http{
lua_code_cache off;}
@@ -20,4 +20,4 @@ location ~*local t = json.decode(str)if t then
ngx.say(" --> ",type(t))
-end
cjson.safe包会在解析失败的时候返回nil
还有一个是redis链接时如果host使用的是域名的话会提示“failed to connect: no resolver defined to resolve “redis.xxxxxx.com””,这里需要使用nginx的resolver指令, resolver 8.8.8.8 valid=3600s;
还有一个是redis链接时如果host使用的是域名的话会提示“failed to connect: no resolver defined to resolve “redis.xxxxxx.com””,这里需要使用nginx的resolver指令, resolver 8.8.8.8 valid=3600s;
\ No newline at end of file
diff --git a/2020/08/02/聊聊-Java-自带的那些逆天工具/index.html b/2020/08/02/聊聊-Java-自带的那些逆天工具/index.html
index 52d3004661..848affae2b 100644
--- a/2020/08/02/聊聊-Java-自带的那些逆天工具/index.html
+++ b/2020/08/02/聊聊-Java-自带的那些逆天工具/index.html
@@ -1,4 +1,4 @@
-聊聊 Java 自带的那些*逆天*工具 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html b/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html
index f159680504..17ca442549 100644
--- a/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html
+++ b/2020/08/06/Linux-下-grep-命令的一点小技巧/index.html
@@ -1,5 +1,5 @@
-Linux 下 grep 命令的一点小技巧 | Nicksxs's Blog
// ---------------------------------------------------- FilterChain Methods/**
* Invoke the next filter in this chain, passing the specified request
@@ -428,4 +428,4 @@
publicStringhello(){return"hello world";}
-}
好了,请求一下,看看 stdout, 搞定完事儿~
\ No newline at end of file
+}
好了,请求一下,看看 stdout, 搞定完事儿~
\ No newline at end of file
diff --git a/2020/09/06/mybatis-的-和-是有啥区别/index.html b/2020/09/06/mybatis-的-和-是有啥区别/index.html
index 4970b6fc99..4df8b7eef8 100644
--- a/2020/09/06/mybatis-的-和-是有啥区别/index.html
+++ b/2020/09/06/mybatis-的-和-是有啥区别/index.html
@@ -1,4 +1,4 @@
