观点的看法,纯主观,这次地铁上这位说的大概意思是足球这个训练什么的很难的,要想赢越南也很难的,不是我们能嘴炮的;在网上看到一个赞同数很多的一个回答,说什么中国是个体育弱国,但是由于有一些乒乓球,跳水等小众项目比较厉害,让民众给误解了,首先我先来反驳下这个偷换概念的观点,第一所谓的体育弱国,跟我们觉得足球不应该这么差没半毛钱关系,因为体育弱国,我们的足球本来就不是顶尖的,也并不是去跟顶尖的球队去争,以足球为例,跟巴西,阿根廷,英国,德国,西班牙,意大利,法国这些足球强国,去比较,我相信没有一个足球迷会这么去做对比,因为我们足球历史最高排名是 1998 年的 37 名,最差是 100 名,把能数出来的强队都数完,估计都还不会到 37,所以根本没有跟强队去做对比,第二体育弱国,我们的体育投入是在逐年降低吗,我们是因战乱没法好好训练踢球?还是这帮傻逼就不争气,前面也说了我们足球世界排名最高 37,最低 100,那么前阵子我们输的越南是第几,目前我们的排名 77 名,越南 92 名,看明白了么,轮排名我们都不至于输越南,然后就是这个排名,这也是我想回应那位地铁上的兄弟,我觉得除了造核弹这种高精尖技术,绝大部分包含足球这类运动,遵循类二八原则,比如满分是 100 分,从 80 提到 90 分或者 90 分提到 100 分非常难,30 分提到 40 分,50 分提到 60 分我觉得都是可以凭后天努力达成的,基本不受天赋限制,这里可以以篮球来类比下,相对足球的确篮球没有那么火,或者行业市值没法比,但是也算是相对大众了,中国在篮球方面相对比较好一点,在 08 年奥运会冲进过八强,那也不是唯一的巅峰,但是我说这个其实是想说明两方面的事情,第一,像篮球一样,状态是有起起伏伏,排名也会变动,但是我觉得至少能维持一个相对稳定的总体排名和持平或者上升的趋势,这恰恰是我们这种所谓的“体育弱国”应该走的路线,第二就是去支持我的类二八原则的,可以看到我们的篮球这两年也很垃圾,排名跌到 29 了,那问题我觉得跟足球是一样的,就是不能脚踏实地,如斯科拉说的,中国篮球太缺少竞争,打得好不好都是这些人打,打输了还是照样拿钱,相对足球,篮球的技术我还是懂一些的,对比 08 年的中国男篮,的确像姚明跟王治郅这样的天赋型+努力型球员少了以后竞争力下降在所难免,但是去对比下基本功,传球,投篮,罚球稳定性,也完全不是一个水平的,这些就是我说的,可以通过努力训练拿 80 分的,只要拿到 80 分,甚至只要拿到 60 分,我觉得应该就还算对得起球迷了,就像 NBA 里球队也会有核心球员的更替,战绩起起伏伏,但是基本功这东西,防守积极性,我觉得不随核心球员的变化而变化,就像姚明这样的天赋,其实他应该还有一些先天缺陷,大脚趾较长等,但是他从 CBA 到 NBA,在 NBA 适应并且打成顶尖中锋,离不开刻苦训练,任何的成功都不是纯天赋的,必须要付出足够的努力。
说回足球,如果像前面那么洗地(体育弱国),那能给我维持住一个稳定的排名我也能接受,问题是我们的经济物质资源比 2000 年前应该有了质的变化,身体素质也越来越好,即使是体育弱国,这么继续走下坡路,半死不活的,不觉得是打了自己的脸么。足球也需要基本功,基本的体能,力量这些,看看现在这些国足运动员的体型,对比下女足,说实话,如果男足这些运动员都练得不错的体脂率,耐力等,成绩即使不好,也不会比现在更差。
纯主观吐槽,勿喷。
-]]>
-
- 生活
- 运动
-
-
- 生活
-
-
springboot 获取 web 应用中所有的接口 url
/2023/08/06/springboot-%E8%8E%B7%E5%8F%96-web-%E5%BA%94%E7%94%A8%E4%B8%AD%E6%89%80%E6%9C%89%E7%9A%84%E6%8E%A5%E5%8F%A3-url/
@@ -12688,6 +12663,31 @@ user3:
中间件
+
+ ssh 小技巧-端口转发
+ /2023/03/26/ssh-%E5%B0%8F%E6%8A%80%E5%B7%A7-%E7%AB%AF%E5%8F%A3%E8%BD%AC%E5%8F%91/
+ 我们在使用 ssh 连接的使用有一个很好用功能,就是端口转发,而且使用的方式也很多样,比如我们经常用 vscode 来做远程开发的话,一般远程连接就可以基于 ssh,前面也介绍过 vscode 的端口转发,并且可以配置到 .ssh/config 配置文件里,只不过最近在一次使用的过程中发现了一个问题,就是在一台 Ubuntu 的某云服务器上想 ssh 到另一台服务器上,并且做下端口映射,但是发现报了个错,
+bind: Cannot assign requested address
+查了下这个问题,猜测是不是端口已经被占用了,查了下并不是,然后想到是不是端口是系统保留的,
+sysctl -a |grep port_range
+结果中
+net.ipv4.ip_local_port_range = 50000 65000 -----意味着50000~65000端口可用
+发现也不是,没有限制,最后才查到这个原因是默认如果有 ipv6 的话会使用 ipv6 的地址做映射
所以如果是命令连接做端口转发的话,
+ssh -4 -L 11234:localhost:1234 x.x.x.x
+使用-4来制定通过 ipv4 地址来做映射
如果是在 .ssh/config 中配置的话可以直接指定所有的连接都走 ipv4
+Host *
+ AddressFamily inet
+inet代表 ipv4,inet6代表 ipv6
AddressFamily 的所有取值范围是:”any”(默认)、”inet”(仅IPv4)、”inet6”(仅IPv6)。
另外此类问题还可以通过 ssh -v 来打印更具体的信息
+]]>
+
+ ssh
+ 技巧
+
+
+ ssh
+ 端口转发
+
+
介绍下最近比较实用的端口转发
/2021/11/14/%E4%BB%8B%E7%BB%8D%E4%B8%8B%E6%9C%80%E8%BF%91%E6%AF%94%E8%BE%83%E5%AE%9E%E7%94%A8%E7%9A%84%E7%AB%AF%E5%8F%A3%E8%BD%AC%E5%8F%91/
@@ -12733,6 +12733,24 @@ user3:
美国
+
+ 关于 npe 的一个小记忆点
+ /2023/07/16/%E5%85%B3%E4%BA%8E-npe-%E7%9A%84%E4%B8%80%E4%B8%AA%E5%B0%8F%E8%AE%B0%E5%BF%86%E7%82%B9/
+ Java 中最常见的一类问题或者说异常就是 NullPointerException,而往往这种异常我们在查看日志的时候都是根据打印出来的异常堆栈找到对应的代码以确定问题,但是有一种情况会出现一个比较奇怪的情况,虽然我们在日志中打印了异常
+log.error("something error", e);
+这样是可以打印出来日志,譬如 slf4j 就可以把异常作为最后一个参数传入
+void error(String var1, Throwable var2);
+有的时候如果不小心把异常通过占位符传入就可能出现异常被吞的情况,不过这点不是这次的重点
即使我们正常作为最后一个参数传入了,也会出现只打印出来
+something error, java.lang.NullPointerException: null
+这样就导致了如果我们这个日志所代表的异常包含的代码范围比较大的话,就不确定具体是哪一行出现的异常,除非对这些代码逻辑非常清楚,这个是为什么呢,其实这也是 jvm 的一种优化机制,像我们目前主要还在用的 jdk8中使用的 jvm 虚拟机 hotspot 的一个热点异常机制,对于这样一直出现的相同异常,就认为是热点异常,后面只会打印异常名,不再打印异常堆栈,这样对于 io 性能能够提供一定的优化保证,这个可以通过 jvm 启动参数
-XX:-OmitStackTraceInFastThrow 来关闭优化,这个问题其实在一开始造成了一定困扰,找不准具体是哪一行代码,不过在知道这个之后简单的重启也能暂时解决问题。
+]]>
+
+ java
+
+
+ java
+
+
从清华美院学姐聊聊我们身边的恶人
/2020/11/29/%E4%BB%8E%E6%B8%85%E5%8D%8E%E7%BE%8E%E9%99%A2%E5%AD%A6%E5%A7%90%E8%81%8A%E8%81%8A%E6%88%91%E4%BB%AC%E8%BA%AB%E8%BE%B9%E7%9A%84%E6%81%B6%E4%BA%BA/
@@ -12775,6 +12793,18 @@ user3:
健康码
+
+ nas 中使用 tmm 刮削视频
+ /2023/07/02/%E4%BD%BF%E7%94%A8-tmm-%E5%88%AE%E5%89%8A%E8%A7%86%E9%A2%91/
+ 最近折腾了个自建的 nas,为了使用 jellyfin 这样的影视应用需要对视频进行刮削,对于电视剧来说还是有些不一样的,
比如我要刮削这部经典电视剧纪晓岚
![]()
像这样的命名方式在 tmm 中是无法识别的,或者就得一集一集进行制定刮削,
![]()
所以第一步需要进行改名
比如这是第一季的,那就是 S01,然后按集数 E01,第一季第一集的文件名就是 S01E01.mkv
然后右键点击搜索刮削,默认会以文件夹名进行搜索,是在 tmdb 数据库进行搜索
![]()
这样除非文件夹名很符合要求,一般都刮削不出来,所以需要有两种刮削方式,一种就是比较标准的命名,这样的名字可以手动先去豆瓣或者 tmdb 搜索,另一个种也可以在豆瓣找到 imdb 的 id 进行搜索
![]()
但有时候也会搜不到,比如这个纪晓岚就是搜不到,但是之前的一些韩剧什么的很多都能搜到
![]()
这个其实是最基本的刮削,但是这样刮削了需要在 jellyfin 那取消元数据下载
![]() ,这样就不会被覆盖
+]]>
,这样就不会被覆盖
+]]>
+
+ nas
+
+
+ nas
+
+
关于读书打卡与分享
/2021/02/07/%E5%85%B3%E4%BA%8E%E8%AF%BB%E4%B9%A6%E6%89%93%E5%8D%A1%E4%B8%8E%E5%88%86%E4%BA%AB/
@@ -12795,39 +12825,22 @@ user3:
- 关于 npe 的一个小记忆点
- /2023/07/16/%E5%85%B3%E4%BA%8E-npe-%E7%9A%84%E4%B8%80%E4%B8%AA%E5%B0%8F%E8%AE%B0%E5%BF%86%E7%82%B9/
- Java 中最常见的一类问题或者说异常就是 NullPointerException,而往往这种异常我们在查看日志的时候都是根据打印出来的异常堆栈找到对应的代码以确定问题,但是有一种情况会出现一个比较奇怪的情况,虽然我们在日志中打印了异常
-log.error("something error", e);
-这样是可以打印出来日志,譬如 slf4j 就可以把异常作为最后一个参数传入
-void error(String var1, Throwable var2);
-有的时候如果不小心把异常通过占位符传入就可能出现异常被吞的情况,不过这点不是这次的重点
即使我们正常作为最后一个参数传入了,也会出现只打印出来
-something error, java.lang.NullPointerException: null
-这样就导致了如果我们这个日志所代表的异常包含的代码范围比较大的话,就不确定具体是哪一行出现的异常,除非对这些代码逻辑非常清楚,这个是为什么呢,其实这也是 jvm 的一种优化机制,像我们目前主要还在用的 jdk8中使用的 jvm 虚拟机 hotspot 的一个热点异常机制,对于这样一直出现的相同异常,就认为是热点异常,后面只会打印异常名,不再打印异常堆栈,这样对于 io 性能能够提供一定的优化保证,这个可以通过 jvm 启动参数
-XX:-OmitStackTraceInFastThrow 来关闭优化,这个问题其实在一开始造成了一定困扰,找不准具体是哪一行代码,不过在知道这个之后简单的重启也能暂时解决问题。
-]]>
-
- java
-
-
- java
-
-
-
- nas 中使用 tmm 刮削视频
- /2023/07/02/%E4%BD%BF%E7%94%A8-tmm-%E5%88%AE%E5%89%8A%E8%A7%86%E9%A2%91/
- 最近折腾了个自建的 nas,为了使用 jellyfin 这样的影视应用需要对视频进行刮削,对于电视剧来说还是有些不一样的,
比如我要刮削这部经典电视剧纪晓岚
![]()
像这样的命名方式在 tmm 中是无法识别的,或者就得一集一集进行制定刮削,
![]()
所以第一步需要进行改名
比如这是第一季的,那就是 S01,然后按集数 E01,第一季第一集的文件名就是 S01E01.mkv
然后右键点击搜索刮削,默认会以文件夹名进行搜索,是在 tmdb 数据库进行搜索
![]()
这样除非文件夹名很符合要求,一般都刮削不出来,所以需要有两种刮削方式,一种就是比较标准的命名,这样的名字可以手动先去豆瓣或者 tmdb 搜索,另一个种也可以在豆瓣找到 imdb 的 id 进行搜索
![]()
但有时候也会搜不到,比如这个纪晓岚就是搜不到,但是之前的一些韩剧什么的很多都能搜到
![]()
这个其实是最基本的刮削,但是这样刮削了需要在 jellyfin 那取消元数据下载
![]() ,这样就不会被覆盖
+
,这样就不会被覆盖
+ 分享一次折腾老旧笔记本的体验
+ /2023/02/05/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%80%81%E6%97%A7%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%9A%84%E4%BD%93%E9%AA%8C/
+ 上大学的时候买了第一个笔记本,是联想的小y,y460,配置应该是 i5+2g 内存,500g 硬盘,ati 5650 的显卡,那时候还是比较时髦的带有集显和独显切换的,一些人也觉得它算是一代“神机”,陪我度过了大学四年,还有毕业后的第一年,记得中间还用的比较曲折,差不多第一学期末的时候硬盘感觉有时候会文件操作卡住,去售后看了下,果然硬盘出问题了,还在当场把硬盘的东西都拷贝到新买的移动硬盘里,不过联想的售后还是比较不错的,在保内可以直接免费换,如果出保了估计就要修不起了,后面出了个很大的问题,就是屏幕花屏了,而且它的花屏是横着的会有那种上升的变化,一开始感觉跟湿度还有温度有点关系,天气冷了就很容易出现,天气热了就好一点,出现的概率小一点,而且是合盖后再开会好,过一会又会上升,只是这么度过了保修期,去售后问了下,修一下要两千多,后来是在玉泉学校里面的维修店,好像是花了六百多,省是省了很多,但是后面使用的时候发现有点漏光,而且两三个亮点,总归还是给我那不富裕的经济条件带来了一个正常屏幕,不过是挺影响使用,严格来说都没法用了,后面基本是大半个屏幕花掉,接近整个屏幕花掉,至此大学就是这么用过去了。
噢对了,中间在大二的时候加了一条 2g 的内存,因为像操作系统课需要用虚拟机,2g 内存不太够,不过那会用的都是 32 位的 win7 系统,实际使用用不到 4g 内存,得使用破解补丁才能识别到,后来在大学毕业后由于收入也低,想换其他电脑,特别是 mac,买不起,电脑在那会还会玩玩 DNF,但是风扇声很大,也想优化下,就买了个 msata 的固态硬盘,因为刚好有个口子留着,在那之前一直搜到的是把光驱位拆掉换上 sata 固态硬盘,这对于那会的我来说操作难度实在有点大,换上了msata 固态之后还是有比较大的提升的,把操作系统装到固态硬盘后其他盘就只放数据了,后面还装过黑苹果,只是不小心被室友强制关机了,之后就起不来了,也不知道啥原因,后续想继续按原来的操作装,也没成功,再往后就配了一台台式机,这个笔记本就放在那没啥用了,后面偶尔会拿出来用一下,特别是疫情那会充当了 LD 的临时使用机器。
最近一次就是想把行车记录仪里的视频导出来,结果上传的时候我点了下 win10 的更新,重启后这个机器就起不来了,一开始以为顶多是个重装系统,结果重装也不行,就进不去,插着 U 盘也起不来,一开始还能进 BIOS,后面就直接进不去了,像内存条脏了,擦下金手指什么的,都没搞定,想着也只可能是主板上的部件坏了,所以就开始了这趟半作死之旅,买了块主板来换,拆这个笔记本是真的够难的,开机键那一条是真的拆不开,后面还把两个扣子扳坏了,里面的排线插口还几个也拔坏了,幸好用买来的主板装上还能用,但是后面就很奇怪了,因为这个电脑装了 Ubuntu 跟 win10 的双系统,Ubuntu 能正常起来,但是 win10 就是起不来,插上老毛桃或者 win10 的启动盘都是起不来,老毛桃是能起来,但是进不了 pe,插启动盘又报 0xc00000e9 错误码,现在想着是不是这个固态硬盘有点问题或者还是内存问题,只能后续再看了,拆机的时候也找不到视频,机器实在是太老了,后面再试试看。
]]>
- nas
+ Windows
+ 小技巧
- nas
+ Windows
- 分享一次折腾老旧笔记本的体验-续续篇
- /2023/02/26/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%80%81%E6%97%A7%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%9A%84%E4%BD%93%E9%AA%8C-%E7%BB%AD%E7%BB%AD%E7%AF%87/
- 上周因为一些事情没回去,买好了内存条这周才回去用,结果不知道是 U 盘的问题还是什么其他原因原来装的那个系统起不来,然后想用之前一直用的 LD 的笔记本,结果 LD 的老笔记本也起不来了,一直卡在启动界面,猜测可能是本身也比较老了,用的机械硬盘会不会被我一直动而损坏了,所以就想搞个老毛桃跟新搞一个启动盘,结果这周最大的坑就在这了,在我的 15 寸 mbp 上用etcher做了个 win10 的启动盘,可能是分区表格式是 GUID,不是 MBR 的,老电脑不能识别,就像装个虚拟机来做启动盘,结果像老毛桃不支持这种用虚拟机的,需要本地磁盘,然后我就有用 bootcamp 安装了个 win10,又没网络,查了下网络需要用 bootcamp 下载 Windows Support 软件,下了好久一直没下完,后来又提示连不上苹果服务器,好不容易下完了,开启 win10 后,安装到一半就蓝屏了,真的是够操蛋的,在这个时候真的很需要有一个 Windows 机器的支持,LD 的那个笔记本也跟我差不多老了,虽然比较慢但之前好歹也还可以用,结果这下也被我弄坏了,家里就没有其他机器可以支持了,有点巧妇难为无米之炊的赶脚,而且还是想再折腾下我的老电脑,后面看看打算做几个 U 盘,分工职责明确,一个老毛桃的PE 盘,老毛桃的虽然不是很纯净的,但是是我一直以来用过内置工具比较全,修复启动功能比较强大的一个 pe,没用过 winpe,后续可以考虑使用下,一个 win7 的启动盘,因为是老电脑,如果后面是新的电脑可以考虑是 win10,一个 win to go 盘,这样我的 mbp 就可以直接用 win10 了,不过想来也还是要有一台 win 机器才比较好,不然很多时候都是在折腾工具,工欲善其事必先利其器,后面也可以考虑能够更深入的去了解主板的一些问题,我原来的那个主板可能是一些小的电阻等问题,如果能自己学习解决就更好了,有时候研究下还是有意思的。
+ 分享一次折腾老旧笔记本的体验-续篇
+ /2023/02/12/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%80%81%E6%97%A7%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%9A%84%E4%BD%93%E9%AA%8C-%E7%BB%AD%E7%AF%87/
+ 接着上一篇的折腾记,因为这周又尝试了一些新的措施和方法,想继续记录分享下,上周的整体情况大概是 Ubuntu 系统能进去了,但是 Windows 进不去,PE 也进不去,Windows 启动盘也进不去,因为我的机器加过一个 msata 的固态,Windows 是装在 msata 固态硬盘里的,Ubuntu 是装在机械硬盘里的,所以有了一种猜测就是可能这个固态硬盘有点问题,还有就是还是怀疑内存的问题,正好家里还有个msata 的固态硬盘,是以前想给LD 的旧笔记本换上的,因为买回来放在那没有及时装,后面会又找不到,直到很后面才找到,LD 也不怎么用那个笔记本了,所以就一直放着了,这次我就想拿来换上。
周末回家我就开始尝试了,换上了新的固态硬盘后,插上 Windows 启动 U 盘,这次一开始看起来有点顺利,在 BIOS 选择 U 盘启动,进入了 Windows 安装界面,但是装到一半,后面重启了之后就一直说硬盘有问题,让重启,但是重启并没有解决问题,变成了一直无效地重复重启,再想进 U 盘启动,就又进不去了,这时候怎么说呢,感觉硬盘不是没有问题,但是呢,问题应该不完全出在这,所以按着总体的逻辑来讲,主板带着cpu 跟显卡,都换掉了,硬盘也换掉了,剩下的就是内存了,可是内存我也尝试过把后面加的那条金士顿拔掉,可还是一样,也尝试过用橡皮擦金手指,这里感觉也很奇怪了,找了一圈了都感觉没啥明确的原因,比如其实我的猜测,主板电池的问题,一些电阻坏掉了,但是主板是换过的,那如果内存有问题,照理我用原装的那条应该会没问题,也有一种非常小的可能,就是两条内存都坏了,或者说这也是一种不太可能的可能,所以最后的办法就打算试试把两条内存都换掉,不过现在网上都找不到这个内存的确切信息了,只能根据大致的型号去买来试试,就怕买来的还是坏的,其实也怕是这个买来的主板因为也是别的拆机下来的,不一定保证完全没问题,要是有类似的问题或者也有别的问题导致开不起来就很尴尬,也没有很多专业的仪器可以排查原因,比如主板有没有什么短路的,对了还有一个就是电源问题,但是电源的问题也就可能是从充电器插的口子到主板的连线,因为 LD 的电源跟我的口子一样,也试过,但是结果还是一样,顺着正常逻辑排查,目前也没有剩下很明确的方向了,只能再尝试下看看。
]]>
Windows
@@ -12857,59 +12870,78 @@ user3:
- 分享一次比较诡异的 Windows 下 U盘无法退出的经历
- /2023/01/29/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%AF%94%E8%BE%83%E8%AF%A1%E5%BC%82%E7%9A%84-Windows-%E4%B8%8B-U%E7%9B%98%E6%97%A0%E6%B3%95%E9%80%80%E5%87%BA%E7%9A%84%E7%BB%8F%E5%8E%86/
- 作为一个 Windows 的老用户,并且也算是 Windows 系统的半个粉丝,但是秉承一贯的优缺点都应该说的原则,Windows 系统有一点缺点是真的挺难受,相信 Windows 用过比较久的都会经历过,就是 U盘无法退出的问题,在比较远古时代,这个问题似乎能采取的措施不多,关机再拔 U盘的方式是一种比较保险的方式,其他貌似有 360这种可以解除占用的,但是需要安装 360 软件,对于目前的使用环境来说有点得不偿失,也是比较流氓的一类软件了,目前在 Windows 环境我主要就安装了个火绒,或者就用 Windows 自带的 defender。
-第一种
最近这次经历也是有火绒的一定责任,在我尝试推出 U盘的时候提示了我被另一个大流氓软件,XlibabaProtect.exe 占用了,这个流氓软件真的是充分展示了某里的技术实力,试过 N 多种办法都关不掉也删不掉,尝试了很多种办法也没办法删除,但是后面换了种思路,一般这种情况肯定是有进程在占用 U盘里的内容,最新版本的 Powertoys 会在文件的右键菜单里添加一个叫 File Locksmith 的功能,可以用于检查正在使用哪些文件以及由哪些进程使用,但是可能是我的使用姿势不对,没有仔细看文档,它里面有个”以管理员身份重启”,可能会有用。
这算是第一种方式,
-第二种
第二种方式是 Windows 任务管理器中性能 tab 下的”打开资源监视器”,
![]() ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是F:
![]() 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
对于前两种方式对我来说都无效,
-第三种
所以尝试了第三种,
就是磁盘脱机的方式,在”计算机”右键管理,点击”磁盘管理”,可以找到 U 盘盘符右键,点击”脱机”,然后再”推出”,这个对我来说也不行
-第四种
这种是唯一对我有效的,在开始菜单搜索”event”,可以搜到”事件查看器”,
![]() ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
最后发现是英特尔的驱动管理程序的一个进程,关掉就退出了,虽然前面说的某里的进程是流氓,但这边是真的冤枉它了
+ 周末我在老丈人家打了天小工
+ /2020/08/16/%E5%91%A8%E6%9C%AB%E6%88%91%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E6%89%93%E4%BA%86%E5%A4%A9%E5%B0%8F%E5%B7%A5/
+ 这周回家提前约好了要去老丈人家帮下忙,因为在翻修下老房子,活不是特别整的那种,所以大部分都是自己干,或者找个大工临时干几天(我们这那种比较专业的泥工匠叫做大工),像我这样去帮忙的,就是干点小工(把给大工帮忙的,干些偏体力活的叫做小工)的活。从大学毕业以后真的蛮少帮家里干活了,以前上学的时候放假还是帮家里淘个米,简单的扫地拖地啥的,当然刚高考完的时候,还去我爸厂里帮忙干了几天的活,实在是比较累,不过现在想着是觉得自己那时候比较牛,而不是特别排斥这个活,相对于现在的工作来说,导致了一系列的职业病,颈椎腰背都很僵硬,眼镜也不好,还有反流,像我爸那种活反而是脑力加体力的比较好的结合。
这一天的活前半部分主要是在清理厨房,瓷砖上的油污和墙上天花板上即将脱落的石灰或者白色涂料层,这种活特别是瓷砖上的油污,之前在自己家里也干活,还是比较熟悉的,不过前面主要是LD 在干,我主要是先搞墙上和天花板上的,干活还是很需要技巧的,如果直接去铲,那基本我会变成一个灰人,而且吸一鼻子灰,老丈人比较专业,先接上软管用水冲,一冲效果特别好,有些石灰涂料层直接就冲掉了,冲完之后先用带加长杆的刀片铲铲了一圈墙面,说实话因为老房子之前租出去了,所以墙面什么的被糟蹋的比较难看,一层一层的,不过这还算还好,后面主要是天花板上的,这可难倒我了,从小我爸妈是比较把我当小孩管着,爬上爬下的基本都是我爸搞定,但是到了老丈人家也只得硬着头皮上了,爬到跳(一种建筑工地用的架子)上,还有点晃,小心脏扑通扑通跳,而且带加长杆的铲子还是比较重的,铲一会手也有点累,不过坚持着铲完了,上面还是比较平整的,不过下来的时候又把我难住了🤦♂️,往下爬的时候有根杆子要跨过去,由于裤子比较紧,强行一把跨过去怕抽筋,所以以一个非常尴尬的姿势停留休息了一会,再跨了过去,幸好事后问 LD,他们都没看到,哈哈哈,然后就是帮忙一起搞瓷砖上的油污,这个太有经验了,不过老丈人更有意思,一会试试啤酒,一会用用沙子,后面在午饭前基本就弄的比较干净了,就坐着等吃饭了,下午午休了会,就继续干活了。
下午是我这次体验的重点了,因为要清理以前贴的墙纸,真的是个很麻烦的活,只能说贴墙纸的师傅活干得太好了,基本不可能整个撕下来,想用铲子一点点铲下来也不行,太轻了就只铲掉表面一层,太重了就把墙纸跟墙面的石灰啥的整个铲下来了,而且手又累又酸,后来想着是不是继续用水冲一下,对着一小面墙试验了下,效果还不错,但是又发现了个问题,那一面墙又有一块是后面糊上去的,铲掉外层的石灰后不平,然后就是最最重头的,也是让我后遗症持续到第二天的,要把那一块糊上去的水泥敲下来,毛估下大概是敲了80%左右,剩下的我的手已经不会用力了,因为那一块应该是要糊上去的始作俑者,就一块里面凹进去的,我拿着榔头敲到我手已经没法使劲了,而且大下午,感觉没五分钟,我的汗已经糊满脸,眼睛也睁不开,不然就流到眼睛里了,此处获得成就一:用榔头敲墙壁,也是个技术加体力的活,而且需要非常好的技巧,否则手马上就废了,敲下去的反作用力,没一会就不行了,然后是看着老丈人兄弟帮忙拆一个柜子,在我看来是个几天都搞不定的活,他轻轻松松在我敲墙的那会就搞定了,以前总觉得我干的活非常有技术含量,可是这个事情真的也是很有技巧啊,它是个把一间房间分隔开的柜子,从底到顶上,还带着门,我还在旁边帮忙撬一下脚踢,一根木条撬半天,唉,成就二:专业的人就是不一样。
最后就是成就三了:我之前沾沾自喜的跑了多少步,做了什么锻炼,其实都是渣渣,像这样干一天活,没经历过的,基本大半天就废了,反过来说,如果能经常去这么干一天活,跑步啥的都是渣渣,消耗的能量远远超过跑个十公里啥的。
]]>
- Windows
- 小技巧
+ 生活
+ 运动
+ 跑步
+ 干活
- Windows
+ 生活
+ 运动
+ 减肥
+ 跑步
+ 干活
- 分享一次折腾老旧笔记本的体验-续篇
- /2023/02/12/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%80%81%E6%97%A7%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%9A%84%E4%BD%93%E9%AA%8C-%E7%BB%AD%E7%AF%87/
- 接着上一篇的折腾记,因为这周又尝试了一些新的措施和方法,想继续记录分享下,上周的整体情况大概是 Ubuntu 系统能进去了,但是 Windows 进不去,PE 也进不去,Windows 启动盘也进不去,因为我的机器加过一个 msata 的固态,Windows 是装在 msata 固态硬盘里的,Ubuntu 是装在机械硬盘里的,所以有了一种猜测就是可能这个固态硬盘有点问题,还有就是还是怀疑内存的问题,正好家里还有个msata 的固态硬盘,是以前想给LD 的旧笔记本换上的,因为买回来放在那没有及时装,后面会又找不到,直到很后面才找到,LD 也不怎么用那个笔记本了,所以就一直放着了,这次我就想拿来换上。
周末回家我就开始尝试了,换上了新的固态硬盘后,插上 Windows 启动 U 盘,这次一开始看起来有点顺利,在 BIOS 选择 U 盘启动,进入了 Windows 安装界面,但是装到一半,后面重启了之后就一直说硬盘有问题,让重启,但是重启并没有解决问题,变成了一直无效地重复重启,再想进 U 盘启动,就又进不去了,这时候怎么说呢,感觉硬盘不是没有问题,但是呢,问题应该不完全出在这,所以按着总体的逻辑来讲,主板带着cpu 跟显卡,都换掉了,硬盘也换掉了,剩下的就是内存了,可是内存我也尝试过把后面加的那条金士顿拔掉,可还是一样,也尝试过用橡皮擦金手指,这里感觉也很奇怪了,找了一圈了都感觉没啥明确的原因,比如其实我的猜测,主板电池的问题,一些电阻坏掉了,但是主板是换过的,那如果内存有问题,照理我用原装的那条应该会没问题,也有一种非常小的可能,就是两条内存都坏了,或者说这也是一种不太可能的可能,所以最后的办法就打算试试把两条内存都换掉,不过现在网上都找不到这个内存的确切信息了,只能根据大致的型号去买来试试,就怕买来的还是坏的,其实也怕是这个买来的主板因为也是别的拆机下来的,不一定保证完全没问题,要是有类似的问题或者也有别的问题导致开不起来就很尴尬,也没有很多专业的仪器可以排查原因,比如主板有没有什么短路的,对了还有一个就是电源问题,但是电源的问题也就可能是从充电器插的口子到主板的连线,因为 LD 的电源跟我的口子一样,也试过,但是结果还是一样,顺着正常逻辑排查,目前也没有剩下很明确的方向了,只能再尝试下看看。
+ 分享记录一下一个 scp 操作方法
+ /2022/02/06/%E5%88%86%E4%BA%AB%E8%AE%B0%E5%BD%95%E4%B8%80%E4%B8%8B%E4%B8%80%E4%B8%AA-scp-%E6%93%8D%E4%BD%9C%E6%96%B9%E6%B3%95/
+ scp 是个在服务器之间拷贝文件的一个常用命令,有时候有个场景是比如我们需要拷贝一些带有共同前缀的文件,但是有一个问题是比如我们有使用 zsh 的话,会出现一个报错,
+zsh: no matches found: root@100.100.100.100://root/prefix*
+这里就比较奇怪了,这个前缀的文件肯定是有的,这里其实是由于 zsh 会对 * 进行展开,这个可以在例如 ls 命令在使用中就可以发现 zsh 有这个特性
需要使用双引号或单引号将路径包起来或者在*之前加反斜杠\来阻止对*展开和转义
+scp root@100.100.100.100://root/prefix* .
+通过使用双引号"进行转义
+scp root@100.100.100.100:"//root/prefix*" .
+或者可以将 shell 从 zsh 切换成 bash
]]>
- Windows
+ shell
小技巧
- Windows
+ scp
- 在老丈人家的小工记三
- /2020/09/13/%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E7%9A%84%E5%B0%8F%E5%B7%A5%E8%AE%B0%E4%B8%89/
- 小工记三前面这两周周末也都去老丈人家帮忙了,上上周周六先是去了那个在装修的旧房子那,把三楼收拾了下,因为要搬进来住,来不及等二楼装修好,就要把三楼里的东西都整理干净,这个活感觉是比较 easy,原来是就准备把三楼当放东西仓储的地方了,我们乡下大部分三层楼都是这么用的,这次也是没办法,之前搬进来的木头什么的都搬出去,主要是这上面灰尘太多,后面清理鼻孔的时候都是黑色的了,把东西都搬出去以后主要是地还是很脏,就扫了地拖了地,因为是水泥地,灰尘又太多了,拖起来都是会灰尘扬起来,整个脱完了的确干净很多,然而这会就出了个大乌龙,我们清理的是三楼的西边一间,结果老丈人上来说要住东边那间的🤦♂️,不过其实西边的也得清理,因为还是要放被子什么的,不算是白费功夫,接着清理东边那间,之前这个房子做过群租房,里面有个高低铺的床,当时觉得可以用在放被子什么的就没扔,只是拆掉了放旁边,我们就把它擦干净了又装好,发现螺丝🔩少了几个,亘古不变的真理,拆了以后装要不就多几个要不就少几个,不是很牢靠,不过用来放放被子省得放地上总还是可以的,对了前面还做了个事情就是铺地毯,其实也不是地毯,就是类似于墙布雨篷布那种,别人不用了送给我们的,三楼水泥地也不会铺瓷砖地板了就放一下,干净好看点,不过大小不合适要裁一下,那把剪刀是真的太难用了,我手都要抽筋了,它就是刀口只有一小个点是能剪下来的,其他都是钝的,后来还是用刀片直接裁,铺好以后,真的感觉也不太一样了,焕然一新的感觉
差不多中午了就去吃饭了,之前两次是去了一家小饭店,还是还比较干净,但是店里菜不好吃,还死贵,这次去了一家小快餐店,口味好,便宜,味道是真的不错,带鱼跟黄鱼都好吃,一点都不腥,我对这类比较腥的鱼真的是很挑剔的,基本上除了家里做的很少吃外面的,那天抱着试试的态度吃了下,真的还不错,后来丈母娘说好像这家老板是给别人结婚喜事酒席当厨师的,怪不得做的好吃,其实本来是有一点小抗拒,怕不干净什么的,后来发现菜很好吃,而且可能是老丈人跟干活的师傅去吃的比较多,老板很客气,我们吃完饭,还给我们买了葡萄吃,不过这家店有一个槽点,就是饭比较不好吃,有时候会夹生,不过后面聊起来其实是这种小菜馆饭点的通病,烧的太早太多容易多出来浪费,烧的迟了不够吃,而且大的电饭锅比较不容易烧好。
下午前面还是在处理三楼的,窗户上各种钉子,实在是太多了,我后面在走廊上排了一排🤦♂️,有些是直接断了,有些是就撬了出来,感觉我在杭州租房也没有这样子各种钉钉子,挂下衣服什么的也不用这么多吧,比较不能理解,搞得到处都是钉子。那天我爸也去帮忙了,主要是在卫生间里做白缝,其实也是个技术活,印象中好像我小时候自己家里也做过这个事情,但是比较模糊了,后面我们三楼搞完了就去帮我爸了,前面是我老婆二爹在那先刷上白缝,这里叫白缝,有些考究的也叫美缝,就是瓷砖铺完之后的缝,如果不去弄的话,里面水泥的颜色就露出来了,而且容易渗水,所以就要用白水泥加胶水搅拌之后糊在缝上,但是也不是直接糊,先要把缝抠一抠,因为铺瓷砖的还不会仔细到每个缝里的水泥都是一样满,而且也需要一些空间糊上去,不然就太表面的一层很容易被水直接冲掉了,然后这次其实也不是用的白水泥,而是直接现成买来就已经配好的用来填缝的,兑水搅拌均匀就好了,后面就主要是我跟我爸在搞,那个时候真的觉得我实在是太胖了,蹲下去真的没一会就受不了了,膝盖什么的太难受了,后面我跪着刷,然后膝盖又疼,也是比较不容易,不过我爸动作很快,我中间跪累了休息一会,我爸就能搞一大片,后面其实我也没做多少(谦虚一下),总体来讲这次不是很累,就是蹲着跪着腿有点受不了,是应该好好减肥了。
+ 在 wsl 2 中开启 ssh 连接
+ /2023/04/23/%E5%9C%A8-wsl-2-%E4%B8%AD%E5%BC%80%E5%90%AF-ssh-%E8%BF%9E%E6%8E%A5/
+ 之前在 wsl 1 中开启 ssh 其实很方便,只要把 sshd 服务起来就好了,但是在 wsl 2 中就不太一样了,
我这边使用的是 wsl 2 中的 Ubuntu 20.04,直接启动 sshd 服务是没法让其他机器连接的,而且都没有 ifconfig 命令可以查看 ip
不过可以用直接用 ip a来查看,可以看到这个 ip 是172网段的,而在 wsl 1 中可以看到 ip 就是 win 的 ip,
所以需要做一些操作,首先要安装 openssl-server
+sudo apt update
+sudo apt install openssh-server
+另外如果需要提高安全性,可以wsl 中配置 hosts.allow
+sshd:192.168.xx.
+先定一个子网段,然后对于ssh的配置,可以做以下修改
+Port 22
+PasswordAuthentication yes
+在进行重启
+sudo service ssh --full-restart
+配置以后发现上面的问题,没法远程登录,因为 wsl 2 是基于 hyper-v 虚拟机实现的,并且 ip 使用的是一个虚拟出来的子网 ip,所以需要在 Windows 这一层配置端口的转发,可以通过命令netsh interface portproxy show v4tov4看到
![]()
截图是我已经添加好了的,先把原来的删除,再进行添加
+netsh interface portproxy delete v4tov4 listenaddress=0.0.0.0 listenport=22
+netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=22 connectaddress=172.19.129.207 connectport=22
+也可以全量删除
+netsh int portproxy reset all
+但是这样也不能直接访问了,还需要开启防火墙
+netsh advfirewall firewall add rule name="WSL SSH" dir=in action=allow protocol=TCP localport=22
+
+
+
]]>
- 生活
- 运动
- 跑步
- 干活
+ wsl
- 生活
- 小技巧
- 运动
- 减肥
- 跑步
- 干活
+ wsl
- 周末我在老丈人家打了天小工
- /2020/08/16/%E5%91%A8%E6%9C%AB%E6%88%91%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E6%89%93%E4%BA%86%E5%A4%A9%E5%B0%8F%E5%B7%A5/
- 这周回家提前约好了要去老丈人家帮下忙,因为在翻修下老房子,活不是特别整的那种,所以大部分都是自己干,或者找个大工临时干几天(我们这那种比较专业的泥工匠叫做大工),像我这样去帮忙的,就是干点小工(把给大工帮忙的,干些偏体力活的叫做小工)的活。从大学毕业以后真的蛮少帮家里干活了,以前上学的时候放假还是帮家里淘个米,简单的扫地拖地啥的,当然刚高考完的时候,还去我爸厂里帮忙干了几天的活,实在是比较累,不过现在想着是觉得自己那时候比较牛,而不是特别排斥这个活,相对于现在的工作来说,导致了一系列的职业病,颈椎腰背都很僵硬,眼镜也不好,还有反流,像我爸那种活反而是脑力加体力的比较好的结合。
这一天的活前半部分主要是在清理厨房,瓷砖上的油污和墙上天花板上即将脱落的石灰或者白色涂料层,这种活特别是瓷砖上的油污,之前在自己家里也干活,还是比较熟悉的,不过前面主要是LD 在干,我主要是先搞墙上和天花板上的,干活还是很需要技巧的,如果直接去铲,那基本我会变成一个灰人,而且吸一鼻子灰,老丈人比较专业,先接上软管用水冲,一冲效果特别好,有些石灰涂料层直接就冲掉了,冲完之后先用带加长杆的刀片铲铲了一圈墙面,说实话因为老房子之前租出去了,所以墙面什么的被糟蹋的比较难看,一层一层的,不过这还算还好,后面主要是天花板上的,这可难倒我了,从小我爸妈是比较把我当小孩管着,爬上爬下的基本都是我爸搞定,但是到了老丈人家也只得硬着头皮上了,爬到跳(一种建筑工地用的架子)上,还有点晃,小心脏扑通扑通跳,而且带加长杆的铲子还是比较重的,铲一会手也有点累,不过坚持着铲完了,上面还是比较平整的,不过下来的时候又把我难住了🤦♂️,往下爬的时候有根杆子要跨过去,由于裤子比较紧,强行一把跨过去怕抽筋,所以以一个非常尴尬的姿势停留休息了一会,再跨了过去,幸好事后问 LD,他们都没看到,哈哈哈,然后就是帮忙一起搞瓷砖上的油污,这个太有经验了,不过老丈人更有意思,一会试试啤酒,一会用用沙子,后面在午饭前基本就弄的比较干净了,就坐着等吃饭了,下午午休了会,就继续干活了。
下午是我这次体验的重点了,因为要清理以前贴的墙纸,真的是个很麻烦的活,只能说贴墙纸的师傅活干得太好了,基本不可能整个撕下来,想用铲子一点点铲下来也不行,太轻了就只铲掉表面一层,太重了就把墙纸跟墙面的石灰啥的整个铲下来了,而且手又累又酸,后来想着是不是继续用水冲一下,对着一小面墙试验了下,效果还不错,但是又发现了个问题,那一面墙又有一块是后面糊上去的,铲掉外层的石灰后不平,然后就是最最重头的,也是让我后遗症持续到第二天的,要把那一块糊上去的水泥敲下来,毛估下大概是敲了80%左右,剩下的我的手已经不会用力了,因为那一块应该是要糊上去的始作俑者,就一块里面凹进去的,我拿着榔头敲到我手已经没法使劲了,而且大下午,感觉没五分钟,我的汗已经糊满脸,眼睛也睁不开,不然就流到眼睛里了,此处获得成就一:用榔头敲墙壁,也是个技术加体力的活,而且需要非常好的技巧,否则手马上就废了,敲下去的反作用力,没一会就不行了,然后是看着老丈人兄弟帮忙拆一个柜子,在我看来是个几天都搞不定的活,他轻轻松松在我敲墙的那会就搞定了,以前总觉得我干的活非常有技术含量,可是这个事情真的也是很有技巧啊,它是个把一间房间分隔开的柜子,从底到顶上,还带着门,我还在旁边帮忙撬一下脚踢,一根木条撬半天,唉,成就二:专业的人就是不一样。
最后就是成就三了:我之前沾沾自喜的跑了多少步,做了什么锻炼,其实都是渣渣,像这样干一天活,没经历过的,基本大半天就废了,反过来说,如果能经常去这么干一天活,跑步啥的都是渣渣,消耗的能量远远超过跑个十公里啥的。
+ 在老丈人家的小工记三
+ /2020/09/13/%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E7%9A%84%E5%B0%8F%E5%B7%A5%E8%AE%B0%E4%B8%89/
+ 小工记三前面这两周周末也都去老丈人家帮忙了,上上周周六先是去了那个在装修的旧房子那,把三楼收拾了下,因为要搬进来住,来不及等二楼装修好,就要把三楼里的东西都整理干净,这个活感觉是比较 easy,原来是就准备把三楼当放东西仓储的地方了,我们乡下大部分三层楼都是这么用的,这次也是没办法,之前搬进来的木头什么的都搬出去,主要是这上面灰尘太多,后面清理鼻孔的时候都是黑色的了,把东西都搬出去以后主要是地还是很脏,就扫了地拖了地,因为是水泥地,灰尘又太多了,拖起来都是会灰尘扬起来,整个脱完了的确干净很多,然而这会就出了个大乌龙,我们清理的是三楼的西边一间,结果老丈人上来说要住东边那间的🤦♂️,不过其实西边的也得清理,因为还是要放被子什么的,不算是白费功夫,接着清理东边那间,之前这个房子做过群租房,里面有个高低铺的床,当时觉得可以用在放被子什么的就没扔,只是拆掉了放旁边,我们就把它擦干净了又装好,发现螺丝🔩少了几个,亘古不变的真理,拆了以后装要不就多几个要不就少几个,不是很牢靠,不过用来放放被子省得放地上总还是可以的,对了前面还做了个事情就是铺地毯,其实也不是地毯,就是类似于墙布雨篷布那种,别人不用了送给我们的,三楼水泥地也不会铺瓷砖地板了就放一下,干净好看点,不过大小不合适要裁一下,那把剪刀是真的太难用了,我手都要抽筋了,它就是刀口只有一小个点是能剪下来的,其他都是钝的,后来还是用刀片直接裁,铺好以后,真的感觉也不太一样了,焕然一新的感觉
差不多中午了就去吃饭了,之前两次是去了一家小饭店,还是还比较干净,但是店里菜不好吃,还死贵,这次去了一家小快餐店,口味好,便宜,味道是真的不错,带鱼跟黄鱼都好吃,一点都不腥,我对这类比较腥的鱼真的是很挑剔的,基本上除了家里做的很少吃外面的,那天抱着试试的态度吃了下,真的还不错,后来丈母娘说好像这家老板是给别人结婚喜事酒席当厨师的,怪不得做的好吃,其实本来是有一点小抗拒,怕不干净什么的,后来发现菜很好吃,而且可能是老丈人跟干活的师傅去吃的比较多,老板很客气,我们吃完饭,还给我们买了葡萄吃,不过这家店有一个槽点,就是饭比较不好吃,有时候会夹生,不过后面聊起来其实是这种小菜馆饭点的通病,烧的太早太多容易多出来浪费,烧的迟了不够吃,而且大的电饭锅比较不容易烧好。
下午前面还是在处理三楼的,窗户上各种钉子,实在是太多了,我后面在走廊上排了一排🤦♂️,有些是直接断了,有些是就撬了出来,感觉我在杭州租房也没有这样子各种钉钉子,挂下衣服什么的也不用这么多吧,比较不能理解,搞得到处都是钉子。那天我爸也去帮忙了,主要是在卫生间里做白缝,其实也是个技术活,印象中好像我小时候自己家里也做过这个事情,但是比较模糊了,后面我们三楼搞完了就去帮我爸了,前面是我老婆二爹在那先刷上白缝,这里叫白缝,有些考究的也叫美缝,就是瓷砖铺完之后的缝,如果不去弄的话,里面水泥的颜色就露出来了,而且容易渗水,所以就要用白水泥加胶水搅拌之后糊在缝上,但是也不是直接糊,先要把缝抠一抠,因为铺瓷砖的还不会仔细到每个缝里的水泥都是一样满,而且也需要一些空间糊上去,不然就太表面的一层很容易被水直接冲掉了,然后这次其实也不是用的白水泥,而是直接现成买来就已经配好的用来填缝的,兑水搅拌均匀就好了,后面就主要是我跟我爸在搞,那个时候真的觉得我实在是太胖了,蹲下去真的没一会就受不了了,膝盖什么的太难受了,后面我跪着刷,然后膝盖又疼,也是比较不容易,不过我爸动作很快,我中间跪累了休息一会,我爸就能搞一大片,后面其实我也没做多少(谦虚一下),总体来讲这次不是很累,就是蹲着跪着腿有点受不了,是应该好好减肥了。
]]>
生活
@@ -12919,6 +12951,7 @@ user3:
生活
+ 小技巧
运动
减肥
跑步
@@ -12946,34 +12979,25 @@ user3:
- 分享记录一下一个 scp 操作方法
- /2022/02/06/%E5%88%86%E4%BA%AB%E8%AE%B0%E5%BD%95%E4%B8%80%E4%B8%8B%E4%B8%80%E4%B8%AA-scp-%E6%93%8D%E4%BD%9C%E6%96%B9%E6%B3%95/
- scp 是个在服务器之间拷贝文件的一个常用命令,有时候有个场景是比如我们需要拷贝一些带有共同前缀的文件,但是有一个问题是比如我们有使用 zsh 的话,会出现一个报错,
-zsh: no matches found: root@100.100.100.100://root/prefix*
-这里就比较奇怪了,这个前缀的文件肯定是有的,这里其实是由于 zsh 会对 * 进行展开,这个可以在例如 ls 命令在使用中就可以发现 zsh 有这个特性
需要使用双引号或单引号将路径包起来或者在*之前加反斜杠\来阻止对*展开和转义
-scp root@100.100.100.100://root/prefix* .
-通过使用双引号"进行转义
-scp root@100.100.100.100:"//root/prefix*" .
-或者可以将 shell 从 zsh 切换成 bash
+ 分享一次折腾老旧笔记本的体验-续续篇
+ /2023/02/26/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%80%81%E6%97%A7%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%9A%84%E4%BD%93%E9%AA%8C-%E7%BB%AD%E7%BB%AD%E7%AF%87/
+ 上周因为一些事情没回去,买好了内存条这周才回去用,结果不知道是 U 盘的问题还是什么其他原因原来装的那个系统起不来,然后想用之前一直用的 LD 的笔记本,结果 LD 的老笔记本也起不来了,一直卡在启动界面,猜测可能是本身也比较老了,用的机械硬盘会不会被我一直动而损坏了,所以就想搞个老毛桃跟新搞一个启动盘,结果这周最大的坑就在这了,在我的 15 寸 mbp 上用etcher做了个 win10 的启动盘,可能是分区表格式是 GUID,不是 MBR 的,老电脑不能识别,就像装个虚拟机来做启动盘,结果像老毛桃不支持这种用虚拟机的,需要本地磁盘,然后我就有用 bootcamp 安装了个 win10,又没网络,查了下网络需要用 bootcamp 下载 Windows Support 软件,下了好久一直没下完,后来又提示连不上苹果服务器,好不容易下完了,开启 win10 后,安装到一半就蓝屏了,真的是够操蛋的,在这个时候真的很需要有一个 Windows 机器的支持,LD 的那个笔记本也跟我差不多老了,虽然比较慢但之前好歹也还可以用,结果这下也被我弄坏了,家里就没有其他机器可以支持了,有点巧妇难为无米之炊的赶脚,而且还是想再折腾下我的老电脑,后面看看打算做几个 U 盘,分工职责明确,一个老毛桃的PE 盘,老毛桃的虽然不是很纯净的,但是是我一直以来用过内置工具比较全,修复启动功能比较强大的一个 pe,没用过 winpe,后续可以考虑使用下,一个 win7 的启动盘,因为是老电脑,如果后面是新的电脑可以考虑是 win10,一个 win to go 盘,这样我的 mbp 就可以直接用 win10 了,不过想来也还是要有一台 win 机器才比较好,不然很多时候都是在折腾工具,工欲善其事必先利其器,后面也可以考虑能够更深入的去了解主板的一些问题,我原来的那个主板可能是一些小的电阻等问题,如果能自己学习解决就更好了,有时候研究下还是有意思的。
]]>
- shell
+ Windows
小技巧
- scp
+ Windows
- 在老丈人家的小工记四
- /2020/09/26/%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E7%9A%84%E5%B0%8F%E5%B7%A5%E8%AE%B0%E5%9B%9B/
- 小工记四第四周去的时候让我们去了现在在住的房子里,去三楼整理东西了,蛮多的东西需要收拾整理,有些需要丢一下,以前往往是把不太要用的东西就放三楼了,但是后面就不会再去收拾整理,LD 跟丈母娘负责收拾,我不太知道哪些还要的,哪些不要了,而且本来也不擅长这种收拾🤦♂️,然后就变成她们收拾出来废纸箱,我负责拆掉,压平,这时候终于觉得体重还算是有点作用,总体来说这个事情我其实也不擅长,不擅长的主要是捆起来,可能我总是小题大做,因为纸箱大小不一,如果不做一下分类,然后把大的折小一些的话,直接绑起来,容易拎起来就散掉了,而且一些鞋盒子这种小件的纸盒会比较薄,冰箱这种大件的比较厚,厚的比较不容易变形,需要大力踩踏,而且扎的时候需要用体重压住捆实了之后那样子才是真的捆实的,不然待会又是松松垮垮容易滑出来散架,因为压住了捆好后,下来了之后箱子就会弹开了把绳子崩紧实,感觉又是掌握到生活小技巧了😃,我这里其实比较单调无聊,然后 LD 那可以说非常厉害了,一共理出来 11 把旧电扇,还有好多没用过全新的不锈钢脸盆大大小小的,感觉比店里在卖的还多,还有是有比较多小时候的东西,特别多小时候的衣服,其实这种对我来说最难了,可能需要读一下断舍离,蛮多东西都舍不得扔,但是其实是没啥用了,然后还占地方,这天应该算是比较轻松的一天了,上午主要是把收拾出来要的和不要的搬下楼,然后下午要去把纸板给卖掉。中午还是去小快餐店吃的,在住的家里理东西还有个好处就是中午吃完饭可以小憩一下,因为我个人是非常依赖午休的,不然下午完全没精神,而且心态也会比较烦躁,一方面是客观的的确比较疲惫,另一方面应该主观心理作用也有点影响,就像上班的时候也是觉得不午睡就会很难受,心理作用也有一点,不过总之能睡还是睡一会,真的没办法就心态好点,吃完午饭之后我们就推着小平板车去收废品的地方卖掉了上午我收拾捆起来的纸板,好像卖了一百多,都是直接过地磅了,不用一捆一捆地称,不过有个小插曲,那里另外一个大爷在倒他的三轮车的时候撞了我一下,还好车速慢,屁股上肉垫后,接下来就比较麻烦了,是LD 她们两姐妹从小到大的书,也要去卖掉,小平板车就载不下了,而且着实也不太好推,轮子不太平,导致推着很累,书有好多箱,本来是想去亲戚家借电动三轮车,因为不会开摩托的那种,摩托的那种 LD 邻居家就有,可是到了那发现那个也是很大,而且刹车是用脚踩的那种,俺爹不太放心,就说第二天周日他有空会帮忙去载了卖掉的,然后比较搞笑的来了,丈母娘看错了时间,以为已经快五点了,就让我们顺便在车里带点东西去在修的房子,放到那边三楼去,到了那还跟老丈人说已经这么迟了要赶紧去菜场买菜了,结果我们回来以后才发现看错了一个小时🤦♂️。
前面可以没提,前三周去的我们一般就周六去一天,然后周日因为要早点回杭州,而且可能想让我们周日能休息下,但是这周就因为周日的时候我爸要去帮忙载书,然后 LD 姐姐也会过来收拾东西,我们周日就又去整理收拾了,周日由于俺爹去的很早,我过去的时候书已经木有了,主要是去收拾东西了,把一些有用没用的继续整理,基本上三楼的就处理完毕了,舒了一大口气,毕竟让丈母娘一个人收拾实在是太累了,但是要扔掉的衣服比较棘手,附近知道的青蛙回收桶被推倒了,其他地方也不知道哪里有,我们就先载了一些东西去在修的房子那,然后去找青蛙桶,结果一个小区可以进,但是已经满了,另一个不让进,后来只能让 LD 姐姐带去她们小区扔了,塞了满满一车。因为要赶回杭州的车就没有等我爸一起回来,他还在那帮忙搞卫生间的墙缝。
虽然这两天不太热,活也不算很吃力,不过我这个体重和易出汗的体质,还是让短袖不知道湿透了多少次,灌了好多水和冰红茶(下午能提提神),回来周一早上称体重也比较喜人,差一点就达到阶段目标,可以想想去哪里吃之前想好的烤肉跟火锅了(估计吃完立马回到解放前)。
+ 小工周记一
+ /2023/03/05/%E5%B0%8F%E5%B7%A5%E5%91%A8%E8%AE%B0%E4%B8%80/
+ 开始修老房子又可以更新这个系列了,比较无聊,就是帮着干点零活的记录,这次过去起的比较早,前几天是在翻新瓦片,到这次周六是收尾了,到了的时候先是继续筛了沙子,上周也筛了,就是只筛了一点点,筛沙子的那个像纱窗一样的还是用一扇中空的中间有一根竖档的门钉上铁丝网做的,就是沙子一直放在外面,原来是有袋子装好的,后来是风吹雨打在上面的都已经破掉,还夹杂了很多树叶什么的,需要过下筛,并且前面都是下雨天,沙子都是湿的,不太像我以前看村里有人造房子筛沙子那样,用铲子铲上去就自己都下去的,湿的就是会在一坨,所以需要铲得比较少,然后撒的比较开,这个需要一点经验,然后如果有人一起的话就可以用扫把按住扫一下,这样就会筛得比较有效,不至于都滑下去,沙子本来大部分是可以筛出来的,还有一点就是这种情况网筛需要放得坡度小一点,不然就更容易直接往下调,袋子没破的就不用过筛了,只是湿掉了的是真的重,筛完了那些破掉了的袋子里的沙子,就没有特别的事情要做了,看到大工在那打墙,有一些敲下来的好的砖头就留着,需要削一下上面的混凝土,据大工说现在砖头要七八毛一块了,后面能够重新利用还是挺值钱的,我跟 LD 就用泥刀和铁锹的在那慢慢削,砖头上的泥灰有的比较牢固有的就像直接是沙子,泥刀刮一下就下来了,有的就结合得比较牢固,不过据说以前的砖头工艺上还比较落后,这个房子差不多是三十年前了的,砖头表面都是有点不平,甚至变形,那时候可能砖头是手工烧制的,现在的砖头比较工艺可好多了,不过可能也贵了很多,后来老丈人也过来了,指导了我们拌泥灰,就是水泥和黄沙混合,以前小时候可喜欢玩这个了,可是就也搞不清楚这个是怎么搅拌的,只看见是水泥跟黄沙围城一圈,中间放水,然后一点点搬进去,首先需要先把干的水泥跟黄沙进行混合,具体的比例是老丈人说的,拌的方式有点像堆沙堆,把水泥黄沙铲起来堆起来,就一直要往这个混合堆的尖尖上堆,这样子它自己滑下来能更好地混合,来回两趟就基本混合均匀了,然后就是跟以前看过的,中间扒拉出一个空间放水,然后慢慢把周围的混合好的泥沙推进去,需要注意不要太着急,旁边的推进去太多太快就会漏水出来,一个是会把旁边的地给弄脏,另一个也铲不回水,然后就是推完所有的都混合水了,就铲起来倒一下,再将铲子翻过来捣几下,后面我们就去吃饭了,去了一家叫金记的,又贵又不太好吃的店,就是离得比较近,六七个人只有六七个菜,吃完要四百多,也是有点离谱了。
下午是重头戏,其实本来倒没啥事,就说帮忙搞下靠背(就是踢脚线上面到窗台附近的用木头还有其他材料的装饰性的),都撬撬掉,但是真的是有点离谱了,首先是撬棒真的很重,20 斤的重量(网上查的,没有真的查过),抡起来还要用力地铲进去,因为就是破坏性的要把整个都撬掉,对于我这种又没技巧又没力气的非专业选手,抡起撬棍铲两下手就开始痛了,只是也比较犟,不想刚开始弄就说太重了要休息,后面都完全靠的一点倔强劲撑着,看着里面的工艺感觉也是不容易的,直着横着的木条有好多,竖的一整条,每隔三五十公分,横着的就是三五十公分,每根都要用钉子钉起来,然后外层好像是贴上去,在同一个面的开了头之后就能靠着蛮力往下撬,但是到了转角就又要重新开头,而且最上面一根横条跟紧邻的那一块,大概十几公分,是横着的三条钉在一起,真的是大力都出不了奇迹了,用撬棍的一头用力地敲打都很震手,要从下面往上铲进去撬开一点,然后再从上面往下敲打,这里比较重要的是要小心钉子,我这次运气比较好,踩下去已经扎到了,不过正好在脚趾缝里,没有扎到脚,还是要小心的,做完这个我的手真的是差不多废了,上臂的疼痛已经动一下就受不了了,后面有撬下了最下面当踢脚线的小瓷砖,这个房子估计中间修过一次,两批水泥糊的,新的那批粘的特别牢,敲敲打打了半天才下来一点点,锤子敲上去跟一整块石头一样,震手又没有进展,整个搞完,楼上又在敲墙了,下面的灰尘也是从没见过,我一直在那洒水都完全没有缓解,就上去跟 LD 一起拣砖头,手痛到只能抬两块砖头都会痛了。
回到家里开始越来越痛,两个手就完全没法动了,应该也是肌肉拉伤了,我这样是没足够的力气也不会什么技巧,像大工说的,他们也累也难,只是为了赚钱,不过他们有了经验跟技巧,会注意怎么使力不容易受伤,怎么样比较省力,还有一点就是即使这么累,他们一般也下午五点半就下班了,真的很累了,至少还有不少时间可以回家休息,而我们的职业呢,就像 LD 说的回家就像住酒店,就只是来洗澡睡个觉,希望能改善吧
]]>
生活
- 运动
- 跑步
- 干活
生活
@@ -12985,47 +13009,23 @@ user3:
- 分享一次折腾老旧笔记本的体验
- /2023/02/05/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%80%81%E6%97%A7%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%9A%84%E4%BD%93%E9%AA%8C/
- 上大学的时候买了第一个笔记本,是联想的小y,y460,配置应该是 i5+2g 内存,500g 硬盘,ati 5650 的显卡,那时候还是比较时髦的带有集显和独显切换的,一些人也觉得它算是一代“神机”,陪我度过了大学四年,还有毕业后的第一年,记得中间还用的比较曲折,差不多第一学期末的时候硬盘感觉有时候会文件操作卡住,去售后看了下,果然硬盘出问题了,还在当场把硬盘的东西都拷贝到新买的移动硬盘里,不过联想的售后还是比较不错的,在保内可以直接免费换,如果出保了估计就要修不起了,后面出了个很大的问题,就是屏幕花屏了,而且它的花屏是横着的会有那种上升的变化,一开始感觉跟湿度还有温度有点关系,天气冷了就很容易出现,天气热了就好一点,出现的概率小一点,而且是合盖后再开会好,过一会又会上升,只是这么度过了保修期,去售后问了下,修一下要两千多,后来是在玉泉学校里面的维修店,好像是花了六百多,省是省了很多,但是后面使用的时候发现有点漏光,而且两三个亮点,总归还是给我那不富裕的经济条件带来了一个正常屏幕,不过是挺影响使用,严格来说都没法用了,后面基本是大半个屏幕花掉,接近整个屏幕花掉,至此大学就是这么用过去了。
噢对了,中间在大二的时候加了一条 2g 的内存,因为像操作系统课需要用虚拟机,2g 内存不太够,不过那会用的都是 32 位的 win7 系统,实际使用用不到 4g 内存,得使用破解补丁才能识别到,后来在大学毕业后由于收入也低,想换其他电脑,特别是 mac,买不起,电脑在那会还会玩玩 DNF,但是风扇声很大,也想优化下,就买了个 msata 的固态硬盘,因为刚好有个口子留着,在那之前一直搜到的是把光驱位拆掉换上 sata 固态硬盘,这对于那会的我来说操作难度实在有点大,换上了msata 固态之后还是有比较大的提升的,把操作系统装到固态硬盘后其他盘就只放数据了,后面还装过黑苹果,只是不小心被室友强制关机了,之后就起不来了,也不知道啥原因,后续想继续按原来的操作装,也没成功,再往后就配了一台台式机,这个笔记本就放在那没啥用了,后面偶尔会拿出来用一下,特别是疫情那会充当了 LD 的临时使用机器。
最近一次就是想把行车记录仪里的视频导出来,结果上传的时候我点了下 win10 的更新,重启后这个机器就起不来了,一开始以为顶多是个重装系统,结果重装也不行,就进不去,插着 U 盘也起不来,一开始还能进 BIOS,后面就直接进不去了,像内存条脏了,擦下金手指什么的,都没搞定,想着也只可能是主板上的部件坏了,所以就开始了这趟半作死之旅,买了块主板来换,拆这个笔记本是真的够难的,开机键那一条是真的拆不开,后面还把两个扣子扳坏了,里面的排线插口还几个也拔坏了,幸好用买来的主板装上还能用,但是后面就很奇怪了,因为这个电脑装了 Ubuntu 跟 win10 的双系统,Ubuntu 能正常起来,但是 win10 就是起不来,插上老毛桃或者 win10 的启动盘都是起不来,老毛桃是能起来,但是进不了 pe,插启动盘又报 0xc00000e9 错误码,现在想着是不是这个固态硬盘有点问题或者还是内存问题,只能后续再看了,拆机的时候也找不到视频,机器实在是太老了,后面再试试看。
-]]>
-
- Windows
- 小技巧
-
-
- Windows
-
-
-
- 在 wsl 2 中开启 ssh 连接
- /2023/04/23/%E5%9C%A8-wsl-2-%E4%B8%AD%E5%BC%80%E5%90%AF-ssh-%E8%BF%9E%E6%8E%A5/
- 之前在 wsl 1 中开启 ssh 其实很方便,只要把 sshd 服务起来就好了,但是在 wsl 2 中就不太一样了,
我这边使用的是 wsl 2 中的 Ubuntu 20.04,直接启动 sshd 服务是没法让其他机器连接的,而且都没有 ifconfig 命令可以查看 ip
不过可以用直接用 ip a来查看,可以看到这个 ip 是172网段的,而在 wsl 1 中可以看到 ip 就是 win 的 ip,
所以需要做一些操作,首先要安装 openssl-server
-sudo apt update
-sudo apt install openssh-server
-另外如果需要提高安全性,可以wsl 中配置 hosts.allow
-sshd:192.168.xx.
-先定一个子网段,然后对于ssh的配置,可以做以下修改
-Port 22
-PasswordAuthentication yes
-在进行重启
-sudo service ssh --full-restart
-配置以后发现上面的问题,没法远程登录,因为 wsl 2 是基于 hyper-v 虚拟机实现的,并且 ip 使用的是一个虚拟出来的子网 ip,所以需要在 Windows 这一层配置端口的转发,可以通过命令netsh interface portproxy show v4tov4看到
![]()
截图是我已经添加好了的,先把原来的删除,再进行添加
-netsh interface portproxy delete v4tov4 listenaddress=0.0.0.0 listenport=22
-netsh interface portproxy add v4tov4 listenaddress=0.0.0.0 listenport=22 connectaddress=172.19.129.207 connectport=22
-也可以全量删除
-netsh int portproxy reset all
-但是这样也不能直接访问了,还需要开启防火墙
-netsh advfirewall firewall add rule name="WSL SSH" dir=in action=allow protocol=TCP localport=22
-
-
-
+ 在老丈人家的小工记四
+ /2020/09/26/%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E7%9A%84%E5%B0%8F%E5%B7%A5%E8%AE%B0%E5%9B%9B/
+ 小工记四第四周去的时候让我们去了现在在住的房子里,去三楼整理东西了,蛮多的东西需要收拾整理,有些需要丢一下,以前往往是把不太要用的东西就放三楼了,但是后面就不会再去收拾整理,LD 跟丈母娘负责收拾,我不太知道哪些还要的,哪些不要了,而且本来也不擅长这种收拾🤦♂️,然后就变成她们收拾出来废纸箱,我负责拆掉,压平,这时候终于觉得体重还算是有点作用,总体来说这个事情我其实也不擅长,不擅长的主要是捆起来,可能我总是小题大做,因为纸箱大小不一,如果不做一下分类,然后把大的折小一些的话,直接绑起来,容易拎起来就散掉了,而且一些鞋盒子这种小件的纸盒会比较薄,冰箱这种大件的比较厚,厚的比较不容易变形,需要大力踩踏,而且扎的时候需要用体重压住捆实了之后那样子才是真的捆实的,不然待会又是松松垮垮容易滑出来散架,因为压住了捆好后,下来了之后箱子就会弹开了把绳子崩紧实,感觉又是掌握到生活小技巧了😃,我这里其实比较单调无聊,然后 LD 那可以说非常厉害了,一共理出来 11 把旧电扇,还有好多没用过全新的不锈钢脸盆大大小小的,感觉比店里在卖的还多,还有是有比较多小时候的东西,特别多小时候的衣服,其实这种对我来说最难了,可能需要读一下断舍离,蛮多东西都舍不得扔,但是其实是没啥用了,然后还占地方,这天应该算是比较轻松的一天了,上午主要是把收拾出来要的和不要的搬下楼,然后下午要去把纸板给卖掉。中午还是去小快餐店吃的,在住的家里理东西还有个好处就是中午吃完饭可以小憩一下,因为我个人是非常依赖午休的,不然下午完全没精神,而且心态也会比较烦躁,一方面是客观的的确比较疲惫,另一方面应该主观心理作用也有点影响,就像上班的时候也是觉得不午睡就会很难受,心理作用也有一点,不过总之能睡还是睡一会,真的没办法就心态好点,吃完午饭之后我们就推着小平板车去收废品的地方卖掉了上午我收拾捆起来的纸板,好像卖了一百多,都是直接过地磅了,不用一捆一捆地称,不过有个小插曲,那里另外一个大爷在倒他的三轮车的时候撞了我一下,还好车速慢,屁股上肉垫后,接下来就比较麻烦了,是LD 她们两姐妹从小到大的书,也要去卖掉,小平板车就载不下了,而且着实也不太好推,轮子不太平,导致推着很累,书有好多箱,本来是想去亲戚家借电动三轮车,因为不会开摩托的那种,摩托的那种 LD 邻居家就有,可是到了那发现那个也是很大,而且刹车是用脚踩的那种,俺爹不太放心,就说第二天周日他有空会帮忙去载了卖掉的,然后比较搞笑的来了,丈母娘看错了时间,以为已经快五点了,就让我们顺便在车里带点东西去在修的房子,放到那边三楼去,到了那还跟老丈人说已经这么迟了要赶紧去菜场买菜了,结果我们回来以后才发现看错了一个小时🤦♂️。
前面可以没提,前三周去的我们一般就周六去一天,然后周日因为要早点回杭州,而且可能想让我们周日能休息下,但是这周就因为周日的时候我爸要去帮忙载书,然后 LD 姐姐也会过来收拾东西,我们周日就又去整理收拾了,周日由于俺爹去的很早,我过去的时候书已经木有了,主要是去收拾东西了,把一些有用没用的继续整理,基本上三楼的就处理完毕了,舒了一大口气,毕竟让丈母娘一个人收拾实在是太累了,但是要扔掉的衣服比较棘手,附近知道的青蛙回收桶被推倒了,其他地方也不知道哪里有,我们就先载了一些东西去在修的房子那,然后去找青蛙桶,结果一个小区可以进,但是已经满了,另一个不让进,后来只能让 LD 姐姐带去她们小区扔了,塞了满满一车。因为要赶回杭州的车就没有等我爸一起回来,他还在那帮忙搞卫生间的墙缝。
虽然这两天不太热,活也不算很吃力,不过我这个体重和易出汗的体质,还是让短袖不知道湿透了多少次,灌了好多水和冰红茶(下午能提提神),回来周一早上称体重也比较喜人,差一点就达到阶段目标,可以想想去哪里吃之前想好的烤肉跟火锅了(估计吃完立马回到解放前)。
]]>
- wsl
+ 生活
+ 运动
+ 跑步
+ 干活
- wsl
+ 生活
+ 小技巧
+ 运动
+ 减肥
+ 跑步
+ 干活
@@ -13063,32 +13063,41 @@ netsh interface portproxy add v4tov4 listenaddress=0
- 是何原因竟让两人深夜奔袭十公里
- /2022/06/05/%E6%98%AF%E4%BD%95%E5%8E%9F%E5%9B%A0%E7%AB%9F%E8%AE%A9%E4%B8%A4%E4%BA%BA%E6%B7%B1%E5%A4%9C%E5%A5%94%E8%A2%AD%E5%8D%81%E5%85%AC%E9%87%8C/
- 偶尔来个标题党,不过也是一次比较神奇的经历
上周五下班后跟 LD 约好去吃牛蛙,某个朋友好像对这类都不太能接受,我以前小时候也不常吃,但是这类其实都是口味比较重,没有那种肉本身的腥味,而且肉质比较特殊,吃过几次以后就有点爱上了,这次刚好是 LD 买的新店开业券,比较优惠(我们俩都是有点勤俭持家的,想着小电驴还有三格电,这家店又有点远,骑车单趟大概要 10 公里左右,有点担心,LD 说应该可以的,就一起骑了过去(跟她轮换着骑电驴和共享单车),结果大概离吃牛蛙的店还有一辆公里的时候,电量就报警了,只有最后一个红色的了,一共是五格,最后一格是红色的,提示我们该充电了,这样子是真的有点慌了,之前开了几个月都是还有一两格电的时候就充电了,没有试验过究竟这最后一格电能开多远,总之先到了再说。
这家牛蛙没想到还挺热闹的,我们到那已经快八点了,还有十几个排队的,有个人还想插队(向来是不惯着这种,一边去),旁边刚好是有些商店就逛了下,就跟常规的商业中心差不多,开业的比较早也算是这一边比较核心的商业综合体了,各种品牌都有,而且还有彩票售卖点的,只是不太理解现在的彩票都是兑图案的,而且要 10 块钱一张,我的概念里还是以前 2 块钱一张的双色球,偶尔能中个五块十块的。排队还剩四五个的时候我们就去门口坐着等了,又等了大概二十分钟才排到我们,靠近我们等的里面的位置,好像好几个小女生在那还叫了外卖奶茶,然后各种拍照,小朋友的生活还是丰富多彩的,我们到了就点了蒜蓉的,没有点传说中紫苏的,菜单上画了 N 个🌶,LD 还是想体验下说下次人多点可以试试,我们俩吃怕太辣了吃不消,口味还是不错的,这家貌似是 LD 闺蜜推荐的,口碑有保证。两个人光吃一个蛙锅就差不多了,本来还想再点个其他的,后面实在吃不下了就没点,吃完还是惯例点了个奶茶,不过是真的不好找,太大了。
本来是就回个家的事了,结果就因为前面铺垫的小电驴已经只有一格电了,标题的深夜奔袭十公里就出现了,这个电驴估计续航也虚标挺严重的,电量也是这样,骑的时候显示只有一格电,关掉再开起来又有三格,然后我们回去骑了没一公里就没电了,这下是真的完球了,觉得车子也比较新,直接停外面也不放心,就开始了深夜的十公里推电驴奔袭,LD 看我太累还帮我中间推了一段,虽然是跑过十公里的,但是推着个没电的电驴,还是着实不容易的,LD 也是陪我推着车走,中间好几次说我们把电驴停着打车回去,把电池带回去充满了明天再过来骑车,可能是心态已经转变了,这应该算是一次很特殊的体验,从我们吃完出来大概十点,到最后我们推到小区,大概是过了两个小时的样子,说句深夜也不太过分,把这次这么推车看成了一种意志力的考验,很多事情也都是怕坚持,或者说怕不能坚持,想走得远,没有持续的努力坚持肯定是不行的,所以还是坚持着把车推回来(好吧,我其实主要是怕车被偷,毕竟刚来杭州上学没多久就被偷了自行车留下了阴影),中间感谢 LD,跟我轮着推了一段路,有些下坡的时候还在那坐着用脚蹬一下,离家里大概还有一公里的时候,有个骑电瓶车的大叔还停下来问我们是车破了还是没电了,应该是出于好意吧,最后快到的时候真的非常渴,买了2.5 升的水被我一口气喝了大半瓶,奶茶已经不能起到解渴的作用了,本来以为这样能消耗很多,结果第二天一称还重了,(我的称一定有问题 233
+ 分享一次比较诡异的 Windows 下 U盘无法退出的经历
+ /2023/01/29/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%AF%94%E8%BE%83%E8%AF%A1%E5%BC%82%E7%9A%84-Windows-%E4%B8%8B-U%E7%9B%98%E6%97%A0%E6%B3%95%E9%80%80%E5%87%BA%E7%9A%84%E7%BB%8F%E5%8E%86/
+ 作为一个 Windows 的老用户,并且也算是 Windows 系统的半个粉丝,但是秉承一贯的优缺点都应该说的原则,Windows 系统有一点缺点是真的挺难受,相信 Windows 用过比较久的都会经历过,就是 U盘无法退出的问题,在比较远古时代,这个问题似乎能采取的措施不多,关机再拔 U盘的方式是一种比较保险的方式,其他貌似有 360这种可以解除占用的,但是需要安装 360 软件,对于目前的使用环境来说有点得不偿失,也是比较流氓的一类软件了,目前在 Windows 环境我主要就安装了个火绒,或者就用 Windows 自带的 defender。
+第一种
最近这次经历也是有火绒的一定责任,在我尝试推出 U盘的时候提示了我被另一个大流氓软件,XlibabaProtect.exe 占用了,这个流氓软件真的是充分展示了某里的技术实力,试过 N 多种办法都关不掉也删不掉,尝试了很多种办法也没办法删除,但是后面换了种思路,一般这种情况肯定是有进程在占用 U盘里的内容,最新版本的 Powertoys 会在文件的右键菜单里添加一个叫 File Locksmith 的功能,可以用于检查正在使用哪些文件以及由哪些进程使用,但是可能是我的使用姿势不对,没有仔细看文档,它里面有个”以管理员身份重启”,可能会有用。
这算是第一种方式,
+第二种
第二种方式是 Windows 任务管理器中性能 tab 下的”打开资源监视器”,
![]() ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是F:
![]() 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
对于前两种方式对我来说都无效,
+第三种
所以尝试了第三种,
就是磁盘脱机的方式,在”计算机”右键管理,点击”磁盘管理”,可以找到 U 盘盘符右键,点击”脱机”,然后再”推出”,这个对我来说也不行
+第四种
这种是唯一对我有效的,在开始菜单搜索”event”,可以搜到”事件查看器”,
![]() ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
最后发现是英特尔的驱动管理程序的一个进程,关掉就退出了,虽然前面说的某里的进程是流氓,但这边是真的冤枉它了
]]>
- 生活
+ Windows
+ 小技巧
- 生活
+ Windows
@@ -13179,6 +13188,44 @@ netsh interface portproxy add v4tov4 listenaddress=0
-
- 我是如何走上跑步这条不归路的
- /2020/07/26/%E6%88%91%E6%98%AF%E5%A6%82%E4%BD%95%E8%B5%B0%E4%B8%8A%E8%B7%91%E6%AD%A5%E8%BF%99%E6%9D%A1%E4%B8%8D%E5%BD%92%E8%B7%AF%E7%9A%84/
- 这周因为没有准备技术方面的内容加之之前有想分享下我和跑步的一些事情,我从小学开始就是个体育渣,因为体重大非常胖,小学的时候要做仰卧起坐,基本是一个都起不来,然后那时候跑步也是要我命那种,跟另外一个比较胖的同学在跑步队尾苟延残喘,只有立定跳远还行。
-时光飞逝,我在初中高中的时候因为爱打篮球,以为自己体质已经有了质的变化,所以在体育课跑步的时候妄图跟一位体育非常好的同学一起跑,结果跟的快断气了,最终还是确认了自己是个体育渣,特别是到了大学的第一次体测跑一千米,跑完直接吐了,一则是大学太宅不运动,二则的确是底子不好。那么怎么会去跑步了呢,其实也没什么特殊的原因,就是工作以后因为运动得更少,体质差,而且越来越胖,所以就想运动下,加之跑步也是我觉得成本最低的运动了,刚好那时候17 年租的地方附近小区周围的路车不太多,一圈刚好一公里多,就觉得开始跑跑看,其实想想以前觉得一千米是非常远的,学校塑胶跑道才 400 米,一千米要两圈半,太难了,但是后来在这个小区周围跑的时候好像跑了一圈以后还能再跑一点,最后跑了两圈,可把自己牛坏了,我都能跑两千米了,哈哈,这是个什么概念呢,大学里最让我绝望的两项体育相关的内容就是一千米和十二分钟跑,一千米把我跑吐了,十二分钟跑及格五圈半也能让我跑完花一周时间恢复以及提前一周心理压力爆炸,虽然我那时候跑的不快,但是已经能跑两千米了,瞬间让自己自信心爆炸,并且跑完步出完汗的感觉是非常棒的,毕竟吃奶茶鸡排都能心安理得了,谁叫我跑步了呢😄,其实现在回去看,那时候跑得还算快的,因为还比较瘦,现在要跑得那么快心跳就太快了,关于心跳什么的后面说,开始建立起自信心之后,对跑步这件事就开始不那么排斥跟害怕了,毕竟我能跑两千米了,然后试试三公里,哇,也可以了呢,三公里是什么概念呢,我大学里跑过最多的一次是十二分钟跑五圈半还是六圈,也就是两公里多,不到三公里,几乎是生涯最长了,一时间产生了一些我可能是个被埋没的运动天才的错觉,其实细想下也能明白,只是速度足够慢了就能跑多一点,毕竟提测一千米是要跑进四分钟才及格,自己跑的时候一千米跑六分多钟已经算不慢了(对我自己来说),但是即使是这样还是对把跑步坚持下去这件事有了很大的正面激励作用,并且由于那时候上下班骑车,整个体重控制的比较理想,导致一时间误会跑步就能非常快的减肥(其实这是我跑步历程中比较大的误区之一),因为会在跑步前后称下体重,如果跑个五公里(后面可以跑五公里了),可能体重就能降 0.5 千克,但实际上这只是这五公里跑步身体流失的水分,喝杯水就回来了,那时候能控制体重主要是骑车跟跑步一起的作用,并且工作压力相对来讲比较小,没有过劳肥。
-后面其实跑步慢慢变得一个比较习惯的运动了,从三公里,到五公里,到七公里,再到十公里,十公里差不多对我来说是个坎,一直还不能比较轻松的跑十公里,可能近一两年好了一些(原谅我只是跟自己比较,跟那些大神比差得不知道多远),其实对我来说每次都是个突破,因为其实与他人比较没有特别大意义,比较顶尖的差得太远,比较普通的也不行,都会打击自信心,比较比我差的就更没意义了,所以其实能挑战自己,能把自己的上限提高才是最有意义的,这也是我看着朋友圈里的一些大神的速度除了佩服赞叹之外没什么其他的惭愧或者说嫌弃自己的感觉(阿 Q 精神😄)。
-一直感性地觉得,跑步能解压,跑完浑身汗,有种把身体的负能量都排出去的感觉,也把吃太多的罪恶感排解掉了🤦♂️,之前朋友有看一本书,书名差不多叫越跑越接近自己,这个也是我觉得挺准确的一句话,当跑到接近极限了,还想再继续再跑一点,再跑一点就能突破自己上一次的最远记录了,再跑一点就能又一次突破自己了,成人以后,毕业以后,进入社会以后,世事总是难以件件顺遂,磕磕绊绊的往前走,总觉得要崩溃了,但是还是得坚持,再熬一下,再拼一下,可能还是失败,但人生呢,运气好的人和事总是小概率的,唯有面对挫折,还是日拱一卒,来日方长,我们再坚持下,没准下一次,没准再跑一会,就能突破自己,达到新的境界。
-另外个人后期对跑步的一些知识和理解也变得深入一些,比如伤膝盖,其实跑步的确伤膝盖,需要做一些准备和防护,最好的是适合自己的跑鞋和比较好的路(最好的是塑胶跑道了),也要注意热身跟跑后的拉伸(虽然我做的很差),还有就是注意心率,每个人有自己的适宜心率,我这就不冒充科普达人了,可以自行搜索关键字,先说到这吧~
-]]>
-
- 生活
- 运动
- 跑步
-
-
- 生活
- 运动
- 减肥
- 跑步
-
-
聊一下 RocketMQ 的 NameServer 源码
/2020/07/05/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84-NameServer-%E6%BA%90%E7%A0%81/
@@ -14636,20 +14662,6 @@ netsh interface portproxy add v4tov4 listenaddress=0 MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
break;
}
- }
- }
-public void putMessagePositionInfo(DispatchRequest dispatchRequest) {
- ConsumeQueue cq = this.findConsumeQueue(dispatchRequest.getTopic(), dispatchRequest.getQueueId());
- cq.putMessagePositionInfoWrapper(dispatchRequest);
- }
-
-真正存储的是在这
-private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
- final long cqOffset) {
-
- if (offset + size <= this.maxPhysicOffset) {
- log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset={}", maxPhysicOffset, offset);
- return true;
- }
-
- this.byteBufferIndex.flip();
- this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
- this.byteBufferIndex.putLong(offset);
- this.byteBufferIndex.putInt(size);
- this.byteBufferIndex.putLong(tagsCode);
-
-这里也可以看到 ConsumeQueue 的存储格式,
-![AA6Tve]()
-偏移量,消息大小,跟 tag 的 hashCode
-]]>
-
- MQ
- RocketMQ
- 消息队列
-
-
- MQ
- 消息队列
- RocketMQ
-
-
-
- 聊一下 RocketMQ 的消息存储二
- /2021/09/12/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E4%BA%8C/
- CommitLog 结构CommitLog 是 rocketmq 的服务端,也就是 broker 存储消息的的文件,跟 kafka 一样,也是顺序写入,当然消息是变长的,生成的规则是每个文件的默认1G =1024 * 1024 * 1024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1 073 741 824Byte;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824, 消息存储的时候会顺序写入文件,当文件满了则写入下一个文件,代码中的定义
-// CommitLog file size,default is 1G
-private int mapedFileSizeCommitLog = 1024 * 1024 * 1024;
-
-![kLahwW]()
-本地跑个 demo 验证下,也是这样,这里奇妙有几个比较巧妙的点(个人观点),首先文件就刚好是 1G,并且按照大小偏移量去生成下一个文件,这样获取消息的时候按大小算一下就知道在哪个文件里了,
-代码中写入 CommitLog 的逻辑可以从这开始看
-public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
- // Set the storage time
- msg.setStoreTimestamp(System.currentTimeMillis());
- // Set the message body BODY CRC (consider the most appropriate setting
- // on the client)
- msg.setBodyCRC(UtilAll.crc32(msg.getBody()));
- // Back to Results
- AppendMessageResult result = null;
-
- StoreStatsService storeStatsService = this.defaultMessageStore.getStoreStatsService();
-
- String topic = msg.getTopic();
- int queueId = msg.getQueueId();
-
- final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
- if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE
- || tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {
- // Delay Delivery
- if (msg.getDelayTimeLevel() > 0) {
- if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
- msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
- }
-
- topic = ScheduleMessageService.SCHEDULE_TOPIC;
- queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
-
- // Backup real topic, queueId
- MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
- MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
- msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
-
- msg.setTopic(topic);
- msg.setQueueId(queueId);
- }
- }
-
- long eclipseTimeInLock = 0;
- MappedFile unlockMappedFile = null;
- MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
-
- putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
- try {
- long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now();
- this.beginTimeInLock = beginLockTimestamp;
-
- // Here settings are stored timestamp, in order to ensure an orderly
- // global
- msg.setStoreTimestamp(beginLockTimestamp);
-
- if (null == mappedFile || mappedFile.isFull()) {
- mappedFile = this.mappedFileQueue.getLastMappedFile(0); // Mark: NewFile may be cause noise
- }
- if (null == mappedFile) {
- log.error("create mapped file1 error, topic: " + msg.getTopic() + " clientAddr: " + msg.getBornHostString());
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, null);
- }
-
- result = mappedFile.appendMessage(msg, this.appendMessageCallback);
- switch (result.getStatus()) {
- case PUT_OK:
- break;
- case END_OF_FILE:
- unlockMappedFile = mappedFile;
- // Create a new file, re-write the message
- mappedFile = this.mappedFileQueue.getLastMappedFile(0);
- if (null == mappedFile) {
- // XXX: warn and notify me
- log.error("create mapped file2 error, topic: " + msg.getTopic() + " clientAddr: " + msg.getBornHostString());
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, result);
- }
- result = mappedFile.appendMessage(msg, this.appendMessageCallback);
- break;
- case MESSAGE_SIZE_EXCEEDED:
- case PROPERTIES_SIZE_EXCEEDED:
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, result);
- case UNKNOWN_ERROR:
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
- default:
- beginTimeInLock = 0;
- return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
- }
-
- eclipseTimeInLock = this.defaultMessageStore.getSystemClock().now() - beginLockTimestamp;
- beginTimeInLock = 0;
- } finally {
- putMessageLock.unlock();
- }
-
- if (eclipseTimeInLock > 500) {
- log.warn("[NOTIFYME]putMessage in lock cost time(ms)={}, bodyLength={} AppendMessageResult={}", eclipseTimeInLock, msg.getBody().length, result);
- }
-
- if (null != unlockMappedFile && this.defaultMessageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {
- this.defaultMessageStore.unlockMappedFile(unlockMappedFile);
- }
-
- PutMessageResult putMessageResult = new PutMessageResult(PutMessageStatus.PUT_OK, result);
+ }
+ }
+public void putMessagePositionInfo(DispatchRequest dispatchRequest) {
+ ConsumeQueue cq = this.findConsumeQueue(dispatchRequest.getTopic(), dispatchRequest.getQueueId());
+ cq.putMessagePositionInfoWrapper(dispatchRequest);
+ }
- // Statistics
- storeStatsService.getSinglePutMessageTopicTimesTotal(msg.getTopic()).incrementAndGet();
- storeStatsService.getSinglePutMessageTopicSizeTotal(topic).addAndGet(result.getWroteBytes());
+真正存储的是在这
+private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,
+ final long cqOffset) {
- handleDiskFlush(result, putMessageResult, msg);
- handleHA(result, putMessageResult, msg);
+ if (offset + size <= this.maxPhysicOffset) {
+ log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset={}", maxPhysicOffset, offset);
+ return true;
+ }
- return putMessageResult;
- }
+ this.byteBufferIndex.flip();
+ this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);
+ this.byteBufferIndex.putLong(offset);
+ this.byteBufferIndex.putInt(size);
+ this.byteBufferIndex.putLong(tagsCode);
-前面也看到在CommitLog 目录下是有大小为 1G 的文件组成,在实现逻辑中,其实是通过 org.apache.rocketmq.store.MappedFileQueue ,内部是存的一个MappedFile的队列,对于写入的场景每次都是通过org.apache.rocketmq.store.MappedFileQueue#getLastMappedFile() 获取最后一个文件,如果还没有创建,或者最后这个文件已经满了,那就调用 org.apache.rocketmq.store.MappedFileQueue#getLastMappedFile(long)
-public MappedFile getLastMappedFile(final long startOffset, boolean needCreate) {
- long createOffset = -1;
- // 调用前面的方法,只是从 mappedFileQueue 获取最后一个
- MappedFile mappedFileLast = getLastMappedFile();
+这里也可以看到 ConsumeQueue 的存储格式,
+![AA6Tve]()
+偏移量,消息大小,跟 tag 的 hashCode
+]]>
+
+ MQ
+ RocketMQ
+ 消息队列
+
+
+ MQ
+ 消息队列
+ RocketMQ
+
+
+
+ 聊一下 SpringBoot 中使用的 cglib 作为动态代理中的一个注意点
+ /2021/09/19/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E4%B8%AD%E4%BD%BF%E7%94%A8%E7%9A%84-cglib-%E4%BD%9C%E4%B8%BA%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86%E4%B8%AD%E7%9A%84%E4%B8%80%E4%B8%AA%E6%B3%A8%E6%84%8F%E7%82%B9/
+ 这个话题是由一次组内同学分享引出来的,首先在 springboot 2.x 开始默认使用了 cglib 作为 aop 的实现,这里也稍微讲一下,在一个 1.x 的老项目里,可以看到AopAutoConfiguration 是这样的
+@Configuration
+@ConditionalOnClass({ EnableAspectJAutoProxy.class, Aspect.class, Advice.class })
+@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
+public class AopAutoConfiguration {
- // 如果为空,计算下创建的偏移量
- if (mappedFileLast == null) {
- createOffset = startOffset - (startOffset % this.mappedFileSize);
- }
-
- // 如果不为空,但是当前的文件写满了
- if (mappedFileLast != null && mappedFileLast.isFull()) {
- // 前一个的偏移量加上单个文件的偏移量,也就是 1G
- createOffset = mappedFileLast.getFileFromOffset() + this.mappedFileSize;
- }
+ @Configuration
+ @EnableAspectJAutoProxy(proxyTargetClass = false)
+ @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false", matchIfMissing = true)
+ public static class JdkDynamicAutoProxyConfiguration {
+ }
- if (createOffset != -1 && needCreate) {
- // 根据 createOffset 转换成文件名进行创建
- String nextFilePath = this.storePath + File.separator + UtilAll.offset2FileName(createOffset);
- String nextNextFilePath = this.storePath + File.separator
- + UtilAll.offset2FileName(createOffset + this.mappedFileSize);
- MappedFile mappedFile = null;
+ @Configuration
+ @EnableAspectJAutoProxy(proxyTargetClass = true)
+ @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true", matchIfMissing = false)
+ public static class CglibAutoProxyConfiguration {
+ }
- // 这里如果allocateMappedFileService 存在,就提交请求
- if (this.allocateMappedFileService != null) {
- mappedFile = this.allocateMappedFileService.putRequestAndReturnMappedFile(nextFilePath,
- nextNextFilePath, this.mappedFileSize);
- } else {
- try {
- // 否则就直接创建
- mappedFile = new MappedFile(nextFilePath, this.mappedFileSize);
- } catch (IOException e) {
- log.error("create mappedFile exception", e);
- }
- }
+}
- if (mappedFile != null) {
- if (this.mappedFiles.isEmpty()) {
- mappedFile.setFirstCreateInQueue(true);
- }
- this.mappedFiles.add(mappedFile);
- }
+而在 2.x 中变成了这样
+@Configuration(proxyBeanMethods = false)
+@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
+public class AopAutoConfiguration {
- return mappedFile;
- }
+ @Configuration(proxyBeanMethods = false)
+ @ConditionalOnClass(Advice.class)
+ static class AspectJAutoProxyingConfiguration {
- return mappedFileLast;
- }
+ @Configuration(proxyBeanMethods = false)
+ @EnableAspectJAutoProxy(proxyTargetClass = false)
+ @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false")
+ static class JdkDynamicAutoProxyConfiguration {
-首先看下直接创建的,
-public MappedFile(final String fileName, final int fileSize) throws IOException {
- init(fileName, fileSize);
- }
-private void init(final String fileName, final int fileSize) throws IOException {
- this.fileName = fileName;
- this.fileSize = fileSize;
- this.file = new File(fileName);
- this.fileFromOffset = Long.parseLong(this.file.getName());
- boolean ok = false;
+ }
- ensureDirOK(this.file.getParent());
+ @Configuration(proxyBeanMethods = false)
+ @EnableAspectJAutoProxy(proxyTargetClass = true)
+ @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",
+ matchIfMissing = true)
+ static class CglibAutoProxyConfiguration {
- try {
- // 通过 RandomAccessFile 创建 fileChannel
- this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
- // 做 mmap 映射
- this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
- TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
- TOTAL_MAPPED_FILES.incrementAndGet();
- ok = true;
- } catch (FileNotFoundException e) {
- log.error("create file channel " + this.fileName + " Failed. ", e);
- throw e;
- } catch (IOException e) {
- log.error("map file " + this.fileName + " Failed. ", e);
- throw e;
- } finally {
- if (!ok && this.fileChannel != null) {
- this.fileChannel.close();
- }
- }
- }
+ }
-如果是提交给AllocateMappedFileService的话就用到了一些异步操作
-public MappedFile putRequestAndReturnMappedFile(String nextFilePath, String nextNextFilePath, int fileSize) {
- int canSubmitRequests = 2;
- if (this.messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
- if (this.messageStore.getMessageStoreConfig().isFastFailIfNoBufferInStorePool()
- && BrokerRole.SLAVE != this.messageStore.getMessageStoreConfig().getBrokerRole()) { //if broker is slave, don't fast fail even no buffer in pool
- canSubmitRequests = this.messageStore.getTransientStorePool().remainBufferNumbs() - this.requestQueue.size();
- }
- }
- // 将请求放在 requestTable 中
- AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);
- boolean nextPutOK = this.requestTable.putIfAbsent(nextFilePath, nextReq) == null;
- // requestTable 使用了 concurrentHashMap,用文件名作为 key,防止并发
- if (nextPutOK) {
- // 这里判断了是否可以提交到 TransientStorePool,涉及读写分离,后面再细聊
- if (canSubmitRequests <= 0) {
- log.warn("[NOTIFYME]TransientStorePool is not enough, so create mapped file error, " +
- "RequestQueueSize : {}, StorePoolSize: {}", this.requestQueue.size(), this.messageStore.getTransientStorePool().remainBufferNumbs());
- this.requestTable.remove(nextFilePath);
- return null;
- }
- // 塞到阻塞队列中
- boolean offerOK = this.requestQueue.offer(nextReq);
- if (!offerOK) {
- log.warn("never expected here, add a request to preallocate queue failed");
- }
- canSubmitRequests--;
- }
+ }
- // 这里的两个提交我猜测是为了多生成一个 CommitLog,
- AllocateRequest nextNextReq = new AllocateRequest(nextNextFilePath, fileSize);
- boolean nextNextPutOK = this.requestTable.putIfAbsent(nextNextFilePath, nextNextReq) == null;
- if (nextNextPutOK) {
- if (canSubmitRequests <= 0) {
- log.warn("[NOTIFYME]TransientStorePool is not enough, so skip preallocate mapped file, " +
- "RequestQueueSize : {}, StorePoolSize: {}", this.requestQueue.size(), this.messageStore.getTransientStorePool().remainBufferNumbs());
- this.requestTable.remove(nextNextFilePath);
- } else {
- boolean offerOK = this.requestQueue.offer(nextNextReq);
