\ No newline at end of file
diff --git a/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html b/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html
index fa88df689b..85114f7fc8 100644
--- a/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html
+++ b/2020/11/01/Apollo-的-value-注解是怎么自动更新的/index.html
@@ -1,4 +1,4 @@
-Apollo 的 value 注解是怎么自动更新的 | Nicksxs's Blog
在前司和目前公司,用的配置中心都是使用的 Apollo,经过了业界验证,比较强大的配置管理系统,特别是在0.10 后开始支持对使用 value 注解的配置值进行自动更新,今天刚好有个同学问到我,就顺便写篇文章记录下,其实也是借助于 spring 强大的 bean 生命周期管理,可以实现BeanPostProcessor接口,使用postProcessBeforeInitialization方法,来对bean 内部的属性和方法进行判断,是否有 value 注解,如果有就是将它注册到一个 map 中,可以看到这个方法com.ctrip.framework.apollo.spring.annotation.SpringValueProcessor#processField
@Override
+Apollo 的 value 注解是怎么自动更新的 | Nicksxs's Blog
在前司和目前公司,用的配置中心都是使用的 Apollo,经过了业界验证,比较强大的配置管理系统,特别是在0.10 后开始支持对使用 value 注解的配置值进行自动更新,今天刚好有个同学问到我,就顺便写篇文章记录下,其实也是借助于 spring 强大的 bean 生命周期管理,可以实现BeanPostProcessor接口,使用postProcessBeforeInitialization方法,来对bean 内部的属性和方法进行判断,是否有 value 注解,如果有就是将它注册到一个 map 中,可以看到这个方法com.ctrip.framework.apollo.spring.annotation.SpringValueProcessor#processField
@OverrideprotectedvoidprocessField(Object bean,String beanName,Field field){// register @Value on fieldValue value = field.getAnnotation(Value.class);
@@ -61,4 +61,4 @@
updateSpringValue(val);}}
- }
其实原理很简单,就是得了解知道下
0%
\ No newline at end of file
+ }
其实原理很简单,就是得了解知道下
0%
\ No newline at end of file
diff --git a/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html b/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html
index 1bca8f51f2..7b66dbfebc 100644
--- a/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html
+++ b/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 105 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal) 题解分析 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html b/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html
index 461c5ca8d7..5cb4b02887 100644
--- a/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html
+++ b/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/index.html
@@ -1,4 +1,4 @@
-Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析 | Nicksxs's Blog
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
int ansNew =Integer.MIN_VALUE;publicintmaxPathSum(TreeNode root){maxSumNew(root);return ansNew;
@@ -21,4 +21,4 @@
int res =Math.max(left + right + root.val, currentSum);
ans =Math.max(res, ans);return currentSum;
-}
\ No newline at end of file
diff --git a/2021/06/06/聊聊如何识别和意识到日常生活中的各类危险/index.html b/2021/06/06/聊聊如何识别和意识到日常生活中的各类危险/index.html
index b0e5bac6d5..7b9ad570db 100644
--- a/2021/06/06/聊聊如何识别和意识到日常生活中的各类危险/index.html
+++ b/2021/06/06/聊聊如何识别和意识到日常生活中的各类危险/index.html
@@ -1 +1 @@
-聊聊如何识别和意识到日常生活中的各类危险 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2021/11/07/聊聊最近平淡的生活/index.html b/2021/11/07/聊聊最近平淡的生活/index.html
index 4f58195e94..437cabbcc2 100644
--- a/2021/11/07/聊聊最近平淡的生活/index.html
+++ b/2021/11/07/聊聊最近平淡的生活/index.html
@@ -1 +1 @@
-聊聊最近平淡的生活之又聊通勤 | Nicksxs's Blog
\ No newline at end of file
diff --git a/2023/08/13/springboot-mappings-注册逻辑/index.html b/2023/08/13/springboot-mappings-注册逻辑/index.html
index e0bbad8522..4b7cc92fda 100644
--- a/2023/08/13/springboot-mappings-注册逻辑/index.html
+++ b/2023/08/13/springboot-mappings-注册逻辑/index.html
@@ -118,4 +118,4 @@
finally{this.readWriteLock.writeLock().unlock();}
- }
底层的存储就是上一篇说的 mappingLookup 来存储信息
0%
\ No newline at end of file
+ }
底层的存储就是上一篇说的 mappingLookup 来存储信息
0%
\ No newline at end of file
diff --git a/2023/08/20/springboot-web-server-启动逻辑/index.html b/2023/08/20/springboot-web-server-启动逻辑/index.html
index 3b11af7d98..f56c6495d9 100644
--- a/2023/08/20/springboot-web-server-启动逻辑/index.html
+++ b/2023/08/20/springboot-web-server-启动逻辑/index.html
@@ -1,4 +1,4 @@
-springboot web server 启动逻辑 - Java - SpringBoot | Nicksxs's Blog
springboot 的一个方便之处就是集成了 web server 进去,接着上一篇继续来看下这个 web server 的启动过程 基于 springboot 的 2.2.9.RELEASE 版本 整个 springboot 体系主体就是看 org.springframework.context.support.AbstractApplicationContext#refresh 刷新方法, 而启动 web server 的方法就是在其中的 OnRefresh
springboot 的一个方便之处就是集成了 web server 进去,接着上一篇继续来看下这个 web server 的启动过程 基于 springboot 的 2.2.9.RELEASE 版本 整个 springboot 体系主体就是看 org.springframework.context.support.AbstractApplicationContext#refresh 刷新方法, 而启动 web server 的方法就是在其中的 OnRefresh
try{// Allows post-processing of the bean factory in context subclasses.postProcessBeanFactory(beanFactory);
@@ -166,4 +166,4 @@
this.server.addService(service);returnthis.server;}
- }
然后就是启动 server,后面可以继续看这个启动 TomcatServer 内部的逻辑
0%
\ No newline at end of file
+ }
然后就是启动 server,后面可以继续看这个启动 TomcatServer 内部的逻辑
0%
\ No newline at end of file
diff --git a/archives/2023/08/index.html b/archives/2023/08/index.html
index 61294e3d35..0e550b3e13 100644
--- a/archives/2023/08/index.html
+++ b/archives/2023/08/index.html
@@ -1 +1 @@
-归档 | Nicksxs's Blog
\ No newline at end of file
diff --git a/archives/2023/index.html b/archives/2023/index.html
index 5d81159cc2..96620492af 100644
--- a/archives/2023/index.html
+++ b/archives/2023/index.html
@@ -1 +1 @@
-归档 | Nicksxs's Blog
\ No newline at end of file
diff --git a/archives/index.html b/archives/index.html
index 67127c6e17..df8e7bc84c 100644
--- a/archives/index.html
+++ b/archives/index.html
@@ -1 +1 @@
-归档 | Nicksxs's Blog
\ No newline at end of file
diff --git a/index.html b/index.html
index 8e198672de..c3145b4ca2 100644
--- a/index.html
+++ b/index.html
@@ -1,4 +1,4 @@
-Nicksxs's Blog - What hurts more, the pain of hard work or the pain of regret?
springboot 的一个方便之处就是集成了 web server 进去,接着上一篇继续来看下这个 web server 的启动过程 基于 springboot 的 2.2.9.RELEASE 版本 整个 springboot 体系主体就是看 org.springframework.context.support.AbstractApplicationContext#refresh 刷新方法, 而启动 web server 的方法就是在其中的 OnRefresh
try{
+Nicksxs's Blog - What hurts more, the pain of hard work or the pain of regret?
springboot 的一个方便之处就是集成了 web server 进去,接着上一篇继续来看下这个 web server 的启动过程 基于 springboot 的 2.2.9.RELEASE 版本 整个 springboot 体系主体就是看 org.springframework.context.support.AbstractApplicationContext#refresh 刷新方法, 而启动 web server 的方法就是在其中的 OnRefresh
try{// Allows post-processing of the bean factory in context subclasses.postProcessBeanFactory(beanFactory);
diff --git a/leancloud.memo b/leancloud.memo
index 4627c43b2d..223222395e 100644
--- a/leancloud.memo
+++ b/leancloud.memo
@@ -228,4 +228,5 @@
{"title":"java 中发起 http 请求时证书问题解决记录","url":"/2023/07/29/java-中发起-http-请求时证书问题解决记录/"},
{"title":"springboot 获取 web 应用中所有的接口 url","url":"/2023/08/06/springboot-获取-web-应用中所有的接口-url/"},
{"title":"springboot mappings 注册逻辑","url":"/2023/08/13/springboot-mappings-注册逻辑/"},
+{"title":"springboot web server 启动逻辑 - Java - SpringBoot","url":"/2023/08/20/springboot-web-server-启动逻辑/"},
]
\ No newline at end of file
diff --git a/leancloud_counter_security_urls.json b/leancloud_counter_security_urls.json
index b5af2840ae..f93e22693b 100644
--- a/leancloud_counter_security_urls.json
+++ b/leancloud_counter_security_urls.json
@@ -1 +1 @@
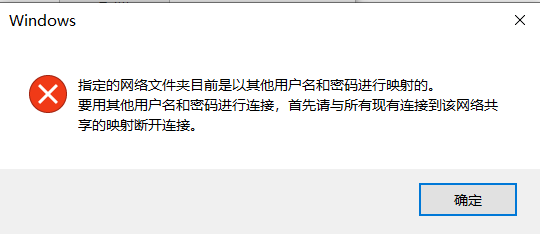
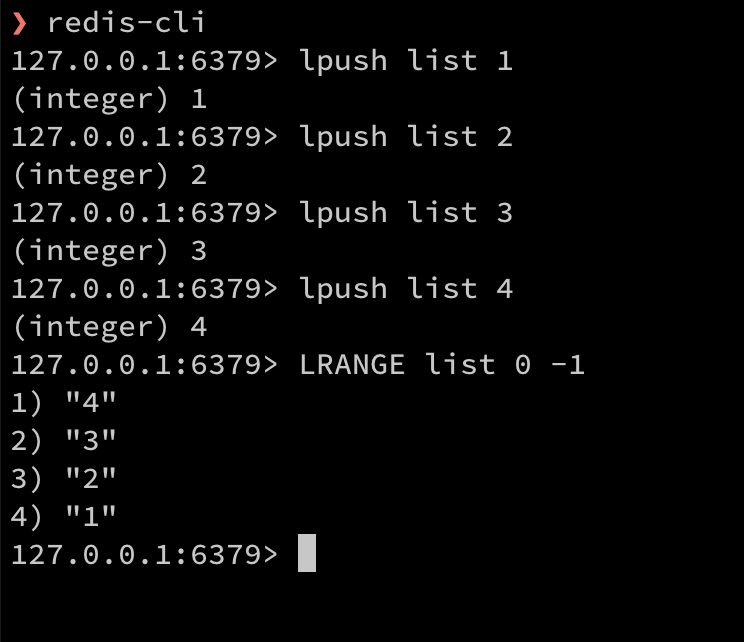
-[{"title":"村上春树《1Q84》读后感","url":"/2019/12/18/1Q84读后感/"},{"title":"2019年终总结","url":"/2020/02/01/2019年终总结/"},{"title":"2020年中总结","url":"/2020/07/11/2020年中总结/"},{"title":"2021 年中总结","url":"/2021/07/18/2021-年中总结/"},{"title":"2020 年终总结","url":"/2021/03/31/2020-年终总结/"},{"title":"2021 年终总结","url":"/2022/01/22/2021-年终总结/"},{"title":"34_Search_for_a_Range","url":"/2016/08/14/34-Search-for-a-Range/"},{"title":"AQS篇二 之 Condition 浅析笔记","url":"/2021/02/21/AQS-之-Condition-浅析笔记/"},{"title":"AQS篇一","url":"/2021/02/14/AQS篇一/"},{"title":"add-two-number","url":"/2015/04/14/Add-Two-Number/"},{"title":"AbstractQueuedSynchronizer","url":"/2019/09/23/AbstractQueuedSynchronizer/"},{"title":"Apollo 客户端启动过程分析","url":"/2022/09/18/Apollo-客户端启动过程分析/"},{"title":"Apollo 的 value 注解是怎么自动更新的","url":"/2020/11/01/Apollo-的-value-注解是怎么自动更新的/"},{"title":"Apollo 如何获取当前环境","url":"/2022/09/04/Apollo-如何获取当前环境/"},{"title":"Clone Graph Part I","url":"/2014/12/30/Clone-Graph-Part-I/"},{"title":"Comparator使用小记","url":"/2020/04/05/Comparator使用小记/"},{"title":"Disruptor 系列二","url":"/2022/02/27/Disruptor-系列二/"},{"title":"Filter, Interceptor, Aop, 啥, 啥, 啥? 这些都是啥?","url":"/2020/08/22/Filter-Intercepter-Aop-啥-啥-啥-这些都是啥/"},{"title":"Dubbo 使用的几个记忆点","url":"/2022/04/02/Dubbo-使用的几个记忆点/"},{"title":"Disruptor 系列一","url":"/2022/02/13/Disruptor-系列一/"},{"title":"G1收集器概述","url":"/2020/02/09/G1收集器概述/"},{"title":"JVM源码分析之G1垃圾收集器分析一","url":"/2019/12/07/JVM-G1-Part-1/"},{"title":"Leetcode 021 合并两个有序链表 ( Merge Two Sorted Lists ) 题解分析","url":"/2021/10/07/Leetcode-021-合并两个有序链表-Merge-Two-Sorted-Lists-题解分析/"},{"title":"Leetcode 028 实现 strStr() ( Implement strStr() ) 题解分析","url":"/2021/10/31/Leetcode-028-实现-strStr-Implement-strStr-题解分析/"},{"title":"2022 年终总结","url":"/2023/01/15/2022-年终总结/"},{"title":"Disruptor 系列三","url":"/2022/09/25/Disruptor-系列三/"},{"title":"Leetcode 053 最大子序和 ( Maximum Subarray ) 题解分析","url":"/2021/11/28/Leetcode-053-最大子序和-Maximum-Subarray-题解分析/"},{"title":"Leetcode 1115 交替打印 FooBar ( Print FooBar Alternately *Medium* ) 题解分析","url":"/2022/05/01/Leetcode-1115-交替打印-FooBar-Print-FooBar-Alternately-Medium-题解分析/"},{"title":"Leetcode 105 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal) 题解分析","url":"/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/"},{"title":"Leetcode 121 买卖股票的最佳时机(Best Time to Buy and Sell Stock) 题解分析","url":"/2021/03/14/Leetcode-121-买卖股票的最佳时机-Best-Time-to-Buy-and-Sell-Stock-题解分析/"},{"title":"Leetcode 104 二叉树的最大深度(Maximum Depth of Binary Tree) 题解分析","url":"/2020/10/25/Leetcode-104-二叉树的最大深度-Maximum-Depth-of-Binary-Tree-题解分析/"},{"title":"Leetcode 1260 二维网格迁移 ( Shift 2D Grid *Easy* ) 题解分析","url":"/2022/07/22/Leetcode-1260-二维网格迁移-Shift-2D-Grid-Easy-题解分析/"},{"title":"Leetcode 155 最小栈(Min Stack) 题解分析","url":"/2020/12/06/Leetcode-155-最小栈-Min-Stack-题解分析/"},{"title":"Leetcode 1862 向下取整数对和 ( Sum of Floored Pairs *Hard* ) 题解分析","url":"/2022/09/11/Leetcode-1862-向下取整数对和-Sum-of-Floored-Pairs-Hard-题解分析/"},{"title":"Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析","url":"/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/"},{"title":"Leetcode 16 最接近的三数之和 ( 3Sum Closest *Medium* ) 题解分析","url":"/2022/08/06/Leetcode-16-最接近的三数之和-3Sum-Closest-Medium-题解分析/"},{"title":"Leetcode 20 有效的括号 ( Valid Parentheses *Easy* ) 题解分析","url":"/2022/07/02/Leetcode-20-有效的括号-Valid-Parentheses-Easy-题解分析/"},{"title":"Leetcode 2 Add Two Numbers 题解分析","url":"/2020/10/11/Leetcode-2-Add-Two-Numbers-题解分析/"},{"title":"Leetcode 278 第一个错误的版本 ( First Bad Version *Easy* ) 题解分析","url":"/2022/08/14/Leetcode-278-第一个错误的版本-First-Bad-Version-Easy-题解分析/"},{"title":"Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析","url":"/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/"},{"title":"Leetcode 234 回文链表(Palindrome Linked List) 题解分析","url":"/2020/11/15/Leetcode-234-回文联表-Palindrome-Linked-List-题解分析/"},{"title":"Leetcode 3 Longest Substring Without Repeating Characters 题解分析","url":"/2020/09/20/Leetcode-3-Longest-Substring-Without-Repeating-Characters-题解分析/"},{"title":"Leetcode 349 两个数组的交集 ( Intersection of Two Arrays *Easy* ) 题解分析","url":"/2022/03/07/Leetcode-349-两个数组的交集-Intersection-of-Two-Arrays-Easy-题解分析/"},{"title":"Leetcode 236 二叉树的最近公共祖先(Lowest Common Ancestor of a Binary Tree) 题解分析","url":"/2021/05/23/Leetcode-236-二叉树的最近公共祖先-Lowest-Common-Ancestor-of-a-Binary-Tree-题解分析/"},{"title":"Leetcode 42 接雨水 (Trapping Rain Water) 题解分析","url":"/2021/07/04/Leetcode-42-接雨水-Trapping-Rain-Water-题解分析/"},{"title":"Leetcode 4 寻找两个正序数组的中位数 ( Median of Two Sorted Arrays *Hard* ) 题解分析","url":"/2022/03/27/Leetcode-4-寻找两个正序数组的中位数-Median-of-Two-Sorted-Arrays-Hard-题解分析/"},{"title":"Leetcode 698 划分为k个相等的子集 ( Partition to K Equal Sum Subsets *Medium* ) 题解分析","url":"/2022/06/19/Leetcode-698-划分为k个相等的子集-Partition-to-K-Equal-Sum-Subsets-Medium-题解分析/"},{"title":"Leetcode 48 旋转图像(Rotate Image) 题解分析","url":"/2021/05/01/Leetcode-48-旋转图像-Rotate-Image-题解分析/"},{"title":"Leetcode 83 删除排序链表中的重复元素 ( Remove Duplicates from Sorted List *Easy* ) 题解分析","url":"/2022/03/13/Leetcode-83-删除排序链表中的重复元素-Remove-Duplicates-from-Sorted-List-Easy-题解分析/"},{"title":"Headscale初体验以及踩坑记","url":"/2023/01/22/Headscale初体验以及踩坑记/"},{"title":"leetcode no.3","url":"/2015/04/15/Leetcode-No-3/"},{"title":"Linux 下 grep 命令的一点小技巧","url":"/2020/08/06/Linux-下-grep-命令的一点小技巧/"},{"title":"MFC 模态对话框","url":"/2014/12/24/MFC 模态对话框/"},{"title":"Maven实用小技巧","url":"/2020/02/16/Maven实用小技巧/"},{"title":"Path Sum","url":"/2015/01/04/Path-Sum/"},{"title":"Number of 1 Bits","url":"/2015/03/11/Number-Of-1-Bits/"},{"title":"Redis_分布式锁","url":"/2019/12/10/Redis-Part-1/"},{"title":"Reverse Bits","url":"/2015/03/11/Reverse-Bits/"},{"title":"Leetcode 885 螺旋矩阵 III ( Spiral Matrix III *Medium* ) 题解分析","url":"/2022/08/23/Leetcode-885-螺旋矩阵-III-Spiral-Matrix-III-Medium-题解分析/"},{"title":"Reverse Integer","url":"/2015/03/13/Reverse-Integer/"},{"title":"ambari-summary","url":"/2017/05/09/ambari-summary/"},{"title":"two sum","url":"/2015/01/14/Two-Sum/"},{"title":"binary-watch","url":"/2016/09/29/binary-watch/"},{"title":"docker-mysql-cluster","url":"/2016/08/14/docker-mysql-cluster/"},{"title":"docker比一般多一点的初学者介绍三","url":"/2020/03/21/docker比一般多一点的初学者介绍三/"},{"title":"docker比一般多一点的初学者介绍二","url":"/2020/03/15/docker比一般多一点的初学者介绍二/"},{"title":"docker比一般多一点的初学者介绍四","url":"/2022/12/25/docker比一般多一点的初学者介绍四/"},{"title":"docker比一般多一点的初学者介绍","url":"/2020/03/08/docker比一般多一点的初学者介绍/"},{"title":"docker使用中发现的echo命令的一个小技巧及其他","url":"/2020/03/29/echo命令的一个小技巧/"},{"title":"dubbo 客户端配置的一个重要知识点","url":"/2022/06/11/dubbo-客户端配置的一个重要知识点/"},{"title":"gogs使用webhook部署react单页应用","url":"/2020/02/22/gogs使用webhook部署react单页应用/"},{"title":"dnsmasq的一个使用注意点","url":"/2023/04/16/dnsmasq的一个使用注意点/"},{"title":"invert-binary-tree","url":"/2015/06/22/invert-binary-tree/"},{"title":"Leetcode 747 至少是其他数字两倍的最大数 ( Largest Number At Least Twice of Others *Easy* ) 题解分析","url":"/2022/10/02/Leetcode-747-至少是其他数字两倍的最大数-Largest-Number-At-Least-Twice-of-Others-Easy-题解分析/"},{"title":"C++ 指针使用中的一个小问题","url":"/2014/12/23/my-new-post/"},{"title":"minimum-size-subarray-sum-209","url":"/2016/10/11/minimum-size-subarray-sum-209/"},{"title":"mybatis 的 foreach 使用的注意点","url":"/2022/07/09/mybatis-的-foreach-使用的注意点/"},{"title":"mybatis 的 $ 和 # 是有啥区别","url":"/2020/09/06/mybatis-的-和-是有啥区别/"},{"title":"hexo 配置系列-接入Algolia搜索","url":"/2023/04/02/hexo-配置系列-接入Algolia搜索/"},{"title":"headscale 添加节点","url":"/2023/07/09/headscale-添加节点/"},{"title":"java 中发起 http 请求时证书问题解决记录","url":"/2023/07/29/java-中发起-http-请求时证书问题解决记录/"},{"title":"github 小技巧-更新 github host key","url":"/2023/03/28/github-小技巧-更新-github-host-key/"},{"title":"mybatis系列-connection连接池解析","url":"/2023/02/19/mybatis系列-connection连接池解析/"},{"title":"mybatis系列-sql 类的简单使用","url":"/2023/03/12/mybatis系列-sql-类的简单使用/"},{"title":"mybatis系列-foreach 解析","url":"/2023/06/11/mybatis系列-foreach-解析/"},{"title":"mybatis 的缓存是怎么回事","url":"/2020/10/03/mybatis-的缓存是怎么回事/"},{"title":"mybatis系列-dataSource解析","url":"/2023/01/08/mybatis系列-dataSource解析/"},{"title":"mybatis系列-mybatis是如何初始化mapper的","url":"/2022/12/04/mybatis是如何初始化mapper的/"},{"title":"nginx 日志小记","url":"/2022/04/17/nginx-日志小记/"},{"title":"openresty","url":"/2019/06/18/openresty/"},{"title":"mybatis系列-typeAliases系统","url":"/2023/01/01/mybatis系列-typeAliases系统/"},{"title":"pcre-intro-and-a-simple-package","url":"/2015/01/16/pcre-intro-and-a-simple-package/"},{"title":"php-abstract-class-and-interface","url":"/2016/11/10/php-abstract-class-and-interface/"},{"title":"mybatis系列-sql 类的简要分析","url":"/2023/03/19/mybatis系列-sql-类的简要分析/"},{"title":"mybatis系列-第一条sql的细节","url":"/2022/12/11/mybatis系列-第一条sql的细节/"},{"title":"mybatis系列-第一条sql的更多细节","url":"/2022/12/18/mybatis系列-第一条sql的更多细节/"},{"title":"rabbitmq-tips","url":"/2017/04/25/rabbitmq-tips/"},{"title":"redis 的 rdb 和 COW 介绍","url":"/2021/08/15/redis-的-rdb-和-COW-介绍/"},{"title":"redis数据结构介绍三-第三部分 整数集合","url":"/2020/01/10/redis数据结构介绍三/"},{"title":"redis数据结构介绍二-第二部分 跳表","url":"/2020/01/04/redis数据结构介绍二/"},{"title":"redis数据结构介绍-第一部分 SDS,链表,字典","url":"/2019/12/26/redis数据结构介绍/"},{"title":"redis数据结构介绍五-第五部分 对象","url":"/2020/01/20/redis数据结构介绍五/"},{"title":"mybatis系列-入门篇","url":"/2022/11/27/mybatis系列-入门篇/"},{"title":"redis淘汰策略复习","url":"/2021/08/01/redis淘汰策略复习/"},{"title":"redis数据结构介绍四-第四部分 压缩表","url":"/2020/01/19/redis数据结构介绍四/"},{"title":"redis系列介绍七-过期策略","url":"/2020/04/12/redis系列介绍七/"},{"title":"redis数据结构介绍六 快表","url":"/2020/01/22/redis数据结构介绍六/"},{"title":"redis过期策略复习","url":"/2021/07/25/redis过期策略复习/"},{"title":"redis系列介绍八-淘汰策略","url":"/2020/04/18/redis系列介绍八/"},{"title":"rust学习笔记-所有权二","url":"/2021/04/18/rust学习笔记-所有权二/"},{"title":"rust学习笔记-所有权三之切片","url":"/2021/05/16/rust学习笔记-所有权三之切片/"},{"title":"spark-little-tips","url":"/2017/03/28/spark-little-tips/"},{"title":"spring event 介绍","url":"/2022/01/30/spring-event-介绍/"},{"title":"springboot mappings 注册逻辑","url":"/2023/08/13/springboot-mappings-注册逻辑/"},{"title":"powershell 初体验","url":"/2022/11/13/powershell-初体验/"},{"title":"rust学习笔记-所有权一","url":"/2021/04/18/rust学习笔记/"},{"title":"springboot 获取 web 应用中所有的接口 url","url":"/2023/08/06/springboot-获取-web-应用中所有的接口-url/"},{"title":"summary-ranges-228","url":"/2016/10/12/summary-ranges-228/"},{"title":"springboot web server 启动逻辑 - Java - SpringBoot","url":"/2023/08/20/springboot-web-server-启动逻辑/"},{"title":"swoole-websocket-test","url":"/2016/07/13/swoole-websocket-test/"},{"title":"wordpress 忘记密码的一种解决方法","url":"/2021/12/05/wordpress-忘记密码的一种解决方法/"},{"title":"《垃圾回收算法手册读书》笔记之整理算法","url":"/2021/03/07/《垃圾回收算法手册读书》笔记之整理算法/"},{"title":"spring boot中的 http 接口返回 json 形式的小注意点","url":"/2023/06/25/spring-boot中的-http-接口返回-json-形式的小注意点/"},{"title":"powershell 初体验二","url":"/2022/11/20/powershell-初体验二/"},{"title":"《长安的荔枝》读后感","url":"/2022/07/17/《长安的荔枝》读后感/"},{"title":"上次的其他 外行聊国足","url":"/2022/03/06/上次的其他-外行聊国足/"},{"title":"win 下 vmware 虚拟机搭建黑裙 nas 的小思路","url":"/2023/06/04/win-下-vmware-虚拟机搭建黑裙-nas-的小思路/"},{"title":"ssh 小技巧-端口转发","url":"/2023/03/26/ssh-小技巧-端口转发/"},{"title":"一个 nginx 的简单记忆点","url":"/2022/08/21/一个-nginx-的简单记忆点/"},{"title":"介绍下最近比较实用的端口转发","url":"/2021/11/14/介绍下最近比较实用的端口转发/"},{"title":"介绍一下 RocketMQ","url":"/2020/06/21/介绍一下-RocketMQ/"},{"title":"从丁仲礼被美国制裁聊点啥","url":"/2020/12/20/从丁仲礼被美国制裁聊点啥/"},{"title":"从清华美院学姐聊聊我们身边的恶人","url":"/2020/11/29/从清华美院学姐聊聊我们身边的恶人/"},{"title":"关于读书打卡与分享","url":"/2021/02/07/关于读书打卡与分享/"},{"title":"关于公共交通再吐个槽","url":"/2021/03/21/关于公共交通再吐个槽/"},{"title":"《寻羊历险记》读后感","url":"/2023/07/23/《寻羊历险记》读后感/"},{"title":"分享一次折腾老旧笔记本的体验-续续篇","url":"/2023/02/26/分享一次折腾老旧笔记本的体验-续续篇/"},{"title":"分享一次折腾老旧笔记本的体验","url":"/2023/02/05/分享一次折腾老旧笔记本的体验/"},{"title":"分享记录一下一个 git 操作方法","url":"/2022/02/06/分享记录一下一个-git-操作方法/"},{"title":"nas 中使用 tmm 刮削视频","url":"/2023/07/02/使用-tmm-刮削视频/"},{"title":"分享记录一下一个 scp 操作方法","url":"/2022/02/06/分享记录一下一个-scp-操作方法/"},{"title":"关于 npe 的一个小记忆点","url":"/2023/07/16/关于-npe-的一个小记忆点/"},{"title":"分享一次折腾老旧笔记本的体验-续篇","url":"/2023/02/12/分享一次折腾老旧笔记本的体验-续篇/"},{"title":"在老丈人家的小工记三","url":"/2020/09/13/在老丈人家的小工记三/"},{"title":"在老丈人家的小工记五","url":"/2020/10/18/在老丈人家的小工记五/"},{"title":"在老丈人家的小工记四","url":"/2020/09/26/在老丈人家的小工记四/"},{"title":"在 wsl 2 中开启 ssh 连接","url":"/2023/04/23/在-wsl-2-中开启-ssh-连接/"},{"title":"寄生虫观后感","url":"/2020/03/01/寄生虫观后感/"},{"title":"我是如何走上跑步这条不归路的","url":"/2020/07/26/我是如何走上跑步这条不归路的/"},{"title":"周末我在老丈人家打了天小工","url":"/2020/08/16/周末我在老丈人家打了天小工/"},{"title":"屯菜惊魂记","url":"/2022/04/24/屯菜惊魂记/"},{"title":"搬运两个 StackOverflow 上的 Mysql 编码相关的问题解答","url":"/2022/01/16/搬运两个-StackOverflow-上的-Mysql-编码相关的问题解答/"},{"title":"是何原因竟让两人深夜奔袭十公里","url":"/2022/06/05/是何原因竟让两人深夜奔袭十公里/"},{"title":"分享一次比较诡异的 Windows 下 U盘无法退出的经历","url":"/2023/01/29/分享一次比较诡异的-Windows-下-U盘无法退出的经历/"},{"title":"看完了扫黑风暴,聊聊感想","url":"/2021/10/24/看完了扫黑风暴-聊聊感想/"},{"title":"小工周记一","url":"/2023/03/05/小工周记一/"},{"title":"给小电驴上牌","url":"/2022/03/20/给小电驴上牌/"},{"title":"聊一下 RocketMQ 的 DefaultMQPushConsumer 源码","url":"/2020/06/26/聊一下-RocketMQ-的-Consumer/"},{"title":"聊一下 RocketMQ 的 NameServer 源码","url":"/2020/07/05/聊一下-RocketMQ-的-NameServer-源码/"},{"title":"聊一下 RocketMQ 的消息存储之 MMAP","url":"/2021/09/04/聊一下-RocketMQ-的消息存储/"},{"title":"聊一下 RocketMQ 的消息存储三","url":"/2021/10/03/聊一下-RocketMQ-的消息存储三/"},{"title":"聊一下 RocketMQ 的消息存储二","url":"/2021/09/12/聊一下-RocketMQ-的消息存储二/"},{"title":"深度学习入门初认识","url":"/2023/04/30/深度学习入门初认识/"},{"title":"聊一下 RocketMQ 的顺序消息","url":"/2021/08/29/聊一下-RocketMQ-的顺序消息/"},{"title":"聊一下 RocketMQ 的消息存储四","url":"/2021/10/17/聊一下-RocketMQ-的消息存储四/"},{"title":"聊一下 SpringBoot 中动态切换数据源的方法","url":"/2021/09/26/聊一下-SpringBoot-中动态切换数据源的方法/"},{"title":"聊一下 SpringBoot 设置非 web 应用的方法","url":"/2022/07/31/聊一下-SpringBoot-设置非-web-应用的方法/"},{"title":"聊在东京奥运会闭幕式这天","url":"/2021/08/08/聊在东京奥运会闭幕式这天/"},{"title":"聊在东京奥运会闭幕式这天-二","url":"/2021/08/19/聊在东京奥运会闭幕式这天-二/"},{"title":"聊聊 Dubbo 的 SPI 续之自适应拓展","url":"/2020/06/06/聊聊-Dubbo-的-SPI-续之自适应拓展/"},{"title":"聊聊 Dubbo 的 SPI","url":"/2020/05/31/聊聊-Dubbo-的-SPI/"},{"title":"聊一下 SpringBoot 中使用的 cglib 作为动态代理中的一个注意点","url":"/2021/09/19/聊一下-SpringBoot-中使用的-cglib-作为动态代理中的一个注意点/"},{"title":"聊聊 Dubbo 的容错机制","url":"/2020/11/22/聊聊-Dubbo-的容错机制/"},{"title":"聊聊 Java 中绕不开的 Synchronized 关键字-二","url":"/2021/06/27/聊聊-Java-中绕不开的-Synchronized-关键字-二/"},{"title":"聊一下关于怎么陪伴学习","url":"/2022/11/06/聊一下关于怎么陪伴学习/"},{"title":"聊聊 Java 的类加载机制一","url":"/2020/11/08/聊聊-Java-的类加载机制/"},{"title":"聊聊 Java 中绕不开的 Synchronized 关键字","url":"/2021/06/20/聊聊-Java-中绕不开的-Synchronized-关键字/"},{"title":"聊聊 Java 的类加载机制二","url":"/2021/06/13/聊聊-Java-的类加载机制二/"},{"title":"聊聊 Java 自带的那些*逆天*工具","url":"/2020/08/02/聊聊-Java-自带的那些逆天工具/"},{"title":"聊聊 Java 的 equals 和 hashCode 方法","url":"/2021/01/03/聊聊-Java-的-equals-和-hashCode-方法/"},{"title":"聊聊 Linux 下的 top 命令","url":"/2021/03/28/聊聊-Linux-下的-top-命令/"},{"title":"聊聊 Sharding-Jdbc 的简单原理初篇","url":"/2021/12/26/聊聊-Sharding-Jdbc-的简单原理初篇/"},{"title":"聊聊 Sharding-Jdbc 的简单使用","url":"/2021/12/12/聊聊-Sharding-Jdbc-的简单使用/"},{"title":"聊聊 dubbo 的线程池","url":"/2021/04/04/聊聊-dubbo-的线程池/"},{"title":"聊聊 RocketMQ 的 Broker 源码","url":"/2020/07/19/聊聊-RocketMQ-的-Broker-源码/"},{"title":"聊聊 Sharding-Jdbc 分库分表下的分页方案","url":"/2022/01/09/聊聊-Sharding-Jdbc-分库分表下的分页方案/"},{"title":"聊聊 mysql 的 MVCC 续篇","url":"/2020/05/02/聊聊-mysql-的-MVCC-续篇/"},{"title":"聊聊 mysql 的 MVCC","url":"/2020/04/26/聊聊-mysql-的-MVCC/"},{"title":"聊聊Java中的单例模式","url":"/2019/12/21/聊聊Java中的单例模式/"},{"title":"聊聊 redis 缓存的应用问题","url":"/2021/01/31/聊聊-redis-缓存的应用问题/"},{"title":"聊聊 mysql 的 MVCC 续续篇之锁分析","url":"/2020/05/10/聊聊-mysql-的-MVCC-续续篇之加锁分析/"},{"title":"聊聊 mysql 索引的一些细节","url":"/2020/12/27/聊聊-mysql-索引的一些细节/"},{"title":"聊聊一次 brew update 引发的血案","url":"/2020/06/13/聊聊一次-brew-update-引发的血案/"},{"title":"聊聊 SpringBoot 自动装配","url":"/2021/07/11/聊聊SpringBoot-自动装配/"},{"title":"聊聊传说中的 ThreadLocal","url":"/2021/05/30/聊聊传说中的-ThreadLocal/"},{"title":"聊聊厦门旅游的好与不好","url":"/2021/04/11/聊聊厦门旅游的好与不好/"},{"title":"聊聊我刚学会的应用诊断方法","url":"/2020/05/22/聊聊我刚学会的应用诊断方法/"},{"title":"聊聊如何识别和意识到日常生活中的各类危险","url":"/2021/06/06/聊聊如何识别和意识到日常生活中的各类危险/"},{"title":"聊聊我的远程工作体验","url":"/2022/06/26/聊聊我的远程工作体验/"},{"title":"聊聊我理解的分布式事务","url":"/2020/05/17/聊聊我理解的分布式事务/"},{"title":"聊聊最近平淡的生活之又聊通勤","url":"/2021/11/07/聊聊最近平淡的生活/"},{"title":"聊聊最近平淡的生活之看《神探狄仁杰》","url":"/2021/12/19/聊聊最近平淡的生活之看《神探狄仁杰》/"},{"title":"聊聊给亲戚朋友的老电脑重装系统那些事儿","url":"/2021/05/09/聊聊给亲戚朋友的老电脑重装系统那些事儿/"},{"title":"聊聊这次换车牌及其他","url":"/2022/02/20/聊聊这次换车牌及其他/"},{"title":"聊聊那些加塞狗","url":"/2021/01/17/聊聊那些加塞狗/"},{"title":"聊聊部分公交车的设计bug","url":"/2021/12/05/聊聊部分公交车的设计bug/"},{"title":"聊聊最近平淡的生活之看看老剧","url":"/2021/11/21/聊聊最近平淡的生活之看看老剧/"},{"title":"聊聊最近平淡的生活之《花束般的恋爱》观后感","url":"/2021/12/31/聊聊最近平淡的生活之《花束般的恋爱》观后感/"},{"title":"记一个容器中 dubbo 注册的小知识点","url":"/2022/10/09/记一个容器中-dubbo-注册的小知识点/"},{"title":"记录一次折腾自组 nas 的失败经历-续续篇","url":"/2023/05/28/记录一次折腾自组-nas-的失败经历-续续篇/"},{"title":"记录一次折腾自组 nas 的失败经历-续篇","url":"/2023/05/14/记录一次折腾自组-nas-的失败经历-续篇/"},{"title":"记录下 Java Stream 的一些高效操作","url":"/2022/05/15/记录下-Java-Lambda-的一些高效操作/"},{"title":"记录一次折腾自组 nas 的失败经历","url":"/2023/05/07/记录一次折腾自组-nas-的失败经历/"},{"title":"记录下 phpunit 的入门使用方法之setUp和tearDown","url":"/2022/10/23/记录下-phpunit-的入门使用方法之setUp和tearDown/"},{"title":"记录一次折腾自组 nas 的失败经历-续续续篇","url":"/2023/06/18/记录一次折腾自组-nas-的失败经历-续续续篇/"},{"title":"记录下 zookeeper 集群迁移和易错点","url":"/2022/05/29/记录下-zookeeper-集群迁移/"},{"title":"解决 网络文件夹目前是以其他用户名和密码进行映射的 问题","url":"/2023/04/09/解决-网络文件夹目前是以其他用户名和密码进行映射的/"},{"title":"这周末我又在老丈人家打了天小工","url":"/2020/08/30/这周末我又在老丈人家打了天小工/"},{"title":"重看了下《蛮荒记》说说感受","url":"/2021/10/10/重看了下《蛮荒记》说说感受/"},{"title":"闲聊下乘公交的用户体验","url":"/2021/02/28/闲聊下乘公交的用户体验/"},{"title":"闲话篇-也算碰到了为老不尊和坏人变老了的典型案例","url":"/2022/05/22/闲话篇-也算碰到了为老不尊和坏人变老了的典型案例/"},{"title":"记录下 phpunit 的入门使用方法","url":"/2022/10/16/记录下-phpunit-的入门使用方法/"},{"title":"闲话篇-路遇神逻辑骑车带娃爹","url":"/2022/05/08/闲话篇-路遇神逻辑骑车带娃爹/"},{"title":"难得的大扫除","url":"/2022/04/10/难得的大扫除/"},{"title":"记录下 redis 的一些使用方法","url":"/2022/10/30/记录下-redis-的一些使用方法/"},{"title":"记录下把小米路由器 4A 千兆版刷成 openwrt 的过程","url":"/2023/05/21/记录下把小米路由器-4A-千兆版刷成-openwrt-的过程/"}]
\ No newline at end of file
+[{"title":"2019年终总结","url":"/2020/02/01/2019年终总结/"},{"title":"2020 年终总结","url":"/2021/03/31/2020-年终总结/"},{"title":"村上春树《1Q84》读后感","url":"/2019/12/18/1Q84读后感/"},{"title":"2020年中总结","url":"/2020/07/11/2020年中总结/"},{"title":"2021 年终总结","url":"/2022/01/22/2021-年终总结/"},{"title":"34_Search_for_a_Range","url":"/2016/08/14/34-Search-for-a-Range/"},{"title":"2022 年终总结","url":"/2023/01/15/2022-年终总结/"},{"title":"AQS篇二 之 Condition 浅析笔记","url":"/2021/02/21/AQS-之-Condition-浅析笔记/"},{"title":"AbstractQueuedSynchronizer","url":"/2019/09/23/AbstractQueuedSynchronizer/"},{"title":"AQS篇一","url":"/2021/02/14/AQS篇一/"},{"title":"add-two-number","url":"/2015/04/14/Add-Two-Number/"},{"title":"Apollo 如何获取当前环境","url":"/2022/09/04/Apollo-如何获取当前环境/"},{"title":"Apollo 客户端启动过程分析","url":"/2022/09/18/Apollo-客户端启动过程分析/"},{"title":"Apollo 的 value 注解是怎么自动更新的","url":"/2020/11/01/Apollo-的-value-注解是怎么自动更新的/"},{"title":"Clone Graph Part I","url":"/2014/12/30/Clone-Graph-Part-I/"},{"title":"Comparator使用小记","url":"/2020/04/05/Comparator使用小记/"},{"title":"2021 年中总结","url":"/2021/07/18/2021-年中总结/"},{"title":"Disruptor 系列三","url":"/2022/09/25/Disruptor-系列三/"},{"title":"Disruptor 系列一","url":"/2022/02/13/Disruptor-系列一/"},{"title":"Disruptor 系列二","url":"/2022/02/27/Disruptor-系列二/"},{"title":"Dubbo 使用的几个记忆点","url":"/2022/04/02/Dubbo-使用的几个记忆点/"},{"title":"Filter, Interceptor, Aop, 啥, 啥, 啥? 这些都是啥?","url":"/2020/08/22/Filter-Intercepter-Aop-啥-啥-啥-这些都是啥/"},{"title":"Leetcode 021 合并两个有序链表 ( Merge Two Sorted Lists ) 题解分析","url":"/2021/10/07/Leetcode-021-合并两个有序链表-Merge-Two-Sorted-Lists-题解分析/"},{"title":"G1收集器概述","url":"/2020/02/09/G1收集器概述/"},{"title":"JVM源码分析之G1垃圾收集器分析一","url":"/2019/12/07/JVM-G1-Part-1/"},{"title":"Leetcode 105 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal) 题解分析","url":"/2020/12/13/Leetcode-105-从前序与中序遍历序列构造二叉树-Construct-Binary-Tree-from-Preorder-and-Inorder-Traversal-题解分析/"},{"title":"Leetcode 053 最大子序和 ( Maximum Subarray ) 题解分析","url":"/2021/11/28/Leetcode-053-最大子序和-Maximum-Subarray-题解分析/"},{"title":"Leetcode 121 买卖股票的最佳时机(Best Time to Buy and Sell Stock) 题解分析","url":"/2021/03/14/Leetcode-121-买卖股票的最佳时机-Best-Time-to-Buy-and-Sell-Stock-题解分析/"},{"title":"Leetcode 1115 交替打印 FooBar ( Print FooBar Alternately *Medium* ) 题解分析","url":"/2022/05/01/Leetcode-1115-交替打印-FooBar-Print-FooBar-Alternately-Medium-题解分析/"},{"title":"Leetcode 028 实现 strStr() ( Implement strStr() ) 题解分析","url":"/2021/10/31/Leetcode-028-实现-strStr-Implement-strStr-题解分析/"},{"title":"Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析","url":"/2021/01/24/Leetcode-124-二叉树中的最大路径和-Binary-Tree-Maximum-Path-Sum-题解分析/"},{"title":"Leetcode 1260 二维网格迁移 ( Shift 2D Grid *Easy* ) 题解分析","url":"/2022/07/22/Leetcode-1260-二维网格迁移-Shift-2D-Grid-Easy-题解分析/"},{"title":"Leetcode 155 最小栈(Min Stack) 题解分析","url":"/2020/12/06/Leetcode-155-最小栈-Min-Stack-题解分析/"},{"title":"Leetcode 16 最接近的三数之和 ( 3Sum Closest *Medium* ) 题解分析","url":"/2022/08/06/Leetcode-16-最接近的三数之和-3Sum-Closest-Medium-题解分析/"},{"title":"Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析","url":"/2021/01/10/Leetcode-160-相交链表-intersection-of-two-linked-lists-题解分析/"},{"title":"Leetcode 104 二叉树的最大深度(Maximum Depth of Binary Tree) 题解分析","url":"/2020/10/25/Leetcode-104-二叉树的最大深度-Maximum-Depth-of-Binary-Tree-题解分析/"},{"title":"Leetcode 2 Add Two Numbers 题解分析","url":"/2020/10/11/Leetcode-2-Add-Two-Numbers-题解分析/"},{"title":"Leetcode 20 有效的括号 ( Valid Parentheses *Easy* ) 题解分析","url":"/2022/07/02/Leetcode-20-有效的括号-Valid-Parentheses-Easy-题解分析/"},{"title":"Leetcode 234 回文链表(Palindrome Linked List) 题解分析","url":"/2020/11/15/Leetcode-234-回文联表-Palindrome-Linked-List-题解分析/"},{"title":"Leetcode 1862 向下取整数对和 ( Sum of Floored Pairs *Hard* ) 题解分析","url":"/2022/09/11/Leetcode-1862-向下取整数对和-Sum-of-Floored-Pairs-Hard-题解分析/"},{"title":"Leetcode 236 二叉树的最近公共祖先(Lowest Common Ancestor of a Binary Tree) 题解分析","url":"/2021/05/23/Leetcode-236-二叉树的最近公共祖先-Lowest-Common-Ancestor-of-a-Binary-Tree-题解分析/"},{"title":"Leetcode 349 两个数组的交集 ( Intersection of Two Arrays *Easy* ) 题解分析","url":"/2022/03/07/Leetcode-349-两个数组的交集-Intersection-of-Two-Arrays-Easy-题解分析/"},{"title":"Leetcode 278 第一个错误的版本 ( First Bad Version *Easy* ) 题解分析","url":"/2022/08/14/Leetcode-278-第一个错误的版本-First-Bad-Version-Easy-题解分析/"},{"title":"Leetcode 3 Longest Substring Without Repeating Characters 题解分析","url":"/2020/09/20/Leetcode-3-Longest-Substring-Without-Repeating-Characters-题解分析/"},{"title":"Leetcode 4 寻找两个正序数组的中位数 ( Median of Two Sorted Arrays *Hard* ) 题解分析","url":"/2022/03/27/Leetcode-4-寻找两个正序数组的中位数-Median-of-Two-Sorted-Arrays-Hard-题解分析/"},{"title":"Leetcode 48 旋转图像(Rotate Image) 题解分析","url":"/2021/05/01/Leetcode-48-旋转图像-Rotate-Image-题解分析/"},{"title":"Leetcode 42 接雨水 (Trapping Rain Water) 题解分析","url":"/2021/07/04/Leetcode-42-接雨水-Trapping-Rain-Water-题解分析/"},{"title":"Leetcode 698 划分为k个相等的子集 ( Partition to K Equal Sum Subsets *Medium* ) 题解分析","url":"/2022/06/19/Leetcode-698-划分为k个相等的子集-Partition-to-K-Equal-Sum-Subsets-Medium-题解分析/"},{"title":"Leetcode 83 删除排序链表中的重复元素 ( Remove Duplicates from Sorted List *Easy* ) 题解分析","url":"/2022/03/13/Leetcode-83-删除排序链表中的重复元素-Remove-Duplicates-from-Sorted-List-Easy-题解分析/"},{"title":"Leetcode 885 螺旋矩阵 III ( Spiral Matrix III *Medium* ) 题解分析","url":"/2022/08/23/Leetcode-885-螺旋矩阵-III-Spiral-Matrix-III-Medium-题解分析/"},{"title":"Linux 下 grep 命令的一点小技巧","url":"/2020/08/06/Linux-下-grep-命令的一点小技巧/"},{"title":"Headscale初体验以及踩坑记","url":"/2023/01/22/Headscale初体验以及踩坑记/"},{"title":"leetcode no.3","url":"/2015/04/15/Leetcode-No-3/"},{"title":"Maven实用小技巧","url":"/2020/02/16/Maven实用小技巧/"},{"title":"Number of 1 Bits","url":"/2015/03/11/Number-Of-1-Bits/"},{"title":"Leetcode 747 至少是其他数字两倍的最大数 ( Largest Number At Least Twice of Others *Easy* ) 题解分析","url":"/2022/10/02/Leetcode-747-至少是其他数字两倍的最大数-Largest-Number-At-Least-Twice-of-Others-Easy-题解分析/"},{"title":"Path Sum","url":"/2015/01/04/Path-Sum/"},{"title":"Redis_分布式锁","url":"/2019/12/10/Redis-Part-1/"},{"title":"Reverse Bits","url":"/2015/03/11/Reverse-Bits/"},{"title":"Reverse Integer","url":"/2015/03/13/Reverse-Integer/"},{"title":"MFC 模态对话框","url":"/2014/12/24/MFC 模态对话框/"},{"title":"ambari-summary","url":"/2017/05/09/ambari-summary/"},{"title":"binary-watch","url":"/2016/09/29/binary-watch/"},{"title":"docker-mysql-cluster","url":"/2016/08/14/docker-mysql-cluster/"},{"title":"docker比一般多一点的初学者介绍","url":"/2020/03/08/docker比一般多一点的初学者介绍/"},{"title":"docker比一般多一点的初学者介绍三","url":"/2020/03/21/docker比一般多一点的初学者介绍三/"},{"title":"two sum","url":"/2015/01/14/Two-Sum/"},{"title":"docker比一般多一点的初学者介绍四","url":"/2022/12/25/docker比一般多一点的初学者介绍四/"},{"title":"dubbo 客户端配置的一个重要知识点","url":"/2022/06/11/dubbo-客户端配置的一个重要知识点/"},{"title":"docker使用中发现的echo命令的一个小技巧及其他","url":"/2020/03/29/echo命令的一个小技巧/"},{"title":"headscale 添加节点","url":"/2023/07/09/headscale-添加节点/"},{"title":"gogs使用webhook部署react单页应用","url":"/2020/02/22/gogs使用webhook部署react单页应用/"},{"title":"docker比一般多一点的初学者介绍二","url":"/2020/03/15/docker比一般多一点的初学者介绍二/"},{"title":"github 小技巧-更新 github host key","url":"/2023/03/28/github-小技巧-更新-github-host-key/"},{"title":"C++ 指针使用中的一个小问题","url":"/2014/12/23/my-new-post/"},{"title":"mybatis 的 $ 和 # 是有啥区别","url":"/2020/09/06/mybatis-的-和-是有啥区别/"},{"title":"minimum-size-subarray-sum-209","url":"/2016/10/11/minimum-size-subarray-sum-209/"},{"title":"mybatis 的 foreach 使用的注意点","url":"/2022/07/09/mybatis-的-foreach-使用的注意点/"},{"title":"mybatis 的缓存是怎么回事","url":"/2020/10/03/mybatis-的缓存是怎么回事/"},{"title":"hexo 