-mybatis 的 $ 和 # 是有啥区别 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2020/11/22/聊聊-Dubbo-的容错机制/index.html b/2020/11/22/聊聊-Dubbo-的容错机制/index.html
index 977728e40c..d6893a63f2 100644
--- a/2020/11/22/聊聊-Dubbo-的容错机制/index.html
+++ b/2020/11/22/聊聊-Dubbo-的容错机制/index.html
@@ -1,4 +1,4 @@
-聊聊 Dubbo 的容错机制 | Nicksxs's Blog
前几天清华美院学姐的热点火了,然后仔细看了下,其实是个学姐诬陷以为其貌不扬的男同学摸她屁股 然后还在朋友圈发文想让他社死,我也是挺晚才知道这个词什么意思,然后后面我看到了这个图片,挺有意思的 本来其实也没什么想聊这个的,是在 B 站看了个吐槽这个的,然后刚好晚上乘公交的时候又碰到了有点类似的问题 故事描述下,我们从始发站做了公交,这辆公交司机上次碰到过一回,就是会比较关注乘客的佩戴情况,主要考虑到目前国内疫情,然后这次在差不多人都坐满的情况下,可能在提示了三次让车内乘客戴好口罩,但是他指的那个中年女性还是没有反应,司机就转头比较大声指着这个乘客(中年女性)让戴好口罩,然后这个乘客(中年女性)就大声的说“我口罩是滑下来了,你指着我干嘛,你态度这么差,要吃了我一样,我要投诉你”等等,然后可能跟她一块的一个中年女性也是这么帮腔指责司机,比较基本的理解,车子里这么多乘客,假如是处于这位乘客口罩滑下来了而不自知的情况下,司机在提示了三次以后回头指着她说,我想的是没什么问题的,但是这位却反而指责这位司机指着她,并且说是态度差,要吃了她,完全是不可理喻的,并且一直喋喋不休说她口罩滑掉了有什么错,要投诉这个司机,让他可以提前退休了,在其他乘客的劝说下司机准备继续开车时,又口吐芬芳“你个傻,你来打我呀”,真的是让我再次体会到了所谓的恶人先告状的又一完美呈现,后面还有个乘客还是表示要打死司机这个傻,让我有点不明所以,俗话说有人是得理不饶人,前提是得理,这种理亏不饶人真的是挺让人长见识的,试想下,司机在提示三次后,这位乘客还是没有把口罩戴好,如何在不指着这位乘客的情况下能准确的提示到她呢,并且觉得语气态度不好,司机要载着一车的人,因为你这一个乘客不戴好口罩而不能正常出发,有些着急应该很正常吧,可能是平时自己在家里耀武扬威的使唤别人习惯了吧,别人不敢这么大声跟她说话,其实想想这位中年女性应该年纪不会很大,还比较时髦的吧,像一些常见的中年杭州本地人可能是不会说傻*这个词的吧。 杭州的公交可能是在二月份疫情还比较严重的时候是要求上车出示健康码,后面比较缓和以后只要求佩戴好口罩,但是在我们小绍兴,目前还是一律要求检验健康码和佩戴口罩,对于疫情中,并且目前阶段国内也时有报出小范围的疫情的情况下,司机尽职要求佩戴好口罩其实也是为了乘客着想,另一种情况如果司机不严格要求,万一车上有个感染者,这位中年女性被传染了,如果能找到这个司机的话,是不是想“打死”这个司机,竟然让感染者上了车,反正她自己是不可能有错的,上来就是对方态度差,要投诉,自己不戴好口罩啥都没错,我就想知道如果因为自己没戴好口罩被感染了,是不是也是司机的错,毕竟没有像仆人那样点头哈腰求着她戴好口罩。 再说回来,整个车就她一个人没戴好口罩,并且还有个细节,其实这个乘客是上了车之后就没戴好了,本来上车的时候是戴好的,这种比较有可能是觉得上车的时候司机那看一眼就好了,如果好好戴着口罩,一点事情都没有,唉,纯粹是太气愤了,调理逻辑什么的就忽略吧
\ No newline at end of file
diff --git a/2020/12/27/聊聊-mysql-索引的一些细节/index.html b/2020/12/27/聊聊-mysql-索引的一些细节/index.html