- if (!offerOK) {
- log.warn("never expected here, add a request to preallocate queue failed");
- }
- }
- }
+为何会加载 AopAutoConfiguration 在前面的文章聊聊 SpringBoot 自动装配里已经介绍过,有兴趣的可以看下,可以发现 springboot 在 2.x 版本开始使用 cglib 作为默认的动态代理实现。
+然后就是出现的问题了,代码是这样的,一个简单的基于 springboot 的带有数据库的插入,对插入代码加了事务注解,
+@Mapper
+public interface StudentMapper {
+ // 就是插入一条数据
+ @Insert("insert into student(name, age)" + "values ('nick', '18')")
+ public Long insert();
+}
- if (hasException) {
- log.warn(this.getServiceName() + " service has exception. so return null");
- return null;
- }
+@Component
+public class StudentManager {
- AllocateRequest result = this.requestTable.get(nextFilePath);
- try {
- // 这里就异步等着
- if (result != null) {
- boolean waitOK = result.getCountDownLatch().await(waitTimeOut, TimeUnit.MILLISECONDS);
- if (!waitOK) {
- log.warn("create mmap timeout " + result.getFilePath() + " " + result.getFileSize());
- return null;
- } else {
- this.requestTable.remove(nextFilePath);
- return result.getMappedFile();
- }
- } else {
- log.error("find preallocate mmap failed, this never happen");
- }
- } catch (InterruptedException e) {
- log.warn(this.getServiceName() + " service has exception. ", e);
- }
+ @Resource
+ private StudentMapper studentMapper;
+
+ public Long createStudent() {
+ return studentMapper.insert();
+ }
+}
- return null;
- }
+@Component
+public class StudentServiceImpl implements StudentService {
-而真正去执行文件操作的就是 AllocateMappedFileService的 run 方法
-public void run() {
- log.info(this.getServiceName() + " service started");
+ @Resource
+ private StudentManager studentManager;
- while (!this.isStopped() && this.mmapOperation()) {
+ // 自己引用
+ @Resource
+ private StudentServiceImpl studentService;
- }
- log.info(this.getServiceName() + " service end");
+ @Override
+ @Transactional
+ public Long createStudent() {
+ Long id = studentManager.createStudent();
+ Long id2 = studentService.createStudent2();
+ return 1L;
+ }
+
+ @Transactional
+ private Long createStudent2() {
+// Integer t = Integer.valueOf("aaa");
+ return studentManager.createStudent();
}
-private boolean mmapOperation() {
- boolean isSuccess = false;
- AllocateRequest req = null;
- try {
- // 从阻塞队列里获取请求
- req = this.requestQueue.take();
- AllocateRequest expectedRequest = this.requestTable.get(req.getFilePath());
- if (null == expectedRequest) {
- log.warn("this mmap request expired, maybe cause timeout " + req.getFilePath() + " "
- + req.getFileSize());
- return true;
- }
- if (expectedRequest != req) {
- log.warn("never expected here, maybe cause timeout " + req.getFilePath() + " "
- + req.getFileSize() + ", req:" + req + ", expectedRequest:" + expectedRequest);
- return true;
- }
+}
- if (req.getMappedFile() == null) {
- long beginTime = System.currentTimeMillis();
+第一个公有方法 createStudent 首先调用了 manager 层的创建方法,然后再通过引入的 studentService 调用了createStudent2,我们先跑一下看看会出现啥情况,果不其然报错了,正是这个报错让我纠结了很久
+![EdR7oB]()
+报了个空指针,而且是在 createStudent2 已经被调用到了,在它的内部,报的 studentManager 是 null,首先 cglib 作为动态代理它是通过继承的方式来实现的,相当于是会在调用目标对象的代理方法时调用 cglib 生成的子类,具体的代理切面逻辑在子类实现,然后在调用目标对象的目标方法,但是继承的方式对于 final 和私有方法其实是没法进行代理的,因为没法继承,所以我最开始的想法是应该通过 studentService 调用 createStudent2 的时候就报错了,也就是不会进入这个方法内部,后面才发现犯了个特别二的错误,继承的方式去调用父类的私有方法,对于 Java 来说是可以调用到的,父类的私有方法并不由子类的InstanceKlass维护,只能通过子类的InstanceKlass找到Java类对应的_super,这样间接地访问。也就是说子类其实是可以访问的,那为啥访问了会报空指针呢,这里报的是studentManager 是空的,可以往依赖注入方面去想,如果忽略依赖注入,我这个studentManager 的确是 null,那是不是就没有被依赖注入呢,但是为啥前面那个可以呢
+这个问题着实查了很久,不废话来看代码
+@Override
+ protected Object invokeJoinpoint() throws Throwable {
+ if (this.methodProxy != null) {
+ // 这里的 target 就是被代理的 bean
+ return this.methodProxy.invoke(this.target, this.arguments);
+ }
+ else {
+ return super.invokeJoinpoint();
+ }
+ }
- MappedFile mappedFile;
- if (messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
- try {
- // 通过 transientStorePool 创建
- mappedFile = ServiceLoader.load(MappedFile.class).iterator().next();
- mappedFile.init(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());
- } catch (RuntimeException e) {
- log.warn("Use default implementation.");
- // 默认创建
- mappedFile = new MappedFile(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());
- }
- } else {
- // 默认创建
- mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());
- }
- long eclipseTime = UtilAll.computeEclipseTimeMilliseconds(beginTime);
- if (eclipseTime > 10) {
- int queueSize = this.requestQueue.size();
- log.warn("create mappedFile spent time(ms) " + eclipseTime + " queue size " + queueSize
- + " " + req.getFilePath() + " " + req.getFileSize());
- }
- // pre write mappedFile
- if (mappedFile.getFileSize() >= this.messageStore.getMessageStoreConfig()
- .getMapedFileSizeCommitLog()
- &&
- this.messageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {
- mappedFile.warmMappedFile(this.messageStore.getMessageStoreConfig().getFlushDiskType(),
- this.messageStore.getMessageStoreConfig().getFlushLeastPagesWhenWarmMapedFile());
- }
+这个是org.springframework.aop.framework.CglibAopProxy.CglibMethodInvocation的代码,其实它在这里不是直接调用 super 也就是父类的方法,而是通过 methodProxy 调用 target 目标对象的方法,也就是原始的 studentService bean 的方法,这样子 spring 管理的已经做好依赖注入的 bean 就能正常起作用,否则就会出现上面的问题,因为 cglib 其实是通过继承来实现,通过将调用转移到子类上加入代理逻辑,我们在简单使用的时候会直接 invokeSuper() 调用父类的方法,但是在这里 spring 的场景里需要去支持 spring 的功能逻辑,所以上面的问题就可以开始来解释了,因为 createStudent 是公共方法,cglib 可以对其进行继承代理,但是在执行逻辑的时候其实是通过调用目标对象,也就是 spring 管理的被代理的目标对象的 bean 调用的 createStudent,而对于下面的 createStudent2 方法因为是私有方法,不会走代理逻辑,也就不会有调用回目标对象的逻辑,只是通过继承关系,在子类中没有这个方法,所以会通过子类的InstanceKlass找到这个类对应的_super,然后调用父类的这个私有方法,这里要搞清楚一个点,从这个代理类直接找到其父类然后调用这个私有方法,这个类是由 cglib 生成的,不是被 spring 管理起来经过依赖注入的 bean,所以是没有 studentManager 这个依赖的,也就出现了前面的问题
+而在前面提到的cglib通过methodProxy调用到目标对象,目标对象是在什么时候设置的呢,其实是在bean的生命周期中,org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization这个接口的在bean的初始化过程中,会调用实现了这个接口的方法,
+@Override
+public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
+ if (bean != null) {
+ Object cacheKey = getCacheKey(bean.getClass(), beanName);
+ if (this.earlyProxyReferences.remove(cacheKey) != bean) {
+ return wrapIfNecessary(bean, beanName, cacheKey);
+ }
+ }
+ return bean;
+}
- req.setMappedFile(mappedFile);
- this.hasException = false;
- isSuccess = true;
- }
- } catch (InterruptedException e) {
- log.warn(this.getServiceName() + " interrupted, possibly by shutdown.");
- this.hasException = true;
- return false;
- } catch (IOException e) {
- log.warn(this.getServiceName() + " service has exception. ", e);
- this.hasException = true;
- if (null != req) {
- requestQueue.offer(req);
- try {
- Thread.sleep(1);
- } catch (InterruptedException ignored) {
- }
- }
- } finally {
- if (req != null && isSuccess)
- // 通知前面等待的
- req.getCountDownLatch().countDown();
- }
- return true;
- }
+具体的逻辑在 org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#wrapIfNecessary这个方法里
+protected Object getCacheKey(Class<?> beanClass, @Nullable String beanName) {
+ if (StringUtils.hasLength(beanName)) {
+ return (FactoryBean.class.isAssignableFrom(beanClass) ?
+ BeanFactory.FACTORY_BEAN_PREFIX + beanName : beanName);
+ }
+ else {
+ return beanClass;
+ }
+ }
+ /**
+ * Wrap the given bean if necessary, i.e. if it is eligible for being proxied.
+ * @param bean the raw bean instance
+ * @param beanName the name of the bean
+ * @param cacheKey the cache key for metadata access
+ * @return a proxy wrapping the bean, or the raw bean instance as-is
+ */
+ protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
+ if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
+ return bean;
+ }
+ if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
+ return bean;
+ }
+ if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
+ this.advisedBeans.put(cacheKey, Boolean.FALSE);
+ return bean;
+ }
+ // Create proxy if we have advice.
+ Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
+ if (specificInterceptors != DO_NOT_PROXY) {
+ this.advisedBeans.put(cacheKey, Boolean.TRUE);
+ Object proxy = createProxy(
+ bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
+ this.proxyTypes.put(cacheKey, proxy.getClass());
+ return proxy;
+ }
+ this.advisedBeans.put(cacheKey, Boolean.FALSE);
+ return bean;
+ }
+然后在 org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#createProxy 中创建了代理类
]]>
- MQ
- RocketMQ
- 消息队列
+ Java
+ SpringBoot
- MQ
- 消息队列
- RocketMQ
+ Java
+ Spring
+ SpringBoot
+ cglib
+ 事务
- 聊一下 RocketMQ 的顺序消息
- /2021/08/29/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E9%A1%BA%E5%BA%8F%E6%B6%88%E6%81%AF/
- rocketmq 里有一种比较特殊的用法,就是顺序消息,比如订单的生命周期里,在创建,支付,签收等状态轮转中,会发出来对应的消息,这里面就比较需要去保证他们的顺序,当然在处理的业务代码也可以做对应的处理,结合消息重投,但是如果这里消息就能保证顺序性了,那么业务代码就能更好的关注业务代码的处理。
-首先有一种情况是全局的有序,比如对于一个 topic 里就得发送线程保证只有一个,内部的 queue 也只有一个,消费线程也只有一个,这样就能比较容易的保证全局顺序性了,但是这里的问题就是完全限制了性能,不是很现实,在真实场景里很多都是比如对于同一个订单,需要去保证状态的轮转是按照预期的顺序来,而不必要全局的有序性。
-对于这类的有序性,需要在发送和接收方都有对应的处理,在发送消息中,需要去指定 selector,即MessageQueueSelector,能够以固定的方式是分配到对应的 MessageQueue
-比如像 RocketMQ 中的示例
-SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
- @Override
- public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
- Long id = (Long) arg; //message queue is selected by #salesOrderID
- long index = id % mqs.size();
- return mqs.get((int) index);
- }
- }, orderList.get(i).getOrderId());
-
-而在消费侧有几个点比较重要,首先我们要保证一个 MessageQueue只被一个消费者消费,消费队列存在broker端,要保证 MessageQueue 只被一个消费者消费,那么消费者在进行消息拉取消费时就必须向mq服务器申请队列锁,消费者申请队列锁的代码存在于RebalanceService消息队列负载的实现代码中。
-List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
- for (MessageQueue mq : mqSet) {
- if (!this.processQueueTable.containsKey(mq)) {
- // 判断是否顺序,如果是顺序消费的,则需要加锁
- if (isOrder && !this.lock(mq)) {
- log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
- continue;
- }
-
- this.removeDirtyOffset(mq);
- ProcessQueue pq = new ProcessQueue();
- long nextOffset = this.computePullFromWhere(mq);
- if (nextOffset >= 0) {
- ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
- if (pre != null) {
- log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
- } else {
- log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
- PullRequest pullRequest = new PullRequest();
- pullRequest.setConsumerGroup(consumerGroup);
- pullRequest.setNextOffset(nextOffset);
- pullRequest.setMessageQueue(mq);
- pullRequest.setProcessQueue(pq);
- pullRequestList.add(pullRequest);
- changed = true;
- }
- } else {
- log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
- }
- }
- }
+ 聊一下 RocketMQ 的消息存储二
+ /2021/09/12/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E4%BA%8C/
+ CommitLog 结构CommitLog 是 rocketmq 的服务端,也就是 broker 存储消息的的文件,跟 kafka 一样,也是顺序写入,当然消息是变长的,生成的规则是每个文件的默认1G =1024 * 1024 * 1024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1 073 741 824Byte;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824, 消息存储的时候会顺序写入文件,当文件满了则写入下一个文件,代码中的定义
+// CommitLog file size,default is 1G
+private int mapedFileSizeCommitLog = 1024 * 1024 * 1024;
-在申请到锁之后会创建 pullRequest 进行消息拉取,消息拉取部分的代码实现在PullMessageService中,
-@Override
- public void run() {
- log.info(this.getServiceName() + " service started");
+![kLahwW]()
+本地跑个 demo 验证下,也是这样,这里奇妙有几个比较巧妙的点(个人观点),首先文件就刚好是 1G,并且按照大小偏移量去生成下一个文件,这样获取消息的时候按大小算一下就知道在哪个文件里了,
+代码中写入 CommitLog 的逻辑可以从这开始看
+public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
+ // Set the storage time
+ msg.setStoreTimestamp(System.currentTimeMillis());
+ // Set the message body BODY CRC (consider the most appropriate setting
+ // on the client)
+ msg.setBodyCRC(UtilAll.crc32(msg.getBody()));
+ // Back to Results
+ AppendMessageResult result = null;
- while (!this.isStopped()) {
- try {
- PullRequest pullRequest = this.pullRequestQueue.take();
- this.pullMessage(pullRequest);
- } catch (InterruptedException ignored) {
- } catch (Exception e) {
- log.error("Pull Message Service Run Method exception", e);
- }
- }
+ StoreStatsService storeStatsService = this.defaultMessageStore.getStoreStatsService();
- log.info(this.getServiceName() + " service end");
- }
+ String topic = msg.getTopic();
+ int queueId = msg.getQueueId();
-消息拉取完后,需要提交到ConsumeMessageService中进行消费,顺序消费的实现为ConsumeMessageOrderlyService,提交消息进行消费的方法为ConsumeMessageOrderlyService#submitConsumeRequest,具体实现如下:
-@Override
-public void submitConsumeRequest(
- final List<MessageExt> msgs,
- final ProcessQueue processQueue,
- final MessageQueue messageQueue,
- final boolean dispathToConsume) {
- if (dispathToConsume) {
- ConsumeRequest consumeRequest = new ConsumeRequest(processQueue, messageQueue);
- this.consumeExecutor.submit(consumeRequest);
- }
-}
+ final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
+ if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE
+ || tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {
+ // Delay Delivery
+ if (msg.getDelayTimeLevel() > 0) {
+ if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
+ msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
+ }
-构建了一个ConsumeRequest对象,它是个实现了 runnable 接口的类,并提交给了线程池来并行消费,看下顺序消费的ConsumeRequest的run方法实现:
-@Override
- public void run() {
- if (this.processQueue.isDropped()) {
- log.warn("run, the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
- return;
+ topic = ScheduleMessageService.SCHEDULE_TOPIC;
+ queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
+
+ // Backup real topic, queueId
+ MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
+ MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
+ msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
+
+ msg.setTopic(topic);
+ msg.setQueueId(queueId);
}
- // 获得 Consumer 消息队列锁,即单个线程独占
- final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
- synchronized (objLock) {
- // (广播模式) 或者 (集群模式 && Broker消息队列锁有效)
- if (MessageModel.BROADCASTING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
- || (this.processQueue.isLocked() && !this.processQueue.isLockExpired())) {
- final long beginTime = System.currentTimeMillis();
- // 循环
- for (boolean continueConsume = true; continueConsume; ) {
- if (this.processQueue.isDropped()) {
- log.warn("the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
- break;
- }
+ }
- // 消息队列分布式锁未锁定,提交延迟获得锁并消费请求
- if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
- && !this.processQueue.isLocked()) {
- log.warn("the message queue not locked, so consume later, {}", this.messageQueue);
- ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 10);
- break;
- }
+ long eclipseTimeInLock = 0;
+ MappedFile unlockMappedFile = null;
+ MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
- // 消息队列分布式锁已经过期,提交延迟获得锁并消费请求
- if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
- && this.processQueue.isLockExpired()) {
- log.warn("the message queue lock expired, so consume later, {}", this.messageQueue);
- ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 10);
- break;
- }
- // 当前周期消费时间超过连续时长,默认:60s,提交延迟消费请求。默认情况下,每消费1分钟休息10ms。
- long interval = System.currentTimeMillis() - beginTime;
- if (interval > MAX_TIME_CONSUME_CONTINUOUSLY) {
- ConsumeMessageOrderlyService.this.submitConsumeRequestLater(processQueue, messageQueue, 10);
- break;
- }
- // 获取消费消息。此处和并发消息请求不同,并发消息请求已经带了消费哪些消息。
- final int consumeBatchSize =
- ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
+ putMessageLock.lock(); //spin or ReentrantLock ,depending on store config
+ try {
+ long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now();
+ this.beginTimeInLock = beginLockTimestamp;
- List<MessageExt> msgs = this.processQueue.takeMessags(consumeBatchSize);
- defaultMQPushConsumerImpl.resetRetryAndNamespace(msgs, defaultMQPushConsumer.getConsumerGroup());
- if (!msgs.isEmpty()) {
- final ConsumeOrderlyContext context = new ConsumeOrderlyContext(this.messageQueue);
+ // Here settings are stored timestamp, in order to ensure an orderly
+ // global
+ msg.setStoreTimestamp(beginLockTimestamp);
- ConsumeOrderlyStatus status = null;
+ if (null == mappedFile || mappedFile.isFull()) {
+ mappedFile = this.mappedFileQueue.getLastMappedFile(0); // Mark: NewFile may be cause noise
+ }
+ if (null == mappedFile) {
+ log.error("create mapped file1 error, topic: " + msg.getTopic() + " clientAddr: " + msg.getBornHostString());
+ beginTimeInLock = 0;
+ return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, null);
+ }
- ConsumeMessageContext consumeMessageContext = null;
- if (ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.hasHook()) {
- consumeMessageContext = new ConsumeMessageContext();
- consumeMessageContext
- .setConsumerGroup(ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumerGroup());
- consumeMessageContext.setNamespace(defaultMQPushConsumer.getNamespace());
- consumeMessageContext.setMq(messageQueue);
- consumeMessageContext.setMsgList(msgs);
- consumeMessageContext.setSuccess(false);
- // init the consume context type
- consumeMessageContext.setProps(new HashMap<String, String>());
- ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.executeHookBefore(consumeMessageContext);
- }
- // 执行消费
- long beginTimestamp = System.currentTimeMillis();
- ConsumeReturnType returnType = ConsumeReturnType.SUCCESS;
- boolean hasException = false;
- try {
- this.processQueue.getLockConsume().lock(); // 锁定处理队列
- if (this.processQueue.isDropped()) {
- log.warn("consumeMessage, the message queue not be able to consume, because it's dropped. {}",
- this.messageQueue);
- break;
- }
+ result = mappedFile.appendMessage(msg, this.appendMessageCallback);
+ switch (result.getStatus()) {
+ case PUT_OK:
+ break;
+ case END_OF_FILE:
+ unlockMappedFile = mappedFile;
+ // Create a new file, re-write the message
+ mappedFile = this.mappedFileQueue.getLastMappedFile(0);
+ if (null == mappedFile) {
+ // XXX: warn and notify me
+ log.error("create mapped file2 error, topic: " + msg.getTopic() + " clientAddr: " + msg.getBornHostString());
+ beginTimeInLock = 0;
+ return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, result);
+ }
+ result = mappedFile.appendMessage(msg, this.appendMessageCallback);
+ break;
+ case MESSAGE_SIZE_EXCEEDED:
+ case PROPERTIES_SIZE_EXCEEDED:
+ beginTimeInLock = 0;
+ return new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, result);
+ case UNKNOWN_ERROR:
+ beginTimeInLock = 0;
+ return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
+ default:
+ beginTimeInLock = 0;
+ return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
+ }
- status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
- } catch (Throwable e) {
- log.warn("consumeMessage exception: {} Group: {} Msgs: {} MQ: {}",
- RemotingHelper.exceptionSimpleDesc(e),
- ConsumeMessageOrderlyService.this.consumerGroup,
- msgs,
- messageQueue);
- hasException = true;
- } finally {
- this.processQueue.getLockConsume().unlock(); // 解锁
- }
+ eclipseTimeInLock = this.defaultMessageStore.getSystemClock().now() - beginLockTimestamp;
+ beginTimeInLock = 0;
+ } finally {
+ putMessageLock.unlock();
+ }
- if (null == status
- || ConsumeOrderlyStatus.ROLLBACK == status
- || ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT == status) {
- log.warn("consumeMessage Orderly return not OK, Group: {} Msgs: {} MQ: {}",
- ConsumeMessageOrderlyService.this.consumerGroup,
- msgs,
- messageQueue);
- }
+ if (eclipseTimeInLock > 500) {
+ log.warn("[NOTIFYME]putMessage in lock cost time(ms)={}, bodyLength={} AppendMessageResult={}", eclipseTimeInLock, msg.getBody().length, result);
+ }
- long consumeRT = System.currentTimeMillis() - beginTimestamp;
- if (null == status) {
- if (hasException) {
- returnType = ConsumeReturnType.EXCEPTION;
- } else {
- returnType = ConsumeReturnType.RETURNNULL;
- }
- } else if (consumeRT >= defaultMQPushConsumer.getConsumeTimeout() * 60 * 1000) {
- returnType = ConsumeReturnType.TIME_OUT;
- } else if (ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT == status) {
- returnType = ConsumeReturnType.FAILED;
- } else if (ConsumeOrderlyStatus.SUCCESS == status) {
- returnType = ConsumeReturnType.SUCCESS;
- }
+ if (null != unlockMappedFile && this.defaultMessageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {
+ this.defaultMessageStore.unlockMappedFile(unlockMappedFile);
+ }
- if (ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.hasHook()) {
- consumeMessageContext.getProps().put(MixAll.CONSUME_CONTEXT_TYPE, returnType.name());
- }
+ PutMessageResult putMessageResult = new PutMessageResult(PutMessageStatus.PUT_OK, result);
- if (null == status) {
- status = ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT;
- }
+ // Statistics
+ storeStatsService.getSinglePutMessageTopicTimesTotal(msg.getTopic()).incrementAndGet();
+ storeStatsService.getSinglePutMessageTopicSizeTotal(topic).addAndGet(result.getWroteBytes());
- if (ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.hasHook()) {
- consumeMessageContext.setStatus(status.toString());
- consumeMessageContext
- .setSuccess(ConsumeOrderlyStatus.SUCCESS == status || ConsumeOrderlyStatus.COMMIT == status);
- ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.executeHookAfter(consumeMessageContext);
- }
+ handleDiskFlush(result, putMessageResult, msg);
+ handleHA(result, putMessageResult, msg);
- ConsumeMessageOrderlyService.this.getConsumerStatsManager()
- .incConsumeRT(ConsumeMessageOrderlyService.this.consumerGroup, messageQueue.getTopic(), consumeRT);
+ return putMessageResult;
+ }
- continueConsume = ConsumeMessageOrderlyService.this.processConsumeResult(msgs, status, context, this);
- } else {
- continueConsume = false;
- }
- }
- } else {
- if (this.processQueue.isDropped()) {
- log.warn("the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
- return;
- }
+前面也看到在CommitLog 目录下是有大小为 1G 的文件组成,在实现逻辑中,其实是通过 org.apache.rocketmq.store.MappedFileQueue ,内部是存的一个MappedFile的队列,对于写入的场景每次都是通过org.apache.rocketmq.store.MappedFileQueue#getLastMappedFile() 获取最后一个文件,如果还没有创建,或者最后这个文件已经满了,那就调用 org.apache.rocketmq.store.MappedFileQueue#getLastMappedFile(long)
+public MappedFile getLastMappedFile(final long startOffset, boolean needCreate) {
+ long createOffset = -1;
+ // 调用前面的方法,只是从 mappedFileQueue 获取最后一个
+ MappedFile mappedFileLast = getLastMappedFile();
- ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 100);
- }
- }
- }
+ // 如果为空,计算下创建的偏移量
+ if (mappedFileLast == null) {
+ createOffset = startOffset - (startOffset % this.mappedFileSize);
+ }
+
+ // 如果不为空,但是当前的文件写满了
+ if (mappedFileLast != null && mappedFileLast.isFull()) {
+ // 前一个的偏移量加上单个文件的偏移量,也就是 1G
+ createOffset = mappedFileLast.getFileFromOffset() + this.mappedFileSize;
+ }
-获取到锁对象后,使用synchronized尝试申请线程级独占锁。
-如果加锁成功,同一时刻只有一个线程进行消息消费。
-如果加锁失败,会延迟100ms重新尝试向broker端申请锁定messageQueue,锁定成功后重新提交消费请求
-创建消息拉取任务时,消息客户端向broker端申请锁定MessageQueue,使得一个MessageQueue同一个时刻只能被一个消费客户端消费。
-消息消费时,多线程针对同一个消息队列的消费先尝试使用synchronized申请独占锁,加锁成功才能进行消费,使得一个MessageQueue同一个时刻只能被一个消费客户端中一个线程消费。
这里其实还有很重要的一点是对processQueue的加锁,这里其实是保证了在 rebalance的过程中如果 processQueue 被分配给了另一个 consumer,但是当前已经被我这个 consumer 再消费,但是没提交,就有可能出现被两个消费者消费,所以得进行加锁保证不受 rebalance 影响。
-]]>
-
- MQ
- RocketMQ
- 消息队列
-
-
- MQ
- 消息队列
- RocketMQ
-
-
-
- 聊一下 RocketMQ 的消息存储四
- /2021/10/17/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E5%9B%9B/
- IndexFile 结构 hash 结构能够通过 key 寻找到对应在 CommitLog 中的位置
-IndexFile 的构建则是分发给这个进行处理
-class CommitLogDispatcherBuildIndex implements CommitLogDispatcher {
+ if (createOffset != -1 && needCreate) {
+ // 根据 createOffset 转换成文件名进行创建
+ String nextFilePath = this.storePath + File.separator + UtilAll.offset2FileName(createOffset);
+ String nextNextFilePath = this.storePath + File.separator
+ + UtilAll.offset2FileName(createOffset + this.mappedFileSize);
+ MappedFile mappedFile = null;
+
+ // 这里如果allocateMappedFileService 存在,就提交请求
+ if (this.allocateMappedFileService != null) {
+ mappedFile = this.allocateMappedFileService.putRequestAndReturnMappedFile(nextFilePath,
+ nextNextFilePath, this.mappedFileSize);
+ } else {
+ try {
+ // 否则就直接创建
+ mappedFile = new MappedFile(nextFilePath, this.mappedFileSize);
+ } catch (IOException e) {
+ log.error("create mappedFile exception", e);
+ }
+ }
- @Override
- public void dispatch(DispatchRequest request) {
- if (DefaultMessageStore.this.messageStoreConfig.isMessageIndexEnable()) {
- DefaultMessageStore.this.indexService.buildIndex(request);
+ if (mappedFile != null) {
+ if (this.mappedFiles.isEmpty()) {
+ mappedFile.setFirstCreateInQueue(true);
+ }
+ this.mappedFiles.add(mappedFile);
+ }
+
+ return mappedFile;
}
+
+ return mappedFileLast;
+ }
+
+首先看下直接创建的,
+public MappedFile(final String fileName, final int fileSize) throws IOException {
+ init(fileName, fileSize);
}
-}
-public void buildIndex(DispatchRequest req) {
- IndexFile indexFile = retryGetAndCreateIndexFile();
- if (indexFile != null) {
- long endPhyOffset = indexFile.getEndPhyOffset();
- DispatchRequest msg = req;
- String topic = msg.getTopic();
- String keys = msg.getKeys();
- if (msg.getCommitLogOffset() < endPhyOffset) {
- return;
- }
+private void init(final String fileName, final int fileSize) throws IOException {
+ this.fileName = fileName;
+ this.fileSize = fileSize;
+ this.file = new File(fileName);
+ this.fileFromOffset = Long.parseLong(this.file.getName());
+ boolean ok = false;
- final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
- switch (tranType) {
- case MessageSysFlag.TRANSACTION_NOT_TYPE:
- case MessageSysFlag.TRANSACTION_PREPARED_TYPE:
- case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
- break;
- case MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
- return;
+ ensureDirOK(this.file.getParent());
+
+ try {
+ // 通过 RandomAccessFile 创建 fileChannel
+ this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
+ // 做 mmap 映射
+ this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
+ TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
+ TOTAL_MAPPED_FILES.incrementAndGet();
+ ok = true;
+ } catch (FileNotFoundException e) {
+ log.error("create file channel " + this.fileName + " Failed. ", e);
+ throw e;
+ } catch (IOException e) {
+ log.error("map file " + this.fileName + " Failed. ", e);
+ throw e;
+ } finally {
+ if (!ok && this.fileChannel != null) {
+ this.fileChannel.close();
}
+ }
+ }
- if (req.getUniqKey() != null) {
- indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()));
- if (indexFile == null) {
- log.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
- return;
- }
+如果是提交给AllocateMappedFileService的话就用到了一些异步操作
+public MappedFile putRequestAndReturnMappedFile(String nextFilePath, String nextNextFilePath, int fileSize) {
+ int canSubmitRequests = 2;
+ if (this.messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
+ if (this.messageStore.getMessageStoreConfig().isFastFailIfNoBufferInStorePool()
+ && BrokerRole.SLAVE != this.messageStore.getMessageStoreConfig().getBrokerRole()) { //if broker is slave, don't fast fail even no buffer in pool
+ canSubmitRequests = this.messageStore.getTransientStorePool().remainBufferNumbs() - this.requestQueue.size();
+ }
+ }
+ // 将请求放在 requestTable 中
+ AllocateRequest nextReq = new AllocateRequest(nextFilePath, fileSize);
+ boolean nextPutOK = this.requestTable.putIfAbsent(nextFilePath, nextReq) == null;
+ // requestTable 使用了 concurrentHashMap,用文件名作为 key,防止并发
+ if (nextPutOK) {
+ // 这里判断了是否可以提交到 TransientStorePool,涉及读写分离,后面再细聊
+ if (canSubmitRequests <= 0) {
+ log.warn("[NOTIFYME]TransientStorePool is not enough, so create mapped file error, " +
+ "RequestQueueSize : {}, StorePoolSize: {}", this.requestQueue.size(), this.messageStore.getTransientStorePool().remainBufferNumbs());
+ this.requestTable.remove(nextFilePath);
+ return null;
+ }
+ // 塞到阻塞队列中
+ boolean offerOK = this.requestQueue.offer(nextReq);
+ if (!offerOK) {
+ log.warn("never expected here, add a request to preallocate queue failed");
}
+ canSubmitRequests--;
+ }
- if (keys != null && keys.length() > 0) {
- String[] keyset = keys.split(MessageConst.KEY_SEPARATOR);
- for (int i = 0; i < keyset.length; i++) {
- String key = keyset[i];
- if (key.length() > 0) {
- indexFile = putKey(indexFile, msg, buildKey(topic, key));
- if (indexFile == null) {
- log.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
- return;
- }
- }
+ // 这里的两个提交我猜测是为了多生成一个 CommitLog,
+ AllocateRequest nextNextReq = new AllocateRequest(nextNextFilePath, fileSize);
+ boolean nextNextPutOK = this.requestTable.putIfAbsent(nextNextFilePath, nextNextReq) == null;
+ if (nextNextPutOK) {
+ if (canSubmitRequests <= 0) {
+ log.warn("[NOTIFYME]TransientStorePool is not enough, so skip preallocate mapped file, " +
+ "RequestQueueSize : {}, StorePoolSize: {}", this.requestQueue.size(), this.messageStore.getTransientStorePool().remainBufferNumbs());
+ this.requestTable.remove(nextNextFilePath);
+ } else {
+ boolean offerOK = this.requestQueue.offer(nextNextReq);
+ if (!offerOK) {
+ log.warn("never expected here, add a request to preallocate queue failed");
}
}
- } else {
- log.error("build index error, stop building index");
}
- }
-配置的数量
-private boolean messageIndexEnable = true;
-private int maxHashSlotNum = 5000000;
-private int maxIndexNum = 5000000 * 4;
+ if (hasException) {
+ log.warn(this.getServiceName() + " service has exception. so return null");
+ return null;
+ }
-最核心的其实是 IndexFile 的结构和如何写入
-public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
- if (this.indexHeader.getIndexCount() < this.indexNum) {
- // 获取 key 的 hash
- int keyHash = indexKeyHashMethod(key);
- // 计算属于哪个 slot
- int slotPos = keyHash % this.hashSlotNum;
- // 计算 slot 位置 因为结构是有个 indexHead,主要是分为三段 header,slot 和 index
- int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
+ AllocateRequest result = this.requestTable.get(nextFilePath);
+ try {
+ // 这里就异步等着
+ if (result != null) {
+ boolean waitOK = result.getCountDownLatch().await(waitTimeOut, TimeUnit.MILLISECONDS);
+ if (!waitOK) {
+ log.warn("create mmap timeout " + result.getFilePath() + " " + result.getFileSize());
+ return null;
+ } else {
+ this.requestTable.remove(nextFilePath);
+ return result.getMappedFile();
+ }
+ } else {
+ log.error("find preallocate mmap failed, this never happen");
+ }
+ } catch (InterruptedException e) {
+ log.warn(this.getServiceName() + " service has exception. ", e);
+ }
- FileLock fileLock = null;
+ return null;
+ }
- try {
+而真正去执行文件操作的就是 AllocateMappedFileService的 run 方法
+public void run() {
+ log.info(this.getServiceName() + " service started");
- // fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
- // false);
- int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
- if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
- slotValue = invalidIndex;
- }
+ while (!this.isStopped() && this.mmapOperation()) {
- long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
+ }
+ log.info(this.getServiceName() + " service end");
+ }
+private boolean mmapOperation() {
+ boolean isSuccess = false;
+ AllocateRequest req = null;
+ try {
+ // 从阻塞队列里获取请求
+ req = this.requestQueue.take();
+ AllocateRequest expectedRequest = this.requestTable.get(req.getFilePath());
+ if (null == expectedRequest) {
+ log.warn("this mmap request expired, maybe cause timeout " + req.getFilePath() + " "
+ + req.getFileSize());
+ return true;
+ }
+ if (expectedRequest != req) {
+ log.warn("never expected here, maybe cause timeout " + req.getFilePath() + " "
+ + req.getFileSize() + ", req:" + req + ", expectedRequest:" + expectedRequest);
+ return true;
+ }
- timeDiff = timeDiff / 1000;
+ if (req.getMappedFile() == null) {
+ long beginTime = System.currentTimeMillis();
- if (this.indexHeader.getBeginTimestamp() <= 0) {
- timeDiff = 0;
- } else if (timeDiff > Integer.MAX_VALUE) {
- timeDiff = Integer.MAX_VALUE;
- } else if (timeDiff < 0) {
- timeDiff = 0;
+ MappedFile mappedFile;
+ if (messageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
+ try {
+ // 通过 transientStorePool 创建
+ mappedFile = ServiceLoader.load(MappedFile.class).iterator().next();
+ mappedFile.init(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());
+ } catch (RuntimeException e) {
+ log.warn("Use default implementation.");
+ // 默认创建
+ mappedFile = new MappedFile(req.getFilePath(), req.getFileSize(), messageStore.getTransientStorePool());
+ }
+ } else {
+ // 默认创建
+ mappedFile = new MappedFile(req.getFilePath(), req.getFileSize());
}
- // 计算索引存放位置,头部 + slot 数量 * slot 大小 + 已有的 index 数量 + index 大小
- int absIndexPos =
- IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
- + this.indexHeader.getIndexCount() * indexSize;
-
- this.mappedByteBuffer.putInt(absIndexPos, keyHash);
- this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
- this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
- this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
-
- // 存放的是数量位移,不是绝对位置
- this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
+ long eclipseTime = UtilAll.computeEclipseTimeMilliseconds(beginTime);
+ if (eclipseTime > 10) {
+ int queueSize = this.requestQueue.size();
+ log.warn("create mappedFile spent time(ms) " + eclipseTime + " queue size " + queueSize
+ + " " + req.getFilePath() + " " + req.getFileSize());
+ }
- if (this.indexHeader.getIndexCount() <= 1) {
- this.indexHeader.setBeginPhyOffset(phyOffset);
- this.indexHeader.setBeginTimestamp(storeTimestamp);
+ // pre write mappedFile
+ if (mappedFile.getFileSize() >= this.messageStore.getMessageStoreConfig()
+ .getMapedFileSizeCommitLog()
+ &&
+ this.messageStore.getMessageStoreConfig().isWarmMapedFileEnable()) {
+ mappedFile.warmMappedFile(this.messageStore.getMessageStoreConfig().getFlushDiskType(),
+ this.messageStore.getMessageStoreConfig().getFlushLeastPagesWhenWarmMapedFile());
}
- this.indexHeader.incHashSlotCount();
- this.indexHeader.incIndexCount();
- this.indexHeader.setEndPhyOffset(phyOffset);
- this.indexHeader.setEndTimestamp(storeTimestamp);
-
- return true;
- } catch (Exception e) {
- log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
- } finally {
- if (fileLock != null) {
- try {
- fileLock.release();
- } catch (IOException e) {
- log.error("Failed to release the lock", e);
- }
+ req.setMappedFile(mappedFile);
+ this.hasException = false;
+ isSuccess = true;
+ }
+ } catch (InterruptedException e) {
+ log.warn(this.getServiceName() + " interrupted, possibly by shutdown.");
+ this.hasException = true;
+ return false;
+ } catch (IOException e) {
+ log.warn(this.getServiceName() + " service has exception. ", e);
+ this.hasException = true;
+ if (null != req) {
+ requestQueue.offer(req);
+ try {
+ Thread.sleep(1);
+ } catch (InterruptedException ignored) {
}
}
- } else {
- log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
- + "; index max num = " + this.indexNum);
+ } finally {
+ if (req != null && isSuccess)
+ // 通知前面等待的
+ req.getCountDownLatch().countDown();
}
+ return true;
+ }
+
+
- return false;
- }
-具体可以看一下这个简略的示意图
![]()
]]>
MQ
@@ -15845,246 +15639,443 @@ netsh interface portproxy add v4tov4 listenaddress=0@Configuration
-@ConditionalOnClass({ EnableAspectJAutoProxy.class, Aspect.class, Advice.class })
-@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
-public class AopAutoConfiguration {
+ 聊一下 RocketMQ 的消息存储四
+ /2021/10/17/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E5%9B%9B/
+ IndexFile 结构 hash 结构能够通过 key 寻找到对应在 CommitLog 中的位置
+IndexFile 的构建则是分发给这个进行处理
+class CommitLogDispatcherBuildIndex implements CommitLogDispatcher {
- @Configuration
- @EnableAspectJAutoProxy(proxyTargetClass = false)
- @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false", matchIfMissing = true)
- public static class JdkDynamicAutoProxyConfiguration {
- }
+ @Override
+ public void dispatch(DispatchRequest request) {
+ if (DefaultMessageStore.this.messageStoreConfig.isMessageIndexEnable()) {
+ DefaultMessageStore.this.indexService.buildIndex(request);
+ }
+ }
+}
+public void buildIndex(DispatchRequest req) {
+ IndexFile indexFile = retryGetAndCreateIndexFile();
+ if (indexFile != null) {
+ long endPhyOffset = indexFile.getEndPhyOffset();
+ DispatchRequest msg = req;
+ String topic = msg.getTopic();
+ String keys = msg.getKeys();
+ if (msg.getCommitLogOffset() < endPhyOffset) {
+ return;
+ }
- @Configuration
- @EnableAspectJAutoProxy(proxyTargetClass = true)
- @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true", matchIfMissing = false)
- public static class CglibAutoProxyConfiguration {
- }
+ final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
+ switch (tranType) {
+ case MessageSysFlag.TRANSACTION_NOT_TYPE:
+ case MessageSysFlag.TRANSACTION_PREPARED_TYPE:
+ case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
+ break;
+ case MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
+ return;
+ }
-}
+ if (req.getUniqKey() != null) {
+ indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()));
+ if (indexFile == null) {
+ log.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
+ return;
+ }
+ }
-而在 2.x 中变成了这样
-@Configuration(proxyBeanMethods = false)
-@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
-public class AopAutoConfiguration {
+ if (keys != null && keys.length() > 0) {
+ String[] keyset = keys.split(MessageConst.KEY_SEPARATOR);
+ for (int i = 0; i < keyset.length; i++) {
+ String key = keyset[i];
+ if (key.length() > 0) {
+ indexFile = putKey(indexFile, msg, buildKey(topic, key));
+ if (indexFile == null) {
+ log.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
+ return;
+ }
+ }
+ }
+ }
+ } else {
+ log.error("build index error, stop building index");
+ }
+ }
- @Configuration(proxyBeanMethods = false)
- @ConditionalOnClass(Advice.class)
- static class AspectJAutoProxyingConfiguration {
+配置的数量
+private boolean messageIndexEnable = true;
+private int maxHashSlotNum = 5000000;
+private int maxIndexNum = 5000000 * 4;
- @Configuration(proxyBeanMethods = false)
- @EnableAspectJAutoProxy(proxyTargetClass = false)
- @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false")
- static class JdkDynamicAutoProxyConfiguration {
+最核心的其实是 IndexFile 的结构和如何写入
+public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
+ if (this.indexHeader.getIndexCount() < this.indexNum) {
+ // 获取 key 的 hash
+ int keyHash = indexKeyHashMethod(key);
+ // 计算属于哪个 slot
+ int slotPos = keyHash % this.hashSlotNum;
+ // 计算 slot 位置 因为结构是有个 indexHead,主要是分为三段 header,slot 和 index
+ int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
- }
+ FileLock fileLock = null;
- @Configuration(proxyBeanMethods = false)
- @EnableAspectJAutoProxy(proxyTargetClass = true)
- @ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",
- matchIfMissing = true)
- static class CglibAutoProxyConfiguration {
+ try {
+
+ // fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
+ // false);
+ int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
+ if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
+ slotValue = invalidIndex;
+ }
+
+ long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
+
+ timeDiff = timeDiff / 1000;
+
+ if (this.indexHeader.getBeginTimestamp() <= 0) {
+ timeDiff = 0;
+ } else if (timeDiff > Integer.MAX_VALUE) {
+ timeDiff = Integer.MAX_VALUE;
+ } else if (timeDiff < 0) {
+ timeDiff = 0;
+ }
+
+ // 计算索引存放位置,头部 + slot 数量 * slot 大小 + 已有的 index 数量 + index 大小
+ int absIndexPos =
+ IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ + this.indexHeader.getIndexCount() * indexSize;
+
+ this.mappedByteBuffer.putInt(absIndexPos, keyHash);
+ this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
+ this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
+ this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
+
+ // 存放的是数量位移,不是绝对位置
+ this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
+
+ if (this.indexHeader.getIndexCount() <= 1) {
+ this.indexHeader.setBeginPhyOffset(phyOffset);
+ this.indexHeader.setBeginTimestamp(storeTimestamp);
+ }
+
+ this.indexHeader.incHashSlotCount();
+ this.indexHeader.incIndexCount();
+ this.indexHeader.setEndPhyOffset(phyOffset);
+ this.indexHeader.setEndTimestamp(storeTimestamp);
+
+ return true;
+ } catch (Exception e) {
+ log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
+ } finally {
+ if (fileLock != null) {
+ try {
+ fileLock.release();
+ } catch (IOException e) {
+ log.error("Failed to release the lock", e);
+ }
+ }
+ }
+ } else {
+ log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ + "; index max num = " + this.indexNum);
+ }
+
+ return false;
+ }
+
+具体可以看一下这个简略的示意图
![]()
+]]>
+
+ MQ
+ RocketMQ
+ 消息队列
+
+
+ MQ
+ 消息队列
+ RocketMQ
+
+
+
+ 聊一下 RocketMQ 的顺序消息
+ /2021/08/29/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E9%A1%BA%E5%BA%8F%E6%B6%88%E6%81%AF/
+ rocketmq 里有一种比较特殊的用法,就是顺序消息,比如订单的生命周期里,在创建,支付,签收等状态轮转中,会发出来对应的消息,这里面就比较需要去保证他们的顺序,当然在处理的业务代码也可以做对应的处理,结合消息重投,但是如果这里消息就能保证顺序性了,那么业务代码就能更好的关注业务代码的处理。
+首先有一种情况是全局的有序,比如对于一个 topic 里就得发送线程保证只有一个,内部的 queue 也只有一个,消费线程也只有一个,这样就能比较容易的保证全局顺序性了,但是这里的问题就是完全限制了性能,不是很现实,在真实场景里很多都是比如对于同一个订单,需要去保证状态的轮转是按照预期的顺序来,而不必要全局的有序性。
+对于这类的有序性,需要在发送和接收方都有对应的处理,在发送消息中,需要去指定 selector,即MessageQueueSelector,能够以固定的方式是分配到对应的 MessageQueue
+比如像 RocketMQ 中的示例
+SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
+ @Override
+ public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
+ Long id = (Long) arg; //message queue is selected by #salesOrderID
+ long index = id % mqs.size();
+ return mqs.get((int) index);
+ }
+ }, orderList.get(i).getOrderId());
+
+而在消费侧有几个点比较重要,首先我们要保证一个 MessageQueue只被一个消费者消费,消费队列存在broker端,要保证 MessageQueue 只被一个消费者消费,那么消费者在进行消息拉取消费时就必须向mq服务器申请队列锁,消费者申请队列锁的代码存在于RebalanceService消息队列负载的实现代码中。
+List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
+ for (MessageQueue mq : mqSet) {
+ if (!this.processQueueTable.containsKey(mq)) {
+ // 判断是否顺序,如果是顺序消费的,则需要加锁
+ if (isOrder && !this.lock(mq)) {
+ log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
+ continue;
+ }
- }
+ this.removeDirtyOffset(mq);
+ ProcessQueue pq = new ProcessQueue();
+ long nextOffset = this.computePullFromWhere(mq);
+ if (nextOffset >= 0) {
+ ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
+ if (pre != null) {
+ log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
+ } else {
+ log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
+ PullRequest pullRequest = new PullRequest();
+ pullRequest.setConsumerGroup(consumerGroup);
+ pullRequest.setNextOffset(nextOffset);
+ pullRequest.setMessageQueue(mq);
+ pullRequest.setProcessQueue(pq);
+ pullRequestList.add(pullRequest);
+ changed = true;
+ }
+ } else {
+ log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
+ }
+ }
+ }
- }
+在申请到锁之后会创建 pullRequest 进行消息拉取,消息拉取部分的代码实现在PullMessageService中,
+@Override
+ public void run() {
+ log.info(this.getServiceName() + " service started");
-为何会加载 AopAutoConfiguration 在前面的文章聊聊 SpringBoot 自动装配里已经介绍过,有兴趣的可以看下,可以发现 springboot 在 2.x 版本开始使用 cglib 作为默认的动态代理实现。
-然后就是出现的问题了,代码是这样的,一个简单的基于 springboot 的带有数据库的插入,对插入代码加了事务注解,
-@Mapper
-public interface StudentMapper {
- // 就是插入一条数据
- @Insert("insert into student(name, age)" + "values ('nick', '18')")
- public Long insert();
-}
+ while (!this.isStopped()) {
+ try {
+ PullRequest pullRequest = this.pullRequestQueue.take();
+ this.pullMessage(pullRequest);
+ } catch (InterruptedException ignored) {
+ } catch (Exception e) {
+ log.error("Pull Message Service Run Method exception", e);
+ }
+ }
-@Component
-public class StudentManager {
+ log.info(this.getServiceName() + " service end");
+ }
- @Resource
- private StudentMapper studentMapper;
-
- public Long createStudent() {
- return studentMapper.insert();
+消息拉取完后,需要提交到ConsumeMessageService中进行消费,顺序消费的实现为ConsumeMessageOrderlyService,提交消息进行消费的方法为ConsumeMessageOrderlyService#submitConsumeRequest,具体实现如下:
+@Override
+public void submitConsumeRequest(
+ final List<MessageExt> msgs,
+ final ProcessQueue processQueue,
+ final MessageQueue messageQueue,
+ final boolean dispathToConsume) {
+ if (dispathToConsume) {
+ ConsumeRequest consumeRequest = new ConsumeRequest(processQueue, messageQueue);
+ this.consumeExecutor.submit(consumeRequest);
}
-}
+}
-@Component
-public class StudentServiceImpl implements StudentService {
+构建了一个ConsumeRequest对象,它是个实现了 runnable 接口的类,并提交给了线程池来并行消费,看下顺序消费的ConsumeRequest的run方法实现:
+@Override
+ public void run() {
+ if (this.processQueue.isDropped()) {
+ log.warn("run, the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
+ return;
+ }
+ // 获得 Consumer 消息队列锁,即单个线程独占
+ final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
+ synchronized (objLock) {
+ // (广播模式) 或者 (集群模式 && Broker消息队列锁有效)
+ if (MessageModel.BROADCASTING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
+ || (this.processQueue.isLocked() && !this.processQueue.isLockExpired())) {
+ final long beginTime = System.currentTimeMillis();
+ // 循环
+ for (boolean continueConsume = true; continueConsume; ) {
+ if (this.processQueue.isDropped()) {
+ log.warn("the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
+ break;
+ }
- @Resource
- private StudentManager studentManager;
+ // 消息队列分布式锁未锁定,提交延迟获得锁并消费请求
+ if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
+ && !this.processQueue.isLocked()) {
+ log.warn("the message queue not locked, so consume later, {}", this.messageQueue);
+ ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 10);
+ break;
+ }
- // 自己引用
- @Resource
- private StudentServiceImpl studentService;
+ // 消息队列分布式锁已经过期,提交延迟获得锁并消费请求
+ if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
+ && this.processQueue.isLockExpired()) {
+ log.warn("the message queue lock expired, so consume later, {}", this.messageQueue);
+ ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 10);
+ break;
+ }
+ // 当前周期消费时间超过连续时长,默认:60s,提交延迟消费请求。默认情况下,每消费1分钟休息10ms。
+ long interval = System.currentTimeMillis() - beginTime;
+ if (interval > MAX_TIME_CONSUME_CONTINUOUSLY) {
+ ConsumeMessageOrderlyService.this.submitConsumeRequestLater(processQueue, messageQueue, 10);
+ break;
+ }
+ // 获取消费消息。此处和并发消息请求不同,并发消息请求已经带了消费哪些消息。
+ final int consumeBatchSize =
+ ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
- @Override
- @Transactional
- public Long createStudent() {
- Long id = studentManager.createStudent();
- Long id2 = studentService.createStudent2();
- return 1L;
- }
+ List<MessageExt> msgs = this.processQueue.takeMessags(consumeBatchSize);
+ defaultMQPushConsumerImpl.resetRetryAndNamespace(msgs, defaultMQPushConsumer.getConsumerGroup());
+ if (!msgs.isEmpty()) {
+ final ConsumeOrderlyContext context = new ConsumeOrderlyContext(this.messageQueue);
- @Transactional
- private Long createStudent2() {
-// Integer t = Integer.valueOf("aaa");
- return studentManager.createStudent();
- }
-}
+ ConsumeOrderlyStatus status = null;
-第一个公有方法 createStudent 首先调用了 manager 层的创建方法,然后再通过引入的 studentService 调用了createStudent2,我们先跑一下看看会出现啥情况,果不其然报错了,正是这个报错让我纠结了很久
-![EdR7oB]()
-报了个空指针,而且是在 createStudent2 已经被调用到了,在它的内部,报的 studentManager 是 null,首先 cglib 作为动态代理它是通过继承的方式来实现的,相当于是会在调用目标对象的代理方法时调用 cglib 生成的子类,具体的代理切面逻辑在子类实现,然后在调用目标对象的目标方法,但是继承的方式对于 final 和私有方法其实是没法进行代理的,因为没法继承,所以我最开始的想法是应该通过 studentService 调用 createStudent2 的时候就报错了,也就是不会进入这个方法内部,后面才发现犯了个特别二的错误,继承的方式去调用父类的私有方法,对于 Java 来说是可以调用到的,父类的私有方法并不由子类的InstanceKlass维护,只能通过子类的InstanceKlass找到Java类对应的_super,这样间接地访问。也就是说子类其实是可以访问的,那为啥访问了会报空指针呢,这里报的是studentManager 是空的,可以往依赖注入方面去想,如果忽略依赖注入,我这个studentManager 的确是 null,那是不是就没有被依赖注入呢,但是为啥前面那个可以呢
-这个问题着实查了很久,不废话来看代码
-@Override
- protected Object invokeJoinpoint() throws Throwable {
- if (this.methodProxy != null) {
- // 这里的 target 就是被代理的 bean
- return this.methodProxy.invoke(this.target, this.arguments);
- }
- else {
- return super.invokeJoinpoint();
- }
- }
+ ConsumeMessageContext consumeMessageContext = null;
+ if (ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.hasHook()) {
+ consumeMessageContext = new ConsumeMessageContext();
+ consumeMessageContext
+ .setConsumerGroup(ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumerGroup());
+ consumeMessageContext.setNamespace(defaultMQPushConsumer.getNamespace());
+ consumeMessageContext.setMq(messageQueue);
+ consumeMessageContext.setMsgList(msgs);
+ consumeMessageContext.setSuccess(false);
+ // init the consume context type
+ consumeMessageContext.setProps(new HashMap<String, String>());
+ ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.executeHookBefore(consumeMessageContext);
+ }
+ // 执行消费
+ long beginTimestamp = System.currentTimeMillis();
+ ConsumeReturnType returnType = ConsumeReturnType.SUCCESS;
+ boolean hasException = false;
+ try {
+ this.processQueue.getLockConsume().lock(); // 锁定处理队列
+ if (this.processQueue.isDropped()) {
+ log.warn("consumeMessage, the message queue not be able to consume, because it's dropped. {}",
+ this.messageQueue);
+ break;
+ }
+ status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
+ } catch (Throwable e) {
+ log.warn("consumeMessage exception: {} Group: {} Msgs: {} MQ: {}",
+ RemotingHelper.exceptionSimpleDesc(e),
+ ConsumeMessageOrderlyService.this.consumerGroup,