配置系列-接入Algolia搜索","url":"/2023/04/02/hexo-配置系列-接入Algolia搜索/"},{"title":"mybatis系列-dataSource解析","url":"/2023/01/08/mybatis系列-dataSource解析/"},{"title":"mybatis系列-sql 类的简单使用","url":"/2023/03/12/mybatis系列-sql-类的简单使用/"},{"title":"java 中发起 http 请求时证书问题解决记录","url":"/2023/07/29/java-中发起-http-请求时证书问题解决记录/"},{"title":"mybatis系列-sql 类的简要分析","url":"/2023/03/19/mybatis系列-sql-类的简要分析/"},{"title":"invert-binary-tree","url":"/2015/06/22/invert-binary-tree/"},{"title":"dnsmasq的一个使用注意点","url":"/2023/04/16/dnsmasq的一个使用注意点/"},{"title":"mybatis系列-mybatis是如何初始化mapper的","url":"/2022/12/04/mybatis是如何初始化mapper的/"},{"title":"mybatis系列-foreach 解析","url":"/2023/06/11/mybatis系列-foreach-解析/"},{"title":"mybatis系列-connection连接池解析","url":"/2023/02/19/mybatis系列-connection连接池解析/"},{"title":"mybatis系列-入门篇","url":"/2022/11/27/mybatis系列-入门篇/"},{"title":"nginx 日志小记","url":"/2022/04/17/nginx-日志小记/"},{"title":"openresty","url":"/2019/06/18/openresty/"},{"title":"pcre-intro-and-a-simple-package","url":"/2015/01/16/pcre-intro-and-a-simple-package/"},{"title":"mybatis系列-第一条sql的更多细节","url":"/2022/12/18/mybatis系列-第一条sql的更多细节/"},{"title":"php-abstract-class-and-interface","url":"/2016/11/10/php-abstract-class-and-interface/"},{"title":"mybatis系列-第一条sql的细节","url":"/2022/12/11/mybatis系列-第一条sql的细节/"},{"title":"rabbitmq-tips","url":"/2017/04/25/rabbitmq-tips/"},{"title":"redis 的 rdb 和 COW 介绍","url":"/2021/08/15/redis-的-rdb-和-COW-介绍/"},{"title":"redis数据结构介绍-第一部分 SDS,链表,字典","url":"/2019/12/26/redis数据结构介绍/"},{"title":"redis数据结构介绍三-第三部分 整数集合","url":"/2020/01/10/redis数据结构介绍三/"},{"title":"redis数据结构介绍二-第二部分 跳表","url":"/2020/01/04/redis数据结构介绍二/"},{"title":"redis数据结构介绍五-第五部分 对象","url":"/2020/01/20/redis数据结构介绍五/"},{"title":"redis数据结构介绍六 快表","url":"/2020/01/22/redis数据结构介绍六/"},{"title":"redis数据结构介绍四-第四部分 压缩表","url":"/2020/01/19/redis数据结构介绍四/"},{"title":"redis淘汰策略复习","url":"/2021/08/01/redis淘汰策略复习/"},{"title":"mybatis系列-typeAliases系统","url":"/2023/01/01/mybatis系列-typeAliases系统/"},{"title":"redis系列介绍七-过期策略","url":"/2020/04/12/redis系列介绍七/"},{"title":"redis系列介绍八-淘汰策略","url":"/2020/04/18/redis系列介绍八/"},{"title":"redis过期策略复习","url":"/2021/07/25/redis过期策略复习/"},{"title":"rust学习笔记-所有权一","url":"/2021/04/18/rust学习笔记/"},{"title":"rust学习笔记-所有权二","url":"/2021/04/18/rust学习笔记-所有权二/"},{"title":"spark-little-tips","url":"/2017/03/28/spark-little-tips/"},{"title":"rust学习笔记-所有权三之切片","url":"/2021/05/16/rust学习笔记-所有权三之切片/"},{"title":"spring event 介绍","url":"/2022/01/30/spring-event-介绍/"},{"title":"springboot mappings 注册逻辑","url":"/2023/08/13/springboot-mappings-注册逻辑/"},{"title":"powershell 初体验","url":"/2022/11/13/powershell-初体验/"},{"title":"springboot web server 启动逻辑","url":"/2023/08/20/springboot-web-server-启动逻辑/"},{"title":"powershell 初体验二","url":"/2022/11/20/powershell-初体验二/"},{"title":"summary-ranges-228","url":"/2016/10/12/summary-ranges-228/"},{"title":"swoole-websocket-test","url":"/2016/07/13/swoole-websocket-test/"},{"title":"wordpress 忘记密码的一种解决方法","url":"/2021/12/05/wordpress-忘记密码的一种解决方法/"},{"title":"win 下 vmware 虚拟机搭建黑裙 nas 的小思路","url":"/2023/06/04/win-下-vmware-虚拟机搭建黑裙-nas-的小思路/"},{"title":"《垃圾回收算法手册读书》笔记之整理算法","url":"/2021/03/07/《垃圾回收算法手册读书》笔记之整理算法/"},{"title":"spring boot中的 http 接口返回 json 形式的小注意点","url":"/2023/06/25/spring-boot中的-http-接口返回-json-形式的小注意点/"},{"title":"springboot 获取 web 应用中所有的接口 url","url":"/2023/08/06/springboot-获取-web-应用中所有的接口-url/"},{"title":"《长安的荔枝》读后感","url":"/2022/07/17/《长安的荔枝》读后感/"},{"title":"一个 nginx 的简单记忆点","url":"/2022/08/21/一个-nginx-的简单记忆点/"},{"title":"上次的其他 外行聊国足","url":"/2022/03/06/上次的其他-外行聊国足/"},{"title":"介绍一下 RocketMQ","url":"/2020/06/21/介绍一下-RocketMQ/"},{"title":"介绍下最近比较实用的端口转发","url":"/2021/11/14/介绍下最近比较实用的端口转发/"},{"title":"ssh 小技巧-端口转发","url":"/2023/03/26/ssh-小技巧-端口转发/"},{"title":"从清华美院学姐聊聊我们身边的恶人","url":"/2020/11/29/从清华美院学姐聊聊我们身边的恶人/"},{"title":"从丁仲礼被美国制裁聊点啥","url":"/2020/12/20/从丁仲礼被美国制裁聊点啥/"},{"title":"关于公共交通再吐个槽","url":"/2021/03/21/关于公共交通再吐个槽/"},{"title":"《寻羊历险记》读后感","url":"/2023/07/23/《寻羊历险记》读后感/"},{"title":"关于读书打卡与分享","url":"/2021/02/07/关于读书打卡与分享/"},{"title":"nas 中使用 tmm 刮削视频","url":"/2023/07/02/使用-tmm-刮削视频/"},{"title":"分享一次折腾老旧笔记本的体验","url":"/2023/02/05/分享一次折腾老旧笔记本的体验/"},{"title":"关于 npe 的一个小记忆点","url":"/2023/07/16/关于-npe-的一个小记忆点/"},{"title":"分享记录一下一个 git 操作方法","url":"/2022/02/06/分享记录一下一个-git-操作方法/"},{"title":"分享记录一下一个 scp 操作方法","url":"/2022/02/06/分享记录一下一个-scp-操作方法/"},{"title":"周末我在老丈人家打了天小工","url":"/2020/08/16/周末我在老丈人家打了天小工/"},{"title":"分享一次折腾老旧笔记本的体验-续续篇","url":"/2023/02/26/分享一次折腾老旧笔记本的体验-续续篇/"},{"title":"在老丈人家的小工记五","url":"/2020/10/18/在老丈人家的小工记五/"},{"title":"在老丈人家的小工记三","url":"/2020/09/13/在老丈人家的小工记三/"},{"title":"在老丈人家的小工记四","url":"/2020/09/26/在老丈人家的小工记四/"},{"title":"小工周记一","url":"/2023/03/05/小工周记一/"},{"title":"分享一次折腾老旧笔记本的体验-续篇","url":"/2023/02/12/分享一次折腾老旧笔记本的体验-续篇/"},{"title":"寄生虫观后感","url":"/2020/03/01/寄生虫观后感/"},{"title":"屯菜惊魂记","url":"/2022/04/24/屯菜惊魂记/"},{"title":"我是如何走上跑步这条不归路的","url":"/2020/07/26/我是如何走上跑步这条不归路的/"},{"title":"是何原因竟让两人深夜奔袭十公里","url":"/2022/06/05/是何原因竟让两人深夜奔袭十公里/"},{"title":"看完了扫黑风暴,聊聊感想","url":"/2021/10/24/看完了扫黑风暴-聊聊感想/"},{"title":"分享一次比较诡异的 Windows 下 U盘无法退出的经历","url":"/2023/01/29/分享一次比较诡异的-Windows-下-U盘无法退出的经历/"},{"title":"聊一下 RocketMQ 的 DefaultMQPushConsumer 源码","url":"/2020/06/26/聊一下-RocketMQ-的-Consumer/"},{"title":"聊一下 RocketMQ 的 NameServer 源码","url":"/2020/07/05/聊一下-RocketMQ-的-NameServer-源码/"},{"title":"给小电驴上牌","url":"/2022/03/20/给小电驴上牌/"},{"title":"聊一下 RocketMQ 的消息存储之 MMAP","url":"/2021/09/04/聊一下-RocketMQ-的消息存储/"},{"title":"搬运两个 StackOverflow 上的 Mysql 编码相关的问题解答","url":"/2022/01/16/搬运两个-StackOverflow-上的-Mysql-编码相关的问题解答/"},{"title":"在 wsl 2 中开启 ssh 连接","url":"/2023/04/23/在-wsl-2-中开启-ssh-连接/"},{"title":"聊一下 RocketMQ 的消息存储三","url":"/2021/10/03/聊一下-RocketMQ-的消息存储三/"},{"title":"聊一下 RocketMQ 的消息存储二","url":"/2021/09/12/聊一下-RocketMQ-的消息存储二/"},{"title":"聊一下 RocketMQ 的消息存储四","url":"/2021/10/17/聊一下-RocketMQ-的消息存储四/"},{"title":"聊一下 RocketMQ 的顺序消息","url":"/2021/08/29/聊一下-RocketMQ-的顺序消息/"},{"title":"聊一下 SpringBoot 中使用的 cglib 作为动态代理中的一个注意点","url":"/2021/09/19/聊一下-SpringBoot-中使用的-cglib-作为动态代理中的一个注意点/"},{"title":"聊一下 SpringBoot 中动态切换数据源的方法","url":"/2021/09/26/聊一下-SpringBoot-中动态切换数据源的方法/"},{"title":"聊一下 SpringBoot 设置非 web 应用的方法","url":"/2022/07/31/聊一下-SpringBoot-设置非-web-应用的方法/"},{"title":"深度学习入门初认识","url":"/2023/04/30/深度学习入门初认识/"},{"title":"聊在东京奥运会闭幕式这天","url":"/2021/08/08/聊在东京奥运会闭幕式这天/"},{"title":"聊在东京奥运会闭幕式这天-二","url":"/2021/08/19/聊在东京奥运会闭幕式这天-二/"},{"title":"聊聊 Dubbo 的 SPI 续之自适应拓展","url":"/2020/06/06/聊聊-Dubbo-的-SPI-续之自适应拓展/"},{"title":"聊聊 Dubbo 的 SPI","url":"/2020/05/31/聊聊-Dubbo-的-SPI/"},{"title":"聊聊 Java 中绕不开的 Synchronized 关键字-二","url":"/2021/06/27/聊聊-Java-中绕不开的-Synchronized-关键字-二/"},{"title":"聊聊 Java 的类加载机制一","url":"/2020/11/08/聊聊-Java-的类加载机制/"},{"title":"聊聊 Dubbo 的容错机制","url":"/2020/11/22/聊聊-Dubbo-的容错机制/"},{"title":"聊聊 Java 中绕不开的 Synchronized 关键字","url":"/2021/06/20/聊聊-Java-中绕不开的-Synchronized-关键字/"},{"title":"聊聊 Java 自带的那些*逆天*工具","url":"/2020/08/02/聊聊-Java-自带的那些逆天工具/"},{"title":"聊聊 Sharding-Jdbc 的简单使用","url":"/2021/12/12/聊聊-Sharding-Jdbc-的简单使用/"},{"title":"聊聊 Java 的 equals 和 hashCode 方法","url":"/2021/01/03/聊聊-Java-的-equals-和-hashCode-方法/"},{"title":"聊聊 Sharding-Jdbc 分库分表下的分页方案","url":"/2022/01/09/聊聊-Sharding-Jdbc-分库分表下的分页方案/"},{"title":"聊聊 Java 的类加载机制二","url":"/2021/06/13/聊聊-Java-的类加载机制二/"},{"title":"聊聊 dubbo 的线程池","url":"/2021/04/04/聊聊-dubbo-的线程池/"},{"title":"聊聊 mysql 的 MVCC 续篇","url":"/2020/05/02/聊聊-mysql-的-MVCC-续篇/"},{"title":"聊一下关于怎么陪伴学习","url":"/2022/11/06/聊一下关于怎么陪伴学习/"},{"title":"聊聊 mysql 的 MVCC 续续篇之锁分析","url":"/2020/05/10/聊聊-mysql-的-MVCC-续续篇之加锁分析/"},{"title":"聊聊 mysql 索引的一些细节","url":"/2020/12/27/聊聊-mysql-索引的一些细节/"},{"title":"聊聊Java中的单例模式","url":"/2019/12/21/聊聊Java中的单例模式/"},{"title":"聊聊 redis 缓存的应用问题","url":"/2021/01/31/聊聊-redis-缓存的应用问题/"},{"title":"聊聊 RocketMQ 的 Broker 源码","url":"/2020/07/19/聊聊-RocketMQ-的-Broker-源码/"},{"title":"聊聊 Sharding-Jdbc 的简单原理初篇","url":"/2021/12/26/聊聊-Sharding-Jdbc-的简单原理初篇/"},{"title":"聊聊 mysql 的 MVCC","url":"/2020/04/26/聊聊-mysql-的-MVCC/"},{"title":"聊聊传说中的 ThreadLocal","url":"/2021/05/30/聊聊传说中的-ThreadLocal/"},{"title":"聊聊一次 brew update 引发的血案","url":"/2020/06/13/聊聊一次-brew-update-引发的血案/"},{"title":"聊聊我刚学会的应用诊断方法","url":"/2020/05/22/聊聊我刚学会的应用诊断方法/"},{"title":"聊聊我的远程工作体验","url":"/2022/06/26/聊聊我的远程工作体验/"},{"title":"聊聊我理解的分布式事务","url":"/2020/05/17/聊聊我理解的分布式事务/"},{"title":"聊聊 Linux 下的 top 命令","url":"/2021/03/28/聊聊-Linux-下的-top-命令/"},{"title":"聊聊最近平淡的生活之《花束般的恋爱》观后感","url":"/2021/12/31/聊聊最近平淡的生活之《花束般的恋爱》观后感/"},{"title":"聊聊 SpringBoot 自动装配","url":"/2021/07/11/聊聊SpringBoot-自动装配/"},{"title":"聊聊最近平淡的生活之又聊通勤","url":"/2021/11/07/聊聊最近平淡的生活/"},{"title":"聊聊最近平淡的生活之看《神探狄仁杰》","url":"/2021/12/19/聊聊最近平淡的生活之看《神探狄仁杰》/"},{"title":"聊聊最近平淡的生活之看看老剧","url":"/2021/11/21/聊聊最近平淡的生活之看看老剧/"},{"title":"聊聊那些加塞狗","url":"/2021/01/17/聊聊那些加塞狗/"},{"title":"聊聊这次换车牌及其他","url":"/2022/02/20/聊聊这次换车牌及其他/"},{"title":"聊聊部分公交车的设计bug","url":"/2021/12/05/聊聊部分公交车的设计bug/"},{"title":"聊聊如何识别和意识到日常生活中的各类危险","url":"/2021/06/06/聊聊如何识别和意识到日常生活中的各类危险/"},{"title":"聊聊给亲戚朋友的老电脑重装系统那些事儿","url":"/2021/05/09/聊聊给亲戚朋友的老电脑重装系统那些事儿/"},{"title":"记一个容器中 dubbo 注册的小知识点","url":"/2022/10/09/记一个容器中-dubbo-注册的小知识点/"},{"title":"记录一次折腾自组 nas 的失败经历-续篇","url":"/2023/05/14/记录一次折腾自组-nas-的失败经历-续篇/"},{"title":"聊聊厦门旅游的好与不好","url":"/2021/04/11/聊聊厦门旅游的好与不好/"},{"title":"记录一次折腾自组 nas 的失败经历-续续篇","url":"/2023/05/28/记录一次折腾自组-nas-的失败经历-续续篇/"},{"title":"记录一次折腾自组 nas 的失败经历-续续续篇","url":"/2023/06/18/记录一次折腾自组-nas-的失败经历-续续续篇/"},{"title":"记录一次折腾自组 nas 的失败经历","url":"/2023/05/07/记录一次折腾自组-nas-的失败经历/"},{"title":"记录下 zookeeper 集群迁移和易错点","url":"/2022/05/29/记录下-zookeeper-集群迁移/"},{"title":"记录下把小米路由器 4A 千兆版刷成 openwrt 的过程","url":"/2023/05/21/记录下把小米路由器-4A-千兆版刷成-openwrt-的过程/"},{"title":"这周末我又在老丈人家打了天小工","url":"/2020/08/30/这周末我又在老丈人家打了天小工/"},{"title":"重看了下《蛮荒记》说说感受","url":"/2021/10/10/重看了下《蛮荒记》说说感受/"},{"title":"记录下 phpunit 的入门使用方法之setUp和tearDown","url":"/2022/10/23/记录下-phpunit-的入门使用方法之setUp和tearDown/"},{"title":"闲话篇-也算碰到了为老不尊和坏人变老了的典型案例","url":"/2022/05/22/闲话篇-也算碰到了为老不尊和坏人变老了的典型案例/"},{"title":"闲聊下乘公交的用户体验","url":"/2021/02/28/闲聊下乘公交的用户体验/"},{"title":"闲话篇-路遇神逻辑骑车带娃爹","url":"/2022/05/08/闲话篇-路遇神逻辑骑车带娃爹/"},{"title":"记录下 redis 的一些使用方法","url":"/2022/10/30/记录下-redis-的一些使用方法/"},{"title":"难得的大扫除","url":"/2022/04/10/难得的大扫除/"},{"title":"解决 网络文件夹目前是以其他用户名和密码进行映射的 问题","url":"/2023/04/09/解决-网络文件夹目前是以其他用户名和密码进行映射的/"},{"title":"记录下 phpunit 的入门使用方法","url":"/2022/10/16/记录下-phpunit-的入门使用方法/"},{"title":"记录下 Java Stream 的一些高效操作","url":"/2022/05/15/记录下-Java-Lambda-的一些高效操作/"}]
\ No newline at end of file
diff --git a/search.xml b/search.xml
index 4f184ab27d..ec78d93937 100644
--- a/search.xml
+++ b/search.xml
@@ -1,25 +1,5 @@
-
- 村上春树《1Q84》读后感
- /2019/12/18/1Q84%E8%AF%BB%E5%90%8E%E6%84%9F/
- 看完了村上春树的《1Q84》,这应该是第五本看的他的书了,继 跑步,挪威的森林,刺杀骑士团长,海边的卡夫卡之后,不是其中最长的,好像是海边的卡夫卡还是刺杀骑士团长比较长一点,都是在微信读书上看的,比较方便,最开始在上面看的是高晓松的《鱼羊野史》,不知道为啥取这个名字,但是还是满吸引我的,不过由于去年的种种,没有很多心思把它看完,而且本身的组织形式就是比较松散的,看到哪算哪,其实一些野史部分是我比较喜欢,有些谈到人物的就不太有兴趣,而且类似于大祥哥吃的东西,反正都是哇,怎么这么好吃,嗯,太爱(niu)你(bi)了,高晓松就是这个人是我最喜欢的 xxx 家,我也没去细究过他有没有说重复过,反正是不太爱,后来因为这书还一度对战争史有了浓厚的兴趣,然而事实告诉我,大部头的战争史,其实正史我是真的啃不下去,我可能只对其中 10%的内容感兴趣,不过终于也在今年把它看完了,好像高晓松的晓说也最终季了,貌似其中讲朝鲜战争的还被和谐了,看样子是说出了一些故事(truth)。
-
/**
+ * Here is the brief description for all the predefined environments:
+ * <ul>
+ * <li>LOCAL: Local Development environment, assume you are working at the beach with no network access</li>
+ * <li>DEV: Development environment</li>
+ * <li>FWS: Feature Web Service Test environment</li>
+ * <li>FAT: Feature Acceptance Test environment</li>
+ * <li>UAT: User Acceptance Test environment</li>
+ * <li>LPT: Load and Performance Test environment</li>
+ * <li>PRO: Production environment</li>
+ * <li>TOOLS: Tooling environment, a special area in production environment which allows
+ * access to test environment, e.g. Apollo Portal should be deployed in tools environment</li>
+ * </ul>
+ */
/**
- * Here is the brief description for all the predefined environments:
- * <ul>
- * <li>LOCAL: Local Development environment, assume you are working at the beach with no network access</li>
- * <li>DEV: Development environment</li>
- * <li>FWS: Feature Web Service Test environment</li>
- * <li>FAT: Feature Acceptance Test environment</li>
- * <li>UAT: User Acceptance Test environment</li>
- * <li>LPT: Load and Performance Test environment</li>
- * <li>PRO: Production environment</li>
- * <li>TOOLS: Tooling environment, a special area in production environment which allows
- * access to test environment, e.g. Apollo Portal should be deployed in tools environment</li>
- * </ul>
- */
classLhsPadding
-{
- protectedlong p1, p2, p3, p4, p5, p6, p7;
-}
-
-classValueextendsLhsPadding
-{
- protectedvolatilelong value;
-}
-
-classRhsPaddingextendsValue
-{
- protectedlong p9, p10, p11, p12, p13, p14, p15;
-}
-
-/**
- * <p>Concurrent sequence class used for tracking the progress of
- * the ring buffer and event processors. Support a number
- * of concurrent operations including CAS and order writes.
- *
- * <p>Also attempts to be more efficient with regards to false
- * sharing by adding padding around the volatile field.
- */
-publicclassSequenceextendsRhsPadding
-{
-
通过代码可以看到,sequence 中其实真正有意义的是 value 字段,因为需要在多线程环境下可见也 使用了volatile 关键字,而 LhsPadding 和 RhsPadding 分别在value 前后填充了各 7 个 long 型的变量,long 型的变量在 Java 中是占用 8 bytes,这样就相当于不管怎么样, value 都会单独使用一个缓存行,使得其不会产生 false sharing 的问题。
EventHandlerGroup<T>createEventProcessors(
+ finalSequence[] barrierSequences,
+ finalEventHandler<?superT>[] eventHandlers)
+ {
+ checkNotStarted();
-importjava.io.IOException;
+ finalSequence[] processorSequences =newSequence[eventHandlers.length];
+ finalSequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
-/**
- * Defines methods that all servlets must implement.
- *
- * <p>
- * A servlet is a small Java program that runs within a Web server. Servlets
- * receive and respond to requests from Web clients, usually across HTTP, the
- * HyperText Transfer Protocol.
- *
- * <p>
- * To implement this interface, you can write a generic servlet that extends
- * <code>javax.servlet.GenericServlet</code> or an HTTP servlet that extends
- * <code>javax.servlet.http.HttpServlet</code>.
- *
- * <p>
- * This interface defines methods to initialize a servlet, to service requests,
- * and to remove a servlet from the server. These are known as life-cycle
- * methods and are called in the following sequence:
- * <ol>
- * <li>The servlet is constructed, then initialized with the <code>init</code>
- * method.
- * <li>Any calls from clients to the <code>service</code> method are handled.
- * <li>The servlet is taken out of service, then destroyed with the
- * <code>destroy</code> method, then garbage collected and finalized.
- * </ol>
- *
- * <p>
- * In addition to the life-cycle methods, this interface provides the
- * <code>getServletConfig</code> method, which the servlet can use to get any
- * startup information, and the <code>getServletInfo</code> method, which allows
- * the servlet to return basic information about itself, such as author,
- * version, and copyright.
- *
- * @see GenericServlet
- * @see javax.servlet.http.HttpServlet
- */
-publicinterfaceServlet{
+ for(int i =0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
+ {
+ finalEventHandler<?superT> eventHandler = eventHandlers[i];
- /**
- * Called by the servlet container to indicate to a servlet that the servlet
- * is being placed into service.
- *
- * <p>
- * The servlet container calls the <code>init</code> method exactly once
- * after instantiating the servlet. The <code>init</code> method must
- * complete successfully before the servlet can receive any requests.
- *
- * <p>
- * The servlet container cannot place the servlet into service if the
- * <code>init</code> method
- * <ol>
- * <li>Throws a <code>ServletException</code>
- * <li>Does not return within a time period defined by the Web server
- * </ol>
- *
- *
- * @param config
- * a <code>ServletConfig</code> object containing the servlet's
- * configuration and initialization parameters
- *
- * @exception ServletException
- * if an exception has occurred that interferes with the
- * servlet's normal operation
- *
- * @see UnavailableException
- * @see #getServletConfig
- */
- publicvoidinit(ServletConfig config)throwsServletException;
+ // 这里将 handler 包装成一个 BatchEventProcessor
+ finalBatchEventProcessor<T> batchEventProcessor =
+ newBatchEventProcessor<>(ringBuffer, barrier, eventHandler);
- /**
- *
- * Returns a {@link ServletConfig} object, which contains initialization and
- * startup parameters for this servlet. The <code>ServletConfig</code>
- * object returned is the one passed to the <code>init</code> method.
- *
- * <p>
- * Implementations of this interface are responsible for storing the
- * <code>ServletConfig</code> object so that this method can return it. The
- * {@link GenericServlet} class, which implements this interface, already
- * does this.
- *
- * @return the <code>ServletConfig</code> object that initializes this
- * servlet
- *
- * @see #init
- */
- publicServletConfiggetServletConfig();
+ if(exceptionHandler !=null)
+ {
+ batchEventProcessor.setExceptionHandler(exceptionHandler);
+ }
- /**
- * Called by the servlet container to allow the servlet to respond to a
- * request.
- *
- * <p>
- * This method is only called after the servlet's <code>init()</code> method
- * has completed successfully.
- *
- * <p>
- * The status code of the response always should be set for a servlet that
- * throws or sends an error.
- *
- *
- * <p>
- * Servlets typically run inside multithreaded servlet containers that can
- * handle multiple requests concurrently. Developers must be aware to
- * synchronize access to any shared resources such as files, network
- * connections, and as well as the servlet's class and instance variables.
- * More information on multithreaded programming in Java is available in <a
- * href
- * ="http://java.sun.com/Series/Tutorial/java/threads/multithreaded.html">
- * the Java tutorial on multi-threaded programming</a>.
- *
- *
- * @param req
- * the <code>ServletRequest</code> object that contains the
- * client's request
- *
- * @param res
- * the <code>ServletResponse</code> object that contains the
- * servlet's response
- *
- * @exception ServletException
- * if an exception occurs that interferes with the servlet's
- * normal operation
- *
- * @exception IOException
- * if an input or output exception occurs
- */
- publicvoidservice(ServletRequest req,ServletResponse res)
- throwsServletException,IOException;
-
- /**
- * Returns information about the servlet, such as author, version, and
- * copyright.
- *
- * <p>
- * The string that this method returns should be plain text and not markup
- * of any kind (such as HTML, XML, etc.).
- *
- * @return a <code>String</code> containing servlet information
- */
- publicStringgetServletInfo();
+ consumerRepository.add(batchEventProcessor, eventHandler, barrier);
+ processorSequences[i]= batchEventProcessor.getSequence();
+ }
- /**
- * Called by the servlet container to indicate to a servlet that the servlet
- * is being taken out of service. This method is only called once all
- * threads within the servlet's <code>service</code> method have exited or
- * after a timeout period has passed. After the servlet container calls this
- * method, it will not call the <code>service</code> method again on this
- * servlet.
- *
- * <p>
- * This method gives the servlet an opportunity to clean up any resources
- * that are being held (for example, memory, file handles, threads) and make
- * sure that any persistent state is synchronized with the servlet's current
- * state in memory.
- */
- publicvoiddestroy();
-}
-
// ---------------------------------------------------- FilterChain Methods
+ updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
- /**
- * Invoke the next filter in this chain, passing the specified request
- * and response. If there are no more filters in this chain, invoke
- * the <code>service()</code> method of the servlet itself.
- *
- * @param request The servlet request we are processing
- * @param response The servlet response we are creating
- *
- * @exception IOException if an input/output error occurs
- * @exception ServletException if a servlet exception occurs
- */
- @Override
- publicvoiddoFilter(ServletRequest request,ServletResponse response)
- throwsIOException,ServletException{
+ returnnewEventHandlerGroup<>(this, consumerRepository, processorSequences);
+ }
这里主要介绍这个比较新的垃圾回收器,在 G1 之前的垃圾回收器都是基于如下图的内存结构分布,有新生代,老年代和永久代(jdk8 之前),然后G1 往前的那些垃圾回收器都有个分代,比如 serial,parallel 等,一般有个应用的组合,最初的 serial 和 serial old,因为新生代和老年代的收集方式不太一样,新生代主要是标记复制,所以有 eden 跟两个 survival区,老年代一般用标记整理方式,而 G1 对这个不太一样。 看一下 G1 的内存分布 可以看到这有很大的不同,G1 通过将内存分成大小相等的 region,每个region是存在于一个连续的虚拟内存范围,对于某个 region 来说其角色是类似于原来的收集器的Eden、Survivor、Old Generation,这个具体在代码层面
-
// We encode the value of the heap region type so the generation can be
- // determined quickly. The tag is split into two parts:
- //
- // major type (young, old, humongous, archive) : top N-1 bits
- // minor type (eden / survivor, starts / cont hum, etc.) : bottom 1 bit
- //
- // If there's need to increase the number of minor types in the
- // future, we'll have to increase the size of the latter and hence
- // decrease the size of the former.
- //
- // 00000 0 [ 0] Free
- //
- // 00001 0 [ 2] Young Mask
- // 00001 0 [ 2] Eden
- // 00001 1 [ 3] Survivor
- //
- // 00010 0 [ 4] Humongous Mask
- // 00100 0 [ 8] Pinned Mask
- // 00110 0 [12] Starts Humongous
- // 00110 1 [13] Continues Humongous
- //
- // 01000 0 [16] Old Mask
- //
- // 10000 0 [32] Archive Mask
- // 11100 0 [56] Open Archive
- // 11100 1 [57] Closed Archive
- //
- typedef enum {
- FreeTag = 0,
-
- YoungMask = 2,
- EdenTag = YoungMask,
- SurvTag = YoungMask + 1,
+ Disruptor 系列二
+ /2022/02/27/Disruptor-%E7%B3%BB%E5%88%97%E4%BA%8C/
+ 这里开始慢慢深入的讲一下 disruptor,首先是 lock free , 相比于前面介绍的两个阻塞队列, disruptor 本身是不直接使用锁的,因为本身的设计是单个线程去生产,通过 cas 来维护头指针, 不直接维护尾指针,这样就减少了锁的使用,提升了性能;第二个是这次介绍的重点, 减少 false sharing 的情况,也就是常说的 伪共享 问题,那么什么叫 伪共享 呢, 这里要扯到一些 cpu 缓存的知识, 譬如我在用的这个笔记本 这里就可能看到 L2 Cache 就是针对每个核的 这里可以看到现代 CPU 的结构里,分为三级缓存,越靠近 cpu 的速度越快,存储容量越小, 而 L1 跟 L2 是 CPU 核专属的每个核都有自己的 L1 和 L2 的,其中 L1 还分为数据和指令, 像我上面的图中显示的 L1 Cache 只有 64KB 大小,其中数据 32KB,指令 32KB, 而 L2 则有 256KB,L3 有 4MB,其中的 Line Size 是我们这里比较重要的一个值, CPU 其实会就近地从 Cache 中读取数据,碰到 Cache Miss 就再往下一级 Cache 读取, 每次读取是按照缓存行 Cache Line 读取,并且也遵循了“就近原则”, 也就是相近的数据有可能也会马上被读取,所以以行的形式读取,然而这也造成了 false sharing, 因为类似于 ArrayBlockingQueue,需要有 takeIndex , putIndex , count , 因为在同一个类中, 很有可能存在于同一个 Cache Line 中,但是这几个值会被不同的线程修改, 导致从 Cache 取出来以后立马就会被失效,所谓的就近原则也就没用了, 因为需要反复地标记 dirty 脏位,然后把 Cache 刷掉,就造成了false sharing这种情况 而在 disruptor 中则使用了填充的方式,让我的头指针能够不产生false sharing
+
classLhsPadding
+{
+ protectedlong p1, p2, p3, p4, p5, p6, p7;
+}
- HumongousMask = 4,
- PinnedMask = 8,
- StartsHumongousTag = HumongousMask | PinnedMask,
- ContinuesHumongousTag = HumongousMask | PinnedMask + 1,
+classValueextendsLhsPadding
+{
+ protectedvolatilelong value;
+}
- OldMask = 16,
- OldTag = OldMask,
+classRhsPaddingextendsValue
+{
+ protectedlong p9, p10, p11, p12, p13, p14, p15;
+}
- // Archive regions are regions with immutable content (i.e. not reclaimed, and
- // not allocated into during regular operation). They differ in the kind of references
- // allowed for the contained objects:
- // - Closed archive regions form a separate self-contained (closed) object graph
- // within the set of all of these regions. No references outside of closed
- // archive regions are allowed.
- // - Open archive regions have no restrictions on the references of their objects.
- // Objects within these regions are allowed to have references to objects
- // contained in any other kind of regions.
- ArchiveMask = 32,
- OpenArchiveTag = ArchiveMask | PinnedMask | OldMask,
- ClosedArchiveTag = ArchiveMask | PinnedMask | OldMask + 1
- } Tag;
+/**
+ * <p>Concurrent sequence class used for tracking the progress of
+ * the ring buffer and event processors. Support a number
+ * of concurrent operations including CAS and order writes.
+ *
+ * <p>Also attempts to be more efficient with regards to false
+ * sharing by adding padding around the volatile field.
+ */
+publicclassSequenceextendsRhsPadding
+{
+
通过代码可以看到,sequence 中其实真正有意义的是 value 字段,因为需要在多线程环境下可见也 使用了volatile 关键字,而 LhsPadding 和 RhsPadding 分别在value 前后填充了各 7 个 long 型的变量,long 型的变量在 Java 中是占用 8 bytes,这样就相当于不管怎么样, value 都会单独使用一个缓存行,使得其不会产生 false sharing 的问题。
+packagejavax.servlet;
- HeapWord* result = op.result();
- bool ret_succeeded = op.prologue_succeeded() && op.pause_succeeded();
- assert(result == NULL || ret_succeeded,
- "the result should be NULL if the VM did not succeed");
- *succeeded = ret_succeeded;
+importjava.io.IOException;
- assert_heap_not_locked();
- return result;
-}
void VM_G1CollectForAllocation::doit() {
- G1CollectedHeap* g1h = G1CollectedHeap::heap();
- assert(!_should_initiate_conc_mark || g1h->should_do_concurrent_full_gc(_gc_cause),
- "only a GC locker, a System.gc(), stats update, whitebox, or a hum allocation induced GC should start a cycle");
+/**
+ * Defines methods that all servlets must implement.
+ *
+ * <p>
+ * A servlet is a small Java program that runs within a Web server. Servlets
+ * receive and respond to requests from Web clients, usually across HTTP, the
+ * HyperText Transfer Protocol.
+ *
+ * <p>
+ * To implement this interface, you can write a generic servlet that extends
+ * <code>javax.servlet.GenericServlet</code> or an HTTP servlet that extends
+ * <code>javax.servlet.http.HttpServlet</code>.
+ *
+ * <p>
+ * This interface defines methods to initialize a servlet, to service requests,
+ * and to remove a servlet from the server. These are known as life-cycle
+ * methods and are called in the following sequence:
+ * <ol>
+ * <li>The servlet is constructed, then initialized with the <code>init</code>
+ * method.
+ * <li>Any calls from clients to the <code>service</code> method are handled.
+ * <li>The servlet is taken out of service, then destroyed with the
+ * <code>destroy</code> method, then garbage collected and finalized.
+ * </ol>
+ *
+ * <p>
+ * In addition to the life-cycle methods, this interface provides the
+ * <code>getServletConfig</code> method, which the servlet can use to get any
+ * startup information, and the <code>getServletInfo</code> method, which allows
+ * the servlet to return basic information about itself, such as author,
+ * version, and copyright.
+ *
+ * @see GenericServlet
+ * @see javax.servlet.http.HttpServlet
+ */
+publicinterfaceServlet{
- if (_word_size > 0) {
- // An allocation has been requested. So, try to do that first.
- _result = g1h->attempt_allocation_at_safepoint(_word_size,
- false /* expect_null_cur_alloc_region */);
- if (_result != NULL) {
- // If we can successfully allocate before we actually do the
- // pause then we will consider this pause successful.
- _pause_succeeded = true;
- return;
- }
- }
+ /**
+ * Called by the servlet container to indicate to a servlet that the servlet
+ * is being placed into service.
+ *
+ * <p>
+ * The servlet container calls the <code>init</code> method exactly once
+ * after instantiating the servlet. The <code>init</code> method must
+ * complete successfully before the servlet can receive any requests.
+ *
+ * <p>
+ * The servlet container cannot place the servlet into service if the
+ * <code>init</code> method
+ * <ol>
+ * <li>Throws a <code>ServletException</code>
+ * <li>Does not return within a time period defined by the Web server
+ * </ol>
+ *
+ *
+ * @param config
+ * a <code>ServletConfig</code> object containing the servlet's
+ * configuration and initialization parameters
+ *
+ * @exception ServletException
+ * if an exception has occurred that interferes with the
+ * servlet's normal operation
+ *
+ * @see UnavailableException
+ * @see #getServletConfig
+ */
+ publicvoidinit(ServletConfig config)throwsServletException;
- GCCauseSetter x(g1h, _gc_cause);
- if (_should_initiate_conc_mark) {
- // It's safer to read old_marking_cycles_completed() here, given
- // that noone else will be updating it concurrently. Since we'll
- // only need it if we're initiating a marking cycle, no point in
- // setting it earlier.
- _old_marking_cycles_completed_before = g1h->old_marking_cycles_completed();
+ /**
+ *
+ * Returns a {@link ServletConfig} object, which contains initialization and
+ * startup parameters for this servlet. The <code>ServletConfig</code>
+ * object returned is the one passed to the <code>init</code> method.
+ *
+ * <p>
+ * Implementations of this interface are responsible for storing the
+ * <code>ServletConfig</code> object so that this method can return it. The
+ * {@link GenericServlet} class, which implements this interface, already
+ * does this.
+ *
+ * @return the <code>ServletConfig</code> object that initializes this
+ * servlet
+ *
+ * @see #init
+ */
+ publicServletConfiggetServletConfig();
- // At this point we are supposed to start a concurrent cycle. We
- // will do so if one is not already in progress.
- bool res = g1h->g1_policy()->force_initial_mark_if_outside_cycle(_gc_cause);
+ /**
+ * Called by the servlet container to allow the servlet to respond to a
+ * request.
+ *
+ * <p>
+ * This method is only called after the servlet's <code>init()</code> method
+ * has completed successfully.
+ *
+ * <p>
+ * The status code of the response always should be set for a servlet that
+ * throws or sends an error.
+ *
+ *
+ * <p>
+ * Servlets typically run inside multithreaded servlet containers that can
+ * handle multiple requests concurrently. Developers must be aware to
+ * synchronize access to any shared resources such as files, network
+ * connections, and as well as the servlet's class and instance variables.
+ * More information on multithreaded programming in Java is available in <a
+ * href
+ * ="http://java.sun.com/Series/Tutorial/java/threads/multithreaded.html">
+ * the Java tutorial on multi-threaded programming</a>.
+ *
+ *
+ * @param req
+ * the <code>ServletRequest</code> object that contains the
+ * client's request
+ *
+ * @param res
+ * the <code>ServletResponse</code> object that contains the
+ * servlet's response
+ *
+ * @exception ServletException
+ * if an exception occurs that interferes with the servlet's
+ * normal operation
+ *
+ * @exception IOException
+ * if an input or output exception occurs
+ */
+ publicvoidservice(ServletRequest req,ServletResponse res)
+ throwsServletException,IOException;
- // The above routine returns true if we were able to force the
- // next GC pause to be an initial mark; it returns false if a
- // marking cycle is already in progress.
- //
- // If a marking cycle is already in progress just return and skip the
- // pause below - if the reason for requesting this initial mark pause
- // was due to a System.gc() then the requesting thread should block in
- // doit_epilogue() until the marking cycle is complete.
- //
- // If this initial mark pause was requested as part of a humongous
- // allocation then we know that the marking cycle must just have
- // been started by another thread (possibly also allocating a humongous
- // object) as there was no active marking cycle when the requesting
- // thread checked before calling collect() in
- // attempt_allocation_humongous(). Retrying the GC, in this case,
- // will cause the requesting thread to spin inside collect() until the
- // just started marking cycle is complete - which may be a while. So
- // we do NOT retry the GC.
- if (!res) {
- assert(_word_size == 0, "Concurrent Full GC/Humongous Object IM shouldn't be allocating");
- if (_gc_cause != GCCause::_g1_humongous_allocation) {
- _should_retry_gc = true;
- }
- return;
- }
- }
-
- // Try a partial collection of some kind.
- _pause_succeeded = g1h->do_collection_pause_at_safepoint(_target_pause_time_ms);
-
- if (_pause_succeeded) {
- if (_word_size > 0) {
- // An allocation had been requested. Do it, eventually trying a stronger
- // kind of GC.
- _result = g1h->satisfy_failed_allocation(_word_size, &_pause_succeeded);
- } else {
- bool should_upgrade_to_full = !g1h->should_do_concurrent_full_gc(_gc_cause) &&
- !g1h->has_regions_left_for_allocation();
- if (should_upgrade_to_full) {
- // There has been a request to perform a GC to free some space. We have no
- // information on how much memory has been asked for. In case there are