index d72565b63c..f2c56a1e68 100644
--- a/2020/12/27/聊聊-mysql-索引的一些细节/index.html
+++ b/2020/12/27/聊聊-mysql-索引的一些细节/index.html
@@ -1,4 +1,4 @@
-聊聊 mysql 索引的一些细节 | Nicksxs's Blog
EXPLAINselect*from null_index_t WHERE null_key isnull;
EXPLAINselect*from null_index_t WHERE null_key isnotnull;
是不是不一样了,这里再补充下我试验使用的 mysql 是 5.7 的,不保证在其他版本的一致性, 其实可以看出随着数据量的变化,mysql 会不会使用索引是会变化的,不是说 is not null 一定会使用,也不是一定不会使用,而是优化器会根据查询成本做个预判,这个预判尽可能会减小查询成本,主要包括回表啥的,但是也不一定完全准确。
\ No newline at end of file
+call nullIndex1();
然后看下我们的 is null 查询
EXPLAINselect*from null_index_t WHERE null_key isnull;
再来看看另一个
EXPLAINselect*from null_index_t WHERE null_key isnotnull;
EXPLAINselect*from null_index_t WHERE null_key isnull;
EXPLAINselect*from null_index_t WHERE null_key isnotnull;
是不是不一样了,这里再补充下我试验使用的 mysql 是 5.7 的,不保证在其他版本的一致性, 其实可以看出随着数据量的变化,mysql 会不会使用索引是会变化的,不是说 is not null 一定会使用,也不是一定不会使用,而是优化器会根据查询成本做个预判,这个预判尽可能会减小查询成本,主要包括回表啥的,但是也不一定完全准确。
\ No newline at end of file
diff --git a/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html b/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html
index 0d7616d348..57f42db3ee 100644
--- a/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html
+++ b/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析 | Nicksxs's Blog
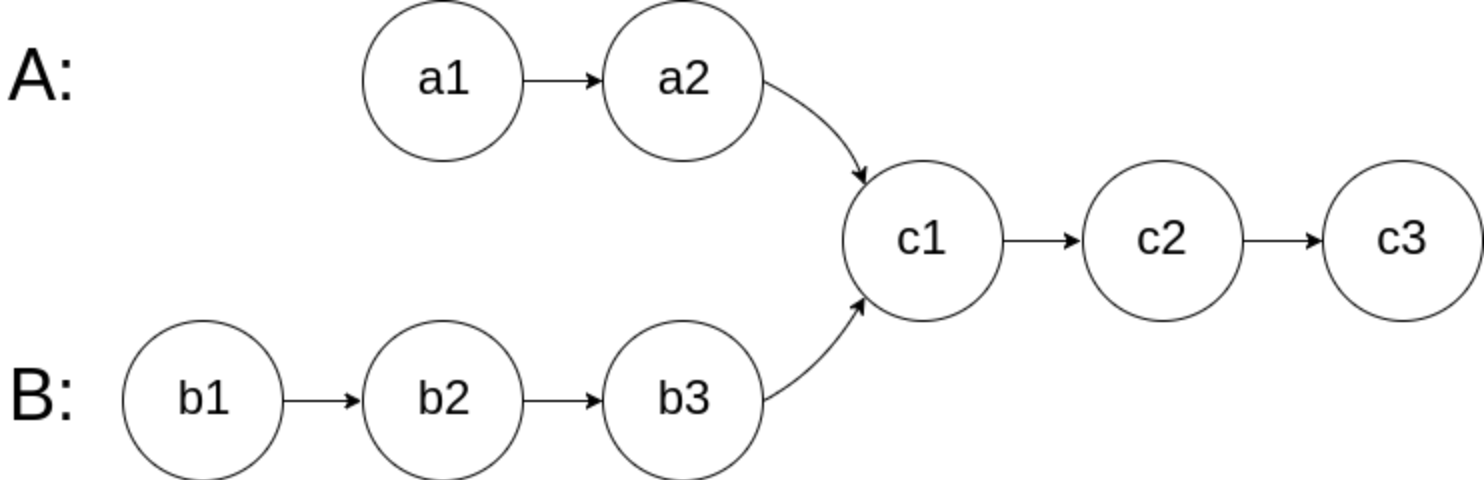
写一个程序找出两个单向链表的交叉起始点,可能是我英语不好,图里画的其实还有一点是交叉以后所有节点都是相同的 Write a program to find the node at which the intersection of two singly linked lists begins.
For example, the following two linked lists: begin to intersect at node c1.
Example 1:
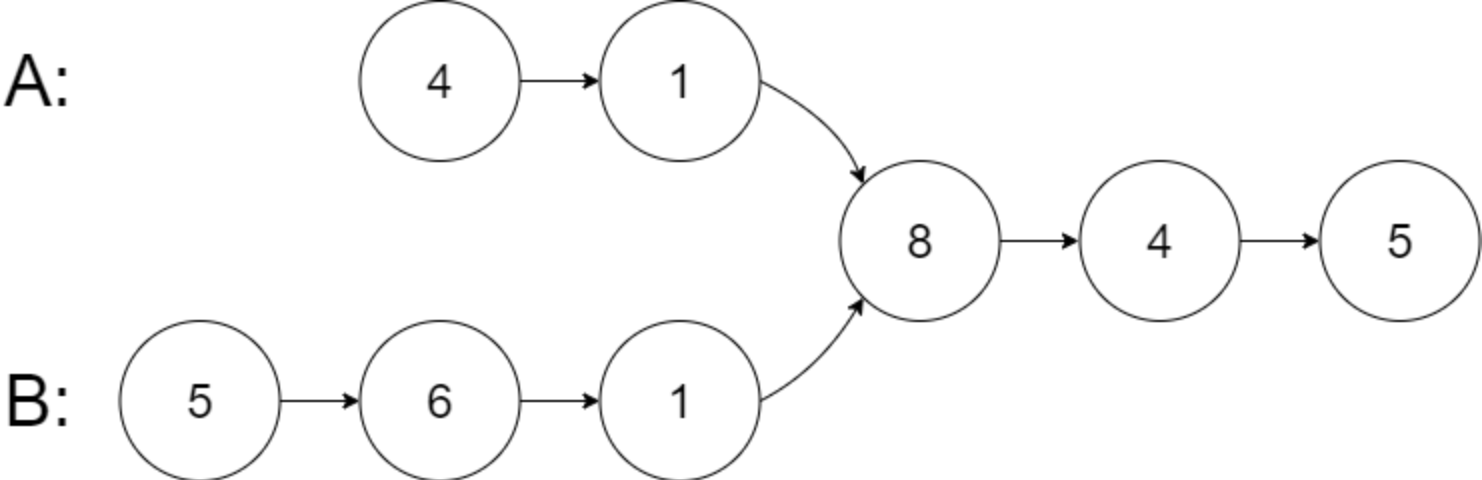
Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