+ msgs,
+ messageQueue);
+ hasException = true;
+ } finally {
+ this.processQueue.getLockConsume().unlock(); // 解锁
+ }
+ if (null == status
+ || ConsumeOrderlyStatus.ROLLBACK == status
+ || ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT == status) {
+ log.warn("consumeMessage Orderly return not OK, Group: {} Msgs: {} MQ: {}",
+ ConsumeMessageOrderlyService.this.consumerGroup,
+ msgs,
+ messageQueue);
+ }
-这个是org.springframework.aop.framework.CglibAopProxy.CglibMethodInvocation的代码,其实它在这里不是直接调用 super 也就是父类的方法,而是通过 methodProxy 调用 target 目标对象的方法,也就是原始的 studentService bean 的方法,这样子 spring 管理的已经做好依赖注入的 bean 就能正常起作用,否则就会出现上面的问题,因为 cglib 其实是通过继承来实现,通过将调用转移到子类上加入代理逻辑,我们在简单使用的时候会直接 invokeSuper() 调用父类的方法,但是在这里 spring 的场景里需要去支持 spring 的功能逻辑,所以上面的问题就可以开始来解释了,因为 createStudent 是公共方法,cglib 可以对其进行继承代理,但是在执行逻辑的时候其实是通过调用目标对象,也就是 spring 管理的被代理的目标对象的 bean 调用的 createStudent,而对于下面的 createStudent2 方法因为是私有方法,不会走代理逻辑,也就不会有调用回目标对象的逻辑,只是通过继承关系,在子类中没有这个方法,所以会通过子类的InstanceKlass找到这个类对应的_super,然后调用父类的这个私有方法,这里要搞清楚一个点,从这个代理类直接找到其父类然后调用这个私有方法,这个类是由 cglib 生成的,不是被 spring 管理起来经过依赖注入的 bean,所以是没有 studentManager 这个依赖的,也就出现了前面的问题
-而在前面提到的cglib通过methodProxy调用到目标对象,目标对象是在什么时候设置的呢,其实是在bean的生命周期中,org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization这个接口的在bean的初始化过程中,会调用实现了这个接口的方法,
-@Override
-public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
- if (bean != null) {
- Object cacheKey = getCacheKey(bean.getClass(), beanName);
- if (this.earlyProxyReferences.remove(cacheKey) != bean) {
- return wrapIfNecessary(bean, beanName, cacheKey);
- }
- }
- return bean;
-}
+ long consumeRT = System.currentTimeMillis() - beginTimestamp;
+ if (null == status) {
+ if (hasException) {
+ returnType = ConsumeReturnType.EXCEPTION;
+ } else {
+ returnType = ConsumeReturnType.RETURNNULL;
+ }
+ } else if (consumeRT >= defaultMQPushConsumer.getConsumeTimeout() * 60 * 1000) {
+ returnType = ConsumeReturnType.TIME_OUT;
+ } else if (ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT == status) {
+ returnType = ConsumeReturnType.FAILED;
+ } else if (ConsumeOrderlyStatus.SUCCESS == status) {
+ returnType = ConsumeReturnType.SUCCESS;
+ }
-具体的逻辑在 org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#wrapIfNecessary这个方法里
-protected Object getCacheKey(Class<?> beanClass, @Nullable String beanName) {
- if (StringUtils.hasLength(beanName)) {
- return (FactoryBean.class.isAssignableFrom(beanClass) ?
- BeanFactory.FACTORY_BEAN_PREFIX + beanName : beanName);
- }
- else {
- return beanClass;
- }
- }
+ if (ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.hasHook()) {
+ consumeMessageContext.getProps().put(MixAll.CONSUME_CONTEXT_TYPE, returnType.name());
+ }
- /**
- * Wrap the given bean if necessary, i.e. if it is eligible for being proxied.
- * @param bean the raw bean instance
- * @param beanName the name of the bean
- * @param cacheKey the cache key for metadata access
- * @return a proxy wrapping the bean, or the raw bean instance as-is
- */
- protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
- if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
- return bean;
- }
- if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
- return bean;
- }
- if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
- this.advisedBeans.put(cacheKey, Boolean.FALSE);
- return bean;
- }
+ if (null == status) {
+ status = ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT;
+ }
- // Create proxy if we have advice.
- Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
- if (specificInterceptors != DO_NOT_PROXY) {
- this.advisedBeans.put(cacheKey, Boolean.TRUE);
- Object proxy = createProxy(
- bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
- this.proxyTypes.put(cacheKey, proxy.getClass());
- return proxy;
- }
+ if (ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.hasHook()) {
+ consumeMessageContext.setStatus(status.toString());
+ consumeMessageContext
+ .setSuccess(ConsumeOrderlyStatus.SUCCESS == status || ConsumeOrderlyStatus.COMMIT == status);
+ ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.executeHookAfter(consumeMessageContext);
+ }
- this.advisedBeans.put(cacheKey, Boolean.FALSE);
- return bean;
- }
+ ConsumeMessageOrderlyService.this.getConsumerStatsManager()
+ .incConsumeRT(ConsumeMessageOrderlyService.this.consumerGroup, messageQueue.getTopic(), consumeRT);
-然后在 org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#createProxy 中创建了代理类
+ continueConsume = ConsumeMessageOrderlyService.this.processConsumeResult(msgs, status, context, this);
+ } else {
+ continueConsume = false;
+ }
+ }
+ } else {
+ if (this.processQueue.isDropped()) {
+ log.warn("the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
+ return;
+ }
+
+ ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 100);
+ }
+ }
+ }
+
+获取到锁对象后,使用synchronized尝试申请线程级独占锁。
+如果加锁成功,同一时刻只有一个线程进行消息消费。
+如果加锁失败,会延迟100ms重新尝试向broker端申请锁定messageQueue,锁定成功后重新提交消费请求
+创建消息拉取任务时,消息客户端向broker端申请锁定MessageQueue,使得一个MessageQueue同一个时刻只能被一个消费客户端消费。
+消息消费时,多线程针对同一个消息队列的消费先尝试使用synchronized申请独占锁,加锁成功才能进行消费,使得一个MessageQueue同一个时刻只能被一个消费客户端中一个线程消费。
这里其实还有很重要的一点是对processQueue的加锁,这里其实是保证了在 rebalance的过程中如果 processQueue 被分配给了另一个 consumer,但是当前已经被我这个 consumer 再消费,但是没提交,就有可能出现被两个消费者消费,所以得进行加锁保证不受 rebalance 影响。
]]>
- Java
- SpringBoot
+ MQ
+ RocketMQ
+ 消息队列
- Java
- Spring
- SpringBoot
- cglib
- 事务
+ MQ
+ 消息队列
+ RocketMQ
- 聊一下 SpringBoot 设置非 web 应用的方法
- /2022/07/31/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E8%AE%BE%E7%BD%AE%E9%9D%9E-web-%E5%BA%94%E7%94%A8%E7%9A%84%E6%96%B9%E6%B3%95/
- 寻找原因这次碰到一个比较奇怪的问题,应该统一发布脚本统一给应用启动参数传了个 -Dserver.port=xxxx,其实这个端口会作为 dubbo 的服务端口,并且应用也不提供 web 服务,但是在启动的时候会报embedded servlet container failed to start. port xxxx was already in use就觉得有点奇怪,仔细看了启动参数猜测可能是这个问题,有可能是依赖的二方三方包带了 spring-web 的包,然后基于 springboot 的 auto configuration 会把这个自己加载,就在本地复现了下这个问题,结果的确是这个问题。
-解决方案
老版本 设置 spring 不带 web 功能
比较老的 springboot 版本,可以使用
-SpringApplication app = new SpringApplication(XXXXXApplication.class);
-app.setWebEnvironment(false);
-app.run(args);
-新版本
新版本的 springboot (>= 2.0.0)可以在 properties 里配置
-spring.main.web-application-type=none
-或者
-SpringApplication app = new SpringApplication(XXXXXApplication.class);
-app.setWebApplicationType(WebApplicationType.NONE);
-这个枚举里还有其他两种配置
-public enum WebApplicationType {
-
- /**
- * The application should not run as a web application and should not start an
- * embedded web server.
- */
- NONE,
-
- /**
- * The application should run as a servlet-based web application and should start an
- * embedded servlet web server.
- */
- SERVLET,
-
- /**
- * The application should run as a reactive web application and should start an
- * embedded reactive web server.
- */
- REACTIVE
-
-}
-相当于是把none 的类型和包括 servlet 和 reactive 放进了枚举类进行控制。
+ 聊在东京奥运会闭幕式这天-二
+ /2021/08/19/%E8%81%8A%E5%9C%A8%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A%E9%97%AD%E5%B9%95%E5%BC%8F%E8%BF%99%E5%A4%A9-%E4%BA%8C/
+ 前面主要还是说了乒乓球的,因为整体还是乒乓球的比赛赛程比较长,比较激烈,扣人心弦,记得那会在公司没法看视频直播,就偶尔看看奥运会官网的比分,还几场马龙樊振东,陈梦被赢了一局就吓尿了,已经被混双那场留下了阴影,其实后面去看看16 年的比赛什么的,中国队虽然拿了这么多冠军,但是自改成 11 分制以来,其实都没办法那么完全彻底地碾压,而且像张继科,樊振东,陈梦都多少有些慢热,现在看来是马龙比较全面,不过看过了马龙,刘国梁,许昕等的一些过往经历,都是起起伏伏,即使是张怡宁这样的大魔王,也经历过逢王楠不赢的阶段,心态无法调整好。
+其实最开始是举重项目,侯志慧是女子 49 公斤级的冠军,这场比赛是全场都看,其实看中国队的举重比赛跟跳水有点像,每一轮都需要到最后才能等到中国队,跳水其实每轮都有,举重会按照自己报的试举重量进行排名,重量大的会在后面举,抓举和挺举各三次试举机会,有时候会看着比较焦虑,一直等不来,怕一上来就没试举成功,而且中国队一般试举重量就是很大的,容易一次试举不成功就马上下一次,连着举其实压力会非常大,说实话真的是外行看热闹,每次都是多懂一点点,这次由于实在是比较无聊,所以看的会比较专心点,对于对应的规则知识点也会多了解一点,同时对于举重,没想到我们国家的这些运动员有这么强,最后八块金牌拿了七块,有一块拿到银牌也是有点因为教练的策略问题,这里其实也稍微知道一点,因为报上去的试举重量是谁小谁先举,并且我们国家都是实力非常强的,所以都会报大一些,并且如果这个项目有实力相近的选手,会比竞对多报一公斤,这样子如果前面竞争对手没举成功,我们把握就很大了,最坏的情况即使对手试举成功了,我们还有机会搏一把,比如谌利军这样的,只是说说感想,举重运动员真的是个比较单纯的群体,而且训练是非常痛苦枯燥的,非常容易受伤,像挺举就有点会压迫呼吸通道,看到好几个都是脸憋得通红,甚至直接因为压迫气道而没法完成后面的挺举,像之前 16 年的举重比赛,有个运动员没成功夺冠就非常愧疚地哭着说对不起祖国,没有获得冠军,这是怎么样的一种歉疚,怎么样的一种纯粹的感情呢,相对应地来说,我又要举男足,男篮的例子了,很多人在那嘲笑我这样对男足男篮愤愤不平的人,说可能我这样的人都没交个税(从缴纳个税的数量比例来算有可能),只是这里有两个打脸的事情,我足额缴纳个税,接近 20%的薪资都缴了个税,并且我买的所有东西都缴了增值税,如果让我这样缴纳了个税,缴纳了增值税的有个人的投票权,我一定会投票不让男足男篮使用我缴纳我的税金,用我们的缴纳的税,打出这么烂的表现,想乒乓球混双,拿个亚军都会被喷,那可是世界第二了,而且是就输了那么一场,足球篮球呢,我觉得是一方面成绩差,因为比赛真的有状态跟心态的影响,偶尔有一场失误非常正常,NBA 被黑八的有这么多强队,但是如果像男足男篮,成绩是越来越差,用范志毅的话来说就是脸都不要了,还有就是精气神,要在比赛中打出胜负欲,保持这种争胜心,才有机会再进步,前火箭队主教练鲁迪·汤姆贾诺维奇的话,“永远不要低估冠军的决心”,即使我现在打不过你,我会在下一次,下下次打败你,竞技体育永远要有这种精神,可以接受一时的失败,但是要保持永远争胜的心。
+第一块金牌是杨倩拿下的,中国队拿奥运会首金也是有政治任务的,而恰恰杨倩这个金牌也有点碰巧是对手最后一枪失误了,当然竞技体育,特别是射击,真的是容不得一点点失误,像前面几届的美国神通埃蒙斯,失之毫厘差之千里,但是这个具体评价就比较少,唯一一点让我比较出戏的就是杨倩真的非常像王刚的徒弟漆二娃,哈哈,微博上也有挺多人觉得像,射击还是个比较可以接受年纪稍大的运动员,需要经验和稳定性,相对来说爆发力体力稍好一点,像庞伟这样的,混合团体10米气手枪金牌,36 岁可能其他项目已经是年龄很大了,不过前面说的举重的吕小军军神也是年纪蛮大了,但是非常强,而且在油管上简直就是个神,相对来说射击是关注比较少,杨倩的也只是看了后面拿到冠军这个结果,有些因为时间或者电视上没放,但是成绩还是不错的,没多少喷点。
+第二篇先到这,纯主观,轻喷。
]]>
- Java
- SpringBoot
+ 生活
+ 运动
- Java
- Spring
- SpringBoot
- 自动装配
- AutoConfiguration
+ 生活
+ 运动
+ 东京奥运会
+ 举重
+ 射击
+
+
+
+ 聊在东京奥运会闭幕式这天
+ /2021/08/08/%E8%81%8A%E5%9C%A8%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A%E9%97%AD%E5%B9%95%E5%BC%8F%E8%BF%99%E5%A4%A9/
+ 这届奥运会有可能是我除了 08 年之外关注度最高的一届奥运会,原因可能是因为最近也没什么电影综艺啥的比较好看,前面看跑男倒还行,不是说多好,也就图一乐,最开始看向往的生活觉得也挺不错的,后面变成了统一来了就看黄磊做饭,然后夸黄磊做饭好吃,然后无聊的说这种生活多么多么美好,单调无聊,差不多弃了,这里面还包括大华不在了,大华其实个人还是有点呱噪的,但是挺能搞气氛,并且也有才华,彭彭跟子枫人是不讨厌,但是撑不起来,所以也导致了前面说的结果,都变成了黄磊彩虹屁现场,虽然偶尔怀疑他是否做得好吃,但是整体还是承认的,可对于一个这么多季了的综艺来说,这样也有点单调了。
+还有奥运会像乒乓球,篮球,跳水这几个都是比较喜欢的项目,篮球🏀是从初中开始就也有在自己在玩的,虽然因为身高啊体质基本没什么天赋,但也算是热爱驱动,差不多到了大学因为比较懒才放下了,初中高中还是有很多时间花在上面,不像别人经常打球跑跑跳跳还能长高,我反而一直都没长个子,也因为这个其实蛮遗憾的,后面想想可能是初中的时候远走他乡去住宿读初中,伙食营养跟不上导致的,可能也是自己的一厢情愿吧,总觉得应该还能再长点个,这一点以后我自己的小孩我应该会特别注意这段时间他/她的营养摄入了;然后像乒乓球🏓的话其实小时候是比较讨厌的,因为家里人,父母都没有这类爱好习惯,我也完全不会,但是小学那会班里的“恶霸”就以公平之名要我们男生每个人都排队打几个,我这种不会的反而又要被嘲笑,这个小时候的阴影让我有了比较不好的印象,对它🏓的改观是在工作以后,前司跟一个同样不会的同事经常在饭点会打打,而且那会因为这个其实身体得到了锻炼,感觉是个不错的健身方式,然后又是中国的优势项目,小时候跟着我爸看孔令辉,那时候完全不懂,印象就觉得老瓦很牛,后面其实也没那么关注,上一届好像看了马龙的比赛;跳水也是中国的优势项目,而且也比较简单,不是说真的很简单,就是我们外行观众看着就看看水花大小图一乐。
+这次的观赛过程其实主要还是在乒乓球上面,现在都有点怪我的乌鸦嘴,混双我一直就不太放心(关我什么事,我也不专业),然后一直觉得混双是不是不太稳,结果那天看的时候也是因为央视一套跟五套都没放,我家的有线电视又是没有五加体育,然后用电脑投屏就很卡,看得也很不爽,同时那天因为看的时候已经是 2:0还是再后面点了,一方面是不懂每队只有一次暂停,另一方面不知道已经用过暂停了,所以就特别怀疑马林是不是只会无脑鼓掌,感觉作为教练,并且是前冠军,应该也能在擦汗间隙,或者局间休息调整的时候多给些战略战术的指导,类似于后面男团小胖打奥恰洛夫,像解说都看出来了,其实奥恰那会的反手特别顺,打得特别凶,那就不能让他能特别顺手的上反手位,这当然是外行比较粗浅的看法,在混双过程中其实除了这个,还有让人很不爽的就是我们的许昕跟刘诗雯有种拿不出破釜沉舟的勇气的感觉,在气势上完全被对面两位日本乒乓球最讨厌的两位对手压制着,我都要输了,我就每一颗都要不让你好过,因为真的不是说没有实力,对面水谷隼也不是多么多么强的,可能上一届男团许昕输给他还留着阴影,但是以许昕 19 年男单世界第一的实力,目前也排在世界前三,输一场不应该成为这种阻力,有一些失误也很可惜,后面孙颖莎真的打得很解气,第二局一度以为又要被翻盘了,结果来了个大逆转,女团的时候也是,感觉在心态上孙颖莎还是很值得肯定的,少年老成这个词很适合,看其他的视频也觉得莎莎萌萌哒,陈梦总感觉还欠一点王者霸气,王曼昱还是可以的,反手很凶,我觉得其实这一届日本女乒就是打得非常凶,即使像平野这种看着很弱的妹子,打的球可一点都不弱,也是这种凶狠的打法,有点要压制中国的感觉,这方面我觉得是需要改善的,打这种要不就是实力上的完全碾压,要不就是我实力虽然比较没强多少,但是你狠我打得比你还狠,越保守越要输,我不太成熟的想法是这样的,还有就是面对逆境,这个就要说到男队的了,樊振东跟马龙在半决赛的时候,特别是男团的第二盘,樊振东打奥恰很好地表现了这个心态,当然樊振东我不是特别了解,据说他是比较善于打相持,比较善于焦灼的情况,不过整体看下来樊振东还是有一些欠缺,就是面对情况的快速转变应对,这一点也是马龙特别强的,虽然看起来马龙真的是年纪大了点,没有 16 年那会满头发胶,油光锃亮的大背头和满脸胶原蛋白的意气风发,大范围运动能力也弱了一点,但是经验和能力的全面性也让他最终能再次站上巅峰,还是非常佩服的,这里提一下张继科,虽然可能天赋上是张继科更强点,但是男乒一直都是有强者出现,能为国家队付出这么多并且一直坚持的可不是人人都可以,即使现在同台竞技马龙打不过张继科我还是更喜欢马龙。再来说说我们的对手,主要分三部分,德国男乒,里面有波尔(我刚听到的时候在想怎么又出来个叫波尔的,是不是像举重的石智勇一样,又来一个同名的,结果是同一个,已经四十岁了),这真是个让人敬佩的对手,实力强,经验丰富,虽然男单有点可惜,但是帮助男团获得银牌,真的是起到了定海神针的作用;奥恰洛夫,以前完全不认识,或者说看过也忘了,这次是真的有点意外,竟然有这么个马龙护法,其实他也坦言非常想赢一次马龙,并且在半决赛也非常接近赢得比赛,是个实力非常强的对手,就是男团半决赛输给张本智和有点可惜,有点被打蒙的感觉,佛朗西斯卡的话也是实力不错的选手,就是可能被奥恰跟波尔的光芒掩盖了,跟波尔在男团第一盘男双的比赛中打败日本那对男双也是非常给力的,说实话,最后打国乒的时候的确是国乒实力更胜一筹,但是即使德国赢了我也是充满尊敬,拼的就是硬实力,就像第二盘奥恰打樊振东,反手是真的很强,反过来看奥恰可能也不是很善于快速调整,樊振东打出来自己的节奏,主攻奥恰的中路,他好像没什么好办法解决。再来说我最讨厌的日本,嗯,小日本,张本智和、水谷隼、伊藤美诚,一一评价下(我是外行,绝对主观评价),张本智和,父母也是中国人,原来叫张智和,改日本籍后加了个本,被微博网友笑称日本尖叫鸡,男单输给了斯洛文尼亚选手,男团里是赢了两场,但是在我看来其实实力上可能比不上全力的奥恰,主要是特别能叫,会干扰对手,如果觉得这种也是种能力我也无话可说,要是有那种吼声能直接把对手震聋的,都不需要打比赛了,我简单记了下,赢一颗球,他要叫八声,用 LD 的话来说烦都烦死了,心态是在面对一些困境顺境的应对调整适应能力,而不是对这种噪音的适应能力,至少我是这么看的,所以我很期待樊振东能好好地虐虐他,因为其他像林昀儒真的是非常优秀的新选手,所谓的国乒克星估计也是小日本自己说说的,国乒其实有很多对手,马龙跟樊振东在男单半决赛碰到的这两个几乎都差点把他们掀翻了,所以还是练好自己的实力再来吹吧,免得打脸;水谷隼的话真的是长相就是特别地讨厌,还搞出那套不打比赛的姿态,男团里被波尔干掉就是很好的例子,波尔虽然真的很强,但毕竟 40 岁了,跟伊藤美诚一起说了吧,伊藤实力说实话是有的,混双中很大一部分的赢面来自于她,刘诗雯做了手术状态不好,许昕失误稍多,但是这种赢球了就感觉我赢了你一辈子一场没输的感觉,还有那种不知道怎么形容的笑,实力强的正常打比赛的我都佩服,像女团决赛里,平野跟石川佳纯的打法其实也很凶狠,但是都是正常的比赛,即使中国队两位实力不济输了也很正常,这种就真的需要像孙颖莎这样的小魔王无视各种魔法攻击,无视你各种花里胡哨的打法的人好好教训一下,混双输了以后了解了下她,感觉实力真的不错,是个大威胁,但是其实我们孙颖莎也是经历了九个月的继续成长,像张怡宁也评价了她,可能后面就没什么空间了,当然如果由张怡宁来打她就更适合了,净整这些有的没的,就打得你没脾气。
+乒乓球的说的有点多,就分篇说了,第一篇先到这。
+]]>
+
+ 生活
+ 运动
+
+
+ 生活
+ 运动
+ 东京奥运会
+ 乒乓球
+ 跳水
@@ -16203,76 +16194,171 @@ app.setWebAp
String extName = ((url.getProtocol() == null) ? "dubbo"
: url.getProtocol());
- if (extName == null) {
- throw new IllegalStateException(
- "Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url(" +
- url.toString() + ") use keys([protocol])");
- }
- // 在这就是实际的通过dubbo 的 spi 去加载实际对应的扩展
- com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol) ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class)
- .getExtension(extName);
+ if (extName == null) {
+ throw new IllegalStateException(
+ "Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url(" +
+ url.toString() + ") use keys([protocol])");
+ }
+ // 在这就是实际的通过dubbo 的 spi 去加载实际对应的扩展
+ com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol) ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class)
+ .getExtension(extName);
+
+ return extension.refer(arg0, arg1);
+ }
+}
+
+]]>
+
+ Java
+ Dubbo
+ RPC
+ SPI
+ Dubbo
+ SPI
+ Adaptive
+
+
+ Java
+ Dubbo
+ RPC
+ SPI
+ Adaptive
+ 自适应拓展
+
+
+
+ 聊聊 Dubbo 的容错机制
+ /2020/11/22/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
+ 之前看了 dubbo 的一些代码,在学习过程中,主要关注那些比较“高级”的内容,SPI,自适应扩展等,却忘了一些作为一个 rpc 框架最核心需要的部分,比如如何通信,序列化,网络,容错机制等等,因为其实这个最核心的就是远程调用,自适应扩展其实就是让代码可扩展性,可读性,更优雅等,写的搓一点其实也问题不大,但是一个合适的通信协议,序列化方法,如何容错等却是真正保证是一个 rpc 框架最重要的要素。
首先来看这张图
![cluster]()
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
各节点关系:
+
+- 这里的
Invoker 是 Provider 的一个可调用 Service 的抽象,Invoker 封装了 Provider 地址及 Service 接口信息
+Directory 代表多个 Invoker,可以把它看成 List<Invoker> ,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Router 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选
+集群容错模式
Failover Cluster
失败自动切换,当出现失败,重试其它服务器 1。通常用于读操作,但重试会带来更长延迟。可通过 retries=”2” 来设置重试次数(不含第一次)。
+重试次数配置如下:
+<dubbo:service retries=”2” />
这里重点看下 Failover Cluster集群模式的实现
+public class FailoverCluster implements Cluster {
+
+ public final static String NAME = "failover";
+
+ public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
+ return new FailoverClusterInvoker<T>(directory);
+ }
+
+}
+这个代码就非常简单,重点需要看FailoverClusterInvoker里的代码,FailoverClusterInvoker继承了AbstractClusterInvoker类,其中invoke 方法是在抽象类里实现的
+@Override
+public Result invoke(final Invocation invocation) throws RpcException {
+ checkWhetherDestroyed();
+ // binding attachments into invocation.
+ // 绑定 attachments 到 invocation 中.
+ Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments();
+ if (contextAttachments != null && contextAttachments.size() != 0) {
+ ((RpcInvocation) invocation).addObjectAttachments(contextAttachments);
+ }
+ // 列举 Invoker
+ List<Invoker<T>> invokers = list(invocation);
+ // 加载 LoadBalance 负载均衡器
+ LoadBalance loadbalance = initLoadBalance(invokers, invocation);
+ RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
+ // 调用 实际的 doInvoke 进行后续操作
+ return doInvoke(invocation, invokers, loadbalance);
+}
+// 这是个抽象方法,实际是由子类实现的
+ protected abstract Result doInvoke(Invocation invocation, List<Invoker<T>> invokers,
+ LoadBalance loadbalance) throws RpcException;
+然后重点就是FailoverClusterInvoker中的doInvoke方法了,其实它里面也就这么一个方法
+@Override
+ @SuppressWarnings({"unchecked", "rawtypes"})
+ public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
+ List<Invoker<T>> copyInvokers = invokers;
+ checkInvokers(copyInvokers, invocation);
+ String methodName = RpcUtils.getMethodName(invocation);
+ // 获取重试次数,这里默认是 2 次,还有可以注意下后面的+1
+ int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1;
+ if (len <= 0) {
+ len = 1;
+ }
+ // retry loop.
+ RpcException le = null; // last exception.
+ List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
+ Set<String> providers = new HashSet<String>(len);
+ // 循环调用,失败重试
+ for (int i = 0; i < len; i++) {
+ //Reselect before retry to avoid a change of candidate `invokers`.
+ //NOTE: if `invokers` changed, then `invoked` also lose accuracy.
+ if (i > 0) {
+ checkWhetherDestroyed();
+ // 在进行重试前重新列举 Invoker,这样做的好处是,如果某个服务挂了,
+ // 通过调用 list 可得到最新可用的 Invoker 列表
+ copyInvokers = list(invocation);
+ // check again
+ // 对 copyinvokers 进行判空检查
+ checkInvokers(copyInvokers, invocation);
+ }
+ // 通过负载均衡来选择 invoker
+ Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
+ // 将其添加到 invoker 到 invoked 列表中
+ invoked.add(invoker);
+ // 设置上下文
+ RpcContext.getContext().setInvokers((List) invoked);
+ try {
+ // 正式调用
+ Result result = invoker.invoke(invocation);
+ if (le != null && logger.isWarnEnabled()) {
+ logger.warn("Although retry the method " + methodName
+ + " in the service " + getInterface().getName()
+ + " was successful by the provider " + invoker.getUrl().getAddress()
+ + ", but there have been failed providers " + providers
+ + " (" + providers.size() + "/" + copyInvokers.size()
+ + ") from the registry " + directory.getUrl().getAddress()
+ + " on the consumer " + NetUtils.getLocalHost()
+ + " using the dubbo version " + Version.getVersion() + ". Last error is: "
+ + le.getMessage(), le);
+ }
+ return result;
+ } catch (RpcException e) {
+ if (e.isBiz()) { // biz exception.
+ throw e;
+ }
+ le = e;
+ } catch (Throwable e) {
+ le = new RpcException(e.getMessage(), e);
+ } finally {
+ providers.add(invoker.getUrl().getAddress());
+ }
+ }
+ throw new RpcException(le.getCode(), "Failed to invoke the method "
+ + methodName + " in the service " + getInterface().getName()
+ + ". Tried " + len + " times of the providers " + providers
+ + " (" + providers.size() + "/" + copyInvokers.size()
+ + ") from the registry " + directory.getUrl().getAddress()
+ + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version "
+ + Version.getVersion() + ". Last error is: "
+ + le.getMessage(), le.getCause() != null ? le.getCause() : le);
+ }
+
- return extension.refer(arg0, arg1);
- }
-}
-
+Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
+Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
+Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
+Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=”2” 来设置最大并行数。
+Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 2。通常用于通知所有提供者更新缓存或日志等本地资源信息。
]]>
Java
+ Dubbo - RPC
Dubbo
- RPC
- SPI
- Dubbo
- SPI
- Adaptive
+ 容错机制
Java
Dubbo
RPC
- SPI
- Adaptive
- 自适应拓展
-
-
-
- 聊在东京奥运会闭幕式这天
- /2021/08/08/%E8%81%8A%E5%9C%A8%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A%E9%97%AD%E5%B9%95%E5%BC%8F%E8%BF%99%E5%A4%A9/
- 这届奥运会有可能是我除了 08 年之外关注度最高的一届奥运会,原因可能是因为最近也没什么电影综艺啥的比较好看,前面看跑男倒还行,不是说多好,也就图一乐,最开始看向往的生活觉得也挺不错的,后面变成了统一来了就看黄磊做饭,然后夸黄磊做饭好吃,然后无聊的说这种生活多么多么美好,单调无聊,差不多弃了,这里面还包括大华不在了,大华其实个人还是有点呱噪的,但是挺能搞气氛,并且也有才华,彭彭跟子枫人是不讨厌,但是撑不起来,所以也导致了前面说的结果,都变成了黄磊彩虹屁现场,虽然偶尔怀疑他是否做得好吃,但是整体还是承认的,可对于一个这么多季了的综艺来说,这样也有点单调了。
-还有奥运会像乒乓球,篮球,跳水这几个都是比较喜欢的项目,篮球🏀是从初中开始就也有在自己在玩的,虽然因为身高啊体质基本没什么天赋,但也算是热爱驱动,差不多到了大学因为比较懒才放下了,初中高中还是有很多时间花在上面,不像别人经常打球跑跑跳跳还能长高,我反而一直都没长个子,也因为这个其实蛮遗憾的,后面想想可能是初中的时候远走他乡去住宿读初中,伙食营养跟不上导致的,可能也是自己的一厢情愿吧,总觉得应该还能再长点个,这一点以后我自己的小孩我应该会特别注意这段时间他/她的营养摄入了;然后像乒乓球🏓的话其实小时候是比较讨厌的,因为家里人,父母都没有这类爱好习惯,我也完全不会,但是小学那会班里的“恶霸”就以公平之名要我们男生每个人都排队打几个,我这种不会的反而又要被嘲笑,这个小时候的阴影让我有了比较不好的印象,对它🏓的改观是在工作以后,前司跟一个同样不会的同事经常在饭点会打打,而且那会因为这个其实身体得到了锻炼,感觉是个不错的健身方式,然后又是中国的优势项目,小时候跟着我爸看孔令辉,那时候完全不懂,印象就觉得老瓦很牛,后面其实也没那么关注,上一届好像看了马龙的比赛;跳水也是中国的优势项目,而且也比较简单,不是说真的很简单,就是我们外行观众看着就看看水花大小图一乐。
-这次的观赛过程其实主要还是在乒乓球上面,现在都有点怪我的乌鸦嘴,混双我一直就不太放心(关我什么事,我也不专业),然后一直觉得混双是不是不太稳,结果那天看的时候也是因为央视一套跟五套都没放,我家的有线电视又是没有五加体育,然后用电脑投屏就很卡,看得也很不爽,同时那天因为看的时候已经是 2:0还是再后面点了,一方面是不懂每队只有一次暂停,另一方面不知道已经用过暂停了,所以就特别怀疑马林是不是只会无脑鼓掌,感觉作为教练,并且是前冠军,应该也能在擦汗间隙,或者局间休息调整的时候多给些战略战术的指导,类似于后面男团小胖打奥恰洛夫,像解说都看出来了,其实奥恰那会的反手特别顺,打得特别凶,那就不能让他能特别顺手的上反手位,这当然是外行比较粗浅的看法,在混双过程中其实除了这个,还有让人很不爽的就是我们的许昕跟刘诗雯有种拿不出破釜沉舟的勇气的感觉,在气势上完全被对面两位日本乒乓球最讨厌的两位对手压制着,我都要输了,我就每一颗都要不让你好过,因为真的不是说没有实力,对面水谷隼也不是多么多么强的,可能上一届男团许昕输给他还留着阴影,但是以许昕 19 年男单世界第一的实力,目前也排在世界前三,输一场不应该成为这种阻力,有一些失误也很可惜,后面孙颖莎真的打得很解气,第二局一度以为又要被翻盘了,结果来了个大逆转,女团的时候也是,感觉在心态上孙颖莎还是很值得肯定的,少年老成这个词很适合,看其他的视频也觉得莎莎萌萌哒,陈梦总感觉还欠一点王者霸气,王曼昱还是可以的,反手很凶,我觉得其实这一届日本女乒就是打得非常凶,即使像平野这种看着很弱的妹子,打的球可一点都不弱,也是这种凶狠的打法,有点要压制中国的感觉,这方面我觉得是需要改善的,打这种要不就是实力上的完全碾压,要不就是我实力虽然比较没强多少,但是你狠我打得比你还狠,越保守越要输,我不太成熟的想法是这样的,还有就是面对逆境,这个就要说到男队的了,樊振东跟马龙在半决赛的时候,特别是男团的第二盘,樊振东打奥恰很好地表现了这个心态,当然樊振东我不是特别了解,据说他是比较善于打相持,比较善于焦灼的情况,不过整体看下来樊振东还是有一些欠缺,就是面对情况的快速转变应对,这一点也是马龙特别强的,虽然看起来马龙真的是年纪大了点,没有 16 年那会满头发胶,油光锃亮的大背头和满脸胶原蛋白的意气风发,大范围运动能力也弱了一点,但是经验和能力的全面性也让他最终能再次站上巅峰,还是非常佩服的,这里提一下张继科,虽然可能天赋上是张继科更强点,但是男乒一直都是有强者出现,能为国家队付出这么多并且一直坚持的可不是人人都可以,即使现在同台竞技马龙打不过张继科我还是更喜欢马龙。再来说说我们的对手,主要分三部分,德国男乒,里面有波尔(我刚听到的时候在想怎么又出来个叫波尔的,是不是像举重的石智勇一样,又来一个同名的,结果是同一个,已经四十岁了),这真是个让人敬佩的对手,实力强,经验丰富,虽然男单有点可惜,但是帮助男团获得银牌,真的是起到了定海神针的作用;奥恰洛夫,以前完全不认识,或者说看过也忘了,这次是真的有点意外,竟然有这么个马龙护法,其实他也坦言非常想赢一次马龙,并且在半决赛也非常接近赢得比赛,是个实力非常强的对手,就是男团半决赛输给张本智和有点可惜,有点被打蒙的感觉,佛朗西斯卡的话也是实力不错的选手,就是可能被奥恰跟波尔的光芒掩盖了,跟波尔在男团第一盘男双的比赛中打败日本那对男双也是非常给力的,说实话,最后打国乒的时候的确是国乒实力更胜一筹,但是即使德国赢了我也是充满尊敬,拼的就是硬实力,就像第二盘奥恰打樊振东,反手是真的很强,反过来看奥恰可能也不是很善于快速调整,樊振东打出来自己的节奏,主攻奥恰的中路,他好像没什么好办法解决。再来说我最讨厌的日本,嗯,小日本,张本智和、水谷隼、伊藤美诚,一一评价下(我是外行,绝对主观评价),张本智和,父母也是中国人,原来叫张智和,改日本籍后加了个本,被微博网友笑称日本尖叫鸡,男单输给了斯洛文尼亚选手,男团里是赢了两场,但是在我看来其实实力上可能比不上全力的奥恰,主要是特别能叫,会干扰对手,如果觉得这种也是种能力我也无话可说,要是有那种吼声能直接把对手震聋的,都不需要打比赛了,我简单记了下,赢一颗球,他要叫八声,用 LD 的话来说烦都烦死了,心态是在面对一些困境顺境的应对调整适应能力,而不是对这种噪音的适应能力,至少我是这么看的,所以我很期待樊振东能好好地虐虐他,因为其他像林昀儒真的是非常优秀的新选手,所谓的国乒克星估计也是小日本自己说说的,国乒其实有很多对手,马龙跟樊振东在男单半决赛碰到的这两个几乎都差点把他们掀翻了,所以还是练好自己的实力再来吹吧,免得打脸;水谷隼的话真的是长相就是特别地讨厌,还搞出那套不打比赛的姿态,男团里被波尔干掉就是很好的例子,波尔虽然真的很强,但毕竟 40 岁了,跟伊藤美诚一起说了吧,伊藤实力说实话是有的,混双中很大一部分的赢面来自于她,刘诗雯做了手术状态不好,许昕失误稍多,但是这种赢球了就感觉我赢了你一辈子一场没输的感觉,还有那种不知道怎么形容的笑,实力强的正常打比赛的我都佩服,像女团决赛里,平野跟石川佳纯的打法其实也很凶狠,但是都是正常的比赛,即使中国队两位实力不济输了也很正常,这种就真的需要像孙颖莎这样的小魔王无视各种魔法攻击,无视你各种花里胡哨的打法的人好好教训一下,混双输了以后了解了下她,感觉实力真的不错,是个大威胁,但是其实我们孙颖莎也是经历了九个月的继续成长,像张怡宁也评价了她,可能后面就没什么空间了,当然如果由张怡宁来打她就更适合了,净整这些有的没的,就打得你没脾气。
-乒乓球的说的有点多,就分篇说了,第一篇先到这。
-]]>
-
- 生活
- 运动
-
-
- 生活
- 运动
- 东京奥运会
- 乒乓球
- 跳水
-
-
-
- 聊在东京奥运会闭幕式这天-二
- /2021/08/19/%E8%81%8A%E5%9C%A8%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A%E9%97%AD%E5%B9%95%E5%BC%8F%E8%BF%99%E5%A4%A9-%E4%BA%8C/
- 前面主要还是说了乒乓球的,因为整体还是乒乓球的比赛赛程比较长,比较激烈,扣人心弦,记得那会在公司没法看视频直播,就偶尔看看奥运会官网的比分,还几场马龙樊振东,陈梦被赢了一局就吓尿了,已经被混双那场留下了阴影,其实后面去看看16 年的比赛什么的,中国队虽然拿了这么多冠军,但是自改成 11 分制以来,其实都没办法那么完全彻底地碾压,而且像张继科,樊振东,陈梦都多少有些慢热,现在看来是马龙比较全面,不过看过了马龙,刘国梁,许昕等的一些过往经历,都是起起伏伏,即使是张怡宁这样的大魔王,也经历过逢王楠不赢的阶段,心态无法调整好。
-其实最开始是举重项目,侯志慧是女子 49 公斤级的冠军,这场比赛是全场都看,其实看中国队的举重比赛跟跳水有点像,每一轮都需要到最后才能等到中国队,跳水其实每轮都有,举重会按照自己报的试举重量进行排名,重量大的会在后面举,抓举和挺举各三次试举机会,有时候会看着比较焦虑,一直等不来,怕一上来就没试举成功,而且中国队一般试举重量就是很大的,容易一次试举不成功就马上下一次,连着举其实压力会非常大,说实话真的是外行看热闹,每次都是多懂一点点,这次由于实在是比较无聊,所以看的会比较专心点,对于对应的规则知识点也会多了解一点,同时对于举重,没想到我们国家的这些运动员有这么强,最后八块金牌拿了七块,有一块拿到银牌也是有点因为教练的策略问题,这里其实也稍微知道一点,因为报上去的试举重量是谁小谁先举,并且我们国家都是实力非常强的,所以都会报大一些,并且如果这个项目有实力相近的选手,会比竞对多报一公斤,这样子如果前面竞争对手没举成功,我们把握就很大了,最坏的情况即使对手试举成功了,我们还有机会搏一把,比如谌利军这样的,只是说说感想,举重运动员真的是个比较单纯的群体,而且训练是非常痛苦枯燥的,非常容易受伤,像挺举就有点会压迫呼吸通道,看到好几个都是脸憋得通红,甚至直接因为压迫气道而没法完成后面的挺举,像之前 16 年的举重比赛,有个运动员没成功夺冠就非常愧疚地哭着说对不起祖国,没有获得冠军,这是怎么样的一种歉疚,怎么样的一种纯粹的感情呢,相对应地来说,我又要举男足,男篮的例子了,很多人在那嘲笑我这样对男足男篮愤愤不平的人,说可能我这样的人都没交个税(从缴纳个税的数量比例来算有可能),只是这里有两个打脸的事情,我足额缴纳个税,接近 20%的薪资都缴了个税,并且我买的所有东西都缴了增值税,如果让我这样缴纳了个税,缴纳了增值税的有个人的投票权,我一定会投票不让男足男篮使用我缴纳我的税金,用我们的缴纳的税,打出这么烂的表现,想乒乓球混双,拿个亚军都会被喷,那可是世界第二了,而且是就输了那么一场,足球篮球呢,我觉得是一方面成绩差,因为比赛真的有状态跟心态的影响,偶尔有一场失误非常正常,NBA 被黑八的有这么多强队,但是如果像男足男篮,成绩是越来越差,用范志毅的话来说就是脸都不要了,还有就是精气神,要在比赛中打出胜负欲,保持这种争胜心,才有机会再进步,前火箭队主教练鲁迪·汤姆贾诺维奇的话,“永远不要低估冠军的决心”,即使我现在打不过你,我会在下一次,下下次打败你,竞技体育永远要有这种精神,可以接受一时的失败,但是要保持永远争胜的心。
-第一块金牌是杨倩拿下的,中国队拿奥运会首金也是有政治任务的,而恰恰杨倩这个金牌也有点碰巧是对手最后一枪失误了,当然竞技体育,特别是射击,真的是容不得一点点失误,像前面几届的美国神通埃蒙斯,失之毫厘差之千里,但是这个具体评价就比较少,唯一一点让我比较出戏的就是杨倩真的非常像王刚的徒弟漆二娃,哈哈,微博上也有挺多人觉得像,射击还是个比较可以接受年纪稍大的运动员,需要经验和稳定性,相对来说爆发力体力稍好一点,像庞伟这样的,混合团体10米气手枪金牌,36 岁可能其他项目已经是年龄很大了,不过前面说的举重的吕小军军神也是年纪蛮大了,但是非常强,而且在油管上简直就是个神,相对来说射击是关注比较少,杨倩的也只是看了后面拿到冠军这个结果,有些因为时间或者电视上没放,但是成绩还是不错的,没多少喷点。
-第二篇先到这,纯主观,轻喷。
-]]>
-
- 生活
- 运动
-
-
- 生活
- 运动
- 东京奥运会
- 举重
- 射击
+ 容错机制
@@ -16450,6 +16536,18 @@ app.setWebAp
自旋
+
+ 聊一下关于怎么陪伴学习
+ /2022/11/06/%E8%81%8A%E4%B8%80%E4%B8%8B%E5%85%B3%E4%BA%8E%E6%80%8E%E4%B9%88%E9%99%AA%E4%BC%B4%E5%AD%A6%E4%B9%A0/
+ 这是一次开车过程中结合网上的一些微博想到的,开车是之前LD买了车后,陪领导练车,其实在一开始练车的时候,我们已经是找了相对很空的封闭路段,路上基本很少有车,偶尔有一辆车,但是LD还是很害怕,车速还只有十几的时候,还很远的对面来车的时候就觉得很慌了,这个时候如果以常理肯定会说这样子完全不用怕,如果克服恐惧真的这么容易的话,问题就不会那么纠结了,人生是很难完全感同身受的,唯有降低预设的基准让事情从头理清楚,害怕了我们就先休息,有车了我们就停下,先适应完全没车的情况,变得更慢一点,如果这时候着急一点,反而会起到反效果,比如只是说不要怕,接着开,甚至有点厌烦了,那基本这个练车也不太成得了了,而正好是有耐心的一起慢慢练习,还有就是第二件是切身体会,就是当道路本来是两条道,但是封了一条的时候,这时候开车如果是像我这样的新手,如果开车时左右边看着的话,车肯定开不好,因为那样会一直左右调整,反而更容易控制不好左右的距离,蹭到旁边的隔离栏,正确的方式应该是专注于正前方的路,这样才能保证左右边距离尽可能均匀,而不是顾左失右或者顾右失左,所以很多陪伴学习需要注意的是方式和耐心,能够识别到关键点那是最好的,但是有时候更需要的是耐心,纯靠耐心不一定能解决问题,但是可能会找到问题关键点。
+]]>
+
+ 生活
+
+
+ 生活
+
+
聊聊 Dubbo 的 SPI
/2020/05/31/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84-SPI/
@@ -16548,138 +16646,210 @@ app.setWebAp
- 聊聊 Dubbo 的容错机制
- /2020/11/22/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
- 之前看了 dubbo 的一些代码,在学习过程中,主要关注那些比较“高级”的内容,SPI,自适应扩展等,却忘了一些作为一个 rpc 框架最核心需要的部分,比如如何通信,序列化,网络,容错机制等等,因为其实这个最核心的就是远程调用,自适应扩展其实就是让代码可扩展性,可读性,更优雅等,写的搓一点其实也问题不大,但是一个合适的通信协议,序列化方法,如何容错等却是真正保证是一个 rpc 框架最重要的要素。
首先来看这张图
![cluster]()
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
各节点关系:
+ 聊聊 Java 的类加载机制一
+ /2020/11/08/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6/
+ 一说到这个主题,想到的应该是双亲委派模型,不过讲的包括但不限于这个,主要内容是参考深入理解 Java 虚拟机书中的介绍,
一个类型的生命周期包含了七个阶段,加载,验证,准备,解析,初始化,使用,卸载。
-- 这里的
Invoker 是 Provider 的一个可调用 Service 的抽象,Invoker 封装了 Provider 地址及 Service 接口信息
-Directory 代表多个 Invoker,可以把它看成 List<Invoker> ,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Router 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选加载
-集群容错模式
Failover Cluster
失败自动切换,当出现失败,重试其它服务器 1。通常用于读操作,但重试会带来更长延迟。可通过 retries=”2” 来设置重试次数(不含第一次)。
-重试次数配置如下:
-<dubbo:service retries=”2” />
这里重点看下 Failover Cluster集群模式的实现
-public class FailoverCluster implements Cluster {
-
- public final static String NAME = "failover";
+
+- 通过一个类的全限定名来获取定义此类的二进制字节流
+- 将这个字节流代表的静态存储结构转化为方法区的运行时数据结构
+- 在内存中生成了一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口
+
+
+
+- 文件格式验证
+- 元数据验证
+- 字节码验证
+- 符号引用验证
+
+
+以上验证、准备、解析 三个阶段又合称为链接阶段,链接阶段要做的是将加载到JVM中的二进制字节流的类数据信息合并到JVM的运行时状态中。
+
+初始化
类的初始化阶段是类加载过程的最后一个步骤,也是除了自定义类加载器之外将主动权交给了应用程序,其实就是执行类构造器()方法的过程,()并不是我们在 Java 代码中直接编写的方法,它是 Javac编译器的自动生成物,()方法是由编译器自动收集类中的所有类变量的复制动作和静态句块(static{}块)中的语句合并产生的,编译器收集的顺序是由语句在原文件中出现的顺序决定的,静态语句块中只能访问定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以复制,但是不能访问,同时还要保证父类的执行先于子类,然后保证多线程下的并发问题
+最终,方法区会存储当前类类信息,包括类的静态变量、类初始化代码(定义静态变量时的赋值语句 和 静态初始化代码块)、实例变量定义、实例初始化代码(定义实例变量时的赋值语句实例代码块和构造方法)和实例方法,还有父类的类信息引用。
+]]>
+
+ Java
+ 类加载
+
+
+
+ 聊聊 Java 中绕不开的 Synchronized 关键字
+ /2021/06/20/%E8%81%8A%E8%81%8A-Java-%E4%B8%AD%E7%BB%95%E4%B8%8D%E5%BC%80%E7%9A%84-Synchronized-%E5%85%B3%E9%94%AE%E5%AD%97/
+ Synchronized 关键字在 Java 的并发体系里也是非常重要的一个内容,首先比较常规的是知道它使用的方式,可以锁对象,可以锁代码块,也可以锁方法,看一个简单的 demo
+public class SynchronizedDemo {
- public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
- return new FailoverClusterInvoker<T>(directory);
+ public static void main(String[] args) {
+ SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
+ synchronizedDemo.lockMethod();
}
-}
-这个代码就非常简单,重点需要看FailoverClusterInvoker里的代码,FailoverClusterInvoker继承了AbstractClusterInvoker类,其中invoke 方法是在抽象类里实现的
-@Override
-public Result invoke(final Invocation invocation) throws RpcException {
- checkWhetherDestroyed();
- // binding attachments into invocation.
- // 绑定 attachments 到 invocation 中.
- Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments();
- if (contextAttachments != null && contextAttachments.size() != 0) {
- ((RpcInvocation) invocation).addObjectAttachments(contextAttachments);
- }
- // 列举 Invoker
- List<Invoker<T>> invokers = list(invocation);
- // 加载 LoadBalance 负载均衡器
- LoadBalance loadbalance = initLoadBalance(invokers, invocation);
- RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
- // 调用 实际的 doInvoke 进行后续操作
- return doInvoke(invocation, invokers, loadbalance);
-}
-// 这是个抽象方法,实际是由子类实现的
- protected abstract Result doInvoke(Invocation invocation, List<Invoker<T>> invokers,
- LoadBalance loadbalance) throws RpcException;
-然后重点就是FailoverClusterInvoker中的doInvoke方法了,其实它里面也就这么一个方法
-@Override
- @SuppressWarnings({"unchecked", "rawtypes"})
- public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
- List<Invoker<T>> copyInvokers = invokers;
- checkInvokers(copyInvokers, invocation);
- String methodName = RpcUtils.getMethodName(invocation);
- // 获取重试次数,这里默认是 2 次,还有可以注意下后面的+1
- int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1;
- if (len <= 0) {
- len = 1;
- }
- // retry loop.
- RpcException le = null; // last exception.
- List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
- Set<String> providers = new HashSet<String>(len);
- // 循环调用,失败重试
- for (int i = 0; i < len; i++) {
- //Reselect before retry to avoid a change of candidate `invokers`.
- //NOTE: if `invokers` changed, then `invoked` also lose accuracy.
- if (i > 0) {
- checkWhetherDestroyed();
- // 在进行重试前重新列举 Invoker,这样做的好处是,如果某个服务挂了,
- // 通过调用 list 可得到最新可用的 Invoker 列表
- copyInvokers = list(invocation);
- // check again
- // 对 copyinvokers 进行判空检查
- checkInvokers(copyInvokers, invocation);
- }
- // 通过负载均衡来选择 invoker
- Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
- // 将其添加到 invoker 到 invoked 列表中
- invoked.add(invoker);
- // 设置上下文
- RpcContext.getContext().setInvokers((List) invoked);
- try {
- // 正式调用
- Result result = invoker.invoke(invocation);
- if (le != null && logger.isWarnEnabled()) {
- logger.warn("Although retry the method " + methodName
- + " in the service " + getInterface().getName()
- + " was successful by the provider " + invoker.getUrl().getAddress()
- + ", but there have been failed providers " + providers
- + " (" + providers.size() + "/" + copyInvokers.size()
- + ") from the registry " + directory.getUrl().getAddress()
- + " on the consumer " + NetUtils.getLocalHost()
- + " using the dubbo version " + Version.getVersion() + ". Last error is: "
- + le.getMessage(), le);
- }
- return result;
- } catch (RpcException e) {
- if (e.isBiz()) { // biz exception.
- throw e;
- }
- le = e;
- } catch (Throwable e) {
- le = new RpcException(e.getMessage(), e);
- } finally {
- providers.add(invoker.getUrl().getAddress());
- }
- }
- throw new RpcException(le.getCode(), "Failed to invoke the method "
- + methodName + " in the service " + getInterface().getName()
- + ". Tried " + len + " times of the providers " + providers
- + " (" + providers.size() + "/" + copyInvokers.size()
- + ") from the registry " + directory.getUrl().getAddress()
- + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version "
- + Version.getVersion() + ". Last error is: "
- + le.getMessage(), le.getCause() != null ? le.getCause() : le);
- }
-
+ public synchronized void lockMethod() {
+ System.out.println("here i'm locked");
+ }
-Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
-Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
-Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
-Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=”2” 来设置最大并行数。
-Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 2。通常用于通知所有提供者更新缓存或日志等本地资源信息。
+ public void lockSynchronizedDemo() {
+ synchronized (this) {
+ System.out.println("here lock class");
+ }
+ }
+}
+
+然后来查看反编译结果,其实代码(日光)之下并无新事,即使是完全不懂的也可以通过一些词义看出一些意义
+ Last modified 2021年6月20日; size 729 bytes
+ MD5 checksum dd9c529863bd7ff839a95481db578ad9
+ Compiled from "SynchronizedDemo.java"
+public class SynchronizedDemo
+ minor version: 0
+ major version: 53
+ flags: (0x0021) ACC_PUBLIC, ACC_SUPER
+ this_class: #2 // SynchronizedDemo
+ super_class: #9 // java/lang/Object
+ interfaces: 0, fields: 0, methods: 4, attributes: 1
+Constant pool:
+ #1 = Methodref #9.#22 // java/lang/Object."<init>":()V
+ #2 = Class #23 // SynchronizedDemo
+ #3 = Methodref #2.#22 // SynchronizedDemo."<init>":()V
+ #4 = Methodref #2.#24 // SynchronizedDemo.lockMethod:()V
+ #5 = Fieldref #25.#26 // java/lang/System.out:Ljava/io/PrintStream;
+ #6 = String #27 // here i\'m locked
+ #7 = Methodref #28.#29 // java/io/PrintStream.println:(Ljava/lang/String;)V
+ #8 = String #30 // here lock class
+ #9 = Class #31 // java/lang/Object
+ #10 = Utf8 <init>
+ #11 = Utf8 ()V
+ #12 = Utf8 Code
+ #13 = Utf8 LineNumberTable
+ #14 = Utf8 main
+ #15 = Utf8 ([Ljava/lang/String;)V
+ #16 = Utf8 lockMethod
+ #17 = Utf8 lockSynchronizedDemo
+ #18 = Utf8 StackMapTable
+ #19 = Class #32 // java/lang/Throwable
+ #20 = Utf8 SourceFile
+ #21 = Utf8 SynchronizedDemo.java
+ #22 = NameAndType #10:#11 // "<init>":()V
+ #23 = Utf8 SynchronizedDemo
+ #24 = NameAndType #16:#11 // lockMethod:()V
+ #25 = Class #33 // java/lang/System
+ #26 = NameAndType #34:#35 // out:Ljava/io/PrintStream;
+ #27 = Utf8 here i\'m locked
+ #28 = Class #36 // java/io/PrintStream
+ #29 = NameAndType #37:#38 // println:(Ljava/lang/String;)V
+ #30 = Utf8 here lock class
+ #31 = Utf8 java/lang/Object
+ #32 = Utf8 java/lang/Throwable
+ #33 = Utf8 java/lang/System
+ #34 = Utf8 out
+ #35 = Utf8 Ljava/io/PrintStream;
+ #36 = Utf8 java/io/PrintStream
+ #37 = Utf8 println
+ #38 = Utf8 (Ljava/lang/String;)V
+{
+ public SynchronizedDemo();
+ descriptor: ()V
+ flags: (0x0001) ACC_PUBLIC
+ Code:
+ stack=1, locals=1, args_size=1
+ 0: aload_0
+ 1: invokespecial #1 // Method java/lang/Object."<init>":()V
+ 4: return
+ LineNumberTable:
+ line 5: 0
+
+ public static void main(java.lang.String[]);
+ descriptor: ([Ljava/lang/String;)V
+ flags: (0x0009) ACC_PUBLIC, ACC_STATIC
+ Code:
+ stack=2, locals=2, args_size=1
+ 0: new #2 // class SynchronizedDemo
+ 3: dup
+ 4: invokespecial #3 // Method "<init>":()V
+ 7: astore_1
+ 8: aload_1
+ 9: invokevirtual #4 // Method lockMethod:()V
+ 12: return
+ LineNumberTable:
+ line 8: 0
+ line 9: 8
+ line 10: 12
+
+ public synchronized void lockMethod();
+ descriptor: ()V
+ flags: (0x0021) ACC_PUBLIC, ACC_SYNCHRONIZED
+ Code:
+ stack=2, locals=1, args_size=1
+ 0: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
+ 3: ldc #6 // String here i\'m locked
+ 5: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
+ 8: return
+ LineNumberTable:
+ line 13: 0
+ line 14: 8
+
+ public void lockSynchronizedDemo();
+ descriptor: ()V
+ flags: (0x0001) ACC_PUBLIC
+ Code:
+ stack=2, locals=3, args_size=1
+ 0: aload_0
+ 1: dup
+ 2: astore_1
+ 3: monitorenter
+ 4: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
+ 7: ldc #8 // String here lock class
+ 9: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
+ 12: aload_1
+ 13: monitorexit
+ 14: goto 22
+ 17: astore_2
+ 18: aload_1
+ 19: monitorexit
+ 20: aload_2
+ 21: athrow
+ 22: return
+ Exception table:
+ from to target type
+ 4 14 17 any
+ 17 20 17 any
+ LineNumberTable:
+ line 17: 0
+ line 18: 4
+ line 19: 12
+ line 20: 22
+ StackMapTable: number_of_entries = 2
+ frame_type = 255 /* full_frame */
+ offset_delta = 17
+ locals = [ class SynchronizedDemo, class java/lang/Object ]
+ stack = [ class java/lang/Throwable ]
+ frame_type = 250 /* chop */
+ offset_delta = 4
+}
+SourceFile: "SynchronizedDemo.java"
+
+其中lockMethod中可以看到是通过 ACC_SYNCHRONIZED flag 来标记是被 synchronized 修饰,前面的 ACC 应该是 access 的意思,并且通过 ACC_PUBLIC 也可以看出来他们是同一类访问权限关键字来控制的,而修饰类则是通过3: monitorenter和13: monitorexit来控制并发,这个是原来就知道,后来看了下才知道修饰方法是不一样的,但是在前期都比较诟病是 synchronized 的性能,像 monitor 也是通过操作系统的mutex lock互斥锁来实现的,相对是比较重的锁,于是在 JDK 1.6 之后对 synchronized 做了一系列优化,包括偏向锁,轻量级锁,并且包括像 ConcurrentHashMap 这类并发集合都有在使用 synchronized 关键字配合 cas 来做并发保护,
+jdk 对于 synchronized 的优化主要在于多重状态锁的升级,最初会使用偏向锁,当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。
而当出现线程尝试进入同步块时发现已有偏向锁,并且是其他线程时,会将锁升级成轻量级锁,并且自旋尝试获取锁,如果自旋成功则表示获取轻量级锁成功,否则将会升级成重量级锁进行阻塞,当然这里具体的还很复杂,说的比较浅薄主体还是想将原先的阻塞互斥锁进行轻量化,区分特殊情况进行加锁。
]]>
Java
- Dubbo - RPC
- Dubbo
- 容错机制
Java
- Dubbo
- RPC
- 容错机制
+ Synchronized
+ 偏向锁
+ 轻量级锁
+ 重量级锁
+ 自旋
@@ -16694,237 +16864,343 @@ public Result invoke(final Invocation invocation) throws RpcException {
if (this == anObject) {
return true;
}
- if (anObject instanceof String) {
- String anotherString = (String)anObject;
- int n = value.length;
- if (n == anotherString.value.length) {
- char v1[] = value;
- char v2[] = anotherString.value;
- int i = 0;
- while (n-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
+ if (anObject instanceof String) {
+ String anotherString = (String)anObject;
+ int n = value.length;
+ if (n == anotherString.value.length) {
+ char v1[] = value;
+ char v2[] = anotherString.value;
+ int i = 0;
+ while (n-- != 0) {
+ if (v1[i] != v2[i])
+ return false;
+ i++;
+ }
+ return true;
+ }
+ }
+ return false;
+ }
+然后呢就是为啥一些书或者 effective java 中写了 equals 跟 hashCode 要一起重写,这里涉及到当对象作为 HashMap 的 key 的时候
首先 HashMap 会使用 hashCode 去判断是否在同一个槽里,然后在通过 equals 去判断是否是同一个 key,是的话就替换,不是的话就链表接下去,如果不重写 hashCode 的话,默认的 object 的hashCode 是 native 方法,根据对象的地址生成的,这样其实对象的值相同的话,因为地址不同,HashMap 也会出现异常,所以需要重写,同时也需要重写 equals 方法,才能确认是同一个 key,而不是落在同一个槽的不同 key.
+]]>
+
+ java
+
+
+ java
+
+
+
+ 聊聊 Java 的类加载机制二
+ /2021/06/13/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6%E4%BA%8C/
+ 类加载器类加载机制中说来说去其实也逃不开类加载器这个话题,我们就来说下类加载器这个话题,Java 在 jdk1.2 以后开始有了
Java 虚拟机设计团队有意把加载阶段中的“通过一个类的全限定名来获取描述该类的二进制字节流”这个动作放到 Java 虚拟机外部去实现,以便让应用程序自己去决定如何去获取所需的类。实现这个动作的代码被称为“类加载器”(Class Loader).
其实在 Java 中类加载器有一个很常用的作用,比如一个类的唯一性,其实是由加载它的类加载器和这个类一起来确定这个类在虚拟机的唯一性,这里也参考下周志明书里的例子
+public class ClassLoaderTest {
+
+ public static void main(String[] args) throws Exception {
+ ClassLoader myLoader = new ClassLoader() {
+ @Override
+ public Class<?> loadClass(String name) throws ClassNotFoundException {
+ try {
+ String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class";
+ InputStream is = getClass().getResourceAsStream(fileName);
+ if (is == null) {
+ return super.loadClass(name);
+ }
+ byte[] b = new byte[is.available()];
+ is.read(b);
+ return defineClass(name, b, 0, b.length);
+ } catch (IOException e) {
+ throw new ClassNotFoundException(name);
+ }
+ }
+ };
+ Object object = myLoader.loadClass("com.nicksxs.demo.ClassLoaderTest").newInstance();
+ System.out.println(object.getClass());
+ System.out.println(object instanceof ClassLoaderTest);
+ }
+}
+可以看下结果
![]()
这里说明了当一个是由虚拟机的应用程序类加载器所加载的和另一个由自己写的自定义类加载器加载的,虽然是同一个类,但是 instanceof 的结果就是 false 的
+双亲委派
自 JDK1.2 以来,Java 一直有些三层类加载器、双亲委派的类加载架构
+启动类加载器
首先是启动类加载器,Bootstrap Class Loader,这个类加载器负责加载放在\lib目录,或者被-Xbootclasspath参数所指定的路径中存放的,而且是Java 虚拟机能够识别的(按照文件名识别,如 rt.jar、tools.jar,名字不符合的类库即使放在 lib 目录中,也不会被加载)类库加载到虚拟机的内存中,启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把家在请求为派给引导类加载器去处理,那直接使用 null 代替即可,可以看下 java.lang.ClassLoader.getClassLoader()方法的代码片段
+/**
+ * Returns the class loader for the class. Some implementations may use
+ * null to represent the bootstrap class loader. This method will return
+ * null in such implementations if this class was loaded by the bootstrap
+ * class loader.
+ *
+ * <p> If a security manager is present, and the caller's class loader is
+ * not null and the caller's class loader is not the same as or an ancestor of
+ * the class loader for the class whose class loader is requested, then
+ * this method calls the security manager's {@code checkPermission}
+ * method with a {@code RuntimePermission("getClassLoader")}
+ * permission to ensure it's ok to access the class loader for the class.
+ *
+ * <p>If this object
+ * represents a primitive type or void, null is returned.
+ *
+ * @return the class loader that loaded the class or interface
+ * represented by this object.
+ * @throws SecurityException
+ * if a security manager exists and its
+ * {@code checkPermission} method denies
+ * access to the class loader for the class.
+ * @see java.lang.ClassLoader
+ * @see SecurityManager#checkPermission
+ * @see java.lang.RuntimePermission
+ */
+ @CallerSensitive
+ public ClassLoader getClassLoader() {
+ ClassLoader cl = getClassLoader0();
+ if (cl == null)
+ return null;
+ SecurityManager sm = System.getSecurityManager();
+ if (sm != null) {
+ ClassLoader.checkClassLoaderPermission(cl, Reflection.getCallerClass());
+ }
+ return cl;
+ }
+扩展类加载器
这个类加载器是在类sun.misc.Launcher.ExtClassLoader中以 Java 代码的形式实现的,它负责在家\lib\ext 目录中,或者被 java.ext.dirs系统变量中所指定的路径中的所有类库,它其实目的是为了实现 Java 系统类库的扩展机制
+应用程序类加载器
这个类加载器是由sun.misc.Launcher.AppClassLoader实现,通过 java 代码,并且是 ClassLoader 类中的 getSystemClassLoader()方法的返回值,可以看一下代码
+/**
+ * Returns the system class loader for delegation. This is the default
+ * delegation parent for new <tt>ClassLoader</tt> instances, and is
+ * typically the class loader used to start the application.
+ *
+ * <p> This method is first invoked early in the runtime's startup
+ * sequence, at which point it creates the system class loader and sets it
+ * as the context class loader of the invoking <tt>Thread</tt>.
+ *
+ * <p> The default system class loader is an implementation-dependent
+ * instance of this class.
+ *
+ * <p> If the system property "<tt>java.system.class.loader</tt>" is defined
+ * when this method is first invoked then the value of that property is
+ * taken to be the name of a class that will be returned as the system
+ * class loader. The class is loaded using the default system class loader
+ * and must define a public constructor that takes a single parameter of
+ * type <tt>ClassLoader</tt> which is used as the delegation parent. An
+ * instance is then created using this constructor with the default system
+ * class loader as the parameter. The resulting class loader is defined
+ * to be the system class loader.
+ *
+ * <p> If a security manager is present, and the invoker's class loader is
+ * not <tt>null</tt> and the invoker's class loader is not the same as or
+ * an ancestor of the system class loader, then this method invokes the
+ * security manager's {@link
+ * SecurityManager#checkPermission(java.security.Permission)
+ * <tt>checkPermission</tt>} method with a {@link
+ * RuntimePermission#RuntimePermission(String)
+ * <tt>RuntimePermission("getClassLoader")</tt>} permission to verify
+ * access to the system class loader. If not, a
+ * <tt>SecurityException</tt> will be thrown. </p>
+ *
+ * @return The system <tt>ClassLoader</tt> for delegation, or
+ * <tt>null</tt> if none
+ *
+ * @throws SecurityException
+ * If a security manager exists and its <tt>checkPermission</tt>
+ * method doesn't allow access to the system class loader.
+ *
+ * @throws IllegalStateException
+ * If invoked recursively during the construction of the class
+ * loader specified by the "<tt>java.system.class.loader</tt>"
+ * property.
+ *
+ * @throws Error
+ * If the system property "<tt>java.system.class.loader</tt>"
+ * is defined but the named class could not be loaded, the
+ * provider class does not define the required constructor, or an
+ * exception is thrown by that constructor when it is invoked. The
+ * underlying cause of the error can be retrieved via the
+ * {@link Throwable#getCause()} method.
+ *
+ * @revised 1.4
+ */
+ @CallerSensitive
+ public static ClassLoader getSystemClassLoader() {
+ initSystemClassLoader();
+ if (scl == null) {
+ return null;
+ }
+ SecurityManager sm = System.getSecurityManager();
+ if (sm != null) {
+ checkClassLoaderPermission(scl, Reflection.getCallerClass());
+ }
+ return scl;
+ }
+ private static synchronized void initSystemClassLoader() {
+ if (!sclSet) {
+ if (scl != null)
+ throw new IllegalStateException("recursive invocation");
+ // 主要的第一步是这
+ sun.misc.Launcher l = sun.misc.Launcher.getLauncher();
+ if (l != null) {
+ Throwable oops = null;
+ // 然后是这
+ scl = l.getClassLoader();
+ try {
+ scl = AccessController.doPrivileged(
+ new SystemClassLoaderAction(scl));
+ } catch (PrivilegedActionException pae) {
+ oops = pae.getCause();
+ if (oops instanceof InvocationTargetException) {
+ oops = oops.getCause();
+ }
+ }
+ if (oops != null) {
+ if (oops instanceof Error) {
+ throw (Error) oops;
+ } else {
+ // wrap the exception
+ throw new Error(oops);
+ }
}
- return true;
}
+ sclSet = true;
}
- return false;
- }
-然后呢就是为啥一些书或者 effective java 中写了 equals 跟 hashCode 要一起重写,这里涉及到当对象作为 HashMap 的 key 的时候
首先 HashMap 会使用 hashCode 去判断是否在同一个槽里,然后在通过 equals 去判断是否是同一个 key,是的话就替换,不是的话就链表接下去,如果不重写 hashCode 的话,默认的 object 的hashCode 是 native 方法,根据对象的地址生成的,这样其实对象的值相同的话,因为地址不同,HashMap 也会出现异常,所以需要重写,同时也需要重写 equals 方法,才能确认是同一个 key,而不是落在同一个槽的不同 key.
-]]>
-
- java
-
-
- java
-
-
-
- 聊聊 Java 的类加载机制一
- /2020/11/08/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6/
- 一说到这个主题,想到的应该是双亲委派模型,不过讲的包括但不限于这个,主要内容是参考深入理解 Java 虚拟机书中的介绍,
一个类型的生命周期包含了七个阶段,加载,验证,准备,解析,初始化,使用,卸载。
-
-
-- 通过一个类的全限定名来获取定义此类的二进制字节流
-- 将这个字节流代表的静态存储结构转化为方法区的运行时数据结构
-- 在内存中生成了一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口
-
-
-
-- 文件格式验证
-- 元数据验证
-- 字节码验证
-- 符号引用验证
-
-
-以上验证、准备、解析 三个阶段又合称为链接阶段,链接阶段要做的是将加载到JVM中的二进制字节流的类数据信息合并到JVM的运行时状态中。
-
-初始化
类的初始化阶段是类加载过程的最后一个步骤,也是除了自定义类加载器之外将主动权交给了应用程序,其实就是执行类构造器()方法的过程,()并不是我们在 Java 代码中直接编写的方法,它是 Javac编译器的自动生成物,()方法是由编译器自动收集类中的所有类变量的复制动作和静态句块(static{}块)中的语句合并产生的,编译器收集的顺序是由语句在原文件中出现的顺序决定的,静态语句块中只能访问定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以复制,但是不能访问,同时还要保证父类的执行先于子类,然后保证多线程下的并发问题
-最终,方法区会存储当前类类信息,包括类的静态变量、类初始化代码(定义静态变量时的赋值语句 和 静态初始化代码块)、实例变量定义、实例初始化代码(定义实例变量时的赋值语句实例代码块和构造方法)和实例方法,还有父类的类信息引用。
-]]>
-
- Java
- 类加载
-
-
-
- 聊聊 Java 中绕不开的 Synchronized 关键字
- /2021/06/20/%E8%81%8A%E8%81%8A-Java-%E4%B8%AD%E7%BB%95%E4%B8%8D%E5%BC%80%E7%9A%84-Synchronized-%E5%85%B3%E9%94%AE%E5%AD%97/
- Synchronized 关键字在 Java 的并发体系里也是非常重要的一个内容,首先比较常规的是知道它使用的方式,可以锁对象,可以锁代码块,也可以锁方法,看一个简单的 demo
-public class SynchronizedDemo {
-
- public static void main(String[] args) {
- SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
- synchronizedDemo.lockMethod();
}
-
- public synchronized void lockMethod() {
- System.out.println("here i'm locked");
+// 接着跟到sun.misc.Launcher#getClassLoader
+public ClassLoader getClassLoader() {
+ return this.loader;
}
+// 然后看到这 sun.misc.Launcher#Launcher
+public Launcher() {
+ Launcher.ExtClassLoader var1;
+ try {
+ var1 = Launcher.ExtClassLoader.getExtClassLoader();
+ } catch (IOException var10) {
+ throw new InternalError("Could not create extension class loader", var10);
+ }
- public void lockSynchronizedDemo() {
- synchronized (this) {
- System.out.println("here lock class");
+ try {
+ // 可以看到 就是 AppClassLoader
+ this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);
+ } catch (IOException var9) {
+ throw new InternalError("Could not create application class loader", var9);
}
- }
-}
-然后来查看反编译结果,其实代码(日光)之下并无新事,即使是完全不懂的也可以通过一些词义看出一些意义
- Last modified 2021年6月20日; size 729 bytes
- MD5 checksum dd9c529863bd7ff839a95481db578ad9
- Compiled from "SynchronizedDemo.java"
-public class SynchronizedDemo
- minor version: 0
- major version: 53
- flags: (0x0021) ACC_PUBLIC, ACC_SUPER
- this_class: #2 // SynchronizedDemo
- super_class: #9 // java/lang/Object
- interfaces: 0, fields: 0, methods: 4, attributes: 1
-Constant pool:
- #1 = Methodref #9.#22 // java/lang/Object."<init>":()V
- #2 = Class #23 // SynchronizedDemo
- #3 = Methodref #2.#22 // SynchronizedDemo."<init>":()V
- #4 = Methodref #2.#24 // SynchronizedDemo.lockMethod:()V
- #5 = Fieldref #25.#26 // java/lang/System.out:Ljava/io/PrintStream;
- #6 = String #27 // here i\'m locked
- #7 = Methodref #28.#29 // java/io/PrintStream.println:(Ljava/lang/String;)V
- #8 = String #30 // here lock class
- #9 = Class #31 // java/lang/Object
- #10 = Utf8 <init>
- #11 = Utf8 ()V
- #12 = Utf8 Code
- #13 = Utf8 LineNumberTable
- #14 = Utf8 main
- #15 = Utf8 ([Ljava/lang/String;)V
- #16 = Utf8 lockMethod
- #17 = Utf8 lockSynchronizedDemo
- #18 = Utf8 StackMapTable
- #19 = Class #32 // java/lang/Throwable
- #20 = Utf8 SourceFile
- #21 = Utf8 SynchronizedDemo.java
- #22 = NameAndType #10:#11 // "<init>":()V
- #23 = Utf8 SynchronizedDemo
- #24 = NameAndType #16:#11 // lockMethod:()V
- #25 = Class #33 // java/lang/System
- #26 = NameAndType #34:#35 // out:Ljava/io/PrintStream;
- #27 = Utf8 here i\'m locked
- #28 = Class #36 // java/io/PrintStream
- #29 = NameAndType #37:#38 // println:(Ljava/lang/String;)V
- #30 = Utf8 here lock class
- #31 = Utf8 java/lang/Object
- #32 = Utf8 java/lang/Throwable
- #33 = Utf8 java/lang/System
- #34 = Utf8 out
- #35 = Utf8 Ljava/io/PrintStream;
- #36 = Utf8 java/io/PrintStream
- #37 = Utf8 println
- #38 = Utf8 (Ljava/lang/String;)V
-{
- public SynchronizedDemo();
- descriptor: ()V
- flags: (0x0001) ACC_PUBLIC
- Code:
- stack=1, locals=1, args_size=1
- 0: aload_0
- 1: invokespecial #1 // Method java/lang/Object."<init>":()V
- 4: return
- LineNumberTable:
- line 5: 0
+ Thread.currentThread().setContextClassLoader(this.loader);
+ String var2 = System.getProperty("java.security.manager");
+ if (var2 != null) {
+ SecurityManager var3 = null;
+ if (!"".equals(var2) && !"default".equals(var2)) {
+ try {
+ var3 = (SecurityManager)this.loader.loadClass(var2).newInstance();
+ } catch (IllegalAccessException var5) {
+ } catch (InstantiationException var6) {
+ } catch (ClassNotFoundException var7) {
+ } catch (ClassCastException var8) {
+ }
+ } else {
+ var3 = new SecurityManager();
+ }
- public static void main(java.lang.String[]);