- // absolutely no regions left to allocate into, do a maximally compacting full GC.
- log_info(gc, ergo)("Attempting maximally compacting collection");
- _pause_succeeded = g1h->do_full_collection(false, /* explicit gc */
- true /* clear_all_soft_refs */);
- }
- }
- guarantee(_pause_succeeded, "Elevated collections during the safepoint must always succeed.");
- } else {
- assert(_result == NULL, "invariant");
- // The only reason for the pause to not be successful is that, the GC locker is
- // active (or has become active since the prologue was executed). In this case
- // we should retry the pause after waiting for the GC locker to become inactive.
- _should_retry_gc = true;
- }
-}
G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
- assert_at_safepoint_on_vm_thread();
- guarantee(!is_gc_active(), "collection is not reentrant");
+ /**
+ * Returns information about the servlet, such as author, version, and
+ * copyright.
+ *
+ * <p>
+ * The string that this method returns should be plain text and not markup
+ * of any kind (such as HTML, XML, etc.).
+ *
+ * @return a <code>String</code> containing servlet information
+ */
+ publicStringgetServletInfo();
- if (GCLocker::check_active_before_gc()) {
- return false;
- }
+ /**
+ * Called by the servlet container to indicate to a servlet that the servlet
+ * is being taken out of service. This method is only called once all
+ * threads within the servlet's <code>service</code> method have exited or
+ * after a timeout period has passed. After the servlet container calls this
+ * method, it will not call the <code>service</code> method again on this
+ * servlet.
+ *
+ * <p>
+ * This method gives the servlet an opportunity to clean up any resources
+ * that are being held (for example, memory, file handles, threads) and make
+ * sure that any persistent state is synchronized with the servlet's current
+ * state in memory.
+ */
+ publicvoiddestroy();
+}
+
publicclassDemoInterceptorextendsHandlerInterceptorAdapter{
+ @Override
+ publicbooleanpreHandle(HttpServletRequest request,HttpServletResponse response,Object handler)throwsException{
+ System.out.println("preHandle test");
+ returntrue;
+ }
- _verifier->check_bitmaps("GC Start");
+ @Override
+ publicvoidpostHandle(HttpServletRequest request,HttpServletResponse response,Object handler,ModelAndView modelAndView)throwsException{
+ System.out.println("postHandle test");
+ }
+}
+@Aspect
+@Component
+publicclassDemoAspect{
-#if COMPILER2_OR_JVMCI
- DerivedPointerTable::clear();
-#endif
+ @Pointcut("execution( public * com.nicksxs.springbootdemo.demo.DemoController.*())")
+ publicvoidpoint(){
- // Please see comment in g1CollectedHeap.hpp and
- // G1CollectedHeap::ref_processing_init() to see how
- // reference processing currently works in G1.
+ }
- // Enable discovery in the STW reference processor
- _ref_processor_stw->enable_discovery();
+ @Before("point()")
+ publicvoiddoBefore(){
+ System.out.println("==doBefore==");
+ }
- {
- // We want to temporarily turn off discovery by the
- // CM ref processor, if necessary, and turn it back on
- // on again later if we do. Using a scoped
- // NoRefDiscovery object will do this.
- NoRefDiscovery no_cm_discovery(_ref_processor_cm);
+ @After("point()")
+ publicvoiddoAfter(){
+ System.out.println("==doAfter==");
+ }
+}
+@RestController
+publicclassDemoController{
- // Forget the current alloc region (we might even choose it to be part
- // of the collection set!).
- _allocator->release_mutator_alloc_region();
+ @RequestMapping("/hello")
+ @ResponseBody
+ publicStringhello(){
+ return"hello world";
+ }
+}
- // This timing is only used by the ergonomics to handle our pause target.
- // It is unclear why this should not include the full pause. We will
- // investigate this in CR 7178365.
- //
- // Preserving the old comment here if that helps the investigation:
- //
- // The elapsed time induced by the start time below deliberately elides
- // the possible verification above.
- double sample_start_time_sec = os::elapsedTime();
+
这里主要介绍这个比较新的垃圾回收器,在 G1 之前的垃圾回收器都是基于如下图的内存结构分布,有新生代,老年代和永久代(jdk8 之前),然后G1 往前的那些垃圾回收器都有个分代,比如 serial,parallel 等,一般有个应用的组合,最初的 serial 和 serial old,因为新生代和老年代的收集方式不太一样,新生代主要是标记复制,所以有 eden 跟两个 survival区,老年代一般用标记整理方式,而 G1 对这个不太一样。 看一下 G1 的内存分布 可以看到这有很大的不同,G1 通过将内存分成大小相等的 region,每个region是存在于一个连续的虚拟内存范围,对于某个 region 来说其角色是类似于原来的收集器的Eden、Survivor、Old Generation,这个具体在代码层面
+
// We encode the value of the heap region type so the generation can be
+ // determined quickly. The tag is split into two parts:
+ //
+ // major type (young, old, humongous, archive) : top N-1 bits
+ // minor type (eden / survivor, starts / cont hum, etc.) : bottom 1 bit
+ //
+ // If there's need to increase the number of minor types in the
+ // future, we'll have to increase the size of the latter and hence
+ // decrease the size of the former.
+ //
+ // 00000 0 [ 0] Free
+ //
+ // 00001 0 [ 2] Young Mask
+ // 00001 0 [ 2] Eden
+ // 00001 1 [ 3] Survivor
+ //
+ // 00010 0 [ 4] Humongous Mask
+ // 00100 0 [ 8] Pinned Mask
+ // 00110 0 [12] Starts Humongous
+ // 00110 1 [13] Continues Humongous
+ //
+ // 01000 0 [16] Old Mask
+ //
+ // 10000 0 [32] Archive Mask
+ // 11100 0 [56] Open Archive
+ // 11100 1 [57] Closed Archive
+ //
+ typedef enum {
+ FreeTag = 0,
- g1_policy()->record_collection_pause_start(sample_start_time_sec);
+ YoungMask = 2,
+ EdenTag = YoungMask,
+ SurvTag = YoungMask + 1,
- if (collector_state()->in_initial_mark_gc()) {
- concurrent_mark()->pre_initial_mark();
- }
+ HumongousMask = 4,
+ PinnedMask = 8,
+ StartsHumongousTag = HumongousMask | PinnedMask,
+ ContinuesHumongousTag = HumongousMask | PinnedMask + 1,
- g1_policy()->finalize_collection_set(target_pause_time_ms, &_survivor);
+ OldMask = 16,
+ OldTag = OldMask,
- evacuation_info.set_collectionset_regions(collection_set()->region_length());
+ // Archive regions are regions with immutable content (i.e. not reclaimed, and
+ // not allocated into during regular operation). They differ in the kind of references
+ // allowed for the contained objects:
+ // - Closed archive regions form a separate self-contained (closed) object graph
+ // within the set of all of these regions. No references outside of closed
+ // archive regions are allowed.
+ // - Open archive regions have no restrictions on the references of their objects.
+ // Objects within these regions are allowed to have references to objects
+ // contained in any other kind of regions.
+ ArchiveMask = 32,
+ OpenArchiveTag = ArchiveMask | PinnedMask | OldMask,
+ ClosedArchiveTag = ArchiveMask | PinnedMask | OldMask + 1
+ } Tag;
- // Make sure the remembered sets are up to date. This needs to be
- // done before register_humongous_regions_with_cset(), because the
- // remembered sets are used there to choose eager reclaim candidates.
- // If the remembered sets are not up to date we might miss some
- // entries that need to be handled.
- g1_rem_set()->cleanupHRRS();
+
void VM_G1CollectForAllocation::doit() {
+ G1CollectedHeap* g1h = G1CollectedHeap::heap();
+ assert(!_should_initiate_conc_mark || g1h->should_do_concurrent_full_gc(_gc_cause),
+ "only a GC locker, a System.gc(), stats update, whitebox, or a hum allocation induced GC should start a cycle");
- // We call this after finalize_cset() to
- // ensure that the CSet has been finalized.
- _cm->verify_no_cset_oops();
+ if (_word_size > 0) {
+ // An allocation has been requested. So, try to do that first.
+ _result = g1h->attempt_allocation_at_safepoint(_word_size,
+ false /* expect_null_cur_alloc_region */);
+ if (_result != NULL) {
+ // If we can successfully allocate before we actually do the
+ // pause then we will consider this pause successful.
+ _pause_succeeded = true;
+ return;
+ }
+ }
- if (_hr_printer.is_active()) {
- G1PrintCollectionSetClosure cl(&_hr_printer);
- _collection_set.iterate(&cl);
- }
+ GCCauseSetter x(g1h, _gc_cause);
+ if (_should_initiate_conc_mark) {
+ // It's safer to read old_marking_cycles_completed() here, given
+ // that noone else will be updating it concurrently. Since we'll
+ // only need it if we're initiating a marking cycle, no point in
+ // setting it earlier.
+ _old_marking_cycles_completed_before = g1h->old_marking_cycles_completed();
- // Initialize the GC alloc regions.
- _allocator->init_gc_alloc_regions(evacuation_info);
+ // At this point we are supposed to start a concurrent cycle. We
+ // will do so if one is not already in progress.
+ bool res = g1h->g1_policy()->force_initial_mark_if_outside_cycle(_gc_cause);
- G1ParScanThreadStateSet per_thread_states(this, workers()->active_workers(), collection_set()->young_region_length());
- pre_evacuate_collection_set();
+ // The above routine returns true if we were able to force the
+ // next GC pause to be an initial mark; it returns false if a
+ // marking cycle is already in progress.
+ //
+ // If a marking cycle is already in progress just return and skip the
+ // pause below - if the reason for requesting this initial mark pause
+ // was due to a System.gc() then the requesting thread should block in
+ // doit_epilogue() until the marking cycle is complete.
+ //
+ // If this initial mark pause was requested as part of a humongous
+ // allocation then we know that the marking cycle must just have
+ // been started by another thread (possibly also allocating a humongous
+ // object) as there was no active marking cycle when the requesting
+ // thread checked before calling collect() in
+ // attempt_allocation_humongous(). Retrying the GC, in this case,
+ // will cause the requesting thread to spin inside collect() until the
+ // just started marking cycle is complete - which may be a while. So
+ // we do NOT retry the GC.
+ if (!res) {
+ assert(_word_size == 0, "Concurrent Full GC/Humongous Object IM shouldn't be allocating");
+ if (_gc_cause != GCCause::_g1_humongous_allocation) {
+ _should_retry_gc = true;
+ }
+ return;
+ }
+ }
- // Actually do the work...
- evacuate_collection_set(&per_thread_states);
+ // Try a partial collection of some kind.
+ _pause_succeeded = g1h->do_collection_pause_at_safepoint(_target_pause_time_ms);
- post_evacuate_collection_set(evacuation_info, &per_thread_states);
+ if (_pause_succeeded) {
+ if (_word_size > 0) {
+ // An allocation had been requested. Do it, eventually trying a stronger
+ // kind of GC.
+ _result = g1h->satisfy_failed_allocation(_word_size, &_pause_succeeded);
+ } else {
+ bool should_upgrade_to_full = !g1h->should_do_concurrent_full_gc(_gc_cause) &&
+ !g1h->has_regions_left_for_allocation();
+ if (should_upgrade_to_full) {
+ // There has been a request to perform a GC to free some space. We have no
+ // information on how much memory has been asked for. In case there are
+ // absolutely no regions left to allocate into, do a maximally compacting full GC.
+ log_info(gc, ergo)("Attempting maximally compacting collection");
+ _pause_succeeded = g1h->do_full_collection(false, /* explicit gc */
+ true /* clear_all_soft_refs */);
+ }
+ }
+ guarantee(_pause_succeeded, "Elevated collections during the safepoint must always succeed.");
+ } else {
+ assert(_result == NULL, "invariant");
+ // The only reason for the pause to not be successful is that, the GC locker is
+ // active (or has become active since the prologue was executed). In this case
+ // we should retry the pause after waiting for the GC locker to become inactive.
+ _should_retry_gc = true;
+ }
+}
G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
+ assert_at_safepoint_on_vm_thread();
+ guarantee(!is_gc_active(), "collection is not reentrant");
- const size_t* surviving_young_words = per_thread_states.surviving_young_words();
- free_collection_set(&_collection_set, evacuation_info, surviving_young_words);
+ if (GCLocker::check_active_before_gc()) {
+ return false;
+ }
- eagerly_reclaim_humongous_regions();
+ _gc_timer_stw->register_gc_start();
- record_obj_copy_mem_stats();
- _survivor_evac_stats.adjust_desired_plab_sz();
- _old_evac_stats.adjust_desired_plab_sz();
+ GCIdMark gc_id_mark;
+ _gc_tracer_stw->report_gc_start(gc_cause(), _gc_timer_stw->gc_start());
- double start = os::elapsedTime();
- start_new_collection_set();
- g1_policy()->phase_times()->record_start_new_cset_time_ms((os::elapsedTime() - start) * 1000.0);
+ SvcGCMarker sgcm(SvcGCMarker::MINOR);
+ ResourceMark rm;
- if (evacuation_failed()) {
- set_used(recalculate_used());
- if (_archive_allocator != NULL) {
- _archive_allocator->clear_used();
- }
- for (uint i = 0; i < ParallelGCThreads; i++) {
- if (_evacuation_failed_info_array[i].has_failed()) {
- _gc_tracer_stw->report_evacuation_failed(_evacuation_failed_info_array[i]);
- }
- }
- } else {
- // The "used" of the the collection set have already been subtracted
- // when they were freed. Add in the bytes evacuated.
- increase_used(g1_policy()->bytes_copied_during_gc());
+ g1_policy()->note_gc_start();
+
+ wait_for_root_region_scanning();
+
+ print_heap_before_gc();
+ print_heap_regions();
+ trace_heap_before_gc(_gc_tracer_stw);
+
+ _verifier->verify_region_sets_optional();
+ _verifier->verify_dirty_young_regions();
+
+ // We should not be doing initial mark unless the conc mark thread is running
+ if (!_cm_thread->should_terminate()) {
+ // This call will decide whether this pause is an initial-mark
+ // pause. If it is, in_initial_mark_gc() will return true
+ // for the duration of this pause.
+ g1_policy()->decide_on_conc_mark_initiation();
+ }
+
+ // We do not allow initial-mark to be piggy-backed on a mixed GC.
+ assert(!collector_state()->in_initial_mark_gc() ||
+ collector_state()->in_young_only_phase(), "sanity");
+
+ // We also do not allow mixed GCs during marking.
+ assert(!collector_state()->mark_or_rebuild_in_progress() || collector_state()->in_young_only_phase(), "sanity");
+
+ // Record whether this pause is an initial mark. When the current
+ // thread has completed its logging output and it's safe to signal
+ // the CM thread, the flag's value in the policy has been reset.
+ bool should_start_conc_mark = collector_state()->in_initial_mark_gc();
+
+ // Inner scope for scope based logging, timers, and stats collection
+ {
+ EvacuationInfo evacuation_info;
+
+ if (collector_state()->in_initial_mark_gc()) {
+ // We are about to start a marking cycle, so we increment the
+ // full collection counter.
+ increment_old_marking_cycles_started();
+ _cm->gc_tracer_cm()->set_gc_cause(gc_cause());
+ }
+
+ _gc_tracer_stw->report_yc_type(collector_state()->yc_type());
+
+ GCTraceCPUTime tcpu;
+
+ G1HeapVerifier::G1VerifyType verify_type;
+ FormatBuffer<> gc_string("Pause Young ");
+ if (collector_state()->in_initial_mark_gc()) {
+ gc_string.append("(Concurrent Start)");
+ verify_type = G1HeapVerifier::G1VerifyConcurrentStart;
+ } else if (collector_state()->in_young_only_phase()) {
+ if (collector_state()->in_young_gc_before_mixed()) {
+ gc_string.append("(Prepare Mixed)");
+ } else {
+ gc_string.append("(Normal)");
+ }
+ verify_type = G1HeapVerifier::G1VerifyYoungNormal;
+ } else {
+ gc_string.append("(Mixed)");
+ verify_type = G1HeapVerifier::G1VerifyMixed;
+ }
+ GCTraceTime(Info, gc) tm(gc_string, NULL, gc_cause(), true);
+
+ uint active_workers = AdaptiveSizePolicy::calc_active_workers(workers()->total_workers(),
+ workers()->active_workers(),
+ Threads::number_of_non_daemon_threads());
+ active_workers = workers()->update_active_workers(active_workers);
+ log_info(gc,task)("Using %u workers of %u for evacuation", active_workers, workers()->total_workers());
+
+ TraceCollectorStats tcs(g1mm()->incremental_collection_counters());
+ TraceMemoryManagerStats tms(&_memory_manager, gc_cause(),
+ collector_state()->yc_type() == Mixed /* allMemoryPoolsAffected */);
+
+ G1HeapTransition heap_transition(this);
+ size_t heap_used_bytes_before_gc = used();
+
+ // Don't dynamically change the number of GC threads this early. A value of
+ // 0 is used to indicate serial work. When parallel work is done,
+ // it will be set.
+
+ { // Call to jvmpi::post_class_unload_events must occur outside of active GC
+ IsGCActiveMark x;
+
+ gc_prologue(false);
+
+ if (VerifyRememberedSets) {
+ log_info(gc, verify)("[Verifying RemSets before GC]");
+ VerifyRegionRemSetClosure v_cl;
+ heap_region_iterate(&v_cl);
+ }
+
+ _verifier->verify_before_gc(verify_type);
+
+ _verifier->check_bitmaps("GC Start");
+
+#if COMPILER2_OR_JVMCI
+ DerivedPointerTable::clear();
+#endif
+
+ // Please see comment in g1CollectedHeap.hpp and
+ // G1CollectedHeap::ref_processing_init() to see how
+ // reference processing currently works in G1.
+
+ // Enable discovery in the STW reference processor
+ _ref_processor_stw->enable_discovery();
+
+ {
+ // We want to temporarily turn off discovery by the
+ // CM ref processor, if necessary, and turn it back on
+ // on again later if we do. Using a scoped
+ // NoRefDiscovery object will do this.
+ NoRefDiscovery no_cm_discovery(_ref_processor_cm);
+
+ // Forget the current alloc region (we might even choose it to be part
+ // of the collection set!).
+ _allocator->release_mutator_alloc_region();
+
+ // This timing is only used by the ergonomics to handle our pause target.
+ // It is unclear why this should not include the full pause. We will
+ // investigate this in CR 7178365.
+ //
+ // Preserving the old comment here if that helps the investigation:
+ //
+ // The elapsed time induced by the start time below deliberately elides
+ // the possible verification above.
+ double sample_start_time_sec = os::elapsedTime();
+
+ g1_policy()->record_collection_pause_start(sample_start_time_sec);
+
+ if (collector_state()->in_initial_mark_gc()) {
+ concurrent_mark()->pre_initial_mark();
+ }
+
+ g1_policy()->finalize_collection_set(target_pause_time_ms, &_survivor);
+
+ evacuation_info.set_collectionset_regions(collection_set()->region_length());
+
+ // Make sure the remembered sets are up to date. This needs to be
+ // done before register_humongous_regions_with_cset(), because the
+ // remembered sets are used there to choose eager reclaim candidates.
+ // If the remembered sets are not up to date we might miss some
+ // entries that need to be handled.
+ g1_rem_set()->cleanupHRRS();
+
+ register_humongous_regions_with_cset();
+
+ assert(_verifier->check_cset_fast_test(), "Inconsistency in the InCSetState table.");
+
+ // We call this after finalize_cset() to
+ // ensure that the CSet has been finalized.
+ _cm->verify_no_cset_oops();
+
+ if (_hr_printer.is_active()) {
+ G1PrintCollectionSetClosure cl(&_hr_printer);
+ _collection_set.iterate(&cl);
+ }
+
+ // Initialize the GC alloc regions.
+ _allocator->init_gc_alloc_regions(evacuation_info);
+
+ G1ParScanThreadStateSet per_thread_states(this, workers()->active_workers(), collection_set()->young_region_length());
+ pre_evacuate_collection_set();
+
+ // Actually do the work...
+ evacuate_collection_set(&per_thread_states);
+
+ post_evacuate_collection_set(evacuation_info, &per_thread_states);
+
+ const size_t* surviving_young_words = per_thread_states.surviving_young_words();
+ free_collection_set(&_collection_set, evacuation_info, surviving_young_words);
+
+ eagerly_reclaim_humongous_regions();
+
+ record_obj_copy_mem_stats();
+ _survivor_evac_stats.adjust_desired_plab_sz();
+ _old_evac_stats.adjust_desired_plab_sz();
+
+ double start = os::elapsedTime();
+ start_new_collection_set();
+ g1_policy()->phase_times()->record_start_new_cset_time_ms((os::elapsedTime() - start) * 1000.0);
+
+ if (evacuation_failed()) {
+ set_used(recalculate_used());
+ if (_archive_allocator != NULL) {
+ _archive_allocator->clear_used();
+ }
+ for (uint i = 0; i < ParallelGCThreads; i++) {
+ if (_evacuation_failed_info_array[i].has_failed()) {
+ _gc_tracer_stw->report_evacuation_failed(_evacuation_failed_info_array[i]);
+ }
+ }
+ } else {
+ // The "used" of the the collection set have already been subtracted
+ // when they were freed. Add in the bytes evacuated.
+ increase_used(g1_policy()->bytes_copied_during_gc());
}
if (collector_state()->in_initial_mark_gc()) {
@@ -3007,66 +3239,219 @@ Node *clone(Node *graph) {
publicintmaxSubArray(int[] nums){
+ int max = nums[0];
+ int sum = nums[0];
+ for(int i =1; i < nums.length; i++){
+ // 这里最重要的就是这一行了,其实就是如果前面的 sum 是小于 0 的,那么就不需要前面的 sum,反正加上了还不如不加大
+ sum =Math.max(nums[i], sum + nums[i]);
+ // max 是用来承载最大值的
+ max =Math.max(max, sum);
+ }
+ return max;
+ }
+]]>
+
+ Java
+ leetcode
+ java
+ DP
+ DP
+
+
+ leetcode
+ java
+ 题解
+ DP
+
+
+
+ Leetcode 1115 交替打印 FooBar ( Print FooBar Alternately *Medium* ) 题解分析
+ /2022/05/01/Leetcode-1115-%E4%BA%A4%E6%9B%BF%E6%89%93%E5%8D%B0-FooBar-Print-FooBar-Alternately-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 无聊想去 roll 一题就看到了有并发题,就找到了这题,其实一眼看我的想法也是用信号量,但是用 condition 应该也是可以处理的,不过这类问题好像本地有点难调,因为它好像是抽取代码执行的,跟直观的逻辑比较不一样 Suppose you are given the following code:
+
classFooBar{
+ publicvoidfoo(){
+ for(int i =0; i < n; i++){
+ print("foo");
+ }
+ }
+
+ publicvoidbar(){
+ for(int i =0; i < n; i++){
+ print("bar");
+ }
+ }
+}
+
The same instance of FooBar will be passed to two different threads:
+
+
thread A will call foo(), while
+
thread B will call bar(). Modify the given program to output "foobar" n times.
+
+
示例
Example 1:
+
Input: n = 1 Output: “foobar” Explanation: There are two threads being fired asynchronously. One of them calls foo(), while the other calls bar(). “foobar” is being output 1 time.
+
+
Example 2:
+
Input: n = 2 Output: “foobarfoobar” Explanation: “foobar” is being output 2 times.
+
+
题解
简析
其实用信号量是很直观的,就是让打印 foo 的线程先拥有信号量,打印后就等待,给 bar 信号量 + 1,然后 bar 线程运行打印消耗 bar 信号量,再给 foo 信号量 + 1
+
code
classFooBar{
+
+ privatefinalSemaphore foo =newSemaphore(1);
+ privatefinalSemaphore bar =newSemaphore(0);
+ privateint n;
+
+ publicFooBar(int n){
+ this.n = n;
+ }
+
+ publicvoidfoo(Runnable printFoo)throwsInterruptedException{
+
+ for(int i =0; i < n; i++){
+ foo.acquire();
+ // printFoo.run() outputs "foo". Do not change or remove this line.
+ printFoo.run();
+ bar.release();
+ }
+ }
+
+ publicvoidbar(Runnable printBar)throwsInterruptedException{
+
+ for(int i =0; i < n; i++){
+ bar.acquire();
+ // printBar.run() outputs "bar". Do not change or remove this line.
+ printBar.run();
+ foo.release();
+ }
+ }
+}
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
+
The path sum of a path is the sum of the node’s values in the path.
+
Given the root of a binary tree, return the maximum path sum of any path.
publicvoidrun()
- {
- if(running.compareAndSet(IDLE,RUNNING))
- {
- sequenceBarrier.clearAlert();
-
- notifyStart();
- try
- {
- if(running.get()==RUNNING)
- {
- processEvents();
- }
- }
- finally
- {
- notifyShutdown();
- running.set(IDLE);
- }
- }
- else
- {
- // This is a little bit of guess work. The running state could of changed to HALTED by
- // this point. However, Java does not have compareAndExchange which is the only way
- // to get it exactly correct.
- if(running.get()==RUNNING)
- {
- thrownewIllegalStateException("Thread is already running");
- }
- else
- {
- earlyExit();
- }
- }
- }
Given a 2D grid of size m x n and an integer k. You need to shift the grid k times.
+
In one shift operation:
+
Element at grid[i][j] moves to grid[i][j + 1]. Element at grid[i][n - 1] moves to grid[i + 1][0]. Element at grid[m - 1][n - 1] moves to grid[0][0]. Return the 2D grid after applying shift operation k times.
+
示例
Example 1:
-
Input: nums = [-2,1,-3,4,-1,2,1,-5,4] Output: 6 Explanation: [4,-1,2,1] has the largest sum = 6.
+
Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 1 Output: [[9,1,2],[3,4,5],[6,7,8]]
-
Example 2:
+
Example 2:
-
Input: nums = [1] Output: 1
+
Input: grid = [[3,8,1,9],[19,7,2,5],[4,6,11,10],[12,0,21,13]], k = 4 Output: [[12,0,21,13],[3,8,1,9],[19,7,2,5],[4,6,11,10]]
-
Example 3:
-
-
Input: nums = [5,4,-1,7,8] Output: 23
+
Example 3:
+
Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 9 Output: [[1,2,3],[4,5,6],[7,8,9]]
publicintmaxSubArray(int[] nums){
- int max = nums[0];
- int sum = nums[0];
- for(int i =1; i < nums.length; i++){
- // 这里最重要的就是这一行了,其实就是如果前面的 sum 是小于 0 的,那么就不需要前面的 sum,反正加上了还不如不加大
- sum =Math.max(nums[i], sum + nums[i]);
- // max 是用来承载最大值的
- max =Math.max(max, sum);
+
提示
+
m == grid.length
+
n == grid[i].length
+
1 <= m <= 50
+
1 <= n <= 50
+
-1000 <= grid[i][j] <= 1000
+
0 <= k <= 100
+
+
解析
这个题主要是矩阵或者说数组的操作,并且题目要返回的是个 List,所以也不用原地操作,只需要找对位置就可以了,k 是多少就相当于让这个二维数组头尾衔接移动 k 个元素
+
代码
publicList<List<Integer>>shiftGrid(int[][] grid,int k){
+ // 行数
+ int m = grid.length;
+ // 列数
+ int n = grid[0].length;
+ // 偏移值,取下模
+ k = k %(m * n);
+ // 反向取下数量,因为我打算直接从头填充新的矩阵
+ /*
+ * 比如
+ * 1 2 3
+ * 4 5 6
+ * 7 8 9
+ * 需要变成
+ * 9 1 2
+ * 3 4 5
+ * 6 7 8
+ * 就要从 9 开始填充
+ */
+ int reverseK = m * n - k;
+ List<List<Integer>> matrix =newArrayList<>();
+ // 这类就是两层循环
+ for(int i =0; i < m; i++){
+ List<Integer> line =newArrayList<>();
+ for(int j =0; j < n; j++){
+ // 数量会随着循环迭代增长, 确认是第几个
+ int currentNum = reverseK + i * n +(j +1);
+ // 这里处理下到达矩阵末尾后减掉 m * n
+ if(currentNum > m * n){
+ currentNum -= m * n;
+ }
+ // 根据矩阵列数 n 算出在原来矩阵的位置
+ int last =(currentNum -1)% n;
+ int passLine =(currentNum -1)/ n;
+
+ line.add(grid[passLine][last]);
+ }
+ matrix.add(line);}
- return max;
- }
]]>
+ return matrix;
+ }
+
+
结果数据
比较慢
+]]>Javaleetcode
@@ -3350,206 +3670,245 @@ Output: 0<
leetcodejava题解
+ Shift 2D Grid
- Leetcode 1115 交替打印 FooBar ( Print FooBar Alternately *Medium* ) 题解分析
- /2022/05/01/Leetcode-1115-%E4%BA%A4%E6%9B%BF%E6%89%93%E5%8D%B0-FooBar-Print-FooBar-Alternately-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 无聊想去 roll 一题就看到了有并发题,就找到了这题,其实一眼看我的想法也是用信号量,但是用 condition 应该也是可以处理的,不过这类问题好像本地有点难调,因为它好像是抽取代码执行的,跟直观的逻辑比较不一样 Suppose you are given the following code:
-
classFooBar{
- publicvoidfoo(){
- for(int i =0; i < n; i++){
- print("foo");
- }
- }
-
- publicvoidbar(){
- for(int i =0; i < n; i++){
- print("bar");
- }
- }
-}
-
The same instance of FooBar will be passed to two different threads:
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time. 设计一个栈,支持压栈,出站,获取栈顶元素,通过常数级复杂度获取栈中的最小元素
-
thread A will call foo(), while
-
thread B will call bar(). Modify the given program to output "foobar" n times.
-
-
示例
Example 1:
-
Input: n = 1 Output: “foobar” Explanation: There are two threads being fired asynchronously. One of them calls foo(), while the other calls bar(). “foobar” is being output 1 time.
-
-
Example 2:
-
Input: n = 2 Output: “foobarfoobar” Explanation: “foobar” is being output 2 times.
-
-
题解
简析
其实用信号量是很直观的,就是让打印 foo 的线程先拥有信号量,打印后就等待,给 bar 信号量 + 1,然后 bar 线程运行打印消耗 bar 信号量,再给 foo 信号量 + 1
写一个程序找出两个单向链表的交叉起始点,可能是我英语不好,图里画的其实还有一点是交叉以后所有节点都是相同的 Write a program to find the node at which the intersection of two singly linked lists begins.
+
For example, the following two linked lists: begin to intersect at node c1.
+
Example 1:
+
Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
+Output: Reference of the node with value = 8
+Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
Given a 2D grid of size m x n and an integer k. You need to shift the grid k times.
-
In one shift operation:
-
Element at grid[i][j] moves to grid[i][j + 1]. Element at grid[i][n - 1] moves to grid[i + 1][0]. Element at grid[m - 1][n - 1] moves to grid[0][0]. Return the 2D grid after applying shift operation k times.
-
示例
Example 1:
-
-
Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 1 Output: [[9,1,2],[3,4,5],[6,7,8]]
-
-
Example 2:
-
-
Input: grid = [[3,8,1,9],[19,7,2,5],[4,6,11,10],[12,0,21,13]], k = 4 Output: [[12,0,21,13],[3,8,1,9],[19,7,2,5],[4,6,11,10]]
-
-
Example 3:
-
Input: grid = [[1,2,3],[4,5,6],[7,8,9]], k = 9 Output: [[1,2,3],[4,5,6],[7,8,9]]
-
-
提示
-
m == grid.length
-
n == grid[i].length
-
1 <= m <= 50
-
1 <= n <= 50
-
-1000 <= grid[i][j] <= 1000
-
0 <= k <= 100
-
-
解析
这个题主要是矩阵或者说数组的操作,并且题目要返回的是个 List,所以也不用原地操作,只需要找对位置就可以了,k 是多少就相当于让这个二维数组头尾衔接移动 k 个元素
-
代码
publicList<List<Integer>>shiftGrid(int[][] grid,int k){
- // 行数
- int m = grid.length;
- // 列数
- int n = grid[0].length;
- // 偏移值,取下模
- k = k %(m * n);
- // 反向取下数量,因为我打算直接从头填充新的矩阵
- /*
- * 比如
- * 1 2 3
- * 4 5 6
- * 7 8 9
- * 需要变成
- * 9 1 2
- * 3 4 5
- * 6 7 8
- * 就要从 9 开始填充
- */
- int reverseK = m * n - k;
- List<List<Integer>> matrix =newArrayList<>();
- // 这类就是两层循环
- for(int i =0; i < m; i++){
- List<Integer> line =newArrayList<>();
- for(int j =0; j < n; j++){
- // 数量会随着循环迭代增长, 确认是第几个
- int currentNum = reverseK + i * n +(j +1);
- // 这里处理下到达矩阵末尾后减掉 m * n
- if(currentNum > m * n){
- currentNum -= m * n;
- }
- // 根据矩阵列数 n 算出在原来矩阵的位置
- int last =(currentNum -1)% n;
- int passLine =(currentNum -1)/ n;
+ Leetcode 2 Add Two Numbers 题解分析
+ /2020/10/11/Leetcode-2-Add-Two-Numbers-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 又 roll 到了一个以前做过的题,不过现在用 Java 也来写一下,是 easy 级别的,所以就简单说下
+
简要介绍
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
+
You may assume the two numbers do not contain any leading zero, except the number 0 itself. 就是给了两个链表,用来表示两个非负的整数,在链表中倒序放着,每个节点包含一位的数字,把他们加起来以后也按照原来的链表结构输出
Given a singly linked list, determine if it is a palindrome. 给定一个单向链表,判断是否是回文链表
+
例一 Example 1:
Input: 1->2 Output: false
+
例二 Example 2:
Input: 1->2->2->1 Output: true
+
挑战下自己
Follow up: Could you do it in O(n) time and O(1) space?
+
简要分析
首先这是个单向链表,如果是双向的就可以一个从头到尾,一个从尾到头,显然那样就没啥意思了,然后想过要不找到中点,然后用一个栈,把前一半塞进栈里,但是这种其实也比较麻烦,比如长度是奇偶数,然后如何找到中点,这倒是可以借助于双指针,还是比较麻烦,再想一想,回文链表,就跟最开始的一样,链表只有单向的,我用个栈不就可以逆向了么,先把链表整个塞进栈里,然后在一个个 pop 出来跟链表从头开始比较,全对上了就是回文了
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
-
The path sum of a path is the sum of the node’s values in the path.
-
Given the root of a binary tree, return the maximum path sum of any path.
+ Leetcode 236 二叉树的最近公共祖先(Lowest Common Ancestor of a Binary Tree) 题解分析
+ /2021/05/23/Leetcode-236-%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88-Lowest-Common-Ancestor-of-a-Binary-Tree-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
+
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
+
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
+
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
+
代码
publicTreeNodelowestCommonAncestor(TreeNode root,TreeNode p,TreeNode q){
+ // 如果当前节点就是 p 或者是 q 的时候,就直接返回了
+ // 当没找到,即 root == null 的时候也会返回 null,这是个重要的点
+ if(root ==null|| root == p || root == q)return root;
+ // 在左子树中找 p 和 q
+ TreeNode left =lowestCommonAncestor(root.left, p, q);
+ // 在右子树中找 p 和 q
+ TreeNode right =lowestCommonAncestor(root.right, p, q);
+ // 当左边是 null 就直接返回右子树,但是这里不表示右边不是 null,所以这个顺序是不影响的
+ // 考虑一种情况,如果一个节点的左右子树都是 null,那么其实对于这个节点来说首先两个子树分别调用
+ // lowestCommonAncestor会在开头就返回 null,那么就是上面 left 跟 right 都是 null,然后走下面的判断的时候
+ // 其实第一个 if 就返回了 null,如此递归返回就能达到当子树中没有找到 p 或者 q 的时候只返回 null
+ if(left ==null){
+ return right;
+ }elseif(right ==null){
+ return left;
+ }else{
+ return root;
+ }
+// if (right == null) {
+// return left;
+// } else if (left == null) {
+// return right;
+// } else {
+// return root;
+// }
+// return left == null ? right : right == null ? left : root;
+ }
]]>Javaleetcode
- Binary Tree
- java
- Binary Tree
+ Lowest Common Ancestor of a Binary Treeleetcodejava题解
- Binary Tree
- 二叉树
+ Lowest Common Ancestor of a Binary Tree
- Leetcode 16 最接近的三数之和 ( 3Sum Closest *Medium* ) 题解分析
- /2022/08/06/Leetcode-16-%E6%9C%80%E6%8E%A5%E8%BF%91%E7%9A%84%E4%B8%89%E6%95%B0%E4%B9%8B%E5%92%8C-3Sum-Closest-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍
Given an integer array nums of length n and an integer target, find three integers in nums such that the sum is closest to target.
-
Return the sum of the three integers.
-
You may assume that each input would have exactly one solution.
-
简单解释下就是之前是要三数之和等于目标值,现在是找到最接近的三数之和。
-
示例
Example 1:
-
Input: nums = [-1,2,1,-4], target = 1 Output: 2 Explanation: The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).
+ Leetcode 349 两个数组的交集 ( Intersection of Two Arrays *Easy* ) 题解分析
+ /2022/03/07/Leetcode-349-%E4%B8%A4%E4%B8%AA%E6%95%B0%E7%BB%84%E7%9A%84%E4%BA%A4%E9%9B%86-Intersection-of-Two-Arrays-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
-
You may assume the two numbers do not contain any leading zero, except the number 0 itself. 就是给了两个链表,用来表示两个非负的整数,在链表中倒序放着,每个节点包含一位的数字,把他们加起来以后也按照原来的链表结构输出
这里唯二需要注意的就是两个点,一个是循环条件需要包含进位值还存在的情况,还有一个是最后一个节点,如果是空的了,就不要在 new 一个出来了,写的比较挫