Output: Reference of the node with value = 8
Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
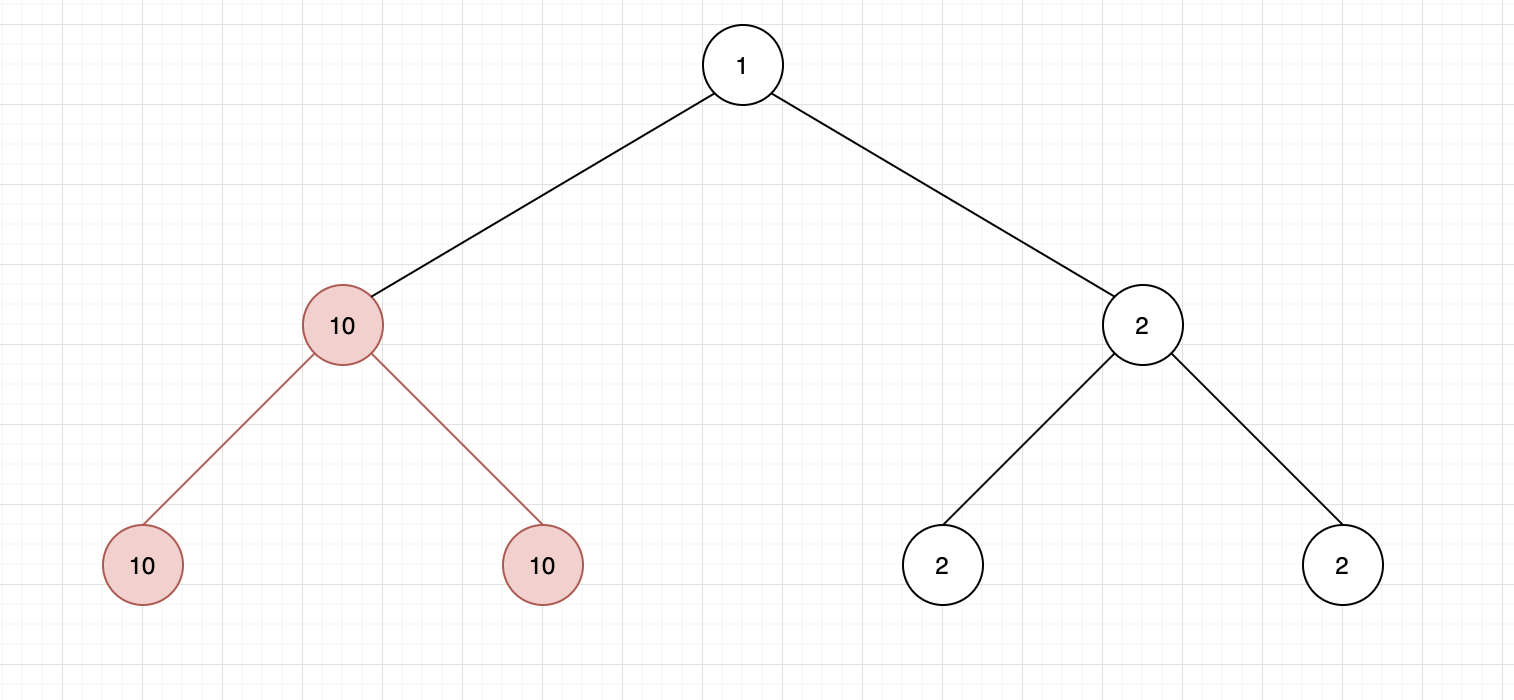
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
int ansNew =Integer.MIN_VALUE;publicintmaxPathSum(TreeNode root){maxSumNew(root);return ansNew;
@@ -21,4 +21,4 @@
int res =Math.max(left + right + root.val, currentSum);
ans =Math.max(res, ans);return currentSum;
-}
\ No newline at end of file
diff --git a/2021/02/21/AQS-之-Condition-浅析笔记/index.html b/2021/02/21/AQS-之-Condition-浅析笔记/index.html
index 8de9c48285..bd2330af4f 100644
--- a/2021/02/21/AQS-之-Condition-浅析笔记/index.html
+++ b/2021/02/21/AQS-之-Condition-浅析笔记/index.html
@@ -1,4 +1,4 @@
-AQS篇二 之 Condition 浅析笔记 | Nicksxs's Blog
这个真的长见识了, 可以看到,原来是 A,B,C 对象引用了 N,这里会在第一次遍历的时候把这种引用反过来,让 N 的对象头部保存下 A 的地址,表示这类引用,然后在遍历到 B 的时候在链起来,到最后就会把所有引用了 N 对象的所有对象通过引线链起来,在第二次遍历的时候就把更新A,B,C 对象引用的 N 地址,并且移动 N 对象
这个真的长见识了, 可以看到,原来是 A,B,C 对象引用了 N,这里会在第一次遍历的时候把这种引用反过来,让 N 的对象头部保存下 A 的地址,表示这类引用,然后在遍历到 B 的时候在链起来,到最后就会把所有引用了 N 对象的所有对象通过引线链起来,在第二次遍历的时候就把更新A,B,C 对象引用的 N 地址,并且移动 N 对象
\ No newline at end of file
diff --git a/2021/03/28/聊聊-Linux-下的-top-命令/index.html b/2021/03/28/聊聊-Linux-下的-top-命令/index.html
index 86b8be8ba9..2354b30c82 100644
--- a/2021/03/28/聊聊-Linux-下的-top-命令/index.html
+++ b/2021/03/28/聊聊-Linux-下的-top-命令/index.html
@@ -1,6 +1,6 @@
-聊聊 Linux 下的 top 命令 | Nicksxs's Blog
top 命令在日常的 Linux 使用中,特别是做一些服务器的简单状态查看,排查故障都起了比较大的作用,但是由于这个命令看到的东西比较多,一般只会看部分,或者说像我这样就会比较片面地看一些信息,比如默认是进程维度的,可以在启动命令的时候加-H进入线程模式
-H :Threads-mode operation
Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later
- this can be changed with the `H' interactive command.