- descriptor: ([Ljava/lang/String;)V
- flags: (0x0009) ACC_PUBLIC, ACC_STATIC
- Code:
- stack=2, locals=2, args_size=1
- 0: new #2 // class SynchronizedDemo
- 3: dup
- 4: invokespecial #3 // Method "<init>":()V
- 7: astore_1
- 8: aload_1
- 9: invokevirtual #4 // Method lockMethod:()V
- 12: return
- LineNumberTable:
- line 8: 0
- line 9: 8
- line 10: 12
+ if (var3 == null) {
+ throw new InternalError("Could not create SecurityManager: " + var2);
+ }
- public synchronized void lockMethod();
- descriptor: ()V
- flags: (0x0021) ACC_PUBLIC, ACC_SYNCHRONIZED
- Code:
- stack=2, locals=1, args_size=1
- 0: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
- 3: ldc #6 // String here i\'m locked
- 5: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
- 8: return
- LineNumberTable:
- line 13: 0
- line 14: 8
+ System.setSecurityManager(var3);
+ }
- public void lockSynchronizedDemo();
- descriptor: ()V
- flags: (0x0001) ACC_PUBLIC
- Code:
- stack=2, locals=3, args_size=1
- 0: aload_0
- 1: dup
- 2: astore_1
- 3: monitorenter
- 4: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
- 7: ldc #8 // String here lock class
- 9: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
- 12: aload_1
- 13: monitorexit
- 14: goto 22
- 17: astore_2
- 18: aload_1
- 19: monitorexit
- 20: aload_2
- 21: athrow
- 22: return
- Exception table:
- from to target type
- 4 14 17 any
- 17 20 17 any
- LineNumberTable:
- line 17: 0
- line 18: 4
- line 19: 12
- line 20: 22
- StackMapTable: number_of_entries = 2
- frame_type = 255 /* full_frame */
- offset_delta = 17
- locals = [ class SynchronizedDemo, class java/lang/Object ]
- stack = [ class java/lang/Throwable ]
- frame_type = 250 /* chop */
- offset_delta = 4
-}
-SourceFile: "SynchronizedDemo.java"
+ }
+它负责加载用户类路径(ClassPath)上所有的类库,我们可以直接在代码中使用这个类加载器,如果我们的代码中没有自定义的类在加载器,一般情况下这个就是程序中默认的类加载器
+双亲委派模型
![]()
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试家在这个类,而是把这个请求为派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的家在请求最终都应该传送到最顶层的启动类加载器中,只有当父类加载器反馈自己无法完成加载请求(它的搜索范围中没有找到所需要的类)时,子加载器才会尝试自己去完成加载。
使用双亲委派模型来组织类加载器之间的关系,一个显而易见的好处就是 Java 中的类随着它的类加载器一起举杯了一种带有优先级的层次关系。例如类 java.lang.Object,它存放在 rt.jar 之中,无论哪一个类加载器要家在这个类,最终都是委派给处于模型最顶层的启动类加载器进行加载,因此 Object 类在程序的各种类加载器环境中都能够保证是同一个类。反之,如果没有使用双薪委派模型,都由各个类加载器自行去加载的话,如果用户自己也编写了一个名为 java.lang.Object 的类,并放在程序的 ClassPath 中,那系统中就会出现多个不同的 Object 类,Java 类型体系中最基础的行为也就无从保证,应用程序将会变得一片混乱。
可以来看下双亲委派模型的代码实现
+/**
+ * Loads the class with the specified <a href="#name">binary name</a>. The
+ * default implementation of this method searches for classes in the
+ * following order:
+ *
+ * <ol>
+ *
+ * <li><p> Invoke {@link #findLoadedClass(String)} to check if the class
+ * has already been loaded. </p></li>
+ *
+ * <li><p> Invoke the {@link #loadClass(String) <tt>loadClass</tt>} method
+ * on the parent class loader. If the parent is <tt>null</tt> the class
+ * loader built-in to the virtual machine is used, instead. </p></li>
+ *
+ * <li><p> Invoke the {@link #findClass(String)} method to find the
+ * class. </p></li>
+ *
+ * </ol>
+ *
+ * <p> If the class was found using the above steps, and the
+ * <tt>resolve</tt> flag is true, this method will then invoke the {@link
+ * #resolveClass(Class)} method on the resulting <tt>Class</tt> object.
+ *
+ * <p> Subclasses of <tt>ClassLoader</tt> are encouraged to override {@link
+ * #findClass(String)}, rather than this method. </p>
+ *
+ * <p> Unless overridden, this method synchronizes on the result of
+ * {@link #getClassLoadingLock <tt>getClassLoadingLock</tt>} method
+ * during the entire class loading process.
+ *
+ * @param name
+ * The <a href="#name">binary name</a> of the class
+ *
+ * @param resolve
+ * If <tt>true</tt> then resolve the class
+ *
+ * @return The resulting <tt>Class</tt> object
+ *
+ * @throws ClassNotFoundException
+ * If the class could not be found
+ */
+ protected Class<?> loadClass(String name, boolean resolve)
+ throws ClassNotFoundException
+ {
+ synchronized (getClassLoadingLock(name)) {
+ // First, check if the class has already been loaded
+ Class<?> c = findLoadedClass(name);
+ if (c == null) {
+ long t0 = System.nanoTime();
+ try {
+ if (parent != null) {
+ // 委托父类加载
+ c = parent.loadClass(name, false);
+ } else {
+ // 使用启动类加载器
+ c = findBootstrapClassOrNull(name);
+ }
+ } catch (ClassNotFoundException e) {
+ // ClassNotFoundException thrown if class not found
+ // from the non-null parent class loader
+ }
-其中lockMethod中可以看到是通过 ACC_SYNCHRONIZED flag 来标记是被 synchronized 修饰,前面的 ACC 应该是 access 的意思,并且通过 ACC_PUBLIC 也可以看出来他们是同一类访问权限关键字来控制的,而修饰类则是通过3: monitorenter和13: monitorexit来控制并发,这个是原来就知道,后来看了下才知道修饰方法是不一样的,但是在前期都比较诟病是 synchronized 的性能,像 monitor 也是通过操作系统的mutex lock互斥锁来实现的,相对是比较重的锁,于是在 JDK 1.6 之后对 synchronized 做了一系列优化,包括偏向锁,轻量级锁,并且包括像 ConcurrentHashMap 这类并发集合都有在使用 synchronized 关键字配合 cas 来做并发保护,
-jdk 对于 synchronized 的优化主要在于多重状态锁的升级,最初会使用偏向锁,当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。
而当出现线程尝试进入同步块时发现已有偏向锁,并且是其他线程时,会将锁升级成轻量级锁,并且自旋尝试获取锁,如果自旋成功则表示获取轻量级锁成功,否则将会升级成重量级锁进行阻塞,当然这里具体的还很复杂,说的比较浅薄主体还是想将原先的阻塞互斥锁进行轻量化,区分特殊情况进行加锁。
+ if (c == null) {
+ // If still not found, then invoke findClass in order
+ // to find the class.
+ long t1 = System.nanoTime();
+ // 调用自己的 findClass() 方法尝试进行加载
+ c = findClass(name);
+
+ // this is the defining class loader; record the stats
+ sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
+ sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
+ sun.misc.PerfCounter.getFindClasses().increment();
+ }
+ }
+ if (resolve) {
+ resolveClass(c);
+ }
+ return c;
+ }
+ }
+破坏双亲委派
关于破坏双亲委派模型,第一次是在 JDK1.2 之后引入了双亲委派模型之前,那么在那之前已经有了类加载器,所以java.lang.ClassLoader 中添加了一个 protected 方法 findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在 loadClass()中编写代码。这个跟上面的逻辑其实类似,当父类加载失败,会调用 findClass()来完成加载;第二次是因为这个模型本身还有一些不足之处,比如 SPI 这种,所以有设计了线程下上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过 java.lang.Thread 类的 java.lang.Thread#setContextClassLoader() 进行设置,然后第三种是为了追求程序动态性,这里有涉及到了 osgi 等概念,就不展开了
]]>
Java
Java
- Synchronized
- 偏向锁
- 轻量级锁
- 重量级锁
- 自旋
+ 类加载
+ 加载
+ 验证
+ 准备
+ 解析
+ 初始化
+ 链接
+ 双亲委派
@@ -17304,510 +17580,239 @@ public Result invoke(final Invocation invocation) throws RpcException {
at java.net.ServerSocket.accept(ServerSocket.java:513)
at sun.management.jmxremote.LocalRMIServerSocketFactory$1.accept(LocalRMIServerSocketFactory.java:52)
at sun.rmi.transport.tcp.TCPTransport$AcceptLoop.executeAcceptLoop(TCPTransport.java:405)
- at sun.rmi.transport.tcp.TCPTransport$AcceptLoop.run(TCPTransport.java:377)
- at java.lang.Thread.run(Thread.java:748)
-
- Locked ownable synchronizers:
- - None
-
-"Service Thread" #9 daemon prio=9 os_prio=31 tid=0x00007fc9df0ce800 nid=0x4103 runnable [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
-
- Locked ownable synchronizers:
- - None
-
-"C1 CompilerThread2" #8 daemon prio=9 os_prio=31 tid=0x00007fc9df0ce000 nid=0x4203 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
-
- Locked ownable synchronizers:
- - None
-
-"C2 CompilerThread1" #7 daemon prio=9 os_prio=31 tid=0x00007fc9de0a3800 nid=0x3503 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
-
- Locked ownable synchronizers:
- - None
-
-"C2 CompilerThread0" #6 daemon prio=9 os_prio=31 tid=0x00007fc9de89b000 nid=0x3403 waiting on condition [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
-
- Locked ownable synchronizers:
- - None
-
-"Monitor Ctrl-Break" #5 daemon prio=5 os_prio=31 tid=0x00007fc9df0ca000 nid=0x3303 runnable [0x0000700005468000]
- java.lang.Thread.State: RUNNABLE
- at java.net.SocketInputStream.socketRead0(Native Method)
- at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
- at java.net.SocketInputStream.read(SocketInputStream.java:171)
- at java.net.SocketInputStream.read(SocketInputStream.java:141)
- at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284)
- at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326)
- at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)
- - locked <0x00000006c001b760> (a java.io.InputStreamReader)
- at java.io.InputStreamReader.read(InputStreamReader.java:184)
- at java.io.BufferedReader.fill(BufferedReader.java:161)
- at java.io.BufferedReader.readLine(BufferedReader.java:324)
- - locked <0x00000006c001b760> (a java.io.InputStreamReader)
- at java.io.BufferedReader.readLine(BufferedReader.java:389)
- at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:64)
-
- Locked ownable synchronizers:
- - None
-
-"Signal Dispatcher" #4 daemon prio=9 os_prio=31 tid=0x00007fc9de824000 nid=0x4503 runnable [0x0000000000000000]
- java.lang.Thread.State: RUNNABLE
-
- Locked ownable synchronizers:
- - None
-
-"Finalizer" #3 daemon prio=8 os_prio=31 tid=0x00007fc9dd811800 nid=0x4f03 in Object.wait() [0x0000700005262000]
- java.lang.Thread.State: WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000006c0008348> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144)
- - locked <0x00000006c0008348> (a java.lang.ref.ReferenceQueue$Lock)
- at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165)
- at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:216)
-
- Locked ownable synchronizers:
- - None
-
-"Reference Handler" #2 daemon prio=10 os_prio=31 tid=0x00007fc9de02a000 nid=0x5003 in Object.wait() [0x000070000515f000]
- java.lang.Thread.State: WAITING (on object monitor)
- at java.lang.Object.wait(Native Method)
- - waiting on <0x00000006c001b940> (a java.lang.ref.Reference$Lock)
- at java.lang.Object.wait(Object.java:502)
- at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
- - locked <0x00000006c001b940> (a java.lang.ref.Reference$Lock)
- at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
+ at sun.rmi.transport.tcp.TCPTransport$AcceptLoop.run(TCPTransport.java:377)
+ at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers:
- None
-"VM Thread" os_prio=31 tid=0x00007fc9df00b800 nid=0x2c03 runnable
-
-"GC task thread#0 (ParallelGC)" os_prio=31 tid=0x00007fc9de805000 nid=0x1e07 runnable
-
-"GC task thread#1 (ParallelGC)" os_prio=31 tid=0x00007fc9de003800 nid=0x2a03 runnable
-
-"GC task thread#2 (ParallelGC)" os_prio=31 tid=0x00007fc9df002000 nid=0x5403 runnable
-
-"GC task thread#3 (ParallelGC)" os_prio=31 tid=0x00007fc9df002800 nid=0x5203 runnable
+"Service Thread" #9 daemon prio=9 os_prio=31 tid=0x00007fc9df0ce800 nid=0x4103 runnable [0x0000000000000000]
+ java.lang.Thread.State: RUNNABLE
-"VM Periodic Task Thread" os_prio=31 tid=0x00007fc9df11a800 nid=0x3a03 waiting on condition
+ Locked ownable synchronizers:
+ - None
-JNI global references: 1087
+"C1 CompilerThread2" #8 daemon prio=9 os_prio=31 tid=0x00007fc9df0ce000 nid=0x4203 waiting on condition [0x0000000000000000]
+ java.lang.Thread.State: RUNNABLE
+ Locked ownable synchronizers:
+ - None
-Found one Java-level deadlock:
-=============================
-"mythread2":
- waiting for ownable synchronizer 0x000000076f5d4330, (a java.util.concurrent.locks.ReentrantLock$NonfairSync),
- which is held by "mythread1"
-"mythread1":
- waiting for ownable synchronizer 0x000000076f5d4360, (a java.util.concurrent.locks.ReentrantLock$NonfairSync),
- which is held by "mythread2"
+"C2 CompilerThread1" #7 daemon prio=9 os_prio=31 tid=0x00007fc9de0a3800 nid=0x3503 waiting on condition [0x0000000000000000]
+ java.lang.Thread.State: RUNNABLE
-Java stack information for the threads listed above:
-===================================================
-"mythread2":
- at sun.misc.Unsafe.park(Native Method)
- - parking to wait for <0x000000076f5d4330> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
- at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
- at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
- at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
- at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
- at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
- at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
- at com.nicksxs.thread_dump_demo.ThreadDumpDemoApplication$2.run(ThreadDumpDemoApplication.java:34)
-"mythread1":
- at sun.misc.Unsafe.park(Native Method)
- - parking to wait for <0x000000076f5d4360> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
- at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
- at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
- at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
- at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
- at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
- at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
- at com.nicksxs.thread_dump_demo.ThreadDumpDemoApplication$1.run(ThreadDumpDemoApplication.java:22)
+ Locked ownable synchronizers:
+ - None
-Found 1 deadlock.
-前面的信息其实上次就看过了,后面就可以发现有个死锁了,
![]()
上面比较长,把主要的截出来,就是这边的,这点就很强大了。
-jmap
惯例还是看一下帮助信息
![]()
这个相对命令比较多,不过因为现在 dump 下来我们可能会用文件模式,然后将文件下载下来使用 mat 进行分析,所以可以使用
jmap -dump:live,format=b,file=heap.bin <pid>
命令照着上面看的就是打印活着的对象,然后以二进制格式,文件名叫 heap.bin 然后最后就是进程 id,打印出来以后可以用 mat 打开
![]()
这样就可以很清晰的看到应用里的各种信息,jmap 直接在命令中还可以看很多信息,比如使用jmap -histo <pid>打印对象的实例数和对象占用的内存
![]()
jmap -finalizerinfo <pid> 打印正在等候回收的对象
![]()
-小tips
对于一些应用内存已经占满了,jstack 和 jmap 可能会连不上的情况,可以使用-F参数强制打印线程或者 dump 文件,但是要注意这两者使用的用户必须与 java 进程启动用户一致,并且使用的 jdk 也要一致
-]]>
-
- Java
- Thread dump
- 问题排查
- 工具
-
-
- Java
- JPS
- JStack
- JMap
-
-
-
- 聊聊 Java 的类加载机制二
- /2021/06/13/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6%E4%BA%8C/
- 类加载器类加载机制中说来说去其实也逃不开类加载器这个话题,我们就来说下类加载器这个话题,Java 在 jdk1.2 以后开始有了
Java 虚拟机设计团队有意把加载阶段中的“通过一个类的全限定名来获取描述该类的二进制字节流”这个动作放到 Java 虚拟机外部去实现,以便让应用程序自己去决定如何去获取所需的类。实现这个动作的代码被称为“类加载器”(Class Loader).
其实在 Java 中类加载器有一个很常用的作用,比如一个类的唯一性,其实是由加载它的类加载器和这个类一起来确定这个类在虚拟机的唯一性,这里也参考下周志明书里的例子
-public class ClassLoaderTest {
+"C2 CompilerThread0" #6 daemon prio=9 os_prio=31 tid=0x00007fc9de89b000 nid=0x3403 waiting on condition [0x0000000000000000]
+ java.lang.Thread.State: RUNNABLE
- public static void main(String[] args) throws Exception {
- ClassLoader myLoader = new ClassLoader() {
- @Override
- public Class<?> loadClass(String name) throws ClassNotFoundException {
- try {
- String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class";
- InputStream is = getClass().getResourceAsStream(fileName);
- if (is == null) {
- return super.loadClass(name);
- }
- byte[] b = new byte[is.available()];
- is.read(b);
- return defineClass(name, b, 0, b.length);
- } catch (IOException e) {
- throw new ClassNotFoundException(name);
- }
- }
- };
- Object object = myLoader.loadClass("com.nicksxs.demo.ClassLoaderTest").newInstance();
- System.out.println(object.getClass());
- System.out.println(object instanceof ClassLoaderTest);
- }
-}
-可以看下结果
![]()
这里说明了当一个是由虚拟机的应用程序类加载器所加载的和另一个由自己写的自定义类加载器加载的,虽然是同一个类,但是 instanceof 的结果就是 false 的
-双亲委派
自 JDK1.2 以来,Java 一直有些三层类加载器、双亲委派的类加载架构
-启动类加载器
首先是启动类加载器,Bootstrap Class Loader,这个类加载器负责加载放在\lib目录,或者被-Xbootclasspath参数所指定的路径中存放的,而且是Java 虚拟机能够识别的(按照文件名识别,如 rt.jar、tools.jar,名字不符合的类库即使放在 lib 目录中,也不会被加载)类库加载到虚拟机的内存中,启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把家在请求为派给引导类加载器去处理,那直接使用 null 代替即可,可以看下 java.lang.ClassLoader.getClassLoader()方法的代码片段
-/**
- * Returns the class loader for the class. Some implementations may use
- * null to represent the bootstrap class loader. This method will return
- * null in such implementations if this class was loaded by the bootstrap
- * class loader.
- *
- * <p> If a security manager is present, and the caller's class loader is
- * not null and the caller's class loader is not the same as or an ancestor of
- * the class loader for the class whose class loader is requested, then
- * this method calls the security manager's {@code checkPermission}
- * method with a {@code RuntimePermission("getClassLoader")}
- * permission to ensure it's ok to access the class loader for the class.
- *
- * <p>If this object
- * represents a primitive type or void, null is returned.
- *
- * @return the class loader that loaded the class or interface
- * represented by this object.
- * @throws SecurityException
- * if a security manager exists and its
- * {@code checkPermission} method denies
- * access to the class loader for the class.
- * @see java.lang.ClassLoader
- * @see SecurityManager#checkPermission
- * @see java.lang.RuntimePermission
- */
- @CallerSensitive
- public ClassLoader getClassLoader() {
- ClassLoader cl = getClassLoader0();
- if (cl == null)
- return null;
- SecurityManager sm = System.getSecurityManager();
- if (sm != null) {
- ClassLoader.checkClassLoaderPermission(cl, Reflection.getCallerClass());
- }
- return cl;
- }
-扩展类加载器
这个类加载器是在类sun.misc.Launcher.ExtClassLoader中以 Java 代码的形式实现的,它负责在家\lib\ext 目录中,或者被 java.ext.dirs系统变量中所指定的路径中的所有类库,它其实目的是为了实现 Java 系统类库的扩展机制
-应用程序类加载器
这个类加载器是由sun.misc.Launcher.AppClassLoader实现,通过 java 代码,并且是 ClassLoader 类中的 getSystemClassLoader()方法的返回值,可以看一下代码
-/**
- * Returns the system class loader for delegation. This is the default
- * delegation parent for new <tt>ClassLoader</tt> instances, and is
- * typically the class loader used to start the application.
- *
- * <p> This method is first invoked early in the runtime's startup
- * sequence, at which point it creates the system class loader and sets it
- * as the context class loader of the invoking <tt>Thread</tt>.
- *
- * <p> The default system class loader is an implementation-dependent
- * instance of this class.
- *
- * <p> If the system property "<tt>java.system.class.loader</tt>" is defined
- * when this method is first invoked then the value of that property is
- * taken to be the name of a class that will be returned as the system
- * class loader. The class is loaded using the default system class loader
- * and must define a public constructor that takes a single parameter of
- * type <tt>ClassLoader</tt> which is used as the delegation parent. An
- * instance is then created using this constructor with the default system
- * class loader as the parameter. The resulting class loader is defined
- * to be the system class loader.
- *
- * <p> If a security manager is present, and the invoker's class loader is
- * not <tt>null</tt> and the invoker's class loader is not the same as or
- * an ancestor of the system class loader, then this method invokes the
- * security manager's {@link
- * SecurityManager#checkPermission(java.security.Permission)
- * <tt>checkPermission</tt>} method with a {@link
- * RuntimePermission#RuntimePermission(String)
- * <tt>RuntimePermission("getClassLoader")</tt>} permission to verify
- * access to the system class loader. If not, a
- * <tt>SecurityException</tt> will be thrown. </p>
- *
- * @return The system <tt>ClassLoader</tt> for delegation, or
- * <tt>null</tt> if none
- *
- * @throws SecurityException
- * If a security manager exists and its <tt>checkPermission</tt>
- * method doesn't allow access to the system class loader.
- *
- * @throws IllegalStateException
- * If invoked recursively during the construction of the class
- * loader specified by the "<tt>java.system.class.loader</tt>"
- * property.
- *
- * @throws Error
- * If the system property "<tt>java.system.class.loader</tt>"
- * is defined but the named class could not be loaded, the
- * provider class does not define the required constructor, or an
- * exception is thrown by that constructor when it is invoked. The
- * underlying cause of the error can be retrieved via the
- * {@link Throwable#getCause()} method.
- *
- * @revised 1.4
- */
- @CallerSensitive
- public static ClassLoader getSystemClassLoader() {
- initSystemClassLoader();
- if (scl == null) {
- return null;
- }
- SecurityManager sm = System.getSecurityManager();
- if (sm != null) {
- checkClassLoaderPermission(scl, Reflection.getCallerClass());
- }
- return scl;
- }
- private static synchronized void initSystemClassLoader() {
- if (!sclSet) {
- if (scl != null)
- throw new IllegalStateException("recursive invocation");
- // 主要的第一步是这
- sun.misc.Launcher l = sun.misc.Launcher.getLauncher();
- if (l != null) {
- Throwable oops = null;
- // 然后是这
- scl = l.getClassLoader();
- try {
- scl = AccessController.doPrivileged(
- new SystemClassLoaderAction(scl));
- } catch (PrivilegedActionException pae) {
- oops = pae.getCause();
- if (oops instanceof InvocationTargetException) {
- oops = oops.getCause();
- }
- }
- if (oops != null) {
- if (oops instanceof Error) {
- throw (Error) oops;
- } else {
- // wrap the exception
- throw new Error(oops);
- }
- }
- }
- sclSet = true;
- }
- }
-// 接着跟到sun.misc.Launcher#getClassLoader
-public ClassLoader getClassLoader() {
- return this.loader;
- }
-// 然后看到这 sun.misc.Launcher#Launcher
-public Launcher() {
- Launcher.ExtClassLoader var1;
- try {
- var1 = Launcher.ExtClassLoader.getExtClassLoader();
- } catch (IOException var10) {
- throw new InternalError("Could not create extension class loader", var10);
- }
+ Locked ownable synchronizers:
+ - None
- try {
- // 可以看到 就是 AppClassLoader
- this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);
- } catch (IOException var9) {
- throw new InternalError("Could not create application class loader", var9);
- }
+"Monitor Ctrl-Break" #5 daemon prio=5 os_prio=31 tid=0x00007fc9df0ca000 nid=0x3303 runnable [0x0000700005468000]
+ java.lang.Thread.State: RUNNABLE
+ at java.net.SocketInputStream.socketRead0(Native Method)
+ at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
+ at java.net.SocketInputStream.read(SocketInputStream.java:171)
+ at java.net.SocketInputStream.read(SocketInputStream.java:141)
+ at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284)
+ at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326)
+ at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)
+ - locked <0x00000006c001b760> (a java.io.InputStreamReader)
+ at java.io.InputStreamReader.read(InputStreamReader.java:184)
+ at java.io.BufferedReader.fill(BufferedReader.java:161)
+ at java.io.BufferedReader.readLine(BufferedReader.java:324)
+ - locked <0x00000006c001b760> (a java.io.InputStreamReader)
+ at java.io.BufferedReader.readLine(BufferedReader.java:389)
+ at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:64)
- Thread.currentThread().setContextClassLoader(this.loader);
- String var2 = System.getProperty("java.security.manager");
- if (var2 != null) {
- SecurityManager var3 = null;
- if (!"".equals(var2) && !"default".equals(var2)) {
- try {
- var3 = (SecurityManager)this.loader.loadClass(var2).newInstance();
- } catch (IllegalAccessException var5) {
- } catch (InstantiationException var6) {
- } catch (ClassNotFoundException var7) {
- } catch (ClassCastException var8) {
- }
- } else {
- var3 = new SecurityManager();
- }
+ Locked ownable synchronizers:
+ - None
- if (var3 == null) {
- throw new InternalError("Could not create SecurityManager: " + var2);
- }
+"Signal Dispatcher" #4 daemon prio=9 os_prio=31 tid=0x00007fc9de824000 nid=0x4503 runnable [0x0000000000000000]
+ java.lang.Thread.State: RUNNABLE
- System.setSecurityManager(var3);
- }
+ Locked ownable synchronizers:
+ - None
- }
-它负责加载用户类路径(ClassPath)上所有的类库,我们可以直接在代码中使用这个类加载器,如果我们的代码中没有自定义的类在加载器,一般情况下这个就是程序中默认的类加载器
-双亲委派模型
![]()
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试家在这个类,而是把这个请求为派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的家在请求最终都应该传送到最顶层的启动类加载器中,只有当父类加载器反馈自己无法完成加载请求(它的搜索范围中没有找到所需要的类)时,子加载器才会尝试自己去完成加载。
使用双亲委派模型来组织类加载器之间的关系,一个显而易见的好处就是 Java 中的类随着它的类加载器一起举杯了一种带有优先级的层次关系。例如类 java.lang.Object,它存放在 rt.jar 之中,无论哪一个类加载器要家在这个类,最终都是委派给处于模型最顶层的启动类加载器进行加载,因此 Object 类在程序的各种类加载器环境中都能够保证是同一个类。反之,如果没有使用双薪委派模型,都由各个类加载器自行去加载的话,如果用户自己也编写了一个名为 java.lang.Object 的类,并放在程序的 ClassPath 中,那系统中就会出现多个不同的 Object 类,Java 类型体系中最基础的行为也就无从保证,应用程序将会变得一片混乱。
可以来看下双亲委派模型的代码实现
-/**
- * Loads the class with the specified <a href="#name">binary name</a>. The
- * default implementation of this method searches for classes in the
- * following order:
- *
- * <ol>
- *
- * <li><p> Invoke {@link #findLoadedClass(String)} to check if the class
- * has already been loaded. </p></li>
- *
- * <li><p> Invoke the {@link #loadClass(String) <tt>loadClass</tt>} method
- * on the parent class loader. If the parent is <tt>null</tt> the class
- * loader built-in to the virtual machine is used, instead. </p></li>
- *
- * <li><p> Invoke the {@link #findClass(String)} method to find the
- * class. </p></li>
- *
- * </ol>
- *
- * <p> If the class was found using the above steps, and the
- * <tt>resolve</tt> flag is true, this method will then invoke the {@link
- * #resolveClass(Class)} method on the resulting <tt>Class</tt> object.
- *
- * <p> Subclasses of <tt>ClassLoader</tt> are encouraged to override {@link
- * #findClass(String)}, rather than this method. </p>
- *
- * <p> Unless overridden, this method synchronizes on the result of
- * {@link #getClassLoadingLock <tt>getClassLoadingLock</tt>} method
- * during the entire class loading process.
- *
- * @param name
- * The <a href="#name">binary name</a> of the class
- *
- * @param resolve
- * If <tt>true</tt> then resolve the class
- *
- * @return The resulting <tt>Class</tt> object
- *
- * @throws ClassNotFoundException
- * If the class could not be found
- */
- protected Class<?> loadClass(String name, boolean resolve)
- throws ClassNotFoundException
- {
- synchronized (getClassLoadingLock(name)) {
- // First, check if the class has already been loaded
- Class<?> c = findLoadedClass(name);
- if (c == null) {
- long t0 = System.nanoTime();
- try {
- if (parent != null) {
- // 委托父类加载
- c = parent.loadClass(name, false);
- } else {
- // 使用启动类加载器
- c = findBootstrapClassOrNull(name);
- }
- } catch (ClassNotFoundException e) {
- // ClassNotFoundException thrown if class not found
- // from the non-null parent class loader
- }
+"Finalizer" #3 daemon prio=8 os_prio=31 tid=0x00007fc9dd811800 nid=0x4f03 in Object.wait() [0x0000700005262000]
+ java.lang.Thread.State: WAITING (on object monitor)
+ at java.lang.Object.wait(Native Method)
+ - waiting on <0x00000006c0008348> (a java.lang.ref.ReferenceQueue$Lock)
+ at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144)
+ - locked <0x00000006c0008348> (a java.lang.ref.ReferenceQueue$Lock)
+ at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165)
+ at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:216)
- if (c == null) {
- // If still not found, then invoke findClass in order
- // to find the class.
- long t1 = System.nanoTime();
- // 调用自己的 findClass() 方法尝试进行加载
- c = findClass(name);
+ Locked ownable synchronizers:
+ - None
- // this is the defining class loader; record the stats
- sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
- sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
- sun.misc.PerfCounter.getFindClasses().increment();
- }
- }
- if (resolve) {
- resolveClass(c);
- }
- return c;
- }
- }
-破坏双亲委派
关于破坏双亲委派模型,第一次是在 JDK1.2 之后引入了双亲委派模型之前,那么在那之前已经有了类加载器,所以java.lang.ClassLoader 中添加了一个 protected 方法 findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在 loadClass()中编写代码。这个跟上面的逻辑其实类似,当父类加载失败,会调用 findClass()来完成加载;第二次是因为这个模型本身还有一些不足之处,比如 SPI 这种,所以有设计了线程下上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过 java.lang.Thread 类的 java.lang.Thread#setContextClassLoader() 进行设置,然后第三种是为了追求程序动态性,这里有涉及到了 osgi 等概念,就不展开了
+"Reference Handler" #2 daemon prio=10 os_prio=31 tid=0x00007fc9de02a000 nid=0x5003 in Object.wait() [0x000070000515f000]
+ java.lang.Thread.State: WAITING (on object monitor)
+ at java.lang.Object.wait(Native Method)
+ - waiting on <0x00000006c001b940> (a java.lang.ref.Reference$Lock)
+ at java.lang.Object.wait(Object.java:502)
+ at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
+ - locked <0x00000006c001b940> (a java.lang.ref.Reference$Lock)
+ at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
+
+ Locked ownable synchronizers:
+ - None
+
+"VM Thread" os_prio=31 tid=0x00007fc9df00b800 nid=0x2c03 runnable
+
+"GC task thread#0 (ParallelGC)" os_prio=31 tid=0x00007fc9de805000 nid=0x1e07 runnable
+
+"GC task thread#1 (ParallelGC)" os_prio=31 tid=0x00007fc9de003800 nid=0x2a03 runnable
+
+"GC task thread#2 (ParallelGC)" os_prio=31 tid=0x00007fc9df002000 nid=0x5403 runnable
+
+"GC task thread#3 (ParallelGC)" os_prio=31 tid=0x00007fc9df002800 nid=0x5203 runnable
+
+"VM Periodic Task Thread" os_prio=31 tid=0x00007fc9df11a800 nid=0x3a03 waiting on condition
+
+JNI global references: 1087
+
+
+Found one Java-level deadlock:
+=============================
+"mythread2":
+ waiting for ownable synchronizer 0x000000076f5d4330, (a java.util.concurrent.locks.ReentrantLock$NonfairSync),
+ which is held by "mythread1"
+"mythread1":
+ waiting for ownable synchronizer 0x000000076f5d4360, (a java.util.concurrent.locks.ReentrantLock$NonfairSync),
+ which is held by "mythread2"
+
+Java stack information for the threads listed above:
+===================================================
+"mythread2":
+ at sun.misc.Unsafe.park(Native Method)
+ - parking to wait for <0x000000076f5d4330> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
+ at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
+ at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
+ at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
+ at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
+ at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
+ at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
+ at com.nicksxs.thread_dump_demo.ThreadDumpDemoApplication$2.run(ThreadDumpDemoApplication.java:34)
+"mythread1":
+ at sun.misc.Unsafe.park(Native Method)
+ - parking to wait for <0x000000076f5d4360> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
+ at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
+ at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
+ at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
+ at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
+ at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
+ at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
+ at com.nicksxs.thread_dump_demo.ThreadDumpDemoApplication$1.run(ThreadDumpDemoApplication.java:22)
+
+Found 1 deadlock.
+前面的信息其实上次就看过了,后面就可以发现有个死锁了,
![]()
上面比较长,把主要的截出来,就是这边的,这点就很强大了。
+jmap
惯例还是看一下帮助信息
![]()
这个相对命令比较多,不过因为现在 dump 下来我们可能会用文件模式,然后将文件下载下来使用 mat 进行分析,所以可以使用
jmap -dump:live,format=b,file=heap.bin <pid>
命令照着上面看的就是打印活着的对象,然后以二进制格式,文件名叫 heap.bin 然后最后就是进程 id,打印出来以后可以用 mat 打开
![]()
这样就可以很清晰的看到应用里的各种信息,jmap 直接在命令中还可以看很多信息,比如使用jmap -histo <pid>打印对象的实例数和对象占用的内存
![]()
jmap -finalizerinfo <pid> 打印正在等候回收的对象
![]()
+小tips
对于一些应用内存已经占满了,jstack 和 jmap 可能会连不上的情况,可以使用-F参数强制打印线程或者 dump 文件,但是要注意这两者使用的用户必须与 java 进程启动用户一致,并且使用的 jdk 也要一致
]]>
Java
+ Thread dump
+ 问题排查
+ 工具
Java
- 类加载
- 加载
- 验证
- 准备
- 解析
- 初始化
- 链接
- 双亲委派
+ JPS
+ JStack
+ JMap
- 聊聊 Linux 下的 top 命令
- /2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
- top 命令在日常的 Linux 使用中,特别是做一些服务器的简单状态查看,排查故障都起了比较大的作用,但是由于这个命令看到的东西比较多,一般只会看部分,或者说像我这样就会比较片面地看一些信息,比如默认是进程维度的,可以在启动命令的时候加-H进入线程模式
--H :Threads-mode operation
- Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later
- this can be changed with the `H' interactive command.
-这样就能用在 Java 中去 jstack 中找到对应的线程
其实还有比较重要的两个操作,
一个是在 top 启动状态下,按c键,这样能把比如说是一个 Java 进程,具体的进程命令显示出来
像这样
执行前是这样
![]()
执行后是这样
![]()
第二个就是排序了
-SORTING of task window
+ 聊聊 Sharding-Jdbc 分库分表下的分页方案
+ /2022/01/09/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E4%B8%8B%E7%9A%84%E5%88%86%E9%A1%B5%E6%96%B9%E6%A1%88/
+ 前面在聊 Sharding-Jdbc 的时候看到了一篇文章,关于一个分页的查询,一直比较直接的想法就是分库分表下的分页是非常不合理的,一般我们的实操方案都是分表加上 ES 搜索做分页,或者通过合表读写分离的方案,因为对于 sharding-jdbc 如果没有带分表键,查询基本都是只能在所有分表都执行一遍,然后再加上分页,基本上是分页越大后续的查询越耗资源,但是仔细的去想这个细节还是这次,就简单说说
首先就是我的分表结构
+CREATE TABLE `student_time_0` (
+ `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
+ `user_id` int(11) NOT NULL,
+ `name` varchar(200) COLLATE utf8_bin DEFAULT NULL,
+ `age` tinyint(3) unsigned DEFAULT NULL,
+ `create_time` bigint(20) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=674 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
+有这样的三个表,student_time_0, student_time_1, student_time_2, 以 user_id 作为分表键,根据表数量取模作为分表依据
这里先构造点数据,
+insert into student_time (`name`, `user_id`, `age`, `create_time`) values (?, ?, ?, ?)
+主要是为了保证 create_time 唯一比较好说明问题,
+int i = 0;
+try (
+ Connection conn = dataSource.getConnection();
+ PreparedStatement ps = conn.prepareStatement(insertSql)) {
+ do {
+ ps.setString(1, localName + new Random().nextInt(100));
+ ps.setLong(2, 10086L + (new Random().nextInt(100)));
+ ps.setInt(3, 18);
+ ps.setLong(4, new Date().getTime());
+
+
+ int result = ps.executeUpdate();
+ LOGGER.info("current execute result: {}", result);
+ Thread.sleep(new Random().nextInt(100));
+ i++;
+ } while (i <= 2000);
+三个表的数据分别是 673,678,650,说明符合预期了,各个表数据不一样,接下来比如我们想要做一个这样的分页查询
+select * from student_time ORDER BY create_time ASC limit 1000, 5;
+student_time 对于我们使用的 sharding-jdbc 来说当然是逻辑表,首先从一无所知去想这个查询如果我们自己来处理应该是怎么做,
首先是不是可以每个表都从 333 开始取 5 条数据,类似于下面的查询,然后进行 15 条的合并重排序获取前面的 5 条
+select * from student_time_0 ORDER BY create_time ASC limit 333, 5;
+select * from student_time_1 ORDER BY create_time ASC limit 333, 5;
+select * from student_time_2 ORDER BY create_time ASC limit 333, 5;
+忽略前面 limit 差的 1,这个结果除非三个表的分布是绝对的均匀,否则结果肯定会出现一定的偏差,以为每个表的 333 这个位置对于其他表来说都不一定是一样的,这样对于最后整体的结果,就会出现偏差
因为一直在纠结怎么让这个更直观的表现出来,所以尝试画了个图
![]()
黑色的框代表我从每个表里按排序从 334 到 338 的 5 条数据, 他们在每个表里都是代表了各自正确的排序值,但是对于我们想要的其实是合表后的 1001,1005 这五条,然后我们假设总的排序值位于前 1000 的分布是第 0 个表是 320 条,第 1 个表是 340 条,第 2 个表是 340 条,那么可以明显地看出来我这么查的结果简单合并肯定是不对的。
那么 sharding-jdbc 是如何保证这个结果的呢,其实就是我在每个表里都查分页偏移量和分页大小那么多的数据,在我这个例子里就是对于 0,1,2 三个分表每个都查 1005 条数据,即使我的数据不平衡到最极端的情况,前 1005 条数据都出在某个分表中,也可以正确获得最后的结果,但是明显的问题就是大分页,数据较多,就会导致非常大的问题,即使如 sharding-jdbc 对于合并排序的优化做得比较好,也还是需要传输那么大量的数据,并且查询也耗时,那么有没有解决方案呢,应该说有两个,或者说主要是想讲后者
第一个办法是像这种查询,如果业务上不需要进行跳页,而是只给下一页,那么我们就能把前一次的最大偏移量的 create_time 记录下来,下一页就可以拿着这个偏移量进行查询,这个比较简单易懂,就不多说了
第二个办法是看的58 沈剑的一篇文章,尝试理解讲述一下,
这个办法的第一步跟前面那个错误的方法或者说不准确的方法一样,先是将分页偏移量平均后在三个表里进行查询
+t0
+334 10158 nick95 18 1641548941767
+335 10098 nick11 18 1641548941879
+336 10167 nick51 18 1641548942089
+337 10167 nick3 18 1641548942119
+338 10170 nick57 18 1641548942169
- For compatibility, this top supports most of the former top sort keys. Since this is primarily a service to former top users, these commands
- do not appear on any help screen.
- command sorted-field supported
- A start time (non-display) No
- M %MEM Yes
- N PID Yes
- P %CPU Yes
- T TIME+ Yes
- Before using any of the following sort provisions, top suggests that you temporarily turn on column highlighting using the `x' interactive com‐
- mand. That will help ensure that the actual sort environment matches your intent.
+t1
+334 10105 nick98 18 1641548939071 最小
+335 10174 nick94 18 1641548939377
+336 10129 nick85 18 1641548939442
+337 10141 nick84 18 1641548939480
+338 10096 nick74 18 1641548939668
- The following interactive commands will only be honored when the current sort field is visible. The sort field might not be visible because:
- 1) there is insufficient Screen Width
- 2) the `f' interactive command turned it Off
+t2
+334 10184 nick11 18 1641548945075
+335 10109 nick93 18 1641548945382
+336 10181 nick41 18 1641548945583
+337 10130 nick80 18 1641548945993
+338 10184 nick19 18 1641548946294 最大
+然后要做什么呢,其实目标比较明白,因为前面那种方法其实就是我知道了前一页的偏移量,所以可以直接当做条件来进行查询,那这里我也想着拿到这个条件,所以我将第一遍查出来的最小的 create_time 和最大的 create_time 找出来,然后再去三个表里查询,其实主要是最小值,因为我拿着最小值去查以后我就能知道这个最小值在每个表里处在什么位置,
+t0
+322 10161 nick81 18 1641548939284
+323 10113 nick16 18 1641548939393
+324 10110 nick56 18 1641548939577
+325 10116 nick69 18 1641548939588
+326 10173 nick51 18 1641548939646
- < :Move-Sort-Field-Left
- Moves the sort column to the left unless the current sort field is the first field being displayed.
+t1
+334 10105 nick98 18 1641548939071
+335 10174 nick94 18 1641548939377
+336 10129 nick85 18 1641548939442
+337 10141 nick84 18 1641548939480
+338 10096 nick74 18 1641548939668
- > :Move-Sort-Field-Right
- Moves the sort column to the right unless the current sort field is the last field being displayed.
-查看 man page 可以找到这一段,其实一般 man page 都是最细致的,只不过因为太多了,有时候懒得看,这里可以通过大写 M 和大写 P 分别按内存和 CPU 排序,下面还有两个小技巧,通过按 x 可以将当前活跃的排序列用不同颜色标出来,然后可以通过<和>直接左右移动排序列
+t2
+297 10136 nick28 18 1641548939161
+298 10142 nick68 18 1641548939177
+299 10124 nick41 18 1641548939237
+300 10148 nick87 18 1641548939510
+301 10169 nick23 18 1641548939715
+我只贴了前五条数据,为了方便知道偏移量,每个分表都使用了自增主键,我们可以看到前一次查询的最小值分别在其他两个表里的位置分别是 322-1 和 297-1,那么对于总体来说这个时间应该是在 322 - 1 + 333 + 297 - 1 = 951,那这样子我只要对后面的数据最多每个表查 1000 - 951 + 5 = 54 条数据再进行合并排序就可以获得最终正确的结果。
这个就是传说中的二次查询法。
]]>
- Linux
- 命令
- 小技巧
- top
- top
- 排序
+ Java
- 排序
- linux
- 小技巧
- top
+ Java
+ Sharding-Jdbc
@@ -18336,32 +18341,51 @@ result = result
- 聊聊 Sharding-Jdbc 的简单原理初篇
- /2021/12/26/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E5%8E%9F%E7%90%86%E5%88%9D%E7%AF%87/
- 在上一篇 sharding-jdbc 的介绍中其实碰到过一个问题,这里也引出了一个比较有意思的话题
就是我在执行 query 的时候犯过一个比较难发现的错误,
-ResultSet resultSet = ps.executeQuery(sql);
-实际上应该是
-ResultSet resultSet = ps.executeQuery();
-而这里的差别就是,是否传 sql 这个参数,首先我们要知道这个 ps 是什么,它也是个接口java.sql.PreparedStatement,而真正的实现类是org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement,我们来看下继承关系
![]()
这里可以看到继承关系里有org.apache.shardingsphere.driver.jdbc.unsupported.AbstractUnsupportedOperationPreparedStatement
那么在我上面的写错的代码里
-@Override
-public final ResultSet executeQuery(final String sql) throws SQLException {
- throw new SQLFeatureNotSupportedException("executeQuery with SQL for PreparedStatement");
-}
-这个报错一开始让我有点懵,后来点进去了发现是这么个异常,但是我其实一开始是用的更新语句,以为更新不支持,因为平时使用没有深究过,以为是不是需要使用 Mybatis 才可以执行更新,但是理论上也不应该,再往上看原来这些异常是由 sharding-jdbc 包装的,也就是在上面说的AbstractUnsupportedOperationPreparedStatement,这其实也是一种设计思想,本身 jdbc 提供了一系列接口,由各家去支持,包括 mysql,sql server,oracle 等,而正因为这个设计,所以 sharding-jdbc 也可以在此基础上进行设计,我们可以总体地看下 sharding-jdbc 的实现基础
![]()
看了前面ShardingSpherePreparedStatement的继承关系,应该也能猜到这里的几个类都是实现了 jdbc 的基础接口,
![]()
在前一篇的 demo 中的
-Connection conn = dataSource.getConnection();
-其实就获得了org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection#ShardingSphereConnection
然后获得java.sql.PreparedStatement
-PreparedStatement ps = conn.prepareStatement(sql)
-就是获取了org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement
然后就是执行
-ResultSet resultSet = ps.executeQuery();
-然后获得结果
org.apache.shardingsphere.driver.jdbc.core.resultset.ShardingSphereResultSet
-其实像 mybatis 也是基于这样去实现的
+ 聊聊 Linux 下的 top 命令
+ /2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
+ top 命令在日常的 Linux 使用中,特别是做一些服务器的简单状态查看,排查故障都起了比较大的作用,但是由于这个命令看到的东西比较多,一般只会看部分,或者说像我这样就会比较片面地看一些信息,比如默认是进程维度的,可以在启动命令的时候加-H进入线程模式
+-H :Threads-mode operation
+ Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later
+ this can be changed with the `H' interactive command.
+这样就能用在 Java 中去 jstack 中找到对应的线程
其实还有比较重要的两个操作,
一个是在 top 启动状态下,按c键,这样能把比如说是一个 Java 进程,具体的进程命令显示出来
像这样
执行前是这样
![]()
执行后是这样
![]()
第二个就是排序了
+SORTING of task window
+
+ For compatibility, this top supports most of the former top sort keys. Since this is primarily a service to former top users, these commands
+ do not appear on any help screen.
+ command sorted-field supported
+ A start time (non-display) No
+ M %MEM Yes
+ N PID Yes
+ P %CPU Yes
+ T TIME+ Yes
+
+ Before using any of the following sort provisions, top suggests that you temporarily turn on column highlighting using the `x' interactive com‐
+ mand. That will help ensure that the actual sort environment matches your intent.
+
+ The following interactive commands will only be honored when the current sort field is visible. The sort field might not be visible because:
+ 1) there is insufficient Screen Width
+ 2) the `f' interactive command turned it Off
+
+ < :Move-Sort-Field-Left
+ Moves the sort column to the left unless the current sort field is the first field being displayed.
+
+ > :Move-Sort-Field-Right
+ Moves the sort column to the right unless the current sort field is the last field being displayed.
+查看 man page 可以找到这一段,其实一般 man page 都是最细致的,只不过因为太多了,有时候懒得看,这里可以通过大写 M 和大写 P 分别按内存和 CPU 排序,下面还有两个小技巧,通过按 x 可以将当前活跃的排序列用不同颜色标出来,然后可以通过<和>直接左右移动排序列
]]>
- Java
+ Linux
+ 命令
+ 小技巧
+ top
+ top
+ 排序
- Java
- Sharding-Jdbc
+ 排序
+ linux
+ 小技巧
+ top
@@ -18470,15 +18494,32 @@ result = result
- 聊一下关于怎么陪伴学习
- /2022/11/06/%E8%81%8A%E4%B8%80%E4%B8%8B%E5%85%B3%E4%BA%8E%E6%80%8E%E4%B9%88%E9%99%AA%E4%BC%B4%E5%AD%A6%E4%B9%A0/
- 这是一次开车过程中结合网上的一些微博想到的,开车是之前LD买了车后,陪领导练车,其实在一开始练车的时候,我们已经是找了相对很空的封闭路段,路上基本很少有车,偶尔有一辆车,但是LD还是很害怕,车速还只有十几的时候,还很远的对面来车的时候就觉得很慌了,这个时候如果以常理肯定会说这样子完全不用怕,如果克服恐惧真的这么容易的话,问题就不会那么纠结了,人生是很难完全感同身受的,唯有降低预设的基准让事情从头理清楚,害怕了我们就先休息,有车了我们就停下,先适应完全没车的情况,变得更慢一点,如果这时候着急一点,反而会起到反效果,比如只是说不要怕,接着开,甚至有点厌烦了,那基本这个练车也不太成得了了,而正好是有耐心的一起慢慢练习,还有就是第二件是切身体会,就是当道路本来是两条道,但是封了一条的时候,这时候开车如果是像我这样的新手,如果开车时左右边看着的话,车肯定开不好,因为那样会一直左右调整,反而更容易控制不好左右的距离,蹭到旁边的隔离栏,正确的方式应该是专注于正前方的路,这样才能保证左右边距离尽可能均匀,而不是顾左失右或者顾右失左,所以很多陪伴学习需要注意的是方式和耐心,能够识别到关键点那是最好的,但是有时候更需要的是耐心,纯靠耐心不一定能解决问题,但是可能会找到问题关键点。
+ 聊聊 Sharding-Jdbc 的简单原理初篇
+ /2021/12/26/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E5%8E%9F%E7%90%86%E5%88%9D%E7%AF%87/
+ 在上一篇 sharding-jdbc 的介绍中其实碰到过一个问题,这里也引出了一个比较有意思的话题
就是我在执行 query 的时候犯过一个比较难发现的错误,
+ResultSet resultSet = ps.executeQuery(sql);
+实际上应该是
+ResultSet resultSet = ps.executeQuery();
+而这里的差别就是,是否传 sql 这个参数,首先我们要知道这个 ps 是什么,它也是个接口java.sql.PreparedStatement,而真正的实现类是org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement,我们来看下继承关系
![]()
这里可以看到继承关系里有org.apache.shardingsphere.driver.jdbc.unsupported.AbstractUnsupportedOperationPreparedStatement
那么在我上面的写错的代码里
+@Override
+public final ResultSet executeQuery(final String sql) throws SQLException {
+ throw new SQLFeatureNotSupportedException("executeQuery with SQL for PreparedStatement");
+}
+这个报错一开始让我有点懵,后来点进去了发现是这么个异常,但是我其实一开始是用的更新语句,以为更新不支持,因为平时使用没有深究过,以为是不是需要使用 Mybatis 才可以执行更新,但是理论上也不应该,再往上看原来这些异常是由 sharding-jdbc 包装的,也就是在上面说的AbstractUnsupportedOperationPreparedStatement,这其实也是一种设计思想,本身 jdbc 提供了一系列接口,由各家去支持,包括 mysql,sql server,oracle 等,而正因为这个设计,所以 sharding-jdbc 也可以在此基础上进行设计,我们可以总体地看下 sharding-jdbc 的实现基础
![]()
看了前面ShardingSpherePreparedStatement的继承关系,应该也能猜到这里的几个类都是实现了 jdbc 的基础接口,
![]()
在前一篇的 demo 中的
+Connection conn = dataSource.getConnection();
+其实就获得了org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection#ShardingSphereConnection
然后获得java.sql.PreparedStatement
+PreparedStatement ps = conn.prepareStatement(sql)
+就是获取了org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement
然后就是执行
+ResultSet resultSet = ps.executeQuery();
+然后获得结果
org.apache.shardingsphere.driver.jdbc.core.resultset.ShardingSphereResultSet
+其实像 mybatis 也是基于这样去实现的
]]>
- 生活
+ Java
- 生活
+ Java
+ Sharding-Jdbc
@@ -18502,6 +18543,102 @@ void ReadView::prepare(trx_id_t id) {
SELECT … FOR UPDATE sets an exclusive next-key lock on every record the search encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
对于一个 for update 查询,在 RR 级别下,会设置一个 next-key lock在每一条被查询到的记录上,next-lock 又是啥呢,其实就是 gap 锁和 record 锁的结合体,比如我在数据库里有 id 是 1,3,5,7,10,对于上面那条查询,查出来的结果就是 1,3,5,7,那么按照文档里描述的,对于这几条记录都会加上next-key lock,也就是(-∞, 1], (1, 3], (3, 5], (5, 7], (7, 10) 这些区间和记录会被锁起来,不让插入,再唠叨一下呢,就是其实如果是只读的事务,光 read view 一致性读就够了,如果是有写操作的呢,就需要锁了。
+]]>
+
+ Mysql
+ C
+ 数据结构
+ 源码
+ Mysql
+
+
+ mysql
+ 数据结构
+ 源码
+ mvcc
+ read view
+ gap lock
+ next-key lock
+ 幻读
+
+
+
+ 聊聊 dubbo 的线程池
+ /2021/04/04/%E8%81%8A%E8%81%8A-dubbo-%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/
+ 之前没注意到这一块,只是比较模糊的印象 dubbo 自己基于 ThreadPoolExecutor 定义了几个线程池,但是没具体看过,主要是觉得就是为了避免使用 jdk 自带的那几个(java.util.concurrent.Executors),防止出现那些问题
看下代码目录主要是这几个
![]() +
+
+- FixedThreadPool:创建一个复用固定个数线程的线程池。
简单看下代码public Executor getExecutor(URL url) {
+ String name = url.getParameter("threadname", "Dubbo");
+ int threads = url.getParameter("threads", 200);
+ int queues = url.getParameter("queues", 0);
+ return new ThreadPoolExecutor(threads, threads, 0L, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
+ }
+可以看到核心线程数跟最大线程数一致,也就是说就不会在核心线程数和最大线程数之间动态变化了
+- LimitedThreadPool:创建一个线程池,这个线程池中线程个数随着需要量动态增加,但是数量不超过配置的阈值的个数,另外空闲线程不会被回收,会一直存在。
public Executor getExecutor(URL url) {
+ String name = url.getParameter("threadname", "Dubbo");
+ int cores = url.getParameter("corethreads", 0);
+ int threads = url.getParameter("threads", 200);
+ int queues = url.getParameter("queues", 0);
+ return new ThreadPoolExecutor(cores, threads, 9223372036854775807L, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
+ }
+这个特点主要是创建了保活时间特别长,即可以认为不会被回收了
+- EagerThreadPool :创建一个线程池,这个线程池当所有核心线程都处于忙碌状态时候,创建新的线程来执行新任务,而不是把任务放入线程池阻塞队列。
public Executor getExecutor(URL url) {
+ String name = url.getParameter("threadname", "Dubbo");
+ int cores = url.getParameter("corethreads", 0);
+ int threads = url.getParameter("threads", 2147483647);
+ int queues = url.getParameter("queues", 0);
+ int alive = url.getParameter("alive", 60000);
+ TaskQueue<Runnable> taskQueue = new TaskQueue(queues <= 0 ? 1 : queues);
+ EagerThreadPoolExecutor executor = new EagerThreadPoolExecutor(cores, threads, (long)alive, TimeUnit.MILLISECONDS, taskQueue, new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
+ taskQueue.setExecutor(executor);
+ return executor;
+ }
+这个是改动最多的一个了,因为需要实现这个机制,有兴趣的可以详细看下
+- CachedThreadPool: 创建一个自适应线程池,当线程处于空闲1分钟时候,线程会被回收,当有新请求到来时候会创建新线程
public Executor getExecutor(URL url) {
+ String name = url.getParameter("threadname", "Dubbo");
+ int cores = url.getParameter("corethreads", 0);
+ int threads = url.getParameter("threads", 2147483647);
+ int queues = url.getParameter("queues", 0);
+ int alive = url.getParameter("alive", 60000);
+ return new ThreadPoolExecutor(cores, threads, (long)alive, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
+ }
+这里可以看到线程池的配置,核心是 0,最大线程数是 2147483647,保活时间是一分钟
只是非常简略的介绍下,有兴趣可以自行阅读代码。
+
+]]>
+
+ Java
+ Dubbo - 线程池
+ Dubbo
+ 线程池
+ ThreadPool
+
+
+ Java
+ Dubbo
+ ThreadPool
+ 线程池
+ FixedThreadPool
+ LimitedThreadPool
+ EagerThreadPool
+ CachedThreadPool
+
+
+
+ 聊聊 mysql 的 MVCC 续续篇之锁分析
+ /2020/05/10/%E8%81%8A%E8%81%8A-mysql-%E7%9A%84-MVCC-%E7%BB%AD%E7%BB%AD%E7%AF%87%E4%B9%8B%E5%8A%A0%E9%94%81%E5%88%86%E6%9E%90/
+ 看完前面两篇水文之后,感觉不得不来分析下 mysql 的锁了,其实前面说到幻读的时候是有个前提没提到的,比如一个select * from table1 where id = 1这种查询语句其实是不会加传说中的锁的,当然这里是指在 RR 或者 RC 隔离级别下,
看一段 mysql官方文档
+
+SELECT ... FROM is a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set to SERIALIZABLE. For SERIALIZABLE level, the search sets shared next-key locks on the index records it encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
+
+纯粹的这种一致性读,实际读取的是快照,也就是基于 read view 的读取方式,除非当前隔离级别是SERIALIZABLE
但是对于以下几类
+
+select * from table where ? lock in share mode;select * from table where ? for update;insert into table values (...);update table set ? where ?;delete from table where ?;
+除了第一条是 S 锁之外,其他都是 X 排他锁,这边在顺带下,S 锁表示共享锁, X 表示独占锁,同为 S 锁之间不冲突,S 与 X,X 与 S,X 与 X 之间都冲突,也就是加了前者,后者就加不上了
我们知道对于 RC 级别会出现幻读现象,对于 RR 级别不会出现,主要的区别是 RR 级别下对于以上的加锁读取都根据情况加上了 gap 锁,那么是不是 RR 级别下以上所有的都是要加 gap 锁呢,当然不是
举个例子,RR 事务隔离级别下,table1 有个主键id 字段
select * from table1 where id = 10 for update
这条语句要加 gap 锁吗?
答案是不需要,这里其实算是我看了这么久的一点自己的理解,啥时候要加 gap 锁,判断的条件是根据我查询的数据是否会因为不加 gap 锁而出现数量的不一致,我上面这条查询语句,在什么情况下会出现查询结果数量不一致呢,只要在这条记录被更新或者删除的时候,有没有可能我第一次查出来一条,第二次变成两条了呢,不可能,因为是主键索引。
再变更下这个题的条件,当 id 不是主键,但是是唯一索引,这样需要怎么加锁,注意问题是怎么加锁,不是需不需要加 gap 锁,这里呢就是稍微延伸一下,把聚簇索引(主键索引)和二级索引带一下,当 id 不是主键,说明是个二级索引,但是它是唯一索引,体会下,首先对于 id = 10这个二级索引肯定要加锁,要不要锁 gap 呢,不用,因为是唯一索引,id = 10 只可能有这一条记录,然后呢,这样是不是就好了,还不行,因为啥,因为它是二级索引,对应的主键索引的记录才是真正的数据,万一被更新掉了咋办,所以在 id = 10 对应的主键索引上也需要加上锁(默认都是 record lock行锁),那主键索引上要不要加 gap 呢,也不用,也是精确定位到这一条记录
最后呢,当 id 不是主键,也不是唯一索引,只是个普通的索引,这里就需要大名鼎鼎的 gap 锁了,
是时候画个图了
![]()
其实核心的目的还是不让这个 id=10 的记录不会出现幻读,那么就需要在 id 这个索引上加上三个 gap 锁,主键索引上就不用了,在 id 索引上已经控制住了id = 10 不会出现幻读,主键索引上这两条对应的记录已经锁了,所以就这样 OK 了
]]>
Mysql
@@ -18601,6 +18738,37 @@ constexpr size_t DATA_ROLL_PTR_LEN read view
+
+ 聊聊 redis 缓存的应用问题
+ /2021/01/31/%E8%81%8A%E8%81%8A-redis-%E7%BC%93%E5%AD%98%E7%9A%84%E5%BA%94%E7%94%A8%E9%97%AE%E9%A2%98/
+ 前面写过一系列的 redis 源码分析的,但是实际上很多的问题还是需要结合实际的使用,然后其实就避不开缓存使用的三个著名问题,穿透,击穿和雪崩,这三个概念也是有着千丝万缕的关系,
+缓存穿透
缓存穿透是指当数据库中本身就不存在这个数据的时候,使用一般的缓存策略时访问不到缓存后就访问数据库,但是因为数据库也没数据,所以如果不做任何策略优化的话,这类数据就每次都会访问一次数据库,对数据库压力也会比较大。
+缓存击穿
缓存击穿跟穿透比较类似的,都是访问缓存不在,然后去访问数据库,与穿透不一样的是击穿是在数据库中存在数据,但是可能由于第一次访问,或者缓存过期了,需要访问到数据库,这对于访问量小的情况其实算是个正常情况,但是随着请求量变高就会引发一些性能隐患。
+缓存雪崩
缓存雪崩就是击穿的大规模集群效应,当大量的缓存过期失效的时候,这些请求都是直接访问到数据库了,会对数据库造成很大的压力。
+对于以上三种场景也有一些比较常见的解决方案,但也不能说是万无一失的,需要随着业务去寻找合适的方案
+解决缓存穿透
对于数据库中就没这个数据的时候,一种是可以对这个 key 设置下空值,即以一个特定的表示是数据库不存在的,这种情况需要合理地调整过期时间,当这个 key 在数据库中有数据了的话,也需要有策略去更新这个值,并且如果这类 key 非常多,这个方法就会不太合适,就可以使用第二种方法,就是布隆过滤器,bloom filter,前置一个布隆过滤器,当这个 key 在数据库不存在的话,先用布隆过滤器挡一道,如果不在的话就直接返回了,当然布隆过滤器不是绝对的准确的
+解决缓存击穿
当一个 key 的缓存过期了,如果大量请求过来访问这个 key,请求都会落在数据库里,这个时候就可以使用一些类似于互斥锁的方式去让一个线程去访问数据库,更新缓存,但是这里其实也有个问题,就是如果是热点 key 其实这种方式也比较危险,万一更新失败,或者更新操作的时候耗时比较久,就会有一大堆请求卡在那,这种情况可能需要有一些异步提前刷新缓存,可以结合具体场景选择方式
+解决缓存雪崩
雪崩的情况是指大批量的 key 都一起过期了,击穿的放大版,大批量的请求都打到数据库上了,一方面有可能直接缓存不可用了,就需要用集群化高可用的缓存服务,然后对于实际使用中也可以使用本地缓存结合 redis 缓存,去提高可用性,再配合一些限流措施,然后就是缓存使用过程总的过期时间最好能加一些随机值,防止在同一时间过期而导致雪崩,结合互斥锁防止大量请求打到数据库。