-]]>
+ return outer;
+ }]]>
Javaleetcode
- java
- linked list
- linked listleetcodejava题解
- linked list
+ Intersection of Two Arrays
@@ -4137,131 +4376,6 @@ Output: [8,9,9,9,0,0,0,1]First Bad Version
-
- Leetcode 160 相交链表(intersection-of-two-linked-lists) 题解分析
- /2021/01/10/Leetcode-160-%E7%9B%B8%E4%BA%A4%E9%93%BE%E8%A1%A8-intersection-of-two-linked-lists-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍
写一个程序找出两个单向链表的交叉起始点,可能是我英语不好,图里画的其实还有一点是交叉以后所有节点都是相同的 Write a program to find the node at which the intersection of two singly linked lists begins.
-
For example, the following two linked lists: begin to intersect at node c1.
-
Example 1:
-
Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
-Output: Reference of the node with value = 8
-Input Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
Given a singly linked list, determine if it is a palindrome. 给定一个单向链表,判断是否是回文链表
-
例一 Example 1:
Input: 1->2 Output: false
-
例二 Example 2:
Input: 1->2->2->1 Output: true
-
挑战下自己
Follow up: Could you do it in O(n) time and O(1) space?
-
简要分析
首先这是个单向链表,如果是双向的就可以一个从头到尾,一个从尾到头,显然那样就没啥意思了,然后想过要不找到中点,然后用一个栈,把前一半塞进栈里,但是这种其实也比较麻烦,比如长度是奇偶数,然后如何找到中点,这倒是可以借助于双指针,还是比较麻烦,再想一想,回文链表,就跟最开始的一样,链表只有单向的,我用个栈不就可以逆向了么,先把链表整个塞进栈里,然后在一个个 pop 出来跟链表从头开始比较,全对上了就是回文了
两个数组的交集,最简单就是两层循环了把两个都存在的找出来,不过还有个要去重的问题,稍微思考下可以使用集合 set 来处理,先把一个数组全丢进去,再对比另外一个,如果出现在第一个集合里就丢进一个新的集合,最后转换成数组,这次我稍微取了个巧,因为看到了提示里的条件,两个数组中的元素都是不大于 1000 的,所以就搞了个 1000 长度的数组,如果在第一个数组出现,就在对应的下标设置成 1,如果在第二个数组也出现了就加 1,
-
code
publicint[]intersection(int[] nums1,int[] nums2){
- // 大小是 1000 的数组,如果没有提示的条件就没法这么做
- // define a array which size is 1000, and can not be done like this without the condition in notice
- int[] inter =newint[1000];
- int[] outer;
- int m =0;
- for(int j : nums1){
- // 这里得是设置成 1,因为有可能 nums1 就出现了重复元素,如果直接++会造成结果重复
- // need to be set 1, cause element in nums1 can be duplicated
- inter[j]=1;
- }
- for(int j : nums2){
- if(inter[j]>0){
- // 这里可以直接+1,因为后面判断只需要判断大于 1
- // just plus 1, cause we can judge with condition that larger than 1
- inter[j]+=1;
- }
+
Javaleetcode
@@ -4394,55 +4513,65 @@ Output: 0<
leetcodejava题解
- Intersection of Two Arrays
+ Median of Two Sorted Arrays
- Leetcode 236 二叉树的最近公共祖先(Lowest Common Ancestor of a Binary Tree) 题解分析
- /2021/05/23/Leetcode-236-%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88-Lowest-Common-Ancestor-of-a-Binary-Tree-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
-
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
-
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
-
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
+
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation. 如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
]]>Javaleetcode
- Lowest Common Ancestor of a Binary Tree
+ Rotate Imageleetcodejava题解
- Lowest Common Ancestor of a Binary Tree
+ Rotate Image
+ 矩阵
@@ -4520,83 +4649,12 @@ maxR[n -
- Leetcode 4 寻找两个正序数组的中位数 ( Median of Two Sorted Arrays *Hard* ) 题解分析
- /2022/03/27/Leetcode-4-%E5%AF%BB%E6%89%BE%E4%B8%A4%E4%B8%AA%E6%AD%A3%E5%BA%8F%E6%95%B0%E7%BB%84%E7%9A%84%E4%B8%AD%E4%BD%8D%E6%95%B0-Median-of-Two-Sorted-Arrays-Hard-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
-
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation. 如图,这道题以前做过,其实一看有点蒙,好像规则很容易描述,但是代码很难写,因为要类似于贪吃蛇那样,后来想着应该会有一些特殊的技巧,比如翻转等
You start at the cell (rStart, cStart) of an rows x cols grid facing east. The northwest corner is at the first row and column in the grid, and the southeast corner is at the last row and column.
+
You will walk in a clockwise spiral shape to visit every position in this grid. Whenever you move outside the grid’s boundary, we continue our walk outside the grid (but may return to the grid boundary later.). Eventually, we reach all rows * cols spaces of the grid.
+
Return an array of coordinates representing the positions of the grid in the order you visited them.
-]]>
-
- C++
-
-
- c++
- mfc
-
- Maven实用小技巧/2020/02/16/Maven%E5%AE%9E%E7%94%A8%E5%B0%8F%E6%8A%80%E5%B7%A7/
@@ -5317,6 +5370,88 @@ OS name: "mac os x", version: "10.14.6", arch: "x86_64&
Maven
+
+ Number of 1 Bits
+ /2015/03/11/Number-Of-1-Bits/
+ Number of 1 Bits
Write a function that takes an unsigned integer and returns the number of ’1’ bits it has (also known as the Hamming weight). For example, the 32-bit integer ‘11’ has binary representation 00000000000000000000000000001011, so the function should return 3.
+
+
分析
从1位到2位到4位逐步的交换
+
+
code
int hammingWeight(uint32_t n) {
+ const uint32_t m1 = 0x55555555; //binary: 0101...
+ const uint32_t m2 = 0x33333333; //binary: 00110011..
+ const uint32_t m4 = 0x0f0f0f0f; //binary: 4 zeros, 4 ones ...
+ const uint32_t m8 = 0x00ff00ff; //binary: 8 zeros, 8 ones ...
+ const uint32_t m16 = 0x0000ffff; //binary: 16 zeros, 16 ones ...
+
+ n = (n & m1 ) + ((n >> 1) & m1 ); //put count of each 2 bits into those 2 bits
+ n = (n & m2 ) + ((n >> 2) & m2 ); //put count of each 4 bits into those 4 bits
+ n = (n & m4 ) + ((n >> 4) & m4 ); //put count of each 8 bits into those 8 bits
+ n = (n & m8 ) + ((n >> 8) & m8 ); //put count of each 16 bits into those 16 bits
+ n = (n & m16) + ((n >> 16) & m16); //put count of each 32 bits into those 32 bits
+ return n;
+
+}
]]>
+
+ leetcode
+
+
+ leetcode
+ c++
+
+
+
+ Leetcode 747 至少是其他数字两倍的最大数 ( Largest Number At Least Twice of Others *Easy* ) 题解分析
+ /2022/10/02/Leetcode-747-%E8%87%B3%E5%B0%91%E6%98%AF%E5%85%B6%E4%BB%96%E6%95%B0%E5%AD%97%E4%B8%A4%E5%80%8D%E7%9A%84%E6%9C%80%E5%A4%A7%E6%95%B0-Largest-Number-At-Least-Twice-of-Others-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
+ 题目介绍
You are given an integer array nums where the largest integer is unique.
+
Determine whether the largest element in the array is at least twice as much as every other number in the array. If it is, return the index of the largest element, or return -1 otherwise. 确认在数组中的最大数是否是其余任意数的两倍大及以上,如果是返回索引,如果不是返回-1
+
示例
Example 1:
+
Input: nums = [3,6,1,0] Output: 1 Explanation: 6 is the largest integer. For every other number in the array x, 6 is at least twice as big as x. The index of value 6 is 1, so we return 1.
+
+
Example 2:
+
Input: nums = [1,2,3,4] Output: -1 Explanation: 4 is less than twice the value of 3, so we return -1.
publicintdominantIndex(int[] nums){
+ int largest =Integer.MIN_VALUE;
+ int second =Integer.MIN_VALUE;
+ int largestIndex =-1;
+ for(int i =0; i < nums.length; i++){
+ // 如果有最大的就更新,同时更新最大值和第二大的
+ if(nums[i]> largest){
+ second = largest;
+ largest = nums[i];
+ largestIndex = i;
+ }elseif(nums[i]> second){
+ // 没有超过最大的,但是比第二大的更大就更新第二大的
+ second = nums[i];
+ }
+ }
+
+ // 判断下是否符合题目要求,要是所有值的两倍及以上
+ if(largest >=2* second){
+ return largestIndex;
+ }else{
+ return-1;
+ }
+}
+
通过图
第一次错了是把第二大的情况只考虑第一种,也有可能最大值完全没经过替换就变成最大值了
+]]>
+
+ Java
+ leetcode
+
+
+ leetcode
+ java
+ 题解
+
+ Path Sum/2015/01/04/Path-Sum/
@@ -5369,36 +5504,6 @@ public:
c++
-
- Number of 1 Bits
- /2015/03/11/Number-Of-1-Bits/
- Number of 1 Bits
Write a function that takes an unsigned integer and returns the number of ’1’ bits it has (also known as the Hamming weight). For example, the 32-bit integer ‘11’ has binary representation 00000000000000000000000000001011, so the function should return 3.
-
-
分析
从1位到2位到4位逐步的交换
-
-
code
int hammingWeight(uint32_t n) {
- const uint32_t m1 = 0x55555555; //binary: 0101...
- const uint32_t m2 = 0x33333333; //binary: 00110011..
- const uint32_t m4 = 0x0f0f0f0f; //binary: 4 zeros, 4 ones ...
- const uint32_t m8 = 0x00ff00ff; //binary: 8 zeros, 8 ones ...
- const uint32_t m16 = 0x0000ffff; //binary: 16 zeros, 16 ones ...
-
- n = (n & m1 ) + ((n >> 1) & m1 ); //put count of each 2 bits into those 2 bits
- n = (n & m2 ) + ((n >> 2) & m2 ); //put count of each 4 bits into those 4 bits
- n = (n & m4 ) + ((n >> 4) & m4 ); //put count of each 8 bits into those 8 bits
- n = (n & m8 ) + ((n >> 8) & m8 ); //put count of each 16 bits into those 16 bits
- n = (n & m16) + ((n >> 16) & m16); //put count of each 32 bits into those 32 bits
- return n;
-
-}
]]>
-
- leetcode
-
-
- leetcode
- c++
-
- Redis_分布式锁/2019/12/10/Redis-Part-1/
@@ -5465,80 +5570,6 @@ public:
c++
-
- Leetcode 885 螺旋矩阵 III ( Spiral Matrix III *Medium* ) 题解分析
- /2022/08/23/Leetcode-885-%E8%9E%BA%E6%97%8B%E7%9F%A9%E9%98%B5-III-Spiral-Matrix-III-Medium-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍
You start at the cell (rStart, cStart) of an rows x cols grid facing east. The northwest corner is at the first row and column in the grid, and the southeast corner is at the last row and column.
-
You will walk in a clockwise spiral shape to visit every position in this grid. Whenever you move outside the grid’s boundary, we continue our walk outside the grid (but may return to the grid boundary later.). Eventually, we reach all rows * cols spaces of the grid.
-
Return an array of coordinates representing the positions of the grid in the order you visited them.
+]]>
+
+ C++
+
+
+ c++
+ mfc
+
+ ambari-summary/2017/05/09/ambari-summary/
@@ -5601,75 +5653,6 @@ public:
cluster
-
- two sum
- /2015/01/14/Two-Sum/
- problem
Given an array of integers, find two numbers such that they add up to a specific target number.
-
The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
-
-
You may assume that each input would have exactly one solution.
#include <stdio.h>
-int main(void)
+ two sum
+ /2015/01/14/Two-Sum/
+ problem
Given an array of integers, find two numbers such that they add up to a specific target number.
+
The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
+
+
You may assume that each input would have exactly one solution.
zkclient=com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter
+curator=com.alibaba.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter
-Run a commandin a new container
WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
+
+IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
+Someone could be eavesdropping on you right now (man-in-the-middle attack)!
+It is also possible that a host key has just been changed.
]]>
-
- leetcode
-
-
- leetcode
- c++
-
-
-
- Leetcode 747 至少是其他数字两倍的最大数 ( Largest Number At Least Twice of Others *Easy* ) 题解分析
- /2022/10/02/Leetcode-747-%E8%87%B3%E5%B0%91%E6%98%AF%E5%85%B6%E4%BB%96%E6%95%B0%E5%AD%97%E4%B8%A4%E5%80%8D%E7%9A%84%E6%9C%80%E5%A4%A7%E6%95%B0-Largest-Number-At-Least-Twice-of-Others-Easy-%E9%A2%98%E8%A7%A3%E5%88%86%E6%9E%90/
- 题目介绍
You are given an integer array nums where the largest integer is unique.
-
Determine whether the largest element in the array is at least twice as much as every other number in the array. If it is, return the index of the largest element, or return -1 otherwise. 确认在数组中的最大数是否是其余任意数的两倍大及以上,如果是返回索引,如果不是返回-1
-
示例
Example 1:
-
Input: nums = [3,6,1,0] Output: 1 Explanation: 6 is the largest integer. For every other number in the array x, 6 is at least twice as big as x. The index of value 6 is 1, so we return 1.
Given an array of n positive integers and a positive integer s, find the minimal length of a subarray of which the sum ≥ s. If there isn’t one, return 0 instead.
-
For example, given the array [2,3,1,2,4,3] and s = 7, the subarray [4,3] has the minimal length under the problem constraint.
包括应用 Id,只搜索的 api key(默认给创建好的那个),indexName 就是最开始创建的 index 名,
-
exportHEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Git Bash
-# set HEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Windows command line
-hexo clean
-hexo algolia
+ minimum-size-subarray-sum-209
+ /2016/10/11/minimum-size-subarray-sum-209/
+ problem
Given an array of n positive integers and a positive integer s, find the minimal length of a subarray of which the sum ≥ s. If there isn’t one, return 0 instead.
+
For example, given the array [2,3,1,2,4,3] and s = 7, the subarray [4,3] has the minimal length under the problem constraint.
public class PerpetualCache implements Cache {
-IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
-Someone could be eavesdropping on you right now (man-in-the-middle attack)!
-It is also possible that a host key has just been changed.
包括应用 Id,只搜索的 api key(默认给创建好的那个),indexName 就是最开始创建的 index 名,
+
exportHEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Git Bash
+# set HEXO_ALGOLIA_INDEXING_KEY=High-privilege API key # Use Windows command line
+hexo clean
+hexo algolia
privatePooledConnectionpopConnection(String username,String password)throwsSQLException{
+ boolean countedWait =false;
+ PooledConnection conn =null;
+ long t =System.currentTimeMillis();
+ int localBadConnectionCount =0;
+
+ while(conn ==null){
+ lock.lock();
+ try{if(!state.idleConnections.isEmpty()){// Pool has available connection
- // 连接池有可用的连接
conn = state.idleConnections.remove(0);if(log.isDebugEnabled()){
log.debug("Checked out connection "+ conn.getRealHashCode()+" from pool.");}}else{// Pool does not have available connection
- // 进入这个分支表示没有空闲连接,但是活跃连接数还没达到最大活跃连接数上限,那么这时候就可以创建一个新连接if(state.activeConnections.size()< poolMaximumActiveConnections){// Can create new connection
- // 这里创建连接我们之前讲过,
conn =newPooledConnection(dataSource.getConnection(),this);if(log.isDebugEnabled()){
log.debug("Created connection "+ conn.getRealHashCode()+".");}}else{// Cannot create new connection
- // 进到这个分支了就表示没法创建新连接了,那么怎么办呢,这里引入了一个 poolMaximumCheckoutTime,这代表了我去控制连接一次被使用的最长时间,如果超过这个时间了,我就要去关闭失效它PooledConnection oldestActiveConnection = state.activeConnections.get(0);long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();if(longestCheckoutTime > poolMaximumCheckoutTime){// Can claim overdue connection
- // 所有超时连接从池中被借出的次数+1
state.claimedOverdueConnectionCount++;
- // 所有超时连接从池中被借出并归还的时间总和 + 当前连接借出时间
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
- // 所有连接从池中被借出并归还的时间总和 + 当前连接借出时间
state.accumulatedCheckoutTime += longestCheckoutTime;
- // 从活跃连接数中移除此连接
state.activeConnections.remove(oldestActiveConnection);
- // 如果该连接不是自动提交的,则尝试回滚if(!oldestActiveConnection.getRealConnection().getAutoCommit()){try{
oldestActiveConnection.getRealConnection().rollback();
@@ -6559,7 +6862,6 @@ It is also possible that a host key has just
log.debug("Bad connection. Could not roll back");}}
- // 用此连接的真实连接再创建一个连接,并设置时间
conn =newPooledConnection(oldestActiveConnection.getRealConnection(),this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
@@ -6569,9 +6871,7 @@ It is also possible that a host key has just
}}else{// Must wait
- // 这样还是获取不到连接就只能等待了try{
- // 标记状态,然后把等待计数+1if(!countedWait){
state.hadToWaitCount++;
countedWait =true;
@@ -6580,9 +6880,7 @@ It is also possible that a host key has just
log.debug("Waiting as long as "+ poolTimeToWait +" milliseconds for connection.");}long wt =System.currentTimeMillis();
- // 等待 poolTimeToWait 时间
condition.await(poolTimeToWait,TimeUnit.MILLISECONDS);
- // 记录等待时间
state.accumulatedWaitTime +=System.currentTimeMillis()- wt;}catch(InterruptedException e){// set interrupt flag
@@ -6592,20 +6890,15 @@ It is also possible that a host key has just
}}}
- // 如果连接不为空if(conn !=null){// ping to server and check the connection is valid or not
- // 判断是否有效if(conn.isValid()){if(!conn.getRealConnection().getAutoCommit()){
- // 回滚未提交的
conn.getRealConnection().rollback();}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
- // 设置时间
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
- // 添加进活跃连接
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime +=System.currentTimeMillis()- t;
@@ -6613,11 +6906,9 @@ It is also possible that a host key has just
if(log.isDebugEnabled()){
log.debug("A bad connection ("+ conn.getRealHashCode()+") was returned from the pool, getting another connection.");}
- // 连接无效,坏连接+1
state.badConnectionCount++;
localBadConnectionCount++;
conn =null;
- // 如果坏连接已经超过了容忍上限,就抛异常if(localBadConnectionCount >(poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)){if(log.isDebugEnabled()){
log.debug("PooledDataSource: Could not get a good connection to the database.");
@@ -6627,75 +6918,26 @@ It is also possible that a host key has just
}}}finally{
- // 释放锁
lock.unlock();}}if(conn ==null){
- // 连接仍为空if(log.isDebugEnabled()){
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}
- // 抛出异常thrownewSQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}
- // fanhui
- return conn;
- }
@Override
- public<T>TselectOne(String statement,Object parameter){
- // Popular vote was to return null on 0 results and throw exception on too many.
- // 都知道是在这进去
- List<T> list =this.selectList(statement, parameter);
- if(list.size()==1){
- return list.get(0);
- }elseif(list.size()>1){
- thrownewTooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: "+ list.size());
- }else{
- returnnull;
- }
- }
+ }
+
这里的拼接方式还需要判断 AND 和 OR 的判断逻辑,其他就没什么特别的了,只是where 语句中的 lastList 不知道是干嘛的,好像只有添加跟赋值的操作,有知道的大神也可以评论指导下
+]]>
+
+ Java
+ Mybatis
+
+
+ Java
+ Mysql
+ Mybatis
+
+
+
+ invert-binary-tree
+ /2015/06/22/invert-binary-tree/
+ Invert a binary tree
+
public<T>TselectOne(String statement,Object parameter){
+ // Popular vote was to return null on 0 results and throw exception on too many.
+ List<T> list =this.selectList(statement, parameter);
+ if(list.size()==1){
+ return list.get(0);
+ }elseif(list.size()>1){
+ thrownewTooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: "+ list.size());
+ }else{
+ returnnull;
+ }
+}
privatePooledConnectionpopConnection(String username,String password)throwsSQLException{
- boolean countedWait =false;
- PooledConnection conn =null;
- long t =System.currentTimeMillis();
- int localBadConnectionCount =0;
-
- while(conn ==null){
- lock.lock();
- try{
- if(!state.idleConnections.isEmpty()){
- // Pool has available connection
- conn = state.idleConnections.remove(0);
- if(log.isDebugEnabled()){
- log.debug("Checked out connection "+ conn.getRealHashCode()+" from pool.");
- }
+ return sqlSource;
+}
+
但是这里可能做的事情比较多
+
protectedMixedSqlNodeparseDynamicTags(XNode node){
+ List<SqlNode> contents =newArrayList<>();
+ // 获取子节点,这里可以把我 xml 中的 SELECT 语句分成三部分,第一部分是 select 到 in,然后是 foreach 部分,最后是\n结束符
+ NodeList children = node.getNode().getChildNodes();
+ for(int i =0; i < children.getLength(); i++){
+ XNode child = node.newXNode(children.item(i));
+ // 第一个节点是个纯 text 节点就会走到这
+ if(child.getNode().getNodeType()==Node.CDATA_SECTION_NODE|| child.getNode().getNodeType()==Node.TEXT_NODE){
+ String data = child.getStringBody("");
+ TextSqlNode textSqlNode =newTextSqlNode(data);
+ if(textSqlNode.isDynamic()){
+ contents.add(textSqlNode);
+ isDynamic =true;}else{
- // Pool does not have available connection
- if(state.activeConnections.size()< poolMaximumActiveConnections){
- // Can create new connection
- conn =newPooledConnection(dataSource.getConnection(),this);
- if(log.isDebugEnabled()){
- log.debug("Created connection "+ conn.getRealHashCode()+".");
- }
- }else{
- // Cannot create new connection
- PooledConnection oldestActiveConnection = state.activeConnections.get(0);
- long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
- if(longestCheckoutTime > poolMaximumCheckoutTime){
- // Can claim overdue connection
- state.claimedOverdueConnectionCount++;
- state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
- state.accumulatedCheckoutTime += longestCheckoutTime;
- state.activeConnections.remove(oldestActiveConnection);
- if(!oldestActiveConnection.getRealConnection().getAutoCommit()){
- try{
- oldestActiveConnection.getRealConnection().rollback();
- }catch(SQLException e){
- /*
- Just log a message for debug and continue to execute the following
- statement like nothing happened.
- Wrap the bad connection with a new PooledConnection, this will help
- to not interrupt current executing thread and give current thread a
- chance to join the next competition for another valid/good database
- connection. At the end of this loop, bad {@link @conn} will be set as null.
- */
- log.debug("Bad connection. Could not roll back");
- }
- }
- conn =newPooledConnection(oldestActiveConnection.getRealConnection(),this);
- conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
- conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
- oldestActiveConnection.invalidate();
- if(log.isDebugEnabled()){
- log.debug("Claimed overdue connection "+ conn.getRealHashCode()+".");
- }
- }else{
- // Must wait
- try{
- if(!countedWait){
- state.hadToWaitCount++;
- countedWait =true;
- }
- if(log.isDebugEnabled()){
- log.debug("Waiting as long as "+ poolTimeToWait +" milliseconds for connection.");
- }
- long wt =System.currentTimeMillis();
- condition.await(poolTimeToWait,TimeUnit.MILLISECONDS);
- state.accumulatedWaitTime +=System.currentTimeMillis()- wt;
- }catch(InterruptedException e){
- // set interrupt flag
- Thread.currentThread().interrupt();
- break;
- }
- }
- }
+ // 在 content 中添加这个 node
+ contents.add(newStaticTextSqlNode(data));}
- if(conn !=null){
- // ping to server and check the connection is valid or not
- if(conn.isValid()){
- if(!conn.getRealConnection().getAutoCommit()){
- conn.getRealConnection().rollback();
- }
- conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
- conn.setCheckoutTimestamp(System.currentTimeMillis());
- conn.setLastUsedTimestamp(System.currentTimeMillis());
- state.activeConnections.add(conn);
- state.requestCount++;
- state.accumulatedRequestTime +=System.currentTimeMillis()- t;
- }else{
- if(log.isDebugEnabled()){
- log.debug("A bad connection ("+ conn.getRealHashCode()+") was returned from the pool, getting another connection.");
- }
- state.badConnectionCount++;
- localBadConnectionCount++;
- conn =null;
- if(localBadConnectionCount >(poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)){
- if(log.isDebugEnabled()){
- log.debug("PooledDataSource: Could not get a good connection to the database.");
- }
- thrownewSQLException("PooledDataSource: Could not get a good connection to the database.");
- }
- }
+ }elseif(child.getNode().getNodeType()==Node.ELEMENT_NODE){// issue #628
+ // 第二个节点是个带 foreach 的,是个内部元素节点
+ String nodeName = child.getNode().getNodeName();
+ // 通过 nodeName 获取处理器
+ NodeHandler handler = nodeHandlerMap.get(nodeName);
+ if(handler ==null){
+ thrownewBuilderException("Unknown element <"+ nodeName +"> in SQL statement.");}
- }finally{
- lock.unlock();
+ // 调用处理器来处理
+ handler.handleNode(child, contents);
+ isDynamic =true;}
-
}
-
- if(conn ==null){
- if(log.isDebugEnabled()){
- log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
- }
- thrownewSQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ // 然后返回这个混合 sql 节点
+ returnnewMixedSqlNode(contents);
+ }
@Override
+ public<T>TselectOne(String statement,Object parameter){
+ // Popular vote was to return null on 0 results and throw exception on too many.
+ // 都知道是在这进去
+ List<T> list =this.selectList(statement, parameter);
+ if(list.size()==1){
+ return list.get(0);
+ }elseif(list.size()>1){
+ thrownewTooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: "+ list.size());
+ }else{
+ returnnull;
+ }
+ }
- return conn;
- }
public<T>TselectOne(String statement,Object parameter){
- // Popular vote was to return null on 0 results and throw exception on too many.
- List<T> list =this.selectList(statement, parameter);
- if(list.size()==1){
- return list.get(0);
- }elseif(list.size()>1){
- thrownewTooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: "+ list.size());
- }else{
- returnnull;
- }
-}
+ if(conn ==null){
+ // 连接仍为空
+ if(log.isDebugEnabled()){
+ log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
+ // 抛出异常
+ thrownewSQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
+ // fanhui
+ return conn;
+ }
+
@Override
+ publicConnectiongetConnection()throwsSQLException{
+ if(connection ==null){
+ openConnection();
+ }
+ return connection;
+ }
- if(oldDb !=null){
- locallyScopedConn.setDatabase(oldDb);
- }
+ protectedvoidopenConnection()throwsSQLException{
+ if(log.isDebugEnabled()){
+ log.debug("Opening JDBC Connection");
+ }
+ connection = dataSource.getConnection();
+ if(level !=null){
+ connection.setTransactionIsolation(level.getLevel());
+ }
+ setDesiredAutoCommit(autoCommit);
+ }
+ @Override
+ publicConnectiongetConnection()throwsSQLException{
+ returnpopConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
+ }
- if(rs !=null){
- this.lastInsertId = rs.getUpdateID();
- this.results = rs;
- }
+privatePooledConnectionpopConnection(String username,String password)throwsSQLException{
+ boolean countedWait =false;
+ PooledConnection conn =null;
+ long t =System.currentTimeMillis();
+ int localBadConnectionCount =0;
- return rs !=null&& rs.hasRows();
- }
+ while(conn ==null){
+ lock.lock();
+ try{
+ if(!state.idleConnections.isEmpty()){
+ // Pool has available connection
+ conn = state.idleConnections.remove(0);
+ if(log.isDebugEnabled()){
+ log.debug("Checked out connection "+ conn.getRealHashCode()+" from pool.");
+ }
+ }else{
+ // Pool does not have available connection
+ if(state.activeConnections.size()< poolMaximumActiveConnections){
+ // Can create new connection
+ // ------------> 走到这里会创建PooledConnection,但是里面会先调用dataSource.getConnection()
+ conn =newPooledConnection(dataSource.getConnection(),this);
+ if(log.isDebugEnabled()){
+ log.debug("Created connection "+ conn.getRealHashCode()+".");
+ }
+ }else{
+ // Cannot create new connection
+ PooledConnection oldestActiveConnection = state.activeConnections.get(0);
+ long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
+ if(longestCheckoutTime > poolMaximumCheckoutTime){
+ // Can claim overdue connection
+ state.claimedOverdueConnectionCount++;
+ state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
+ state.accumulatedCheckoutTime += longestCheckoutTime;
+ state.activeConnections.remove(oldestActiveConnection);
+ if(!oldestActiveConnection.getRealConnection().getAutoCommit()){
+ try{
+ oldestActiveConnection.getRealConnection().rollback();
+ }catch(SQLException e){
+ /*
+ Just log a message for debug and continue to execute the following
+ statement like nothing happened.
+ Wrap the bad connection with a new PooledConnection, this will help
+ to not interrupt current executing thread and give current thread a
+ chance to join the next competition for another valid/good database
+ connection. At the end of this loop, bad {@link @conn} will be set as null.
+ */
+ log.debug("Bad connection. Could not roll back");
+ }
+ }
+ conn =newPooledConnection(oldestActiveConnection.getRealConnection(),this);
+ conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
+ conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
+ oldestActiveConnection.invalidate();
+ if(log.isDebugEnabled()){
+ log.debug("Claimed overdue connection "+ conn.getRealHashCode()+".");
+ }
+ }else{
+ // Must wait
+ try{
+ if(!countedWait){
+ state.hadToWaitCount++;
+ countedWait =true;}
+ if(log.isDebugEnabled()){
+ log.debug("Waiting as long as "+ poolTimeToWait +" milliseconds for connection.");
+ }
+ long wt =System.currentTimeMillis();
+ condition.await(poolTimeToWait,TimeUnit.MILLISECONDS);
+ state.accumulatedWaitTime +=System.currentTimeMillis()- wt;
+ }catch(InterruptedException e){
+ // set interrupt flag
+ Thread.currentThread().interrupt();
+ break;
+ }}
- }catch(CJException var11){
- throwSQLExceptionsMapping.translateException(var11,this.getExceptionInterceptor());
+ }}
- }
+ if(conn !=null){
+ // ping to server and check the connection is valid or not
+ if(conn.isValid()){
+ if(!conn.getRealConnection().getAutoCommit()){
+ conn.getRealConnection().rollback();
+ }
+ conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
+ conn.setCheckoutTimestamp(System.currentTimeMillis());
+ conn.setLastUsedTimestamp(System.currentTimeMillis());
+ state.activeConnections.add(conn);
+ state.requestCount++;
+ state.accumulatedRequestTime +=System.currentTimeMillis()- t;
+ }else{
+ if(log.isDebugEnabled()){
+ log.debug("A bad connection ("+ conn.getRealHashCode()+") was returned from the pool, getting another connection.");
+ }
+ state.badConnectionCount++;
+ localBadConnectionCount++;
+ conn =null;
+ if(localBadConnectionCount >(poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)){
+ if(log.isDebugEnabled()){
+ log.debug("PooledDataSource: Could not get a good connection to the database.");
+ }
+ thrownewSQLException("PooledDataSource: Could not get a good connection to the database.");
+ }
+ }
+ }
+ }finally{
+ lock.unlock();
+ }
-]]>
+ if(conn ==null){
+ if(log.isDebugEnabled()){
+ log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
+ thrownewSQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ }
-
+ return(getConnection(url, info,Reflection.getCallerClass()));
+ }
+privatestaticConnectiongetConnection(
+ String url,java.util.Properties info,Class<?> caller)throwsSQLException{
+ /*
+ * When callerCl is null, we should check the application's
+ * (which is invoking this class indirectly)
+ * classloader, so that the JDBC driver class outside rt.jar
+ * can be loaded from here.
+ */
+ ClassLoader callerCL = caller !=null? caller.getClassLoader():null;
+ synchronized(DriverManager.class){
+ // synchronize loading of the correct classloader.
+ if(callerCL ==null){
+ callerCL =Thread.currentThread().getContextClassLoader();
+ }
+ }
-
+ // Walk through the loaded registeredDrivers attempting to make a connection.
+ // Remember the first exception that gets raised so we can reraise it.
+ SQLException reason =null;
-
- while(conn ==null){
- lock.lock();
- try{
- if(!state.idleConnections.isEmpty()){
- // Pool has available connection
- conn = state.idleConnections.remove(0);
- if(log.isDebugEnabled()){
- log.debug("Checked out connection "+ conn.getRealHashCode()+" from pool.");
- }
- }else{
- // Pool does not have available connection
- if(state.activeConnections.size()< poolMaximumActiveConnections){
- // Can create new connection
- // ------------> 走到这里会创建PooledConnection,但是里面会先调用dataSource.getConnection()
- conn =newPooledConnection(dataSource.getConnection(),this);
- if(log.isDebugEnabled()){
- log.debug("Created connection "+ conn.getRealHashCode()+".");
- }
- }else{
- // Cannot create new connection
- PooledConnection oldestActiveConnection = state.activeConnections.get(0);
- long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
- if(longestCheckoutTime > poolMaximumCheckoutTime){
- // Can claim overdue connection
- state.claimedOverdueConnectionCount++;
- state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
- state.accumulatedCheckoutTime += longestCheckoutTime;
- state.activeConnections.remove(oldestActiveConnection);
- if(!oldestActiveConnection.getRealConnection().getAutoCommit()){
- try{
- oldestActiveConnection.getRealConnection().rollback();
- }catch(SQLException e){
- /*
- Just log a message for debug and continue to execute the following
- statement like nothing happened.
- Wrap the bad connection with a new PooledConnection, this will help
- to not interrupt current executing thread and give current thread a
- chance to join the next competition for another valid/good database
- connection. At the end of this loop, bad {@link @conn} will be set as null.
- */
- log.debug("Bad connection. Could not roll back");
- }
- }
- conn =newPooledConnection(oldestActiveConnection.getRealConnection(),this);
- conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
- conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
- oldestActiveConnection.invalidate();
- if(log.isDebugEnabled()){
- log.debug("Claimed overdue connection "+ conn.getRealHashCode()+".");
- }
- }else{
- // Must wait
- try{
- if(!countedWait){
- state.hadToWaitCount++;
- countedWait =true;
- }
- if(log.isDebugEnabled()){
- log.debug("Waiting as long as "+ poolTimeToWait +" milliseconds for connection.");
- }
- long wt =System.currentTimeMillis();
- condition.await(poolTimeToWait,TimeUnit.MILLISECONDS);
- state.accumulatedWaitTime +=System.currentTimeMillis()- wt;
- }catch(InterruptedException e){
- // set interrupt flag
- Thread.currentThread().interrupt();
- break;
- }
- }
- }
- }
- if(conn !=null){
- // ping to server and check the connection is valid or not
- if(conn.isValid()){
- if(!conn.getRealConnection().getAutoCommit()){
- conn.getRealConnection().rollback();
- }
- conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
- conn.setCheckoutTimestamp(System.currentTimeMillis());
- conn.setLastUsedTimestamp(System.currentTimeMillis());
- state.activeConnections.add(conn);