SORTING of task window
For compatibility, this top supports most of the former top sort keys. Since this is primarily a service to former top users, these commands
do not appear on any help screen.
diff --git a/2021/03/31/2020-年终总结/index.html b/2021/03/31/2020-年终总结/index.html
index a62b29932f..27b67400ee 100644
--- a/2021/03/31/2020-年终总结/index.html
+++ b/2021/03/31/2020-年终总结/index.html
@@ -1 +1 @@
-2020 年终总结 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/04/04/聊聊-dubbo-的线程池/index.html b/2021/04/04/聊聊-dubbo-的线程池/index.html
index fab2fc0929..2126e3e6c1 100644
--- a/2021/04/04/聊聊-dubbo-的线程池/index.html
+++ b/2021/04/04/聊聊-dubbo-的线程池/index.html
@@ -1,4 +1,4 @@
-聊聊 dubbo 的线程池 | Nicksxs's Blog
fnmain(){let reference_to_nothing =dangle();}fndangle()->&String{let s =String::from("hello");&s
-}
这里可以看到其实在 dangle函数返回后,这里的 s 理论上就离开了作用域,但是由于返回了 s 的引用,在 main 函数中就会拿着这个引用,就会出现如下错误
总结
最后总结下
在任何一个段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用。
引用总是有效的。
\ No newline at end of file
+}
这里可以看到其实在 dangle函数返回后,这里的 s 理论上就离开了作用域,但是由于返回了 s 的引用,在 main 函数中就会拿着这个引用,就会出现如下错误
总结
最后总结下
在任何一个段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用。
引用总是有效的。
\ No newline at end of file
diff --git a/2021/04/18/rust学习笔记/index.html b/2021/04/18/rust学习笔记/index.html
index deb80b4e5e..58316aceea 100644
--- a/2021/04/18/rust学习笔记/index.html
+++ b/2021/04/18/rust学习笔记/index.html
@@ -1,8 +1,8 @@
-rust学习笔记-所有权一 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/05/01/Leetcode-48-旋转图像-Rotate-Image-题解分析/index.html b/2021/05/01/Leetcode-48-旋转图像-Rotate-Image-题解分析/index.html
index 1a03517284..92a6492003 100644
--- a/2021/05/01/Leetcode-48-旋转图像-Rotate-Image-题解分析/index.html
+++ b/2021/05/01/Leetcode-48-旋转图像-Rotate-Image-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 48 旋转图像(Rotate Image) 题解分析 | Nicksxs's Blog
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation. 如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
代码
直接上码
publicvoidrotate(int[][] matrix){
+Leetcode 48 旋转图像(Rotate Image) 题解分析 | Nicksxs's Blog
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation. 如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
/**
* Returns the class loader for the class. Some implementations may use
* null to represent the bootstrap class loader. This method will return
* null in such implementations if this class was loaded by the bootstrap
@@ -199,7 +199,7 @@
System.setSecurityManager(var3);}
- }
/**
* Loads the class with the specified <a href="#name">binary name</a>. The
* default implementation of this method searches for classes in the
* following order:
diff --git a/2021/06/27/聊聊-Java-中绕不开的-Synchronized-关键字-二/index.html b/2021/06/27/聊聊-Java-中绕不开的-Synchronized-关键字-二/index.html
index 3c520627de..2371b8c102 100644
--- a/2021/06/27/聊聊-Java-中绕不开的-Synchronized-关键字-二/index.html
+++ b/2021/06/27/聊聊-Java-中绕不开的-Synchronized-关键字-二/index.html
@@ -1,4 +1,4 @@
-聊聊 Java 中绕不开的 Synchronized 关键字-二 | Nicksxs's Blog
// Bit-format of an object header (most significant first, big endian layout below)://// 32 bits:// --------