+]]>
+
+ Redis
+ 应用
+ 缓存
+ 缓存
+ 穿透
+ 击穿
+ 雪崩
+
+
+ Redis
+ 缓存穿透
+ 缓存击穿
+ 缓存雪崩
+ 布隆过滤器
+ bloom filter
+ 互斥锁
+
+
聊聊 mysql 索引的一些细节
/2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
@@ -18666,37 +18834,6 @@ $
procedure
-
- 聊聊 redis 缓存的应用问题
- /2021/01/31/%E8%81%8A%E8%81%8A-redis-%E7%BC%93%E5%AD%98%E7%9A%84%E5%BA%94%E7%94%A8%E9%97%AE%E9%A2%98/
- 前面写过一系列的 redis 源码分析的,但是实际上很多的问题还是需要结合实际的使用,然后其实就避不开缓存使用的三个著名问题,穿透,击穿和雪崩,这三个概念也是有着千丝万缕的关系,
-缓存穿透
缓存穿透是指当数据库中本身就不存在这个数据的时候,使用一般的缓存策略时访问不到缓存后就访问数据库,但是因为数据库也没数据,所以如果不做任何策略优化的话,这类数据就每次都会访问一次数据库,对数据库压力也会比较大。
-缓存击穿
缓存击穿跟穿透比较类似的,都是访问缓存不在,然后去访问数据库,与穿透不一样的是击穿是在数据库中存在数据,但是可能由于第一次访问,或者缓存过期了,需要访问到数据库,这对于访问量小的情况其实算是个正常情况,但是随着请求量变高就会引发一些性能隐患。
-缓存雪崩
缓存雪崩就是击穿的大规模集群效应,当大量的缓存过期失效的时候,这些请求都是直接访问到数据库了,会对数据库造成很大的压力。
-对于以上三种场景也有一些比较常见的解决方案,但也不能说是万无一失的,需要随着业务去寻找合适的方案
-解决缓存穿透
对于数据库中就没这个数据的时候,一种是可以对这个 key 设置下空值,即以一个特定的表示是数据库不存在的,这种情况需要合理地调整过期时间,当这个 key 在数据库中有数据了的话,也需要有策略去更新这个值,并且如果这类 key 非常多,这个方法就会不太合适,就可以使用第二种方法,就是布隆过滤器,bloom filter,前置一个布隆过滤器,当这个 key 在数据库不存在的话,先用布隆过滤器挡一道,如果不在的话就直接返回了,当然布隆过滤器不是绝对的准确的
-解决缓存击穿
当一个 key 的缓存过期了,如果大量请求过来访问这个 key,请求都会落在数据库里,这个时候就可以使用一些类似于互斥锁的方式去让一个线程去访问数据库,更新缓存,但是这里其实也有个问题,就是如果是热点 key 其实这种方式也比较危险,万一更新失败,或者更新操作的时候耗时比较久,就会有一大堆请求卡在那,这种情况可能需要有一些异步提前刷新缓存,可以结合具体场景选择方式
-解决缓存雪崩
雪崩的情况是指大批量的 key 都一起过期了,击穿的放大版,大批量的请求都打到数据库上了,一方面有可能直接缓存不可用了,就需要用集群化高可用的缓存服务,然后对于实际使用中也可以使用本地缓存结合 redis 缓存,去提高可用性,再配合一些限流措施,然后就是缓存使用过程总的过期时间最好能加一些随机值,防止在同一时间过期而导致雪崩,结合互斥锁防止大量请求打到数据库。
-]]>
-
- Redis
- 应用
- 缓存
- 缓存
- 穿透
- 击穿
- 雪崩
-
-
- Redis
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 布隆过滤器
- bloom filter
- 互斥锁
-
-
聊聊Java中的单例模式
/2019/12/21/%E8%81%8A%E8%81%8AJava%E4%B8%AD%E7%9A%84%E5%8D%95%E4%BE%8B%E6%A8%A1%E5%BC%8F/
@@ -18741,35 +18878,254 @@ $
第一点,为啥不在 getInstance 上整个代码块加 synchronized,这个其实比较容易理解,就是锁的力度太大,性能太差了,这点其实也要去理解,可以举个夸张的例子,比如我一个电商的服务,如果为了避免一个人的订单出现问题,是不是可以从请求入口就把他锁住,到请求结束释放,那么里面做的事情都有保障,然而这显然不可能,因为我们想要这种竞态条件抢占资源的时间尽量减少,防止其他线程等待。
第二点,为啥synchronized之已经检查了 instance == null,还要在里面再检查一次,这个有个术语,叫 double check lock,但是为啥要这么做呢,其实很简单,想象当有两个线程,都过了第一步为空判断,这个时候只有一个线程能拿到这个锁,另一个线程就等待了,如果不再判断一次,那么第一个线程新建完对象释放锁之后,第二个线程又能拿到锁,再去创建一个对象。
第三点,为啥要volatile关键字,原先对它的理解是它修饰的变量在 JMM 中能及时将变量值写到主存中,但是它还有个很重要的作用,就是防止指令重排序,instance = new Singleton();这行代码其实在底层是分成三条指令执行的,第一条是在堆上申请了一块内存放这个对象,但是对象的字段啥的都还是默认值,第二条是设置对象的值,比如上面的 m 是 9,然后第三条是将这个对象和虚拟机栈上的指针建立引用关联,那么如果我不用volatile关键字,这三条指令就有可能出现重排,比如变成了 1-3-2 这种顺序,当执行完第二步时,有个线程来访问这个对象了,先判断是不是空,发现不是空的,就拿去直接用了,是不是就出现问题了,所以这个volatile也是不可缺少的
嵌套类
public class Singleton3 {
- private Singleton3() {}
- // 主要是使用了 嵌套类可以访问外部类的静态属性和静态方法 的特性
- private static class Holder {
- private static Singleton3 instance = new Singleton3();
- }
- public static Singleton3 getInstance() {
- return Holder.instance;
- }
-}
-这个我个人感觉是饿汉模式的升级版,可以在调用getInstance的时候去实例化对象,也是比较推荐的
-枚举单例
public enum Singleton {
- INSTANCE;
-
- public void doSomething(){
- //todo doSomething
- }
-}
-枚举很特殊,它在类加载的时候会初始化里面的所有的实例,而且 JVM 保证了它们不会再被实例化,所以它天生就是单例的。
+ private Singleton3() {}
+ // 主要是使用了 嵌套类可以访问外部类的静态属性和静态方法 的特性
+ private static class Holder {
+ private static Singleton3 instance = new Singleton3();
+ }
+ public static Singleton3 getInstance() {
+ return Holder.instance;
+ }
+}
+这个我个人感觉是饿汉模式的升级版,可以在调用getInstance的时候去实例化对象,也是比较推荐的
+枚举单例
public enum Singleton {
+ INSTANCE;
+
+ public void doSomething(){
+ //todo doSomething
+ }
+}
+枚举很特殊,它在类加载的时候会初始化里面的所有的实例,而且 JVM 保证了它们不会再被实例化,所以它天生就是单例的。
+]]>
+
+ Java
+ Design Patterns
+ Singleton
+
+
+ 设计模式
+ Design Patterns
+ 单例
+ Singleton
+
+
+
+ 聊聊一次 brew update 引发的血案
+ /2020/06/13/%E8%81%8A%E8%81%8A%E4%B8%80%E6%AC%A1-brew-update-%E5%BC%95%E5%8F%91%E7%9A%84%E8%A1%80%E6%A1%88/
+ 熟悉我的人(谁熟悉你啊🙄)知道我以前写过 PHP,虽然现在在工作中没用到了,但是自己的一些小工具还是会用 PHP 来写,但是在 Mac 碰到了一个环境相关的问题,因为我也是个更新狂魔,用了 brew 之后因为 gfw 的原因,如果长时间不更新,有时候要装一个用它装一个软件的话,前置的更新耗时就会让人非常头大,所以我基本会隔天 update 一下,但是这样会带来一个很心烦的问题,就是像这样,因为我是要用一个固定版本的 PHP,如果一直升需要一直配扩展啥的也很麻烦,如果一直升级 PHP 到最新版可能会比较少碰到这个问题
+dyld: Library not loaded: /usr/local/opt/icu4c/lib/libicui18n.64.dylib
+这是什么鬼啊,然后我去这个目录下看了下,已经都是libicui18n.67.dylib了,而且它没有把原来的版本保留下来,首先这个是个叫 icu4c是啥玩意,谷歌了一下
+
+ICU4C是ICU在C/C++平台下的版本, ICU(International Component for Unicode)是基于”IBM公共许可证”的,与开源组织合作研究的, 用于支持软件国际化的开源项目。ICU4C提供了C/C++平台强大的国际化开发能力,软件开发者几乎可以使用ICU4C解决任何国际化的问题,根据各地的风俗和语言习惯,实现对数字、货币、时间、日期、和消息的格式化、解析,对字符串进行大小写转换、整理、搜索和排序等功能,必须一提的是,ICU4C提供了强大的BIDI算法,对阿拉伯语等BIDI语言提供了完善的支持。
+
+然后首先想到的解决方案就是能不能我使用brew install icu4c@64来重装下原来的版本,发现不行,并木有,之前的做法就只能是去网上把 64 的下载下来,然后放到这个目录,比较麻烦不智能,虽然没抱着希望在谷歌着,不过这次竟然给我找到了一个我认为非常 nice 的解决方案,因为是在 Stack Overflow 找到的,本着写给像我这样的小小白看的,那就稍微翻译一下
第一步,我们到 brew的目录下
+cd $(brew --prefix)/Homebrew/Library/Taps/homebrew/homebrew-core/Formula
+这个可以理解为是 maven 的 pom 文件,不过有很多不同之处,使用ruby 写的,然后一个文件对应一个组件或者软件,那我们看下有个叫icu4c.rb的文件,
第二步看看它的提交历史
+git log --follow icu4c.rb
+在 git log 的海洋中寻找,寻找它的(64版本)的身影
![]()
第三步注意这三个红框,Stack Overflow 给出来的答案这一步是找到这个 commit id 直接切出一个新分支
+git checkout -b icu4c-63 e7f0f10dc63b1dc1061d475f1a61d01b70ef2cb7
+其实注意 commit id 旁边的红框,这个是有tag 的,可以直接
+git checkout icu4c-64
+PS: 因为我的问题是出在 64 的问题,Stack Overflow 回答的是 63 的,反正是一样的解决方法
第四部,切回去之后我们就可以用 brew 提供的基于文件的安装命令来重新装上 64 版本
+brew reinstall ./icu4c.rb
+然后就是第五步,切换版本
+brew switch icu4c 64.2
+最后把分支切回来
+git checkout master
+是不是感觉很厉害的解决方法,大佬还提供了一个更牛的,直接写个 zsh 方法
+# zsh
+function hiicu64() {
+ local last_dir=$(pwd)
+
+ cd $(brew --prefix)/Homebrew/Library/Taps/homebrew/homebrew-core/Formula
+ git checkout icu4c-4
+ brew reinstall ./icu4c.rb
+ brew switch icu4c 64.2
+ git checkout master
+
+ cd $last_dir
+}
+对应自己的版本改改版本号就可以了,非常好用。
+]]>
+
+ Mac
+ PHP
+ Homebrew
+ PHP
+ icu4c
+
+
+ Mac
+ PHP
+ Homebrew
+ icu4c
+ zsh
+
+
+
+ 聊聊如何识别和意识到日常生活中的各类危险
+ /2021/06/06/%E8%81%8A%E8%81%8A%E5%A6%82%E4%BD%95%E8%AF%86%E5%88%AB%E5%92%8C%E6%84%8F%E8%AF%86%E5%88%B0%E6%97%A5%E5%B8%B8%E7%94%9F%E6%B4%BB%E4%B8%AD%E7%9A%84%E5%90%84%E7%B1%BB%E5%8D%B1%E9%99%A9/
+ 这篇博客的灵感又是来自于我从绍兴来杭州的路上,在我们进站以后上电梯快到的时候,突然前面不动了,右边我能看到的是有个人的行李箱一时拎不起来,另一边后面看到其实是个小孩子在那哭闹,一位妈妈就在那停着安抚或者可能有点手足无措,其实这一点应该是在几年前慢慢意识到是个非常危险的场景,特别是像绍兴北站这样上去站台是非常长的电梯,因为最近扩建改造,车次减少了很多,所以每一班都有很多人,检票上站台的电梯都是满员运转,试想这种情况,如果刚才那位妈妈再多停留一点时间,很可能就会出现后面的人上不来被挤下去,再严重点就是踩踏事件,但是这类情况很少人真的意识到,非常明显的例子就是很多人拿着比较大比较重的行李箱,不走垂梯,并且在快到的时候没有提前准备好,有可能在玩手机啥的,如果提不动,后面又是挤满人了,就很可能出现前面说的这种情况,并且其实这种是非紧急情况,大多数人都没有心理准备,一旦发生后果可能就会很严重,例如火灾地震疏散大部分人或者说负责引导的都是指示要有序撤离,防止踩踏,但是普通坐个扶梯,一般都不会有这个意识,但是如果这个时间比较长,出现了人员站不住往后倒了,真的会很严重。所以如果自己是带娃的或者带了很重的行李箱的,请提前做好准备,看到前面有人带的,最好也保持一定距离。
还有比如日常走路,旁边有车子停着的情况,比较基本的看车灯有没有亮着,亮着的是否是倒车灯,这种应该特别注意远离,至少保持距离,不能挨着走,很多人特别是一些老年人,在一些人比较多的路上,往往完全无视旁边这些车的状态,我走我的路,谁敢阻拦我,管他车在那动不动,其实真的非常危险,车子本身有视线死角,再加上司机的驾驶习惯和状态,想去送死跟碰瓷的除外,还有就是有一些车会比较特殊,车子发动着,但是没灯,可能是车子灯坏了或者司机通过什么方式关了灯,这种比较难避开,不过如果车子打着了,一般会有比较大的热量散发,车子刚灭了也会有,反正能远离点尽量远离,从轿车的车前面走过挨着走要比从屁股后面挨着走稍微安全一些,但也最好不要挨着车走。
最后一点其实是我觉得是我自己比较怕死,一般对来向的车或者从侧面出来的车会做更长的预判距离,特别是电瓶车,一般是不让人的,像送外卖的小哥,的确他们不太容易,但是真的很危险啊,基本就生死看刹车,能刹住就赚了,刹不住就看身子骨扛不扛撞了,只是这里要多说点又要谈到资本的趋利性了,总是想法设法的压榨以获取更多的利益,也不扯远了,能远离就远离吧。
+]]>
+
+ 生活
+
+
+ 生活
+ 糟心事
+ 扶梯
+ 踩踏
+ 安全
+ 电瓶车
+
+
+
+ 聊聊传说中的 ThreadLocal
+ /2021/05/30/%E8%81%8A%E8%81%8A%E4%BC%A0%E8%AF%B4%E4%B8%AD%E7%9A%84-ThreadLocal/
+ 说来也惭愧,这个 ThreadLocal 其实一直都是一知半解,而且看了一下之后还发现记错了,所以还是记录下
原先记忆里的都是反过来,一个 ThreadLocal 是里面按照 thread 作为 key,存储线程内容的,真的是半解都米有,完全是错的,这样就得用 concurrentHashMap 这种去存储并且要锁定线程了,然后内容也只能存一个了,想想简直智障
+究竟是啥结构
比如我们在代码中 new 一个 ThreadLocal,
+public static void main(String[] args) {
+ ThreadLocal<Man> tl = new ThreadLocal<>();
+
+ new Thread(() -> {
+ try {
+ TimeUnit.SECONDS.sleep(2);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(tl.get());
+ }).start();
+ new Thread(() -> {
+ try {
+ TimeUnit.SECONDS.sleep(1);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ tl.set(new Man());
+ }).start();
+ }
+
+ static class Man {
+ String name = "nick";
+ }
+这里构造了两个线程,一个先往里设值,一个后从里取,运行看下结果,
![]()
知道这个用法的话肯定知道是取不到值的,只是具体的原理原来搞错了,我们来看下设值 set 方法
+public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+}
+写博客这会我才明白我原来咋会错得这么离谱,看到第一行代码 t 就是当前线程,然后第二行就是用这个线程去getMap,然后我是把这个当成从 map 里取值了,其实这里是
+ThreadLocalMap getMap(Thread t) {
+ return t.threadLocals;
+}
+获取 t 的 threadLocals 成员变量,那这个 threadLocals 又是啥呢
![]()
它其实是线程 Thread 中的一个类型是java.lang.ThreadLocal.ThreadLocalMap的成员变量
这是 ThreadLocal 的一个静态成员变量
+static class ThreadLocalMap {
+
+ /**
+ * The entries in this hash map extend WeakReference, using
+ * its main ref field as the key (which is always a
+ * ThreadLocal object). Note that null keys (i.e. entry.get()
+ * == null) mean that the key is no longer referenced, so the
+ * entry can be expunged from table. Such entries are referred to
+ * as "stale entries" in the code that follows.
+ */
+ static class Entry extends WeakReference<ThreadLocal<?>> {
+ /** The value associated with this ThreadLocal. */
+ Object value;
+
+ Entry(ThreadLocal<?> k, Object v) {
+ super(k);
+ value = v;
+ }
+ }
+ }
+全部代码有点长,只截取了一小部分,然后我们再回头来分析前面说的 set 过程,再 copy 下代码
+public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+}
+获取到 map 以后呢,如果 map 不为空,就往 map 里 set,这里注意 key 是啥,其实是当前这个 ThreadLocal,这里就比较明白了究竟是啥结构,每个线程都会维护自身的 ThreadLocalMap,它是线程的一个成员变量,当创建 ThreadLocal 的时候,进行设值的时候其实是往这个 map 里以 ThreadLocal 作为 key,往里设 value。
+内存泄漏是什么鬼
这里又要看下前面的 ThreadLocalMap 结构了,类似 HashMap,它有个 Entry 结构,在设置的时候会先包装成一个 Entry
+private void set(ThreadLocal<?> key, Object value) {
+
+ // We don't use a fast path as with get() because it is at
+ // least as common to use set() to create new entries as
+ // it is to replace existing ones, in which case, a fast
+ // path would fail more often than not.
+
+ Entry[] tab = table;
+ int len = tab.length;
+ int i = key.threadLocalHashCode & (len-1);
+
+ for (Entry e = tab[i];
+ e != null;
+ e = tab[i = nextIndex(i, len)]) {
+ ThreadLocal<?> k = e.get();
+
+ if (k == key) {
+ e.value = value;
+ return;
+ }
+
+ if (k == null) {
+ replaceStaleEntry(key, value, i);
+ return;
+ }
+ }
+
+ tab[i] = new Entry(key, value);
+ int sz = ++size;
+ if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+}
+这里其实比较重要的就是前面的 Entry 的构造方法,Entry 是个 WeakReference 的子类,然后在构造方法里可以看到 key 会被包装成一个弱引用,这里为什么使用弱引用,其实是方便这个 key 被回收,如果前面的 ThreadLocal tl实例被设置成 null 了,如果这里是直接的强引用的话,就只能等到线程整个回收了,但是其实是弱引用也会有问题,主要是因为这个 value,如果在 ThreadLocal tl 被设置成 null 了,那么其实这个 value 就会没法被访问到,所以最好的操作还是在使用完了就 remove 掉
]]>
Java
- Design Patterns
- Singleton
- 设计模式
- Design Patterns
- 单例
- Singleton
+ Java
+ ThreadLocal
+ 弱引用
+ 内存泄漏
+ WeakReference
+
+
+
+ 聊聊厦门旅游的好与不好
+ /2021/04/11/%E8%81%8A%E8%81%8A%E5%8E%A6%E9%97%A8%E6%97%85%E6%B8%B8%E7%9A%84%E5%A5%BD%E4%B8%8E%E4%B8%8D%E5%A5%BD/
+ 这几天去了趟厦门,原来几年前就想去了,本来都请好假了,后面因为一些事情没去成,这次刚好公司组织,就跟 LD 一起去了厦门,也不洋洋洒洒地写游记了,后面可能会有,今天先来总结下好的地方和比较坑的地方。
这次主要去了中山路、鼓浪屿、曾厝(cuo)垵、植物园、灵玲马戏团,因为住的离环岛路比较近,还有幸现场看了下厦门马拉松,其中
+中山路
这里看上去是有点民国时期的建筑风格,部分像那种电视里的租界啥的,不过这次去的时候都在翻修,路一大半拦起来了,听导游说这里往里面走有个局口街,然后上次听前同事说厦门比较有名的就是沙茶面和海蛎煎,不出意料的不太爱吃,沙茶面比较普通,可能是没吃到正宗的,海蛎煎吃不惯,倒是有个大叔的沙茶里脊还不错,在局口街那,还有小哥在那拍,应该也算是个网红打卡点了,然后吃了个油条麻糍也还不错,总体如果是看建筑的话可能最近不是个好时间,个人也没这方面爱好,吃的话最好多打听打听沙茶面跟海蛎煎哪里正宗。如果不知道哪家好吃,也不爱看这类建筑的可以排个坑。
+鼓浪屿
鼓浪屿也是完全没啥概念,需要乘船过去,但是只要二十分钟,岛上没有机动车,基本都靠走,有几个比较有名的地方,菽庄花园,里面有钢琴博物馆,对这个感兴趣的可以去看看,旁边是沙滩还可以逛逛,然后有各种博物馆,风琴啥的,岛上最大的特色是巷子多,道听途说有三百多条小巷,还有几个网红打卡点,周杰伦晴天墙,还有个最美转角,都是挤满了人排队打卡拍照,不过如果不着急,慢慢悠悠逛逛还是不错的,比较推荐,推荐值☆☆
+曾厝垵
一直读不对这个字,都是叫:那个曾什么垵,愧对语文老师,这里到算是意外之喜,鼓浪屿回来已经挺累了,不过由于比较饿(什么原因后面说),并且离住的地方不远,就过去逛了逛,东西还蛮好吃的,芒果挺便宜,一大杯才十块,无骨鸡爪很贵,不是特别爱,臭豆腐不错的,也不算很贵,这里想起来,那边八婆婆的豆乳烧仙草还不错的,去中山路那会喝了,来曾厝垵也买了,奶茶爱好者可以试试,含糖量应该很高,不爱甜食或者减肥的同学慎重考虑好了再尝试,晚上那边从牌坊出来,沿着环岛路挺多夜宵店什么的,非常推荐,推荐值☆☆☆☆
+植物园
植物园还是挺名副其实的,有热带植物,沙漠多肉,因为赶时间逛得不多,热带雨林植物那太多人了,都是在那拍照,而且我指的拍照都是拍人照,本身就很小的路,各种十八线网红,或者普通游客在那摆 pose 拍照,挺无语的;沙漠多肉比较惊喜,好多比人高的仙人掌,一大片的仙人球,很可恶的是好多大仙人掌上都有人刻字,越来越体会到,我们社会人多了,什么样的都有,而且不少;还看了下百花厅,但没什么特别的,可能赶时间比较着急,没仔细看,比较推荐,推荐值☆☆☆
+灵玲马戏团
对这个其实比较排斥,主要是比较晚了,跑的有点远(我太懒了),一开始真的挺拉低体验感受的,上来个什么书法家,现场画马,卖画;不过后面的还算值回票价,主题是花木兰,空中动作应该很考验基本功,然后那些老外的飞轮还跳绳(不知道学名叫啥),动物那块不太忍心看,应该是吃了不少苦头,不过人都这样就往后点再心疼动物吧。
+总结
厦门是个非常适合干饭人的地方,吃饭的地方大部分是差不多一桌菜十个左右就完了,而且上来就一大碗饭,一瓶雪碧一瓶可乐,对于经常是家里跟亲戚吃饭都得十几二十个菜的乡下人来说,不太吃得惯这样的🤦♂️,当然很有可能是我们预算不足,点的差。但是有一点是我回杭州深有感触的,感觉杭州司机的素质真的是跟厦门的司机差了比较多,杭州除非公交车停了,否则人行道很难看到主动让人的,当然这里拿厦门这个旅游城市来对比也不是很公平,不过这也是体现城市现代化文明水平的一个维度吧。
+]]>
+
+ 生活
+ 旅游
+
+
+ 生活
+ 杭州
+ 旅游
+ 厦门
+ 中山路
+ 局口街
+ 鼓浪屿
+ 曾厝垵
+ 植物园
+ 马戏团
+ 沙茶面
+ 海蛎煎
@@ -19106,239 +19462,20 @@ $
# DataSource initializer detectors
org.springframework.boot.sql.init.dependency.DatabaseInitializerDetector=\
org.springframework.boot.autoconfigure.flyway.FlywayMigrationInitializerDatabaseInitializerDetector
-
-
-上面根据 org.springframework.boot.autoconfigure.EnableAutoConfiguration 获取的各个配置类,在通过反射加载就能得到一堆 JavaConfig配置类,然后再根据 ConditionalOnProperty等条件配置加载具体的 bean,大致就是这么个逻辑
-]]>
-
- Java
- SpringBoot
-
-
- Java
- Spring
- SpringBoot
- 自动装配
- AutoConfiguration
-
-
-
- 聊聊一次 brew update 引发的血案
- /2020/06/13/%E8%81%8A%E8%81%8A%E4%B8%80%E6%AC%A1-brew-update-%E5%BC%95%E5%8F%91%E7%9A%84%E8%A1%80%E6%A1%88/
- 熟悉我的人(谁熟悉你啊🙄)知道我以前写过 PHP,虽然现在在工作中没用到了,但是自己的一些小工具还是会用 PHP 来写,但是在 Mac 碰到了一个环境相关的问题,因为我也是个更新狂魔,用了 brew 之后因为 gfw 的原因,如果长时间不更新,有时候要装一个用它装一个软件的话,前置的更新耗时就会让人非常头大,所以我基本会隔天 update 一下,但是这样会带来一个很心烦的问题,就是像这样,因为我是要用一个固定版本的 PHP,如果一直升需要一直配扩展啥的也很麻烦,如果一直升级 PHP 到最新版可能会比较少碰到这个问题
-dyld: Library not loaded: /usr/local/opt/icu4c/lib/libicui18n.64.dylib
-这是什么鬼啊,然后我去这个目录下看了下,已经都是libicui18n.67.dylib了,而且它没有把原来的版本保留下来,首先这个是个叫 icu4c是啥玩意,谷歌了一下
-
-ICU4C是ICU在C/C++平台下的版本, ICU(International Component for Unicode)是基于”IBM公共许可证”的,与开源组织合作研究的, 用于支持软件国际化的开源项目。ICU4C提供了C/C++平台强大的国际化开发能力,软件开发者几乎可以使用ICU4C解决任何国际化的问题,根据各地的风俗和语言习惯,实现对数字、货币、时间、日期、和消息的格式化、解析,对字符串进行大小写转换、整理、搜索和排序等功能,必须一提的是,ICU4C提供了强大的BIDI算法,对阿拉伯语等BIDI语言提供了完善的支持。
-
-然后首先想到的解决方案就是能不能我使用brew install icu4c@64来重装下原来的版本,发现不行,并木有,之前的做法就只能是去网上把 64 的下载下来,然后放到这个目录,比较麻烦不智能,虽然没抱着希望在谷歌着,不过这次竟然给我找到了一个我认为非常 nice 的解决方案,因为是在 Stack Overflow 找到的,本着写给像我这样的小小白看的,那就稍微翻译一下
第一步,我们到 brew的目录下
-cd $(brew --prefix)/Homebrew/Library/Taps/homebrew/homebrew-core/Formula
-这个可以理解为是 maven 的 pom 文件,不过有很多不同之处,使用ruby 写的,然后一个文件对应一个组件或者软件,那我们看下有个叫icu4c.rb的文件,
第二步看看它的提交历史
-git log --follow icu4c.rb
-在 git log 的海洋中寻找,寻找它的(64版本)的身影
![]()
第三步注意这三个红框,Stack Overflow 给出来的答案这一步是找到这个 commit id 直接切出一个新分支
-git checkout -b icu4c-63 e7f0f10dc63b1dc1061d475f1a61d01b70ef2cb7
-其实注意 commit id 旁边的红框,这个是有tag 的,可以直接
-git checkout icu4c-64
-PS: 因为我的问题是出在 64 的问题,Stack Overflow 回答的是 63 的,反正是一样的解决方法
第四部,切回去之后我们就可以用 brew 提供的基于文件的安装命令来重新装上 64 版本
-brew reinstall ./icu4c.rb
-然后就是第五步,切换版本
-brew switch icu4c 64.2
-最后把分支切回来
-git checkout master
-是不是感觉很厉害的解决方法,大佬还提供了一个更牛的,直接写个 zsh 方法
-# zsh
-function hiicu64() {
- local last_dir=$(pwd)
-
- cd $(brew --prefix)/Homebrew/Library/Taps/homebrew/homebrew-core/Formula
- git checkout icu4c-4
- brew reinstall ./icu4c.rb
- brew switch icu4c 64.2
- git checkout master
-
- cd $last_dir
-}
-对应自己的版本改改版本号就可以了,非常好用。
-]]>
-
- Mac
- PHP
- Homebrew
- PHP
- icu4c
-
-
- Mac
- PHP
- Homebrew
- icu4c
- zsh
-
-
-
- 聊聊传说中的 ThreadLocal
- /2021/05/30/%E8%81%8A%E8%81%8A%E4%BC%A0%E8%AF%B4%E4%B8%AD%E7%9A%84-ThreadLocal/
- 说来也惭愧,这个 ThreadLocal 其实一直都是一知半解,而且看了一下之后还发现记错了,所以还是记录下
原先记忆里的都是反过来,一个 ThreadLocal 是里面按照 thread 作为 key,存储线程内容的,真的是半解都米有,完全是错的,这样就得用 concurrentHashMap 这种去存储并且要锁定线程了,然后内容也只能存一个了,想想简直智障
-究竟是啥结构
比如我们在代码中 new 一个 ThreadLocal,
-public static void main(String[] args) {
- ThreadLocal<Man> tl = new ThreadLocal<>();
-
- new Thread(() -> {
- try {
- TimeUnit.SECONDS.sleep(2);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(tl.get());
- }).start();
- new Thread(() -> {
- try {
- TimeUnit.SECONDS.sleep(1);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- tl.set(new Man());
- }).start();
- }
-
- static class Man {
- String name = "nick";
- }
-这里构造了两个线程,一个先往里设值,一个后从里取,运行看下结果,
![]()
知道这个用法的话肯定知道是取不到值的,只是具体的原理原来搞错了,我们来看下设值 set 方法
-public void set(T value) {
- Thread t = Thread.currentThread();
- ThreadLocalMap map = getMap(t);
- if (map != null)
- map.set(this, value);
- else
- createMap(t, value);
-}
-写博客这会我才明白我原来咋会错得这么离谱,看到第一行代码 t 就是当前线程,然后第二行就是用这个线程去getMap,然后我是把这个当成从 map 里取值了,其实这里是
-ThreadLocalMap getMap(Thread t) {
- return t.threadLocals;
-}
-获取 t 的 threadLocals 成员变量,那这个 threadLocals 又是啥呢
![]()
它其实是线程 Thread 中的一个类型是java.lang.ThreadLocal.ThreadLocalMap的成员变量
这是 ThreadLocal 的一个静态成员变量
-static class ThreadLocalMap {
-
- /**
- * The entries in this hash map extend WeakReference, using
- * its main ref field as the key (which is always a
- * ThreadLocal object). Note that null keys (i.e. entry.get()
- * == null) mean that the key is no longer referenced, so the
- * entry can be expunged from table. Such entries are referred to
- * as "stale entries" in the code that follows.
- */
- static class Entry extends WeakReference<ThreadLocal<?>> {
- /** The value associated with this ThreadLocal. */
- Object value;
-
- Entry(ThreadLocal<?> k, Object v) {
- super(k);
- value = v;
- }
- }
- }
-全部代码有点长,只截取了一小部分,然后我们再回头来分析前面说的 set 过程,再 copy 下代码
-public void set(T value) {
- Thread t = Thread.currentThread();
- ThreadLocalMap map = getMap(t);
- if (map != null)
- map.set(this, value);
- else
- createMap(t, value);
-}
-获取到 map 以后呢,如果 map 不为空,就往 map 里 set,这里注意 key 是啥,其实是当前这个 ThreadLocal,这里就比较明白了究竟是啥结构,每个线程都会维护自身的 ThreadLocalMap,它是线程的一个成员变量,当创建 ThreadLocal 的时候,进行设值的时候其实是往这个 map 里以 ThreadLocal 作为 key,往里设 value。
-内存泄漏是什么鬼
这里又要看下前面的 ThreadLocalMap 结构了,类似 HashMap,它有个 Entry 结构,在设置的时候会先包装成一个 Entry
-private void set(ThreadLocal<?> key, Object value) {
-
- // We don't use a fast path as with get() because it is at
- // least as common to use set() to create new entries as
- // it is to replace existing ones, in which case, a fast
- // path would fail more often than not.
-
- Entry[] tab = table;
- int len = tab.length;
- int i = key.threadLocalHashCode & (len-1);
-
- for (Entry e = tab[i];
- e != null;
- e = tab[i = nextIndex(i, len)]) {
- ThreadLocal<?> k = e.get();
-
- if (k == key) {
- e.value = value;
- return;
- }
-
- if (k == null) {
- replaceStaleEntry(key, value, i);
- return;
- }
- }
-
- tab[i] = new Entry(key, value);
- int sz = ++size;
- if (!cleanSomeSlots(i, sz) && sz >= threshold)
- rehash();
-}
-这里其实比较重要的就是前面的 Entry 的构造方法,Entry 是个 WeakReference 的子类,然后在构造方法里可以看到 key 会被包装成一个弱引用,这里为什么使用弱引用,其实是方便这个 key 被回收,如果前面的 ThreadLocal tl实例被设置成 null 了,如果这里是直接的强引用的话,就只能等到线程整个回收了,但是其实是弱引用也会有问题,主要是因为这个 value,如果在 ThreadLocal tl 被设置成 null 了,那么其实这个 value 就会没法被访问到,所以最好的操作还是在使用完了就 remove 掉
+
+
+上面根据 org.springframework.boot.autoconfigure.EnableAutoConfiguration 获取的各个配置类,在通过反射加载就能得到一堆 JavaConfig配置类,然后再根据 ConditionalOnProperty等条件配置加载具体的 bean,大致就是这么个逻辑
]]>
Java
+ SpringBoot
Java
- ThreadLocal
- 弱引用
- 内存泄漏
- WeakReference
-
-
-
- 聊聊厦门旅游的好与不好
- /2021/04/11/%E8%81%8A%E8%81%8A%E5%8E%A6%E9%97%A8%E6%97%85%E6%B8%B8%E7%9A%84%E5%A5%BD%E4%B8%8E%E4%B8%8D%E5%A5%BD/
- 这几天去了趟厦门,原来几年前就想去了,本来都请好假了,后面因为一些事情没去成,这次刚好公司组织,就跟 LD 一起去了厦门,也不洋洋洒洒地写游记了,后面可能会有,今天先来总结下好的地方和比较坑的地方。
这次主要去了中山路、鼓浪屿、曾厝(cuo)垵、植物园、灵玲马戏团,因为住的离环岛路比较近,还有幸现场看了下厦门马拉松,其中
-中山路
这里看上去是有点民国时期的建筑风格,部分像那种电视里的租界啥的,不过这次去的时候都在翻修,路一大半拦起来了,听导游说这里往里面走有个局口街,然后上次听前同事说厦门比较有名的就是沙茶面和海蛎煎,不出意料的不太爱吃,沙茶面比较普通,可能是没吃到正宗的,海蛎煎吃不惯,倒是有个大叔的沙茶里脊还不错,在局口街那,还有小哥在那拍,应该也算是个网红打卡点了,然后吃了个油条麻糍也还不错,总体如果是看建筑的话可能最近不是个好时间,个人也没这方面爱好,吃的话最好多打听打听沙茶面跟海蛎煎哪里正宗。如果不知道哪家好吃,也不爱看这类建筑的可以排个坑。
-鼓浪屿
鼓浪屿也是完全没啥概念,需要乘船过去,但是只要二十分钟,岛上没有机动车,基本都靠走,有几个比较有名的地方,菽庄花园,里面有钢琴博物馆,对这个感兴趣的可以去看看,旁边是沙滩还可以逛逛,然后有各种博物馆,风琴啥的,岛上最大的特色是巷子多,道听途说有三百多条小巷,还有几个网红打卡点,周杰伦晴天墙,还有个最美转角,都是挤满了人排队打卡拍照,不过如果不着急,慢慢悠悠逛逛还是不错的,比较推荐,推荐值☆☆
-曾厝垵
一直读不对这个字,都是叫:那个曾什么垵,愧对语文老师,这里到算是意外之喜,鼓浪屿回来已经挺累了,不过由于比较饿(什么原因后面说),并且离住的地方不远,就过去逛了逛,东西还蛮好吃的,芒果挺便宜,一大杯才十块,无骨鸡爪很贵,不是特别爱,臭豆腐不错的,也不算很贵,这里想起来,那边八婆婆的豆乳烧仙草还不错的,去中山路那会喝了,来曾厝垵也买了,奶茶爱好者可以试试,含糖量应该很高,不爱甜食或者减肥的同学慎重考虑好了再尝试,晚上那边从牌坊出来,沿着环岛路挺多夜宵店什么的,非常推荐,推荐值☆☆☆☆
-植物园
植物园还是挺名副其实的,有热带植物,沙漠多肉,因为赶时间逛得不多,热带雨林植物那太多人了,都是在那拍照,而且我指的拍照都是拍人照,本身就很小的路,各种十八线网红,或者普通游客在那摆 pose 拍照,挺无语的;沙漠多肉比较惊喜,好多比人高的仙人掌,一大片的仙人球,很可恶的是好多大仙人掌上都有人刻字,越来越体会到,我们社会人多了,什么样的都有,而且不少;还看了下百花厅,但没什么特别的,可能赶时间比较着急,没仔细看,比较推荐,推荐值☆☆☆
-灵玲马戏团
对这个其实比较排斥,主要是比较晚了,跑的有点远(我太懒了),一开始真的挺拉低体验感受的,上来个什么书法家,现场画马,卖画;不过后面的还算值回票价,主题是花木兰,空中动作应该很考验基本功,然后那些老外的飞轮还跳绳(不知道学名叫啥),动物那块不太忍心看,应该是吃了不少苦头,不过人都这样就往后点再心疼动物吧。
-总结
厦门是个非常适合干饭人的地方,吃饭的地方大部分是差不多一桌菜十个左右就完了,而且上来就一大碗饭,一瓶雪碧一瓶可乐,对于经常是家里跟亲戚吃饭都得十几二十个菜的乡下人来说,不太吃得惯这样的🤦♂️,当然很有可能是我们预算不足,点的差。但是有一点是我回杭州深有感触的,感觉杭州司机的素质真的是跟厦门的司机差了比较多,杭州除非公交车停了,否则人行道很难看到主动让人的,当然这里拿厦门这个旅游城市来对比也不是很公平,不过这也是体现城市现代化文明水平的一个维度吧。
-]]>
-
- 生活
- 旅游
-
-
- 生活
- 杭州
- 旅游
- 厦门
- 中山路
- 局口街
- 鼓浪屿
- 曾厝垵
- 植物园
- 马戏团
- 沙茶面
- 海蛎煎
-
-
-
- 聊聊如何识别和意识到日常生活中的各类危险
- /2021/06/06/%E8%81%8A%E8%81%8A%E5%A6%82%E4%BD%95%E8%AF%86%E5%88%AB%E5%92%8C%E6%84%8F%E8%AF%86%E5%88%B0%E6%97%A5%E5%B8%B8%E7%94%9F%E6%B4%BB%E4%B8%AD%E7%9A%84%E5%90%84%E7%B1%BB%E5%8D%B1%E9%99%A9/
- 这篇博客的灵感又是来自于我从绍兴来杭州的路上,在我们进站以后上电梯快到的时候,突然前面不动了,右边我能看到的是有个人的行李箱一时拎不起来,另一边后面看到其实是个小孩子在那哭闹,一位妈妈就在那停着安抚或者可能有点手足无措,其实这一点应该是在几年前慢慢意识到是个非常危险的场景,特别是像绍兴北站这样上去站台是非常长的电梯,因为最近扩建改造,车次减少了很多,所以每一班都有很多人,检票上站台的电梯都是满员运转,试想这种情况,如果刚才那位妈妈再多停留一点时间,很可能就会出现后面的人上不来被挤下去,再严重点就是踩踏事件,但是这类情况很少人真的意识到,非常明显的例子就是很多人拿着比较大比较重的行李箱,不走垂梯,并且在快到的时候没有提前准备好,有可能在玩手机啥的,如果提不动,后面又是挤满人了,就很可能出现前面说的这种情况,并且其实这种是非紧急情况,大多数人都没有心理准备,一旦发生后果可能就会很严重,例如火灾地震疏散大部分人或者说负责引导的都是指示要有序撤离,防止踩踏,但是普通坐个扶梯,一般都不会有这个意识,但是如果这个时间比较长,出现了人员站不住往后倒了,真的会很严重。所以如果自己是带娃的或者带了很重的行李箱的,请提前做好准备,看到前面有人带的,最好也保持一定距离。
还有比如日常走路,旁边有车子停着的情况,比较基本的看车灯有没有亮着,亮着的是否是倒车灯,这种应该特别注意远离,至少保持距离,不能挨着走,很多人特别是一些老年人,在一些人比较多的路上,往往完全无视旁边这些车的状态,我走我的路,谁敢阻拦我,管他车在那动不动,其实真的非常危险,车子本身有视线死角,再加上司机的驾驶习惯和状态,想去送死跟碰瓷的除外,还有就是有一些车会比较特殊,车子发动着,但是没灯,可能是车子灯坏了或者司机通过什么方式关了灯,这种比较难避开,不过如果车子打着了,一般会有比较大的热量散发,车子刚灭了也会有,反正能远离点尽量远离,从轿车的车前面走过挨着走要比从屁股后面挨着走稍微安全一些,但也最好不要挨着车走。
最后一点其实是我觉得是我自己比较怕死,一般对来向的车或者从侧面出来的车会做更长的预判距离,特别是电瓶车,一般是不让人的,像送外卖的小哥,的确他们不太容易,但是真的很危险啊,基本就生死看刹车,能刹住就赚了,刹不住就看身子骨扛不扛撞了,只是这里要多说点又要谈到资本的趋利性了,总是想法设法的压榨以获取更多的利益,也不扯远了,能远离就远离吧。
-]]>
-
- 生活
-
-
- 生活
- 糟心事
- 扶梯
- 踩踏
- 安全
- 电瓶车
+ Spring
+ SpringBoot
+ 自动装配
+ AutoConfiguration
@@ -19365,50 +19502,6 @@ $
Thread dump
-
- 聊聊我理解的分布式事务
- /2020/05/17/%E8%81%8A%E8%81%8A%E6%88%91%E7%90%86%E8%A7%A3%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/
- 前面说了mysql数据库的事务相关的,那事务是用来干嘛的,这里得补一下ACID,
-
-ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
-
-
-Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。[1]
-Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。[1]
-Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。[1]
-Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。[1]
-
-在mysql中,借助于MVCC,各种级别的锁,日志等特性来实现了事务的ACID,但是这个我们通常是对于一个数据库服务的定义,常见的情况下我们的数据库随着业务发展也会从单实例变成多实例,组成主从Master-Slave架构,这个时候其实会有一些问题随之出现,比如说主从同步延迟,假如在业务代码中做了读写分离,对于一些敏感度较低的数据其实问题不是很大,只要主从延迟不到特别夸张的地步一般都是可以忍受的,但是对于一些核心的业务数据,比如订单之类的,不能忍受数据不一致,下了单了,付了款了,一刷订单列表,发现这个订单还没支付,甚至订单都没在,这对于用户来讲是恨不能容忍的错误,那么这里就需要一些措施,要不就不读写分离,要不就在 redis 这类缓存下订单,或者支付后加个延时等,这些都是一些补偿措施,并且这也是一个不太切当的例子,比较合适的例子也可以用这个下单来说,一般在电商平台下单会有挺多要做的事情,比如像下面这个图
-![]()
-下单的是后要冻结核销优惠券,如果账户里有钱要冻结扣除账户里的钱,如果使用了J 豆也一样,可能还有 E 卡,忽略我借用的平台,因为目前一般后台服务化之后,可能每一项都是对应的一个后台服务,我们期望的执行过程是要不全成功,要不就全保持执行前状态,不能是部分扣减核销成功了,部分还不行,所以我们处理这种情况会引入一些通用的方案,第一种叫二阶段提交,
-
-二阶段提交(英语:Two-phase Commit)是指在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法。通常,二阶段提交也被称为是一种协议(Protocol)。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为: 参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
-
-对于上面的例子,我们将整个过程分成两个阶段,首先是提交请求阶段,这个阶段大概需要做的是确定资源存在,锁定资源,可能还要做好失败后回滚的准备,如果这些都 ok 了那么就响应成功,这里其实用到了一个叫事务的协调者的角色,类似于裁判员,每个节点都反馈第一阶段成功后,开始执行第二阶段,也就是实际执行操作,这里也是需要所有节点都反馈成功后才是执行成功,要不就是失败回滚。其实常用的分布式事务的解决方案主要也是基于此方案的改进,比如后面介绍的三阶段提交,有三阶段提交就是因为二阶段提交比较尴尬的几个点,
-
-- 第一是对于两阶段提交,其中默认只有协调者有超时时间,当一个参与者进入卡死状态时只能依赖协调者的超时来结束任务,这中间的时间参与者都是锁定着资源
-- 第二是协调者的单点问题,万一挂了,参与者就会在那傻等着
-
-所以三阶段提交引入了各节点的超时机制和一个准备阶段,首先是一个can commit阶段,询问下各个节点有没有资源,能不能进行操作,这个阶段不阻塞,只是提前做个摸底,这个阶段其实人畜无害,但是能提高成功率,在这个阶段如果就有节点反馈是不接受的,那就不用执行下去了,也没有锁资源,然后第二阶段是 pre commit ,这个阶段做的事情跟原来的 第一阶段比较类似,然后是第三阶段do commit,其实三阶段提交我个人觉得只是加了个超时,和准备阶段,好像木有根本性的解决的两阶段提交的问题,后续可以再看看一些论文来思考讨论下。
-2020年05月24日22:11 更新
这里跟朋友讨论了下,好像想通了最核心的一点,对于前面说的那个场景,如果是两阶段提交,如果各个节点中有一个没回应,并且协调者也挂了,这个时候会有什么情况呢,再加一个假设,其实比如这个一阶段其实是检验就失败的,理论上应该大家都释放资源,那么对于这种异常情况,其他的参与者就不知所措了,就傻傻地锁着资源阻塞着,那么三阶段提交的意义就出现了,把第一阶段拆开,那么即使在这个阶段出现上述的异常,即也不会锁定资源,同时参与者也有超时机制,在第二阶段锁定资源出现异常是,其他参与者节点等超时后就自动释放资源了,也就没啥问题了,不过对于那种异常恢复后的一些情况还是没有很好地解决,需要借助 zk 等,后面有空可以讲讲 paxos 跟 raft 等
-]]>
-
- 分布式事务
- 两阶段提交
- 三阶段提交
-
-
- 分布式事务
- 两阶段提交
- 三阶段提交
- 2PC
- 3PC
-
-
聊聊我的远程工作体验
/2022/06/26/%E8%81%8A%E8%81%8A%E6%88%91%E7%9A%84%E8%BF%9C%E7%A8%8B%E5%B7%A5%E4%BD%9C%E4%BD%93%E9%AA%8C/
@@ -19423,299 +19516,159 @@ $
- 聊聊最近平淡的生活之又聊通勤
- /2021/11/07/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB/
- 一直以来过着特别平淡普通的生活,不过大多数人应该都这样吧,也许有些人可以把平凡的生活过得精彩,最简单的说明就是朋友圈吧,看我一年的盆友圈虽然在发,不过大概 90%的都是发发跑步的打卡,偶尔会有稀稀拉拉的点赞,天天上班,也不喜欢发什么状态,觉得没什么人关注,索性不发。
-只是这么平淡的生活就有一些自己比较心烦纠结的,之前有提到过的交通,最近似乎又发现了一点,就真相总是让人跌破眼镜,以前觉得我可能是胆子比较小,所以会觉得怎么路上这些电瓶都是这么肆无忌惮的往我冲过来,后面慢慢有一种借用电视剧读心神探的概念,安全距离,觉得大部分人跟我一样,骑电瓶车什么的总还是有个安全距离,只是可能这个安全距离对于不同的人不一样,那些骑电瓶车的潜意识里的安全距离是非常短,所以经常会骑车离着你非常近才会刹车,但是这个安全距离理论最近又被推翻了,因为经历过几次电瓶车就是已经跟你有身体接触了,但是没到把人撞倒的程度,似乎这些骑电瓶车的觉得步行的行人在人行道上是空气,蹭一下也无所谓,反正不能挡我的路,总感觉要不是我在前面骑自行车太慢挡着电瓶车,不然他们都能起飞去干掉 F35 解放湾湾了;
-另一个问题应该是说我们交通规则普及的太少,虽然我们没有路权这个名词概念,但是其实是有这个优先级的,包括像杭州是以公交车在人行道礼让行人闻名的,其实这个文明的行为只限于人行道在直行路中间的,大部分在十字路口,右转的公交车很少会让直行人行道的,前提是直行的绿灯的时候,特别是像公交车这样,车身特别长,右转的时候会有比较大的死角,如果是公交车先转,行人或者自行车很容易被卷进去,非常危险的,私家车就更不用说了,反正右转即使人行道上人非常多要转的也是一秒都不等,所以我自己在开车的时候是尽量在右转的时候等人行道上的行人或者骑车的走完,因为总会觉得我是不是有点双标,骑车走路的时候希望开车的能按规则让我,自己开车的时候又想赶紧开走,所以在开车的时候尽量做到让行车和骑车的。
-还有个其实是写着写着想起来的,比如我骑车左转的时候,因为我是左转到对角那就到了,跟那些左转后要再直行的不一样,我们应该在学车的时候也学过,超车要从左边超,但是往往那些骑电瓶车的在左转的时候会从我右边超过来再往左边撇过去,如果留的空间大还好,有些电瓶车就是如果车头超过了就不管他的车屁股,如果我不减速,自行车就被刮倒了,可能的确是别人就不是人,只要不把你撞倒就无所谓,反正为了你自己不被撞倒你肯定会让的。
-]]>
-
- 生活
-
-
- 生活
- 糟心事
- 规则
- 电瓶车
- 骑车
-
-
-
- 聊聊最近平淡的生活之《花束般的恋爱》观后感
- /2021/12/31/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E3%80%8A%E8%8A%B1%E6%9D%9F%E8%88%AC%E7%9A%84%E6%81%8B%E7%88%B1%E3%80%8B%E8%A7%82%E5%90%8E%E6%84%9F/
- 周末在领导的提议下看了豆瓣的年度榜单,本来感觉没啥心情看的,看到主演有有村架纯就觉得可以看一下,颜值即正义嘛,男主小麦跟女主小娟(后面简称小麦跟小娟)是两个在一次非常偶然的没赶上地铁末班车事件中相识,这里得说下日本这种通宵营业的店好像挺不错的,看着也挺正常,国内估计只有酒吧之类的可以。晚上去的地方是有点暗暗的,好像也有点类似酒吧,旁边有类似于 dj 那种,然后同桌的还有除了男女主的另外一对男女,也是因为没赶上地铁末班车的,但也是陌生人,然后小麦突然看到了有个非常有名的电影人,小娟竟然也认识,然后旁边那对完全不认识,还在那吹自己看过很多电影,比如《肖申克的救赎》,于是男女主都特别鄙夷地看着他们,然后他们又去了另一个有点像泡澡的地方席地而坐,他们发现了自己的鞋子都是一样的,然后在女的去上厕所的时候,小麦暗恋的学姐也来了,然后小麦就去跟学姐他们一起坐了,小娟回来后有点不开心就说去朋友家睡,幸好小麦看出来了(他竟然看出来了,本来以为应该是没填过恋爱很木讷的),就追出去,然后就去了小麦家,到了家小娟发现小麦家的书柜上的书简直就跟她自己家的一模一样,小麦还给小娟吹了头发,一起吃烤饭团,看电影,第二天送小娟上了公交,还约好了一起看木乃伊展,然而并没有交换联系方式,但是他们还是约上了一起看了木乃伊展,在餐馆就出现了片头那一幕的来源,因为餐馆他们想一起听歌,就用有线耳机一人一个耳朵听,但是旁边就有个大叔说“你们是不是不爱音乐,左右耳朵是不一样的,只有一起听才是真正的音乐”这样的话,然后的剧情有点跳,因为是指他们一直在这家餐馆吃饭,中间有他们一起出去玩情节穿插着,也是在这他们确立了关系,可以说主体就是体现了他们非常的合拍和默契,就像一些影评说的,这部电影是说如何跟百分百合拍的人分手,然后就是正常的恋爱开始啪啪啪,一直腻在床上,也没去就业说明会,后面也有讲了一点小麦带着小娟去认识他的朋友,也把小娟介绍给了他们认识,这里算是个小伏笔,后面他们分手也有这里的人的一些关系,接下去的剧情说实话我是不太喜欢的,如果一部八分的电影只是说恋爱被现实打败的话,我觉得在我这是不合格的,但是事实也是这样,小麦其实是有家里的资助,所以后面还是按自己的喜好给一些机构画点插画,小娟则要出去工作,因为小娟家庭观念也是要让她出去有正经工作,用脚指头想也能知道肯定不顺利,然后就是暂时在一家蛋糕店工作,小麦就每天去接小娟,日子过得甜甜蜜蜜,后面小娟在自己的努力下考了个什么资格证,去了一家医院还是什么做前台行政,这中间当然就有父母来见面吃饭了,他们在开始恋爱不久就同居合租了,然后小娟父母就是来说要让她有个正经工作,对男的说的话就是人生就是责任这类的话,而小麦爸爸算是个导火索,因为小麦家里是做烟花生意的,他爸让他就做烟花生意,因为要回老家,并且小麦也不想做,所以就拒绝了,然后他爸就说不给他每个月五万的资助,这也导致了小麦需要去找工作,这个过程也是很辛苦,本来想要年前找好工作,然后事与愿违,后面有一次小娟被同事吐槽怎么从来不去团建,于是她就去了(我以为会拒绝),正在团建的时候小麦给她电话,说找到工作了,是一个创业物流公司这种,这里剧情就是我觉得比较俗套的,小麦各种被虐,累成狗,但是就像小娟爸爸说的话,人生就是责任,所以一直在坚持,但是这样也导致了跟小娟的交流也越来越少,他们原来最爱的漫画,爱玩的游戏,也只剩小娟一个人看,一个人玩,而正是这个时候,小娟说她辞掉了工作,去做一个不是太靠谱的漫画改造的密室逃脱,然后这里其实有一点后面争议很大的,就是这个工作其实是前面小麦介绍给小娟的那些朋友中一个的女朋友介绍的,而在有个剧情就是小娟有一次在这个密室逃脱的老板怀里醒过来,是在 KTV 那样的场景里,这就有很多人觉得小娟是不是出轨了,我觉得其实不那么重要,因为这个离职的事情已经让一切矛盾都摆在眼前,小麦其实是接受这种需要承担责任的生活,也想着要跟小娟结婚,但是小娟似乎还是想要过着那样理想的生活,做自己想做的事情,看自己爱看的漫画,也要小麦能像以前那样一直那么默契的有着相同的爱好,这里的触发点其实还有个是那个小麦的朋友(也就是他女朋友介绍小娟那个不靠谱工作的)的葬礼上,小麦在参加完葬礼后有挺多想倾诉的,而小娟只是想睡了,这个让小麦第二天起来都不想理小娟,只是这里我不太理解,难道这点闹情绪都不能接受吗,所谓的合拍也只是毫无限制的情况下的合拍吧,真正的生活怎么可能如此理想呢,即使没有物质生活的压力,也会有其他的各种压力和限制,在这之后其实小麦想说的是小娟是不是没有想跟自己继续在一起的想法了,而小娟觉得都不说话了,还怎么结婚呢,后面其实导演搞了个小 trick,突然放了异常婚礼,但是不是男女主的,我并不觉得这个桥段很好,在婚礼里男女主都觉得自己想要跟对方说分手了,但是当他们去了最开始一直去的餐馆的时候,一个算是一个现实映照的就是他们一直坐的位子被占了,可能也是导演想通过这个来说明他们已经回不去了,在餐馆交谈的时候,小麦其实是说他们结婚吧,并没有想前面婚礼上预设地要分手,但是小娟放弃了,不想结婚,因为不想过那样的生活了,而小麦觉得可能生活就是那样,不可能一直保持刚恋爱时候的那种感觉,生活就是责任,人生就意味着责任。
-我的一些观点也在前面说了,恋爱到婚姻,即使物质没问题,经济没问题,也会有各种各样的问题,需要一起去解决,因为结婚就意味着需要相互扶持,而不是各取所需,可能我的要求比较高,后面男女主在分手后还一起住了一段时间,我原来还在想会不会通过这个方式让他们继续去磨合同步,只是我失望了,最后给个打分可能是 5 到 6 分吧,勉强及格,好的影视剧应该源于生活高于生活,这一部可能还比不上生活。
-]]>
-
- 生活
-
-
- 生活
- 看剧
-
-
-
- 聊聊最近平淡的生活之看《神探狄仁杰》
- /2021/12/19/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E7%9C%8B%E3%80%8A%E7%A5%9E%E6%8E%A2%E7%8B%84%E4%BB%81%E6%9D%B0%E3%80%8B/
- 其实最近看的不止这一部,前面看了《继承者们》,《少年包青天》这些,就一起聊下,其中看《继承者们》算是个人比较喜欢,以前就有这种看剧的习惯,这个跟《一生一世》里任嘉伦说自己看《寻秦记》看了几十遍一样,我看喜欢的剧也基本上会看不止五遍,继承者们是有帅哥美女看,而且印象中剧情也挺甜的,一般情况下最好是已经有点遗忘剧情了,因为我个人觉得看剧分两种,无聊了又心情不太好,可以看些这类轻松又看过的剧,可以不完全专心地看剧,另外有心情专心看的时候,可以看一些需要思考,一些探案类的或者烧脑类。
最近看了《神探狄仁杰》,因为跟前面看的《少年包青天》都是这类古装探案剧,正好有些感想,《少年包青天》算是儿时阴影,本来是不太会去看的,正好有一次有机会跟 LD 一起看了会就也觉得比较有意思就看了下去,不得不说,以前的这些剧还是很不错的,包括剧情和演员,第一部一共是 40 集,看的过程中也发现了大概是五个案子,平均八集一个案子,整体节奏还是比较慢的,但是基本每个案子其实都是构思得很巧妙,很久以前看过但是现在基本不太记得剧情了,每个案子在前面几集的时候基本都猜不到犯案逻辑,但是在看了狄仁杰之后,发现两部剧也有比较大的差别,少年包青天相对来说逻辑性会更强一些,个人主观觉得推理的严谨性更高,可能剧本打磨上更将就一下,而狄仁杰因为要提现他的个人强项,不比少年包青天中有公孙策一时瑜亮的情节,狄仁杰中分工明确,李元芳是个武力担当,曾泰是捧哏的,相对来说是狄仁杰在案子里从始至终地推进案情,有些甚至有些玄乎,会有一些跳脱跟不合理,有些像是狄仁杰的奇遇,不过这些想法是私人的观点,并不是想要评孰优孰劣;第二个感受是不知道是不是年代关系,特别是少年包青天,每个案件的大 boss 基本都不是个完全的坏人,甚至都是比较情有可原的可怜人,因为一些特殊原因,而好几个都是包拯身边的人,这一点其实跟狄仁杰里第一个使团惊魂案件比较类似,虎敬晖也是个人物形象比较丰满的角色,不是个标签化的淡薄形象,跟金木兰的感情和反叛行动在最后都说明的缘由,而且也有随着跟狄仁杰一起办案被其影响感化,最终为了救狄仁杰而被金木兰所杀,只是这样金木兰这个角色就会有些偏执和符号化,当然剧本肯定不是能面面俱到,这样的剧本已经比现在很多流量剧的好很多了。还想到了前阵子看的《指环王》中的白袍萨鲁曼在剧中也是个比较单薄的角色,这样的电影彪炳影史也没办法把个个人物都设计得完整有血有肉,或者说这本来也是应该有侧重点,当然其实我也不觉得指环王就是绝对的最好的,因为相对来说故事情节的复杂性等真的不如西游记,只是在 86 版之后的各种乱七八糟的翻牌和乱拍已经让这个真正的王者神话故事有点力不从心,这里边有部西游记后传是个人还比较喜欢的,虽然武打动作比较鬼畜,但是剧情基本是无敌的,在西游的架构上衍生出来这么完整丰富的故事,人物角色也都有各自的出彩点。
说回狄仁杰,在这之前也看过徐克拍的几部狄仁杰的电影版,第一部刘德华拍得相对完成度更高,故事性也可圈可点,后面几部就是剧情拉胯,靠特效拉回来一点分,虽说这个也是所谓的狄仁杰宇宙的构思在里面但是现在来看基本是跟西游那些差不多,完全没有整体性可言,打一枪换一个地方,演员也没有延续性,剧情也是前后跳脱,没什么关联跟承上启下,导致质量层次不一,更不用谈什么狄仁杰宇宙了,不过这个事情也是难说,原因很多,现在资本都是更加趋利的,一些需要更长久时间才能有回报的投资是很难获得资本青睐,所以只能将重心投给选择一些流量明星,而本来应该将资源投给剧本打磨的基本就没了,再深入说也没意义了,社会现状就是这样。
还有一点感想是,以前的剧里的拍摄环境还是比较惨的,看着一些房子,甚至皇宫都是比较破旧的,地面还是石板这种,想想以前的演员的环境再想想现在的,比如成龙说的,以前他拍剧就是啪摔了,问这条有没有过,过了就直接送医院,而不是现在可能手蹭破点皮就大叫,甚至还有饭圈这些破事。
-]]>
-
- 生活
-
-
- 生活
- 看剧
-
-
-
- 聊聊最近平淡的生活之看看老剧
- /2021/11/21/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E7%9C%8B%E7%9C%8B%E8%80%81%E5%89%A7/
- 最近因为也没什么好看的新剧和综艺所以就看看一些以前看过的老剧,我是个非常念旧的人吧,很多剧都会反反复复地看,一方面之前看过觉得好看的的确是一直记着,还有就是平时工作完了回来就想能放松下,剧情太纠结的,太烧脑的都不喜欢,也就是我常挂在口头的不喜欢看费脑子的剧,跟我不喜欢狼人杀的原因也类似。
-前面其实是看的太阳的后裔,跟 LD 一起看的,之前其实算是看过一点,但是没有看的很完整,并且很多剧情也忘了,只是这个我我可能看得更少一点,因为最开始的时候觉得男主应该是男二,可能对长得这样的男主并且是这样的人设有点失望,感觉不是特别像个特种兵,但是由于本来也比较火,而且 LD 比较喜欢就从这个开始看了,有两个点是比较想说的
-韩剧虽然被吐槽的很多,但是很多剧的质量,情节把控还是优于目前非常多国内剧的,相对来说剧情发展的前后承接不是那么硬凹出来的,而且人设都立得住,这个是非常重要的,很多国内剧怎么说呢,就是当爹的看起来就比儿子没大几岁,三四十岁的人去演一个十岁出头的小姑娘,除非容貌异常,比如刘晓庆这种,不然就会觉得导演在把我们观众当傻子。瞬间就没有想看下去的欲望了。
-再一点就是情节是大众都能接受度比较高的,现在有很多普遍会找一些新奇的视角,比如卖腐,想某某令,两部都叫某某令,这其实是一个点,延伸出去就是跟前面说的一点有点类似,xx 老祖,人看着就二三十,叫 xx 老祖,(喜欢的人轻喷哈)然后名字有一堆,同一个人物一会叫这个名字,一会又叫另一个名字,然后一堆死表情。
-因为今天有个特殊的事情发生,所以简短的写(shui)一篇了
-]]>
-
- 生活
-
-
- 生活
- 看剧
-
-
-
- 聊聊 Sharding-Jdbc 分库分表下的分页方案
- /2022/01/09/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E4%B8%8B%E7%9A%84%E5%88%86%E9%A1%B5%E6%96%B9%E6%A1%88/
- 前面在聊 Sharding-Jdbc 的时候看到了一篇文章,关于一个分页的查询,一直比较直接的想法就是分库分表下的分页是非常不合理的,一般我们的实操方案都是分表加上 ES 搜索做分页,或者通过合表读写分离的方案,因为对于 sharding-jdbc 如果没有带分表键,查询基本都是只能在所有分表都执行一遍,然后再加上分页,基本上是分页越大后续的查询越耗资源,但是仔细的去想这个细节还是这次,就简单说说
首先就是我的分表结构
-CREATE TABLE `student_time_0` (
- `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
- `user_id` int(11) NOT NULL,
- `name` varchar(200) COLLATE utf8_bin DEFAULT NULL,
- `age` tinyint(3) unsigned DEFAULT NULL,
- `create_time` bigint(20) DEFAULT NULL,
- PRIMARY KEY (`id`)
-) ENGINE=InnoDB AUTO_INCREMENT=674 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-有这样的三个表,student_time_0, student_time_1, student_time_2, 以 user_id 作为分表键,根据表数量取模作为分表依据
这里先构造点数据,
-insert into student_time (`name`, `user_id`, `age`, `create_time`) values (?, ?, ?, ?)
-主要是为了保证 create_time 唯一比较好说明问题,
-int i = 0;
-try (
- Connection conn = dataSource.getConnection();
- PreparedStatement ps = conn.prepareStatement(insertSql)) {
- do {
- ps.setString(1, localName + new Random().nextInt(100));
- ps.setLong(2, 10086L + (new Random().nextInt(100)));
- ps.setInt(3, 18);
- ps.setLong(4, new Date().getTime());
-
-
- int result = ps.executeUpdate();
- LOGGER.info("current execute result: {}", result);
- Thread.sleep(new Random().nextInt(100));
- i++;
- } while (i <= 2000);
-三个表的数据分别是 673,678,650,说明符合预期了,各个表数据不一样,接下来比如我们想要做一个这样的分页查询
-select * from student_time ORDER BY create_time ASC limit 1000, 5;
-student_time 对于我们使用的 sharding-jdbc 来说当然是逻辑表,首先从一无所知去想这个查询如果我们自己来处理应该是怎么做,
首先是不是可以每个表都从 333 开始取 5 条数据,类似于下面的查询,然后进行 15 条的合并重排序获取前面的 5 条
-select * from student_time_0 ORDER BY create_time ASC limit 333, 5;
-select * from student_time_1 ORDER BY create_time ASC limit 333, 5;
-select * from student_time_2 ORDER BY create_time ASC limit 333, 5;
-忽略前面 limit 差的 1,这个结果除非三个表的分布是绝对的均匀,否则结果肯定会出现一定的偏差,以为每个表的 333 这个位置对于其他表来说都不一定是一样的,这样对于最后整体的结果,就会出现偏差
因为一直在纠结怎么让这个更直观的表现出来,所以尝试画了个图
![]()
黑色的框代表我从每个表里按排序从 334 到 338 的 5 条数据, 他们在每个表里都是代表了各自正确的排序值,但是对于我们想要的其实是合表后的 1001,1005 这五条,然后我们假设总的排序值位于前 1000 的分布是第 0 个表是 320 条,第 1 个表是 340 条,第 2 个表是 340 条,那么可以明显地看出来我这么查的结果简单合并肯定是不对的。
那么 sharding-jdbc 是如何保证这个结果的呢,其实就是我在每个表里都查分页偏移量和分页大小那么多的数据,在我这个例子里就是对于 0,1,2 三个分表每个都查 1005 条数据,即使我的数据不平衡到最极端的情况,前 1005 条数据都出在某个分表中,也可以正确获得最后的结果,但是明显的问题就是大分页,数据较多,就会导致非常大的问题,即使如 sharding-jdbc 对于合并排序的优化做得比较好,也还是需要传输那么大量的数据,并且查询也耗时,那么有没有解决方案呢,应该说有两个,或者说主要是想讲后者
第一个办法是像这种查询,如果业务上不需要进行跳页,而是只给下一页,那么我们就能把前一次的最大偏移量的 create_time 记录下来,下一页就可以拿着这个偏移量进行查询,这个比较简单易懂,就不多说了
第二个办法是看的58 沈剑的一篇文章,尝试理解讲述一下,
这个办法的第一步跟前面那个错误的方法或者说不准确的方法一样,先是将分页偏移量平均后在三个表里进行查询
-t0
-334 10158 nick95 18 1641548941767
-335 10098 nick11 18 1641548941879
-336 10167 nick51 18 1641548942089
-337 10167 nick3 18 1641548942119
-338 10170 nick57 18 1641548942169
-
-
-t1
-334 10105 nick98 18 1641548939071 最小
-335 10174 nick94 18 1641548939377
-336 10129 nick85 18 1641548939442
-337 10141 nick84 18 1641548939480
-338 10096 nick74 18 1641548939668
-
-t2
-334 10184 nick11 18 1641548945075
-335 10109 nick93 18 1641548945382
-336 10181 nick41 18 1641548945583
-337 10130 nick80 18 1641548945993
-338 10184 nick19 18 1641548946294 最大
-然后要做什么呢,其实目标比较明白,因为前面那种方法其实就是我知道了前一页的偏移量,所以可以直接当做条件来进行查询,那这里我也想着拿到这个条件,所以我将第一遍查出来的最小的 create_time 和最大的 create_time 找出来,然后再去三个表里查询,其实主要是最小值,因为我拿着最小值去查以后我就能知道这个最小值在每个表里处在什么位置,
-t0
-322 10161 nick81 18 1641548939284
-323 10113 nick16 18 1641548939393
-324 10110 nick56 18 1641548939577
-325 10116 nick69 18 1641548939588
-326 10173 nick51 18 1641548939646
-
-t1
-334 10105 nick98 18 1641548939071
-335 10174 nick94 18 1641548939377
-336 10129 nick85 18 1641548939442
-337 10141 nick84 18 1641548939480
-338 10096 nick74 18 1641548939668
-
-t2
-297 10136 nick28 18 1641548939161
-298 10142 nick68 18 1641548939177
-299 10124 nick41 18 1641548939237
-300 10148 nick87 18 1641548939510
-301 10169 nick23 18 1641548939715
-我只贴了前五条数据,为了方便知道偏移量,每个分表都使用了自增主键,我们可以看到前一次查询的最小值分别在其他两个表里的位置分别是 322-1 和 297-1,那么对于总体来说这个时间应该是在 322 - 1 + 333 + 297 - 1 = 951,那这样子我只要对后面的数据最多每个表查 1000 - 951 + 5 = 54 条数据再进行合并排序就可以获得最终正确的结果。
这个就是传说中的二次查询法。
+ 聊聊我理解的分布式事务
+ /2020/05/17/%E8%81%8A%E8%81%8A%E6%88%91%E7%90%86%E8%A7%A3%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/
+ 前面说了mysql数据库的事务相关的,那事务是用来干嘛的,这里得补一下ACID,
+
+ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
+
+
+Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。[1]
+Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。[1]
+Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。[1]
+Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。[1]
+
+在mysql中,借助于MVCC,各种级别的锁,日志等特性来实现了事务的ACID,但是这个我们通常是对于一个数据库服务的定义,常见的情况下我们的数据库随着业务发展也会从单实例变成多实例,组成主从Master-Slave架构,这个时候其实会有一些问题随之出现,比如说主从同步延迟,假如在业务代码中做了读写分离,对于一些敏感度较低的数据其实问题不是很大,只要主从延迟不到特别夸张的地步一般都是可以忍受的,但是对于一些核心的业务数据,比如订单之类的,不能忍受数据不一致,下了单了,付了款了,一刷订单列表,发现这个订单还没支付,甚至订单都没在,这对于用户来讲是恨不能容忍的错误,那么这里就需要一些措施,要不就不读写分离,要不就在 redis 这类缓存下订单,或者支付后加个延时等,这些都是一些补偿措施,并且这也是一个不太切当的例子,比较合适的例子也可以用这个下单来说,一般在电商平台下单会有挺多要做的事情,比如像下面这个图
+![]()
+下单的是后要冻结核销优惠券,如果账户里有钱要冻结扣除账户里的钱,如果使用了J 豆也一样,可能还有 E 卡,忽略我借用的平台,因为目前一般后台服务化之后,可能每一项都是对应的一个后台服务,我们期望的执行过程是要不全成功,要不就全保持执行前状态,不能是部分扣减核销成功了,部分还不行,所以我们处理这种情况会引入一些通用的方案,第一种叫二阶段提交,
+
+二阶段提交(英语:Two-phase Commit)是指在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法。通常,二阶段提交也被称为是一种协议(Protocol)。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为: 参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
+
+对于上面的例子,我们将整个过程分成两个阶段,首先是提交请求阶段,这个阶段大概需要做的是确定资源存在,锁定资源,可能还要做好失败后回滚的准备,如果这些都 ok 了那么就响应成功,这里其实用到了一个叫事务的协调者的角色,类似于裁判员,每个节点都反馈第一阶段成功后,开始执行第二阶段,也就是实际执行操作,这里也是需要所有节点都反馈成功后才是执行成功,要不就是失败回滚。其实常用的分布式事务的解决方案主要也是基于此方案的改进,比如后面介绍的三阶段提交,有三阶段提交就是因为二阶段提交比较尴尬的几个点,
+
+- 第一是对于两阶段提交,其中默认只有协调者有超时时间,当一个参与者进入卡死状态时只能依赖协调者的超时来结束任务,这中间的时间参与者都是锁定着资源
+- 第二是协调者的单点问题,万一挂了,参与者就会在那傻等着
+
+所以三阶段提交引入了各节点的超时机制和一个准备阶段,首先是一个can commit阶段,询问下各个节点有没有资源,能不能进行操作,这个阶段不阻塞,只是提前做个摸底,这个阶段其实人畜无害,但是能提高成功率,在这个阶段如果就有节点反馈是不接受的,那就不用执行下去了,也没有锁资源,然后第二阶段是 pre commit ,这个阶段做的事情跟原来的 第一阶段比较类似,然后是第三阶段do commit,其实三阶段提交我个人觉得只是加了个超时,和准备阶段,好像木有根本性的解决的两阶段提交的问题,后续可以再看看一些论文来思考讨论下。
+2020年05月24日22:11 更新
这里跟朋友讨论了下,好像想通了最核心的一点,对于前面说的那个场景,如果是两阶段提交,如果各个节点中有一个没回应,并且协调者也挂了,这个时候会有什么情况呢,再加一个假设,其实比如这个一阶段其实是检验就失败的,理论上应该大家都释放资源,那么对于这种异常情况,其他的参与者就不知所措了,就傻傻地锁着资源阻塞着,那么三阶段提交的意义就出现了,把第一阶段拆开,那么即使在这个阶段出现上述的异常,即也不会锁定资源,同时参与者也有超时机制,在第二阶段锁定资源出现异常是,其他参与者节点等超时后就自动释放资源了,也就没啥问题了,不过对于那种异常恢复后的一些情况还是没有很好地解决,需要借助 zk 等,后面有空可以讲讲 paxos 跟 raft 等
]]>
- Java
+ 分布式事务
+ 两阶段提交
+ 三阶段提交
- Java
- Sharding-Jdbc
+ 分布式事务
+ 两阶段提交
+ 三阶段提交
+ 2PC
+ 3PC
- 聊聊 dubbo 的线程池
- /2021/04/04/%E8%81%8A%E8%81%8A-dubbo-%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/
- 之前没注意到这一块,只是比较模糊的印象 dubbo 自己基于 ThreadPoolExecutor 定义了几个线程池,但是没具体看过,主要是觉得就是为了避免使用 jdk 自带的那几个(java.util.concurrent.Executors),防止出现那些问题
看下代码目录主要是这几个
![]() -
-
-- FixedThreadPool:创建一个复用固定个数线程的线程池。
简单看下代码public Executor getExecutor(URL url) {
- String name = url.getParameter("threadname", "Dubbo");
- int threads = url.getParameter("threads", 200);
- int queues = url.getParameter("queues", 0);
- return new ThreadPoolExecutor(threads, threads, 0L, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
- }
-可以看到核心线程数跟最大线程数一致,也就是说就不会在核心线程数和最大线程数之间动态变化了
-- LimitedThreadPool:创建一个线程池,这个线程池中线程个数随着需要量动态增加,但是数量不超过配置的阈值的个数,另外空闲线程不会被回收,会一直存在。
public Executor getExecutor(URL url) {
- String name = url.getParameter("threadname", "Dubbo");
- int cores = url.getParameter("corethreads", 0);
- int threads = url.getParameter("threads", 200);
- int queues = url.getParameter("queues", 0);
- return new ThreadPoolExecutor(cores, threads, 9223372036854775807L, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
- }
-这个特点主要是创建了保活时间特别长,即可以认为不会被回收了
-- EagerThreadPool :创建一个线程池,这个线程池当所有核心线程都处于忙碌状态时候,创建新的线程来执行新任务,而不是把任务放入线程池阻塞队列。
public Executor getExecutor(URL url) {
- String name = url.getParameter("threadname", "Dubbo");
- int cores = url.getParameter("corethreads", 0);
- int threads = url.getParameter("threads", 2147483647);
- int queues = url.getParameter("queues", 0);
- int alive = url.getParameter("alive", 60000);
- TaskQueue<Runnable> taskQueue = new TaskQueue(queues <= 0 ? 1 : queues);
- EagerThreadPoolExecutor executor = new EagerThreadPoolExecutor(cores, threads, (long)alive, TimeUnit.MILLISECONDS, taskQueue, new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
- taskQueue.setExecutor(executor);
- return executor;
- }
-这个是改动最多的一个了,因为需要实现这个机制,有兴趣的可以详细看下
-- CachedThreadPool: 创建一个自适应线程池,当线程处于空闲1分钟时候,线程会被回收,当有新请求到来时候会创建新线程
public Executor getExecutor(URL url) {
- String name = url.getParameter("threadname", "Dubbo");
- int cores = url.getParameter("corethreads", 0);
- int threads = url.getParameter("threads", 2147483647);
- int queues = url.getParameter("queues", 0);
- int alive = url.getParameter("alive", 60000);
- return new ThreadPoolExecutor(cores, threads, (long)alive, TimeUnit.MILLISECONDS, (BlockingQueue)(queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue() : new LinkedBlockingQueue(queues))), new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
- }
-这里可以看到线程池的配置,核心是 0,最大线程数是 2147483647,保活时间是一分钟
只是非常简略的介绍下,有兴趣可以自行阅读代码。
-
+ 聊一下 SpringBoot 设置非 web 应用的方法
+ /2022/07/31/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E8%AE%BE%E7%BD%AE%E9%9D%9E-web-%E5%BA%94%E7%94%A8%E7%9A%84%E6%96%B9%E6%B3%95/
+ 寻找原因这次碰到一个比较奇怪的问题,应该统一发布脚本统一给应用启动参数传了个 -Dserver.port=xxxx,其实这个端口会作为 dubbo 的服务端口,并且应用也不提供 web 服务,但是在启动的时候会报embedded servlet container failed to start. port xxxx was already in use就觉得有点奇怪,仔细看了启动参数猜测可能是这个问题,有可能是依赖的二方三方包带了 spring-web 的包,然后基于 springboot 的 auto configuration 会把这个自己加载,就在本地复现了下这个问题,结果的确是这个问题。
+解决方案
老版本 设置 spring 不带 web 功能
比较老的 springboot 版本,可以使用
+SpringApplication app = new SpringApplication(XXXXXApplication.class);
+app.setWebEnvironment(false);
+app.run(args);
+新版本
新版本的 springboot (>= 2.0.0)可以在 properties 里配置
+spring.main.web-application-type=none
+或者
+SpringApplication app = new SpringApplication(XXXXXApplication.class);
+app.setWebApplicationType(WebApplicationType.NONE);
+这个枚举里还有其他两种配置
+public enum WebApplicationType {
+
+ /**
+ * The application should not run as a web application and should not start an
+ * embedded web server.
+ */
+ NONE,
+
+ /**
+ * The application should run as a servlet-based web application and should start an
+ * embedded servlet web server.
+ */
+ SERVLET,
+
+ /**
+ * The application should run as a reactive web application and should start an
+ * embedded reactive web server.
+ */
+ REACTIVE
+
+}
+相当于是把none 的类型和包括 servlet 和 reactive 放进了枚举类进行控制。
]]>
Java
- Dubbo - 线程池
- Dubbo
- 线程池
- ThreadPool
+ SpringBoot
Java
- Dubbo
- ThreadPool
- 线程池
- FixedThreadPool
- LimitedThreadPool
- EagerThreadPool
- CachedThreadPool
+ Spring
+ SpringBoot
+ 自动装配
+ AutoConfiguration
- 聊聊那些加塞狗
- /2021/01/17/%E8%81%8A%E8%81%8A%E9%82%A3%E4%BA%9B%E5%8A%A0%E5%A1%9E%E7%8B%97/
- 今天真的是被气得不轻,情况是碰到一个有 70 多秒的直行红灯,然后直行就排了很长的队,但是左转车道没车,就有好几辆车占着左转车道,准备往直行车道插队加塞,一般这种加塞的,会挑个不太计较的,如果前面一辆不让的话就再等等,我因为赶着回家,就不想让,结果那辆车几次车头直接往里冲,当时怒气值基本已经蓄满了,我真的是分毫都不想让,如果路上都是让着这种人的,那么这种情况只会越来越严重,我理解的这种心态,就赌你怕麻烦,多一事不如少一事,结果就是每次都能顺利插队加塞,其实延伸到我们社会中的种种实质性的排队或者等同于排队的情况,都已经有这种惯有思维,一方面这种不符合规则,可能在严重程度上容易被很多人所忽视,基本上已经被很多人当成是“合理”行为,另一方面,对于这些“微小”的违规行为,本身管理层面也基本没有想要管的意思,就更多的成为了纵容这些行为的导火索,并且大多数人都是想着如果不让,发生点小剐小蹭的要浪费很多时间精力来处理,甚至会觉得会被别人觉得自己太小气等等,诸多内外成本结合起来,会真的去硬刚的可能少之又少了,这样也就让更多的人觉得这种行为是被默许的,再举个非常小的例子,以我们公司疫情期间的盒饭发放为例,有两个比较“有意思”的事情,第一个就是因为疫情,本来是让排队要间隔一米,但是可能除了我比较怕死会跟前面的人保持点距离基本没别人会不挨着前面的人,甚至我跟我前面的人保持点距离,后面的同学会推着我让我上去;第二个是关于拿饭,这么多人排着队拿饭,然后有部分同学,一个人拿好几份,帮组里其他人的都拿了,有些甚至一个人拿十份,假如这个盒饭发放是说明了可以按部门直接全领了那就没啥问题,但是当时的状况是个人排队领自己的那一份,如果一个同学直接帮着组里十几个人都拿了,后面排队的人是什么感受呢,甚至有些是看到队伍排长了,就找队伍里自己认识的比较靠前的人说你帮我也拿一份,其实作为我这个比较按规矩办事的“愣头青”来说,我是比较不能接受这两件小事里的行为的,再往下说可能就有点偏激了,先说到这~
+ 聊聊最近平淡的生活之又聊通勤
+ /2021/11/07/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB/
+ 一直以来过着特别平淡普通的生活,不过大多数人应该都这样吧,也许有些人可以把平凡的生活过得精彩,最简单的说明就是朋友圈吧,看我一年的盆友圈虽然在发,不过大概 90%的都是发发跑步的打卡,偶尔会有稀稀拉拉的点赞,天天上班,也不喜欢发什么状态,觉得没什么人关注,索性不发。
+只是这么平淡的生活就有一些自己比较心烦纠结的,之前有提到过的交通,最近似乎又发现了一点,就真相总是让人跌破眼镜,以前觉得我可能是胆子比较小,所以会觉得怎么路上这些电瓶都是这么肆无忌惮的往我冲过来,后面慢慢有一种借用电视剧读心神探的概念,安全距离,觉得大部分人跟我一样,骑电瓶车什么的总还是有个安全距离,只是可能这个安全距离对于不同的人不一样,那些骑电瓶车的潜意识里的安全距离是非常短,所以经常会骑车离着你非常近才会刹车,但是这个安全距离理论最近又被推翻了,因为经历过几次电瓶车就是已经跟你有身体接触了,但是没到把人撞倒的程度,似乎这些骑电瓶车的觉得步行的行人在人行道上是空气,蹭一下也无所谓,反正不能挡我的路,总感觉要不是我在前面骑自行车太慢挡着电瓶车,不然他们都能起飞去干掉 F35 解放湾湾了;
+另一个问题应该是说我们交通规则普及的太少,虽然我们没有路权这个名词概念,但是其实是有这个优先级的,包括像杭州是以公交车在人行道礼让行人闻名的,其实这个文明的行为只限于人行道在直行路中间的,大部分在十字路口,右转的公交车很少会让直行人行道的,前提是直行的绿灯的时候,特别是像公交车这样,车身特别长,右转的时候会有比较大的死角,如果是公交车先转,行人或者自行车很容易被卷进去,非常危险的,私家车就更不用说了,反正右转即使人行道上人非常多要转的也是一秒都不等,所以我自己在开车的时候是尽量在右转的时候等人行道上的行人或者骑车的走完,因为总会觉得我是不是有点双标,骑车走路的时候希望开车的能按规则让我,自己开车的时候又想赶紧开走,所以在开车的时候尽量做到让行车和骑车的。
+还有个其实是写着写着想起来的,比如我骑车左转的时候,因为我是左转到对角那就到了,跟那些左转后要再直行的不一样,我们应该在学车的时候也学过,超车要从左边超,但是往往那些骑电瓶车的在左转的时候会从我右边超过来再往左边撇过去,如果留的空间大还好,有些电瓶车就是如果车头超过了就不管他的车屁股,如果我不减速,自行车就被刮倒了,可能的确是别人就不是人,只要不把你撞倒就无所谓,反正为了你自己不被撞倒你肯定会让的。
]]>
生活
- 开车
生活
- 开车
- 加塞
糟心事
规则
+ 电瓶车
+ 骑车
- 聊聊部分公交车的设计bug
- /2021/12/05/%E8%81%8A%E8%81%8A%E9%83%A8%E5%88%86%E5%85%AC%E4%BA%A4%E8%BD%A6%E7%9A%84%E8%AE%BE%E8%AE%A1bug/
- 今天惯例坐公交回住的地方,不小心撞了头,原因是我们想坐倒数第二排,然后LD 走在我后面,我就走到最后一排中间等着,但是最后一排是高一截的,等 LD 坐进去以后,我就往前走,结果撞到了车顶的扶手杆子的一端,差点撞昏了去,这里我觉得其实杆子长度应该短一点,不然从最后一排出来,还是有比较大概率因为没注意看而撞到头,特别是没注意看的情况,发力其实会比较大,一头撞上就会像我这样,眼前一黑,又痛得要死。
还有一点就是座位设计了,先来看个图
![]()
图里大致画了两条线,因为可能是轮胎还是什么原因,后排中间会有那么大的突起,但是看两条红线可以发现,靠近过道的座位边缘跟地面突起的边缘不是一样宽的,这样导致的结果就是坐着的时候有一个脚没地儿搁,要不就得侧着斜着坐,或者就是一个脚悬空,短程的可能还好,路程远一点还是比较难受的,特别是像我现在这样,大腿外侧有点难受的情况,就会更难受。
虽然说这两个点,基本是屁用没有,但是我也是在自己这个博客说说,也当是个树洞了。
+ 聊聊最近平淡的生活之《花束般的恋爱》观后感
+ /2021/12/31/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E3%80%8A%E8%8A%B1%E6%9D%9F%E8%88%AC%E7%9A%84%E6%81%8B%E7%88%B1%E3%80%8B%E8%A7%82%E5%90%8E%E6%84%9F/
+ 周末在领导的提议下看了豆瓣的年度榜单,本来感觉没啥心情看的,看到主演有有村架纯就觉得可以看一下,颜值即正义嘛,男主小麦跟女主小娟(后面简称小麦跟小娟)是两个在一次非常偶然的没赶上地铁末班车事件中相识,这里得说下日本这种通宵营业的店好像挺不错的,看着也挺正常,国内估计只有酒吧之类的可以。晚上去的地方是有点暗暗的,好像也有点类似酒吧,旁边有类似于 dj 那种,然后同桌的还有除了男女主的另外一对男女,也是因为没赶上地铁末班车的,但也是陌生人,然后小麦突然看到了有个非常有名的电影人,小娟竟然也认识,然后旁边那对完全不认识,还在那吹自己看过很多电影,比如《肖申克的救赎》,于是男女主都特别鄙夷地看着他们,然后他们又去了另一个有点像泡澡的地方席地而坐,他们发现了自己的鞋子都是一样的,然后在女的去上厕所的时候,小麦暗恋的学姐也来了,然后小麦就去跟学姐他们一起坐了,小娟回来后有点不开心就说去朋友家睡,幸好小麦看出来了(他竟然看出来了,本来以为应该是没填过恋爱很木讷的),就追出去,然后就去了小麦家,到了家小娟发现小麦家的书柜上的书简直就跟她自己家的一模一样,小麦还给小娟吹了头发,一起吃烤饭团,看电影,第二天送小娟上了公交,还约好了一起看木乃伊展,然而并没有交换联系方式,但是他们还是约上了一起看了木乃伊展,在餐馆就出现了片头那一幕的来源,因为餐馆他们想一起听歌,就用有线耳机一人一个耳朵听,但是旁边就有个大叔说“你们是不是不爱音乐,左右耳朵是不一样的,只有一起听才是真正的音乐”这样的话,然后的剧情有点跳,因为是指他们一直在这家餐馆吃饭,中间有他们一起出去玩情节穿插着,也是在这他们确立了关系,可以说主体就是体现了他们非常的合拍和默契,就像一些影评说的,这部电影是说如何跟百分百合拍的人分手,然后就是正常的恋爱开始啪啪啪,一直腻在床上,也没去就业说明会,后面也有讲了一点小麦带着小娟去认识他的朋友,也把小娟介绍给了他们认识,这里算是个小伏笔,后面他们分手也有这里的人的一些关系,接下去的剧情说实话我是不太喜欢的,如果一部八分的电影只是说恋爱被现实打败的话,我觉得在我这是不合格的,但是事实也是这样,小麦其实是有家里的资助,所以后面还是按自己的喜好给一些机构画点插画,小娟则要出去工作,因为小娟家庭观念也是要让她出去有正经工作,用脚指头想也能知道肯定不顺利,然后就是暂时在一家蛋糕店工作,小麦就每天去接小娟,日子过得甜甜蜜蜜,后面小娟在自己的努力下考了个什么资格证,去了一家医院还是什么做前台行政,这中间当然就有父母来见面吃饭了,他们在开始恋爱不久就同居合租了,然后小娟父母就是来说要让她有个正经工作,对男的说的话就是人生就是责任这类的话,而小麦爸爸算是个导火索,因为小麦家里是做烟花生意的,他爸让他就做烟花生意,因为要回老家,并且小麦也不想做,所以就拒绝了,然后他爸就说不给他每个月五万的资助,这也导致了小麦需要去找工作,这个过程也是很辛苦,本来想要年前找好工作,然后事与愿违,后面有一次小娟被同事吐槽怎么从来不去团建,于是她就去了(我以为会拒绝),正在团建的时候小麦给她电话,说找到工作了,是一个创业物流公司这种,这里剧情就是我觉得比较俗套的,小麦各种被虐,累成狗,但是就像小娟爸爸说的话,人生就是责任,所以一直在坚持,但是这样也导致了跟小娟的交流也越来越少,他们原来最爱的漫画,爱玩的游戏,也只剩小娟一个人看,一个人玩,而正是这个时候,小娟说她辞掉了工作,去做一个不是太靠谱的漫画改造的密室逃脱,然后这里其实有一点后面争议很大的,就是这个工作其实是前面小麦介绍给小娟的那些朋友中一个的女朋友介绍的,而在有个剧情就是小娟有一次在这个密室逃脱的老板怀里醒过来,是在 KTV 那样的场景里,这就有很多人觉得小娟是不是出轨了,我觉得其实不那么重要,因为这个离职的事情已经让一切矛盾都摆在眼前,小麦其实是接受这种需要承担责任的生活,也想着要跟小娟结婚,但是小娟似乎还是想要过着那样理想的生活,做自己想做的事情,看自己爱看的漫画,也要小麦能像以前那样一直那么默契的有着相同的爱好,这里的触发点其实还有个是那个小麦的朋友(也就是他女朋友介绍小娟那个不靠谱工作的)的葬礼上,小麦在参加完葬礼后有挺多想倾诉的,而小娟只是想睡了,这个让小麦第二天起来都不想理小娟,只是这里我不太理解,难道这点闹情绪都不能接受吗,所谓的合拍也只是毫无限制的情况下的合拍吧,真正的生活怎么可能如此理想呢,即使没有物质生活的压力,也会有其他的各种压力和限制,在这之后其实小麦想说的是小娟是不是没有想跟自己继续在一起的想法了,而小娟觉得都不说话了,还怎么结婚呢,后面其实导演搞了个小 trick,突然放了异常婚礼,但是不是男女主的,我并不觉得这个桥段很好,在婚礼里男女主都觉得自己想要跟对方说分手了,但是当他们去了最开始一直去的餐馆的时候,一个算是一个现实映照的就是他们一直坐的位子被占了,可能也是导演想通过这个来说明他们已经回不去了,在餐馆交谈的时候,小麦其实是说他们结婚吧,并没有想前面婚礼上预设地要分手,但是小娟放弃了,不想结婚,因为不想过那样的生活了,而小麦觉得可能生活就是那样,不可能一直保持刚恋爱时候的那种感觉,生活就是责任,人生就意味着责任。
+我的一些观点也在前面说了,恋爱到婚姻,即使物质没问题,经济没问题,也会有各种各样的问题,需要一起去解决,因为结婚就意味着需要相互扶持,而不是各取所需,可能我的要求比较高,后面男女主在分手后还一起住了一段时间,我原来还在想会不会通过这个方式让他们继续去磨合同步,只是我失望了,最后给个打分可能是 5 到 6 分吧,勉强及格,好的影视剧应该源于生活高于生活,这一部可能还比不上生活。
]]>
生活
生活
- 公交
- 杭州
+ 看剧
- 聊聊 mysql 的 MVCC 续续篇之锁分析
- /2020/05/10/%E8%81%8A%E8%81%8A-mysql-%E7%9A%84-MVCC-%E7%BB%AD%E7%BB%AD%E7%AF%87%E4%B9%8B%E5%8A%A0%E9%94%81%E5%88%86%E6%9E%90/
- 看完前面两篇水文之后,感觉不得不来分析下 mysql 的锁了,其实前面说到幻读的时候是有个前提没提到的,比如一个select * from table1 where id = 1这种查询语句其实是不会加传说中的锁的,当然这里是指在 RR 或者 RC 隔离级别下,
看一段 mysql官方文档
-
-SELECT ... FROM is a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set to SERIALIZABLE. For SERIALIZABLE level, the search sets shared next-key locks on the index records it encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
-
-纯粹的这种一致性读,实际读取的是快照,也就是基于 read view 的读取方式,除非当前隔离级别是SERIALIZABLE
但是对于以下几类
-
-select * from table where ? lock in share mode;select * from table where ? for update;insert into table values (...);update table set ? where ?;delete from table where ?;
-除了第一条是 S 锁之外,其他都是 X 排他锁,这边在顺带下,S 锁表示共享锁, X 表示独占锁,同为 S 锁之间不冲突,S 与 X,X 与 S,X 与 X 之间都冲突,也就是加了前者,后者就加不上了
我们知道对于 RC 级别会出现幻读现象,对于 RR 级别不会出现,主要的区别是 RR 级别下对于以上的加锁读取都根据情况加上了 gap 锁,那么是不是 RR 级别下以上所有的都是要加 gap 锁呢,当然不是
举个例子,RR 事务隔离级别下,table1 有个主键id 字段
select * from table1 where id = 10 for update
这条语句要加 gap 锁吗?
答案是不需要,这里其实算是我看了这么久的一点自己的理解,啥时候要加 gap 锁,判断的条件是根据我查询的数据是否会因为不加 gap 锁而出现数量的不一致,我上面这条查询语句,在什么情况下会出现查询结果数量不一致呢,只要在这条记录被更新或者删除的时候,有没有可能我第一次查出来一条,第二次变成两条了呢,不可能,因为是主键索引。
再变更下这个题的条件,当 id 不是主键,但是是唯一索引,这样需要怎么加锁,注意问题是怎么加锁,不是需不需要加 gap 锁,这里呢就是稍微延伸一下,把聚簇索引(主键索引)和二级索引带一下,当 id 不是主键,说明是个二级索引,但是它是唯一索引,体会下,首先对于 id = 10这个二级索引肯定要加锁,要不要锁 gap 呢,不用,因为是唯一索引,id = 10 只可能有这一条记录,然后呢,这样是不是就好了,还不行,因为啥,因为它是二级索引,对应的主键索引的记录才是真正的数据,万一被更新掉了咋办,所以在 id = 10 对应的主键索引上也需要加上锁(默认都是 record lock行锁),那主键索引上要不要加 gap 呢,也不用,也是精确定位到这一条记录
最后呢,当 id 不是主键,也不是唯一索引,只是个普通的索引,这里就需要大名鼎鼎的 gap 锁了,
是时候画个图了
![]()
其实核心的目的还是不让这个 id=10 的记录不会出现幻读,那么就需要在 id 这个索引上加上三个 gap 锁,主键索引上就不用了,在 id 索引上已经控制住了id = 10 不会出现幻读,主键索引上这两条对应的记录已经锁了,所以就这样 OK 了
+ 聊聊最近平淡的生活之看《神探狄仁杰》
+ /2021/12/19/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E7%9C%8B%E3%80%8A%E7%A5%9E%E6%8E%A2%E7%8B%84%E4%BB%81%E6%9D%B0%E3%80%8B/
+ 其实最近看的不止这一部,前面看了《继承者们》,《少年包青天》这些,就一起聊下,其中看《继承者们》算是个人比较喜欢,以前就有这种看剧的习惯,这个跟《一生一世》里任嘉伦说自己看《寻秦记》看了几十遍一样,我看喜欢的剧也基本上会看不止五遍,继承者们是有帅哥美女看,而且印象中剧情也挺甜的,一般情况下最好是已经有点遗忘剧情了,因为我个人觉得看剧分两种,无聊了又心情不太好,可以看些这类轻松又看过的剧,可以不完全专心地看剧,另外有心情专心看的时候,可以看一些需要思考,一些探案类的或者烧脑类。