- state.requestCount++;
- state.accumulatedRequestTime +=System.currentTimeMillis()- t;
- }else{
- if(log.isDebugEnabled()){
- log.debug("A bad connection ("+ conn.getRealHashCode()+") was returned from the pool, getting another connection.");
- }
- state.badConnectionCount++;
- localBadConnectionCount++;
- conn =null;
- if(localBadConnectionCount >(poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)){
- if(log.isDebugEnabled()){
- log.debug("PooledDataSource: Could not get a good connection to the database.");
- }
- thrownewSQLException("PooledDataSource: Could not get a good connection to the database.");
- }
- }
- }
- }finally{
- lock.unlock();
- }
+
- if(conn ==null){
- if(log.isDebugEnabled()){
- log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+
然后是调用的真实的query方法
+
@Override
+public<E>List<E>query(MappedStatement ms,Object parameterObject,RowBounds rowBounds,ResultHandler resultHandler,CacheKey key,BoundSql boundSql)
+ throwsSQLException{
+ Cache cache = ms.getCache();
+ if(cache !=null){
+ flushCacheIfRequired(ms);
+ if(ms.isUseCache()&& resultHandler ==null){
+ ensureNoOutParams(ms, boundSql);
+ @SuppressWarnings("unchecked")
+ List<E> list =(List<E>) tcm.getObject(cache, key);
+ if(list ==null){
+ list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
+ tcm.putObject(cache, key, list);// issue #578 and #116}
- thrownewSQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
+ return list;}
-
- return conn;
- }
- return(getConnection(url, info,Reflection.getCallerClass()));
- }
-privatestaticConnectiongetConnection(
- String url,java.util.Properties info,Class<?> caller)throwsSQLException{
- /*
- * When callerCl is null, we should check the application's
- * (which is invoking this class indirectly)
- * classloader, so that the JDBC driver class outside rt.jar
- * can be loaded from here.
- */
- ClassLoader callerCL = caller !=null? caller.getClassLoader():null;
- synchronized(DriverManager.class){
- // synchronize loading of the correct classloader.
- if(callerCL ==null){
- callerCL =Thread.currentThread().getContextClassLoader();
- }
- }
+
- println("DriverManager.getConnection(\""+ url +"\")");
-
- // Walk through the loaded registeredDrivers attempting to make a connection.
- // Remember the first exception that gets raised so we can reraise it.
- SQLException reason =null;
-
- for(DriverInfo aDriver : registeredDrivers){
- // If the caller does not have permission to load the driver then
- // skip it.
- if(isDriverAllowed(aDriver.driver, callerCL)){
- try{
- // ----------> driver[className=com.mysql.cj.jdbc.Driver@64030b91]
- println(" trying "+ aDriver.driver.getClass().getName());
- Connection con = aDriver.driver.connect(url, info);
- if(con !=null){
- // Success!
- println("getConnection returning "+ aDriver.driver.getClass().getName());
- return(con);
- }
- }catch(SQLException ex){
- if(reason ==null){
- reason = ex;
+
这里引用了 redis 在 github 上最早的 2.2 版本的代码,代码路径是https://github.com/antirez/redis/blob/2.2/src/sds.h,可以看到这个结构体里只有仨元素,两个 int 型和一个 char 型数组,两个 int 型其实就是我说的优化,因为 C 语言本身的字符串数组,有两个问题,一个是要知道它实际已被占用的长度,需要去遍历这个数组,第二个就是比较容易踩坑的是遍历的时候要注意它有个以\0作为结尾的特点;通过上面的两个 int 型参数,一个是知道字符串目前的长度,一个是知道字符串还剩余多少位空间,这样子坐着两个操作从 O(N)简化到了O(1)了,还有第二个 free 还有个比较重要的作用就是能防止 C 字符串的溢出问题,在存储之前可以先判断 free 长度,如果长度不够就先扩容了,先介绍到这,这个系列可以写蛮多的,慢慢介绍吧
+
链表
链表是比较常见的数据结构了,但是因为 redis 是用 C 写的,所以在不依赖第三方库的情况下只能自己写一个了,redis 的链表是个有头的链表,而且是无环的,具体的结构我也找了 github 上最早版本的代码
这里引用了 redis 在 github 上最早的 2.2 版本的代码,代码路径是https://github.com/antirez/redis/blob/2.2/src/sds.h,可以看到这个结构体里只有仨元素,两个 int 型和一个 char 型数组,两个 int 型其实就是我说的优化,因为 C 语言本身的字符串数组,有两个问题,一个是要知道它实际已被占用的长度,需要去遍历这个数组,第二个就是比较容易踩坑的是遍历的时候要注意它有个以\0作为结尾的特点;通过上面的两个 int 型参数,一个是知道字符串目前的长度,一个是知道字符串还剩余多少位空间,这样子坐着两个操作从 O(N)简化到了O(1)了,还有第二个 free 还有个比较重要的作用就是能防止 C 字符串的溢出问题,在存储之前可以先判断 free 长度,如果长度不够就先扩容了,先介绍到这,这个系列可以写蛮多的,慢慢介绍吧
-
链表
链表是比较常见的数据结构了,但是因为 redis 是用 C 写的,所以在不依赖第三方库的情况下只能自己写一个了,redis 的链表是个有头的链表,而且是无环的,具体的结构我也找了 github 上最早版本的代码
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
+ * We use bit fields keep the quicklistNode at 32 bytes.
+ * count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
+ * encoding: 2 bits, RAW=1, LZF=2.
+ * container: 2 bits, NONE=1, ZIPLIST=2.
+ * recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
+ * attempted_compress: 1 bit, boolean, used for verifying during testing.
+ * extra: 10 bits, free for future use; pads out the remainder of 32 bits */
+typedef struct quicklistNode {
+ struct quicklistNode *prev;
+ struct quicklistNode *next;
+ unsigned char *zl;
+ unsigned int sz; /* ziplist size in bytes */
+ unsigned int count : 16; /* count of items in ziplist */
+ unsigned int encoding : 2; /* RAW==1 or LZF==2 */
+ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
+ unsigned int recompress : 1; /* was this node previous compressed? */
+ unsigned int attempted_compress : 1; /* node can't compress; too small */
+ unsigned int extra : 10; /* more bits to steal for future usage */
+} quicklistNode;
- publicStudentDOselectStudent(Long id);
-}
-
就可以可以通过mapper接口获取方法,这样就不用涉及到未知的变量转换等异常
-
try(SqlSession session = sqlSessionFactory.openSession()){
- StudentMapper mapper = session.getMapper(StudentMapper.class);
- StudentDO studentDO = mapper.selectStudent(1L);
- System.out.println("id is "+ studentDO.getId()+" name is "+studentDO.getName());
-}catch(Exception e){
- e.printStackTrace();
-}
* |00pppppp| - 1 byte
-* String value with length less than or equal to 63 bytes (6 bits).
-* "pppppp" represents the unsigned 6 bit length.
-* |01pppppp|qqqqqqqq| - 2 bytes
-* String value with length less than or equal to 16383 bytes (14 bits).
-* IMPORTANT: The 14 bit number is stored in big endian.
-* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
-* String value with length greater than or equal to 16384 bytes.
-* Only the 4 bytes following the first byte represents the length
-* up to 32^2-1. The 6 lower bits of the first byte are not used and
-* are set to zero.
-* IMPORTANT: The 32 bit number is stored in big endian.
-* |11000000| - 3 bytes
-* Integer encoded as int16_t (2 bytes).
-* |11010000| - 5 bytes
-* Integer encoded as int32_t (4 bytes).
-* |11100000| - 9 bytes
-* Integer encoded as int64_t (8 bytes).
-* |11110000| - 4 bytes
-* Integer encoded as 24 bit signed (3 bytes).
-* |11111110| - 2 bytes
-* Integer encoded as 8 bit signed (1 byte).
-* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
-* Unsigned integer from 0 to 12. The encoded value is actually from
-* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
-* subtracted from the encoded 4 bit value to obtain the right value.
-* |11111111| - End of ziplist special entry.
+/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
+ * 'sz' is byte length of 'compressed' field.
+ * 'compressed' is LZF data with total (compressed) length 'sz'
+ * NOTE: uncompressed length is stored in quicklistNode->sz.
+ * When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
+typedef struct quicklistLZF {
+ unsigned int sz; /* LZF size in bytes*/
+ char compressed[];
+} quicklistLZF;
+
+/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
+ * 'count' is the number of total entries.
+ * 'len' is the number of quicklist nodes.
+ * 'compress' is: -1 if compression disabled, otherwise it's the number
+ * of quicklistNodes to leave uncompressed at ends of quicklist.
+ * 'fill' is the user-requested (or default) fill factor. */
+typedef struct quicklist {
+ quicklistNode *head;
+ quicklistNode *tail;
+ unsigned long count; /* total count of all entries in all ziplists */
+ unsigned long len; /* number of quicklistNodes */
+ int fill : 16; /* fill factor for individual nodes */
+ unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
+} quicklist;
+
/* This function is called when we are going to perform some operation
- * in a given key, but such key may be already logically expired even if
- * it still exists in the database. The main way this function is called
- * is via lookupKey*() family of functions.
- *
- * The behavior of the function depends on the replication role of the
- * instance, because slave instances do not expire keys, they wait
- * for DELs from the master for consistency matters. However even
- * slaves will try to have a coherent return value for the function,
- * so that read commands executed in the slave side will be able to
- * behave like if the key is expired even if still present (because the
- * master has yet to propagate the DEL).
- *
- * In masters as a side effect of finding a key which is expired, such
- * key will be evicted from the database. Also this may trigger the
- * propagation of a DEL/UNLINK command in AOF / replication stream.
- *
- * The return value of the function is 0 if the key is still valid,
- * otherwise the function returns 1 if the key is expired. */
-int expireIfNeeded(redisDb *db, robj *key) {
- if (!keyIsExpired(db,key)) return 0;
-
- /* If we are running in the context of a slave, instead of
- * evicting the expired key from the database, we return ASAP:
- * the slave key expiration is controlled by the master that will
- * send us synthesized DEL operations for expired keys.
- *
- * Still we try to return the right information to the caller,
- * that is, 0 if we think the key should be still valid, 1 if
- * we think the key is expired at this time. */
- if (server.masterhost != NULL) return 1;
-
- /* Delete the key */
- server.stat_expiredkeys++;
- propagateExpire(db,key,server.lazyfree_lazy_expire);
- notifyKeyspaceEvent(NOTIFY_EXPIRED,
- "expired",key,db->id);
- return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
- dbSyncDelete(db,key);
-}
-
-/* Check if the key is expired. */
-int keyIsExpired(redisDb *db, robj *key) {
- mstime_t when = getExpire(db,key);
- mstime_t now;
-
- if (when < 0) return 0; /* No expire for this key */
-
- /* Don't expire anything while loading. It will be done later. */
- if (server.loading) return 0;
-
- /* If we are in the context of a Lua script, we pretend that time is
- * blocked to when the Lua script started. This way a key can expire
- * only the first time it is accessed and not in the middle of the
- * script execution, making propagation to slaves / AOF consistent.
- * See issue #1525 on Github for more information. */
- if (server.lua_caller) {
- now = server.lua_time_start;
- }
- /* If we are in the middle of a command execution, we still want to use
- * a reference time that does not change: in that case we just use the
- * cached time, that we update before each call in the call() function.
- * This way we avoid that commands such as RPOPLPUSH or similar, that
- * may re-open the same key multiple times, can invalidate an already
- * open object in a next call, if the next call will see the key expired,
- * while the first did not. */
- else if (server.fixed_time_expire > 0) {
- now = server.mstime;
- }
- /* For the other cases, we want to use the most fresh time we have. */
- else {
- now = mstime();
- }
-
- /* The key expired if the current (virtual or real) time is greater
- * than the expire time of the key. */
- return now > when;
-}
-/* Return the expire time of the specified key, or -1 if no expire
- * is associated with this key (i.e. the key is non volatile) */
-long long getExpire(redisDb *db, robj *key) {
- dictEntry *de;
+ redis数据结构介绍四-第四部分 压缩表
+ /2020/01/19/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%BB%8B%E7%BB%8D%E5%9B%9B/
+ 在 redis 中还有一类表型数据结构叫压缩表,ziplist,它的目的是替代链表,链表是个很容易理解的数据结构,双向链表有前后指针,有带头结点的有的不带,但是链表有个比较大的问题是相对于普通的数组,它的内存不连续,碎片化的存储,内存利用效率不高,而且指针寻址相对于直接使用偏移量的话,也有一定的效率劣势,当然这不是主要的原因,ziplist 设计的主要目的是让链表的内存使用更高效
+
+
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. 这是摘自 redis 源码中ziplist.c 文件的注释,也说明了原因,它的大概结构是这样子
* |00pppppp| - 1 byte
+* String value with length less than or equal to 63 bytes (6 bits).
+* "pppppp" represents the unsigned 6 bit length.
+* |01pppppp|qqqqqqqq| - 2 bytes
+* String value with length less than or equal to 16383 bytes (14 bits).
+* IMPORTANT: The 14 bit number is stored in big endian.
+* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
+* String value with length greater than or equal to 16384 bytes.
+* Only the 4 bytes following the first byte represents the length
+* up to 32^2-1. The 6 lower bits of the first byte are not used and
+* are set to zero.
+* IMPORTANT: The 32 bit number is stored in big endian.
+* |11000000| - 3 bytes
+* Integer encoded as int16_t (2 bytes).
+* |11010000| - 5 bytes
+* Integer encoded as int32_t (4 bytes).
+* |11100000| - 9 bytes
+* Integer encoded as int64_t (8 bytes).
+* |11110000| - 4 bytes
+* Integer encoded as 24 bit signed (3 bytes).
+* |11111110| - 2 bytes
+* Integer encoded as 8 bit signed (1 byte).
+* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
+* Unsigned integer from 0 to 12. The encoded value is actually from
+* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
+* subtracted from the encoded 4 bit value to obtain the right value.
+* |11111111| - End of ziplist special entry.
publicConfiguration(){
+ typeAliasRegistry.registerAlias("JDBC",JdbcTransactionFactory.class);
+ typeAliasRegistry.registerAlias("MANAGED",ManagedTransactionFactory.class);
- /* The entry was found in the expire dict, this means it should also
- * be present in the main dict (safety check). */
- serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
- return dictGetSignedIntegerVal(de);
-}
/* This function handles 'background' operations we are required to do
- * incrementally in Redis databases, such as active key expiring, resizing,
- * rehashing. */
-void databasesCron(void) {
- /* Expire keys by random sampling. Not required for slaves
- * as master will synthesize DELs for us. */
- if (server.active_expire_enabled) {
- if (server.masterhost == NULL) {
- activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
- } else {
- expireSlaveKeys();
- }
- }
+ typeAliasRegistry.registerAlias("JNDI",JndiDataSourceFactory.class);
+ typeAliasRegistry.registerAlias("POOLED",PooledDataSourceFactory.class);
+ typeAliasRegistry.registerAlias("UNPOOLED",UnpooledDataSourceFactory.class);
- /* Defrag keys gradually. */
- activeDefragCycle();
+ typeAliasRegistry.registerAlias("PERPETUAL",PerpetualCache.class);
+ typeAliasRegistry.registerAlias("FIFO",FifoCache.class);
+ typeAliasRegistry.registerAlias("LRU",LruCache.class);
+ typeAliasRegistry.registerAlias("SOFT",SoftCache.class);
+ typeAliasRegistry.registerAlias("WEAK",WeakCache.class);
- /* Perform hash tables rehashing if needed, but only if there are no
- * other processes saving the DB on disk. Otherwise rehashing is bad
- * as will cause a lot of copy-on-write of memory pages. */
- if (!hasActiveChildProcess()) {
- /* We use global counters so if we stop the computation at a given
- * DB we'll be able to start from the successive in the next
- * cron loop iteration. */
- static unsigned int resize_db = 0;
- static unsigned int rehash_db = 0;
- int dbs_per_call = CRON_DBS_PER_CALL;
- int j;
+ typeAliasRegistry.registerAlias("DB_VENDOR",VendorDatabaseIdProvider.class);
- /* Don't test more DBs than we have. */
- if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
+ typeAliasRegistry.registerAlias("XML",XMLLanguageDriver.class);
+ typeAliasRegistry.registerAlias("RAW",RawLanguageDriver.class);
- /* Resize */
- for (j = 0; j < dbs_per_call; j++) {
- tryResizeHashTables(resize_db % server.dbnum);
- resize_db++;
- }
+ typeAliasRegistry.registerAlias("SLF4J",Slf4jImpl.class);
+ typeAliasRegistry.registerAlias("COMMONS_LOGGING",JakartaCommonsLoggingImpl.class);
+ typeAliasRegistry.registerAlias("LOG4J",Log4jImpl.class);
+ typeAliasRegistry.registerAlias("LOG4J2",Log4j2Impl.class);
+ typeAliasRegistry.registerAlias("JDK_LOGGING",Jdk14LoggingImpl.class);
+ typeAliasRegistry.registerAlias("STDOUT_LOGGING",StdOutImpl.class);
+ typeAliasRegistry.registerAlias("NO_LOGGING",NoLoggingImpl.class);
- /* Rehash */
- if (server.activerehashing) {
- for (j = 0; j < dbs_per_call; j++) {
- int work_done = incrementallyRehash(rehash_db);
- if (work_done) {
- /* If the function did some work, stop here, we'll do
- * more at the next cron loop. */
- break;
- } else {
- /* If this db didn't need rehash, we'll try the next one. */
- rehash_db++;
- rehash_db %= server.dbnum;
- }
- }
- }
- }
-}
-/* Try to expire a few timed out keys. The algorithm used is adaptive and
- * will use few CPU cycles if there are few expiring keys, otherwise
- * it will get more aggressive to avoid that too much memory is used by
- * keys that can be removed from the keyspace.
- *
- * Every expire cycle tests multiple databases: the next call will start
- * again from the next db, with the exception of exists for time limit: in that
- * case we restart again from the last database we were processing. Anyway
- * no more than CRON_DBS_PER_CALL databases are tested at every iteration.
- *
- * The function can perform more or less work, depending on the "type"
- * argument. It can execute a "fast cycle" or a "slow cycle". The slow
- * cycle is the main way we collect expired cycles: this happens with
- * the "server.hz" frequency (usually 10 hertz).
- *
- * However the slow cycle can exit for timeout, since it used too much time.
- * For this reason the function is also invoked to perform a fast cycle
- * at every event loop cycle, in the beforeSleep() function. The fast cycle
- * will try to perform less work, but will do it much more often.
- *
- * The following are the details of the two expire cycles and their stop
- * conditions:
- *
- * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a
- * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION
- * microseconds, and is not repeated again before the same amount of time.
- * The cycle will also refuse to run at all if the latest slow cycle did not
- * terminate because of a time limit condition.
- *
- * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is
- * executed, where the time limit is a percentage of the REDIS_HZ period
- * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. In the
- * fast cycle, the check of every database is interrupted once the number
- * of already expired keys in the database is estimated to be lower than
+ typeAliasRegistry.registerAlias("CGLIB",CglibProxyFactory.class);
+ typeAliasRegistry.registerAlias("JAVASSIST",JavassistProxyFactory.class);
+
+ languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
+ languageRegistry.register(RawLanguageDriver.class);
+ }
/* This function is called when we are going to perform some operation
+ * in a given key, but such key may be already logically expired even if
+ * it still exists in the database. The main way this function is called
+ * is via lookupKey*() family of functions.
+ *
+ * The behavior of the function depends on the replication role of the
+ * instance, because slave instances do not expire keys, they wait
+ * for DELs from the master for consistency matters. However even
+ * slaves will try to have a coherent return value for the function,
+ * so that read commands executed in the slave side will be able to
+ * behave like if the key is expired even if still present (because the
+ * master has yet to propagate the DEL).
+ *
+ * In masters as a side effect of finding a key which is expired, such
+ * key will be evicted from the database. Also this may trigger the
+ * propagation of a DEL/UNLINK command in AOF / replication stream.
+ *
+ * The return value of the function is 0 if the key is still valid,
+ * otherwise the function returns 1 if the key is expired. */
+int expireIfNeeded(redisDb *db, robj *key) {
+ if (!keyIsExpired(db,key)) return 0;
+
+ /* If we are running in the context of a slave, instead of
+ * evicting the expired key from the database, we return ASAP:
+ * the slave key expiration is controlled by the master that will
+ * send us synthesized DEL operations for expired keys.
+ *
+ * Still we try to return the right information to the caller,
+ * that is, 0 if we think the key should be still valid, 1 if
+ * we think the key is expired at this time. */
+ if (server.masterhost != NULL) return 1;
+
+ /* Delete the key */
+ server.stat_expiredkeys++;
+ propagateExpire(db,key,server.lazyfree_lazy_expire);
+ notifyKeyspaceEvent(NOTIFY_EXPIRED,
+ "expired",key,db->id);
+ return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
+ dbSyncDelete(db,key);
+}
+
+/* Check if the key is expired. */
+int keyIsExpired(redisDb *db, robj *key) {
+ mstime_t when = getExpire(db,key);
+ mstime_t now;
+
+ if (when < 0) return 0; /* No expire for this key */
+
+ /* Don't expire anything while loading. It will be done later. */
+ if (server.loading) return 0;
+
+ /* If we are in the context of a Lua script, we pretend that time is
+ * blocked to when the Lua script started. This way a key can expire
+ * only the first time it is accessed and not in the middle of the
+ * script execution, making propagation to slaves / AOF consistent.
+ * See issue #1525 on Github for more information. */
+ if (server.lua_caller) {
+ now = server.lua_time_start;
+ }
+ /* If we are in the middle of a command execution, we still want to use
+ * a reference time that does not change: in that case we just use the
+ * cached time, that we update before each call in the call() function.
+ * This way we avoid that commands such as RPOPLPUSH or similar, that
+ * may re-open the same key multiple times, can invalidate an already
+ * open object in a next call, if the next call will see the key expired,
+ * while the first did not. */
+ else if (server.fixed_time_expire > 0) {
+ now = server.mstime;
+ }
+ /* For the other cases, we want to use the most fresh time we have. */
+ else {
+ now = mstime();
+ }
+
+ /* The key expired if the current (virtual or real) time is greater
+ * than the expire time of the key. */
+ return now > when;
+}
+/* Return the expire time of the specified key, or -1 if no expire
+ * is associated with this key (i.e. the key is non volatile) */
+long long getExpire(redisDb *db, robj *key) {
+ dictEntry *de;
+
+ /* No expire? return ASAP */
+ if (dictSize(db->expires) == 0 ||
+ (de = dictFind(db->expires,key->ptr)) == NULL) return -1;
+
+ /* The entry was found in the expire dict, this means it should also
+ * be present in the main dict (safety check). */
+ serverAssertWithInfo(NULL,key,dictFind(db->dict,key->ptr) != NULL);
+ return dictGetSignedIntegerVal(de);
+}
/* This function handles 'background' operations we are required to do
+ * incrementally in Redis databases, such as active key expiring, resizing,
+ * rehashing. */
+void databasesCron(void) {
+ /* Expire keys by random sampling. Not required for slaves
+ * as master will synthesize DELs for us. */
+ if (server.active_expire_enabled) {
+ if (server.masterhost == NULL) {
+ activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
+ } else {
+ expireSlaveKeys();
+ }
+ }
+
+ /* Defrag keys gradually. */
+ activeDefragCycle();
+
+ /* Perform hash tables rehashing if needed, but only if there are no
+ * other processes saving the DB on disk. Otherwise rehashing is bad
+ * as will cause a lot of copy-on-write of memory pages. */
+ if (!hasActiveChildProcess()) {
+ /* We use global counters so if we stop the computation at a given
+ * DB we'll be able to start from the successive in the next
+ * cron loop iteration. */
+ static unsigned int resize_db = 0;
+ static unsigned int rehash_db = 0;
+ int dbs_per_call = CRON_DBS_PER_CALL;
+ int j;
+
+ /* Don't test more DBs than we have. */
+ if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
+
+ /* Resize */
+ for (j = 0; j < dbs_per_call; j++) {
+ tryResizeHashTables(resize_db % server.dbnum);
+ resize_db++;
+ }
+
+ /* Rehash */
+ if (server.activerehashing) {
+ for (j = 0; j < dbs_per_call; j++) {
+ int work_done = incrementallyRehash(rehash_db);
+ if (work_done) {
+ /* If the function did some work, stop here, we'll do
+ * more at the next cron loop. */
+ break;
+ } else {
+ /* If this db didn't need rehash, we'll try the next one. */
+ rehash_db++;
+ rehash_db %= server.dbnum;
+ }
+ }
+ }
+ }
+}
+/* Try to expire a few timed out keys. The algorithm used is adaptive and
+ * will use few CPU cycles if there are few expiring keys, otherwise
+ * it will get more aggressive to avoid that too much memory is used by
+ * keys that can be removed from the keyspace.
+ *
+ * Every expire cycle tests multiple databases: the next call will start
+ * again from the next db, with the exception of exists for time limit: in that
+ * case we restart again from the last database we were processing. Anyway
+ * no more than CRON_DBS_PER_CALL databases are tested at every iteration.
+ *
+ * The function can perform more or less work, depending on the "type"
+ * argument. It can execute a "fast cycle" or a "slow cycle". The slow
+ * cycle is the main way we collect expired cycles: this happens with
+ * the "server.hz" frequency (usually 10 hertz).
+ *
+ * However the slow cycle can exit for timeout, since it used too much time.
+ * For this reason the function is also invoked to perform a fast cycle
+ * at every event loop cycle, in the beforeSleep() function. The fast cycle
+ * will try to perform less work, but will do it much more often.
+ *
+ * The following are the details of the two expire cycles and their stop
+ * conditions:
+ *
+ * If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a
+ * "fast" expire cycle that takes no longer than EXPIRE_FAST_CYCLE_DURATION
+ * microseconds, and is not repeated again before the same amount of time.
+ * The cycle will also refuse to run at all if the latest slow cycle did not
+ * terminate because of a time limit condition.
+ *
+ * If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is
+ * executed, where the time limit is a percentage of the REDIS_HZ period
+ * as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. In the
+ * fast cycle, the check of every database is interrupted once the number
+ * of already expired keys in the database is estimated to be lower than
* a given percentage, in order to avoid doing too much work to gain too
* little memory.
*
@@ -10447,261 +10664,6 @@ timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;源码
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
- * We use bit fields keep the quicklistNode at 32 bytes.
- * count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
- * encoding: 2 bits, RAW=1, LZF=2.
- * container: 2 bits, NONE=1, ZIPLIST=2.
- * recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
- * attempted_compress: 1 bit, boolean, used for verifying during testing.
- * extra: 10 bits, free for future use; pads out the remainder of 32 bits */
-typedef struct quicklistNode {
- struct quicklistNode *prev;
- struct quicklistNode *next;
- unsigned char *zl;
- unsigned int sz; /* ziplist size in bytes */
- unsigned int count : 16; /* count of items in ziplist */
- unsigned int encoding : 2; /* RAW==1 or LZF==2 */
- unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
- unsigned int recompress : 1; /* was this node previous compressed? */
- unsigned int attempted_compress : 1; /* node can't compress; too small */
- unsigned int extra : 10; /* more bits to steal for future usage */
-} quicklistNode;
-
-/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
- * 'sz' is byte length of 'compressed' field.
- * 'compressed' is LZF data with total (compressed) length 'sz'
- * NOTE: uncompressed length is stored in quicklistNode->sz.
- * When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
-typedef struct quicklistLZF {
- unsigned int sz; /* LZF size in bytes*/
- char compressed[];
-} quicklistLZF;
-
-/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
- * 'count' is the number of total entries.
- * 'len' is the number of quicklist nodes.
- * 'compress' is: -1 if compression disabled, otherwise it's the number
- * of quicklistNodes to leave uncompressed at ends of quicklist.
- * 'fill' is the user-requested (or default) fill factor. */
-typedef struct quicklist {
- quicklistNode *head;
- quicklistNode *tail;
- unsigned long count; /* total count of all entries in all ziplists */
- unsigned long len; /* number of quicklistNodes */
- int fill : 16; /* fill factor for individual nodes */
- unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
-} quicklist;
# Redis calls an internal function to perform many background tasks, like
-# closing connections of clients in timeout, purging expired keys that are
-# never requested, and so forth.
-#
-# Not all tasks are performed with the same frequency, but Redis checks for
-# tasks to perform according to the specified "hz" value.
-#
-# By default "hz" is set to 10. Raising the value will use more CPU when
-# Redis is idle, but at the same time will make Redis more responsive when
-# there are many keys expiring at the same time, and timeouts may be
-# handled with more precision.
-#
-# The range is between 1 and 500, however a value over 100 is usually not
-# a good idea. Most users should use the default of 10 and raise this up to
-# 100 only in environments where very low latency is required.
-hz 10
fnmain(){
- let s1 =String::from("hello");
- let len =calculate_length(&s1);
-
- println!("The length of '{}' is {}", s1, len);
-}
-fncalculate_length(s:&String)->usize{
- s.len()
-}
# Redis calls an internal function to perform many background tasks, like
+# closing connections of clients in timeout, purging expired keys that are
+# never requested, and so forth.
+#
+# Not all tasks are performed with the same frequency, but Redis checks for
+# tasks to perform according to the specified "hz" value.
+#
+# By default "hz" is set to 10. Raising the value will use more CPU when
+# Redis is idle, but at the same time will make Redis more responsive when
+# there are many keys expiring at the same time, and timeouts may be
+# handled with more precision.
+#
+# The range is between 1 and 500, however a value over 100 is usually not
+# a good idea. Most users should use the default of 10 and raise this up to
+# 100 only in environments where very low latency is required.
+hz 10
fnmain(){
+ let s1 =String::from("hello");
+ let len =calculate_length(&s1);
+
+ println!("The length of '{}' is {}", s1, len);
+}
+fncalculate_length(s:&String)->usize{
+ s.len()
+}
-]]>
-
- data analysis
-
-
- spark
- python
-
- spring event 介绍/2022/01/30/spring-event-%E4%BB%8B%E7%BB%8D/
@@ -11700,163 +11737,31 @@ b 1 这里有两个重点:
-
s 在进入作用域后才变得有效
-
它会保持自己的有效性直到自己离开作用域为止
-
-
然后看个案例
-
let x =5;
-let y = x;
-
这个其实有两种,一般可以认为比较多实现的会使用 copy on write 之类的,先让两个都指向同一个快 5 的存储,在发生变更后开始正式拷贝,但是涉及到内存处理的便利性,对于这类简单类型,可以直接拷贝 但是对于非基础类型
-
let s1 =String::from("hello");
-let s2 = s1;
+ springboot web server 启动逻辑
+ /2023/08/20/springboot-web-server-%E5%90%AF%E5%8A%A8%E9%80%BB%E8%BE%91/
+ springboot 的一个方便之处就是集成了 web server 进去,接着上一篇继续来看下这个 web server 的启动过程 基于 springboot 的 2.2.9.RELEASE 版本 整个 springboot 体系主体就是看 org.springframework.context.support.AbstractApplicationContext#refresh 刷新方法, 而启动 web server 的方法就是在其中的 OnRefresh
+
try{
+ // Allows post-processing of the bean factory in context subclasses.
+ postProcessBeanFactory(beanFactory);
-println!("{}, world!", s1);
-
有可能认为有两种内存分布可能 先看下 string 的内存结构 第一种可能是 第二种是 我们来尝试编译下 发现有这个错误,其实在 rust 中let y = x这个行为的实质是移动,在赋值给 y 之后 x 就无效了 这样子就不会造成脱离作用域时,对同一块内存区域的二次释放,如果需要复制,可以使用 clone 方法
-
let s1 =String::from("hello");
-let s2 = s1.clone();
+ // Invoke factory processors registered as beans in the context.
+ invokeBeanFactoryPostProcessors(beanFactory);
-println!("s1 = {}, s2 = {}", s1, s2);
For those people still arriving at this question in 2020 or later, there are newer options that may be better than both of these. For example, utf8mb4_0900_ai_ci.
-
All these collations are for the UTF-8 character encoding. The differences are in how text is sorted and compared.
-
_unicode_ci and _general_ci are two different sets of rules for sorting and comparing text according to the way we expect. Newer versions of MySQL introduce new sets of rules, too, such as _0900_ai_ci for equivalent rules based on Unicode 9.0 - and with no equivalent _general_ci variant. People reading this now should probably use one of these newer collations instead of either _unicode_ci or _general_ci. The description of those older collations below is provided for interest only.