@@ -28,13 +28,13 @@
L l =newL();System.out.println(ClassLayout.parseInstance(l).toPrintable());}
-}
publicclassObjectHeaderDemo{publicstaticvoidmain(String[] args)throwsInterruptedException{TimeUnit.SECONDS.sleep(5);L l =newL();System.out.println(ClassLayout.parseInstance(l).toPrintable());}
-}
可以看到偏向锁设置已经开启了,我们来是一下加个偏向锁
publicclassObjectHeaderDemo{
+}
可以看到偏向锁设置已经开启了,我们来是一下加个偏向锁
publicclassObjectHeaderDemo{publicstaticvoidmain(String[] args)throwsInterruptedException{TimeUnit.SECONDS.sleep(5);L l =newL();
@@ -46,7 +46,7 @@
System.out.println("2\n"+ClassLayout.parseInstance(l).toPrintable());}}
-}
publicPutMessageResultputMessage(finalMessageExtBrokerInner msg){// Set the storage time
msg.setStoreTimestamp(System.currentTimeMillis());// Set the message body BODY CRC (consider the most appropriate setting
diff --git a/2021/09/19/聊一下-SpringBoot-中使用的-cglib-作为动态代理中的一个注意点/index.html b/2021/09/19/聊一下-SpringBoot-中使用的-cglib-作为动态代理中的一个注意点/index.html
index 20116583d5..0ab304d46b 100644
--- a/2021/09/19/聊一下-SpringBoot-中使用的-cglib-作为动态代理中的一个注意点/index.html
+++ b/2021/09/19/聊一下-SpringBoot-中使用的-cglib-作为动态代理中的一个注意点/index.html
@@ -1,4 +1,4 @@
-聊一下 SpringBoot 中使用的 cglib 作为动态代理中的一个注意点 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/10/03/聊一下-RocketMQ-的消息存储三/index.html b/2021/10/03/聊一下-RocketMQ-的消息存储三/index.html
index 065f1253d0..076bfef4f1 100644
--- a/2021/10/03/聊一下-RocketMQ-的消息存储三/index.html
+++ b/2021/10/03/聊一下-RocketMQ-的消息存储三/index.html
@@ -1,7 +1,7 @@
-聊一下 RocketMQ 的消息存储三 | Nicksxs's Blog
\ No newline at end of file
+ this.byteBufferIndex.putLong(tagsCode);
这里也可以看到 ConsumeQueue 的存储格式,
偏移量,消息大小,跟 tag 的 hashCode
\ No newline at end of file
diff --git a/2021/10/07/Leetcode-021-合并两个有序链表-Merge-Two-Sorted-Lists-题解分析/index.html b/2021/10/07/Leetcode-021-合并两个有序链表-Merge-Two-Sorted-Lists-题解分析/index.html
index c111377cb8..eb394eb22f 100644
--- a/2021/10/07/Leetcode-021-合并两个有序链表-Merge-Two-Sorted-Lists-题解分析/index.html
+++ b/2021/10/07/Leetcode-021-合并两个有序链表-Merge-Two-Sorted-Lists-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 021 合并两个有序链表 ( Merge Two Sorted Lists ) 题解分析 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/10/17/聊一下-RocketMQ-的消息存储四/index.html b/2021/10/17/聊一下-RocketMQ-的消息存储四/index.html
index 74f291c46a..f3b67c2d81 100644
--- a/2021/10/17/聊一下-RocketMQ-的消息存储四/index.html
+++ b/2021/10/17/聊一下-RocketMQ-的消息存储四/index.html
@@ -1,4 +1,4 @@
-聊一下 RocketMQ 的消息存储四 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/11/14/介绍下最近比较实用的端口转发/index.html b/2021/11/14/介绍下最近比较实用的端口转发/index.html
index 1e6d32b494..e4638b2dfe 100644
--- a/2021/11/14/介绍下最近比较实用的端口转发/index.html
+++ b/2021/11/14/介绍下最近比较实用的端口转发/index.html
@@ -1,4 +1,4 @@
-介绍下最近比较实用的端口转发 | Nicksxs's Blog
UPDATE wp_users SET user_pass = MD5('123456')WHERE ID =1;
然后就能用自己的账户跟刚才更新的密码登录了。
\ No newline at end of file
diff --git a/2021/12/05/聊聊部分公交车的设计bug/index.html b/2021/12/05/聊聊部分公交车的设计bug/index.html
index 8e63a4d803..4aae3e2650 100644
--- a/2021/12/05/聊聊部分公交车的设计bug/index.html