最近看了《神探狄仁杰》,因为跟前面看的《少年包青天》都是这类古装探案剧,正好有些感想,《少年包青天》算是儿时阴影,本来是不太会去看的,正好有一次有机会跟 LD 一起看了会就也觉得比较有意思就看了下去,不得不说,以前的这些剧还是很不错的,包括剧情和演员,第一部一共是 40 集,看的过程中也发现了大概是五个案子,平均八集一个案子,整体节奏还是比较慢的,但是基本每个案子其实都是构思得很巧妙,很久以前看过但是现在基本不太记得剧情了,每个案子在前面几集的时候基本都猜不到犯案逻辑,但是在看了狄仁杰之后,发现两部剧也有比较大的差别,少年包青天相对来说逻辑性会更强一些,个人主观觉得推理的严谨性更高,可能剧本打磨上更将就一下,而狄仁杰因为要提现他的个人强项,不比少年包青天中有公孙策一时瑜亮的情节,狄仁杰中分工明确,李元芳是个武力担当,曾泰是捧哏的,相对来说是狄仁杰在案子里从始至终地推进案情,有些甚至有些玄乎,会有一些跳脱跟不合理,有些像是狄仁杰的奇遇,不过这些想法是私人的观点,并不是想要评孰优孰劣;第二个感受是不知道是不是年代关系,特别是少年包青天,每个案件的大 boss 基本都不是个完全的坏人,甚至都是比较情有可原的可怜人,因为一些特殊原因,而好几个都是包拯身边的人,这一点其实跟狄仁杰里第一个使团惊魂案件比较类似,虎敬晖也是个人物形象比较丰满的角色,不是个标签化的淡薄形象,跟金木兰的感情和反叛行动在最后都说明的缘由,而且也有随着跟狄仁杰一起办案被其影响感化,最终为了救狄仁杰而被金木兰所杀,只是这样金木兰这个角色就会有些偏执和符号化,当然剧本肯定不是能面面俱到,这样的剧本已经比现在很多流量剧的好很多了。还想到了前阵子看的《指环王》中的白袍萨鲁曼在剧中也是个比较单薄的角色,这样的电影彪炳影史也没办法把个个人物都设计得完整有血有肉,或者说这本来也是应该有侧重点,当然其实我也不觉得指环王就是绝对的最好的,因为相对来说故事情节的复杂性等真的不如西游记,只是在 86 版之后的各种乱七八糟的翻牌和乱拍已经让这个真正的王者神话故事有点力不从心,这里边有部西游记后传是个人还比较喜欢的,虽然武打动作比较鬼畜,但是剧情基本是无敌的,在西游的架构上衍生出来这么完整丰富的故事,人物角色也都有各自的出彩点。
说回狄仁杰,在这之前也看过徐克拍的几部狄仁杰的电影版,第一部刘德华拍得相对完成度更高,故事性也可圈可点,后面几部就是剧情拉胯,靠特效拉回来一点分,虽说这个也是所谓的狄仁杰宇宙的构思在里面但是现在来看基本是跟西游那些差不多,完全没有整体性可言,打一枪换一个地方,演员也没有延续性,剧情也是前后跳脱,没什么关联跟承上启下,导致质量层次不一,更不用谈什么狄仁杰宇宙了,不过这个事情也是难说,原因很多,现在资本都是更加趋利的,一些需要更长久时间才能有回报的投资是很难获得资本青睐,所以只能将重心投给选择一些流量明星,而本来应该将资源投给剧本打磨的基本就没了,再深入说也没意义了,社会现状就是这样。
还有一点感想是,以前的剧里的拍摄环境还是比较惨的,看着一些房子,甚至皇宫都是比较破旧的,地面还是石板这种,想想以前的演员的环境再想想现在的,比如成龙说的,以前他拍剧就是啪摔了,问这条有没有过,过了就直接送医院,而不是现在可能手蹭破点皮就大叫,甚至还有饭圈这些破事。
]]>
- Mysql
- C
- 数据结构
- 源码
- Mysql
+ 生活
- mysql
- 数据结构
- 源码
- mvcc
- read view
- gap lock
- next-key lock
- 幻读
+ 生活
+ 看剧
- 聊聊这次换车牌及其他
- /2022/02/20/%E8%81%8A%E8%81%8A%E8%BF%99%E6%AC%A1%E6%8D%A2%E8%BD%A6%E7%89%8C%E5%8F%8A%E5%85%B6%E4%BB%96/
- 去年 8 月份运气比较好,摇到了车牌,本来其实应该很早就开始摇的,前面第一次换工作没注意社保断缴了一个月,也是大意失荆州,后面到了 17 年社保满两年了,好像只摇了一次,还是就没摇过,有点忘了,好像是什么原因导致那次也没摇成功,但是后面暂住证就取消了,需要居住证,居住证又要一年及以上的租房合同,并且那会买车以后也不怎么开,住的地方车位还好,但是公司车位一个月要两三千,甚至还是打车上下班比较实惠,所以也没放在心上,后面摇到房以后,也觉得应该准备起来车子,就开始办了居住证,居住证其实还可以用劳动合同,而且办起来也挺快,大概是三四月份开始摇,到 8 月份的某一天收到短信说摇到了,一开始还挺开心,不过心里抱着也不怎么开,也没怎么大放在心上,不过这里有一点就是我把那个照片直接发出去,上面有着我的身份证号,被 LD 说了一顿,以后也应该小心点,但是后面不知道是哪里看了下,说杭州上牌已经需要国六标准的车了,瞬间感觉是空欢喜了,可是有同事说是可以的,我就又打了官方的电话,结果说可以的,要先转籍,然后再做上牌。
-转籍其实是很方便的,在交警 12123 App 上申请就行了,在转籍以后,需要去实地验车,验车的话,在支付宝-杭州交警生活号里进行预约,找就近的车管所就好,需要准备一些东西,首先是行驶证,机动车登记证书,身份证,居住证,还有车上需要准备的东西是要有三脚架和反光背心,反光背心是最近几个月开始要的,问过之前去验车的只需要三脚架就好了,预约好了的话建议是赶上班时间越早越好,不然过去排队时间要很久,而且人多了以后会很乱,各种插队,而且有很多都是汽车销售,一个销售带着一堆车,我们附近那个进去的小路没一会就堵满车,进去需要先排队,然后扫码,接着交资料,这两个都排着队,如果去晚了就要排很久的队,交完资料才是排队等验车,验车就是打开引擎盖,有人会帮忙拓印发动机车架号,然后验车的会各种检查一下,车里面,还有后备箱,建议车内整理干净点,后备箱不要放杂物,检验完了之后,需要把三脚架跟反光背心放在后备箱盖子上,人在旁边拍个照,然后需要把车牌遮住后再拍个车子的照片,再之后就是去把车牌卸了,这个多吐槽下,那边应该是本来那边师傅帮忙卸车牌,结果他就说是教我们拆,虽然也不算难,但是不排除师傅有在偷懒,完了之后就是把旧车牌交回去,然后需要在手机上(警察叔叔 App)提交各种资料,包括身份证,行驶证,机动车登记证书,提交了之后就等寄车牌过来了。
-这里面缺失的一个环节就是选号了,选号杭州有两个方式,一种就是根据交管局定期发布的选号号段,可以自定义拼 20 个号,在手机上的交警 12123 App 上可以三个一组的形式提交,如果有没被选走的,就可以预选到这个了,但是这种就是也需要有一定策略,最新出的号段能选中的概率大一点,然后数字全是 8,6 这种的肯定会一早就被选走,然后如果跟我一样可以提前选下尾号,因为尾号数字影响限号,我比较有可能周五回家,所以得避开 5,0 的,第二种就是 50 选一跟以前新车选号一样,就不介绍了。第一种选中了以后可以在前面交还旧车牌的时候填上等着寄过来了,因为我是第一种选中的,第二种也可以在手机上选,也在可以在交还车牌的时候现场选。
-总体过程其实是 LD 在各种查资料跟帮我跑来跑去,要不是 LD,估计在交管局那边我就懵逼了,各种插队,而且车子开着车子,也不能随便跑,所以建议办这个的时候有个人一起比较好。
+ 聊聊那些加塞狗
+ /2021/01/17/%E8%81%8A%E8%81%8A%E9%82%A3%E4%BA%9B%E5%8A%A0%E5%A1%9E%E7%8B%97/
+ 今天真的是被气得不轻,情况是碰到一个有 70 多秒的直行红灯,然后直行就排了很长的队,但是左转车道没车,就有好几辆车占着左转车道,准备往直行车道插队加塞,一般这种加塞的,会挑个不太计较的,如果前面一辆不让的话就再等等,我因为赶着回家,就不想让,结果那辆车几次车头直接往里冲,当时怒气值基本已经蓄满了,我真的是分毫都不想让,如果路上都是让着这种人的,那么这种情况只会越来越严重,我理解的这种心态,就赌你怕麻烦,多一事不如少一事,结果就是每次都能顺利插队加塞,其实延伸到我们社会中的种种实质性的排队或者等同于排队的情况,都已经有这种惯有思维,一方面这种不符合规则,可能在严重程度上容易被很多人所忽视,基本上已经被很多人当成是“合理”行为,另一方面,对于这些“微小”的违规行为,本身管理层面也基本没有想要管的意思,就更多的成为了纵容这些行为的导火索,并且大多数人都是想着如果不让,发生点小剐小蹭的要浪费很多时间精力来处理,甚至会觉得会被别人觉得自己太小气等等,诸多内外成本结合起来,会真的去硬刚的可能少之又少了,这样也就让更多的人觉得这种行为是被默许的,再举个非常小的例子,以我们公司疫情期间的盒饭发放为例,有两个比较“有意思”的事情,第一个就是因为疫情,本来是让排队要间隔一米,但是可能除了我比较怕死会跟前面的人保持点距离基本没别人会不挨着前面的人,甚至我跟我前面的人保持点距离,后面的同学会推着我让我上去;第二个是关于拿饭,这么多人排着队拿饭,然后有部分同学,一个人拿好几份,帮组里其他人的都拿了,有些甚至一个人拿十份,假如这个盒饭发放是说明了可以按部门直接全领了那就没啥问题,但是当时的状况是个人排队领自己的那一份,如果一个同学直接帮着组里十几个人都拿了,后面排队的人是什么感受呢,甚至有些是看到队伍排长了,就找队伍里自己认识的比较靠前的人说你帮我也拿一份,其实作为我这个比较按规矩办事的“愣头青”来说,我是比较不能接受这两件小事里的行为的,再往下说可能就有点偏激了,先说到这~
]]>
生活
+ 开车
生活
- 换车牌
+ 开车
+ 加塞
+ 糟心事
+ 规则
@@ -19738,49 +19691,52 @@ t2
- 记录一次折腾自组 nas 的失败经历-续续篇
- /2023/05/28/%E8%AE%B0%E5%BD%95%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%87%AA%E7%BB%84-nas-%E7%9A%84%E5%A4%B1%E8%B4%A5%E7%BB%8F%E5%8E%86-%E7%BB%AD%E7%BB%AD%E7%AF%87/
- 之前这个机器已经算是跑起来了,虽然不是很完善也不是最佳实践,不过这篇可能也不算是失败经历了,因为最后成功跑起来了,在没法装最新版的 exsi 的情况下,并且我后面买的华硕 z370 主板点不亮,所以我也有点死心就直接用Windows 下装 vmware workstation 装虚拟机,然后直通硬盘来做 nas,这样可能对于其他人来说是很垃圾的方案,不过因为我很多常用软件的都是在 Windows 环境下的,并且纯黑裙的环境会比较浪费,相比一些同学在群晖里安装 Windows 虚拟机,我觉得还是反过来比较好,毕竟 vmware 做虚拟机应该是比群晖专业点,不过这个方案也有一些问题
第一种方式是直接找网上同学分享的处理好引导的 vmx,这种我碰到了一个问题就是在打开虚拟机安装群晖系统.pat的时候会提示“无法安装此文件,文件可能已损坏”,这其实不是真的文件已损坏,应该是群晖在做校验的时候存在什么条件没有通过,尝试了断网等方式都不成功,所以后来就用了比较釜底抽薪的方案,直接使用大佬开源的 arpl 引导制作工具
第二种方式一开始是躺在我 B 站收藏夹里,有个 up 制作的,做得很细致,也把很多细节也解释了,过程其实不难,就是按步骤一步步执行,但是一开始选择了 918+的系统在我的方案里安装不了,会提示无法安装,经过视频下的评论的知道,尝试使用 920+的系统就顺利安装成功了,这里唯一的区别就是在添加硬盘的时候要选择物理磁盘,然后 vmware 给出的硬盘选项是Physical0, Physical1,记得别选错了,然后在启动后我租了 raid5,4 块 4T 的盘,可以组成一个 10T 多一点的存储空间,打算用来作为比较长读写的区域,更大的盘可能就会作为只读区域,减小写入量。后面还有一些问题待解决,一个是电源,考虑换个稍好一点,因为目前看下来电源风扇的噪音比较大,还有就是主板,最近看中了微星的 z390,不过价格比较贵,打算慢慢蹲蹲看。
+ 聊聊最近平淡的生活之看看老剧
+ /2021/11/21/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E7%9C%8B%E7%9C%8B%E8%80%81%E5%89%A7/
+ 最近因为也没什么好看的新剧和综艺所以就看看一些以前看过的老剧,我是个非常念旧的人吧,很多剧都会反反复复地看,一方面之前看过觉得好看的的确是一直记着,还有就是平时工作完了回来就想能放松下,剧情太纠结的,太烧脑的都不喜欢,也就是我常挂在口头的不喜欢看费脑子的剧,跟我不喜欢狼人杀的原因也类似。
+前面其实是看的太阳的后裔,跟 LD 一起看的,之前其实算是看过一点,但是没有看的很完整,并且很多剧情也忘了,只是这个我我可能看得更少一点,因为最开始的时候觉得男主应该是男二,可能对长得这样的男主并且是这样的人设有点失望,感觉不是特别像个特种兵,但是由于本来也比较火,而且 LD 比较喜欢就从这个开始看了,有两个点是比较想说的
+韩剧虽然被吐槽的很多,但是很多剧的质量,情节把控还是优于目前非常多国内剧的,相对来说剧情发展的前后承接不是那么硬凹出来的,而且人设都立得住,这个是非常重要的,很多国内剧怎么说呢,就是当爹的看起来就比儿子没大几岁,三四十岁的人去演一个十岁出头的小姑娘,除非容貌异常,比如刘晓庆这种,不然就会觉得导演在把我们观众当傻子。瞬间就没有想看下去的欲望了。
+再一点就是情节是大众都能接受度比较高的,现在有很多普遍会找一些新奇的视角,比如卖腐,想某某令,两部都叫某某令,这其实是一个点,延伸出去就是跟前面说的一点有点类似,xx 老祖,人看着就二三十,叫 xx 老祖,(喜欢的人轻喷哈)然后名字有一堆,同一个人物一会叫这个名字,一会又叫另一个名字,然后一堆死表情。
+因为今天有个特殊的事情发生,所以简短的写(shui)一篇了
]]>
- nas
+ 生活
- nas
+ 生活
+ 看剧
- 记录一次折腾自组 nas 的失败经历-续篇
- /2023/05/14/%E8%AE%B0%E5%BD%95%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%87%AA%E7%BB%84-nas-%E7%9A%84%E5%A4%B1%E8%B4%A5%E7%BB%8F%E5%8E%86-%E7%BB%AD%E7%AF%87/
- 上次记录了前面的一些失败经验,最重要的点还没提到,先发一下配置单
cpu i7-8700k
主板 技嘉 z370m-ds3h
内存 光威 ddr4-3200Mhz
硬盘 京东京造 512g
散热 利民 PA120
电源 先马平头哥额定 550w
机箱 爱国者半岛铁盒 F10
cpu 跟主板是板 U 套装某鱼买的二手的,说实话如果不是后面的网卡问题,这个板 U 套装还是比较良心的,一次点亮(以前没组装过,还不知道有点不亮的情况,后面就体验到了),但是这里就出现了一个很大的坑,因为我这次是想要在裸机上装 exsi,然后看到了群里苏大的一篇 exsi 最新版本 8 的镜像构建文章,硬件也不是很旧,就想着用最新的系统,镜像写进 ventoy 后启动发现报错找不到网卡,这会我还没发现问题的严重性,想着按一些教程打个驱动进去就好了,而且我还以为驱动只要跟镜像 iso 放一块就行了,后面随着深入了解就知道要把驱动打进 iso 镜像里,但是找了一通发现我的网卡是瑞昱的 RTL8168,这个型号的板载网卡,走的是 PCIE 通道,有驱动的最后支持的系统是 exsi6.7,再往后就没有完整打包好的社区版驱动可以使用了,所以这是踩的第一个大坑,照理这个事情也没这么大问题,退回来 6.7 不就行了,问题恰恰是我那时候还不懂,又想用更新的系统,所以就在网上搜了半天,发现华硕的 z370 tuf gaming 系列是用的 intel 的网卡,社区的网卡驱动对 intel 的网卡支持比较好,所以想着还是换个主板算了,其实还有不少选择,买个 pcie 的 intel 网卡或者 usb 的其他千兆网卡,有个说出来可能比较难理解的,usb 的社区版驱动反而比 pcie 的支持得广,pcie 的还是只支持 intel 的。
在某多多上买了个二手的 z370 tuf gaming 主板,结果踩到了第二个坑,可能比较小白的经验是,前面因为买的板 U 套装,他 cpu 是直接装在主板上邮给我的,所以我没装过 cpu,这回买来这块二手的华硕主板对我来说是第一次装 cpu,不过好像难度不大,一下就装好了,但结果就很惨,就是点不亮,散热器风扇会转,但是键盘灯不亮,而且散热风扇还转得很快,我还试着把内存换个槽,结果四个槽都不行,这个时候就很害怕了,看上去这家店也不像是太坑的,毕竟大量地在卖,所以我就很担心是不是前面 cpu 装的不对,把针脚什么的搞坏了,这个时候已经搞到晚上很迟了,但还是忍不住又装回原来的技嘉主板试了下,幸好能正常点亮,算了,还是就用技嘉这块主板吧,接口配置稍微差了点,网卡也不支持最新版的 exsi,所以我就用 vmware workstation 了,在 win10 的 lstc 上装一个,有点性能损耗就损耗吧,反正我也不暴力使用,能跑跑其他 Ubuntu 虚拟机啥的就可以了,或者回到前面的结果,可以装 6.7 的,网上带了瑞昱网卡驱动的 exsi6.7 的镜像挺多的,可以自己打一个或者用别人打包好的。折腾不止踩坑不止呐。
+ 聊聊部分公交车的设计bug
+ /2021/12/05/%E8%81%8A%E8%81%8A%E9%83%A8%E5%88%86%E5%85%AC%E4%BA%A4%E8%BD%A6%E7%9A%84%E8%AE%BE%E8%AE%A1bug/
+ 今天惯例坐公交回住的地方,不小心撞了头,原因是我们想坐倒数第二排,然后LD 走在我后面,我就走到最后一排中间等着,但是最后一排是高一截的,等 LD 坐进去以后,我就往前走,结果撞到了车顶的扶手杆子的一端,差点撞昏了去,这里我觉得其实杆子长度应该短一点,不然从最后一排出来,还是有比较大概率因为没注意看而撞到头,特别是没注意看的情况,发力其实会比较大,一头撞上就会像我这样,眼前一黑,又痛得要死。
还有一点就是座位设计了,先来看个图
![]()
图里大致画了两条线,因为可能是轮胎还是什么原因,后排中间会有那么大的突起,但是看两条红线可以发现,靠近过道的座位边缘跟地面突起的边缘不是一样宽的,这样导致的结果就是坐着的时候有一个脚没地儿搁,要不就得侧着斜着坐,或者就是一个脚悬空,短程的可能还好,路程远一点还是比较难受的,特别是像我现在这样,大腿外侧有点难受的情况,就会更难受。
虽然说这两个点,基本是屁用没有,但是我也是在自己这个博客说说,也当是个树洞了。
]]>
- nas
+ 生活
- nas
+ 生活
+ 公交
+ 杭州
- 解决 网络文件夹目前是以其他用户名和密码进行映射的 问题
- /2023/04/09/%E8%A7%A3%E5%86%B3-%E7%BD%91%E7%BB%9C%E6%96%87%E4%BB%B6%E5%A4%B9%E7%9B%AE%E5%89%8D%E6%98%AF%E4%BB%A5%E5%85%B6%E4%BB%96%E7%94%A8%E6%88%B7%E5%90%8D%E5%92%8C%E5%AF%86%E7%A0%81%E8%BF%9B%E8%A1%8C%E6%98%A0%E5%B0%84%E7%9A%84/
- 之前在使用 smb 协议在 Windows 中共享磁盘使用映射网络驱动器的时候,如果前一次登录过账号密码后面有了改动,或者前一次改错了,
就会出现这样的提示
![]()
应该是 Windows 已经把之前的连接记录下来了,即使是链接不成功的
可以通过在 cmd 或者 powershell 执行 net use 命令查看当前已经连接的
![]()
这样就可以用命令来把这个删除
net use [NETNAME] /delete
比如这边就可以
net use \\xxxxxxxx\f /delete
然后再重新输入账号密码就好了
关于net use的命令使用方式可以参考
-net use [{<DeviceName> | *}] [\\<ComputerName>\<ShareName>[\<volume>]] [{<Password> | *}]] [/user:[<DomainName>\]<UserName] >[/user:[<DottedDomainName>\]<UserName>] [/user: [<UserName@DottedDomainName>] [/savecred] [/smartcard] [{/delete | /persistent:{yes | no}}]
-net use [<DeviceName> [/home[{<Password> | *}] [/delete:{yes | no}]]
-net use [/persistent:{yes | no}]
-
+ 记录一次折腾自组 nas 的失败经历-续篇
+ /2023/05/14/%E8%AE%B0%E5%BD%95%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%87%AA%E7%BB%84-nas-%E7%9A%84%E5%A4%B1%E8%B4%A5%E7%BB%8F%E5%8E%86-%E7%BB%AD%E7%AF%87/
+ 上次记录了前面的一些失败经验,最重要的点还没提到,先发一下配置单
cpu i7-8700k
主板 技嘉 z370m-ds3h
内存 光威 ddr4-3200Mhz
硬盘 京东京造 512g
散热 利民 PA120
电源 先马平头哥额定 550w
机箱 爱国者半岛铁盒 F10
cpu 跟主板是板 U 套装某鱼买的二手的,说实话如果不是后面的网卡问题,这个板 U 套装还是比较良心的,一次点亮(以前没组装过,还不知道有点不亮的情况,后面就体验到了),但是这里就出现了一个很大的坑,因为我这次是想要在裸机上装 exsi,然后看到了群里苏大的一篇 exsi 最新版本 8 的镜像构建文章,硬件也不是很旧,就想着用最新的系统,镜像写进 ventoy 后启动发现报错找不到网卡,这会我还没发现问题的严重性,想着按一些教程打个驱动进去就好了,而且我还以为驱动只要跟镜像 iso 放一块就行了,后面随着深入了解就知道要把驱动打进 iso 镜像里,但是找了一通发现我的网卡是瑞昱的 RTL8168,这个型号的板载网卡,走的是 PCIE 通道,有驱动的最后支持的系统是 exsi6.7,再往后就没有完整打包好的社区版驱动可以使用了,所以这是踩的第一个大坑,照理这个事情也没这么大问题,退回来 6.7 不就行了,问题恰恰是我那时候还不懂,又想用更新的系统,所以就在网上搜了半天,发现华硕的 z370 tuf gaming 系列是用的 intel 的网卡,社区的网卡驱动对 intel 的网卡支持比较好,所以想着还是换个主板算了,其实还有不少选择,买个 pcie 的 intel 网卡或者 usb 的其他千兆网卡,有个说出来可能比较难理解的,usb 的社区版驱动反而比 pcie 的支持得广,pcie 的还是只支持 intel 的。
在某多多上买了个二手的 z370 tuf gaming 主板,结果踩到了第二个坑,可能比较小白的经验是,前面因为买的板 U 套装,他 cpu 是直接装在主板上邮给我的,所以我没装过 cpu,这回买来这块二手的华硕主板对我来说是第一次装 cpu,不过好像难度不大,一下就装好了,但结果就很惨,就是点不亮,散热器风扇会转,但是键盘灯不亮,而且散热风扇还转得很快,我还试着把内存换个槽,结果四个槽都不行,这个时候就很害怕了,看上去这家店也不像是太坑的,毕竟大量地在卖,所以我就很担心是不是前面 cpu 装的不对,把针脚什么的搞坏了,这个时候已经搞到晚上很迟了,但还是忍不住又装回原来的技嘉主板试了下,幸好能正常点亮,算了,还是就用技嘉这块主板吧,接口配置稍微差了点,网卡也不支持最新版的 exsi,所以我就用 vmware workstation 了,在 win10 的 lstc 上装一个,有点性能损耗就损耗吧,反正我也不暴力使用,能跑跑其他 Ubuntu 虚拟机啥的就可以了,或者回到前面的结果,可以装 6.7 的,网上带了瑞昱网卡驱动的 exsi6.7 的镜像挺多的,可以自己打一个或者用别人打包好的。折腾不止踩坑不止呐。
]]>
- 技巧
+ nas
- windows
+ nas
- 记录一次折腾自组 nas 的失败经历
- /2023/05/07/%E8%AE%B0%E5%BD%95%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%87%AA%E7%BB%84-nas-%E7%9A%84%E5%A4%B1%E8%B4%A5%E7%BB%8F%E5%8E%86/
- 鉴于现在市面上的成品 nas 对于我来说要不就是太贵了,要不就是便宜的盘位少,性能比较差,很多 nas 主打还有用 docker 什么的,但是性能对于我个人比较特殊的使用方式来说还是不太够用的,比如现在比较性能好的 nas 像绿联新出的 DX4600,用的是N5105,passmark 分数还不如我 15 年买的 pc 上的 i5 4590,当然很多人是考虑功耗,这也是萝卜青菜各有所爱,可能我算下来还是觉得没多大必要
然后就是考虑用什么硬件配置了,这个流派也有很多种,
用蜗牛星际的原版硬件其实对于需求不大的也是挺好的,整套的都解决了,cpu 用 j1900 如果就做 nas 应该也够了,我没选的原因一方面是性能不符合我的要求,另一方面是现在市面上的机器大部分都是战损成色,而且也不太便宜,如果成色比较好的能够 400 以内拿下整机的话感觉还算可以,cpu 换成 j4125 或者 j3455 再加个 100 也能接受,但基本比较少有这种价格,之前看到一个换了 j3455 的只要 360,犹豫了下没下手,其他很多的都是 j1900 的都要 600 左右
然后是各类 E3,E5 和商用服务器类型的,这种的特点是功耗大,其实 cpu 很便宜,E5 2630V3 跟 2630V4 都只要十几块钱,性能过得去,没有选的主要是机箱占地方也比较贵,还有是商用的怕很多系统需要自己找驱动什么的,配件比如 HBA 卡这种,买的不兼容什么的还是挺麻烦的,另外噪音也是个比较大的问题,租的房子比较小,即使放客厅也是靠着卧室的墙边,如果以后换大一点的房子倒是可以考虑
最后就是我目前选的方案,就是普通的民用机器,找盘位多一点的机箱,我原来的 4590 的机器的机箱就不错,但是已经停产了,二手的太重了闲鱼都不出外地,cpu 跟主板其实考虑了很久,因为从 4590 开始核显就能硬解 H264 这种常规的视频了,考虑用intel 四代的 i3 或者 i5 应该纯 nas 来讲是足够用了,但是这样就跟我现在已经有的 4590 有点重叠了,而且也觉得最好是能性能好一些的,就开始看一些稍新一点的,很多用的多的有 i3-8100,跟 i3-10100 这种,但是这些已经被炒的价格比较高,寻寻觅觅了很久看中了 i5-8600,这个价格跟 8500 差不多,性能还好一些,主板就是我标题说的最“失败”的一个点了,主要是因为主板自带的网卡是 Realtek 的,至于更具体的后面会专门介绍,机箱是图便宜买的爱国者半岛铁盒的 F10,内存就买了一根光威的 32g 的,装系统的硬盘是用了以前囤的京东京造的麒麟系列,但是现在对这个系列挺不看好,之前有个盘就掉盘了,维修体验一开始也不好,半个多月维修,电源也是图便宜买的一个先马的平头哥系列,额定 550w 只要 140 左右,整体的机器就攒齐了,但是很多问题也随之出现了
第一个问题是买的二手的板 U 套装,结果寄过来的时候没带挡板,导致一开始装上了又要拆下来;第二个问题是主机贪便宜,主机上固定主板螺丝的螺柱拧不进去,后来店家告诉我让我可以用电源固定的螺丝先拧一下才把螺柱拧进去;第三个问题是因为没什么装机经验导致的,散热装的太累了,因为要兼容各种主板,还有各种螺丝,装的时候也着急;第四个问题是电源的比较便宜,一方面比较不放心安全性,另一方面是我想多装几个硬盘,电源直出的只有四个 sata 口,需要买转接线,从 D 型的 4pin 口子转出来;第五个问题也是电源,主板电源线有点不太够,走背线就比较困难
以上主要是装机的困难,下一篇介绍作为 nas 的各种问题吧
+ 记录一次折腾自组 nas 的失败经历-续续篇
+ /2023/05/28/%E8%AE%B0%E5%BD%95%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%87%AA%E7%BB%84-nas-%E7%9A%84%E5%A4%B1%E8%B4%A5%E7%BB%8F%E5%8E%86-%E7%BB%AD%E7%BB%AD%E7%AF%87/
+ 之前这个机器已经算是跑起来了,虽然不是很完善也不是最佳实践,不过这篇可能也不算是失败经历了,因为最后成功跑起来了,在没法装最新版的 exsi 的情况下,并且我后面买的华硕 z370 主板点不亮,所以我也有点死心就直接用Windows 下装 vmware workstation 装虚拟机,然后直通硬盘来做 nas,这样可能对于其他人来说是很垃圾的方案,不过因为我很多常用软件的都是在 Windows 环境下的,并且纯黑裙的环境会比较浪费,相比一些同学在群晖里安装 Windows 虚拟机,我觉得还是反过来比较好,毕竟 vmware 做虚拟机应该是比群晖专业点,不过这个方案也有一些问题
第一种方式是直接找网上同学分享的处理好引导的 vmx,这种我碰到了一个问题就是在打开虚拟机安装群晖系统.pat的时候会提示“无法安装此文件,文件可能已损坏”,这其实不是真的文件已损坏,应该是群晖在做校验的时候存在什么条件没有通过,尝试了断网等方式都不成功,所以后来就用了比较釜底抽薪的方案,直接使用大佬开源的 arpl 引导制作工具
第二种方式一开始是躺在我 B 站收藏夹里,有个 up 制作的,做得很细致,也把很多细节也解释了,过程其实不难,就是按步骤一步步执行,但是一开始选择了 918+的系统在我的方案里安装不了,会提示无法安装,经过视频下的评论的知道,尝试使用 920+的系统就顺利安装成功了,这里唯一的区别就是在添加硬盘的时候要选择物理磁盘,然后 vmware 给出的硬盘选项是Physical0, Physical1,记得别选错了,然后在启动后我租了 raid5,4 块 4T 的盘,可以组成一个 10T 多一点的存储空间,打算用来作为比较长读写的区域,更大的盘可能就会作为只读区域,减小写入量。后面还有一些问题待解决,一个是电源,考虑换个稍好一点,因为目前看下来电源风扇的噪音比较大,还有就是主板,最近看中了微星的 z390,不过价格比较贵,打算慢慢蹲蹲看。
]]>
nas
@@ -19863,145 +19819,113 @@ net use [/很方便的变成了以 userId 作为 key,以相同 userId 的 StudentRecord 的 List 作为 value 的 map 结构
]]>
- java
+ java
+
+
+ java
+ stream
+
+
+
+ 聊聊这次换车牌及其他
+ /2022/02/20/%E8%81%8A%E8%81%8A%E8%BF%99%E6%AC%A1%E6%8D%A2%E8%BD%A6%E7%89%8C%E5%8F%8A%E5%85%B6%E4%BB%96/
+ 去年 8 月份运气比较好,摇到了车牌,本来其实应该很早就开始摇的,前面第一次换工作没注意社保断缴了一个月,也是大意失荆州,后面到了 17 年社保满两年了,好像只摇了一次,还是就没摇过,有点忘了,好像是什么原因导致那次也没摇成功,但是后面暂住证就取消了,需要居住证,居住证又要一年及以上的租房合同,并且那会买车以后也不怎么开,住的地方车位还好,但是公司车位一个月要两三千,甚至还是打车上下班比较实惠,所以也没放在心上,后面摇到房以后,也觉得应该准备起来车子,就开始办了居住证,居住证其实还可以用劳动合同,而且办起来也挺快,大概是三四月份开始摇,到 8 月份的某一天收到短信说摇到了,一开始还挺开心,不过心里抱着也不怎么开,也没怎么大放在心上,不过这里有一点就是我把那个照片直接发出去,上面有着我的身份证号,被 LD 说了一顿,以后也应该小心点,但是后面不知道是哪里看了下,说杭州上牌已经需要国六标准的车了,瞬间感觉是空欢喜了,可是有同事说是可以的,我就又打了官方的电话,结果说可以的,要先转籍,然后再做上牌。
+转籍其实是很方便的,在交警 12123 App 上申请就行了,在转籍以后,需要去实地验车,验车的话,在支付宝-杭州交警生活号里进行预约,找就近的车管所就好,需要准备一些东西,首先是行驶证,机动车登记证书,身份证,居住证,还有车上需要准备的东西是要有三脚架和反光背心,反光背心是最近几个月开始要的,问过之前去验车的只需要三脚架就好了,预约好了的话建议是赶上班时间越早越好,不然过去排队时间要很久,而且人多了以后会很乱,各种插队,而且有很多都是汽车销售,一个销售带着一堆车,我们附近那个进去的小路没一会就堵满车,进去需要先排队,然后扫码,接着交资料,这两个都排着队,如果去晚了就要排很久的队,交完资料才是排队等验车,验车就是打开引擎盖,有人会帮忙拓印发动机车架号,然后验车的会各种检查一下,车里面,还有后备箱,建议车内整理干净点,后备箱不要放杂物,检验完了之后,需要把三脚架跟反光背心放在后备箱盖子上,人在旁边拍个照,然后需要把车牌遮住后再拍个车子的照片,再之后就是去把车牌卸了,这个多吐槽下,那边应该是本来那边师傅帮忙卸车牌,结果他就说是教我们拆,虽然也不算难,但是不排除师傅有在偷懒,完了之后就是把旧车牌交回去,然后需要在手机上(警察叔叔 App)提交各种资料,包括身份证,行驶证,机动车登记证书,提交了之后就等寄车牌过来了。
+这里面缺失的一个环节就是选号了,选号杭州有两个方式,一种就是根据交管局定期发布的选号号段,可以自定义拼 20 个号,在手机上的交警 12123 App 上可以三个一组的形式提交,如果有没被选走的,就可以预选到这个了,但是这种就是也需要有一定策略,最新出的号段能选中的概率大一点,然后数字全是 8,6 这种的肯定会一早就被选走,然后如果跟我一样可以提前选下尾号,因为尾号数字影响限号,我比较有可能周五回家,所以得避开 5,0 的,第二种就是 50 选一跟以前新车选号一样,就不介绍了。第一种选中了以后可以在前面交还旧车牌的时候填上等着寄过来了,因为我是第一种选中的,第二种也可以在手机上选,也在可以在交还车牌的时候现场选。
+总体过程其实是 LD 在各种查资料跟帮我跑来跑去,要不是 LD,估计在交管局那边我就懵逼了,各种插队,而且车子开着车子,也不能随便跑,所以建议办这个的时候有个人一起比较好。
+]]>
+
+ 生活
- java
- stream
+ 生活
+ 换车牌
- 记一个容器中 dubbo 注册的小知识点
- /2022/10/09/%E8%AE%B0%E4%B8%80%E4%B8%AA%E5%AE%B9%E5%99%A8%E4%B8%AD-dubbo-%E6%B3%A8%E5%86%8C%E7%9A%84%E5%B0%8F%E7%9F%A5%E8%AF%86%E7%82%B9/
- 在目前环境下使用容器部署Java应用还是挺普遍的,但是有一些问题也是随之而来需要解决的,比如容器中应用的dubbo注册,在比较早的版本的dubbo中,就是简单地获取网卡的ip地址。
具体代码在这个方法里 com.alibaba.dubbo.config.ServiceConfig#doExportUrlsFor1Protocol
-private void doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List<URL> registryURLs) {
- String name = protocolConfig.getName();
- if (name == null || name.length() == 0) {
- name = "dubbo";
- }
-
- String host = protocolConfig.getHost();
- if (provider != null && (host == null || host.length() == 0)) {
- host = provider.getHost();
- }
- boolean anyhost = false;
- if (NetUtils.isInvalidLocalHost(host)) {
- anyhost = true;
- try {
- host = InetAddress.getLocalHost().getHostAddress();
- } catch (UnknownHostException e) {
- logger.warn(e.getMessage(), e);
- }
- if (NetUtils.isInvalidLocalHost(host)) {
- if (registryURLs != null && registryURLs.size() > 0) {
- for (URL registryURL : registryURLs) {
- try {
- Socket socket = new Socket();
- try {
- SocketAddress addr = new InetSocketAddress(registryURL.getHost(), registryURL.getPort());
- socket.connect(addr, 1000);
- host = socket.getLocalAddress().getHostAddress();
- break;
- } finally {
- try {
- socket.close();
- } catch (Throwable e) {}
- }
- } catch (Exception e) {
- logger.warn(e.getMessage(), e);
- }
- }
- }
- if (NetUtils.isInvalidLocalHost(host)) {
- host = NetUtils.getLocalHost();
- }
- }
- }
-通过jdk自带的方法 java.net.InetAddress#getLocalHost来获取本机地址,这样子对于容器来讲,获取到容器内部ip注册上去其实是没办法被调用到的,
而在之后的版本中例如dubbo 2.6.5,则可以通过在docker中设置环境变量的形式来注入docker所在的宿主机地址,
代码同样在com.alibaba.dubbo.config.ServiceConfig#doExportUrlsFor1Protocol这个方法中,但是获取host的方法变成了 com.alibaba.dubbo.config.ServiceConfig#findConfigedHosts
-private String findConfigedHosts(ProtocolConfig protocolConfig, List<URL> registryURLs, Map<String, String> map) {
- boolean anyhost = false;
+ 记录下 phpunit 的入门使用方法
+ /2022/10/16/%E8%AE%B0%E5%BD%95%E4%B8%8B-phpunit-%E7%9A%84%E5%85%A5%E9%97%A8%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95/
+ 这周开始打算写个比较简单的php工具包,然后顺带学习使用下php的单元测试,通过phpunit还是比较方便的,首先就composer require phpunit/phpunit
安装下 phpunit, 前面包就是通过 composer init 创建,装完依赖后就可以把自动加载代码生成下 composer dump-autoload
目录结构差不多这样
+.
+├── composer.json
+├── composer.lock
+├── oldfile.txt
+├── phpunit.xml
+├── src
+│ └── Rename.php
+└── tests
+ └── RenameTest.php
- String hostToBind = getValueFromConfig(protocolConfig, Constants.DUBBO_IP_TO_BIND);
- if (hostToBind != null && hostToBind.length() > 0 && isInvalidLocalHost(hostToBind)) {
- throw new IllegalArgumentException("Specified invalid bind ip from property:" + Constants.DUBBO_IP_TO_BIND + ", value:" + hostToBind);
- }
+2 directories, 6 files
+src/是源码,tests/是放的单测,比较重要的是phpunit.xml
+<?xml version="1.0" encoding="UTF-8"?>
+<phpunit colors="true" bootstrap="vendor/autoload.php">
+ <testsuites>
+ <testsuite name="php-rename">
+ <directory>./tests/</directory>
+ </testsuite>
+ </testsuites>
+</phpunit>
+其中bootstrap就是需要把依赖包的自动加载入口配上,因为这个作为一个package,也会指出命名空间
然后就是testsuite的路径,源码中
+<?php
+namespace Nicksxs\PhpRename;
- // if bind ip is not found in environment, keep looking up
- if (hostToBind == null || hostToBind.length() == 0) {
- hostToBind = protocolConfig.getHost();
- if (provider != null && (hostToBind == null || hostToBind.length() == 0)) {
- hostToBind = provider.getHost();
- }
- if (isInvalidLocalHost(hostToBind)) {
- anyhost = true;
- try {
- hostToBind = InetAddress.getLocalHost().getHostAddress();
- } catch (UnknownHostException e) {
- logger.warn(e.getMessage(), e);
- }
- if (isInvalidLocalHost(hostToBind)) {
- if (registryURLs != null && !registryURLs.isEmpty()) {
- for (URL registryURL : registryURLs) {
- if (Constants.MULTICAST.equalsIgnoreCase(registryURL.getParameter("registry"))) {
- // skip multicast registry since we cannot connect to it via Socket
- continue;
- }
- try {
- Socket socket = new Socket();
- try {
- SocketAddress addr = new InetSocketAddress(registryURL.getHost(), registryURL.getPort());
- socket.connect(addr, 1000);
- hostToBind = socket.getLocalAddress().getHostAddress();
- break;
- } finally {
- try {
- socket.close();
- } catch (Throwable e) {
- }
- }
- } catch (Exception e) {
- logger.warn(e.getMessage(), e);
- }
- }
- }
- if (isInvalidLocalHost(hostToBind)) {
- hostToBind = getLocalHost();
- }
- }
- }
+class Rename
+{
+ public static function renameSingleFile($file, $newFileName): bool
+ {
+ if(!is_file($file)) {
+ echo "it's not a file";
+ return false;
}
+ $fileInfo = pathinfo($file);
+ return rename($file, $fileInfo["dirname"] . DIRECTORY_SEPARATOR . $newFileName . "." . $fileInfo["extension"]);
+ }
+}
+就是一个简单的重命名
然后test代码是这样,
+<?php
- map.put(Constants.BIND_IP_KEY, hostToBind);
+// require_once 'vendor/autoload.php';
- // registry ip is not used for bind ip by default
- String hostToRegistry = getValueFromConfig(protocolConfig, Constants.DUBBO_IP_TO_REGISTRY);
- if (hostToRegistry != null && hostToRegistry.length() > 0 && isInvalidLocalHost(hostToRegistry)) {
- throw new IllegalArgumentException("Specified invalid registry ip from property:" + Constants.DUBBO_IP_TO_REGISTRY + ", value:" + hostToRegistry);
- } else if (hostToRegistry == null || hostToRegistry.length() == 0) {
- // bind ip is used as registry ip by default
- hostToRegistry = hostToBind;
- }
+use PHPUnit\Framework\TestCase;
+use Nicksxs\PhpRename\Rename;
+use function PHPUnit\Framework\assertEquals;
- map.put(Constants.ANYHOST_KEY, String.valueOf(anyhost));
+class RenameTest extends TestCase
+{
+ public function setUp() :void
+ {
+ $myfile = fopen(__DIR__ . DIRECTORY_SEPARATOR . "oldfile.txt", "w") or die("Unable to open file!");
+ $txt = "file test1\n";
+ fwrite($myfile, $txt);
+ fclose($myfile);
+ }
+ public function testRename()
+ {
+ Rename::renameSingleFile(__DIR__ . DIRECTORY_SEPARATOR . "oldfile.txt", "newfile");
+ assertEquals(is_file(__DIR__ . DIRECTORY_SEPARATOR . "newfile.txt"), true);
+ }
- return hostToRegistry;
- }
-String hostToRegistry = getValueFromConfig(protocolConfig, Constants.DUBBO_IP_TO_REGISTRY);
就是这一行,
-private String getValueFromConfig(ProtocolConfig protocolConfig, String key) {
- String protocolPrefix = protocolConfig.getName().toUpperCase() + "_";
- String port = ConfigUtils.getSystemProperty(protocolPrefix + key);
- if (port == null || port.length() == 0) {
- port = ConfigUtils.getSystemProperty(key);
+ protected function tearDown(): void
+ {
+ unlink(__DIR__ . DIRECTORY_SEPARATOR . "newfile.txt");
}
- return port;
-}
-也就是配置了DUBBO_IP_TO_REGISTRY这个环境变量
+}
+setUp 跟 tearDown 就是初始化跟结束清理的,但是注意如果不指明 __DIR__ ,待会的目录就会在执行 vendor/bin/phpunit 下面,
或者也可以指定在一个 tmp/ 目录下
最后就可以通过vendor/bin/phpunit 来执行测试
执行结果
+❯ vendor/bin/phpunit
+PHPUnit 9.5.25 by Sebastian Bergmann and contributors.
+
+. 1 / 1 (100%)
+
+Time: 00:00.005, Memory: 6.00 MB
+
+OK (1 test, 1 assertion)
]]>
- java
+ php
- dubbo
+ php
@@ -20056,6 +19980,18 @@ OK (2 t
php
+
+ 记录一次折腾自组 nas 的失败经历
+ /2023/05/07/%E8%AE%B0%E5%BD%95%E4%B8%80%E6%AC%A1%E6%8A%98%E8%85%BE%E8%87%AA%E7%BB%84-nas-%E7%9A%84%E5%A4%B1%E8%B4%A5%E7%BB%8F%E5%8E%86/
+ 鉴于现在市面上的成品 nas 对于我来说要不就是太贵了,要不就是便宜的盘位少,性能比较差,很多 nas 主打还有用 docker 什么的,但是性能对于我个人比较特殊的使用方式来说还是不太够用的,比如现在比较性能好的 nas 像绿联新出的 DX4600,用的是N5105,passmark 分数还不如我 15 年买的 pc 上的 i5 4590,当然很多人是考虑功耗,这也是萝卜青菜各有所爱,可能我算下来还是觉得没多大必要
然后就是考虑用什么硬件配置了,这个流派也有很多种,
用蜗牛星际的原版硬件其实对于需求不大的也是挺好的,整套的都解决了,cpu 用 j1900 如果就做 nas 应该也够了,我没选的原因一方面是性能不符合我的要求,另一方面是现在市面上的机器大部分都是战损成色,而且也不太便宜,如果成色比较好的能够 400 以内拿下整机的话感觉还算可以,cpu 换成 j4125 或者 j3455 再加个 100 也能接受,但基本比较少有这种价格,之前看到一个换了 j3455 的只要 360,犹豫了下没下手,其他很多的都是 j1900 的都要 600 左右
然后是各类 E3,E5 和商用服务器类型的,这种的特点是功耗大,其实 cpu 很便宜,E5 2630V3 跟 2630V4 都只要十几块钱,性能过得去,没有选的主要是机箱占地方也比较贵,还有是商用的怕很多系统需要自己找驱动什么的,配件比如 HBA 卡这种,买的不兼容什么的还是挺麻烦的,另外噪音也是个比较大的问题,租的房子比较小,即使放客厅也是靠着卧室的墙边,如果以后换大一点的房子倒是可以考虑
最后就是我目前选的方案,就是普通的民用机器,找盘位多一点的机箱,我原来的 4590 的机器的机箱就不错,但是已经停产了,二手的太重了闲鱼都不出外地,cpu 跟主板其实考虑了很久,因为从 4590 开始核显就能硬解 H264 这种常规的视频了,考虑用intel 四代的 i3 或者 i5 应该纯 nas 来讲是足够用了,但是这样就跟我现在已经有的 4590 有点重叠了,而且也觉得最好是能性能好一些的,就开始看一些稍新一点的,很多用的多的有 i3-8100,跟 i3-10100 这种,但是这些已经被炒的价格比较高,寻寻觅觅了很久看中了 i5-8600,这个价格跟 8500 差不多,性能还好一些,主板就是我标题说的最“失败”的一个点了,主要是因为主板自带的网卡是 Realtek 的,至于更具体的后面会专门介绍,机箱是图便宜买的爱国者半岛铁盒的 F10,内存就买了一根光威的 32g 的,装系统的硬盘是用了以前囤的京东京造的麒麟系列,但是现在对这个系列挺不看好,之前有个盘就掉盘了,维修体验一开始也不好,半个多月维修,电源也是图便宜买的一个先马的平头哥系列,额定 550w 只要 140 左右,整体的机器就攒齐了,但是很多问题也随之出现了
第一个问题是买的二手的板 U 套装,结果寄过来的时候没带挡板,导致一开始装上了又要拆下来;第二个问题是主机贪便宜,主机上固定主板螺丝的螺柱拧不进去,后来店家告诉我让我可以用电源固定的螺丝先拧一下才把螺柱拧进去;第三个问题是因为没什么装机经验导致的,散热装的太累了,因为要兼容各种主板,还有各种螺丝,装的时候也着急;第四个问题是电源的比较便宜,一方面比较不放心安全性,另一方面是我想多装几个硬盘,电源直出的只有四个 sata 口,需要买转接线,从 D 型的 4pin 口子转出来;第五个问题也是电源,主板电源线有点不太够,走背线就比较困难
以上主要是装机的困难,下一篇介绍作为 nas 的各种问题吧
+]]>
+
+ nas
+
+
+ nas
+
+
记录下 zookeeper 集群迁移和易错点
/2022/05/29/%E8%AE%B0%E5%BD%95%E4%B8%8B-zookeeper-%E9%9B%86%E7%BE%A4%E8%BF%81%E7%A7%BB/
@@ -20104,6 +20040,20 @@ zk3 192.168.2.3
+
+ 记录下 redis 的一些使用方法
+ /2022/10/30/%E8%AE%B0%E5%BD%95%E4%B8%8B-redis-%E7%9A%84%E4%B8%80%E4%BA%9B%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95/
+ 虽然说之前讲解过一些redis源码相关的,但是说实话,redis的各种使用其实有时候有点生疏,或者在一些特定的使用场景中,一些使用方法还是需要学习和记录的
+获取所有数据
获取list类型的所有元素,可以使用 lrange , 直接用lrange key 0 -1
比如
![]()
这里有一些方便的就是可以不用知道长度,直接全返回,或者如果想拿到特定区间的就可以直接指定起止范围,
![]()
这样就不用一个个pop出来
+裁剪list
前面用了lrange取得了一个范围的数据,如果想将数据直接移除,那可以用 ltrim ,
![]()
这两个命令就可以从list里取出批量数据,并且能从list里删除这部分数据
+]]>
+
+ redis
+
+
+ redis
+
+
这周末我又在老丈人家打了天小工
/2020/08/30/%E8%BF%99%E5%91%A8%E6%9C%AB%E6%88%91%E5%8F%88%E5%9C%A8%E8%80%81%E4%B8%88%E4%BA%BA%E5%AE%B6%E6%89%93%E4%BA%86%E5%A4%A9%E5%B0%8F%E5%B7%A5/
@@ -20111,32 +20061,58 @@ zk3 192.168.2.3
+
+ 重看了下《蛮荒记》说说感受
+ /2021/10/10/%E9%87%8D%E7%9C%8B%E4%BA%86%E4%B8%8B%E3%80%8A%E8%9B%AE%E8%8D%92%E8%AE%B0%E3%80%8B%E8%AF%B4%E8%AF%B4%E6%84%9F%E5%8F%97/
+ 周末把《蛮荒记》看完了,前面是发现微信读书有《搜神记》和《蛮荒记》,但是《搜神记》看了会发现很多都是跳段了,不知道为啥,貌似也没什么少儿不宜的情节,所以就上网找了原版来看,为什么看这个呢,主要还是高中的时候看过,觉得写得很不错,属于那时候的玄幻小说里的独一档,基于山海经创造了一个半架空的大荒宇宙,五族帝尊,人物名都是听说过的,而且又能契合部分历史,整个故事布局非常宏大,并且情节矛盾埋得很深,这里就不对具体情节作介绍了,只是聊聊对书中的一些人物和情节的看法感受。
+乌丝兰玛是个贯穿两部,甚至在蛮荒的最后还要再搞事情,极其坚定的自以为是的大 boss,其实除了最后被我们的主人公打败,前面几乎就是无所不能,下了一盘无比巨大的棋,主人公都只是其中一个棋子和意外,但是正如很多反派,一直以来都是背着一个信念,并且这个所谓的信念是比较正义的,只是为了这个正义的信念和目标却做了各种丧尽天良的事情,说起来跟灭霸有点像,为了环保哈哈,相对来说感觉姬远玄也只是个最大牌的工具人,或者说是中间人,深爱的妹妹冰夷也意外被蚩尤怒拿一血。
+但是中间那个赤霞仙子一定要给烈烟石的心上锁,导致最后认不出来蚩尤,也间接导致了蚩尤被杀,如果不考虑最后情节或者推动故事的需求,这个还是我很讨厌的,有点类似于《驴得水》里那个校长,看着貌似是个正常的,做的事情也是正派,但是其实是害人不浅,即使南阳仙子因此被抛进了火山,那也是有贱人在那挑食,并且赤松子是赤飚怒的儿子,烈烟石跟蚩尤又没这层关系,就很像倚天屠龙记里的灭绝师太和极品家丁里的那个玉德仙坊的院主,后者还好一些,前者几乎就是导致周芷若一生悲剧的始作俑者,自己偏执的善恶观,还要给徒弟灌输如此恶毒的理念和让她立下像紧箍咒似的誓言,在人一生中本来就有很多不能如愿的,又被最亲最尊敬的人下了这样的紧箍咒,人生的不幸也加倍了。
+似乎习惯了总要有个总结的,想说的应该是我觉得这些剧也好,书也好,我觉得最坏的人可能是大部分人眼中的一些次要人物,或者至少大 boss 才是最坏的人,当然这个坏也不是严格的二分法,只是我觉得最让我觉得负面的人物,这些人可能看起来情景出现的不多,只是说了很少的话,做了很少的事,但是在我看来却做了最大的恶。
+]]>
+
+ 生活
+
+
+ 生活
+ 看书
+
+
+
+ 闲话篇-也算碰到了为老不尊和坏人变老了的典型案例
+ /2022/05/22/%E9%97%B2%E8%AF%9D%E7%AF%87-%E4%B9%9F%E7%AE%97%E7%A2%B0%E5%88%B0%E4%BA%86%E4%B8%BA%E8%80%81%E4%B8%8D%E5%B0%8A%E5%92%8C%E5%9D%8F%E4%BA%BA%E5%8F%98%E8%80%81%E4%BA%86%E7%9A%84%E5%85%B8%E5%9E%8B%E6%A1%88%E4%BE%8B/
+ 在目前的房子也差不多租了四五年了,楼下邻居换了两拨了,我们这栋楼装修了不知道多少次,因为是学区的原因,房子交易的频率还是比较高的,不过比较神奇的我们对门的没换过,而且一直也没什么交集(除了后面说的水管爆裂),就进出的时候偶尔看到应该是住着一对老夫妻,感觉年纪也有个七八十了。
+对对面这户人家的印象,就是对面的老头子经常是我出门上班去了他回来,看着他颤颤巍巍地走楼梯,我看到了都靠边走,而且有几次还听见好像是他儿子在说他,”年假这么大了,还是少出去吧”,说实话除了这次的事情,之前就有一次水管阀门爆裂了,算是有点交集,那次大概是去年冬天,天气已经很冷了,我们周日下午回来看到楼梯有点湿,但是没什么特别的异常就没怎么注意,到晚上洗完澡,楼下的邻居就来敲门,说我们门外的水表那一直在流水,出门一看真的是懵了,外面水表那在哗哗哗地流水,导致楼梯那就跟水帘洞一样,仔细看看是对面家的水表阀门那在漏水,我只能先用塑料袋包一下,然后大冬天(刚洗完澡)穿着凉拖跑下去找物业保安,走到一楼的时候发现水一直流到一楼了,楼梯上都是水流下来,五楼那是最惨的,感觉门框周边都浸透了,五楼的也是态度比较差的让我一定要把水弄好了,但是前面也说了谁是从对门那户的水表阀那出来的,理论上应该让对面的处理,结果我敲门敲了半天对面都没反应,想着我放着不管也不太好,就去找了物业保安,保安上来看了只能先把总阀关了,我也打电话给维修自来水管的,自来水公司的人过了会也是真的来修了,我那会是挺怕不来修,自来水公司的师傅到了以后拿开一看是对面那户的有个阀门估计是自己换上去的,跟我们这的完全不一样,看上去就比较劣质,师傅也挺气的,大晚上被叫过来,我又尝试着去敲门也还是没人应,也没办法,对面老人家我敲太响到时候出来说我吓到他们啥的,第二天去说也没现场了。
+前面的这件事是个重要铺垫,前几天 LD 下班后把厨余垃圾套好袋子放在门口,打算等我下班了因为要去做核酸(hz 48 小时核酸)顺便带下去,结果到了七点多,说对面的老太太在那疯狂砸门了,LD 被吓到了不敢开门,老太太在外面一边砸门一边骂,“你们年轻人怎么素质这么差”(他们家也经常在门口放垃圾,我们刚来住的时候在楼梯转角他们就放这个废弃的洗衣机,每次走楼梯带点东西都要小心翼翼地走,不然都过不去,然后我赶紧赶回去,结果她听到我回家了,还特意开门继续骂,“你们年轻人怎么素质这么差,垃圾放在这里”,我说我们刚才放在这,打算待会做核酸的时候去扔掉,结果他们家老头,都已经没了牙齿,在那瞪大眼睛说,“你们早上就放在这了的,”我说是LD 刚才下班了放的,争论了一会,我说这个事情我们门口放了垃圾,这会我就去扔掉了,但是你们家老太太这么砸门总不太好,像之前门口水管爆掉了,我敲了门没人应,我也没要砸门一定把你们叫醒,结果老头老太说我们的水管从来没换过,不可能破的(其实到这,再往后说就没意思了,跟这么不要脸的人说多了也只是瞎扯),一会又回到这个垃圾的问题,那个老头说“你们昨天就放在这里了的”,睁着眼说瞎话可真是 666,感觉不是老太太拦着点他马上就要冲上来揍我了一样,事后我想想,这种情况我大概只能躺地上装死了,当这个事情发生之前我真的快把前面说的事情(水管阀坏了)给忘了,虽然这是理论上不该我来处理,除非是老头老太太请求我帮忙,这事后面我也从没说起过,本来完全没交集,对他们的是怎么样的人也没概念,总觉得年纪大了可能还比较心宽和蔼点,结果没想到就是一典型的坏人变老了,我说你们这么砸门,我老婆都被吓得不敢开门,结果对面老头老太太的儿子也出来了说,“我们就是敲下门,我母亲是机关单位退休的,所以肯定不会敲门很大声的,你老婆觉得吓到了是你们人生观价值观有问题”,听到这话我差点笑出来,连着两个可笑至极的脑残逻辑,无语他妈给无语开门,无语到家了。对门家我们之前有个印象就是因为我们都是顶楼,这边老小区以前都是把前后阳台包进来的,然后社区就来咨询大家的意见是不是统一把包进来的违建拆掉,还特地上来六楼跟他们说,结果对面的老头就说,“我要去住建局投诉你们”,本来这个事情是违法的,但是社区的意思也是征求各位业主的意见,结果感觉是社区上门强拆了一样,为老不尊,坏人变老了的典范了。
+]]>
+
+ 生活
生活
- 运动
- 减肥
- 跑步
- 干活
- 重看了下《蛮荒记》说说感受
- /2021/10/10/%E9%87%8D%E7%9C%8B%E4%BA%86%E4%B8%8B%E3%80%8A%E8%9B%AE%E8%8D%92%E8%AE%B0%E3%80%8B%E8%AF%B4%E8%AF%B4%E6%84%9F%E5%8F%97/
- 周末把《蛮荒记》看完了,前面是发现微信读书有《搜神记》和《蛮荒记》,但是《搜神记》看了会发现很多都是跳段了,不知道为啥,貌似也没什么少儿不宜的情节,所以就上网找了原版来看,为什么看这个呢,主要还是高中的时候看过,觉得写得很不错,属于那时候的玄幻小说里的独一档,基于山海经创造了一个半架空的大荒宇宙,五族帝尊,人物名都是听说过的,而且又能契合部分历史,整个故事布局非常宏大,并且情节矛盾埋得很深,这里就不对具体情节作介绍了,只是聊聊对书中的一些人物和情节的看法感受。
-乌丝兰玛是个贯穿两部,甚至在蛮荒的最后还要再搞事情,极其坚定的自以为是的大 boss,其实除了最后被我们的主人公打败,前面几乎就是无所不能,下了一盘无比巨大的棋,主人公都只是其中一个棋子和意外,但是正如很多反派,一直以来都是背着一个信念,并且这个所谓的信念是比较正义的,只是为了这个正义的信念和目标却做了各种丧尽天良的事情,说起来跟灭霸有点像,为了环保哈哈,相对来说感觉姬远玄也只是个最大牌的工具人,或者说是中间人,深爱的妹妹冰夷也意外被蚩尤怒拿一血。
-但是中间那个赤霞仙子一定要给烈烟石的心上锁,导致最后认不出来蚩尤,也间接导致了蚩尤被杀,如果不考虑最后情节或者推动故事的需求,这个还是我很讨厌的,有点类似于《驴得水》里那个校长,看着貌似是个正常的,做的事情也是正派,但是其实是害人不浅,即使南阳仙子因此被抛进了火山,那也是有贱人在那挑食,并且赤松子是赤飚怒的儿子,烈烟石跟蚩尤又没这层关系,就很像倚天屠龙记里的灭绝师太和极品家丁里的那个玉德仙坊的院主,后者还好一些,前者几乎就是导致周芷若一生悲剧的始作俑者,自己偏执的善恶观,还要给徒弟灌输如此恶毒的理念和让她立下像紧箍咒似的誓言,在人一生中本来就有很多不能如愿的,又被最亲最尊敬的人下了这样的紧箍咒,人生的不幸也加倍了。
-似乎习惯了总要有个总结的,想说的应该是我觉得这些剧也好,书也好,我觉得最坏的人可能是大部分人眼中的一些次要人物,或者至少大 boss 才是最坏的人,当然这个坏也不是严格的二分法,只是我觉得最让我觉得负面的人物,这些人可能看起来情景出现的不多,只是说了很少的话,做了很少的事,但是在我看来却做了最大的恶。
+ 记录下把小米路由器 4A 千兆版刷成 openwrt 的过程
+ /2023/05/21/%E8%AE%B0%E5%BD%95%E4%B8%8B%E6%8A%8A%E5%B0%8F%E7%B1%B3%E8%B7%AF%E7%94%B1%E5%99%A8-4A-%E5%8D%83%E5%85%86%E7%89%88%E5%88%B7%E6%88%90-openwrt-%E7%9A%84%E8%BF%87%E7%A8%8B/
+ 之前在绍兴家里的一条宽带送了个小米路由器 4A,正好原来的小米路由器 3 不知道为啥经常断流不稳定,而且只支持百兆,这边用了 200M 的宽带,感觉也比较浪费,所以就动了这个心思,但是还是有蛮多坑的,首先是看到了一篇文章,写的比较详细,
看到的就是这篇文章
这里使用的是 OpenWRTInvasion 这个项目来破解 ssh,首先这里有个最常见的一个问题,就是文件拉不到,所以有一些可行的方法就是自己起一个http 服务,可以修改脚本代码,直接从这个启动的 http 服务拉取已经下载下的文件,就这个问题我就尝试了很多次,还有就是这个 OpenWRTInvasion 最后一个支持 Windows 的版本就是 0.0.7,后面的版本其实做了很多的优化解决了文件的问题,一开始碰到的问题是本地起了文件服务但是没请求,或者请求了但后续 ssh 没有正常破解,我就换了 Mac 用最新版本的OpenWRTInvasion来尝试进行破解,发现还是不行,结果查了不少资料发现最根本的问题是这个路由器的新版本就不支持这种破解了,因为这个路由器新的版本都是 v2 版本,也就是2.30.x 版本的系统了,原来支持的是 2.28.x 的这些系统,后来幸好是找到了这个版本的系统支持的另一个恩山大神的文章,根据这个文章提供的工具进行破解就成功了,但是破解要多尝试几次,我第一次是失败的,小米路由器 4A 千兆版的版本号也会写作 R4Av2,在搜索一些资料的时候也可以用这个型号去搜,可能也是另一种黑话,路由器以前刷过梅林,padavan,还是第一次刷 openwrt,都已经忘了以前是怎么刷的来着,感觉现在越来越难刷了,特别是 ssh,想给我的 ax6 刷个 openwrt,发现前提是需要先有一个 openwrt 的路由器,简直了,变成先有鸡还是先有蛋的问题了,所以我把这个小米 4A 刷成 openwrt 也有这个考虑,毕竟 4A 配置上不太高,openwrt 各种插件可能还跑不起来,权当做练手和到时候用来开 AX6 的工具了。
]]>
生活
- 生活
- 看书
+ 路由器
@@ -20161,20 +20137,6 @@ zk3 192.168.2.3
-
- 闲话篇-也算碰到了为老不尊和坏人变老了的典型案例
- /2022/05/22/%E9%97%B2%E8%AF%9D%E7%AF%87-%E4%B9%9F%E7%AE%97%E7%A2%B0%E5%88%B0%E4%BA%86%E4%B8%BA%E8%80%81%E4%B8%8D%E5%B0%8A%E5%92%8C%E5%9D%8F%E4%BA%BA%E5%8F%98%E8%80%81%E4%BA%86%E7%9A%84%E5%85%B8%E5%9E%8B%E6%A1%88%E4%BE%8B/
- 在目前的房子也差不多租了四五年了,楼下邻居换了两拨了,我们这栋楼装修了不知道多少次,因为是学区的原因,房子交易的频率还是比较高的,不过比较神奇的我们对门的没换过,而且一直也没什么交集(除了后面说的水管爆裂),就进出的时候偶尔看到应该是住着一对老夫妻,感觉年纪也有个七八十了。
-对对面这户人家的印象,就是对面的老头子经常是我出门上班去了他回来,看着他颤颤巍巍地走楼梯,我看到了都靠边走,而且有几次还听见好像是他儿子在说他,”年假这么大了,还是少出去吧”,说实话除了这次的事情,之前就有一次水管阀门爆裂了,算是有点交集,那次大概是去年冬天,天气已经很冷了,我们周日下午回来看到楼梯有点湿,但是没什么特别的异常就没怎么注意,到晚上洗完澡,楼下的邻居就来敲门,说我们门外的水表那一直在流水,出门一看真的是懵了,外面水表那在哗哗哗地流水,导致楼梯那就跟水帘洞一样,仔细看看是对面家的水表阀门那在漏水,我只能先用塑料袋包一下,然后大冬天(刚洗完澡)穿着凉拖跑下去找物业保安,走到一楼的时候发现水一直流到一楼了,楼梯上都是水流下来,五楼那是最惨的,感觉门框周边都浸透了,五楼的也是态度比较差的让我一定要把水弄好了,但是前面也说了谁是从对门那户的水表阀那出来的,理论上应该让对面的处理,结果我敲门敲了半天对面都没反应,想着我放着不管也不太好,就去找了物业保安,保安上来看了只能先把总阀关了,我也打电话给维修自来水管的,自来水公司的人过了会也是真的来修了,我那会是挺怕不来修,自来水公司的师傅到了以后拿开一看是对面那户的有个阀门估计是自己换上去的,跟我们这的完全不一样,看上去就比较劣质,师傅也挺气的,大晚上被叫过来,我又尝试着去敲门也还是没人应,也没办法,对面老人家我敲太响到时候出来说我吓到他们啥的,第二天去说也没现场了。
-前面的这件事是个重要铺垫,前几天 LD 下班后把厨余垃圾套好袋子放在门口,打算等我下班了因为要去做核酸(hz 48 小时核酸)顺便带下去,结果到了七点多,说对面的老太太在那疯狂砸门了,LD 被吓到了不敢开门,老太太在外面一边砸门一边骂,“你们年轻人怎么素质这么差”(他们家也经常在门口放垃圾,我们刚来住的时候在楼梯转角他们就放这个废弃的洗衣机,每次走楼梯带点东西都要小心翼翼地走,不然都过不去,然后我赶紧赶回去,结果她听到我回家了,还特意开门继续骂,“你们年轻人怎么素质这么差,垃圾放在这里”,我说我们刚才放在这,打算待会做核酸的时候去扔掉,结果他们家老头,都已经没了牙齿,在那瞪大眼睛说,“你们早上就放在这了的,”我说是LD 刚才下班了放的,争论了一会,我说这个事情我们门口放了垃圾,这会我就去扔掉了,但是你们家老太太这么砸门总不太好,像之前门口水管爆掉了,我敲了门没人应,我也没要砸门一定把你们叫醒,结果老头老太说我们的水管从来没换过,不可能破的(其实到这,再往后说就没意思了,跟这么不要脸的人说多了也只是瞎扯),一会又回到这个垃圾的问题,那个老头说“你们昨天就放在这里了的”,睁着眼说瞎话可真是 666,感觉不是老太太拦着点他马上就要冲上来揍我了一样,事后我想想,这种情况我大概只能躺地上装死了,当这个事情发生之前我真的快把前面说的事情(水管阀坏了)给忘了,虽然这是理论上不该我来处理,除非是老头老太太请求我帮忙,这事后面我也从没说起过,本来完全没交集,对他们的是怎么样的人也没概念,总觉得年纪大了可能还比较心宽和蔼点,结果没想到就是一典型的坏人变老了,我说你们这么砸门,我老婆都被吓得不敢开门,结果对面老头老太太的儿子也出来了说,“我们就是敲下门,我母亲是机关单位退休的,所以肯定不会敲门很大声的,你老婆觉得吓到了是你们人生观价值观有问题”,听到这话我差点笑出来,连着两个可笑至极的脑残逻辑,无语他妈给无语开门,无语到家了。对门家我们之前有个印象就是因为我们都是顶楼,这边老小区以前都是把前后阳台包进来的,然后社区就来咨询大家的意见是不是统一把包进来的违建拆掉,还特地上来六楼跟他们说,结果对面的老头就说,“我要去住建局投诉你们”,本来这个事情是违法的,但是社区的意思也是征求各位业主的意见,结果感觉是社区上门强拆了一样,为老不尊,坏人变老了的典范了。
-]]>
-
- 生活
-
-
- 生活
-
-
难得的大扫除
/2022/04/10/%E9%9A%BE%E5%BE%97%E7%9A%84%E5%A4%A7%E6%89%AB%E9%99%A4/
@@ -20204,115 +20166,153 @@ zk3 192.168.2.3
- 记录下把小米路由器 4A 千兆版刷成 openwrt 的过程
- /2023/05/21/%E8%AE%B0%E5%BD%95%E4%B8%8B%E6%8A%8A%E5%B0%8F%E7%B1%B3%E8%B7%AF%E7%94%B1%E5%99%A8-4A-%E5%8D%83%E5%85%86%E7%89%88%E5%88%B7%E6%88%90-openwrt-%E7%9A%84%E8%BF%87%E7%A8%8B/
- 之前在绍兴家里的一条宽带送了个小米路由器 4A,正好原来的小米路由器 3 不知道为啥经常断流不稳定,而且只支持百兆,这边用了 200M 的宽带,感觉也比较浪费,所以就动了这个心思,但是还是有蛮多坑的,首先是看到了一篇文章,写的比较详细,
看到的就是这篇文章
这里使用的是 OpenWRTInvasion 这个项目来破解 ssh,首先这里有个最常见的一个问题,就是文件拉不到,所以有一些可行的方法就是自己起一个http 服务,可以修改脚本代码,直接从这个启动的 http 服务拉取已经下载下的文件,就这个问题我就尝试了很多次,还有就是这个 OpenWRTInvasion 最后一个支持 Windows 的版本就是 0.0.7,后面的版本其实做了很多的优化解决了文件的问题,一开始碰到的问题是本地起了文件服务但是没请求,或者请求了但后续 ssh 没有正常破解,我就换了 Mac 用最新版本的OpenWRTInvasion来尝试进行破解,发现还是不行,结果查了不少资料发现最根本的问题是这个路由器的新版本就不支持这种破解了,因为这个路由器新的版本都是 v2 版本,也就是2.30.x 版本的系统了,原来支持的是 2.28.x 的这些系统,后来幸好是找到了这个版本的系统支持的另一个恩山大神的文章,根据这个文章提供的工具进行破解就成功了,但是破解要多尝试几次,我第一次是失败的,小米路由器 4A 千兆版的版本号也会写作 R4Av2,在搜索一些资料的时候也可以用这个型号去搜,可能也是另一种黑话,路由器以前刷过梅林,padavan,还是第一次刷 openwrt,都已经忘了以前是怎么刷的来着,感觉现在越来越难刷了,特别是 ssh,想给我的 ax6 刷个 openwrt,发现前提是需要先有一个 openwrt 的路由器,简直了,变成先有鸡还是先有蛋的问题了,所以我把这个小米 4A 刷成 openwrt 也有这个考虑,毕竟 4A 配置上不太高,openwrt 各种插件可能还跑不起来,权当做练手和到时候用来开 AX6 的工具了。
-]]>
-
- 生活
-
-
- 路由器
-
-
-
- 记录下 phpunit 的入门使用方法
- /2022/10/16/%E8%AE%B0%E5%BD%95%E4%B8%8B-phpunit-%E7%9A%84%E5%85%A5%E9%97%A8%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95/
- 这周开始打算写个比较简单的php工具包,然后顺带学习使用下php的单元测试,通过phpunit还是比较方便的,首先就composer require phpunit/phpunit
安装下 phpunit, 前面包就是通过 composer init 创建,装完依赖后就可以把自动加载代码生成下 composer dump-autoload
目录结构差不多这样
-.
-├── composer.json
-├── composer.lock
-├── oldfile.txt
-├── phpunit.xml
-├── src
-│ └── Rename.php
-└── tests
- └── RenameTest.php
-
-2 directories, 6 files
-src/是源码,tests/是放的单测,比较重要的是phpunit.xml
-<?xml version="1.0" encoding="UTF-8"?>
-<phpunit colors="true" bootstrap="vendor/autoload.php">
- <testsuites>
- <testsuite name="php-rename">
- <directory>./tests/</directory>
- </testsuite>
- </testsuites>
-</phpunit>
-其中bootstrap就是需要把依赖包的自动加载入口配上,因为这个作为一个package,也会指出命名空间
然后就是testsuite的路径,源码中
-<?php
-namespace Nicksxs\PhpRename;
-
-class Rename
-{
- public static function renameSingleFile($file, $newFileName): bool
- {
- if(!is_file($file)) {
- echo "it's not a file";
- return false;
+ 记一个容器中 dubbo 注册的小知识点
+ /2022/10/09/%E8%AE%B0%E4%B8%80%E4%B8%AA%E5%AE%B9%E5%99%A8%E4%B8%AD-dubbo-%E6%B3%A8%E5%86%8C%E7%9A%84%E5%B0%8F%E7%9F%A5%E8%AF%86%E7%82%B9/
+ 在目前环境下使用容器部署Java应用还是挺普遍的,但是有一些问题也是随之而来需要解决的,比如容器中应用的dubbo注册,在比较早的版本的dubbo中,就是简单地获取网卡的ip地址。
具体代码在这个方法里 com.alibaba.dubbo.config.ServiceConfig#doExportUrlsFor1Protocol
+private void doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List<URL> registryURLs) {
+ String name = protocolConfig.getName();
+ if (name == null || name.length() == 0) {
+ name = "dubbo";
}
- $fileInfo = pathinfo($file);
- return rename($file, $fileInfo["dirname"] . DIRECTORY_SEPARATOR . $newFileName . "." . $fileInfo["extension"]);
- }
-}
-就是一个简单的重命名
然后test代码是这样,
-<?php
-// require_once 'vendor/autoload.php';
+ String host = protocolConfig.getHost();
+ if (provider != null && (host == null || host.length() == 0)) {
+ host = provider.getHost();
+ }
+ boolean anyhost = false;
+ if (NetUtils.isInvalidLocalHost(host)) {
+ anyhost = true;
+ try {
+ host = InetAddress.getLocalHost().getHostAddress();
+ } catch (UnknownHostException e) {
+ logger.warn(e.getMessage(), e);
+ }
+ if (NetUtils.isInvalidLocalHost(host)) {
+ if (registryURLs != null && registryURLs.size() > 0) {
+ for (URL registryURL : registryURLs) {
+ try {
+ Socket socket = new Socket();
+ try {
+ SocketAddress addr = new InetSocketAddress(registryURL.getHost(), registryURL.getPort());
+ socket.connect(addr, 1000);
+ host = socket.getLocalAddress().getHostAddress();
+ break;
+ } finally {
+ try {
+ socket.close();
+ } catch (Throwable e) {}
+ }
+ } catch (Exception e) {
+ logger.warn(e.getMessage(), e);
+ }
+ }
+ }
+ if (NetUtils.isInvalidLocalHost(host)) {
+ host = NetUtils.getLocalHost();
+ }
+ }
+ }
+通过jdk自带的方法 java.net.InetAddress#getLocalHost来获取本机地址,这样子对于容器来讲,获取到容器内部ip注册上去其实是没办法被调用到的,
而在之后的版本中例如dubbo 2.6.5,则可以通过在docker中设置环境变量的形式来注入docker所在的宿主机地址,
代码同样在com.alibaba.dubbo.config.ServiceConfig#doExportUrlsFor1Protocol这个方法中,但是获取host的方法变成了 com.alibaba.dubbo.config.ServiceConfig#findConfigedHosts
+private String findConfigedHosts(ProtocolConfig protocolConfig, List<URL> registryURLs, Map<String, String> map) {
+ boolean anyhost = false;
-use PHPUnit\Framework\TestCase;
-use Nicksxs\PhpRename\Rename;
-use function PHPUnit\Framework\assertEquals;
+ String hostToBind = getValueFromConfig(protocolConfig, Constants.DUBBO_IP_TO_BIND);
+ if (hostToBind != null && hostToBind.length() > 0 && isInvalidLocalHost(hostToBind)) {
+ throw new IllegalArgumentException("Specified invalid bind ip from property:" + Constants.DUBBO_IP_TO_BIND + ", value:" + hostToBind);
+ }
-class RenameTest extends TestCase
-{
- public function setUp() :void
- {
- $myfile = fopen(__DIR__ . DIRECTORY_SEPARATOR . "oldfile.txt", "w") or die("Unable to open file!");
- $txt = "file test1\n";
- fwrite($myfile, $txt);
- fclose($myfile);
- }
- public function testRename()
- {
- Rename::renameSingleFile(__DIR__ . DIRECTORY_SEPARATOR . "oldfile.txt", "newfile");
- assertEquals(is_file(__DIR__ . DIRECTORY_SEPARATOR . "newfile.txt"), true);
- }
+ // if bind ip is not found in environment, keep looking up
+ if (hostToBind == null || hostToBind.length() == 0) {
+ hostToBind = protocolConfig.getHost();
+ if (provider != null && (hostToBind == null || hostToBind.length() == 0)) {
+ hostToBind = provider.getHost();
+ }
+ if (isInvalidLocalHost(hostToBind)) {
+ anyhost = true;
+ try {
+ hostToBind = InetAddress.getLocalHost().getHostAddress();
+ } catch (UnknownHostException e) {
+ logger.warn(e.getMessage(), e);
+ }
+ if (isInvalidLocalHost(hostToBind)) {
+ if (registryURLs != null && !registryURLs.isEmpty()) {
+ for (URL registryURL : registryURLs) {
+ if (Constants.MULTICAST.equalsIgnoreCase(registryURL.getParameter("registry"))) {
+ // skip multicast registry since we cannot connect to it via Socket
+ continue;
+ }
+ try {
+ Socket socket = new Socket();
+ try {
+ SocketAddress addr = new InetSocketAddress(registryURL.getHost(), registryURL.getPort());
+ socket.connect(addr, 1000);
+ hostToBind = socket.getLocalAddress().getHostAddress();
+ break;
+ } finally {
+ try {
+ socket.close();
+ } catch (Throwable e) {
+ }
+ }
+ } catch (Exception e) {
+ logger.warn(e.getMessage(), e);
+ }
+ }
+ }
+ if (isInvalidLocalHost(hostToBind)) {
+ hostToBind = getLocalHost();
+ }
+ }
+ }
+ }
- protected function tearDown(): void
- {
- unlink(__DIR__ . DIRECTORY_SEPARATOR . "newfile.txt");
- }
-}
-setUp 跟 tearDown 就是初始化跟结束清理的,但是注意如果不指明 __DIR__ ,待会的目录就会在执行 vendor/bin/phpunit 下面,
或者也可以指定在一个 tmp/ 目录下
最后就可以通过vendor/bin/phpunit 来执行测试
执行结果
-❯ vendor/bin/phpunit
-PHPUnit 9.5.25 by Sebastian Bergmann and contributors.
+ map.put(Constants.BIND_IP_KEY, hostToBind);
-. 1 / 1 (100%)
+ // registry ip is not used for bind ip by default
+ String hostToRegistry = getValueFromConfig(protocolConfig, Constants.DUBBO_IP_TO_REGISTRY);
+ if (hostToRegistry != null && hostToRegistry.length() > 0 && isInvalidLocalHost(hostToRegistry)) {
+ throw new IllegalArgumentException("Specified invalid registry ip from property:" + Constants.DUBBO_IP_TO_REGISTRY + ", value:" + hostToRegistry);
+ } else if (hostToRegistry == null || hostToRegistry.length() == 0) {
+ // bind ip is used as registry ip by default
+ hostToRegistry = hostToBind;
+ }
-Time: 00:00.005, Memory: 6.00 MB
+ map.put(Constants.ANYHOST_KEY, String.valueOf(anyhost));
-OK (1 test, 1 assertion)
+ return hostToRegistry;
+ }
+String hostToRegistry = getValueFromConfig(protocolConfig, Constants.DUBBO_IP_TO_REGISTRY);
就是这一行,
+private String getValueFromConfig(ProtocolConfig protocolConfig, String key) {
+ String protocolPrefix = protocolConfig.getName().toUpperCase() + "_";
+ String port = ConfigUtils.getSystemProperty(protocolPrefix + key);
+ if (port == null || port.length() == 0) {
+ port = ConfigUtils.getSystemProperty(key);
+ }
+ return port;
+}
+也就是配置了DUBBO_IP_TO_REGISTRY这个环境变量
]]>
- php
+ java
- php
+ dubbo
- 记录下 redis 的一些使用方法
- /2022/10/30/%E8%AE%B0%E5%BD%95%E4%B8%8B-redis-%E7%9A%84%E4%B8%80%E4%BA%9B%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95/
- 虽然说之前讲解过一些redis源码相关的,但是说实话,redis的各种使用其实有时候有点生疏,或者在一些特定的使用场景中,一些使用方法还是需要学习和记录的
-获取所有数据
获取list类型的所有元素,可以使用 lrange , 直接用lrange key 0 -1
比如
![]()
这里有一些方便的就是可以不用知道长度,直接全返回,或者如果想拿到特定区间的就可以直接指定起止范围,
![]()
这样就不用一个个pop出来
-裁剪list
前面用了lrange取得了一个范围的数据,如果想将数据直接移除,那可以用 ltrim ,
![]()
这两个命令就可以从list里取出批量数据,并且能从list里删除这部分数据
+ 解决 网络文件夹目前是以其他用户名和密码进行映射的 问题
+ /2023/04/09/%E8%A7%A3%E5%86%B3-%E7%BD%91%E7%BB%9C%E6%96%87%E4%BB%B6%E5%A4%B9%E7%9B%AE%E5%89%8D%E6%98%AF%E4%BB%A5%E5%85%B6%E4%BB%96%E7%94%A8%E6%88%B7%E5%90%8D%E5%92%8C%E5%AF%86%E7%A0%81%E8%BF%9B%E8%A1%8C%E6%98%A0%E5%B0%84%E7%9A%84/
+ 之前在使用 smb 协议在 Windows 中共享磁盘使用映射网络驱动器的时候,如果前一次登录过账号密码后面有了改动,或者前一次改错了,
就会出现这样的提示
![]()
应该是 Windows 已经把之前的连接记录下来了,即使是链接不成功的
可以通过在 cmd 或者 powershell 执行 net use 命令查看当前已经连接的
![]()
这样就可以用命令来把这个删除
net use [NETNAME] /delete
比如这边就可以
net use \\xxxxxxxx\f /delete
然后再重新输入账号密码就好了
关于net use的命令使用方式可以参考
+net use [{<DeviceName> | *}] [\\<ComputerName>\<ShareName>[\<volume>]] [{<Password> | *}]] [/user:[<DomainName>\]<UserName] >[/user:[<DottedDomainName>\]<UserName>] [/user: [<UserName@DottedDomainName>] [/savecred] [/smartcard] [{/delete | /persistent:{yes | no}}]
+net use [<DeviceName> [/home[{<Password> | *}] [/delete:{yes | no}]]
+net use [/persistent:{yes | no}]
+
]]>
- redis
+ 技巧
- redis
+ windows
diff --git a/sitemap.xml b/sitemap.xml
index 94dd0a8841..63418fcad9 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -623,7 +623,7 @@
- https://nicksxs.me/2021/02/21/AQS-%E4%B9%8B-Condition-%E6%B5%85%E6%9E%90%E7%AC%94%E8%AE%B0/
+ https://nicksxs.me/2021/03/31/2020-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
2022-06-11
@@ -632,7 +632,7 @@
- https://nicksxs.me/2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
+ https://nicksxs.me/2021/02/21/AQS-%E4%B9%8B-Condition-%E6%B5%85%E6%9E%90%E7%AC%94%E8%AE%B0/
2022-06-11
@@ -650,7 +650,7 @@
- https://nicksxs.me/2020/08/22/Filter-Intercepter-Aop-%E5%95%A5-%E5%95%A5-%E5%95%A5-%E8%BF%99%E4%BA%9B%E9%83%BD%E6%98%AF%E5%95%A5/
+ https://nicksxs.me/2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
2022-06-11
@@ -659,7 +659,7 @@
- https://nicksxs.me/2021/01/24/Leetcode-124-%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E7%9A%84%E6%9C%80%E5%A4%A7%E8%B7%AF%E5%BE%84%E5%92%8C-Binary-Tree-Maximum-Path-Sum-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2020/08/22/Filter-Intercepter-Aop-%E5%95%A5-%E5%95%A5-%E5%95%A5-%E8%BF%99%E4%BA%9B%E9%83%BD%E6%98%AF%E5%95%A5/
2022-06-11
@@ -668,7 +668,7 @@
- https://nicksxs.me/2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2021/01/24/Leetcode-124-%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E7%9A%84%E6%9C%80%E5%A4%A7%E8%B7%AF%E5%BE%84%E5%92%8C-Binary-Tree-Maximum-Path-Sum-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
@@ -677,7 +677,7 @@
- https://nicksxs.me/2021/07/04/Leetcode-42-%E6%8E%A5%E9%9B%A8%E6%B0%B4-Trapping-Rain-Water-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
@@ -695,7 +695,7 @@
- https://nicksxs.me/2022/03/13/Leetcode-83-%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0-Remove-Duplicates-from-Sorted-List-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ https://nicksxs.me/2020/08/06/Linux-%E4%B8%8B-grep-%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E7%82%B9%E5%B0%8F%E6%8A%80%E5%B7%A7/
2022-06-11
@@ -704,7 +704,7 @@
- https://nicksxs.me/2020/08/06/Linux-%E4%B8%8B-grep-%E5%91%BD%E4%BB%A4%E7%9A%84%E4%B8%80%E7%82%B9%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ https://nicksxs.me/2022/03/13/Leetcode-83-%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0-Remove-Duplicates-from-Sorted-List-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
@@ -713,7 +713,7 @@
- https://nicksxs.me/2021/03/31/2020-%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ https://nicksxs.me/2021/07/04/Leetcode-42-%E6%8E%A5%E9%9B%A8%E6%B0%B4-Trapping-Rain-Water-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
2022-06-11
@@ -758,7 +758,7 @@
- https://nicksxs.me/2021/12/05/wordpress-%E5%BF%98%E8%AE%B0%E5%AF%86%E7%A0%81%E7%9A%84%E4%B8%80%E7%A7%8D%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
+ https://nicksxs.me/2021/03/07/%E3%80%8A%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E7%AE%97%E6%B3%95%E6%89%8B%E5%86%8C%E8%AF%BB%E4%B9%A6%E3%80%8B%E7%AC%94%E8%AE%B0%E4%B9%8B%E6%95%B4%E7%90%86%E7%AE%97%E6%B3%95/
2022-06-11
@@ -767,7 +767,7 @@
- https://nicksxs.me/2021/03/07/%E3%80%8A%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E7%AE%97%E6%B3%95%E6%89%8B%E5%86%8C%E8%AF%BB%E4%B9%A6%E3%80%8B%E7%AC%94%E8%AE%B0%E4%B9%8B%E6%95%B4%E7%90%86%E7%AE%97%E6%B3%95/
+ https://nicksxs.me/2021/12/05/wordpress-%E5%BF%98%E8%AE%B0%E5%AF%86%E7%A0%81%E7%9A%84%E4%B8%80%E7%A7%8D%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95/
2022-06-11
@@ -821,7 +821,7 @@
- https://nicksxs.me/2021/09/12/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E4%BA%8C/
+ https://nicksxs.me/2021/09/19/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E4%B8%AD%E4%BD%BF%E7%94%A8%E7%9A%84-cglib-%E4%BD%9C%E4%B8%BA%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86%E4%B8%AD%E7%9A%84%E4%B8%80%E4%B8%AA%E6%B3%A8%E6%84%8F%E7%82%B9/
2022-06-11
@@ -830,7 +830,7 @@
- https://nicksxs.me/2021/10/17/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E5%9B%9B/
+ https://nicksxs.me/2021/09/12/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E4%BA%8C/
2022-06-11
@@ -848,7 +848,7 @@
- https://nicksxs.me/2021/09/19/%E8%81%8A%E4%B8%80%E4%B8%8B-SpringBoot-%E4%B8%AD%E4%BD%BF%E7%94%A8%E7%9A%84-cglib-%E4%BD%9C%E4%B8%BA%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86%E4%B8%AD%E7%9A%84%E4%B8%80%E4%B8%AA%E6%B3%A8%E6%84%8F%E7%82%B9/
+ https://nicksxs.me/2021/10/17/%E8%81%8A%E4%B8%80%E4%B8%8B-RocketMQ-%E7%9A%84%E6%B6%88%E6%81%AF%E5%AD%98%E5%82%A8%E5%9B%9B/
2022-06-11
@@ -857,7 +857,7 @@
- https://nicksxs.me/2021/06/27/%E8%81%8A%E8%81%8A-Java-%E4%B8%AD%E7%BB%95%E4%B8%8D%E5%BC%80%E7%9A%84-Synchronized-%E5%85%B3%E9%94%AE%E5%AD%97-%E4%BA%8C/
+ https://nicksxs.me/2020/11/22/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
2022-06-11
@@ -866,7 +866,7 @@
- https://nicksxs.me/2020/11/22/%E8%81%8A%E8%81%8A-Dubbo-%E7%9A%84%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
+ https://nicksxs.me/2021/06/27/%E8%81%8A%E8%81%8A-Java-%E4%B8%AD%E7%BB%95%E4%B8%8D%E5%BC%80%E7%9A%84-Synchronized-%E5%85%B3%E9%94%AE%E5%AD%97-%E4%BA%8C/
2022-06-11
@@ -875,7 +875,7 @@
- https://nicksxs.me/2020/08/02/%E8%81%8A%E8%81%8A-Java-%E8%87%AA%E5%B8%A6%E7%9A%84%E9%82%A3%E4%BA%9B%E9%80%86%E5%A4%A9%E5%B7%A5%E5%85%B7/
+ https://nicksxs.me/2021/06/13/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6%E4%BA%8C/
2022-06-11
@@ -884,7 +884,7 @@
- https://nicksxs.me/2021/06/13/%E8%81%8A%E8%81%8A-Java-%E7%9A%84%E7%B1%BB%E5%8A%A0%E8%BD%BD%E6%9C%BA%E5%88%B6%E4%BA%8C/
+ https://nicksxs.me/2020/08/02/%E8%81%8A%E8%81%8A-Java-%E8%87%AA%E5%B8%A6%E7%9A%84%E9%82%A3%E4%BA%9B%E9%80%86%E5%A4%A9%E5%B7%A5%E5%85%B7/
2022-06-11
@@ -893,7 +893,7 @@
- https://nicksxs.me/2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
+ https://nicksxs.me/2022/01/09/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E4%B8%8B%E7%9A%84%E5%88%86%E9%A1%B5%E6%96%B9%E6%A1%88/
2022-06-11
@@ -902,7 +902,7 @@
- https://nicksxs.me/2021/12/26/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E5%8E%9F%E7%90%86%E5%88%9D%E7%AF%87/
+ https://nicksxs.me/2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
2022-06-11
@@ -920,7 +920,7 @@
- https://nicksxs.me/2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
+ https://nicksxs.me/2021/12/26/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E5%8E%9F%E7%90%86%E5%88%9D%E7%AF%87/
2022-06-11
@@ -929,7 +929,7 @@
- https://nicksxs.me/2021/05/30/%E8%81%8A%E8%81%8A%E4%BC%A0%E8%AF%B4%E4%B8%AD%E7%9A%84-ThreadLocal/
+ https://nicksxs.me/2021/04/04/%E8%81%8A%E8%81%8A-dubbo-%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/
2022-06-11
@@ -938,7 +938,7 @@
- https://nicksxs.me/2022/01/09/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E4%B8%8B%E7%9A%84%E5%88%86%E9%A1%B5%E6%96%B9%E6%A1%88/
+ https://nicksxs.me/2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
2022-06-11
@@ -947,7 +947,7 @@
- https://nicksxs.me/2021/04/04/%E8%81%8A%E8%81%8A-dubbo-%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/
+ https://nicksxs.me/2021/05/30/%E8%81%8A%E8%81%8A%E4%BC%A0%E8%AF%B4%E4%B8%AD%E7%9A%84-ThreadLocal/
2022-06-11
@@ -1829,7 +1829,7 @@
- https://nicksxs.me/2019/12/10/Redis-Part-1/
+ https://nicksxs.me/2015/03/11/Reverse-Bits/
2020-01-12
@@ -1838,7 +1838,7 @@
- https://nicksxs.me/2015/03/11/Reverse-Bits/
+ https://nicksxs.me/2019/12/10/Redis-Part-1/