-
MySQL is currently transitioning away from an older, flawed UTF-8 implementation. For now, you need to use utf8mb4 instead of utf8 for the character encoding part, to ensure you are getting the fixed version. The flawed version remains for backward compatibility, though it is being deprecated.
-
Key differences
-
utf8mb4_unicode_ci is based on the official Unicode rules for universal sorting and comparison, which sorts accurately in a wide range of languages.
-
utf8mb4_general_ci is a simplified set of sorting rules which aims to do as well as it can while taking many short-cuts designed to improve speed. It does not follow the Unicode rules and will result in undesirable sorting or comparison in some situations, such as when using particular languages or characters.
-
On modern servers, this performance boost will be all but negligible. It was devised in a time when servers had a tiny fraction of the CPU performance of today’s computers.
-
Benefits of utf8mb4_unicode_ci over utf8mb4_general_ci
-
utf8mb4_unicode_ci, which uses the Unicode rules for sorting and comparison, employs a fairly complex algorithm for correct sorting in a wide range of languages and when using a wide range of special characters. These rules need to take into account language-specific conventions; not everybody sorts their characters in what we would call ‘alphabetical order’.
-
As far as Latin (ie “European”) languages go, there is not much difference between the Unicode sorting and the simplified utf8mb4_general_cisorting in MySQL, but there are still a few differences:
-
For examples, the Unicode collation sorts “ß” like “ss”, and “Œ” like “OE” as people using those characters would normally want, whereas utf8mb4_general_cisorts them as single characters (presumably like “s” and “e” respectively).
-
Some Unicode characters are defined as ignorable, which means they shouldn’t count toward the sort order and the comparison should move on to the next character instead. utf8mb4_unicode_cihandles these properly.
-
In non-latin languages, such as Asian languages or languages with different alphabets, there may be a lot more differences between Unicode sorting and the simplified utf8mb4_general_cisorting. The suitability of utf8mb4_general_ciwill depend heavily on the language used. For some languages, it’ll be quite inadequate.
-
What should you use?
-
There is almost certainly no reason to use utf8mb4_general_cianymore, as we have left behind the point where CPU speed is low enough that the performance difference would be important. Your database will almost certainly be limited by other bottlenecks than this.
-
In the past, some people recommended to use utf8mb4_general_ciexcept when accurate sorting was going to be important enough to justify the performance cost. Today, that performance cost has all but disappeared, and developers are treating internationalization more seriously.
-
There’s an argument to be made that if speed is more important to you than accuracy, you may as well not do any sorting at all. It’s trivial to make an algorithm faster if you do not need it to be accurate. So, utf8mb4_general_ciis a compromise that’s probably not needed for speed reasons and probably also not suitable for accuracy reasons.
-
One other thing I’ll add is that even if you know your application only supports the English language, it may still need to deal with people’s names, which can often contain characters used in other languages in which it is just as important to sort correctly. Using the Unicode rules for everything helps add peace of mind that the very smart Unicode people have worked very hard to make sorting work properly.
-
What the parts mean
-
Firstly, ci is for case-insensitive sorting and comparison. This means it’s suitable for textual data, and case is not important. The other types of collation are cs (case-sensitive) for textual data where case is important, and bin, for where the encoding needs to match, bit for bit, which is suitable for fields which are really encoded binary data (including, for example, Base64). Case-sensitive sorting leads to some weird results and case-sensitive comparison can result in duplicate values differing only in letter case, so case-sensitive collations are falling out of favor for textual data - if case is significant to you, then otherwise ignorable punctuation and so on is probably also significant, and a binary collation might be more appropriate.
-
Next, unicode or general refers to the specific sorting and comparison rules - in particular, the way text is normalized or compared. There are many different sets of rules for the utf8mb4 character encoding, with unicode and general being two that attempt to work well in all possible languages rather than one specific one. The differences between these two sets of rules are the subject of this answer. Note that unicode uses rules from Unicode 4.0. Recent versions of MySQL add the rulesets unicode_520 using rules from Unicode 5.2, and 0900 (dropping the “unicode_” part) using rules from Unicode 9.0.
-
And lastly, utf8mb4 is of course the character encoding used internally. In this answer I’m talking only about Unicode based encodings.
UTF-8is a variable-length encoding. In the case of UTF-8, this means that storing one code point requires one to four bytes. However, MySQL’s encoding called “utf8” (alias of “utf8mb3”) only stores a maximum of three bytes per code point.
This is what (a previous version of the same page at)the MySQL documentationhas to say about it:
-
-
The character set named utf8[/utf8mb3] uses a maximum of three bytes per character and contains only BMP characters. As of MySQL 5.5.3, the utf8mb4 character set uses a maximum of four bytes per character supports supplemental characters:
-
-
For a BMP character, utf8[/utf8mb3] and utf8mb4 have identical storage characteristics: same code values, same encoding, same length.
-
For a supplementary character, utf8[/utf8mb3] cannot store the character at all, while utf8mb4 requires four bytes to store it. Since utf8[/utf8mb3] cannot store the character at all, you do not have any supplementary characters in utf8[/utf8mb3] columns and you need not worry about converting characters or losing data when upgrading utf8[/utf8mb3] data from older versions of MySQL.
第二种方式是 Windows 任务管理器中性能 tab 下的”打开资源监视器”, ,假如我的 U 盘的盘符是F: 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 对于前两种方式对我来说都无效,
-
第三种
所以尝试了第三种, 就是磁盘脱机的方式,在”计算机”右键管理,点击”磁盘管理”,可以找到 U 盘盘符右键,点击”脱机”,然后再”推出”,这个对我来说也不行
-
第四种
这种是唯一对我有效的,在开始菜单搜索”event”,可以搜到”事件查看器”, ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息 最后发现是英特尔的驱动管理程序的一个进程,关掉就退出了,虽然前面说的某里的进程是流氓,但这边是真的冤枉它了
+ 分享一次比较诡异的 Windows 下 U盘无法退出的经历
+ /2023/01/29/%E5%88%86%E4%BA%AB%E4%B8%80%E6%AC%A1%E6%AF%94%E8%BE%83%E8%AF%A1%E5%BC%82%E7%9A%84-Windows-%E4%B8%8B-U%E7%9B%98%E6%97%A0%E6%B3%95%E9%80%80%E5%87%BA%E7%9A%84%E7%BB%8F%E5%8E%86/
+ 作为一个 Windows 的老用户,并且也算是 Windows 系统的半个粉丝,但是秉承一贯的优缺点都应该说的原则,Windows 系统有一点缺点是真的挺难受,相信 Windows 用过比较久的都会经历过,就是 U盘无法退出的问题,在比较远古时代,这个问题似乎能采取的措施不多,关机再拔 U盘的方式是一种比较保险的方式,其他貌似有 360这种可以解除占用的,但是需要安装 360 软件,对于目前的使用环境来说有点得不偿失,也是比较流氓的一类软件了,目前在 Windows 环境我主要就安装了个火绒,或者就用 Windows 自带的 defender。
+
第二种方式是 Windows 任务管理器中性能 tab 下的”打开资源监视器”, ,假如我的 U 盘的盘符是F: 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 对于前两种方式对我来说都无效,
+
第三种
所以尝试了第三种, 就是磁盘脱机的方式,在”计算机”右键管理,点击”磁盘管理”,可以找到 U 盘盘符右键,点击”脱机”,然后再”推出”,这个对我来说也不行
+
第四种
这种是唯一对我有效的,在开始菜单搜索”event”,可以搜到”事件查看器”, ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息 最后发现是英特尔的驱动管理程序的一个进程,关掉就退出了,虽然前面说的某里的进程是流氓,但这边是真的冤枉它了
For those people still arriving at this question in 2020 or later, there are newer options that may be better than both of these. For example, utf8mb4_0900_ai_ci.
+
All these collations are for the UTF-8 character encoding. The differences are in how text is sorted and compared.
+
_unicode_ci and _general_ci are two different sets of rules for sorting and comparing text according to the way we expect. Newer versions of MySQL introduce new sets of rules, too, such as _0900_ai_ci for equivalent rules based on Unicode 9.0 - and with no equivalent _general_ci variant. People reading this now should probably use one of these newer collations instead of either _unicode_ci or _general_ci. The description of those older collations below is provided for interest only.
+
MySQL is currently transitioning away from an older, flawed UTF-8 implementation. For now, you need to use utf8mb4 instead of utf8 for the character encoding part, to ensure you are getting the fixed version. The flawed version remains for backward compatibility, though it is being deprecated.
+
Key differences
+
utf8mb4_unicode_ci is based on the official Unicode rules for universal sorting and comparison, which sorts accurately in a wide range of languages.
+
utf8mb4_general_ci is a simplified set of sorting rules which aims to do as well as it can while taking many short-cuts designed to improve speed. It does not follow the Unicode rules and will result in undesirable sorting or comparison in some situations, such as when using particular languages or characters.
+
On modern servers, this performance boost will be all but negligible. It was devised in a time when servers had a tiny fraction of the CPU performance of today’s computers.
+
Benefits of utf8mb4_unicode_ci over utf8mb4_general_ci
+
utf8mb4_unicode_ci, which uses the Unicode rules for sorting and comparison, employs a fairly complex algorithm for correct sorting in a wide range of languages and when using a wide range of special characters. These rules need to take into account language-specific conventions; not everybody sorts their characters in what we would call ‘alphabetical order’.
+
As far as Latin (ie “European”) languages go, there is not much difference between the Unicode sorting and the simplified utf8mb4_general_cisorting in MySQL, but there are still a few differences:
+
For examples, the Unicode collation sorts “ß” like “ss”, and “Œ” like “OE” as people using those characters would normally want, whereas utf8mb4_general_cisorts them as single characters (presumably like “s” and “e” respectively).
+
Some Unicode characters are defined as ignorable, which means they shouldn’t count toward the sort order and the comparison should move on to the next character instead. utf8mb4_unicode_cihandles these properly.
+
In non-latin languages, such as Asian languages or languages with different alphabets, there may be a lot more differences between Unicode sorting and the simplified utf8mb4_general_cisorting. The suitability of utf8mb4_general_ciwill depend heavily on the language used. For some languages, it’ll be quite inadequate.
+
What should you use?
+
There is almost certainly no reason to use utf8mb4_general_cianymore, as we have left behind the point where CPU speed is low enough that the performance difference would be important. Your database will almost certainly be limited by other bottlenecks than this.
+
In the past, some people recommended to use utf8mb4_general_ciexcept when accurate sorting was going to be important enough to justify the performance cost. Today, that performance cost has all but disappeared, and developers are treating internationalization more seriously.
+
There’s an argument to be made that if speed is more important to you than accuracy, you may as well not do any sorting at all. It’s trivial to make an algorithm faster if you do not need it to be accurate. So, utf8mb4_general_ciis a compromise that’s probably not needed for speed reasons and probably also not suitable for accuracy reasons.
+
One other thing I’ll add is that even if you know your application only supports the English language, it may still need to deal with people’s names, which can often contain characters used in other languages in which it is just as important to sort correctly. Using the Unicode rules for everything helps add peace of mind that the very smart Unicode people have worked very hard to make sorting work properly.
+
What the parts mean
+
Firstly, ci is for case-insensitive sorting and comparison. This means it’s suitable for textual data, and case is not important. The other types of collation are cs (case-sensitive) for textual data where case is important, and bin, for where the encoding needs to match, bit for bit, which is suitable for fields which are really encoded binary data (including, for example, Base64). Case-sensitive sorting leads to some weird results and case-sensitive comparison can result in duplicate values differing only in letter case, so case-sensitive collations are falling out of favor for textual data - if case is significant to you, then otherwise ignorable punctuation and so on is probably also significant, and a binary collation might be more appropriate.
+
Next, unicode or general refers to the specific sorting and comparison rules - in particular, the way text is normalized or compared. There are many different sets of rules for the utf8mb4 character encoding, with unicode and general being two that attempt to work well in all possible languages rather than one specific one. The differences between these two sets of rules are the subject of this answer. Note that unicode uses rules from Unicode 4.0. Recent versions of MySQL add the rulesets unicode_520 using rules from Unicode 5.2, and 0900 (dropping the “unicode_” part) using rules from Unicode 9.0.
+
And lastly, utf8mb4 is of course the character encoding used internally. In this answer I’m talking only about Unicode based encodings.
UTF-8is a variable-length encoding. In the case of UTF-8, this means that storing one code point requires one to four bytes. However, MySQL’s encoding called “utf8” (alias of “utf8mb3”) only stores a maximum of three bytes per code point.
This is what (a previous version of the same page at)the MySQL documentationhas to say about it:
+
+
The character set named utf8[/utf8mb3] uses a maximum of three bytes per character and contains only BMP characters. As of MySQL 5.5.3, the utf8mb4 character set uses a maximum of four bytes per character supports supplemental characters:
+
+
For a BMP character, utf8[/utf8mb3] and utf8mb4 have identical storage characteristics: same code values, same encoding, same length.
+
For a supplementary character, utf8[/utf8mb3] cannot store the character at all, while utf8mb4 requires four bytes to store it. Since utf8[/utf8mb3] cannot store the character at all, you do not have any supplementary characters in utf8[/utf8mb3] columns and you need not worry about converting characters or losing data when upgrading utf8[/utf8mb3] data from older versions of MySQL.
- /**
- * Wrap the given bean if necessary, i.e. if it is eligible for being proxied.
- * @param bean the raw bean instance
- * @param beanName the name of the bean
- * @param cacheKey the cache key for metadata access
- * @return a proxy wrapping the bean, or the raw bean instance as-is
- */
- protectedObjectwrapIfNecessary(Object bean,String beanName,Object cacheKey){
- if(StringUtils.hasLength(beanName)&&this.targetSourcedBeans.contains(beanName)){
- return bean;
- }
- if(Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))){
- return bean;
- }
- if(isInfrastructureClass(bean.getClass())||shouldSkip(bean.getClass(), beanName)){
- this.advisedBeans.put(cacheKey,Boolean.FALSE);
- return bean;
+
/**
- * Returns the class loader for the class. Some implementations may use
- * null to represent the bootstrap class loader. This method will return
- * null in such implementations if this class was loaded by the bootstrap
- * class loader.
- *
- * <p> If a security manager is present, and the caller's class loader is
- * not null and the caller's class loader is not the same as or an ancestor of
- * the class loader for the class whose class loader is requested, then
- * this method calls the security manager's {@code checkPermission}
- * method with a {@code RuntimePermission("getClassLoader")}
- * permission to ensure it's ok to access the class loader for the class.
- *
- * <p>If this object
- * represents a primitive type or void, null is returned.
- *
- * @return the class loader that loaded the class or interface
- * represented by this object.
- * @throws SecurityException
- * if a security manager exists and its
- * {@code checkPermission} method denies
- * access to the class loader for the class.
- * @see java.lang.ClassLoader
- * @see SecurityManager#checkPermission
- * @see java.lang.RuntimePermission
- */
- @CallerSensitive
- publicClassLoadergetClassLoader(){
- ClassLoader cl =getClassLoader0();
- if(cl ==null)
- returnnull;
- SecurityManager sm =System.getSecurityManager();
- if(sm !=null){
- ClassLoader.checkClassLoaderPermission(cl,Reflection.getCallerClass());
- }
- return cl;
- }
/**
- * Returns the system class loader for delegation. This is the default
- * delegation parent for new <tt>ClassLoader</tt> instances, and is
- * typically the class loader used to start the application.
- *
- * <p> This method is first invoked early in the runtime's startup
- * sequence, at which point it creates the system class loader and sets it
- * as the context class loader of the invoking <tt>Thread</tt>.
- *
- * <p> The default system class loader is an implementation-dependent
- * instance of this class.
- *
- * <p> If the system property "<tt>java.system.class.loader</tt>" is defined
- * when this method is first invoked then the value of that property is
- * taken to be the name of a class that will be returned as the system
- * class loader. The class is loaded using the default system class loader
- * and must define a public constructor that takes a single parameter of
- * type <tt>ClassLoader</tt> which is used as the delegation parent. An
- * instance is then created using this constructor with the default system
- * class loader as the parameter. The resulting class loader is defined
- * to be the system class loader.
- *
- * <p> If a security manager is present, and the invoker's class loader is
- * not <tt>null</tt> and the invoker's class loader is not the same as or
- * an ancestor of the system class loader, then this method invokes the
- * security manager's {@link
- * SecurityManager#checkPermission(java.security.Permission)
- * <tt>checkPermission</tt>} method with a {@link
- * RuntimePermission#RuntimePermission(String)
- * <tt>RuntimePermission("getClassLoader")</tt>} permission to verify
- * access to the system class loader. If not, a
- * <tt>SecurityException</tt> will be thrown. </p>
- *
- * @return The system <tt>ClassLoader</tt> for delegation, or
- * <tt>null</tt> if none
- *
- * @throws SecurityException
- * If a security manager exists and its <tt>checkPermission</tt>
- * method doesn't allow access to the system class loader.
- *
- * @throws IllegalStateException
- * If invoked recursively during the construction of the class
- * loader specified by the "<tt>java.system.class.loader</tt>"
- * property.
- *
- * @throws Error
- * If the system property "<tt>java.system.class.loader</tt>"
- * is defined but the named class could not be loaded, the
- * provider class does not define the required constructor, or an
- * exception is thrown by that constructor when it is invoked. The
- * underlying cause of the error can be retrieved via the
- * {@link Throwable#getCause()} method.
- *
- * @revised 1.4
- */
- @CallerSensitive
- publicstaticClassLoadergetSystemClassLoader(){
- initSystemClassLoader();
- if(scl ==null){
- returnnull;
- }
- SecurityManager sm =System.getSecurityManager();
- if(sm !=null){
- checkClassLoaderPermission(scl,Reflection.getCallerClass());
- }
- return scl;
- }
- privatestaticsynchronizedvoidinitSystemClassLoader(){
- if(!sclSet){
- if(scl !=null)
- thrownewIllegalStateException("recursive invocation");
- // 主要的第一步是这
- sun.misc.Launcher l =sun.misc.Launcher.getLauncher();
- if(l !=null){
- Throwable oops =null;
- // 然后是这
- scl = l.getClassLoader();
+ Thread t2 =newThread(){
+ @Override
+ publicvoidrun(){try{
- scl =AccessController.doPrivileged(
- newSystemClassLoaderAction(scl));
- }catch(PrivilegedActionException pae){
- oops = pae.getCause();
- if(oops instanceofInvocationTargetException){
- oops = oops.getCause();
- }
- }
- if(oops !=null){
- if(oops instanceofError){
- throw(Error) oops;
- }else{
- // wrap the exception
- thrownewError(oops);
- }
+ lock2.lock();
+ TimeUnit.SECONDS.sleep(1);
+ lock1.lock();
+ }catch(InterruptedException e){
+ e.printStackTrace();}}
- sclSet =true;
- }
- }
-// 接着跟到sun.misc.Launcher#getClassLoader
-publicClassLoadergetClassLoader(){
- returnthis.loader;
- }
-// 然后看到这 sun.misc.Launcher#Launcher
-publicLauncher(){
- Launcher.ExtClassLoader var1;
- try{
- var1 =Launcher.ExtClassLoader.getExtClassLoader();
- }catch(IOException var10){
- thrownewInternalError("Could not create extension class loader", var10);
- }
-
- try{
- // 可以看到 就是 AppClassLoader
- this.loader =Launcher.AppClassLoader.getAppClassLoader(var1);
- }catch(IOException var9){
- thrownewInternalError("Could not create application class loader", var9);
- }
-
- Thread.currentThread().setContextClassLoader(this.loader);
- String var2 =System.getProperty("java.security.manager");
- if(var2 !=null){
- SecurityManager var3 =null;
- if(!"".equals(var2)&&!"default".equals(var2)){
- try{
- var3 =(SecurityManager)this.loader.loadClass(var2).newInstance();
- }catch(IllegalAccessException var5){
- }catch(InstantiationException var6){
- }catch(ClassNotFoundException var7){
- }catch(ClassCastException var8){
- }
- }else{
- var3 =newSecurityManager();
- }
-
- if(var3 ==null){
- thrownewInternalError("Could not create SecurityManager: "+ var2);
- }
-
- System.setSecurityManager(var3);
- }
-
- }
/**
- * Loads the class with the specified <a href="#name">binary name</a>. The
- * default implementation of this method searches for classes in the
- * following order:
- *
- * <ol>
- *
- * <li><p> Invoke {@link #findLoadedClass(String)} to check if the class
- * has already been loaded. </p></li>
- *
- * <li><p> Invoke the {@link #loadClass(String) <tt>loadClass</tt>} method
- * on the parent class loader. If the parent is <tt>null</tt> the class
- * loader built-in to the virtual machine is used, instead. </p></li>
- *
- * <li><p> Invoke the {@link #findClass(String)} method to find the
- * class. </p></li>
- *
- * </ol>
- *
- * <p> If the class was found using the above steps, and the
- * <tt>resolve</tt> flag is true, this method will then invoke the {@link
- * #resolveClass(Class)} method on the resulting <tt>Class</tt> object.
- *
- * <p> Subclasses of <tt>ClassLoader</tt> are encouraged to override {@link
- * #findClass(String)}, rather than this method. </p>
- *
- * <p> Unless overridden, this method synchronizes on the result of
- * {@link #getClassLoadingLock <tt>getClassLoadingLock</tt>} method
- * during the entire class loading process.
- *
- * @param name
- * The <a href="#name">binary name</a> of the class
- *
- * @param resolve
- * If <tt>true</tt> then resolve the class
- *
- * @return The resulting <tt>Class</tt> object
- *
- * @throws ClassNotFoundException
- * If the class could not be found
- */
- protectedClass<?>loadClass(String name,boolean resolve)
- throwsClassNotFoundException
- {
- synchronized(getClassLoadingLock(name)){
- // First, check if the class has already been loaded
- Class<?> c =findLoadedClass(name);
- if(c ==null){
- long t0 =System.nanoTime();
- try{
- if(parent !=null){
- // 委托父类加载
- c = parent.loadClass(name,false);
- }else{
- // 使用启动类加载器
- c =findBootstrapClassOrNull(name);
- }
- }catch(ClassNotFoundException e){
- // ClassNotFoundException thrown if class not found
- // from the non-null parent class loader
- }
-
- if(c ==null){
- // If still not found, then invoke findClass in order
- // to find the class.
- long t1 =System.nanoTime();
- // 调用自己的 findClass() 方法尝试进行加载
- c =findClass(name);
-
- // this is the defining class loader; record the stats
- sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
- sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
- sun.misc.PerfCounter.getFindClasses().increment();
- }
- }
- if(resolve){
- resolveClass(c);
- }
- return c;
- }
- }
-]]>
-
- java
-
-
- java
-
-
-
- 聊聊 Linux 下的 top 命令
- /2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
- top 命令在日常的 Linux 使用中,特别是做一些服务器的简单状态查看,排查故障都起了比较大的作用,但是由于这个命令看到的东西比较多,一般只会看部分,或者说像我这样就会比较片面地看一些信息,比如默认是进程维度的,可以在启动命令的时候加-H进入线程模式
-
-H :Threads-mode operation
- Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later
- this can be changed with the `H' interactive command.
SORTING of task window
-
- For compatibility, this top supports most of the former top sort keys. Since this is primarily a service to former top users, these commands
- do not appear on any help screen.
- command sorted-field supported
- A start time (non-display) No
- M %MEM Yes
- N PID Yes
- P %CPU Yes
- T TIME+ Yes
+ 聊聊 Sharding-Jdbc 的简单使用
+ /2021/12/12/%E8%81%8A%E8%81%8A-Sharding-Jdbc-%E7%9A%84%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8/
+ 我们在日常工作中还是使用比较多的分库分表组件的,其中比较优秀的就有 Sharding-Jdbc,一开始由当当开源,后来捐献给了 Apache,说一下简单使用,因为原来经常的使用都是基于 xml 跟 properties 组合起来使用,这里主要试下用 Java Config 来配置 首先是通过 Spring Initializr 创建个带 jdbc 的 Spring Boot 项目,然后引入主要的依赖
+
+// 注意这里的注解,可以让 Spring 自动帮忙加载,也就是 Java Config 的核心
+@Configuration
+publicclassMysqlConfig{
- Before using any of the following sort provisions, top suggests that you temporarily turn on column highlighting using the `x' interactive com‐
- mand. That will help ensure that the actual sort environment matches your intent.
+ @Bean
+ publicDataSourcedataSource()throwsSQLException{
+ // Configure actual data sources
+ Map<String,DataSource> dataSourceMap =newHashMap<>();
- The following interactive commands will only be honored when the current sort field is visible. The sort field might not be visible because:
- 1) there is insufficient Screen Width
- 2) the `f' interactive command turned it Off
-
- < :Move-Sort-Field-Left
- Moves the sort column to the left unless the current sort field is the first field being displayed.
-
- > :Move-Sort-Field-Right
- Moves the sort column to the right unless the current sort field is the last field being displayed.
-
查看 man page 可以找到这一段,其实一般 man page 都是最细致的,只不过因为太多了,有时候懒得看,这里可以通过大写 M 和大写 P 分别按内存和 CPU 排序,下面还有两个小技巧,通过按 x 可以将当前活跃的排序列用不同颜色标出来,然后可以通过<和>直接左右移动排序列
-]]>
-
- Linux
- 命令
- 小技巧
- top
- top
- 排序
-
-
- 排序
- linux
- 小技巧
- top
-
-
@Override
-publicfinalResultSetexecuteQuery(finalString sql)throwsSQLException{
- thrownewSQLFeatureNotSupportedException("executeQuery with SQL for PreparedStatement");
-}
publicbooleaninitialize()throwsCloneNotSupportedException{
- boolean result =this.topicConfigManager.load();
- result = result &&this.consumerOffsetManager.load();
- result = result &&this.subscriptionGroupManager.load();
- result = result &&this.consumerFilterManager.load();
+ int result = ps.executeUpdate();
+ LOGGER.info("current execute result: {}", result);
+ Thread.sleep(newRandom().nextInt(100));
+ i++;
+ }while(i <=2000);
select * from student_time_0 ORDER BY create_time ASC limit 333, 5;
+select * from student_time_1 ORDER BY create_time ASC limit 333, 5;
+select * from student_time_2 ORDER BY create_time ASC limit 333, 5;
/**
+ * Returns the class loader for the class. Some implementations may use
+ * null to represent the bootstrap class loader. This method will return
+ * null in such implementations if this class was loaded by the bootstrap
+ * class loader.
+ *
+ * <p> If a security manager is present, and the caller's class loader is
+ * not null and the caller's class loader is not the same as or an ancestor of
+ * the class loader for the class whose class loader is requested, then
+ * this method calls the security manager's {@code checkPermission}
+ * method with a {@code RuntimePermission("getClassLoader")}
+ * permission to ensure it's ok to access the class loader for the class.
+ *
+ * <p>If this object
+ * represents a primitive type or void, null is returned.
+ *
+ * @return the class loader that loaded the class or interface
+ * represented by this object.
+ * @throws SecurityException
+ * if a security manager exists and its
+ * {@code checkPermission} method denies
+ * access to the class loader for the class.
+ * @see java.lang.ClassLoader
+ * @see SecurityManager#checkPermission
+ * @see java.lang.RuntimePermission
+ */
+ @CallerSensitive
+ publicClassLoadergetClassLoader(){
+ ClassLoader cl =getClassLoader0();
+ if(cl ==null)
+ returnnull;
+ SecurityManager sm =System.getSecurityManager();
+ if(sm !=null){
+ ClassLoader.checkClassLoaderPermission(cl,Reflection.getCallerClass());
+ }
+ return cl;
+ }
/**
+ * Returns the system class loader for delegation. This is the default
+ * delegation parent for new <tt>ClassLoader</tt> instances, and is
+ * typically the class loader used to start the application.
+ *
+ * <p> This method is first invoked early in the runtime's startup
+ * sequence, at which point it creates the system class loader and sets it
+ * as the context class loader of the invoking <tt>Thread</tt>.
+ *
+ * <p> The default system class loader is an implementation-dependent
+ * instance of this class.
+ *
+ * <p> If the system property "<tt>java.system.class.loader</tt>" is defined
+ * when this method is first invoked then the value of that property is
+ * taken to be the name of a class that will be returned as the system
+ * class loader. The class is loaded using the default system class loader
+ * and must define a public constructor that takes a single parameter of
+ * type <tt>ClassLoader</tt> which is used as the delegation parent. An
+ * instance is then created using this constructor with the default system
+ * class loader as the parameter. The resulting class loader is defined
+ * to be the system class loader.
+ *
+ * <p> If a security manager is present, and the invoker's class loader is
+ * not <tt>null</tt> and the invoker's class loader is not the same as or
+ * an ancestor of the system class loader, then this method invokes the
+ * security manager's {@link
+ * SecurityManager#checkPermission(java.security.Permission)
+ * <tt>checkPermission</tt>} method with a {@link
+ * RuntimePermission#RuntimePermission(String)
+ * <tt>RuntimePermission("getClassLoader")</tt>} permission to verify
+ * access to the system class loader. If not, a
+ * <tt>SecurityException</tt> will be thrown. </p>
+ *
+ * @return The system <tt>ClassLoader</tt> for delegation, or
+ * <tt>null</tt> if none
+ *
+ * @throws SecurityException
+ * If a security manager exists and its <tt>checkPermission</tt>
+ * method doesn't allow access to the system class loader.
+ *
+ * @throws IllegalStateException
+ * If invoked recursively during the construction of the class
+ * loader specified by the "<tt>java.system.class.loader</tt>"
+ * property.
+ *
+ * @throws Error
+ * If the system property "<tt>java.system.class.loader</tt>"
+ * is defined but the named class could not be loaded, the
+ * provider class does not define the required constructor, or an
+ * exception is thrown by that constructor when it is invoked. The
+ * underlying cause of the error can be retrieved via the
+ * {@link Throwable#getCause()} method.
+ *
+ * @revised 1.4
+ */
+ @CallerSensitive
+ publicstaticClassLoadergetSystemClassLoader(){
+ initSystemClassLoader();
+ if(scl ==null){
+ returnnull;
+ }
+ SecurityManager sm =System.getSecurityManager();
+ if(sm !=null){
+ checkClassLoaderPermission(scl,Reflection.getCallerClass());
+ }
+ return scl;
+ }
+ privatestaticsynchronizedvoidinitSystemClassLoader(){
+ if(!sclSet){
+ if(scl !=null)
+ thrownewIllegalStateException("recursive invocation");
+ // 主要的第一步是这
+ sun.misc.Launcher l =sun.misc.Launcher.getLauncher();
+ if(l !=null){
+ Throwable oops =null;
+ // 然后是这
+ scl = l.getClassLoader();
+ try{
+ scl =AccessController.doPrivileged(
+ newSystemClassLoaderAction(scl));
+ }catch(PrivilegedActionException pae){
+ oops = pae.getCause();
+ if(oops instanceofInvocationTargetException){
+ oops = oops.getCause();
+ }
+ }
+ if(oops !=null){
+ if(oops instanceofError){