+++ b/2021/12/05/聊聊部分公交车的设计bug/index.html
@@ -1 +1 @@
-聊聊部分公交车的设计bug | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/12/12/聊聊-Sharding-Jdbc-的简单使用/index.html b/2021/12/12/聊聊-Sharding-Jdbc-的简单使用/index.html
index 6d6d3496f4..da8f77bc11 100644
--- a/2021/12/12/聊聊-Sharding-Jdbc-的简单使用/index.html
+++ b/2021/12/12/聊聊-Sharding-Jdbc-的简单使用/index.html
@@ -1,4 +1,4 @@
-聊聊 Sharding-Jdbc 的简单使用 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/12/26/聊聊-Sharding-Jdbc-的简单原理初篇/index.html b/2021/12/26/聊聊-Sharding-Jdbc-的简单原理初篇/index.html
index e0febc6c23..5b5c2c00c3 100644
--- a/2021/12/26/聊聊-Sharding-Jdbc-的简单原理初篇/index.html
+++ b/2021/12/26/聊聊-Sharding-Jdbc-的简单原理初篇/index.html
@@ -1,4 +1,4 @@
-聊聊 Sharding-Jdbc 的简单原理初篇 | Nicksxs's Blog
@OverridepublicfinalResultSetexecuteQuery(finalString sql)throwsSQLException{thrownewSQLFeatureNotSupportedException("executeQuery with SQL for PreparedStatement");
-}
\ No newline at end of file
diff --git a/2022/01/09/聊聊-Sharding-Jdbc-分库分表下的分页方案/index.html b/2022/01/09/聊聊-Sharding-Jdbc-分库分表下的分页方案/index.html
index a776cdd80f..6931c9fba7 100644
--- a/2022/01/09/聊聊-Sharding-Jdbc-分库分表下的分页方案/index.html
+++ b/2022/01/09/聊聊-Sharding-Jdbc-分库分表下的分页方案/index.html
@@ -1,4 +1,4 @@
-聊聊 Sharding-Jdbc 分库分表下的分页方案 | Nicksxs's Blog
select * from student_time_0 ORDER BY create_time ASC limit 333, 5;
select * from student_time_1 ORDER BY create_time ASC limit 333, 5;
-select * from student_time_2 ORDER BY create_time ASC limit 333, 5;
\ No newline at end of file
diff --git a/2022/02/06/分享记录一下一个-git-操作方法/index.html b/2022/02/06/分享记录一下一个-git-操作方法/index.html
index eb1260d3c6..11cf55c2bd 100644
--- a/2022/02/06/分享记录一下一个-git-操作方法/index.html
+++ b/2022/02/06/分享记录一下一个-git-操作方法/index.html
@@ -1,2 +1,2 @@
-分享记录一下一个 git 操作方法 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2022/02/13/Disruptor-系列一/index.html b/2022/02/13/Disruptor-系列一/index.html
index 8a04eaf1ac..3f57304937 100644
--- a/2022/02/13/Disruptor-系列一/index.html
+++ b/2022/02/13/Disruptor-系列一/index.html
@@ -1,4 +1,4 @@
-Disruptor 系列一 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2022/02/27/Disruptor-系列二/index.html b/2022/02/27/Disruptor-系列二/index.html
index c05d45268a..6b5cf9a4c9 100644
--- a/2022/02/27/Disruptor-系列二/index.html
+++ b/2022/02/27/Disruptor-系列二/index.html
@@ -1,4 +1,4 @@
-Disruptor 系列二 | Nicksxs's Blog
int n = height.length;if(n <=2){return0;}
@@ -115,13 +115,13 @@ maxR[n -L l =newL();System.out.println(ClassLayout.parseInstance(l).toPrintable());}
-}
publicclassObjectHeaderDemo{publicstaticvoidmain(String[] args)throwsInterruptedException{TimeUnit.SECONDS.sleep(5);L l =newL();System.out.println(ClassLayout.parseInstance(l).toPrintable());}
-}
\ No newline at end of file
diff --git a/page/12/index.html b/page/12/index.html
index 2a82318b48..d28d010292 100644
--- a/page/12/index.html
+++ b/page/12/index.html
@@ -167,7 +167,7 @@
System.out.println(object.getClass());System.out.println(object instanceofClassLoaderTest);}
-}
/**
* Returns the class loader for the class. Some implementations may use