2020-01-12
@@ -1856,7 +1856,7 @@
- https://nicksxs.me/2015/01/14/Two-Sum/
+ https://nicksxs.me/2016/09/29/binary-watch/
2020-01-12
@@ -1874,7 +1874,7 @@
- https://nicksxs.me/2016/09/29/binary-watch/
+ https://nicksxs.me/2015/01/14/Two-Sum/
2020-01-12
@@ -1991,7 +1991,7 @@
- https://nicksxs.me/2015/04/15/Leetcode-No-3/
+ https://nicksxs.me/2015/03/11/Number-Of-1-Bits/
2020-01-12
@@ -2000,7 +2000,7 @@
- https://nicksxs.me/2015/03/11/Number-Of-1-Bits/
+ https://nicksxs.me/2015/01/04/Path-Sum/
2020-01-12
@@ -2009,7 +2009,7 @@
- https://nicksxs.me/2015/01/04/Path-Sum/
+ https://nicksxs.me/2015/04/15/Leetcode-No-3/
2020-01-12
@@ -2036,7 +2036,7 @@
- https://nicksxs.me/2017/04/25/rabbitmq-tips/
+ https://nicksxs.me/2015/01/16/pcre-intro-and-a-simple-package/
2020-01-12
@@ -2045,7 +2045,7 @@
- https://nicksxs.me/2017/03/28/spark-little-tips/
+ https://nicksxs.me/2017/04/25/rabbitmq-tips/
2020-01-12
@@ -2054,7 +2054,7 @@
- https://nicksxs.me/2015/01/16/pcre-intro-and-a-simple-package/
+ https://nicksxs.me/2017/03/28/spark-little-tips/
2020-01-12
@@ -2119,7 +2119,7 @@
https://nicksxs.me/
- 2023-09-05
+ 2023-09-06
daily
1.0
@@ -2127,3180 +2127,3180 @@
https://nicksxs.me/tags/%E7%94%9F%E6%B4%BB/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Java/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/JVM/
- 2023-09-05
+ https://nicksxs.me/tags/2020/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/C/
- 2023-09-05
+ https://nicksxs.me/tags/2021/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/leetcode/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%8B%96%E6%9B%B4/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/java/
- 2023-09-05
+ https://nicksxs.me/tags/Java/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Binary-Tree/
- 2023-09-05
+ https://nicksxs.me/tags/JVM/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/DFS/
- 2023-09-05
+ https://nicksxs.me/tags/C/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%BA%8C%E5%8F%89%E6%A0%91/
- 2023-09-05
+ https://nicksxs.me/tags/leetcode/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E9%A2%98%E8%A7%A3/
- 2023-09-05
+ https://nicksxs.me/tags/java/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Linked-List/
- 2023-09-05
+ https://nicksxs.me/tags/Binary-Tree/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/nas/
- 2023-09-05
+ https://nicksxs.me/tags/DFS/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%BA%8C%E5%8F%89%E6%A0%91/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/2020/
- 2023-09-05
+ https://nicksxs.me/tags/%E9%A2%98%E8%A7%A3/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/2021/
- 2023-09-05
+ https://nicksxs.me/tags/Linked-List/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%8B%96%E6%9B%B4/
- 2023-09-05
+ https://nicksxs.me/tags/nas/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%AF%BB%E5%90%8E%E6%84%9F/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/2019/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%B9%B4%E4%B8%AD%E6%80%BB%E7%BB%93/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%8A%80%E6%9C%AF/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%AF%BB%E4%B9%A6/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/c/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%B9%B6%E5%8F%91/
- 2023-09-05
+ https://nicksxs.me/tags/aqs/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/j-u-c/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%B9%B6%E5%8F%91/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/aqs/
- 2023-09-05
+ https://nicksxs.me/tags/j-u-c/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/condition/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/await/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/signal/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/lock/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/unlock/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Apollo/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/environment/
- 2023-09-05
+ https://nicksxs.me/tags/value/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/value/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%B3%A8%E8%A7%A3/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%B3%A8%E8%A7%A3/
- 2023-09-05
+ https://nicksxs.me/tags/environment/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Stream/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Comparator/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%8E%92%E5%BA%8F/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/sort/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/nullsfirst/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Disruptor/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/tags/Dubbo/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/RPC/
- 2023-09-05
+ https://nicksxs.me/tags/2022/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1/
- 2023-09-05
+ https://nicksxs.me/tags/2023/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Filter/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Interceptor/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/AOP/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Spring/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Tomcat/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Servlet/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Web/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/G1/
- 2023-09-05
+ https://nicksxs.me/tags/Dubbo/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/GC/
- 2023-09-05
+ https://nicksxs.me/tags/RPC/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Garbage-First-Collector/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/2022/
- 2023-09-05
+ https://nicksxs.me/tags/headscale/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/2023/
- 2023-09-05
+ https://nicksxs.me/tags/G1/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E9%80%92%E5%BD%92/
- 2023-09-05
+ https://nicksxs.me/tags/GC/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Preorder-Traversal/
- 2023-09-05
+ https://nicksxs.me/tags/Garbage-First-Collector/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Inorder-Traversal/
- 2023-09-05
+ https://nicksxs.me/tags/Print-FooBar-Alternately/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%89%8D%E5%BA%8F/
- 2023-09-05
+ https://nicksxs.me/tags/%E9%80%92%E5%BD%92/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%B8%AD%E5%BA%8F/
- 2023-09-05
+ https://nicksxs.me/tags/Preorder-Traversal/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Print-FooBar-Alternately/
- 2023-09-05
+ https://nicksxs.me/tags/Inorder-Traversal/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/DP/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%89%8D%E5%BA%8F/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/%E4%B8%AD%E5%BA%8F/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/3Sum-Closest/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Shift-2D-Grid/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/stack/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/min-stack/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%9C%80%E5%B0%8F%E6%A0%88/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/leetcode-155/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/3Sum-Closest/
- 2023-09-05
+ https://nicksxs.me/tags/DP/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/linked-list/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Lowest-Common-Ancestor-of-a-Binary-Tree/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/First-Bad-Version/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/string/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Intersection-of-Two-Arrays/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/headscale/
- 2023-09-05
+ https://nicksxs.me/tags/Median-of-Two-Sorted-Arrays/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Median-of-Two-Sorted-Arrays/
- 2023-09-05
+ https://nicksxs.me/tags/Rotate-Image/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/dp/
- 2023-09-05
+ https://nicksxs.me/tags/%E7%9F%A9%E9%98%B5/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%BB%A3%E7%A0%81%E9%A2%98%E8%A7%A3/
- 2023-09-05
+ https://nicksxs.me/tags/linux/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Trapping-Rain-Water/
- 2023-09-05
+ https://nicksxs.me/tags/grep/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%8E%A5%E9%9B%A8%E6%B0%B4/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%BD%AC%E4%B9%89/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Leetcode-42/
- 2023-09-05
+ https://nicksxs.me/tags/Remove-Duplicates-from-Sorted-List/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Rotate-Image/
- 2023-09-05
+ https://nicksxs.me/tags/dp/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%9F%A9%E9%98%B5/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/tags/Remove-Duplicates-from-Sorted-List/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%BB%A3%E7%A0%81%E9%A2%98%E8%A7%A3/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/linux/
- 2023-09-05
+ https://nicksxs.me/tags/Trapping-Rain-Water/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/grep/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%8E%A5%E9%9B%A8%E6%B0%B4/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%BD%AC%E4%B9%89/
- 2023-09-05
+ https://nicksxs.me/tags/Leetcode-42/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/mfc/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Maven/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/C/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Redis/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Distributed-Lock/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/hadoop/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/cluster/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/docker/
- 2023-09-05
+ https://nicksxs.me/tags/Docker/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/mysql/
- 2023-09-05
+ https://nicksxs.me/tags/namespace/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/dnsmasq/
- 2023-09-05
+ https://nicksxs.me/tags/cgroup/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Docker/
- 2023-09-05
+ https://nicksxs.me/tags/docker/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/namespace/
- 2023-09-05
+ https://nicksxs.me/tags/mysql/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/cgroup/
- 2023-09-05
+ https://nicksxs.me/tags/dnsmasq/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Dockerfile/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/echo/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/uname/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8F%91%E8%A1%8C%E7%89%88/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Gogs/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Webhook/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/ssh/
- 2023-09-05
+ https://nicksxs.me/tags/Mysql/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%AB%AF%E5%8F%A3%E8%BD%AC%E5%8F%91/
- 2023-09-05
+ https://nicksxs.me/tags/Mybatis/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8D%9A%E5%AE%A2%EF%BC%8C%E6%96%87%E7%AB%A0/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Mysql/
- 2023-09-05
+ https://nicksxs.me/tags/Sql%E6%B3%A8%E5%85%A5/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Mybatis/
- 2023-09-05
+ https://nicksxs.me/tags/ssh/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Sql%E6%B3%A8%E5%85%A5/
- 2023-09-05
+ https://nicksxs.me/tags/%E7%AB%AF%E5%8F%A3%E8%BD%AC%E5%8F%91/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/hexo/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%BC%93%E5%AD%98/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/nginx/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%97%A5%E5%BF%97/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/openresty/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/php/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/powershell/
- 2023-09-05
+ https://nicksxs.me/tags/redis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/mq/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/im/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%BA%90%E7%A0%81/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/redis/
- 2023-09-05
+ https://nicksxs.me/tags/powershell/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
- 2023-09-05
+ https://nicksxs.me/tags/mq/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%BA%90%E7%A0%81/
- 2023-09-05
+ https://nicksxs.me/tags/im/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%B7%98%E6%B1%B0%E7%AD%96%E7%95%A5/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%BA%94%E7%94%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Evict/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%BF%87%E6%9C%9F%E7%AD%96%E7%95%A5/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Rust/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%89%80%E6%9C%89%E6%9D%83/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%86%85%E5%AD%98%E5%88%86%E5%B8%83/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%96%B0%E8%AF%AD%E8%A8%80/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8F%AF%E5%8F%98%E5%BC%95%E7%94%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E4%B8%8D%E5%8F%AF%E5%8F%98%E5%BC%95%E7%94%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%88%87%E7%89%87/
- 2023-09-05
+ https://nicksxs.me/tags/spark/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/spark/
- 2023-09-05
+ https://nicksxs.me/tags/python/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/python/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%88%87%E7%89%87/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Spring-Event/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/SpringBoot/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/websocket/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/swoole/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/WordPress/
- 2023-09-05
+ https://nicksxs.me/tags/gc/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%B0%8F%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%A0%87%E8%AE%B0%E6%95%B4%E7%90%86/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/gc/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%A0%87%E8%AE%B0%E6%95%B4%E7%90%86/
- 2023-09-05
+ https://nicksxs.me/tags/jvm/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6/
- 2023-09-05
+ https://nicksxs.me/tags/WordPress/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/jvm/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/MQ/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/RocketMQ/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%89%8A%E5%B3%B0%E5%A1%AB%E8%B0%B7/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E4%B8%AD%E9%97%B4%E4%BB%B6/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%90%90%E6%A7%BD/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%96%AB%E6%83%85/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%BE%8E%E5%9B%BD/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%85%AC%E4%BA%A4%E8%BD%A6/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8F%A3%E7%BD%A9/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%9D%80%E4%BA%BA%E8%AF%9B%E5%BF%83/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%BC%80%E8%BD%A6/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8A%A0%E5%A1%9E/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%B3%9F%E5%BF%83%E4%BA%8B/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%A7%84%E5%88%99/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%85%AC%E4%BA%A4/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%B7%AF%E6%94%BF%E8%A7%84%E5%88%92/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%9F%BA%E7%A1%80%E8%AE%BE%E6%96%BD/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%9D%AD%E5%B7%9E/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%81%A5%E5%BA%B7%E7%A0%81/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%89%93%E5%8D%A1/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%B9%B8%E7%A6%8F%E4%BA%86%E5%90%97/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%B6%B3%E7%90%83/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Windows/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/git/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%BF%90%E5%8A%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%87%8F%E8%82%A5/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%B7%91%E6%AD%A5/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%B9%B2%E6%B4%BB/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/scp/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/wsl/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%BD%B1%E8%AF%84/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%AF%84%E7%94%9F%E8%99%AB/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%9B%A4%E7%89%A9%E8%B5%84/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%AD%97%E7%AC%A6%E9%9B%86/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%BC%96%E7%A0%81/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/utf8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/utf8mb4/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/utf8mb4-0900-ai-ci/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/utf8mb4-unicode-ci/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/utf8mb4-general-ci/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/tags/DefaultMQPushConsumer/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/NameServer/
- 2023-09-05
+ https://nicksxs.me/tags/DefaultMQPushConsumer/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Druid/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%95%B0%E6%8D%AE%E6%BA%90%E5%8A%A8%E6%80%81%E5%88%87%E6%8D%A2/
- 2023-09-05
+ https://nicksxs.me/tags/NameServer/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/
- 2023-09-05
+ https://nicksxs.me/tags/cglib/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/cglib/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%BA%8B%E5%8A%A1/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%BA%8B%E5%8A%A1/
- 2023-09-05
+ https://nicksxs.me/tags/Druid/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%87%AA%E5%8A%A8%E8%A3%85%E9%85%8D/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%95%B0%E6%8D%AE%E6%BA%90%E5%8A%A8%E6%80%81%E5%88%87%E6%8D%A2/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/AutoConfiguration/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/SPI/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%B8%BE%E9%87%8D/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Adaptive/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%B0%84%E5%87%BB/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%87%AA%E9%80%82%E5%BA%94%E6%8B%93%E5%B1%95/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%B9%92%E4%B9%93%E7%90%83/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%B8%9C%E4%BA%AC%E5%A5%A5%E8%BF%90%E4%BC%9A/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%B7%B3%E6%B0%B4/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%B9%92%E4%B9%93%E7%90%83/
- 2023-09-05
+ https://nicksxs.me/tags/SPI/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%B7%B3%E6%B0%B4/
- 2023-09-05
+ https://nicksxs.me/tags/Adaptive/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%B8%BE%E9%87%8D/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%87%AA%E9%80%82%E5%BA%94%E6%8B%93%E5%B1%95/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%B0%84%E5%87%BB/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Synchronized/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%81%8F%E5%90%91%E9%94%81/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%BD%BB%E9%87%8F%E7%BA%A7%E9%94%81/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E9%87%8D%E9%87%8F%E7%BA%A7%E9%94%81/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%87%AA%E6%97%8B/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
- 2023-09-05
+ https://nicksxs.me/tags/%E7%B1%BB%E5%8A%A0%E8%BD%BD/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/JPS/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%8A%A0%E8%BD%BD/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/JStack/
- 2023-09-05
+ https://nicksxs.me/tags/%E9%AA%8C%E8%AF%81/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/JMap/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%87%86%E5%A4%87/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%B1%BB%E5%8A%A0%E8%BD%BD/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%A7%A3%E6%9E%90/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%8A%A0%E8%BD%BD/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%88%9D%E5%A7%8B%E5%8C%96/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E9%AA%8C%E8%AF%81/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/tags/%E5%87%86%E5%A4%87/
- 2023-09-05
+ https://nicksxs.me/tags/%E9%93%BE%E6%8E%A5/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%A7%A3%E6%9E%90/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%8F%8C%E4%BA%B2%E5%A7%94%E6%B4%BE/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%88%9D%E5%A7%8B%E5%8C%96/
- 2023-09-05
+ https://nicksxs.me/tags/JPS/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E9%93%BE%E6%8E%A5/
- 2023-09-05
+ https://nicksxs.me/tags/JStack/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%8F%8C%E4%BA%B2%E5%A7%94%E6%B4%BE/
- 2023-09-05
+ https://nicksxs.me/tags/JMap/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/top/
- 2023-09-05
+ https://nicksxs.me/tags/Sharding-Jdbc/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Broker/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Sharding-Jdbc/
- 2023-09-05
+ https://nicksxs.me/tags/top/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/mvcc/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/read-view/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/gap-lock/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/next-key-lock/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%B9%BB%E8%AF%BB/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%B4%A2%E5%BC%95/
- 2023-09-05
+ https://nicksxs.me/tags/ThreadPool/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/is-null/
- 2023-09-05
+ https://nicksxs.me/tags/%E7%BA%BF%E7%A8%8B%E6%B1%A0/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/is-not-null/
- 2023-09-05
+ https://nicksxs.me/tags/FixedThreadPool/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/procedure/
- 2023-09-05
+ https://nicksxs.me/tags/LimitedThreadPool/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/EagerThreadPool/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/CachedThreadPool/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%BC%93%E5%AD%98%E7%A9%BF%E9%80%8F/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%BC%93%E5%AD%98%E5%87%BB%E7%A9%BF/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E7%BC%93%E5%AD%98%E9%9B%AA%E5%B4%A9/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/bloom-filter/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E4%BA%92%E6%96%A5%E9%94%81/
- 2023-09-05
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/%E7%B4%A2%E5%BC%95/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/is-null/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/is-not-null/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/procedure/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Design-Patterns/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8D%95%E4%BE%8B/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Singleton/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Mac/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/PHP/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/Homebrew/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/icu4c/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/zsh/
- 2023-09-05
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/%E6%89%B6%E6%A2%AF/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/%E8%B8%A9%E8%B8%8F/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/%E5%AE%89%E5%85%A8/
+ 2023-09-06
+ weekly
+ 0.2
+
+
+
+ https://nicksxs.me/tags/%E7%94%B5%E7%93%B6%E8%BD%A6/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/ThreadLocal/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%BC%B1%E5%BC%95%E7%94%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%86%85%E5%AD%98%E6%B3%84%E6%BC%8F/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/WeakReference/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%97%85%E6%B8%B8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%8E%A6%E9%97%A8/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E4%B8%AD%E5%B1%B1%E8%B7%AF/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%B1%80%E5%8F%A3%E8%A1%97/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E9%BC%93%E6%B5%AA%E5%B1%BF/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%9B%BE%E5%8E%9D%E5%9E%B5/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%A4%8D%E7%89%A9%E5%9B%AD/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E9%A9%AC%E6%88%8F%E5%9B%A2/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%B2%99%E8%8C%B6%E9%9D%A2/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E6%B5%B7%E8%9B%8E%E7%85%8E/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/tags/%E6%89%B6%E6%A2%AF/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%B8%A9%E8%B8%8F/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%87%AA%E5%8A%A8%E8%A3%85%E9%85%8D/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%AE%89%E5%85%A8/
- 2023-09-05
+ https://nicksxs.me/tags/AutoConfiguration/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%94%B5%E7%93%B6%E8%BD%A6/
- 2023-09-05
+ https://nicksxs.me/tags/Thread-dump/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/Thread-dump/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%BF%9C%E7%A8%8B%E5%8A%9E%E5%85%AC/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E4%B8%A4%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/%E4%B8%89%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/2PC/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/3PC/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%BF%9C%E7%A8%8B%E5%8A%9E%E5%85%AC/
- 2023-09-05
+ https://nicksxs.me/tags/%E9%AA%91%E8%BD%A6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E9%AA%91%E8%BD%A6/
- 2023-09-05
+ https://nicksxs.me/tags/%E7%9C%8B%E5%89%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%9C%8B%E5%89%A7/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%A3%85%E7%94%B5%E8%84%91/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/ThreadPool/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%80%81%E7%94%B5%E8%84%91/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%BA%BF%E7%A8%8B%E6%B1%A0/
- 2023-09-05
+ https://nicksxs.me/tags/360-%E5%85%A8%E5%AE%B6%E6%A1%B6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/FixedThreadPool/
- 2023-09-05
+ https://nicksxs.me/tags/%E4%BF%AE%E7%94%B5%E8%84%91%E7%9A%84/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/LimitedThreadPool/
- 2023-09-05
+ https://nicksxs.me/tags/stream/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/EagerThreadPool/
- 2023-09-05
+ https://nicksxs.me/tags/%E6%8D%A2%E8%BD%A6%E7%89%8C/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/CachedThreadPool/
- 2023-09-05
+ https://nicksxs.me/tags/zookeeper/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E6%8D%A2%E8%BD%A6%E7%89%8C/
- 2023-09-05
+ https://nicksxs.me/tags/%E7%9C%8B%E4%B9%A6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%A3%85%E7%94%B5%E8%84%91/
- 2023-09-05
+ https://nicksxs.me/tags/%E8%B7%AF%E7%94%B1%E5%99%A8/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%80%81%E7%94%B5%E8%84%91/
- 2023-09-05
+ https://nicksxs.me/tags/%E9%AB%98%E9%80%9F/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/360-%E5%85%A8%E5%AE%B6%E6%A1%B6/
- 2023-09-05
+ https://nicksxs.me/tags/%E5%A4%A7%E6%89%AB%E9%99%A4/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E4%BF%AE%E7%94%B5%E8%84%91%E7%9A%84/
- 2023-09-05
+ https://nicksxs.me/tags/dubbo/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/tags/windows/
- 2023-09-05
+ 2023-09-06
weekly
0.2
+
+
- https://nicksxs.me/tags/stream/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/dubbo/
- 2023-09-05
+ https://nicksxs.me/categories/Java/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/zookeeper/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E7%9C%8B%E4%B9%A6/
- 2023-09-05
+ https://nicksxs.me/categories/Java/JVM/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E9%AB%98%E9%80%9F/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/2020/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E5%A4%A7%E6%89%AB%E9%99%A4/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/tags/%E8%B7%AF%E7%94%B1%E5%99%A8/
- 2023-09-05
+ https://nicksxs.me/categories/Java/leetcode/
+ 2023-09-06
weekly
0.2
-
-
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/
- 2023-09-05
+ https://nicksxs.me/categories/Java/GC/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/JVM/
- 2023-09-05
+ https://nicksxs.me/categories/Binary-Tree/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/leetcode/
- 2023-09-05
+ https://nicksxs.me/categories/nas/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/leetcode/
- 2023-09-05
+ https://nicksxs.me/categories/Linked-List/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/GC/
- 2023-09-05
+ https://nicksxs.me/categories/C/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Binary-Tree/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/2020/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Linked-List/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/C/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/java/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/nas/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/leetcode/java/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/leetcode/java/Binary-Tree/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/2019/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E4%B8%AD%E6%80%BB%E7%BB%93/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/leetcode/java/Linked-List/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/2020/
- 2023-09-05
+ https://nicksxs.me/categories/java/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Java/%E5%B9%B6%E5%8F%91/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E6%9D%91%E4%B8%8A%E6%98%A5%E6%A0%91/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/java/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Apollo/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/2019/
- 2023-09-05
+ https://nicksxs.me/categories/Java/%E9%9B%86%E5%90%88/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/leetcode/java/Binary-Tree/DFS/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E6%9D%91%E4%B8%8A%E6%98%A5%E6%A0%91/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Apollo/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/java/Binary-Tree/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E4%B8%AD%E6%80%BB%E7%BB%93/2020/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/%E9%9B%86%E5%90%88/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Dubbo/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%B9%B4%E4%B8%AD%E6%80%BB%E7%BB%93/2021/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Dubbo/
- 2023-09-05
+ https://nicksxs.me/categories/Filter/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Filter/
- 2023-09-05
+ https://nicksxs.me/categories/headscale/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/java/Linked-List/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/DP/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Apollo/value/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/stack/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Apollo/value/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/java/Binary-Tree/DFS/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/linked-list/
- 2023-09-05
+ https://nicksxs.me/categories/DP/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Java/leetcode/Lowest-Common-Ancestor-of-a-Binary-Tree/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/headscale/
- 2023-09-05
+ https://nicksxs.me/categories/linked-list/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/%E5%AD%97%E7%AC%A6%E4%B8%B2-online/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Java/leetcode/Rotate-Image/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Interceptor-AOP/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Linux/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B9%B4%E7%BB%88%E6%80%BB%E7%BB%93/2020/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Maven/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Maven/
- 2023-09-05
+ https://nicksxs.me/categories/Redis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Redis/
- 2023-09-05
+ https://nicksxs.me/categories/data-analysis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/leetcode/java/DP/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/java/stack/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/data-analysis/
- 2023-09-05
+ https://nicksxs.me/categories/Docker/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/leetcode/java/stack/
- 2023-09-05
+ https://nicksxs.me/categories/docker/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/docker/
- 2023-09-05
+ https://nicksxs.me/categories/dns/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/dns/
- 2023-09-05
+ https://nicksxs.me/categories/leetcode/java/DP/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Docker/
- 2023-09-05
+ https://nicksxs.me/categories/%E6%8C%81%E7%BB%AD%E9%9B%86%E6%88%90/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/leetcode/java/linked-list/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E6%8C%81%E7%BB%AD%E9%9B%86%E6%88%90/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Mybatis/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/leetcode/java/string/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/ssh/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Spring/
- 2023-09-05
+ https://nicksxs.me/categories/hexo/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Mybatis/
- 2023-09-05
+ https://nicksxs.me/categories/Spring/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Redis/Distributed-Lock/
- 2023-09-05
- weekly
- 0.2
-
-
-
- https://nicksxs.me/categories/Docker/%E4%BB%8B%E7%BB%8D/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/ssh/%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/nginx/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Spring/Servlet/
- 2023-09-05
+ https://nicksxs.me/categories/php/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Mybatis/Mysql/
- 2023-09-05
+ https://nicksxs.me/categories/redis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/grep/
- 2023-09-05
+ https://nicksxs.me/categories/Docker/%E4%BB%8B%E7%BB%8D/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mysql/
- 2023-09-05
+ https://nicksxs.me/categories/Redis/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/C/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%AD%E8%A8%80/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/echo/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Spring/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Spring/Servlet/Interceptor/
- 2023-09-05
+ https://nicksxs.me/categories/Java/SpringBoot/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Mybatis/Mysql/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mysql/Sql%E6%B3%A8%E5%85%A5/
- 2023-09-05
+ https://nicksxs.me/categories/Java/gc/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/C/Redis/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E7%94%9F%E6%B4%BB/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Docker/%E5%8F%91%E8%A1%8C%E7%89%88%E6%9C%AC/
- 2023-09-05
+ https://nicksxs.me/categories/Mysql/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Spring/Servlet/Interceptor/AOP/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/grep/
- 2023-09-05
+ https://nicksxs.me/categories/ssh/%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Spring/Mybatis/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E8%BF%90%E5%8A%A8/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/grep/%E6%9F%A5%E6%97%A5%E5%BF%97/
- 2023-09-05
+ https://nicksxs.me/categories/hexo/%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/hexo/
- 2023-09-05
+ https://nicksxs.me/categories/Spring/Servlet/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mybatis/
- 2023-09-05
+ https://nicksxs.me/categories/MQ/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/hexo/%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mybatis/%E7%BC%93%E5%AD%98/
- 2023-09-05
+ https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/grep/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/nginx/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%85%AC%E4%BA%A4/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/php/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E7%99%BD%E5%B2%A9%E6%9D%BE/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E8%AF%AD%E8%A8%80/
- 2023-09-05
+ https://nicksxs.me/categories/Windows/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/redis/
- 2023-09-05
+ https://nicksxs.me/categories/Mybatis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Redis/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
- 2023-09-05
+ https://nicksxs.me/categories/git/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E8%AF%AD%E8%A8%80/Rust/
- 2023-09-05
+ https://nicksxs.me/categories/shell/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Redis/%E6%BA%90%E7%A0%81/
- 2023-09-05
+ https://nicksxs.me/categories/wsl/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Rust/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%BD%B1%E8%AF%84/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Spring/
- 2023-09-05
+ https://nicksxs.me/categories/C/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/SpringBoot/
- 2023-09-05
+ https://nicksxs.me/categories/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/gc/
- 2023-09-05
+ https://nicksxs.me/categories/Redis/%E6%BA%90%E7%A0%81/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E7%94%9F%E6%B4%BB/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Dubbo/RPC/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E8%BF%90%E5%8A%A8/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo-RPC/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/MQ/
- 2023-09-05
+ https://nicksxs.me/categories/Java/%E7%B1%BB%E5%8A%A0%E8%BD%BD/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/
- 2023-09-05
+ https://nicksxs.me/categories/Thread-dump/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%85%AC%E4%BA%A4/
- 2023-09-05
+ https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/top/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E7%99%BD%E5%B2%A9%E6%9D%BE/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo-%E7%BA%BF%E7%A8%8B%E6%B1%A0/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Windows/
- 2023-09-05
+ https://nicksxs.me/categories/Redis/%E5%BA%94%E7%94%A8/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/git/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Design-Patterns/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/shell/
- 2023-09-05
+ https://nicksxs.me/categories/Mac/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/wsl/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E6%97%85%E6%B8%B8/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%BD%B1%E8%AF%84/
- 2023-09-05
+ https://nicksxs.me/categories/SpringBoot/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/gc/jvm/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%AD%E8%A8%80/Rust/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Dubbo/RPC/
- 2023-09-05
+ https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/echo/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/MQ/RocketMQ/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%BC%80%E8%BD%A6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/%E7%96%AB%E6%83%85/
- 2023-09-05
+ https://nicksxs.me/categories/Rust/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo-RPC/
- 2023-09-05
+ https://nicksxs.me/categories/Java/gc/jvm/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/%E7%B1%BB%E5%8A%A0%E8%BD%BD/
- 2023-09-05
+ https://nicksxs.me/categories/Mysql/Sql%E6%B3%A8%E5%85%A5/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Thread-dump/
- 2023-09-05
+ https://nicksxs.me/categories/Spring/Servlet/Interceptor/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E7%99%BD%E5%B2%A9%E6%9D%BE/%E5%B9%B8%E7%A6%8F%E4%BA%86%E5%90%97/
- 2023-09-05
+ https://nicksxs.me/categories/MQ/RocketMQ/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Linux/%E5%91%BD%E4%BB%A4/top/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/%E7%96%AB%E6%83%85/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Windows/%E5%B0%8F%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/grep/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/git/%E5%B0%8F%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/%E8%AF%BB%E5%90%8E%E6%84%9F/%E7%99%BD%E5%B2%A9%E6%9D%BE/%E5%B9%B8%E7%A6%8F%E4%BA%86%E5%90%97/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mysql/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
- 2023-09-05
+ https://nicksxs.me/categories/Windows/%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mysql/%E7%B4%A2%E5%BC%95/
- 2023-09-05
+ https://nicksxs.me/categories/Mybatis/%E7%BC%93%E5%AD%98/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Redis/%E5%BA%94%E7%94%A8/
- 2023-09-05
+ https://nicksxs.me/categories/git/%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Design-Patterns/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E8%BF%90%E5%8A%A8/%E8%B7%91%E6%AD%A5/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E8%BF%90%E5%8A%A8/%E8%B7%91%E6%AD%A5/
- 2023-09-05
+ https://nicksxs.me/categories/shell/%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mac/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%BD%B1%E8%AF%84/2020/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/SpringBoot/
- 2023-09-05
+ https://nicksxs.me/categories/C/Redis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E6%97%85%E6%B8%B8/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Dubbo/RPC/SPI/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/shell/%E5%B0%8F%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/%E9%97%AE%E9%A2%98%E6%8E%92%E6%9F%A5/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%BC%80%E8%BD%A6/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/top/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo-%E7%BA%BF%E7%A8%8B%E6%B1%A0/
- 2023-09-05
+ https://nicksxs.me/categories/Mysql/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%BD%B1%E8%AF%84/2020/
- 2023-09-05
+ https://nicksxs.me/categories/Redis/%E7%BC%93%E5%AD%98/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E6%8A%80%E5%B7%A7/
- 2023-09-05
+ https://nicksxs.me/categories/Mysql/%E7%B4%A2%E5%BC%95/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Dubbo/RPC/SPI/
- 2023-09-05
+ https://nicksxs.me/categories/Java/Singleton/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/
- 2023-09-05
+ https://nicksxs.me/categories/Mac/PHP/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/%E7%96%AB%E6%83%85/%E7%BE%8E%E5%9B%BD/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/%E4%B8%A4%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo/
- 2023-09-05
+ https://nicksxs.me/categories/Docker/%E5%8F%91%E8%A1%8C%E7%89%88%E6%9C%AC/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/%E7%96%AB%E6%83%85/%E5%8F%A3%E7%BD%A9/
- 2023-09-05
+ https://nicksxs.me/categories/Spring/Mybatis/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E9%97%AE%E9%A2%98%E6%8E%92%E6%9F%A5/
- 2023-09-05
+ https://nicksxs.me/categories/Spring/Servlet/Interceptor/AOP/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/top/
- 2023-09-05
+ https://nicksxs.me/categories/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mysql/%E6%BA%90%E7%A0%81/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/%E7%96%AB%E6%83%85/%E7%BE%8E%E5%9B%BD/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/C/Mysql/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/grep/%E6%9F%A5%E6%97%A5%E5%BF%97/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Redis/%E7%BC%93%E5%AD%98/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E5%90%90%E6%A7%BD/%E7%96%AB%E6%83%85/%E5%8F%A3%E7%BD%A9/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Java/Singleton/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E8%BF%90%E5%8A%A8/%E8%B7%91%E6%AD%A5/%E5%B9%B2%E6%B4%BB/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%94%9F%E6%B4%BB/%E8%BF%90%E5%8A%A8/%E8%B7%91%E6%AD%A5/%E5%B9%B2%E6%B4%BB/
- 2023-09-05
+ https://nicksxs.me/categories/MQ/RocketMQ/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Mac/PHP/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo/SPI/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/%E4%B8%A4%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo/%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/MQ/RocketMQ/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B7%A5%E5%85%B7/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/RocketMQ/
- 2023-09-05
+ https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/top/%E6%8E%92%E5%BA%8F/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo/%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6/
- 2023-09-05
+ https://nicksxs.me/categories/Mysql/%E6%BA%90%E7%A0%81/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B7%A5%E5%85%B7/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo/%E7%BA%BF%E7%A8%8B%E6%B1%A0/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/top/%E6%8E%92%E5%BA%8F/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/
- 2023-09-05
+ https://nicksxs.me/categories/C/Mysql/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/Mac/Homebrew/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/%E4%B8%89%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo/%E7%BA%BF%E7%A8%8B%E6%B1%A0/
- 2023-09-05
+ https://nicksxs.me/categories/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/RocketMQ/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo/SPI/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo/SPI/Adaptive/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E4%B8%AD%E9%97%B4%E4%BB%B6/
- 2023-09-05
+ https://nicksxs.me/categories/Dubbo/%E7%BA%BF%E7%A8%8B%E6%B1%A0/ThreadPool/
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/%E7%A9%BF%E9%80%8F/
- 2023-09-05
+ 2023-09-06
weekly
0.2
https://nicksxs.me/categories/PHP/
- 2023-09-05
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo/%E7%BA%BF%E7%A8%8B%E6%B1%A0/ThreadPool/
- 2023-09-05
+ https://nicksxs.me/categories/%E4%B8%AD%E9%97%B4%E4%BB%B6/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/Dubbo/SPI/Adaptive/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/%E7%A9%BF%E9%80%8F/%E5%87%BB%E7%A9%BF/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E4%B8%AD%E9%97%B4%E4%BB%B6/RocketMQ/
- 2023-09-05
+ https://nicksxs.me/categories/PHP/icu4c/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/%E7%A9%BF%E9%80%8F/%E5%87%BB%E7%A9%BF/
- 2023-09-05
+ https://nicksxs.me/categories/%E4%B8%AD%E9%97%B4%E4%BB%B6/RocketMQ/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/PHP/icu4c/
- 2023-09-05
+ https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/%E7%A9%BF%E9%80%8F/%E5%87%BB%E7%A9%BF/%E9%9B%AA%E5%B4%A9/
+ 2023-09-06
weekly
0.2
- https://nicksxs.me/categories/%E7%BC%93%E5%AD%98/%E7%A9%BF%E9%80%8F/%E5%87%BB%E7%A9%BF/%E9%9B%AA%E5%B4%A9/
- 2023-09-05
+ https://nicksxs.me/categories/%E6%8A%80%E5%B7%A7/
+ 2023-09-06
weekly
0.2
diff --git a/tags/Dubbo/index.html b/tags/Dubbo/index.html
index f751a41cfe..6720875979 100644
--- a/tags/Dubbo/index.html
+++ b/tags/Dubbo/index.html
@@ -1 +1 @@
-标签: dubbo | Nicksxs's Blog 标签: dubbo | Nicksxs's Blog 标签: windows | Nicksxs's Blog 标签: windows | Nicksxs's Blog 标签: Docker | Nicksxs's Blog 标签: docker | Nicksxs's Blog 标签: Java | Nicksxs's Blog 标签: java | Nicksxs's Blog java 标签
2022