+ throw(Error) oops;
+ }else{
+ // wrap the exception
+ thrownewError(oops);
+ }
+ }
+ }
+ sclSet =true;
+ }
+ }
+// 接着跟到sun.misc.Launcher#getClassLoader
+publicClassLoadergetClassLoader(){
+ returnthis.loader;
+ }
+// 然后看到这 sun.misc.Launcher#Launcher
+publicLauncher(){
+ Launcher.ExtClassLoader var1;
+ try{
+ var1 =Launcher.ExtClassLoader.getExtClassLoader();
+ }catch(IOException var10){
+ thrownewInternalError("Could not create extension class loader", var10);}
- this.allocateMappedFileService.start();
-
- this.indexService.start();
+ try{
+ // 可以看到 就是 AppClassLoader
+ this.loader =Launcher.AppClassLoader.getAppClassLoader(var1);
+ }catch(IOException var9){
+ thrownewInternalError("Could not create application class loader", var9);
+ }
- this.dispatcherList =newLinkedList<>();
- this.dispatcherList.addLast(newCommitLogDispatcherBuildConsumeQueue());
- this.dispatcherList.addLast(newCommitLogDispatcherBuildIndex());
-
- File file =newFile(StorePathConfigHelper.getLockFile(messageStoreConfig.getStorePathRootDir()));
- MappedFile.ensureDirOK(file.getParent());
- lockFile =newRandomAccessFile(file,"rw");
- }
publicvoidstart()throwsException{
-
- lock = lockFile.getChannel().tryLock(0,1,false);
- if(lock ==null|| lock.isShared()||!lock.isValid()){
- thrownewRuntimeException("Lock failed,MQ already started");
- }
-
- lockFile.getChannel().write(ByteBuffer.wrap("lock".getBytes()));
- lockFile.getChannel().force(true);
- {
- /**
- * 1. Make sure the fast-forward messages to be truncated during the recovering according to the max physical offset of the commitlog;
- * 2. DLedger committedPos may be missing, so the maxPhysicalPosInLogicQueue maybe bigger that maxOffset returned by DLedgerCommitLog, just let it go;
- * 3. Calculate the reput offset according to the consume queue;
- * 4. Make sure the fall-behind messages to be dispatched before starting the commitlog, especially when the broker role are automatically changed.
- */
- long maxPhysicalPosInLogicQueue = commitLog.getMinOffset();
- for(ConcurrentMap<Integer,ConsumeQueue> maps :this.consumeQueueTable.values()){
- for(ConsumeQueue logic : maps.values()){
- if(logic.getMaxPhysicOffset()> maxPhysicalPosInLogicQueue){
- maxPhysicalPosInLogicQueue = logic.getMaxPhysicOffset();
- }
- }
- }
- if(maxPhysicalPosInLogicQueue <0){
- maxPhysicalPosInLogicQueue =0;
- }
- if(maxPhysicalPosInLogicQueue <this.commitLog.getMinOffset()){
- maxPhysicalPosInLogicQueue =this.commitLog.getMinOffset();
- /**
- * This happens in following conditions:
- * 1. If someone removes all the consumequeue files or the disk get damaged.
- * 2. Launch a new broker, and copy the commitlog from other brokers.
- *
- * All the conditions has the same in common that the maxPhysicalPosInLogicQueue should be 0.
- * If the maxPhysicalPosInLogicQueue is gt 0, there maybe something wrong.
- */
- log.warn("[TooSmallCqOffset] maxPhysicalPosInLogicQueue={} clMinOffset={}", maxPhysicalPosInLogicQueue,this.commitLog.getMinOffset());}
- log.info("[SetReputOffset] maxPhysicalPosInLogicQueue={} clMinOffset={} clMaxOffset={} clConfirmedOffset={}",
- maxPhysicalPosInLogicQueue,this.commitLog.getMinOffset(),this.commitLog.getMaxOffset(),this.commitLog.getConfirmOffset());
- this.reputMessageService.setReputFromOffset(maxPhysicalPosInLogicQueue);
- this.reputMessageService.start();
-
- /**
- * 1. Finish dispatching the messages fall behind, then to start other services.
- * 2. DLedger committedPos may be missing, so here just require dispatchBehindBytes <= 0
- */
- while(true){
- if(dispatchBehindBytes()<=0){
- break;
- }
- Thread.sleep(1000);
- log.info("Try to finish doing reput the messages fall behind during the starting, reputOffset={} maxOffset={} behind={}",this.reputMessageService.getReputFromOffset(),this.getMaxPhyOffset(),this.dispatchBehindBytes());
+ if(resolve){
+ resolveClass(c);}
- this.recoverTopicQueueTable();
- }
-
- if(!messageStoreConfig.isEnableDLegerCommitLog()){
- this.haService.start();
- this.handleScheduleMessageService(messageStoreConfig.getBrokerRole());
+ return c;}
-
- this.flushConsumeQueueService.start();
- this.commitLog.start();
- this.storeStatsService.start();
-
- this.createTempFile();
- this.addScheduleTask();
- this.shutdown =false;
- }
select * from student_time_0 ORDER BY create_time ASC limit 333, 5;
-select * from student_time_1 ORDER BY create_time ASC limit 333, 5;
-select * from student_time_2 ORDER BY create_time ASC limit 333, 5;
腆着脸说虽然这个不可行,但是思路是对的,具体实行起来需要做一系列(肥肠多)的改动,首先根据我的理解,其实这个拷贝一个表是变成拷贝一条记录,但是如果有多个事务,那就得拷贝多次,这个问题其实可以借助版本管理系统来解释,在用版本管理系统,git 之类的之前,很原始的可能是开发完一个功能后,就打个压缩包用时间等信息命名,然后如果后面要找回这个就直接用这个压缩包的就行了,后来有了 svn,git 中心式和分布式的版本管理系统,它的一个特点是粒度可以控制到文件和代码行级别,对应的我们的 mysql 事务是不是也可以从一开始预想的表级别细化到行的级别,可能之前很多人都了解过,数据库的一行记录除了我们用户自定义的字段,还有一些额外的字段,去源码data0type.h里捞一下
-
/* Precise data types for system columns and the length of those columns;
-NOTE: the values must run from 0 up in the order given! All codes must
-be less than 256 */
-#defineDATA_ROW_ID0/* row id: a 48-bit integer */
-#defineDATA_ROW_ID_LEN6/* stored length for row id */
-
-/** Transaction id: 6 bytes */
-constexpr size_t DATA_TRX_ID =1;
-
-/** Transaction ID type size in bytes. */
-constexpr size_t DATA_TRX_ID_LEN =6;
-
-/** Rollback data pointer: 7 bytes */
-constexpr size_t DATA_ROLL_PTR =2;
-
-/** Rollback data pointer type size in bytes. */
-constexpr size_t DATA_ROLL_PTR_LEN =7;
如果记录的事务 id 介于 m_low_limit_id 和 m_up_limit_id 之间,则要判断它是否在 m_ids 中,如果在,不可见,如果不在,表示已提交,可见 具体的代码捞一下看看
/** Check whether the changes by id are visible.
- @param[in] id transaction id to check against the view
- @param[in] name table name
- @return whether the view sees the modifications of id. */
- bool changes_visible(trx_id_t id, const table_name_t &name) const
- MY_ATTRIBUTE((warn_unused_result)) {
- ut_ad(id > 0);
-
- if (id < m_up_limit_id || id == m_creator_trx_id) {
- return (true);
- }
-
- check_trx_id_sanity(id, name);
-
- if (id >= m_low_limit_id) {
- return (false);
-
- } else if (m_ids.empty()) {
- return (true);
- }
-
- const ids_t::value_type *p = m_ids.data();
-
- return (!std::binary_search(p, p + m_ids.size(), id));
- }
-
+ 聊一下关于怎么陪伴学习
+ /2022/11/06/%E8%81%8A%E4%B8%80%E4%B8%8B%E5%85%B3%E4%BA%8E%E6%80%8E%E4%B9%88%E9%99%AA%E4%BC%B4%E5%AD%A6%E4%B9%A0/
+ 这是一次开车过程中结合网上的一些微博想到的,开车是之前LD买了车后,陪领导练车,其实在一开始练车的时候,我们已经是找了相对很空的封闭路段,路上基本很少有车,偶尔有一辆车,但是LD还是很害怕,车速还只有十几的时候,还很远的对面来车的时候就觉得很慌了,这个时候如果以常理肯定会说这样子完全不用怕,如果克服恐惧真的这么容易的话,问题就不会那么纠结了,人生是很难完全感同身受的,唯有降低预设的基准让事情从头理清楚,害怕了我们就先休息,有车了我们就停下,先适应完全没车的情况,变得更慢一点,如果这时候着急一点,反而会起到反效果,比如只是说不要怕,接着开,甚至有点厌烦了,那基本这个练车也不太成得了了,而正好是有耐心的一起慢慢练习,还有就是第二件是切身体会,就是当道路本来是两条道,但是封了一条的时候,这时候开车如果是像我这样的新手,如果开车时左右边看着的话,车肯定开不好,因为那样会一直左右调整,反而更容易控制不好左右的距离,蹭到旁边的隔离栏,正确的方式应该是专注于正前方的路,这样才能保证左右边距离尽可能均匀,而不是顾左失右或者顾右失左,所以很多陪伴学习需要注意的是方式和耐心,能够识别到关键点那是最好的,但是有时候更需要的是耐心,纯靠耐心不一定能解决问题,但是可能会找到问题关键点。
+]]>
+
+ 生活
+
+
+ 生活
+
+
+
+ 聊聊 mysql 的 MVCC 续续篇之锁分析
+ /2020/05/10/%E8%81%8A%E8%81%8A-mysql-%E7%9A%84-MVCC-%E7%BB%AD%E7%BB%AD%E7%AF%87%E4%B9%8B%E5%8A%A0%E9%94%81%E5%88%86%E6%9E%90/
+ 看完前面两篇水文之后,感觉不得不来分析下 mysql 的锁了,其实前面说到幻读的时候是有个前提没提到的,比如一个select * from table1 where id = 1这种查询语句其实是不会加传说中的锁的,当然这里是指在 RR 或者 RC 隔离级别下, 看一段 mysql官方文档
+
+
SELECT ... FROM is a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set to SERIALIZABLE. For SERIALIZABLE level, the search sets shared next-key locks on the index records it encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
除了第一条是 S 锁之外,其他都是 X 排他锁,这边在顺带下,S 锁表示共享锁, X 表示独占锁,同为 S 锁之间不冲突,S 与 X,X 与 S,X 与 X 之间都冲突,也就是加了前者,后者就加不上了 我们知道对于 RC 级别会出现幻读现象,对于 RR 级别不会出现,主要的区别是 RR 级别下对于以上的加锁读取都根据情况加上了 gap 锁,那么是不是 RR 级别下以上所有的都是要加 gap 锁呢,当然不是 举个例子,RR 事务隔离级别下,table1 有个主键id 字段 select * from table1 where id = 10 for update 这条语句要加 gap 锁吗? 答案是不需要,这里其实算是我看了这么久的一点自己的理解,啥时候要加 gap 锁,判断的条件是根据我查询的数据是否会因为不加 gap 锁而出现数量的不一致,我上面这条查询语句,在什么情况下会出现查询结果数量不一致呢,只要在这条记录被更新或者删除的时候,有没有可能我第一次查出来一条,第二次变成两条了呢,不可能,因为是主键索引。 再变更下这个题的条件,当 id 不是主键,但是是唯一索引,这样需要怎么加锁,注意问题是怎么加锁,不是需不需要加 gap 锁,这里呢就是稍微延伸一下,把聚簇索引(主键索引)和二级索引带一下,当 id 不是主键,说明是个二级索引,但是它是唯一索引,体会下,首先对于 id = 10这个二级索引肯定要加锁,要不要锁 gap 呢,不用,因为是唯一索引,id = 10 只可能有这一条记录,然后呢,这样是不是就好了,还不行,因为啥,因为它是二级索引,对应的主键索引的记录才是真正的数据,万一被更新掉了咋办,所以在 id = 10 对应的主键索引上也需要加上锁(默认都是 record lock行锁),那主键索引上要不要加 gap 呢,也不用,也是精确定位到这一条记录 最后呢,当 id 不是主键,也不是唯一索引,只是个普通的索引,这里就需要大名鼎鼎的 gap 锁了, 是时候画个图了 其实核心的目的还是不让这个 id=10 的记录不会出现幻读,那么就需要在 id 这个索引上加上三个 gap 锁,主键索引上就不用了,在 id 索引上已经控制住了id = 10 不会出现幻读,主键索引上这两条对应的记录已经锁了,所以就这样 OK 了
public class Singleton1 {
- // 首先,将构造方法变成私有的
- private Singleton1() {};
- // 创建私有静态实例,这样第一次使用的时候就会进行创建
- private static Singleton instance = new Singleton1();
-
- // 使用这个对象都是通过这个 getInstance 来获取
- public static Singleton1 getInstance() {
- return instance;
- }
- // 瞎写一个静态方法。这里想说的是,如果我们只是要调用 Singleton.getDate(...),
- // 本来是不想要生成 Singleton 实例的,不过没办法,已经生成了
- public static Date getDate(String mode) {return new Date();}
-}
+ 聊聊 mysql 索引的一些细节
+ /2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
+ 前几天同事问了我个 mysql 索引的问题,虽然大概知道,但是还是想来实践下,就是 is null,is not null 这类查询是否能用索引,可能之前有些网上的文章说都是不能用索引,但是其实不是,我们来看个小试验
+
EXPLAINselect*from null_index_t WHERE null_key isnull;
+
+
EXPLAINselect*from null_index_t WHERE null_key isnotnull;
+
是不是不一样了,这里再补充下我试验使用的 mysql 是 5.7 的,不保证在其他版本的一致性, 其实可以看出随着数据量的变化,mysql 会不会使用索引是会变化的,不是说 is not null 一定会使用,也不是一定不会使用,而是优化器会根据查询成本做个预判,这个预判尽可能会减小查询成本,主要包括回表啥的,但是也不一定完全准确。
+]]>
+
+ Mysql
+ C
+ 索引
+ Mysql
+
+
+ mysql
+ 索引
+ is null
+ is not null
+ procedure
+
+
+
+ 聊聊Java中的单例模式
+ /2019/12/21/%E8%81%8A%E8%81%8AJava%E4%B8%AD%E7%9A%84%E5%8D%95%E4%BE%8B%E6%A8%A1%E5%BC%8F/
+ 这是个 Java 面试的高频问题,我也遇到过,以往都是觉得这类题没意思,网上一搜一大堆,也不愿意记,其实说回来,主要还是没静下心来好好去理解,今天无意中看到一个课程,基本帮我把一些疑惑的点讲清楚了,首先单例是啥意思,这个其实是有范围一说,比如我起了个Spring Boot应用,在这个应用范围内,我的常规 bean 是单例的,意味着 getBean 的时候其实永远只会拿到那一个对象,那要怎么来写一个单例呢,首先就是传说中的饿汉模式,也是最简单的
+
饿汉模式
public class Singleton1 {
+ // 首先,将构造方法变成私有的
+ private Singleton1() {};
+ // 创建私有静态实例,这样第一次使用的时候就会进行创建
+ private static Singleton instance = new Singleton1();
+
+ // 使用这个对象都是通过这个 getInstance 来获取
+ public static Singleton1 getInstance() {
+ return instance;
+ }
+ // 瞎写一个静态方法。这里想说的是,如果我们只是要调用 Singleton.getDate(...),
+ // 本来是不想要生成 Singleton 实例的,不过没办法,已经生成了
+ public static Date getDate(String mode) {return new Date();}
+}
public class Singleton2 {
// 首先,也是先堵死 new Singleton() 这条路,将构造方法变成私有
@@ -18594,753 +18012,1302 @@ constexpr size_t DATA_ROLL_PTR_LEN
- 聊聊 mysql 的 MVCC 续续篇之锁分析
- /2020/05/10/%E8%81%8A%E8%81%8A-mysql-%E7%9A%84-MVCC-%E7%BB%AD%E7%BB%AD%E7%AF%87%E4%B9%8B%E5%8A%A0%E9%94%81%E5%88%86%E6%9E%90/
- 看完前面两篇水文之后,感觉不得不来分析下 mysql 的锁了,其实前面说到幻读的时候是有个前提没提到的,比如一个select * from table1 where id = 1这种查询语句其实是不会加传说中的锁的,当然这里是指在 RR 或者 RC 隔离级别下, 看一段 mysql官方文档
-
-
SELECT ... FROM is a consistent read, reading a snapshot of the database and setting no locks unless the transaction isolation level is set to SERIALIZABLE. For SERIALIZABLE level, the search sets shared next-key locks on the index records it encounters. However, only an index record lock is required for statements that lock rows using a unique index to search for a unique row.
除了第一条是 S 锁之外,其他都是 X 排他锁,这边在顺带下,S 锁表示共享锁, X 表示独占锁,同为 S 锁之间不冲突,S 与 X,X 与 S,X 与 X 之间都冲突,也就是加了前者,后者就加不上了 我们知道对于 RC 级别会出现幻读现象,对于 RR 级别不会出现,主要的区别是 RR 级别下对于以上的加锁读取都根据情况加上了 gap 锁,那么是不是 RR 级别下以上所有的都是要加 gap 锁呢,当然不是 举个例子,RR 事务隔离级别下,table1 有个主键id 字段 select * from table1 where id = 10 for update 这条语句要加 gap 锁吗? 答案是不需要,这里其实算是我看了这么久的一点自己的理解,啥时候要加 gap 锁,判断的条件是根据我查询的数据是否会因为不加 gap 锁而出现数量的不一致,我上面这条查询语句,在什么情况下会出现查询结果数量不一致呢,只要在这条记录被更新或者删除的时候,有没有可能我第一次查出来一条,第二次变成两条了呢,不可能,因为是主键索引。 再变更下这个题的条件,当 id 不是主键,但是是唯一索引,这样需要怎么加锁,注意问题是怎么加锁,不是需不需要加 gap 锁,这里呢就是稍微延伸一下,把聚簇索引(主键索引)和二级索引带一下,当 id 不是主键,说明是个二级索引,但是它是唯一索引,体会下,首先对于 id = 10这个二级索引肯定要加锁,要不要锁 gap 呢,不用,因为是唯一索引,id = 10 只可能有这一条记录,然后呢,这样是不是就好了,还不行,因为啥,因为它是二级索引,对应的主键索引的记录才是真正的数据,万一被更新掉了咋办,所以在 id = 10 对应的主键索引上也需要加上锁(默认都是 record lock行锁),那主键索引上要不要加 gap 呢,也不用,也是精确定位到这一条记录 最后呢,当 id 不是主键,也不是唯一索引,只是个普通的索引,这里就需要大名鼎鼎的 gap 锁了, 是时候画个图了 其实核心的目的还是不让这个 id=10 的记录不会出现幻读,那么就需要在 id 这个索引上加上三个 gap 锁,主键索引上就不用了,在 id 索引上已经控制住了id = 10 不会出现幻读,主键索引上这两条对应的记录已经锁了,所以就这样 OK 了
-]]>
-
- Mysql
- C
- 数据结构
- 源码
- Mysql
-
-
- mysql
- 数据结构
- 源码
- mvcc
- read view
- gap lock
- next-key lock
- 幻读
-
-
-
- 聊聊 mysql 索引的一些细节
- /2020/12/27/%E8%81%8A%E8%81%8A-mysql-%E7%B4%A2%E5%BC%95%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/
- 前几天同事问了我个 mysql 索引的问题,虽然大概知道,但是还是想来实践下,就是 is null,is not null 这类查询是否能用索引,可能之前有些网上的文章说都是不能用索引,但是其实不是,我们来看个小试验
-
EXPLAINselect*from null_index_t WHERE null_key isnull;
-
-
EXPLAINselect*from null_index_t WHERE null_key isnotnull;
-
是不是不一样了,这里再补充下我试验使用的 mysql 是 5.7 的,不保证在其他版本的一致性, 其实可以看出随着数据量的变化,mysql 会不会使用索引是会变化的,不是说 is not null 一定会使用,也不是一定不会使用,而是优化器会根据查询成本做个预判,这个预判尽可能会减小查询成本,主要包括回表啥的,但是也不一定完全准确。
-]]>
-
- Mysql
- C
- 索引
- Mysql
-
-
- mysql
- 索引
- is null
- is not null
- procedure
-
-
-
- 聊聊一次 brew update 引发的血案
- /2020/06/13/%E8%81%8A%E8%81%8A%E4%B8%80%E6%AC%A1-brew-update-%E5%BC%95%E5%8F%91%E7%9A%84%E8%A1%80%E6%A1%88/
- 熟悉我的人(谁熟悉你啊🙄)知道我以前写过 PHP,虽然现在在工作中没用到了,但是自己的一些小工具还是会用 PHP 来写,但是在 Mac 碰到了一个环境相关的问题,因为我也是个更新狂魔,用了 brew 之后因为 gfw 的原因,如果长时间不更新,有时候要装一个用它装一个软件的话,前置的更新耗时就会让人非常头大,所以我基本会隔天 update 一下,但是这样会带来一个很心烦的问题,就是像这样,因为我是要用一个固定版本的 PHP,如果一直升需要一直配扩展啥的也很麻烦,如果一直升级 PHP 到最新版可能会比较少碰到这个问题
-
dyld: Library not loaded: /usr/local/opt/icu4c/lib/libicui18n.64.dylib
publicbooleaninitialize()throwsCloneNotSupportedException{
+ boolean result =this.topicConfigManager.load();
- /**
- * Static helper that can be used to run a {@link SpringApplication} from the
- * specified source using default settings.
- * @param primarySource the primary source to load
- * @param args the application arguments (usually passed from a Java main method)
- * @return the running {@link ApplicationContext}
- */
-
然后就是上面调用的 run 方法
-
publicstaticConfigurableApplicationContextrun(Class<?> primarySource,String... args){
- returnrun(newClass<?>[]{ primarySource }, args);
+ result = result &&this.consumerOffsetManager.load();
+ result = result &&this.subscriptionGroupManager.load();
+ result = result &&this.consumerFilterManager.load();
/**
- * Create a new {@link SpringApplication} instance. The application context will load
- * beans from the specified primary sources (see {@link SpringApplication class-level}
- * documentation for details. The instance can be customized before calling
- * {@link #run(String...)}.
- * @param primarySources the primary bean sources
- * @see #run(Class, String[])
- * @see #SpringApplication(ResourceLoader, Class...)
- * @see #setSources(Set)
- */
+result = result &&this.messageStore.load();
staticclassThreadLocalMap{
+ this.heartbeatExecutor =newBrokerFixedThreadPoolExecutor(
+ this.brokerConfig.getHeartbeatThreadPoolNums(),
+ this.brokerConfig.getHeartbeatThreadPoolNums(),
+ 1000*60,
+ TimeUnit.MILLISECONDS,
+ this.heartbeatThreadPoolQueue,
+ newThreadFactoryImpl("HeartbeatThread_",true));
- /**
- * The entries in this hash map extend WeakReference, using
- * its main ref field as the key (which is always a
- * ThreadLocal object). Note that null keys (i.e. entry.get()
- * == null) mean that the key is no longer referenced, so the
- * entry can be expunged from table. Such entries are referred to
- * as "stale entries" in the code that follows.
- */
- staticclassEntryextendsWeakReference<ThreadLocal<?>>{
- /** The value associated with this ThreadLocal. */
- Object value;
+ this.endTransactionExecutor =newBrokerFixedThreadPoolExecutor(
+ this.brokerConfig.getEndTransactionThreadPoolNums(),
+ this.brokerConfig.getEndTransactionThreadPoolNums(),
+ 1000*60,
+ TimeUnit.MILLISECONDS,
+ this.endTransactionThreadPoolQueue,
+ newThreadFactoryImpl("EndTransactionThread_"));
- Entry(ThreadLocal<?> k,Object v){
- super(k);
- value = v;
- }
- }
- }
-]]>
-
- 生活
- 旅游
-
-
- 生活
- 杭州
- 旅游
- 厦门
- 中山路
- 局口街
- 鼓浪屿
- 曾厝垵
- 植物园
- 马戏团
- 沙茶面
- 海蛎煎
-
-
-
- 聊聊我刚学会的应用诊断方法
- /2020/05/22/%E8%81%8A%E8%81%8A%E6%88%91%E5%88%9A%E5%AD%A6%E4%BC%9A%E7%9A%84%E5%BA%94%E7%94%A8%E8%AF%8A%E6%96%AD%E6%96%B9%E6%B3%95/
- 因为传说中的出身问题,我以前写的是PHP,在使用 swoole 之前,基本的应用调试手段就是简单粗暴的 var_dump,exit,对于单进程模型的 PHP 也是简单有效,技术栈换成 Java 之后,就变得没那么容易,一方面是需要编译,另一方面是一般都是基于 spring 的项目,如果问题定位比较模糊,那框架层的是很难靠简单的 System.out.println 或者打 log 解决,(PS:我觉得可能我写的东西比较适合从 PHP 这种弱类型语言转到 Java 的小白同学)这个时候一方面因为是 Java,有了非常好用的 idea IDE 的支持,可以各种花式调试,条件断点尤其牛叉,但是又因为有 Spring+Java 的双重原因,有些情况下单步调试可以把手按废掉,这也是我之前一直比较困惑苦逼的点,后来随着慢慢精(jiang)进(you)之后,比如对于一个 oom 的情况,我们可以通过启动参数加上-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=xx/xx 来配置溢出时的堆dump 日志,获取到这个文件后,我们可以通过像 Memory Analyzer (MAT)[https://www.eclipse.org/mat/] (The Eclipse Memory Analyzer is a fast and feature-rich Java heap analyzer that helps you find memory leaks and reduce memory consumption.)来查看诊断问题所在,之前用到的时候是因为有个死循环一直往链表里塞数据,属于比较简单的,后来一次是由于运维进行应用迁移时按默认的统一配置了堆内存大小,导致内存的确不够用,所以溢出了, 今天想说的其实主要是我们的 thread dump,这也是我最近才真正用的一个方法,可能真的很小白了,用过 ide 的单步调试其实都知道会有一个一层层的玩意,比如函数从 A,调用了 B,再从 B 调用了 C,一直往下(因为是 Java,所以还有很多🤦♂️),这个其实也是大部分语言的调用模型,利用了栈这个数据结构,通过这个结构我们可以知道代码的调用链路,由于对于一个 spring 应用,在本身框架代码量非常庞大的情况下,外加如果应用代码也是非常多的时候,有时候通过单步调试真的很难短时间定位到问题,需要非常大的耐心和仔细观察,当然不是说完全不行,举个例子当我的应用经常启动需要非常长的时间,因为本身应用有非常多个 bean,比较难说究竟是 bean 的加载的确很慢还是有什么异常原因,这种时候就可以使用 thread dump 了,具体怎么操作呢 如果在idea 中运行或者调试时,可以直接点击这个照相机一样的按钮,右边就会出现了左边会显示所有的线程,右边会显示线程栈,
-
"main@1" prio=5 tid=0x1 nid=NA runnable
- java.lang.Thread.State: RUNNABLE
- at TreeDistance.treeDist(TreeDistance.java:64)
- at TreeDistance.treeDist(TreeDistance.java:65)
- at TreeDistance.treeDist(TreeDistance.java:65)
- at TreeDistance.treeDist(TreeDistance.java:65)
- at TreeDistance.main(TreeDistance.java:45)
publicvoidstart()throwsException{
+
+ lock = lockFile.getChannel().tryLock(0,1,false);
+ if(lock ==null|| lock.isShared()||!lock.isValid()){
+ thrownewRuntimeException("Lock failed,MQ already started");
+ }
+
+ lockFile.getChannel().write(ByteBuffer.wrap("lock".getBytes()));
+ lockFile.getChannel().force(true);
+ {
+ /**
+ * 1. Make sure the fast-forward messages to be truncated during the recovering according to the max physical offset of the commitlog;
+ * 2. DLedger committedPos may be missing, so the maxPhysicalPosInLogicQueue maybe bigger that maxOffset returned by DLedgerCommitLog, just let it go;
+ * 3. Calculate the reput offset according to the consume queue;
+ * 4. Make sure the fall-behind messages to be dispatched before starting the commitlog, especially when the broker role are automatically changed.
+ */
+ long maxPhysicalPosInLogicQueue = commitLog.getMinOffset();
+ for(ConcurrentMap<Integer,ConsumeQueue> maps :this.consumeQueueTable.values()){
+ for(ConsumeQueue logic : maps.values()){
+ if(logic.getMaxPhysicOffset()> maxPhysicalPosInLogicQueue){
+ maxPhysicalPosInLogicQueue = logic.getMaxPhysicOffset();
+ }
+ }
+ }
+ if(maxPhysicalPosInLogicQueue <0){
+ maxPhysicalPosInLogicQueue =0;
+ }
+ if(maxPhysicalPosInLogicQueue <this.commitLog.getMinOffset()){
+ maxPhysicalPosInLogicQueue =this.commitLog.getMinOffset();
+ /**
+ * This happens in following conditions:
+ * 1. If someone removes all the consumequeue files or the disk get damaged.
+ * 2. Launch a new broker, and copy the commitlog from other brokers.
+ *
+ * All the conditions has the same in common that the maxPhysicalPosInLogicQueue should be 0.
+ * If the maxPhysicalPosInLogicQueue is gt 0, there maybe something wrong.
+ */
+ log.warn("[TooSmallCqOffset] maxPhysicalPosInLogicQueue={} clMinOffset={}", maxPhysicalPosInLogicQueue,this.commitLog.getMinOffset());
+ }
+ log.info("[SetReputOffset] maxPhysicalPosInLogicQueue={} clMinOffset={} clMaxOffset={} clConfirmedOffset={}",
+ maxPhysicalPosInLogicQueue,this.commitLog.getMinOffset(),this.commitLog.getMaxOffset(),this.commitLog.getConfirmOffset());
+ this.reputMessageService.setReputFromOffset(maxPhysicalPosInLogicQueue);
+ this.reputMessageService.start();
+
+ /**
+ * 1. Finish dispatching the messages fall behind, then to start other services.
+ * 2. DLedger committedPos may be missing, so here just require dispatchBehindBytes <= 0
+ */
+ while(true){
+ if(dispatchBehindBytes()<=0){
+ break;
+ }
+ Thread.sleep(1000);
+ log.info("Try to finish doing reput the messages fall behind during the starting, reputOffset={} maxOffset={} behind={}",this.reputMessageService.getReputFromOffset(),this.getMaxPhyOffset(),this.dispatchBehindBytes());
+ }
+ this.recoverTopicQueueTable();
+ }
+
+ if(!messageStoreConfig.isEnableDLegerCommitLog()){
+ this.haService.start();
+ this.handleScheduleMessageService(messageStoreConfig.getBrokerRole());
+ }
+
+ this.flushConsumeQueueService.start();
+ this.commitLog.start();
+ this.storeStatsService.start();
+
+ this.createTempFile();
+ this.addScheduleTask();
+ this.shutdown =false;
+ }
@Override
+publicfinalResultSetexecuteQuery(finalString sql)throwsSQLException{
+ thrownewSQLFeatureNotSupportedException("executeQuery with SQL for PreparedStatement");
+}
下单的是后要冻结核销优惠券,如果账户里有钱要冻结扣除账户里的钱,如果使用了J 豆也一样,可能还有 E 卡,忽略我借用的平台,因为目前一般后台服务化之后,可能每一项都是对应的一个后台服务,我们期望的执行过程是要不全成功,要不就全保持执行前状态,不能是部分扣减核销成功了,部分还不行,所以我们处理这种情况会引入一些通用的方案,第一种叫二阶段提交,
对于上面的例子,我们将整个过程分成两个阶段,首先是提交请求阶段,这个阶段大概需要做的是确定资源存在,锁定资源,可能还要做好失败后回滚的准备,如果这些都 ok 了那么就响应成功,这里其实用到了一个叫事务的协调者的角色,类似于裁判员,每个节点都反馈第一阶段成功后,开始执行第二阶段,也就是实际执行操作,这里也是需要所有节点都反馈成功后才是执行成功,要不就是失败回滚。其实常用的分布式事务的解决方案主要也是基于此方案的改进,比如后面介绍的三阶段提交,有三阶段提交就是因为二阶段提交比较尴尬的几个点,
腆着脸说虽然这个不可行,但是思路是对的,具体实行起来需要做一系列(肥肠多)的改动,首先根据我的理解,其实这个拷贝一个表是变成拷贝一条记录,但是如果有多个事务,那就得拷贝多次,这个问题其实可以借助版本管理系统来解释,在用版本管理系统,git 之类的之前,很原始的可能是开发完一个功能后,就打个压缩包用时间等信息命名,然后如果后面要找回这个就直接用这个压缩包的就行了,后来有了 svn,git 中心式和分布式的版本管理系统,它的一个特点是粒度可以控制到文件和代码行级别,对应的我们的 mysql 事务是不是也可以从一开始预想的表级别细化到行的级别,可能之前很多人都了解过,数据库的一行记录除了我们用户自定义的字段,还有一些额外的字段,去源码data0type.h里捞一下
+
/* Precise data types for system columns and the length of those columns;
+NOTE: the values must run from 0 up in the order given! All codes must
+be less than 256 */
+#defineDATA_ROW_ID0/* row id: a 48-bit integer */
+#defineDATA_ROW_ID_LEN6/* stored length for row id */
+
+/** Transaction id: 6 bytes */
+constexpr size_t DATA_TRX_ID =1;
+
+/** Transaction ID type size in bytes. */
+constexpr size_t DATA_TRX_ID_LEN =6;
+
+/** Rollback data pointer: 7 bytes */
+constexpr size_t DATA_ROLL_PTR =2;
+
+/** Rollback data pointer type size in bytes. */
+constexpr size_t DATA_ROLL_PTR_LEN =7;
如果记录的事务 id 介于 m_low_limit_id 和 m_up_limit_id 之间,则要判断它是否在 m_ids 中,如果在,不可见,如果不在,表示已提交,可见 具体的代码捞一下看看
/** Check whether the changes by id are visible.
+ @param[in] id transaction id to check against the view
+ @param[in] name table name
+ @return whether the view sees the modifications of id. */
+ bool changes_visible(trx_id_t id, const table_name_t &name) const
+ MY_ATTRIBUTE((warn_unused_result)) {
+ ut_ad(id > 0);
+
+ if (id < m_up_limit_id || id == m_creator_trx_id) {
+ return (true);
+ }
+
+ check_trx_id_sanity(id, name);
+
+ if (id >= m_low_limit_id) {
+ return (false);
+
+ } else if (m_ids.empty()) {
+ return (true);
+ }
+
+ const ids_t::value_type *p = m_ids.data();
+
+ return (!std::binary_search(p, p + m_ids.size(), id));
+ }
staticclassThreadLocalMap{
+
+ /**
+ * The entries in this hash map extend WeakReference, using
+ * its main ref field as the key (which is always a
+ * ThreadLocal object). Note that null keys (i.e. entry.get()
+ * == null) mean that the key is no longer referenced, so the
+ * entry can be expunged from table. Such entries are referred to
+ * as "stale entries" in the code that follows.
+ */
+ staticclassEntryextendsWeakReference<ThreadLocal<?>>{
+ /** The value associated with this ThreadLocal. */
+ Object value;
+
+ Entry(ThreadLocal<?> k,Object v){
+ super(k);
+ value = v;
+ }
+ }
+ }
privatevoidset(ThreadLocal<?> key,Object value){
+
+ // We don't use a fast path as with get() because it is at
+ // least as common to use set() to create new entries as
+ // it is to replace existing ones, in which case, a fast
+ // path would fail more often than not.
+
+ Entry[] tab = table;
+ int len = tab.length;
+ int i = key.threadLocalHashCode &(len-1);
+
+ for(Entry e = tab[i];
+ e !=null;
+ e = tab[i =nextIndex(i, len)]){
+ ThreadLocal<?> k = e.get();
+
+ if(k == key){
+ e.value = value;
+ return;
+ }
+
+ if(k ==null){
+ replaceStaleEntry(key, value, i);
+ return;
+ }
+ }
+
+ tab[i]=newEntry(key, value);
+ int sz =++size;
+ if(!cleanSomeSlots(i, sz)&& sz >= threshold)
+ rehash();
+}
+]]>
+
+ Mac
+ PHP
+ Homebrew
+ PHP
+ icu4c
+
+
+ Mac
+ PHP
+ Homebrew
+ icu4c
+ zsh
+
+
+
+ 聊聊我刚学会的应用诊断方法
+ /2020/05/22/%E8%81%8A%E8%81%8A%E6%88%91%E5%88%9A%E5%AD%A6%E4%BC%9A%E7%9A%84%E5%BA%94%E7%94%A8%E8%AF%8A%E6%96%AD%E6%96%B9%E6%B3%95/
+ 因为传说中的出身问题,我以前写的是PHP,在使用 swoole 之前,基本的应用调试手段就是简单粗暴的 var_dump,exit,对于单进程模型的 PHP 也是简单有效,技术栈换成 Java 之后,就变得没那么容易,一方面是需要编译,另一方面是一般都是基于 spring 的项目,如果问题定位比较模糊,那框架层的是很难靠简单的 System.out.println 或者打 log 解决,(PS:我觉得可能我写的东西比较适合从 PHP 这种弱类型语言转到 Java 的小白同学)这个时候一方面因为是 Java,有了非常好用的 idea IDE 的支持,可以各种花式调试,条件断点尤其牛叉,但是又因为有 Spring+Java 的双重原因,有些情况下单步调试可以把手按废掉,这也是我之前一直比较困惑苦逼的点,后来随着慢慢精(jiang)进(you)之后,比如对于一个 oom 的情况,我们可以通过启动参数加上-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=xx/xx 来配置溢出时的堆dump 日志,获取到这个文件后,我们可以通过像 Memory Analyzer (MAT)[https://www.eclipse.org/mat/] (The Eclipse Memory Analyzer is a fast and feature-rich Java heap analyzer that helps you find memory leaks and reduce memory consumption.)来查看诊断问题所在,之前用到的时候是因为有个死循环一直往链表里塞数据,属于比较简单的,后来一次是由于运维进行应用迁移时按默认的统一配置了堆内存大小,导致内存的确不够用,所以溢出了, 今天想说的其实主要是我们的 thread dump,这也是我最近才真正用的一个方法,可能真的很小白了,用过 ide 的单步调试其实都知道会有一个一层层的玩意,比如函数从 A,调用了 B,再从 B 调用了 C,一直往下(因为是 Java,所以还有很多🤦♂️),这个其实也是大部分语言的调用模型,利用了栈这个数据结构,通过这个结构我们可以知道代码的调用链路,由于对于一个 spring 应用,在本身框架代码量非常庞大的情况下,外加如果应用代码也是非常多的时候,有时候通过单步调试真的很难短时间定位到问题,需要非常大的耐心和仔细观察,当然不是说完全不行,举个例子当我的应用经常启动需要非常长的时间,因为本身应用有非常多个 bean,比较难说究竟是 bean 的加载的确很慢还是有什么异常原因,这种时候就可以使用 thread dump 了,具体怎么操作呢 如果在idea 中运行或者调试时,可以直接点击这个照相机一样的按钮,右边就会出现了左边会显示所有的线程,右边会显示线程栈,
+
"main@1" prio=5 tid=0x1 nid=NA runnable
+ java.lang.Thread.State: RUNNABLE
+ at TreeDistance.treeDist(TreeDistance.java:64)
+ at TreeDistance.treeDist(TreeDistance.java:65)
+ at TreeDistance.treeDist(TreeDistance.java:65)
+ at TreeDistance.treeDist(TreeDistance.java:65)
+ at TreeDistance.main(TreeDistance.java:45)
下单的是后要冻结核销优惠券,如果账户里有钱要冻结扣除账户里的钱,如果使用了J 豆也一样,可能还有 E 卡,忽略我借用的平台,因为目前一般后台服务化之后,可能每一项都是对应的一个后台服务,我们期望的执行过程是要不全成功,要不就全保持执行前状态,不能是部分扣减核销成功了,部分还不行,所以我们处理这种情况会引入一些通用的方案,第一种叫二阶段提交,
对于上面的例子,我们将整个过程分成两个阶段,首先是提交请求阶段,这个阶段大概需要做的是确定资源存在,锁定资源,可能还要做好失败后回滚的准备,如果这些都 ok 了那么就响应成功,这里其实用到了一个叫事务的协调者的角色,类似于裁判员,每个节点都反馈第一阶段成功后,开始执行第二阶段,也就是实际执行操作,这里也是需要所有节点都反馈成功后才是执行成功,要不就是失败回滚。其实常用的分布式事务的解决方案主要也是基于此方案的改进,比如后面介绍的三阶段提交,有三阶段提交就是因为二阶段提交比较尴尬的几个点,
+]]>
+
+ 分布式事务
+ 两阶段提交
+ 三阶段提交
+
+
+ 分布式事务
+ 两阶段提交
+ 三阶段提交
+ 2PC
+ 3PC
+
+
+
+ 聊聊 Linux 下的 top 命令
+ /2021/03/28/%E8%81%8A%E8%81%8A-Linux-%E4%B8%8B%E7%9A%84-top-%E5%91%BD%E4%BB%A4/
+ top 命令在日常的 Linux 使用中,特别是做一些服务器的简单状态查看,排查故障都起了比较大的作用,但是由于这个命令看到的东西比较多,一般只会看部分,或者说像我这样就会比较片面地看一些信息,比如默认是进程维度的,可以在启动命令的时候加-H进入线程模式
+
-H :Threads-mode operation
+ Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later
+ this can be changed with the `H' interactive command.
SORTING of task window
+
+ For compatibility, this top supports most of the former top sort keys. Since this is primarily a service to former top users, these commands
+ do not appear on any help screen.
+ command sorted-field supported
+ A start time (non-display) No
+ M %MEM Yes
+ N PID Yes
+ P %CPU Yes
+ T TIME+ Yes
+
+ Before using any of the following sort provisions, top suggests that you temporarily turn on column highlighting using the `x' interactive com‐
+ mand. That will help ensure that the actual sort environment matches your intent.
+
+ The following interactive commands will only be honored when the current sort field is visible. The sort field might not be visible because:
+ 1) there is insufficient Screen Width
+ 2) the `f' interactive command turned it Off
+
+ < :Move-Sort-Field-Left
+ Moves the sort column to the left unless the current sort field is the first field being displayed.
+
+ > :Move-Sort-Field-Right
+ Moves the sort column to the right unless the current sort field is the last field being displayed.
+
查看 man page 可以找到这一段,其实一般 man page 都是最细致的,只不过因为太多了,有时候懒得看,这里可以通过大写 M 和大写 P 分别按内存和 CPU 排序,下面还有两个小技巧,通过按 x 可以将当前活跃的排序列用不同颜色标出来,然后可以通过<和>直接左右移动排序列
+]]>
+
+ Linux
+ 命令
+ 小技巧
+ top
+ top
+ 排序
+
+
+ 排序
+ linux
+ 小技巧
+ top
+
+
+
+ 聊聊最近平淡的生活之《花束般的恋爱》观后感
+ /2021/12/31/%E8%81%8A%E8%81%8A%E6%9C%80%E8%BF%91%E5%B9%B3%E6%B7%A1%E7%9A%84%E7%94%9F%E6%B4%BB%E4%B9%8B%E3%80%8A%E8%8A%B1%E6%9D%9F%E8%88%AC%E7%9A%84%E6%81%8B%E7%88%B1%E3%80%8B%E8%A7%82%E5%90%8E%E6%84%9F/
+ 周末在领导的提议下看了豆瓣的年度榜单,本来感觉没啥心情看的,看到主演有有村架纯就觉得可以看一下,颜值即正义嘛,男主小麦跟女主小娟(后面简称小麦跟小娟)是两个在一次非常偶然的没赶上地铁末班车事件中相识,这里得说下日本这种通宵营业的店好像挺不错的,看着也挺正常,国内估计只有酒吧之类的可以。晚上去的地方是有点暗暗的,好像也有点类似酒吧,旁边有类似于 dj 那种,然后同桌的还有除了男女主的另外一对男女,也是因为没赶上地铁末班车的,但也是陌生人,然后小麦突然看到了有个非常有名的电影人,小娟竟然也认识,然后旁边那对完全不认识,还在那吹自己看过很多电影,比如《肖申克的救赎》,于是男女主都特别鄙夷地看着他们,然后他们又去了另一个有点像泡澡的地方席地而坐,他们发现了自己的鞋子都是一样的,然后在女的去上厕所的时候,小麦暗恋的学姐也来了,然后小麦就去跟学姐他们一起坐了,小娟回来后有点不开心就说去朋友家睡,幸好小麦看出来了(他竟然看出来了,本来以为应该是没填过恋爱很木讷的),就追出去,然后就去了小麦家,到了家小娟发现小麦家的书柜上的书简直就跟她自己家的一模一样,小麦还给小娟吹了头发,一起吃烤饭团,看电影,第二天送小娟上了公交,还约好了一起看木乃伊展,然而并没有交换联系方式,但是他们还是约上了一起看了木乃伊展,在餐馆就出现了片头那一幕的来源,因为餐馆他们想一起听歌,就用有线耳机一人一个耳朵听,但是旁边就有个大叔说“你们是不是不爱音乐,左右耳朵是不一样的,只有一起听才是真正的音乐”这样的话,然后的剧情有点跳,因为是指他们一直在这家餐馆吃饭,中间有他们一起出去玩情节穿插着,也是在这他们确立了关系,可以说主体就是体现了他们非常的合拍和默契,就像一些影评说的,这部电影是说如何跟百分百合拍的人分手,然后就是正常的恋爱开始啪啪啪,一直腻在床上,也没去就业说明会,后面也有讲了一点小麦带着小娟去认识他的朋友,也把小娟介绍给了他们认识,这里算是个小伏笔,后面他们分手也有这里的人的一些关系,接下去的剧情说实话我是不太喜欢的,如果一部八分的电影只是说恋爱被现实打败的话,我觉得在我这是不合格的,但是事实也是这样,小麦其实是有家里的资助,所以后面还是按自己的喜好给一些机构画点插画,小娟则要出去工作,因为小娟家庭观念也是要让她出去有正经工作,用脚指头想也能知道肯定不顺利,然后就是暂时在一家蛋糕店工作,小麦就每天去接小娟,日子过得甜甜蜜蜜,后面小娟在自己的努力下考了个什么资格证,去了一家医院还是什么做前台行政,这中间当然就有父母来见面吃饭了,他们在开始恋爱不久就同居合租了,然后小娟父母就是来说要让她有个正经工作,对男的说的话就是人生就是责任这类的话,而小麦爸爸算是个导火索,因为小麦家里是做烟花生意的,他爸让他就做烟花生意,因为要回老家,并且小麦也不想做,所以就拒绝了,然后他爸就说不给他每个月五万的资助,这也导致了小麦需要去找工作,这个过程也是很辛苦,本来想要年前找好工作,然后事与愿违,后面有一次小娟被同事吐槽怎么从来不去团建,于是她就去了(我以为会拒绝),正在团建的时候小麦给她电话,说找到工作了,是一个创业物流公司这种,这里剧情就是我觉得比较俗套的,小麦各种被虐,累成狗,但是就像小娟爸爸说的话,人生就是责任,所以一直在坚持,但是这样也导致了跟小娟的交流也越来越少,他们原来最爱的漫画,爱玩的游戏,也只剩小娟一个人看,一个人玩,而正是这个时候,小娟说她辞掉了工作,去做一个不是太靠谱的漫画改造的密室逃脱,然后这里其实有一点后面争议很大的,就是这个工作其实是前面小麦介绍给小娟的那些朋友中一个的女朋友介绍的,而在有个剧情就是小娟有一次在这个密室逃脱的老板怀里醒过来,是在 KTV 那样的场景里,这就有很多人觉得小娟是不是出轨了,我觉得其实不那么重要,因为这个离职的事情已经让一切矛盾都摆在眼前,小麦其实是接受这种需要承担责任的生活,也想着要跟小娟结婚,但是小娟似乎还是想要过着那样理想的生活,做自己想做的事情,看自己爱看的漫画,也要小麦能像以前那样一直那么默契的有着相同的爱好,这里的触发点其实还有个是那个小麦的朋友(也就是他女朋友介绍小娟那个不靠谱工作的)的葬礼上,小麦在参加完葬礼后有挺多想倾诉的,而小娟只是想睡了,这个让小麦第二天起来都不想理小娟,只是这里我不太理解,难道这点闹情绪都不能接受吗,所谓的合拍也只是毫无限制的情况下的合拍吧,真正的生活怎么可能如此理想呢,即使没有物质生活的压力,也会有其他的各种压力和限制,在这之后其实小麦想说的是小娟是不是没有想跟自己继续在一起的想法了,而小娟觉得都不说话了,还怎么结婚呢,后面其实导演搞了个小 trick,突然放了异常婚礼,但是不是男女主的,我并不觉得这个桥段很好,在婚礼里男女主都觉得自己想要跟对方说分手了,但是当他们去了最开始一直去的餐馆的时候,一个算是一个现实映照的就是他们一直坐的位子被占了,可能也是导演想通过这个来说明他们已经回不去了,在餐馆交谈的时候,小麦其实是说他们结婚吧,并没有想前面婚礼上预设地要分手,但是小娟放弃了,不想结婚,因为不想过那样的生活了,而小麦觉得可能生活就是那样,不可能一直保持刚恋爱时候的那种感觉,生活就是责任,人生就意味着责任。
+
publicstaticvoidmain(String[] args){
+ SpringApplication.run(SpbDemoApplication.class, args);
+ }
+
+ /**
+ * Static helper that can be used to run a {@link SpringApplication} from the
+ * specified source using default settings.
+ * @param primarySource the primary source to load
+ * @param args the application arguments (usually passed from a Java main method)
+ * @return the running {@link ApplicationContext}
+ */
+
然后就是上面调用的 run 方法
+
publicstaticConfigurableApplicationContextrun(Class<?> primarySource,String... args){
+ returnrun(newClass<?>[]{ primarySource }, args);
+}
+
+/**
+ * Static helper that can be used to run a {@link SpringApplication} from the
+ * specified sources using default settings and user supplied arguments.
+ * @param primarySources the primary sources to load
+ * @param args the application arguments (usually passed from a Java main method)
+ * @return the running {@link ApplicationContext}
+ */
再一点就是情节是大众都能接受度比较高的,现在有很多普遍会找一些新奇的视角,比如卖腐,想某某令,两部都叫某某令,这其实是一个点,延伸出去就是跟前面说的一点有点类似,xx 老祖,人看着就二三十,叫 xx 老祖,(喜欢的人轻喷哈)然后名字有一堆,同一个人物一会叫这个名字,一会又叫另一个名字,然后一堆死表情。
再一点就是情节是大众都能接受度比较高的,现在有很多普遍会找一些新奇的视角,比如卖腐,想某某令,两部都叫某某令,这其实是一个点,延伸出去就是跟前面说的一点有点类似,xx 老祖,人看着就二三十,叫 xx 老祖,(喜欢的人轻喷哈)然后名字有一堆,同一个人物一会叫这个名字,一会又叫另一个名字,然后一堆死表情。
\ No newline at end of file
diff --git a/tags/Windows/index.html b/tags/Windows/index.html
index e4a24e8db2..ce2a90b682 100644
--- a/tags/Windows/index.html
+++ b/tags/Windows/index.html
@@ -1 +1 @@
-标签: windows | Nicksxs's Blog
\ No newline at end of file
diff --git a/tags/php/index.html b/tags/php/index.html
index b04493f782..b106a60688 100644
--- a/tags/php/index.html
+++ b/tags/php/index.html
@@ -1 +1 @@
-标签: PHP | Nicksxs's Blog
YVd/rzeR6SLLcDFYEidcybldM= src=https://cdnjs.cloudflare.com/ajax/libs/algoliasearch/4.14.3/algoliasearch-lite.umd.js>
\ No newline at end of file
+标签: PHP | Nicksxs's Blog