* null to represent the bootstrap class loader. This method will return
* null in such implementations if this class was loaded by the bootstrap
@@ -344,7 +344,7 @@
System.setSecurityManager(var3);}
- }
/**
* Loads the class with the specified <a href="#name">binary name</a>. The
* default implementation of this method searches for classes in the
* following order:
@@ -447,7 +447,7 @@
staticclassMan{String name ="nick";
- }
这里构造了两个线程,一个先往里设值,一个后从里取,运行看下结果, 知道这个用法的话肯定知道是取不到值的,只是具体的原理原来搞错了,我们来看下设值 set 方法
publicvoidset(T value){
+ }
这里构造了两个线程,一个先往里设值,一个后从里取,运行看下结果, 知道这个用法的话肯定知道是取不到值的,只是具体的原理原来搞错了,我们来看下设值 set 方法
staticclassThreadLocalMap{/**
* The entries in this hash map extend WeakReference, using
diff --git a/page/13/index.html b/page/13/index.html
index 13a9ddea92..2717a3e111 100644
--- a/page/13/index.html
+++ b/page/13/index.html
@@ -29,7 +29,7 @@
println!("the first word is: {}", word);}
那再执行 main 函数的时候就会抛错,因为 word 还是个切片,需要保证 s 的有效性,并且其实我们可以将函数申明成
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation. 如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation. 如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
fnmain(){let reference_to_nothing =dangle();}fndangle()->&String{let s =String::from("hello");&s
-}
这里可以看到其实在 dangle函数返回后,这里的 s 理论上就离开了作用域,但是由于返回了 s 的引用,在 main 函数中就会拿着这个引用,就会出现如下错误
总结
最后总结下
在任何一个段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用。
引用总是有效的。
\ No newline at end of file
+}
这里可以看到其实在 dangle函数返回后,这里的 s 理论上就离开了作用域,但是由于返回了 s 的引用,在 main 函数中就会拿着这个引用,就会出现如下错误
总结
最后总结下
在任何一个段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用。
引用总是有效的。
\ No newline at end of file
diff --git a/page/14/index.html b/page/14/index.html
index 9fc9f20b2e..9ae1c82d68 100644
--- a/page/14/index.html
+++ b/page/14/index.html
@@ -1,4 +1,4 @@
-Nicksxs's Blog
top 命令在日常的 Linux 使用中,特别是做一些服务器的简单状态查看,排查故障都起了比较大的作用,但是由于这个命令看到的东西比较多,一般只会看部分,或者说像我这样就会比较片面地看一些信息,比如默认是进程维度的,可以在启动命令的时候加-H进入线程模式
-H :Threads-mode operation
Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later
- this can be changed with the `H' interactive command.
SORTING of task window
For compatibility, this top supports most of the former top sort keys. Since this is primarily a service to former top users, these commands
do not appear on any help screen.
diff --git a/page/15/index.html b/page/15/index.html
index 4f0492473f..3af7aec0f9 100644
--- a/page/15/index.html
+++ b/page/15/index.html
@@ -19,7 +19,7 @@
}}return maxSofar;
-}
这个真的长见识了, 可以看到,原来是 A,B,C 对象引用了 N,这里会在第一次遍历的时候把这种引用反过来,让 N 的对象头部保存下 A 的地址,表示这类引用,然后在遍历到 B 的时候在链起来,到最后就会把所有引用了 N 对象的所有对象通过引线链起来,在第二次遍历的时候就把更新A,B,C 对象引用的 N 地址,并且移动 N 对象
这个真的长见识了, 可以看到,原来是 A,B,C 对象引用了 N,这里会在第一次遍历的时候把这种引用反过来,让 N 的对象头部保存下 A 的地址,表示这类引用,然后在遍历到 B 的时候在链起来,到最后就会把所有引用了 N 对象的所有对象通过引线链起来,在第二次遍历的时候就把更新A,B,C 对象引用的 N 地址,并且移动 N 对象
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.





























 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换 好像是这里了
好像是这里了




 再看这个图,我们发现在这的时候还没有进行替换
再看这个图,我们发现在这的时候还没有进行替换 好像是这里了
好像是这里了