 ,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,
,图中一共有四个槽的存储空间,依次访问顺序是 A B C D E D F,





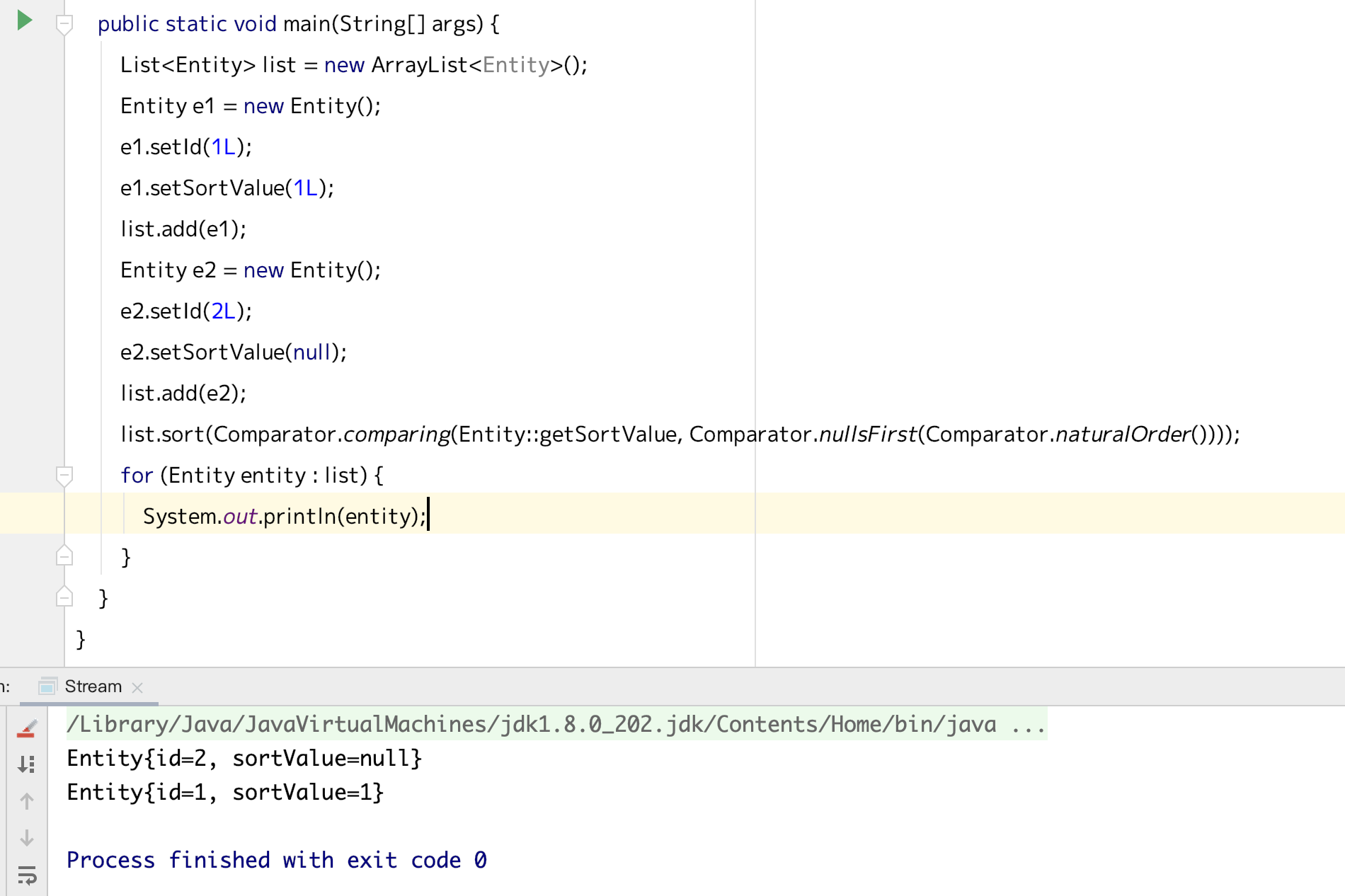



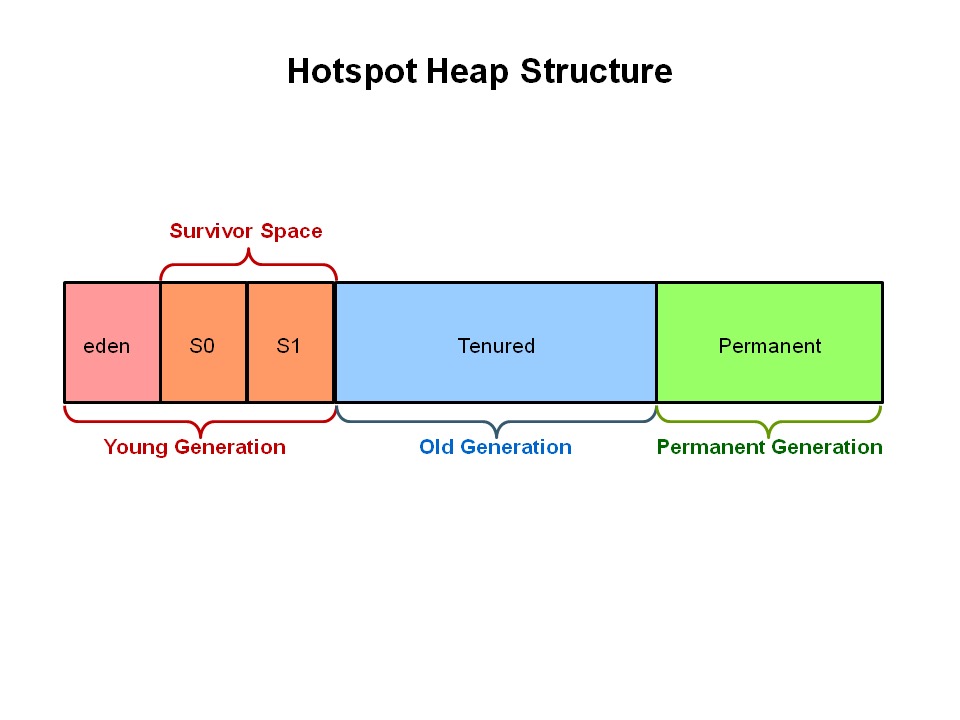



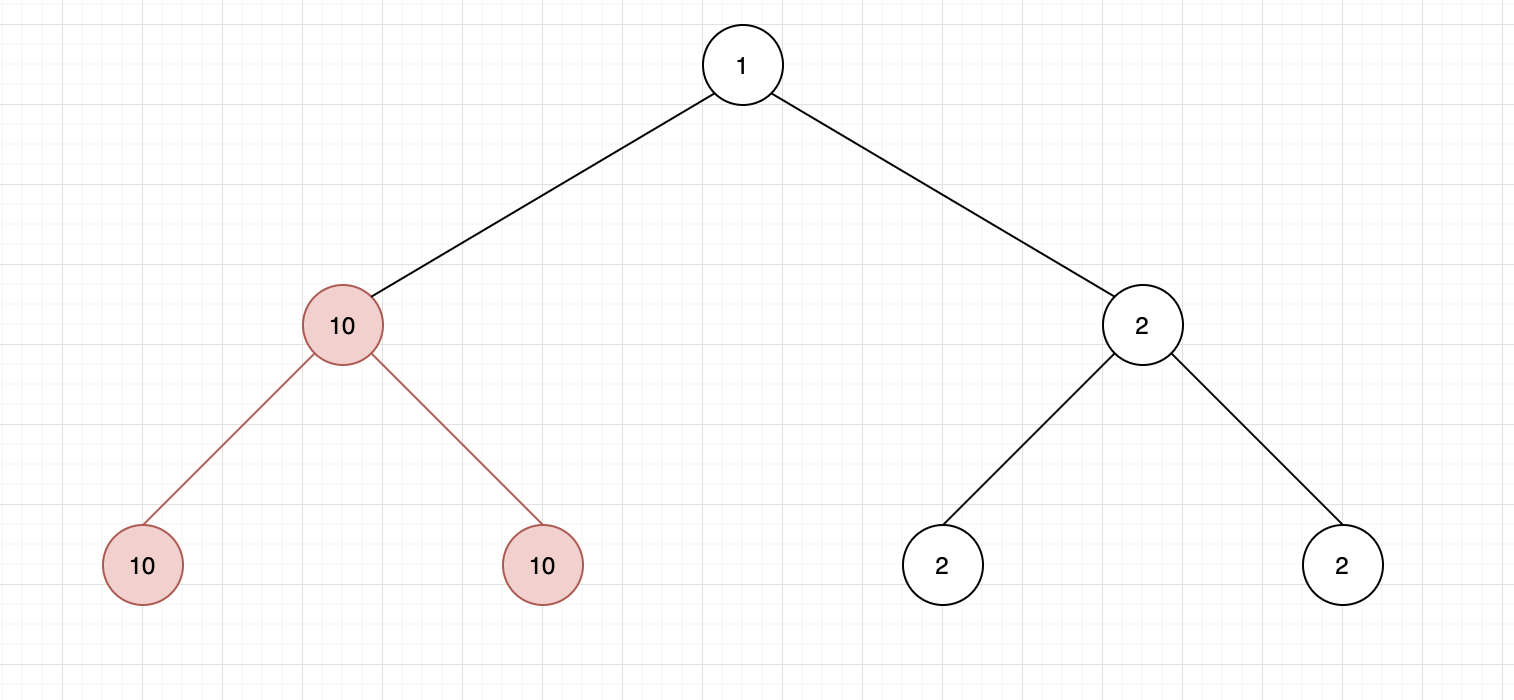












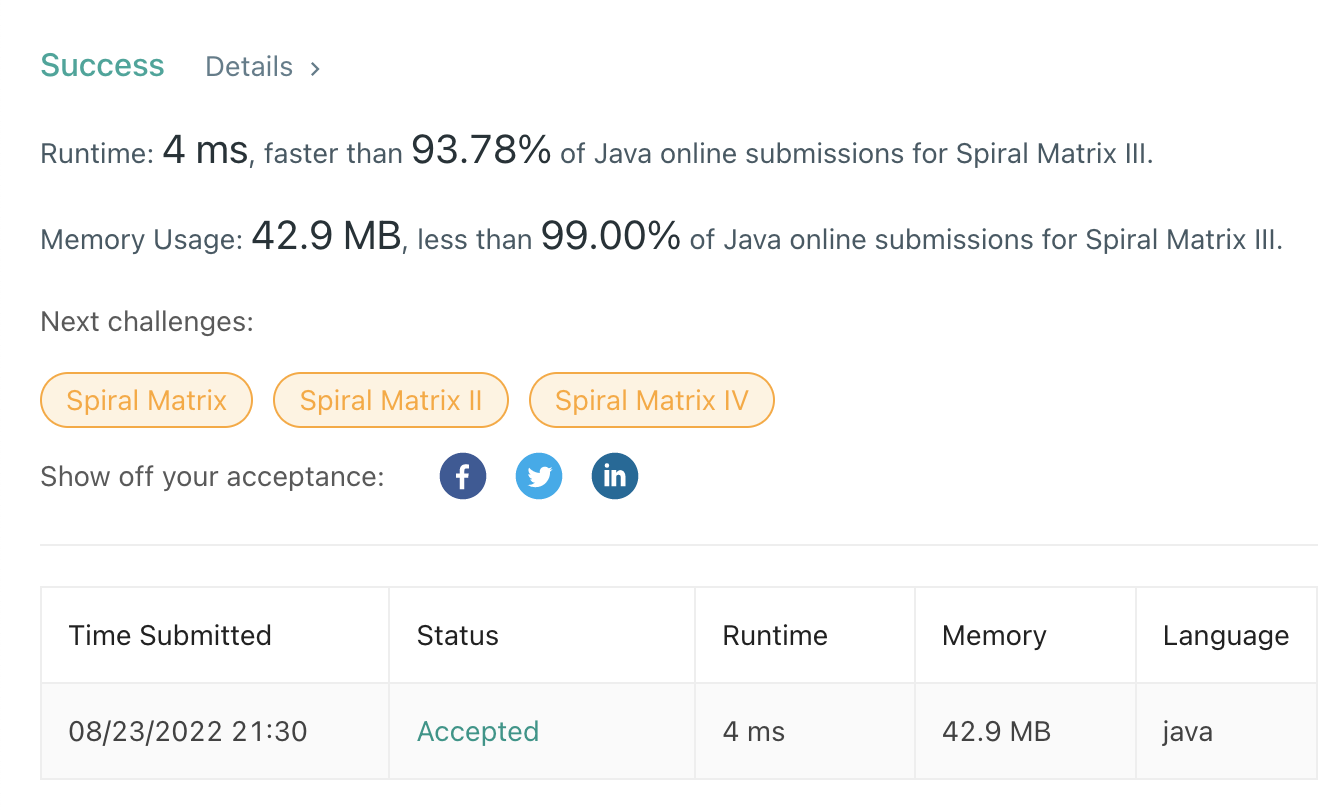


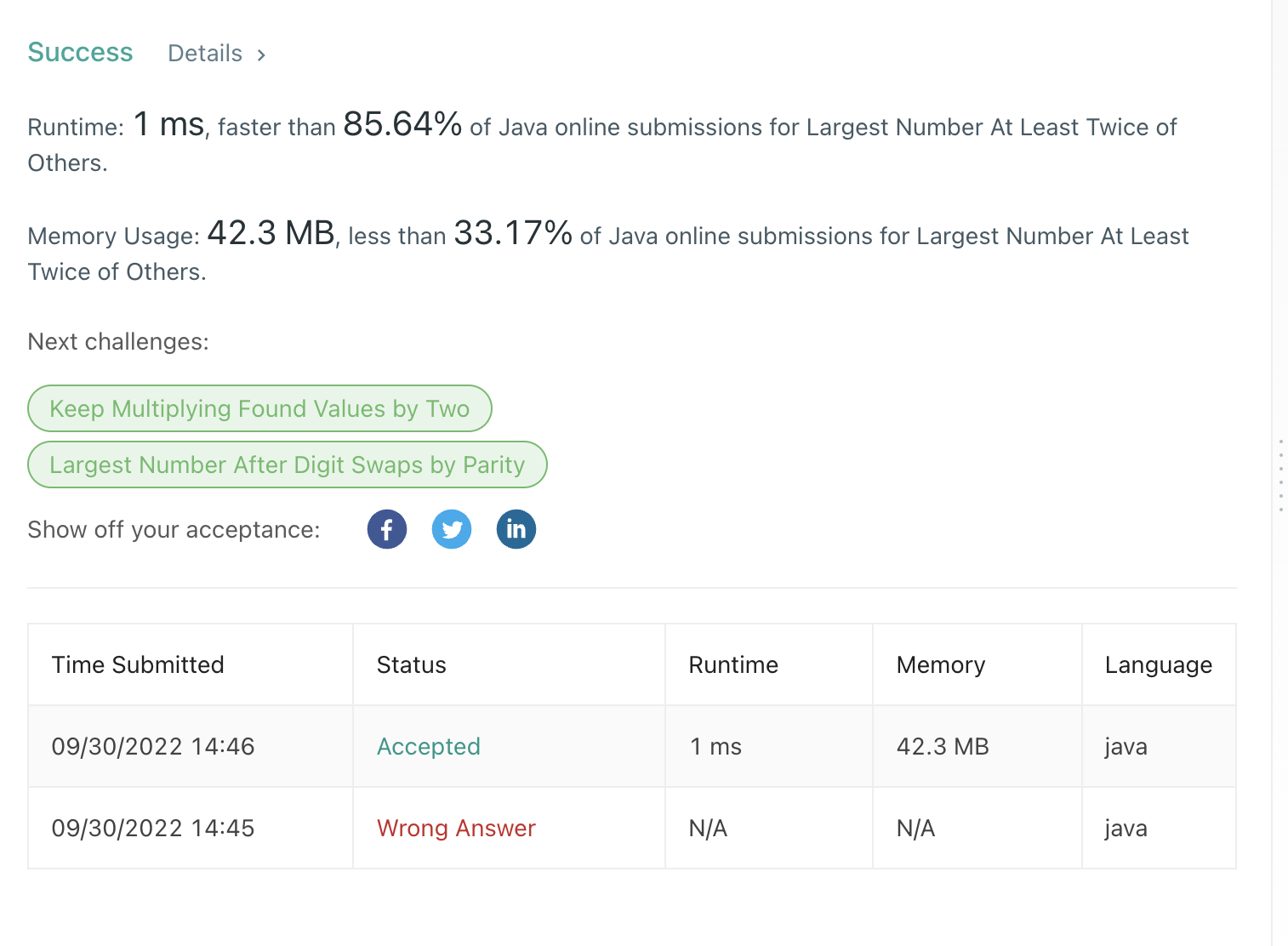
![9G5FE[9%@7%G(B`Q7]E)5@R.png](https://ooo.0o0.ooo/2016/08/10/57aac43029559.png)





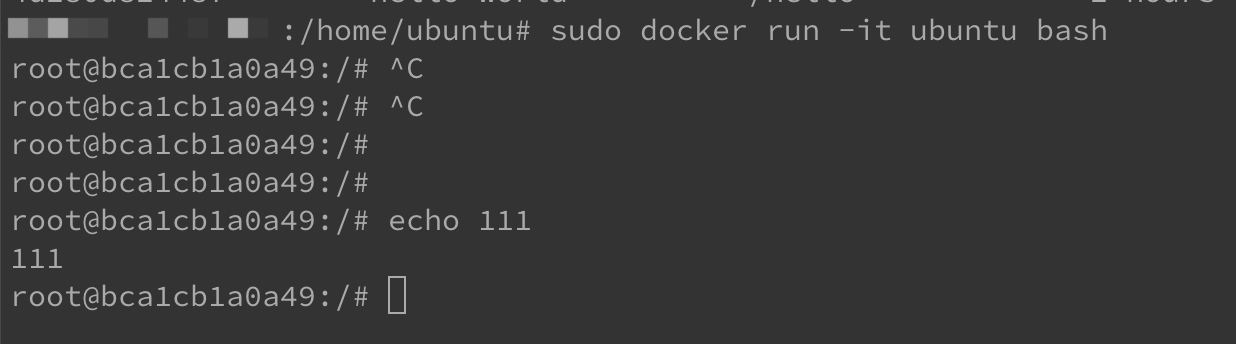
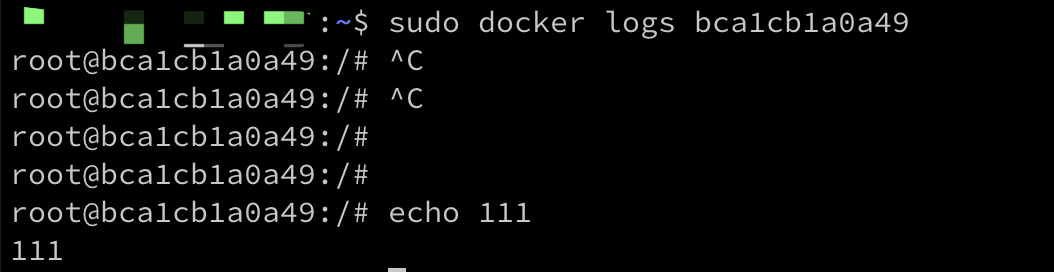


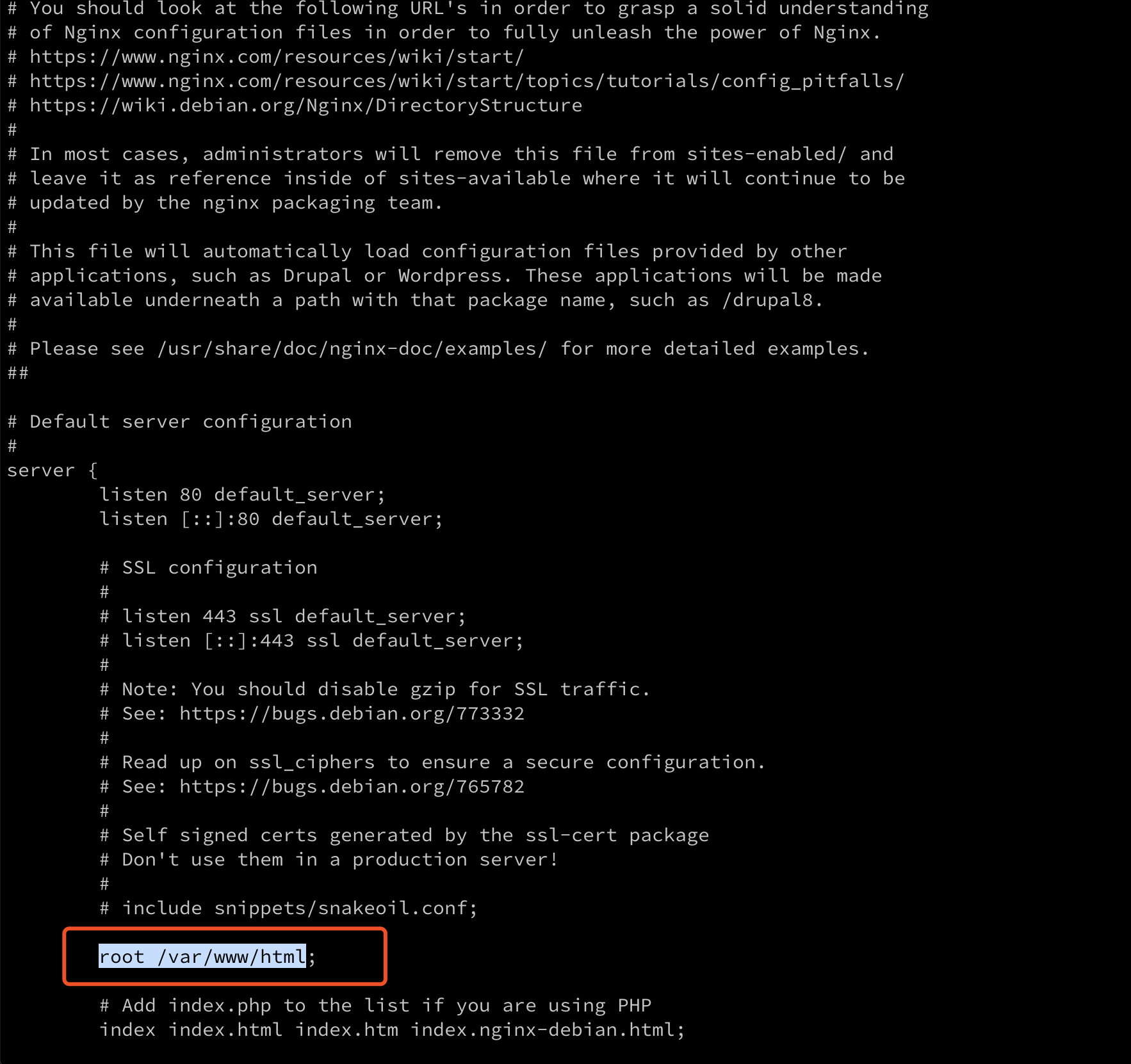

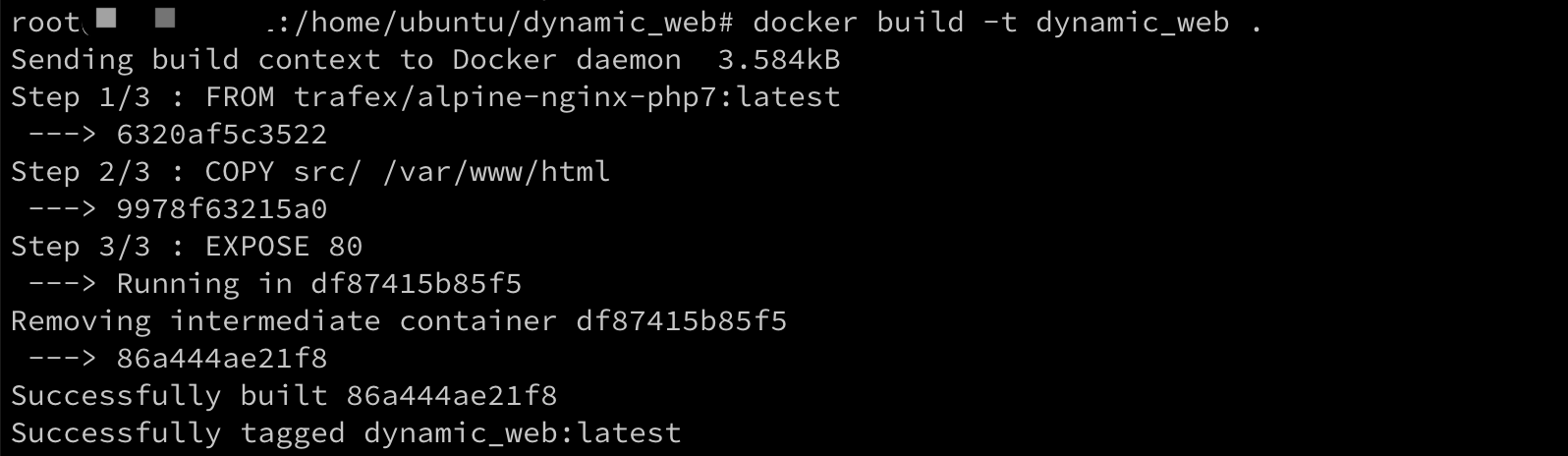
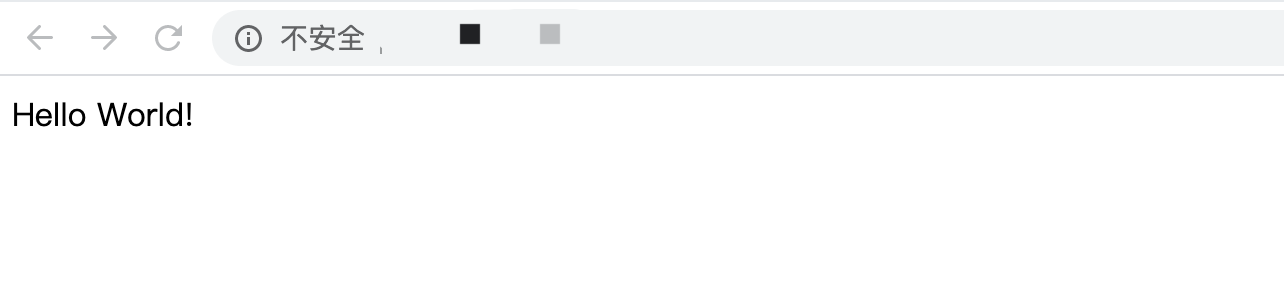


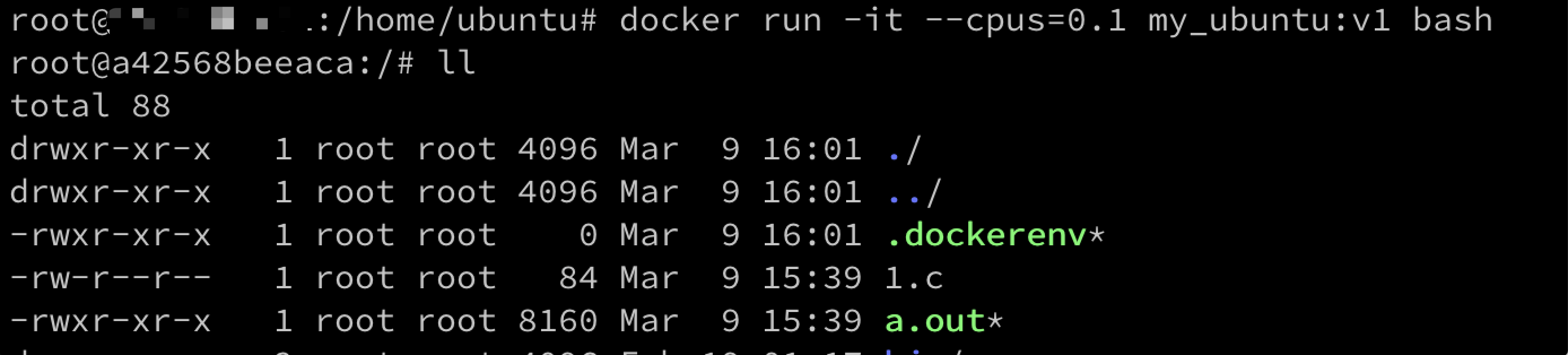

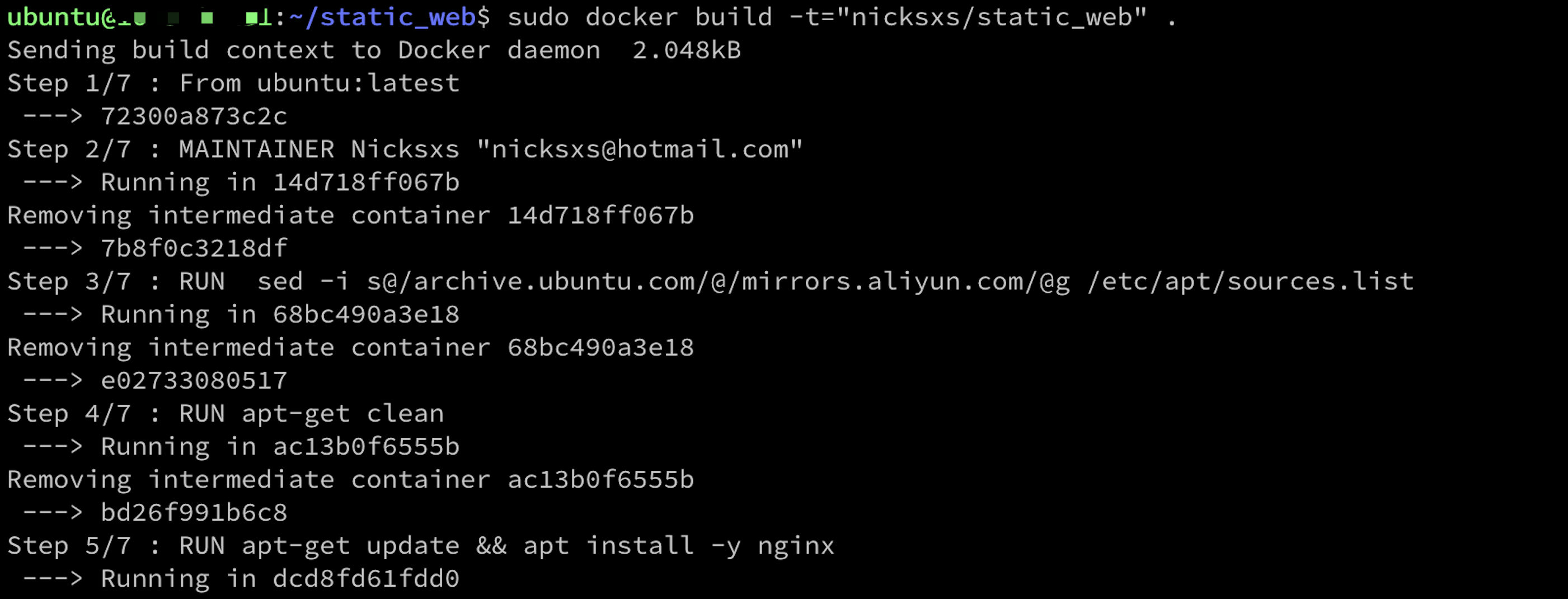
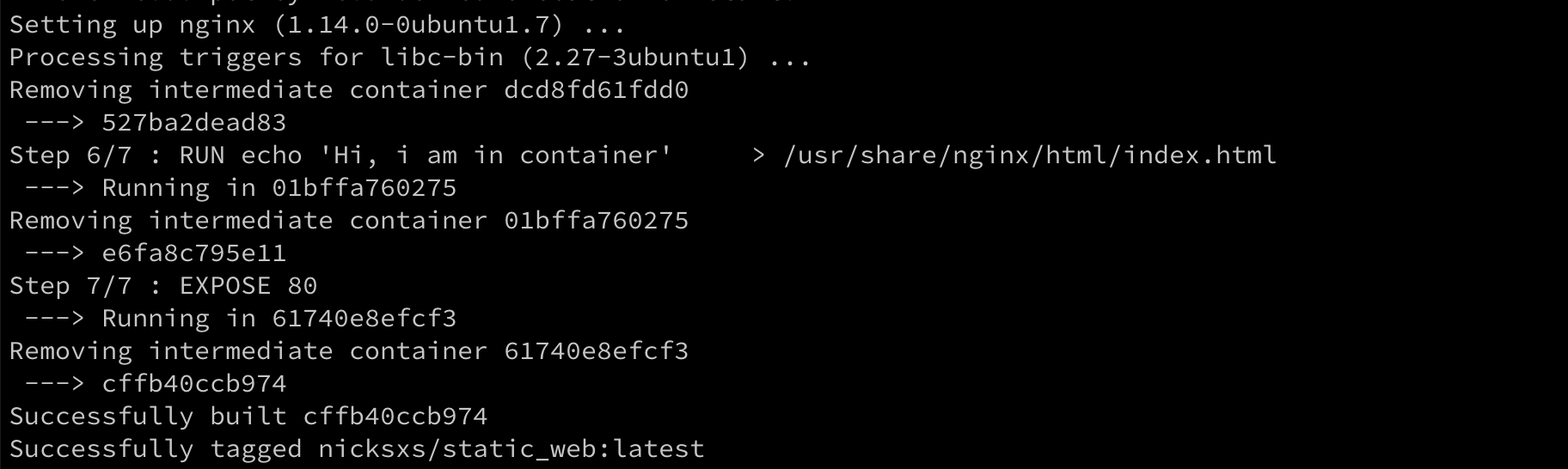

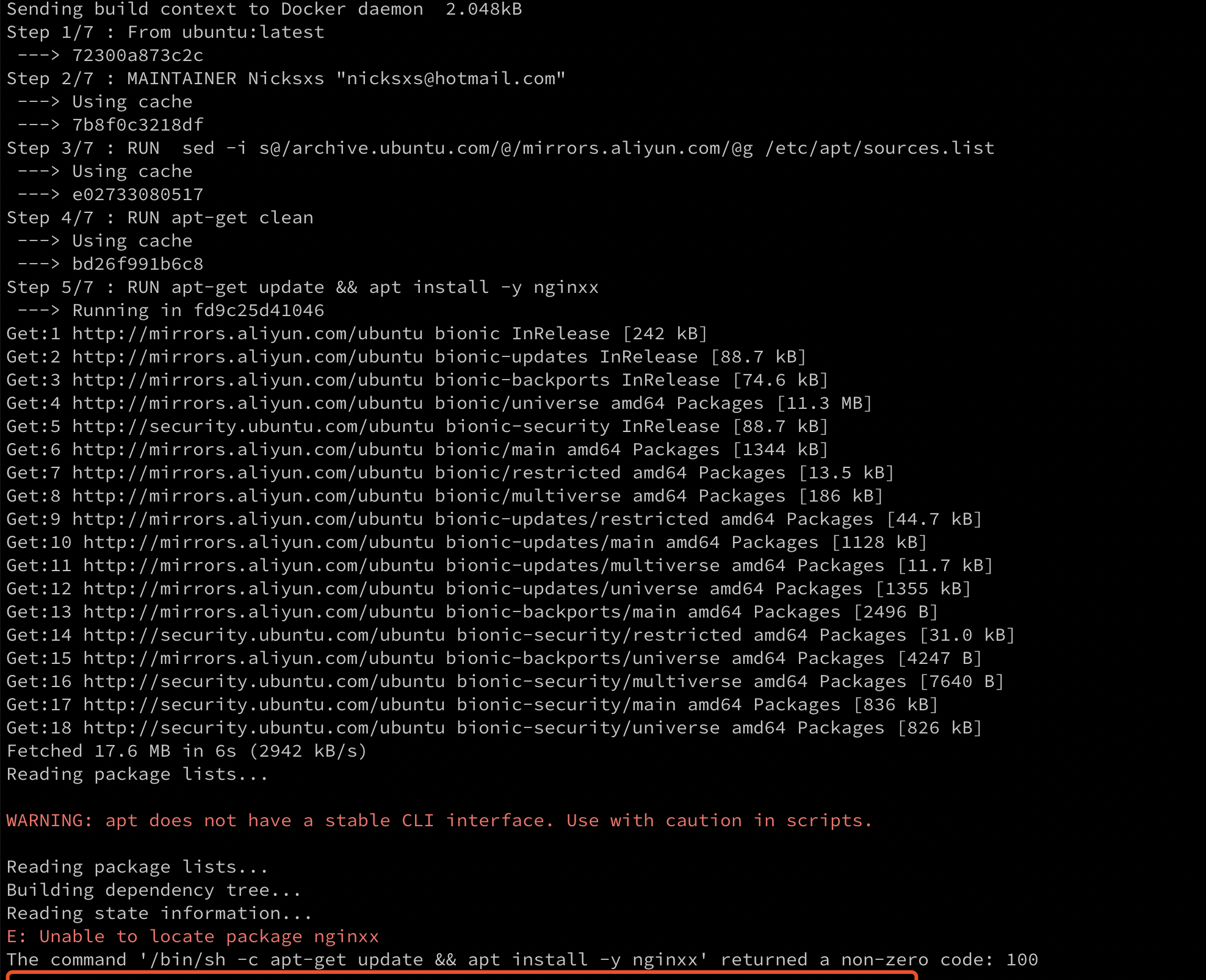








 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换 好像是这里了
好像是这里了
















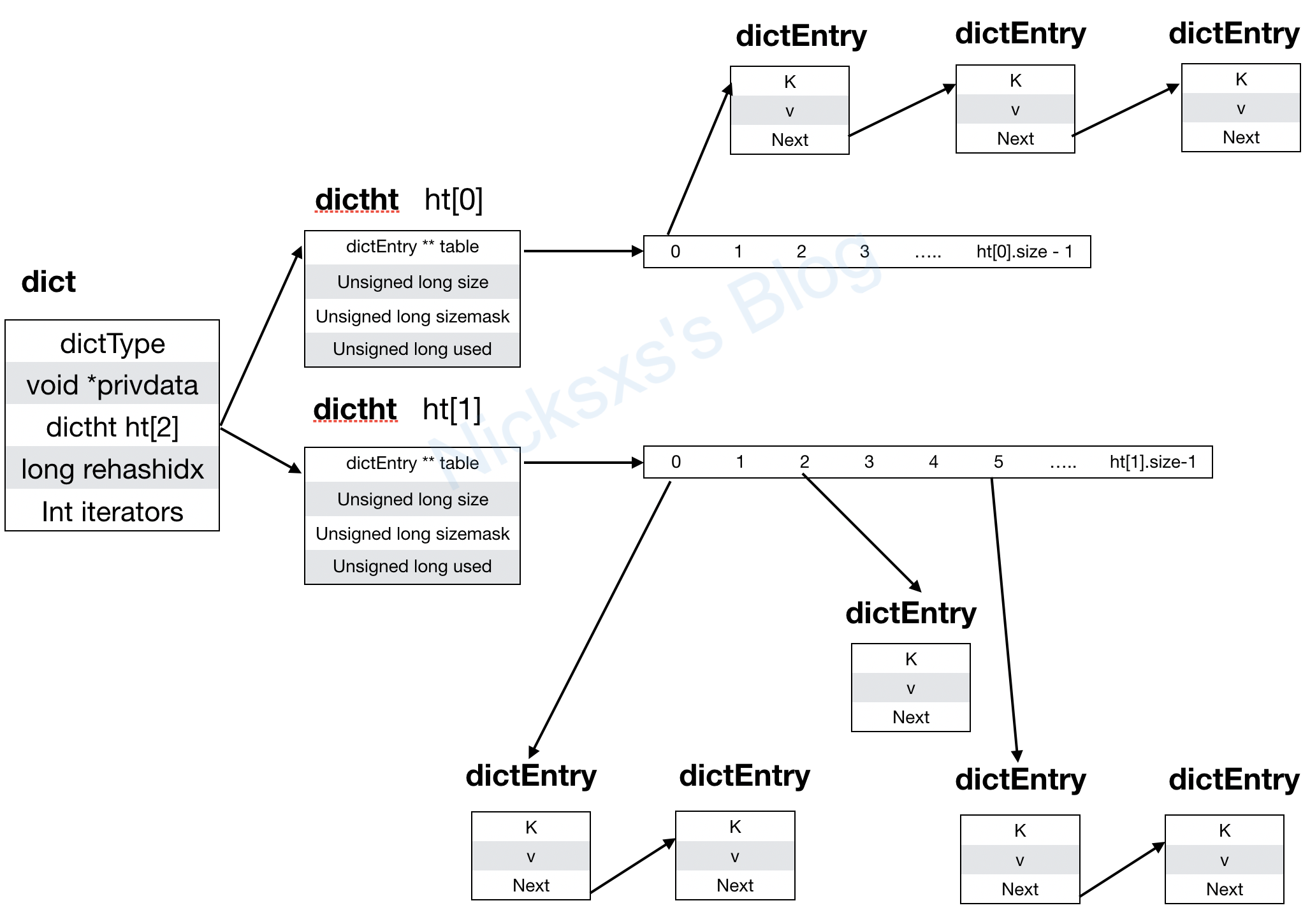

 -
-













 ,这样就不会被覆盖
+]]>
,这样就不会被覆盖
+]]> ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息


















 +
+