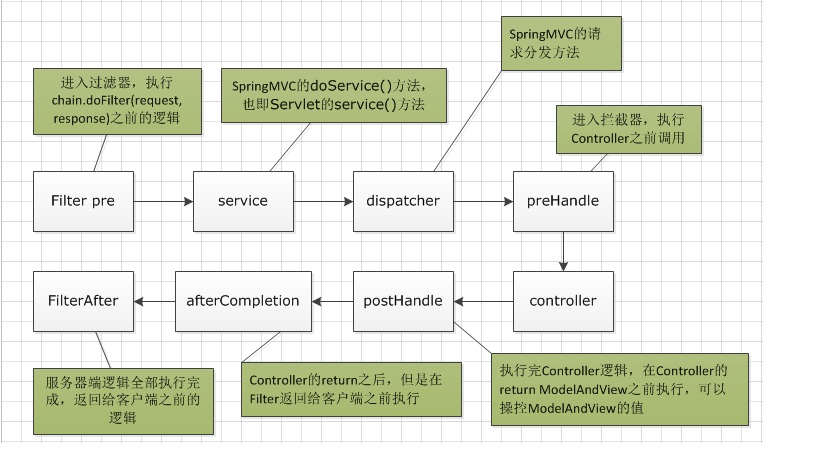

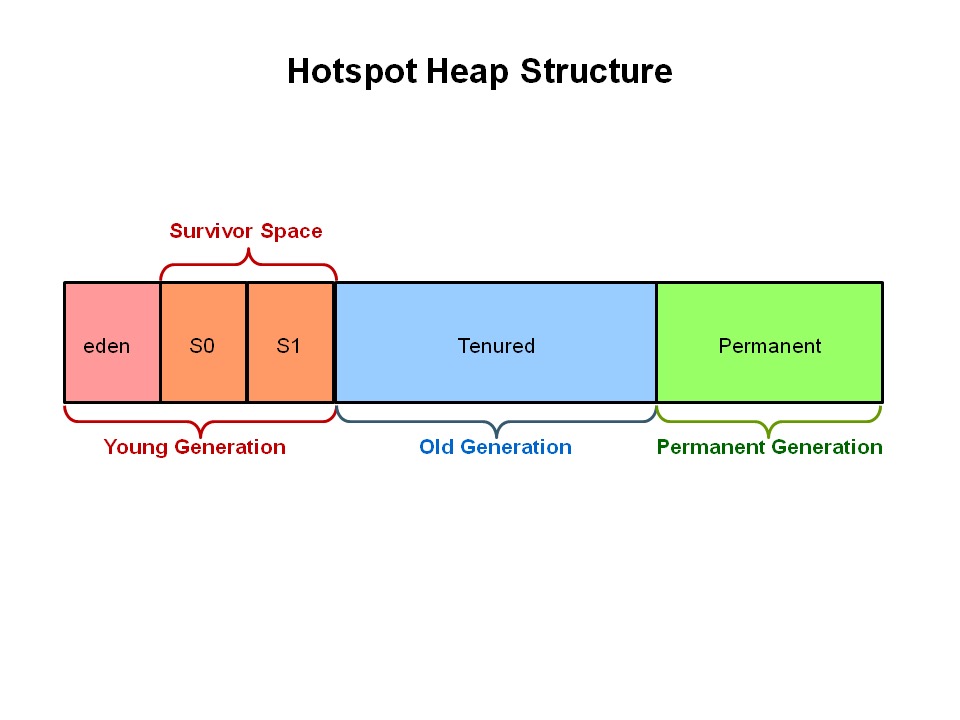



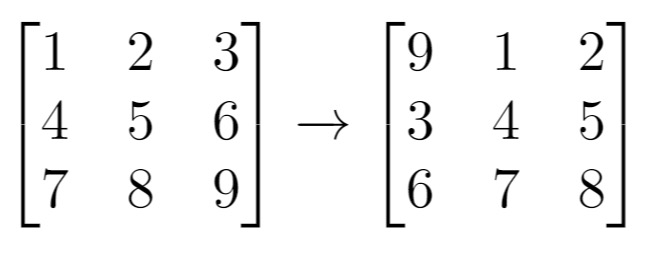


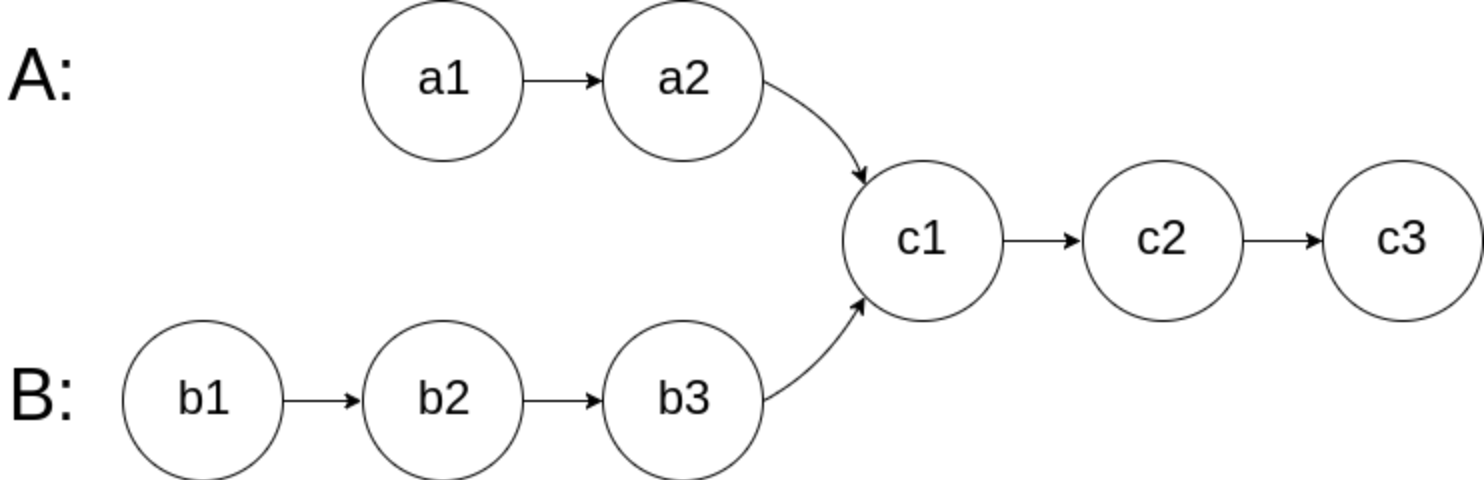
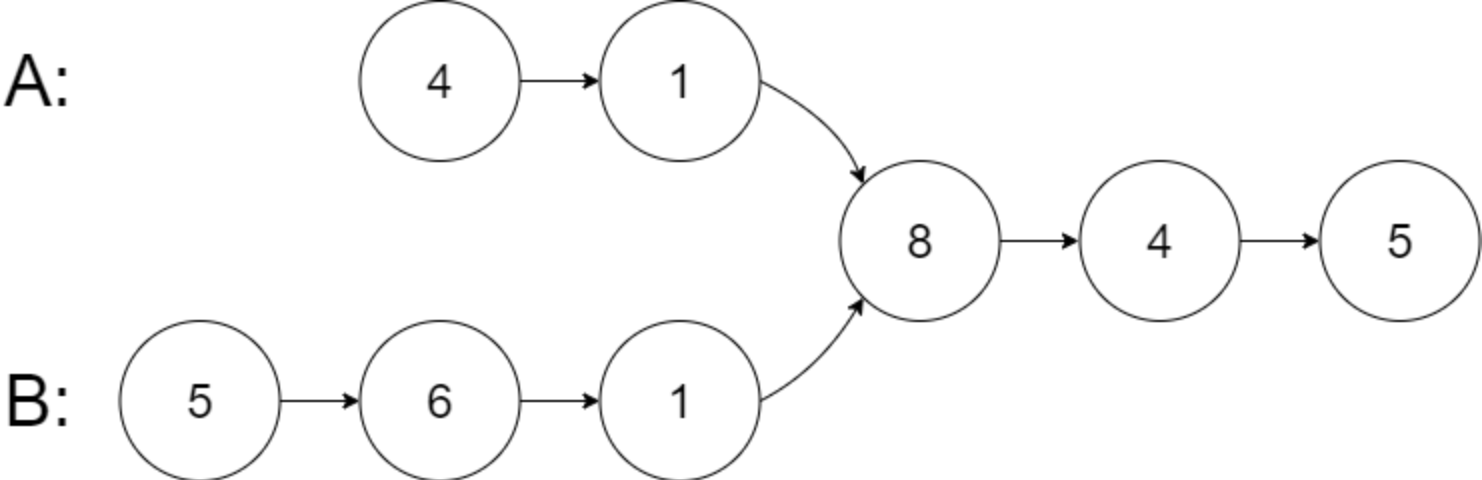





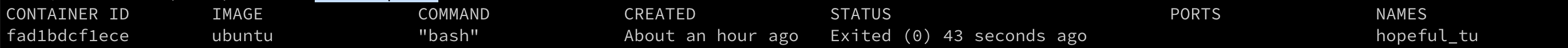

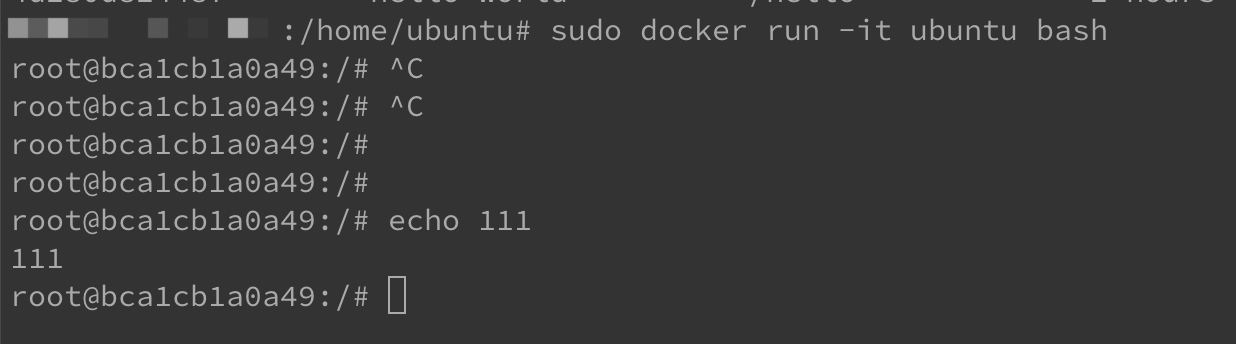
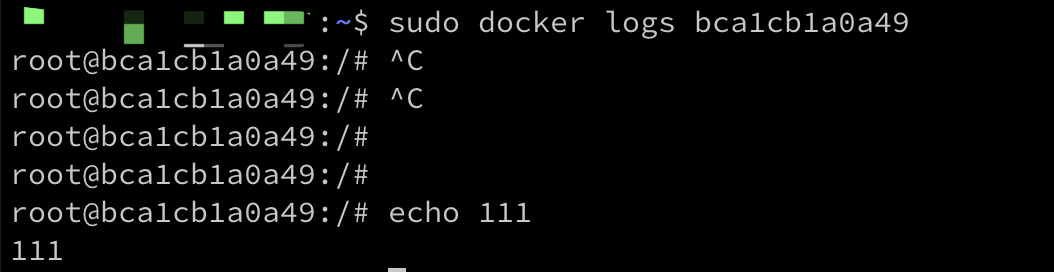


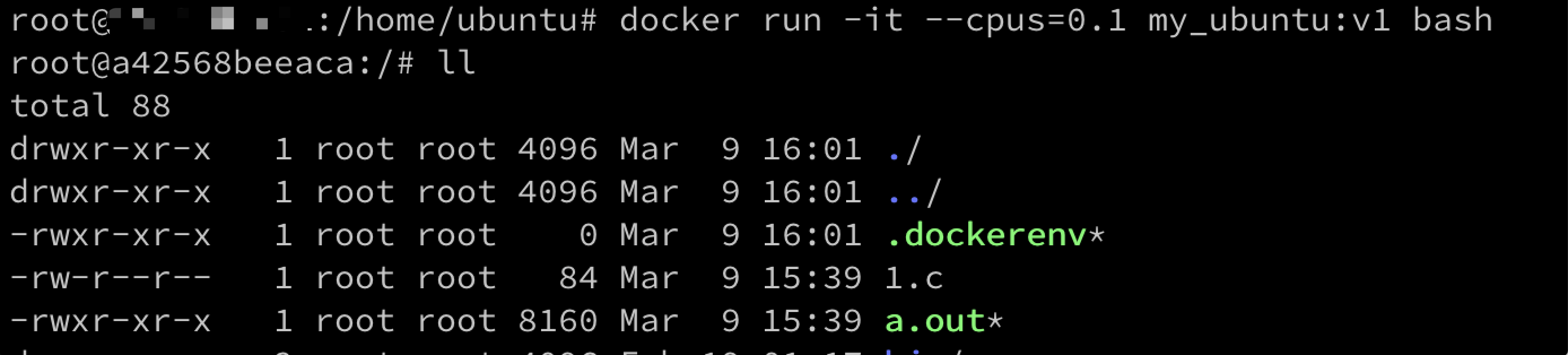

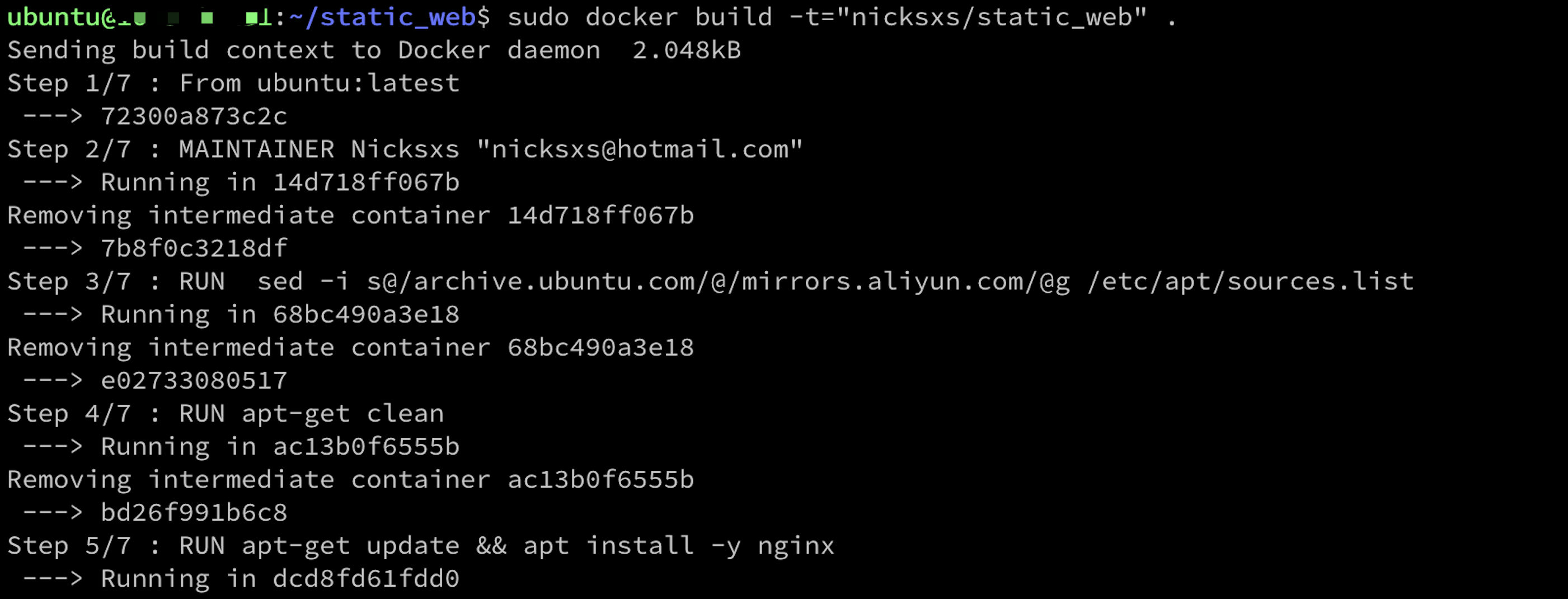
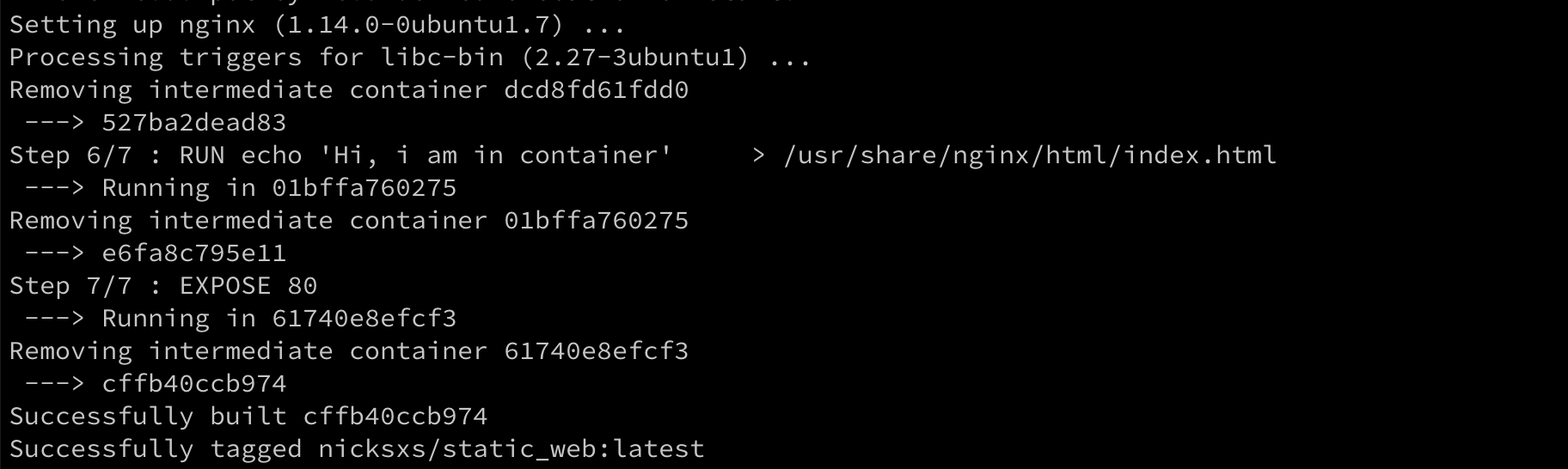

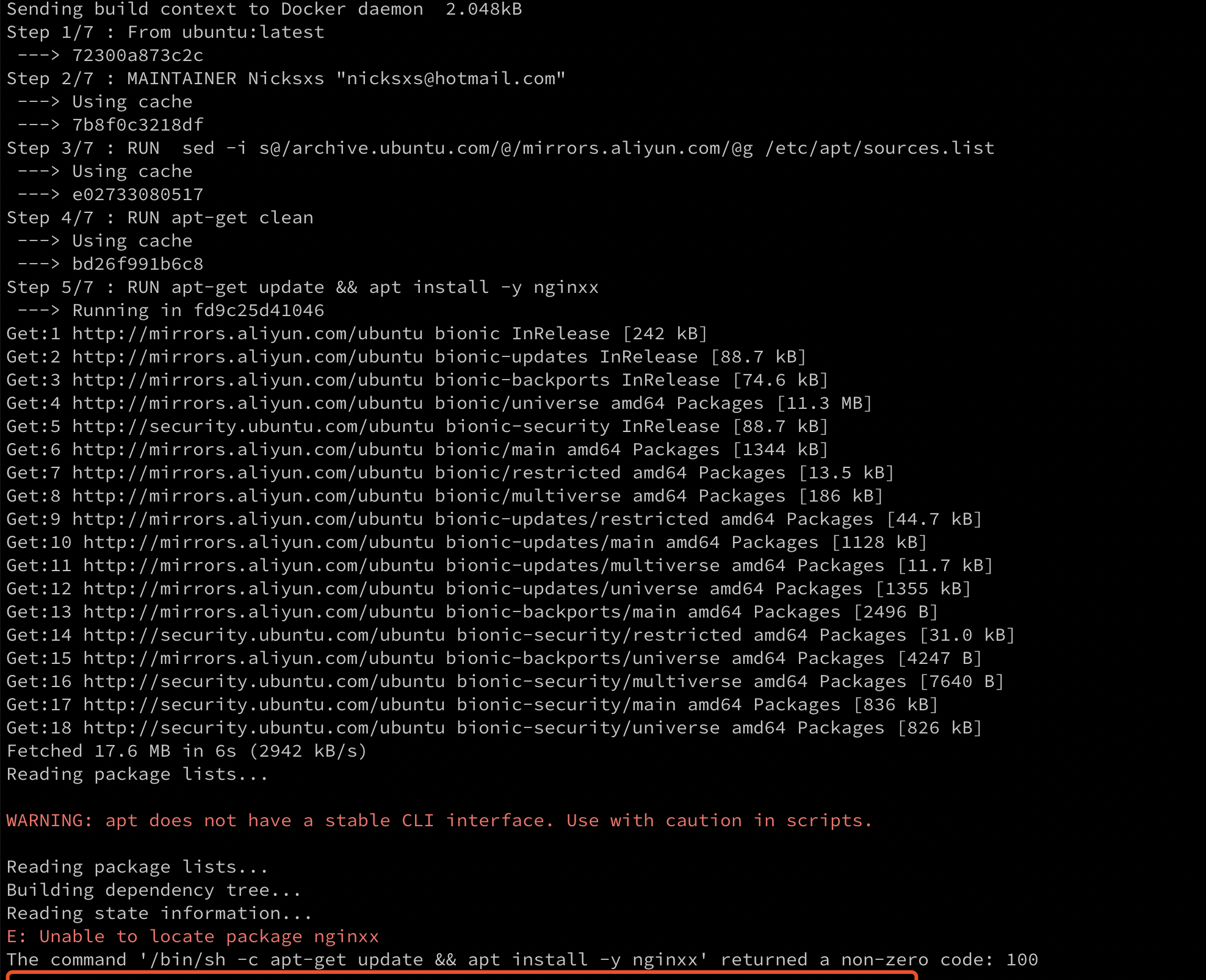

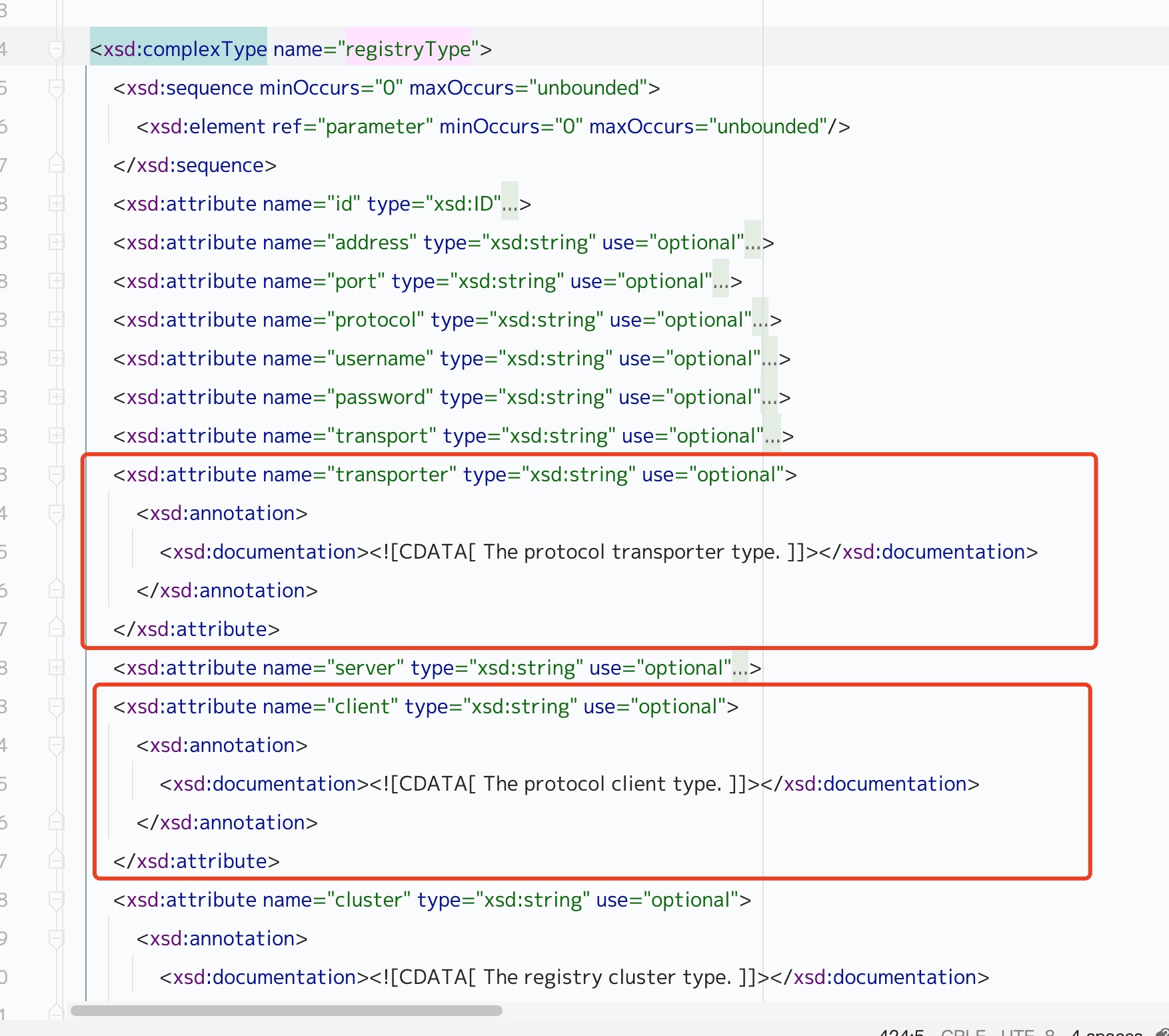
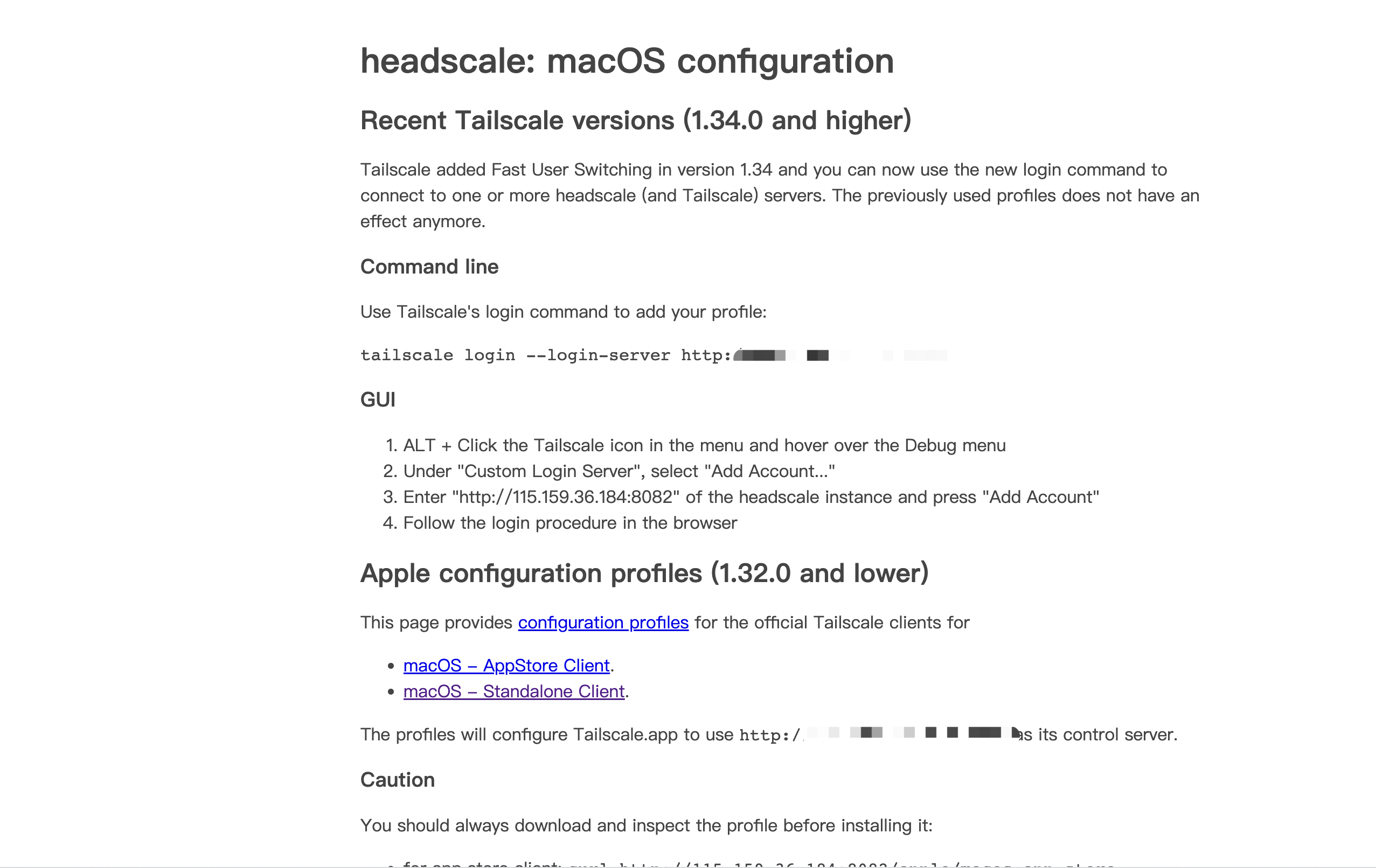

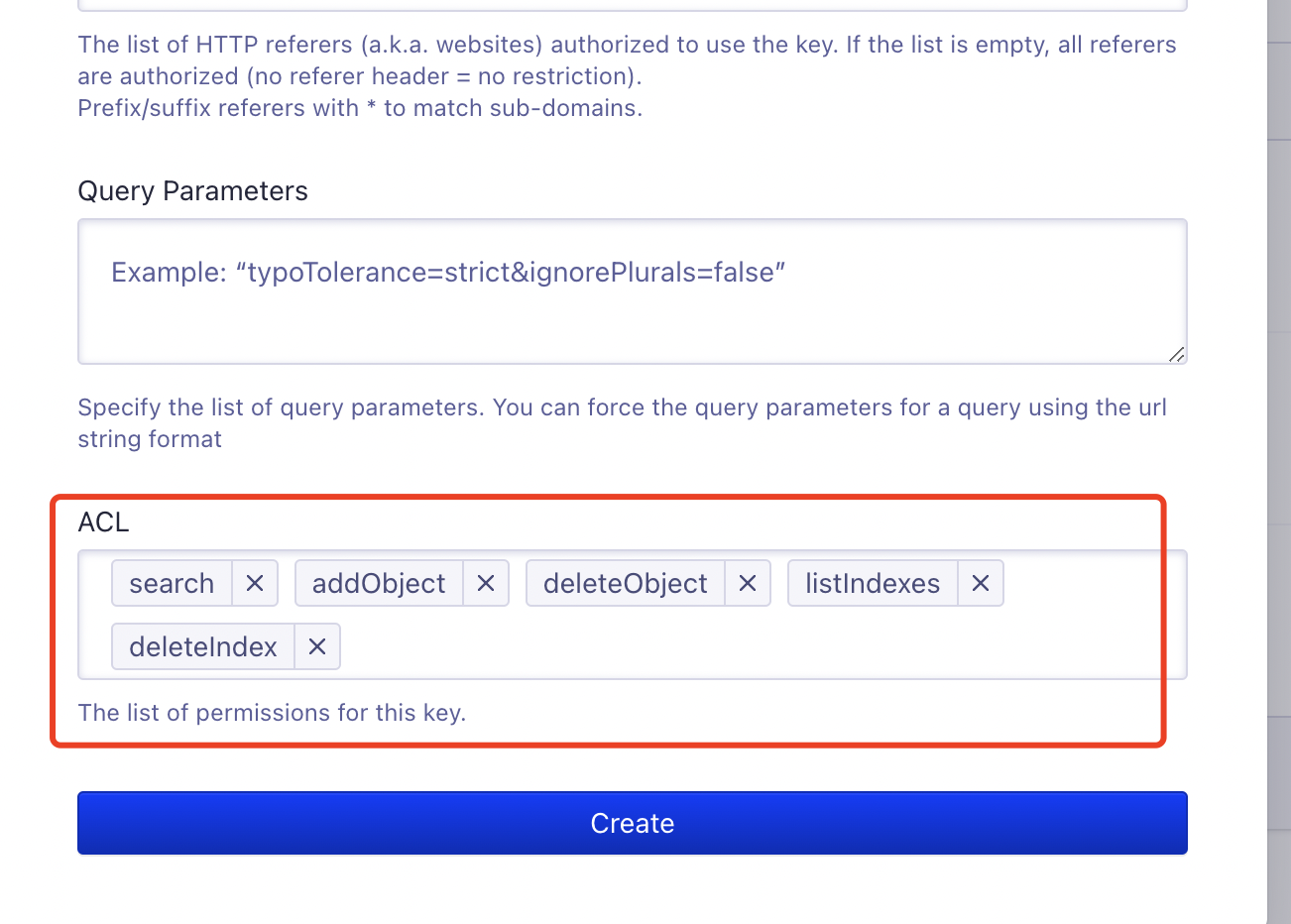




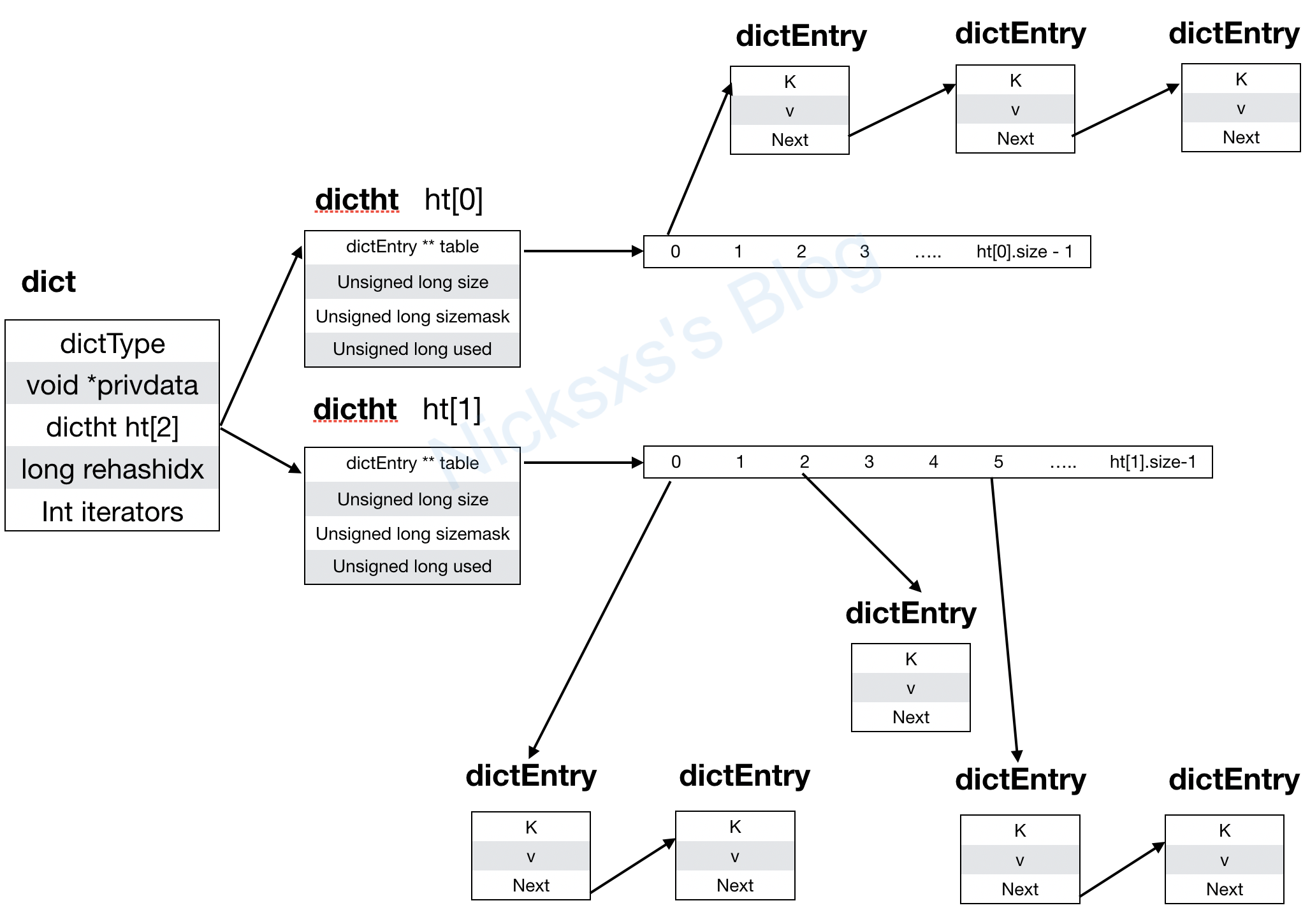

 -
-

















 ,这样就不会被覆盖
+]]>
,这样就不会被覆盖
+]]>
 ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息




















 -
-